Глава 12. Выполнение обычного обслуживания при помощи Ansible
Содержание
По мере прохождения этой книги, вы осуществили множество шагов определения и сборки среды Linux для своего предприятия, которые поддерживают автоматизацию. Темне менее, содействие Ansible на этом не заканчивается. Даже некая собранная и активно применяемая среда требует сопровождения и вмешательства время от времени. Исторически такие вмешательства выполнялись вручную системными администраторами с применением команд оболочки или сенариев.
Как мы уже многократно обсуждали это на протяжении данной книги, выполяемые руками задачи представляют ряд проблем для предприятия - не в последнюю очередь по той причине что они могут быть не документированы как положено, а следовательно существует крутая кривая обучения для нового персонала. Кроме того, в игру вступают наши старые приятели - способность к аудиту и повторяемость - как вы можете быть уверенными в том кто, что и когда сделал, когда любой регистрируется в соответствующей оболочке ваших машин Linux и выполняет задачи вручную?
В этой главе мы изучим те способы, которыми Ansible способен содействовать вашему предприятию в повседневном управлении имеющимся штатом Linux и, в особенности, при выполнении задач повседневного регламента. Ansible обладает чрезвычайной мощностью и ваши возможности для повседневного сопровождения не ограничиваются приводимыми в этой главе примерами - скорее, они предназначены для вашего старта и отображают на примерах те виды задач, которые мы можете быть способными автоматизировать.
В частности, в данной главе мы рассмотрим такие вопросы:
-
Приведение в порядок дискового пространства
-
Отслеживание сдвига настроек
-
Управление процессами при помощи Ansible
-
Раскрутка обновлений при помощи Ansible
Данная глава содержит примеры, основывающиеся на следующих технологиях:
-
Сервер Ubuntu 18.04 LTS
-
CentOS 7.6
-
Ansible 2.8
Для прохождения этих примеров вам потребуется доступ к двум серверам или виртуальным машинам с запущенными в них по одной из перечисленных здесь операционных систем, а также Ansible. Обратите внимание, что приводимые в этой главе примеры могут быть по своей природе разрушительными (например, они устанавливают и убирают установку пакетов и вносят изменения в настройки сервера), и при их исполнении как есть, они подразумевают запуск в некой изолированной среде.
После того как вы убедились в безопасности той среды, в которой вы работаете, давайте начнём с рассмотрения установки новых программных пакетов при помощи Ansible.
Все обсуждаемые в этой книге примеры доступны в GitHub.
Одной из наиболее рутинных и обыденных (и всё же жизненно важных) задач, которые должен выполнять некий системный администратор на постоянной основе это очистка дискового пространства. Хотя в идеале системы должны вести себя хорошо - например, файлы журналов должны обращаться, а временные файлы очищаться - на практике в нашей индустрии хорошо известно что это не всегда имеет место. Сам автор этой книги работал в средах, в которых очистка определённого каталога рассматривалась как некая повседневная задача - следовательно первичный кандидат для автоматизации.
Конечно же, вы бы могли просто произвольным образом удалять файлы из некой файловой системы. Все подобные этой задачи
следует выполнять неким точным манером. Давайте продолжим практическим примером - поскольку это гипотетическая ситуация,
давайте создадим некие проверочные файлы для работы с ними. Допустим, что наше вымышленное приложение ежедневно создаёт
некий файл данных и никогда не прорежает свой каталог data. Для их синтеза мы можем
создать некие файлы данных следующим образом:
$ sudo mkdir -p /var/lib/appdata
$ for i in $(seq 1 20); do DATE=$(date -d "-$i days" +%y%m%d%H%M); sudo touch -t $DATE /var/lib/appdata/$DATE; done
Наши предыдущие команды создали некий каталог с названием /var/lib/appdata,
а далее создали по одному (пустому) файлу для каждого из дней на протяжении последних 20 дней. Конечно, мы можем создавать
файлы с данными, но для данного примера это не сделает никаких отличий - мы не хотим засорять диск!
Теперь давайте предположим что наш диск заполняется и мы желаем усечь данный каталог, оставляя лишь последние 5 дней.
Если бы мы выполняли это вручную, мы бы могли воспользоваться почтенной командой find
для перечисления тех файлов, которые отвечают нашему критерию и удалить все более старые. Это могло бы выглядеть как- то
так:
$ sudo find /var/lib/appdata -mtime +5 -exec rm -f '{}' \;
Это достаточно простая команда и вы можете удивиться, узнав насколько часто подобные команды встречаются в руководствах для серверов Linux. Давайте улучшим её с помощью Ansible. Мы знаем, что если мы реализуем её в Ansble, будет иметь место следующее:
-
Имеющийся механизм Ansible будет возвращать некое соответствующее состояние -
ok,changedилиfailedв зависимости от предпринятого действия. Приведённая в предыдущем блоке кода командаfindвозврати тот же самый вывод и код выхода, в зависимости от того удалит она какие- нибудь файлы или нет. -
Тот код Ansible, который мы пишем, будет самодокументирован - например, он начнётся с некого надлежащего
name- возможно,Prune /var/lib/appdata. -
Наш код Ansible может запускаться из AWX или Ansible Tower, обеспечивая что эта повседневная задача может делегироваться сответствующей команде при помощи встроенного упралвения доступом на основе ролей.
-
Кроме того, данной задаче может быть придано дружелюбное пользователю название в AWX, что подразумевает то, что операторам не потребуется никаких специальных познаний для того чтобы вскочить и начать действенно работать по содействию управлению средой Linux.
-
AWX и Ansible Tower в точности регистрируют весь вывод из выполняемых задач чтобы обеспечить возможность аудита таких заданий очистки в дальнейшем.
Естественно, никакое из этих преимуществ Ansible на данный момент времени не является для нас новым - мы часто ссылались на них на протяжении этой книги. Тем не менее, я хочу поразить вас получаемыми преимуществами действенной автоматизации конкретного предприятия. Давайте начнём с определения некой роли для выполнения в точности этой функции - подрезки некого каталога файлов со сроком старше 5 дней при помощи Ansible:
-
Мы начнём с применения модуля
findAnsible, который позволит нам собрать некий список объектов файловой системы (таких как файлы или каталоги), в точности как это делает и команда оболочкиfind. Мы выполнимregisterполучаемого вывода в некой переменной Ansible для его применения в последующем:- name: Find all files older than {{ max_age }} in {{ target_dir }} find: paths: "{{ target_dir }}" age: "{{ max_age }}" recurse: yes register: prune_listЭтот фрагмент показанного здесь кода должен достаточно хорошо пояснять себя самостоятельно - обратите внимание, тем не менее, что мы воспользовались переменными для своих параметров
pathиage; для этого имеется веское основание. Почти все роли повторно применяют код, а когда мы определяем эти параметры при помощи переменных, мы способны повторно применять эту роль для усечения прочих каталогов (к примеру, для прочих приложений), без необходимости изменения самого кода данной роли. Вы также обнаружите что мы можем применять переменные в установленномnameданной задачи - очень полезно и действенно при возврате к аудиту исполнений Ansible в дальнейшем. -
Наш модуль
findсоберёт некий перечень файлов,которые нам следует удалить - однако, имея целью выполнения аудита, нам может быть полезным выдать на печать эти названия файлов в общий вывод Ansible чтобы обеспечить что мы сможем позднее вернуться и отыскать в точности то, что было удалено. Обратите внимание, что мы можем выводит на печать больше сведений чам просто название пути - возможно, также могли бы оказаться полезными и перехватываемые сведения о размере и временной метке? Всё это доступно в нашей перехваченной ранее переменнойprune_listи вам оставлено в качестве упражнения для изучения этого. (Совет: заменитеmsg: "{{ item.path }}"наmsg: "{{ item }}", чтобы поссмотреть все перехватываемые в вашей задачеfindсведения.) Выполните такой код:- name: Print file list for auditing purposes debug: msg: "{{ item.path }}" loop: "{{ prune_list.files }}" loop_control: label: "{{ item.path }}"В данном случае мы просто применяем некий цикл Ansible для выполнения итераций по всем выработанным нашим модулем
findданным - в частности, выделяя словарьpathиз соответствующего словаряfilesвнутри нашей переменной. Значение параметраloop_controlпрепятствует выводу на печать всей структуры словаря выше для каждого сообщенияdebug, вместо этого применяя значениеpathдля каждого файла в качестве значенияlabel. -
Наконец, мы применяем модуль
fileдля удаления необходимых файлов, вновь обходяв циклеprune_list, в точноси как мы это делали ранее, следующим образом:- name: Prune {{ target_dir }} file: path: "{{ item.path }}" state: absent loop: "{{ prune_list.files }}" loop_control: label: "{{ item.path }}" -
Покончив с данной ролью, нам следует задать значения переменных для своего воспроизведения - в данном примере я определяю их в своём плейбуке
site.yml, который так ссылается на нашу новую роль:--- - name: Prune Directory hosts: all become: yes vars: max_age: "5d" target_dir: "/var/lib/appdata" roles: - pruneappdata
Выполнение этого кода для наших выработанных ранее в этом разделе файлов проверки приводит в результате к выводу, который выглядит как- то так:
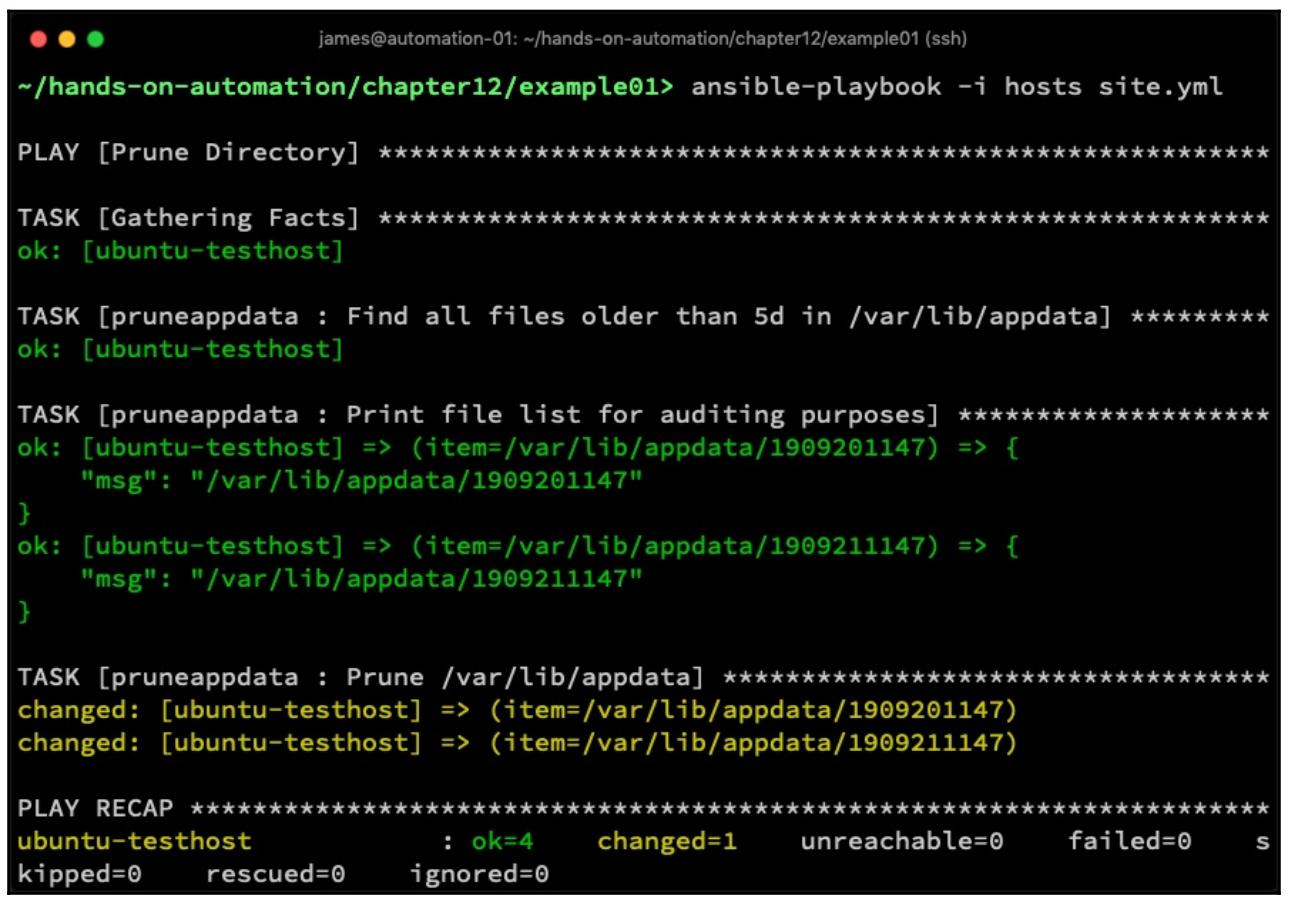
Для представленного выше снимка экрана набор файлов проверки был снижен,чтобы гарантировать что он поместится на данном экране - однако вы можете ясно видеть этот вывод и какие файлы были удалены.
Хотя хорошая уборка и существенная часть сопровождения сервера, порой желательно предпринимать действие (такое как
подрезка некого каталога), только когда оно абсолютно необходимо. Что если бы мы решили, что эту роль надлежит выполнять только
когда в файловой системе, содержащей /var/lib/appdata, остаётся менее 10%?
Наш следующийпроцесс показывает как можно применять Ansible для выполнения уборки по условию, выполняя работу только когдадиск заполнен более чем на 90%:
-
Мы начинаемс изменения имеющейся у нас роли - преждевсего мы добавляем в эту роль некую новую задачу для получения значения занятости диска в процентах для своего каталога
target:--- - name: Obtain free disk space for {{ target_dir }} shell: df -h "{{ target_dir }}" | tail -n 1 | awk {'print $5 '} | sed 's/%//g' register: dfresult changed_when: falseХотя и имеются факты Ansible, содержащие сведения о занятости диска, здесь мы применяем команду
df, так как она способна запросить наш каталог непосредственно - мы обязаны каким- то образом отслеживать это обратно для той точки монтирования, в которой он расположен если нам надлежит успешно применять факты Ansible. Мы также можем воспользоватьсяchanged_when: false, поскольку в противном случае эта задача оболочки всегда будет отображать некий результат изменения, что может приводить к путанице в получаемом выводе - это запрос только длячтения, поэтому ничто небыло изменено! -
После получения этих сведений и их регистрации в соответствующей переменной
dfresult, мы далее оборачиваемсвой имеющийся код неким блоком. Блок в Ansible это просто какой- то способ обёртки набора задач воедино - таким образом, вместо того чтобы помещать некое условиеwhenдля каждой из трёх задач из нашего более раннего примера, мы просто помещаем данное условие вместо этого на данный блок. Наш блок может начинаться как- то так:- name: Run file pruning only if disk usage is greater than 90 percent block: - name: Find all files older than {{ max_age }} in {{ target_dir }} find:Обратите внимание, что наш предыдущий набор задач теперь выделен оступом в два пробела. Это обеспечит то, что Ansible понимает его как часть соответствующего блока. Выделите отступом все имеющиеся задачи и завершите этот блок таким кодом:
loop_control: label: "{{ item.path }}" when: dfresult.stdout|int > 90Здесь мы воспользовались значением стандартного вывода, перехваченного в нашей переменной
dfresult, привели его к некому целому а заетм проверили чтобы посмотреть не превышает ли оно 90%. Таким образом, мы выполняем свою задачу подрезки только когда наша файловая система заполнена более чем на 90%. Естественно, это всего лишь одно условие - вы можете получать любые необходимые вам сведения чтобы выполнять любую из своих задач для всего разнообразия прочих случаев. Выполнение этой роли на моём проверочном сервере, который обладает менее чем 90% занятостью диска, показало что задачи подрезки были пропущены все целиком, что можно увидеть на приводимом далее снимке экрана:
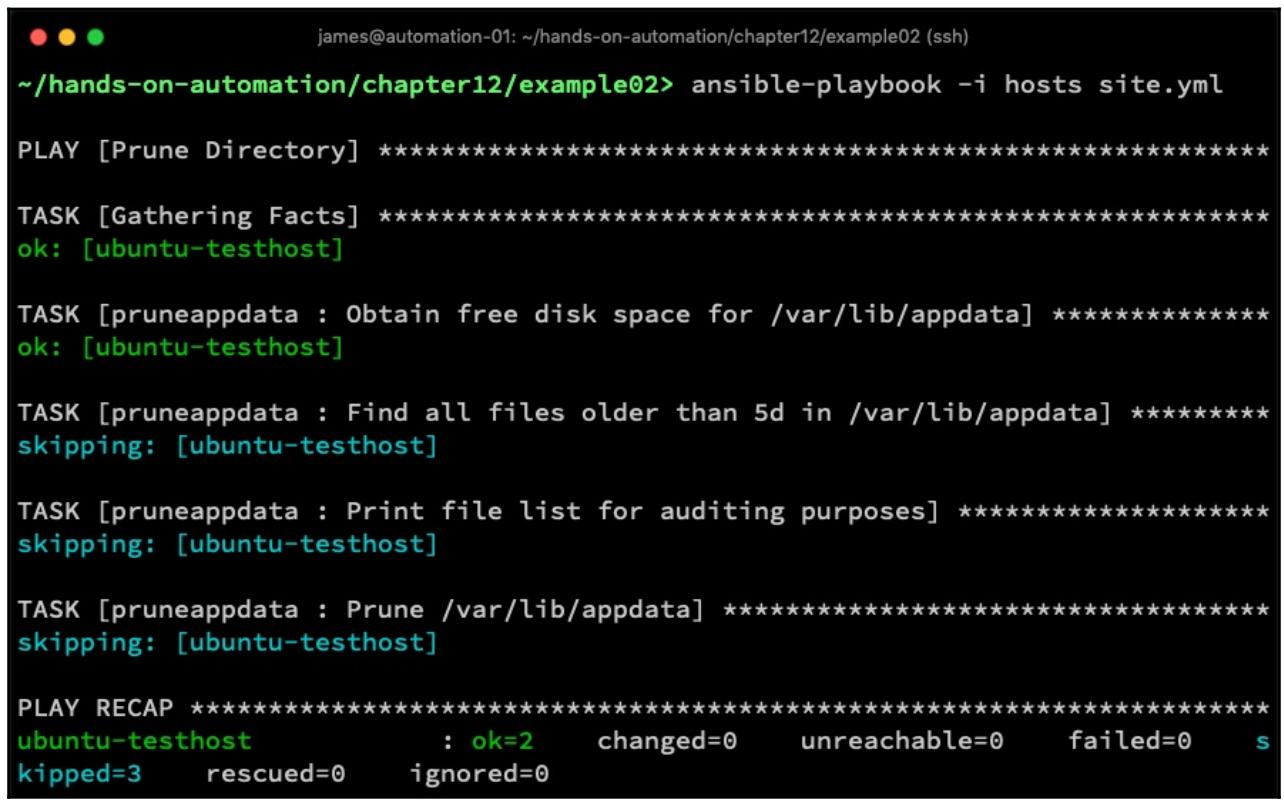
Таким образом, нам становится достаточно простым осуществление задач повседневной уборки дисков по большому штату предприятия и - как это всегда имеет место в Ansible - только небеса ограничивают то что вы можете сделать. Надеемся, что все примеры из данного раздела снабдят вас некими мыслями с чего начинать. В своём следующем разделе мы рассмотрим как можно применять Ansible для действенного отслеживания смещения настроек по всему штату Linux.
В Главе 7, Управление настройками при помощи Ansible мы изучили те способы, коими Ansible может применяться как для развёртывания конфигурации в масштабах некого предприятия, так и для их усиления. Давайте теперь основываясь на этом, предпримем нечто ещё - отслеживание отклонений от конфигурации.
Как мы это уже обсуждали в Главе 1, Построение стандартной среды работы в Linux, выполняемые вручную изменения являются злом автоматизации. Помимо этого также имеется риск для безопасности. Давайте отработаем здесь некий конкретный пример для демонстрации. Как мы уже и предполагали ранее в данной книге, предлагается управлять имеющимися настройками сервера SSH (Secure Shell) с помощью Ansible. SSH это стандартный протокол для управления серверами Linux и он может применяться не только для управления, но и для файлового обмена. Короче говоря, это один из ключевых механизмов, при помощи которого люди будут осуществлять доступ к вашим серверам, а следовательно жизненно важна его безопасность.
Тем не менее, также распространённым является и то, что разный персонал должен выполнять к серверам Linux доступ от имени root. Будь то разработчики, развёртывающие код, или системные администраторы, выполняющие повседневную (или исправляющую поломки) работу, для большого числа персонала рассматривается как исключительно обычное наличие доступа от имени root к некому серверу. Это отлично, когда все ведут себя как надо и активно придерживаются принципов автоматизации в вашем предприятии. Однако что произойдёт когда некто внесёт изменения без авторизации?
Через установленную настройку SSH они могут включить вход в систему от имени root. Они могут включить аутентификацию на сонове пароля, в то время как вы отключили это в предпочтение аутентификации на основании ключа. Во многих случаях такие изменения выполняются в угоду лени - например, файлы копировать проще от имени пользователя root.
Безотносительно основных намерений и корня причины, некто вручную вносящий такие изменения в развёрнутый вами ранее сервер Linux это проблема. Однако как вы её выявите? Несомненно, у вас нет времени на регистрацию во всех серверах и проверке соответствующих файлов вручную. Тем не менее, Ansible способен вам помочь.
В Главе 7, Управление настройками при помощи Ansible, мы предложили простой пример Ansible, который развёртывает необходимую конфигурацию сервера SSH из какого- то шаблона и перезапускает при помощи обработчика эту службу SSH когда данная настройка была изменена.
На самом деле мы можем повторно воспользоваться этим кодом с целью проверок отклонения от наших настроек. Даже без внесения
каких бы то ни было изменений в код мы можем запускать надлежащий плейбук в Ansible в режиме проверки.
Режим проверки не вносит никаких изменений в ту систему, в которой он исполняется - вместо этого он предпринимает всё от него
зависящее в предсказании любых изменений, которые могут произойти. Величина надёжности этих предсказаний очень сильно
зависит от применяемых в этой роли модулей. К примеру, модуль template способен
надёжно предсказывать изменения, ибо он знает будет ли тот файл, который подлежит записи отличаться от имеющегося в данный
момент файла. И наоборот, модуль shell может никогда незнать имеющегося отличия
между результатами change и ok, потому как
является таким модулем общего назначения (хотя он и способен выявлять отказы с обоснованной степенью точности). Таким образом,
я сторонник строгого применения changed_when при использовании данного модуля.
Давайте посмотрим что случится когда мы повторно выполним описанную ранее роль securesshd,
причём на этот раз в режиме проверки. Получаемый результат можно рассмотреть на приводимом ниже снимке экрана:
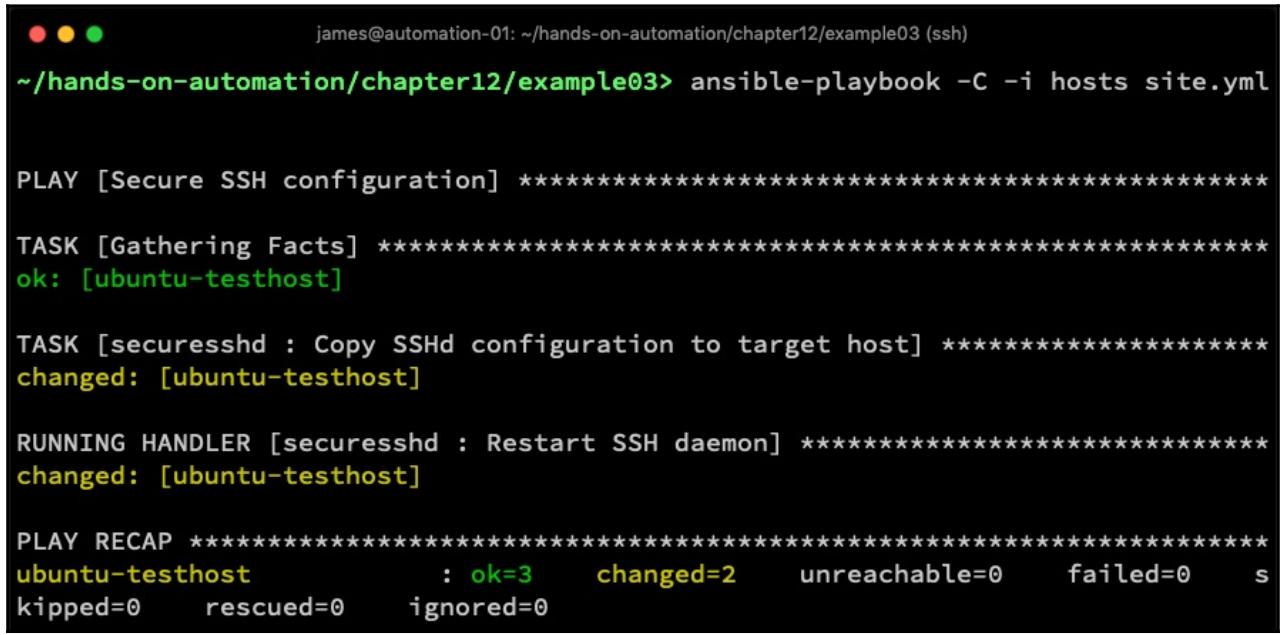
Здесь мы видим что некто на самом деле изменил рассматриваемую конфигурацию сервера SSH - если бы она соответствовала предоставленному нами шаблону, получаемый вывод вместо этого выглядел бы так:
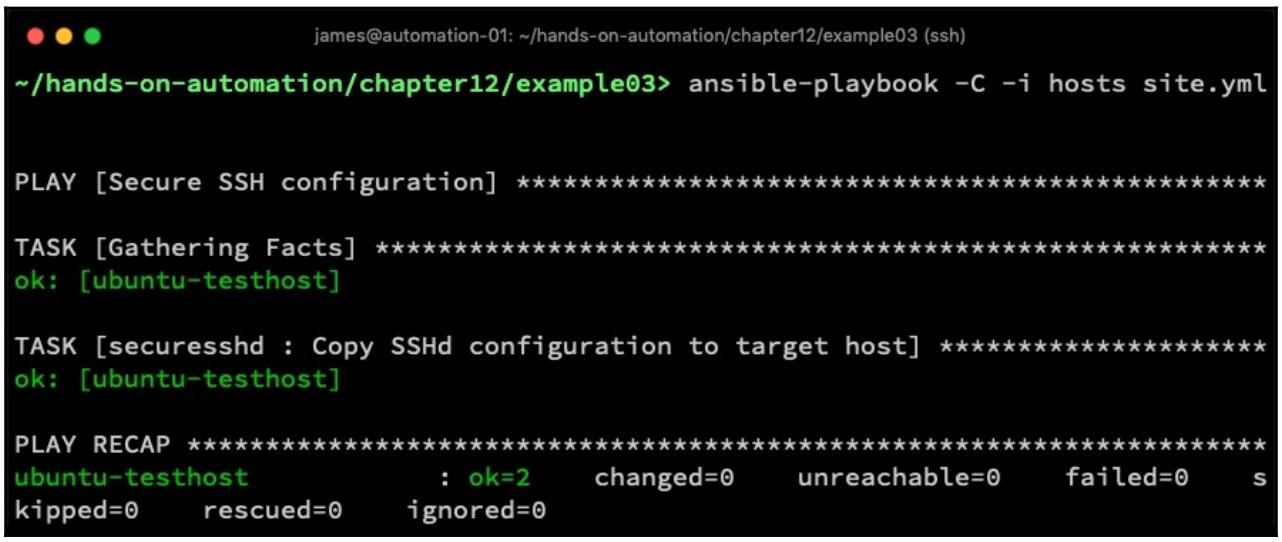
До сих пор всё нормально - вы можете выполнить это для сотен, или даже тысяч, серверов и вы будете знать что все
результаты changed поступают от серверов, в которых имеющаяся настройка SSH
больше не соответствует установленному шаблону. Вы даже можете запустить этот плейбук снова для исправления имеющегося
положения дел, только на этот раз не в режиме проверки (то есть без установки флага
-C в вашей командной сроке).
В таких средах как AWX или Ansible Tower, задания (то есть, исполняемые плейбуки) разбиты на категории по двум
различным состояниям - успешные и отказавшие. Успешные относятся к этой категории когда запущенный на выполнение плейбук
производит лишь результаты changed или ok.
Отказ, однако поступает от одного или более возвращённых от выполняемого плейбука состояний
failed или unreachable.
Таким образом, мы можем расширить свой плейбук, заставив его выдавать состояние failed
если соответствующий файл конфигурации отличается от установленной шаблоном версии. основа этой роли остаётся в точности
тем же самым, но для своей задачи шаблона мы добаляем следующие условия:
loop_control:
label: "{{ item.path }}"
when: dfresult.stdout|int > 90
Это оказывает приводимое ниже воздействия на выполняемые этой задачей операцию:
-
Получаемый данной задачей результат регистрируется в имеющейся переменной
template_result. -
Мы изменяем значение состояния отказа этой задачи на следующие:
-
Результат задачи установленного шаблона был изменён и мы исполняем её в режиме проверки.
-
Либо задача установленного шаблона отказала по какой- то иной причине - это сулчай перехвата всего чтобы обеспечить что мы всё ещё правильно выдаём отчёт о прочих состояниях отказа (например, отказ доступа к некому файлу).
-
В выражении failed_when вы будете наблюдать применение и логического
or, и логического and - мощного способа
расширения соответствующей операции Ansible. Теперь, когда мы запускаем этот плейбук в режиме проверки и проверяемый файл
был изменён, мы наблюдаем такой результат:
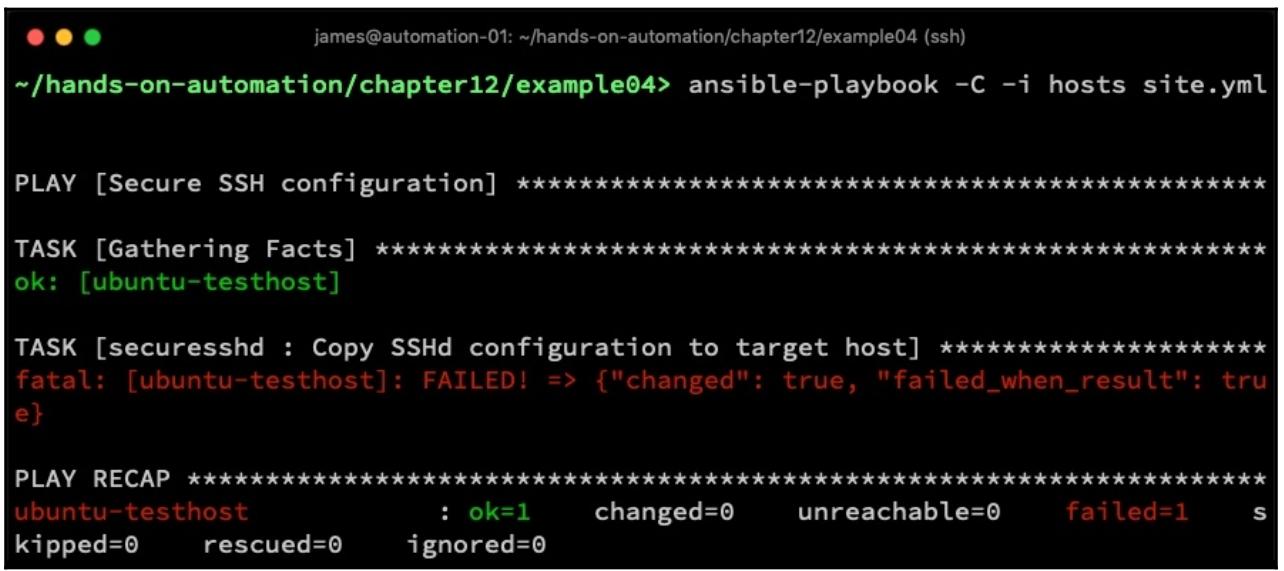
Теперь мы можем очень отчётливо увидеть что в нашем хосте имеется некая проблема и о ней также будет сообщено как об отказе в отчёте в AWX и Ansible Tower.
Конечно, это работает очень хорошо для простых текстовых файлов. А что относительно двоичных файлов, тем не менее?
Конечно же, Ansible не является полной заменой для таких инструментов отслеживания целостности файла, как
AIDE
(Advanced Intrusion Detection Environment) или достопочтенном
Tripwire - однако он способен также содействовать и
в применении двоичных файлов. В действительности процесс очень простой. Давайте предположим, что вы желаете гарантировать
целостность /bin/bash - это та оболочка, которую все применяют по умолчанию в
большинстве систем, а потому целостность этого файла исключительно важна. Если у вас имеется пространство для хранения своего
первоначального двоичного файла в вашем сервере Ansible, тогда вы можете воспользоваться модулем
copy для копирования его по всем своим целевым хостам. Модуль
copy применяет вычисление контрольной суммы для определения того требуется или нет
копировать данный файл, а раз так, вы можете быть уверенным, что когда результаты вашего модуля
copy в состоянии changed, тогда ваш целевой
файл отличается от вашей первоначальной версии и его целостность скомпрометирована. Надлежащая роль для этого выглядела
бы очень похожей на наш пример шаблона здесь:
---
- name: Copy bash binary to target host
copy:
src: files/bash
dest: /bin/bash
owner: root
group: root
mode: 0755
register: copy_result
failed_when: (copy_result.changed and ansible_check_mode == True) or copy_result.failed
Конечно, хранение первоначальных двиоичных файлов в вашем сервере Ansible нельзя назвать действенным, а к тому же
означает что вам придётся отслеживать их актуальность на текущий момент одновременно с расписанием внесения исправлений
в ваши серверы, что не желательно когда у вас имеется для проверки большое число файлов. К счастью, имеющийся в Ansible
модуль stat способен вырабатывать контрольные суммы, а также возвращать массу
прочих полезных сведений относительно файлов, а потому мы сможем очень просто написать некий плейбук для проверки своего
двоичного файла для Bash на предмет его подмены, выполняя следующий код:
---
- name: Get sha256 sum of /bin/bash
stat:
path: /bin/bash
checksum_algorithm: sha256
get_checksum: yes
register: binstat
- name: Verify checksum of /bin/bash
fail:
msg: "Integrity failure - /bin/bash may have been compromised!"
when: binstat.stat.checksum != 'da85596376bf384c14525c50ca010e9ab96952cb811b4abe188c9ef1b75bff9a'
Это очень простой пример и его значительно можно расширить снабдив значением пути к файлу и его именем, а также
контрольной суммой в виде переменной вместо статических значений. Также можно выполнить цикл по некому словарю файлов
и соответствующих им контрольным суммам - эти задачи оставлены вам для упражнений и это полностью возможно с применением
уже рассмотренных нами в этой книге технологий. Теперь, если мы запустим данный плейбук (в режиме проверки или без него)
мы обнаружим результат отказа когда целостность нашего Bash не обеспечена и ok
в противном случае:
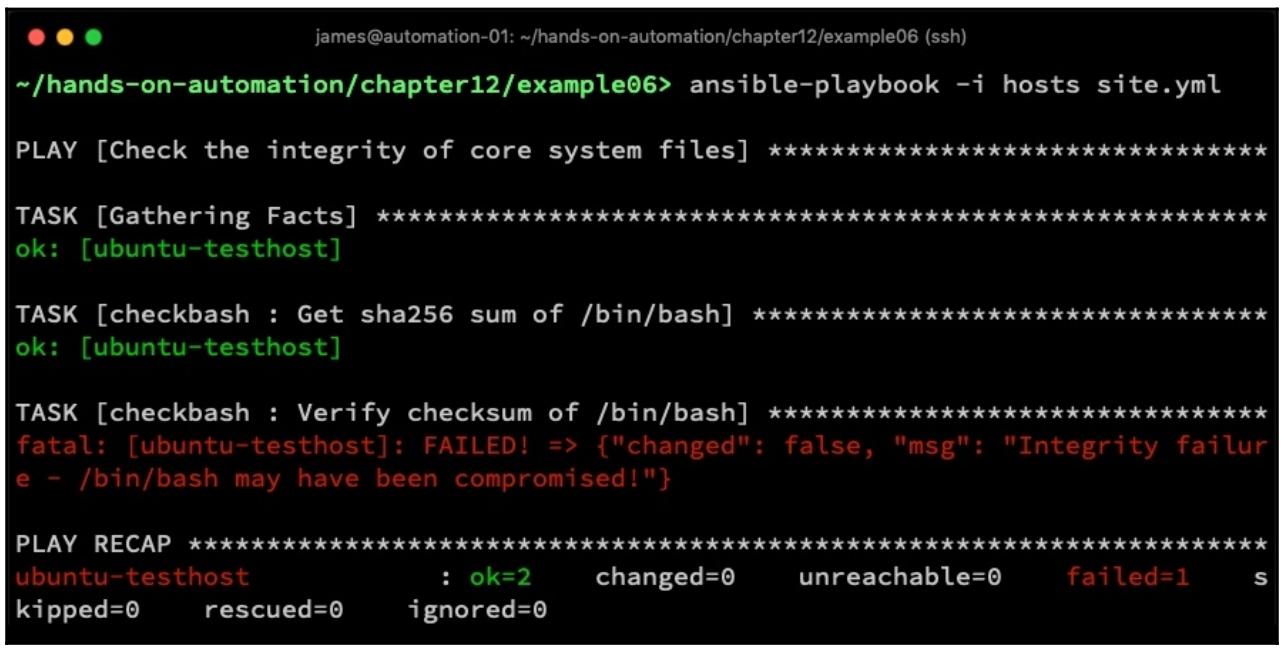
Подсчёт контрольных сумм можно применять также и для проверки наличия целостности файлов настроек, а потому данный пример роли служит хорошей основой для любых проверок целостности которые вы могли бы предпринимать.
Теперь мы покончили со своим изучением отслеживанием файла и целостности при помощи Ansible, а следовательно, с возможностью проверки отклонения конфигурации. В своём следующем разделе данной главы мы рассмотрим как Ansible может применяться для управления процессами по некому штату корпоративного Linux.
Рано или поздно вы заканчиваете с потребностью управления и возможно даже прибиваете внутри своего предприятия процессы
одного или более серверовLinux. Очевидно, это не идеальный сценарий и в повседневных действиях большинством служб
надлежит управлять через модуль service Ansible, многие примеры которого мы наблюдали в
этой книге.
Однако, что если вам всё же реально необходимо уничтожить некий подвисший процесс? Очевидно, что системный администратор может выполнить SSH для такого ошибочного сервера и выдать команду, подобную такой:
$ ps -ef | grep <processname> | grep -v grep | awk '{print $2}'
$ kill <PID1> <PID2>
В случае когда этот процесс упорствует против завершения, тогда может возникнуть потребность в следующей команде:
$ ps -ef | grep <processname> | grep -v grep | awk '{print $2}'
$ kill -9 <PID1> <PID2>
Хотя это и достаточно стандартная практика, в которой большинство системных администраторов будут хорошо разбираться (и даже,
возможно, обладать своими собственными предпочтениями в инструментах обработки, например pkill),
она сталкивается с той же самой проблемой,что и большинство ручных вмешательств в некотором сервере - как вы можете отследить
что произошло и какие именно процессы были затронуты? Когда применялись PID
(process ID, идентификаторы процессов), тогда даже при доступе к имеющейся
истории команд, всё ещё невозможно сказать какой процесс исторически удерживал это численной значение PID.
То что мы предлагаем тут, не является обычным использованием Ansible - однако при том, когда мы выполняем запуск через такие инструменты как AWX или Ansible Tower, мы смогли бы отслеживать все выполненные действия, причём совместно с подробностями того, кто их выполнял, если только помещаем надлежащее название процесса в некий параметр, который также является целевым. Это может оказаться полезеым, когда в последующем становится необходимым проанализировать всю историю некой проблемы, по причине того что сделает простым проверку какие серверы были задействованы и какие процессы имелись целью, а также точные значения временных меток.
Давайте соберём некую роль для выполнения в точности этого набора задач. Эта глава первоначально была написана под Ansible 2.8, который не был снабжён модулем для управления процессами, а потому наш следующий пример применяет для обработки данного случая естественные команды оболочки:
-
Мы начинаем запуск перечисления процессов, который мы уже предлагали ранее в этом разделе, но на этот раз регистрируя получаемый список PID в некой переменной Ansible, следующим образом:
--- - name: Get PID's of running processes matching {{ procname }} shell: "ps -ef | grep -w {{ procname }} | grep -v grep | grep -v ansible | awk '{print $2\",\"$8}'" register: process_idsБольшинство знакомых со сценарием оболочки должы быть способными разобраться в этой строке - мы фильтруем таблицу процессов системы для полностью совпадающих по слову со значением переменной Ansible
procname, и удаляем все посторонние названия процессов, которые могли бы поступать в наш вывод и вносить в него путаницу, такие какgrepиansible. Наконец мы применяемawkдля преобразования полученного вывода в разделённый запятыми список, содержащий значение PID в своей первой колонке и сосбтвенно значение имени процесса во второй. -
Теперь нам следует предпринять действия по данному выводу. Мы теперь пройдём в цикле по заполненной ранее переменной
process_ids, вызывая командуkillдля значения первой колонки из полученного вывода (которое является номером PID):- name: Attempt to kill processes nicely shell: "kill {{ item.split(',')[0] }}" loop: "{{ process_ids.stdout_lines }}" loop_control: label: "{{ item }}"Злесь вы наблюдаете использование фильтрации Jinja2 - мы можем применять встроенную функцию
splitдля расщепления созданных нами в предыдущем блоке кода данных, получая только первую колонку из вывода (численное значение PID). Тем не менее мы пользуемся соответствующей меткойloop_controlдля настройки значения метки, содержащей как значение PID, так и названия процесса, что может быть очень полезным при варианте аудита или отладки. -
Всякий исушённый системный администратор знаком с тем, что недостаточно просто вызвать для некого процесса команду
kill- некоторые процессы следует убивать принудительно, так как они зависли. Не все процессы осуществляют выход немедленно, поэтому мы воспользуемся модулем Ansiblewait_forдля проверки соответствующего PID в каталоге/proc- когда он превратится вabsent, мы знаем что этот процесс выполнил выход. Выполним такой код:- name: Wait for processes to exit wait_for: path: "/proc/{{ item.split(',')[0] }}" timeout: 5 state: absent loop: "{{ process_ids.stdout_lines }}" ignore_errors: yes register: exit_resultsМы установили значение таймаута равным 5 секундам - однако вам следует установить его в соотвествии со своей средой. И снова, мы регистрируем получаемый вывод в некой переменной - нам требуется знать какой из процессов отказал в выходе, а следовательно попытаться уничтожить его принудительно. Обратите внимание, что здесь мы установили
ignore_errors, ибо модульwait_forвоспроизводит некую ошибку когда в пределах заданного значенияtimeoutне возникло желательное нам состояние (то есть/proc/PIDсталabsent). В нашей роли это не рассматривается в качестве ошибки, а всего лишь указывает на последующую обработку. -
Теперь мы в цикле обходим результаты своей задачи
wait_for- однако на этот раз мыпользуемся функцией Jinja2selectattrдля выбора тольео элементов словаря, которые обладают подтверждённымfailed; мы не желаем принудительно завершать не существующие PID. Выполните такой код:name: Forcefully kill stuck processes shell: "kill -9 {{ item.item.split(',')[0] }}" loop: "{{ exit_results.results | selectattr('failed') | list }}" loop_control: label: "{{ item.item }}"Теперь мы попытались уничтожить зависшие процессы при помощи флага
-9- обычно достаточного для уничтожения большинства подвисших процессов. Опять обратите внимание на использование фильтрации Jinja2 и тщательную маркировкуцикла для обеспечения того, что мы сможем воспользоваться получаемым выводом данной роли для целей аудита и отладки. -
Теперь мы запускаем полученный плейбук, определяя значение для
procname- не существует никакого заданного по умолчания процесса для уничтожения и мне не кажется безопасной настройка некого значения по умолчанию для данной переменной. Таким образом, в своём следующем снимке экрана я применяю значение флага-eпри вызове соответствующей командыansible-playbook:
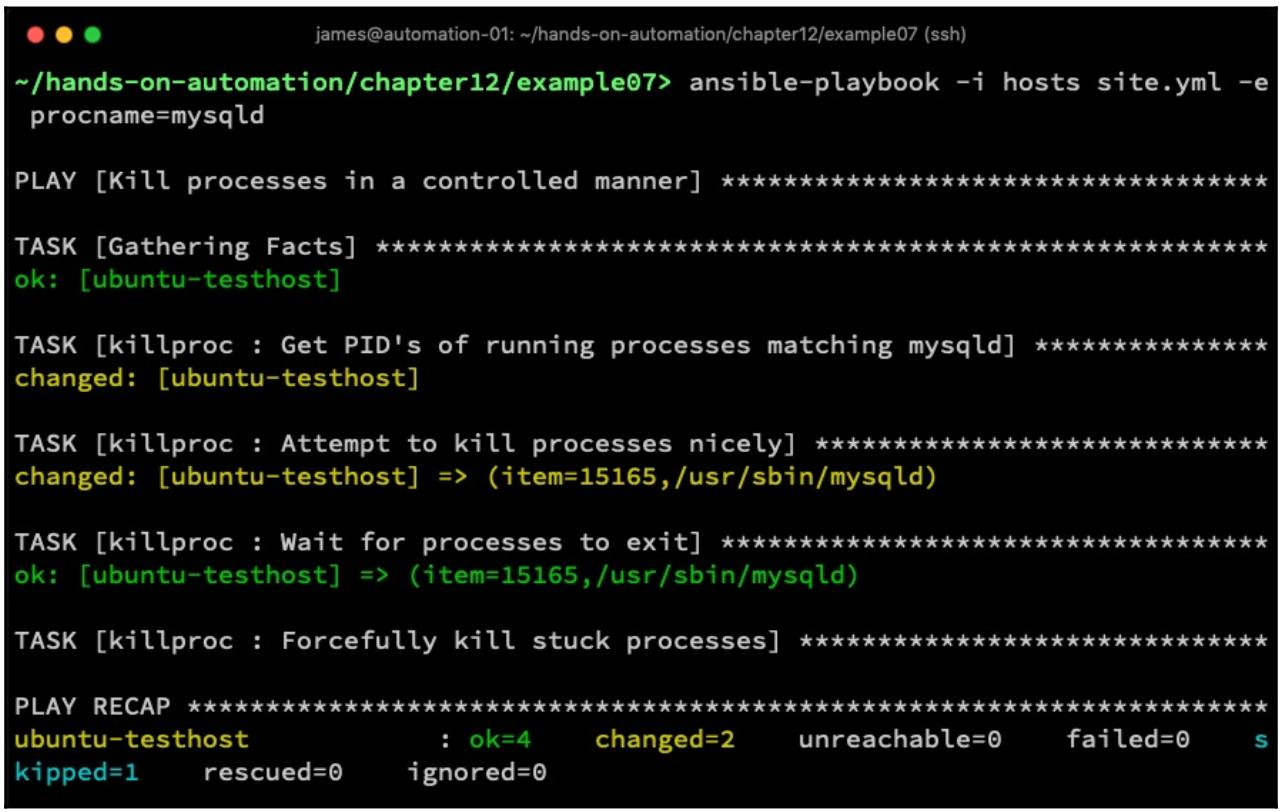
Из своего предыдущего снимка экрана мы можем чётко видеть, что наш плейбук уничтожил имевшийся процесс
mysqld, а получаемый вывод этого плейбука тщательный и лаконичный, но при этом
содержит достаточные сведения для отладки, если такая потребность возникнет.
В качестве добавки, когда вы применяете Ansible 2.8 или более позднюю версию, теперь имеется собственный модуль Ansible
с названием pids, который возвращает чёткий, ясный перечеь PID для некого заданного
названия процесса при его исполнении. Приспособив свою роль под эту новую функциональность, мы сможем, прежде всего,
избавиться от команд оболочки и заменить их модулем pids, что будет намного проще
читать, например:
---
- name: Get PID's of running processes matching {{ procname }}
pids:
name: "{{ procname }}"
register: process_ids
Начиная с данного момента рассматриваемая роль почти идентична той, что приведена ранее, за исключением того, что
вместо выработанного командой оболочки разделяемого запятыми списка мы обладаем простым списком, который просто содержит
значение PID для каждого из запущенных процессов,которые соответствуют по названию значению переменной
procname. Тем самым, нам больше не требуется применять расщепление Jinja2 для
своей переменной при исполнении по ней команд. Выполните следующий код:
- name: Attempt to kill processes nicely
shell: "kill {{ item }}"
loop:
"{{ process_ids.pids }}"
loop_control:
label: "{{ item }}"
- name: Wait for processes to exit
wait_for:
path: "/proc/{{ item }}"
timeout: 5
state: absent
loop:
"{{ process_ids.pids }}"
ignore_errors: yes
register: exit_results
- name: Forcefully kill stuck processes
shell: "kill -9 {{ item.item }}"
loop:
"{{ exit_results.results | selectattr('failed') | list }}"
loop_control:
label: "{{ item.item }}"
Этот кодовый блок выполняет ту же самую функцию что и ранее, но только теперь слегка лучше для представлен для своего
прочтения, так как мы снизили число необходимых фильтров Jinja2 и избавились от команд оболочки, благодаря модулю
pids. Данная технология, в сочетании с обсуждавшимся ранее модулем
service должна послужить вам здоровой основой чтобы соответствовать всем вашим
потребностям в управлении процессами при помощи Ansible.
В своём следующем и завершающем эту главу разделе мы взглянем на то, как применять Ansible когда в нашем клсетере имеется множество узлов, а вы желаете обслужить их все одним махом.
Никакая глава по повседневному сопровождению не может считаться законченной без рассмотрения накатки обновлений. До сих пор в данной книге мы придерживались в своих примеров просто одного или двух хостов и на их основе работали со всеми примерами, которые способны масштабироваться на управление сотнями, если не тысячами серверов при помощи тех же самых ролей и плейбуков.
По большому счёту это остаётся верным - однако, имеются определённые особые обстоятельства, когда возможно нам необходимо более глубоко рассматривать действия Ansible. Давайте соберём некий гипотетический пример, в котором у нас позади некого балансировщика нагрузки имеются четыре сервера веб приложений. Требуется развернуть новый выпуск кода нашего веб приложения, причём этот процесс развёртывания требует множества этапов (а тем самым множества задач Ansible). В нашем простом примере этот процесс развёртывания будет состоять из:
-
Развёртывания в соответствующем сервере необходимого кода веб приложения.
-
Перезапуск данной службы веб сервера для подхвата своего нового кода.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
В некой промышленной среде вы, почти несомненно, пожелаете предпринять и последующие шаги для обеспечения целостности своей веб службы - например, когда она позади некого балансировщика нагрузки, вы можете изъять её из обслуживания на протяжении развёртывания применяемого кода, а также оеспечить то, что она не вернётся к обслуживанию пока не будет подтверждена её работа надлежащим образом. Мы не ожидаем, что все читающие эту книгу будут обладать доступом к подобным средам, а потому данный пример был оставлен простым, чтобы обеспечить возможность попытки его воспроизведения каждым. |
Для выполнения этой задачи вы запросто сможете написать образец некой роли Ansible - вот, приведём некий образец:
---
- name: Deploy new code
template:
src: templates/web.html.j2
dest: /var/www/html/web.html
- name: Restart web server
service:
name: nginx
state: restarted
Данный код по очереди выполнитьнаши два шага,как мы того и желали. Однако давайте рассмотрим что случится при запуске данной роли в неком плейбуке. Получаемый результат отображён на приводимом ниже снимке экрана:
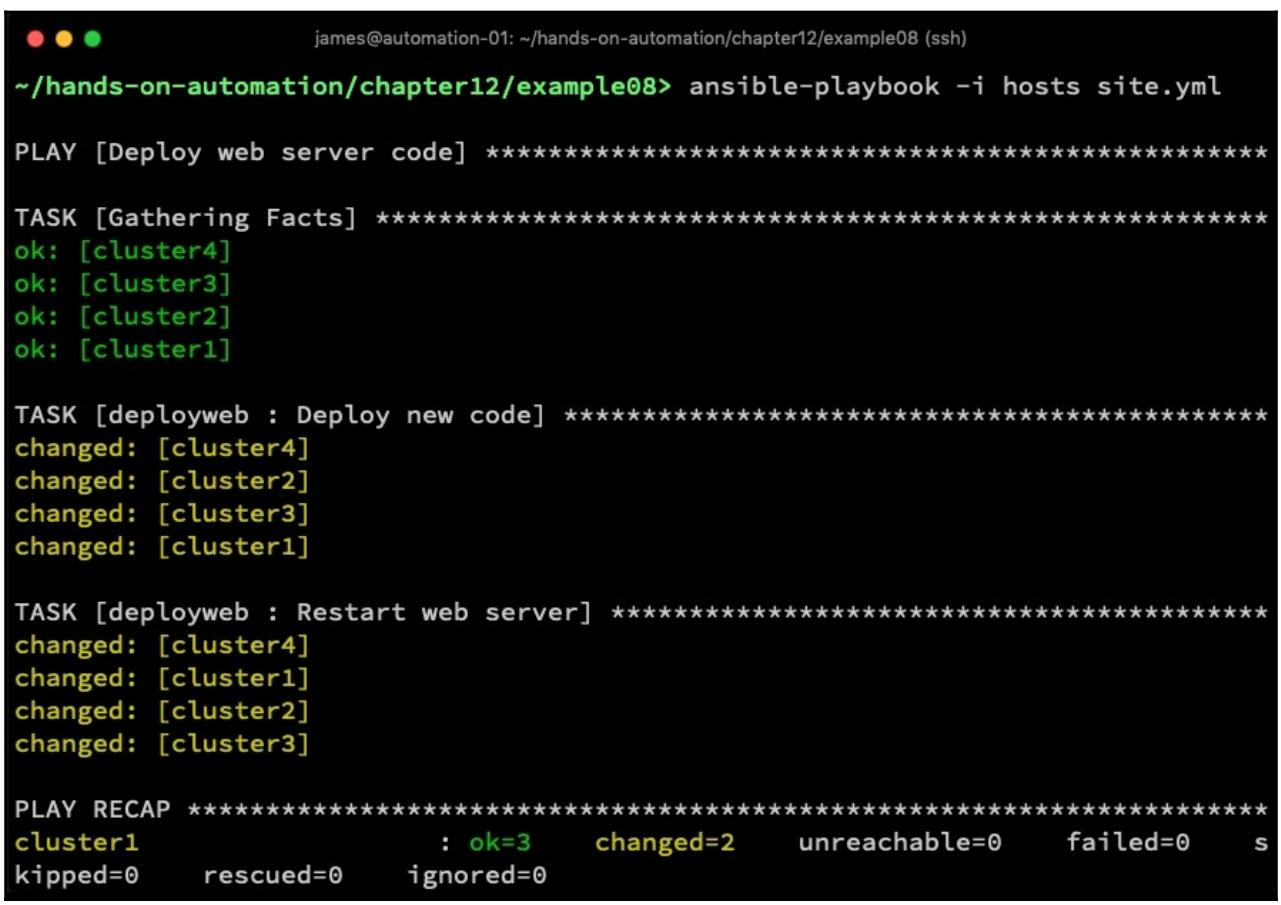
Обратите внимание как Ansible выполнил своизадачи. Прежде всего необходимый новый код был развёрнут на все четыре сервера. Токо затем они были перезапущены. Это может быть нежелательным по целому ряду причин. Например, данные серверы могут пребывать в несогласовнанном состоянии после выполненной первой задачи и вам бу не хотелось чтобы все четыре сервера были одновременно в неустойчивом состоянии, ибо некто применяющий данное веб приложение столкнулся бы с ошибками. Кроме того, если по какой- то причине ваш плейбук отработает неверно и произведёт состояние отказа, он точно отрубит все четыре сервера, тем самым прервав веб приложение для всех и вызвав простой службы.
Для предотвращения возникновения такого рода проблем мы можем воспользоваться ключевым словом
serial, чтобы запросить у Ansible за раз выполнять обновление лишь для заданного
числа серверов. К примеру, когда мы вставляем в вызывающий данную роль плейбук site.yml
строку serial: 2, неожиданно поведение становится достаточно иным, что отображает
наш приводимый ниже снимок экрана:
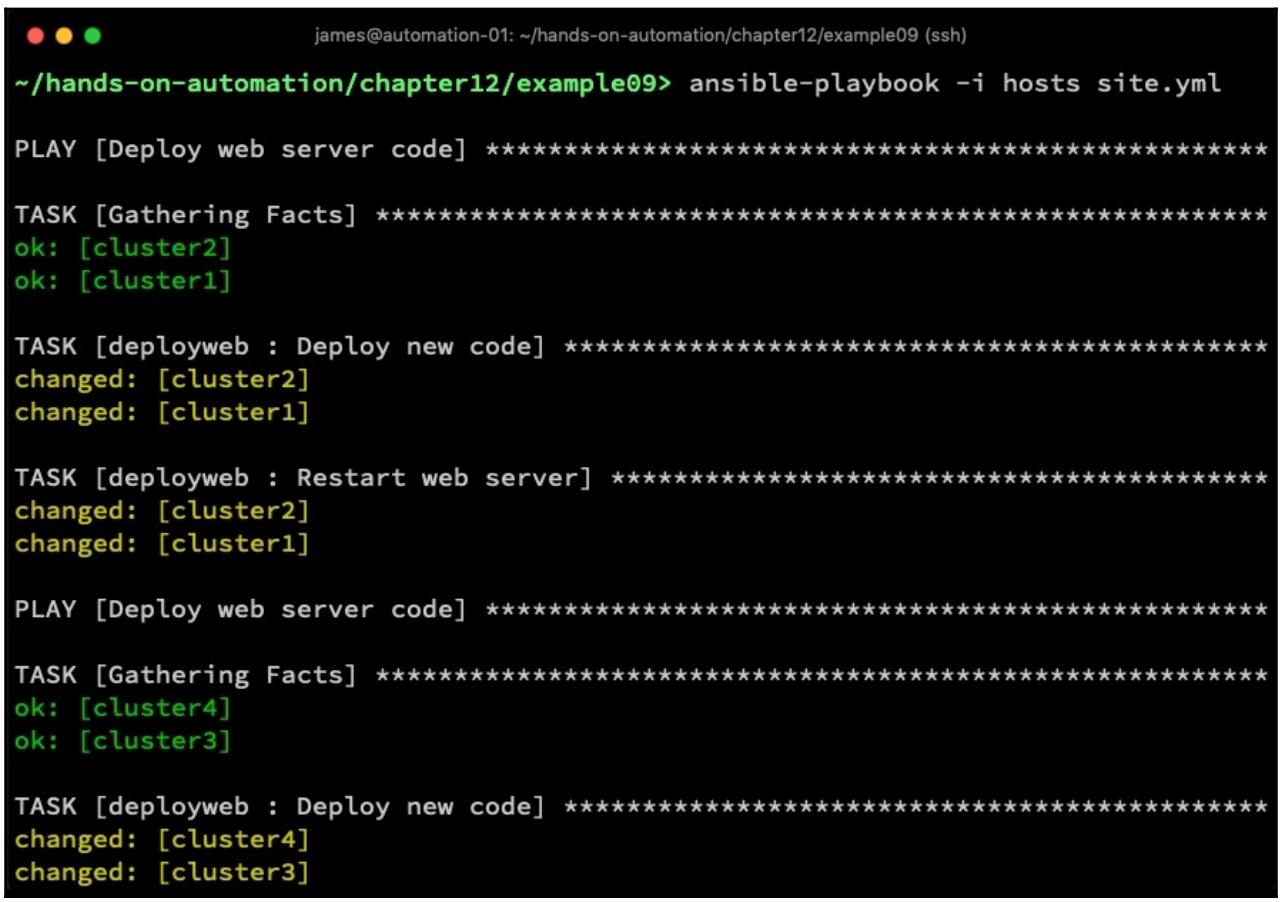
Для сохранения места наш предыдущий вывод усечён, но ясно даёт понять, что наш плейбук теперь за раз запускает только на
двух серверах - таким образом на протяжении начальной фазы неустойчивы только cluster1
и cluster2, в то время как cluster3 и
cluster4 остаются согласованными и нетронутыми. Только когда на наших первых двух
серверах выполнены все задачи, мы продолжим со следующими двумя.
Также важна и обработка отказов, причём если в вашем коде или плейбуке содержится некая проблема, опасность автоматизации
состоит в том, что вы запросто можете разрушить всю среду целиком. Например, когда наша задача
Deploy new code отказывает на всех серверах, запуск такого плейбука за раз на двух
серверах не поможет. Ansible всё ещё полностью выполнит именно то что у него запрошено - в данном случае обвалит все
четыре сервера.
При данных обстоятелствах хорошей мыслью было бы дабавить в ваш плейбук также и соответствующий параметр
max_fail_percentage. Например, когда мы установим его равным
50, Ansible остановит обработку хостов как только 50% его описи завершится
отказом,что демонстрирует наш следующий снимок экрана:
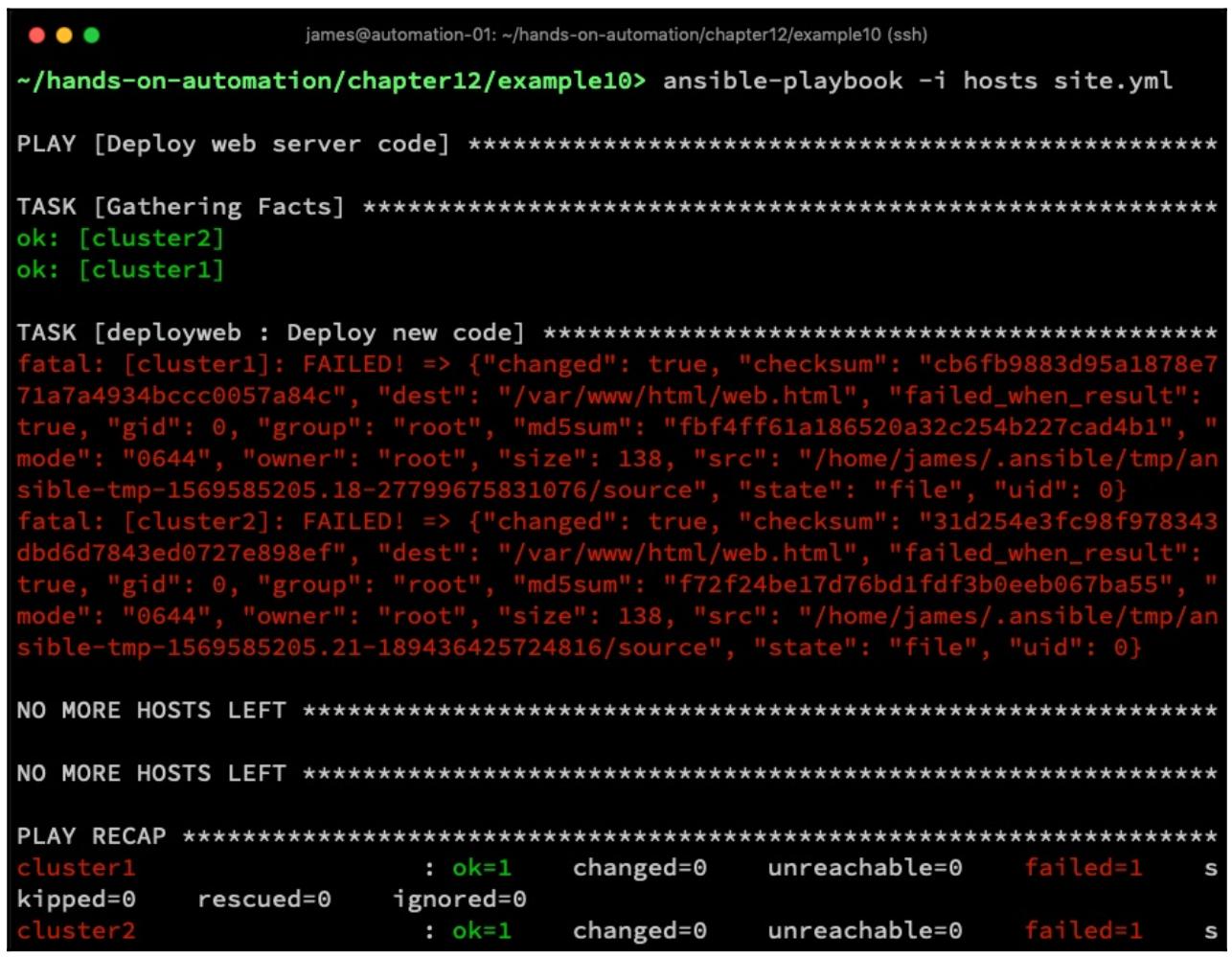
Как мы можем здесь увидеть, даже несмотря на то, что наша опись осталась без изменений, Ansible остановился после обработки
cluster1 и cluster2 - так как они завершились
отказом, он не предпринимает никаких задач для cluster3 и
cluster4; таким образом, по крайней мере два хоста остаются в службе с верным кодом,
позволяя пользователям продолжить применение этого веб приложения, причём несмотря на иевший место оказ.
При работе с крупными средами с балансировкой нагрузки важно пользоваться этими свойствами Ansible чтобы обеспечивать то, что отказы распространятся на штат серверов целиком. Этим мы завершаем рассмотрение применения Ansible в повседневном сопровождении серверов - как и всегда, имеющиеся возможности безграничны, но мы вновь надеемся что эта глава санбдит вас неким вдохновением и примерами, на основании которых можно выполнять построение.
Ansible является очень мощным инструментом, однако не только для управления развёртыванием и настройкой. Несмотря на то, что это его центральные преимущества, он также мощен в содействии и когда дело доходит до задач повседневного сопровождения. Как и всегда, напару с некими подобными AWX или Ansible Tower инструментами управления предприятием, он становится невероятно важным при управлении вашим штатом Linux, в особенности для целей аудита и отладки.
В этой главе вы изучили как убирать дисковое пространство при помощи Ansible и как выполнять это по условию. Далее вы изучили как Ansible способен содействовать в отслеживании отклонений от настроек и даже выдавать предупреждения о возможных внедрениях в двоичные файлы. Вы изучили как при помощи Ansible управлять процессами на удалённых серверах и, наконец, как осуществлять раскрутку обновлений аккуратным и управляемым образом по некому пулу серверов с балансировкой нагрузок.
В своей следующей главе мы рассмотрим работу с безопасностью ваших серверов Linux неким стандартным образом при помощи эталонного тестирования CIS.
-
Почему имеет смысл воспользоваться получаемым командой
dfвыводом вместо некого факта Ansible при изучении дискового пространства? -
Какой модуль Ansible используется для определения местоположения файлов на основании такого критерия, как их возраст?
-
Почему важно отслеживать отклонения от настроек?
-
Каковы два способа, которыми вы можете отслеживать в Ansible файлы настроек в текстовом виде на предмет их изменений?
-
Как бы вы управляли службой
systemdв неком удалённом сервере при помощи Ansible? -
Как называется встроенная в Ansible фильтрация, которая может помогать с обработкой строк вывода (например, для расщепления раздленных запятой списков)?
-
Как бы вы расщепляли разделяемый запятой список в некой переменной Ansible?
-
Почему не желательно выполнять все задачи на всех серверах за раз при работе в некой среде с балансировкой нагрузок?
-
Какая функциональность Ansible способна предотвращать от раскрутки вами ошибочных задач на всех серверах?
Для более глубокого понимания Ansible, будьте добры ознакомиться с Mastering Ansible, Third Edition — James Freeman и Jesse Keating {Прим. пер.: рекомендуем также свой перевод этого 3 издания Полного руководства Ansible Джеймса Фримана и Джесса Китинга}.