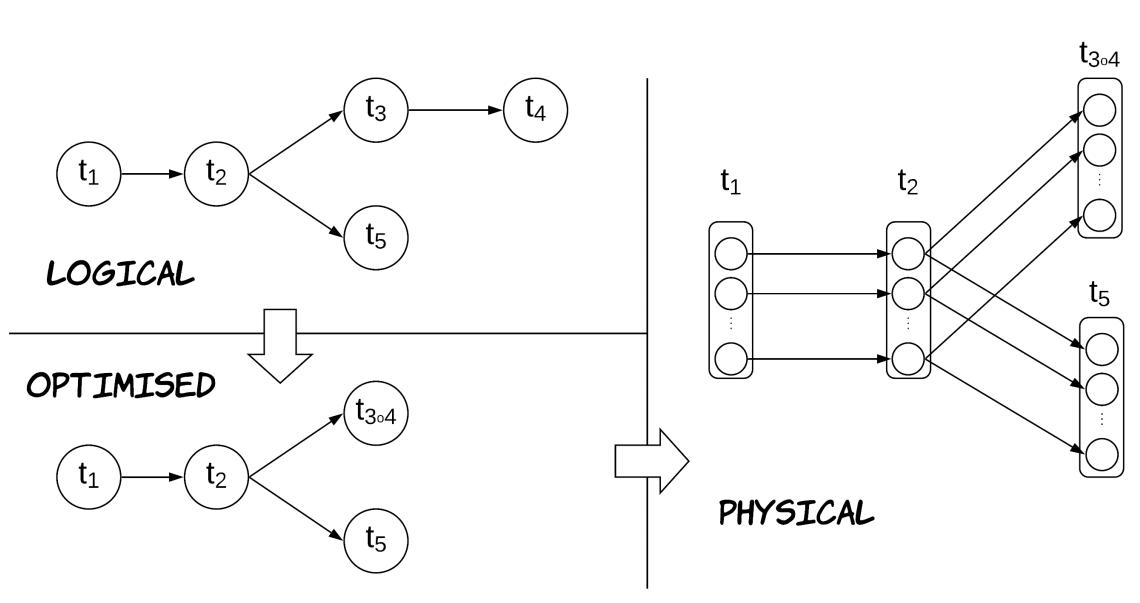
Глава 7. Примеры для изучения
Содержание
- Глава 7. Примеры для изучения
- Распределённые файловые системы (HDFS/ GFS)
- Распределённые системы координации (Zookeeper/ Chubby/ etcd)
- Распределённые хранилища данных
- Распределённые системы обмена сообщениями (Kafka)
- Распределённое управление кластерами (Kubernetes)
- Распределённый журнал регистрации (Corda)
- Распределённые системы обработки данных
Данная глава более подробно изучает некие особенные примеры распределённых систем. Часть этих систем коммерчески доступны и широко используются. Некоторые из них были разработаны и применялись внутри компаний, но их архитектура была общедоступно опубликована в научных статьях. Основная цель этой главы двоякая: прежде всего предоставить обзор основных категорий распределённых систем, а затем пояснять как эти системы описанные на данный момент принципы.
Тем не менее, имейте в виду, что некоторые из этих описываемых в данной главе систем могли эволюционировать с момента написания этих строк. В качестве справки ниже приводится таблицу, содержащую значения версий соотнесённых систем на момент написания, когда они доступны.
| Система | Версия |
|---|---|
HDFS |
3.1.2 |
Zookeeper |
3.5.5 |
Hbase |
2.0 |
Cassandra |
3.11.4 |
FaunaDB |
2.7 |
Kafka |
2.3.1 |
Kubernetes |
1.13.12 |
Corda |
4.1 |
Spark |
2.4.4 |
Flink |
1.8 |
Google File System (GFS)[52] является собственной разработанной Google распределённой файловой системой, которая стимулировала Hadoop Distributed File System (HDFS)[53], распределённую файловую систему, которая была разработана как проект Apache. Как это поясняется позднее, в этих двух системах все основные принципы архитектуры аналогичны, при том что имеются небольшие отличия.
Основными требованиями для \тих распределённых файловых систем были следующие:
-
отказоустойчивость: способность к работе даже в случае отказа некоторых машин системы.
-
масштабируемость: собственно возможность масштабировать данную систему до существенно больших размеров как в смысле числа файлов, так и в плане размеров файлов.
-
оптимизация для пакетных операций: данная система должна быть оптимизирована сценариев применения, вовлечённых в пакетные операции, например, приложений, которые осуществляют обработку и анализ гигантских наборов данных. Это подразумевает, что пропускная способность более важна нежели задержки и ожидается что большинство из имеющихся файлов изменяются добавлением данных в конец вместо перезаписи имеющихся сведений.
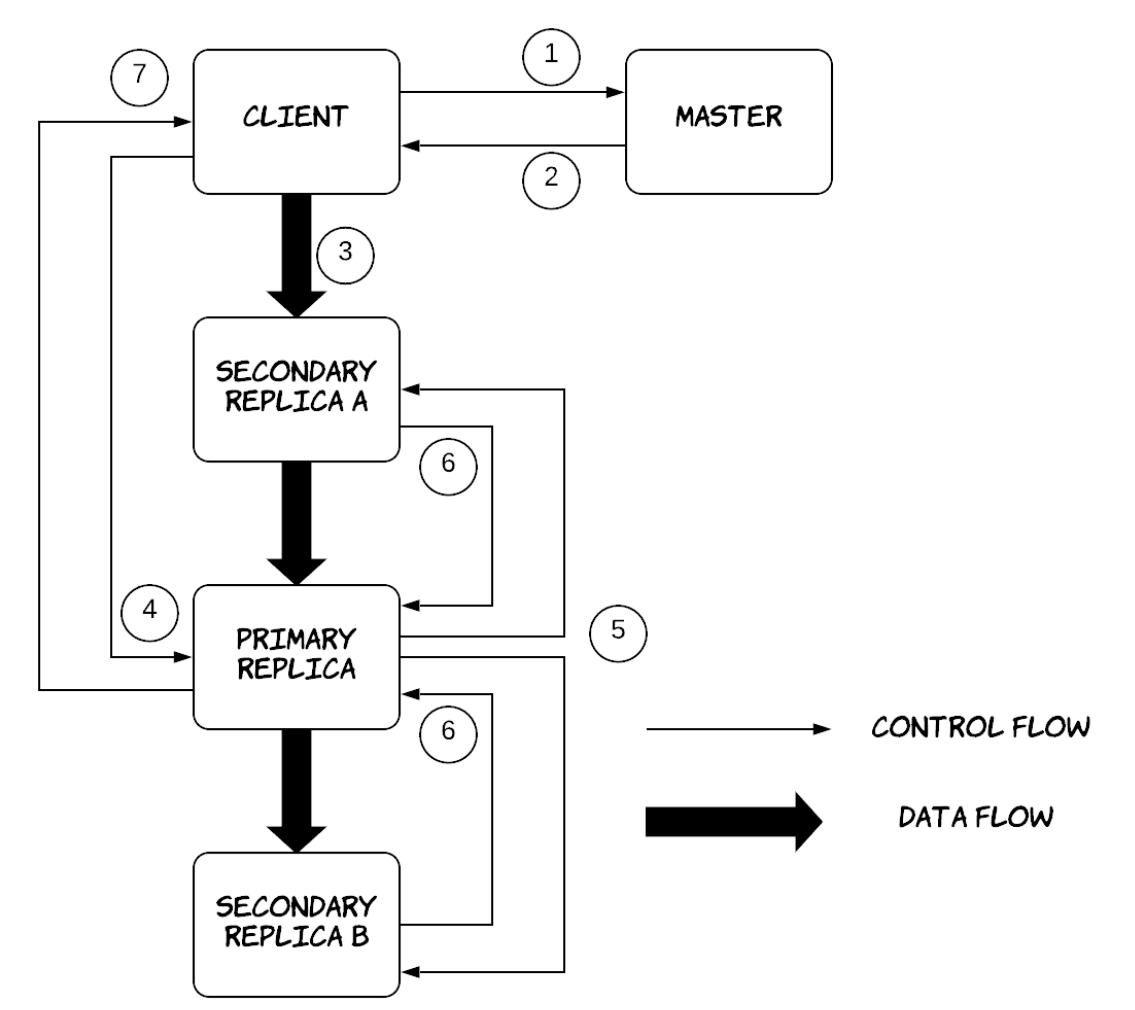
Рисунок 7.1 отображает обзор архитектуры GFS на верхнем уровне. Кластер GFS составлен из единственного узла хозяина и множества узлов серверов порций. Узлы серверов порций (chunkserver) отвечают за хранение и обслуживания данных самих файлов, в то время как имеющийся узел хозяина ответственен за сопровождение необходимых метаданных файловой системы, информируя клиентов относительно того какой сервер порций хранит конкретную часть некого файла и осуществляет необходимые административные задачи, такие как сборка мусора коллекции лишившихся предков порций или миграцию данных в процессе отказов. Обратите внимание, что архитектура HDFS аналогична, за исключением того, что узел хозяина носит название Узела имён (Namenode), а узлы порций именуются Узлами данных (Datanodes).
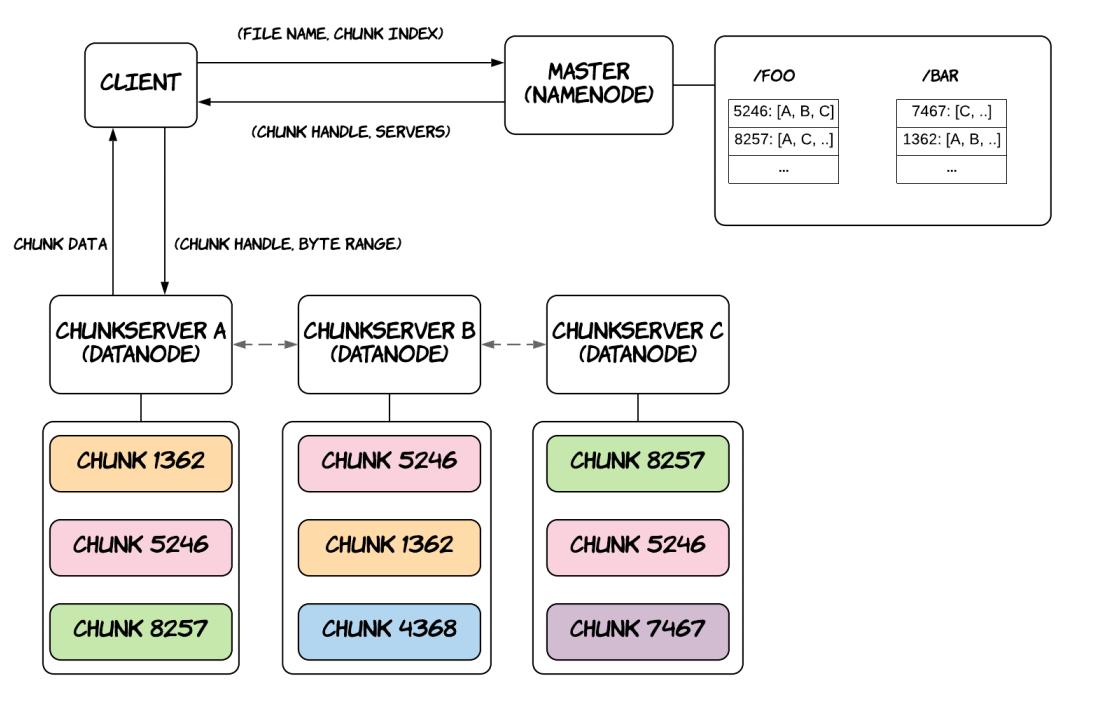
Каждый файл делится на порции (chunks) фиксированного размера, которые идентифицируются неизменными и глобально уникальными 64- битными дескрипторами порций (chunk handle), назначаемые их хозяином в процессе создания порции. Серверы порций хранят фрагменты на локальных дисках в виде обычных файлов. Эта система имеет в своём штате как разбиение на разделы (partitioning), так и репликации: она разбивает файлы на разделы по различным серверам порций и реплицирует каждую порцию по множеству серверов порций. Первое улучшает производительность, а второе улучшает доступность и надёжность данных. Эта система также учитывает установленную топологию центра обработки данных, который обычно составляется из множества стоек серверов. Это имеет различные последствия, например, входная или выходная пропускная способность на стойку может быть ниже общей пропускной способности всех машин в стойке, а отказ одного общего ресурса в стойке (скажем, сетевого коммутатора или канала питания) способен приводить к отключению всех машин в этой стойке.
При создании новой порции и помещении её изначально пустых реплик, хозяин пытается использовать серверы порций с заполненностью ниже средней. Он также пробует применять сервера порций, которые обладают меньшим числом последних созданий, так как таким образом можно предсказывать надвигающийся загруженный обмен записи. Тем самым, установленный хозяин пытается балансировать загруженностью дисковой и сетевой полос пропускания по всему кластеру. После принятия решения о том где размещать реплики, этот хозяин также следует настроенной политике размещения реплик. По умолчанию, он попытается хранить две реплики в двух различных узлах, которые располагаются в двух раздельных стойках. Это является неким компромиссом между высокой сетевой полосой пропускания и надёжностью данных.
Имеющиеся клиенты могут создавать, считывать, записывать и удалять файлы из установленной распределённой файловой системы применяя некую библиотеку GFS клиента, скомпонованной с его приложением, которая абстрагирует некоторые подробности реализации. К примеру, такие приложения способны работать на основании смещения в байтах для файлов, а соответствующая библиотека клиента имеет возможность транслировать эти байтовые смещения внадлежащие индексы порций, взаимодействуя со своим хозяином для выборки необходимого дескриптора порции чтобы предоставлять индекс порции и значение местоположения связанных с ними серверов порций и в конечном счёте взаимодействовать с надлежащим сервером порций (скорее всего ближайшим) для выборки требуемых данных. Рисунок 7.1 отображет этот рабочий поток для операции считывания. Клиенты кэшируют необходимые метаданные для локального местоположения фрагментов, поэтому им приходится взаимодействовать с хозяином относительно новых порций или когда истекает срок действия кэширования. В процессе обусловленной отказами миграции порций, клиенты органично запрашивают свежие сведения у своего хозяина, когда они осознают что установленные старые серверы порций не способны более обслуживать соответствующие сведения для своей определённой порции. С лругой стороны клиенты не кэшируют свои действительные данные порции, поскольку ожидается, что они будут передаваться из огромных файлов и обладать рабочими наборами, которые черезчур велики для извлечения выгоды от кэширования.
Установленный хозяин хранит необходимые пространства имён файлов и порций, установленной соответствие от файлов к порциям и значения местоположений фрагментов. Все метаданные хранятся в памяти соответствующего хозяина. Имеющиеся пространства имён и соответствия также удерживаются постоянными путём регистрации операций преобразования (например, создания файла, переименования и т.п.) в неком журнале операций, который хранится на локальном диске этого хозяина и реплицируется в удалённых машинах. Установленный узел хозяина также устанавливает контрольные точки состояния своей памяти на диске при значительном росте своего журнала. В результате, в случае отказа этого хозяина имеющийся образ его файловой системы может быть перестроен путём загрузки последней контрольной точки в память и воспроизводства соответствующих операций журнала с данной точки далее. Изменения файлового пространства имён является атомарным и линеаризуемым. Это достигается за счёт исполнения данных операций в отдельном узле, а именно в узле хозяина. Установленный журнал операций определяет некий глобальный общий порядок для этих операций, а сам узел хозяина также использует блокировки чтения- записи в установленном ассоциированном пространстве имён узлов для выполнения надлежащего упорядочения ао всех одновременных записях.
GFS поддерживает множество одновременных записей для некого отдельного файла. Рисунок 7.2 иллюстрирует как это происходит. Соответствующий клиент вначале взаимодействует со своим узлом хозяина для идентификации тех серверов порций, которые содержат необходимые относящиеся к делу порции. Затем такие клиенты приступают к активной доставке своих данных во все установленные реплики применяя некий вид цепочек репликации. Соответствующие серверы порций помещаются в цепочку в зависимости от установленной сетевой топологии, а данные активно доставляются линейным образом вдоль такой цепочки. Например, определённый клиент выполняет активную доставку необходимых данных в свой первый сервер порций в установленной цепочке, который передаёт эти данный во второй сервер порций и так далее. Это способствует полному применению сетевой полосы пропускания каждой машины, исключая узкие места в отдельном узле. Имеющийся хозяин предоставляет аренду каждой порции в одном из серверов порций, которая назначается первичной репликой, отвечающей за упорядочение всех изменений в данной порции. После активной доставки всех данных в серверы порций, соответствующий клиент отправляет запрос записи в надлежащую первичную реплику, который указывает доставленные ранее данные. Первичная реплика назначает упорядоченные последовательные номера всем необходимым изменениям, применяет их локально, а затем перенаправляет запрос записи во все вторичные реплики, которые применяют необходимые изменения с тем же самым последовательным номером, что и выставлен в их первичной реплике. После того как все вторичные реплики выдали подтверждение записи в свой первичную реплику, эта первичная реплика может выдать подтверждение записи своему клиенту.
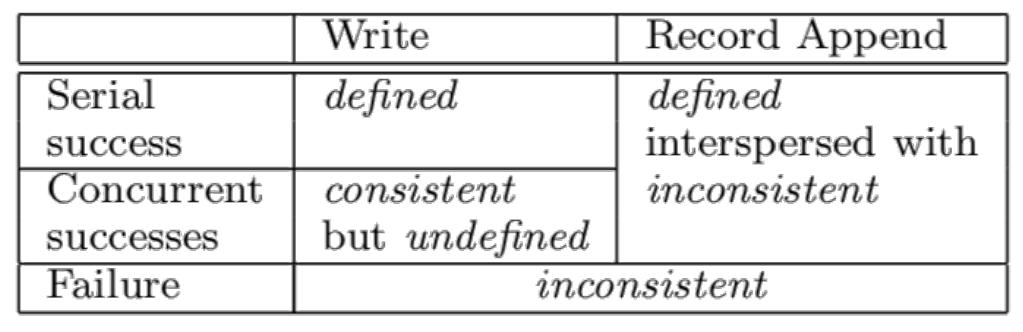
Естественно, данный поток уязвим к частичным отказам. Например, задумайтесь о ситуации, при которой запущенная первичная реплика испытывает крушение посреди осуществления некой записи. По истечению срока аренды вторичная реплика может запросить свою аренду и приступить к возложению нового последовательного номера, который может не совпадать с записями прочих реплик в прошлом. В результате некая запись может сохраниться лишь в некоторых репликах или может храниться в разных порядках в различных репликах. GFS предоставляет индивидуальную модель согласованности для операций записи. Значение состояния некой области файла после изменения зависит от самого типа изменения, было ли оно успешным или нет, а также от присутствия одновременных изменений. Область файла является согласованной когда все клиенты будут наблюдать одни и те же данные, причём независимо от тех реплик из которых они считывают. Область определяется после изменения данных файла если они согласованы и клиенты будут наблюдать что эти изменения записаны целиком. Если некое изменение завершается успешно без вмешательства со стороны одновременных записей, определяется подвергшаяся воздействию запись: все клиенты всегда увидят что было записано в изменении. Одновременные успешные изменения оставляют такую область в неопределённом, но не противоречивом состоянии: все имеющиеся клиенты наблюдают одни и те же данные, однако они могут не отражать то что записано каким- либо одним изменением. Как правило, оно состоит из смешанных фрагментов различных изменений. Неудачное изменение превращает такую оласть в противоречивый: разные клиенты порой могут наблюдать отличающиеся данные. Помимо обычных записей GFS также предоставляет некую дополнительную операцию изменения: записи добавления в конец (record appends). Запись добавления в конец приводит к тому, что данные добавляются атомарно по крайней мере один раз даже при наличии множественных изменений, однако по некому выбираемому GFS смещению, которое и возвращается соответствующему клиенту. Предполагается, что клиенты будут повторять отказавшие записи добавления в конец, а GFS гарантирует, что каждая реплика будет содержать необходимые данные своей операции как некий атомарный элемент по крайней мере один раз по тому же самому смещению. Тем не менее, GFS способна вставлять заполнение или дубликаты записей между ними. Как результат, успешное добавление запис в конец создаёт определённые области, перемежающиеся с противоречивыми областями. Рисунок 7.3 содержит сводные сведения относительно модели согласованности GFS.
Приложения имеют возможность приспособления этой модели упрощённой согласованности GFS, применяя несколько простых приёмов на прикладном уровне: использование дополнений в конец вместо перезаписей, контрольных точек и сохранения самостоятельно подтверждаемых, самостоятельно идентифицируемых записей. Добавление в конец намного более действенно и более устойчиво к отказам приложений по сравнению со случайными записями. Каждая подготовленная записывающей стороной запись может содержать дополнительные сведения, такие как контрольные суммы для проверки её достоверности. Затем записывающая сторона выявлять и отбрасывать дополнительные заполнения и фрагменты записи при помощи этих контрольных сумм. Когда не приемлемы случайные дубликаты, например если они способны включать не идемпотентные операции, такая считывающая сторона способна их отфильтровывать их, применяя уникальные идентификаторы записей, которые выбираются и сохраняются соответствующей записывающей стороной.
HDFS предприняла слегка иной способ для упрощения семантики операций изменений. В частности, HDFS поддерживает одновременно лишь одну запись. Она обеспечивает только для операций добавления в конец (а не перезаписи). Она также не предоставляет операцию записи в коней, поскольку отсутствуют одновременные записи и она несколько иначе обрабатывает частичные сбои в соответствующем конвейере репликации, целиком удаляя отказавшие узлы из соответствующего набора реплик для обеспечения одного и того же содержимого во всех имеющихся репликах.И GFS, и HDFS предоставляют приложениям сведения о том, где хранится некая область какого- то файла. Это позволяет соответствующим приложениям планировать выполнения заданий, что сводит к минимуму перегрузку сетевой среды и повышая общую пропускную способность рассматриваемой системы. Данный принцип также носит название перемещения вычислений в сторону данных.
На данный момент должно бть очевидным, что кординация является центральным моментом в распределённых системах. Даже если каждый компнент распределённой системы способен правильно функционировать изолированно, необходимо также убедиться что они также будут верно работать при одновременном оперировании. Этого можно достигнуть через некий вид координации между такими компонентами. Как это показано в разделе о консенсусе, во многих крайних случаях такая координация может оказаться достаточно сложной. Как следствие, реализация таких алгоритмов координации для всякой новой системы с нуля будет неэффективной, к тому же создавая большой риск ошибок. Напротив, если бы имелась отдельная система, которая могла бы предоставлять такую форму координации в виде некого API, прочим системам было бы намного проще выгружать все функции координации в подобную систему.
Из данной потребности родилось несколько различных систем. Подобной системой, внутренне реализованной в Google и применяемой из некоторого числа различных систем для целей координации была Chubby[54]. Частично вдохновлённой Chubby системой стала Zookeeper[55], изначально разрабатывавшаяся в Yahoo и позднее превратившаяся в проект Apache. Она широко применялась во многих компаниях для осуществления координации в распределённых системах, включая некоторые из систем, являющихся частями экосистемы Hadoop. Другой системой, которая реализует аналогичные примитивы координации и формирует саму основу плоскости управления Kubernetes является etcd. Как и можно было ожидать, эти системы во многом схожи, но также они обладают и небольшими различиями. В целях краткости, данная глава сосредоточится на Zookeeper, предоставляя некий обзор её архитектуры, но также она попытается прокоментировать все основные отличия прочих двух систем, в случае их значимости.
Давайте рассмотрим API Zookeeper, который по- существу является иерархическим пространством имён, аналогичным некой
файловой системе (Chubby также предоставляет некое иерархическое пространство имён, в то время как etcd производит некий
интерфейс ключ- значение.) Всякое имя представляет некую последовательность элементов пути, разделяемых слешем
(/). Каждое имя представляет некий узел данных (носящий название
znode), который способен содержать некий элемент метаданных и дочерние узлы.
Например, /a/b рассматривается как потомок соответствующего узла
/a. Установленный API содержит основные операции, которые могут применяться для
создания узлов, удаления узлов, проверки наличия определённого узла, списка имеющихся потомков для некого узла и чтения
набора имеющихся данных какого- то узла. Существует два вида znode: обыяные узлы
(regular nodes) и эфемерные узлы (недолговечные, ephemeral nodes). Обычные узлы
создаются и удаляются клиентами в явном виде. эфемерные узлы способны также удаляться самой системой по истечению
создавшего их сеанса (то есть по причине отказа). Кроме того, когда какой- то клиент создаёт некий новый узел, он
способен устанавливать некий последовательный флаг (sequential flag). Созданные
с таким флагом узлы обладают соответствующим значением монотонно возрастающего счётчика, добавляемого в конец
предоставляемого префикса. Zookeeper также предоставляет некий API, который позволяет клиентам получать уведомления об
изменениях без опроса, носящего название сторожей (watches). При операциях
чтения клиенты имеют возможность установки некого сторожевого флага с тем, чтобы они получали уведомления от самой
сстемы когда полученные ими сведения подверглись изменению. Когда некий сервер Zookeeper ничего не получает от какого-
то клиента более предписанного таймаута, он рассматривает такого клиента как отказавшего и прекращает его сеанс.
Это удаляет вся связанные с ним эфемерные узлы и удаляет регистрацию всех зарегистрированных в данном сеансе сторожей.
Соответствующие операции обновления могут получать некий ожидаемый номер версии, что делает возможным собственно
реализацию условных обновлений, разрешающую любые проистекающие из одновременных запросов на обновление конфликтов.
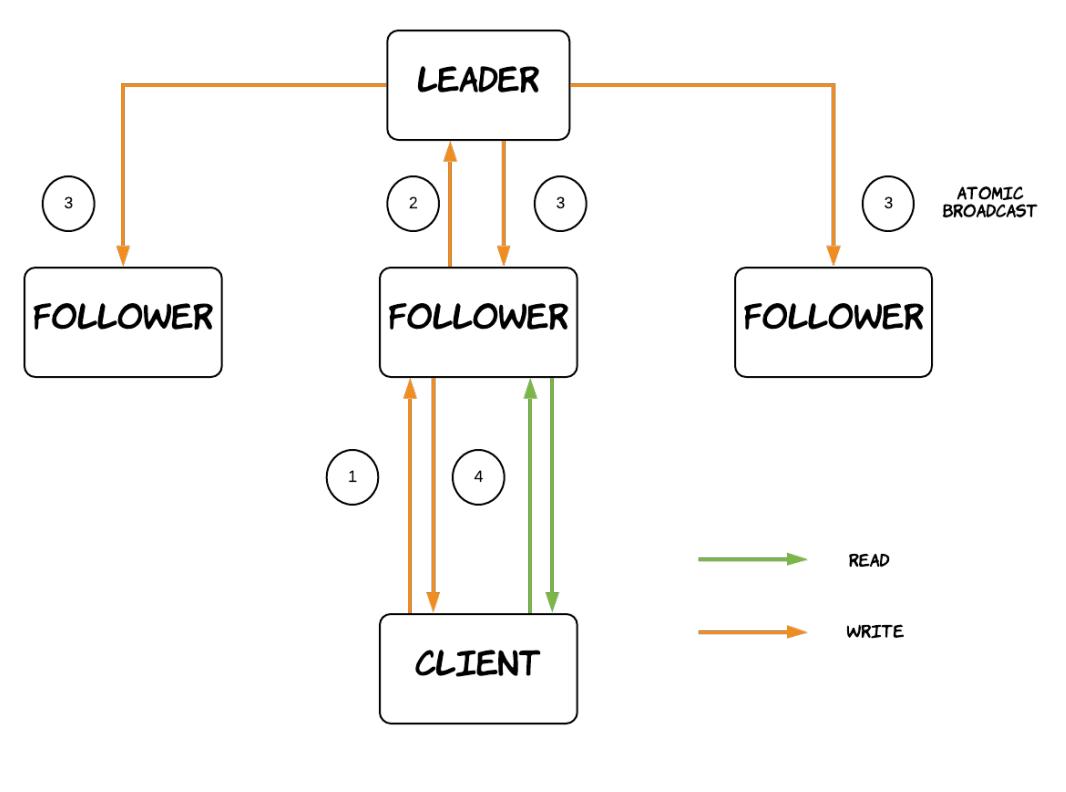
Узлы Zookeeper формируют некий кластер, носящий название ансамбля Zookeeper
(Zookeepe ensemble). Один из этих узлов проектируется в качестве лидера,
а все прочие имеющиеся узлы являются последователями
(followers). Zookeeper пользуется собственным протоколом атомарного широковещания под названием
Zab[56][57].
Данный протокол применяется в запросе на выбор необходимого лидера и реплицирует все операции записи своим последователям
(Chubby для этой цели применяет Paxos, а уесв gjkmpetvncz Raft.) Каждый из этих узлов обладает в памяти некой копией
основного состояния Zookeeper. Все изменения также записываются в некий долговечный журнал с упреждающей записью, который
может применяться для восстановления. Все имеющиеся узлы могут обслуживать запросы на чтением при помощи своей локальной
базы данных. Последователи обязаны переправлять все запросы на запись своему узлу лидеру, дожидаться успешной репликации/
широкого вещания данного запроса и затем отвечать своему клиенту. Считывания могут обслуживаться локально без какого бы то
ни было взаимодействия между узлами, а потому они чрезвычайно быстрые. Тем не менее, некий узел последователь может
отставать от своего узла лидера, а потому считывание клиентом может не обязательно отражать самую последнюю выполненную
запись. По этой причине Zookeeper предоставляет некую дополнительную операцию с названием sync.
Клиенты способны инициировать какой- то sync перед выполнением считывания. В
таком случае данное считывание отразит все операции записи, произошедшие до вызова этого
sync. Самой операции sync не требуется
распространение широковещательным протоколом, она просто помещается в самый конец очереди имеющегося лидера и
переправляется лишь связанному с ней последователю. (Напротив, Chubby как запросы чтения, так и запросы на запись направляются
его хозяину. Это обладает определённым преимуществом увеличения согласованности, однако негативной стороной является снижение
пропускной способности. Для смягчения этого клиенты Chubby выполняют интенсивное кэширование, а установленный хозяин
отвечает за отзыв установленного кэширования перед завершением записи, что превращает данную систему слегка более
чувствительной к отказам клиентов.)
В результате Zookeeper предоставляет 2 следующие гарантии безопасности:
-
Линеаризуемые записи: все обновляющие состояние Zookeeper запросы являются сериализуемыми и соблюдают приоритет. Как упоминалось ранее, когда не применяется
sync, записи не являются линеаризуемыми по отношению к считываниям. -
Порядок FIFO клиента: все запросы от определённого клиента выполняются в том порядке, в котором они были отправления этим клиентом.
Имеется ещё одна важная гарантия упорядоченности: если некий клиент ожидает какого- то изменения, этот клиент обнаружит соответствующее событие уведомления прежде чем он обнаружит такое новое состояние системы после того как происходит это изменение. В результате, когда некий клиент получает какое- то уведомление и осуществляет некое чтение, получаемый результат будет отражать все записи, по крайней мере на момент той, которая и включила данное уведомление.
Zookeeper также предоставляет две такие гарантии живучести и надёжности:
-
когда большинство серверов активно и взаимодействует, данная служба будет доступна
-
если соответствующая служба успешно отвечает на запрос изменения, такое изменение сохраняется при любом числе сбоев до тех пор, пока может восстанавливаться кворум
Как уже упоминалось ранее, широковещательный атомарный протокол Zookeeper (ZAB, Zookeeper atomic broadcast)
используется для согласования лидера в ансамбле, синхронизации имеющихся реплик, управления необходимым широковещанием
обновления транзакций и восстановления из состояния краха в некое допустимое состояние. Этот протокол совместно
разделяет с прочими протоколами консенсуса, такими как Paxos или Raft множество характеристик. В ZAB транзакции
идентифицируются особым типом идентификатора, именуемого zxid.
Этот идентификатор составлен из двух частей, <e, c>, где
e выступает соответствующим номером эпохи того лидера, который произвёл
данную транзакцию, а c некое целое значение, выступающее в роли счётчика для
данной эпохи. Значение счётчика c инкрементально увеличивается при введении
всякий раз установленным лидером новой транзакции, в то время как e
инкрементально увеличивается когда становится активным новый лидер. Этот протокол состоит из 4 основных фаз:
-
Выбор лидера: на этом этапе для проведения выборов инициализируется одноранговый обмен. Этот этап заканчивается после того за некого лидера проголосовал кворум. Данный лидер является перспективным и превращается в признанного лидера только по окончанию 3 этапа.
-
Обнаружение: на данной фазе выбранный лидер взаимодействует с имеющимися последователями для выявления самой современной последовательности принятых в кворуме транзакций и установления новой эпохи с тем, чтобы предыдущие лидеры не имели возможности фикировать новые предложения.
-
Синхронизация: на этой стадии выбранный лидер синхронизует все реплики в имеющемся ансамбле при помощи соответствующей истории лидера с предыдущего этапа. По завершению данной стадии об этом лидере говорится как ставшем признанным (established).
-
Широковещательная рассылка: на данном этапе наш лидер получает запросы на запись и осуществляет широковещательную рассылку всех связанных с ними транзакций. Этот этап продолжается до тех пор, пока этот лидер не утрачивает своего лидерства, которое фактически поддерживается через сердцебиения в сторону последователей.
На практике Zookeeper применяет алгоритм выбора лидера, носящего наименование FLE (Fast Leader Election, быстрого выбора лидера), применяющего некую оптимизацию. Он пытается выбирать в качестве лидера того однорангового партнёра, который обладает наиболее современной историей в процессе получения кворума. Это осуществляется для минимизации необходимого на этапе Обнаружения обмена данными между таким лидером и его последователями.
Имеющийся API Zookeeper может применяться для сборки более мощных примитивов. Некоторыми подобными образцами могут служить следующие:
-
Управление конфигурацией: Это достигается просто наличием надлежащего узла, который необходим для публикации некоторой информации о настройках, созданных на znode
zcи записывать эти настройки в качестве данных такого znode. Путь к этому znode предоставляется прочим узлам в данной системе, которые поучают настройки, считывая их сzc. Они также регистрируют сторожа с тем, чтобы получать сведения об изменении данных настроек. Когда оно происходит, они получают уведомление и осуществляют новое считывание для обладания самыми последними настройками. -
Участие в группе: Некий узел
zgназначается для представления необходимой группы. Когда какой- то узел желает присоединиться к этой группе, он создаёт некий эфемерный узел потомка нижеzg. Когда каждый узел обладает неким уникальным именем или идентификатором, их можно использовать в качестве надлежащего названия такого дочернего узла. В качестве альтернативы, соответствующие узлы могут воспользоваться своим последовательным флагом для получения некого уникального имени, получаемого от Zookeeper. Такие узлы также способны содержать дополнительные метаданные для участников этой группы, к примеру, адреса и порты. Узлы могут получать членство в соответствующей группе ожидая соответствующего потомкаzg. Когда некий узел также желает отслеживать изменения участников этой группы, он может зарегистрировать некого сторожа. В случае падения узлов, связанные с ними эфемерные узлы автоматически удаляются, что сигнализирует об их удалении из данной группы. -
Простая блокировка: Простейшим способом реализации блокировок является применение простого "lock file" (файла блокировки), который представлен каким- то znode. Для получения блокировки некий клиент пробует сздать такой выделенный znode с соответствующим эфемерным флагом. Когда такое создание успешно, этот клиент удерживает данную блокировку. В противном случае данный клиент имеет возможность установки сторожа на создаваемый узел для получения уведомления если эта блокировка высвобождается с тем чтобы повторно выполнить попытку овладения ею. Соответствующая блокировка высвобождается в случае если её клиент в явном виде удаляет этот znode или когда он погибает.
-
Блокировка без стадного эффекта: Наш предыдущий шаблон страдает от стадного эффекта: когда имеется множество клиентов в ожидании обладания некой блокировкой, они все одновременно получают уведомления и пытаются завладеть этой блокировкой даже если её может заполучить лишь один, что приводит к ненужному конфликту. Существует и иной способ реализации блокировок во избежание данной проблемы. Все те клиенты, которые участвуют в состязании за данной блокировкой, пробуют создать некий последовательный, эфемерный znode с одним и тем же префиксом (а именно,
/lock-). овладевает этой блокировкой тот клиент, который имеет наименьший последовательный номер. Все остающиеся клиенты регистрируют сторожей для данного znode с соответствующим следующим наинизшим последовательным номером. После того как некий узел получает уведомление, он может выполнить проверку что он теперь самый нижний последовательный номер, что означает что он заполучил данную блокировку. В противном случае он регистрирует нового сторожа для следующего Znode с наименьшим последовательным номером.
Аналогичным образом могут собираться прочие примитивы, такие как блокировки чтения/ записи, барьеры и т.п.. Такие шаблоны обычно имеют в Zookeeper название рецептов.
Этот раздел изучит некоторые основные категории распределённых хранилищ данных. Здесь нет возможности охватить все доступные хранилища данных. Более того, всякое хранилище данных обладает некими особенными свойствами , которые могут делать его отличным от прочих, а потому не просто устанавливать ясные границы между ними и классивицировать их по хорошо определённым категориям. По этой причине хранилища данных группируются их наиболее основных архитектурных характеристик и истории их появления. Полезно также провести сопоставление этих систем и попытаться понять сильнейшие стороны и слабые места каждой из них.
BigTable[7] является распределённой системой хранения которая изначально была разработана в Google и послужила вдохновением для HBase, распределённого хранилища данных, которое является частью общего проекта Apache Hadoop. Как и ожидалось, сами архитектуры этих двух систем очень близки, поэтому данный раздел сосредоточится на HBase, которая является системой с открытым исходным кодом.
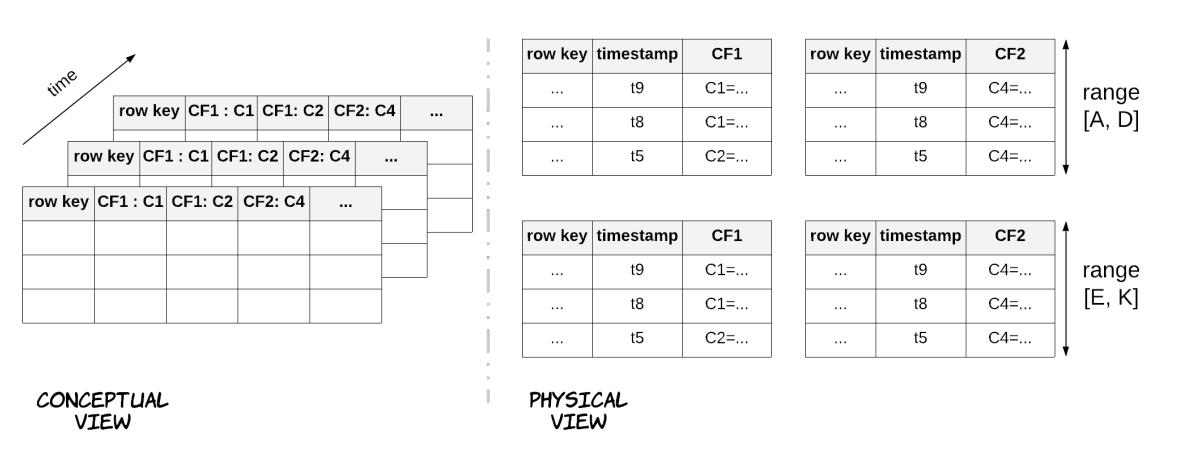
HBase предоставляет в качестве модели данных слабо связанную сортированную карту со множеством измерений, как это отображено на Рисунке 7.6. Это соответствие индексируется по ключу строки, ключу столбца и временной отметке, в то время как каждое значение в этом соответствии является неким массивом байт без их интерпретации. Соответствующие столбцы далее группируются в семейства столбцов. Все участники некого семейства столбцов хранятся совместно физически в соответствующей файловой системе и определённый пользователь может определять настройки конфигурации для каждого семейства, таких как тип сжатия или кэширование в памяти. Семейства столбцов нуждаются в определении заранее, в процессе задания схемы, однако столбцы могут создаваться динамически. Более того, данная система поддерживает небольшое число семейств столбцов, но при этом не ограниченное число столбцов. Значения ключей также байты без интерпретации, а строки всех таблиц физически хранятся в лексикографическом порядке значений ключей. Каждая таблица разбивается на разделы горизонтально с применением диапазонов разбиения на разделы на основании значения ключа строки в сегментах, именуемых регионами (regions). Основная цель данной модели данных и описываемой позднее архитектуры состоит в том чтобы позволить пользователю управлять собственно физической схемой данных с тем, чтобы связанные данные хранились поблизости друг от друга.
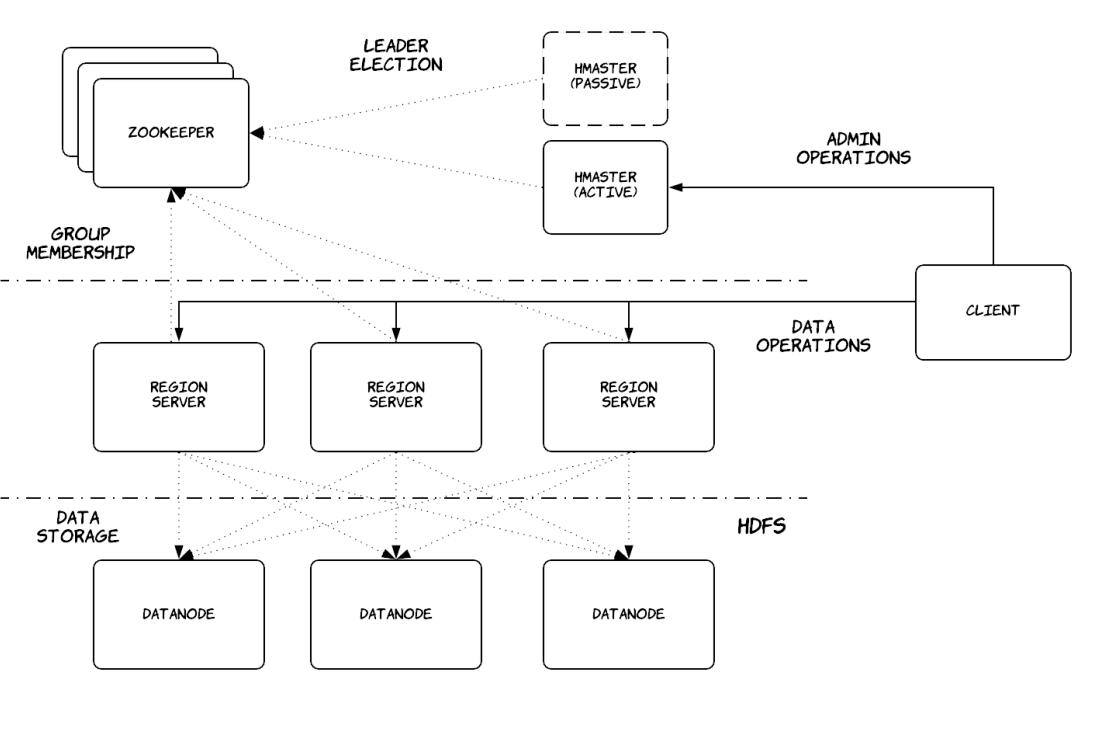
Рисунок 7.7 отображает архитетуру HBase на верхнем уровне, которая в свою очередь основывается на архитектуре хозяин- подчинённый. Соответствующий хозяин именуется HMaster, а его подчинённые носят название региональными серверами. HMaster ответственен за назначение регионов серверам регионов, обнаружением добавления серверов регионов и истечения их срока действия, балансировку нагрузки региональных серверов и обработку изменений схемы. Каждый региональный сервер управляет набором регионов, обрабатывает запросы на чтение и запись в загружаемых им регионах и расщепляет становящиеся слишком большими регионы. Как и прочие распределённые системы с единым хозяином, клиенты не взаимодействуют с самим хозяином относительно операций потока данных, а лишь для операций потока управления для недопущения того чтобы это стало узким местом производительности всей системы. Для осуществления выбора лидера необходимого узла хозяина HBase применяет Zookeeper, сопровождая групповое участие региональных серверов, храня значение местоположения начальной раскрутки данных HBase, а также запоминая сведения схемы и списки управления доступом. Каждый региональный сервер хранит все данные связанных с ним регионов в HDFS, что обеспечивает необходимую избыточность. Региональный сервер может размещаться в той же самой машине, что и узел данных HDFS и минимизировать сетевой обмен.
Имеется некая особая таблица HBase, именуемая таблицей META, которая содержит
необходимое соответствие между регионами и серверами регионов в используемом кластере. Само местоположение этой
таблицы хранится в Zookeeper. В результате, когда некому клиенту требуется в самый первый раз выпонить чтение/ запись
в HBase, он вначале взаимодействует с Zookeeper для выборки значения регионального сервера, размещающего необходимую
таблицу META, далее взаимодейтсвует с этим региональным сервером для поиска
желаемой им таблицы и наконец отправляет надлежащие операции чтения/ записи в этот сервер. Этот клиент кэширует
локально местоположение необходимой таблицы META и уже считанные из этой таблицы
сведения для повторного использования. Первоначально хозяева HMaster состязаются за создание эфемерного узла в
Zookeeper. Первый осуществивший это становится активным хозяином, а второй ожидает уведомлений от Zookeeper о сбое
активного хозяина. Аналогично, региональные серверы создают эфемерные узлы в отслеживаемом самим HMaster каталоге из
Zookeeper. Таким образом данный HMaster получает сведения о региональных серверах, которые присоединяются к его
кластеру или покидают его, поэтому он может надлежащим образом управлять выделением регионов.
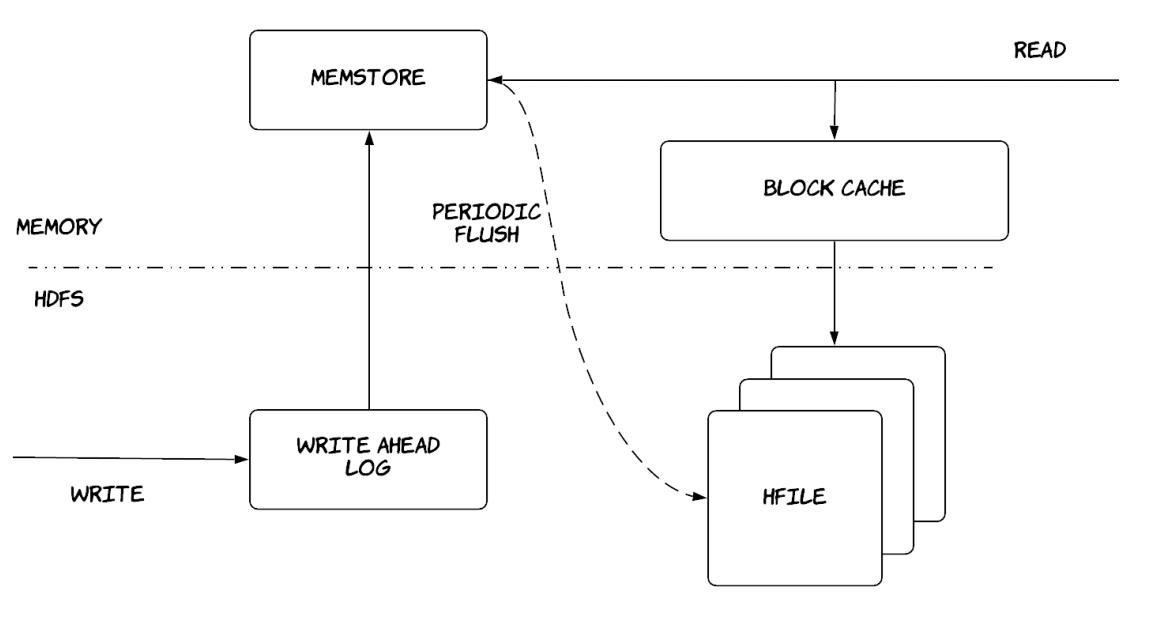
Добавление в конец является более действенным нежели случайные записи, в особенности в такой файловой системе как HDFS. Региональные серверы пытаются извлекать преимущества из этого факта применяя такие компоненты для сохранения и выборки данных:
-
MemStore: используется в качестве кэша записи. Операции записи изначально выполняются в этой структуре данных, которая хранится в оперативной памяти и могут действенно сортироваться перед записью на диск. Операции записи буферируются в этой структуре данных и периодчески сохраняются в HDFS после сортировки.
-
HFile: это тот файл в HDFS, который хранит на диске отсортированные записи ключ- значение.
-
WAL (Write ahead log, журнал упреждающей записи): он запоминает операции, которые не были удержаны в постоянном хранилище и запоминаются дишь в соответствующем MemStore. Он также хранится в HDFS и применяется для восстановления в случае отказа регионального сервера.
-
BlockCache: это кэш чтения. Он хранит в памяти часто считывеммые данные, а давно использовавшиеся данные отселяются по мере заполнения данного кэша.
В результате операции записи вначале проходят через WAL и MemStore и в конечном счёте завершаются сохранением в HFiles {этот шаблон имеет происхождение от структуры данных, носящей название LSM- log-structured merge - соединения структурированных журналов}, как это показано на Рисунке 7.8. Операции чтения обязаны выполнять считываие как из MemStore, так и из BlockCache и имеющихся HFiles и объединять получаемые результатыю Это может быть достаточно неэффективным, а потому имеется ряд применяемых оптимизаций. Как уже упоминалось ранее, столбцы группируются по своим семействам столбцов и хранятся по- отдельности. В результате необходимо выполнять запросы лишь к тем HFiles, которые содержат необходимое семейство столбцов. Все имеющиеся в HFiles записи хранятся в лексикографическом порядке и они содержат некий индекс в самом конце своего файла, который может удерживаться в памяти, а потому могут находить необходимые данные без считывания соответствующего файла целиком. Всякий HFile также содержит значение временного диапазона содержащихся в нём записей во избежание ненужных считываний файлов, которые не содержат требуемых данных. Для снижения общего числа подлежщих считыванию HFiles также используются Фильтры Блума; это особые структуры данных, которые упрощают выявление того где не могут содержаться некие данные не содержатся в неком файле, применяя крайне незначительный объём памяти. Существует также фоновый процесс, носящий название уплотнения (compaction), который сливает множество HFiles в единый HFile, удаляя прочие версии данных, в которых больше нет необходимости, тем самым снижая общее число HFiles, которые следует инспектировать в процессе операций считывания.
Некоторые из предоставляемых HBase гарантий таковы:
-
Атомарность:
-
Изменяющие множество строк операции являются атомарными.
-
Возвращающая код успешного завершения операции осуществлена удачно.
-
Возвращающая код отказа операция отказывает целиком.
-
Операция с таймаутом может быть успешной или отказавшей. Однако она не может быть частично успешной или отказавшей.
-
Это справедливо даже когда изменения производятся во множестве фамилий столбцов в пределах некой строки. (Это достигается за счёт тонкой грануляции блокировок на основе строк. Обратите внимание, что HBase по- существу неизменна, а потомув этом требуется участие только MemStore, чтоб превращает это в очень эффективное действо.)
-
-
Изменяющие множество строк операции не будут атомарными. К примеру, операции изменения строк
'a','b'и'c'могут вернуть изменёнными некоторые, но не все строки. В таком случае данная операция возвращает некий список кодов, некоторые из которых могут быть кодом успехов, отказов или таймаутов. -
Hbase предоставляет операции с условием, имеющие название
checkAndPut, которые происходят атомарно как типичные операцииcompareAndSet(CAS), которые можно обнаружить во многих аппаратных архитектурах.
-
-
Согласованность и изолированность:
-
Чтения/ записи единственной строки являются линеаризуемыми.
-
Когда некий клиент получает успешный отклик для всякого изменения, это изменение немедленно становится видимым как для этого клиента, так и для любого клиента, с которым оно взаимодействует впоследствии через побочные каналы.
-
-
HBase предоставляет операцию
scan, которая предоставляет действенные итерации по множеству строк. Эта операция не являет собой некого согласованного представления данной таблицы и не выставляет изолированности моментального снимка, вместо этого:-
Всякая возвращаемая
scanстрока является согласованным представлением, т.е. данная версия этой строки целиком существует в некий определённый момент времени. -
Операция
scanобязана отражать все изменения, зафиксированные представленные до этого сканирования и может отражать некоторые изменения, следующие за данным построением сканирования.
-
-
-
Надёжность:
-
Все наблюдаемые данные также являются надёжно сохраняемыми. Это означает, что что некое считывание никогда не возвратит дянные, которые не были сохранены на постоянной основе на диске.
-
Любые возвращающие успешный отклик операции изменения были сохраенены на постоянной основе.
-
Любые сохранённые на постоянной основе операции сохраняются по крайней мере на
nразличных серверах (Namenodes), гдеnявляется настраиваемым в HDFS множителем.
-
Как уже упоминалось ранее, HBase и Bigtable обоадают очень схожей архитектурой со слегка отличающимися названиями для различных компонентов и разными зависимостями. Приводимая далее таблица содержит соответствия между понятиями HBase и соответствующими концепциями в Bigtable.
| HBase | Bigtable | ||
|---|---|---|---|
region |
tablet |
||
region server |
tablet server |
||
Zookeeper |
Chubby |
||
HDFS |
GFS |
HFile |
SSTable |
MemStore |
Memtable |
Cassandra является распределённым хранилищем данных, которое сочетает идеи из работ Dynamo[8](Также имеется некая отдельная распределённая система с названием DynamoDB. Она доступна на коммерческих условиях, однако до сих пор подробности относительно её внутренней архетиктуры не стали достоянием общественности. Тем не менее, эта система имеет множество сходств с Cassandra, например, такие как собственно модель данных и тунелируемая согласованность) и Bigtable[7]. Первоначально она была разработана Facebook [9], однако далее она превратилась в открытый код и стала неким проектом Apache. На протяжении данного периода, она существенно эволюционировала от своей первоначальной реализации. (Основные представляемые в этом разделе сведения относятся к состоянию данного проекта на момент написания этих строк.) Самыми основными целями проекта Cassandra являлись чрезвычайно высокая доступность, производительность (высокая пропускная способность/ низкая задержка с ударением на рабочие нагрузки с интенсивной записью) при не имеющем границ инкрементальном масштабировании. Как поясняется позднее, для достижения этих целей в угоду приносятся прочие свойства, такие как сильная согласованность.
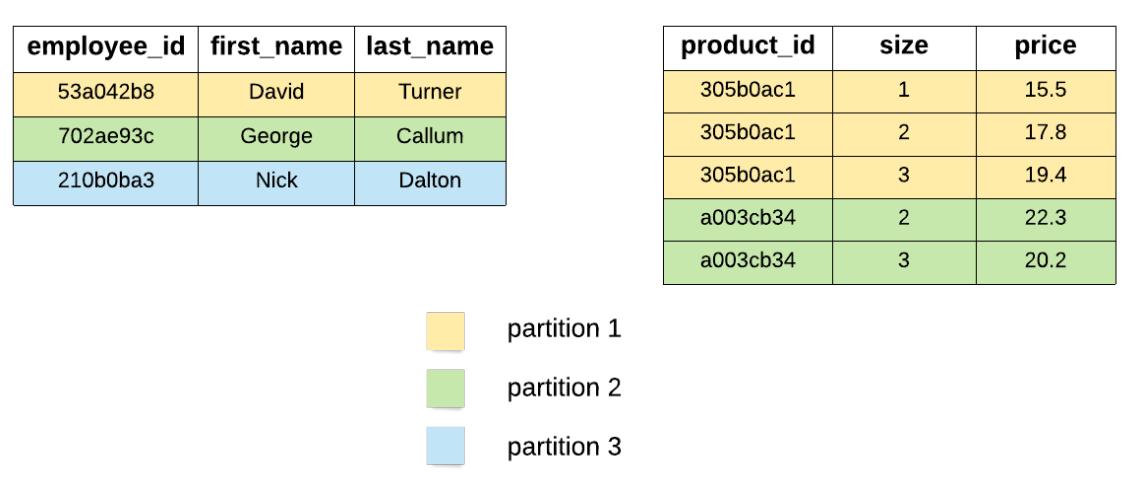
Основная модель данных достаточно простая: она составляется на самом верхнем уровне их пространств ключей (keyspaces), которые способны содержать большое число таблиц. Каждая таблица хранит данные в наборах строк и характеризуется некой схемой. Такая схема определяемся заданной структурой каждой строки, состоящей из определяемых разнообразных столбцов и их типов. Данная схема также определяет значение первичного ключа (primary key), который является столбцом или неким набором столбцов, обладающих уникальными значениями для каждой строки. Определённый первичный ключ может обладать двумя компонентами: самым первым компонентом является его ключ раздела (partition key) и он именно и является обязательным, в то время как его второй компонент содержит свои столбцы кластеризации (clustering columns), а они являются не обязательными. Когда присутствуют оба компонента, тогда такой первичный ключ носит название составного первичного ключа (compound primary key). Более того, если имеющийся ключ состоит из множества столбцов, он именуется разделённым ключом разделов (composite partition key). Рисунок 7.9 содержит некие образцы двух таблиц, причём одна обладает простым первичным ключом, а другая имеет некий составной первичный ключ.

Имеющийся первичный ключ таблицы является одной из наиболее важных частей установленной схемы, ибо он определяет каким образом данные распределяются по его системе,а также как они хранятся в каждом из узлов. Самый первый компонент такого первичного ключа, ключ раздела задаёт собственно распределение данных. Все строки некой таблицы концептуально расщепляются на различные разделы (partitions), где каждый раздел содержит лишь строки с тем же самым значением для заданного ключа раздела. Все такие строки, относящиеся к некому отдельному разделу гарантированно сохраняются совместно в одних и тех же узлах, в то время как относящиеся к различным разделам строки могут распределяться по различным узлам. Значение второго компонента определённого первичного ключа, его столбцы кластеризации, определяют как будут храниться на диске строки одного и того же раздела. В частности, строки одного и того же раздела будут храниться в возрастающем порядке своих заданных столбцов кластеризации, если только не определено иное. Рисунок 7.10, разработанный на основании нашего предыдущего образца, показывает как данные из двух таблиц будут на практике расщепляться на разделы и сохраняться.
Cassandra распеределяет имеющиеся разделы некой таблицы по доступным узлам при помощи
согласованного хэширования (consistent hashing),
применяя также и виртуальные узлы для предоставления сбалансированных разделов с тонкой грануляцией. В результате,
все имеющиеся виртуальные узлы некого кластера Cassandra соответствуют некому особому значению в имеющемся кольце,
именуемому маркером (token), который задаёт какие разделы
будут относиться к данному виртуальному узлу. В частоности, всякий виртуальный узел содержит все те разделы, чьи
ключи раздела (при хэшировании) попадают в значение диапазона между его маркером и значением маркера предыдущего
виртуального узла в этом кольце. (13Cassandra также поддерживает некий вид разбиения на разделы диапазона через
значение ByteOrderedPartitioner. Тем не менее, это в основном доступно с целями
обратной совместимости и не рекомендуется к применению, поскольку это может вызывать проблемы с горячими пятнами и
с несбалансированным распределением данных.) Каждый узел Cassandra может назначаться множеству виртуальных узлов. Каждый
раздел также реплицируется по N, где N
является неким настраиваемым для пространства ключей числом и носит название
множителя репликаций (replication factor).
Существует множество стратегий репликации, которые определяют как выбираются конкретные дополнительные
N-1 узлов. Самая простая стратегия просто выбирает значение последующих
узлов по часовой стрелке в установленном кольце. Более сложные стратегии также учитывают имеющуюся сетевую топологию
своих узлов для такого выбора. Сам механизм хранения вдохновлён Bigtable и основывается на фиксации журнала,
содержащего все имеющиеся изменения и некой memtable, которая периодически сбрасывается в SSTables, которые
также периодически сливаются посредством уплотнений.
Имеющиеся узлы рассматриваемого кластера периодически взаимодействуют друг с другом через протокол gossip (болтовни), обмениваясь сведениями о состоянии и топологии относительно себя и прочих узлов, о которых они осведомлены. Данным процессом новые сведения поступательно распространяются по всему кластеру. Тем самым узлы также способны отслеживать какие узлы отвечают за какие диапазоны маркера, а потому они могут согласованно выполнять маршрутизацию запросов. Они способны также выявлять какие узлы жизнеспообны, а какие нет стем, чтобы иметь возможность пропускать отправку запросов в недостижимые узлы. Доступны инструменты администрирования, которые могут применяться неким оператором для указания некому узлу в данном кластере удалять другой узел, который испытал падение на постоянной основе в данном кольце. Все относящиеся к такому узлу разделы будут реплицированы на некий иной узел из всех остающихся реплик. Имеется необходимость в неком процессе первоначальной раскрутки, который сделает возможным самым первым узлам соединиться в общий кластер. По этой причине, некий набор узлов проектируется в качестве посевных узлов (seed nodes) и они могут быть определены в процессе запуска для всех имеющихся узлов данного кластера через некий файл настроек или при помощи какой- то сторонней системы.
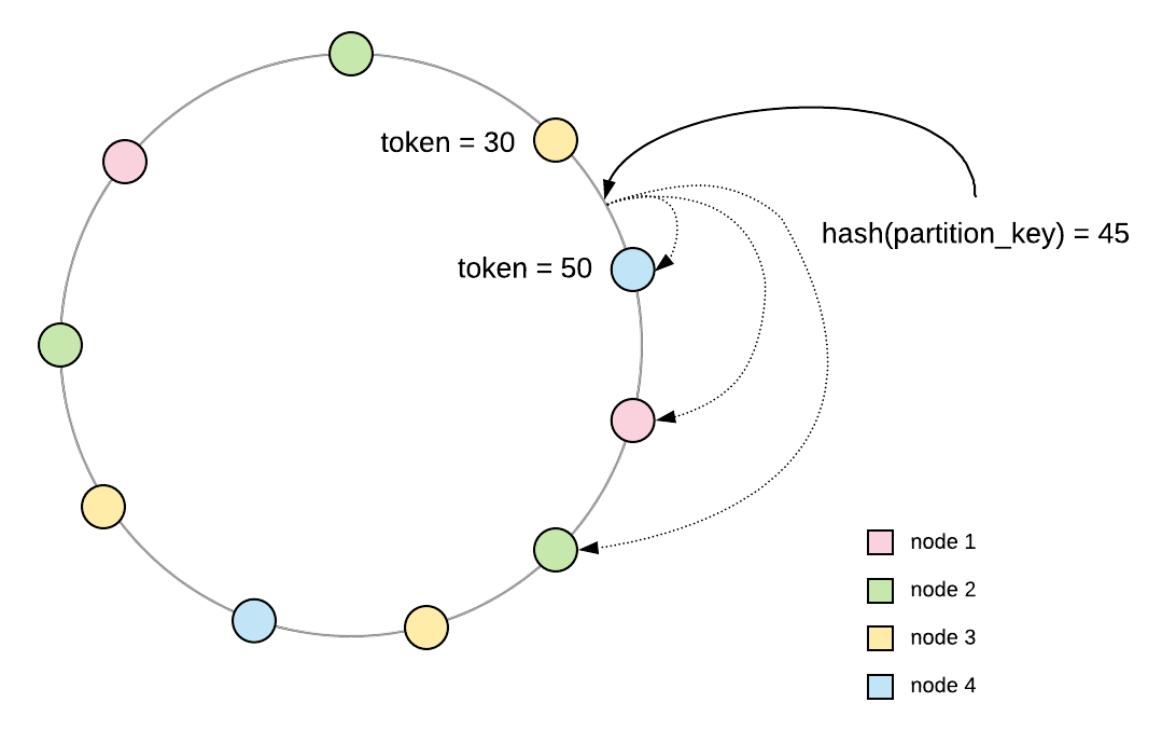
Cassandra не обладает никаким представлением о каком бы то ни было лидере или первичном узле. Все узлы реплик рассматриваются как равные. Всякий приходящий запрос может быть направлен в любой узел из её кластера. Такой узел носит название координирующего узла и он отвечает за управлением всего выполнения полученного запроса от имени своего клиента. Такой узел выявляет те узлы, которые содержат необходимые сведения для конкретного запрашиваемого раздела и выполняет диспетчеризацию поступивших запросов. После успешного сбора необходимых откликов он отвечает своему клиенту. Принимая во внимание то, что не существует никакого ведущего и что все узлы реплик равны,они такде способны одновременно обрабатывать запросы на запись. В результате, нет нужды в в некой схеме разрешения конфликтов и Cassandra пользуется схемой выигрывает последняя запись (LWW- last- write- wins). Всяуая записываемая строка поставляется с некой временной отметкой. При осуществлении считывания надлежащий координатор собирает все отклики из имеющихся узлов реплик и возвращает лишь одну с самой последней временной отметкой.
Надлежащий клиент также способен задавать политики, которые определяют как выбирается такой координирующий узел. Такая политика может выбирать узлы координации случайным образом неким карусельным манером, выбирая наиболее ближний узел, либо выбирая один из имеющихся узлов реплик для снижения последующих скачков (hops) по сетевой среде. Аналогично понятию посевных узлов, драйвер соответствующего клиента снабжается некими сведениями о настройке, которые содержат перечень пунктов контактов (contact points), являющихся узлами данного кластера. Этот клиент первоначально пробует и выполняет подключение к одному из этих узлов для получения некого представления обо всём имеющемся кластере и стать способным отправлять запросы куда угодно.
При взаимодействии с узлами Cassandra клиенты могут задавать различные уровни согласованности, что делает для них возможной надлежащую оптимизацию согласованности, доступности или задержки. Сам клиент способен определять желаемый уровень согласованности считываний и желательный уровень согласованности выполнения записи, при которых каждый уровень согласованности предоставляет различные гарантии. Некоторые из имеющихся уровней доступности таковы:
-
ALL: Некая операция записи должна быть выполнена во всех узлах реплик в имеющемся кластере для конкретного соответствующего раздела. Некое считываение возвращает необходимую запись только после получения откликов от всех реплик, в то время как эта операция завершится отказом кога некая отдельная реплика не откликнется. Данный вариант предоставляет наивысшую согласованность и самую низкую доступность. -
QUORUM: Некая запись должна быть выполнена в каком- то кворуме узлов реплик по всем центрам обработки данных. Операция считывания возвращает получаемую запись после предоставления откликов от некого кворума реплик из всех центров обработки данных. Этот вариант предоставляет некую сбалансированность между строгой согласованностью и терпимостью к небольшому числу отказов. -
ONE: Какая-то операция записи может быть осуществлена по крайней мере в одном узле рплик. читывание возвращает полученную запись после появления отклика от единственного узла реплик. Такой вариант предоставляет наивысшую высокую доступность, но пожвержен риску считывания устаревших данных по причине того, что полученная в отклике реплика может не доставлять самую последнюю запись.
Рассматриваемые два уровня согласованности не являются независимыми, а потому при выборе надлежащего уровня
следует рассматривать имеющиеся взаимосвязи между ними. В предположении что некое пространство ключей имеет
множитель репликаций N, а число клиентов, которые выполняют чтения с
согласованностью чтений R при том что записей с согласованностью записи
W, тогда некая операция считывания гарантированно
отразит самую последнюю успешную операцию записи пока
R + W > N. Например, это может достигаться путём выполнения и считываний и
записей на уровне QUORUM. В качестве альтернативы, этого же можно достичь
выполнением чтений на уровне ONE, а записей на уровне
ALL и наоборот. Во всех этих ситуациях по крайней мере один узел из набора
считываний будет присутствовать в соответствующем наборе записи, тем самым наблюдая самую последнюю запись. Тем не
менее, каждый из них предоставляет различные уровни доступности, надёжности, задержек и согласованности для
операций чтения и записи.
Как это уже отображалось до сих пор, Cassandra отдаёт предпочтение высокой доступности и производительности над согласованностью данных. В результате она содержит в своём штате различные механизмы, которые гарантируют своему кластеру способность продолжать обрабатывать операции даже в процессе отказов узлов, а разделы и реплики способны вновь сходиться после восстановления настолько быстро, насколько это возможно. Нкоторые из этих механизмов следующие:
-
намекающий пас (hinted handoff)
-
восстановление считывания
-
антиэнтропийное восстановление
Намекающий пас происходит в процессе операций записи: когда соответствующий координатор не способен контактировать с необходимым числом реплик, тогда этот координатор может локально сохранить получаемый результат данной операции ипередать его в соответствующий отказавший узел после его восстановления. Восстанавливающее считывание происходит в процесе операции чтения: когда её координатор получает от находящихся с ним в контакте реплик конфликтующие сведения, он разрешает данный конфликт выбором самой последней записи и её синронной отправкой во все устаревшие реплики перед откликом на данный запрос считывания. Агтиэнтропийное восстановление происходит в в фоновом режиме: узлы реплик обмениваются своими данными для некого заданного диапазона и если обнарыживают отличия, они оставляют для каждой из записей самые последние сведения, придерживаясь стратегии LWW. Однако это вовлекает в себя большие наборы данных, а потому важно минимизировать потребление полосы пропускания сетевой среды. По этой причине, имеющиеся узлы кодируют все данные некого диапазона в каком- то дереве Меркель и поступательно обмениваются частями этого дерева с тем, чтобы они были способны выявлять те находящиеся в конфликте сведения, которые подлежат обмену.
Важно отметить, что по умолчанию операции в некой отдельной строке не линеаризуемы даже с применением кворумов большинства. Для осознания этого полезно понимать как обрабатываются в Cassandra частичные отказы и сетевые задержки. Давайте испробуем два различных сценария.
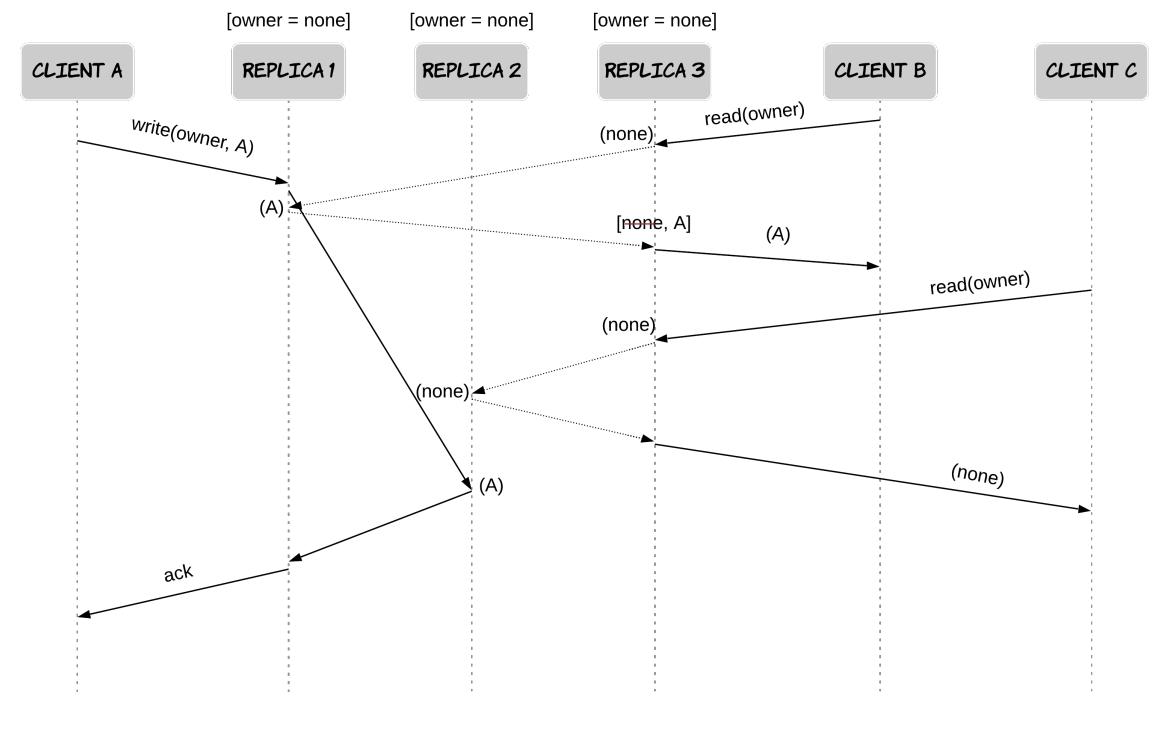
-
Вначале предположим, что не применяется восстановление считывания. Наша система состоит из трёх различных реплик с единственной строкой, которая модержит единственный столбец
ownerсо значением"none". Клиент A первоначально выполняет некую операцию записи в наборowner = A. Пока осуществляется данная операция, два различных клиента B и C последовательно выполняют операцию чтения дляowner. Имеющийся у клиента B кворум большинства содержит одну реплику которая уже получила выполняемую операцию записи, в то время как клиент C контактирует с неким кворумом узлов, который ещё не получил её. В результате клиент B считываетowner = A, в то время как клиент C считываетowner = none, даже если операция последнего началась после завершении операции первого, что нарушает линеаризуемость. Рисунок 7.12 содержит схему, иллюстрирующую это явление.
-
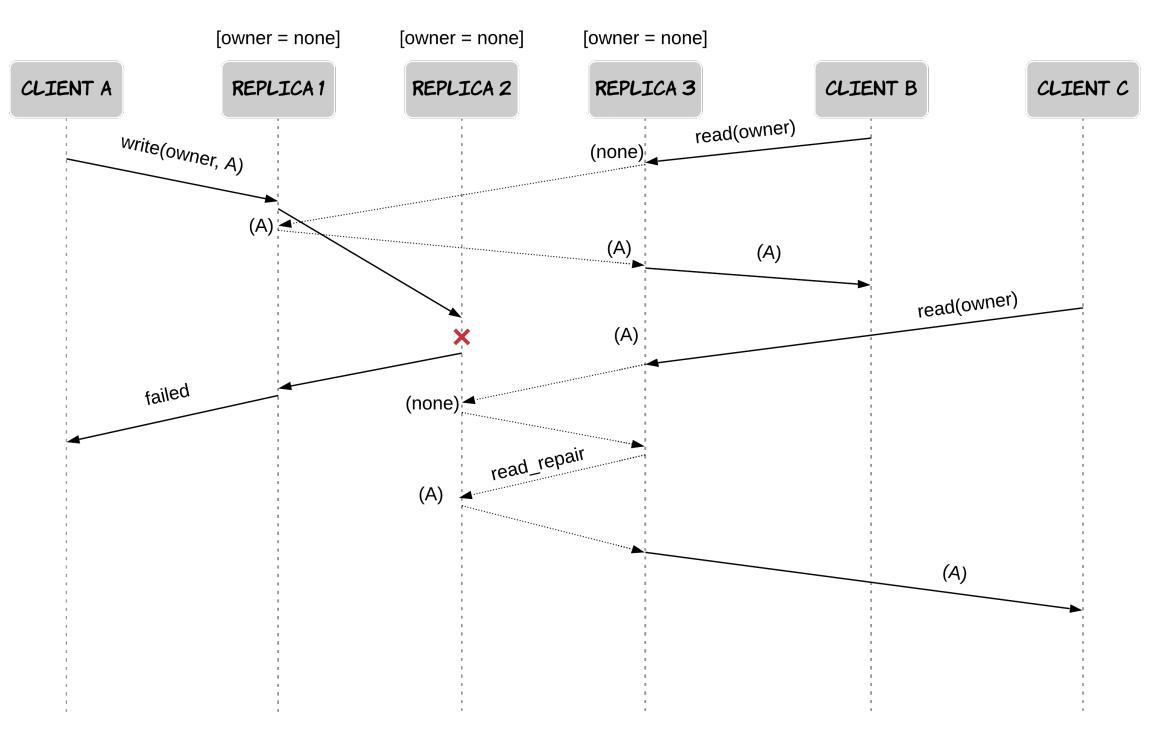
Нарушение линеаризуемости из пердыдущего примера можно было бы прекратить при применении восстанавливающего считывания, так как чтение клиентом B распространило бы надлежащее значение в реплику 2 и клиент C также считал бы
owner = A. Поэтому, давайте допустим, что используется восстанавливающее считывание и испытаем иной сценарий. Клиент A снова выполняет операцию записи в наборowner = A. Эта запись завершается успешно в одной реплике и отказывает в другой реплике. В результате, данная запись рассматривается неудачной и её координатор возвращает своему клиенту отклик об отказе. После этого, клиент B выполняет некую операцию чтения, которая применяет кворум, содержащий ту реплику, когда соответствующая предыдущая запись была успешной. Cassandra осуществляет восстанавливающее считывание с применением стратегии LWW, тем смым распространяя полученное значение в реплику 2. Как следствие, завершившаяся неудачей операция записи повлияла на состояние имеющейся базы данных, нарушая тем самым линеаризуемость. Этот пример отображён на Рисунке 7.13.
Cassandra предоставляет иной уровень согласованности, который даёт гарантии
линеаризуемости. Этот уровень носит название
SERIAL, а соответствующие операции чтения/ записи, выполняемые на данном уровне,
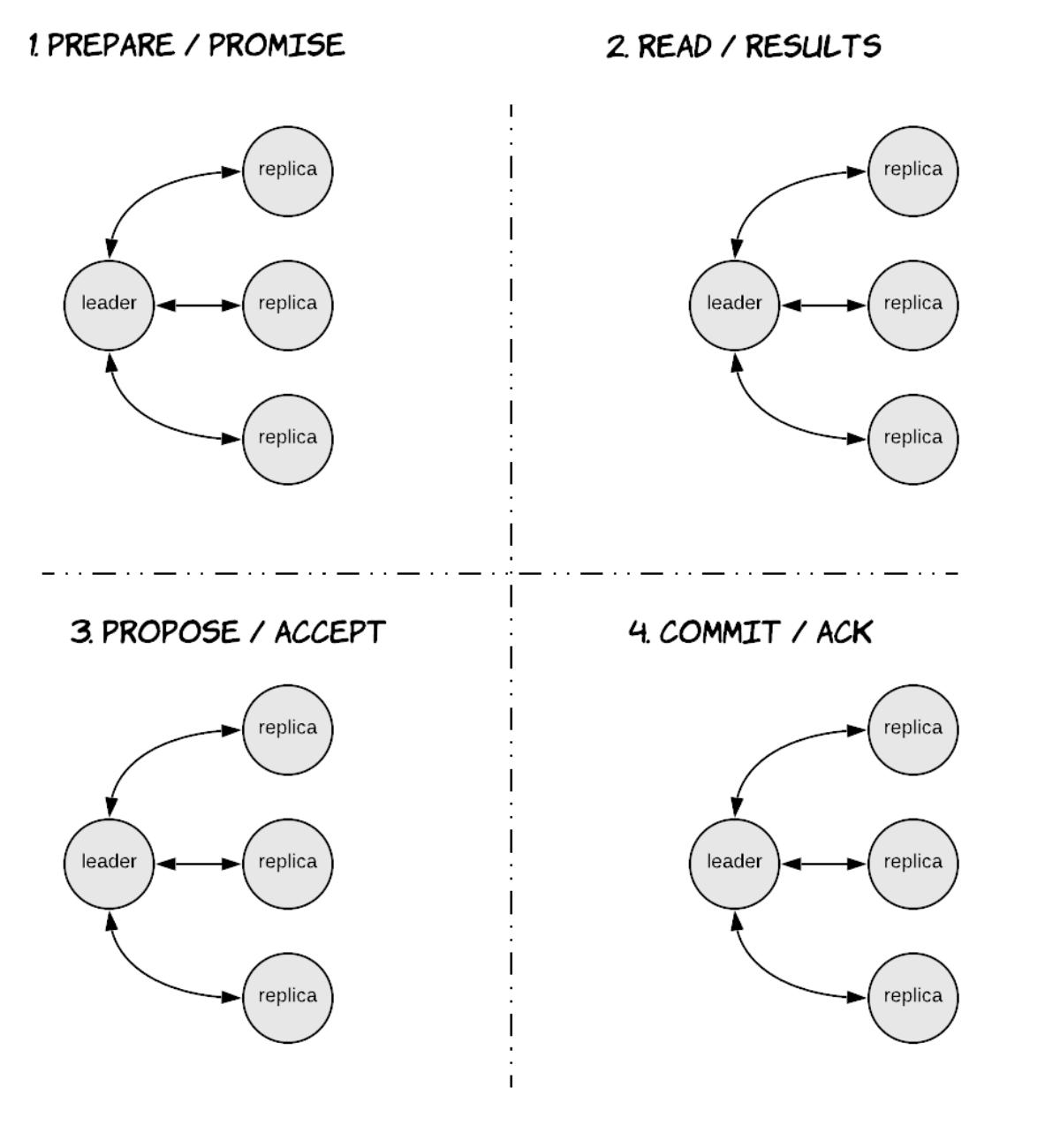
также именуются транзакциями с малым весом. Этот уровень реализуется при помощи 4- фазного протокола на основе
Paxos, что отображено на
Рисунке 7.14.
Третья и четвёртая фазы данного протокола в точности представляют Paxos и удовлетворяют тем же самым потребностям:
первая фаза носит название prepare (подготовки) и относится к тем узлам,
которые пробуют получить голоса до распространиения некого значения,которое выполняется на третьей фазе, носящей
название propose (предложения). При запуске на уровне
SERIAL, данные операции записи являются условными, применяющими выражение
IF, что также носит название CAS (compare-and-set - сравни и установи).
Вторая фаза этого протокола носит название read и используется для выборки
необходимых данных для проверки того удовлетворяется ли установленное условие прежде чем продолжить предложением.
Самая последняя фаза носит название commit (фиксация) и применяется для
перемещения принятого значения в хранилище Cassandra и делает возможным новый раунд согласования, тем самым
снова снимая блокировку одновременного LWW. Выполняемые при SERIAL
операции чтения и записи гарантированно линеаризуемы. Операции считывания зафиксируют все принятые предложения,
которые пока не были фиксированы как часть данной операции чтения. Операции запси под
SERIAL требуют содержания некой условной части.
В Cassandra выполнение некого запроса, который не пользуется установленным первичным ключом гарантированно будет не эффективным, по причине того, что нам потребуется осуществлять сканирование всей таблицы с запросом всех имеющихся в нашем кластере узлов. Для этого существуют две альтернативы: вторичные индексы и материализованные представления. Вторичный индекс может определяться в виде неких столбцов в таблице. Запросу на основе этих столбцов всё ещё потребуется запрашивать все узлы данной системы, но по крайней мере каждый узел будет обладать более действенным способом выборки необходимых сведений без сканирования всех имеющихся данных. Материализованное представление может определяться как некий запрос для существующей таблицы с вновь заданным ключом раздела. Такое материализовнное представление сопровождается как некая отдельная таблица и все изменения в его первоначальной таблице в конечном счёте распространяются и на неё. В результате, эти два подхода являются предметом для следующего компромисса:
-
Вторичные индексы наиболее подходят для столбцов с высокой кардинальностью, в о время как материализованные представления более подходят для столбцов с меньшими значениями кардинальности, ибо они хранятся в виде обычных таблиц.
-
Ожидается, что материализованные представления будут белее деейственными в процессе операций чтения по сравнению с операциями вторичных индексов, так как запрашиваются лишь те узлы, которые содержат соответствующие разделы.
-
Вторичные индексы гарантированно выступают строго согласованными, в то время как материализованные представления являются согласованными в конечном счёте.
Cassandra не предоставляет операций соединений, по причине того, что они были бы не эффективными из- за распределённости данных. В результате, пользователи сталкиваются с денормализацией своих данных потенциально вулючая одни и те же сведения во множество таблиц с тем, чтобы их можно было бы действенно считывать только из минимального числа узлов. Это означает, что любые операции обновления таких данных потребуют обновлений в большом числе таблиц, однако это ожидается достаточно эффективным. Cassandra предоставляет 2 предпочтения пакетных операций, которые способны обновлять множество разделов и таблиц: пакеты logged и unlogged (с журналированием и без него). Пакеты с журналами предоставляют дополнительные гарантии атомарности, что подразумевает что либо все предложения операций данного пакета войдут в действие, либо ни одна из них. Это помогает гарантировать что все те таблицы, которые совместно применяют такие денормализованные данные будут находится в согласованном друг с другом состоянии. Тем не менее, это достигается за счёт регистрации данного пакета как некого элемента в системной таблице, которая реплицируется и далее осуществляет все операции, что делает их менее эффективными по сравнению с пакетами без журналирования. И паветы с журналированием, и пакеты без оного не предоставляют никакой изоляции, поэтому одновременные запросы могут наблюдать соответствующие эффекты того, что часть их операций всего лишь временные.
Spanner является распределённым хранилищем данных, которое изначально было разработано для собственных нужд Google[5][59], а впоследствии выпущено в общий доступ как часть платформы Google.
Модель данных Spanner очень близка к модели данных классических реляционных баз данных. Некая база данных в Spanner способна содержать одну или более таблиц, которые могут содержать множество строк. Каждая строка содержит некое значение для всякого определяемого столбца, а один или более столбцов определяются в качестве соответствующего первичного ключа данной таблицы, который обязан быть уникальным для каждой из строк. Всякая таблица содержит некую схему, которая определяет необходимые типы данных для каждого столбца.
Разделы Spanner имеющихся в таблице данные разбиваются при помощи горизонтального
разбиения диапазонов на разделы. Строки некой таблицы разбиваются на разделы множеством сегментов,
именуемых расколами (splits). Некий раскол является каким- то диапазоном
непрерывных строк, в которых сами строки упорядочены значением соответствующего первичного ключа. Spanner обладает
возможностью динамического расщепления на основе нагрузки, поэтому любой
раскол, который получает экстремальный объём обмена может и далее расщепляться и сохраняться на серверах с меньшим
обменом. Его пользователи могут также определять между таблицами взаимоотношения
предок- потомок, с тем чтобы связанные строки из этих таблиц размещались
совместно, превращая операции соединения в более действенные. Некая таблица C
может быть объявлена как потомок таблицы A при помощи ключевого слова
INTERLEAVE и гарантируя что значение первичного ключа его родительской таблицы
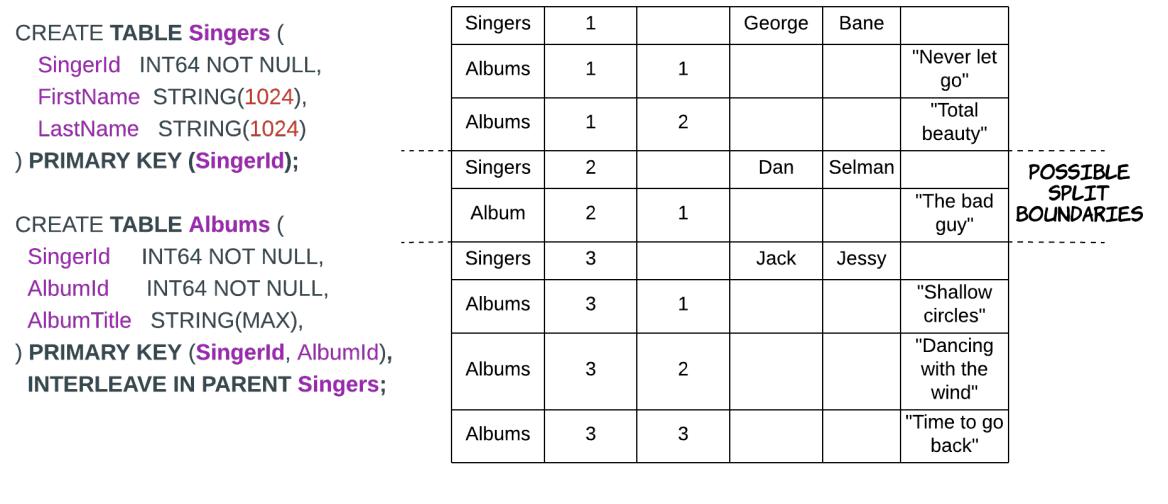
выступает в качестве префикса общего первичного ключа этой дочерней таблицы. Некий пример показывается на
Рисунке 7.15,
на котором родительская таблица Singers перемежается с с дочерней таблицей
под названием Albums. Spanner обеспечивает что соответствующая строка некой
родительской таблицы и все связанные с ней строки его дочерней таблицы никогда не будут назначаться в разные расколы.
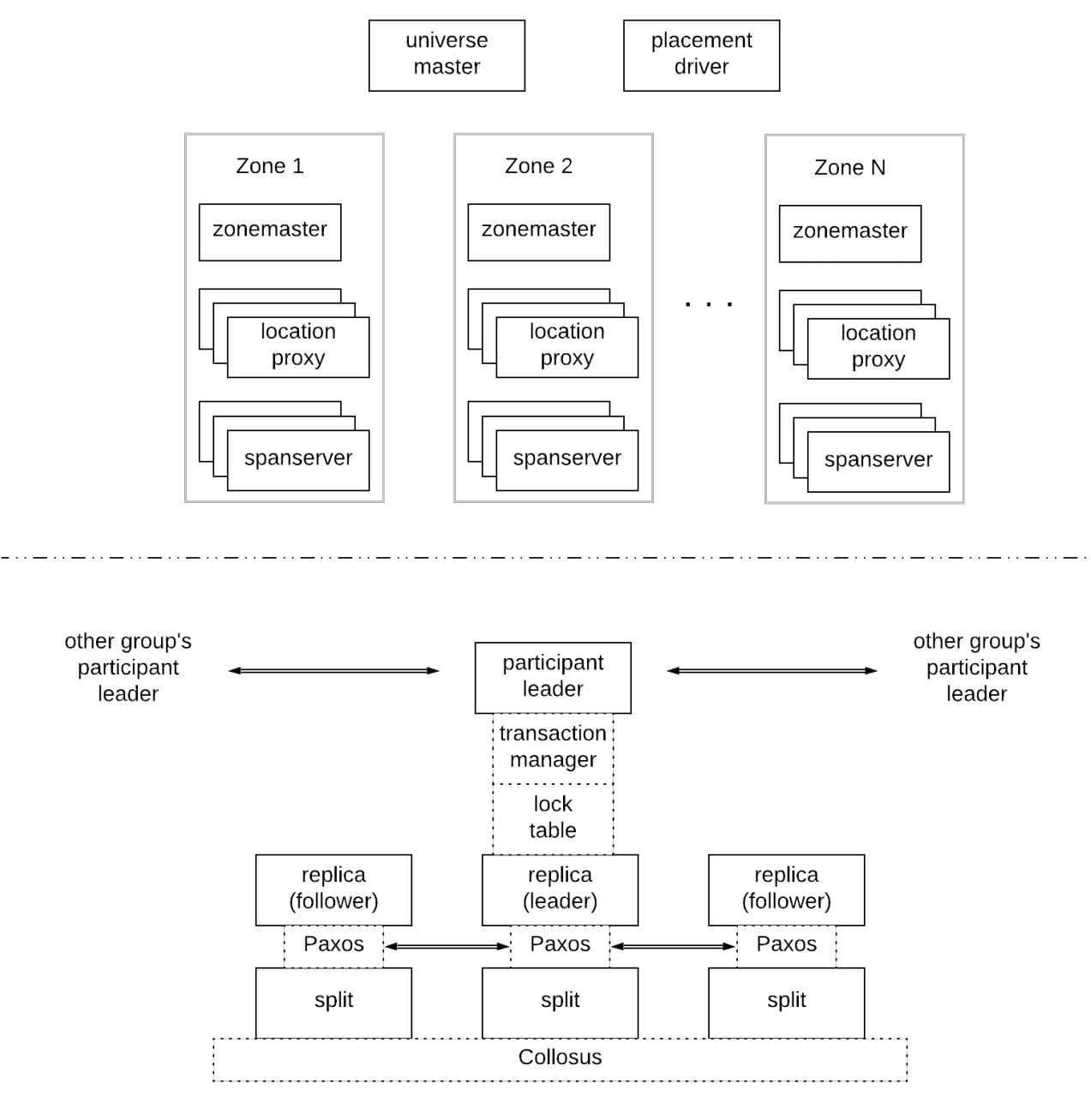
Некое развёртывание Spanner именуется вселенной (universe) и оно составляется из зон, которые выступают в роли элементов административных развёртываний, физической изоляции и репликаций (т.е. центров обработки данных). Всякая зона обладает неким хозяином зоны (zonemaster) и от сотен до нескольких тысяч шаговых серверов (spanservers). Первый из упомянутых отвечает за выделение данных шаговым серверам, в то время как последующие обрабатывают запросы чтения/ записи от клиентов и хранят данные. Для определения местоположения шаговых серверов, которые обслуживают конкретные порции данных клиенты пользуются посредниками местоположения (location proxies) на основе зон. Имеющийся хозяин вселенной (universe master) отображает сведения о состоянии относительно всех зон для устранения неисправностей, а соответствующий драйвер размещения (placement driver) обрабатывает автоматические перемещения данных между зонами, к примеру, по причинам балансировки нагрузки.
Каждый шаговый сервер может управлять множеством расколов, а каждый раскол реплицируется для целей доступности, надёжности и производительности по множеству зон. (На самом деле всякий раскол хранится в некой распределённой файловой системе, носящей название Колосса - Colossus - которая является преемником GFS, которая уже предоставляет репликацию на уровне байт. Тем не менее, Spanner добавляет другой уровень репликации для предоставления дополнительных преимуществ доступности сведений и географической локальности.) Все такие реплики некого раскола формируют группу Paxos. Одна из таких реплик выбирается в качестве лидера и отвечает за получение входящих запросов на запись и их репликации в соответствующей группе через какой- то раунд Paxos. Все прочие имеющиеся реплики являются последователями (followers) и способны обслуживать некие виды запроов на чтение. Spanner пользуется лидерами с длительным временем жизни с арендой лидера на основании временного диапазона, которые по умолчанию обновляются каждые 10 секунд. Spanner пользуется пессимистичным контролем одновременности для гарантии надлежащей изоляции между одновременными транзакциями, в частности, двух- фазной блокировкой. Установленный для каждой эпохи группы реплик лидер сопровождает таблицу блокировок, которая устанавливает соответствие диапазонов ключей для блокирования под эту цель состояний. (На практике такие блокировки также реплицируются в соответствующих репликах этой группы для покрытия отказов своего лидера.) Spanner также предоставляет поддержку распределённых транзакций, которые вовлекают в действие множество расколов, которые потенциально относятся к различным группам реплик. Это достигается за счёт двухэтапной фиксации по всем вовлечённым группам. В результате, имеющийся в каждой группе лидер также реализует какого- то диспетчера транзакции для принятия участия в необходимой двухэтапной фиксации. Те лидеры каждой из групп, которые принимают участие носят название участвующих лидеров (participant leaders), а все реплики последователей каждой из таких групп именуются участвующими подчинёнными (participant slaves). Более конкретно, одна из таких групп выбирается в качестве необходимого для ротокола двухэтапной фиксации координатора, а имеющиеся в такой группе реплики носят, соответственно, названия координирующего лидера и координирующих подчинённых.
Spanner пользуется для записей времени новейшим API под названием
TrueTime[60], который
стал тем ключом достижения желаемого для большинства имеющихся гарантий согласованности, предоставляемых Spanner.
Этот API непосредственно выставляет неопределённость часов,а узлы могут дожидаться этой неопределённости при сопоставлении
полученных от разных часов временных отметок. Когда такая неопределённость (uncertainty) возрастает по присчине какого- то
отказа, это проявится как возрастающая латентность по причине того что узлам придётся ожидать более продолжительные
периоды времени. TrueTime предоставляет время в качестве TTInterval, который
является неким интервалом [earliest, latest] (наиболее раннего, наиболее позднего)
с границами неопределённости времени. Данный API предоставляет метод TT.now(),
который возвращает TTInterval, гарантированно содержащий значение
абсолютного времени, на протяжении которого данный метод был вызван. (Как поясняется в нашей главе о времени, это
предполагает существование некого идеального абсолютного времени, которое
использует всю Землю как единую систему отсчёта и вырабатывается с применением нескольких атомных часов.
подробнее...).
Он также предоставляет два удобных метода TT.after(t) и
TT.before(t), которые определяют будет ли
t несомненно в прошлом или в будущем. По существу это всего лишь обёртки вокруг
TT.now(), так как TT.after(t) = t < TT.now().earliest,
а TT.before(t) = t > TT.now().latest. В результате Spanner способен назначать
временные отметки транзакциям, которые обладают глобальным значением и способны сравниваться узлами, обладающими
различными часами. TrueTime реализуется неким набором машин хозяев времени
(time master) в центре обработке данных и демоном подчинённого времени
(timeslave daemon) в каждой машине. Эти хозяева могут пользоваться одной из двух различных форм эталонного времени,
либо GPS, либо атомными часами, поскольку они обладают различными режимами отказов. Имеющиеся серверы хозяев
периодически сравнивают своё эталонное время и они также проводят перекрёстную проверку с которой их эталонное время
увеличивается по сравнению с их локальными часами, исключая себся из общего кластера в случае существенного
расхождения. Демоны для синхронизации своих локальных часов опрашивают разнообразных хозяев и объявляют некую
неопределённость e, которая соответствует половине ширины соответствующего
интервала (latest - earliest) / 2. Эта неопределённость зависит от задержек
взаимодействия хозяин - демон значения неопределённости значения времени хозяина. Такая неопределённость является
пилообразной функцией времени, которая медленно растёт между синхронизациями. В промышленной среде Google среднее
значение такой неопределённости составляло 4 миллисекунда.
Spanner поддерживает следующие типы операций:
-
автономные (строгие или устаревшие) считывания
-
транзакции исключительного считывания
-
транзакции исключительной записи
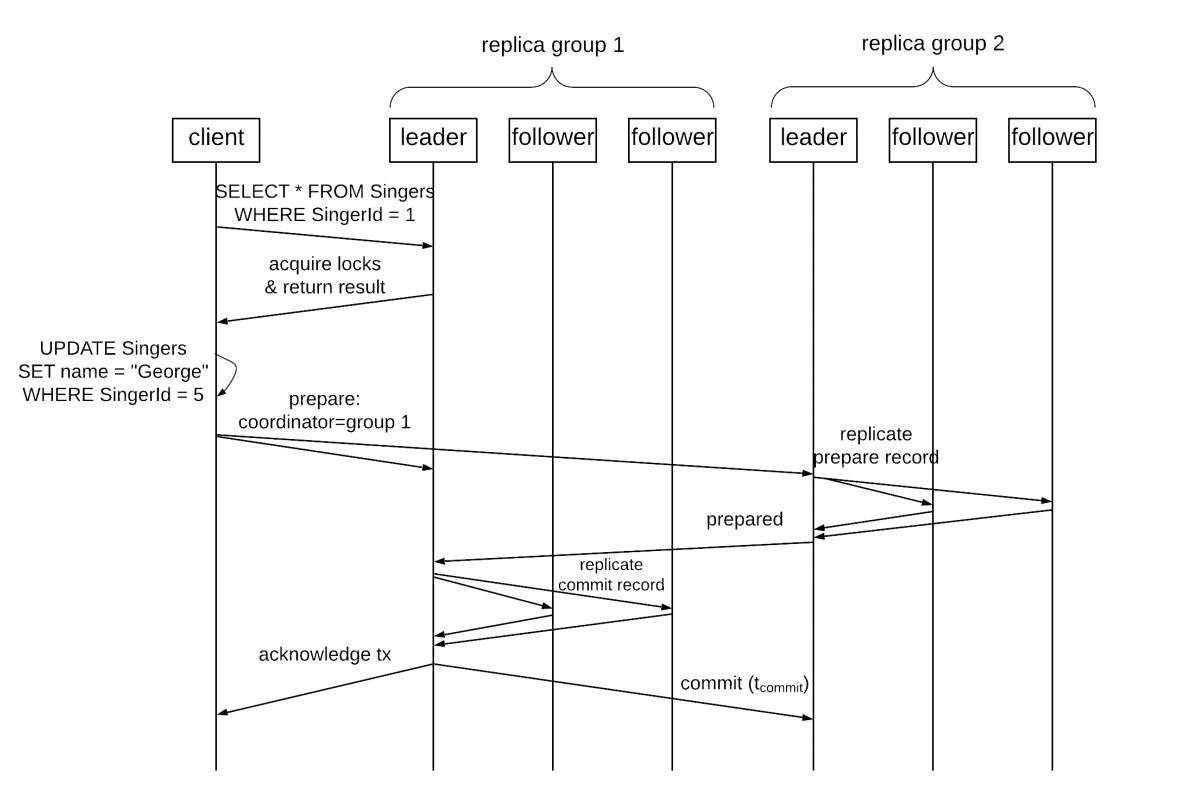
Транзакции считывания - записи могут содержать как операции чтения так и/ или записи. Они предоставляют полные свойства ACID для всех операций данной транзакции. Точнее, транзакции считывания - записи не являются просто упорядочиваемыми, однако они являются строго упорядочиваемыми. (На самом деле документация Spanner применяет для строгоq упорядочиваемости - strict serializability - наименование "внешней непротиворечивости") - external consistency - но оба понятия по сути предоставляют одни и те же гарантии.) Некая транзакция считывания - записи исполняет какой- то набор операций чтения и записи атомарно в некий отдельный момент времени. Как уже пояснялось ранее, Spanner достигает этих свойств при помощи двухфазного блокирования для изоляции и двухфазной фиксации для атомарности по множеству расколов. Более детально этот рабочий поток представлен следующим образом:
-
После открытия некой транзакции, клиент отправляет все операции считывания определённому ведущему той группы реплик, которая управляет тем расколом, который содержит необходимые строки. Этот лидер выставляет блокировки считывания для всех вовлечённых строк и столбцов перед обслуживанием этих запросов на чтение. Всякое чтение также возвращает значение временной отметки всех считанных данных.
-
Все операции записи локально буферируются в самом клиенте до того момента, пока не зафиксируется эта транзакция. Пока данная транзакция открыта, этот клиент отправляет сообщения активности (keepalive) для пряпятствия тому, чтобы уаствующие лидеры завершили бы транзакцию по таймауту.
-
После того как клиент завершает все считывания и буферирует все записи, он запускает надлежащий протокол двухфазной фиксации. (Такая двухфазная фиксация необходима только когда эта транзакция осуществляет доступ к данным из множества групп реплик. В противном случае установленный лидер соответствующей единственной группы реплик способен фиксировать эту транзакцию только через Paxos.) Он выбирает одного из участвующих в процессе лидеров в качестве координирующего лидера и отправляет запрос на подготовку всем имеющимся участвующим лидерам совместно с самоё идентификацией установленного координирующего лидера. На этом этапе также все вовлечённые в операции записи участвующие лидеры получают все буферированные записи.
-
Каждый участвующий лидер выставляет все необходимые блокировки записи, выбирает временную отметку подготовки, которая превышает все временные отметки предыдущих транзакций и регистрирует некую запись подготовки в своей группе реплик через Paxos. Этот лидер также реплицирует все запрошенные блокировки в свои реплики для обеспечения их удержания даже в случае отказа самого лидера. Затем он выдаёт отклик установленному координирующему лидеру со значением временной отметки подготовки.
-
Установленный координирующий лидер дожидается необходимых откликов подготовки от всех участвующих лидеров. По завершению, он выставляет блокировки на запись и выбирает значение временной отметки фиксации данной транзакции
s. Оно должно быть больше или равняться всем временным отметкам подготовки от всех участвующих лидеров, причём быть большим нежелиTT.now().latestна тот момент, когда установленный координатор получил соответствующий запрос фиксации от своего клиента и больше чем все те временные отметки, которые он назначал предыдущим транзакциям. Затем установленный координатор регистрирует в журнале некую запись фиксации в своей группе реплик посредством Paxos и далее отправляет значение временной отметки фиксации своему клиенту и всем имеющимся участвующим лидерам. На самом деле, этот координатор выполняет ожиданиеTT.after(s)перед выполнением этого для обеспечения того, что клиенты не будут иметь возможности наблюдать какие бы то ни было фиксированныеsданные пока не станет истинным наступлениеTT.after(s). -
Все участники регистрируют результат данной транзакции через Paxos в своей группе реплик, применяет записи этой транзакции к отметке времени фиксации и потом снимает все удерживаемые этой транзакцией блокировки.
Рисунок 7.17 содержит некую визуализацию этой
последовательности. Стоит отметить, что в данной схеме все проблемы с доступностью двухфазной фиксации частично
смягчаются тем фактом, что и все участники, и установленный координатор по существу выступают некой группой
Paxos. Поэтому, в случае падения одного из определённых узлов лидеров, другая реплика из этой группы реплик в
конечном счёте выявит это, предпримет необходимые действия и окажет содействие выполнению своего протокола.
Более того, данный протокол двухфазной блокировке способен иметь результатом тупиковые ситуации. Spanner разрешает
такие ситуации через схему wound-wait (ожидания ранения)[61],
при которой некой транзакции TX1 позволяется прерывать транзакцию
TX2, которая удерживает желательную блокировку только когда
TX1 старше чем
TX2.
Spanner нуждается в неком способе узнавать актуальность какой- то реплики для удовлетворения операции чтения.
По этой причине все реплики отслеживают некое значение, именуемое временем безопасности
tsafe, которое является максимальным значением временных отметок при
которых данная реплика актуальна. Таким образом, некая реплика может быть безопасно считана при некой временгой
отметке t, когда t ≤ tsafe.
Это значение вычисляется как tsafe = min(tsafePaxos,
tsafeTM). tsafePaxos это значение временной отметки
самой наивысшей применённой записи Paxos в некой группе реплик и представляет значение наивысшей отметки уровня, ниже
которого записи больше не будут происходить относительно Paxos. tsafeTM вычисляется как
mini(si,gprepare) над всеми подготовленными
транзакциями Ti (но пока не зафиксированными) в некой грппе реплик
g. Если таких транзакций нет, тогда
tsafeTM = + ∞.
Транзакции исключительного считывания позволяют клиенту осуществлять множество чтений в момент времени с одной и той
же временной отметкой и эти операции также обеспечивают строгое
упорядочение. Неким занимательным свойством операций исключительного считывания является то, что им
не требуется удерживать какие бы то ни было блокировки и они не блокируют прочие транзакции. Основной причиной этого
является то, что такие транзакции выполняют чтения в некий заданный временной отметкой момент, который выбирается таким
образом, чтобы гарантировать что все одновременные / последующие операции записи будут обновлять данные в некий
более поздний момент временной отметки. Значение временной отметки выбирается в самом начале данной транзакции
как TT.now().latest и не оно применяется для всех необходимых операций чтения,
которые выполняются как чсть данной транзакции. В целом, все операции чтения для временной отметки
tread могут обслуживаться любой актуальной репликой
g, что подразумевает, что
tread ≤ tsafe,g. Точнее:
-
В некоторых слчаях какая- то реплика может быть несомненно актуальной в соответствии с её внутренним состоянием и через TrueTime для обслуживания необходимых считываний и выполняет их.
-
В неких иных ситцациях може не иметься уверенности что она отслеживает самые последние сведения. Тогда она може запросить установленного лидера своей группы относительно значения верменной отметки самой последней транзакции, необходимой ей чтобы обслужить такое чтение.
-
Когда такая реплика сама по себе выступает установленным лидером, она способна продолжаться напрямую, ибо она всегда актуальна.
Spanner также поддерживает автономные ситывания вне значений контекста транзакций. Это не отличается существенным образом от всех операций считывания, выполняющихся как часть транзакций исключительного считывания. Например, их выполнение следует той же самой логике применяя некую заданную временную отметку. Эти чтения могут быть прочными (strong) или устаревшими (stale). Некое прочное чтение является считываием в текщий момент временной отметки и обеспечивает наблюдение всех данных, которые были зафиксированы до мемента начала этого считывания. Устаревшее считывание является чтением в момент временной отметки в определённом прошлом, которое может быть представлено соответствующим приложением или вычислено Spanner на основании определённой верхней границы устаревания. Некое устаревшее считывание ожидает обладания меньшей задержкой за счёт устаревания сведений, поскольку менее вероятно что соответствующей реплике потребуется ожидание перед обслуживанием её запроса.
Существует также и иной вид операций, носящих название разбиваемых на разделы DML. Они позволяют клиенту определять операцию обновления/ удаления в неком декларативном виде, который затем выполняется параллельно в каждой группе реплик. Такие параллельность и сами локально ассоциируемые данные превращают эти операции в очень действенные. Тем не менее, это сопровождается некими компромиссами. Такие операции обязаны быть целиком разбиваемыми на части, что подразумевает, что они должны вырааться как объединение некого набора операторов, причём каждый оператор выполняет доступ к отдельной строке своей таблицы, причём каждый оператор не имеет доступа к прочим таблицам. Это обеспечивает что всякая группа реплик будет способна исполнять такую операцию локально без какой бы то ни было координации с прочими группами реплик. Более того, такие операции должны быть идемпотентными, так как Spanner может выполнять некий оператор множество раз для одной и той же группы по причине переповторов на сетевом уровне. Spanner не обеспечивает гарантий атомарности для каждого оператора по всей таблице целиком, однако он предоставляет гарантии атомарности для каждой группы. Это означает, что некий оператор может выполняться лишь один раз для неких строк в определённой таблице, например, когда этот пользователь прекращает данную операцию по середине пути, или её исполнение отказывает в некоторых расщеплениях по причине нарушений ограничений.
FaunaDB является распределённым хранилищем данных, которое черпает вдохновение из протокола Calvin[62] для архитектуры своего ядра. Calvin основывается на следующем центральном соображении: реплицируя входные данные вместо действия на все различные узлы своей системы становится возможным обладать системой, которая более детерминирована когда все имеющиеся узлы без отказов проходят серез одни и те же состояния. Такой детерминизм способен избавляться определённой необходимости протоколов согласования, таких как двухфазная фиксация, при осуществлении распределённых транзакций, ибо все вовлекаемые в эту транзакцию узлы могут полагаться друг на друга выполняя обработку в точности тем же способом.
Абстрактно эта архитектура составляется из трёх уровней:
-
Уровень секвенирования: он ответственнен за получение входных данных/ команд и размещения их в неком глобаоьном порядке, который достигается через некий протокол согласования. Именно эта последовательность операций будет исполняться во всех имеющихся узлах.
-
Уровень составления расписания: отвечает за оркестрацию собственно выполнения транзакций применяя схему детерменированных блокировок для обеспечения эквивалентности соответствующему последовательному порядку определённому его уровнем секвенирования, при этом к тому же допуская одновременность выполнения транзакций.
-
Уровень сохранения: он отвечает за всю схему физических данных.
На практике каждый узел в FaunaDB одновременно выполняет три роли:
-
координатора запроса: отвечает за получение и обработку некого запроса. Как будет объяснено позднее, соответствующий запрос может обрабатываться локально или отправляться на прочие узлы, что основывается на его типе.
-
репликация данных: ответственна за сохранение данных и их обслуживание в процессе операций чтения.
-
журнал реплик: отвечает за достижение консенсуса по устанавливаемому порядку и его добавлению к имеющемуся глобально упорядоченному журналу.
Некий кластер составляется из трёх или более логический центров обработки данных (ЦОД), а данные разбиваются на разделы внутри ЦОД и реплицируются по ЦОД для увеличения производительности и доступности. Аналогично Spanner, консервируется множество версий всех элементов данных. FaunaDB применяет для консенсуса слега изменённую под себя версию Raft, который агрегирует запросы и для улучшения пропускной способности реплицирует их в пакеты. (эти пакеты именуются эпохами и обычное окно пакетирования составляет 10 миллисекунд с тем, чтобы получаемое воздействие на задержку не было значительным. Само упорядочение запросов достигается сочетанием значения номера эпохи и значения индекса в соответствующем запросе этого пакета.) Когда некий запрос достигает координатора запроса, он упреждающе выполняет необходимую транзакцию со значением самой последней известной временной отметки регистрации для обнаружения всех данных, к которым осуществляется доступ их этой транзакции, что также именуется замыслами (intents) чтения или записи. Сама обработка после этого отличается в зависимости от значения типа запроса:
-
Когда такой запрос является транзакцией чтения - записи, он переправляется в журнал реплик, что оеспечивает его запись в качестве части соответствующего следующего пакета, как подтверждённого через консенсус со всеми прочими репликами. Этот запрос затем переправляется во все реплики данных, которые содержат ассоциированные данные. Некое занимательное отличие от прочих систем состоит в том, что в FaunaDB обмен данными на этом этапе является основанном на активной доставке (push- based), а не на пассивной доставке (pull- based). Например, когда на протяжении некой транзакции реплике A требуется выполнить какую- то запись на основании данных, коими владеет реплика B, предполагается, что реплика Bотправляет необходимые данные в реплику A, вместо того чтобы их запрашивала реплика A. (Значительным преимуществом этого является меньшее число обмена сообщениями, что влечёт за собой снижение задержек. Допустим вопрос о том, а что произойдёт в случае отказа того узла, который предполагается отправляющим необходимые данные. В этом случае соответствующая реплика данных может вернуться обратно к запросу необходимых данных от прочих реплик в этом разделе.) В результате, каждая реплика данных блокируется до тех пор, пока она не получит от прочих реплик все необходимые сведения. Затем она разрешает эту транзакцию, применяет все локальные записи и выдаёт подтверждение об успехе своему координатору запроса. Важно отметить, что данные могут измениться с тех пор как осуществилось упреждающее выполнение их координатора запроса. Когда это происходит, такая транзакция будет прервана и потенциально может быть повторена, однако это будет неким единодушным решением, ибо все имеющиеся узлы будут выполнять эти операции в одном и том же порядке. Благодаря этому нет никакой потребности для каког бы то ни было протокла согласования, скажем, двухфазной фиксации.
-
Когда рассматриваемый запрос является транзакцией исключительного считывания, он отправляется в ту реплику (те реплики), которые содержат необходимые ассоциированные сведения или обрабатывается локально, если так получилось, что сам координатор запроса содержит все необходимые данные. Данная транзакция помечается временной отметкой с самой последней временной отметкой регистрации в журнале и для этой временной отметки и выполняются все операции считывания. Соответствующая библиотека клиента также поддерживает значение временной отметки наблюдавшейся на данный момент самой наивысшец позиции в журнале, что используется для обеспечения монотонно возрастающего упреждающего представления устанавливаемого порядка транзакции. Это обеспечивает причинную согласованность (causal consistency) в тех случаях, когда соответствующий клиент переключается с узла A на узел B в то время как узел B запаздывает относительно узла A в осуществлении транзакций из установленного журнала.
В отношении гарантий транзакции чтения - записи являются строго
упорядочиваемыми, а транзакции с исключительным чтением выступают просто
упорядочиваемыми. Тем не менее, транзакции с исключительным
чтением могут опционально становиться строго упорядочиваемыми пр помощи так называемых конечных точек
линеаризации. В этом случае такое считывание сочетается с записью без
операции и исполняется как обычная транзакция чтения - записи, проходящая через консенсус, тем самым получая некий
скачок (hit) задержки.
Для достижения подобных гарантий транзакции чтения - записи пользуются некой схемой пессимистичного управления
одновременностью на основе блокировок чтения, записи. Этот протокол является детерминированным, что подразумевает
что он обеспечивает получение и высвобождение блокировок всеми узлами в точности в том же самом порядке.
(Занимательным преимуществом этого является то, что предотвращаются взаимные блокировки. Существует литература,
которая более подробно изучает эти преимущества детерменизма в системах баз
данных[63]). Такой порядок определяется установленным в
общем журнале порядком соответствующих транзакций. Обратите внимание, что не препятствует одновременному выполнению
транзакций, это всего лишь требует чтобы блокировки для транзакции ti
могут быть запрошены только после выполнения запросов (и потенциально высвобождений) для всех предыдущих
транзакций tj (j < i)
Это означает, что все те данные, к которым выполняют доступ транзакции чтения/ записи должны быть известны заранее (Как уже пояснялось ранее, это не является строгим требованием, так как имеющийся координатор запроса осуществляет некий первоначальный запрос рекогнасцировки и содержит необходимые во всех подчинённых транзакциях результаты. По этой причине все имеющиеся реплики способны снова выполнять считывания в процессе этого исполнения данной транзакции и выявлять были ли изменены наборы чтения/ записи, причём при этом данная транзакция может быть прервана и повторена. Данная технология носит название OLLP - Optimistic Lock Location Prediction, Оптимистичного предсказания местоположения блокировки). Это означает, что FaunaDB не способна поддерживать интерактивные транзакции . Интерактивные транзакции являются такими, при которых клиент способен отслеживать открытие и выполнение операций динамически и при этом потенциально осуществлять прочие не относящиеся к этой базе данных операции. В пртивоположность этому, в FaunaDB транзакции объявляются один раз и отправляются на обработку. Интерактивные транзакции всё ещё могут имитироваться через некое сочетание считываний моментальных снимков и операций сравнения- и- замены (compare-and-swap).
Рисунок 7.18 содержит некое концептуальное представление описывавшейся до сих пор архитектуры. На этом рисунке каждая роль отображается отдельно для того чтобы вооружить пониманием того как эти различные функции взыимодействуют. Тем не менее, некий отдельный узел способен выполнять все эти роли, как это пояснялось ранее.
Apache Kafka является системой обмена сообщениями с открытым исходным кодом, изначально разработанная Linkedin[64][65], а затем пожертвованная Apache Software Foundation. Первоочередными целями Kafka были:
-
производительность: возможность обмена сообщениями между системами с высокой пропускной способностью и низкими задержками.
-
масштабируемость: способность инкрементально масштабироваться на большие тома данных добавляя в имеющуюся систему дополнительные узлы.
-
надёжность и доотупность: способность предоставления надёжности и доступности данных даже при наличии отказов узлов.
Центральным понятием Kafka выступает тематический раздел (topic). Некий тематический раздел это какая- то упорядоченная коллекция сообщений. Для всякого тематического раздела может иметься множество поставщиков, которые записывают в него сообщения. Также может существовать множество потребителей, которые считывают из него сообщения. (Это подразумевает что Kafka способна поддерживать как модель точка - точка, так и издатель - подписчик в зависимости от используемого число потребителей.) Для достижения производительности и масштабируемости каждый тематический раздел сопровождается как некий разбитый на разделы журнал, который хранится на множестве узлов, именуемых брокерами. Каждый раздел упорядочен, причём неизменной последовательностью сообщений, где каждому сообщению назначается некий номер последовательного идентификатора, имеющего название смещения (offset), который уникальным образом указывает на всякое сообщение внутри данного раздела. Сообщения от поставщиков всегда добавляются в самый конец своего журнала. Потребители способны поглощать записи в любом порядке в котором они желают предоставлять некое смещение, однако обычно потребитель будет выставлять наперёд свои смещения линейным образом по мере того как он считывает записи. Это предоставляет некую полезную гибкость, которая делает возможным для потребителей выполнять такие вещи как воспроизводить данные начиная с некого более старого смещения или пропускать сообщения и начинать с более поздних смещений. Все сообщения хранятся Kafka на постоянной основе и удерживаются для некого настраиваемого периода, носящего название периода срока хранения, причём вне зависимости от того поглощались ли они какими- то клиентами.
Как уже пояснялось ранее, все журналы разбиваются на разделы по множеству серверов в неком кластере Kafka. Записываемые поставщиками сообщения распределяются по этим разделам. Это может выполняться просто неким карусельным образом для балансировки нагрузки, либо значение раздела может выбираться конкретным поставщиком в соответствии с некой функцией семантики разбиения на разделы (например, на основании некого атрибута в данном сообщении и функции разбиения на разделы), а потому такие родственные сообщения хранятся в одном и том же разделе. Каждый потребитель некого тематического раздела может обладать множеством экземпляров потребителя для увеличения производительности, которые идентифицируются посредством некого имени группы потребителя. Поглощение реализуется таким образом, что разделы в неком журнале подразделяются по установленным экземплярам потребителя, а потому каждый экземпляр выступает исключительным потребителем некой "справедливой доли" разделов. В результате, всякое публикуемое в неком тематическом разделе сообщение доставляется одному экземпляру потребителя внутри всякой группы потребителей. Всякий раздел также реплицируется по некому настраиваемому числу узлов для устойчивости к отказам. Каждый разде обладает одним узлом, который выступает в роли лидера, а ноль или более серверов действуют в качестве последователей (followers). Установленный лидер обрабатывает все запросы на чтение и запись для своего раздела, в то время как последователи пассивно реплицируют своего лидера. В случае отказа установленного лидера один из имеющихся последователей будет выявлен автоматически и станет новым установленным лидером.
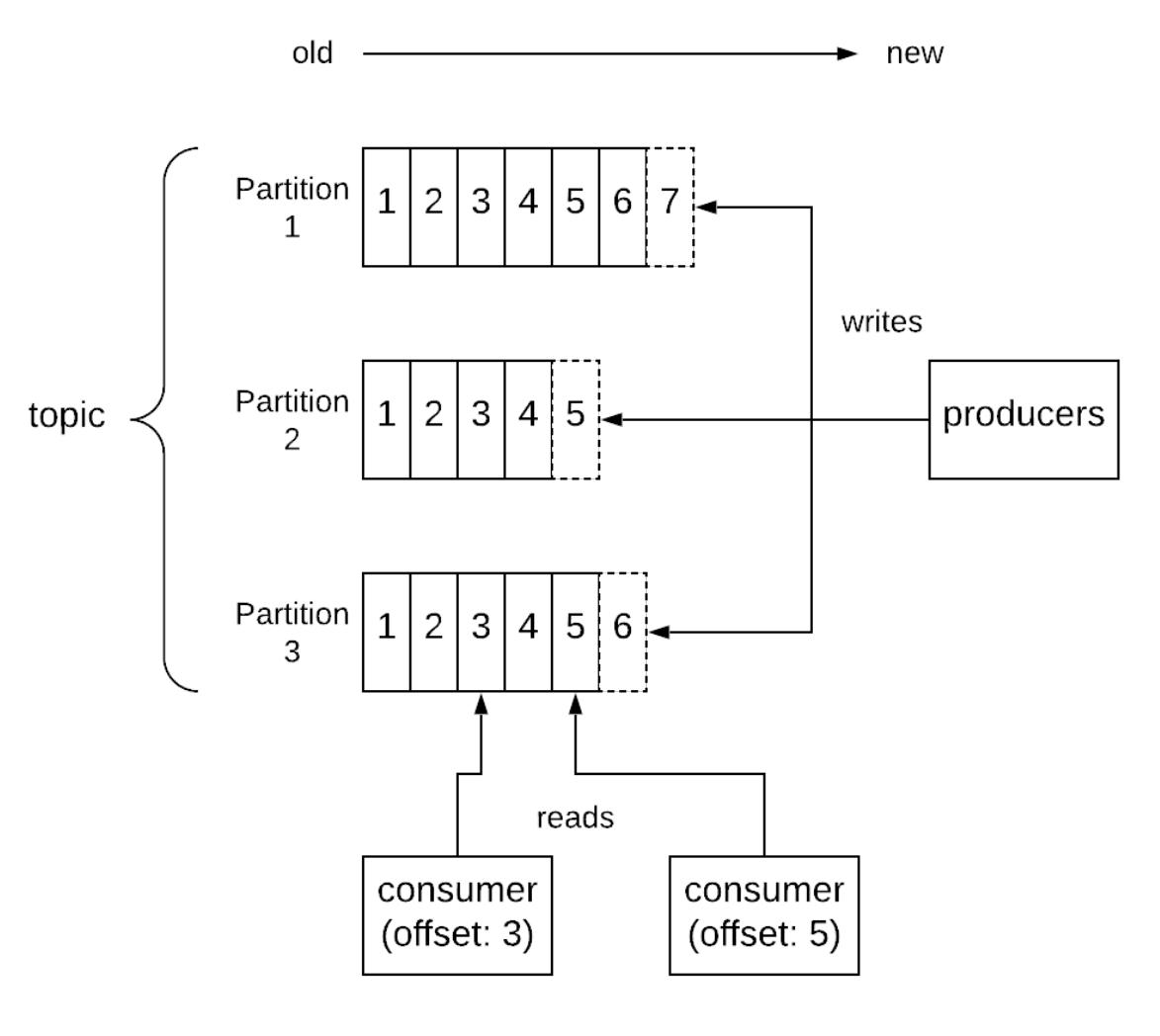
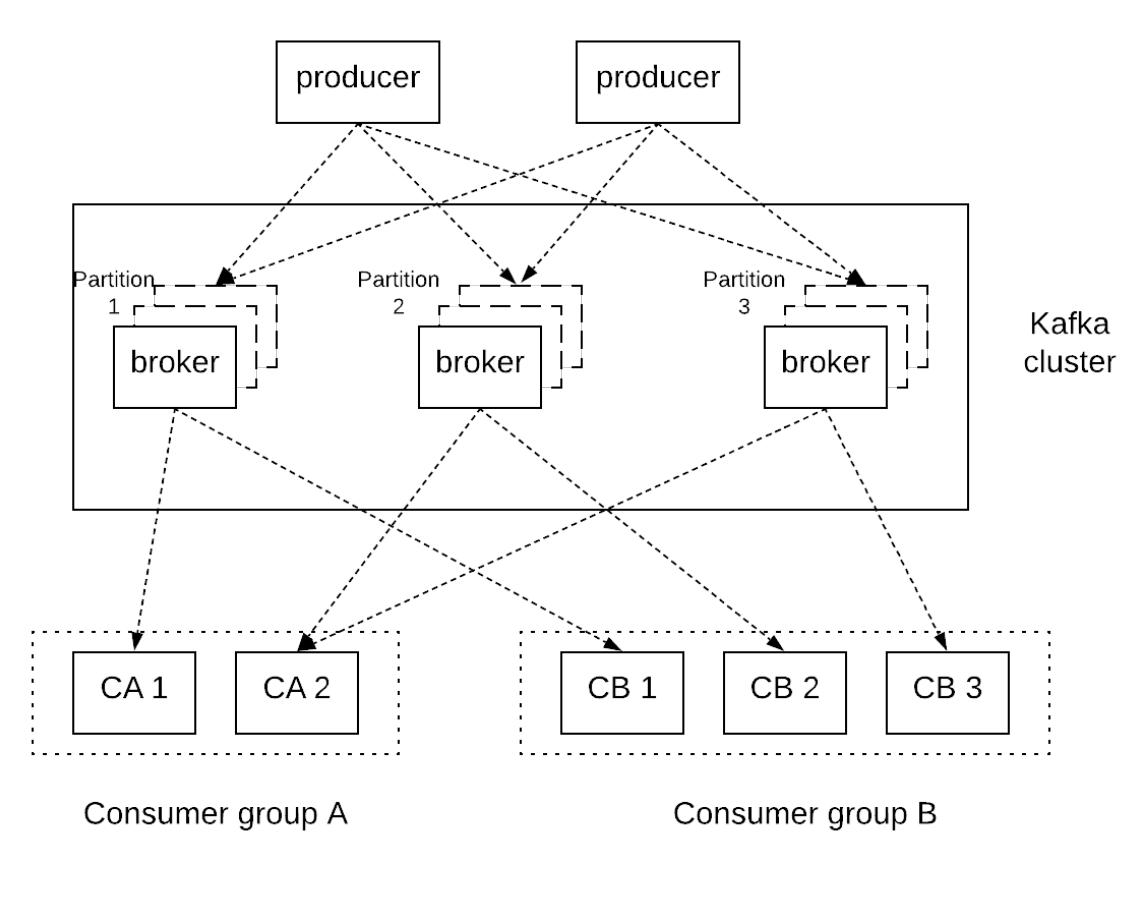
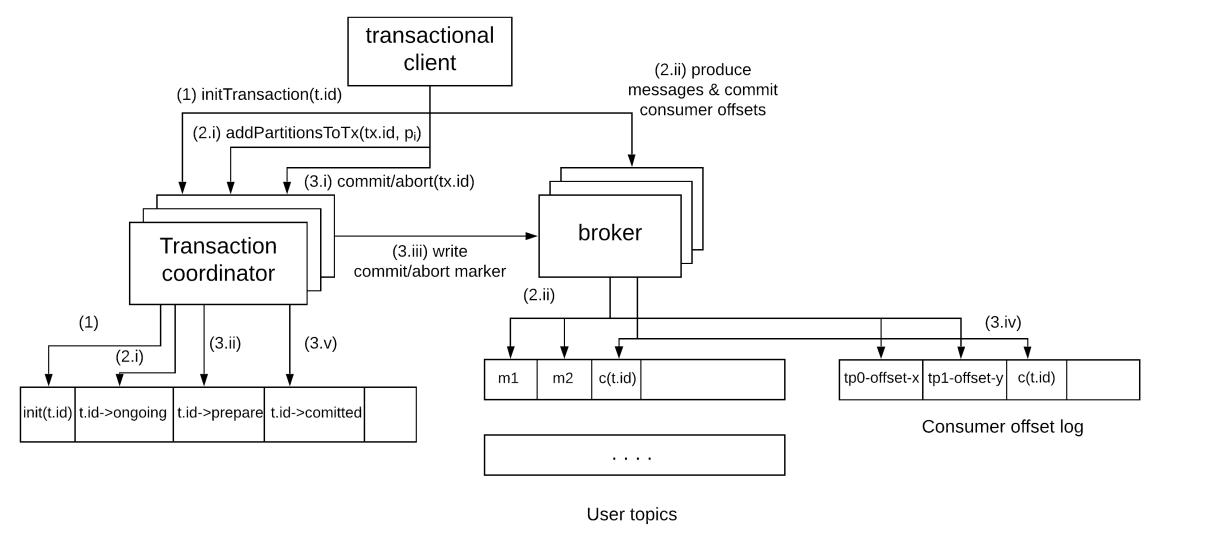
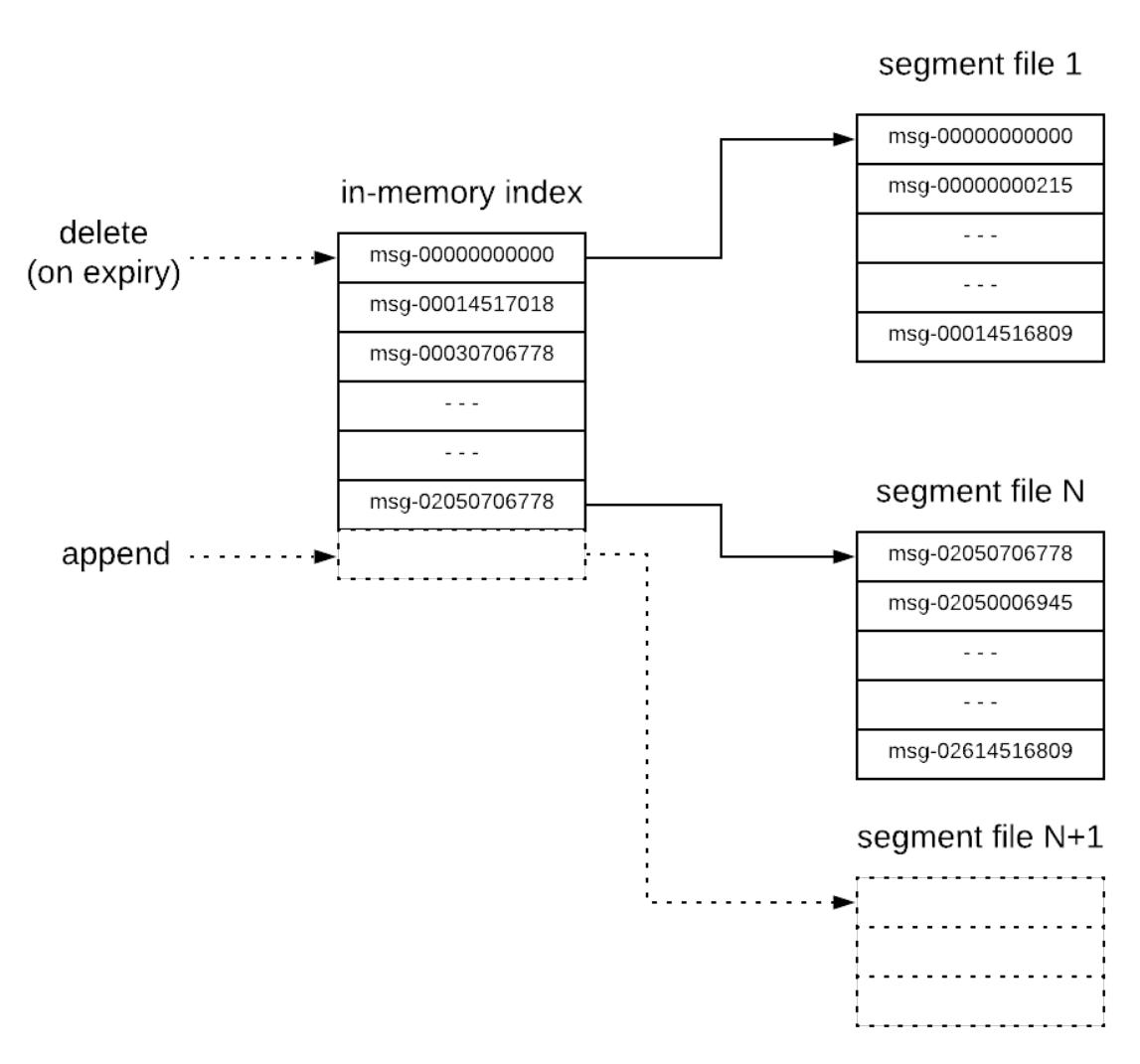
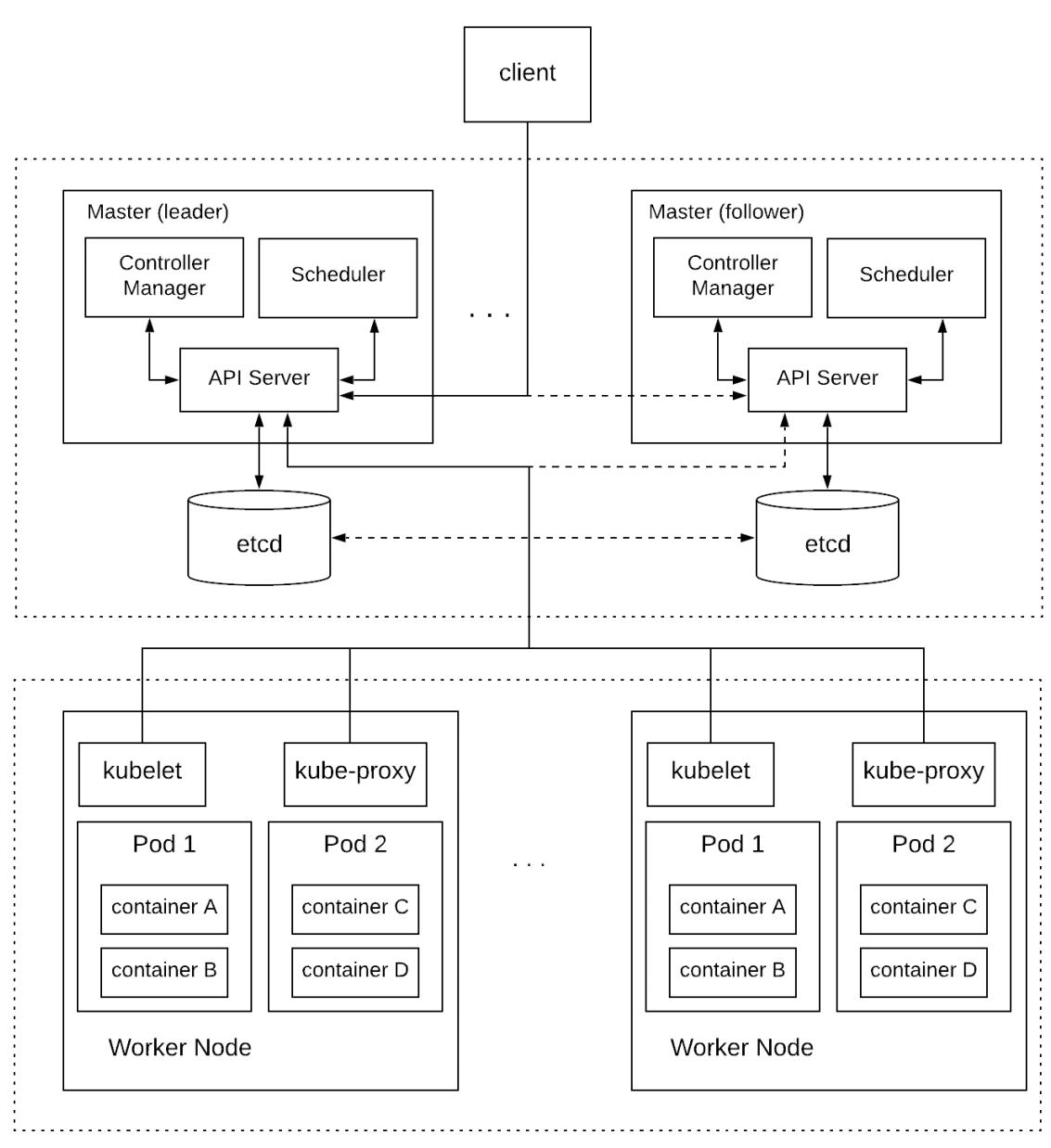
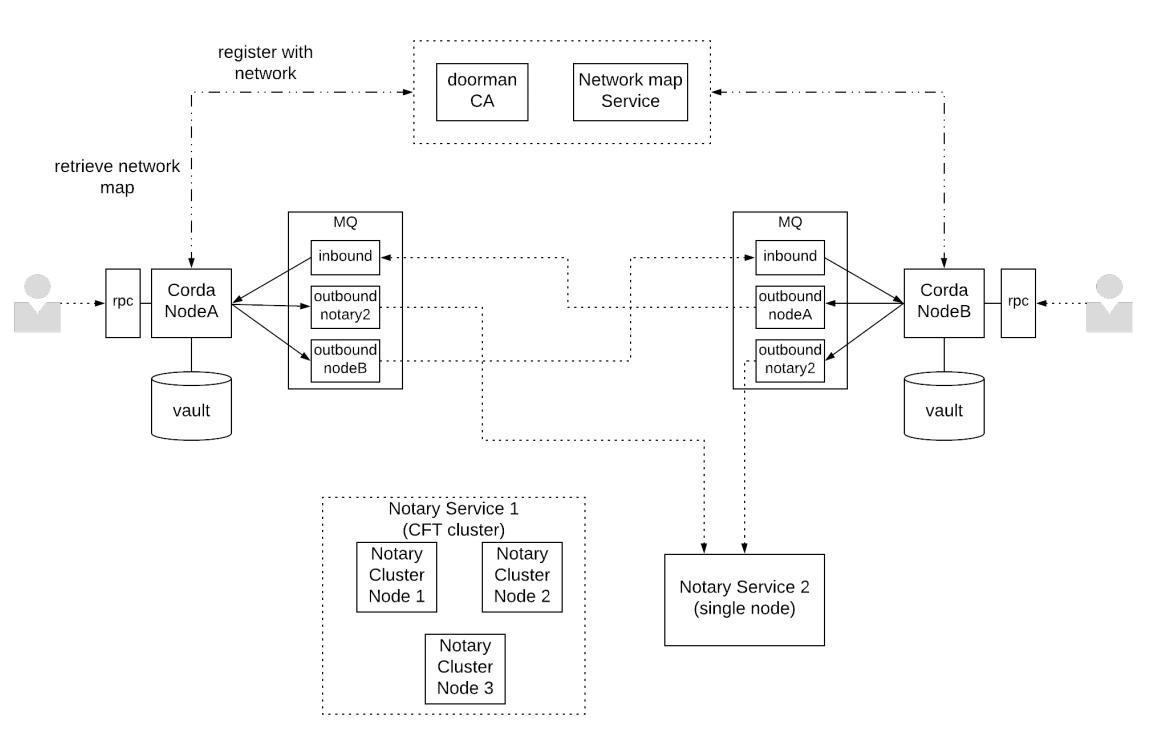
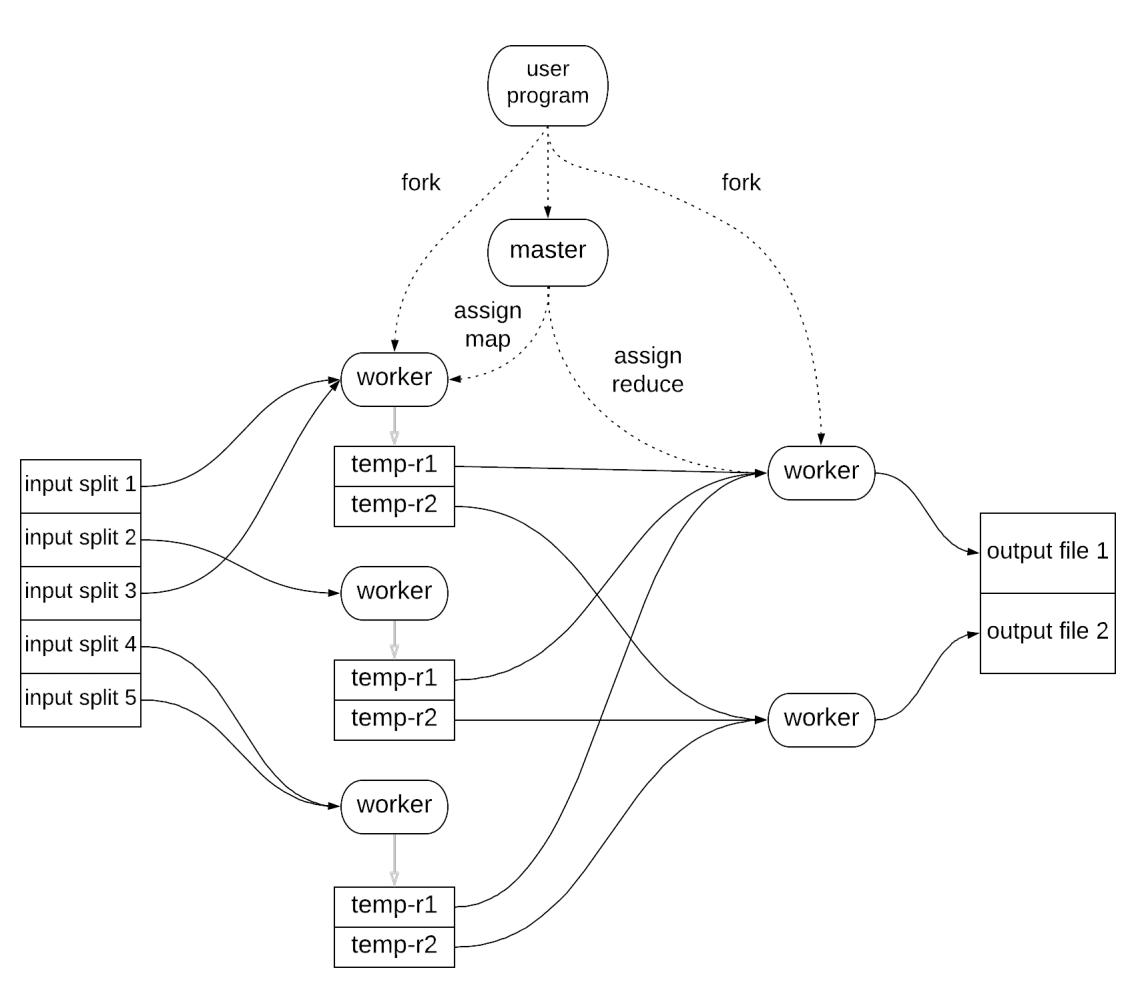
Рисунок 7.29
Примеры узких и широких зависимостей. Все большие прямоугольники являюся некими RDD, в то время как серые прямоугольники представляют разделы соответствующего RDD.
Рисунок 7.31
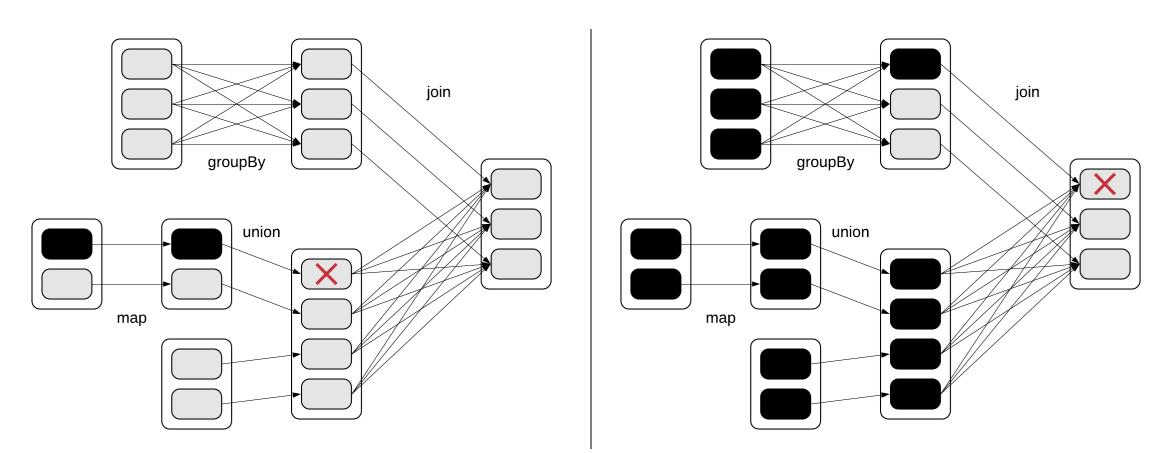
Воздействие широких зависимостей на восстановление после отказов. Красные кресты указывают на отказ некой задачи, вычисляющей определённый раздел какого- то RDD. Чёрные прямоугольники пердставляют соответствующие разделы RDD, которые требуется вычислять повторно когда они не сохранены.