Эталонная архитектура для инфраструктуры данных Искусственного Интеллекта и Машинного обучения
Официальный документ
Copyright © 2024 MinIO
Опубликовано MinIO
275 Shoreline Dr, Ste 100,
Redwood City, CA 94065,
United States
2024-07-19
В корпоративном Искусственном интеллекте присутствуют два основных типа моделей: Различающие (Дискриминативные) и Порождающие (Генеративные). {Прим. пер.: В современной литературе discriminative и generative переводятся именно как Дискриминативные и Генеративные, но с нашей точки зрения Различающие и Порождающие точнее передают смысл моделей.} Различающие модели применяются для классификации или прогнозирования данных, в то время как Порождающие модели используются для создания новых данных. Несмотря на то, что в последнее время преобладает Порождающий ИИ, организации по- прежнему работают с обоими типами ИИ. Различающий ИИ продолжает оставаться важной инициативой для организаций, которые желают оперировать более действенно и преследуют дополнительную выгоду. Эти различные типы ИИ имеют очень много общего, но, в то же самое время, имеются существенные различия, которые необходимо принимать во внимание при построении вашей собственной инфраструктуры данных ИИ.
Организациям не стоит создавать инфраструктуру, предназначенную только исключительно под ИИ, оставляя в стороне такие рабочие нагрузки как Бизнес аналитика, Анализ данных и Науки о данных, оставляя их за забором. Существует возможность создать полноценную инфраструктуру, которая поддерживает все потребности вашей организации - Бизнес аналитику, Анализ данных, Науку о данных, Различающий ИИ и Порождающий ИИ.
В другой статье мы представляли эталонную архитектуру для современных возможностей Озера данных (хранилища разнородных данных) для обслуживания потребностей Бизнес аналитики, Анализа данных, Науки о данных, а также ИИ/ МО (искусственного интеллекта и машинного обучения). Давайте пересмотрим эту современную эталонную архитектуру Озера данных и выделим те возможности, которыми она обладает для поддержки рабочих нагрузок ИИ/ МО.
{Прим. пер.: доступные решения DGX 2024}
Современное Озеро данных (Data lake) - это на половину Склад данных (Data Warehouse), а на другую Озеро данных, причём для всего использует хранилище объектов. Применение хранилища объектов имеет смысл для Озера данных, ибо хранилище объектов предназначено для неструктурированных данных, к хранению которых и предназначено Озеро данных. Тем не менее, применение хранилища объектов для Склада данных (Data Warehouse) может показаться странным, однако построенный таким образом Склад данных представляет собой следующее поколение Складов данных. Это стало возможным благодаря разработанным Netflix, Uber и Databricks спецификациям Open Table Format (OTFs), бесшовно применяющими хранилище объектов для Склада данных.
Спецификации OTF это Apache Iceberg, Apache Hudi и Delta Lake. Они были разработаны, соответственно, Netflix, Uber и Databricks, поскольку на рынке отсутствовали удовлетворяющие их потребностям продукты. По сути, то что они делают (разными способами) это определение Склада данных, которое может быть создано поверх хранилища объектов (MinIO). Хранилище объектов обеспечивает сочетание масштабируемой ёмкости с высокой производительностью, на что неспособны прочие решения хранения. Поскольку это современные спецификации, они обладают расширенными функциональными возможностями, которых не имеют ранее разработанные Склады данных, например, эволюцией раздела, эволюцией схемы, а также ветвлением с нулевым копированием. Наконец, благодаря построению Склада данных на основе хранилища объектов, вы можете применять то же самое хранилище объектов для неструктурированных данных, таких как изображения, видео файлы, аудио файлы и документы. Как правило, неструктурированные данные хранятся в том, что в отрасли именуется Озером данных. Применение хранилища объектов в качестве основы, причём как для вашего Озера данных, так и для вашего Склада данных, в результате приводит к решению, способному хранить все ваши данные. Структурированное хранилище располагается в базирующемся на OTF Складе данных, а неструктурированные данные проживают в Озере данных. Для обоих случаев можно применять один и тот же экземпляр MinIO.
В MinIO мы называем такое сочетание базирующегося на OTF Склада данных и Озера данных, современного Озера данных, и мы рассматриваем это как базу для всех ваших рабочих нагрузок ИИ/ МО (искусственного интеллекта и машинного обучения, AI/ ML). Именно здесь собираются, хранятся и обрабатываются и преобразуются данные. Применяющие Различающий ИИ модели обучение (контролируемое, неконтролируемое обучения и обучение с подкреплением) зачастую требуют решения, способные обрабатывать структурированных данные, которые могут обитать в Складе данных. С другой стороны, когда вы обучаете большие языковые модели (LLM), вам следует управлять неструктурированными данными или документами в их необработанном или переработанном видах в соответствующем Озере данных.
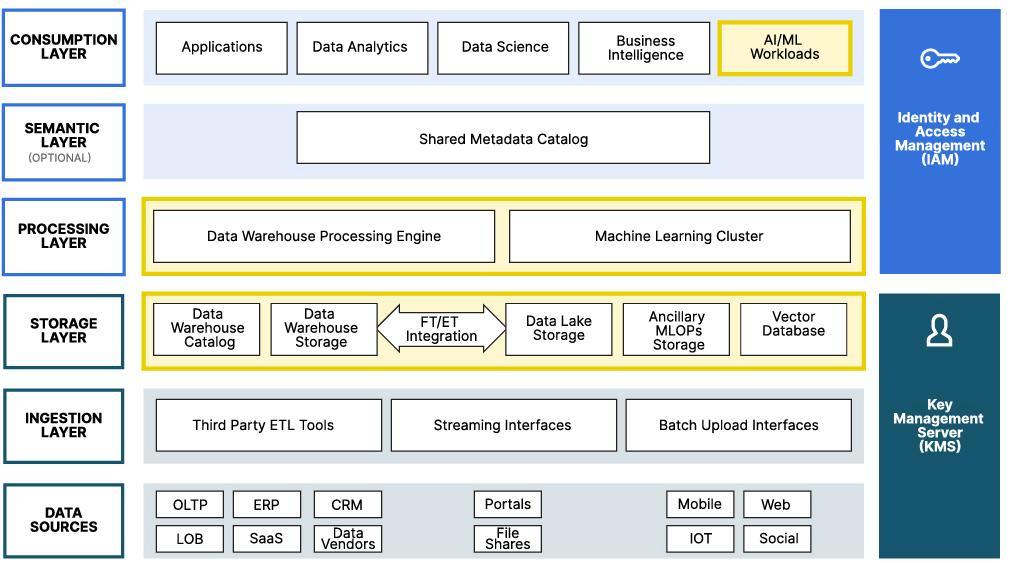
Данная статья сосредоточена на таких областях Современной эталонной архитектуры Озера данных для рабочих нагрузок ИИ/ МО. Эти области функциональных возможностей перечисляются ниже. Визуальное отображение такого современного Озера данных показано выше. Были выделены те уровни, на которых можно обнаружить обсуждаемые области функциональности.
-
Различающий ИИ
-
Хранилище для неструктурированных данных
-
Хранилище для частично структурированных данных
-
Ветвление с нулевым копированием в Складе данных
-
-
Порождающий ИИ
-
Построение Индивидуального свода при помощи векторной базы данных
-
Построение Конвейера документов
-
Генерацию с учётом дополняющих релевантных сведений (RAG)
-
Тонкую настройку Больших языковых моделей (LLM)
-
Измерение точности LLM
-
-
Операции машинного обучения
Данная статья также рассматривает текущее состояние GPU и того, каким образом они оказывают воздействие на вашу инфраструктуру данных ИИ. К тому же мы рассмотрим пару сценариев, которые иллюстрируют каким образом строить вашу инфраструктуру и как её не следует собирать. Наконец, эта статья представит ряд рекомендаций для построения вашей собственной Инфраструктуры данных ИИ.
-
Текущее состояние GPU
-
Проблема голодных GPU
-
Перенапряжение Хранилища объектов
-
-
История двух контор
-
План построения вашей собственной инфраструктуры данных ИИ
Различающий (Дискриминативный) ИИ для обучения требует всех типов моделей данных. Модели для распознавания образов и голоса будут пользоваться неструктурированными данными в виде файлов образов и аудио. С другой стороны, модели выявления мошенничества и медицинской диагностики выполняют прогнозы базируясь на структурированных данных. Давайте рассмотрим варианты хранения и манипуляций необходимых Различающему ИИ данных, доступных в современном Озере данных.
Неструктурированные данные будут расположены в нашем Озере данных, где они могут применяться для моделей обучения и проверок. Перед обучением (прежде чем запущен цикл эпох) обучающие наборы могут быть размещены в оперативной памяти. Однако, когда обучающие наборы велики и не будут помещаться в оперативной памяти, прежде чем приступать к обучению, вам придётся загружать перечень объектов и выполнять в своём цикле эпох выборку самих реальных объектов при обработке каждого пакета. Это может создавать нагрузку на ваше Озеро данных когда вы применяете при его построении высокоскоростной сетевой среды и высокоскоростных дисковых устройств. Если ваши модели обучения с данными не способны помещаться в оперативной памяти, тогда подумайте о создании своего Озера хранения с сетевой средой 100Gb и с дисками NVMe.
Для хранения частично структурированных файлов, таких как файлы Parquet, AVRO, JSON и даже CSV, внутри современного Озера данных имеется ряд возможностей. Самый простой вариант состоит в их хранении в Озере данных тем же способом, что и неструктурированные данные. Когда данные этих частично структурированных файлов не требуются прочим поддерживаемым современным Озером данных рабочим нагрузкам (таким как Бизнес аналитика, Анализ данных и Наука данных), это самый лучший способ.
Другой вариант заключается в загрузке таких файлов в ваш Склад данных, где прочие рабочие нагрузки могут пользоваться ими. Когда данные загружены в ваш Склад данных, для выполнения экспериментов с ними вы можете применять Ветвление с нулевым копированием.
Разработка функциональных возможностей (Feature engineering) - это метод улучшения применяемых для обучения модели данных. Очень удобная функциональная возможность, которой обладают Склады хранения на основе OTF является Ветвление с нулевым копированием. Она делает возможным ветвление данных точно так же, как можно разветвлять код в репозитории Git. Как следует из самого названия, данная функциональная возможность не создаёт копию обрабатываемых данных - вместо этого она пользуется уровнем метаданных OTF для реализации своим Складом хранения создания видимости уникальной копии данных. Вычислительные математики могут поэкспериментировать с ветвью - когда их эксперименты окажутся успешными, они смогут соединить свою ветвь обратно с основной веткой, дабы ею могли бы пользоваться прочие исследователи. Когда их эксперимент не увенчается успехом, такая ветвь может быть удалена.
Все модель, будь то построенные Scikit-Learn небольшие модели, построенные при помощи PyTorch или TensorFlow индивидуальные нейронные сети, либо большие языковые модели (LLM), основанные на архитектуре Transformer, в качестве входных данных требуют чисел, а на выходе также производят числа. Этот простой факт предъявляет ряд дополнительных требований к вашей инфраструктуре ИИ/ МО раз вы заинтересованы в Порождающем (Генеративном) ИИ, где слова должны быть преобразованы в числа (или, как мы обнаружим, в векторы). Решение с применением Порождающего ИИпревращается в ещё более сложное, когда для улучшения получаемых от LLM ответов вы желаете воспользоваться частными документами, содержащими собственные данные вашей компании. Подобное расширение может быть представлено в виде Генерации с учётом дополняющих релевантных сведений (RAG) или Тонкой настройки LLM.
Данный раздел обсудит все эти методики (превращение слов в числа, RAG и тонкую настройку), а также их воздействие на инфраструктуру ИИ. Давайте начнём с обсуждения того как выстраивать Индивидуальный свод (Custom Corpus) и где он должен располагаться.
Если вы всерьёз относитесь к Порождающему ИИ, ваш Индивидуальный свод (custom corpus) обязан определять вашу организацию. Он должен содержать обладающие знаниями документы, которых нет ни у кого иного, причём содержащими правдивые и точные сведения. Кроме того, ваш Индивидуальный свод должен быть построен при помощи Векторной базы данных. Векторная база данных индексирует, хранит документы и предоставляет к ним доступ совместно с их векторными вложениями, являющиеся числовыми представлениями ваших документов. (Это решает описанную выше проблему с числами.)
Векторные базы данных предоставляют функциональную возможность семантического поиска. То, как это осуществляется требует больших математических навыков и является сложным процессом. Тем не менее, семантический поиск прост для понимания. Допустим, вы желаете отыскать все относящиеся к "artificial intelligence" документы. Для осуществления этого в обычной базе данных вам потребуется выполнять поиск по всем возможным сокращениям, синонимам и относящимся к "artificial intelligence" терминам. Ваш запрос выглядел бы примерно так:
SELECT snippet
FROM MyCorpusTable
WHERE (text like '%artificial intelligence%' OR
text like '%ai%' OR
text like '%machine learning%' OR
text like '%ml%' OR
... без остановок ...
Поиск вручную не только тяжек и подвержен ошибкам, но и сам по себе осуществляется очень медленно. Векторная база данных обладает возможностью принять подобный приведённому ниже запрос и выполнить такой запрос быстрее при большей точности. Если вы желаете воспользоваться Генерация с учётом дополняющих релевантных сведений (RAG), важна возможность быстрого и точного осуществления семантических запросов.
{
Get {
MyCorpusTable(nearText: {concepts: ["artificial intelligence"]})
{snippet}
}
}
Ещё одной важной подлежащей рассмотрению стороной вашего Индивидуального свода выступает безопасность. Доступ к документам обязан соответствовать ограничениям на доступ к оригинальным документам. (Было бы прискорбно, если бы стажёр смог бы получить доступ к финансовым результатам вашего Финансового директора, которые пока не были опубликованы на Wall Street.) В рамках вашей Векторной базы данных вам следует настроить авторизацию в соответствии с уровнями исходного содержимого. Это можно осуществить, интегрировав вашу Векторную базу данных с имеющимся в вашей организации решением идентификации и управления доступом.
В своей основе, Векторные базы данных хранят неструктурированные данные. Тем самым, для своего решения хранения они должны пользоваться вашим Озером данных.
К несчастью, большинство организаций не обладает единственным репозиторием с чёткими и точными документами. Кроме того, документы разбросаны по самой организации и различным порталам команд во множестве форматов. Следовательно, самым первым шагом при построении Индивидуального свода (custom corpus) является выстраивание конвейера, который бы принимал бы лишь те документы, которые были допущены к использованию при помощи Порождающего ИИ и помещал бы их в вашу Векторную базу данных. Для больших глобальных организаций потенциально это может оказаться самой сложной задачей решения Порождающего ИИ. Как правило, команды размещают в порталах черновики документации. Также могут присутствовать документы, представляющие собой произвольные размышления о том что могло бы иметься. Эти документы не обязаны становиться составной частью Индивидуального свода, ибо они не совсем точно отражают ведение дел. К сожалению, фильтрация подобных документов будет производиться вручную.
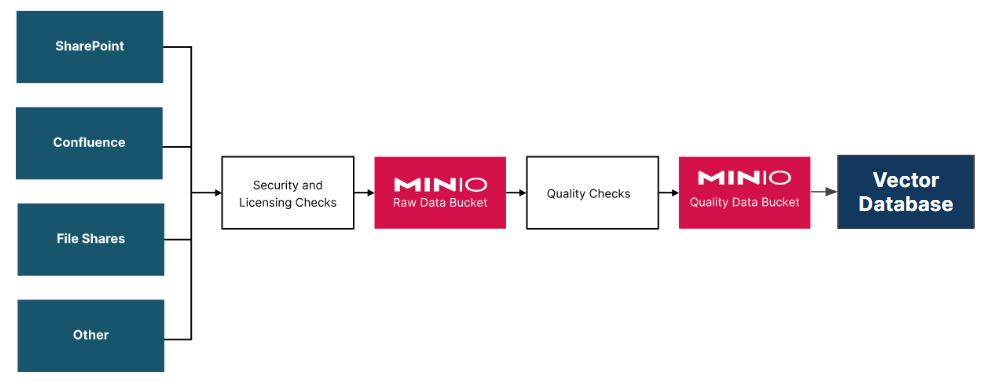
Конвейер документов также обязан преобразовывать все документы в текст. К счастью, некоторые библиотеки с открытым исходным кодом способны осуществлять это для многих распространённых форматов документов. Кроме того, конвейер документов обязан разбивать документы на сегменты меньшего размера перед их сохранением в вашей Векторной базе данных. Это обусловлено ограничением на размер приглашения (prompt) при применении такого документа для Генерация с учётом дополняющих релевантных сведений (RAG), что мы обсудим в одном из идущих далее разделов.
При тонкой настройке Большой языковой модели (LLM), мы к тому же слегка обучаем её при помощи сведений Индивидуального свода (custom corpus). Это может оказаться хорошим способом получения LLM для конкретной предметной области. Хотя данный вариант требует от компьютера осуществления точной настройки в соответствии с вашим Индивидуальным сводом, это не столь трудоёмко как обучение модели с нуля и может быть выполнено в сжатые сроки.
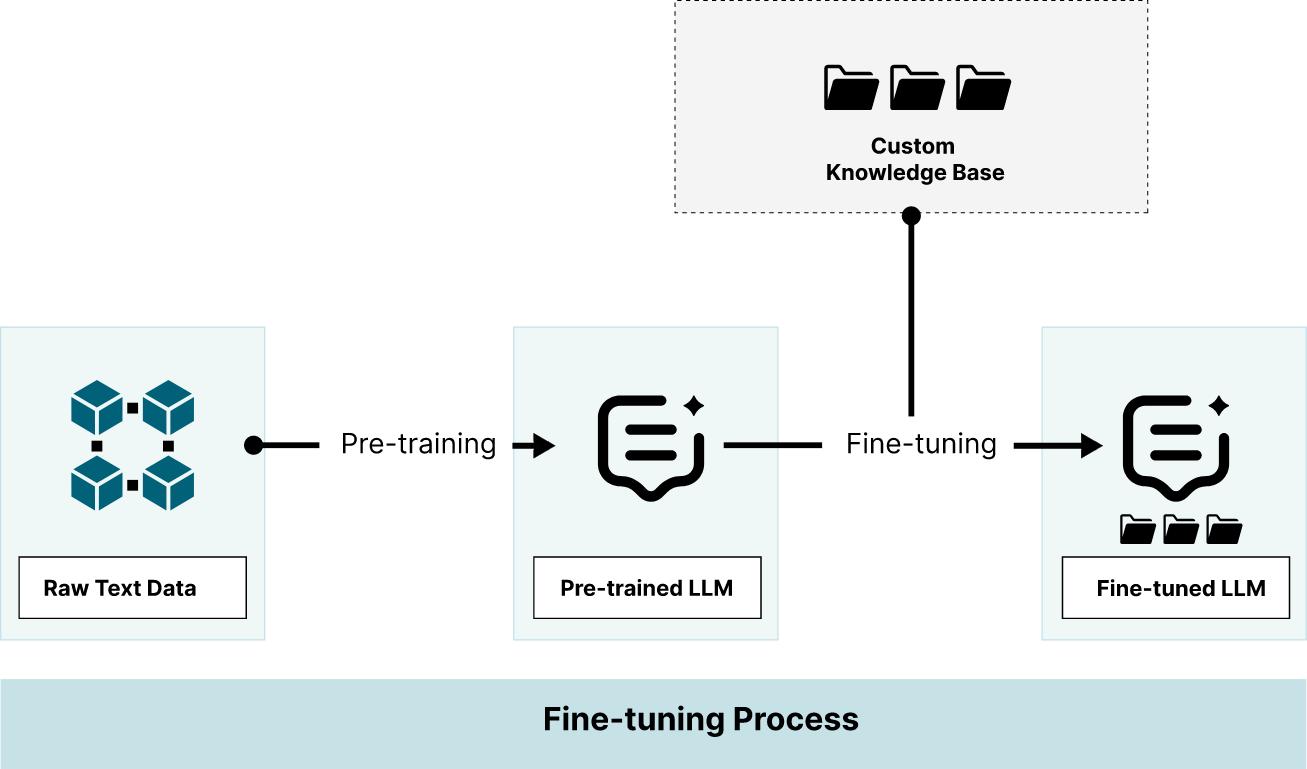
Когда ваша область содержит не применяемые в повседневной жизни термины, качество откликов отстраиваемой LLM может существенно улучшать тонкая настройка. К примеру, от тонкой настройки могут выигрывать проекты, в которых используются документы из области медицинских исследований, экологических изысканий и всего, что связано с естественными науками. При тонкой настройке принимаются во внимание встречающиеся в документах весьма специфические термины, причём они преобразуются в параметрические показатели вашей модели. Прежде чем принимать решение о подобном подходе, необходимо разобраться с преимуществами и недостатками тонкой настройки.
- Недостатки
Тонкая настройка требовательна к вычислительным ресурсам.
Её толкование не возможно.
Вам периодически будет требоваться повторная тонкая настройка при вовлечении новых Индивидуальных сводов.
Следует иметь в виду "глюки".
Невозможна безопасность на уровне документа.
- Преимущества
Посредством тонкой настройки применяемая LLM обладает знаниями из вашего Индивидуального свода.
Процесс вывода менее сложен чем при RAG.
Хотя тонкая настройка и хороший способ обучения применяемой LLM вашему делу, она приводит к размыванию рассматриваемых данных, ибо большинство LLM содержит миллиарды параметров и по всем этим параметрам будут распределяться ваши данные. Самым большим недостатком тонкой настройки выступает невозможность авторизации на уровне документа. Как только документ применяется для тонкой настройки, его сведения становятся частью этой модели. Невозможно ограничивать эту информацию на основе уровней авторизации пользователей.
Давайте рассмотрим метод, который сочетает ваши индивидуальные и параметрические данные во время вывода.
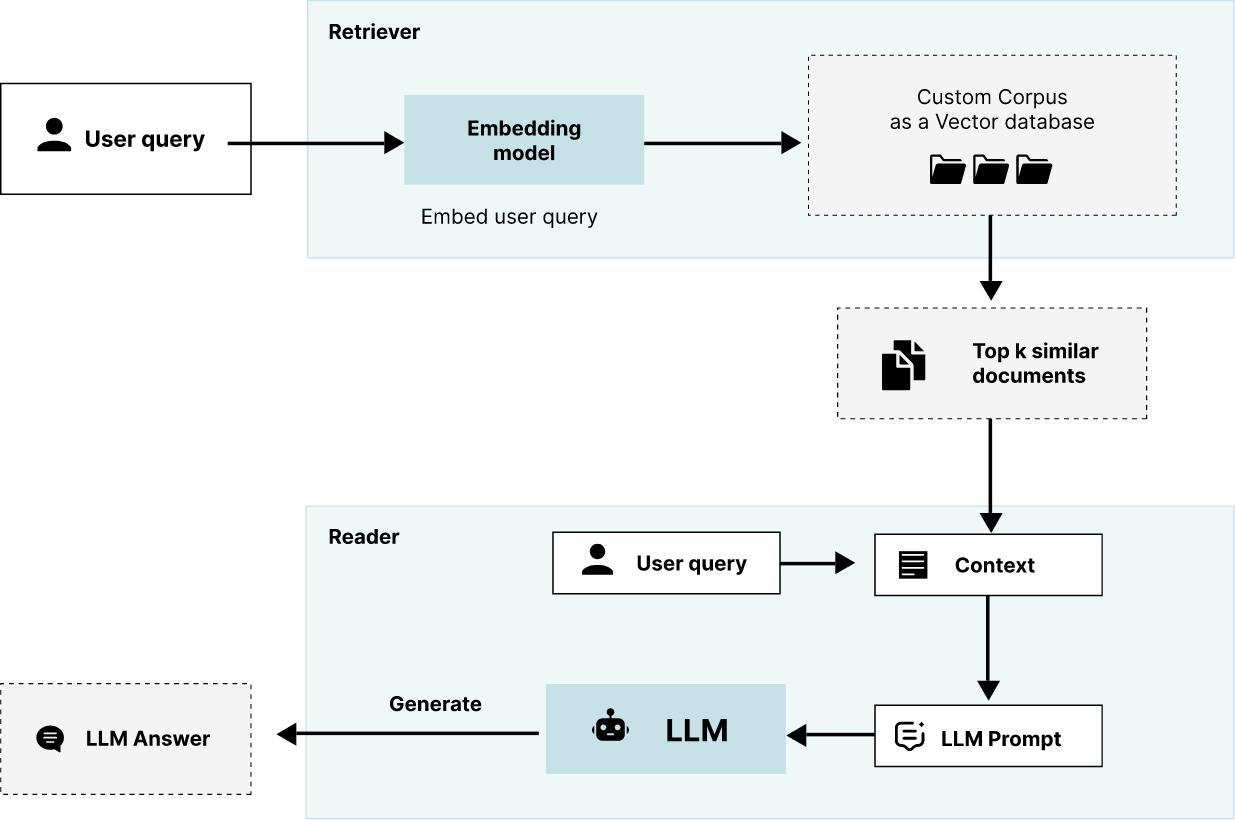
Генерация с учётом дополняющих релевантных сведений (Retrieval Augmented Generation, RAG) это методика, которая начинается с задаваемого вопроса - для соединения таких вопросов с дополнительными сведениями используется Векторная база данных, а затем этот вопрос и данные передаются в LLM для создания содержимого. При применении RAG не требуется обучение, так как мы обучили применяемую LLM отправляя ей соответствующие фрагменты текстов из нашего свода качественных документов.
При применении задачи вопроса- ответа это работает следующим образом: в интерфейсе пользователя приложения он задаёт вопрос - в частности, применяемые в нём слова - и, при помощи Векторной базы данных, производится поиск в вашем своде качественных документов на предмет соответствующих контексту фрагментов текста. Эти фрагменты и исходный запрос будут отправлены в применяемую LLM. Весь этот пакет - вопрос плюс фрагменты текста (содержимое) носят название приглашения (prompt). Соответствующая LLM применяет эти сведения для выработки ответа вам. Это может показаться глупым - раз вы уже знаете ответ (ваши фрагменты), зачем беспокоиться об LLM? Но помните, всё это происходит в режиме реального времени и основная цель заключается в том чтобы произвести текст - нечто, что вы способны скопировать и вставить в своё исследование. Для создания того текста, который содержит сведения из вашего Индивидуального свода вам требуется надлежащая LLM.
Это более сложно нежели тонкая настройка. Тем не менее, применима авторизация пользователя, поскольку во время вывода соответствующие документы (либо фрагменты документов) выбираются из вашей Векторной базы. Ниже перечислены преимущества и недостатки RAG:
- Недостатки
Поток вывода более сложный.
- Преимущества
Применяемая LLM обладает знаниями из вашего Индивидуального свода.
Толкование имеет место.
Не требуется никакой тонкой настройки.
"Глюки" значительно уменьшены и их можно контролировать изучая результаты запросов Векторной базы данных.
Допустима реализация авторизации.
Для лучшего понимания важности операций машинного обучения (MLOp), полезно сопоставить создание моделей с обычной разработкой приложений. Обычная разработка приложений, такая как реализация новой микрослужбы, добавляющей в некое приложение новую функциональную возможность, начинается с пересмотра спецификации. В первую очередь разрабатываются новые все структуры данных либо любые изменения в существующих структурах данных. С момента начала кодирования структура данных не должна меняться. Далее реализуется служба и в данном процессе главным видом деятельности выступает кодирование. Также выполняется кодирование тестирование модулей и всего проекта в целом. Такие тесты подтверждают исправность самого кода и верную реализацию установленной спецификации. Перед развёртыванием всего приложения их можно запускать автоматически при помощи конвейера CI/ CD.
Создание модели и её обучение разные вещи. Самый первый шаг состоит в том чтобы разобраться с необработанными данными и необходимыми нам прогнозами. Инженерам машинного обучения (ML, МО) приходится писать код для реализации своих нейронных сетей или настройки некого алгоритма, тем не менее программирование не является их первичной активностью. Основной деятельностью у них является повторение экспериментов. В ходе экспериментов будут меняться собственно структура данных, построение модели а также применяемые параметры. После каждого эксперимента создаются метрики и они показывают как работала данная модель в процессе обучения. Эти метрики применяются для подтверждения качества своей модели. После того как данная модель готова ко встраиванию в приложение, её необходимо преобразовать в пакет и развернуть.
MLOp, сокращение для Machine Learning Operations (операций машинного обучения) это набор практических приёмов и инструментов, имеющих целью решение этих различий. Наиболее часто ассоциируемые с MLOp в наши дни функциональные возможности это отслеживание экспериментов и совместная работа, но имеющиеся сегодня в отрасли инструменты MLOp способны делать намного больше. Скажем, они способны предоставлять среду исполнения для ваших экспериментов, а также могут собирать в пакеты и развёртывать модели, как только они будут готовы к интеграции в приложение. ниже приводится расширенный набор функциональных возможностей инструментов MLOp в настоящее время. Это перечень также содержит и прочие подлежащие рассмотрению моменты, к слову, сопровождение и интеграцию данных.
-
Поддержку основных участников - Методики и функциональные возможности MLOp постоянно развиваются. Вы желаете сопровождаемый основными участниками инструментарий, которые гарантирует что эти инструменты пребывают в постоянных разработке и улучшениях.
-
Интеграция с современным Озером данных - Эксперименты производят великое множество структурированных и неструктурированных данных. В идеале они могут храниться в соответствующих Складе данных и Озере данных. Тем не менее, многие инструменты MLOp вертятся вокруг открытых форматов таблиц (OFT), которые положили начало современному Озеру данных, а потому большинство из них будет обладать собственным решением для своих структурированных данных.
-
Отслеживание эксперимента - Держим на глазу всякий набор данных эксперимента, все модели, гиперпараметры и метрики. Отслеживание экспериментов к тому же обязано способствовать повторяемости.
-
Облегчение совместной работы - позвольте членам команды просматривать результаты всех проводимых инженерами МО экспериментов.
-
Сборка модели в пакеты - Упаковка вашей модели таким образом, чтобы она была доступна из прочих сред программирования.
-
Обслуживание моделей - Развёртывание моделей в формальных средах организации. Если вы обнаружили способ включения своих моделей в имеющийся конвейере CI/ CD, вам это будет необходимо.
-
Регистрация моделей - Сопровождение всех версий моделей.
-
Функции без сервера - Некоторые инструменты предоставляют функциональные возможности, позволяющие снабжать код комментариями таким образом, что функция или модель имеет возможность развёртывать в службу контейнера для проведения экспериментов в кластере.
-
Возможности конвейера данных - Ряд инструментов MLOp имеют целью предоставление полного набора возможностей по всему приложению и обладают свойствами, которые позволяют вам строить конвейеры для выборки и сохранения ваших сырых данных. Когда вы уже обладаете конвейером данных, вам это не требуется.
-
Возможности обучаемого конвейера - Это способность организации ваших безсерверных функций в некий Направленный граф без зацикливаний (Directed Acyclic Graph). Также позволяет планировать и запускать конвейеры обучения.
Цепь настолько же прочна, как её самое слабое звено, а ваша инфраструктура ИИ/ МО работает настолько же быстро, насколько быстро работает ваш самый медленный компонент. Когда вы натаскиваете модели машинного обучения при помощи GPU, самым слабым звеном может стать ваше решение хранения данных. В результате мы получаем то, что именуется "проблемой голодающего графического процессора". Данная проблема голодания GPU возникает когда ваша сетевая среда или ваше решение хранения данных не способны достаточно быстро передавать данные обучения логике обучения, дабы полностью задействовать ваши графические процессоры. Симптомы достаточно очевидны. Если вы наблюдаете за своими GPU, вы обнаружите, что они никогда не достигают своей максимальной нагрузки. Если вы провели замеры своего кода обучения, вы обнаружите, что в общем времени обучения преобладают операции ввода/ вывода.
К сожалению, для тех, кто борется с данной проблемой, у нас плохие новости. Графические процессоры становятся всё более быстрыми. Давайте взглянем на текущее состояние GPU, а также на ряд сделанных при их помощи достижений, дабы осознать, что в ближайшие годы эта проблема будет лишь усугубляться.
Графические процессоры становятся всё быстрее. Причём, не только их теоретическая производительность растёт, но увеличиваются также память и полоса пропускания. Давайте взглянем на эти три характеристики наиболее последних GPU Nvidia, A100, H100 и H200.
| GPU | Производительность | Память | Полоса пропускания памяти |
|---|---|---|---|
A100 |
624TFLOPS |
{ 80GB} |
{2.039TB/s} |
|
1 979TFLOPS |
80GB |
3.35TB/s |
|
1 979TFLOPS |
141GB |
4.8TB/s |
|
{?4 400TFLOPS/ |
{192GB, 2x96GB} |
{8TB/s} |
Стоит привести ряд соображений по приведённым выше статистическим данным. Во- первых, H100 и H200 обладают одинаковой производительностью - 1979TFLOPS, что в 3.17 раз выше нежели у A100. {Прим. пер.: B100 и B200 строятся на двух кристаллах каждый, при этом достигнута большая плотность транзисторов в каждом из кристаллов}. У H100 в два раза больше памяти, чем у A100 и пропускная способность памяти увеличена на аналогичную величину - что разумно, в противном случае графический процессор будет голодать. {Прим. пер.: Так в тексте, на практике A100 в SXM исполнении обладает приведёнными нами (исправленными) характеристиками.} H200 может обрабатывать колоссальные 141 ГБ памяти, а пропускная способность его памяти также увеличена пропорционально по сравнению с другими графическими процессорами.
Взглянем на каждый из этих статистических показателей более подробно и обсудим что он означает для машинного обучения.
Производительность - Терафлоп (TFLOP) это один триллион (10^12) операций с плавающей точкой в секунду {Прим. пер.: точнее, BFLOPS16, не IEEE FLOPS16! См. наше замечание в заголовке таблицы.} Трудно сопоставлять TFLOP с запросом на операции ввода/ вывода в гигабайтах, поскольку происходящие во время обучения модели операции с плавающей запятой включают в себя простые тензорные математические вычисления, а также первые производные от функции потерь (так называемые градиенты). Тем не менее, допустимо относительное сравнение. Рассматривая приведённые выше статистические данные, мы видим, что H100 и H200, которые оба работают с производительностью 1979 терафлопс, в три раза быстрее когда всё прочее способно поддерживать повышение производительности {Прим. пер.: закон Амдала.}
Память GPU - Также носящая название Оперативной видеопамяти (Video RAM) или графической оперативной памяти (Graphics RAM). Память GPU обособлена от основной системной памяти (RAM, main memory) и целенаправленно приспособлена под выполняемые графическим процессором интенсивные задачи графической обработки. Память графического процессора определяет размер пакета при обучении моделей. В прошлом, при перемещении с ЦПУ на графический процессор размер пакета уменьшался. Однако по мере того, как память графического процессора по размеру догоняет память центрального процессора, применяемый для обучения GPU размер пакета будет увеличиваться. Одновременное увеличение производительности и объёма памяти приводят к увеличению числа запросов, при которых каждый гигабайт обучающих данных обрабатывается быстрее.
Полоса пропускания памяти - Представляйте себе полосу пропускания памяти GPU как соединяющее память и вычислительные ядра "шоссе" {Прим. пер.: на языке ИТ - шину}. Она определяет какой объём данных может быть передан за единицу времени. Точно также как более широкое шоссе позволяет за определённый промежуток времени проехать большему числу машин, более высокая полоса пропускания памяти допускает перемещение большего объёма данных между памятью и графическим процессором. Как видите, разработчики этих графических процессоров увеличили полосу пропускания памяти для каждой новой версии пропорционально объёму памяти; следовательно, внутренняя шина самой микросхемы не будет узким местом.
Если у вас возникла проблема с голоданием графического процессора, рассмотрите возможность применения сетевой среды 100G {Прим. пер.: или даже 200G, либо 400G, как это предусмотрено в современных серверах DGX} и дисков NVMe. Недавний эталонный тест с применением MinIO в такой конфигурации достиг 325GiB для GET и для 165GiB PUT всего с 32 узлами имеющихся в продаже накопителей SSD NVMe.
По мере развития мира компьютеров и падения цен на микросхемы оперативной памяти (DRAM), мы обнаруживаем, что конфигурации серверов зачастую поставляются с 512ГБ и более. Когда вы имеете дело с более крупными проектами, даже со сверхплотными дисками NVMe, общее число серверов, помноженное на объём оперативной памяти этих серверов способно быстро увеличиваться - до многих ТБ на экземпляр.
Этот пул оперативной памяти можно настроить как распределённый общий пул памяти и это идеально подходит для рабочих нагрузок, требующих массивных операций ввода/ вывода в секунду (IOPS) и пропускной производительности. В результате мы создали MinIO Cache, делающий возможным для наших клиентов Корпоративного и малого корпоративного уровней настраивать их инфраструктуру для дальнейшего получения преимуществ такого пула совместно используемой оперативной памяти по улучшению производительности основных рабочих нагрузок ИИ - таких как GPU обучение - при одновременном сохранении полной сохраняемости.
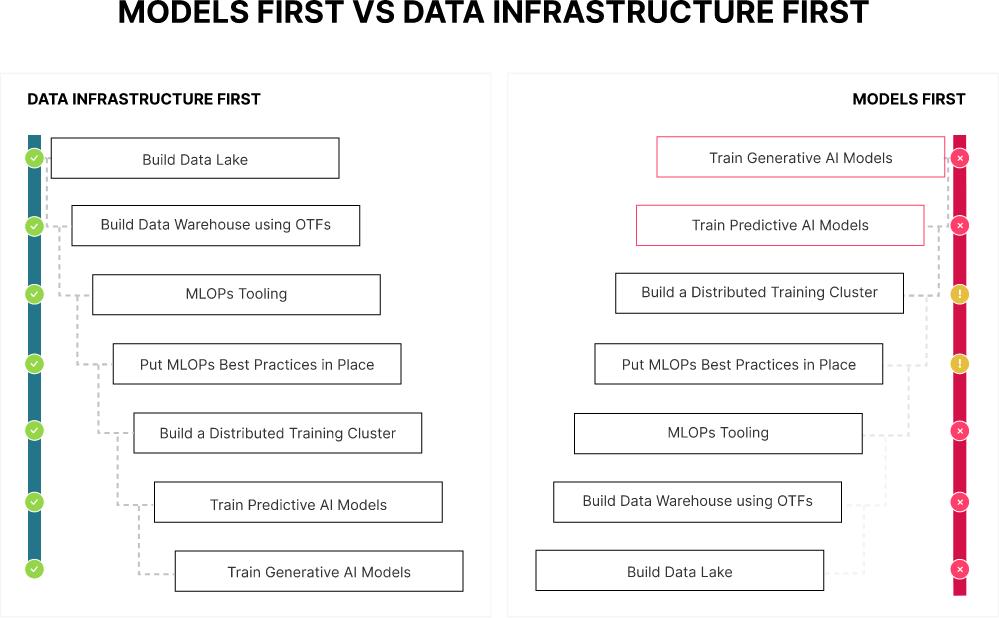
В качестве заключительного мысленного эксперимента давайте расскажем вымышленную историю двух организаций, которые в своём путешествии по искусственному интеллекту и машинному обучению применяют два совершенно различных подхода. В организации №1 имеется культура "итеративных улучшений". Они полагают, что любые крупные инициативы могут быть разбиты на более мелкие и более управляемые проекты. Такие более мелкие проекты далее управляются таким образом, чтобы каждый последующий опирался на результаты предыдущего проекта для решения задач всё большей и большей сложности. Они также предпочитают небольшие проекты, организованные таким образом, чтобы каждый из них приносил пользу общему делу. Они обнаружили, что направленные исключительно на улучшение инфраструктуры или модернизацию программного обеспечения проекты без каких- либо новых функциональных возможностей для ведения их дел, не очень популярны среди контролирующих бюджет руководителей. Тем самым они осознали, что запрос модных устройств хранения данных и вычислительных кластеров для проверки концепции Порождающего ИИ не самый лучший способ организации улучшения инфраструктуры и новых возможностей программного обеспечения. Вместо этого они начнут с малого с применением инфраструктурных продуктов, которые способны масштабироваться по мере роста и стартуют с простых моделей искусственного интеллекта для получения собственного инструментария операций машинного обучения (MLOp) и усвоить как работать при помощи имеющихся команд DevOps {коллективов автоматизации и интеграции между собой процессов разработки и ИТ персонала} и конвейеров CI/CD {автоматизации процессов доставки ПО}.
В организации №2 присутствует культура "блестящих проектов". Когда в отрасли появляется новая идея, она сначала решает сложную задачу, демонстрируя всю свою техническую мощь. Они обнаружили, что такие проекты весьма заметны как внутри, так и снаружи. Если же что- то сломается, это всегда смогут починить сообразительные парни.
Организация №1 создала структуру своего первого проекта, построив часть инфраструктуры данных искусственного интеллекта и одновременно работая над рекомендательной моделью для своей основной площадки электронной коммерции. Такая модель рекомендаций была относительно простой в обучении. Это Различающий (Дискриминативные) ИИ, применяющая уже имеющиеся в общем ресурсе файлов наборов данных. Тем не менее, по окончанию данного проекта их команда также создала небольшое (но масштабируемое) современное Озеро данных, реализовала инструментарий операций машинного обучения и разработала некоторые передовые методы обучения и развёртывания моделей. Несмотря на то, что эта модель не сложная, она всё же повысила действенность их площадки. Они воспользовались этими положительными результатами для получения финансирования своего следующего проекта, который станет Производящим (Генеративным) решением ИИ.
Организация №2 построила чат- бот для своей площадки электронной коммерции, который отвечал на вопросы клиентов о продукции. Большие языковые модели (LLM) достаточно сложны - их команда не была знакома с Тонкой настройкой и Генерацией с учётом дополняющих релевантных сведений (RAG) - а потому все циклы построения данного проекта были сосредоточены вокруг быстрого продвижения по крутой кривой обучения. Когда модель была завершена, она дала приемлемые результаты - ничего особенного. К сожалению, пришлось прибегнуть к загрузке вручную в пред производственную и производственную среды, поскольку для его развёртывания не было инструментария операций машинного обучения (MLOp). У самой модели также имелся ряд проблем со стабильностью в промышленном решении. В кластере, в котором он работал, не хватало вычислительной мощности для Производящей рабочей нагрузки ИИ. Имелось несколько обращений с первым уровнем серьёзности, что повлекло за собой экстренное увеличение кластера, дабы LLM не выходила из строя в условиях интенсивного обмена. По завершению данного проекта, рассуждения о былом определили, что им необходимо наращивать свою инфраструктуру если они желают добиться успеха при помощи ИИ.
Приведённый выше рассказ представляет собой повествование о двух крайних обстоятельствах. Построение моделей ИИ (как Различающих, так и Порождающих) существенно отличается от разработки обычного программного обеспечения. Это следует принимать во внимание при попадании в очередь усилий по ИИ/ МО. Представленный ниже рисунок визуально отображает рассказанную в предыдущем разделе воображаемую историю. Это сопоставительное отражение подхода Сначала инфраструктура данных ИИ и подхода Изначально модель. Как показала приведённая выше история, всякий из приводимых ниже кирпичиков для первого подхода к инфраструктуре не обязательно должен быть обособленным проектом. Организациям следует искать творческих способов достижения ИИ в то время как выполняется построение их инфраструктуры - этого можно добиться, осознав возможности ИИ, начав с простого, а затем выбирая проекты ИИ всё возрастающей сложности.
Данная статья излагает наш опыт работы с предприятиями над созданием современной эталонной архитектуры Озера данных (Data lake) для искусственного интеллекта и машинного обучения. В ней определяются основные компоненты, ключевые строительные блоки и компромиссы различных подходов к Искусственному интеллекту. Основополагающим элементом выступает современное Озеро данных, отстраиваемое поверх хранилища объектов. Такое хранилище объектов обязано обеспечивать производительность при любом масштабе - когда масштаб составляет сотни петабайт, а зачастую и экзабайты.
Мы ожидаем, что следуя такой эталонной архитектуре пользователь будет иметь возможность создания гибкой, расширяемой инфраструктуры данных, которая, хотя и не ориентирована на искусственный интеллект и машинное обучение, будет одинаково производительной при любых рабочих нагрузках OLAP. Для получения конкретных рекомендаций по составным частям пишите мне по адресу keith@min.io {Прим. пер.: или обратитесь к нам}.