Глава 7. Ceph под колпаком
В данной главе мы изучим следующие рецепты:
-
Масштабируемость и высокая доступность Ceph
-
Понимание механизма CRUSH
-
Карта CRUSH изнутри
-
Карта кластера Ceph
-
Мониторы высокой доступности
-
Аутентификация и авторизация Ceph
-
Динамическое управление Ceph кластером
-
Группы размещения Ceph
-
Состояние групп размещения
-
Создание пулов Ceph на специфических OSD
Содержание
- 7. Ceph под колпаком
- Введение
- Масштабируемость и высокая доступность Ceph
- Понимание механизма CRUSH
- Карта CRUSH изнутри
- Карта кластера Ceph
- Мониторы высокой доступности
- Аутентификация и авторизация Ceph
- Динамическое управление Ceph кластером
- Группы размещения Ceph
- Состояние групп размещения
- Создание пулов Ceph на специфических OSD
В этой главе мы погрузимся во внутреннюю работу Ceph в понимании её функциональности такой как масштабирование, высокая доступность, аутентификация и авторизация. Также мы рассмотрим карту CRUSH, которая является одной из важнейших частей вашего кластера Ceph. Наконец мы пройдёмся по динамическому управлению кластером и настройкам карты CRUSH для пулов Ceph.
Чтобы понимать масштабируемость и высокую доступность Ceph, давайте вначале обсудим архитектуру традиционных систем хранения. Согласно этой архитектуре для хранения и получения данных клиенты общаются с централизованной компонентой, известной как контроллер или шлюз. Такие контроллеры хранения работают как единая точка контакта для пользовательских запросов. Следующая схема иллюстрирует эту ситуацию.
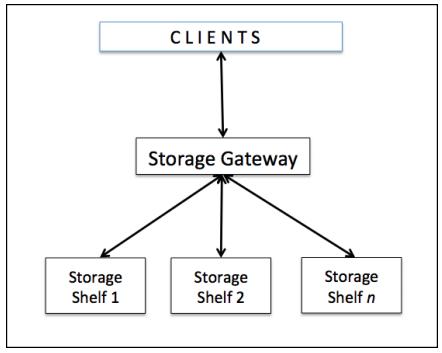
Такой шлюз хранения, который работает как единая точка входа в систему хранения также становится единой точкой отказа. Это также накладывает ограничение как на производительность, так и на масштабируемость при включении единой точки отказа, такой, что в случае если централизованный компонент выключается, отключается также и вся система.
Ceph не следует такой традиционной архитектуре систем хранения; он был полностью переработан под следующее поколение систем хранения. Ceph устраняет централизованный шлюз, позволяя клиентам взаимодействовать с демонами OSD напрямую. Следующая схема иллюстрирует как клиенты взаимодействуют с вашим кластером Ceph:
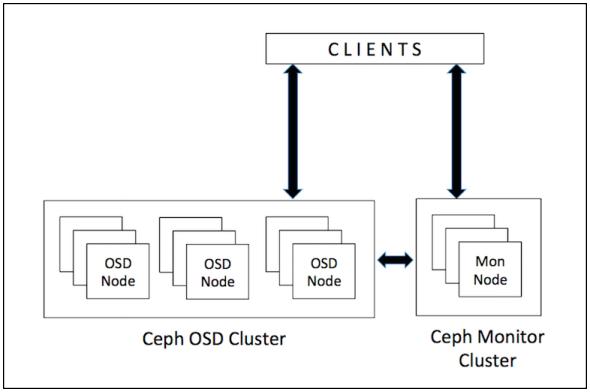
Демоны OSD Ceph создают объекты и их реплики на других узлах Ceph чтобы гарантировать сохранность данных и высокую доступность. Ceph
также применяет кластер мониторов для гарантированности высокой доступности и устранения централизации, Ceph применяет алгоритм, называемый
CRUSH, что является аббревиатурой от
Controlled Replication Under Scalable Hashing
(Управляемых масштабируемым хешированием репликаций). С помощью CRUSH клиент по запросу вычисляет где должны быть записаны его данные или
откуда их следует считать. В следующем рецепте мы исследуем подробности алгоритма CRUSH в Ceph.
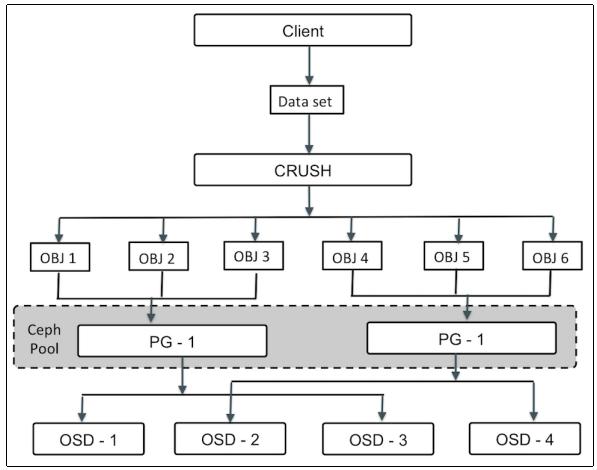
Когда дело доходит до хранения и управления данными, Ceph применяет алгоритм CRUSH, который является интеллектуальным механизмом распределения данных Ceph. Как уже обсуждалось в предыдущем рецепте, традиционные системы хранения применяют централизованную таблицу метаданных/ индексов для знаний о том гда хранятся данные пользователя. Ceph, с другой стороны, применяет алгоритм CRUSHЮ который детерминированно вычисляет где ваши данные должны быть записаны и откуда считаны. Вместо сохранения метаданных CRUSH вычисляет метаданные по запросу, тем самым удаляя необходимость централизованного сервера/ шлюза в качестве брокера. Он уполномачивает клиентов Ceph вычислять метаданные, что называется просмотром CRUSH (CRUSH lookup), и взаимодействовать с OSD напрямую.
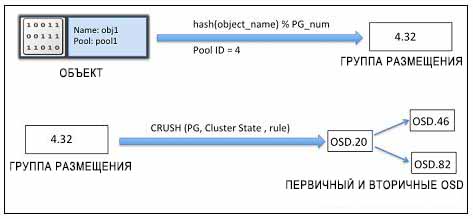
Для операций чтения и записи в кластере Ceph клиенты вначале взаимодействуют с монитором Ceph и извлекают копию карты кластера, которая содержит 5 карт, а именно карты монитора, OSD, MDS, а также CRUSH и PG; мы обсудим эти карты позже в данной главе. Эти карты кластера помогают клиентам знать состояние и конфигурацию вашего кластера Ceph. Далее данные преобразуются в объекты с помощью имени объекта, а также имени/ идентификатора пула. Этот объект затем хэшируется с номером группы размещения (PG) для выработки окончательной PG в пределах требуемого пула Ceph. Эта вычисленная группа размещения затем проходит через функцию просмотра CRUSH для определения первичного, вторичного и третичного местоположений OSD для хранения и извлечения данных.
Когда клиент получает точный идентификатор OSD, он взаимодействует с OSD напрямую и сохраняет свои данные. Все эти операции Создание линейно масштабируемых программно- управляемых систем хранения данных (FusionStorage/Ceph) {Прим. пер.: Ceph не одинок в своём подходе к вычислению местоположения данных взамен хранения метаданных такого местоположения, аналогично работает FusionStorage - проприетарное решение Huawei. Здесь вместо CRUSH применяется DHT, а вместо объектов хранятся блоки. Подробнее со сравнением FusionStorage и Ceph можно ознакомиться в нашей 2й презентации, 二(yee) НСКФ-2015 (Создание линейно масштабируемых программно- управляемых систем хранения данных). } Следующая диаграмма иллюстрирует весь этот процесс:
Чтобы узнать что находится внутри карты CRUSH, а также для её простого изменения нам необходимо выделить и декомпилировать её чтобы преобразовать в читаемую человеком форму. Следующая схема иллюстрирует этот процесс:
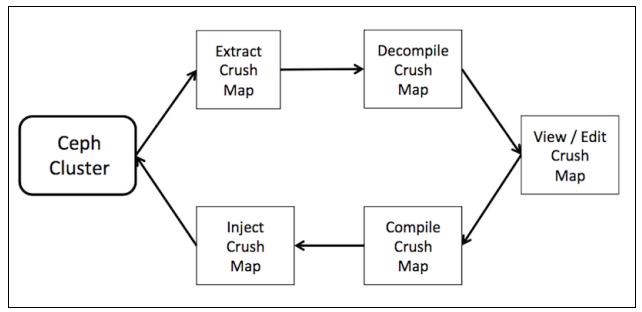
Изменения в вашем кластере производимые такой картой CRUSH являются динамическими, то есть, если новая карта CRUSH внедряется в ваш кластер Ceph, все изменения вступают в действие незамедлительно, на лету.
Сейчас мы взглянем на такую карту CRUSH нашего кластера Ceph:
-
Выделите вашу карту CRUSH с любого из своих узлов монитора:
# ceph osd getcrushmap -o crushmap_compiled_file
-
Когда вы получите вашу карту CRUSH, декомпилируйте её в читаемую человеком/ редактируемую форму:
# crushtool -d crushmap_compiled_file -o crushmap_decompiled_file
На данный момент файл вывода,
crushmap_decompiled_file, может быть просмотрен/ отредактирован вами в предпочитаемом вами редакторе. В нашем следующем рецепте мы изучим как вносить изменения в вашу карту CRUSH. -
Когда изменения внесены, вам следует скомпилировать эти изменения:
# crushtool -c crushmap_decompiled_file -o newcrushmap
-
Наконец, внедрите обновлённую скомпилированную карту CRUSH в свой кластер Ceph:
# ceph osd setcrushmap -i newcrushmap
Теперь мы знаем как изменять нашу карту CRUSH Ceph, давайте разберёмся что находится внутри этой карты CRUSH. Карта CRUSH содержит четыре основных раздела; вот они:
-
Devices (устройства): Этот раздел карты CRUSH хранит перечень всех OSD в вашем кластере. OSD является физическим диском, соответствующим демону
ceph-osd. Чтобы отображать группы размещения (PG) в ваши устройства OSD, для CRUSH необходим список устройств OSD. Этот перечень устройств появляется в начале карты CRUSH для объявления ваших устройств в карте CRUSH. Ниже приводится пример списка устройств:#devices device 0 osd.0 device 1 osd.1 device 2 osd.2 device 3 osd.3 device 4 osd.4 device 5 osd.5 device 6 osd.6 device 7 osd.7 device 8 osd.8
-
Bucket types (типы сегментов): Здесь определяются типы сегментов, применяемые в вашей иерархии CRUSH. Сегменты состоят из логической агрегации физического местоположения (например, рядов, стоек, шасси, хостов и тому подобного) и связанных с ними весов. Они способствуют иерархии узлов (
nodes) и листьев (nodes), при которой сегментnodeпредставляет физическое местоположение и может объединять другие сегменты узлов и листьев в вашей иерархии. Сегментleafпредставляет демонceph-osdи лежащее в его основе физическое устройство. Следующая таблица приводит перечень типов сегментов по умолчанию:Номер Bucket Описание 0
OSDДемон OSD (например,
osd.1,osd.2и так далее).1
HostИмя хоста, содержащего одно или более OSD.
2
RackВычислительная стойка, содержащая один или более хостов.
3
RowРяд в последовательности стоек.
4
RoomПомещение, содержащее стойки и их ряды с хостами.
5
Data CenterФизический центр обработки данных, состоящий из помещений.
6
RootЭто начало иерархии сегментов.
CRUSH также поддерживает создание пользовательских типов сегментов, такие типы сегментов по умолчанию могут быть удалены, а новые типы могут быть добавлены в соответствии с вашими потребностями.
-
Bucket instances (экземпляры сегмента): Когда вы определяете тип сегмента, вы должны определить экземпляры для ваших хостов. Экземпляр сегмента требует тип сегмента, уникальное имя (строка), уникальный идентификатор, отображаемый отрицательным целым, вес относительно общей ёмкости его элементов, алгоритс сегмента (по умолчанию, straw), а также хэш (по умолчанию, 0, отражающий CRUSH Hash rjenkins1). Сегмент может иметь один или более элементов, а эти элементы могут состоять из прочих сегментов или OSD. Элемент должен иметь вес, который отражает относительный вес этого элемента. Общий синтаксис типа сегмента выглядит следующим образом:
[bucket-type] [bucket-name] { id [a unique negative numeric ID] weight [the relative capacity the item] alg [ the bucket type: uniform | list | tree | straw | straw2] hash [the hash type: 0 by default] item [item-name] weight [weight] }Сейчас мы вкратце обсудим параметры, применяемые для экземпляров сегментов CRUSH:
-
bucket-type: Это тип сегмента, в котором мы должны определить местоположение OSD в иерархии CRUSH. -
bucket-name: Уникальное имя сегмента. -
id: идентификатор, выраженный как отрицательное целое. -
weight: Ceph записывает данные произвольным образом по всем дискам в вашем кластере, что помогает в производительности и лучшем распределении данных. Вес заставляет все ваши диски участвовать в вашем кластере и гарантировать, что все диски кластера используются одинаково, вне зависимости от их ёмкости. Для обеспечения этого Ceph применяет механизм весов. CRUSH назначает вес каждому OSD. Чем выше вес какого-то OSD, тем большую физическую ёмкость он имеет. Вес является относительной разницей между ёмкостями устройств. Мы рекомендуем применять 1.00 как относительный вес устройства хранения 1ТБ. Аналогично, вес 0.5 будет представлять примерно 500ГБ, а вес 3.00 будет соответствовать приблизительно 3ТБ. -
alg: Ceph поддерживает множество типов алгоритмов сегмента на ваш выбор. Эти алгоритмы отличаются друг от друга на основании производительности и эффективности реорганизации. Давайте кратко обсудим эти типы {алгоритмов} сегментов:-
Uniform: Единообразный сегмент может применяться если устройства хранения имеют примерно одинаковые веса. Для не единообразных весов не следует применять этот тип сегмента. Добавление или удаление устройств в этот сегмент требуют полной перетасовки данных, что делает этот тип менее эффективным.
-
List: Списочные сегменты объединяют его содержимое как присоединённый список и может содержать устройства хранения с произвольными весами. В случае расширения кластера, новые устройства хранения могут добавляться в заголовок присоединённого списка с минимальной миграцией данных. Однако, удаление устройства хранения требует значительного объёма перемещений данных. Следовательно, такой тип сегмента удобен для сценариев, при которых добавление новых устройств в ваш кластер чрезвычайно часто или не существует. Кроме того, списочные сегменты эффективны для малых наборов элементов, однако они могут не удовлетворять большим наборам.
-
Tree: Сегменты деревьев сохраняют свои элементы в виде двоичного дерева. Они более эффективны по сравнению со списочными сегментами, поскольку сегменты содержат большее множество элементов. Сегменты деревьев являются структурированными как деревья двоичного поиска с весами при элементах в качестве их листьев. Каждый внутренний узел знает общий вес своего левого и правого поддерева и помечается в соответствии с фиксированной стратегией. Сегменты деревьев являются многосторонним благом, предоставляя исключительную производительность и достойную эффективность реорганизации.
-
Straw: Чтобы выбрать элемент с применением сегмента списков или деревьев, должно быть вычислено ограниченное число хэшей и сравнено по весу. они используют стратегию разделяй и властвуй, которая отдаёт предпочтение определённым элементам (например, находящимся в начале списка). Это повышает вашу производительность процесса размещения реплик, однако вносит умеренную реорганизацию при изменении содержимого сегмента из- за добавления, удаления или изменения веса.
Тип сегмента соломинки позволяет всем элементам честно конкурировать друг с другом за размещение реплик. При сценариях, когда ожидается удаление и эффективность реорганизации имеет решающее значение, сегменты соломинки обеспечивают оптимальное поведение миграции между поддеревьями. Такой тип сегмента позволяет всем элементам справедливо "конкурировать" друг с другом за размещение реплик благодаря процессу жеребьёвки соломинками.
-
Straw2: Это улучшенный сегмент соломинки, который корректно исключает любое перемещение данных между элементами A и B когда не изменяются веса ни A, ни B. Другими словами, если мы выравниваем вес элемента C, добавляя к нему новое устройство, или удаляя его совсем, перемещение данных будет иметь место только на C или с него, и никогда между прочими элементами в вашем сегменте. Таким образом, алгоритм Straw2 уменьшает необходимый объём миграции данных при внесении изменений в ваш кластер.
-
-
hash: Все сегменты применяют алгоритм хэширования. В настоящее время Ceph поддерживает rjenkins1. Введите 0, если ваш хэш установлен на выбор rjenkins1. -
item: Сегмент может иметь один или более элементов. Эти элементы могут состоять из сегментов узлов или листьев. Элементы могут иметь вес, который отражает относительный вес этого элемента.
Следующий снимок экрана иллюстрирует экземпляр сегмента CRUSH. Здесь у нас присутствуют три экземпляра хоста сегмента. Эти экземпляры сегмента хоста состоят из сегментов OSD:
# buckets host ceph-node2 { id -3 # do not change unnecessarily # weight 0.030 alg straw hash 0 # rjenkinsl item osd.3 weight 0.010 item osd.4 weight 0.010 item osd.5 weight 0.010 } host ceph-node3 { id -4 # do not change unnecessarily # weight 0.030 alg straw hash 0 # rjenkinsl item osd.6 weight 0.010 item osd.7 weight 0.010 item osd.8 weight 0.010 } host ceph-node1 { id -2 # do not change unnecessarily # weight 0.030 alg straw hash 0 # rjenkinsl item osd.1 weight 0.010 item osd.2 weight 0.010 item osd.0 weight 0.010 } -
-
Rules (правила): Карта CRUSH содержит правила, которые предписывают размещение данных в пулах. Как следует из названия, эти правила определяют свойства пула и способ, которым данные сохраняются в данном пуле. Они определяют политику репликации и размещения, которая позволяет CRUSH сохранять объекты в кластере Ceph. Карта CRUSH по умолчанию содержит правила для пулов по умолчанию, т.е.
rbd. Общий синтаксис правила CRUSH выглядит следующим образом:rule <rulename> { ruleset <ruleset> type [ replicated | erasure ] min_size <min-size> max_size <max-size> step take <bucket-type> step [choose|chooseleaf] [firstn] <num> <bucket-type> step emit }Теперь мы кратко объясним эти используемые в правилах CRUSH параметры:
-
ruleset: Целое значение; классифицирует некое правило, как относящееся к набору правил. -
type: Строковое значение; определяет тип пула который может быть либо replicated, либо erasure coded. -
min_size: Целое значение; если пул делает меньшее число реплик, чем предписывает это значение, CRUSH не выбирает это правило. -
max_size: Целое значение; если пул делает большее число реплик, чем предписывает это значение, CRUSH не выбирает это правило. -
step take: Берёт имя сегмента и начинает итерировать дерево вниз. -
step choose firstn {num} type {bucket-type}: Выбирает число (N) сегментов заданного типа, где число (N) обычно число реплик в данном пуле (т.е. размер пула):-
Если
num == 0, то выбратьNсегментов -
Если
num > 0 && < N, то выбратьnumсегментов -
Если
num < 0, то выбратьN - numсегментов
Пример:
step choose firstn 1 type rowВ этом примере
num = 1и если предположить что размер пула равен 3, то CRUSH будет вычислять это условие как1 > 0 && < 3. Следовательно, он выберет тип сегмента 1 row. -
-
step chooseleaf firstn {num} type {bucket-type}: Это правило вначале выберет набор сегментовbucket-type, а затем выберет узел листа из поддерева каждого сегмента в нашем наборе сегментов. Число сегментов в наборе (N) обычно число реплик в данном пуле (т.е. размер пула):-
Если
num == 0, то выбратьNсегментов -
Если
num > 0 && < N, то выбратьnumсегментов -
Если
num < 0, то выбратьN - numсегментов
Пример:
step chooseleaf firstn 0 type rowВ этом примере
num = 0и если предположить что размер пула равен 3, то CRUSH будет вычислять это условие как0 == 0и затем выберет узел листа из своего поддерева каждого сегмента. Таким образом, CRUSH выберет 3 листовых узла.step emit: Этот первый вывод текущего значения и освобождение стека. Как правило, применяется в конце правила, но может также применяться для формирования различных деревьев в том же правиле. -
-
Мониторы Ceph отвечают за наблюдение жизнеспособности всего кластера, а также поддержание состояния вхождения в состав кластера, состояние узлов однорангового обмена, а также информации о конфигурации кластера. Монитор Ceph выполняет эти задачи поддерживая главную копию карты кластера. Карта кластера включает в себя карты монитора, карты OSD, карты групп размещения (PG), карту CRUSH, а также карту MDS. Все эти карты вместе называются картами кластера. Давайте быстро взглянем на функциональность каждой из карт:
-
Monitor map (карта монитора): Она содержит сквозную информацию об узле монитора, которая содержит идентификатор вашего кластера Ceph, имя хоста монитора, а также IP адрес с номером порта. Он также хранит текущую эпоху для создания карты вместе со временем последнего изменения. Вы можете проверить карту монитора вашего кластера, выполнив следующее:
# ceph mon dump
-
OSD map (карта устройств хранения объектов): Хранит некоторые общие поля, такие как идентификатор кластера, эпоху создания карты OSD и последнего изменения, а также информацию, связанную с пулами, такую как имена пулов, идентификатор пула, тип, уровень репликации и группы размещения. Она также хранит информацию об OSD, такую как количество, состояние, вес, интервал последней очистки, а также информацию хоста. Вы можете проверить карты ваших OSD кластера выполнив команду:
# ceph osd dump
-
PG map (карта групп размещения): Содержит версию PG, временной штамп, последнюю эпоху карты OSD, полное отношение, а также информацию связанную с этим отношением (весовым коэффициентом). Она также содержит отслеживание всех идентификаторов PG, количество объектов, состояние, штамп состояния, наборы работающих (up) и активных OSD, а также, наконец, подробности очистки. Для проверки карты PG кластера выполните:
# ceph pg dump
-
CRUSH map (карта Управляемых масштабируемым хешированием репликаций): Содержит информацию о ваших устройствах кластера, сегментах (bucket), иерархии доменов отказа, а также определённых для этого домена отказа с хранящимися данными правил. Для проверки вашей карты CRUSH выполните:
# ceph osd crush dump
-
MDS map (карта сервера метаданных): Она хранит информацию о текущей эпохе карты MDS, создании карты и времени изменения идентификатор пула данных и метаданных, количество MDS кластера, а также состояние вашего MDS. Для проверки вашей карты MDS выполните:
# ceph mds dump
Монитор Ceph не хранит и не обслуживает данные клиентов; он обслуживает обновление карт кластера клиентам а также прочим узлам кластера. Клиенты и другие узлы кластера периодически сверяются с мониторами на предмет самой последней копии карт кластера. Перед тем как клиенты смогут записать или считать данные, они должны связаться с монитором Ceph и получить самую последнюю копию карты вашего кластера.
Кластер хранения Ceph может работать с одним монитором, однако, это создаёт риск единственной точки отказа для вашего кластера; то есть, если монитор отключается, клиенты Ceph не смогут читать и записывать данные. Чтобы преодолеть это, обычный кластер Ceph состоит из кластера мониторов Ceph. Архитектура Ceph со многими мониторами вырабатывает кворум и обеспечивает консенсус для распределённого принятия решений в кластере с применением алгоритма Paxos {см. также habrahabr} Число мониторов в вашем кластере должно быть нечётным числом; абсолютным необходимым минимумом является один узел монитора, а рекомендуемое число три. Поскольку мониторы работают в кворуме, более половины от общего числа мониторов должны быть всегда доступны для предотвращения проблем раздвоения сознания. Один из мониторов кластера выступает в роли ведущего (leader). Если ведущий монитор недоступен, другие узлы монитора имеют право стать ведущими. Промышленный кластер должен иметь по крайней мере три узла мониторов для предоставления высокой доступности.
В данном рецепте мы обсудим применяемый Ceph механизм аутентификации и авторизации. Пользователи являются либо отдельными персонами, либо такими приложениями, которые применяют клиентов Ceph для взаимодействия с демонами вашего кластера хранения Ceph. Следующая схема иллюстрирует такие потоки:
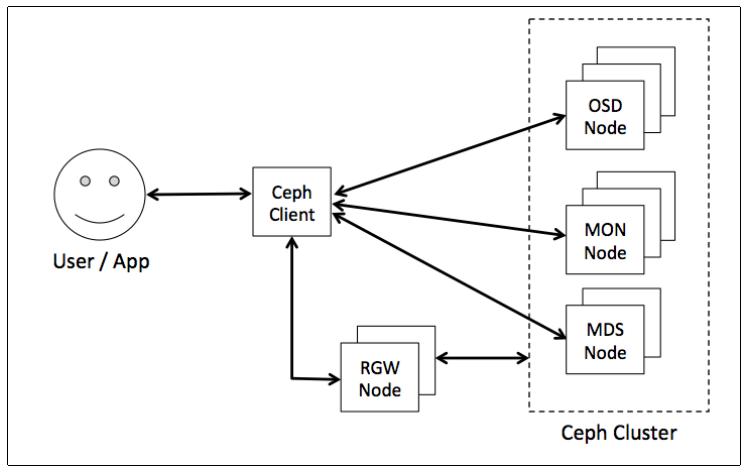
Ceph предоставляет два режима аутентификации. Это:
-
None: При этом режиме любой пользователь может получать доступ к кластеру Ceph без аутентификации. Этот режим по умолчанию запрещён. Криптографическая аутентификация, которая включает в себя кодирование и дешифрацию ключей пользователя имеет некое вычислительную стоимость. Вы можете запретить аутентификацию Ceph, если вы уверены, что инфраструктура сетевой среды безопасна, клиенты/ узлы кластера Ceph имеют установленные права, и вы хотите сохранить некую вычислительную мощность запрещая аутентификацию. Однако это не рекомендуется, и вы можете подвергаться риску атаки злоумышленника в роли посредника. {Прим. пер.: в своей книге Полная виртуализация, Ли Р. Сюрбер излагает другую стратегию, основанную на контроле сетевой среды, которая позволяет использовать данный режим аутентификации Ceph при гарантировании безопасности.} Всё же, если вам интересно запрещение аутентификации Ceph, вы можете выполнить его добавив следующие параметры в глобальный раздел файла настроек вашего Ceph на всех узлах с последуюей перезагрузкой службы Ceph:
auth cluster required = none auth service required = none auth client required = none
-
Cephx: Для идентификации пользователей и проектов с целью предотвращения атак злоумышленников в роли посредника, Ceph предоставляет систему аутентификации Cephx для удостоверения подлинности пользователей и демонов. Протокол Cephx работает в некоторой степени аналогично Kerberos и позволяет клиентам получать доступ к кластеру Ceph. Следует знать, что gротокол Cephx не шифрует данные. В кластере Ceph протокол Cephx разрешён по умолчанию. Если вы отключили Cephx добавив в свой файл настроек конфигурации кластера предыдущие параметры аутентификации, то вы можете включить Cephx двумя способами. Одним из них будет простое удаление всех записей auth из вашего файла настроек конфигурации кластера, содержащих none, или вы можете в явном виде разрешить Cephx добавив следующие параметры в ваш файл настроек кластера и перезапустив ваши службы Ceph:
auth cluster required = cephx auth service required = cephx auth client required = cephx
Теперь. когда мы обсудили различные режимы аутентификации Ceph, давайте узнаем как в пределах Ceph работают аутентификация и авторизация.
Для доступа к вашему кластеру Ceph в роли агента/ пользователя/ приложения вызовите клиента Ceph для взаимодействия с вашим узлом монитора кластера. Обычно кластер Ceph имеет более одного монитора и клиент Ceph может соединиться с любым из узлов монитора для инициализации процесса аутентификации. Такая архитектура со множеством мониторов Ceph устраняет ситуацию с единой точкой отказа в процессе вашей аутентификации.
Для применения Cephx администратор, т.е. client.admin должен создать учётную запись в вашем кластере
Ceph. Для создания учётной записи пользователя, пользователь client.admin вызывает команду
ceph auth get-or-create key. Подсистема аутентификации Ceph генерирует имя пользователя и ключ
безопасности, сохраняя эту информацию в вашем мониторе Ceph и возвращая ключ безопасности пользователя пользователю
client.admin, который вызвал команду создания данного пользователя. Системный администратор Ceph должен
сделать доступным для совместного применения эти имя и ключ безопасности тем клиентам Ceph, которые хотят применять службу хранения Ceph
безопасным образом. Следующая схема отображает весь этот процесс:
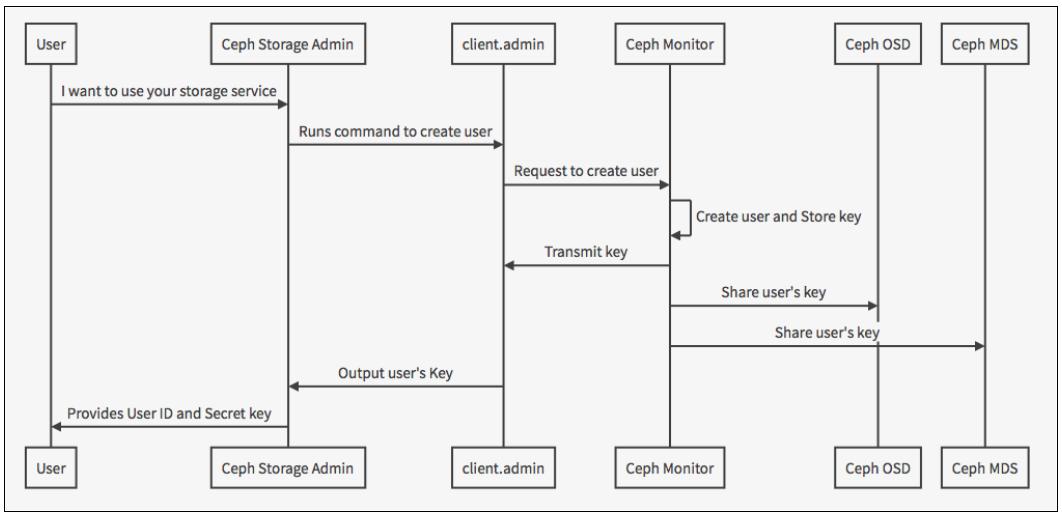
В последнем рецепте мы изучили процесс создания клиента и то, как ключи безопасности сохраняются на узлах кластера. Теперь мы исследуем как пользователи устанавливают подлинность при помощи Ceph и получают доступ к узлам Ceph.
Чтобы получить доступ к вашему кластеру Ceph, клиент вначале должен связаться со своим узлом монитора и переслать только своё имя пользователя. Протокол Cephx работает таким образом, что обе части имеют возможность подтвердить что они имеют копию данного ключа без его реального обнажения. Это та причина, почему клиент отсылает только имя пользователя а не свой ключ безопасности.
Затем монитор генерирует ключ сеанса для данного пользователя и кодирует его применяя связанный с этим пользователем ключ безопасности. Далее монитор пересылает закодированный ключ сеанса назад этому клиенту. Потом данный клиент дешифрует полученные данные своим ключом для обретения ключа сеанса. Такой ключ сеанса остаётся действительным для данного пользователя на протяжении заданного текущего сеанса.
С помощью ключ сеанса данный пользователь запрашивает маркер (ticket) у монитора Ceph. Монитор Ceph проверяет этот ключ сеанса и затем генерирует маркер (ticket), закодированный ключом безопасности пользователя и отсылает его данному пользователю. Клиент декодирует маркер и применяет его для подписи запросов к OSD и серверам метаданных по всему кластеру.
Протокол аутентификации Cephx проверяет подлинность текущей связи между данным клиентом и вашими узлами Ceph. Каждое пересылаемое между клиентом и узлами Ceph сообщение после своей первоначальной аутентификации подписывается при помощи маркера, следовательно мониторы, OSD и узлы метаданных могут проверять их своим общим ключом безопасности. Кроме того, срок действия маркера Cephx ограничен, поэтому атакующий не сможет применить маркер с истекшим сроком или ключ сессии для получения доступа к кластеру. Следующая схема иллюстрирует весь процесс аутентификации который был объяснён:
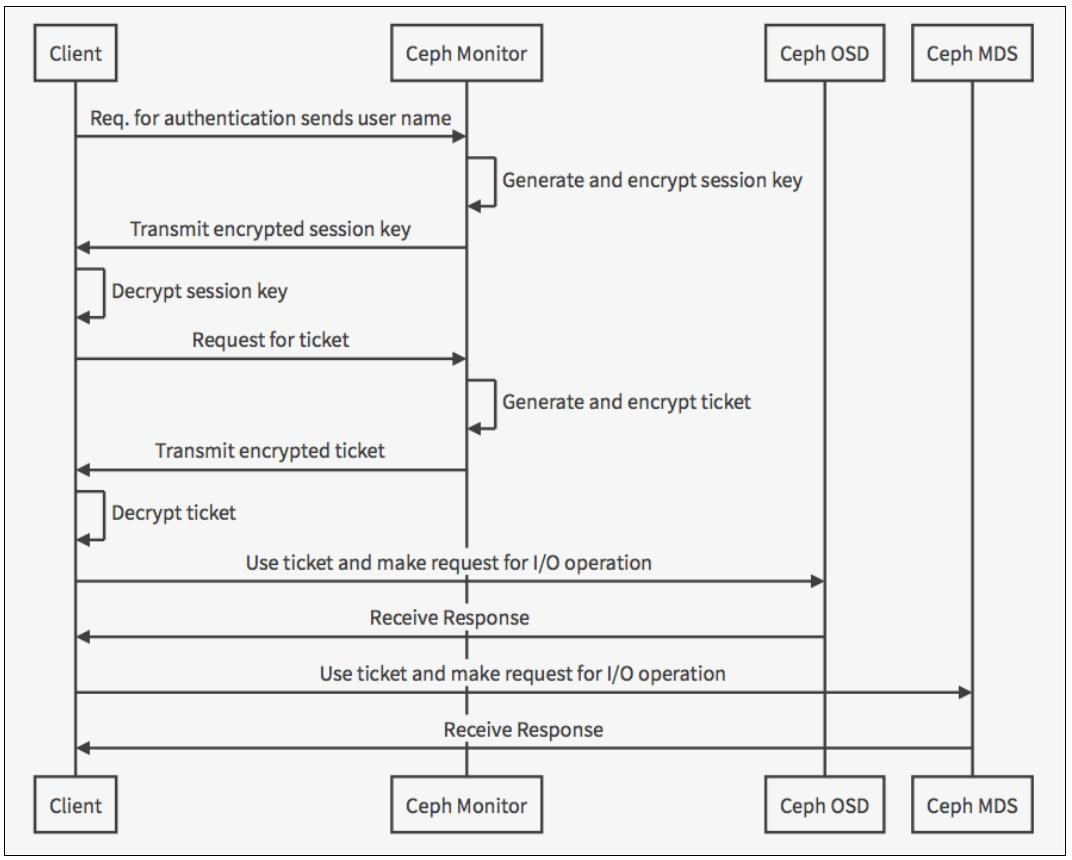
В последнем рецепте мы рассмотрели применяемый Ceph процесс аутентификации. В данном рецепте мы изучим процесс авторизации. Когда
пользователь аутентифицирован, он авторизуется для различных типов доступа, активностей или ролей. Ceph применяет термин возможности
(capabilities), который сокращается до
caps. Возможности являются правами, получаемые пользователем, которые
определяют уровень доступа с которым он может работать в кластере. Синтаксис capability выглядит
следующим образом:
{daemon-type} 'allow {capability}' [{daemon-type} 'allow {capability}']
-
Monitor caps: Включает параметры
r,w,x, а такжеallow profiles {cap}. Например:mon 'allow rwx' or mon 'allow profile osd'
-
OSD caps: Включает параметры
r,w,x,class-read,class-writeиprofile osd. Например:osd 'allow rwx' or osd 'allow class-read, allow rwx pool=rbd'
-
MDS caps: Требует только
allow. Например:mds 'allow'
Давайте изучим все такие возможности:
-
allow: Подразумевает толькоrwдля MDS. -
r: Предоставляет пользователю доступ по чтению, который необходим монитору для чтения карты CRUSH. -
w: Предоставляет пользователю доступ по записи в объекты. -
x: Предоставляет пользователю возможность методов класса вызова, включая чтение и запись, а также права выполнения операций аутентификации на мониторах. -
class-read: Это подмножествоx, которое позволяет пользователям вызывать методы чтения класса. -
class-write: Это подмножествоx, которое позволяет пользователям вызывать методы записи класса. -
*: Предоставляет пользователям полные права (r,wиx) на определяемом пуле, а также выполнять команды администратора. -
profile osd: Позволяет пользователям соединяться в качестве OSD с другими OSD или мониторами. Применяется для трафика проверки жизнеспособности (heartbeat) OSD и отчётов о состоянии. -
profile mds: Позволяет пользователям соединяться в качестве MDS с другими MDS. -
profile bootstrap-osd: Позволяет пользователям выполнять самозагрузку OSD. Например, инструментыceph-deployиceph-diskприменяют пользователяclient.bootstrap-osd, который имеет права добавлять ключи и выполнять самозагрузку OSD. -
profile bootstrap-mds: Позволяет пользователям выполнять самозагрузку сервера метаданных. Например, инструментыceph-deployиceph-diskприменяют пользователяclient.bootstrap-mds, который имеет права добавлять ключи и выполнять самозагрузку сервера метаданных.
Пользователь может быть индивидуальным пользователем или приложением, например, cinder/ nova в случае OpenStack. Создание пользователей позволяет
вам управлять тем, кто может иметь доступ к вашему кластеру хранения Ceph, его пулам и данным в пределах этих пулов. В Ceph пользователь
должен иметь тип, который всегда client, а также идентификатор, который может быть любым именем. Поэтому
допустимым синтаксисом в Ceph является TYPE.ID, или client.<name>,
например, client.admin или client.cinder.
В следующем рецепте мы дополнительно обсудим управление пользователем Ceph путём выполнения некоторых команд:/p>
-
Для вывода списка пользователей в вашем кластере выполните следующую команду:
# ceph auth list
Вывод этой команды покажет их для каждого типа демона, Ceph создаёт пользователей с различными возможностями. Она также отобразит пользователя
client.admin, который является пользователем администратором кластера. -
Для извлечения определённого пользователя, например,
client.admin, выполните:# ceph auth get client.admin [root@ceph-node1 ~]# ceph auth get client.admin exported keyring for client.admin [client.admin] key = AQAfgAhvmExcGBAAfRAg084RHNtmfK83iheelg== caps mds = "allow" caps mon = "allow *" caps osd = "allow *" [root@ceph-node1 ~]#
-
Создайте пользователя
client.hari:# ceph auth get-or-create client.hari [root@ceph-node1 ~]# ceph auth get-or-create client.hari [client.hari] key = AQBm5W1ineFHRAAhzvxxEkzn9D98HCxIu9EyQ== [root@ceph-node1 ~]#
Это создаёт пользователя
client.hariбез каких бы то ни было возможностей, а пользователь без таковых не может применяться. -
Добавьте возможности пользователю
client.hari:# ceph auth caps client.hari mon 'allow r' osd 'allow rwx pool=rbd' [root@ceph-node1 ~]# ceph auth caps client.hari mon 'allow r' osd 'allow rwx pool=rbd' updated caps for client.hari [root@ceph-node1 ~]#
-
Выведем перечень возможностей нашего пользователя:
# ceph auth get client.hari [root@ceph-node1 ~]# ceph auth get client.hari exported keyring for client.hari [client.hari] key = AQBmSN1VZCeFHRAAhZvXXEkZn9D98HCXIu9EyQ== caps mon = "allow r" caps osd = "allow rwx pool=rbd" [root@ceph-node1 ~]#
Давайте быстро повторим вкратце как клиенты получают доступ к кластеру Ceph. Чтобы выполнить операцию записи в вашем кластере Ceph, клиент получает самую последнюю копию карты кластера от своего монитора Ceph (если он ещё не имеет её). Карта кластера предоставляет информацию о компоновке этого кластера Ceph. Затем данный клиент записывает/ считывает объект, который хранится в пуле Ceph. Следующая схема демонстрирует этот процесс целиком:
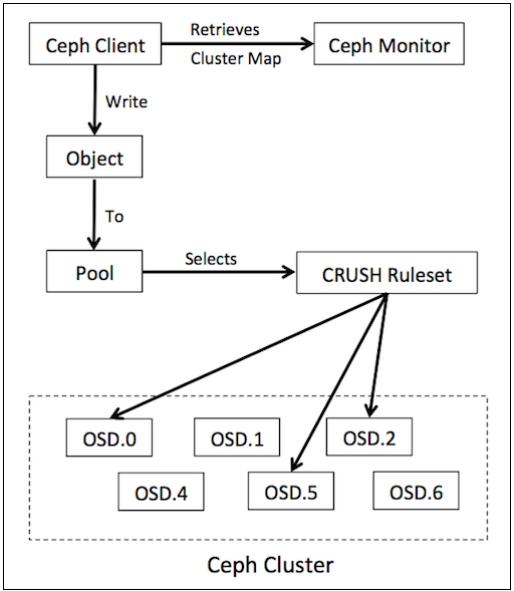
Теперь давайте разберёмся с процессом хранения данных внутри вашего кластера Ceph. Ceph хранит данные в логических разделах, называемых пулами. Эти пулы содержат множество групп размещения (PG), которые по очереди сохраняют объекты. Ceph является реальной распределённой системой, в которой объект реплицируется и сохраняется каждый раз по различным OSD. Данный механизм объясняется при помощи следующей схемы, на которой я попытался представить как объекты сохраняются в кластере:
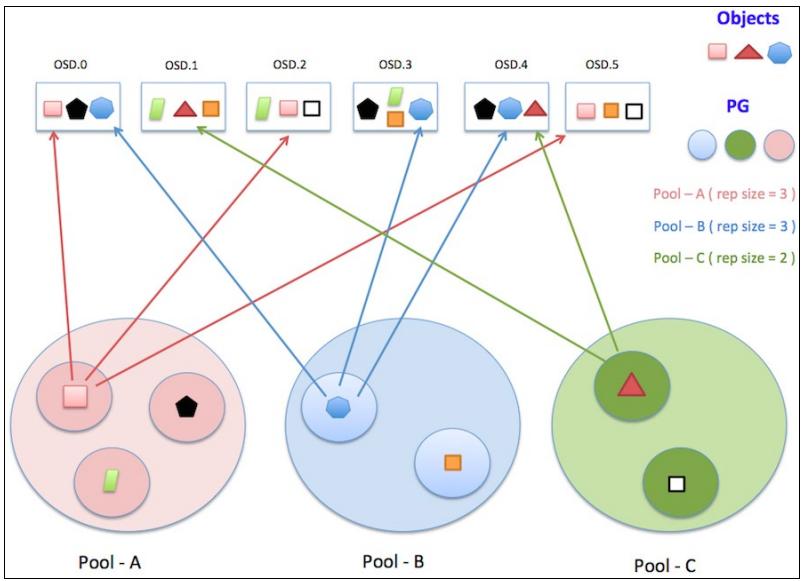
Группа размещения (PG, Placement Group) является логической коллекцией объектов, которые реплицированы по OSD для обеспечения надёжности в системе хранения. В зависимости от установленного уровня репликаций пула Ceph, каждая группа размещения реплицируется и распределяется на более чем одно OSD кластера Ceph. Вы можете рассматривать PG как логический контейнер, содержащий множество объектов таким образом, что этот логический контейнер соответствует множеству OSD.
Группы размещения существенны для масштабируемости и производительности системы хранения Ceph. В отсутствии PG было бы трудно управлять и отслеживать десятки миллионов объектов, которые реплицируются и распространяются по сотням OSD. Управление этими объектами без PG приводило бы в результате к избыточным вычислениям. Вместо индивидуального управления каждым объектом, система должна управлять вашими группами размещения с многочисленными объектами. Это делает Ceph более управляемой и менее сложной системой.
Каждой группе размещения необходимы некоторые ресурсы системы, поскольку они управляют множеством объектов. Число PG в кластере должно педантично подсчитываться, и эта процедура обсуждается позднее в данной книге. Обычно, увеличение числа групп размещения в вашем кластере выполняет повторную балансировку нагрузки OSD. Рекомендуемое значение PG на OSD составляет от 50 до 100 во избежание высокого использования ресурсов на узле OSD. По мере возрастания объёмов данных на кластере Ceph, вам необходимо подстраивать ваш кластер выравнивая значение ваших PG. Когда устройства в кластере добавляются или удаляются устройства, CRUSH управляет перемещением групп размещения наиболее оптимальным образом.
Теперь мы получили представление о том, как группы размещения Ceph хранят свои данные на множестве OSD для обеспечения надёжности и высокой доступности. Эти OSD называются первичным, вторичным, третичным и так далее, и они относятся к набору, который называется действующим набором (acting set) для этой группы размещения. Для каждого действующего набора PG первый OSD является первичным, а последующие вторичным и третичным.
Для лучшего понимания давайте отыщем действующий набор для группы размещения в нашем кластере Ceph:
-
Добавим в пул rbd временный объект с именем hosts:
# rados put -p rbd hosts /etc/hosts
-
Проверим имя PG для объекта hosts:
# ceph osd map rbd hosts [root@ceph-node1 ~]# rados put -p rbd hosts /etc/hosts [root@ceph-node1 ~]# [root@ceph-node1 ~]# rados is -p rbd | grep -i hosts hosts [root@ceph-node1 ~]# ceph osd map rbd hosts osdmap e4376 pool 'rbd' (0) object 'hosts' -> pg 0.ealb298e (0.8e) -> up ([8,2,4], p8) acting ([8,2,4], p8) [root@ceph-node1 ~]#
Когда вы рассмотрите вывод, Placement Group (0.8e) имеет
up set [8,2,4] и acting
set [8,2,4]. Следовательно, здесь osd.8 первичный OSD, а
osd.2 и osd.4 являются вторичным и третичным OSD. Первичное
OSD является единственным OSD, которое принимает операции записи клиента. Когда получается запрос read,
по умолчанию он также приходит на первичное OSD, но мы можем изменить такое поведение, установив ассоциированное чтение (read affinity).
Включенное (up) OSD остаётся в рабочем наборе (up set), так же как и в активном наборе. Если первичное OSD выходит из строя, оно вначале удаляется из рабочего набора (up set), а затем из активного набора. Вторичное устройство после этого продвигается на место первичного OSD. Ceph восстанавливает группы размещения отказавшего OSD на новое OSD, а затем добавляет его в рабочий и активный наборы для гарантирования высокой доступности. В кластере Ceph некое OSD может быть первичным OSD для некоторых PG и в то же время оно может быть вторичным или третичным OSD для других PG.
Группы размещения Ceph могут представлять различные состояния на основе того что происходит в вашем кластере в данный момент времени.
Чтобы узнать состояние PG вы можете просмотреть вывод команды ceph status. В данном рецепте мы
рассмотрим эти различные состояния поясним что означает на самом деле каждое состояние.
-
Creating: Эта PG создётся. Обчычно это происходит при создании пула или когда в пуле увеличивается число PG.
-
Active: Все PG активны, и запросы к этой PG будут обработаны.
-
Clean: Все объекты в этой PG реплицированы необходимое число раз.
-
Down: Реплика с необходимыми данными отключена, поэтому PG выключена (down).
-
Replay: Эта PG ждёт клиентов для операций воспроизведения после краха OSD.
-
Splitting: Данная PG разделяется на множество PG. Обычно PG достигает такого состояния когда для существующего пула увеличивается число групп размещения. Например, если вы увеличиваете число PG пула
rbdc 64 до 128, существующие PG расщепляются и некоторые из их объектов будут перемещены в новые PG. -
Scrubbing: Данная PG проверяется на непротиворечивость.
-
Degraded: Некоторые объекты в этой PG не реплицированы должное число раз.
-
Inconsistent: Эта реплика PG содержит противоречивость. Например, существует неверный размер объекта или объекты утрачены водной реплике после завершения репликации.
-
Peering: В данной PG выполняется процесс однорангового обмена (Peering), в котором осуществляется попытка привести OSD, которое хранит реплики данной PG в соответствие с состоянием объектов и метаданных в этой PG.
-
Repair: Эта PG проверяется и все найденные противоречия будут устранены (по возможности).
-
Recovering: Объекты мигрируют/ синхронизируются с репликами. В случае останова OSD его содержимое может отставать от текущего состояния прочих реплик в данной PG. Поэтому PG переходит всостояние восстановления и объекты будут мигрировать/ синхронизироваться с репликами.
-
Backfill: Когда новое OSD присоединяется к вашему кластеру, CRUSH переназначает PG с существующих OSD в вашем кластере на вновь добавленное OSD. По завершению заполнения такое новое OSD начнёт обслуживать запросы по их возникновению.
-
Backfill-wait: PG ожидает в очереди начала заполнения.
-
Incomplete: PG утратила необходимый период истории из своего журнала. Это обычно происходит когда содержащее необходимую информацию OSD отказывает или не доступно.
-
Stale: Данная PG находится в неизвестном состоянии - мониторы не получили для неё обновления поскольку отображение PG изменилось. Когда вы запускаете свой кластер, обычно можно увидеть такое устаревшее состояние пока не завершится процесс однорангового обмена.
-
Remapped: Когда изменяется обслуживающий PG активный набор, его данные мигрируют со старого активного набора на новый активный набор. Обслуживание запросов новым первичным OSD может потребовать некоторого времени. Поэтому он может попросить ваш старый первичный OSD продолжить обслуживать запросы пока не завершится миграция данной PG. Когда миграция данных завершится, карты применяют новый первичный OSD нашей новой активной группы.
Кластер Ceph обычно состоит из ряда узлов имеющих множество дисковых устройств. Причём, эти дисковые устройства могут быть различных типов. Например, ваши узлы Ceph могут содержать диски ATA, NL-SAS, SAS, SSD или даже PCIe, и тому подобное. Ceph предоставляет вам гибкость создавать пулы на определённых типах устройств. Например, вы можете создать высокопроизводительный пул SSD из набора дисков SSD, или вы можете создать пул с большой ёмкостью и низкой стоимостью с применением дисков SATA.
В данном рецепте мы узнаем как создать пул с именем ssd-pool на основе SSD дисков, а также
другой пул с именем sata-pool, который базируется на SATA дисках. Достигнув этого, мы изменим
карту CRUSH и выполним необходимые настройки.
Кластер Ceph, который мы разворачиваем и с которым дальше проигрываем различные сценарии на протяжении данной книги располагается на виртуальных машинах и не имеет в своей основе настоящих SSD дисков. Следовательно мы будем предполагать, что у нас есть несколько виртуальных дисков, выступающих в роли SSD дисков для учебных целей. Если вы будете выполнять данное упражнение в кластере Ceph с настоящими SSD дисками, не потребуются никакие изменения.
Для последующей демонстрации давайте предположим, что osd.0,
osd.3 и osd.6 являются SSD дисками и мы будем создавать на
этих дисках пул SSD. Аналогично, osd.1, osd.5 и
osd.7 являются SATA дисками, которые будут размещать пул SATA.
Давайте приступим к настройке:
-
Получим текущую карту CRUSH и декомпилируем её:
# ceph osd getcrushmap -o crushmapdump # crushtool -d crushmapdump -o crushmapdump-decompiled [root@ceph-node1 ~]# ceph osd getcrushmap -o crushmapdump got crush map from osdmap epoch 4443 [root@ceph-node1 ~]# [root@ceph-node1 ~]# crushtool -d crushmapdump -o crushmapdump-decompiled [root@ceph-node1 ~]# ls -l crushmapdump-decompiled -rw-r--r-- 1 root root 1360 Sep 1 21:41 crushmapdump-decompiled [root@ceph-node1 ~]#
-
Изменим файл
crushmapdump-decompiledкарты CRUSH и добавим следующий раздел после раздела root default:root ssd { id -5 alg straw hash 0 item osd.0 weight 0.010 item osd.3 weight 0.010 item osd.6 weight 0.010 } root sata { id -6 alg straw hash 0 item osd.1 weight 0.010 item osd.4 weight 0.010 item osd.7 weight 0.010 } -
Создадим правила CRUSH добавив следующие правила в разделе правил вашей карты CRUSH, затем сохраним и завершим редактирование:
rule ssd-pool { ruleset 1 type replicated min_size 1 max_size 10 step take ssd step chooseleaf firstn 0 type osd step emit } rule sata-pool { ruleset 2 type replicated min_size 1 max_size 10 step take sata step chooseleaf firstn 0 type osd step emit } -
Скомпилируем и внедрим изменённую новую карту CRUSH в наш кластер Ceph:
# crushtool -c crushmapdump-decompiled -o crushmapdump-compiled # ceph osd setcrushmap -i crushmapdump-compiled
-
После того, как карта CRUSH применена к вашему кластеру Ceph, проверьте обзор его дерева OSD на предмет новой систематизации и отметьте сегменты (bucket) корня
ssdиsata:# ceph osd tree [root@ceph-node1 ~]# ceph osd tree ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -6 0.02998 root sata 1 0.00999 osd.1 up 1.00000 1.00000 4 0.00999 osd.4 up 1.00000 1.00000 7 0.00999 osd.7 up 1.00000 1.00000 -5 0.02998 root ssd 0 0.00999 osd.0 up 1.00000 1.00000 3 0.00999 osd.3 up 1.00000 1.00000 6 0.00999 osd.6 up 1.00000 1.00000 -1 0.09000 root default -3 0.03000 host ceph-node2 3 0.00999 osd.3 up 1.00000 1.00000 4 0.00999 osd.4 up 1.00000 1.00000 5 0.00999 osd.5 up 1.00000 1.00000 -4 0.03000 host ceph-node3 6 0.00999 osd.6 up 1.00000 1.00000 7 0.00999 osd.7 up 1.00000 1.00000 8 0.00999 osd.8 up 1.00000 1.00000 -2 0.03000 host ceph-node1 1 0.00999 osd.1 up 1.00000 1.00000 2 0.00999 osd.2 up 1.00000 1.00000 0 0.00999 osd.0 up 1.00000 1.00000 [root@ceph-node1 ~]#
-
Создайте и проверьте ваш
ssd-pool.![[Замечание]](/common/images/admon/note.png)
Замечание Так как маленький кластер на виртуальных машинах, мы создадим эти пулы с небольшим числом групп размещения.
-
Создайте
ssd-pool:# ceph osd pool create ssd-pool 8 8
-
Проверьте
ssd-pool; заметьте, чтоcrush_rulesetустановлен в значение0, что является значением по умолчанию:# ceph osd dump | grep -i ssd [root@ceph-node1 ~]# ceph osd pool create ssd-pool 8 8 pool 'ssd-pool' created [root@ceph-node1 ~]# ceph osd dump | grep ssd pool 45 'ssd-pool' replicated size 3 min_size 2 crush_ruleset 0 object hash rjenkins pg_num 8 pgp_num 8 last_change 4446 flags hashpspool stripe,idth 0 [root@ceph-node1 ~]#
-
Давайте изменим значение
crush_rulesetна1, поскольку этот новы пул создан на дисках SSD:# ceph osd pool set ssd-pool crush_ruleset 1
-
Проверим пул и отметим изменения в
crush_ruleset:# ceph osd dump | grep -i ssd [root@ceph-node1 ~]# ceph osd pool set ssd-pool crush_ruleset 1 set pool 45 crush_ruleset to 1 [root@ceph-node1 ~]# ceph osd dump | grep ssd pool 45 'ssd-pool' replicated size 3 minimize 2 crush_ruleset 1 object_hash rjenkins pg_num 8 pgp.num 8 last_change 4448 flags hashpspool stripe_width 0 [root@ceph-node1 ~]#
-
-
Аналогично создаём и проверяем
sata-pool.[root@ceph-node1 ~]# ceph osd pool create sata-pool 8 8 pool 'sata-pool' created [root@ceph-node1 ~]# ceph osd dump | grep -i sata pool 46 'sata-pool' replicated size 3 min_size 2 crush_ruleset 0 object_hash rjenkins pg_num 8 pgp_num 8 last_change 4450 flags hashpspool stripe_width 0 [root@ceph-node1 ~]# [root@ceph-node1 ~]# ceph osd pool set sata-pool crush_ruleset 2 set pool 46 crush_ruleset to 1 [root@ceph-node1 ~]# [root@ceph-node1 ~]# ceph osd dump | grep -i sata pool 46 'sata-pool' replicated size 3 min_size 2 crush_ruleset 2 object_hash rjenkins pg_num 8 pgp_num 8 last_change 4452 flags hashpspool stripe_width 0 [root@ceph-node1 ~]#
-
Давайте добавим некоторые объекты в эти пулы:
-
Поскольку данные пулы новые, они не должны содержать никаких объектов, однако, давайте проверим это применив команду
rados list:# rados -p ssd-pool ls # rados -p sata-pool ls
-
Сейчас мы добавим некий объект вэти пулы используя команду
rados put. Её синтаксис таков:rados -p <pool_name> put <object_name> <file_name>.# rados -p ssd-pool put dummy_object1 /etc/hosts # rados -p sata-pool put dummy_object1 /etc/hosts
-
Применяя команду
rados list, выведем перечень этих пулов. Вы должны получить имена объектов, сохранённых на предыдущем этапе.# rados -p ssd-pool ls # rados -p sata-pool ls [root@ceph-node1 ~]# rados -p ssd-pool ls [root@ceph-node1 ~]# rados -p sata-pool ls [root@ceph-node1 ~]# [root@ceph-node1 ~]# rados -p ssd-pool put dummy_object1 /etc/hosts [root@ceph-node1 ~]# rados -p sata-pool put dummy_object1 /etc/hosts [root@ceph-node1 ~]# [root@ceph-node1 ~]# rados -p ssd-pool is dummy_object1 [root@ceph-node1 ~]# rados -p sata-pool is dummy_object1 [root@ceph-node1 ~]#
-
-
Теперь вставка всего этого раздела должна проверить что эти объекты были сохранены в правильном наборе OSD:
-
Для нашего
ssd-pool, у нас применяются OSD 0, 3 и 6. Проверьтеosd mapcssd-pool, применяя следующий синтаксис:ceph osd map <pool_name> <object_name>.# ceph osd map ssd-pool dummy_object1
-
Аналогично, проверьте объекты в
sata-pool:# ceph osd map sata-pool dummy_object1 [root@ceph-node1 ~]# ceph osd map ssd-pool dummy_object1 psdmap e4455 pool 'ssd-pool' (45) object 'dummy_objectl' -> pg 45.71968e96 (45.6) -> up ([3,0,6], p3) acting ([3,0,6], p3) [root@ceph-node1 ~]# [root@ceph-node1 ~]# ceph osd map sata-pool dummy_objectl1 osdmap e4455 pool 'sata-pool' (46) object 'dummy_objectl' -> pg 46.71968e96 (46.6) -> up ([1,7,4], pl) acting ([1,7,4], pl) [root@ceph-node1 ~]#
-
Как показано на предыдущем снимке экрана, объект, который создан в ssd-pool на самом
деле хранится в наборе OSD [3,0,6], а объекты, которые созданы в пуле
sata-pool, были сохранены в наборе OSD [1,7,4]. Этот вывод был
ожидаем, и он подтверждает, что созданный нами пул верно использует набор OSD, как это было предписано. Такой тип настроек может быть очень
полезным в промышленных установках, в которых вам захочется создать быстрый пул только на базе SSD и пул со средней/ малой производительностью
основанный на шпиндельных дисках.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
{Прим. пер.: чтобы полностью использовать полосу пропускания SSD, они должны расщепляться примерно между 5 OSD (по опыту Mirantis), для включения такой возможности вам необходимо удалить OSD, созданные на этих SSD при установке, разделить каждый SSD на пять разделов и создать на них OSD. см., например, раздел 6.1 Эталонной архитектуры для компактного облачного решения с применением Mirantis OpenStack 9.1 и оборудования Dell EMC.} |