Shingled Erasure Code (SHEC)
Резюме
Драночный код затирания (Shingled Erasure Code, SHEC или исходный SHEC) [1] является кодом затирания с эффективным восстановлением и высокой настраиваемостью. Более того, SHEC расширяется на множественный SHEC (mSHEC), чья компоновка автоматически собирается из сочетания исходных компоновок SHEC в ответ на предписанные каждым пользователем надежность и эффективность использования пространства и, как результат, приводит к улучшению эффективность восстановления исходного SHEC.
Владельцы
-
Takeshi Miyamae (Fujitsu Laboratories Ltd., miyamae.takeshi@jp.fujitsu.com)
-
Takanori Nakao (Fujitsu Laboratories Ltd., nakao.takanori@jp.fujitsu.com)
-
Kensuke Shiozawa (Fujitsu Laboratories Ltd., shiozawa.kennsu@jp.fujitsu.com)
Заинтересованные стороны
Текущее состояние
У нас имеется работающий прототип SHEC для Firefly/Giant и все его локальные испытания завершены.
(И SHEC, и mSHEC работают в редакции Firefly, поскольку ему достаточно API прикрепляемых программ (plugin) кода затирания Firefly и алгоритма CRUSH.)
Подробное описание
-
Исходный SHEC
SHEC является кодом затирания с локальными группами сравнимости по модулю и диапазоны вычислений перекрываются друг с другом, аналогично выравниванию гонтовых пластин (дранок) на крыше дома. Пример расположения соответствий SHEC демонстрируется на Рисунке 1.
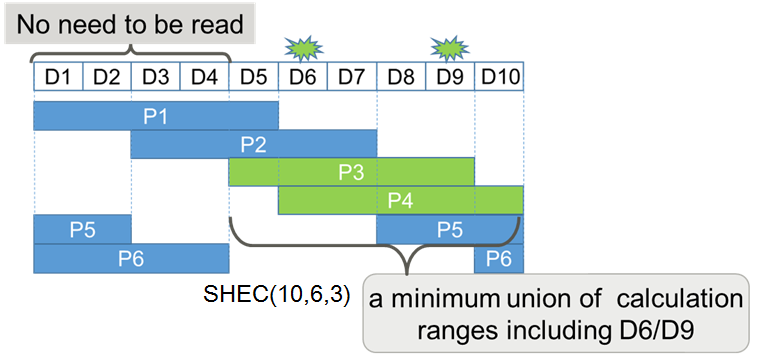
Рисунок 1 Пример расположения соответствий SHEC
SHEC(k,m,c) обозначает схему SHEC, которая имеет k порций данных, m порций коррекции и оценку надежности c. Оценка надежности является средним значением порций коррекции, которые покрывают каждую порцию данных.
SHEC имеет определенные преимущества. Во- первых, SHEC является эффективным для восстановления, поскольку SHEC всегда использует локальные коррекции для восстановления пропавших порций даже в случае отказа множества дисков.
Далее, SHEC обладает хорошей настраиваемостью, благодаря присущей SHEC особой компоновке, которая плотно заполняет область эффективного восстановления в трех измерениях (минимизации пространства, эффективности восстановления и надежности), как это показывает карта свойств на Рисунке 2. Локализации кода Рида- Соломона (Reed Solomon) изображены участками окружностей и разрежены в сравнении и расположением SHEC.
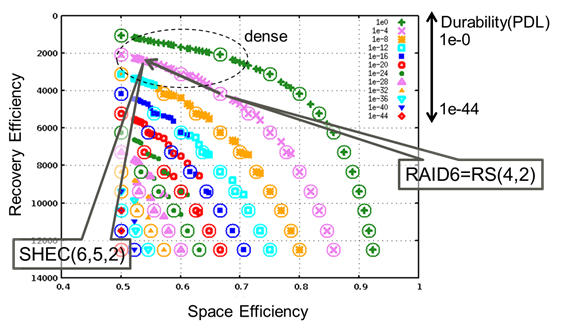
Рисунок 2 Карта свойств SHEC
- Множественный SHEC (mSHEC)
Тем не менее, исходный SHEC может получить более высокую эффективность восстановления только в ущерб надежности или эффективности использования пространства. Для достижения более высокой эффективности восстановления без таких жертв мы комбинируем множество различных исходных расположений SHEC в одно (mSHEC, Рисунок 3).
mSHEC(k,m,c) автоматически выбирает наиболее эффективную локализацию для восстановления среди всех, удовлетворяющих m=m1+m2 и c=c1+c2. Это основной источник эффективности восстановления mSHEC.
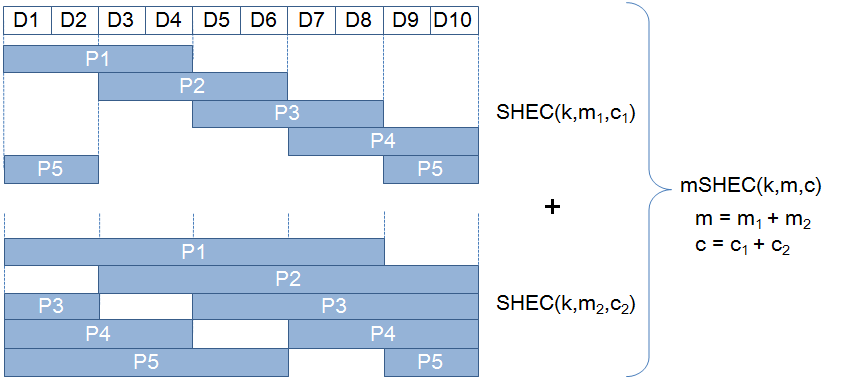
Рисунок 3 Расположение множественного SHEC
В отличие от исходного SHEC, чья эффективность восстановления была почти такой же как у кода Рида- Соломона (Рисунок 2), эффективность восстановления mSHEC улучшается, как это показано на Рисунке 4.
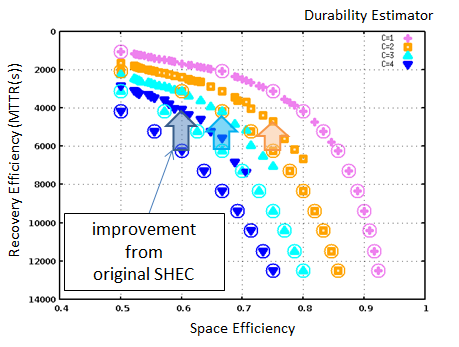
Рисунок 4 Карта свойств mSHEC
На первый взгляд схема mSHEC выглядит усложненной, однако шаблоны mSHEC также вырабатываются автоматически как ответ на запрашиваемые надежность и эффективность использования пространства, а пользователям нет нужды знать детали этих схем.
В заключение: mSHEC следует использовать, когда наиболее важна эффективность восстановления. Рисунок 5 представляет собой для пользователей схему выбора соответствующей подключаемой программы кодирования затирания (EC plugin) для пользователей.
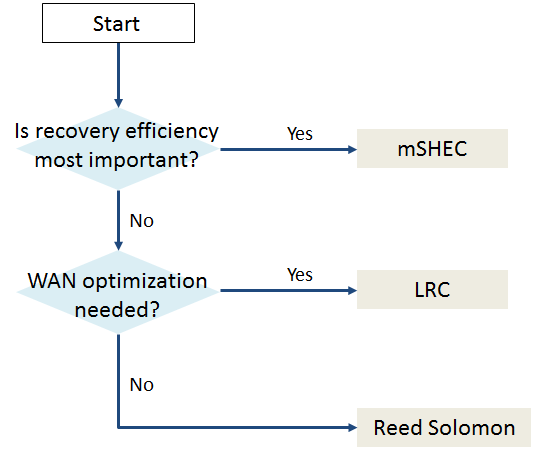
Рисунок 5 Схема для выбора EC Plugin
Ссылки
[1] Erasure Code with Shingled Local Parity Groups for Efficient Recovery from Multiple Disk Failures (HotDep'14)
https://www.usenix.org/conference/hotdep14/workshop-program/presentation/miyamae
http://www.slideshare.net/miyamae199...s021slideshare (presentation slides)
Элементы в работе
- Тестирование в редакциях Giant/Hammer
Проблемы кодирования
- Task 1
- Task 2
- Task 3
Вопросы построения / издания
- Task 1
- Task 2
- Task 3
Задачи документирования
- Task 1
- Task 2
- Task 3
Обсуждаемые вопросы
- Task 1
- Task 2
- Task 3
Код затирания с драночными локальными группами коррекции для эффективного восстановления при множественных отказах дисков.
Перевод Erasure Code with Shingled Local Parity Groups for Efficient Recovery from Multiple Disk Failures
Takeshi Miyamae Takanori Nakao Kensuke Shiozawa
{miyamae.takeshi, nakao.takanori, shiozawa.kennsu}@jp.fujitsu.com
Fujitsu Laboratories Ltd.
Аннотация
Постоянно растущие важность и объем цифровых данных, генерируемых службами ИВТ привели к запросу на высоко надежные и эффективные в отношении пространства технологии хранения содержания. Код затирания (erasure code) может быть эффективным решением для таких решений, однако имеющиеся в настоящее время решения не эффективно обрабатывают одновременный выход из строя множества дисков. Мы предлагаем драночный код затирания (SHEC, Shingled Erasure Code), код затирания с локальными группами коррекции, накладывающимися друг на друга для обеспечения обеспечения эффективного восстановления при множественных отказах дисков, при этом обеспечивая подстройку под требования пользователя конфликтующих свойств эффективности использования пространства и надежности. Мы получили подтверждения того, что SHEC отвечает требованиям проекта применив результаты численного исследования взаимосвязи между вступающими в конфликт характеристиками, а также оценки производительности реальной реализации SHEC для Ceph, варианта программного обеспечения с открытым исходным кодом масштабируемого хранилища объектов.
1. Введение
Постоянно растущая важность цифрового содержания, создаваемого поставщиками услуг в области ИВТ, привела к росту спроса на высоко надежные технологии хранения содержания. Для служб ИВТ техника тройного реплицирования данных на протяжении лет отвечала этим потребностям, однако ее низкая эффективность использования пространства (умножение на три хранилища для данных пользователя), делало это решение менее привлекательным для поставщиков услуг. Код затирания является надежной техникой хранения с меньшим объемом избыточной информации (корректировки, соответствий по модулю) и быстро получает популярность.
С увеличением вычислительных мощностей приходят эффективность использования пространства и долговечность кодирования затирания. В частности, накладные расходы на восстановление, связанные с отказами дисков, сильно влияют на доступность и производительность служб ИВТ, если не будут должным образом управляться операции восстановления. Регулирование пропускными способностями процессора и операций ввода/ вывода для восстановления с целью минимизации помех от восстановления является одной из наиболее распространенных практик [18], однако контроль над зависимостью от восстановления влечет за собой увеличение продолжительности восстановления, что, в свою очередь, делает хранилище менее надежным. Поэтому производительность восстановления сама по себе стала целью исследований кода затирания в последнее время [10].
Последними замечательными достижениями в повышении производительности являются Microsoft LRC (MS-LRC) [9] и Facebook Xorbas [10]. Они используют понятие локального соответствия при котором несколько экземпляров соответствия по модулю (избыточных кодов) вычисляются на основе только подмножеств всего набора данных. Принимая во внимание то, что количество передаваемых данных уменьшается только до этого подмножества набора данных, восстановление потребляет меньший объем всех ресурсов ИВТ и становится более быстрым.
Однако, при множественных отказах дисков MSLRC и Xorbas используют глобальные соответствия по модулю, которые включают информацию корректирующих кодов, вычисляемую по всему набору данных и, соответственно, при операциях восстановления передаются большие объемы данных. Поскольку в реальном мире каждый отказы дисков часто коррелируют [16], мы имеем мотивацию создания нового кода затирания, который будет надежным в отношении множественных отказов дисков.
В этой статье мы предлагаем драночный код затирания (SHEC, Shingled Erasure Code), в котором локальные группы соответствий по модулю перекрывают друг друга. Данный код разработан для эффективного восстановления при множественных отказах дисков, причем эффективность использования пространства и долговечность настраиваются пользователем. Чтобы подтвердить цели проектирования SHEC, мы вначале изучим во втором разделе взаимосвязи между тремя характеристиками кода затирания (эффективность использования пространства, надежность и эффективность восстановления) с нашими различными макетами локальных групп соответствия по модулю (корректирующих кодов). Затем мы покажем, что для достижения оптимального сочетания планируемых свойств пользователя регулируется локализация. В третьем разделе мы покажем вышеупомянутую эффективность восстановления SHEC путем оценки реализации SHEC в Ceph [14], варианте программного обеспечения с открытым исходным кодом масштабируемого хранилища объектов.
2. Анализ локальных групп соответствия и новый код
2.1. Свойства локальных групп соответствия
В данной статье мы называем каждый отделенный элемент данных в полосе кода затирания "порцией данных", а каждую локальную группу соответствия по модулю (корректирующего кода) "порцией соответствия". Мы определяем локализацию ограниченной в размерах (локальной) группы соответствия как число порций данных для вычисления каждой порции соответствия по модулю (корректирующего кода).
Мы выбираем три основные характеристики кода затирания для групп локальных соответствия:
- Эффективность использования пространства
- Надежность
- Эффективность восстановления
Первое свойство, эффективность использования пространства, определяется как соотношение порций данных и вычисляется как k/(k+m) (k: число порций данных, m: число порций соответствий по модулю), что отображает стоимостную эффективность.
Вторая характеристика, надежность, определяется как вероятность потери данных, что показано в уравнении (1) [17].
PDL = nPf × (1 / MTBF) × (MTTR / MTBF)f-1
(1)
PDL: Вероятность потери данных (Probability of data loss)
MTTR: Среднее время восстановления (Mean time to recovery)
MTBF: Среднее время между отказами (Mean time between failures)
n: Общее число дисков
f: Число одновременно отказавших дисков
nPf: n!/(n-f)!
Последнее свойство, эффективность восстановления, определяется как обратное значение накладных расходов на восстановление (затраты на восстановление означают соотношение считываемых порций ко всем порциям данных, задействованных в процессе восстановления). Как правило, чем меньше локализация, тем выше эффективность восстановления. Эффективность восстановления повышает доступность или производительность служб ИВТ.
Далее, мы сейчас объясним три способа компромиссов взаимоотношений между указанными характеристиками затирания кода, как показано на Рисунке 1а. Во- первых, отметим взаимосвязь между эффективностью использования пространства и надежностью. Этот компромисс очевиден, поскольку если мы добавляем соответствия по модулю, надежность возрастает, в то время как эффективность использования пространства уменьшается (компромисс №1, tradeoff #1). Вторая взаимосвязь состоит между надежностью и эффективностью восстановления. Если мы понижаем локализацию для увеличения эффективности восстановления, то число порций соответствий по модулю, покрывающих каждую порцию данных уменьшается, что указывает на снижение надежности (компромисс №2, tradeoff #2). Последняя взаимосвязь состоит между эффективностью использования пространства и эффективностью восстановления. Для уменьшения локализации при той же надежности мы должны добавить больше локальных соотношений по модулю для сохранения числа соотношений, покрывающих каждую порцию данных, что указывает на понижение эффективности использования пространства.
Пользователи обычно полагают, что надежность не должна приноситься в жертву для повышения эффективности восстановления. В таком случае, мы, как правило, предполагаем жертву эффективности использования пространства в противовес надежности, поскольку эффективность использования пространства и эффективность восстановления также совместно используют компромисс взаимоотношений (#3).
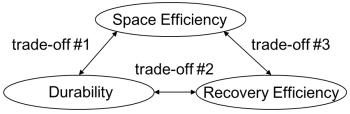
Рисунок 1а Три способа компромиссов
В оставшейся части данной статьи мы предложим и испробуем новый код затирания с локальными группами соотношения по модулю, основанном на приведенном выше анализе.
2.2. Драночный код затирания
Мы предлагаем новый код затирания, драночный код затирания (SHEC, Shingled Erasure Code), который разрабатывается для для эффективного восстановления в случае множественного отказов дисков с настраиваемыми под требования пользователя эффективностью использования пространства и надежностью. SHEC является кодом затирания с локальными группами соответствия по модулю и диапазоны вычисления локального соответствия по модулю сдвигаются и соответствия перекрывают друг друга аналогично дранкам на крыше здания. Все локальные группы соответствия имеют одну и ту же локализацию и сдвигаются на практически почти постоянные интервалы. SHEC(k,m,l) представляет схему с k порциями данных, m порциями соответствий по модулю и локализацией l. {Прим.пер.: обращаем ваше внимание на то, что в данной статье принято обозначение метода, отличное от приводимого выше перевода описания метода с сайта Ceph, а именно: там использовалось обозначение SHEC(k,m,c), где c обозначало оценку надежности метода, равную ml/k в терминах данной статьи.}
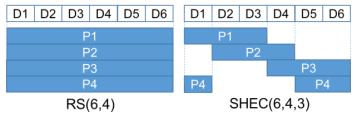
Среднее число порций соответствия, которое имеет отношение к каждой порции данных равно ml/k. Поскольку отказ ml/k+1 порций данных или соответствий может вызвать потерю данных, мы используем ml/k как оценку долговечности SHEC. Например, в случае SHEC(10,6,5) оценка равна 3 (= ml/k= 6*5/10) и четыре отказа D1/P1/P5/P6 вызовут потерю данных, поскольку D1 не может быть восстановлен из оставшихся порций (Рисунок 2а).
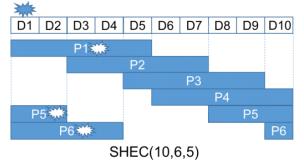
Рисунок 2а Оценка долговечности SHEC
В случае множественного отказа порций данных SHEC восстанавливает данные из множества порций соответствия. Обычно существует множество комбинаций порций соответствий, которые восстанавливают отказавшие порции. SHEC выбирает те, которые требуют меньшее число чтений дисков. Например, когда отказывают присутствующие на Рисунке 2а D6/D9, SHEC выберет P3/P4, поскольку объединение вычислительных диапазонов P3/P4 имеет результатом шесть непрерывных порций данных и размер объединения (который указывает количество данных, подлежащих чтению) является наименьшим среди всех кандидатов пар порций соответствий по модулю (корректирующих кодов).
Чтобы продемонстрировать фактор улучшения надежности мы сравним SHEC(6,4,3) c представителем простых локальных групп соответствия по модулю (SLPG, Рисунок 3а). Если одновременно отказывают D1/D2/D3, SLPG не может быть восстановлен, поскольку к D1/D2/D3 имеют отношение только P1/P3. В противоположность этому, SHEC(6,4,3) может быть восстановлен по P1/P2/P4. Для всех моделей отказов случаи потери данных для SHEC(6,4,3) составляют половину от потерь данных для SLPG. Это означает, что надежность SHEC(6,4,3) вдвое выше чем у SLPG при тех же значениях эффективности использования пространства и восстановления. Более того, чем выше значение оценки надежности, тем больше значение коэффициента улучшения надежности (Рисунок 4а). Улучшение связано со сдвигом диапазона вычислений для каждого локального соответствия по модулю (корректирующего кода).
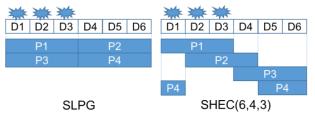
Рисунок 3а Сопоставление SLPG и SHEC
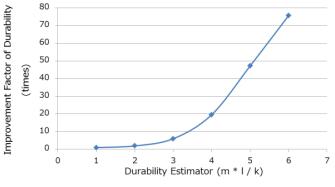
Рисунок 4а Коэффициент улучшения надежности
Формулировка генерирующей матрицы SHEC очень проста. Во- первых мы создаем генерирующую матрицу систематического кода Рида- Соломона (сокращенно записываемого в данной статье как RS(k,m)). Далее каждый элемент матрицы, чья надлежащая порция данных не используется для вычисления надлежащей порции соответствия (корректирующегокода) устанавливается равной нулю (Рисунок 5а). Использование процессора прямо пропорционально числу ненулевых элементов матрицы.
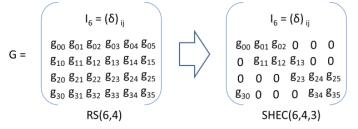
Рисунок 5а Генерирующая матрица SHEC
В этом разделе мы покажем, что SHEC обеспечивает шаблоны с меньшими затратами на восстановление,
при этом обеспечивая соответствие требованиям пользователя конфликтующих свойств эффективности использования пространства и
надежности. Ограничиваясь только значащими значениями, SHEC способен создавать более 100 различных наборов
параметров в трехмерном пространстве свойств. Мы укажем на некоторые из этих наборов и сравним их свойства кода затирания.
Давайте начнем с SHEC(4,2,4), эквивалентного RAID6 набора параметров SHEC, и найдем альтернативные кандидатуры, которые имеют более
эффективное восстановление практически с той же надежностью (Таблица 1). В этом случае мы жертвуем эффективностью использования
пространства и мы можем рассмотреть кандидатуры SHEC(4,3,3) и SHEC(6,4,3).
Таблица 1 Кандидаты с эквивалентной надежностью Давайте подыщем других кандидатов с бОльшей эффективностью восстановления при почти равной
эффективности использования пространства (Таблица 2). В этом случае мы жертвуем надежностью и мы получаем кандидатами
SHEC(5,3,3) и SHEC(7,4,3).
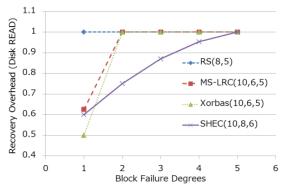
Таблица 2 Кандидаты с эквивалентной эффективностью использования пространства Мы сравнили теоретические затраты на восстановление между кодом Рида- Соломона, MS-LRC,
Xorbas и SHEC при условии практически одинаковой надежности (Рисунок 6а). Затраты на восстановление с применением SHEC меньше чем
во всех остальных случаях при отказе двух и более дисков. Остальные варианты еще хуже, поскольку они должны в данном случае
использовать глобальные соответствия по модулю (корректирующие коды).
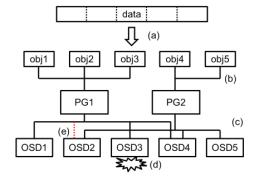
Рисунок 6а Сравнение затрат на восстановление различных кодов Мы сделали оценку SHEC в Ceph. Кластер Ceph содержит большое число демонов хранения объектов
(OSD). Каждый OSD соответствует устройству хранения. В данной статье OSD обозначает целое дисковое устройство. Группа размещения
(PG, Placement Group) является набором OSD, в которых случайно распределены порции данных и соответствий по модулю (корректирующих
кодов). Когда данные записываются в кластер Ceph, (a) эти данные дробятся на объекты Ceph размером 4МБ.
Далее, (b) группа размещения (PG) определяется значением хэш-тега для имени данного объекта. Наконец, (c) каждый элемент данных
или порция соответствия (корректирующий код) сохраняется в одном из OSD, назначенном этой PG. Если (d) OSD отказывает, другой
OSD назначается деградировавшей PG и потерянная порция восстанавливается в OSD с оставшихся порций в действующем наборе.
Рисунок 7а Архитектура Ceph Начиная с редакции v0.80.1 (Firefly), объектное хранилище Ceph имеет интерфейс подключаемых программ
для кода затирания. В качестве кода по умолчанию он поддерживает код Рида- Соломона, а в качестве альтернативы мы реализовали SHEC.
Интерфейс является достаточным для реализации SHEC, поскольку он содержит полезную функцию Мы сделали оценку эффективности восстановления SHEC(6,4,3), а для сопоставления выбрали RS(6,4)
(Рисунок 8а). Сравнение с Xorbas или MS-LRC выходит за рамки данной статьи.
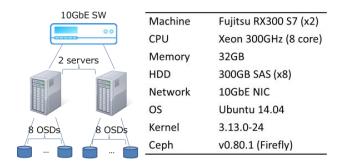
Рисунок 8а Размещение соответствий по модулю для сравнения Установленные аппаратные средства и версии программного обеспечения для тестирования приведены на
Рисунке 9а.
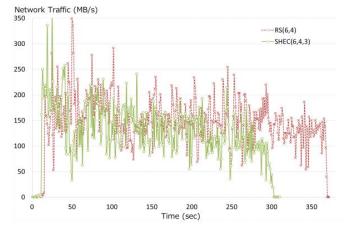
Рисунок 9а Установленная аппаратура и версии программного обеспечения Мы подготовили 100ГБ данных (25 000 объектов по 4МБ) и измерили время восстановления при отказе
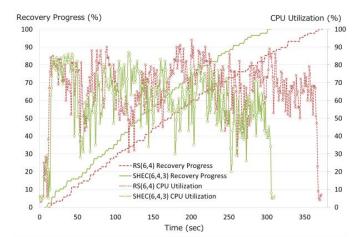
двух OSD в каждом из вариантов RS(6,4) и SHEC(6,4,3). Мы установили число потоков восстановления равным пяти. Вначале мы
увидели, что общие затраты ЦПУ для SHEC(6,4,3) были примерно на 20% ниже чем для RS(6,4), как это показано на Рисунке 10а.
Мы сочли, что в основном это обусловлено упрощением генерирующей матрицы (Рисунок 5а), поскольку использование процессора прямо
пропорционально числу ненулевых элементов матрицы. Далее, затраты на восстановление RS(6,4) равны 1.00 (число считываемых порций равно k), в то время,
как для SHEC(6,4,3) они равны 0.74 (Таблица 1). По этой причине мы оценили вначале время восстановления SHEC(6,4,3) как 74% от
RS(6,4). Однако, эксперимент показал, что хотя объем считываемых с диска данных составлял 74%, действительное время восстановления
составляло 81.4% от RS(6,4) (Рисунок 10а). Причина заключалась в существовании определенно узкого места. Мы предположили, что один из ресурсов
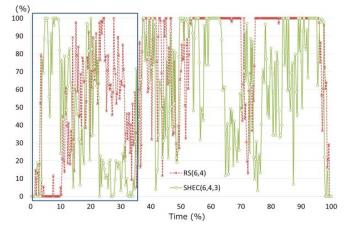
системы является бутылочным горлышком, и действительно, диски выглядят узким местом (Рисунок 11а), в то время как ЦПУ и сеть
(Рисунок 10а, Рисунок 12а) совсем не являются таковыми. Однако, бутылочное горлышко за счет дисков не является непрерывным.
Рассмотрев Рисунок 11а, мы видим, что пропускная способность дисков не используется полностью на протяжении 35% от всего времени
восстановления (в прямоугольнике) и мы можем повторно сделать оценку времени восстановления SHEC(6,4,3) следующим образом: 0.74 * (1-0.35) + 1.0 * 0.35 = 0.831
(2) Результат составил 83% от RS(6,4), что примерно равно действительному соотношению, 81.4%. В конце концов мы пришли к выводу, что затраты на восстановление SHEC уменьшились по сравнению с
кодом Рида- Соломона. Однако, в условиях нашего теста 70% эффективности восстановления SHEC воплощается в уменьшении времени
ожидания выполнения восстановления, а 30% реализуется как уменьшение от пропускной способности дисков, используемых для
выполнения восстановления. Более того, мы получили аналогичные результаты при попытке сравнения между RS(5,3) и SHEC(5,3,3)
в случае отказа одного OSD.
Рисунок 10а Выполнение восстановления и использование ЦПУ
Рисунок 11а Использование диска
Рисунок 12а Сетевой обмен Различные системы хранения используют код затирания [1] для реализации более высокой
надежности хранения данных на протяжении длительных периодов времени. В особенности, хорошо известный RAID [1], основанный
на коде Рида- Соломона, который был реализован практически во всех высоконадежных системах хранения. После того, как Google предал гласности свою файловую систему (Google File System) [3], которая
использовала тройные репликации с рассеиванием их по общедоступным дискам, другие основные облачные хранилища, такие как
Amazon HDFS [4] и хранилище Microsoft Azure [5] последовали в этом направлении. Однако, поскольку создаваемые службами ИВТ
объемы данных начали расти взрывообразно, вновь произошла переоценка эффективности использования пространства кодом затирания [6]. В последние годы затраты на восстановление стали рассматриваться как существенная проблема кодов
затирания, в особенности для распределенных или масштабируемых систем хранения [9], [10]. Многие исследователи предложили
методы, включая технологии локального соответствия по модулю для уменьшения затрат на восстановление. Коды WEAVER [7] предложили
общий метод, который содержит большинство локальных шаблонов соответствия по модулю (корректирующих кодов). Пирамидальные коды
Microsoft (Microsoft Pyramid Codes) [8], а впоследствии коды локальной реконструкции Azur (MS-LRC) [9], а также Facebook
Xorbas [10] изучили надежность локальных кодов соответствия. МС-LRC настаивал, что вероятность утраты данных (случай теоретически
не декодируемой информации) ограничен незначительным уровнем. С другой стороны Xorbas исследовал на высоком теоретическом
уровне взаимосвязь между локальностью и расстояниями между кодами. Восстанавливающие (Regenerating) коды [11], [12] предложили
интересный подход, в котором обсуждаются оптимальный компромисс между эффективностью использования пространства и пропускной
способностью восстановления с помощью анализа на "основе отсечений". Циклические коды Рида- Соломона (Rotated
Reed-Solomon Codes) [13] предлагают локальные соответствия имеют аналогичные шаблоны SHEC. Тем не менее, они характеризуются
числом дисков данных, фактически ограниченными для продукта парами целых чисел. Фонтанный (Fountain) код [19] также способен
использовать скользящие окна, однако выбирает слишком вероятностный подход. Во- первых, мы предложили SHEC, новый затирающий код, разработанный для высокоэффективного
восстановления, в особенности, в случае множественных отказов дисков. Во-вторых, мы показали что SHEC предоставляет схемы с
бОльшей эффективностью, чем коды Рида- Соломона, при этом гарантируя, что конфликтующие характеристики эффективности использования
пространства и надежности устанавливаются в соответствии с требованиями пользователя. Наконец, с помощью экспериментов
мы продемонстрировали, что восстановление с применением SHEC действительно быстрее чем применение кодов Рида- Соломона. Тем не менее, демонстрация превосходства SHEC над современными кодами (Xorbas и MS-LRC) без
каких- либо жертв со стороны эффективности использования пространства или надежности может оказаться не такой простой.
Таким образом, мы будем в будущем расширять концепцию нормального SHEC в сторону несимметричности или объединения с глобальными
соответствиями по модулю. [1] L. Rizzo. Effective erasure codes for reliable computer
communication protocols. Computer Communication Review, April 1997. [2] David A. Patterson, Garth A. Gibson, and Randy H. Katz.
A case for redundant arrays of inexpensive disks (RAID). In Proceedings of the 1988 ACM SIGMOD
International Conference on Management of Data, pages 109-116, Chicago, Illinois, September 1988. [3] Ghemawat, S., Gobioff, H., and Leung, S.-T. The Google File System.
In 19th Symposium on Operating Systems Principles. Lake George, NY. 29-43, December 2003. [4] K. Shvachko, H. Kuang, S. Radia, and R. Chansler.
The hadoop distributed file system. In Proceedings of the 2010 IEEE 26th Symposium on Mass Storage
Systems and Technologies (MSST), pages 1 -10, Washington, DC, USA, 2010. IEEE Computer Society [5] B. Calder, J. Wang, A. Ogus, N. Nilakantan, A. Skjolsvold,
S. McKelvie, Y. Xu, S. Srivastav, J. Wu, H. Simitci, J. Haridas, C. Uddaraju, H. Khatri, A. Edwards,
V. Bedekar, S. Mainali, R. Abbasi, A. Agarwal, M. Fahim ul Haq, M. Ikram ul Haq, D. Bhardwaj, S. Dayanand,
A. Adusumilli, M. McNett, S. Sankaran, K. Manivannan, and L. Rigas. Windows Azure storage: A highly
available cloud storage service with strong consistency. In Symposium on Operating Systems Principles, 2011. [6] H. Weatherspoon and J. D. Kubiatowicz. Erasure coding vs. replication:
A quantitiative comparison. In Procs. of IPTPS, 2002. [7] J. L. Hafner. WEAVER Codes: Highly fault tolerant erasure
codes for storage systems. FAST 2005, San Francisco, CA, Dec. 2005. [8] C. Huang, M. Chen, and J. Li. Pyramid codes: Flexible schemes
to trade space for access efficiency in reliable data storage systems. Presented at the
IEEE Int. Symp. Network Computing and Applications, Jul. 2007. [9] C. Huang, H. Simitci, Y. Xu, A.Ogus, B. Calder, P. Gopalan,
J. Li, and S. Yekhanin. Erasure coding in Windows Azure Storage. Presented at the USENIX Annu. Tech.
Conf., Boston, MA, 2012. [10] M. Sathiamoorthy, M. Asteris, D. S. Papailiopoulos, A. G. Dimakis,
R. Vadali, S. Chen, D. Borthakur. XORing elephants: novel erasure codes for big data.
In Proc. of the Very Large Data Bases conference (VLDB), 2013, pp. 325-336. [11] Y. Wu, A. G. Dimakis, and K. Ramchandran. Deterministic regenerating
codes for distributed storage. Presented at the Allerton Con. Control, Computing, and Communication,
Urbana-Champaign, IL, Sep. 2007. [12] K. V. Rashmi, N. B. Shah, P. V. Kumar, and K. Ramchandran. Explicit
and optimal exact-regenerating codes for the minimum-bandwidth point in distributed storage. In Proc.
IEEE Int. Symp. Information Theory (ISIT), Austin, Jun. 2010, pp. 1938-1942. [13] O. Khan, R. Burns, J. Plank, W. Pierce, and C. Huang. Rethinking
erasure codes for cloud file systems: Minimizing I/O for recovery and degraded reads. In FAST 2012. [14] S. Weil, S. Brandt, E. Miller, D. Long, and C. Maltzahn.
Ceph: A scalable, high-performance distributed file system. In Proc. of the 7th Symposium
on Operating Systems Design and Implementation, Seattle, WA, November 2006. [15] S. A. Weil, S. A. Brandt, E. L. Miller, and C. Maltzahn.
CRUSH: Controlled, scalable, decentralized placement of replicated data. In Proc. Supercomputing
(SC), 2006. [16] D. Ford, F. Labelle, F. Popovici, M. Stokely, V.-A. Truong,
L. Barroso, C. Grimes, and S. Quinlan. Availability in globally distributed storage systems.
In OSDI, 2010. [17] Richard Elling. A story of two MTTDL models. Ramblings from Richard’s Ranch,
2007. Retrieved from
https://blogs.oracle.com/relling/entry/a_story_of_two_mttdl [18] M. Silberstein, L. Ganesh, Y. Wang, L. Alvisi and M. Dahlin.
Lazy means smart: Reducing repair bandwidth costs in erasure-coded distributed storage.
In Proc. SYSTOR, Jun. 2014. [19] M. Asteris and A. G. Dimakis. Repairable fountain codes.
In Proc. Int. Symp. Inform. Theory, Cambridge, MA, July 2012, pp. 1752–1756.2.3. Сравнение наборов параметров SHEC
k
l
m
ml/k
Эфф. исп.
пространства
Надежность
(за год)
Затраты на восст.
(1x/2x отказа)
4
2
4
2
67%
1.44E-17
1.00/1.00
4
3
3
2.25
57%
1.60E-18
0.75/1.00
6
4
3
2
60%
3.46E-18
0.50/0.74
k
l
m
ml/k
Эфф. исп.
пространства
Надежность
(за год)
Затраты на восст.
(1x/2x отказа)
4
2
4
2
67%
1.44E-17
1.00/1.00
5
3
3
1.8
63%
1.22E-10
0.60/0.90
6
4
3
1.71
64%
1.65E-10
0.43/0.69
2.4. Сравнение с другими кодами затирания
3. Реализация и оценки
3.1. Архитектура Ceph
3.2. Реализация SHEC
minimum_to_decode(),
которая возвращает множество номеров порций, требующееся для декодирования утраченных порций. SHEC возвращает подмножество номеров
порций, которое возвращает код Рида- Соломона.3.3. Условия тестирования
3.4. Производительность восстановления SHEC
4. Связанные работы
5. Заключение и дальнейшие работы
6. Ссылки
- © Copyright 2015 Ceph Wiki, Module-Project Ltd (перевод)