Глава 4. Язык и грамматика Python
Содержание
Основная цель компилятора состоит в преобразовании одного языка в другой. Представляйте себе компилятор транслятором. Вы, наверное, слышали о трансляторе, который слушает как вы говорите по- английски, а затем повторяет ваши слова на другом языке, например, японском.
Для выполнения этого ваш транслятор должен понимать установленные грамматические структуры обоих языков, как источника, так и получателя.
Некоторые компиляторы будут компилировать на машинном коде нижнего уровня, который напрямую может исполняться в некой системе. Другие компиляторы будут компилировать в некий промежуточный язык, для его исполнения некой виртуальной машиной.
Одним из подлежащих рассмотрению вопросов при выборе компилятора заключается в требованиях переносимости системы. Java и .NET CLR будут выполнять компиляцию в некий промежуточный язык с тем, чтобы скомпилированный код являлся переносимым по множеству системных архитектур. C, Go, C++ и Pascal будут компилировать в исполняемый файл кода. Этот исполняемый файл собран для той платфрмы, под которую он был скомпилирован.
Приложения Python обычно распространяются в виде исходного кода. Основная роль интерпретатора Python заключается в преобразовании такого исходного кода Python и его исполнении за один шаг. CPython времени выполнения выполняет компиляцию вашего кода при его запуске в первый раз. Этот шаг не видим его обычному пользователю.
Код Python не компилируется в машинный код. Он компилируется в некий промежуточный язык нижнего уровня с названием
bytecode (байтного кода). Такой байтный код хранится в файлах
.pyc и кэшируется для исполнения. Если вы запустите то же самое приложение без изменения своего исходного
кода, он окажется быстрее при своём повторном исполнении. Это обусловлено тем, что он загружает откомпилированный байтовый код вместо его повторной
компиляции всякий раз.
Символ C в CPython означает ссылку на язык программирования C. указывающей на то, что этот дистрибутив Python написан на чистом C. Тем не менее, многие модули стандартной библиотеки написаны на чистом Python или на сочетании C и Python.
Итак, почему наш компилятор CPython написан на C, а не на Python?
Ответ основывается на том как работают компиляторы. Существует два типа компиляторов:
-
Компиляторы с самостоятельной поддержкой это те компиляторы, которые написаны на том языке, который они компилируют, например, компилятор Go. Это выполняется процессом, называемым bootstrapping (самозапуск).
-
Компиляторов исходного кода в исходный код, то есть компиляторов, написанных на другом языке, который уже обладает компилятором.
Когда вы пишите некий новый язык программирования с чистого листа, вам требуется некое исполняемое приложение для компиляции вашего компилятора! Вам требуется некий компилятор чтобы исполнять что бы то ни было, а потому когда разрабатывается некий новый язык, они пишутся начале на более старом, более устоявшемся языке программирования. Также имеются доступными инструменты, которые берут некую спецификацию языка и создают некий синтаксический анализ, который вы скоро изучите в этой главе. Популярные компиляторы компиляторов включают в свой состав GNU Bison, Yacc и ANTLR.
![[Совет]](/common/images/admon/tip.png) | Смотри также |
|---|---|
|
Если вы желаете получить дополнительные сведения о синтаксических анализаторах, обратитесь к проекту Lark. Lark это синтаксический анализатор для свободной от контекста грамматики, написанной на Python. |
Исключительным примером компилятора с самостоятельным запуском выступает язык программирования Go. Самый первый компилятор Go был написан на C, затем, раз Go оказался доступным для компиляции, его компилятор был повторно написан на Go.
CPython, с другой стороны, придерживается своего наследия C. Многие стандартные библиотечные модули, например, модуль
ssl или модуль sockets написаны на C для доступа к API нижнего
уровня операционной системы.
Все API в ядрах Windows и Linux для создания сетевых сокетов, работы с их файловой системой или взаимодействия с дисплеем были написаны на C, а потому это делает существенным для уровня расширения Python оставаться сосредоточенным на языке программирования C. Позднее в этой книге вы рассмотрите стандартную библиотеку Python и её модули C.
Существует также компилятор Python написанный на Python с названием PyPy. Логотипом PyPy выступает Ouroboros для представления самодостаточной природы этого компилятора.
Другим примером кросс- компилятора для Python выступает Jython. Jython написан на Java и компилирует из исходного кода в байтовый код Java. Точно также как CPython упрощает импорт библиотек C и их применение в Python, Jython упрощает импорт опорных модулей и классов Java.
Самый первый шаг создания некого компилятора состоит в определении самого языка. Например, эо недопустимо для Python:
def my_example() <str> :
{
void* result = ;
}
Самому компилятору требуются строгие правила для грамматической структуры его языка программирования прежде чем он попробует их исполнить.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Во всей оставшейся книге Для Windows: Для Linux: Для macOS: |
Содержащийся в CPython исходный код является определением языка программирования Python. Этот документ является технической спецификацией, используемой всеми имеющимися интерпретаторами Python.
Данная спецификация представлена как в читаемом человеком формате, так и в считываемом машиной формате. Внутри этого документа содержится подробное толкование языка программирования Python, структурирующего что допустимо и как каждый оператор обязан себя вести.
Каталог Doc/reference содержит толкование
reStructuredText всех функциональных возможностей языка
Python. Это файлы с официального справочного руководства Python docs.python.org/3/reference.
Внутри этого каталога находятся файлы, которые вам надлежит понимать для всего языка, структуры и ключевых слов:

Внутри Doc/reference/compound_stmts.rst вы можете видеть некий простой пример определения
оператора with.
Оператор with имеет большое число форм, самой простой выступает реализация экземпляра диспетчера контекста
и встроенный блок кода:
with x():
...
Вы можете назначить полученный результат некой переменной при помощи ключевого слова as:
with x() as y:
...
Вы также можете соединять цепочки диспетчеров контекста совместно при помощи запятой:
with x() as y, z() as jk:
...
Эта документация содержится в читаемой человеком спецификации своего языка программирования. Машинно- читаемая спецификация располагается в
отдельном файле, Grammar/python.gram.
Файл грамматики Python пользуется спецификацией грамматики синтаксического разбора выражений (PEG, parsing expression grammar). В файле грамматики вы можете пользоваться следующей нотацией:
-
*для повтора -
+для по крайней мере одного повтора -
[]для необязательных частей -
|для альтернатив -
()для группирования
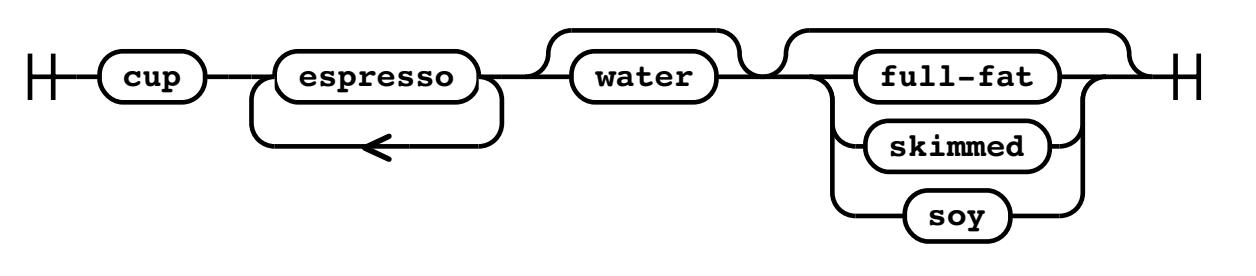
В качестве примера задумайтесь о том, как вы определяете чашку кофе:
-
Она должна обладать чашкой
-
Она обязана содержать по крайней мере одну дозу эспрессо и может содержать множество доз
-
Она может иметь молоко, но это не обязательно
-
Она может иметь воду, но это не обязательно
-
Она может иметь молоко, затем молоко может быть разных типов, например, сливками, обезжиренным или соевым
Будучи определённым в PEG, заказ кофе мог бы выглядеть как- то так:
coffee: 'cup' ('espresso')+ ['water'] [milk]
milk: 'full-fat' | 'skimmed' | 'soy'
|
| Смотри также |
|---|---|
|
В CPython 3.9, исходный код CPython имеет два грамматических файла. Одна наследуемая грамматика писалась в свободной от контекста
нотации с названием Backus-Naur Form
(BNF). В CPython 3.10, соответствующий файл грамматики BNF
( BNF не является специфичной для Python и часто используется в качестве нотации для грамматики во многих прочих языках программирования. |
В этой главе вы будете визуализировать грамматику железнодорожными диаграммами. Вот железнодорожная диаграмма для нашего оператора кофе:
В железнодорожной рекламе всякая возможная комбинация выстроена в линию слева направо. Необязательные операторы могут быть обойдены, а некоторые операторы могут формироваться в виде циклов.
Существует несколько форм оператора while. Самая простая содержит некое выражение, далее завершающее
:, за которым следует блок кода:
while finished == True:
do_things()
В качестве альтернативы вы можете применять некое выражение присваивания, на которое грамматика ссылается как на
named_expression (именованное выражение). Это новая функциональная возможность начиная с Python 3.8:
while letters := read(document, 10):
print(letters)
В качестве необязательного элемента, за операторами while может следовать оператор
else и блок:
while item := next(iterable):
print(item)
else:
print("Iterable is empty")
Если вы отыщите в своём грамматическом файле while_stmt, тогда вы можете обнаружить такое определение:
hile_stmt[stmt_ty]:
| 'while' a=named_expression ':' b=block c=[else_block] ...
Всё, что заключено в кавычки, является неким строковым литералом с названием терминал. Терминалы это то, что распознаётся в качестве ключевых слов.
В этих двух строках существуют ссылки на два прочих определения:
-
blockссылается на блок кода с одним или множеством операторов. -
named_expressionссылается на простое выражение или назначаемое выражение.
Будучи визуализированным в железнодорожной диаграмме, наш оператор while выглядит подобно
следующему:

В качестве более сложного примера, оператор try определяется в грамматике следующим образом:
try_stmt[stmt_ty]:
| 'try' ':' b=block f=finally_block { _Py_Try(b, NULL, NULL, f, EXTRA) }
| 'try' ':' b=block ex=except_block+ el=[else_block] f=[finally_block]..
except_block[excepthandler_ty]:
| 'except' e=expression t=['as' z=target { z }] ':' b=block {
_Py_ExceptHandler(e, (t) ? ((expr_ty) t)->v.Name.id : NULL, b, ...
| 'except' ':' b=block { _Py_ExceptHandler(NULL, NULL, b, EXTRA) }
finally_block[asdl_seq*]: 'finally' ':' a=block { a }
Существует два применения оператора try:
-
tryс единственным операторомfinally -
tryс одним или множеством выраженийexcept, за которым следует необязательныйelse, а затем необязательныйfinally.
Вот те же самые варианты, вызуализируемые железнодорожной диаграммой:
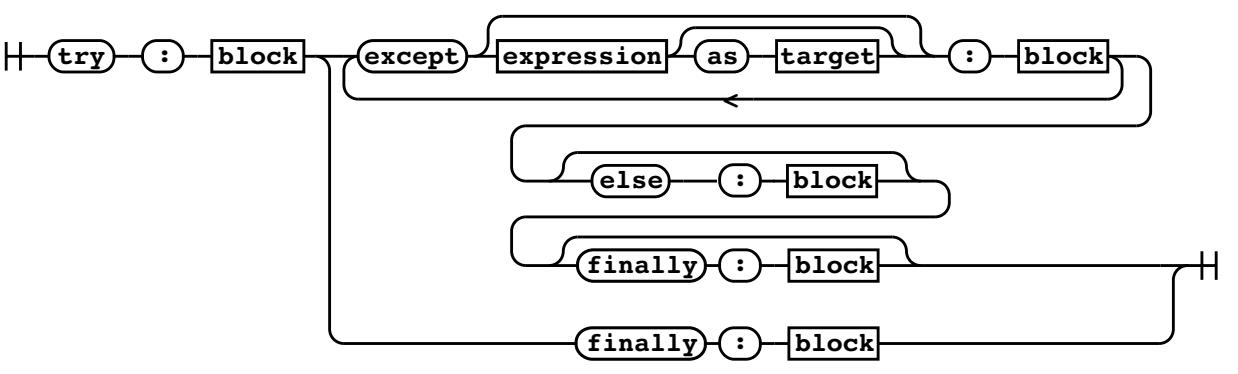
Оператор try это хороший образец более сложной структуры.
Если вы желаете разобраться в подробностях языка программирования Python, прочтите его грамматику, определяемую в
Grammar/python.gram
Файл грамматики сам по себе никогда не применяется компилятором Python. Вместо этого некий генератор синтаксического разбора считывает соответствующий файл и вырабатывает синтаксический анализатор. Если вы вносите изменения в свой файл грамматики, тогда вам надлежит повторно сгенерировать его синтаксический анализатор и повторно выполнить компиляцию CPython.
Имеющийся синтаксический анализатор CPython был переписан в Python 3.9 из автомата таблицы синтаксического анализа (модуль
pgen) в синтаксический анализатор контекстной грамматики.
В Python 3.9 его старый синтаксический анализатор доступен из командной строки при использовании соответствующего флага
-X oldparser, а в Python 3.10 он удалён полностью. Данная книга ссылается на новый синтаксический
анализатор, реализованный в 3.9.
Чтобы увидеть pegen, наш новый генератор PEG, введённый в CPython 3.9 в действии, вы можете изменить часть имеющейся
грамматики Python. Отыщите в Grammar/python.gram
small_stmt чтобы увидеть установленное определение для небольших операторов:
small_stmt[stmt_ty] (memo):
| assignment
| e=star_expressions { _Py_Expr(e, EXTRA) }
| &'return' return_stmt
| &('import' | 'from') import_stmt
| &'raise' raise_stmt
| 'pass' { _Py_Pass(EXTRA) }
| &'del' del_stmt
| &'yield' yield_stmt
| &'assert' assert_stmt
| 'break' { _Py_Break(EXTRA) }
| 'continue' { _Py_Continue(EXTRA) }
| &'global' global_stmt
| &'nonlocal' nonlocal_stmt
В частности, наша строка 'pass' { _Py_Pass(EXTRA) } служит для
pass (передачи) оператора:

Измените эту строку на приём терминалов (ключевых слов) 'pass' или
'proceed' в качестве ключевых слов, добавив выбор, | и
литерал 'proceed':
| ('pass'|'proceed') { _Py_Pass(EXTRA) }
Затем повторно соберите имеющиеся грамматические файлы. CPython поставляется со сценариями для автоматической повторной выработки грамматики.
В macOS и Linux запустите цель make regen-pegen:
$ make regen-pegen
Для Windows приведите в действие приглашение командной строки в каталоге PCBuild и запустите
build.bat с установленным флагом --regen:
> build.bat --regen
Вы должны обнаружить некий вывод, отображающий что был повторно выработан файл
Parser/pegen/parse.c.
При наличии такой повторно выработанной таблицы синтаксического анализа, когда вы повторно скомпилируете CPython, он воспользуется вашим новым синтаксисом. Воспользуйтесь теми же самыми шагами компиляции, которые вы применяли для своей операционной системы в нашей последней главе.
Если код скомпилирован успешно, тогда вы сможете выполнить свой новый исполняемый файл CPython и запустите REPL.
В полученном REPL вы можете теперь попробовать определить некую функцию. Вместо применения оператора pass
воспользуйтесь альтернативным ключевым словом proceed, которое вы скомпилировали в своей грамматике
Python:
$ ./python
Python 3.9 (tags/v3.9:9cf67522, Oct 5 2020, 10:00:00)
[Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> def example():
... proceed
...
>>> example()
Поздравляем, вы изменили синтаксис CPython и скомпилировали свою собственную версию CPython!
Далее давайте изучим лексемы и их взаимосвязь с грамматикой.
Помимо файла грамматики в нашей папке Grammar имеется файл
Grammar/Tokens, который содержит все уникальные типы, обнаруживаемые в
качестве узлов листьев в неком дереве синтаксического разбора. Всякая лексема (токен) обладает названием и выработанным уникальным
идентификатором. Значения имён упрощают ссылки на лексемы в соответствующем обработчике лексем (tokenizer).
|
| Замечание |
|---|---|
|
Файл |
Например, левая круглая скобка (left parenthesis) имеет название LPAR, а двоеточие именуется как
SEMI. Позднее в этой книге вы увидите эти лексемы:
LPAR '('
RPAR ')'
LSQB '['
RSQB ']'
COLON ':'
COMMA ','
SEMI ';'
Как и в случае с файлом Grammar, если вы вносите изменения в файл
Grammar/Tokens, вам потребуется повторно выполнить
pegen.
Чтобы увидеть лексемы в действии, вы можете воспользоваться модулем tokenize из CPython.
|
| Замечание |
|---|---|
|
Этот написанный на Python обработчик лексем выступает в роли модуля утилиты. Реальный синтаксический анализатор Python применяет иной процесс для идентификации лексем. |
Создайте простой сценарий Python с названием test_tokens.py:
cpython-book-samples/13/test_tokens.py
# Demo application
def my_function():
proceed
Дайте этот файл test_tokens.py на вход модулю, собираемому в стандартной библиотеке, с названием
tokenize. Вы обнаружите список лексем по строкам и символам. Для вывода в точности (exact) названий
лексем воспользуйтесь флагом -e:
$ ./python -m tokenize -e test_tokens.py
0,0-0,0: ENCODING 'utf-8'
1,0-1,14: COMMENT '# Demo application'
1,14-1,15: NL '\n'
2,0-2,3: NAME 'def'
2,4-2,15: NAME 'my_function'
2,15-2,16: LPAR '('
2,16-2,17: RPAR ')'
2,17-2,18: COLON ':'
2,18-2,19: NEWLINE '\n'
3,0-3,3: INDENT ' '
3,3-3,7: NAME 'proceed'
3,7-3,8: NEWLINE '\n'
4,0-4,0: DEDENT ''
4,0-4,0: ENDMARKER ''
В этом выводе самый первый столбец является диапазоном координат значений строк и столбцов,вторая колонка представляет название соответствующей лексемы, а последняя колонка это само значение данной лексемы.
В своём выводе применяемый модуль tokenize подразумевает наличие некоторых лексем:
-
Токен
ENCODINGдляutf-8. -
Некий
DEDENTдля закрытия объявления рассматриваемой функции. -
Некий
ENDMARKERдля закрытия соответствующего файла -
Пустая строка в самом конце
Хорошей практикой является присутствие пустой строки в самом конце ваших исходных файлов Python. Если вы пропустите её, CPython добавит её вам.
Модуль tokenize написан на чистом Python и располагается в
Lib/tokenize.py.
Чтбы увидеть подробные показания синтаксического анализатора C вы можете запустить отладочную сборку Python с установленным флагом
-d. Воспользуйтесь ранее созданным вами сценарием test_tokens.py,
запустите его следующим образом:
$ ./python -d test_tokens.py
> file[0-0]: statements? $
> statements[0-0]: statement+
> _loop1_11[0-0]: statement
> statement[0-0]: compound_stmt
...
+ statements[0-10]: statement+ succeeded!
+ file[0-11]: statements? $ succeeded!
В этом выводе вы можете обнаружить что он выделил proceed в качестве ключевого слова. В своей следующей
главе вы обнаружите как выполнение исполняемого файла Python достигает своего обработчика лексем и что происходит там для выполнения вашего
кода.
Чтобы очистить свой код, верните обратно изменения в Grammar/python.gram,
повторно выработайте свою грамматику снова и затем очистите свою сборку и повторно выполните компиляцию.
Для macOS и Linux воспользуйтесь следующим:
$ git checkout -- Grammar/python.gram
$ make regen-pegen
$ make -j2 -s
Или примените такое в Windows:
> git checkout -- Grammar/python.gram
> build.bat --regen
> build.bat -t CleanAll
> build.bat -t Build
В этой главе вы получили введение в определение грамматики Python и генератора синтаксического анализатора. В нашей следующей главе вы расширите эти знания до сборки более сложных синтаксических функциональных возможностей, некого оператора "почти-равенства".
На практике изменения для грамматики Python должны аккуратно рассматриваться и обсуждаться. Существуют две причины для такого уровня внимательного исследования:
-
Наличие слишком большого числа функциональных возможностей языка или сложности грамматики противоречили бы духу Python о простоте и удобочитаемости.
-
Изменения в грамматике вводят обратную несовместимость, что создаёт работу всем разработчикам.
Когда разработчик ядра Python предлагаЕт некое изменение в установленной грамматике,он обязан внести предложение в PEP (Python Enhancement Proposal, План расширения Python). Все PEP нумеруются и нндексируются в PEP. Документы PEP 5 документирует руководство по развитию языка и определяет какие изменения должны предлагаться PEP.
Индексе PEP вы можете отслеживать проектируемые, отвергнутые и принятые PEP для последующих версий CPython. Участники также имеют возможность предложения в сам язык за пределами группы разработки ядра через список электронной рассылки идей python.
После того как PEP приходит к согласию и проект финализировался, управляющий совет обязан принять или отклонить его. Основной мандат управляющего совета, определённый в PEP 13, постулирует, что участники совета должны работать над "сопровождением качества и стабильности собственно языка программирования Python и интерпретатора CPython".