Глава 1. Введение в контейнеры Linux
Содержание
- Глава 1. Введение в контейнеры Linux
В наши дни, широко применяемой практикой является развёртывание приложений внутри контейнеров Linux определённого вида, в первую очередь благодаря заслугам эволюции развития инструментария и простоте применения их в настоящее время. Даже несмотря на то, что контейнеры Linux или виртуализация на уровне операционной системы в том или ином виде представлены на протяжении более десяти лет, потребовался определённый срок чтобы эта технология созрела и вошла в основное направление эксплуатации. Одной из причин для этого является тот факт, что технологии на основе гипервизоров, такие как KVM и Xen имели возможность решать большую часть имевшихся ограничений ядра Linux на протяжении длительного времени и наличие представляемых ими накладных расходов не рассматривалось в качестве некой проблемы. Однако, по мере наступления пространств имён ядра и cgroup (control groups, групп управления), благодаря применению контейнеров становится возможным такое понятие, как виртуализации с малым весом.
В данной главе мы рассмотрим следующие темы:
-
Эволюция ядра ОС и его ранние ограничения
-
Различия между контейнерной виртуализацией и виртуализацией платформ
-
Связанные с пространствами имён и cgroups понятия и терминологию
-
Некий пример применения изоляции ресурса и управления при помощи пространств имён сетевой среды и cgroups
Текущее состояние контейнеров Linux является прямым результатом тех проблем, которые пытались решать разработчики первоначальных ОС - управление памятью, вводом/ выводом и обработка расписаний наиболее эффективным образом.
В прошлом только один процесс мог планироваться к работе, тратя впустую драгоценные циклы ЦПУ при блокировке
некоторых операций ввода/ вывода. Единственным решением такой проблемы была разработка более хороших
планировщиков ЦПУ с тем, чтобы большая часть работы могла размещаться
равномерным (fair) образом для максимального использования ЦПУ.
Даже хотя современные планировщики, такие как CFS
(Completely Fair Scheduler, Совершенно
справедливый планировщик) в Linux выполняют громадную работу равноправного выделения объёмов памяти каждому
процессу, тем не менее имеются сильные основания для наличия возможности давать больший или меньший приоритет
некоторому процессу или его подпроцессам. Обычно это можно осуществлять при помощи системного вызова
nice(), либо политиками расписания в реальном масштабе времени,
однако имеются ограничения на тот уровень грануляции или управления, которого можно достичь.
Аналогично, прежде чем появлась виртуальная память, множество процессов вынуждены были получать память из совместного пула физической памяти. Именно виртуальная память предоставила некий вид изоляции памяти для процесса, в том смысле, что процессы имели бы своё собственное адресное пространство, и расширило имеющуюся доступную память за счёт некоторой подкачки, однако всё ещё не было хорошего способа ограничения того, сколько памяти может использовать каждый процесс и его потомки.
Что ещё больше усложняло этот предмет, так это исполнение различных рабочих нагрузок на одном и том же физическом сервере обычно имело результатом отрицательное воздействие на все работающие службы. Некая утечка памяти или тревога ядра (kernel panic) вызываемая одним приложением приводило к отказу всей операционной системы целиком. Например, становится проблематичной совместная работа некоего веб сервера, который в основном связан с памятью и какой бы то ни было службы базы данных, которая является нагруженной вводом/ выводом. В усилиях по обходу подобных ситуаций системным администраторам приходилось разделять различные приложения между неким серверов, оставляя ряд машин недозагруженными, в особенности в определённое время суток, когда имеется не так много работы для исполнения. Это аналогично проблеме, при которой блокируемый обслуживанием какого- то ввода/ вывода отдельно работающий процесс тратит впустую ресурсы ЦПУ и памяти.
Решением данной проблемы является применение виртуализации на основе гипервизора, контейнеров, либо комбинирования обоих методов.
Сам гипервизор как часть имеющейся операционной системы отвечает за управление жизненным циклом виртуальных машин и и мелся в наличии начиная с самых ранних дней машин мейнфреймов в конце 1960-х. Наиболее современные реализации, такие как Xen и KVM могут отслеживать своё возникновение к той эпохе. Самая основная причина для широкой адаптации таких технологий примерно с 2005 состояло в необходимости лучшего управления и применения всё возрастающих кластеров компьютерных ресурсов. Врождённая безопасность наличия некоторого дополнительного уровня между имеющимися виртуальными машинами и самой ОС хоста было хорошей отправной точкой для наличия такой безопасности, хотя как и с некоторыми прочими вновь заимствованными технологиями, имелись неприятные происшествия с безопасностью.
Тем не менее, заимствование полной виртуализации и паравиртуализации значительно улучшили тот способ, которым применялись серверы и предоставлялись приложения. Фактически виртуализация подобная KVM или Xen всё ещё широко применяются в наши дни, в особенности в облаках с множеством арендаторов и таких облачных технологиях как OpenStack.
Гипервизоры предоставляют следующие преимущества в плане обозначенных выше проблем:
-
Возможность исполнения различных операционных систем на одном и том же физическом сервере
-
Более гранулированное управление выделения ресурсов
-
Изоляция процесов - некая тревога ядра или конкретная виртуальная машина не будут оказывать воздействия на ОС самого хоста
-
Отдельный стек сетевой среды и наличие возможности управления обменом для каждой виртуалной машины индивидуально
-
Снижение капитальных и эксплутационных расходов за счёт упрощения управления центром обработки данных и лучшего использования имеющихся ресурсов серверов
Вполне возможно, самой главной причиной против применения такого вида технологии виртулизации сегодня является внутренне присущие накладные расходы использования множества ядер одной и той же смой ОС. Было бы намного лучше, в терминах комплексности, если бы ОС хоста могла предоставить данный уровень изоляции без наличия необходимости для увеличения аппаратных средств в требуемых ЦПУ, либо применять эмулирующее программное обеспечение, подобное QEMU, или даже модули ядра навроде KVM. Исполняя некую полную операционную систему в какой- то виртуальной машине, даже просто для достижения некоторого уровня ограничения для любого отдельного веб сервера, не является наиболее эффективным выделением ресурсов.
На протяжении последнего десятилетия в имеющемся ядре Linux были выполнены различные улучшения для того чтобы сделать возможной такую функциональность, однако наименьшие накладные расходы - в первую очередь пространства имён ядра и cgroups. Одной из самых ощутимых технологий для усиления этих изменений были LXC, начиная с ядра 2.6.24 и примерно с промежутка времени 2008 года. Даже хотя LXC и не являются наиболее старшей технологией контейнеризации, она помогает запитывать наблюдаемую нами сегодня ревоюцию контейнеров.
Основные преимущества применения LXC включают в себя:
-
Более низкие накладные расходы и сложность в сравнении с исполнением некоторого гипервизора
-
Меньший отпечаток на один контейнер
-
Время запуска в диапазоне милисекунд
-
Естественная поддержка ядра
Стоит отметить, что контейнеры не являются в своей сущности настолько же безопасными, как её имеет некий гипервизор между всеми виртуальными машинами и самой ОС хоста. Однако, в последние годы был достигнут значительный прогресс для сокращения этого зазора при помощи технологий MAC (Mandatory Access Control, Мандатного управления доступом - Прим. пер.: не допускающего передачи прав доступа между пользователями), таких как SELinux или AppArmor, возможностей ядра и cgroups, что будет продемонстрировано в последующих главах.
Пространтсва имён являются основой легковесности процесса виртуализации. они позволяют некому процессу и
его потомкам иметь различные обзоры лежащей в их основе системы. Это достигается добавлением системных
вызовов unshare() и setns()
и определённое вложение шести новых постоянных флагов передаваемых в системные вызовы
clone(), unshare() и
setns():
-
clone(): создаёт некий новый процесс и прикрепляет его к некоторому вновь определённому пространству имён -
unshare(): подключает имеющийся текущий процесс к некоторому вновь определённому пространству имён -
setns(): подключает некий процесс к уже имеющемуся пространству имён
Имеются шесть пространств имён в нстоящее время применяемых LXC, причём дополнительные разрабатываются:
-
Пространства имён
Mount, определяемое флагомCLONE_NEWNS -
Пространства имён
UTS, определяемое флагомCLONE_NEWUTS -
Пространства имён
IPC, определяемое флагомCLONE_NEWIPC -
Пространства имён
PID, определяемое флагомCLONE_NEWPID -
Пространства имён
User, определяемое флагомCLONE_NEWUSER -
Пространства имён
Network, определяемое флагомCLONE_NEWNET
Давайте взглянем более подробно на каждое из них и рассмотрим некоторые примены пространств пользователей, что поможет нам лучше понять что происходит под капотом.
Пространства имён Mount впервые
появились в ядре 2.4.19 в 2002 и предоставляли отдельный обзор точек монтирования имеющихся файловых систем
для самого процесса и его потомков. При монтировании файловой системы или её демонтаже данное изменение будет
отмечено всеми процессами так как все они совместно используют одно и то же пространство имён. Когда данный
флаг CLONE_NEWNS передаётся определённому системному вызову
clone(), такой новый процесс получает некую копию смонтированного
дерева данного вызывающего процесса, которое он затем может изменять без воздействия на свой родительский
процесс. Начиная с этого момента все монтирования и демонтажи в данном определённом по умолчанию пространстве
имён будут видны в имеющемся новом пространстве имён, однако изменения в пространстве имён mount для каждого
из процессов не будут отмечаться за его пределами.
Конкретный прототип clone() является таким:
#define _GNU_SOURCE
#include &дt;sched.h>
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
Некий пример вызова, который создаёт какой- то дочерний процесс в каком- то новом пространстве имён mount выглядит при мерно так:
child_pid = clone(childFunc, child_stack + STACK_SIZE, CLONE_NEWNS | SIGCHLD, argv[1]);
При создании такого дочернего процесса он исполняет передаваемую функцию
childFunc, которая выполнит свою работу в данном новом пространстве
имён mount.
Пакет util-linux предоставляет инструменты пользовательского
пространства, которые реализуют вызов unshare(), который фактически
удаляет из совместного использования все обозначенные пространства имён от своего родительского процесса.
Чтобы продемонстрировать это:
-
Вначале откройте некий терминал и создайте некий каталог в
/tmpследующим образом:root@server:~# mkdir /tmp/mount_ns root@server:~# -
Далее переместите имеющийся текущий процесс
bashв его собственное пространство имён mountпередав данный флаг mount вunshare:root@server:~# unshare -m /bin/bash root@server:~# -
Данный процесс
bashтеперь находится в некотором отдельном пространстве имён. Давайте проверим имеющийся связанный с этим пространством имён номер inode:root@server:~# readlink /proc/$$/ns/mnt mnt:[4026532211] root@server:~# -
Далее создадим временную точку монтирования:
root@server:~# mount -n -t tmpfs tmpfs /tmp/mount_ns root@server:~# -
Кроме того проверим, что вы можете видеть эту точку монтирования из вновь созданного пространства имён:
root@server:~# df -h | grep mount_ns tmpfs 3.9G 0 3.9G 0% /tmp/mount_ns root@server:~# cat /proc/mounts | grep mount_ns tmpfs /tmp/mount_ns tmpfs rw,relatime 0 0 root@server:~#Как и ожидалось, данная точка монтирования видна, так как она является частью того простраства имён, которое мы создали и из которого исполняется данный текущий процесс
bash. -
Далее запустим некий новый терминальный сеанс и отобразим из него его идентификатор пространства имён inode:
root@server:~# readlink /proc/$$/ns/mnt mnt:[4026531840] root@server:~#Заметим, что он отличается от того пространства имён mount, которое находится в другом терминале.
-
Наконец проверим что такая новая точка монтирования видна в данном новом терминале:
root@server:~# cat /proc/mounts | grep mount_ns root@server:~# df -h | grep mount_ns root@server:~#
Ничего удивительного в том, что данная точка монтирования не видна из определённого по умолчанию пространства имён.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
В контексте для LXC пространства имён mount являются полезными, так как они предоставляют
некий способ для какого- то отличия расположения файловых систем существующих внутри определённого
контейнера. Не лишним будет отметить, что до появления пространства имён mount некое аналогичное
ограждение процесса можно было получить при помощи системного вызова |
Пространства имён UTS
(Unix Timesharing) предоставляют изоляцию для
имеющегося имени хоста и имени домена таким образом, что каждый контейнер LXC может монтировать свой
собственный идентификатор как возвращаемый командой hostname -f.
Это необходимо для большинства приложений которые полагаются на некий надлежащий набор имени хоста.
Чтобы создать некий сеанс bash в каком- то новом пространстве имён UTS
мы можем вновь применить утилиту unshare, которая использует
имеющийся системный вызов unshare() для создания определённого
пространства имён и системный вызов execve() для исполнения в нём
bash:
root@server:~# hostname
server
root@server:~# unshare -u /bin/bash
root@server:~# hostname uts-namespace
root@server:~# hostname
uts-namespace
root@server:~# cat /proc/sys/kernel/hostname
uts-namespace
root@server:~#
Как показывает предыдущий вывод, текущим именем хоста внутри данного пространства имён
является uts-namespace.
Далее, из другого терминала, проверим текущее имя хоста и убедимся что оно не изменилось:
root@server:~# hostname
server
root@server:~#
Как и ожидалось, данное имя хоста изменилось только в нашем новом пространстве имён UTS.
Чтобы увидеть все реальные системные вызовы, которые использует данная команда
unshare, мы можем исполнить имеющуюся утилиту
strace:
root@server:~# strace -s 2000 -f unshare -u /bin/bash
...
unshare(CLONE_NEWUTS) = 0
getgid() = 0
setgid(0) = 0
getuid() = 0
setuid(0) = 0
execve("/bin/bash", ["/bin/bash"], [/* 15 vars */]) = 0
...
Из данного вывода мы можем увидеть, что исполненная команда unshare
требует системных вызовов unshare() и
execve(), а также флаг CLONE_NEWUTS
для определения нового пространства имён UTS.
Пространства имён IPC ( Interprocess Communication) предоставляют изоляцию для некоторого набора IPC и возможностей синхронизации. Эти возможности предоставляют некий способ обмена данными и синхронизации своих действий между потоками (threads) и процессами. Они предоставляют такие примитивы, как семафоры, блокировки файлов, а также их взаимное исключение помимо прочего, которые необходимы для наличия реального отделения процесса в контейнере.
Пространства имён PID
(Process ID) предоставляют определённую возможность
иметь некий идентификатор (ID), который уже имеется в определённом по умолчанию пространстве имён, например, ID
1. Это делает для некоторого системного init возможным работать в
каком- то контейнере с различными прочими процессами без каких бы то ни было коллизий со всеми остальными
имеющимися в той же самой ОС PID.
Чтобы продемонстрировать эту концепцию, откроем pid_namespace.c:
#define _GNU_SOURCE
#include <stdlib.h>
#include <stdio.h>
#include <signal.h>
#include <sched.h>
static int childFunc(void *arg)
{
printf("Process ID in child = %ld\n", (long) getpid());
}
Вначале мы включим все заголовки иопределим функцию ту childFunc,
которая применит определённый системный вызов clone(). Эта функция
выводит имеющийся дочерний PID при помощи встроенного системного вызова
getpid():
static char child_stack[1024*1024];
int main(int argc, char *argv[])
{
pid_t child_pid;
child_pid = clone(childFunc, child_stack + (1024*1024),
CLONE_NEWPID | SIGCHLD, NULL);
printf("PID of cloned process: %ld\n", (long) child_pid);
waitpid(child_pid, NULL, 0);
exit(EXIT_SUCCESS);
}
В данной функции main() мы определяем нужный нам размер стека и
вызываем clone(), передавая имеющуюся дочернюю функцию
childFunc, указатель на определённый нами стек, конкретные флаг
CLONE_NEWPID и сигнал SIGCHLD.
Данный флаг CLONE_NEWPID предписывает
clone() создать некое новое пространство имён PID, а данный
флаг SIGCHLD уведомляет имеющийся родительский процесс когда
прекращается один из его потомков. Данный родительский процесс будет блокироваться в
waitpid() если такой дочерний процесс не был прекращён.
Скомпилируем и затем выполним эту программу следующим образом:
root@server:~# gcc pid_namespace.c -o pid_namespace
root@server:~# ./pid_namespace
PID of cloned process: 17705
Process ID in child = 1
root@server:~#
Из её вывода мы можем видеть, что наш дочерний процесс имеет некий PID 1
внутри своего пространства имён и 17705 за его пределами.
|
| Замечание |
|---|---|
|
Отметим, что для краткости в данных примерах кода была опущена обработка ошибок. |
Пространства имён User позволяют
некоторому процессу внутри какого- либо пространства имён иметь какие- то идентификаторы пользователя и
группы, которые отличаются от имеющихся в определённом по умолчанию пространстве имён. В данном контексте
для LXC это делает возможным для некоторого процесса исполняться с правами root
внутри данного контейнера и при этом иметь вовне непривилегированный идентификатор. Это добавляет некий
тонкий уровень безопасности, так как прорыв для данного контейнера будет иметь результатом непривилегированного
пользователя. Это возможно благодаря ядру 3.8, которое ввело существенную возможность для непривилегированных
пользовательских процессов создавать пространства имён user.
Чтобы создать некое новое пространство имён user в качестве непривилегированного пользователя и иметь
внутри root, мы можем воспользоваться утилитой
unshare. Давайте установи самую последнюю версию из source:
root@ubuntu:~# cd /usr/src/
root@ubuntu:/usr/src# wget
https://www.kernel.org/pub/linux/utils/util-linux/v2.28/util-linux-2.28.tar.gz
root@ubuntu:/usr/src# tar zxfv util-linux-2.28.tar.gz
root@ubuntu:/usr/src# cd util-linux-2.28/
root@ubuntu:/usr/src/util-linux-2.28# ./configure
root@ubuntu:/usr/src/util-linux-2.28# make && make install
root@ubuntu:/usr/src/util-linux-2.28# unshare --map-root-user --user sh -c whoami
root
root@ubuntu:/usr/src/util-linux-2.28#
Мы также можем воспользоваться системным вызовом clone()
с определённым флагом CLONE_NEWUSER чтобы создать некий процесс
в каком- то пространстве имён user, что демонстрирует следующая программа:
#define _GNU_SOURCE
#include <stdlib.h>
#include <stdio.h>
#include <signal.h>
#include <sched.h>
static int childFunc(void *arg)
{
printf("UID inside the namespace is %ld\n", (long) geteuid());
printf("GID inside the namespace is %ld\n", (long) getegid());
}
static char child_stack[1024*1024];
int main(int argc, char *argv[])
{
pid_t child_pid;
chil_pid = clone(childFunc, child_stack + (1024*1024), CLONE_NEWUSER | SIGCHLD, NULL);
printf("UID outside the namespace is %ld\n", (long) geteuid());
printf("GID outside the namespace is %ld\n", (long) getegid());
waitpid(child_pid, NULL, 0);
exit(EXIT_SUCCESS);
}
После компиляции и исполнения вывод будет выглядеть аналогично этому, когда мы исполняем его с правами
root - UID 0:
root@server:~# gcc user_namespace.c -o user_namespace
root@server:~# ./user_namespace
UID outside the namespace is 0
GID outside the namespace is 0
UID inside the namespace is 65534
GID inside the namespace is 65534
root@server:~#
Пространство имён Network предоставляет изоляцию имеющихся сетевых ресурсов, таких как сетевые устройства, адреса, маршруты и правила межсетевого экранирования. Оно в действительности создаёт некую логическую копию всего сетевого стека, что делает возможным для множества процессов прослушивать один и тот же порт из множества пространств имён. Именно это лежит в основе сетевой среды в LXC и имеется достаточно большое число прочих вариантов применения, где это может стать удобным.
Имеющийся пакет iproute2 предоставляет очень полезные инструменты
пространства имён, которые мы можем применять для экспериментирования с имеющимися пространствами имён Network,
причём он устанавливается по умолчанию почти во всех системах Linux.
Всегда имеется единственное определённое по умолчанию пространство имён network, которое называется корневым пространством имён, в котором изначально назначены все сетевые интерфейсы. Чтобы просмотреть перечень всех имеющихся сетевых интерфейсов, которые относятся к имеющемуся определённым по умолчанию пространству имён, выполните следующую команду:
root@server:~# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 0e:d5:0e:b0:a3:47 brd ff:ff:ff:ff:ff:ff
root@server:~#
В данном случае имеются два интерфейса - lo и
etho.
Чтобы перечислить их настройки мы можем выполнить следующее:
root@server:~# ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc pfifo_fast state UP group default qlen 1000
link/ether 0e:d5:0e:b0:a3:47 brd ff:ff:ff:ff:ff:ff
inet 10.1.32.40/24 brd 10.1.32.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::cd5:eff:feb0:a347/64 scope link
valid_lft forever preferred_lft forever
root@server:~#
Кроме того, чтобы вывести перечень всех маршрутов из корневого пространства имён network, выполните следующее:
root@server:~# ip r s
default via 10.1.32.1 dev eth0
10.1.32.0/24 dev eth0 proto kernel scope link src 10.1.32.40
root@server:~#
Давайте создадим два новых пространства имён network с названиями ns1
и ns1 и выведем их перечень:
root@server:~# ip netns add ns1
root@server:~# ip netns add ns2
root@server:~# ip netns
ns2
ns1
root@server:~#
Теперь, когда у нас имеются такие новые пространства имён, мы можем выполнять в них команды:
root@server:~# ip netns exec ns1 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
root@server:~#
Предыдущий вывод показывает, что в имеющемся пространстве имён ns1
имеется толко один сетевой интерфейс, а именно интерфейс lo -
кольцевой проверки, причём он находится в состоянии DOWN.
Мы также можем запустить новый сеанс bash внутри данного
пространства имён и вывести перечень всех интерфейсов аналогичным образом:
root@server:~# ip netns exec ns1 bash
root@server:~# ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
root@server:~# exit
root@server:~#
Это более удобно для исполнения множества команд, вместо того чтобы определять каждую команду по одной за раз. Данные два пространства имён network не очень много дают для практики, если они не соединены ни с чем, поэтому давайте свяжем их друг с другом. Чтобы сделать это мы применим некий программный мост называемый Open vSwitch.
Open vSwitch работает в точности так же как обычный сетевой мост и следовательно он перешлёт кадры между виртуальными портами, которые мы определим. После этого к нему могут быть подключены такие виртуальные машины как KVM, Xen, а также контейнеры LXC или Docker.
Большинство дистрибутивов на основе Debian, такие как Ubuntu, предоставляют некий пакет, поэтому давайте установим его:
root@server:~# apt-get install -y openvswitch-switch
root@server:~#
Это установит и запустит неоьбходимый демон Open vSwitch. Самое время для создания нужного нам моста;
мы назовём его OVS-1:
root@server:~# ovs-vsctl add-br OVS-1
root@server:~# ovs-vsctl show
0ea38b4f-8943-4d5b-8d80-62ccb73ec9ec
Bridge "OVS-1"
Port "OVS-1"
Interface "OVS-1"
type: internal
ovs_version: "2.0.2"
root@server:~#
|
| Замечание |
|---|---|
|
Если вы желаете поэкспериментирвать с самой последней версией Opn vSwitch, вы можете загрузить её исходный код с http://openvswitch.org/download/ и откомпилировать его. |
Вновь созданный мост можно теперь увидеть в имеющемся корневом пространстве имён:
root@server:~# ip a s OVS-1
4: OVS-1: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 9a:4b:56:97:3b:46 brd ff:ff:ff:ff:ff:ff
inet6 fe80::f0d9:78ff:fe72:3d77/64 scope link
valid_lft forever preferred_lft forever
root@server:~#
Чтобы соединить оба пространства имён network, давайте вначале создадим некую виртуальную пару интерфейсов для каждого пространства имён:
root@server:~# ip link add eth1-ns1 type veth peer name veth-ns1
root@server:~# ip link add eth1-ns2 type veth peer name veth-ns2
root@server:~#
Предыдущие две команды создали четыре виртуальных интерфейса eth1-ns1,
eth1-ns2, veth1-ns1 и
veth1-ns2. Эти имена могут быть произвольными.
Чтобы перечислить все интерфейсы, которые являются частью имеющегося корневого пространства имеён, выполните:
root@server:~# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 0e:d5:0e:b0:a3:47 brd ff:ff:ff:ff:ff:ff
3: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default
link/ether 82:bf:52:d3:de:7e brd ff:ff:ff:ff:ff:ff
4: OVS-1: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/ether 9a:4b:56:97:3b:46 brd ff:ff:ff:ff:ff:ff
5: veth-ns1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 1a:7c:74:48:73:a9 brd ff:ff:ff:ff:ff:ff
6: eth1-ns1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 8e:99:3f:b8:43:31 brd ff:ff:ff:ff:ff:ff
7: veth-ns2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 5a:0d:34:87:ea:96 brd ff:ff:ff:ff:ff:ff
8: eth1-ns2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether fa:71:b8:a1:7f:85 brd ff:ff:ff:ff:ff:ff
root@server:~#
Давайте назначим имеющиеся интерфейсы eth1-ns1 и
eth1-ns2 в свои пространства имён ns1
и ns2:
root@server:~# ip link set eth1-ns1 netns ns1
root@server:~# ip link set eth1-ns2 netns ns2
Кро ме этого убедимся что они видны внутри каждого из этих пространств имён network:
root@server:~# ip netns exec ns1 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
6: eth1-ns1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 8e:99:3f:b8:43:31 brd ff:ff:ff:ff:ff:ff
root@server:~#
root@server:~# ip netns exec ns2 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
8: eth1-ns2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether fa:71:b8:a1:7f:85 brd ff:ff:ff:ff:ff:ff
root@server:~#
Отметим, что каждое пространство имён теперь имеет два назначенных интерфейса -
lo и eth1-ns*.
Если мы выведем перечень устройств из имеющегося корневого пространства имён, мы должны увидеть, что все
интерфейсы, которые мы только что переместили в ns1 и
ns2 больше не видны:
root@server:~# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 0e:d5:0e:b0:a3:47 brd ff:ff:ff:ff:ff:ff
3: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default
link/ether 82:bf:52:d3:de:7e brd ff:ff:ff:ff:ff:ff
4: OVS-1: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/ether 9a:4b:56:97:3b:46 brd ff:ff:ff:ff:ff:ff
5: veth-ns1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 1a:7c:74:48:73:a9 brd ff:ff:ff:ff:ff:ff
7: veth-ns2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 5a:0d:34:87:ea:96 brd ff:ff:ff:ff:ff:ff
root@server:~#
Настало время подключить все оставшиеся из двух имеющихся виртуальных конвейеров, а именно интерфейсы
veth1-ns1 и veth1-ns2 к
имеющемуся мосту:
root@server:~# ovs-vsctl add-port OVS-1 veth-ns1
root@server:~# ovs-vsctl add-port OVS-1 veth-ns2
root@server:~# ovs-vsctl show
0ea38b4f-8943-4d5b-8d80-62ccb73ec9ec
Bridge "OVS-1"
Port "OVS-1"
Interface "OVS-1"
type: internal
Port "veth-ns1"
Interface "veth-ns1"
Port "veth-ns2"
Interface "veth-ns2"
ovs_version: "2.0.2"
root@server:~#
Из приведённого предыдущего вывода очевидно, что имеющийся мост теперь имеет два порта,
veth1-ns1 и veth1-ns2.
Последним оставшимся моментом является поднятие всех сетевых интерфейсов и назначение IP адресов:
root@server:~# ip link set veth-ns1 up
root@server:~# ip link set veth-ns2 up
root@server:~# ip netns exec ns1 ip link set dev lo up
root@server:~# ip netns exec ns1 ip link set dev eth1-ns1 up
root@server:~# ip netns exec ns1 ip address add 192.168.0.1/24 dev eth1-ns1
root@server:~# ip netns exec ns1 ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
6: eth1-ns1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 8e:99:3f:b8:43:31 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.1/24 scope global eth1-ns1
valid_lft forever preferred_lft forever
inet6 fe80::8c99:3fff:feb8:4331/64 scope link
valid_lft forever preferred_lft forever
root@server:~#
Аналогично для нашего пространства имён ns2:
root@server:~# ip netns exec ns2 ip link set dev lo up
root@server:~# ip netns exec ns2 ip link set dev eth1-ns2 up
root@server:~# ip netns exec ns2 ip address add 192.168.0.2/24 dev eth1-ns2
root@server:~# ip netns exec ns2 ip a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
8: eth1-ns2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether fa:71:b8:a1:7f:85 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.2/24 scope global eth1-ns2
valid_lft forever preferred_lft forever
inet6 fe80::f871:b8ff:fea1:7f85/64 scope link
valid_lft forever preferred_lft forever
root@server:~#
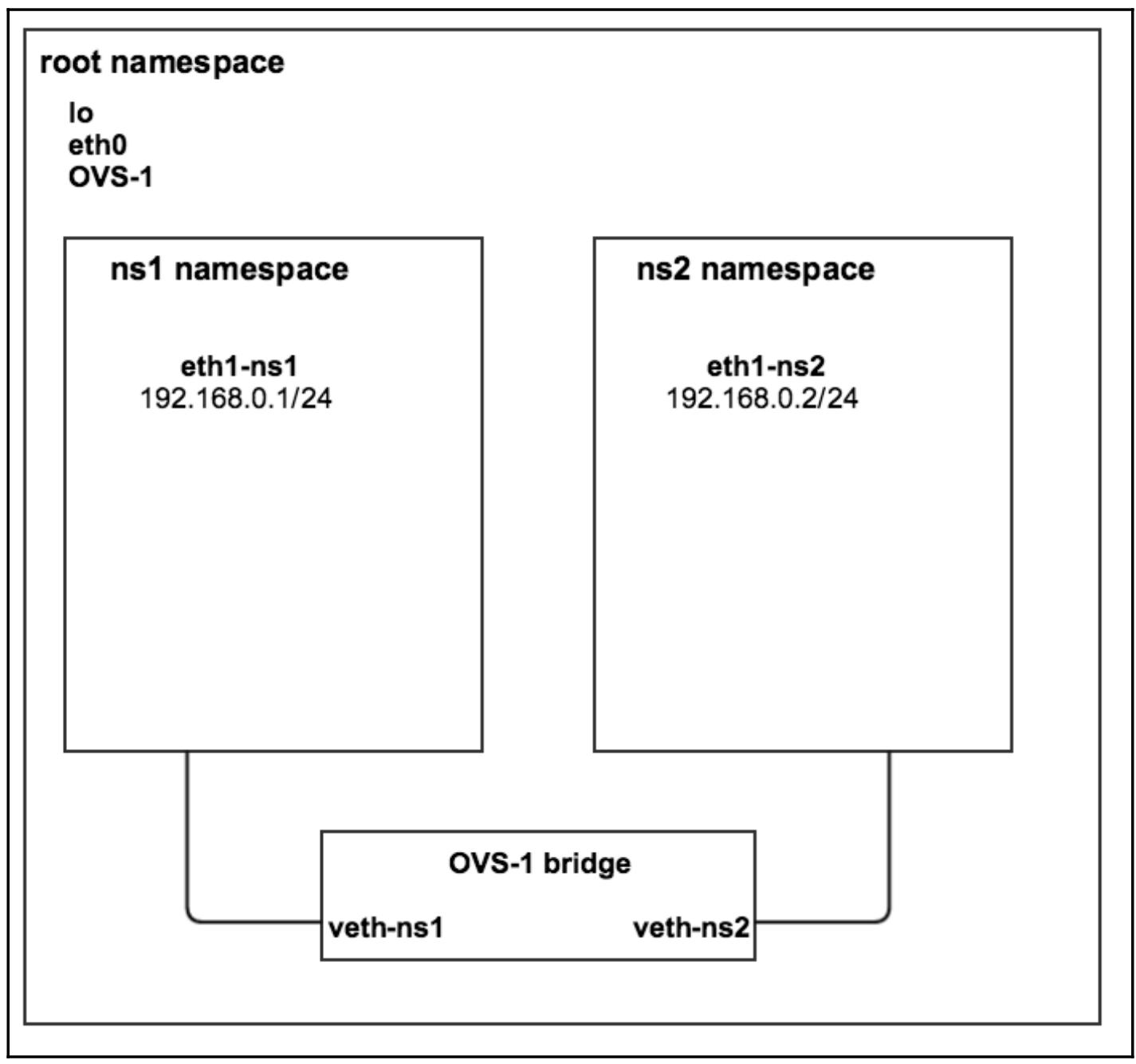
Таким образом мы установили некоторое соединение между обоими пространствами имён network
ns1 и ns2 через имеющийся
мост Open vSwitch. Чтобы убедиться в этом давайте воспользуемся ping:
root@server:~# ip netns exec ns1 ping -c 3 192.168.0.2
PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data.
64 bytes from 192.168.0.2: icmp_seq=1 ttl=64 time=0.414 ms
64 bytes from 192.168.0.2: icmp_seq=2 ttl=64 time=0.027 ms
64 bytes from 192.168.0.2: icmp_seq=3 ttl=64 time=0.030 ms
--- 192.168.0.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1998ms
rtt min/avg/max/mdev = 0.027/0.157/0.414/0.181 ms
root@server:~#
root@server:~# ip netns exec ns2 ping -c 3 192.168.0.1
PING 192.168.0.1 (192.168.0.1) 56(84) bytes of data.
64 bytes from 192.168.0.1: icmp_seq=1 ttl=64 time=0.150 ms
64 bytes from 192.168.0.1: icmp_seq=2 ttl=64 time=0.025 ms
64 bytes from 192.168.0.1: icmp_seq=3 ttl=64 time=0.027 ms
--- 192.168.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.025/0.067/0.150/0.058 ms
root@server:~#
Open vSwitch делает возможным назначение тегов VLAN для сетевых интерфейсов, что имеет результатом изоляцию обмена между пространствами имён Это может быть полезным в некоторых сценариях, когда у вас имеется множество пространств имён и вы желаете иметь связь между некоторыми их них.
Следующий пример демонстрирует как пометить тегом имеющиеся интерфейсы в пространствах имён
ns1 и ns2 с тем, чтобы
весь обмен не был видим из каждого из имеющихся двух пространств имён network:
root@server:~# ovs-vsctl set port veth-ns1 tag=100
root@server:~# ovs-vsctl set port veth-ns2 tag=200
root@server:~# ovs-vsctl show
0ea38b4f-8943-4d5b-8d80-62ccb73ec9ec
Bridge "OVS-1"
Port "OVS-1"
Interface "OVS-1"
type: internal
Port "veth-ns1"
tag: 100
Interface "veth-ns1"
Port "veth-ns2"
tag: 200
Interface "veth-ns2"
ovs_version: "2.0.2"
root@server:~#
Оба этих пространства имён теперь должны быть изолированными в своих собственных VLAN и
ping должен отказывать:
root@server:~# ip netns exec ns1 ping -c 3 192.168.0.2
PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data.
--- 192.168.0.2 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 1999ms
root@server:~# ip netns exec ns2 ping -c 3 192.168.0.1
PING 192.168.0.1 (192.168.0.1) 56(84) bytes of data.
--- 192.168.0.1 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 1999ms
root@server:~#
При создании некоторого нового пространства имён network вы можете также воспользоваться утилитой
unshare, которую мы видели в своих примерах пространств имён
mount и UTC:
root@server:~# unshare --net /bin/bash
root@server:~# ip a s
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
root@server:~# exit
root@server
Cgroups являются ключевым свойством, которое делает возможным тонко гранулированное управление выделения ресурсов для некоторого отдельного процесса или какой- то группы процессов, называемых задачами (tasks). В данном контексте для LXC это достаточно важно, так как делает возможными пределы назначений на то сколько некий определённый контейнер может использовать памяти, времени ЦПУ или ввода/ вывода. {Прим. пер.: аналогом в Windows являются job objects, объекты задания.}
Те cgroups, которыми мы более всего интересумся, приведены в таблице ниже:
| Подсистема | Описание | Определяется в |
|---|---|---|
|
Выделяет задачам время ЦПУ |
|
|
Учётные записи для использования ЦПУ |
|
|
Назначает ядра ЦПУ задачам |
|
|
Выделяет задачам оперативную память |
|
|
Ограничивает доступ ввода/ вывода к устройствам |
|
|
Позволяет/ запрещает доступ к устройствам |
|
|
Приостанавливает/ возобновляет задачи |
|
|
Помечает тегами сетевые пакеты |
|
|
Определяет приоритет сетевого обмена |
|
|
Ограничивает HugeTLB |
|
Cgroups иерархически организованы, представляя себя в виде каталога в
VFS
(Virtual File System, Виртуальной файловой
системе). Аналогично иерархии процессов, при которой все процессы происходят от самого первого процесса
init или systemd, cgroups
наследуют некоторые из имеющихся свойств своих родителей. В имеющейся системе может существовать
множество иерархий cgroups, причём каждая представляет некую отдельную группу ресурсов. Имеется возможность
иметь иерархии, которые объединяют две или более подсистем, например, оперативную память и ввод/ вывод, а
назначенные некоторой группе задачи будут иметь пределы, применяемые к этим ресурсам.
|
| Замечание |
|---|---|
|
Если вы интересуетесь тем как имеющиеся различные подсистемы реализованы в имеющемся ядре, установите доступный исходный код ядра и просмотрите все файлы C, отображённые в третьей колонке приведённой выше таблицы. |
Следующая схема помогает визуализировать отдельную иерархию, котрая имеет две подключённые к ней подсистемы - ЦПУ и ввод/ вывод:
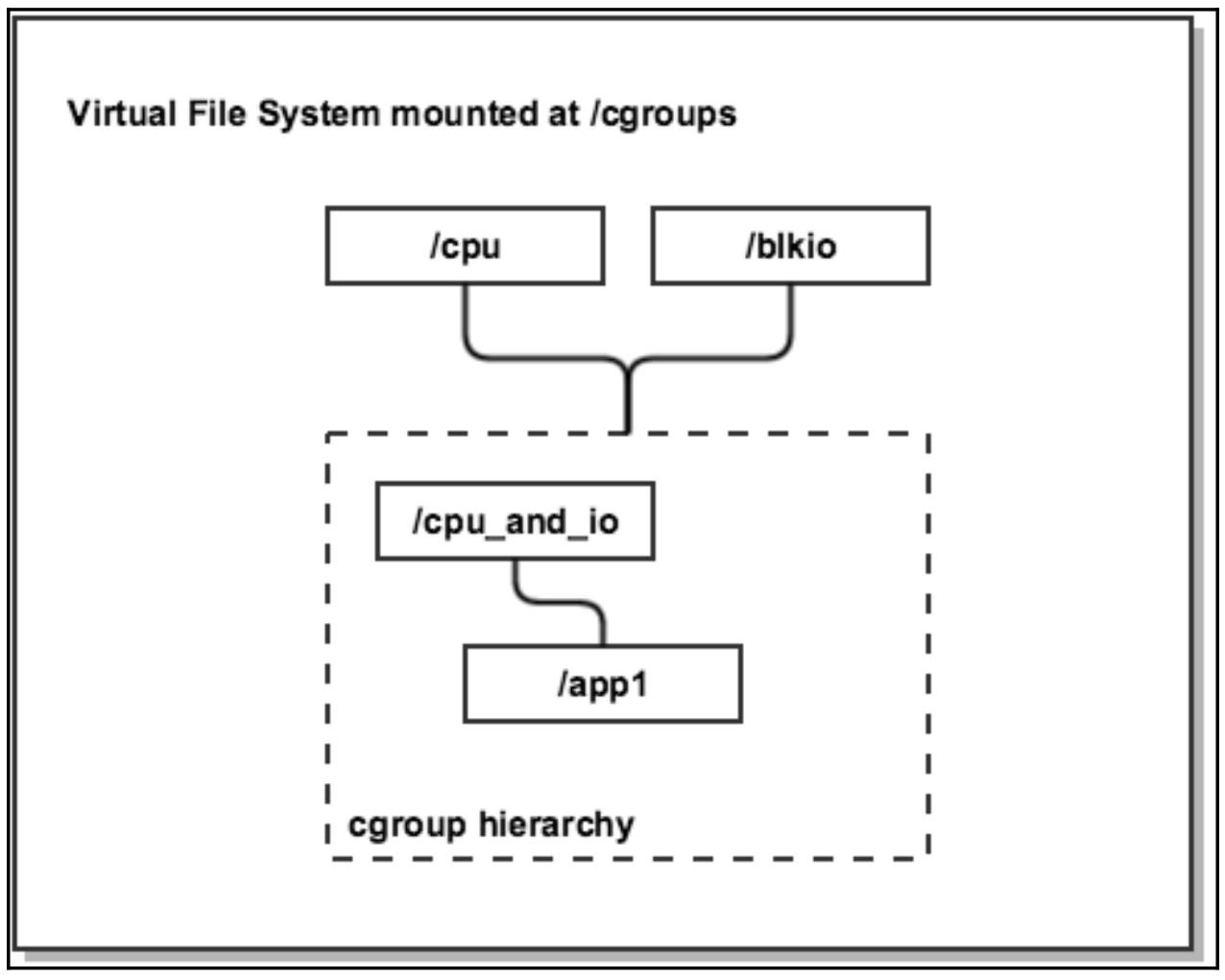
Cgroups могут применяться двумя способами:
-
Путём манипуляций вручную файлов и каталогов в некоторой смонтированной VFS
-
При помощи инструментов пространства пользователя, предоставляемых различными пакетами, такими как
cgroup-binв Debian/ Ubuntu иlibcgroupв RHEL/ CentOS.
Давайте взглянем на несколько примеров из практики того как применять cgroups для ограничения ресурсов. Это позволит нам лучше понять то как работают контейнеры.
Ограничение пропускной способности ввода/ вывода
Давайте предположим, что у нас имеются два исполняющиеся в некотором сервере приложения, которые имеют
тяжёлые пределы ввода/ вывода: app1 и
app2. Мы бы хотели предоставить большую полосу пропускания для
app1 в течение рабочего дня, а для
app2 ночью. Такой тип приоритезации пропускной способности ввода/
вывода может быть выполнен при помощи подсистемы blkio.
Вначале давайте подключим необходимую подсистему blkio
смонтировав имеющуюся VFS cgroup:
root@server:~# mkdir -p /cgroup/blkio
root@server:~# mount -t cgroup -o blkio blkio /cgroup/blkio
root@server:~# cat /proc/mounts | grep cgroup
blkio /cgroup/blkio cgroup rw, relatime, blkio, crelease_agent=/run/cgmanager/agents/cgm-release-agent.blkio 0 0
root@server:~#
Затем создадим две группы приоритетов, которые будут частью одной и той же иерархии
blkio:
root@server:~# mkdir /cgroup/blkio/high_io
root@server:~# mkdir /cgroup/blkio/low_io
root@server:~#
Нам необходимо получить PID, имеющиеся для наших app1 и
app2, а потом назначить их созданным группам
high_io и low_io:
root@server:~# pidof app1 | while read PID; do echo $PID >> /cgroup/blkio/high_io/tasks; done
root@server:~# pidof app2 | while read PID; do echo $PID >> /cgroup/blkio/low_io/tasks; done
root@server:~#
Именно файл tasks является тем местом, в котором мы определяем
какие заданные пределы процессов/ задач должны применяться.
Наконец, давайте установим соотношение 10:1 для cgroups high_io и
low_io. Задачи в этих cgroups будут немедленно использовать только те
ресурсы, которые становятся доступными для них:
root@server:~# echo 1000 > /cgroup/blkio/high_io/blkio.weight
root@server:~# echo 100 > /cgroup/blkio/low_io/blkio.weight
root@server:~#
Файл blkio.weight определяет тот вес доступа к вводу/ выводу,
который возможен некоторому процессу или группе процессов со значениями в диапазоне от 100 до 1 000. В
данном примере имеющиеся значения 1000 и
100 создают некое соотношение 10:1.
При этом приложение с самым низким приоритетом, app2,
будет использовать только примерно 10 процентов от общего объёма доступных операций ввода/ вывода, в то время как
приложение с наивысшим приоритетом, app1, будет применять около
90 процентов.
Если вы выведите список своего каталога high_io в Ubuntu, вы
увидите следующие файлы:
root@server:~# ls -la /cgroup/blkio/high_io/
drwxr-xr-x 2 root root 0 Aug 24 16:14 .
drwxr-xr-x 4 root root 0 Aug 19 21:14 ..
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_merged
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_merged_recursive
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_queued
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_queued_recursive
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_service_bytes
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_service_bytes_recursive
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_serviced
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_serviced_recursive
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_service_time
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_service_time_recursive
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_wait_time
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.io_wait_time_recursive
-rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.leaf_weight
-rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.leaf_weight_device
--w------- 1 root root 0 Aug 24 16:14 blkio.reset_stats
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.sectors
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.sectors_recursive
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.io_service_bytes
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.io_serviced
-rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.read_bps_device
-rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.read_iops_device
-rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.write_bps_device
-rw-r--r-- 1 root root 0 Aug 24 16:14 blkio.throttle.write_iops_device
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.time
-r--r--r-- 1 root root 0 Aug 24 16:14 blkio.time_recursive
-rw-r--r-- 1 root root 0 Aug 24 16:49 blkio.weight
-rw-r--r-- 1 root root 0 Aug 24 17:01 blkio.weight_device
-rw-r--r-- 1 root root 0 Aug 24 16:14 cgroup.clone_children
--w--w--w- 1 root root 0 Aug 24 16:14 cgroup.event_control
-rw-r--r-- 1 root root 0 Aug 24 16:14 cgroup.procs
-rw-r--r-- 1 root root 0 Aug 24 16:14 notify_on_release
-rw-r--r-- 1 root root 0 Aug 24 16:14 tasks
root@server:~#
Из предыдущего вывода вы можете видеть, что доступны для записи только некоторые файлы. Это зависит от различных установок ОС, таких как какой из планировщиков ввода/ вывода будет применяться.
Мы уже видели для чего применяются файлы tasks и
blkio.weight. Ниже приводится краткое описание наиболее часто
применяемых файлов в данной подсистеме blkio:
| Файл | Описание |
|---|---|
|
Общее число чтений/ записей, sync или async, слитых в запросы |
|
Общее число находящихся в очереди в определёный момент времени чтений/ записей, sync или async, слитых в запросы |
|
Общее число байт, переданных к или от данного определённого устройства |
|
Общее число операций ввода/ вывода исполненных для данного определённого устройства |
|
Общий объём времени между отправкой запроса и выполнением запроса в наносекундах для данного определённого устройства |
|
Общий объём времени операций ввода/ вывода, потраченных на ожидание в очередях планировщика для данного определённого устройства |
|
Аналогично |
|
Запись некоторого целого в данный фал сбросит все статистики |
|
Общее число секторов, переданных к или от данного определённого устройства |
|
Общее число байт, переданных к или от данного диска |
|
Общее число операций ввода/ вывода выполненных для данного определённого диска |
|
Общее дисковое время выделенное некоторому устройству в милисекундах |
|
Определяет вес для некоторой иерархии cgroups |
|
Аналогично |
|
Подключает задачи к данной cgroups |
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Один момент, который следует иметь в виду состоит в том, что запись в эти файлы напрямую для осуществления изменений не сохранится после перезапуска данного сервера. Позже в данной главе вы изучите как применять инструменты пространства пользователя для выработки постоянно действующих файлов настройки. |
Ограничение использования памяти
Имеющаяся подсистема memory управляет тем сколько оперативной
памяти представляется и доступно для применения процессами. Это может быть в особенности полезно в средах
со множеством арендаторов, где требуется лучший контроль над тем сколько памяти может использовать некий
пользовательский процесс, либо для ограничения жадных в отношении памяти приложений. Контейнерные
решения подобные LXC могут применять подсистему memory для управления
самим размером имеющихся экземпляров без необходимости перезапуска каждого конкретного контейнера.
Данная подсистема memory осуществляет учёт ресурса, например,
отслеживание имеющегося применения анонимных страниц, файлового кэша, кэшей свопа, а также иерархического
ведения учёта, причём все они представляются при возникающем превышении. По этой причине данная группа
memory по умолчанию отключена в некоторых дистрибутивах Linux.
Если приведённая ниже команда выдаёт отказ, вам следует разрешить её, определив приведённый ниже параметр
и выполнив перезапуск:
root@server:~# vim /etc/default/grub
RUB_CMDLINE_LINUX_DEFAULT="cgroup_enable=memory"
root@server:~# grub-update && reboot
Вначале давайте смонтируем необходимую cgroup memory:
root@server:~# mkdir -p /cgroup/memory
root@server:~# mount -t cgroup -o memory memory /cgroup/memory
root@server:~# cat /proc/mounts | grep memory
memory /cgroup/memory cgroup rw, relatime, memory,
release_agent=/run/cgmanager/agents/cgm-release-agent.memory 0 0
root@server:~#
Затем установим значение памяти app1 в 1 GB:
root@server:~# mkdir /cgroup/memory/app1
root@server:~# echo 1G > /cgroup/memory/app1/memory.limit_in_bytes
root@server:~# cat /cgroup/memory/app1/memory.limit_in_bytes
1073741824
root@server:~# pidof app1 | while read PID; do echo $PID >> /cgroup/memory/app1/tasks; done
root@server:~#
Аналогично описанной подсистеме blkio, имеющийся файл
tasks применяется для определения конкретного PID тех процессов,
которые мы добавляем в имеющуюся иерархию cgroups, в файл
memory.limit_in_bytes определяет сколько памяти в байтах необходимо
сделать доступной.
Иерархия памяти app1 содержит следующие файлы:
root@server:~# ls -la /cgroup/memory/app1/
drwxr-xr-x 2 root root 0 Aug 24 22:05 .
drwxr-xr-x 3 root root 0 Aug 19 21:02 ..
-rw-r--r-- 1 root root 0 Aug 24 22:05 cgroup.clone_children
--w--w--w- 1 root root 0 Aug 24 22:05 cgroup.event_control
-rw-r--r-- 1 root root 0 Aug 24 22:05 cgroup.procs
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.failcnt
--w------- 1 root root 0 Aug 24 22:05 memory.force_empty
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.failcnt
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.limit_in_bytes
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.slabinfo
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.tcp.failcnt
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 root root 0 Aug 24 22:05 memory.kmem.usage_in_bytes
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.limit_in_bytes
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.max_usage_in_bytes
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.move_charge_at_immigrate
-r--r--r-- 1 root root 0 Aug 24 22:05 memory.numa_stat
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.oom_control
---------- 1 root root 0 Aug 24 22:05 memory.pressure_level
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.soft_limit_in_bytes
-r--r--r-- 1 root root 0 Aug 24 22:05 memory.stat
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.swappiness
-r--r--r-- 1 root root 0 Aug 24 22:05 memory.usage_in_bytes
-rw-r--r-- 1 root root 0 Aug 24 22:05 memory.use_hierarchy
-rw-r--r-- 1 root root 0 Aug 24 22:05 tasks
root@server:~#
Все файлы и их функции в имеющейся подсистеме памяти описаны в следующей таблице:
| Файл | Описание |
|---|---|
|
Показывает общее число достижения предела памяти |
|
Если установлено в |
|
Показывает общее число достижения предела памяти ядра |
|
Устанавливает или показывает жёсткий предел памяти ядра |
|
Показывает максимальное использование памяти ядра |
|
Показывает общее число достижения предела памяти буфера TCP |
|
Устанавливает или показывает жёсткий предел для памяти буфера TCP |
|
Показывает максимальное использование памяти буфера TCP |
|
Показывает текущее использование памяти буфера TCP |
|
Показывает текущее использование памяти ядра |
|
Устанавливает или показывает предел использования памяти |
|
Показывает максимальное использование памяти |
|
Устанавливает или показывает управление перемещением расходов |
|
Показывает общий объём использования памяти для каждого узла NUMA |
|
Устанавливает или показывает имеющееся управление OOM |
|
Устанавливает уведомления об острой необходимости памяти |
|
Устанавливает или показывает мягкий предел использования памяти |
|
Показывает различные статистики |
|
Устанавливает или показывает уровень подкачки |
|
Показывает текущее использование памяти |
|
Устанавливает восстановление памяти из дочерних процессов |
|
Подключает задачи к данной cgroups |
Ограничение объёма доступной для некоторого процесса памяти может переключить имеющийся подавитель (killer) OOM (Out Of Memory, Нехватки памяти), который может отключить (kill) исполняющуюся задачу. Если это является нежелательным поведением и вы предпочитаете придержать данный процесс в ожидании освобождения памяти, имеется возможность запрета подавителя OOM:
root@server:~# cat /cgroup/memory/app1/memory.oom_control
oom_kill_disable 0
under_oom 0
root@server:~# echo 1 > /cgroup/memory/app1/memory.oom_control
root@server:~#
Данная cgroup memory предоставляет широкий разброс учётных записей
статистик в имеющемся файле memory.stat, которые могут представлять
интерес:
root@server:~# head /cgroup/memory/app1/memory.stat
cache 43325 # Number of bytes of page cache memory - Число байт страницы кэш памяти
rss 55d43 # Number of bytes of anonymous and swap cache memory - Число байт анонимной кэш памяти и кэш памяти подкачки
rss_huge 0 # Number of anonymous transparent hugepages - Число анонимных прозрачных гигантских страниц
mapped_file 2 # Number of bytes of mapped file - Число байт файла соответствия
writeback 0 # Number of bytes of cache queued for syncing - Число байт кэшированной очереди для синхронизации
pgpgin 0 # Number of charging events to the memory cgroup - Число событий загрузки в данную cgroup memory
pgpgout 0 # Number of uncharging events to the memory cgroup - Число событий выгрузки в данную cgroup memory
pgfault 0 # Total number of page faults - Общее число отсутствия страниц
pgmajfault 0 # Number of major page faults - Число главных отсутствий страниц
inactive_anon 0 # Anonymous and swap cache memory on inactive LRU list - Анонимная или подкачиваемая кэш память в списке неактивных только что использованных
Если вам необходимо запустить некую новую задачу в имеющейся иерархии памяти app1,
вы можете переместить запущенный текущий процесс оболочки в имеющийся файл tasks и
все прочие процессы, запускаемые из этой оболочки будут прямыми потомками и унаследуют имеющиеся свойства
той же самой cgroup:
root@server:~# echo $$ > /cgroup/memory/app1/tasks
root@server:~# echo "The memory limit is now applied to all processes started from this shell"
Подсистемы cpu и cpuset
Подсистема cpu планирует время ЦПУ для иерархий cgroup и их
задач. Он предоставляет более тонкое управление временем исполнения ЦПУ чем определённое по умолчанию
поведение CFS.
Такая подсистема cpuset делает возможным назначение ядер ЦПУ
некоторому набору задач аналогично команде taskset в Linux.
Самое главное преимущество в том, что подсистемы cpu и
cpuset предоставляют лучшее использование для каждого ядра в высоко
ограниченных по ЦПУ приложениях. Они также позволяют распределённые нагрузки между ядрами, которые в противном
случае простаивают в определённое время суток. В контексте для сред со множеством арендаторов, исполняющих
большое число контейнеров LXC, cgroups cpu и
cpuset дают возможность создания различных размеров и свойств
экземпляров, например, выставляя только одно ядро каждому контейнеру с запланированным временем работы
40 процентов.
В качестве примера давайте предположим, что у нас имеются два процесса app1
и app2 и мы бы хотели, чтобы app1
использовал 60 процентов всего времени ЦПУ, а app2 только 40
процентов. Мы начинаем с монтирования имеющейся VFS cgroup:
root@server:~# mkdir -p /cgroup/cpu
root@server:~# mount -t cgroup -o cpu cpu /cgroup/cpu
root@server:~# cat /proc/mounts | grep cpu
cpu /cgroup/cpu cgroup rw, relatime, cpu,
release_agent=/run/cgmanager/agents/cgm-release-agent.cpu 0 0
Затем мы создаём две дочерние иерархии:
root@server:~# mkdir /cgroup/cpu/limit_60_percent
root@server:~# mkdir /cgroup/cpu/limit_40_percent
Также назначаем каждой совместный ресурс ЦПУ, в котором app1
получит 60 процентов, а app2 получит 40 процентов общего
запланированного времени:
root@server:~# echo 600 > /cgroup/cpu/limit_60_percent/cpu.shares
root@server:~# echo 400 > /cgroup/cpu/limit_40_percent/cpu.shares
Наконец, мы перемещаем их PID в соответствующие файлы tasks:
root@server:~# pidof app1 | while read PID; do echo $PID >> /cgroup/cpu/limit_60_percent/tasks; done
root@server:~# pidof app2 | while read PID; do echo $PID >> /cgroup/cpu/limit_40_percent/tasks; done
root@server:~#
Подсистема cpu содержит следующий файлы управления:
root@server:~# ls -la /cgroup/cpu/limit_60_percent/
drwxr-xr-x 2 root root 0 Aug 25 15:13 .
drwxr-xr-x 4 root root 0 Aug 19 21:02 ..
-rw-r--r-- 1 root root 0 Aug 25 15:13 cgroup.clone_children
--w--w--w- 1 root root 0 Aug 25 15:13 cgroup.event_control
-rw-r--r-- 1 root root 0 Aug 25 15:13 cgroup.procs
-rw-r--r-- 1 root root 0 Aug 25 15:13 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 Aug 25 15:13 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 Aug 25 15:14 cpu.shares
-r--r--r-- 1 root root 0 Aug 25 15:13 cpu.stat
-rw-r--r-- 1 root root 0 Aug 25 15:13 notify_on_release
-rw-r--r-- 1 root root 0 Aug 25 15:13 tasks
root@server:~#
Вот краткое пояснение каждого:
| Файл | Описание |
|---|---|
|
Перераспределение ресурса ЦПУ в милисекундах |
|
Длительность исполнения задач в микросекундах в течении одного периода
|
|
Относительный совместный ресурс времени ЦПУ доступного для всех задач |
|
Показывает статистики времени ЦПУ |
|
Подключает задачи к данной cgroups |
Имеющийся файл cpu.stat представляет определённый интерес:
root@server:~# cat /cgroup/cpu/limit_60_percent/cpu.stat
nr_periods 0 # number of elapsed period intervals, as specified in -- число пройденных интервалов, определённое в
# cpu.cfs_period_us
nr_throttled 0 # number of times a task was not scheduled to run -- число раз которое задача не была спланирована к исполнению
# because of quota limit -- из за ограничения по квоте
throttled_time 0 # total time in nanoseconds for which tasks have been -- общее время в наносекундах в течение которого задачи
# throttled -- подвергались дросселированию
root@server:~#
Чтобы продемонстрировать как работает подсистема cpuset,
давайте создадим иерархии cpuset с названием
app1, содержащую ЦПУ 0 и 1. Вторая cgroup
app2 будет содержать только ЦПУ 1:
root@server:~# mkdir /cgroup/cpuset
root@server:~# mount -t cgroup -o cpuset cpuset /cgroup/cpuset
root@server:~# mkdir /cgroup/cpuset/app{1..2}
root@server:~# echo 0-1 > /cgroup/cpuset/app1/cpuset.cpus
root@server:~# echo 1 > /cgroup/cpuset/app2/cpuset.cpus
root@server:~# pidof app1 | while read PID; do echo $PID >> /cgroup/cpuset/app1/tasks limit_60_percent/tasks; done
root@server:~# pidof app2 | while read PID; do echo $PID >> /cgroup/cpuset/app2/tasks limit_40_percent/tasks; done
root@server:~#
Чтобы проверить что наш процесс app1 прикреплён к ЦПУ 0 и 1
мы можем воспользоваться:
root@server:~# taskset -c -p $(pidof app1)
pid 8052's current affinity list: 0,1
root@server:~# taskset -c -p $(pidof app2)
pid 8052's current affinity list: 1
root@server:~#
Иерархия cpuset app1
содержит следующие файлы:
root@server:~# ls -la /cgroup/cpuset/app1/
drwxr-xr-x 2 root root 0 Aug 25 16:47 .
drwxr-xr-x 5 root root 0 Aug 19 21:02 ..
-rw-r--r-- 1 root root 0 Aug 25 16:47 cgroup.clone_children
--w--w--w- 1 root root 0 Aug 25 16:47 cgroup.event_control
-rw-r--r-- 1 root root 0 Aug 25 16:47 cgroup.procs
-rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.cpu_exclusive
-rw-r--r-- 1 root root 0 Aug 25 17:57 cpuset.cpus
-rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.mem_exclusive
-rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.mem_hardwall
-rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.memory_migrate
-r--r--r-- 1 root root 0 Aug 25 16:47 cpuset.memory_pressure
-rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.memory_spread_page
-rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.memory_spread_slab
-rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.mems
-rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.sched_load_balance
-rw-r--r-- 1 root root 0 Aug 25 16:47 cpuset.sched_relax_domain_level
-rw-r--r-- 1 root root 0 Aug 25 16:47 notify_on_release
-rw-r--r-- 1 root root 0 Aug 25 17:13 tasks
root@server:~#
Краткое описание всех управляющих файлов таково:
| Файл | Описание |
|---|---|
|
Проверяет должны ли прочие иерархии |
|
Список общих физических номеров имеющихся ЦПУ по которым процессы в этом
|
|
Должен ли |
|
Проверяет должны ли все выделения задачам пользователей оставатся раздельными |
|
Проверяет должна ли некая страница памяти мигрировать на новый узел в случае изменения
значения |
|
Содержит среднее значение воздействия памяти, создаваемое данным процессом |
|
Проверяется если буферы файловой системы должны равномерно распределяться по всем узлам памяти |
|
Проверяет должны ли кэши slab равномерно распределяться по имеющимся
|
|
Определяет те узлы памяти, которые разрешены для доступа задачи в данной cgroups |
|
Проверяет должны ли имеющиеся балансировщики ядра выполнять загрузку по всем ЦПУ в данном
|
|
Содержит общую ширину имеющегося диапазона ЦПУ по которому данное ядро должно пытаться выполнять балансировку нагрузок |
|
Проверяет должна ли иерархия получать особую обработку после того как она освобождается и никакие процессы её не используют |
|
Подключает задачи к данной cgroups |
Подсистема cgroup freezer
Подсистема freezer может применяться для приостановки имеющегося
текущего состояния исполняющихся задач для целей их анализа или для создания некоторой контрольной точки,
которая может применяться для миграции данного процесса на какой-то другой сервер. Другой вариант применения
состоит в том, что когда некий процесс отрицательно воздействует на всю систему и имеется потребность в его
временной паузе, причём без утраты данных о его текущем состоянии.
Следующий пример отображает как приостановить имеющееся исполнение имеющегося в top процесса, проверить его состояние и затем восстановить его.
Вначале смонтируем подсистему freezer и создадим необходимую
новую иерархию:
root@server:~# mkdir /cgroup/freezer
root@server:~# mount -t cgroup -o freezer freezer /cgroup/freezer
root@server:~# mkdir /cgroup/freezer/frozen_group
root@server:~# cat /proc/mounts | grep freezer
freezer /cgroup/freezer cgroup
rw,relatime,freezer,release_agent=/run/cgmanager/agents/cgm-releaseagent.freezer 0 0
root@server:~#
В некотором новом терминале запустим процесс top и понаблюдаем за
его периодическими обновлениями. Вернёмся обратно в первоначальный терминал, добавим полученный из
top необходимый PID в созданный файл заданий
frozen_group и рассмотрим его состояние:
root@server:~# echo 25731 > /cgroup/freezer/frozen_group/tasks
root@server:~# cat /cgroup/freezer/frozen_group/freezer.state
THAWED
root@server:~#
Чтобы заморозить данный процесс, повторить следующее:
root@server:~# echo FROZEN > /cgroup/freezer/frozen_group/freezer.state
root@server:~# cat /cgroup/freezer/frozen_group/freezer.state
FROZEN
root@server:~# cat /proc/25s731/status | grep -i state
State: D (disk sleep)
root@server:~#
Отметим, что имеющийся вывод процесса top больше ничего не обновляет, а выполним инспекцию его файла состояния вы можете увидеть, что он теперь находится в заблокированном состоянии.
Для его восстановления выполните следующее:
root@server:~# echo THAWED > /cgroup/freezer/frozen_group/freezer.state
root@server:~# cat /proc/29328/status | grep -i state
State: S (sleeping)
root@server:~#
Проверка иерархии frozen_group даёт следующие файлы:
root@server:~# ls -la /cgroup/freezer/frozen_group/
drwxr-xr-x 2 root root 0 Aug 25 20:50 .
drwxr-xr-x 4 root root 0 Aug 19 21:02 ..
-rw-r--r-- 1 root root 0 Aug 25 20:50 cgroup.clone_children
--w--w--w- 1 root root 0 Aug 25 20:50 cgroup.event_control
-rw-r--r-- 1 root root 0 Aug 25 20:50 cgroup.procs
-r--r--r-- 1 root root 0 Aug 25 20:50 freezer.parent_freezing
-r--r--r-- 1 root root 0 Aug 25 20:50 freezer.self_freezing
-rw-r--r-- 1 root root 0 Aug 25 21:00 freezer.state
-rw-r--r-- 1 root root 0 Aug 25 20:50 notify_on_release
-rw-r--r-- 1 root root 0 Aug 25 20:59 tasks
root@server:~#
Несколько представляющих интерес файлов описываются в приводимой ниже таблице:
| Файл | Описание |
|---|---|
|
Отображает имеющееся состояние родителя. Показывает |
|
Отображает собственное состояние. Показывает |
|
Устанавливает текущее состояние данной cgroup либо в |
|
Подключает задачи к данной cgroups |
Использование инструментов userspace для управления cgroups и сохраняемыми изменениями
Работа с подсистемами имеющихся cgroups путём прямых манипуляций каталогов и файлов является неким простым и удобным способом для прототипирования и тестовых изменений, однако это имеет и некоторые обратные стороны, а именно, все сделанные изменения не сохраняются после перезапуска некоторого сервера, а также имеется не так много сообщений об ошибках и их обработки.
Для решения этого имеются пакеты, которые предоставляют инструменты пользовательского пространства и демоны, которые достаточно просто применять. Давайте посмотрим несколько примеров.
Чтобы установить эти инструменты в Debian/ Ubuntu выполните следующее:
root@server:~# apt-get install -y cgroup-bin cgroup-lite libcgroup1
root@server:~# service cgroup-lite start
В RHEL/CentOS исполнение таково:
root@server:~# yum install libcgroup
root@server:~# service cgconfig start
Для монтажа всех подсистем выполните приводимое ниже:
root@server:~# cgroups-mount
root@server:~# cat /proc/mounts | grep cgroup
cgroup /sys/fs/cgroup/memory cgroup
rw,relatime,memory,release_agent=/run/cgmanager/agents/cgm-releaseagent.memory 0 0
cgroup /sys/fs/cgroup/devices cgroup
rw,relatime,devices,release_agent=/run/cgmanager/agents/cgm-releaseagent.devices 0 0
cgroup /sys/fs/cgroup/freezer cgroup
rw,relatime,freezer,release_agent=/run/cgmanager/agents/cgm-releaseagent.freezer 0 0
cgroup /sys/fs/cgroup/blkio cgroup
rw,relatime,blkio,release_agent=/run/cgmanager/agents/cgm-releaseagent.blkio 0 0
cgroup /sys/fs/cgroup/perf_event cgroup
rw,relatime,perf_event,release_agent=/run/cgmanager/agents/cgm-releaseagent.perf_event 0 0
cgroup /sys/fs/cgroup/hugetlb cgroup
rw,relatime,hugetlb,release_agent=/run/cgmanager/agents/cgm-releaseagent.hugetlb 0 0
cgroup /sys/fs/cgroup/cpuset cgroup
rw,relatime,cpuset,release_agent=/run/cgmanager/agents/cgm-releaseagent.cpuset,clone_children 0 0
cgroup /sys/fs/cgroup/cpu cgroup
rw,relatime,cpu,release_agent=/run/cgmanager/agents/cgm-release-agent.cpu 0 0
cgroup /sys/fs/cgroup/cpuacct cgroup
rw,relatime,cpuacct,release_agent=/run/cgmanager/agents/cgm-releaseagent.cpuacct 0 0
В предыдущем выводе отметим местоположение имеющихся cgroups -
/sys/fs/cgroup. Именно оно является устанавливаемым по умолчанию во
многих дистрибутивах Linux и в большинстве случаев имеются уже смонтированными различные подсистемы.
Чтобы проверить что подсистемы cgroups используются, мы можем выполнить это следующими командами:
root@server:~# cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 7 1 1
cpu 8 2 1
cpuacct 9 1 1
memory 10 2 1
devices 11 1 1
freezer 12 1 1
blkio 6 3 1
perf_event 13 1 1
hugetlb 14 1 1
Далее создадим некую иерархию blkio и добавим в неё некий уже
исполняющийся процесс при помощи cgclassify. Это аналогично тому,
что мы делали ранее путём создания каталога и необходимых файлов вручную:
root@server:~# cgcreate -g blkio:high_io
root@server:~# cgcreate -g blkio:low_io
root@server:~# cgclassify -g blkio:low_io $(pidof app1)
root@server:~# cat /sys/fs/cgroup/blkio/low_io/tasks
8052
root@server:~# cgset -r blkio.weight=1000 high_io
root@server:~# cgset -r blkio.weight=100 low_io
root@server:~# cat /sys/fs/cgroup/blkio/high_io/blkio.weight
1000
root@server:~#
Теперь, когда мы определили необходимые cgroups high_io и
low_io и добавили в них некий процесс, давайте создадим некий файл
настройки, который может применяться позже для повторного применения и установки:
root@server:~# cgsnapshot -s -f /tmp/cgconfig_io.conf
cpuset = /sys/fs/cgroup/cpuset;
cpu = /sys/fs/cgroup/cpu;
cpuacct = /sys/fs/cgroup/cpuacct;
memory = /sys/fs/cgroup/memory;
devices = /sys/fs/cgroup/devices;
freezer = /sys/fs/cgroup/freezer;
blkio = /sys/fs/cgroup/blkio;
perf_event = /sys/fs/cgroup/perf_event;
hugetlb = /sys/fs/cgroup/hugetlb;
root@server:~# cat /tmp/cgconfig_io.conf
# Configuration file generated by cgsnapshot
mount {
blkio = /sys/fs/cgroup/blkio;
}
group low_io {
blkio {
blkio.leaf_weight="500";
blkio.leaf_weight_device="";
blkio.weight="100";
blkio.weight_device="";
blkio.throttle.write_iops_device="";
blkio.throttle.read_iops_device="";
blkio.throttle.write_bps_device="";
blkio.throttle.read_bps_device=";
blkio.reset_stats="";
}
}
group high_io {
blkio {
blkio.leaf_weight="500";
blkio.leaf_weight_device="";
blkio.weight="1000";
blkio.weight_device="";
blkio.throttle.write_iops_device="";
blkio.throttle.read_iops_device="";
blkio.throttle.write_bps_device="";
blkio.throttle.read_bps_device="";
blkio.reset_stats="";
}
}
root@server:~#
Чтобы запустить некий новый процесс в high_io мы можем
применить имеющуюся команду cgexec:
root@server:~# cgexec -g blkio:high_io bash
root@server:~# echo $$
19654
root@server:~# cat /sys/fs/cgroup/blkio/high_io/tasks
19654
root@server:~#
В предыдущем примере мы запустили новый процесс bash в
cgroup high_io, что
подтверждается просмотром имеющегося файла tasks.
Чтобы переместить уже исполняющийся процесс в имеющуюся подсистему memory
вначале мы создадим необходимые группы high_prio и
low_prio и переместим требуемые задачи при помощи
cgclassify:
root@server:~# cgcreate -g cpu,memory:high_prio
root@server:~# cgcreate -g cpu,memory:low_prio
root@server:~# cgclassify -g cpu,memory:high_prio 8052
root@server:~# cat /sys/fs/cgroup/memory/high_prio/tasks
8052
root@server:~# cat /sys/fs/cgroup/cpu/high_prio/tasks
8052
root@server:~#
Чтобы установить пределы для памяти и ЦПУ мы можем воспользоваться командой
cgset. В противовес, вспомните что мы применяли команду
echo для ручного перемещения необходимых PID и пределов
памяти в файлы назначения tasks и
memory.limit_in_bytes:
root@server:~# cgset -r memory.limit_in_bytes=1G low_prio
root@server:~# cat /sys/fs/cgroup/memory/low_prio/memory.limit_in_bytes
1073741824
root@server:~# cgset -r cpu.shares=1000 high_prio
root@server:~# cat /sys/fs/cgroup/cpu/high_prio/cpu.shares
1000
root@server:~#
Чтобы посмотреть как выглядит иерархия, мы можем воспользоваться утилитой
lscgroup:
root@server:~# lscgroup
cpuset:/
cpu:/
cpu:/low_prio
cpu:/high_prio
cpuacct:/
memory:/
memory:/low_prio
memory:/high_prio
devices:/
freezer:/
blkio:/
blkio:/low_io
blkio:/high_io
perf_event:/
hugetlb:/
root@server:~#
Предыдущий вывод подтверждает наличие иерархий blkio,
memory и cpu, а также их
потомков.
После завершения вы можете удалить имеющиеся иерархии при помощи
cgdelete, который удаляет все соответствующие каталоги в VFS:
root@server:~# cgdelete -g cpu,memory:high_prio
root@server:~# cgdelete -g cpu,memory:low_prio
root@server:~# lscgroup
cpuset:/
cpu:/
cpuacct:/
memory:/
devices:/
freezer:/
blkio:/
blkio:/low_io
blkio:/high_io
perf_event:/
hugetlb:/
root@server:~#
Для полной очистки cgroups мы можем применить утилиту cgclear,
которая размонтирует все каталоги cgroups:
root@server:~# cgclear
root@server:~# lscgroup
cgroups can't be listed: Cgroup is not mounted
root@server:~#
Управление ресурсами при помощи systemd
При увеличении применения systemd в качестве системы init
были предложены новые способы манипулирования cgroups. Например, если в имеющемся ядре включён контроллер
cpu, systemd по умолчанию будет создавать некую cgroup для каждой
службы. такое поведение может быть изменено добавлением или удалением подсистем cgroups в имеющемся файле
настроек systemd, обычно находящемся в
/etc/systemd/system.conf.
Если в данном сервере исполняется монжество служб, по умолчанию все ресурсы ЦПУ будут разделяться между
ними в равной степени, так как systemd назначит каждому равные веса.
Чтобы изменить такое поведение для некоторого приложения мы можем изменить обслуживающий его файл и определить
необходимые совместные ресурсы ЦПУ, выделяемой памяти, а также вводе/ вывода.
Приводимый ниже пример демонстрирует как изменить имеющиеся пределы совместных ресурсов ЦПУ, памяти и ввода/ вывода для определённого процесса nginx:
root@server:~# vim /etc/systemd/system/nginx.service
.include /usr/lib/systemd/system/httpd.service
[Service]
CPUShares=2000
MemoryLimit=1G
BlockIOWeight=100
Чтобы применить все изменения, вначале перезагрузим systemd,
а затем nginx:
root@server:~# systemctl daemon-reload
root@server:~# systemctl restart httpd.service
root@server:~#
Это создаст и изменит все необходимые файлы управления в
/etc/systemd/system.conf и применит необходимые пределы.
Появление пространств имён ядра и cgrups делает возможной изоляцию групп процессов в некий самоограниченный пакет виртуализации с малым весом; мы называем их контейнерами. В данной главе мы рассмотрели как контейнеры предоставляют те же свойства, что и прочие полностью упакованные технологии виртуализации на основе гипервизора, подобные KVM и Xen без необходимого перегруза исполнением множества ядер одной и той же операционной системы. LXC получает все преимущества от \ cgroups и пространств имён Linux для достижения данного уровня изолированности и управления ресурсами.
Пр и помощи полученной в данной главе основы вы будете способны лучше понять что происходит под капотом и это сделает более простыми поиск неисправностей и поддержку полного жизненного цикла контейнеров Linux, которые мы будем изучать в последующих главах.