Глава 1. Введение
Содержание
Человеческое сообщество пребывает в эпохе информационного взрыва, когда данные растут в геометрической прогрессии. Эта эпоха получила название "эры Больших данных" с характеристиками пяти V, а именно, volume, velocity, variety, veracity и value (объёма, скорости, разнообразия, достоверности и ценности). Для решения связанных с пятью большими V проблем появляется новая область - высокопроизводительные вычисления Больших данных, основная цель которой - вывод высокопроизводительных вычислений (HPC, high performance computing), обработки Больших данных и Глубинных вычислений на "траекторию конвергентности". Данная книга призвана предоставить углублённый обзор данной области, а также связанных с ней технических вызовов, подходов и решений. Эта глава предоставляет общий обзор тем исследований и задач в данной области, а также общую схему всей книги.
За последнее десятилетие Большие данные изменили то, как люди осознают и применяют имеющуюся мощность данных как в бизнесе, так и в исследовательской сфере. Большие данные превратились в один из важнейших элементов бизнес- аналитики. Большие данные, высокопроизводительные вычисления, а также Глубинное обучение/ Машинное обучение (DL/ML, deep learning/machine learning) объединяются для решения задач обработки данных крупного масштаба. Выполнение высокопроизводительных нагрузок анализа данных в средах высокопроизводительных вычислений и облачных вычислений приобретает всё большую популярность. Согласно недавнему отчёту Hyperion (Norton et al., 2020), высокопроизводительные рабочие нагрузки анализа данных значительно выросли за последние несколько лет как с точки зрения бюджетных ассигнований, так и в отношении организационной направленности. Эта тенденция будет продолжать расти в течении следующего десятилетия. Область Больших данных расширяется до "Гигантских данных" (Wang et al.).
В этом контексте возникают ложные задачи по следующим основным четырём направлениям: (1) осознание характеристик и тенденций Больших данных; (2) понимание взаимодействия между Большими данными, высокопроизводительными вычислениями и Глубинным/ Машинным обучением; (3) понимание основных тенденций технологий высокопроизводительных вычислений (обработка, сетевое взаимодействие и хранение) для ускорения обработки Больших данных; а также (4) осознание преимуществ ускорения обработки Больших данных.
Традиционно задачи и решения Больших данных характеризовались тремя V (volume, velocity и variety - объём скорость и разнообразие). В последние годы к ним добавилась четвёртая V (veracity - достоверность). Эти характеристики отражены на Рисунке 1.1. Объём отражает подлежащий обработке объём данных в состоянии покоя. Скорость относится к перемещениям данных. Разнообразие соотносится с огромным разнообразием подлежащих обработке типов данных. Достоверность ссылается на сомнительные сведения.
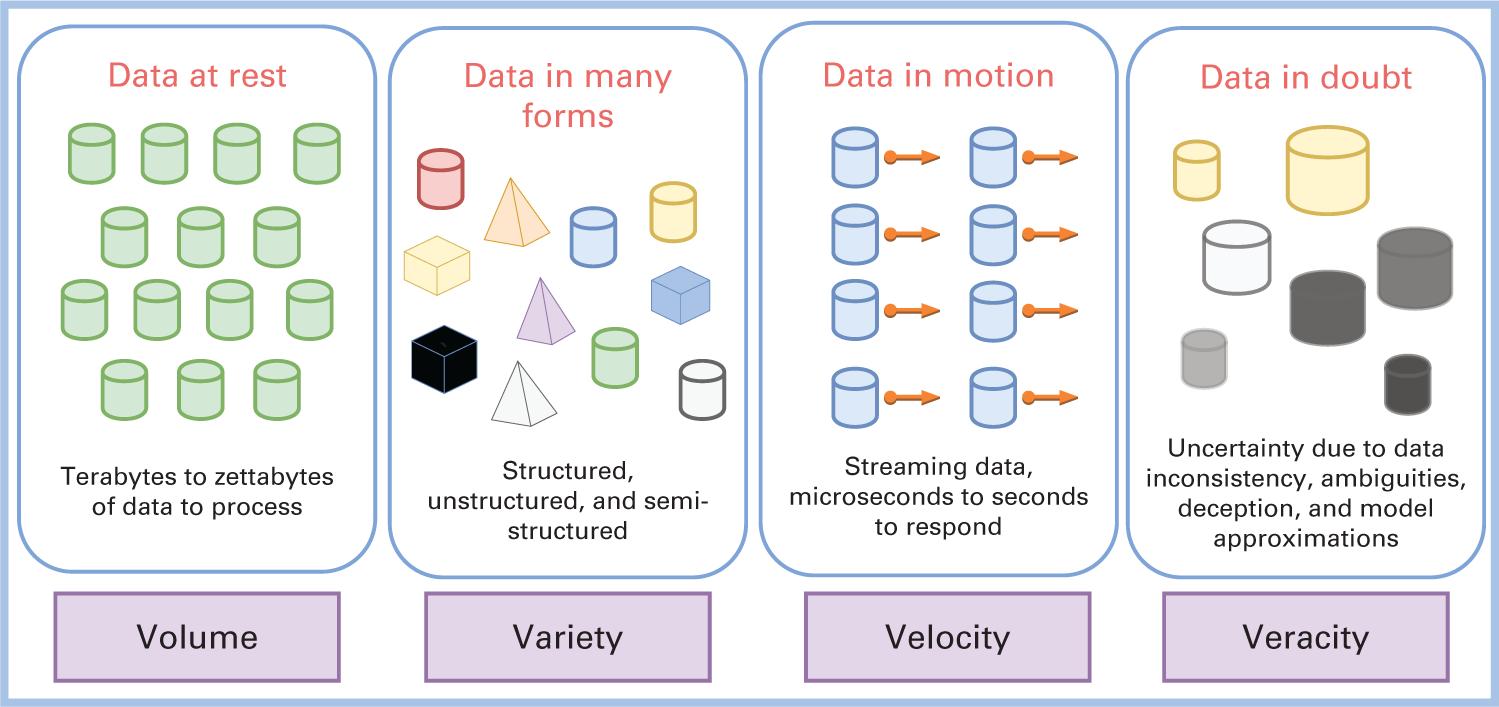
Данные вырабатываются во всех разнообразных видах и формах из множества различных предприятий, организаций и субъектов. На Рисунке 1.2 проиллюстрировано количество данных, вырабатываемых каждую минуту дня разнообразными субъектами в 2020 году. Например, каждую минуту на YouTube загружаются пятьсот часов видео. Каждую минуту пользователи WhatsApp публикуют около 41.67 миллиона сообщений. Amazon отправляет 6659 посылок каждую минуту. Это влечёт за собой большой вызов при разработке соответствующих систем обработки аналитики Больших данных.

Действенная обработка Больших данных с четырьмя V сопряжена с большим числом сложных задач технологий текущего поколения, в особенности, с постоянно растущими данными. Большие объёмы данных как правило приводят к внешней обработке данных и их перемещению, а также к существенным узким местам ввода/ вывода (I/O). С другой стороны, данные в движении, также именуемые как "большая скорость", требуют обработки данных в реальном масштабе времени. Это возлагает высокие требования к лежащим в основе системам вычислительных ресурсов, сетевых сред и хранилищ. Третья V (variety, разнообразие) привела к разработке сообществом Больших данных ряда сред обработки данных, например, Hadoop, Spark, Flink, Storm, Kafka.
Тем не менее, маловероятно, что ближайшем будущем будет создана единая стандартная спецификация или реализация, что затрудняет продвижение сред с высокой оптимизацией. Предлагаемые в литературе и сообществе оптимизации наших дней, в целом, проводились в индивидуальном порядке. Тем самым, для решения относящихся в четырём V задач обработки Больших данных следующего поколения, крайне важно разработать стеки программного обеспечения для Больших данных следующего поколения, которые способны обрабатывать данные высокопроизводительным и масштабируемым образом и которые способны оптимально применять лежащие в основе сетевую среду, вычисления и возможности хранения. При данных обстоятельствах в контексте обработки Больших данных была добавлена пятая V (value, ценность). Ценность определённых данных и связанных с ними бизнес- аналитики, которая должна получаться из таких данных, может различаться в разных организациях. Для определённой организации конкретный тип данных может иметь важной значение. Тем самым, такая организация будет готова приложить существенные усилия (и затраты) для обработки этих сведений. Для другой организации такой критичности может и не иметься. Такая тенденция приводит к разнообразным предложениям ценности в имеющемся сообществе Больших данных для обработки разных видов информации.
В целом, системы управления и обработки данных текущего поколения в современных центрах обработки данных (ЦОД) работают на двух основных уровнях: уровне интерфейса и на уровне сервера. программные компоненты уровня интерфейса обычно развёртываются для обслуживания запросов на доступ к данным и для оперативной обработки данных. Соответствующие программные компоненты управления и обработки данных на этом уровне обычно включают (1) веб - серверы, такие как Apache HTTP Server, NGINX, Tomcat и так далее; (2) базы данных, такие как MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server и тому подобные; (3) уровень распределённого кэширования, например, Memcached, Redis и прочие; (4) базы данных NoSQL (Not Only SQL), скажем, HBase, MongoDB и иные. С точки зрения значения производительности, такие приложения реального времени требуют чтобы данные программные системы уровня интерфейса в ЦОД обрабатывали бы данные с низкой задержкой и при высокой пропускной способности с тем, чтобы ЦОД был способен предоставлять позитивную практику пользователей. Именно поэтому системные администраторы, как правило, предпочитают поверх традиционной системы баз данных предпочитают развёртывать распределённый уровень кэширования. Посредством подобного уровня кэширования многие запросы данных могут непосредственно обслуживаться копиями кэшируемых в оперативной памяти данных, что намного быстрее загрузки этих данных из их систем баз данных.
По мере роста обрабатываемых и хранимых программными системами объёмов данных, эти сведения постепенно будут перемещаться на уровень серверов для последующей обработки, такой как интеллектуальный анализ данных, очистка данных, Машинное обучение, складирование данных и тому подобного. Основная цель программных компонентов серверного уровня состоит в добыче ценности в автономном режиме из гигантского объёма данных при помощи заданий аналитики данных и Машинного обучения или Глубинного обучения. Соответствующие программные компоненты для управления и обработки данных этого уровня обычно содержат (1) распределённые системы хранения, такие как распределённая файловая система Hadoop (HDFS, Hadoop Distributed File System), Ceph, Swift и тому подобные; (2) программное обеспечение (ПО) промежуточного уровня для анализа данных, такое как Hadoop, Spark, Flink и иное; (3) среды Машинного обучения или Глубинного обучения, например, TensorFlow, PyTorch и им подобные; (4) различные инструменты или библиотеки для анализа данных и Машинного обучения, подобные MLlib, Keras и т.д. С точки зрения производительности, наиболее важными свойствами таких серверных систем в ЦОД выступают высокая пропускная способность и горизонтальная масштабируемость.
В данной книге мы обсудим имеющиеся программные модели и архитектуры программного обеспечения некоторых образцов систем как для уровня интерфейса, так и для серверного уровня. Дополнительные сведения можно обнаружить в Главах 2 и 3.
За последние несколько лет программные средства аналитики Больших данных и управления ими были значительно улучшены в плане производительности и масштабируемости. Среди н=разнообразных факторов, эволюция аппаратных средств выступает одной из ключевых сторон, определяющих развитие систем анализа и управления Большими данными. На протяжении последних лет наблюдается быстрый рост числа ядер процессоров и столь же впечатляющие увеличение объёма оперативной памяти и пропускной способности сетевой среды в современных кластерных системах как в центрах высокопроизводительных вычислений, так и в центрах обработки данных (ЦОД). Такой рост был вызван текущими тенденциями в архитектурах с большим числом/ множеством ядер, появлением технологий гетерогенной памяти (например, DRAM, энергонезависимой памяти - NVM, nonvolatile memory) (Qureshi et al., 2009; Kültürsay et al., 2013), либо постоянной памяти [PMEM, persistent memory], памяти с высокой пропускной способностью, твердотельных накопителей NVM Express [NVMe-SSD], а также высокоскоростных интерконнектов, таких как InfiniBand, Omni-Path, RDMA (т.е. удалённого прямого доступа к памяти, remote direct memory access) по расширенному конвергентному Ethernet (RoCE, RDMA over converged enhanced Ethernet) и тому подобных.
Такие архитектуры с большим числом/ множеством ядер, гетерогенная память и высокоскоростные интерконнекты в настоящее время набирают обороты для разработки сред HPC и облачных вычислений нового поколения. Эти новые аппаратные архитектуры с более высокой производительностью и современными функциональными способностями открывают массу возможностей для повторного проектирования стеков программного обеспечения аналитики Больших данных и управления ими для достижения беспрецедентных производительности и масштабируемости.
Таким образом, разработка стеков программного обеспечения для аналитики Больших данных и управления ими с учётом возможностей аппаратных средств и их архитектуры превратилась в плодотворную область исследований. Мы наблюдали большое число интересных результатов исследований и многообещающих улучшений производительности, обусловленных оптимизацией с учётом архитектуры от современных технологий памяти (например, NVM/PMEM), высокоскоростных интерконнектов (таких как сетевые среды с поддержкой RDMA) для облегчения имеющегося ввода/ вывода и узких мест связи, в сторону архитектур параллельной обработки аналитики Больших данных и управления стеками ПО с большим числом/ множеством ядер.
Для решения задач, связанных с обработкой и хранением гигантских объёмов подлежащих обработке и хранению научных сведений в сообществе высокопроизводительных вычислений широкое распространение получили передовые технологии. Современные системы высокопроизводительных вычислений и связанное с ними ПО промежуточного уровня (например, интерфейс обмена сообщениями, или MPI - message passing interface, а также параллельные файловые системы) в последние десятилетия эксплуатируют имеющиеся достижения в технологиях HPC (архитектуры с большим числом/ множеством ядер, сетевые среды с поддержкой RDMA, NVRAM и SSD). Однако стандартные для устанавливаемых готовых стеков ПО аналитики и управления Большими данными (например, Hadoop, Spark, Flink, Memcached) не полностью овладели такими технологиями. К примеру, недавние исследования (Rahman et al., 2014; Lu et al., 2014; Islam et al., 2016b; Shankar, Lu, Islam, et al., 2016; Y. Wang et al., 2015; Lim et al., 2014; Huang et al., 2014; Arulraj et al., 2015) пролили свет на возможные улучшения производительности различного ПО промежуточного уровня для Больших данных за счёт применения RDMA в сетевой среде Infiniband, байтовой адресации и постоянства NVM. В данной книге, в Главе 4, мы более подробно обсудим технологические тенденции в современных кластерах HPC и в ЦОД.
В последние годы наше сообщество наблюдает важную конвергенцию {сходимость} между тремя большими областями - HPC, Большими данными и Глубинным обучением, что отражено на Рисунке 1.3. Поскольку среды высокопроизводительных вычислений продолжает предоставлять всё более и более современные возможности, сообщество Больших данных в наши дни способно применять такие возможности. В то же время мы также наблюдаем, что сообщество Глубинного обучения способно применять как технологические достижения в области высокопроизводительных вычислений, так и в области Больших данных для формирования двух своих основных столпов: беспрецедентных вычислительных возможностей и гигантского объёма данных под модели обучения. Такой цикл конвергенции продолжается на протяжении многих лет. Мы полагаем, что данная тенденция принесёт пользу всем трём областям и мы обнаружим, что эти сообщества предлагают и разрабатывают всё более совершенные решения для достижения более высоких производительности и масштабируемости под конечные приложения.
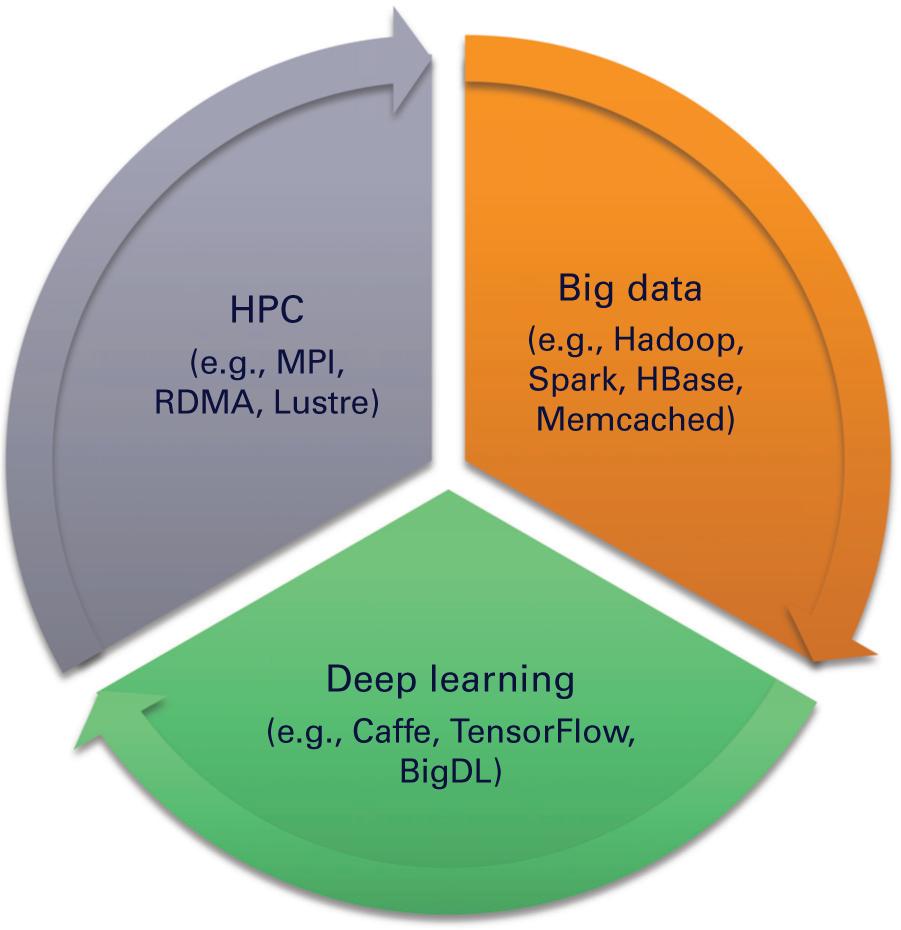
Такая сходимость высокопроизводительных вычислений, Больших данных и Глубинного обучения превращаются в следующую возможность для бизнеса, которая меняет правила игры. Данная тенденция привела к большому числу важных исследований и разработок в областях, направленных на приведение HPC, обработки Больших данных и Глубинного обучения на сходящуюся траекторию. Как показано на Рисунке 1.4, с точки зрения пользователя нам приходится давать ответы на множество критически важных вопросов и проблем для достижения подобной конвергенции. Вот некоторые примеры вопросов:
Рисунок 1.4

Проблемы приведения HPC, Больших данных и Глубинного обучения на траекторию конвергенции
-
Где находятся основные узкие места в текущей обработке Больших данных и ПО промежуточного уровня Глубинного обучения (например, в Hadoop, Spark, TensorFlow, PyTorch)?
-
Можно ли смягчить такие узкие места при помощи новых архитектур, получающих преимущества технологий HPC?
-
Способны ли интерконнекты HPC с применением RDMA, которые широко распространены в системах HPC, сулить преимущества системам и приложениям обработки Больших данных и Глубинного обучения?
-
Могут ли кластеры HPC с высокопроизводительными системами хранения (например, PMEM, NVMe-SSD, параллельной файловой системой) обеспечить преимущества приложениям Больших данных и Глубинного обучения?
-
Каких улучшений производительности можно добиться за счёт улучшения архитектуры и проектирования кода?
-
Как проектировать эталонное тестирование для оценки значения производительности ПО промежуточного уровня Больших данных и Глубинного обучения в кластерах HPC?
Несомненно, к данному перечню вопросов можно добавить ещё ряд вопросов. Чтобы помочь ответить на эти вопросы, данная книга признана предоставить подробный и систематический обзор последних результатов исследований по основным темам для "HPC + Большие данные + Глубинное обучение в кластерах HPC и в облачных решениях".
В качестве отправной точки изучения таких исследовательских возможностей мы можем попытаться развернуть и запустить задания Больших данных и Глубинного обучения современного поколения (например, задания Hadoop, Spark, TensorFlow) в имеющихся средах HPC, как это отражено на Рисунке 1.5. Благодаря определению характеристик и анализу производительности рабочей нагрузки мы способны изучить потенциальные узкие места для эффективности и масштабируемости в таких модели исполнения и стеке.
Рисунок 1.5

Способны ли мы действенно запускать задания Больших данных и Глубинного обучения в имеющихся средах HPC?
На Рисунке 1.6 представлен общий обзор связанных с этим задач, достижения вычислений Больших данных в системах HPC и облачных вычислений. Самый нижний уровень на этом рисунке показаны различные виды передовых технологий, предоставляемых средами HPC и облачных вычислений, таких как высокоскоростные технологии сетевых сред, архитектуры высокопроизводительных и общедоступных вычислительных систем, а также современных технологий хранения. Верхний уровень на этом же рисунке отражает потребителей технологий, таких как приложения с интенсивным применением данных, эталонные тесты и рабочие нагрузки. В середине у нас имеются три важных уровня, которые способствуют обеспечению близкой к пиковой производительности от имеющегося уровня оборудования для соответствующего уровня приложений. Этими тремя уровнями выступают уровень библиотеки коммуникации и ввода/ вывода, уровня программирования и уровень промежуточного ПО обработки и управления Большими данными. Каждый из этих уровней должен быть действенно спроектирован для предоставления максимальных производительности и гибкости компонентам верхнего уровня.
Рисунок 1.6
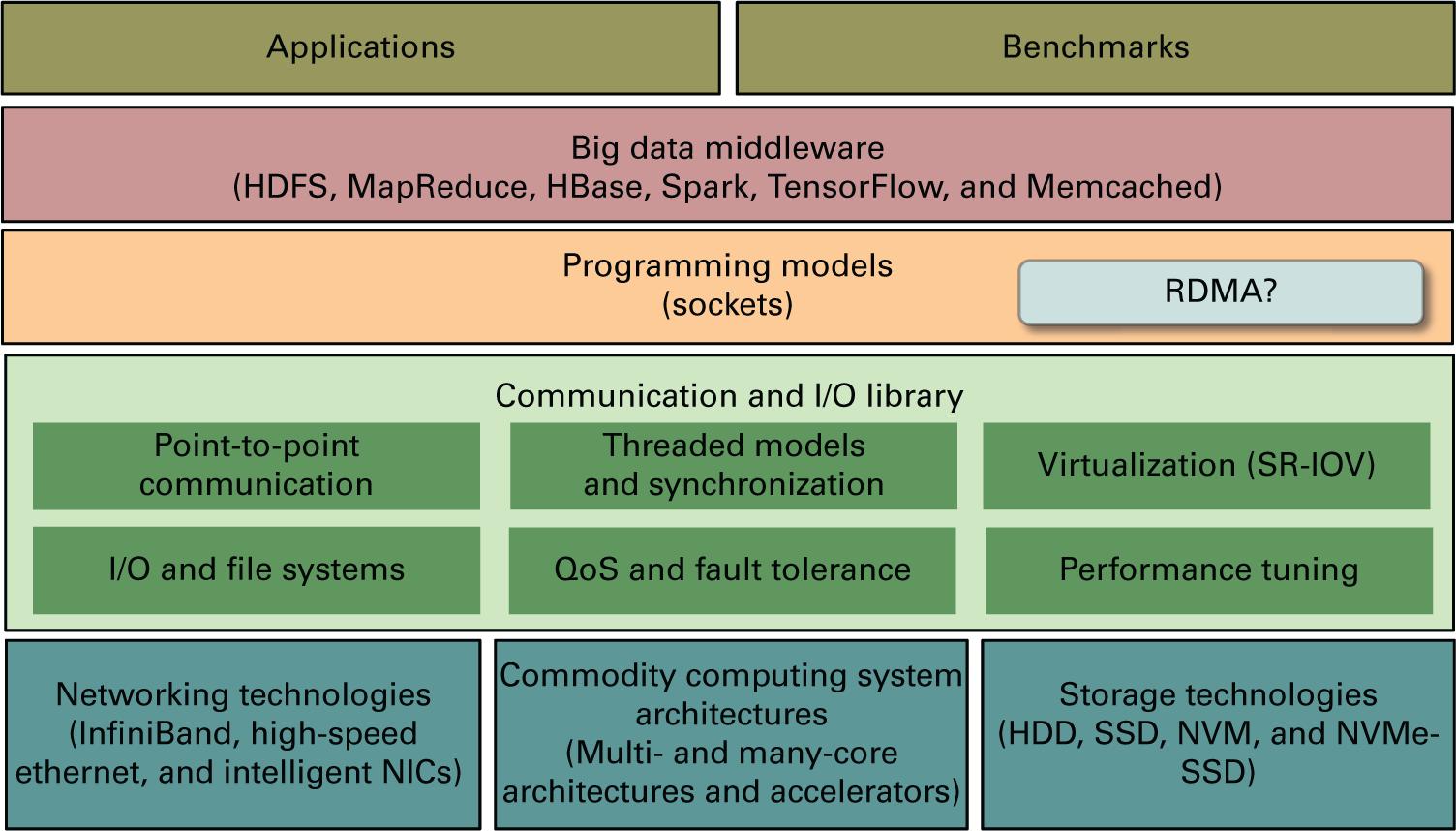
Задачи высокопроизводительного вычисления Больших данных. HDD, hard disk drive; NICs, network interface cards; QoS, quality of service; SR-IOV, single root input/output virtualization
Основные задачи проектирования высокопроизводительного и масштабируемого уровня коммуникации и ввода/ вывода включают в себя разработку действенных протоколов связи точка- точка, моделей потоков и механизмов синхронизации, поддержку виртуализации с производительностью, близкой к естественной, низкой задержкой и высокой пропускной способностью операций ввода/ вывода в файловых системах или системах хранения, поддержкой качества обслуживания и отказоустойчивости, регулировкой производительности и тому подобным. Все эти свойства являются критически важными функциональными возможностями для желаемой библиотеки коммуникации и ввода/ вывода в высокопроизводительном стеке вычислений Больших данных. Успешным образцом такого уровня коммуникации и ввода/ вывода выступает MPI сообщества HPC. К сожалению, сообщество Больших данных пока не разработало стандартизованный уровень коммуникации и ввода/ вывода, который можно было бы рассматривать как некий этап "перед MPI" (R. Lu et al., 2014; Lu et al., 2011). Уроки истории говорят нам о том, что для высокопроизводительных вычислений Больших данных требуется стандартная и действенная среда коммуникации и ввода/ вывода.
Традиционно ПО промежуточного слоя для обработки и управления Большими данными, такое как Hadoop, Spark, HBase, Memcached и тому подобное, разрабатываются поверх обычных протоколов коммуникации и ввода/ вывода, таких как TCP/IP, удалённый вызов процедур (RPC, remote procedure call), файловых системных вызовов и тому подобного. Эти протоколы построены с применением понятий и интерфейсов, ориентированных на операционную систему, таких как сокеты, POSIX (Portable Operating System Interface) и так далее. Такие модели программирования обычно обладают более высокими накладными расходами из- за переключения контекста и буферных копий между пространством пользователя и пространством ядра (Rahman et al., 2014; Lu et al., 2014; Islam et al., 2016b, Shankar, Lu, Islam, et al., 2016). С появлением всё более и более современных технологий, предоставляемых лежащим в основе аппаратным уровнем, становятся доступными новые модели программирования и интерфейсы, которые способны обеспечивать приложениям истинное пространство пользователя, а также протоколы коммуникацию и ввода/ вывода с нулевым копированием. Например, RDMA выступает одной из таких многообещающих моделей коммуникации, причём она широко применяется в сообществе HPC на протяжении более чем двадцати лет. Кроме того, в сообществе систем хранения данных появляются модели программирования на основе PMEM и NVMe-SSD, которые продемонстрировали преимущества высокой производительности для интенсивно применяющих данные приложений, по сравнению с традиционными подходами ввода/ вывода на основе POSIX. (Klimovic et al., 2017; Cao et al., 2018; Xia et al., 2017; Islam et al., 2016b). Такие новые модели программирования не только значительно улучшают производительность и масштабируемость ПО промежуточного уровня для обработки Больших данных и управления ими, но также открывают множество новых возможностей проектирования кода для систем и приложений верхнего уровня.
Вместо применения таких общедоступных аппаратных платформ и технологий (таких как RDMA, NVMe, PMEM) исследовательского сообщества, многие высокотехнологичные компании (например, Google и Amazon) производят свои собственные микросхемы, материнские платы, сетевые среды и тому подобное. Их сетевые средства, ввод/ вывод и стеки программного обеспечения предположительно оптимизированы под эксплуатацию тех уникальных возможностей, которые предоставляются их аппаратными средствами. По причине отсутствия технических подробностей о подобных частных разработках мы не будем обсуждать их в этой книге. Тем не менее, основная цель всех этих проектов одна и та же: это попытка существенно повысить производительность и масштабируемость систем аналитики и управления Большими данными текущего поколения для решения всё возрастающих задач гигантских или больших данных.
Тем временем, следует отметить, что несколько крупных поставщиков облачных служб (таких как Microsoft Azure, AWS, Oracle Cloud ив своих последних экземплярах HPC внедряют сетевые технологии HPC (такие как InfiniBand и RoCE). Таким образом, обсуждаемые в данной книге проекты также способны работать в подобных экземплярах высокопроизводительных вычислений в своих облачных решениях. Даже многие ЦОД социальных площадок, таких как Facebook, Microsoft, Alibaba и т.п. также перешли на применение сетевых технологий HPC InfiniBand и RoCE. Дополнительно к традиционной рабочей нагрузке аналитики Больших данных в настоящее время выполняются рабочие потоки Глубинного обучения и искусственного интеллекта. Подробнее о таких проектах облачных решений будет рассказано в Главе 11.
Дополнительные технические задачи проектирования высокопроизводительных вычислительных систем Больших данных и приложений будут подробно обсуждены в Главе 5.
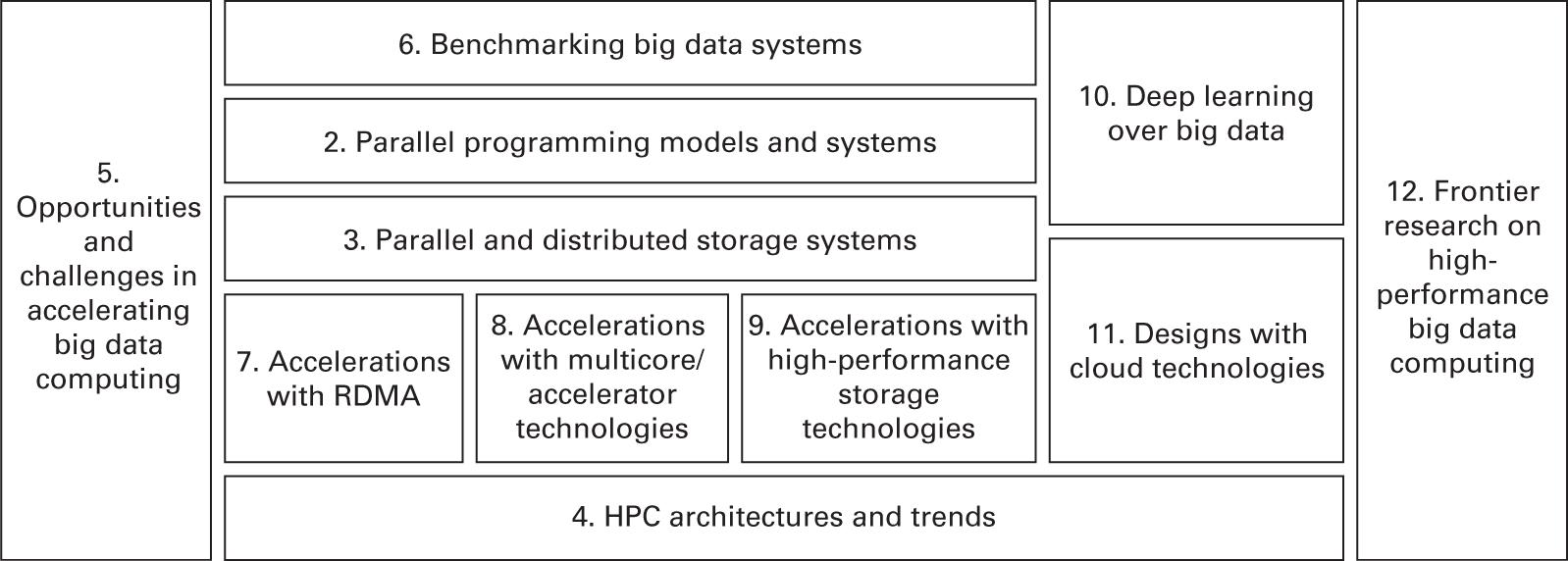
На основании предыдущих рассуждений исследовательских задач достижения высокопроизводительных вычислений Больших данных, данная книга была организована следующими пятью частями и двенадцатью главами в сумме, как это показано на Рисунке 1.7.
-
Главы 1-4 описываются основные вводные понятия и базовые знания, необходимые для хорошего понимания высокопроизводительных вычислений, Больших данных, Глубинного обучения и т.п.. В Главе 1 представлен общий взгляд на область высокопроизводительных вычислений Больших данных. В Главе 2 описываются популярные платформы обработки данных и модели программирования, применяемые для анализа Больших данных в средах высокопроизводительных вычислений и ЦОД. В Главе 3 представлен обзор уровня системы хранения, применяемого для ускорения рабочих нагрузок с интенсивным использованием сведений в средах высокопроизводительных вычислений и ЦОД. В Главе 4 описываются аппаратные возможности и тенденции, которые уже доступны и возникают для применения обработки данных в средах высокопроизводительных вычислений и ЦОД.
-
Глава 5 предоставляет дополнительное обсуждение технических вызовов и возможностей для ускорения вычислений Больших данных. В частности, мы суммируем шесть конкретных задач со стороны точек зрения вычислений, коммуникации, памяти, хранения, совместного проектирования, определения характеристик и эталонного тестирования рабочей нагрузки, а также развёртывания системы и управления ею.
-
В Главе 6 даётся обзор различных эталонных тестов и рабочих нагрузок, проектируемых и разрабатываемых для оценки имеющихся и появляющихся систем промежуточного ПО работы с Большими данными.
-
Главы 7-9 включают подробное описание проектирования и ускорения вычислительных систем и приложений для работы с Большими данными с применением технологий высокопроизводительных сетевых решений, вычислений и хранения. В Главе 7 представлены задачи и варианты, связанные с проектированием подсистем и протоколов коммуникации с поддержкой RDMA для ПО промежуточного уровня Больших данных. В Главе 8 представлены планы по ускорению различных компонентов экосистемы Больших данных на существующих и новых гетерогенных вычислительных архитектурах. В Главе 9 предоставлены различные варианты архитектуры и дизайна, связанные с созданием файловой системы или хранилища данных с применением высокопроизводительных технологий хранения для ПО промежуточного уровня Больших данных. В данных главах представлены всесторонние обзоры разнообразных современных разработок и ускорений систем обработки и хранения Больших данных.
-
В главах 10-12 подробно обсуждаются некоторые вопросы современных исследований в области высокопроизводительных вычислений Больших данных. В Главе 10 обсуждаются задачи проектирования высокопроизводительных стеков Глубинного обучения на основе Больших данных (DLoBD). В этой главе анализируются некоторые представительные стеки DLoBD. В Главе 11 представлен обзор облачных технологий высокопроизводительных вычислений и обсуждаются несколько представительных исследований сообщества о том, как удовлетворить требованиям действенного исполнения приложений высокопроизводительных вычислений и Больших данных в Облачном решении. В Главе 12 обсуждаются современные и, вероятно, перспективные направления исследований для достижения высокопроизводительных вычислений Больших данных.
В этой главе мы представили обзор характеристик и тенденций Больших данных. Мы также разделили имеющиеся системы управления данными и их обработки на два широких уровня: уровень интерфейса и серверный уровень. Также обсуждаются соответствующие задачи проектирования и оптимизации для каждого из уровней. Затем мы рассмотрели технологические тенденции в средах высокопроизводительных вычислений и центров обработки данных. Основываясь на этих рассуждениях, мы выделили возможности и проблемы конвергенции высокопроизводительных вычислений, Больших данных и Глубинного обучения. Мы поделили эту книгу на двенадцать глав, которые поспособствуют читателям лучше разобраться каждую из изучаемых тем. Основная цель данной книги - подробно обсудить многие важные исследования и разработки в данной отрасли для объяснения как ПО промежуточного уровня / прикладное ПО Больших данных и Глубинного обучения может быть переработано и ускорено для применения преимуществ технологий высокопроизводительных вычислений с тем, чтобы и рабочие нагрузки Глубинного обучения имели возможность исполняться в той же самой среде что и HPC.
Мы надеемся, что при помощи нашей книги сообщества из разных областей смогут изучить больше возможностей для сотрудничества для объединения высокопроизводительных вычислений, обработки Больших данных и Глубинного обучения в траекторию сходимости.