Глава 10. ZFS: Зеттабайт файловая система
Содержание
Рисунок 10.4 отображает структуру блочного указателя. В отличие от традиционного блочного указателя USF из 8 байт, который ссылается на номер блока в пределах дискового раздела блочный указатель является 128- байтовой структурой, которая содержит указатели на в точности три копии блока, причем все на разных дисках, сопровождаемые размером блока и его контрольной суммой. Сохранение контрольной суммы в отдельности от данных позволяет обнаруживать такие ошибки как неправильно адресованные чтения и записи. Если бы контрольная сумма хранилась в самом блоке данных, чтение или запись по ошибочному адресу казались бы правильными, поскольку одновременно бы по неверному адресу записывались бы и сами данные, и их контрольная сумма.
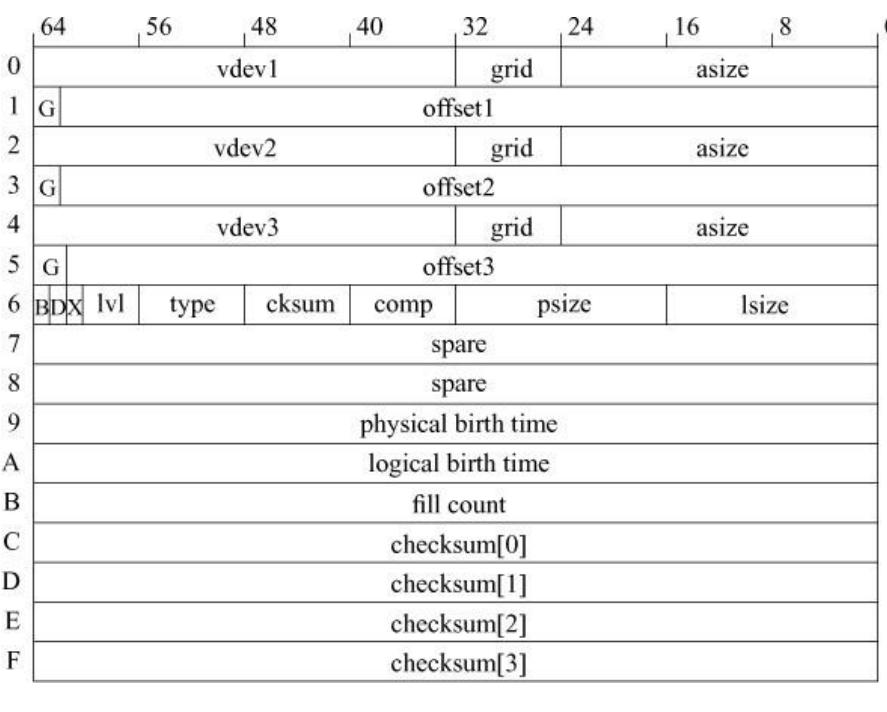
Рисунок 10.4 Описание указателя на блок. Ключи: vdev — идентификатор виртуального устройства; grid — информация расположения RAIDZ (зарезервировано для последующего использования); asize — выделенный размер (включая контрольную сумму RAIDZ и заголовки блока набора {gang-block}); G — флаг блока набора {gang-block}; offset — смещение в виртуальном устройстве; B — флаг порядка байт (endianness); D — флаг дедупликации; X — неиспользуемый флаг; lvl — число уровней косвенной адресации для данных описываемых данным блочным указателем; type — тип объекта DMU; cksum — идентификатор функции контрольной суммы; comp — идентификатор функции сжатия; psize — физический размер (после сжатия); lsize — логический размер; physical birth time — группа транзакции в которой физически размещен данный блок, ноль если идентичен logical birth time; logical birth time — группа транзакции в которой данный был размещен данный логический блок; fill count — число ненулевых блоков, соответствующих данному блочному указателю; checksum[ ] — 256-битная контрольная сумма данных, описываемых данным блочным указателем.
По умолчанию ZFS вычисляет контрольные суммы всех блоков, которыми она управляет. Поскольку многоядерный процессоры стали повседневностью, стоимость вычислений центральным процессором контрольных сумм незначительна при сопоставлении со стоимостью производительности операций ввода/ вывода.
Для систем с множеством дисков первой линией обороны против порчи данных или их утраты является RAID. Если блок данных или даже целый диск будут утрачены, структура RAID диска может восстановить данные. Для систем, в которых только один диск, таких как портативные компьютеры и таких как вторичная резервная копия для систем с множеством дисков, работающих в RAID, ZFS по умолчанию предоставляет двойную избыточность для всех метаданных. Таким образом все блочные указатели, которые ссылаются на метаданные, будут иметь задействованными два из трех полей в блочном указателе. Файловые системы могут быть настроены на репликацию всех данных. При этом все блочные указатели, которые ссылаются на данные пользователей будут иметь используемыми два из трех полей блочных указателей. При работе в таком режиме ZFS использует тройное резервирование для всех метаданных. Таким образом, блочные указатели метаданных будут иметь задействованными все три поля блочного указателя.
Каждый блок имеет сопутствующее ему время порождения. Время порождения измеряется в количестве контрольных точек, которые были приняты с момента создания пула ZFS. Когда пул создается в первый раз, группа транзакций (TXG) устанавливается в ноль. Каждый раз, когда создается контрольная точка, увеличивается на единицу значение группы транзакций. Проблема с использованием секунд с начала эпохи для времени порождения в том, что секунды с начала эпохи могут не быть монотонно возрастающими, если батарея поддержки аппаратных часов отказывает или если демон времени устанавливает неправильную информацию о времени. Самосогласованность обеспечивается применением группы транзакций вместо секунд с начала эпохи. Это также гарантирует, что если две контрольные точки выполняются в период менее 1 секунды между ними, время порождении блоков для двух контрольных точек можно различать. Как будет описано в следующем разделе, время порождения служит для определения того, что блок не имеет ссылок на себя и он может быть освобожден.
Флаг дедупликации идентифицирует блок, который находится в таблице дедупликации. Флаг используется при попытке освободить блок. Если флаг дедупликации установлен, ZFS должна найти соответствующую запись в таблице дедупликации и уменьшить его счетчик ссылок, так как блок может быть освобожден только тогда, когда счетчик ссылок достигает нулевого значения. В таблица дедупликации огромна, следовательно, как правило, она не умещается в памяти. Ее части считываются в память по мере необходимости. Таким образом, проверка на нахождения блока в таблице дедупликации дорога, особенно если требуемый блок таблицы дедупликации не находится в памяти. Если флаг дедупликации не установлен, ZFS может избегать затрат на поиск блока в таблице дедупликации.
Большинство блоков имеют только логическое время порождения, которое равен TXG, в которой они были созданы. Физическое время порождения требуется только блокам дедупликации. При первой записи блока он получает только логическое время порождения. Если то же содержимое записывается вновь, модуль дедупликации создает новый блочный указатель на оригинал. Новый блочный указатель имеет логическое время порождения текущей TXG, однако физическое время порождения соответствует TXG логическому времени порождения первоначального блока. Причина, по которой необходимо физическое время порождения заключается в том что, когда файловая система обходится после сбоя диска для реконструкции RAIDZ, ядро знает действительное число созданий блока и, следовательно, знает, какие из них должны быть восстановлены.
Обычно, когда модулю SPA нужно выделить блок заданного размера, он в состоянии сделать это. Однако, когда пул неиспользуемых блоков становится небольшим, может не оказаться единого блока с достаточно большим пространством для выполнения запроса. В этом случае SPA должен выделить два или более блоков меньшего размера для создания блока большего размера. Эти мелкие части описываются массивом указателей в структуре, которая называется заголовком блока набора {gang-block}. В случае когда ссылка на указатель блока является одним из таких заголовков блока набора, устанавливается флаг блока набора для того, чтобы заголовок мог быть интерпретирован в системе ввода/ вывода для сбора вместе составляющих блок частей.
Каждый блочный указатель имеет три связанных с ним размера:
-
lsize- логический размер блока. -
psize- физический размер блока, который может быть меньше логического размера блока, если он был сжат. -
asize- выделенный (allocated) размер на диске, содержащий контрольную сумму RAIDZ и заголовки блока набора.
Для блоков, которые имеют ссылки блоков косвенной адресации также поддерживается уровень ссылок. Поскольку любой
dnode использует фиксированное число уровней
косвенной адресации, как описывалось ранее в данном подразделе, поддержка счетчика уровня в блочном указателе применяется
исключительно для проверки согласованности и не требуется для обычных операций. Аналогично, поле типа известно, следовательно
оно используется только для проверки непротиворечивости.
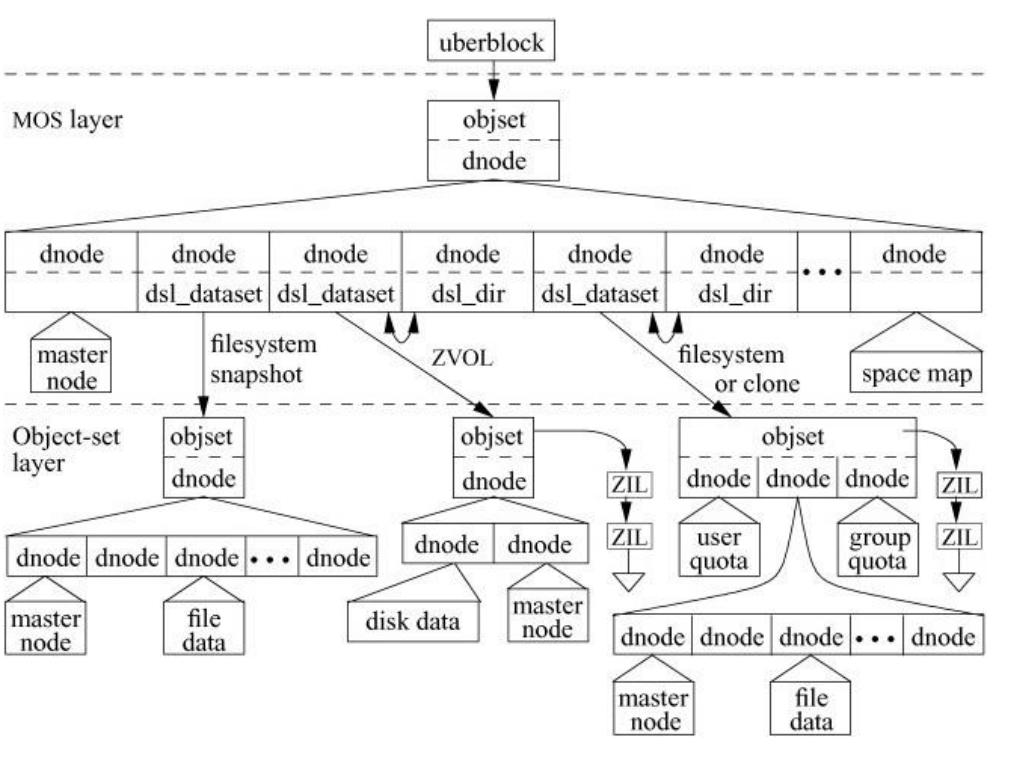
В отличие от перезаписываемых файловых систем, подобных UFS, которые непрерывно обновляют свои состояния на диске,
ZFS собирает все обновления файловой системы в памяти. Периодически она записывает все изменения в неиспользуемую область диска для создания
контрольной точки. Никакие из изменений в состоянии на диске не видны, пока не выполнена окончательная запись контрольной точки, которая
обновляет корень пула ZFS, uberblock. Таким образом файловая система ZFS всегда согласована;
то есть, она переходит из одного согласованного состояния в новое согласованное состояние.
Каждая контрольная точка берется по всему пулу и влияет на каждую файловую систему, снимок, клон, и ZVOL в данном пуле, в одно и то же время.
ZFS называет эти контрольные точки группами транзакций (transaction groups), или сокращенно
TXG. Все снимки, выполняемые в различных файловых системах, при этом
находящиеся в пределах одной и той же контрольной точки, будут согласованы в один и тот же момент времени. Таким образом, два различных снимка
в пределах одного пула с одной и той же TXG точно будут синхронизированы друг с другом во времени. С другой стороны будет трудно получить
согласованные снимки в двух различных пулах, поскольку создание контрольной точки требует точной координации.
Многие операции в ZFS, такие как способ, которым записываются файлы, являются атомарными для различных процессов выполняющих системные
вызовы write в один и тот же файл, и обрабатываются аналогично традиционным файловым системам с
перезаписью, подобным UFS. Данный раздел не будет описывать функциональные возможности, аналогичные UFS, описанные в
Главе 9. Этот раздел детализирует операции, выполняемые с помощью файловой системы ZFS,
которые значительно отличаются по функциональности от того, как они выполняются в UFS.
Все обновления файловых систем, клонов, и ZVOL в пуле накапливаются в памяти до тех пор, пока не пройдет заданное время (по умолчанию 5 секунд), пока не накопятся 64 Мбайт измененных данных, или не выполнятся административные действия, которые потребуют контрольную точку, например запрос снимка. Чтобы сбросить новые данные на диск, ZFS должен принять контрольную точку в пул.
Принятие контрольной точки требует, чтобы все изменения в файловой системе, выполненные начиная с предыдущей контрольной точки, были сохранены на диске. Первый шаг заключается в получении согласованного состояние для файловой системы, которое требует чтобы все системные вызовы изменения данных файловой системы должны быть завершены. ZFS применяет методику, аналогичную описанной в разделе 9.7, как это происходит на 3 шаге выполнения снимка в UFS. В частности, процессам, которые уже выполняются в подобных системных вызовах, разрешено завершить эти системные вызовы. Контрольная точка продолжается, пока все незавершенные системные вызовы не завершатся.
Запись всех составляющих контрольную точку дисковых блоков может занять несколько секунд. Запрещение изменений во время всего такого
периода приведет к неприемлемым задержкам работающих в системе приложений. Чтобы избежать такой задержки, все записываемые измененные блоки,
образующие контрольную точку помечаются маркером их группы транзакций (TXG).
Новые изменения файловых систем, клонов, и ZVOL помечаются новой группой транзакций. Если изменение определяет, что подлежащий изменению блок
отмечен как часть обрабатываемой контрольной точки, ZFS делает копию этого блока в памяти и модификация производится в копии. Скопированные блоки
становятся частью следующей контрольной точки. По мере того, как ввод/ вывод на блоках, которые являются частью текущей контрольной точки,
завершается, ZFS должен решить, как обрабатывать буферы в памяти. Если они не были скопированы, они могут быть отмечены как доступные
для текущего использования. Если они были скопированы, то их содержание в настоящее время устарело, поэтому содержащая устаревшую копию
память освобождается.
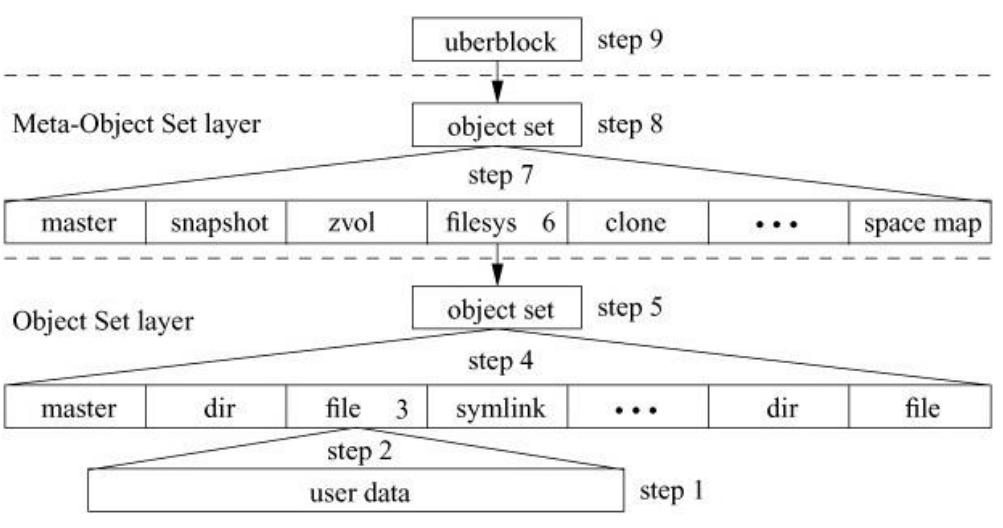
Рисунок 10.7 отображает девять шагов, которые должны быть выполнены для сброса изменений в файл, в который были добавлены данные с момента последней контрольной точки:
-
Все блоки новых данных должны быть записаны. Если запись осуществляется поверх существующих данных, измененные блоки данных должны быть записаны в новое место, поскольку ZFS никогда не перезаписывает существующие данные.
-
Обычно обновление требует обновления указателя на блок в одном из косвенных блоков файла. Поскольку косвенный блок был изменен, будет необходимо записать его в новое местоположение, что означает, что косвенный блок, на который ссылается на него необходимо будет изменить Эти модификации продолжаются вверх по дереву косвенной адресации вплоть до
dnodeдля данного файла. -
Обновите
dnodeдля файла, чтобы он ссылался на местоположение нового блока для вершины косвенных указателей. Поскольку ZFS не может перезаписывать существующийdnodeпри его изменении, он должна записать копию блока, содержащегоdnodeс обновленным размером и новым указателем на блок.В UFS, чтение в
inodeтребует выделения пространства памяти, который составляет размерdnodeвключая пространство, необходимое для храненияdinodeна диске, чтения в блок диска, который содержитinode, копированиеdinodeиз дискового блока во вновь выделенную область памяти с последующим освобождением буфера диска. Записьinodeобратно на диск требует чтения в блок диска, который содержитinode, копирование измененногоinodeв соответствующую часть буфера с последующей записью обновленного буфера обратно на диск.В ZFS, чтение в
dnodeначинается с выделения пространства в памяти, которая составляет размерdnodeв памяти.dnodeв памяти не содержитdnodeдиска; он содержит только указатель на часть на диске. ZFS считывает и блокирует в памяти блок диска, который содержитdnodeдиска. Затем устанавливает указатель наdnode, чтобы указывать на его на дисковую часть в буфере диска. Записьdnodeобратно на диск требует только того, чтобы содержащий модифицированнуюdnodeбуфер диска был записан на новое место.Преимуществом подхода ZFS является меньшее копирование из памяти в память и меньшее число операций ввода/ вывода за счет использования дополнительной памяти. Для системы с 100 000 кэшированными узлами, UFS будет использовать 50 Мегабайт памяти, в то время как ZFS как правило, использует 200 Мегабайт и может применять до 1,6 Гигабайт памяти.
Первоначальная файловая система со структурированным журналом (LFS, log-structured filesystem) собирала все свои измененные
inodeвместе в наборы по 64, которые затем могли быть упакованы в 16-килобайтные блоки. Недостатком такого подхода является то, что он требует дополнительного файла метаданных, который отображает номерinodeв местоположение на диске. ZFS просто записывает все находящиеся в памяти блоки диска, которые содержат модифицированныеdnode. При обновлении указателей на блоки в их измененных objsetdnode, не существует никаких требований для отдельного файла метаданных для отслеживания их местонахождения, поскольку они могут быть найдены с помощью простого поиска по их известному смещению в objsetdnode. Хотя этот подход требует большего ввода/ вывода по сравнению с методикой LFS, это упрощает и ускоряет последующие подстановкиdnode. -
После обновления всех dnode файловой системы ссылающиеся на них измененные указатели на блоки распространяются вверх по косвенным блокам objset файловой системы аналогично тому как это выполнялось для файла на шаге 2.
-
Для того чтобы ссылаться на новое местоположение вершины указателей косвенных objset dnode обновляется объект objset dnode.
-
Чтобы ссылаться на новую копию objset файловой системы, на которую он указывает, обновляется указатель на блок в MOS dsl_dataset.
-
После того, как указатели dsl_dataset были обновлены и указывают на свои новые объекты objset, ссылающиеся на них измененные указатели на блоки распространяются вверх по косвенным блокам objset MOS аналогично способу, применявшемуся на шагах 2 и 4 для данного файла и objset-ам файловой системы.
-
Чтобы ссылаться на новое местоположение блока для вершины его косвенных указателей обновляется объект
dnodeobjset MOS. -
Когда все эти изменения записаны в их местоположения на диске, последний шаг в создании контрольной точки заключается в обновлении указателя на блок в
uberblockс тем, чтобы он указывал на новый objset MOS и обновлении его группы транзакцийTXGдля отражения новой контрольной точки. Обновленныйuberblockзатем записывается в его новое местоположение, как это описано в разделе10.3.
ZFS хранит все сохраненные в журнале изменения уровня ZPL в памяти. Журнал обрабатывается записями целей ZFS
(ZIL, ZFS Intent Log). Примерами элементов протоколирования
являются:
-
Требования к аппаратным средствам
-
Требования к аппаратным средствам
-
Требования к аппаратным средствам