Lazy Means Smart
Интеллектуальные отложенные средства: уменьшение стоимости пропускной способности восстановления в распределенных хранилищах с кодом затирания.
Перевод Lazy Means Smart: Reducing Repair Bandwidth Costs in Erasure-coded Distributed Storage
Mark Silberstein1, Lakshmi Ganesh2, Yang Wang3, Lorenzo Alvisi3, Mike Dahlin3,4
1Technion, 2Facebook, 3The University of Texas at Austin, 4Gooogle
Аннотация
Схемы кодирования затирания обеспечивают более высокую надежность при более низкой стоимости хранения и, таким образом, представляют собой привлекательную альтернативу репликациям в распределенных системах хранения, в частности, для хранения к "холодным" данным с редким доступом. Такие схемы, однако, требуют на порядок более высокой пропускной способности восстановления для поддержания постоянного уровня надежности перед лицом отказов узлов. В данной статье мы предлагаем отложенное восстановление (lazy recovery), технику для уменьшения потребности в пропускной способности восстановления до уровня хранилища с репликациями. Ключевая догадка состоит в том, что аккуратная настройка скорости восстановления существенно снижает пропускную способность восстановления, сохраняя влияние на низкие производительность чтения и надежность данных. Мы покажем преимущества отложенного восстановления с помощью подробного моделирования с использованием правдоподобной распределенной конфигурации системы хранения и опубликованных параметров отказов компонентов. Например, когда отложенное восстановление применяется к наиболее часто применяемому кодированию RS(14,10), оно уменьшает пропускную способность на значение до 76%, даже ниже чем при репликациях, одновременно увеличивая количество деградирующих полос на 0.1 процентных пунктов. Отложенное восстановление хорошо работает с различными схемами кодирования затирания, в том числе с недавно предложенными кодами с эффективной пропускной способностью, достигая двукратного прироста множителя дополнительной экономии пропускной способности.
1. Введение
Схемы с кодированием затирания, например коды Рида- Соломона (RS), являются привлекательной альтернативой репликациям в распределенных системах хранения (DSS, distributed storage systems), поскольку они делают возможным оптимальный баланс между стоимостью хранения и надежностью данных. Они рассматриваются как относительно хорошо подогнанные под хранение относительно редко используемые "холодные" данные [3,15]. которые представляют все большую часть в крупномасштабных системах хранения [21,24].
Тем не менее, широкому внедрению кодов затирания в DSS с холодными данными препятствуют их чрезмерные требования к сетевой среде при восстановлении данных после сбоев – хорошо известная проблема пропускной способности восстановления [25, 18, 27, 26]. А именно, когда узел хранения испытывает отказ. например, из- за сбоя оборудования, его содержание должно быть оперативно восстановлено на другом узле во избежание утраты данных. Восстановление одного блока данных в системе хранения с кодированием затирания RS(n,k) влечет за собой передачу k блоков от k продолжающих работу узлов в сети. Для сравнения, в системах на основе репликаций передается только один блок для восстановления одного утраченного блока. Такое кратное k увеличение в обмене при восстановлении имеет результатом резкое увеличение нагрузки на сеть на фоне установившегося значения, в особенности, в крупных центрах обработки данных, где интенсивность отказов высока. Например, в режиме реальном Facebook DSS до 3% от общего числа узлов хранения отказывают каждый день [27]. Использование хранилища с кодированием RS(14,10) в этой системе имеет в результате сотни Терабайт обмена для восстановления сквозь коммутаторы поверх стоек (TOR, Top-Of-Rack) [26]. Таким образом сеть занята, даже если сам DSS простаивает и не обслуживает никаких внешних пользователей (как это обычно и бывает для системы холодного хранения), что увеличивает потребление электроэнергии и не дает узлам переходить в спящий режим. Кроме того, такой трафик составляет значительную часть от общего объема сетевой среды и растет совместно с масштабами системы и емкостью жестких дисков. Все эти факторы препятствуют принятию стандартных кодов затирания.
Общая практика для того, чтобы справиться с растущим сетевым обменом, заключается в регулировании пропускной способности сети, доступной для задач восстановления. Это, однако, увеличивает число деградировавших полос неуправляемым образом(полосы с одним или более утраченными или отключенными блоками), которые, в свою очередь, сильно влияют на производительность чтения и надежность данных. Широко распространенная политика сглаживания такого негативного эффекта заключается в выставлении приоритетов восстановления полос с бОльшим числом отказавших узлов [9,26], тем самым более эффективно используя имеющуюся ограниченную полосу пропускания. Однако в общем случае регулирование расхода не эффективно понижает общий обмен восстановления после отказа, поскольку подавляющее большинство отказов получает восстановление сразу – было установлено, что 98% деградировавших полос в DSS Facebook имело только один отказавший блок [26].
В данной статье мы предлагаем отложенное восстановление (lazy recovery), технику уменьшения объема сетевого обмена для восстановления в кодированном затиранием DSS до уровня трех репликаций, но без потери надежности первой. Идея проста: восстановление деградировавших полос может быть отложено до тех пор, пока риск потери данных остается терпимым, таким образом используя нелинейный компромисс между пропускной способностью восстановления и вероятностью потери данных. Ключевой задачей, однако, является поиск практического механизма помещения системы в требуемую рабочую точку на кривой компромисса. Например, откладывание восстановления до тех пор, пока число остающихся работающими узлов не падает ниже определенного порога восстановления, как это было впервые предложено в одноранговой системе хранения TotalRecall [2], не является в крупномасштабных сценариях DSS. Мы предлагаем новую схему отложенного восстановления, которая делает возможным управление мелкого уровня поведением системы и достигает значительного снижения пропускной способности за счет относительно небольшого снижения в надежности и доступности данных.
Реалистичная оценка нашей схемы требует оценку его воздействия на надежность, доступность и пропускную способность в DSS масштаба Петабайт на протяжении нескольких лет работы. Осуществление такой оценки в реальной системе невозможно. Таким образом мы реализовали подробную распределенную модель хранения — ds-sim (detailed distributed storage simulator, доступен для загрузки по адресу https://code.google.com/p/ds-sim), которая имитирует долгосрочное поведение стационарной DSS. Модель принимает в качестве входных данных настройку системы и кодирование данных, а также схему восстановления и дальше работает моделируя сбои в основных областях отказов (диск, машина, стойка) скрытых отказов блоков, замены машины, а также приводит в действие глобальные ограничения сети.
Мы смоделировали 3ПБ систему используя распределения отказов и восстановлений из реальных трассировок отказов крупномасштабных вычислительных кластеров [30], а также из публикаций, характеризующих промышленные среды [7, 9, 30, 31, 23]. Мы оценили различные популярные схемы кодирования затирания и показали, что наши механизмы отложенного восстановления способны значительно снизить полосу пропускания восстановления. Например, полоса пропускания восстановления кодов RS(14,10) уменьшается в 4 раза, даже ниже уровня методов с тремя репликациями. Кроме того, отложенное восстановление хорошо работает в сочетании с недавно предложенными кодами локального восстановления (LRC, locally-repairable codes) [25, 18], еще больше понижая их полосу пропускания до половины значения.
Основной вклад данной статьи состоит в :
- Новом механизме, который позволяет значительно уменьшать полосу пропускания восстановления в хранилищах с кодом затирания и разработан для крупномасштабных DSS.
- Подробной модели DSS ds-sim для оценки долгосрочных требований к надежности, доступности и полосы пропускания восстановления для различных схем хранения. ds-sim моделирует правдоподобные сценарии отказов, такие как коррелированные поломки, скрытые отказы дисковых блоков и замена оборудования.
- Оценкe потребностей в полосе пропускания различных систем хранения с применением собранных в течение длительных периодов трассировок и распределений отказов в промышленных крупномасштабных системах хранения.
Оставшаяся часть данной статьи организована следующим образом. В следующем разделе мы приводим обзор кодирования затирания и связанных с этим проблем пропускной способности восстановления. Мы детально описываем схему отложенного восстановления в разделе 3, представляем нашу модель распределенного хранилища в разделе 4, а оценку отложенного восстановления в разделе 5. Раздел 6 описывает связанные работы, а раздел 7 содержит выводы.
2. Коды затирания и проблема пропускной способности восстановления
В данном разделе мы вкратце объясним использование кодов затирания в DSS на примере кодов Рида- Соломона, а затем объясним проблему полосы пропускания восстановления. В системе хранения RS(n,k) каждое множество k блоков данных размера b кодируется в n блоков размера b, создавая отдельную полосу (stripe) данных. Каждая полоса содержит k систематических блоков, которые хранят начальные данные содержимого и n-k дополнительных блоков соответствия по модулю. О методе хранения с тремя репликациями можно говорить как о тривиальной форме RS кодирования с k = 1 и n = 3. {Прим.пер.: в Драночном коде затирания SHEC(k1,m,l) каждый блок из множества k систематических блоков разбивается на k1 порций данных размера b/k1 и кодируется m порциями соответствий по модулю размера l*b/k1, сдвигающимися друг относительно друга подобно гонтовым пластинам на драночной крыше, также создавая отдельную полосу данных, в рамках которой может осуществляться восстановление.} Блоки из каждой полосы распределяются по n различным узлам хранения для обеспечения максимальной устойчивости к отказам. При отсутствии сбоев начальные данные могут получаться без дополнительного декодирования посредством чтения содержимого соответствующих систематических блоков. Однако, если один или более систематических блоков недоступен, полоса называется деградировавшей. Содержимое утраченных блоков может быть восстановлено из любых k блоков полосы с продолжающих работу узлов.
Как и в системах хранения с репликациями, содержание отказавших узлов должно быть восстановлено во избежание возможной потери данных. Процесс восстановление предъявляет значительные требования к пропускной способности сети и может создавать значительную нагрузку даже при отсутствии внешних запросов ввода/ вывода. Реконструкция одного блока данных требует чтения значений всей полосы данных (k блоков). Это приводит к кратному k раздуванию полосы пропускания, т.е. восстановление b байт требует передачи b * k байт данных. Сравните это с репликациями: восстановление утраченного блока (реплики) требует чтения только одного блока. Наша цель заключается в создании стационарных требований к полосе пропускания хранилищ с кодированием затирания соразмерную с полосой, необходимой хранилищам с репликациями при сохранении преимуществ отказоустойчивости кодирования затирания.
В оставшейся части статьи мы определим полосу как надежную если достаточное число ее блоков остается в рабочем состоянии (даже если они автономны) так, что данных в полосе могут быть восстановлены. С другой стороны полоса считается доступной, если все ее систематические блоки подключены так, что для чтения полосы не требуется никакая реконструкция.
В следующем разделе мы покажем как отложенное восстановление ограничивает полосу пропускания процесса восстановления при сохранении высокой надежности и доступности хранилища с кодированием затирания.
3. Отложенное восстановление
Основная идея, лежащая в основе схемы отложенного восстановления, заключается в уменьшении скорости восстановления, тем самым снижая необходимую для этого пропускную способность сети, но без существенного влияния на надежность. Рисунок 1 предоставляет интуитивное понимание, стоящее за этим подходом. График показывает вероятность одного блока данных на протяжении 10 лет — количественной меры надежности данных, хранящихся в DSS — как функции скорости восстановления данных для схемы кодирования RS(14,10). Мы используем схему цепей Маркова, как и в работе [12], для получения графика. Хотя и хорошо известно, что Марковские модели раздувают значения среднего времени потери данных (MTTDL, Mean-Time-To-Data Loss), они все-таки полезны для качественного анализа поведения системы [12]. Этот простой эксперимент подчеркивает убывающую отдачу от возрастающей скорости восстановления по мере того, как система становится более надежной: вероятность потери одного блока 10-19 в течение 10 лет, действительно, в 10 раз выше 10-20, однако это может сохранить половину сетевого обмена восстановления все же остающегося достаточным для практических целей.
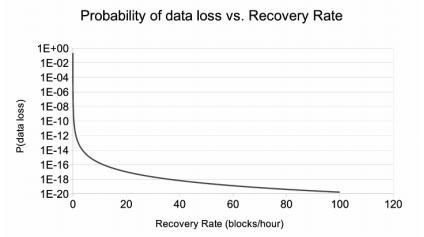
Рисунок 1 Теоретический компромисс между надежностью и скоростью восстановления
Основная задача, однако, заключается в разработке практического механизма для использования этого компромисса в реальной системе.
Схема I. Отложенное восстановление для всех.
Одно из возможных решений вдохновлено работой, выполненной в контексте одноранговых (P2P) сетей хранения [22,2], заключается в откладывании восстановления отказавших блоков до тех пор, пока число доступных блоков не достигнет заданного порога восстановления r. Например, для RS(15,10) и r = 13 система будет ожидать двух откахавших блоков в полосе до переключения на восстановление полосы. Интуитивно есть ощущение, что вероятность безвозвратной потери данных с применением отложенного восстановления, использующего кодирование RS(15,10) должна быть примерно равна вероятности начального RS(14,10) с энергичным восстановлением, поскольку обе схемы восстановления включаются когда остаются рабочими 13 блоков.
Отсрочка восстановления дает два преимущества: во- первых мы можем восстановить два блока почти по той же стоимости сетевых ресурсов, что и при восстановлении одного — для восстановления одного блока следует считать десять и записать один (итого 11× полоса пропускания для восстановления), в то время как для восстановления двух блоков все еще необходимо читать 10, а записать два (итого 12× полоса пропускания, или 6× амортизированная полоса пропускания на восстановление); во- вторых, если блок недоступен из-за временного события, например, отказа сети, задержка в его восстановлении дает этому событию больше времени для прихода в себя (т.е. пока не восстановится подключение к сети) и, таким образом, избежать избыточных ремонтных работ.
Базовая схема отложенного восстановления может показаться аналогичной стандартной практике задержки восстановления вышедших из строя узлов на фиксированный промежуток времени (обычно 15 минут [9]), чтобы избежать не нужного ремонта коротких временных отказов. Основная разница, однако, что схема с отсрочкой не передает никаких данных пока не понадобится восстановление, вне зависимости от того, сколько времени прошло после отказа, а затем восстанавливает несколько блоков в пакете, тем самым заведомо передавая меньше блоков по сравнению со стандартной схемой задержки восстановления.
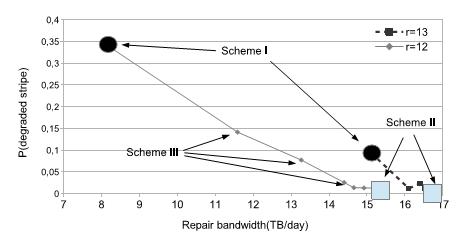
Рисунок 2 Влияние отложенного восстановления на среднее количество деградировавших порций для RS(15,12). Выделенные точки обозначают случаи, в которых включается восстановление после r отказов (простое откладывание) и когда непрерывно возникающие отказы всегда имеют более высокий приоритет (откладывание с приоритетом).
Отложенное восстановление было первоначально предложено в контексте одноранговой системы хранения TotalRecall, однако оказался недостаточно эффективным для DSS. Наше моделирование показывает (Рисунок 2), что снижение порога восстановления на единицу может резко увеличить количество деградировавших полос. Например, для схемы RS(15,10), установка порога восстановления r = 12 дает в результате то, что примерно 30% от всех полос хранения должны всегда деградировать. С другой стороны, увеличение порога до r = 13 помогает понизить число деградировавших полос но перемещает систему непосредственно в другую крайность функции компромисса (Рисунок 2), теряя все свои запасы пропускной способности.
Схема II. Отложенное восстановление только для временных отказов.
Неэффективность Схемы I связана с тем, что деградировавшие в результате окончательных отказов полосы остаются деградировавшими без ремонта слишком долго (поскольку разрушившийся жесткий диск никогда не будет восстанавливаться самостоятельно, в то время как временные отказы в конечном итоге восстановятся даже без явного процесса восстановления). Следовательно, мы должны улучшить нашу схему с тем, чтобы она различала окончательные отказы диска от временных отказов машин: в случае окончательного отказа запускается процесс восстановления, как только он обнаружен, в то время как временный отказ обслуживается с отсрочкой. В управляемой среде, такой как центр обработки данных, существует достаточно информации чтобы отличать постоянные события подобные замене оборудования от временных событий, таких как аварийный отказ машины, перезапуск или обновление программного обеспечения.
Разделение политик восстановления на окончательные и временные отказы улучшает эффективность начального подхода отсрочки. Однако, как мы видим на Рисунке 2, эта схема до сих пор не способна обеспечить точное управление выбором рабочей точки функции компромисса.
Схема III. Порог динамичного восстановления.
Схема II может быть улучшена путем динамической регулировки политики восстановления в зависимости от состояния системы в целом. Мы введем лимит по всей системе на число деградировавших полос с окончательно потерянными блоками. Всякий раз, когда число окончательных отказов превышает установленный предел, мы временно повышаем порог восстановления на всю систему до тех пор, пока не уменьшится число таких полос. Заметим, что обеспечение общесистемных пределов применение глобальных изменений политик подобное используемым в данной схеме может быть эффективно осуществлено в централизованно управляемой, хорошо обслуживаемой DSS, однако может оказаться не реализуемым в гораздо менее управляемой одноранговой среде хранения.
В дальнейшем мы вначале опишем свою методологию оценки, а затем представим результаты, демонстрирующие эффективность этой улучшенной схемы с отложенным восстановлением.
4. Методология оценки
Оценка эффективности отложенного восстановления в отношении снижения полосы пропускания восстановления и его причастности к доступности и надежности представляет собой большую проблему. Неразумно запускать прототип и замерять его показатели, поскольку потребуется большое число машин для работы на протяжении многих лет для получения статистически значимого результата.
Как это принято при исследовании других систем хранения, [20, 9, 25], мы применяем комбинацию симуляции и моделирования с одной стороны,мы строим симулятор ds-sim для оценки того, как полоса пропускания восстановления и доступность зависят от комбинации событий отказов, настройки аппаратных средств, схемы кодирования и стратегии восстановления. С другой стороны, чтобы перехватывать неустранимые события потери данных, которые являются крайне редкими, в особенности для кодов затирания, мы используем модель Марковской цепи для сравнения надежности различных схем кодирования.
4.1. Моделирование для оценки полосы пропускания и доступности
ds-sim имитирует поведение системы в течение нескольких лет. Например, в нашем моделировании мы воспользовались одним десятилетием. Входные данные содержат спецификации конфигурации аппаратуры, такие как размеры дисков и емкость общей сетевой среды, статистические свойства отказов и восстановления размещенных компонентов исследуемой системы хранения, а также схему кодирования данных. Симулятор возвращает стационарные и мгновенные значения использования полосы пропускания сети, число деградировавших полос, количество окончательно утраченных блоков, а также различные другие свойства динамической системы.
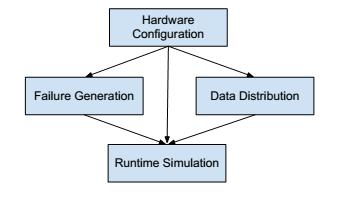
Рисунок 3 Модель распределенной системы хранения
ds-sim состоит из четырех основных строительных блоков (Рисунок 3):
Конфигурация системы хранения.
ds-sim имитирует обычно используемую трех-уровневую древовидную структуру компонентов системы хранения, содержащую стойки, машины и диски. Каждый компонент верхнего уровня может иметь множество компонентов нижнего уровня в качестве потомков. Если отказывает родительский компонент, все его потомки помечаются как недоступные, эффективно имитируя отказы в отдельной области сбоя.
Имитация схемы хранения.
Как и в реальной системе, данные хранятся в блоках [10, 28, 3]. Множество блоков формирует полосу (stripe). Данные внутри каждой полосы либо реплицируются, либо кодируются затиранием: для n- репликаций полоса охватывает все реплики блока; для RS(n,k) схемы кодирования полоса охватывает k начальных блоков и n-k блоков соответствия по модулю. ds-sim случайным образом выбирает n стоек для хранения n блоков полосы в различных областях отказа, следуя обычной практике в промышленных установках [9].
Генерация событий отказов.
ds-sim создает события отказов и восстановления для каждого компонента аппаратуры используя либо синтетическое распределение вероятности, либо трассировку отказов. Некоторые события, например отказы машин, создаются автономно до начала моделирования, однако другие, например, события отложенного восстановления, зависят от динамического поведения системы и создаются во время осуществления имитации. Мы подключаем отдельные распределения отказов и восстановлений для каждого компонента хранилища: диска, машины и стойки.
- Отказы диска: Включают в себя как скрытые отказы так и окончательный выход из строя дисков. Скрытые отказы повреждают сектор диска случайным образом, оказывая воздействие на отдельный блок данных. Они могут быть обнаружены и восстановлены в течение периодических чтений всего содержимого диска, техника, называющаяся очищающей (scrubbing) [7, 9]. Окончательные отказы диска предполагаются невосстановимыми, окончательно разрушающими все блоки на диске.
- Отказы машины: Содержат временные отказы (которые не разрушают дисковые компоненты) и окончательные отказы (которые также выводят изстроя дисковые компоненты). Временные отказы обычно приписываются замедлению сети или обслуживанию. Окончательные поломки представляют собой обновление оборудования сервера, которое, в соответствии с отчетами, происходит один раз в три года [8]. Поэтому восстановление после окончательной поломки машины предполагается начать сразу после отказа. В то время как восстановление после временного сбоя машины начинается после наперед заданной временной задержки, например, 15 минут [9], если так диктует политика отложенного восстановления.
- Отказы стойки: Считаются временными (т.е. они не разрушают компоненты серверов).
Хотя мы и не имитируем в явном виде коррелированные отказы для каждого компонента в отдельности, основные области отказов моделируются с использованием компонентов верхнего уровня, вызывающе сбои всех содержащихся в них компонентов.
Обратите внимание, что ds-sim позволяет пользователям определять различные модели или параметры различным группам компонентов. Например, одна группа дисков может быть настроена как двухлетняя, в то время как другая группа может быть настроена как новая, следовательно, они могут иметь разные частоты отказов.
Моделирование выполнения.
Наконец, путем комбинирования всей перечисленной выше информации, ds-sim выполняет имитацию работы, записывая все мгновенные свойства системы, содержащие полосу пропускания и число деградировавший полос. Обратите внимание, что ds-sim не предназначен для оценки производительности чтения или записи системы. Симулятор отслеживает каждыйблок в системе. Полоса, к которой принадлежит блок помечается как доступная, недоступная, деградировавшая или утраченная, в зависимости от состояния ее соответствующих блоков и моделируемой системы хранения. Для схем с n- репликациями деградировавшее состояние не имеет значения, поскольку полоса либо доступна пока хотя бы один блок подключен, либо недоступна в противоположном сучае. Для для схемы с кодом затирания RS(n,k) полоса помечается как деградировавшая, если существует меньше чем n блоков и недоступной или утраченной, если существует меньше k блоков.
4.1. Марковская модель для оценки надежности
ds-sim может быть использована для оценки надежности исследуемой системы. Однако, было обнаружено [12], что события потери надежности для схем кодирования затирания происходят настолько редко, что моделирование требует очень большого числа итераций для получения статистически значимого результата. Таким образом для получения результатов надежности мы обращаемся к Марковской модели [13]. По сравнению с моделированием, Марковские модели известны как раздувающие абсолютные значения надежности, однако они полезны для целей сравнения [14].
Вы воспользуемся стандартной параллельной моделью восстановления для репликаций и кодов затирания [12]. Отложенное восстановление моделируется удалением переходов восстановления из состояний, которые имеют больше доступных порции восстановления, чем установленное для порога восстановления значение. Рисунок 4 представляет схему отложенного восстановления с четырьмя узлами соответствия по модулю и задержкой восстановления до отказа трех узлов. Метки состояний представляют число отказавших узлов. Обратите внимание, что такой подход не учитывает динамичный рост порога восстановления в нашей реальной схеме.
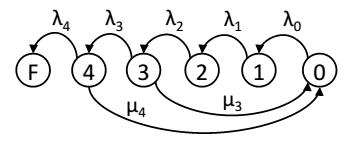
Рисунок 4 Марковская модель для оценки надежности отложенного восстановления, допускает три не восстановленных отказа.
Вооружившись ds-sim и Марковской моделью мы теперь выполним оценку эффективности нашей схемы отложенного восстановления.
5. Результаты
Мы выполнили имитацию хранилища 3ПБайт данных работающего на протяжении десятилетия. Рисунок 6 описывает все смоделированные нами отказы и списки наших выборов параметра модели отказа, а также их источники. W(γ, λ, β) обозначает распределение Вейбулла, а Exp(λ) Обозначает экспоненциальное распределение. Рисунок 5 приводит перечень используемых нами параметров системы хранения. Мы задаем следующий вопрос:Насколько эффективной является наша схема отложенного восстановления в управляемой полосе пропускания процесса восстановления? и каково ее влияние на доступность и долговечность данных?
| Параметр | Значение |
| Общий объем данных | 3 ПБайт |
| Емкость диска | 750 ГБайт |
| Дисков в машине | 20 |
| Машин в стойке | 11 |
| Доступная для восстановления полоса пропускания | 650 ТБайт/ день [5] |
| Длительность | 10 лет |
| Число итераций | 25 000 |
Рисунок 5 Параметры моделирования.
| Тип отказа | Следствие | MTBF | MTTR |
| Скрытая ошибка | Разрушенная порций | Exp(1/1год) [7] | W(6, 1000, 3) [7] (очистки) |
| Отказ диска | Потеря порций | W(0, 52лет, 1.12) [7] | W(36s, 108s, 3) [31] |
| Отказ машины | Недоступность порций | Exp( 1/ 0.331года ) [9], трассировки [30] | GFS traces [23] |
| Потеря машины | Потеря порций | 0.008%/месяц [31] | Основано на потоке запасных частей |
| Отказ стойки | Недоступность порций | Exp(1/10лет) [9] | W(10часов, 24часов, 1) [23] |
Рисунок 6 Модели отказов компонентов системы хранения.
Рисунки 7 и 8 отвечают на оба вопроса. Они сравнивают некоторые представительные схемы систем хранения по представляющим интерес параметрам. Метки для отложенных схем строятся как n-k-r, где (n, k) определяет схему кодирования, а r порог восстановления. Рассматриваемыми нами схемами- соискателями являются: схема с тремя репликациями, оригинальная RS(14,10), RS(14,10) с отложенным восстановлением (14-10-12), а также RS(15,10) с отложенным восстановлением (15-10-12).
Мы также сравниваем отложенное восстановление с двумя недавно предложенными схемами кодирования затирания с эффективным восстановлением: Xorbas(16,10,12) [27] и Azure(16,12,14) [18]. Наконец, мы скомбинируем эти кодыэффективного восстановления с отложенным восстановлением (Xorbas+LAZY), (Azure+LAZY), установив порог восстановления взначения 12 и 14 соответственно.
Все результаты нормализованы по отношению к схеме с тремя репликациями. Значение, помечающее каждую вершину группы столбиковых диаграмм показывает действительное значение схемы с репликациями.
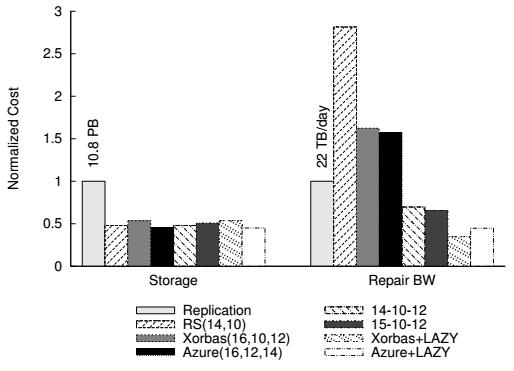
Рисунок 7 Требования хранилища и полоса пропускания отложенного восстановления в сравнении с схемами без задержек.
Из Рисунка 7 мы видим, что схемы отложенного восстановления дают 4x уменьшение в полосе пропускания восстановления в сравнении с базовым кодом затирания, причем 70% этого сохранения приходят от маскирования временных отказов, в то время как оставшиеся 30% из амортизации восстановления блоков (это разделение не показано на рисунке). В этом отношении мы превосходим схемы кодирования эффективного восстановления Azure и Xorbas более чем в два раза. На самом деле мы даже превосходим схему с полными репликациями, которая, будучи менее надежной (и не допускающей задержек) испытывает болшее число событий восстановления. Отметим, что вычисленная средняя пропускная способность восстановления примерно в 4 раза ниже, чем сообщает Facebook [26], в частности, по той причине, что размер DSS Facebook примерно на 50% больше размера моделируемой DSS. Однако точный размер в статье не указан и мы делаем его оценку с применением других публикаций о DSS Facebook [27].
Воздействие отложенного восстановления на надежность и доступность показано на Рисунке 8. Во- первых, мы сравним часть деградировавших данных в каждой из схем- претендентов. Мы видим, что отложенное восстановление увеличивает эту часть более чем на два порядка в сравнении со схемой с тремя репликациями. Однако, когда мы сравниваем эту часть с RS(14,10), мы видим увеличение только в 2 раза, с 0.1% до 0.2%. Вполне возможно, что незначительные потери доступности должны привести к деградации 0.2% холодных данных. В отношении вероятности потери данных мы наблюдаем более существенное влияние. Тем не менее, они по- прежнему на два порядка лучше чем в системах хранения с репликациями. Кроме того, фактическое изменение надежности также зависит от схемы кодирования. Например, для Xorbas+LAZY вероятность потери данных только в 6 × выше чем в оригинальной схеме Xorbas.
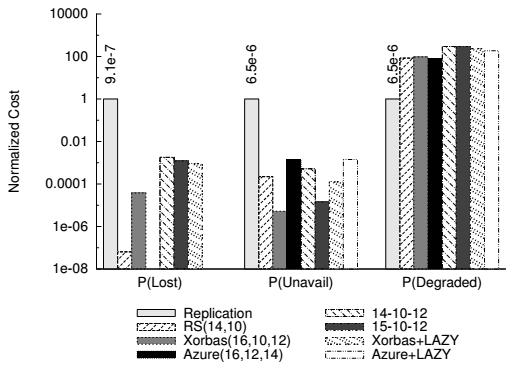
Рисунок 8 Вероятность потери данных, недоступности данных и части деградировавших полос отложенного восстановления в сопоставлении со схемами без задержек.
Рисунок 9 показывает, что сохранение полосы пропускания, которое мы предсказываем с применением нашей модели отказов даже более скромное, чем мы получаем с применением реальных данных трассировок [30]. Мы применяем трассировку 19 и 20 из репозитория CFDR для наполнения генератора событий отказов ds-sim. Каждая строка на рисунке представляет одну трассировку. Как мы можем видеть, здесь отложенное восстановление достигает значительной экономии полосы пропускания восстановления, до 20 × для схемы (15-10-12), при всего двукратном увеличении количества деградировавших полос.
| 14-10-13 | 14-10-12 | 15-10-12 | |
| P (деградировавших) | 0.006 0.006 | 0.011 (x1.6) 0.010 (x1.9) | 0.012 (x1.8) 0.012 (x1.8) |
| Полоса пропускания восстановления ТБайт/день | 51 43 | 4.1 (x12) 3.2 (x13) | 2.5 (x20) 2.3 (x18) |
Рисунок 9 Оценка отложенного восстановления с применением трассировки. Значение в скобках является улучшением по сравнению с RS(14,10)
6. Связанные работы
Кодирование затирания в целом и оптимизация полосы пропускания в частности имеют богатый список литературы; мы представляем здесь краткий обзор каждого раздела и объясняем какнаше решение вписывается в их контекст. Затем мы закрываем данный раздел описанием предыдущих применений отложенного восстановления в системах хранения.
Кодирование затирания в системах хранения..
Схемы с кодированием затиранием были приняты как для промышленных, так и для исследовательских систем хранения [23, 18, 17, 22, 2, 16, 1] благодаря их доказанному компромиссу оптимальное хранение — надежность. Из них наиболее широко используются коды Рида- Соломона; однако, при наличии отказавших узлов, они требуют на порядок бОльшую полосу пропускания по сравнению со схемами восстановления с репликациями. Чтобы решить эту проблему последние системы [5, 18, 26] повернулись лицом к эффективным в отношении полосы пропускания кодам затирания, как мы опишем далее.
Эффективные в отношении полосы пропускания коды затирания..
Для оптимизации полосы пропускания процесса восстановления были предложены новые коды затирания: коды регенерации [6] достигают теоретически оптимальной полосы пропускания восстановления для зоны охвата заданного хранилища, однако в настоящее время они непрактичны, поскольку требуют расщепления данных на экспоненциальное количество порций [29]. Последняя работа [19] описывает применение кодов с эффективной полосой пропускания для распределенного хранилища, однако она требует вдвое бОльшего хранилища при уменьшении полосы пропускания наполовину. Другой набор кодов, примененный в Facebook Xorbas [5, 27], снижает требования к полосе пропускания в два раза для первого отказа с примерно 15% дополнительной стоимостью хранения. Коды локального восстановления (LRC, Local Reconstruction Codes) [18] в системе хранения Windows Azure используют дополнительные блоки соответствия по модулю, построенные с применением подмножества систематических блоков, что делает возможным в среднем выполнение восстановления с меньшим числом чтений. Коды Piggiback [26] предлагают элегантную схему, которая уменьшает полосу пропускания восстановления на 25%.
Вместо разработки новых схем кодирования наша работа направлена на уменьшение полосы пропускания процесса восстановления путем откладывания восстановления до того момента времени, когда оно действительно необходимо. Мы полагаем, что такой подход является ортогональным к выбору схемы кодирования и может быть объединен с любой схемой для обеспечения лучшего использования полосы пропускания. Например, как мы уже показали в оценке, это эффективно как для кодов Рида- Соломона так и для кодов с эффективной полосой пропускания, подобным кодам Xorbas(16,10) и Azure(16,12).
Еще одна идея дополняющая нашу работу заключается в оптимизации восстановления путем сведения к минимуму количества избыточной информации, считываемой с разных узлов [20].
Отложенное восстановление в системах хранения.
Отложенное восстановление не является новой идеей в системах хранения данных. TotalRecall [2] представило идею об отложенном восстановлении в одноранговых хранилищах. Giroire и др. [11] показали как настроить частоту восстановления данных для одноранговых систем хранения. Чун и др. [4] показали эффективность настройки скорости восстановления в системах хранения с репликациями в широкой области сетевых настроек. Насколько нам известно, наша работа впервые применила эту идею к схемам кодирования затирания в центрах обработки данных и выполнила ее оценку с правдоподобными моделями отказа для этих установок.
7. Выводы
В данной статье мы показали, что наш изящное отложенное восстановление помогает амортизировать стоимсоть пропускной способности процесса восстановления, делая кодирование затирания жизнеспособной альтернативой для хранения холодных данных. Кроме того, мы продемонстрировали нелинейную по своей сути взаимосвязь между потребностями полосы пропускания восстановления и числом деградировавших полос и показали, что эта кривая требует аккуратного двойственного подхода для достижения желаемого снижения затрат на полосу пропускания при сохранении контроля над деградирующими полосами (и,следовательно, надежностью данных). Наша схема отложенного восстановления достигает этого путем динамической регулировки порогов восстановления для окончательных отказов в зависимости от состояния системы в целом при выполнении отложенного восстановления для временных отказов. Применив моделирование, мы показали, что эта схема снижает полосу пропускания восстановления в 4 раза для популярного кодирования Рида- Соломона 10 из 14 — сделав его совместимым с затратами схемы стремя репликациями — при сохранении высокого уровня надежности и доступности.
6. Ссылки
[1] M. Abd-El-Malek, W. V. C. II, C. Cranor, G. R. Ganger, J. Hendricks, A. J. Klosterman, M. Mesnier, M. Prasad, B. Salmon, R. R. Sambasivan,S. Sinnamohideen, J. D. Strunk, E. Thereska, M. Wachs, and J. J. Wylie. Ursa minor: Versatile cluster-based storage. In FAST, 2005.
[2] R. Bhagwan, K. Tati, Y.-C. Cheng, S. Savage, and G. M. Voelker. Total recall: System support for automated availability management. In NSDI, volume 4, pages 25–25, 2004.
[3] B. Calder, J. Wang, A. Ogus, N. Nilakantan, A. Skjolsvold, S. McKelvie, Y. Xu, S. Srivastav, J. Wu, H. Simitci, J. Haridas, C. Uddaraju, H. Khatri, A. Edwards, V. Bedekar, S. Mainali, R. Abbasi, A. Agarwal, M. F. u. Haq, M. I. u. Haq, D. Bhardwaj, S. Dayanand, A. Adusumilli, M. McNett, S. Sankaran, K. Manivannan, and L. Rigas. Windows azure storage: a highly available cloud storage service with strong consistency. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, SOSP’11, pages 143–157, New York, NY, USA, 2011. ACM.
[4] B.-G. Chun, F. Dabek, A. Haeberlen, E. Sit, H. Weatherspoon, M. F. Kaashoek, J. Kubiatowicz, and R. Morris. Efficient replica maintenance for distributed storage systems. In NSDI, 2006.
[5] A. Dimakis. Technical talk. http://ita.ucsd.edu/workshop/12/files/abstract/abstract_764.txt.
[6] A. G. Dimakis, P. B. Godfrey, Y. Wu, M. J. Wainwright, and K. Ramchandran. Network coding for distributed storage systems. IEEE Trans. Inf. Theor., 56(9):4539–4551, Sept. 2010.
[7] J. Elerath and M. Pecht. A highly accurate method for assessing reliability of redundant arrays of inexpensive disks (raid). Computers, IEEE Transactions on, 58(3):289 –299, march 2009.
[8] Erasure Coding for Distributed Storage Wiki. http://csi.usc.edu/~dimakis/StorageWiki/doku.php.
[9] D. Ford, F. Labelle, F. I. Popovici, M. Stokely, V.-A. Truong, L. Barroso, C. Grimes, and S. Quinlan. Availability in globally distributed storage systems. In OSDI, pages 61–74, 2010.
[10] S. Ghemawat, H. Gobioff, and S.-T. Leung. The google file system. In Proceedings of the nineteenth ACM symposium on Operating systems principles, SOSP’03, pages 29–43, New York, NY, USA, 2003. ACM.
[11] F. Giroire, J. Monteiro, and S. Perennes. Peer-to-peer storage systems: a practical guideline to be lazy. In GlobeCom, 2010.
[12] K. Greenan. Reliability and power-efficiency in erasure-coded storage systems. PhD thesis, UCSC, 2009.
[13] K. Greenan, E. L. Miller, and J. Wylie. Reliability of xor-based erasure codes on heterogeneous devices. In Proceedings of the 38th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN 2008), pages 147–156, June 2008.
[14] K. M. Greenan, J. S. Plank, and J. J. Wylie. Mean time to meaningless: Mttdl, markov models, and storage system reliability. In Proceedings of the 2nd USENIX conference on Hot topics in storage and file systems, HotStorage’10, pages 5–5, Berkeley, CA, USA, 2010. USENIX Association.
[15] Hadoop Scalability at Facebook. http://download.yandex.ru/company/experience/yac/Molkov.pdf.
[16] A. Haeberlen, A. Mislove, and P. Druschel. Glacier: Highly durable, decentralized storage despite massive correlated failures. In Proceedings of the USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2005.
[17] HDFS RAID . http://wiki.apache.org/hadoop/HDFS-RAID
[18] C. Huang, H. Simitci, Y. Xu, A. Ogus, B. Calder, P. Gopalan, J. Li, and S. Yekhanin. Erasure coding in windows azure storage. In USENIX ATC, 2012.
[19] Y. HuâĂă, H. C. H. Chenâ Ăă, P. P. C. Lee, and Y. Tang. Nccloud: Applying network coding for the storage repair in a cloud-of-clouds. In FAST, 2012.
[20] Y. HuâĂă, H. C. H. Chenâ Ăă, P. P. C. Lee, and Y. Tang. Rethinking erasure codes for cloud file systems: Minimizing i/o for recovery and degraded reads. In FAST, 201.
[21] R. T. Kaushik and M. Bhandarkar. Greenhdfs: towards an energy-conserving, storage-efficient, hybrid hadoop compute cluster. In Proceedings of the 2010 international conference on Power aware computing and systems, HotPower’10, pages 1–9, Berkeley, CA, USA, 2010. USENIX Association.
[22] J. Kubiatowicz, D. Bindel, Y. Chen, S. Czerwinski, P. Eaton, D. Geels, R. Gummadi, S. Rhea, H. Weatherspoon, W. Weimer, C. Wells, and B. Zhao. OceanStore: An Architecture for Global-Scale Persistent Storage. In Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2000.
[23] Large-Scale Distributed Systems at Google: Current Systems and Future Directions. http://www.cs.cornell.edu/projects/ladis2009/talks/dean-keynote-ladis2009.pdf.
[24] A. W. Leung, S. Pasupathy, G. Goodson, and E. L. Miller. Measurement and analysis of large-scale network file system workloads. In USENIX 2008 Annual Technical Conference on Annual Technical Conference, ATC’08, pages 213–226, Berkeley, CA, USA, 2008. USENIX Association.
[25] D. S. Papailiopoulos, J. Luo, A. G. Dimakis, C. Huang, and J. Li. Simple regenerating codes: Network coding for cloud storage. CoRR, abs/1109.0264, 2011.
[26] K. Rashmi, N. B. Shah, D. Gu, H. Kuang, D. Borthakur, and K. Ramchandran. A solution to the network challenges of data recovery in erasure-coded distributed storage systems: A study on the facebook warehouse cluster. In USENIX HotStorage 2013, 2013.
[27] M. Sathiamoorthy, M. Asteris, D. Papailiopoulos, A. G. Dimakis, R. Vadali, S. Chen, and D. Borthakur. Xoring elephants: Novel erasure codes for big data. Proceedings of the VLDB Endowment (to appear), 2013.
[28] K. Shvachko, H. Kuang, S. Radia, and R. Chansler. The Hadoop Distributed File System. In MSST, 2010.
[29] I. Tamo, Z. Wang, and J. Bruck. Mds array codes with optimal rebuilding. In ISIT, pages 1240–1244, 2011.
[30] The computer failure data repository. http://cfdr.usenix.org.
[31] The Hadoop Distributed File System. http://www.aosabook.org/en/hdfs.html.
- © Copyright 2015 Ceph Wiki, Module-Project Ltd (перевод)