Глава 5. Мониторинг кластеров Ceph с применением Calamari
В данной главе мы охватим:
-
Мониторинг кластера Ceph - классический путь
-
Мониторинг кластеров Ceph
-
Введение в Ceph Calamari
-
Построение пакетов Calamari сервер
-
Построение пакетов Calamari клиент
-
Наладка главного сервера Calamari
-
Добавление узлов Ceph в Calamari
-
Мониторинг кластера Ceph в инструментальной панели Calamari
-
Обнаружение ошибок Calamari
Содержание
- 5. Мониторинг кластеров Ceph с применением Calamari
- Введение
- Мониторинг кластера Ceph - классический путь
- Мониторинг кластеров Ceph
- Наблюдение за мониторами Ceph
- Мониторинг OSD Ceph
- Мониторинг MDS Ceph
- Введение в Ceph Calamari
- Построение пакетов Calamari сервер
- Построение пакетов Calamari клиент
- Наладка главного сервера Calamari
- Добавление узлов Ceph в Calamari
- Мониторинг кластера Ceph в инструментальной панели Calamari
- Обнаружение ошибок Calamari
Вне зависимости от того есть ли у вас небольшой, средний или экзамасштабный кластер, мониторинг является наиболее критически важной частью вашей инфраструктуры. После окончания вами проектирования, развёртывания и реализации промышленных служб вашего кластера Ceph, мониторинг становится главной обязанностью администратора системы хранения. В данной главе мы узнаем о различных подходах к наблюдению за вашим кластером Ceph и его компонентами. Мы рассмотрим как мониторинг через командную строку (CLI), так и через графический интерфейс (GUI), использующий встроенный инструментария CLI; мы также внедрим Calamari, являющийся инструментальной панелью управления кластером Ceph с открытым исходным кодом.
Будучи администратором системы хранения, вам необходимо отслеживать ваш кластер хранения Ceph и выяснять что происходит в нём в данный момент. Регулярное и дисциплинированное отслеживание держит вас в курсе о состоянии вашего кластера. На основании уведомлений мониторинга вы получите небольшой зазор по времени для принятия необходимых мер до отключения службы.
Наблюдение за кластером Ceph является повседневной задачей, которая включает в себя мониторинг MON, OSD, MDS, PG, а также подготовку служб хранения таких, как RBD, Radosgw, CephFS и клиентов Ceph. По умолчанию Ceph поставляется с богатым набором инструментария командной строки и API для выполнения наблюдения за этими компонентами. Кроме того, существуют проекты с открытым исходным кодом которые интенсивно развиваются для целей мониторинга кластеров Ceph в инструментальной панели единого обзора с GUI. В следующем рецепте мы сосредоточимся на инструментах CLI Ceph для мониторинга кластера.
В этом рецепте мы будем изучать команды, применяемые для мониторинга всего кластера Ceph.
Здесь мы распространяемся о мониторинге вашего кластера Ceph. Далее шаги раскрываются в поясняющих темах.
Проверка жизнеспособности кластера
Для проверки жизнеспособности вашего кластера примените команду ceph с последующим
health в качестве параметра:
# ceph health
Вывод этой команды будет состоять из нескольких разделов, разделяемых точкой с запятой:
[root@ceph-node1 ~]# ceph health HEALTH_WARN 64 pgs degraded; 1408 pgs stuck unclean; recovery 1/5744 objects degraded (0.017%) [root@ceph-node1 ~]#
Первый раздел вывода показывает что ваш кластер находится в состоянии предостережения, HEALTH_WARN,
поскольку 64 группы размещения (PG, placement groups) деградировали. Второй
раздел представляет, что 1408 PG не очищены, третий раздел вывода представляет, что кластер выполняет восстановление 1 из 5744 объектов и
этот кластер на 0.017% деградировал. Если ваш кластер жизнеспособен, вы получите вывод, что HEALTH_OK.
Для получения дополнительных деталей по состоянию вашего кластера примените команду ceph health detail.
Эта команда сообщит вам обо всех PG, которые не активны и не очищены, т.е. здесь будут выведены с подробностями все PG, которые не очищены,
не согласованы и деградировали. Если ваш кластер в жизнеспособен, вы получите вывод, что HEALTH_OK.
Вывод этой команды будет состоять из нескольких разделов, разделяемых точкой с запятой:
[root@ceph-node2 ceph]# ceph health detail HEALTH_ERR 61 pgs degraded; 6 pgs inconsistent; 1312 pgs stuck unclean; recovery 3/5746 objects degraded (0.052%); 8 scrub errors pg 9.76 is stuck unclean since forever, current state active+remapped, last acting [7,3,2] pg 8.77 is stuck unclean since forever, current state active+remapped, last acting [4,6,8] pg 7.78 is stuck unclean for 788849.714074, current state active+remapped, last acting [6,5,1] pg 6.79 is stuck unclean since forever, current state active+remapped, last acting [4,7,8] pg 5.7a is stuck unclean since forever, current state active+remapped, last acting [7,4,2] pg 4.7b is stuck unclean since forever, current state active+remapped, last acting [7,3,1] pg 11.74 is stuck unclean for 788413.925336, current state active+remapped, last acting [4,7,8] pg 10.75 is stuck unclean for 788412.797947, current state active+remapped, last acting [7,3,0]
Мониторинг событий кластера
Вы можете наблюдать за событиями кластера применяя команду ceph с параметром
-w. Эта команда высветит сообщения обо всех событиях вашего кластера, включая информационные (INF),
предостерегающие (WRN) и сообщения об ошибках (ERR) в реальном времени. Вывод данной команды будет непрерывным, изменяемым кластеров вживую;
для возврата в оболочку вы можете применить Ctrl + C:
# ceph -w
[root@ceph-node1 ~]# ceph -w
cluster 9609b429-eee2-4e23-af31-28a24fcf5cbc
health HEALTH_OK
monmap e3: 3 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0}, election epoch 640, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3
mdsmap e68: 1/1/1 up {0=ceph-node2=up:active}
osdmap e1821: 9 osds: 9 up, 9 in
pgmap v20731: 1628 pgs, 45 pools, 2422 MB data, 3742 objects
7605 MB used, 127 GB / 134 GB avail
1628 active+clean
2015-06-06 20:13:27.047075 mon.0 [INF] pgmap v20731: 1628 pgs: 1628 active+clean; 2422 MB data, 7605 MB used, 127 GB / 134 GB avail; 7931 kB/s, 1 objects/s recovering
2015-06-06 20:14:25.958762 mon.0 [INF] from.'client.? 192.168.1.103:0/1008239' entity='cli ent.admin' cmd.[{"prefix": "pg repair", "pgid": "43.29"}]: dispatch
2015-06-06 20:14:32.031029 mon.0 [INF] pgmap v20732: 1628 pgs: 1628 active+clean; 2422 MB data, 7605 MB used, 127 GB / 134 GB avail
2015-06-06 20:14:57.541278 mon.0 [INF] pgmap v20733: 1628 pgs: 1628 active+clean; 2422 MB data, 7621 MB used, 127 GB / 134 GB avail
2015-06-06 20:15:02.371735 mon.0 [INF] pgmap v20734: 1628 pgs: 1628 active+clean; 2422 MB data, 7633 MB used, 127 GB / 134 GB avail
Существуют также прочие параметры, которые могут применяться с командой ceph для сбора различных
типов подробностей сообщений. Это:
-
--watch-debug: для отслеживания сообщений отладки -
--watch-info: для отслеживания информационных сообщений -
--watch-sec: для отслеживания сообщений безопасности -
--watch-warn: для отслеживания предупреждающих сообщений -
--watch-error: для отслеживания сообщений об ошибке
Статистика использования кластера
Чтобы узнать статистику использования пространства вашего кластера примените команду ceph с параметром
df. Эта команда покажет общий размер кластера, доступный размер, используемый размер и проценты. Она также
высветит информацию о пулах, такую как имя пула, идентификатор, использование и число объектов в каждом пуле:
# ceph df [root@ceph-node1 ..]# ceph df GLOBAL: SIZE AVAIL RAW USED %RAW USED 134G 127G 7440M 5.39 POOLS: NAME ID USED %USED MAX AVAIL OBJECTS rbd 0 114M 0.08 42924M 2629 images 1 53002k 0.04 42924M 12 volumes 2 47 0 42924M 8 vms 3 208M 0.15 42924M 31 .rgw.root 4 162 0 42924M 2 .rgw.control 5 0 0 42924M 8 .rgw 6 2731 0 42924M 15 .rgw.gc 7 0 0 42924M 32 .users.uid 8 736 0 42924M 4 .users.email 9 8 0 42924M 1 .users 10 16 0 42924M 2 .users.swift 11 8 0 42924M 1 .rgw.buckets.index 12 0 0 42924M 9 .rgw.buckets 13 1744 0 42924M 4
Проверка состояния кластера
Проверка состояния кластера является наиболее общей и наиболее частой операцией при управлении кластером Ceph. Вы можете проверить состояние
вашего кластера с применением команды ceph и status в качестве
параметра:
# ceph status
Вместо подкоманды status вы можете применить более короткую версию, -s,
как опцию:
# ceph -s
Следующий снимок экрана покажет состояние нашего кластера:
[root@ceph-node1 ~]# ceph -s
cluster 9609b429-eee2-4e23-af31-28a24fcf5cbc
health HEALTH_OK
monmap e3: 3 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3=192.168.1.103:6789/0}, election epoch 640, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3
mdsmap e73: 1/1/1 up {0=ceph-node2=up:active}
osdmap el823: 9 osds: 9 up, 9 in
pgmap v20762: 1628 pgs, 45 pools, 2422 MB data, 3742 objects
7440 MB used, 127 GB / 134 GB avail
1628 active+clean
[root@ceph-node1 ~]#
Эта команда выводит на экран массу полезной информации для вашего кластера Ceph:
-
cluster: Эта команда представляет ваш уникальный идентификатор кластера Ceph. -
health: Эта команда показывает жизнеспособность кластера -
monmap: Эта команда представляет версию эпохи карты монитора, информацию о мониторе, версию эпохи выбора монитора и состояние кворума монитора. -
mdsmap: Эта команда представляет вашу версию эпохиmdsmapи ваше состояниеmdsmap. -
osdmap: Эта команда представляет вашу эпохуosdmap, общее число OSD (total), число работающих OSD (up) и число OSD в наличии (in). -
pgmap: Эта команда показывает вашу версиюpgmap, общее число PG, число пулов, используемая ёмкость для одной копии, а также общее число объектов. Она также отображает информацию об использовании кластера, включая размер использования, размер свободного пространства и общий размер. Наконец, она отображает состояние PG.
![[Замечание]](/common/images/admon/note.png)
Записи аутентификации вашего кластера
Ceph работает с системой аутентификации на основе ключей. Все компоненты кластера взаимодействуют друг с другом раз они подвергаются
аутентификации системы на основе ключей. Вы можете применить команду ceph с подкомандой
auth list для получения списка всех ваших ключей:
# ceph auth list
Обычно кластер Ceph развёртывается с более чем одним экземпляром MON для высокой доступности. Так как существует большое число мониторов, они должны достигать кворума для поддержки надлежащего функционирования кластера.
Мы сосредоточимся сейчас на командах для наблюдения за мониторами. Шаги будут раскрываться в поясняющих темах.
Проверка состояния монитора
Для отображения состояния монитора кластера и карты MAP воспользуйтесь командой ceph с дополнительным
параметром либо mon stat либо mon dump:
# ceph mon stat # ceph mon dump
Следующий снимок экрана отображает вывод этих команд:
[root@ceph-node1 ~]# ceph mon stat
e3: 3 mons at {ceph-node1=192.168.1.101:6789/0,ceph-node2=192.168.1.102:6789/0,ceph-node3 =192.168.1.103:6789/0}, election epoch 640, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3
[root@ceph-node1 ~]#
[root@ceph-node1 ~]# ceph mon dump
dumped monmap epoch 3
epoch 3
fsid 9609b429-eee2-4e23-af31-28a24fcf5cbc
last_changed 2015-03-18 00:20:07.092486
created 0.000000
0: 192.168.1.101:6789/0 mon.ceph-node1
1: 192.168.1.102:6789/0 mon.ceph-node2
2: 192.168.1.103:6789/0 mon.ceph-node3
[root@ceph-node1 ~]#
Проверка состояния кворума мониторов
Для поддержания кворума между мониторами Ceph кластер всегда должен иметь более половины доступных в кластере мониторов. Проверка
состояния кворума вашего кластера очень полезна во время определения проблем с мониторами. Вы можете проверить состояние кворума
при помощи команды ceph с подкомандой quorum_status:
# ceph quorum_status -f json-pretty
Следующий снимок отображает вывод этой команды:
[root@ceph-node1 ~]# ceph quorum_status -f json-pretty
{ "election_epoch": 640,
"quorum": [
0,
1,
2],
"quorum_names": [
"ceph-node1",
"ceph-node2",
"ceph-node3"],
"quorum_leader_name": "ceph-node1",
"monmap": { "epoch": 3,
"fsid": "9609b429-eee2-4e23-af31-28a24fcf5cbc",
"modified": "2015-03-18 00:20:07.092486,
"created": "0.000000",
"mons": [
{ "rank": 0,
"name": "ceph-node1",
"addr": "192.168.1.101:6789\/0"},
{ "rank": 1,
"name": "ceph-node2",
"addr": "192.168.1.102:6789\/0},
{ "rank": 2,
"name": "ceph-node3",
"addr": "192.168.1.103:6789\/0"}]}}
[root@ceph-node1 ~]#
Состояние кворума высвечивает election_epoch, что является номером версии выборов и
quorum_leader_name, которое обозначает имя вашего хоста, руководящего кворумом. Оно также
отображает эпоху карты монитора и идентификатор кластера. Каждому монитору кластера выделяется ранг. Для операций ввода/ вывода
клиенты вначале соединяются с ведущим монитором кворума; если ваш ведущий монитор недоступен, клиент тогда соединяется со следующим
по рангу монитором.
Мониторинг OSD является решающей задачей и требует полного внимания, поскольку существует множество OSD для наблюдения и заботы. Чем больше ваш кластер, тем больше OSD он будет иметь и тем более скурпулёзное наблюдение вам потребуется. Обычно хосты кластеров Ceph заполнены большим числом дисков, поэтому вероятность столкнуться с отказом OSD очень высока.
Мы сосредоточимся сейчас на командах для наблюдения за OSD. Шаги будут раскрываться в последующих поясняющих темах:
Обзор дерева OSD
Обзор дерева OSD очевидно полезен для получения информации о состояниях OSD таких как IN или
OUT и UP или DOWN.
Обзор дерева OSD отображает все узлы со всеми их OSD и их местоположение в карте CRUSH. Вы можете попробовать отображение своего
дерева OSD с применением следующей команды:
# ceph osd tree [root@ceph-node1 ~]# ceph osd tree # id weight type name up/down reweight -1 0.08995 root default -2 0.02998 host ceph-node1 0 0.009995 osd.0 up 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 -3 0.02998 host ceph-node2 3 0.009995 osd.3 up 1 4 0.009995 osd.4 up 1 5 0.009995 osd.5 up 1 -4 0.02998 host ceph-node3 6 0.009995 osd.6 up 1 7 0.009995 osd.7 up 1 8 0.009995 osd.8 up 1 [root@ceph-node1 ~]#
эта команда отображает различную полезную информацию для OSD Ceph, такую как вес, состояние UP/DOWN
и IN/OUT. Выдача будет прекрасно отформатирована в виде вашей карты Ceph CRUSH. Если вы
сопровождаете большой кластер, этот формат даст вам преимущества определения местоположения OSD и его сервера хоста в длинном
перечне.
Статистика OSD
Чтобы проверить статистику OSD, примените # ceph osd stat; эта команда поможет вам получить
эпоху карты, общее число OSD и их состояния IN и UP.
Для получения подробной информации о кластере Ceph и OSD выполните следующую команду:
# ceph osd dump
Это очень полезная команда, которая выведет эпоху карты ваших OSD, подробности пула, включающие его идентификатор, имя пула, тип пула, т.е. реплицируемый или затираемый (erasure, кодируемый), набор правил CRUSH и PG. Эта команда также отобразит информацию по каждому OSD, такую как идентификатор OSD, его состояние, вес, эпоху интервала последней очистки и тому подобное. Вся эта информация очень полезна для мониторинга кластера и обнаружения ошибок.
Вы также можете сделать чёрный список OSD для предотвращения их соединения с прочим OSD с тем, чтобы не осуществлялся никакой процесс тактов определения жизнеспособности. В основном он применяется для предотвращения запаздываний сервера метаданных в создании плохих изменений данных в вашем OSD, чёрнные списки ведутся Ceph самостоятельно и не требуют ручного вмешательства, однако о них стоит знать.
Для отображения клиентов в чёрном списке выполните следующую команду:
# ceph osd blacklist ls
Проверка вашей карты CRUSH
Вы можете запрашивать свою карту CRUSH непосредственно из команд # ceph osd. Утилита командной
строки карты CRUSH может сохранить много времени системного администратора, по сравнению с обычным способом просмотра и её редактирования
после декомпиляции вашей карты CRUSH:
-
Для просмотра карты CRUSH выполните следующую команду:
# ceph osd crush dump
-
Для просмотра правил карты CRUSH выполните следующую команду:
# ceph osd crush rule list
-
Для просмотра подробностей правил карты CRUSH выполните следующую команду:
# ceph osd crush rule dump <crush_rule_name>
Следующий рисунок отображает вывод нашего запроса карты CRUSH:
[root@ceph-node1 ~]# ceph osd crush rule list
[
"replicated_rulesee]
[root@ceph-node1 ~]#
[root@ceph-node1 ~]# ceph osd crush rule dump replicated_ruleset
{ "rule_id": 0,
"rule_name": "replicated_ruleset",
"ruleset": 0,
"type": 1,
"min_size": 1,
"maxsize": 10,
"steps": [
{ "op": "take",
"item": -1,
"item_name": "default"},
{ "op": "chooseleaf_firstn",
"num": 0,
"type": "host"},
{ "op": "emit"}]}
[root@ceph-node1 ~]#
Если вы управляете большим кластером с несколькими сотнями OSD, иногда бывает трудно найти местоположение определённого OSD в карте
CRUSH. Это также трудно сделать, если ваша карта CRUSH содержит множественную иерархию сегментов (bucket). Вы можете воспользоваться
ceph osd find для поиска некоего OSD и определении его местоположения в карте CRUSH:
# ceph osd find <Numeric_OSD_ID>
[root@ceph-node1 ~]# ceph osd find 4
{ "osd": 4,
"ip": "192.168.1.102:6811\/3897",
"crush_location": { "host": "ceph-node2",
"root": "default}}
[root@ceph-node1 ~]#
[root@ceph-node1 ~]#
Мониторинг PG
OSD хранят PG, причём каждая PG содержит объекты. Общая жизнеспособность кластера в основном зависит от PG. Кластер будет оставаться в
состоянии HEALTH_OK только если все PG находятся в состоянии active
+ clean. Если ваш кластер Ceph испытывает проблемы с жизнеспособностью, то существует вероятность, что
ваши группы размещения не active + clean. Группы размещения
могут существовать в различных состояниях, и даже в комбинации состояний. Вот некоторые состояния, в которых могут находиться PG:
-
Creating: PG создана. -
Peering: Процесс приведения в действие всех ваших OSD которые хранят PG в соответствие между состоянием всех объектов включая их метаданные в этой PG {Прим. пер.: одноранговый обмен}. -
Active: когда операция однорангового обмена завершится, Ceph отображает все PG как активные. В активном состоянии данные в вашей PG доступны в первичной PG и её реплике для операций вводо/ вывода. -
Clean: Состояние очищено означает, что первичный и вторичный OSD успешно выполнили одноранговый обмен и никакие PG не перемещаются из своего правильного местоположения. Оно также показывает, что PG реплицированы необходимое число раз. -
Down: Это означает, что реплика со своими необходимыми данными отключена, поэтому PG выключена. -
Degraded: Когда OSD переходит вDOWN, Ceph изменяет состояние всех своих PG, которые назначены на этот OSD наDEGRADED. После того как OSD становитсяUP, оно должно выполнить одноранговый обмен вновь чтобы очистить деграировашие PG. Если OSD остаётсяDOWNиOUTболее чем 300 секунд, Ceph выполняет восстановление всех своих деградировавших PG из PG их реплик для поддержания необходимого количества реплик. Клиенты могут выполнять ввод/ вывод даже после того как PG находятся в деградировавшем состоянии. -
Recovering: Когда OSD переходит вDOWN, содержимое этих PG такого OSD берётся из содержимого PG реплик в других OSD. Когда OSD возвращается вUP, Ceph инициирует операцию восстановления этой PG чтобы поддержать её актуальность с PG реплики и прочих OSD. -
Backfilling: Когда новое OSD добавлен в ваш кластер, Ceph пытается выполнить балансировку данных перемещая некоторые PG с других OSD на этот новое OSD; этот процесс называется заплонением (backfilling). Когда заполнение выполнится для данной PG, ваше OSD может принимать участие в вводе/ выводе клиента. -
Remapped: Всякий раз когда существуют изменения в вашем действующем наборе (acting set) PG, происходит миграция данных со старого действующего набора OSD на новый действующий набор OSD. Эта операция может занять некоторое время в зависимости от размера данных которое подлежит миграции на новый OSD. В течение этого времени старый первичный OSD старого действующего набора обслуживает запросы клиентов. Как только операция миграции завершится, Ceph воспользуется новым первичным OSD из этой действующем наборе. -
Stale: OSD Ceph выдают сообщение о своей статистике монитору Ceph каждые 0.5 секунд; если их первичные OSD действующего набора OSD возможно отказывают в предоставлении сообщений своей статистики мониторам, или прочие OSD сообщили что первичный OSD перешёл вDOWN, монитор рассматривает эту PG как утратившую силу (stale).
Вы можете пронаблюдать за PG применив следующие команды:
-
Чтобы получить состояние PG, выполните
# ceph pg stat:[root@ceph-node1 ~]# ceph pg stat v20780: 1628 pgs: 1628 active+clean; 2422 MB data, 7440 MB used, 127 GB / 134 GB avail [root@ceph-node1 ~]#
Вывод команды
pg statотобразит много информации в специфическом формате:vNNNN: X pgs: Y active+clean; R MB data, U MB used, F GB / T GB avail.Где переменные определены следующим образом:
-
vNNNN: Это номер версии карты вашей PG -
X: Общее число PG -
Y: Число PG, которые имеют состояниеactive+clean -
R: сохранённые сырые данные -
U: реально сохранённые после репликаций данные -
F: оставшаяся свободная ёмкость -
T: Общая ёмкость
-
-
Для получения списка PG, выполните следующее:
# ceph pg dump -f json-pretty
Эта команда сгенерирует много существенной информации по отношению к PG, например версию карты PG, идентификатор PG, состояние PG, действующий набор, первичный действующий набор и тому подобное. Вывод этой команды может быть гигантским в зависимости от числа PG в вашем кластере.
-
Чтобы запросить подробную информацию для определённой PG выполните следующую команду, имеющую такой синтаксис
ceph pg <PG_ID> query:# ceph pg 2.7d query
-
Чтобы выдать перечень застрявших (stuck) PG выполните следующую команду, имеющую такой синтаксис
ceph pg dump_stuck < unclean | Inactive | stale > query:# ceph pg dump_stuck unclean
Серверы метаданных используются исключительно для CephFS, которая пока не готова к промышленному применению на настоящий момент.
Сервер метаданных имеет различные состояния, такие как, UP, DOWN,
ACTIVE и INACTIVE. При выполнении мониторинга
MDS вам следует проверять что состояние MDS UP и ACTIVE.
Следующие команды помогут вам получит информацию связанную с MDS Ceph.
Мы сосредоточимся сейчас на командах для наблюдения за OSD. Шаги будут раскрываться в последующих поясняющих темах:
-
Проверьте перечень файловых систем CephFS:
# ceph fs ls
-
Проверьте состояние MDS:
# ceph mds stat
-
Отобразите подробности вашего сервера метаданных:
# ceph mds dump [root@ceph-node1 ~]# ceph fs ls name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ] [root@ceph-node1 ~]# [root@ceph-node1 ~]# ceph mds stat e73: 1/1/1 up {O=ceph-node2=up:active} [root@ceph-node1 ~]# [root@ceph-node1 ~]# ceph mds dump dumped mdsmap epoch 73 epoch 73 flags 0 created 2015-05-19 00:18:45.398790 modified 2015-06-06 20:15:21.386153 tableserver 0 root 0 session_timeout 60 session_autoclose 300 max_file_size 1099511627776 last failure 0 last_failure_osd_epoch 1822 compat compat={},rocompat=11,incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table} max_mds 1 in 0 up {0=47181} failed stopped data_pools 43 metadata_pool 44 inline_data disabled 47181: 192.168.1.102:6800/7314 'ceph-node2' mds 0.15 up:active seq 6 [root@ceph-node1 ~]#
Calamari является платформой управления для Ceph; привлекательной инструментальной панелью для мониторинга и управления вашим кластером Ceph. Она была изначально разработана компанией Inktank как проприетарное программное обеспечение, и была продуктом Inktank Ceph Enterprise, который предлагался их пользователям. Сразу после приобретения Inktank компанией Red Hat, она стала открытым исходным кодом Red Hat, 30 мая 2014. Calamari имеет различные великолепные наборы функциональности, а их последующая дорожная карта весьма впечатляет. Calamari имеет две части, причём каждая часть имеет свои собственные репозитории:
-
Frontend: Это основанный на браузере графический интерфейс пользователя, который в основном реализован на JavaScript. Часть внешнего интерфейса (Frontend) применяет Calamari REST API и строится на модульной основе, поэтому каждый компонент внешнего интерфейса может обновляться независимо. Внешний интерфейс Calamari стал открытым исходным кодом с лицензией MIT; вы можете найти его в репозитории https://github.com/ceph/calamari-clients.
-
Backend: Серверная часть (Backend) Calamari является ядром платформы, которое написано на Python. Она также применяет прочие компоненты, такие как SaltStack, ZeroRPC, graphite, Django-rest-framework, Django, gevent и тому подобные, а также предоставляет новый REST API для интеграции с Ceph и другими системами. Calamari был переделан в своей новой версии, в которой он использует REST API для взаимодействия сосвоим кластером Ceph. Предыдущая редакция Calamari применяла Ceph REST API, который является слегка ограничительным для этих целей. Серверная часть Calamari является открытым исходным кодом с лицензией LGPL2+; вы можете найти её репозиторий по адресу; https://github.com/ceph/calamari.
Calamari имеет хорошую документацию доступную на http://calamari.readthedocs.org; являетесь ли вы оператором или разработчиком, работающим над Calamari или разработчиком, применяющим Calamati REST API, эта документация является хорошим источником информации для начала вашей работы с Calamari. Как и Ceph, Calamari разрабатывается как восходящий продукт; вы можете включиться в Calamari на IRC по адресу irc://irc.oftc.net/ceph, зарегистрироваться в почтовой рассылке на ceph-calamari@ceph.com, или послав запрос на учётную запись Calamari GitHub на https://github.com/ceph/calamari и https://github.com/ceph/calamariclients.
В настоящее время Calamari не предоставляет готовых к установке пакетов, поэтому вам придётся построить их для своей среды. В этом рецепте мы изучим построение пакетов сервера Calamari Ceph из исходных кодов. Построение таких пакетов иногда является серъёзным вызовом, поскольку вы можете не выполнить его одним ударом. Поэтому, чтобы уменьшить сложность, я построил такие пакеты для вас и вы можете их загрузить с https://github.com/ksingh7/cephcalamari-packages, поэтому можете пропустить следующие два рецепта, напрямую перескочив на необходимые условия для установки. Для тех, кому интересно построение пакетов из исходных кодов, давайте приступим. {Прим. пер.: также см. Глава 15. Инструменты разработки в нашем переводе "Как работает Linux" Брайана Варда}.
Calamari предоставляет готовую к применению конфигурацию Vagrant для некоторых типов ОС. Определите тип вашего работающего хоста Calamari, для которого вы хотите построить пакеты; в нашем случае это CentOS7.
-
Клонируйте репозиторий сервера Calamari с применением следующей команды:
$ git clone https://github.com/ceph/calamari.git
-
Diamond является демоном Python, который собирает метрики системы и публикует их в Graphite. Он способен собирать метрики ЦПУ, оперативной памяти, сетевой среды, ввода/ вывода, нагрузок и дисков. Для дополнительной информации по Diamond обратитесь к http://diamond.readthedocs.org/. В настоящее время Calamari производит своё собственное ответвление Diamond. Для получения Diamond клонируйте следующий репозиторий:
$ cd calamari/vagrant/centos-build
-
В репоитории
calamariвы найдёте каталогvagrant, который предоставляет среду разработки для различных типов операционных систем. Переместитесь в следующий путь для CentOS:teeri:git ksinghS git clone https://github.com/ceph/calamari.git Cloning into 'calamari'... remote: Counting objects: 11265, done. remote: Total 11265 (delta 0), reused 0 (delta 0), pack-reused 11265 Receiving objects: 100% (11265/11265), 20.83 MiB 1 1.62 MiB/s, done. Resolving deltas: 100% (6064/6064), done. Checking connectivity... done. teeri:git ksinghS teeri:git ksinghS git clone https://github.com/ceph/Diamond.git --branch.calamari Cloning into 'Diamond'... remote: Counting objects: 18182, done. remote: Total 18182 (delta 0), reused 0 (delta 0), pack-reused 18182 Receiving objects: 100% (18182/18182), 4.15 MiB 1 2.28 MiB/s, done. Resolving deltas: 100% (7151/7151), done. Checking connectivity... done. teeri:git ksinghS teeri:git ksinghS cd calamari/vagrant/centos-build teeri:centos-build ksinghS teeri:centos-build ksinghS ls -l total 8 -rw-r--r-- 1 ksingh staff 1114 Jun 7 21:05 Vagrantfile drwxr-xr-x 4 ksingh staff 136 Jun 7 21:05 salt teeri:centos-build ksinghS
-
На момент написания этой главы Vagrant не предоставлял скомпонованной настройки для CentOS7. {Прим. пер.: На момент перевода
calamari/vagrant/centos7-buildприсутствует, так что следующие два шага можно пропустить}. Итак, мы модифицируем среду CentOS6 Vagrant, установивconfig.vm.boxкакconfig.vm.box = "boxcutter/centos71". -
Поднимем блок Vagrant воспользовавшись следующей командой:
$ vagrant up => default: Running provisioner: salt... Copying salt minion config to vm. Checking if salt-minion ls installed salt-minion was not found. Checking if salt-call is installed salt-call was not found. Bootstrapping Salt... (this, may take a while) Salt successfully configured and installed! run_overstate set to false. Not running state.oyerstate. run_highstate set to false. Not running state.highstate.
-
На данный момент наша среда разработки CentOS7 готова; мы должны зарегистрироваться на этой машине и выполнить
salt-callдля начала построения пакетов:$ vagrant ssh $ sudo salt-call state.highstate [vagrant@local host ~] $ [vagrant@local host ~] $ sudo salt-call state .highstate [INFO ] Loading fresh modules for state activity [INFO ] Fetching file from saltenv 'base', ** done ** 'top.sls'
-
Процесс построения займёт некоторое время; наконец, вы должны получить вывод похожий на следующее:
Summary ------------ Succeeded: 9 (changed=6) Failed: 0 ------------ Total states run: 9 [vagrant@local host ~]$
-
На данный момент у вас имеется окончательно скомпонованные пакеты для сервера Calamari и Diamond. Вы можете найти установочные файлы RPM на один каталог выше вашего клонированного репозитория
calamari.
В этом рецепте мы изучим построение пакетов клиента Calamari. Большинство шагов аналогичны тому, что мы делали в предыдущем разделе, то есть при построении пакета сервера.
-
Клонируйте репозиторий клиента Calamari:
$ git clone https://github.com/ceph/calamari-clients.git
-
Измените рабочий каталог на тот, который предоставляет среду Diamond Centos:
$ cd calamari-clients/vagrant/centos-package
-
Измените среду
Vagrantfileи установитеconfig.vm.boxследующим образом:config.vm.box = "boxcutter/centos71". {Прим. пер.: На момент переводаcalamari/vagrant/centos7-buildприсутствует, так что это шаг можно пропустить}. -
Далее поднимем нашу машину:
$ vagrant up
-
На данный момент наша среда разработки CentOS7 готова; мы должны зарегистрироваться на этой машине и выполнить
salt-callдля начала построения пакетов:$ vagrant ssh $ sudo salt-call state.highstate
-
Процесс построения займёт некоторое время; наконец, вы должны получить вывод похожий на следующее:
----------- ID: copyout_build_product Function: cmd.run Result: True Comment: Command "cp calamari-clients*tar.gz /git/" run Changes: ---------- pid: 25090 retcode: 0 stderr: stdщге: Summary ------------- Succeeded: 13 Failed: 0 ------------- Total: 13 [vagrant@local host ~]$
-
На данный момент у вас имеется окончательно скомпонованные пакеты для клиента Calamari и вы можете найти установочные файлы RPM на один каталог выше вашего клонированного репозитория
calamari.
В последних рецептах мы скомпилировали необходимые для Calamari пакеты, которые включают в себя calamari-server,
calamari-client и diamond. Если вы не компилировали
эти пакеты, вы можете загрузить их из моего репозитория GitHub: https://github.com/ksingh7/ceph-calamari-packages/tree/master/CentOS-el7:
В данной демонстрации мы настроим ceph-node1 в качестве главного (master) сервера, а также как
узел salt-minion, а ceph-node2 и
ceph-node3 только как подчинённые (minion) узлы salt-minion.
На момент написания этого рецепта Calamari не поддерживал salt версии 2015, поэтому я умышленно применил версию salt 2014.
Давайте начнём установку сервера Calamari:
-
На
ceph-node1установите зависимости пакетов требующиеся salt и серверу Calamari:yum install -y python-crypto PyYAML systemd-python yum-utils m2crypto pciutils python-msgpack systemd-python python-zmq
-
ceph-node1сервера Calamari:$ git clone https://github.com/ceph/calamari-clients.git
-
По умолчанию, CentOS7 установит самую последнюю версию salt, поэтому, чтобы установить версию salt 2014, настройте salt repo:
# wget https://copr.fedoraproject.org/coprs/saltstack/salt/repo/epel-7/saltstack-salt-epel-7.repo -O /etc/yum.repos.d/saltstacksalt-epel-7.repo
-
Установите salt master и salt minion версии 2014.7.5:
# yum --disablerepo="*" --enablerepo="salt*" install -y saltmaster-2014.7.5-1.el7.centos
-
Поскольку данная установка выполняется исключительно для тестовых целей, мы остановим и запретим межсетевой экран:
# systemctl stop firewalld # systemctl disable firewalld
-
Далее установим пакет сервера Calamari. Убедимся что это не обновит версию salt до 2015:
# yum install https://github.com/ksingh7/ceph-calamari-packages/raw/master/CentOS-el7/calamari-server-1.3.0.1-49_g828960a.el7.centos.x86_64.rpm
-
Далее установим пакет сервера Calamari, который устанавливает компоненты инструментальной панели Calamari:
# yum install -y https://github.com/ksingh7/ceph-calamaripackages/raw/master/CentOS-el7/calamari-clients-1.2.2-32_g931ee58.el7.centos.x86_64.rpm
-
Сделаем доступной и запустим службу
salt-master:# systemctl enable salt-master # systemctl restart salt-master
-
На данный момент сервер Calamari установлен и мы должны настроить его выполнив следующую команду:
# calamari-ctl initialize [root@ceph-node1 ~]# calamari-ctl initialize [INFO] Loading configuration.. [INFO] Starting/enabling salt... [INFO] Starting/enabling postgres... [INFO] Initializing database... [INFO] You will now be prompted for login detai1s for the administrative user account. This is the account you will use to log into the web interface once setup is complete. username (1eave blank to use 'root') : root Email address: karan_singhl@live.com Password: Password (again): Superuser created successfully. [INFO] Initializing web interface... [INFO] Starting/enabling services... [INFO] Restarting services... [INFO] Complete. [root@ceph-node1 ~]#
-
На момент написания этого раздела Calamari имел известный баг (обновление подключённого подчинённого), который завершался с ошибкой в процессе шага инициализации Calamari. Вы можете пропустить этот шаг если ваша команда инициализации
calamari-ctlпрошла успешно. Для коррекции этого бага измените файл/opt/calamari/venv/lib/python2.7/site-packages/calamari_cthulhu-0.1-py2.7.egg/cthulhu/calamari_ctl.pyupdate_connected_minions(), закомментировав строку 255, которая выдаёт сообщение сервера Calamari:[root@ceph-node1 cthulhu]# cat calamari_ctl.py | grep "update_connectedminions()" | grep -v def # update_connected_minions() [root@ceph-node1 cthulhul#
-
Далее переместитесь в инструментальную панель Calamari набрав в своём браузере
http://192.168.1.101/dashboard/и предоставив имя пользователяrootи пароль, который вы установили на последнем шаге.
-
Когда вы зарегистрируетесь в инструментальной панели Calamari, вы увидите экран аналогичный приводимому ниже; на данный момент это новая установка Calamari, нам необходимо добавить в неё узлы Ceph, и это будет описано в следующем разделе.

На данный момент у нас есть работающий главный сервер Calamari. Чтобы наблюдать за вашим кластером Ceph при помощи Calamari, нам нужно добавить узлы Ceph в Calamari. Давайте начнём это.
-
На
ceph-node2иceph-node3сделайте доступными репозитории salt 2014yum:# wget https://copr.fedoraproject.org/coprs/saltstack/salt/repo/epel-7/saltstack-salt-epel-7.repo -O /etc/yum.repos.d/saltstack-salt-epel-7.repo
-
Установите зависимости пакетов вручную:
# yum install -y python-crypto PyYAML systemd-python yum-utils m2crypto pciutils python-msgpack systemd-python python-zmq
Теперь выполняем эти шаги на ceph-node1, ceph-node2,
а также как и на ceph-node3:
-
Установите пакет
salt-minion-2014:# yum --disablerepo="*" --enablerepo="salt*" install -y saltminion-2014.7.5-1.el7.centos
-
Установите пакет Diamond:
# yum install -y https://github.com/ksingh7/ceph-calamaripackages/raw/master/CentOS-el7/diamond-3.4.582-0.noarch.rpm
Сделайте доступной и запустите службу Diamond:
# systemctl enable diamond # systemctl restart diamond
-
Далее настройте подчинённые salt на применение
ceph-node1в качестве главного узла Calamari:# echo "master: ceph-node1" > /etc/salt/minion.d/calamari.conf
-
Сделайте доступной и запустите службу
salt-minion:ctl enable salt-minion # systemctl restart salt-minion
Теперь
salt-minion, т.е. узлы Calamari Ceph настроены для применения главным сервером Calamari. Далее нам необходимо зарегистрироваться на главном сервере Calamari, т.е. наceph-node1чтобы перечислить и принять ключи salt от подчинённых. -
На
ceph-node1выведем следующим образом список salt-key:# salt-key -L
-
Далее примем salt-key подчинённых:
# salt-key -A
-
Проверим приём ключей подчинённых:
# salt-key -L [root@ceph-node1 etc]# salt-key -L Accepted Keys: ceph-node1 ceph-node2 ceph-node3 Unaccepted Keys: Rejected Keys:
-
Наконец, откроем свой браузер и посетим инструментальную панель Calamari для проверки вашего кластера:
![[Предостережение]](/common/images/admon/warning.png)
Предостережение Иногда случается, что Calamari не может найти кластер Ceph сразу после приёма ключей подчинённых salt. В этом случае дайте некоторое время Calamari и salt изучить кластер Ceph.
Наблюдение за кластером Ceph из инструментальной панели Calamari достаточно непосредственное. Давайте посмотрим как:
-
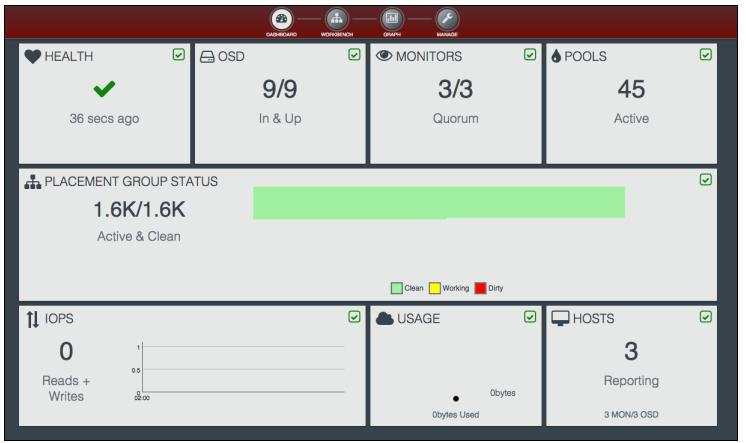
Инструментальная панель отображает массу полезной информации:
-
OSD могут наблюдаться с помощью параметра рабочего места OSD:
-
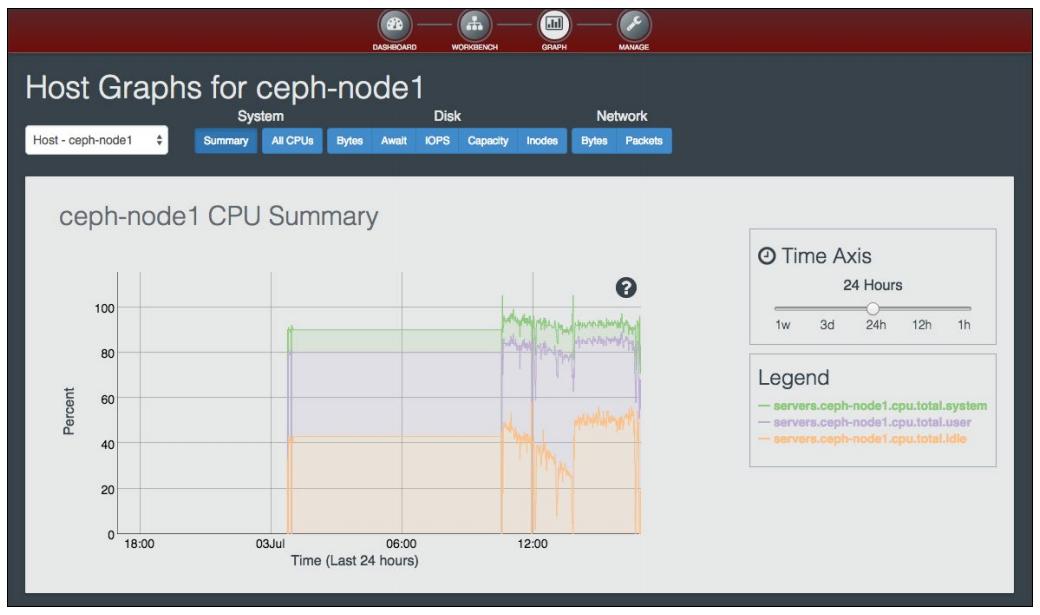
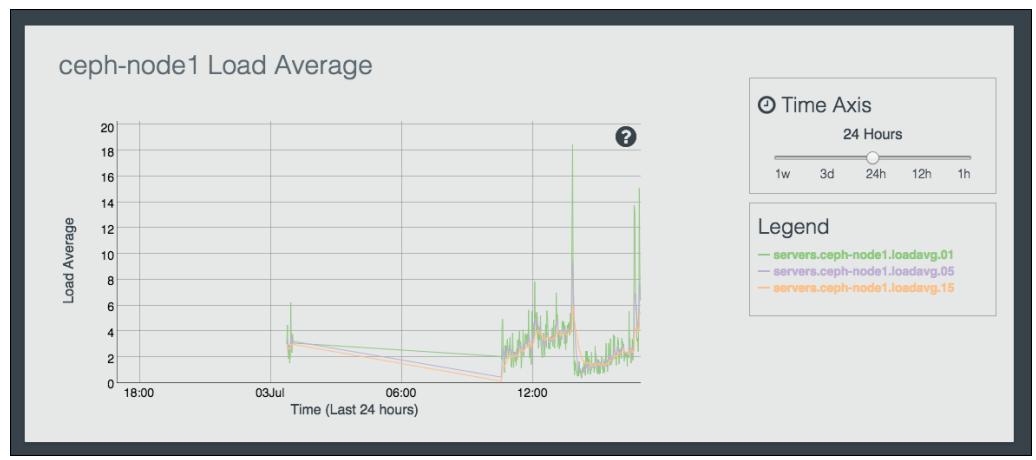
Calamari даёт некоторые прекрасные возможности наблюдения использования ресурсов хоста в форме графиков. Следующий график представляет сводку ЦПУ для
ceph-node1:
-
Этот график представляет среднюю загруженность
ceph-node1; для лучшего понимания изучите условные обозначения (legend):
-
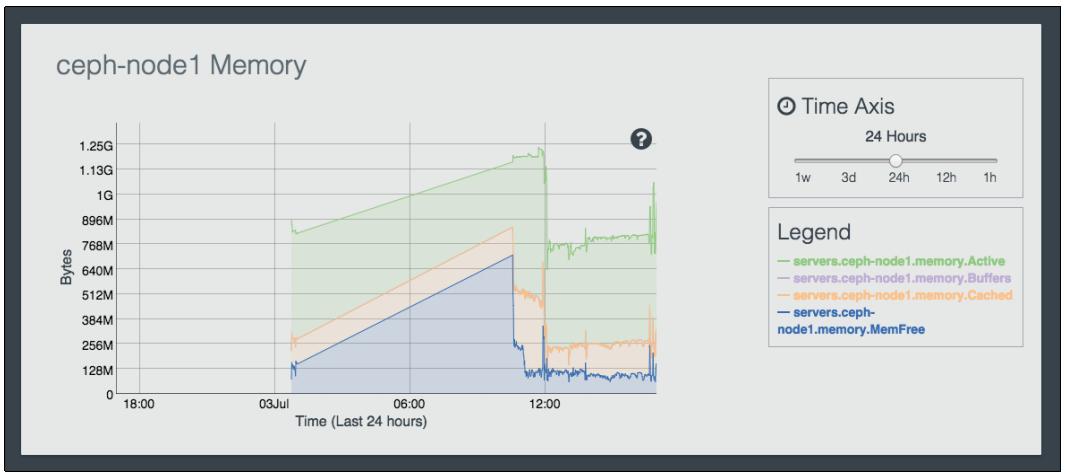
Наконец, далее представлен график использования оперативной памяти на
ceph-node2. Вы также можете смотреть на использование памяти во временном представлении выравнивая параметрTime Axisв правой стороне панели:
Нахождение ошибок Calamari порой очень хитроумно. В этом рецепте я привожу некую коллекцию руководств, которые помогут вам находить ошибки вашего окружения Calamari.
-
Проверьте, доступны ли для сервера Calamari, т.е. salt-master, его подчинённые, т.е salt-minor:
'*' test.ping
-
Убедитесь что salt-master может опрашbвать ваш кластер Ceph и получать от кластера информацию:
# salt '*' ceph.get_heartbeats output
-
Проверьте, что salt-minor узел (узел кластера Ceph) может связаться с salt-minor:
# salt-minion -l debug
-
Если salt-minor выдаёт ошибку
The Salt Master server's public key did not authenticate!в файл журналаsalt-minor, т.е./var/log/salt:2015-06-26 09:57:27,531 [salt.crypt][CRITICAL] The Salt Master server's public key did not authenticate! The master may need to be updated if it is a version of Salt lower than 2014.7.5, or If you are confident that you are connecting to a valid Salt Master, then remove the master public key and restart the Salt Minion. The master public key can be found at: /etc/salt/pki/minion/minion_master.pub
-
Чтобы решить эту проблему, нам нужно удалить salt-key
minionа также общедоступный ключ главного сервера и посторно созать их оба с применением следующих команд:# rm -rf /etc/salt/pki/minion/minion_master.pub # systemctl stop salt-minion
Теперь выполним следующий набор шагов:
-
На
salt-masterудалим ключ подчинённого:# salt-key -L # slat-key -D <minion name>
-
Запустим службу
salt-minion:# systemctl start salt-minion
-
На
salt-masterпримем новый ключ подчинённого:# salt-key -L # salt-key -A
-
Наконец, на
salt-minionприменим# salt-minion -lи убедимся, что не получаем ошибку вновь.
-
-
Выполнение команды
calamari-ctl initializeраспространяет ошибкуcould not connect to server: Connection refusedследующим образом:[root@ceph—node1]# calamari—ctl initialize [INFO] Loading configuration.. [INFO] Starting/enabling salt... [INFO] Starting/enabling postgres... [ERROR] (OperationalError) could not connect to server: Connection refused Is the server running on host "localhost" (::1) and accepting TCP/IP connections on port 5432? сould not connect to server: Connection refused Is the server running on host "localhost" (127.0.0.1) and accepting TCP/IP connections on port 5432? None None [ERROR] We are sorry, an unexpected error occurred. Debugging information has been written to a file at '/tmp/2015-06-24_1919.txti', please include this when seeking technical support. [root@ceph—node1]#
Тогда выполним приводимый ниже набор шагов:
-
Вначале проверим, что служба
postgresвыполняется:# systemctl status postgres
-
Зарегистрируемся на
postgresи проверим существует ли база данных Calamari или нет:# sudo -u postgres psql List postgres databases # \l [root@ceph-node1]# sudo -u postgres psql psql (9.2.10) Type "help" for help. postgres=# postgres=# \l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+-------------+-------------+----------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | template@ | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres templatel | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres (3 rows) postgres=#
-
Вы можете увидеть что не существует базы данных с именем
calamari; тогда вам необходимо выполнитьsaltдля создания пользователя и базы данныхcalamariвpostgres:# salt-call --local state.template /opt/calamari/salt-local/postgres.sls
-
Наконец, повторно выполним
# calamari-ctl initialize; теперь это должно работать.
-
-
Командная строка
calamari-ctl initializeне отрабатывается и распространяет ошибкуUpdating already connected nodes. failed with rc=2как показано ниже на снимке экрана:[root@ceph-node1 ~]# calamari-ctl initialize [INFO] Loading configuration.. [INFO] Starting/enabling salt... [INFO] Starting/enabling postgres... [INFO] Initializing database... [INFO] You will now be prompted for login details for the administrative user account. This is the account you will use to log into the web interface once setup is complete. Username (leave blank to use 'root'): Email address: karan_singhl@live.com Password: Password (again): Superuser created successfully. [INFO] Initializing web interface... [INFO] Starting/enabling services... [INFO] Updating already connected nodes. [ERROR] Updating already connected nodes. failed with rc=2 [ERROR] We are sorry, an unexpected error occurred. Debugging information has been written to a file at 'tmp/2015-06-22_1855.txt', please include this when seeking technical support.
-
Чтобы исправить эту ошибку, измените файл
/opt/calamari/venv/lib/python2.7/sitepackages/calamari_cthulhu-0.1-py2.7.egg/cthulhu/calamari_ctl.pyи уберите комментарий в строке 255, который выводитceph-node3сделайте доступными репозитории salt 2014update_connected_minions():[root@ceph-node1 cthulhu]# cat calamari_ctl.py | grep "update_connected_minions()" | grep -v def # update_connected_minions() [root@ceph-node1 cthulhul#