Дополнение B. Дерево индексации в твердотельных устройствах
Yinan Li*, Bingsheng He, Robin Jun Yang, Qiong Luo, Ke Yi
Hong Kong University of Science and Technology
{fyinanli, saven, yjrobin, luo, yikeg}@cse.ust.hk
Содержание
- Дополнение B. Дерево индексации в твердотельных устройствах
- Краткий обзор
- Введение
- Подготовка и относящиеся к ней работы
- FD- дерево
- Анализ стоимости и модель стоимости
- Результаты экспериментов
- Выводы
- Ссылки
- Приложение A. Начальные сведения по флэш SSD
- Приложение B. Псевдокод алгоритма
- Приложение С. Анализ стоимости и модель стоимости
- Приложение D. Подробности экспериментальной настройки
В этом разделе мы представим архитектуру FD- дерева. Наша цель состоит в минимизации общего числа небольших произвольных записей и ограничить эти произвольные записи в пределах небольшой области и в то же время предоставлять высоко эффективный поиск. Для простоты мы предполагаем уникальность всех ключей индексации в неком FD- дереве. Применяемая на протяжении этой статьи нотация сведена в Таблице B-1
| Параметры | Описание |
|---|---|
B |
размер страницы (байты) |
Li |
iй уровень FD- дерева |
|Li| |
ёмкость Li (общее число вхождений) |
l |
число уровней FD- дерева |
k |
логарифмическое соотношение размеров между соседними уровнями |
n |
число записей в данном соотношении индексации |
f |
число вхождений в странице |
В своём проекте для некой индексации во флэш SSD мы рассмотрим три таких принципа.
-
П1. Преобразование произвольных записей в последовательные. Нам следует воспользоваться преимуществами последовательных записей и избегать произвольных за счёт проектирования передовых структур данных.
-
П2. Ограничение произвольных записей внутри ограниченной области. Предыдущие исследования [4, 6] сообщали что произвольные записи на флэш SSD в небольшой области (512кБ - 8МБ) обладают производительностью, сопоставимой с последовательными записями.
-
П3. Поддержка оптимизации ввода/ вывода множества страниц. Доступ ко множеству страниц в некой операции ввода/ вывода более действенна чем доступ к каждой странице по отдельности.
Некое FD- дерево составляется из множества уровней, обозначаемых как L0 ~ Li-1. Самый верхний уровень, L0, является небольшим B+- деревом, именуемым головным деревом. Размер соответствующего узла этого головного дерева равняется размеру страницы B его флеш SSD. Всякий последующий уровень, Li (1 ≤ i < l) являются отсортированными прогонами (run) в непрерывных страницах. Рисунок B-2 a) иллюстрирует структуру некого FD- дерева. Это FD- дерево имеет три уровня, само головное дерево и два сортированных прогона. Его головное дерево является двухуровневым B+- деревом. С помощью технологии фрагментарного каскадирования (fractional cascading), определённые листовые узлы данного головного дерева содержат указатели на сортированный прогон L1. Все нелистовые уровни в FD- дереве содержат указатели на сортированные прогоны на уровень непосредственно ниже своего.
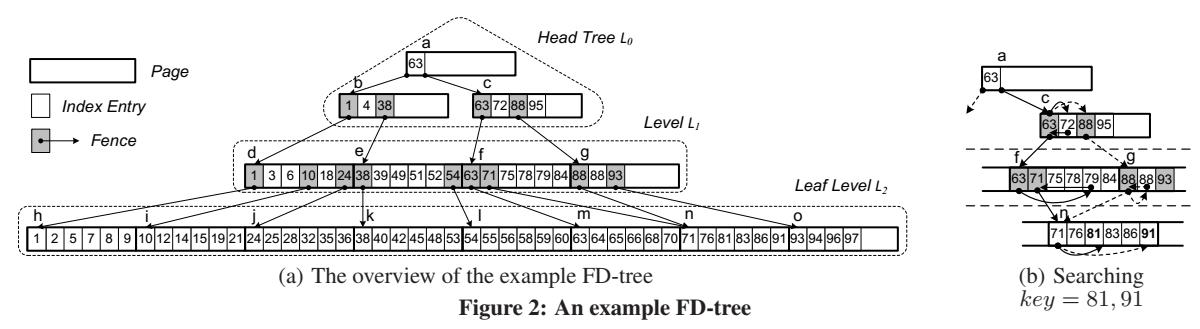
Каждый уровень FD- дерева обладает некой ёмкостью (capasity) в терминах вхождений, обозначаемой как |Li|. Следуя логарифмическому методу, мы устанавливаем уровни с некой пошаговой ёмкостью, т.е. |Li+1| = k ∙ |Li| (0 ≤ i ≤ l-2), где k это значение логарифмического соотношения размеров между соседними уровнями. Таким образом, |Li| = ki ∙ |L0|. Все обновления первоначально выполняются в установленном головном дереве, а затем постепенно мигрируют в сортированные прогоны на нижние уровни пакетно по мере расходования установленной ёмкости уровня. Следуя принципу проектирования П2, величина максимального размера установленного головного дерева устанавливается равным размеру значения области локальности, в рамках которой произвольные записи имеют производительность, аналогичную последовательным. Значение размера области локальности в устройствах наших дней обычно в пределах от 128кБ до 8МБ [4, 6].
Мы разбиваем вхождения в FD- дерево на категории двух видов, индексные вхождения и преграды (fetches - мосты - согласно охватывающей книге). На каждом уровне FD- дерева имеющиеся индексные вхождения и преграды организованы в восходящем порядке своих ключей.
-
Индексные вхождения (Index Entry). Некое индексное входение содержит три поля: ключ индекса, key, а также некий идентификатор записи, rid, для индексации записи данных и type, указывающий на роль вхождения в установленном логарифмическом удалении FD- дерева. В зависимости от type, мы и далее разбиваем на категории индексные вхождения на два вида, фильтрующие вхождения и нормальные вхождения.
-
Фильтрующее вхождение (type = Filter). Некое фильтрующее вхождение это отметка удаления. Это фильтрующее вхождение вставляется в FD- дерево при неком удалении для указания того что относящаяся к нему запись была номинально удалена. Она обладает теми же самыми ключом и идентификатором записи, что и удалённое индексное вхождение. Мы именуем такой удалённый индекс как фантомное вхождение (phantom entry), поскольку оно логически было удалено, но физически пока не удалено из данного индекса.
-
Нормальное вхождение (type = Normal). Все индексные вхождения, отличающиеся от фильтрующих вхождений, носят название нормальных вхождений.
-
-
Преграда (fence, мост). Преграда это некое вхождение с тремя полями: каким- то значением ключа, key, неким type и pid, значении идентификатора определённой страницы в идущем непосредственно ниже уровне, в который поиск проследует далее. По- существу, некая преграда {мост} это указатель, ключ которого выбран из индексного вхождения в FD- дереве.
Инвариант 1.Самая первая запись каждой страницы это преграда {мост}.Инвариант 2.Значение диапазона ключей между некой преградой {мостом} и следующей за ним преградой {мостом} на том же самом уровне содержится в том диапазоне ключей соответствующей страницы, на которую указывает эта преграда {мост}.В зависимости от того, будет ли значение определённого ключа рассматриваемой преграды на уровне Li выбираться с уровня Li или с уровня Li+1, мы разбиваем преграды на уровне Li на два вида, внутренние преграды и внешние преграды.
-
Внешняя преграда (type = External). Значение ключа некой внешней преграды {моста} на уровне Li выбирается с уровня Li+1. Для страницы P на уровне Li+1 мы выбираем значение ключа самой первой записи из P в качестве значения ключа этой преграды и устанавливаем значение поля pid для данной преграды в качестве идентификатора P для удовлетворения
Инварианта 2. -
Внутренняя преграда (type = Internal). Значение ключа некой внутренней преграды {моста} на уровне Li выбирается с самого уровня Li. Если значение самого первого вхождения произвольной страницы P не является внешней преградой, мы добавляем некую внутреннюю преграду в самый первый разъём данной страницы для удовлетворения
Инварианта 1. Значением ключа такой внутренней преграды устанавливается значением ключа самого первого индексного вхождения e со страницы P. Значение поля pid такой внутренней преграды устанавливается равным идентификатору соответствующей страницы на следующем уровне, для которой диапазон ключей охавтывает e. Например, на Рисунке B-2 a) запись88со страницыgэто некая внутренняя преграда, которая указывает на страницуn, причём она та же самая, что и внешняя преграда71со страницыf.
-
В соответствии с установленным определением для внешней преграды, общее число внешних преград на уровне Li равняется общему числу страниц на уровне Li+1, т.е. |Li+1|/f, где f равно общему числу вхождений в некой странице. Общее число внутренних преград на уровне Li, по крайней мере, составляет |Li|/f, так как каждая страница содержит по крайней мере одну внутреннюю преграду. Максимальное значение преград на уровне Li, (|Li| + |Li+1|)/f должно быть меньше общего числа вхождений в Li, достигая k < f - 1.
FD- дерево поддерживает пять общих операций запросов: поиск, вставку, слияние, удаление и обновление. За псевдокодом алгоритмов обратитесь к Приложению B.
Поиск. Некий поиск индекса в FD- дереве требует поиска на каждом уровне сверху донизу. Запрос может быть точечным поиском с неким предикатом эквивалентности, или поиском диапазона с предикатом диапазона.
Для выполнения точечного поиска по некому искомому ключу K мы вначале выполняем
просмотр в своём головном дереве, точно так же как и в стандартном B+- дереве. Далее мы выполняем поиск на каждом уровне
вслед за значением pid соответствующей преграды {моста}. Внутри некой страницы
P на уровне Li осуществляется
двоичный поиск для поиска наилучшего ключа равного или меньшего чем K. Допустим,
соответствующее вхождение ei содержит такой ключ. Затем мы сканируем
сортированный прогон справа налево пока не обнаружим некую преграду ej.
Поскольку все вхождения с ключами между ei.key и
ej.key в нашем следующем уровне Li+1
появляются на соответствующей странице ej.pid
(Инвариант 2), мы далее следуем по указателю ej.pid
на эту страницу для поиска вхождений на своём следующем уровне. Тем самым мы обходим всё дерево сверху вниз, следуя по
pid принятых преград.
Так как некое фильтрующее вхождение вставляется в наше FD- дерево после какого- то удаления и превращает своё старое вхождение в некое фантомное вхождение, некий поиск может получить набор результата, содержащий как фильтрующее вхождение, так и соответствующее ему фантомное вхождение. Когда это имеет место, нам необходимо удалить из полученного в результате поиска набора фильтрующие вхождения и фантомные вхождения с тем же самым ключом и парой значения указателя.
В соответствии с Инвариантом 1 некий поиск по крайней мере может найти
соответствующую преграду в самом первом разъёме любой страницы при сканировании такой страницы в обратном порядке.
Тем самым, когда нет дубликатов, поиск сталкивается только с одной преградой на странице каждого уровня. Именно по этой
причине мы ввели внутренние преграды. Когда данные скошены, соответствующие индексные вхождения между двумя последовательными
внешними вхождениями, Fj и Fj+1
могут распространяться на множество страниц. Некому стартующему между Fj и
Fj+1 сканированию необходимо пройти по множеству страниц для получения своей
предыдущей преграды Fj. При наличии соответствующих внутренних преград такое
сканирование останавливается соответствующим внутренними преградами в самом первом разъёме каждой из страниц.
Рисунок B-2 b) иллюстрирует такой путь поиска ключа
81 (сплошная линия) и ключа 91
(пунктирная линия) в нашем примере FD- дерева с Рисунка B-2 a).
На каждом уровне он находит соответствующую страницу из следующего уровня сортированных прогонов. При поиске
91 на уровне L1, установленная
на странице g преграда 88 препятствует
данному сканированию в выборке страницы f при поиске соответствующей внешней
преграды 71.
Поиск диапазона аналогичен точечному поиску за исключением того, что он способен выбирать на каждом уровне множество страниц. Получая значение преграды, удовлетворяющее значению предиката на своём текущем уровне Li, нам становится известно об общем числе страниц, которое будет просканировано на соответствующем следующем уровне, Li+1, прежде чем мы столкнёмся с преградой на этих страницах. Более того, эти страницы хранятся непрерывным образом. Данное свойство предоставляет нам возможность выборки точного числа соответствующих страниц со своего следующего уровня в некой операции ввода/ вывода применяя оптимизацию ввода/ вывода множества страниц (П3).
Вставка. некое новое вхождение изначально вставляется первым в своё головное дерево L0. Когда общее число вхождений в этом головном дереве L0 превосходит его ёмкость |L0|, для L0 и L1 выполняется операция слияния с целью осуществления миграции всех вхождений L0 на L1. В результате, число произвольных записей ограничено в рамках установленного головного дерева, следуя принципу П2.
Слияние. Процесс слияния выполняется между двумя прилегающими уровнями когда меньший из них достигает предела своей ёмкости. Данная операция слияния последовательно два соответствующих входных потока и сочетает их в один сортированный прогон в непрерывных страницах. Вновь создаваемый уровень Li состоит из всех индексных вхождений из Li-1, а также всех индексных вхождений и внешних преград из Li. Мы оставляем в Li все внешние преграды, так как соответствующий уровень (Li+1), на который указывают эти внешние вхождения не изменился. По мере необходимости конструируются соответствующие внутренние преграды Li. В то же самое время перестраиваются соответствующие новые уровни Lj (0 ≤ j < i) для соответствующих конструируемых с вновь создаваемого уровня Li внешних преград. То есть, получая два прилегающих уровня, Li-1 и Li, наш процесс слияния вырабатывает i + 1 новых сортированных прогонов для обновления всех уровней с L0 до Li. Если такой получаемый новый уровень Li исчерпывает свою ёмкость, сливаются Li и Li+1. Этот процесс продолжается пока самый большой из двух вновь вырабатываемых уровней не перестанет исчерпывать свою ёмкость.
Данная операция слияния вовлекает в свой процесс только последовательные чтения и записи, тем самым мы успешно преобразуем свои произвольные записи вставки в последовательные считывания и записи, следуя своему принципу проектирования П1. Мы и далее оптимизируем производительнсоть своих операций ввода/ вывода применяя оптимизацию ввода/ вывода множества страниц следуя принципу П3. Так как страницы на каждом уровне FD- дерева хранятся непрерывным образом на соответствующем флэш- дискемы выполняем выборку множества страниц единым запросом ввода/ вывода. Аналогично, так как заново сгенерированные сортированные прогоны записываются последовательно, мы также записываем множество страниц единым запросом. Подходящее число страниц в неком запросе ввода/ вывода устанавливается равным размеру единицы доступа при котором скорость обмена шаблона последовательного доступа достигает максимального значения.
Удаление. Некое удаление в FD- дереве обрабатывается каким- то аналогичным вставке методом: оно сначала выполняется в установленном головном дереве, а затем мигрирует на свои нижние уровни по мере возникновения слияний. Такая схема логарифмического удаления снижает амортизационные расходы. Отметим, что известный метод ленивого удаления, широко используемый в жёстких дисках, на которых основывается индексация, который помечает некое вхождение как неверное, не эффективен для флеш SSD, так как операция пометки это небольшая произвольная запись.
Самый первый шаг состоит в выполнении удаления в имеющемся головном дереве L0, так как произвольные записи в нашем головном дереве ограничены пространством и очень эффективны. Затем, мы выполняем удаление на всех прочих уровнях вставляя особое вхождение с названием фильтрующего вхождения. Такое подлежащее удалению вхождение далее становится фантомным вхождением и оставляется нетронутым. В частности, мы вначале выполняем в своём FD- дереве поиск примеяя соответствующий предикат для этого удаления. Такой поиск выявляет все подлежащие удалению индексные вхождения. Новые вхождения (фильтрующие вхождения) с тем же самым ключом и значением указателя что и эти вхождения вставляются в наше FD- дерево. Собственно реальное удаление осуществляется при операции слияния когда фильтрующие вхождения встречают свои соответствующие фантомные вхождения.
В процессе такого слияния в пакете выполняется физическое удаление. Когда некое фильтрующее вхождение достигает своего соответствующего фантомного вхождения, оба вхождения отвергаются и не будут более появляться в получаемом результате слияния. Таким образом и выполняется физическое удаление. Обратите внимание, что благодаря обработке фильтрующих вхождений и их фантомных вхождений, вновь вырабатываемый сортированный прогон может быть меньше старого.
Объём накладных расходов пространства фильтрующих и фантомных вхождений низок. Поскольку самый нижний уровень Li-1 не содержит никаких фильтрующих или фантомных вхождений, эти вхождения в худшем случае занимают все уровни кроме самого нижнего, чей общий размер всего лишь около 1 / k всего индексного пространства. Так как k обычно велико, фильтрующие и фантомные вхождения оказывают низкое воздействие на производительность.
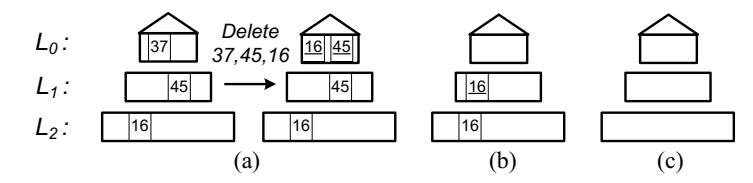
Рисунок B-3 иллюстрирует некий пример такого процесса удаления.
Мы помечаем свои фильтрующие вхождения сплошным подчёркиванием. На Рисунке B-3 a) мы удаляем свои индексные вхождения 37 для
L0, 45 для
L1 и 16 для
L2. Поскольку вхождение 37
находится в нашем головном дереве L0, оно удаляется непосредственно из
L0. Соответствующие фильтрующие вхождения
45 и 16 вставляются в наше головное дерево.
По мере выполнения прочих вставок и удалений, наше головное дерево постепенно становится большим. Когда оно заполняется и
выполняется слияние L0 и L1,
как это показано на Рисунке B-3 b), фильтрующее вхождение
45 сталкивается со своим фантомным вхождением и оба вхождения отвергаются. При
вставке большего числа вхождений в значения индексов и когда происходит слияние между
L1 и L2, как это показано на
Рисунке B-3 c), отвергаются фильтрующее вхождение
16 и соответствующее ему фантомное вхождение.
Обновление. Операция обновления реализуется как некое удаление для старого значения со следующей за ним вставкой.
Хотя логарифмический метод и снижает амортизированную стоимость вставок в FD- дерево, в наихудшем случае стоимость всё ещё остаётся высокой. В наихудшем случае у всех отсортированных прогонов заканчивается их ёмкость после одиночной операции вставки и всё FD- дерево должно быть целеком переписано. Этот процесс может иметь результатом некое недопустимое время отклика. В результате, мы предлагаем некую простую и действенную схему решения данной проблемы. В качестве некого образца мы выбираем процесс возврата отчуждения для вставок, так как удаления и обновления обрабатываются аналогично.
Рисунок B-4 демонстрирует основную идею возврата отчуждений вставок в FD- дереве, которая состоит в перекрытии процесса выполнения операций вставок и слияния. В частности, получая под слияние Nmerge вхождений, мы делим эти Nmerge вхождений на |L0| разделов и со временем комбинируем вхождения в неком разделе после выполнения некой вставки. В результате общая затратная стоимость соответствующей операции слияния возмещается |L0| операциями вставок. Тем самым наихудшее время на вставки уменьшается примерно на множитель |L0|, причём средняя стоимость остаётся неизменной.
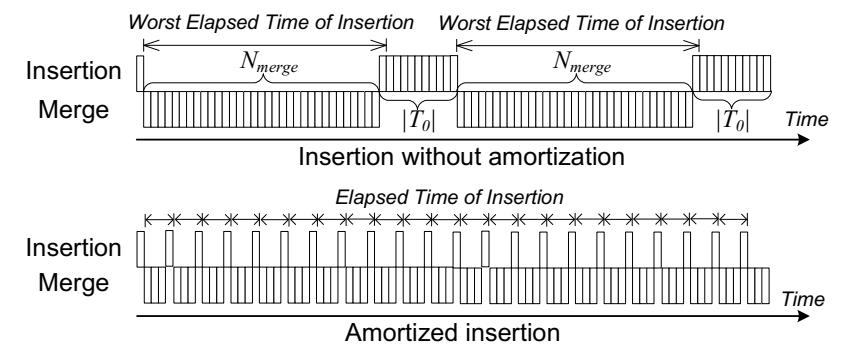
Чтобы перекрывать время исполнения вставок и слияния мы поддерживаем два головных дерева. Как только некое головное дерево L0 наполняется, новые вхождения вставляются в другой экземпляр, то есть во временное головное дерево L'0, в то время как само слияние выполняется для L0. Этот процесс слияния аналогичен тому, что мы описали в разделе 3.3, за исключением того что внешние преграды {мосты} из соответствующих нижних уровней вставляются в L'0 одна за другой вместо выполнения пакетом. После того как данное слияние завершено, L'0 уже был заполнен и все врешние преграды уже были вставлены в L'0. При возврате отчуждений после завершения слияния мы меняем местми L0 и L'0 для последующих вставок и слияний.
С помощью возврата отчуждений запросы поиска индекса могут продолжаться даже в процессе слияния. Так как первоначальное FD- дерево (L0 ~ Ll-1) содержит все первоначальные вхождения вставленными до самой операции слияния, а временное головное дерево L'0 хранит все вновь созданные вхождения, мы можем осуществлять просмотр как в своём первоначальном FD- дереве (L0 ~ Ll-1), так и в нашем временном головном дереве L'0. Значение размера временного головного дерева (T'0) настолько мало, что скорее всего умещается в памяти и значение накладных расходов производительности поиска с возвратом отчуждений незначительно.

[1] D. Agrawal, D. Ganesan, R. Sitaraman, Y. Diao, and S. Singh. Lazy-adaptive tree: An optimized index structure for flash devices. PVLDB, 2(1):361–372, 2009 .
[2] L. Arge. The buffer tree: A new technique for optimal i/o-algorithms. In WADS, 1995. .
[3] J. L. Bentley. Decomposable searching problems. Inf. Process. Lett., 8(5), 1979.2009 .
[4] L. Bouganim, B. T. Jonsson, and P. Bonnet. uflip: Understanding flash io patterns. In CIDR, 2009. .
[5] B. Chazelle and L. J. Guibas. Fractional cascading: I. a data structuring technique. Algorithmica, 1(2), 1986. .
[6] F. Chen, D. Koufaty, and X. Zhang. Understanding intrinsic characteristics and system implications of flash memory based solid state drives. In SIGMETRICS, 2009 .
[7] S. Chen. Flashlogging: Exploiting flash devices for synchronous logging performance. In SIGMOD Conference, 2009 .
[8] D. Comer. The ubiquitous b-tree. ACM Comput. Surv., 11(2), 1979. .
[9] E. Gal and S. Toledo. Algorithms and data structures for flash memories. ACM Comput. Surv., 37(2), 2005 .
[11] G. Graefe. The five-minute rule 20 years later: and how flash memory changes the rules. ACM Queue, 6(4):40–52, 2008 .
[12] J. Gray and B. Fitzgerald. Flash disk opportunity for server applications. ACM Queue, 6(4):18–23, 2008 .
[13] J. M. Hellerstein, M. Stonebraker, and J. R. Hamilton. Architecture of a database system. Foundations and Trends in Databases, 1(2), 2007 .
[14] H. V. Jagadish, P. P. S. Narayan, S. Seshadri, S. Sudarshan, and R. Kanneganti. Incremental organization for data recording and warehousing. In VLDB, 1997 .
[15] C. Jermaine, A. Datta, and E. Omiecinski. A novel index supporting high volume data warehouse insertion. In VLDB, 1999 .
[16] K. Kimura and T. Kobayashi. Trends in high-density flash memory technologies. In IEEE Conference on Electron Devices and Solid-State Circuits, 2003 .
[17] S.-W. Lee and B. Moon. Design of flash-based dbms: an in-page logging approach. In SIGMOD Conference, 2007 .
[18] S.-W. Lee, B. Moon, C. Park, J.-M. Kim, and S.-W. Kim. A case for flash memory ssd in enterprise database applications. In SIGMOD Conference, 2008 .
[19] Y. Li, B. He, Q. Luo, and K. Yi. Tree indexing on flash disks. In ICDE, 2009 .
[20] C. Manning. Yaffs: the nand-specific flash file system. 2002 .
[21] P. Muth, P. E. O’Neil, A. Pick, and G. Weikum. Design, implementation, and performance of the lham log-structured history data access method. In VLDB, 1998 .
[22] D. Myers. On the use of nand flash memory in high-performance relational databases. MIT Msc Thesis, 2008 .
[23] S. Nath and A. Kansal. Flashdb: dynamic self-tuning database for nand flash. In IPSN, 2007 .
[24] P. E. O’Neil, E. Cheng, D. Gawlick, and E. J. O’Neil. The log-structured merge-tree (lsm-tree). Acta Inf., 33(4), 1996 .
[25] M. Rosenblum and J. K. Ousterhout. The design and implementation of a log-structured file system. ACM Trans. Comput. Syst., 10(1), 1992 .
[26] D. Tsirogiannis, S. Harizopoulos, M. A. Shah, J. L. Wiener, and G. Graefe. Query processing techniques for solid state drives. In SIGMOD Conference, 2009 .
[27] D. Woodhouse. Jffs: The journalling flash file system. In Ottawa Linux Symposium, 2001 .
[28] C.-H. Wu, T.-W. Kuo, and L. P. Chang. An efficient b-tree layer implementation for flash-memory storage systems. In RTCSA, 2003 .