Глава 11. Управление базой данных
Содержание
Никакой стек приложений не является законченным без данных и они обычно хранятся в некой базе данных. Существуют мириады баз данных на выбор когда вашей платформой является Linux, причём все темы управления и администрирования базами данных часто гарантированно дпют целую книгу саму по себе - на практике обычно одна книга под технологию базы данных. Несмотря на обширность этой темы, небольшое знание Ansible может оказать значительное содействие когда речь заходит об администрировании базой данных.
Тем не менее, будете ли вы устанавливать некий новый сервер базы данных, либо осуществлять задачи сопровождения или администрирования для имеющегося, всё ещё применим наш первоначальный принцип, изложенный в Главе 1, Построение стандартной среды работы в Linux. Действительно, зачем вам предпринимать стандартизацию своей среды Linux и обеспечивать автоматизацией все внесения изменений, настаивая на управлении на уровне баз данных исключительно только вручную? Это запросто может приводить к утрате стандартизации, возможности аудита и даже отслеживаемости (например, того кто, когда и какие изменения вносил?). Ansible способен выполнять действия с базой данных и настраивать их через модули. Возможно, это не заменяет некоторые из наиболее утончённых инструментов управления базами данных, которые присутствуют на рынке, но, когда они способны управляться через командную строку, их можно исполнять от вашего имени, а также позаботиться о самих по себе многих из задач. В конечном счёте, вы желаете чтобы все изменения документировались (или были самостоятельно документируемыми), а также подлежали бы аудиту и реально помочь вам в этом способен Ansible (в сочетании с Ansible Tower или AWX). В данной главе рассматриваются методы, способные оказать вам в содействии этому.
В данной главе будут рассмотрены такие вопросы:
-
Установка баз данных посредством Ansible
-
Импорт и экспорт данных
-
Осуществление повседневного сопровождения
Данная глава содержит примеры, основывающиеся на следующих технологиях:
-
Сервер Ubuntu 18.04 LTS
-
CentOS 7.6
-
Ansible 2.8
Для прохождения этих примеров вам потребуется доступ к двум серверам или виртуальным машинам с запущенными в них по одной из перечисленных здесь операционных систем, а также Ansible. Обратите внимание, что приводимые в этой главе примеры могут быть по своей природе разрушительными (например, они устанавливают и убирают установку пакетов и вносят изменения в настройки сервера), и при их исполнении как есть, они подразумевают запуск в некой изолированной среде.
После того как вы убедились в безопасности той среды, в которой вы работаете, давайте начнём с рассмотрения установки новых программных пакетов при помощи Ansible.
Все обсуждаемые в этой книге примеры доступны в GitHub.
В Главе 7, Управление настройками при помощи Ansible, мы изучили несколько примеров установки пакетов и пользовались для некоторых из своих примеров базой данных MariaDB. Естественно MariaDB всего лишь одна из мириадов доступных в Linux баз данных, причём здесь имеется слишком много подробностей для рассмотрения. Тем не менее, Ansible способен помочь вам в установке в Linux практически любого сервера баз данных и в данной главе мы проследуем чередой примеров, которые снабдят вас необходимыми инструментами и техническими приёмами для установки вашего собственного сервера баз данных, причём вне зависимости от того, какую именно применяете вы.
Давайте в своём следующем разделе приступим к сборке своего образца установки MariaDB.
Хотя ранее в этой книге мы и устанавливали собственный пакет mariadb-server,
поставляемый с CentOS 7, большинство нуждающихся в неком сервере MariaDB предприятий выбрало бы стандартизацию
определённого выпуска напрямую из MariaDB. Зачастую он более современный, чем те выпуски, которыми снабжается некий
конкретный выпуск Linux, а следовательно предоставляет более новые характеристики, а иногда и улучшения производительности.
Кроме того, выполнение стандартизации некого выпуска напрямую с MariaDB обеспечивает слаженность вашей платформы,
того принципа, которому следуем на протяжении всей этой книги.
Давайте остановимся на неком простом примере - допустим, вы запускаете в своей инфраструктуре Red Hat Enterprise Linux (RHEL) 7. Он снабжён MariaDB версии 5.5.64. Теперь, предположим, вы желаете выполнить стандартизацию своей инфраструктуры с более новым выпуском RHEL 8 - когда вы полагаетесь на те пакеты, которые поставляются Red Hat, это несомненно подвигнет вас на до версии 10.3.11 MariaDB, подразумевая что вы обновите не только свою инфраструктуру Linux, но также и свои базы данных.
Вместо этого было бы лучше осуществлять стандартизацию с упреждением напрямую с самого MariaDB. На момент написания этих строк самой стабильной версией MariaDB являлась 10.4 - однако давайте допустим, что вы придерживаетесь стандарта с версией 10.3, поскольку он известен как наиболее последний успешный для вашей среды.
Данный процесс установки достаточно прямолинеен и хорошо задокументирован на собственном веб сайте MariaDB - https://mariadb.com/kb/en/library/yum/ для придерживающихся CentOS и Red Hat примеров. Тем не менее, это подробности процесса установки вручную, а мы бы желали автоматизировать его при помощи Ansible. Давайте теперь соберём его в настоящий, рабочий пример на Ansible.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
В данном примере мы будем следовать тем инструкциям от MariaDB, которые содержат выгрузку необходимых пакетов из их репозитория. Хотя для упрощения мы последуем именно им в данном примере, вы, тем не менее, можете зеркалировать репозитории пакетов MariaDB в Pulp или Katello, как это было подробно описано в Главе 8, Управление репозиторием предприятия при помощи Pulp и Главе 9, Внесение исправлений при помощи Katello. . |
-
прежде всего мы можем заметить в документации по установке, что нам потребуется создать некий файл
.repo, чтобы указатьyumоткуда выгружать необходимые пакеты. Для осуществления этого мы можем воспользоваться неким шаблоном, таким, в котором может задаваться некой переменной применяемая версия MariaDB, и тем самым изменить её в дальнейшем при переходе к версии 10.4 (либо в конечном счёте любую последующую версию), когда сочтём это необходимым.Итак, наш файл шаблона
roles/installmariadb/templates/mariadb.repo.j2будет выглядеть как- то так:[mariadb] name = MariaDB baseurl = http://yum.mariadb.org/{{ mariadb_version }}/centos7-amd64 gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB gpgcheck=1 -
После его создания нам также требуется создать некое значение по умолчанию для данной переменной, чтобы предотвратить какие бы то ни было проблемы или ошибки если она не задана при запуске соответствующей роли - оно будет определяться в
roles/installmariadb/defaults/main.yml. Обычно данная переменная предоставлялась бы в в надлежащем файле описи для некого конкретного сервера или группы серверов, либо одним из многих прочих поддерживаемых в Ansible способов, однако файлdefaultsпредоставляет некую ловушку на случай когда вы пропустили определение. Выполните такой код:--- mariadb_version: "10.3" -
Задав данное значение мы теперь можем приступить к сборке необходимых задач своей роли в
roles/installmariadb/tasks/main.ymlследующим образом:--- - name: Populate MariaDB yum template on target host template: src: templates/mariadb.repo.j2 dest: /etc/yum.repos.d/mariadb.repo owner: root group: root mode: '0644'Это снабдит нас записью в надлежащий сервер корректного файла репозитория, а в случае даже если он неверно изменён,восстановит его первоначальное желательное состояние.
![[Замечание]](/common/images/admon/note.png)
Замечание В CentOS или RHEL вы также можете воспользоваться для осуществления данной задачи модулем Ansible
yum_repository- однако от обладает тем недостатком, что не позволяет изменять некое установленное определение имеющегося репозитория, а следовательно, в той ситуации, когда мы можем пожелать изменить значение версии своего репозитория, нам лучше применять некий шаблон. -
Далее нам надлежит очистить свой кэш
yum- это в особенности важно при обновлении MariaDB до новой версии, ибо названия пакетов будут теми же самыми, а имеющиеся в кэше данные способны вызвать проблемы при установке. В данный момент времени очистка имеющегося кэшаyumдостигается с помощью модуляshellдля запуска соответствующей командыyum clean all. Однако поскольку это некая команда оболочки, она будет выполняться всегда, а это можно рассматривать как уступку эффективности - в особенности когда данную команду надлежит запускать во всех последующих действиях с пакетом, необходимых для обновления вашего кэша вновь, даже когда мы не изменяли определение значения определения репозитория MariaDB. Таким образом, мы бы желали запускать его лишь задача нашего модуляtemplateимеет результатом некое изменение состояния.Для этого нам следует вначале добавить такую строку в свою задачу
templateчтобы сохранять необходимые результаты данной задачи:register: mariadbtemplate -
Теперь, когда мы задали свою команду оболочки, мы можем указать Ansible запускать её только когда наша задача
templateприводит в результате к состояниюchangedследующим образом:- name: Clean out yum cache only if template was changed shell: "yum clean all" when: mariadbtemplate.changed -
Располагая надлежащим образом очищенным кэшем, теперь мы можем установить все необходимые пакеты MariaDB - приводимый далее в блоке кода перечень данной задачи взят из документации MariaDB, на которую мы ссылались ранее вэтом разделе,но вам следует подгонять его с учётом точных собственных требований:
- name: Install MariaDB packages yum: name: - MariaDB-server - galera - MariaDB-client - MariaDB-shared - MariaDB-backup - MariaDB-common state: latestПрименение
state: latestобеспечивает что вы всегда устанавливаете самые последние пакеты из указанного файла репозитория, созданного вашей задачейtemplate. Тем самым данная роль может применяться в равной степени как для изначальной установки, так и для обновления до самой последней версии. Тем не менее, когда вам не желательно подобное поведение, измените данный оператор наstate: present- это всего лишь обеспечит установку в вашем целевом хосте всех перечисленных пакетов. Когда они присутствуют, это не вызовет их обновления до самой последней версии - а всего лишь выдаст значение состоянияokи продолжит выполнение следующей задачей, даже в случае наличия обновлений. -
После установки необходимых пакетов нам следует обеспечить что данная служба сервера затем запускается в момент начальной загрузки. Вероятно мы желаем запустить её и сейчас с тем, чтобы мы имели возможность выполнить работы по первоначальной настройке в ней. Итак, мы добавим окончательную задачу для своей роли
installmariadbкоторая выглядит как- то так:- name: Ensure mariadb-server service starts on boot and is started now service: name: mariadb state: started enabled: yes -
Кроме того, нам известно, что - name: Ensure mariadb-server service starts on boot and is started now service: name: mariadb state: started enabled: yes обладает включённым по умолчанию межсетевым экраном - а раз так, нам надлежит изменить имеющиеся правила данного межсетевого экрана чтобы обеспечить возможность доступа к нашему вновь установленному серверу MariaDB. Задача осуществления этого будет выглядеть как- то так:
- name: Open firewall port for MariaDB server firewalld: service: mysql permanent: yes state: enabled immediate: yes -
Давайте теперь запустим эту роль и рассмотрим её в действии - её вывод должен выглядеть похожим на следующее:
Для сохранения места приведённый вывод был усечён, однако он ясно отображает прохождение нашей установки.
Обратите внимание, что все предупредительные сообщения были безопасно проигнорированы - имеющийся механизм Ansible
обнаружил нашу команду yum clean all и услужливо предложил нам воспользоваться
своим модулем yum, однако этот модуль yum
не снабжает нас той функциональностью, которая нам нужна, а следовательно мы вместо этого пользуемся модулем
shell.
Обладая поднятой и запущенной базой данных нам необходимо далее осуществить три задачи, определённые на верхнем уровне следующим образом:
-
Обновить полученные настройки MariaDB.
-
Осуществить меры безопасности для данной установки MariaDB
-
Загрузить в соответствующую базу данных первоначальные данные (или схемы).
Что касается этих задач, мы подробно изучили применяемые в Ansible методы модуля
template для управления настройками MariaDB в
Главе 7, Управление настройками при помощи Ansible
(см. соответствующий раздел Проведение
масштабируемых изменений динамических конфигураций), а раз так, здесь мы не будем вдаваться в детали -
тем не менее, проверьте структуру файла настроек под выбранную вами версию MariaDB, поскольку она может быть
отличной от показанной в вышеупомянутой главе.
|
| Совет |
|---|---|
|
После того как вы установили в подобной CentOS платформе RPM MariaDB, вы можете обнаружить где обитают
соответствующий файл настроек, выполнив команду |
Таким образом, в предположении что вы получили на руки установку и настройку своего сервера баз данных, давайте
продолжим работы по её безопасности. Они, по крайней мере, потребуют изменить целиком значение пароля
root, хотя также надлежащая практика рекомендует также удалить и удалённый
доступ root, полученную базу данных test, а также учётные записи анонимного
пользователя, которые предоставляются установкой MariaDB по умолчанию.
|
| Совет |
|---|---|
|
MariaDB поставляется с утилитой командной строки с названием |
Для отделения этих задач от собственно установки мы создадим некую новую роль с названием
securemariadb. Прежде чем мы сможем определить необходимые задачи, нам следует
определить некую переменную для содержания значения пароля root под установку MariaDB. Отметим, что обычно вам бы
следовало предоставлять это более безопасноым образом - возможно при помощи файла Vault Ansible, или применяя
имеющиеся современные свойства в AWX или Ansible Tower. Для упрощения,в данном примере мы зададим некий файл переменных
в данной роли (roles/securemariadb/vars/main.yml) таким образом:
---
mariadb_root_password: "securepw"
Теперь давайте соберём необходимые задачи для данной роли. Для применения в управлении базами данных Ansible содержит несколько собственных модулей и здесь мы можем воспользоваться этим для внесения необходимых изменений в свобю базу данных MariaDB.
|
| Замечание |
|---|---|
|
Тем не менее, обратите внимание, что некоторые модули обладают определёными требованиями Python и в случае с
нашим примером системы - MariaDB в CentOS - нам следует установить |
Осознавая это, самым первым шагом при сборке нашей роли является установка данного предварительно необходимого пакета Python следующим образом:
---
- name: Install the MariaDB Python module required by Ansible
yum:
name: MySQL-python
state: latest
Псле данной установки нашей немедленной задачей является установка значения пароля в соответствующей локальной учётной записи root и предотвращении регистрации кого бы то ни было без аутентификации. Исполните такой код:
- name: Set the local root password
mysql_user:
user: root
password: "{{ mariadb_root_password }}"
host: "localhost"
До сих пор это был пример из учебника для того как применять имеющийся модуль mysql_user
- однако в данном месте имеется некий поворот в использовании. Наш предыдущий пример пользуется преимуществом того
факта, что не установлен никакой пароль root - осуществляется манипуляция этой базой данных в неявном виде от имени
root в силу того факта, что мы поместим в своём файле
site.yml установку become: yes
и тем самым наш плкйбук будет запущен от имени root. На тот момент, когда
исполняется данная задача, наш пользователь root не обладает никаким паролем, а следовательно вышеупомянутая задача
выполнится успешно.
Ответом на это является добавление соответствующих параметров login_user
и login_password в наш модуль для всех последующих задач для обеспечения нашей
успешной аутентификации в соответствующей базе данных для осуществления необходимых задач.
|
| Совет |
|---|---|
|
Данная роль выполнится успешно лишь один раз с момента написания - при повторном запуске для пользователя
root MariaDB будет установлен некий пароль и предыдущая задача завершится неудачно. Тем не менее, если мы определим
|
Осознавая это условие, мы теперь способны добавить в свою роль другую задачу для удаления имеющихся учётных записей удалённого root следующим образом:
- name: Delete root MariaDB user for remote logins
mysql_user:
user: root
host: "{{ ansible_fqdn }}"
state: absent
login_user: root
login_password: "{{ mariadb_root_password }}"
И вновь этот код достаточно поясняет себя самостоятельно - тем не менее, также обратите внимание на то, что вторичный запуск этой задачи также даст некую ошибку, на это раз по той причине, что при повторном запуске данные полномочия отсутствуют, так как мы удалили их при первом исполнении. Итак, почти несомненно данная роль только для однократного запуска - либо следовало бы применять аккуратное рассмотрение для данного кода и надлежащую логику обработки ошибки.
Теперь мы добавляем задачу для удаления установленных учётных записей анонимных пользователей таким образом:
- name: Delete anonymous MariaDB user
mysql_user:
user: ""
host: "{{ item }}"
state: absent
login_user: root
login_password: "{{ mariadb_root_password }}"
loop:
- "{{ ansible_fqdn }}"
- localhost
Здесь вы обнаружите применение некого loop - он применяется для удаления
как имеющихся локальных, так и удалённых полномочий напару внутри единственной задачи. Наконец, мы удаляем
установленную базу данных test, которая избыточна для большинства вариантов
применения в предприятиях, выполняя такой код:
- name: Delete the test database
mysql_db:
db: test
state: absent
login_user: root
login_password: "{{ mariadb_root_password }}"
Полностью завершив данную роль, мы можем запустить её обычным образом и сделать вновь установленную базу данных безопасной. Получаемый вывод должен выглядеть как- то так:
При помощи этих двух ролей и неких входных данных из Главы 7, Управление настройками при помощи Ansible, мы успешно установили, настроили и оседлали безопасной базу данных MariaDB в CentOS. Это, очевидно, слишком конкретный пример - тем не менее, если бы вы выполняли его в Ubuntu, такой процесс был бы очень похожим. Основные отличия были бы следующими:
-
Во всехзадачах вместо модуля
yumвы бы пользовались модулемapt. -
Для Ubuntu следовало бы изменить названия пакетов.
-
Задание источника репозитория следовало бы осуществить в
/etc/aptвместо/etc/yum.repos.d, причём с соответствующей наладкой формата этого файла. -
Для MariaDB в Ubuntu пути настроек могут отличаться.
-
Обычно, вместо
firewalldUbuntu применяетufw- а по умолчанию выможете обнаружить чтоufwотключён, и поэтому данный шаг можно будет пропустить.
Принимая во внимание эти изменения, наш предыдущий процесс можно очень быстро приспособить для Ubuntu (или,
в конечном счёте, для любой иной платформы, в предположении что выполнены все надлежащие изменения). После того
как необходимые пакеты установлены и настроены, благодаря тому что модули mysql_user
и mysql_db являются кроссплатформенными, они будут в равной степени успешно
работать во всех поддерживаемых платформах.
До сих пор в данной книге мы были очень интенсивно сосредоточены на MariaDB это не связано с каким бы то ни было врождённым пристрастием по отношению к этой базе данных и действительно не следует к этому относиться как к некой рекомендации. Она просто была выбрана в качестве уместного примера и строилась на протяжении всего текста. Прежде чем мы продолжим рассмотрение интересующего нас процесса загрузки данных или схем во вновь установленную базу данных, в своём следующем разделе мы кратко рассмотрим как применять данный только что изученный нами процесс в другой популярной базе данных Linux - PostgreSQL.
В этом разделе мы продемонстрируем как наши принципы и рассмотренные нами на верхнем уровне до сих пор для MariaDB в CentOS процессы могут применяться для иной платформы. Рассматривая эти процессы на верхнем уровне, их можно применять практически к любой базе данных и любой платформе при надлежащем внимании к деталям. В данном случае мы установим сервер PostgreSQL на сервере Ubuntu, а далее осуществим меры по безопасности настроив значение пароля root - естественно, аналогично тому процессу, который мы выполнили в своём предыдущем разделе.
Давайте начнём с создания роли с названием installpostgres. В этой роли мы
вновь определим некий шаблон для выгрузки необходимого пакета из официальных источников PostreSQL, на этот раз -
естественно - подгоняя их под то основание, что мы применяем сервер Ubuntu, а не CentOS. Приводимый далее код
отображает наш файл шаблона - обратите внимание что он специфичен для сервера Ubuntu 18.04 LTS - имеет кодовое имя
bionic:
deb http://apt.postgresql.org/pub/repos/apt/ bionic-pgdg main
Как и ранее, после определения источника нашего пакета мы можем продолжить создавать необходимые задачи, которые
установят надлежащую базу данных. В случае Ubuntu нам следует добавить вручную в имеющееся для
apt кольцо ключей необходимый ключ подписи пакета. Таким образом, наши задачи внутри
создаваемой роли начинаются таким образом:
---
- name: Populate PostgreSQL apt template on target host
template:
src: templates/pgdg.list.j2
dest: /etc/apt/sources.list.d/pgdg.list
owner: root
group: root
mode: '0644'
Здесь мы также можем воспользоваться apt_repository, однако для согласованности
со своим предыдущим примером MariaDB мы применяем шаблон. Оба подхода приводят к одному и тому же результату.
Поместив куда требуется пакет template, далее нам надлежит добавить в
кольцо ключей apt значение ключа подписи пакета таким манером:
- name: Add key for PostgreSQL packages
apt_key:
url: https://www.postgresql.org/media/keys/ACCC4CF8.asc
state: present
После этого (в соответствии с документацией https://www.postgresql.org/download/linux/ubuntu/) устанавливаются
postgresql-11 и прочие пакеты:
- name: Install PostgreSQL 11 packages
apt:
name:
- postgresql-11
- postgresql-client-11
state: latest
update_cache: yes
Поскольку наш устанавливаемый по умолчанию сервер Ubuntu не запускает какой бы то ни было межсетевой экран, наша завершающая задача в данном плейбуке состоит в запуске данной службы и обеспечении того, что она запускается в момент начальной загрузки следующим образом:
- name: Ensure PostgreSQL service is installed and started at boot time
service:
name: postgresql
state: started
enabled: yes
Запуск этого должен выдать вам вывод, похожий на следующее:
По умолчанию, устанавливаемый стандартным образом PostgreSQL намного более
безопасен нежели MariaDB. Без каких бы то ни было дополнительных настроек никакая удалённая регистрация в нём не
доступна вовсе и, хотя никакой пользователь и не назначается учётной записи суперпользователя, к нему можно
осуществлять доступ исключительно с локальной машины от имени учётной записи пользователя
postgres. Аналогично нет никакой проверочной базы данных для её удаления.
Таким образом, хотя на своём верхнем уровне этот процесс и аналогичен, вам следует быть информированным о нюансах обоих серверов применяемых нами баз данных и лежащих в их основе операционных систем.
Следуя примеру и чтобы покончить с данным разделом, давайте создадим некую базу данных с названием
production и связанного с ней пользователя с именем
produser, которому будет предоставлен доступ к ней. Хотя технически это и
пересекается с нашим следующим разделом по загрузке первоначальных данных, мы предоставляем здесь это по
аналогии с нашим предыдущим разделом MariaDB и показываем как применять собственные модули Ansible для PostreSQL.
-
Давайте создадим некую роль с названием
setuppostgresи начнём определять задачи установки пакетов Ubuntu, необходимых для поддержки подулей PostgreSQL Ansible таким образом:--- - name: Install PostgreSQL Ansible support packages apt: name: python-psycopg2 state: latest -
После этого мы добавим задачу создания необходимой базы данных (это очень простой пример - вы можете следовать своим собственным требованиям):
- name: Create production database postgresql_db: name: production state: present become_user: postgres -
Обратите внимание как мы пользуемся имеющейся локальной учётной записью
postgresв своей целевой машине для доступа суперпользователя к базе данных при помощи соответствующего оператораbecome_user. Далее мы добавляем необходимого пользователя, снабжая его полномочиями для этой базы данных следующим образом:- name: Add produser account to database postgresql_user: db: production name: produser password: securepw priv: ALL state: present become_user: postgresКак обычно, вам не следует просто определять значение пароля в открытом тексте - это было сделано для простоты. Как правило, для переменных подставляются надлежащие данные, а если эти переменные являются чувствительно важными, они либо шифруются в надлежащем месте при помощи Vault Ansible, либо выдаётся приглашение для пользователя на их ввод при выполнении данного плейбука.
-
Теперь, чтобы получить PostgreSQL ожидающим удалённых подключений для данного пользователя, нам потребуется осуществить два дополнительных действия. Нам потребуется добавить в
pg_hba.confнекую строку, чтобы указать PostgreSQL на возможность только что созданного нами пользователя выполнять доступ к этой базе данных из надлежащей сетевой среды - наш приводимый далее пример показывает как, но проверьте что вы подогнали его под свою сетевую среду и её требования:- name: Grant produser access to the production database over the local network postgresql_pg_hba: dest: /etc/postgresql/11/main/pg_hba.conf contype: host users: produser source: 192.168.81.0/24 databases: production method: md5 -
нам также следует изменить параметр
listen_addressesв имеющемся файлеpostgresql.conf, который по по умолчанию настроен лишь на локальное подключение. Точное местоположение данного файла будет отличаться в зависимости от вашей операционной системы и версии PostgreSQL - наш следующий пример показан в предположении нашей установки PostgreSQL 11 на сервере Ubuntu 18.04:- name: Ensure PostgreSQL is listening for remote connections lineinfile: dest: /etc/postgresql/11/main/postgresql.conf regexp: '^listen_addresses =' line: listen_addresses = '*' notify: Restart PostgreSQL -
Наблюдательный читатель мог заметить, что здесь мы также воспользовались обработчиком - наша служба
postgresqlдолжна перезапуститься чтобы подхватить все изменения в данном файле. Тем не менее, это должно выполняться только в с лучае изменений в данном файле, и поэтому мы применяем обработчики. Наш файлhandlers/main.ymlбудет выглядеть так:--- - name: Restart PostgreSQL service: name: postgresql state: restarted -
После того как наш плейбук собран,мы можем запустить его и вывод должен оказаться похожим на приводимый далее снимок экрана:
Хотя этот пример и не является репликацией в строгом смысле для нашего инструмента
mysql_secure_installation из предыдущего раздела, он на самом деле
показывает как применять собственные модули Ansible для настройки базы данных PostreSQL и её безопасности
и отображает насколько мощно Ansible способствует вам в настройке серверов баз данных и их безопасности. Эти же
принципы можно применять практически ко всем серверам баз данных, которые совместимы с Linux, хотя сами доступные
для каждой из баз данных модули могут и отличаться. Полный перечень модулей можно найти
здесь.
Теперь, когда мы рассмотрели сам процесс установки сервера баз данных, в своём следующем разделе мы соберём свою установку для работы и загрузим начальные сведения и схемы.
Никакая база данных не завершается просто установкой необходимого программного обеспечения и его настройкой - часто имеется важный промежуточный этап, который включает в себя загрузку некого первоначального набора данных. Это может быть резервная копия предыдущей базы данных, некий набор данных для целей проверок с удалёнными секретными сведениями, либо просто некая схема, в которую могут загружаться данные приложения.
Хотя Ansible обладает модулями для ограниченного набора функций базы данных, имеющаяся здесь функциональность
не такая полная как для прочих задач автоматизации. Наиболее полной предлагаемой поддержкой для базы данных со стороны
Ansible является сопровождение для PostgreSQL - с поддержкой в меньших размерах для некоторых прочих баз данных.
При помощи разумного применения модуля shell любая выполняемая вручную задача,
которую вы осуществляете в своей командной строке может быть реплицирована в некую задачу Ansible. Когда, к примеру,
некая база данных уже существует, вам следует применять к задачам логическую схему для обработки ошибок или условий
и мы рассмотрим некий пример этого в своём следующем разделе.
В нашем следующем разделе мы рассмотрим как вы можете применять Ansible для автоматизации обсуждаемой задачи загрузки образца базы данных в некую базу данных MariaDB.
MariaDB является хорошим выбором для данной главы, потому что она предлагает рассчитанное на большую аудиторию
представление когда речь заходит об управлении базой данных с помощью Ansible. В Ansible имеется некий собственный
модуль, но он не является полным для всех задач которые вы можете пожелать выполнять. В результате мы разработаем свой
следующий пример, который автоматизирует необходимую загрузку образца набора данных с применением лишь модулей
Ansible shell. Затем мы разработаем это так, чтобы показать как это можно
было бы совершить при помощи модуля mysql_db чтобы снабдить вас неким прямым
сопоставлением между этими двумя технологиями автоматизации.
|
| Замечание |
|---|---|
|
Обратите внимание, что все последующие выполняемые с помощью модуля |
Что касается образцов баз данных, мы будем работать с общедоступным образцом базы данных Сотрудников, поскольку она доступна для всех читающих данную книгу. Естественно, вы можете выбрать для работы свой собственный набор данных - тем не менее, как и всегда, мы надеемся что наш следующий практический пример научит вас навыкам, необходимым для загрузки данных во вновь установленную базу данных при помощи Ansible:
-
Для начала давайте создадим некую роль с названием
loadmariadb. В каталогеrolesэтой структуры создайте каталог с названиемfiles/и клонируйте соответствующий образец базы данныхemployees. Он общедоступен через GitHub и на момент написания этих строк его можно клонировать при помощи такой команды:$ git clone https://github.com/datacharmer/test_db.git -
Начиная с этого момента мы создаём внутри этой роли каталог
tasks/и записываем там необходимый код для самих задач нашей роли. Для начала нам потребуется скопировать собственно файлы базы данных в наш сервер базы данных выполняя такой код:--- - name: Copy sample database to server copy: src: "{{ item }}" dest: /tmp/ loop: - files/test_db/employees.sql - files/test_db/load_departments.dump - files/test_db/load_employees.dump - files/test_db/load_dept_emp.dump - files/test_db/load_dept_manager.dump - files/test_db/load_titles.dump - files/test_db/load_salaries1.dump - files/test_db/load_salaries2.dump - files/test_db/load_salaries3.dump - files/test_db/show_elapsed.sql -
После того как на наш сервер скопированы необходимые файлы данных, именно они становятся предметом загрузки в созданную базу данных. Тем не менее, для этой задачи нет никакого модуля, а потому нам приходится вернуться к некой команде оболочки для обработки этого, как это отображено в следующем блоке кода:
- name: Load sample data into database shell: "mysql -u root --password={{ mariadb_root_password }} < /tmp/employees.sql" args: chdir: /tmp -
Сами по себе создаваемые задачи роли являются простыми - однако прежде чем мы сможем запускать свой плейбук, нам потребуется настроить значение переменной
mariadb_root_password, причём в идеале в vault, но для упрощения в данной книге мы поместим её в открытом текстовом файлеvarsв данной роли. основной файлvars/main.ymlдолжен выглядеть примерно так:--- mariadb_root_password: "securepw"Как вы могли уловить, данный плейбук полагает что вы уже установили и настроили MariaDB некой предыдущей ролью - применяемое в нашем предыдущем блоке кода значение пароля установлено в предыдущем разделе когда мы устанавливали MariaDB и осуществляли мероприятия по её безопасности.
-
Выполнение данного плейбука должно дать результаты подобные таким:
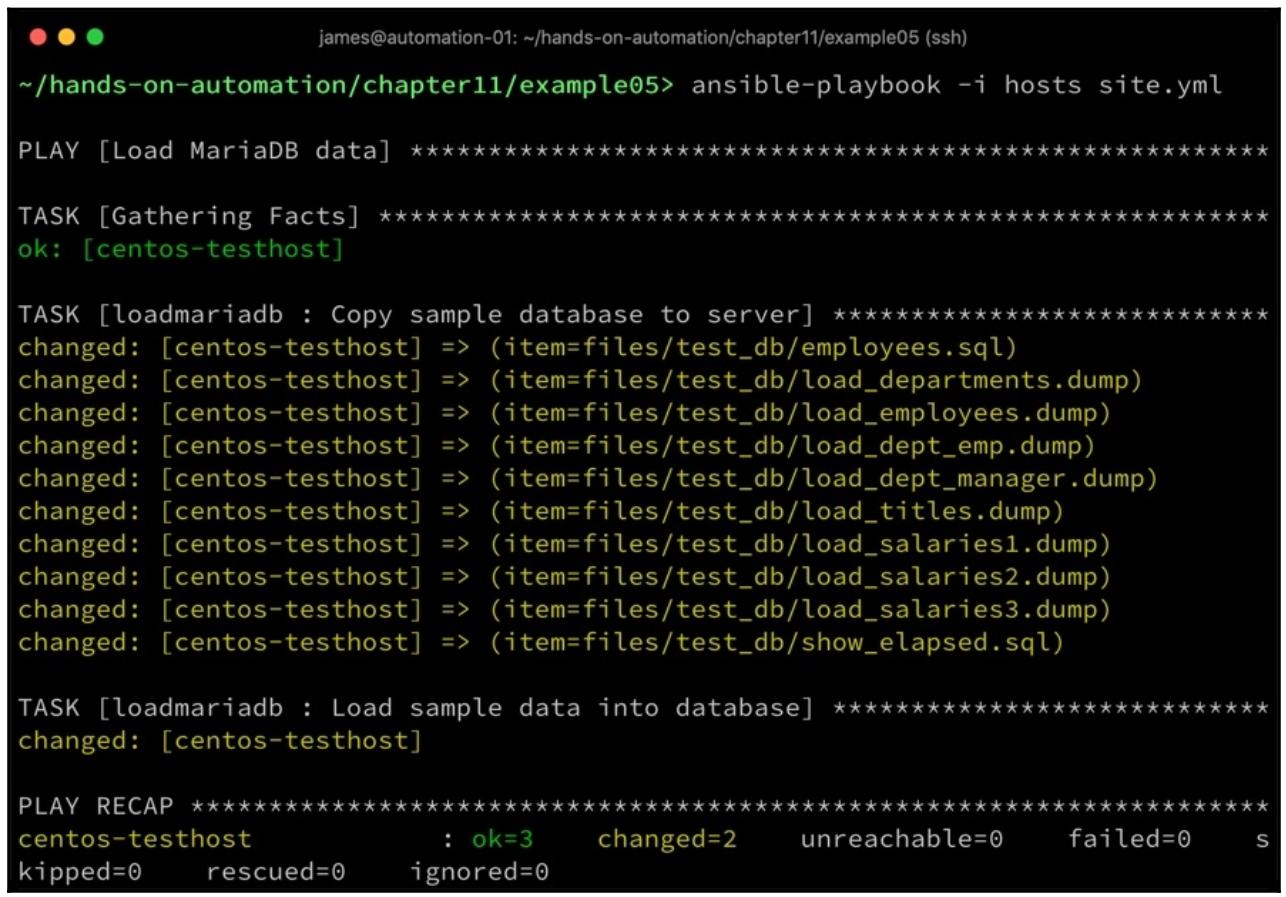
Здесь мы загрузили в свою базу данных не только некий образец схемы, но также и пример данных. Если то требуется, на своём предприятии вы можете выбирать выполнение этих задач по отдельности.
Вроятно вы заметили, что этот плейбук чрезвычайно не безопасен. Как мы уже обсуждали ранее, основная проблема
применения имеющегося в плейбуках Ansible модуля shell состоит в том, что
получаемые этой задачей результаты будут отличаться, так как применяемая команда оболочки исполняется всегда, вне
зависимости от того следует её выполнять или нет. Таким образом, когда вы выполняете этот плейбук для сервера с уже
имеющейся базой данных с названием employees, она бы переписала все имеющиеся
данные сведениями данного примера! В противоположность этому имеющийся модуль copy,
который копирует необходимые файлы только когда их уже нет на его принимающей стороне.
Учитывая на момент написания этих строк собственных модулей базы данных, нам потребуется разработать более разумный способ запуска данной команды. В данном случае мы мажем воспользоваться некими встроенными в Ansible интеллектуальными обработчиками ошибок.
Модуль shell предполагает что его команда выполнена успешно когда он
возвращает нулевой код выхода. Эти результаты данной задачи возвращаются значением состояния changed,
которое мы наблюдали при выполнении данного плейбука. Однако, когда значение кода выходане нулевое, наш модуль
shell вместо этого вернёт состояние failed.
мы можем воспользоваться преимуществом этих сведений и соединить их с полезной командой MariaDB, которая возвратит нулевой код выхода если база данных, к которой мы выполняем запросы, существует и не нулевое когда её нет. В качестве примера рассмотрим следуюший снимок экрана:
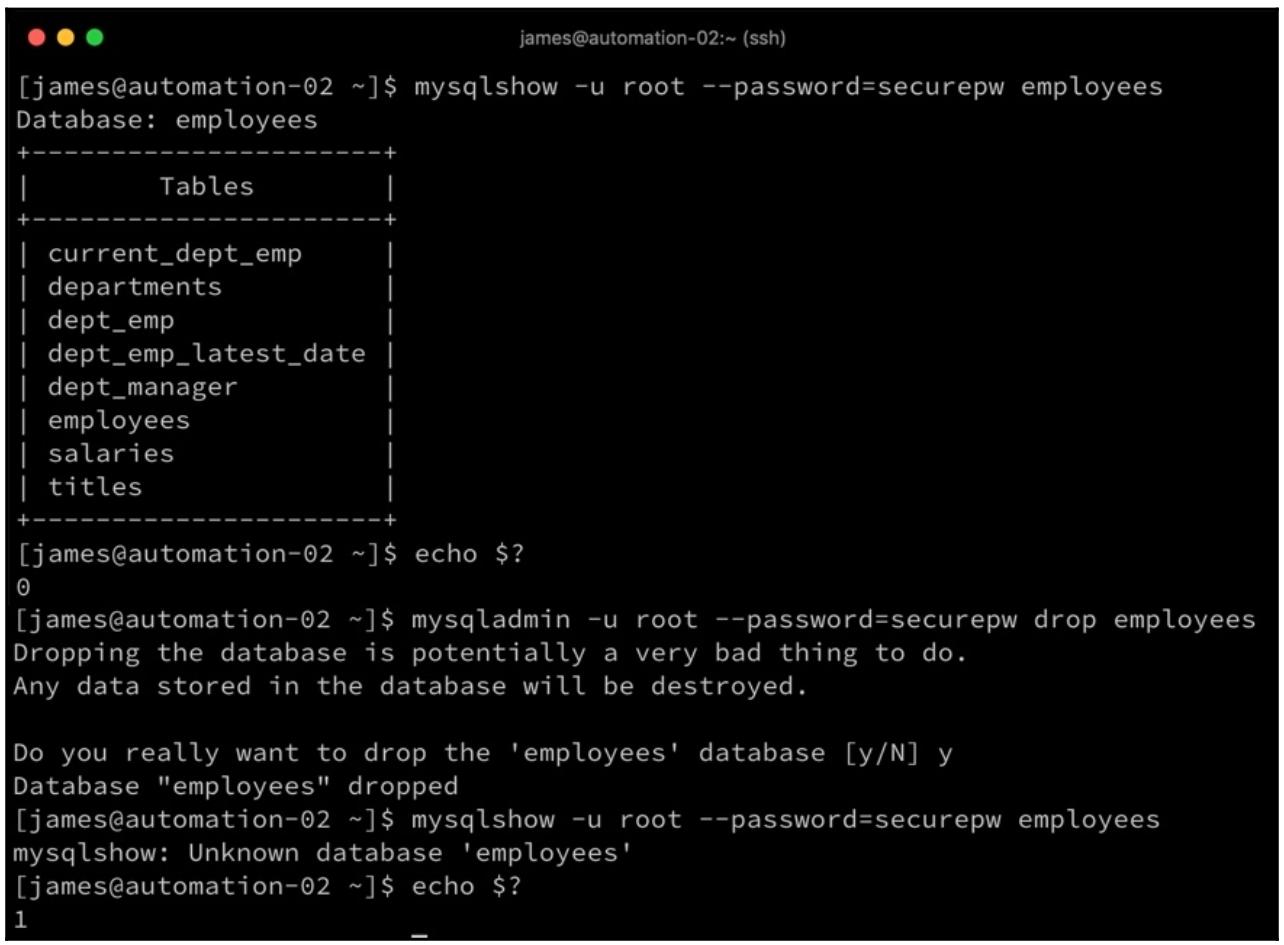
Мы можем воспользоваться этой командой, запуская её перед нашей загружающей данные задачей. Мы можем игнорировать от этой команды все ошибки и вместо этого регистрировать их в некой переменной. Мы можем воспользоваться ею для запуска по условию необходимой загрузки данных, загружая их только в случае возникновения некой ошибки (это именно тот случай, когда наша база данных отсутствует, а потому наша загрузки данных является безопасной).
Сама задача копирования остаётся той же самой, однако самый конец в хвосте этой задачи теперь выглядит так:
- name: Check to see if the database exists
shell: "mysqlshow -u root --password={{ mariadb_root_password }} employees"
ignore_errors: true
register: dbexists
- name: Load sample data into database
shell: "mysql -u root --password={{ mariadb_root_password }} < /tmp/employees.sql"
args:
chdir: /tmp
when: dbexists.rc != 0
Теперь мы будем загружать необходимые данные только когда эта база данных не существует. С целью предоставления в данном примере этот код был упрощён и мы оставляем вас вольными для его расширения - например, путём помещения соответствующих имён файлов и названия базы данных в некую переменную с тем, чтобы данная роль стала способной к повторному использованию в различных обстоятельствах (что, в конечном счёте, и является основными целями написания некой роли).
Когда теперь мы запускаем это код, мы можем обнаружить что он работает как мы и хотели - при его первом запуске необходимые данные загружаются, как это отображено на нашем следующем снимке экрана:
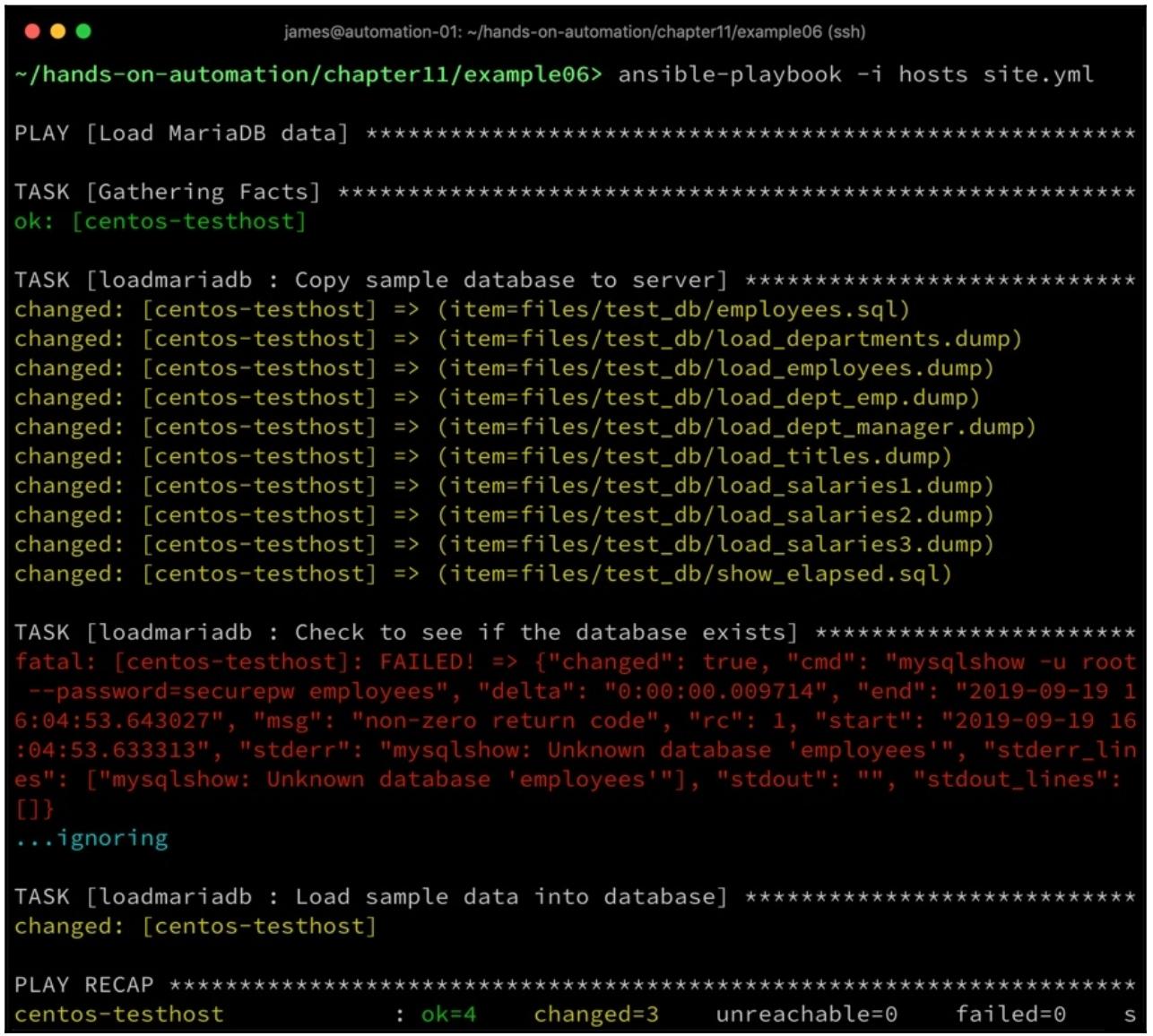
Тем не менее, при повторном запускке это не так - наш приводимый далее снимок экрана показывает, что когда наш плейбук запускается вторично, тогда загрузка данных опускается, так как эта база данных уже существует:
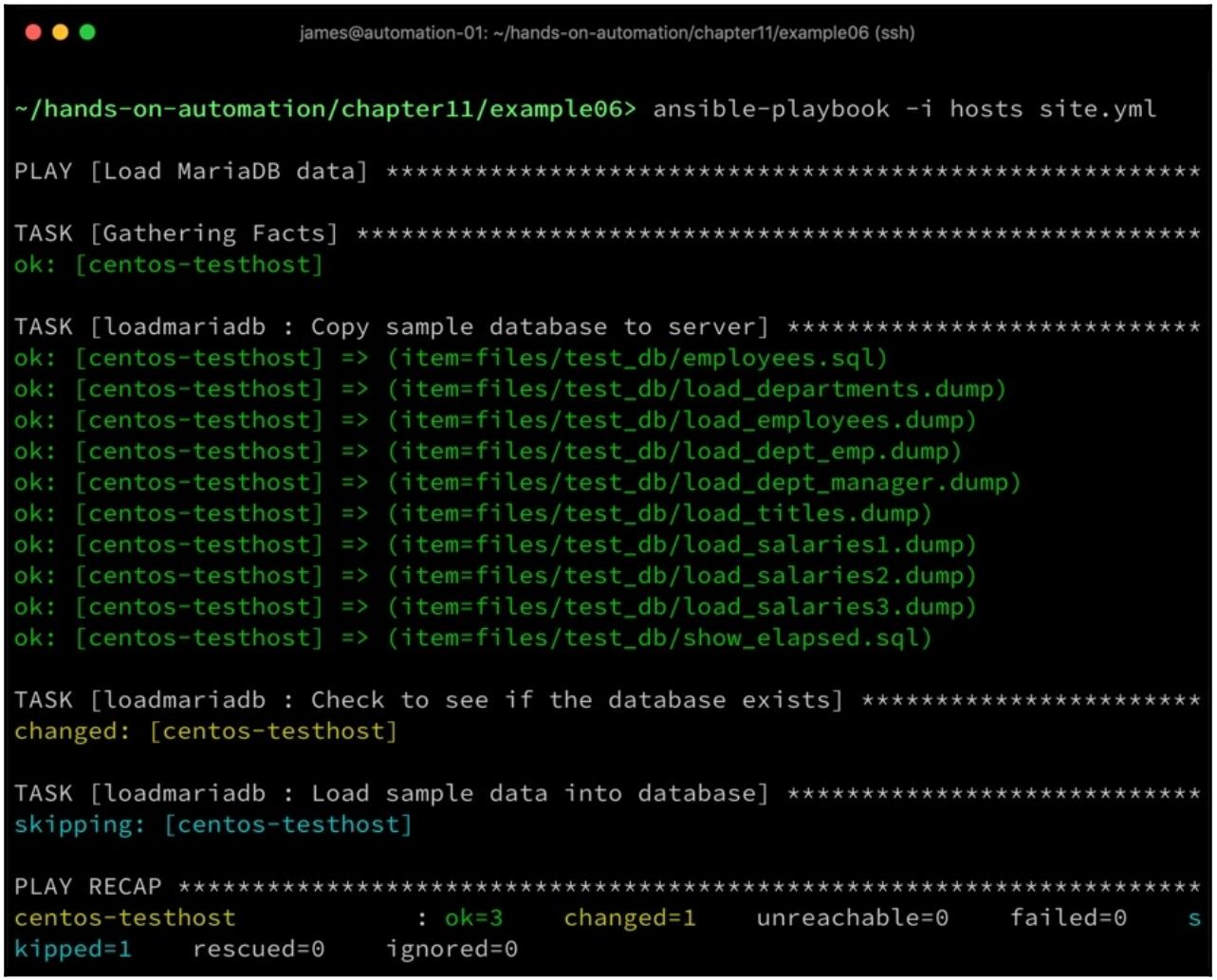
Хотя эти примеры и относятся только к MariaDB, сам выполняющийся здесь процесс на верхнем уровне работает с практически
всякой базой данных.Основным ключевым элементом здесь является применение модуля shell
для загрузки необходимых данных и/ или схемы, но делать это таким образом, чтобы сократить возможность перезаписи некой
действующей базы данных в случае когда наш плейбук запускается дважды. Вам следует расширять эту логику на все выполняемые
вами задачи - ваша окончательная цель должна состоять в том чтобы когда ваш плейбук запускается непредумышленно, тогда
для уже имеющейся базы данных не происходит никаких разрушений.
Покончив с этим примером, неплохо бы отметить что Ansible предоставляет модуль с названием
mysql_db, который является его собственным для обработки таких задач, как выдача
дампа или импорт сведений базы данных. Давайте теперь разработаем некий пример,который применяет собственный
модуль mysql_db:
-
Если бы мы разрабатывали некую роль для выполнения в точности той же самой задачи, которую мы показывали до этого, но при помощи собственного модуля, нам бы для начала следовало выполнить все проверки чтобы обнаружить существовала ли эта база данных ранее, регистрируя получаемый результат в некой переменной подобно следующему:
--- - name: Check to see if the database exists shell: "mysqlshow -u root --password={{ mariadb_root_password }} employees" ignore_errors: true register: dbexists -
Затем мы создаём в своём файле задач некий
block, так как нет никакого смысла запускать какие бы то ни было задачи после данного шага раз эта база данных существует. Нашblockприменяет выражениеwhen, которым мы пользовались ранее, для определения того следует ли выполнять имеющиеся внутри него задачи или нет:- name: Import new database only if it doesn't already exist block: when: dbexists.rc != 0 -
Внутри этого
blockмы копируем все необходимые файлы SQL для импорта точно так же,как мы делали это ранее, подобно следующему:- name: Copy sample database to server copy: src: "{{ item }}" dest: /tmp/ loop: - files/test_db/employees.sql - files/test_db/load_departments.dump - files/test_db/load_employees.dump - files/test_db/load_dept_emp.dump - files/test_db/load_dept_manager.dump - files/test_db/load_titles.dump - files/test_db/load_salaries1.dump - files/test_db/load_salaries2.dump - files/test_db/load_salaries3.dump - files/test_db/show_elapsed.sql -
Теперь возникает важное отличие между применением модулей
shellиmysql_db. При использовании модуляshellмы применяем параметрchdirдля изменения своего рабочего каталога на/tmp, который и является тем местом, в который были скопированы наши файлы SQL. Наш модульmysql_dbне обладает параметромchdir(или его эквивалентом), а потому завершится отказом попытка загрузки маски файлов*.dump, которые имеют источник черезemployees.sql. Для обработки этого мы применяем модульreplaceAnsible для добавления полного пути к этим файлам в соответствующих строках вemployees.sql, следующим образом:- name: Add full paths to employees.sql as mysql_db won't know where to load them from otherwise replace: path: /tmp/employees.sql regexp: '^source (.*)$' replace: 'source /tmp/\1' -
Наконец, мы применяем модуль
mysql_dbдля загрузки необходимых данных (это аналогично применению соответствующей команды оболочки, которую мы применяли в своём предыдущем примере):- name: Load sample data into database mysql_db: name: all state: import target: /tmp/employees.sql login_user: root login_password: "{{ mariadb_root_password }}" -
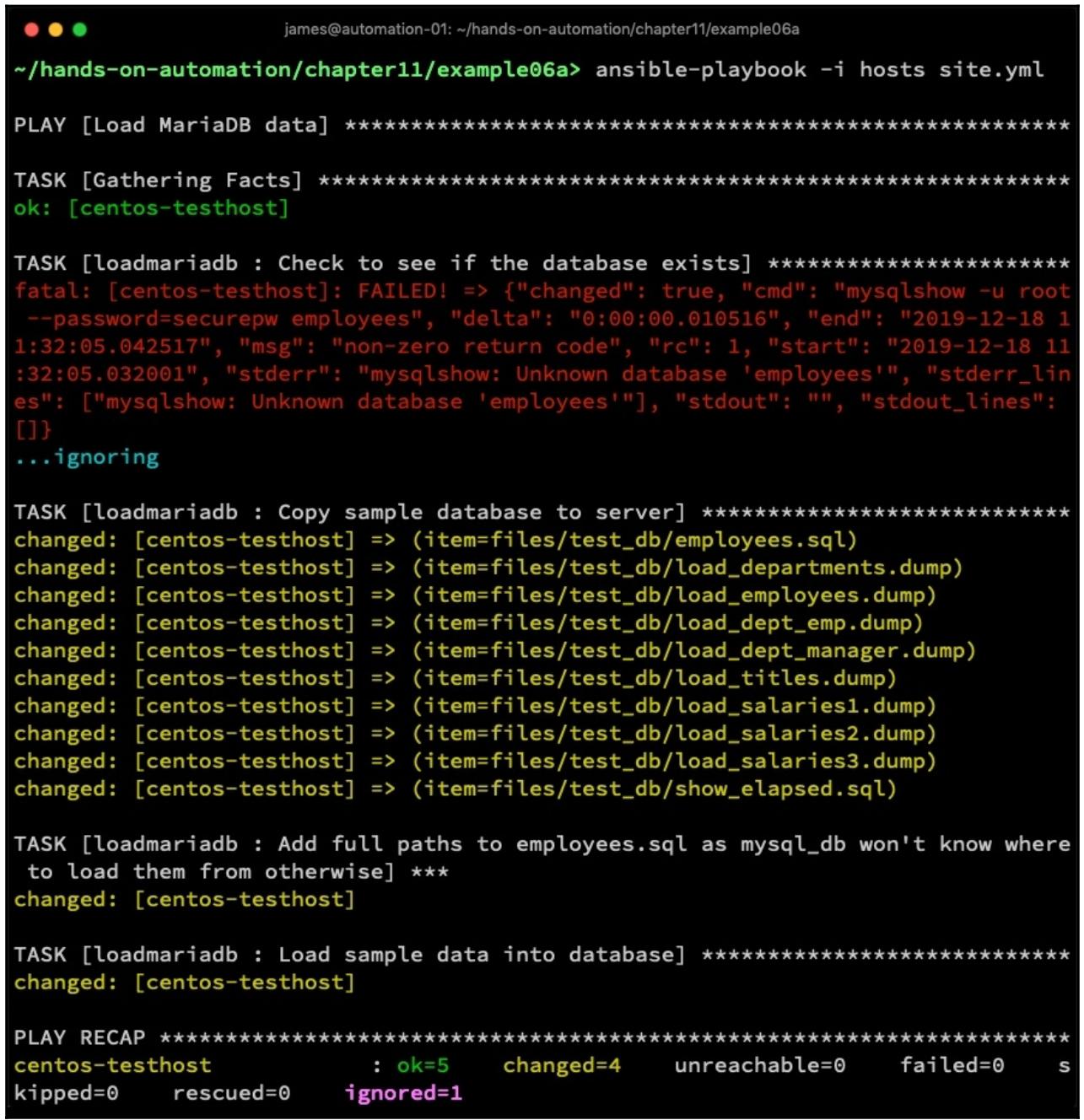
Когда мы запустим этот код, он предоставит нам тот же самый результат, которым снабжадла нас наша предыдущая роль, которая применяла модуль
shell, как это отображено на приводимом ниже снимке экрана:
Этот процесс в равной степени также хорошо работает и для резервных копий баз данных. Если бы мы применяли модуль
shell, мы бы воспользовались командой
mysqldump для резервного копирования базы данных, а затем скопировали бы дынные
резервной копии в свой хост Ansible (или, даже в другой) для архивирования. Некий образец фрагмента кода для достижения
этого можно сконструировать так:
-
Поскольку мы желаем чтобы значение имени файла резервной копии было бы динамическим и содержало бы полезные сведения, такие как значение текущей даты и имя хоста в котором осуществляется данное резервное копирование, мы применям модуль
set_fact, совместно и некоторыми прочими внутренними переменными Ansible для задания имени файла для своих данных резервной копии следующим образом:--- - name: Define a variable for the backup file name set_fact: db_filename: "/tmp/{{ inventory_hostname }}-backup-{{ ansible_date_time.date }}.sql" -
Затем мы применяем модуль
shellдля запускаmysqldumpс надлежащими параметрами для создания некой резервной копии - более глубокое их рассмотрение выходит за предмет данной книги, однако наш следующий пример создаёт некую резервную копию всех баз данных в ввшем сервере без блокирования своих таблиц на протяжении данного резервного копирования:- name: Back up the database shell: "mysqldump -u root --password={{ mariadb_root_password }} --all-databases --single-transaction --lock-tables=false --quick > {{ db_filename }}" -
После этого используется модуль
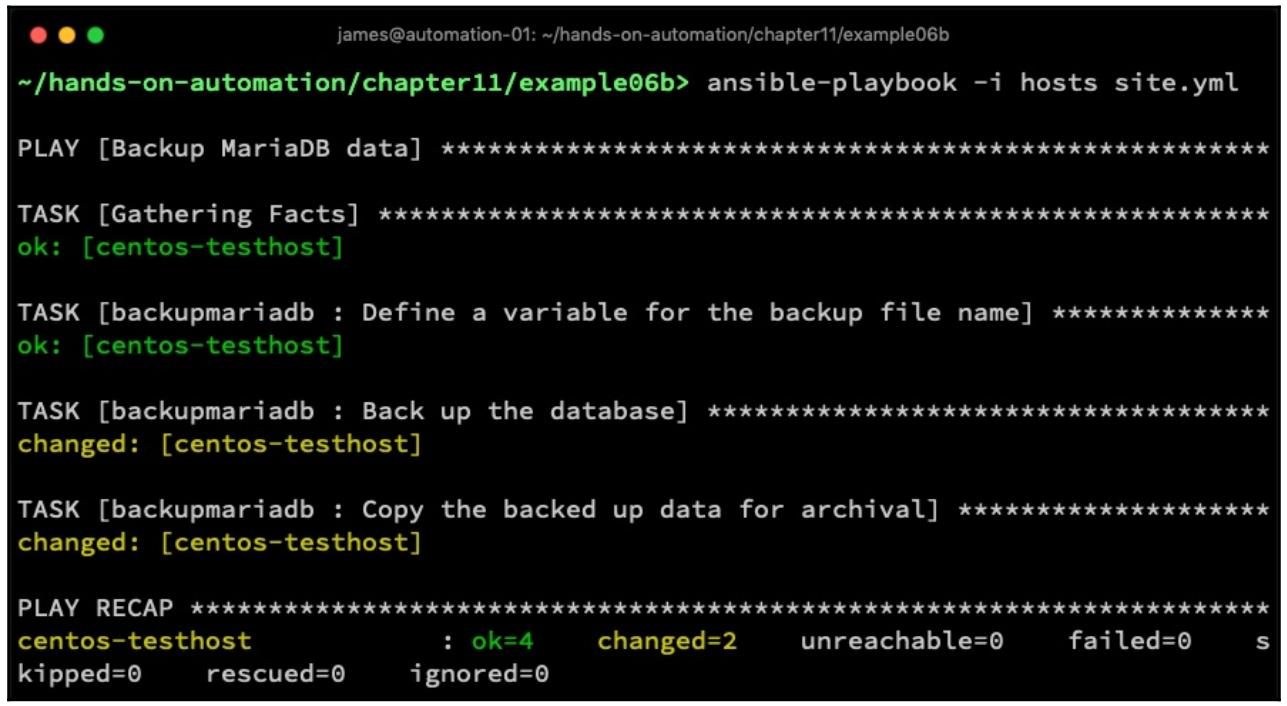
fetchдля выборки данных для архивирования -fetchработает в точности как и модульcopy, который мы применяли ранее в этом разделе, за исключением того что он копирует данные в обратном направлении (то есть из указанного в описи хоста в свой сервер Ansible). Выполните такой код:- name: Copy the backed up data for archival fetch: src: "{{ db_filename }}" dest: "/backup" -
Исполнение этого обычным образом имеет результатом полное резервное копирование указанной базыданных с копированием получаемого в конечном счёте файла на наш сервер Ansible, как это отображено на следующем снимке экрана:
Этот же пример может быть достигнут при помощи модуля mysql_db, в точности
как мы это делали ранее - задачи set_fact и
fetch остаются прежними, в то время как задача
shell заменяется таким кодом:
- name: Back up the database
mysql_db:
state: dump
name: all
target: "{{ db_filename }}"
login_user: root
login_password: "{{ mariadb_root_password }}"
Тем самым, Ansible сособен содействовать вам как в загрузке данных в ваши базы данных, так и в их резервном
копировании. Как мы уже обсуждали вначале, обычно лучше применять собственные модули Ansible (такие как
mysql_db), если они доступны, однакокогда собственные модули отсутствуют или
не предоставляют требующейся вам функциональности, соответствующий модуль shell
способен содействовать вам в предоставлении вам применения необходимой правильной логики в нём.
Теперь, когда мы рассмотрели процесс создания баз данных и загрузки в них сведений, мы продолжим в следующем разделе демонстрацию того как опираясь на проделанную работу выполнять повседневное обслуживание базы данных при помощи Ansible.
Загрузка схем и/ или данных не единственная задача, которую вы бы были способны выполнять при помощи Ansible с базой данных.
Порой в некую базу данных требуется вмешательство вручную. К примеру, PostgreSQL время от времени требует операций VACUUM
для высвобождения не используемого пространства в имеющейся базе данных. MariaDB обладает инструментарием сопровождения с
названием mysqlcheck, который может применяться для проверки имеющейся целостности
таблиц и осуществления оптимизации. Всякая платформа будет обладать своими собственными, присущими ей, инструментами для
операций поддержки и вам рекомендуется следовать таким практическим приёмам для сопровождения базы данных в выбранной вами
платформе. Более того, порой необходимо в некой базе данных выполнять простые изменения. Например, может потребоваться удаление
(или обновление) некой строки из какой- то таблицы для очистки от некой ошибочной ситуации, которая могла произойти в
одном из приложений.
Естественно, все эти действия могут быть выполнены вручную - однако это (как правило) приводит к некоторой степени риска утраты отслеживания того что происходит, кто запускал задачу и как она выполнилась (например, какие варианты были предоставлены). Когда мы переносим этот пример в мир Ansible и AWX, неожиданно мы получаем полный аудит следов действий и мы в точности знаем что было осуществлено и как это выполнялось. Более того, когда для некой задачи требуются особенные варианты, они будут сохранены внутри установленного плейбука и тем самым здесь будет также доступной и предоставляемое Ansible самодокументирование.
Поскольку наши примеры до сих пор вращались в целом вокруг MariaDB, давайте рассмотрим как осуществит полную регламентную очистку некой таблицы из PostgreSQL с помощью Ansible.
PostgreSQL это некий особый случай в Ansible, так как он обладает большим числом естественных модулей для сопровождения
действий с базой данных нежели большинство прочих баз данных. Давайте рассмотрим некий образцовый вариант: осуществление
очистки в таблице sales.creditcard из общедоступного примера базы данных
AdventureWorks (доступной здесь).
|
| Замечание |
|---|---|
|
Регламентная очистка является присущим PostgreSQL сопроводительным процессом и тем, что вы можете пожелать рассматривать как запускаемый на постоянной основе, в особенности когда ваши таблицы обладают множеством удалений и изменений. Хотя полное обсуждение этого и выходит за рамки данной книги, важно иметь в виду, что являющиеся предметом этих действий таблицы могут со временем раздуваться и запросу становятся медленными, а очистка является тем способом, которым можно высвобождать неиспользуемое пространство и вновь ускорять запросы. |
Теперь, для осуществления очистки данной таблицы вам придётся зарегистрироваться в клиентской утилите
psql с надлежащими полномочиями и после этого запустить следующую команду для
подключения к необходимой базе данных и выполнению своей задачи:
postgres=# \c AdventureWorks
AdventureWorks=# vacuum full sales.creditcard;
В реальном предприятии это была бы некая задача, которая осуществляется на намного большем числе таблиц и даже баз
данных, но здесь мы снова придерживаемся простоты своего примера для демонстрации основных вовлекаемых принципов. Их
масштабирование мы оставляем далее для выполнения вами в качестве упражнения. Давайте автоматизируем это для начала при
помощи модуля shell в Ansible. Это полезный пример, так как данная технология будет
работать с большинством основных баз данных - просто вам потребуется установить все необходимые команды для вашего
определённого действия по сопровождению и затем выполнить их.
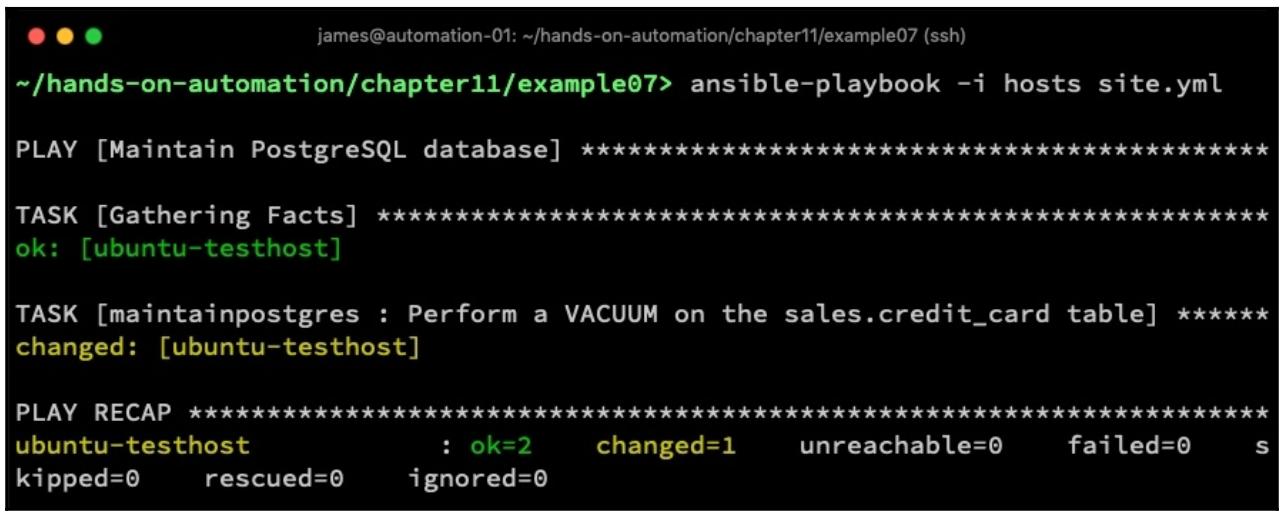
Некий образец роли для выполнения данной задачи выглядел бы так:
---
- name: Perform a VACUUM on the sales.credit_card table
shell: psql -c "VACUUM FULL sales.creditcard" AdventureWorks
become: yes
become_user: postgres
Обратите внимание - что как и ранее - применение самого модуля shell
с соответствующей командой очень простое, за исключением того, что на этот раз мы пользуемся параметром
become_user для переключения на учётную запись пользователя
postgres, который обладает правами суперпользователя для этой базы данных в том
хосте, к которому мы подключены. Давайте рассмотрим что происходит когда вы выполним это:
Естественно, это можно расширить на практически любую прочую базу данных - например, вы можете воспользоваться
инструментарием клиента mysql в базе данных MariaDB или даже инструментом
mysqlcheck, как это обсуждалось ранее. Основное ограничение на практике
состоит в том, что вы можете составить сценарий для запуска соответствующего модуляshell,
а по той причине, что Ansible исполняет свои команды поверх SSH на самом сервере соответствующей базы данных,
вам не требуется беспокоиться относительно открытия вашей базы данных на доступ через сетевую среду - всё это
может оставаться тщательно запертым.
Дополнительно к использованию модуля shell Ansible предлагает нам свой вариант
реального выполнения запросов напрямую из модуля с названием postgresql_query.
Он является уникальным, хотя такую поддержку можно добавлять к любой рочей базе данных если некто пожелал бы написать
подобный модуль и представить его.
К сожалению, до появления версии 2.9 Ansible, не было возможности расширения нашего примера VACUUM для этого,
поскольку имевшийся модуль postgresql_query запускал транзакции внутри некого блока
и он был не способен исполнять VACUUM внутри блока транзакции. Если вы работаете с версией 2.9 или более поздней, вы
теперь можете запускать VACUUM при помощи показанного тут кода:
---
- name: Perform a VACUUM on the sales.credit_card table
postgresql_query:
db: AdventureWorks
query: VACUUM sales.creditcard
autocommit: yes
become_user: postgres
become: yes
При помощи другого простого примера мы также можем воспользоваться модулем postgresql_query
для прямых манипуляций со своей базой данных.
Допустим, что произошла некая ошибка в приложении, применяющем эту базу данных и оператору необходимо вручную вставить некий номер кредитной карты в имеющуюся базу данных. Соответствующий код SQL для выполнения этого может выглядеть как- то так:
INSERT INTO sales.creditcard ( creditcardid, cardtype, cardnumber, expmonth, expyear ) VALUES ( 0, 'Visa', '0000000000000000', '11', '2019' );
Мы бы могли получить тот же самый конечный результат в Ansible при помощи роли, которая выглядит следующим образом:
---
- name: Manually insert data into the creditcard table
postgresql_query:
db: AdventureWorks
query: INSERT INTO sales.creditcard ( creditcardid, cardtype, cardnumber, expmonth, expyear ) VALUES ( 0, 'Visa', '0000000000000000', '11', '2019' );
become_user: postgres
become: yes
Естественно, вы будете применять для необходимых данных переменные, а чувствительные сведения, подобные указанным, всегда обязаны храниться в vault (или, возможно, вводиться вручную при выполнении этой роли).
|
| Совет |
|---|---|
|
AWX обладает функциональностью с названием Surveys (Опросы), которая предоставляет конкретному пользователю последовательность предварительно определённых вопросов и ответов перед исполнением некого плейбука. Ответы на эти вопросы сохраняются в переменных Ansible - тем самым, подобные предыдущей роли имеют возможность параметризации и запуска из AWX со всеми введёнными в Опросник ответами, отклоняя потребность в каком бы то ни было vault и рассмотрении хранения чувствительных данных пользователя в Ansible. |
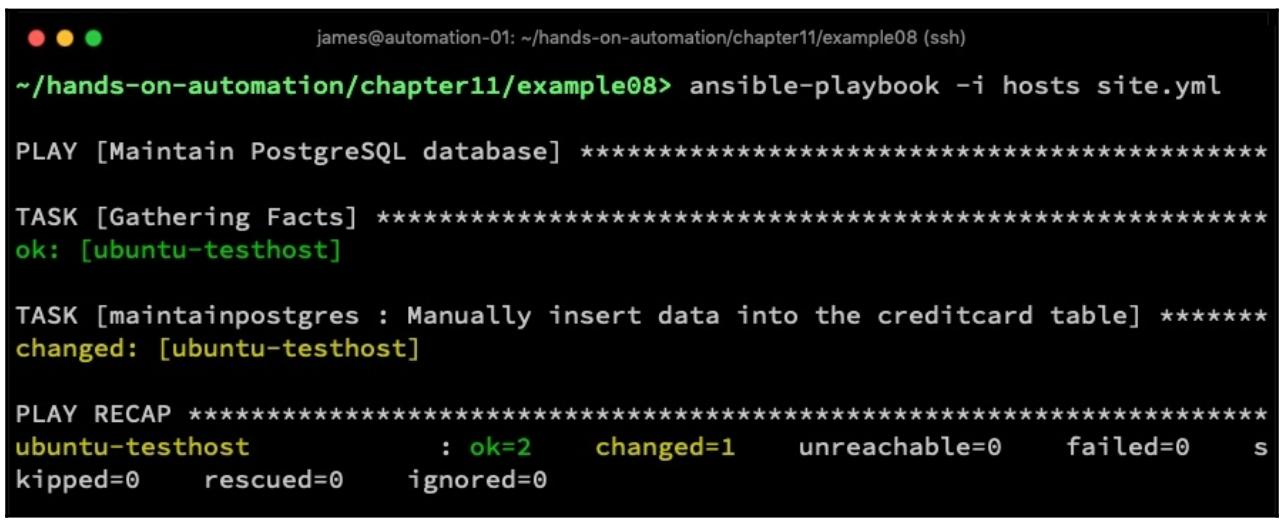
Здесь вы можете увидеть, что при выполнении нами данной роли мы на самом деле получаем изменение состояния когда наша
операция INSERT успешна - очень полезно для отслеживания подобных задач и обеспечения
того что они были исполнены как мы того и желали. Приводимый ниже снимок экрана отображает то что данная роль была выполнена,
а значение состояния changed обозначает успешность вставки данных в соответствующую
таблицу sales.creditcard:
Когда дело доходит до управления базой данных при помощи Ansible имеющийся мир в действительности является вашей устрицей и, вне зависимости от требуемой вами задачи, желательно чтобы все задачи базы данных обрабатывались стандартным, повторяемым и подлежащим аудиту образом, как и весь прочий штат вашего корпоративного Linux. Есть надежда, что данная глава каким- то образом показала вам как этого добиваться.
Базы данных составляют часть ядра имеющегося в большинстве предприятий стека предложений и имеется доступными в Linux масса баз данных. Хотя многие базы данных обладают своими собственными инструментами управления, Ansible хорошо подходит для управления широким массивом задач координации баз данных, начиная с услуг установки баз данных и загрузки первоначальных данных или хем (или даже восстановления из резервных копий), вплоть до задач повседневного сопровождения. Сочетание обработки ошибок Ansible с автоматизацией безопасности практически безгранично для типов задач управления базами данных, которые вы способны выполнять при помощи Ansible.
В этой главе вы изучили как применять Ansible для установки серверов баз данных неким последовательным и повторяемым манером. Затем вы изучили как импортировать первоначальные данные и схемы и как расширить это на автоматизацию задач резервного копирования. Наконец, вы получили практические навыки некоторых задач повседневного обслуживания баз данных при помощи Ansible.
В своей следующей главе мы рассмотрим как Ansible может способствовать в задачах повседневного регламента ваших серверов Linux.
-
Почему имеет смысл устанавливать ваши платформы баз данных и сопровождать их при помощи Ansible?
-
В чём состоят рекомендации для управления файлами настроек баз данных с применением Ansible?
-
Как Ansible способен помочь вам в сохранении безопасности базы данных в вашей сетевой среде?
-
Когда бы вы воспользовались имеющимся модулем
shellвместо собственных модулей баз данных Ansible? -
Зачем бы вы могли пожелать выполнять повседневный регламент с помощью Ansible?
-
Как бы вы выполняли резервное копирование базы данных PostgreSQL при помощи Ansible?
-
Какой бы модуль вы бы применили для манипуляций имеющимися пользователями базы данных MariaDB?
-
Как PostgreSQL поддерживает уникальность в Ansible в настоящее время?
Для более глубокого понимания Ansible, будьте добры ознакомиться с Mastering Ansible, Third Edition — James Freeman и Jesse Keating {Прим. пер.: рекомендуем также свой перевод этого 3 издания Полного руководства Ansible Джеймса Фримана и Джесса Китинга}.
Для дополнительного изучения особенностей управления базой данных PostgreSQL, отсылаем читателей к Learning PostgreSQL 11, Third Edition — Andrey Volkov, Salahadin Juba.
Аналогично за добавочными сведениями относительно управления базой данных MariaDB, читатели могут обратиться к MariaDB Essentials — Federico Razzoli, Emilien Kenler.
Полный перечень доступных в Ansible модулей, читатели могут найти по этой ссылке.