Глава 5. Возможности и проблемы ускорения вычислений Больших данных
Содержание
- Глава 5. Возможности и проблемы ускорения вычислений Больших данных
- Обзор
- C1: Проблемы вычислений
- C2: Проблемы взаимодействия и перемещения данных
- C3: Проблемы управления памятью и хранением
- C4: Проблемы совместной разработки систем и приложений Больших данных
- C5: Проблемы снятия характеристик и эталонного тестирования рабочей нагрузки Больших данных
- C6: Проблемы развёртывания и управления
- Выводы
В предыдущих главах был представлен обзор моделей и систем параллельного программирования, параллельных и распределённых систем хранения, а также архитектуры и тенденции высокопроизводительных вычислений (HPC). Однако для разработки систем и приложений обработки Больших данных, обладающих высокими производительностью и масштабируемостью имеется большое число фундаментальных проблем и возможностей, стоящих перед сообществом Больших данных. В этой главе представлено краткое обсуждение таких проблем и возможностей ускорения обработки Больших данных. В частности, мы суммируем шесть конкретных задач с точки зрения вычислений, связи, памяти/ хранилища, разработки кода, определения характеристик рабочих нагрузок и эталонного тестирования, а также развёртывания системы и управления ею. Осознание этих задач поможет данному сообществу предлагать более совершенные архитектуры для высокопроизводительных вычислений систем и приложений Больших данных следующего поколения.
Приложения с интенсивным применением данных или приложения Больших данных испытали серьёзные проблемы с технологиями текущего поколения, такими как обработка данных вне ядра (core), существенные узкие места ввода/ вывода, обмен штабелями данных и тому подобное. В последние несколько лет ускорение обработки Больших данных и управления программным обеспечением (ПО) промежуточного уровня превратились в горячие темы исследований. Одним из движущих факторов этого выступает быстрый рост мощности и возможностей архитектур с большим числом ядер/ множеством ядер, зарождающиеся технологии неоднородной памяти (например, оперативной памяти - DRAM, NVM (Qureshi et al., 2009; Kültürsay et al., 2013), HBM, NVMe-SSD), а также высокоскоростных интерконнектов, таких как InfiniBand, Omni-Path, RoCE и им подобных, всего того, что мы обсуждали в Главе 4.
Достижения с большим числом/ множеством ядер процессоров и ускорителей, сетевых сред и технологий неоднородных памяти/ хранилищ предоставляют совершенно новые возможности для проектирования вычисления, взаимодействия и подсистем ввода/ вывода под значительное ускорение современных сред Больших данных и приходящих им на смену инфраструктур. Основываясь на наблюдаемых в современных средах обработки данных подвижках парадигмы, мы предвидим, что в последующих инфраструктурах HPC и облачных вычислений будет разрабатываться всё более и более высокопроизводительные системы, среды выполнения и приложения вычисления Больших данных.
В данной главе сначала представлена предполагаемая нами архитектура для инфраструктур HPC и облачных вычислений следующего поколения. В сообществе HPC подобные системы обычно носят название высокопроизводительных систем вычислений следующего поколения (HEC, "high-end computing"). Такие передовые системы позволяют научным сотрудникам и инженерам решать грандиозные задачи в своих областях и вносить существенный вклад в их отраслях. Примеры таких областей включают астрофизику, анализ землетрясений, предсказание погоды, моделирование нанонаук, многомасштабное и мультифизическое моделирование, биологические вычисления, вычислительную гидродинамику и так далее. Помимо традиционных научных вычислений, значительные требования к системам HEC предъявляют такие отрасли как аналитика Больших данных, Машинное и Глубинное обучение.
Даже несмотря на то, что приложения Больших данных в системах HPC сильно отличаются по масштабу и характеристикам данных от приложений Больших данных в центрах обработки данных (ЦОД) или в облачных решениях, системные исследователи обеих областей имеют общие цели, например, значительное повышение производительности, масштабируемости, загруженности ресурсов, управляемости и тому подобного для приложений Больших данных. В этой книге мы обсуждаем как достигать эти общие цели для систем и приложений Больших данных следующего поколения как в инфраструктурах HPC, так и в средах облачных вычислений, то есть в системах HEC. Современные архитектуры и ускорения систем и приложений Больших данных в облачных решениях обсуждаются в Главе 11.
Системы HEC стабильно развиваются на протяжении последних двух десятилетий. В течение последнего десятилетия большое внимание уделялось разработке и применению систем экза- масштаба The ASCAC Subcommittee on Exascale Computing, 2010). С 2018 года сообщество пребывает в периоде перед экза- масштабом В июне 2018 года была анонсирована система Summit (Oak Ridge National Laboratory, 2018) с производительностью 200 петаFLOPS. В июне 2020 года была объявлена самым быстрым суперкомпьютером в мире система Fugaku (RIKEN Center for Computational Science (R-CCS), 2020). После обновления в ноябре 2020 года производительность Fugaku достигла нового мирового рекорда в 442 петаFLOPS. Ряд стран (США, Китай и Япония) и Европейский Союз занимаются и будут заниматься разработкой систем экза- масштаба в период 2021- 2023 годов. В частности, разрабатываются три будущие системы экза- масштаба в США. Ожидается, чо суперкомпьютер Aurora (Argonne National Lab, 2021) будет доставлен в Argonne National Laboratory (ANL) Intel и Cray (в настоящее время Hewlett Packard Enterprise). Он может стать первым действующим суперкомпьютером с экзаFLOPS в ANL в 2022 году {Прим. пер.: первым суперкомпьютером с экзаFLOPS в июне 2022 года стала система HPE Cray EX Department of Energy (DOE), достигшая пиковой производительности 1.102 экзаFLOPS/c с применением 8 730 112 ядер (3е поколение ЦПУ AMD EPYC™ и ускорители вычислений AMD Instinct™ 250X), запуск суперкомпьютера ANL Aurora отложен до конца 2022, в основном, в связи с задержкой выхода на рынок его ЦПУ Intel.}. Ещё один суперкомпьютер, El Capitan (Lawrence Livermore National Laboratory (LLNL), 2020), будет установлен в Ливерморской национальной лаборатории Лоуренса и может начать работу в начале 2023 г. Ожидается, что его производительность составит 2 экзафлопс. По мере развёртывания и использования большего количества систем HEC будет постоянно возникать потребность в запуске приложений для работы с Большими данными следующего поколения с большей степенью детализации, более точными временными шагами, большими размерами данных и т.д.
Основываясь на грядущих технологических тенденциях мы предполагаем, что некоторые из систем HEC следующего поколения будут обладать архитектурой, показанной на Рисунке 5.1. системы будут иметь большое число плотно упакованных узлов, соединённых между собой сетями со скоростью в терабиты в секунду или выше (DOE Workshop Report, 2011). Плотные узлы будут неоднородными (гетерогенными) и составляться из ЦПУ, ускорителей, сопроцессоров, а также FPGA/ ASIC. Сами ЦПУ также могут представлять смесь из мощных и слабых ядер. Эти узлы также будут обладать большим объёмом памяти с сочетанием различных технологий, таких как NVRAM и трёхмерная стековая память. Все компоненты внутри узла или между узлами будут связаны чрезвычайно высокоскоростными интерконнектами. Такая архитектура будет способна обеспечивать большой объём одновременных соединений между различными компонентами (ЦПУ, ускорителями и памятью) без конфликтов. Поскольку каждый узел будет достаточно плотным, все узлы должны подключаться к всеобщей сетевой среде со скоростью обмена в терабиты в секунду посредством множества адаптеров/ портов. Это обеспечит хороший баланс между обменов внутри узлов и между узлами.
Рисунок 5.1
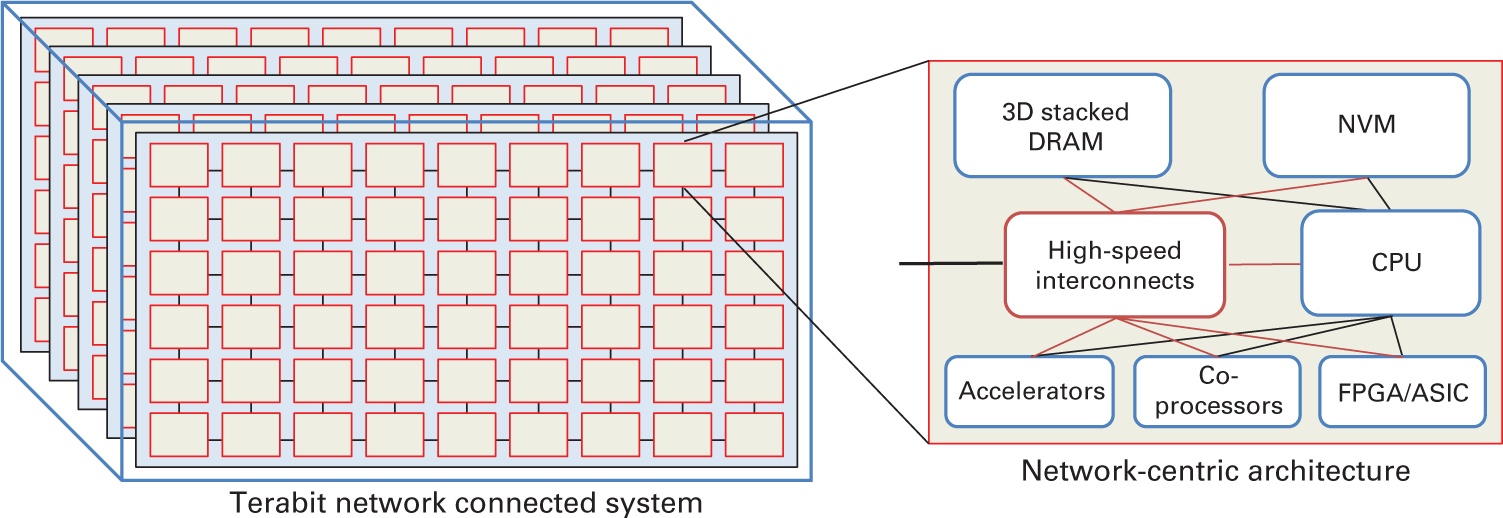
Предполагаемая архитектура систем HEC следующего поколения. Представлено Panda et al. (2018).
Действенное применение систем и приложений для работы с Большими данными поверх таких предполагаемых систем HEC это нетривиальная задача. Поскольку системы Больших данных предназначены для обработки огромных объёмов данных, критически важно проектировать размещение данных, перемещение данных, планирование заданий и прочие задания в стеках Больших данных для применения всех доступных преимуществ NVRAM, HBM, SSD, сетевых сред, графических процессоров, FPGA, а также многоядерных ЦПУ разумным образом для снижения значений времени доступа к данным, управления и обработки данных. Подход совместного проектирования требует целостного понимания характеристик вычислений, связи и ввода/ вывода сред Больших данных, а также взаимодействия между различными уровнями приложений, ПО промежуточного уровня и оборудования.
Для осознания вышеупомянутых стоящих перед сообществом Больших данных фундаментальных задач, в данной главе предпринимается попытка обобщения шести конкретных задач (обозначаемых C1 - C6) на разных уровнях, что отражено на Рисунке 5.2.
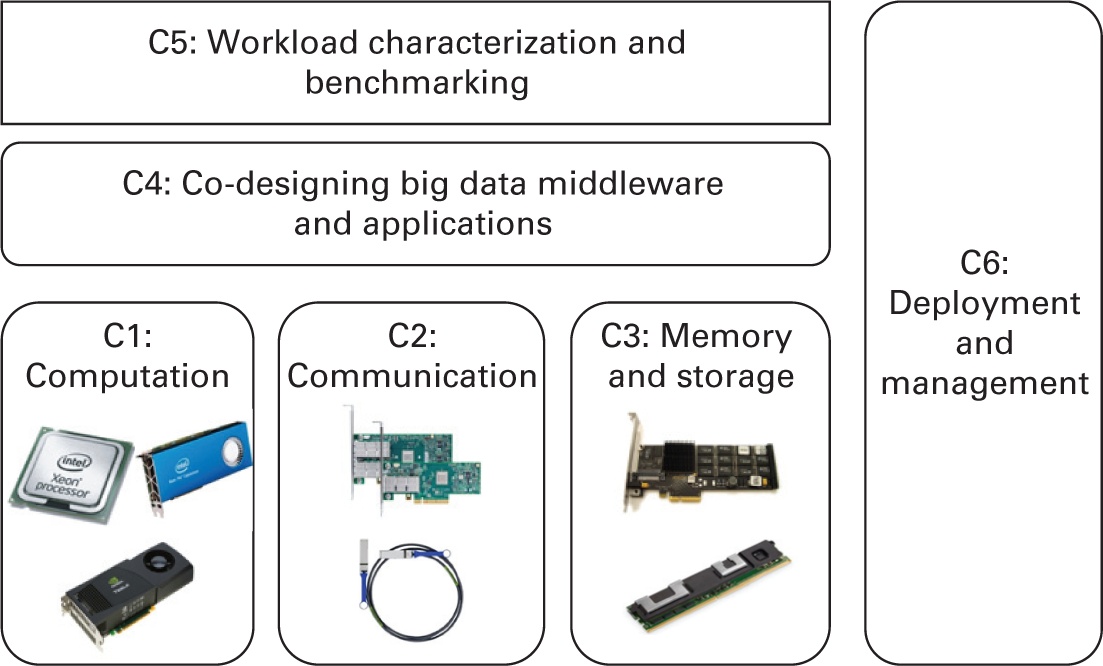
-
C1: Вычислительные задачи достижения высокой производительности вычислений Больших данных
-
C2: Задачи взаимодействия или перемещения данных достижения высокой производительности вычислений Больших данных
-
C3: Задачи управления памятью и хранения достижения высокой производительности вычислений Больших данных
-
C4: Задачи совместного кодирования ПО промежуточного уровня и приложений Больших данных
-
C5: Задачи оценки характеристик и эталонного тестирования рабочих нагрузок Больших данных
-
C6: Задачи развёртывания систем и приложений Больших данных и управления ими.
В последующих разделах этой главы мы вкратце обсудим подробности этих задач.
Как это уже обсуждалось в Главе 4, платформы наших дней с современными вычислениями поддерживают в узле примерно 32-128 вычислительных ядер. Такие платформы быстро изменяются и превращаются в неоднородные при помощи многоядерных процессоров и ускорителей, таких как GPU NVIDIA, GPU AMD, FPGA, ASIC, помимо прочего. По мере появления архитектур с большим числом/ множеством ядер, предоставлять действенные решения под нагрузкой и работающие автономно для приложений с интенсивными вычислениями в области Больших данных. Подобное повторное проектирование и оптимизации способны содействовать приложениям промежуточного уровня Больших данных в применении процессоров с большим числом ядер и ускорителей для вычислений, а также для увеличения возможностей перекрытия некоторыми иными этапами при общем вычислении, тем самым улучшая производительность и масштабирование. Тем не менее, для действенного применения таких ресурсов HPC нам требуется решать большое число основополагающих задач систем и приложений Больших данных.
Действенное проектирование ЦПУ с поддержкой NUMA: Nonuniform memory access (NUMA, доступ к неоднородной памяти) это распространённая микроархитектура современных ЦПУ. Применяя NUMA, ядра в одном ЦПУ узла NUMA способны выполнять доступ к своей собственной локальной памяти намного быстрее чем они способны выполнять доступ к удалённой памяти (не локальной) в ином узде NUMA. В такой ситуации, когда размещение данных или операции доступа происходят в удалённой памяти NUMA, значение производительности приложений и систем Больших данных существенно страдает. К сожалению, большая часть современного ПО промежуточного уровня Больших данных, например, Hadoop и Spark, спроектированы в архитектурах не осведомлённых об этом. Тем самым, поскольку их механизмы вычислений не могут быть осведомлены в полной мере об NUMA, а следовательно будут терять в производительности по причине штрафов за счёт доступа к удалённой памяти NUMA. В имеющейся литературе существует большое число исследований (Ott, 2011; Lu, Shi, Shankar et al., 2017), которые обсуждают как оптимизировать значение производительности приложений и систем Больших данных в архитектурах NUMA. Однако они всё ещё не применяются на систематической основе в современных системах Больших данных, потому как многие технические проблемы NUMA должны решаться в различных компонентах и слоях таких систем Больших данных. В частности, для создания действенных проектов с поддержкой NUMA в системах и приложениях Больших данных требуется балансировка рабочих нагрузок между ядрами в различных узлах NUMA, добиваться хорошей локальности для всех операций доступа к данным, избегать возможного перемещения данных и накладных расходов перегруженности соединений и так далее. Всё это составляет основополагающие задачи разработки действенных схем с поддержкой NUMA в системах и приложениях Больших данных в современных архитектурах ЦПУ следующего поколения.
Эффективное проектирование работы с векторами с применением SIMD в ЦПУ: В современных архитектурах ЦПУ со множеством ядер (например, процессоры Intel Xeon), в которых поддерживается параллелизм данных через векторную обработку, был проведён ряд направленных на применение инструкций SIMD (single instruction, multiple data, одной инструкции со множеством данных) ЦПУ исследований на предмет ускорения вычислений для рабочих нагрузок с интенсивным использованием данных. Применение инструкций SIMD для разрешения одновременности данных изучалось для ускорения операторов баз данных, таких как сканирование, соединение и агрегирование (Polychroniou et al., 2015; Zhou and Ross, 2002), а также для фильтрации Блума (Polychroniou and Ross, 2014, Lu, Wan, et al., 2019). Инструкции SIMD также применялись для обеспечения одновременного поиска данных по хэш- таблицам (Shankar et al., 2019b) в операциях соединения (join) (Ross, 2007; Behrens et al., 2018; Polychroniou et al., 2015). Современные ЦПУ Intel Skylake и Cascade Lake поддерживают векторные инструкции SSE (128-bit), AVX2 (256-bit), а также AVX-512 (512-bit). В частности, для 512-битных расширений инструкций SIMD AVX (AVX-512) под ISA x86, у нас имеется возможность работать со всей строкой кэша в одной инструкции. Таким образом, при таких растущих возможностях векторной обработки в современных аппаратных средствах у нас имеется возможность применения различной ширины вектора SIMD ЦПУ для обеспечения разной степени параллелизма данных при таком подходе к векторизации SIMD. Такие варианты технологии SIMD определяют важные задачи: какой тип параллелизма SIMD (аппаратные возможности или векторные инструкции ЦПУ) мы можем применять для ускорения систм Больших данных для конкретной рабочей нагрузки приложения? Существуют ли какие- либо руководства по проектированию или инструменты для SIMD, которые поспособствуют исследователям и разработчикам при создании своих действенных векторных вычислительных механизмов в системах Больших данных? Для ответов н эти вопросы могут оказаться полезными некоторые предварительные ноборы инструментария эталонного тестирования, например, SimdHT-Bench (Shankar et al., 2019b).
Проектирование поддержки ускорителей в стеках Больших данных: В современных кластерах HPC и ЦОД широко применяются такие ускорители как графические процессоры. Графические процессоры предлагают значительно более высокую пиковую производительность по сравнению с традиционными ЦПУ. Хотя GPU в основном применялись для ускорения вычислений, вовлечённых в научные приложения, а также в приложения Машинного и Глубинного обучения, их использование в стеках Больших данных стало предметом научных исследований. Одна из таких работ (Al-Kiswany et al., 2013) посвящена разгрузке основанных на хэшировании ресурсоёмких примитивов и представлению методов действенного применения вычислительной мощности GPU. Менее требовательное к вычислениям ПО промежуточного слоя, такое как хранилища KV, также исследует возможность применения конструкций с поддержкой GPU. MemcachedGPU (Hetherington et al., 2015) предложил ускоренное хранилище KV, которое может использовать всю систему на современном оборудовании за счёт выгрузки обработки пакетов UDP (User Datagram Protocol) и операций доступа к хеш-таблицам в GPU. MegaKV (K. Zhang, Wang, et al., 2015) пользуется большой полосой пропускания памяти современных графических процессоров и его возможности скрытия данных для достижения более высокой пропускной способности сервера. Во многих исследованиях также предлагались системы баз данных и складирования данных с поддержкой GPU (Govindaraju et al., 2004; Yuan, Yuan and Lee, Rubao and Zhang, Xiaodong, 2013). В литературе также доступны проекты на основе графического процессора в системах, подобных MapReduce (Yuan et al., 2016; Govindaraju et al., 2011). Как правило, существуют различные способы применения графических процессоров или других ускорителей в стеках Больших данных. Один из подходов состоит в применении графических процессоров для ускорения рабочих нагрузок Больших данных или библиотек без изменения их интерфейсов и моделей программирования. При таком подходе для беспрепятственной интеграции графических процессоров необходимо в стеки Больших данных внести значительные улучшения. Улучшение не может быть полностью совместимо с их аналогами на базе ЦПУ. Другой подход к применению графических процессоров или иных ускорителей состоит в автоматическом создании кода CUDA из кода ЦПУ, что, обычно, требует поддержки на уровне компилятора. Кроме того, некоторые стеки Больших данных выбирают прямую интеграцию некоторых ядер (kernel) или библиотек приложений с поддержкой графического процессора, которые обычно изначально написаны с применением CUDA. Все эти подходы требуют больших усилий для повторного проектирования вычислительных механизмов, управления ресурсами и подсистем планирования задач в стеках Больших данных. В конечном счёте, такие изменения создадут множество технических задач.
Для прочих типов ускорителей или процессорных устройств, таких как FPGA или ASIC имеются аналогичные только что рассмотренным нами здесь технические задачи. В Главе 8 мы дополнительно обсудим многие усовершенствованные технологии ускорения с применением большого числа/ множества ядер для достижения высокопроизводительных вычислений Больших данных.
Современные системы HEC и приходящие им на смену будут снабжаться высокоскоростным интерконнектом. Такие современные сетевые технологии будут предоставлять неограниченные возможности и критически важные вызовы для проектирования действенных и масштабируемых механизмов взаимодействий и перемещений данных.
Уплотнённые неоднородные сетевые технологии: Разнородные сетевые технологии могут применяться на различных уровнях (внутри ядер, внутри узлов, внутри стойки и между стойками) в зависимости от компромиссов мощности и производительности. Например, как уже обсуждалось в Главе 4, интерконнект NVLink может быть оптимальным на уровне обмена внутри узла для подключения как ЦПУ, так и GPU. Соединение InfiniBand или RoCE может быть оптимальным на уровне между узлами и между стойками. Эти современные сетевые технологии также позволят гибко устанавливать топологии большой размерности внутри ядер, внутри стойки, а также между стойками. Такие технологии также позволят гибко применять шаблоны связи один- ко- многим, многие- к- одному и многие- ко- многим с превосходной производительностью. Таким образом, сосуществование таких гетерогенных технологий в заданной системе предоставит верхним уровням большую гибкость для разработки протоколов взаимодействия с высокой эффективностью. Поскольку высокоскоростные сети следующего поколения будут работать на скоростях сотен гигабит или нескольких терабит, механизмы связи на различных уровнях системы должны соединяться воедино для обеспечения наилучшей производительности сквозного подключения между любыми двумя процессами в своей системе. В противном случае преимущества таких современных технологий не будут применяться должным образом. Перечислим ряд имеющихся задач для проектировщиков HEC систем следующего поколения и для создания инновационных решений.
Действенное сетевой взаимодействие и протоколы вычислений: высокопроизводительные сетевые технологии совершенствуются, всё больше и больше возможностей выгружаются в имеющуюся сетевую среду, что влечёт за собой эру "сетевых вычислений". Имеющиеся и нарождающиеся в современных высокоскоростных сетевых средах схемы, такие как CORE-Direct (Collectives Offload Resource Engine) (Mellanox, 2010), Erasure Coding Offloading (Shi and Lu, 2019, 2020) и Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) (Graham et al., 2016) являются хорошими примерами этой тенденции. Технология CORE-Direct способна разгружать коллективные операции MPI из библиотеки программного обеспечения (ПО) в сетевую среду, что делает возможным предоставление перекрывающихся с вычислениями соединений (Mellanox, 2010). Аналогичным образом, функция разгрузки Удаляющего кодирования (Erasure Coding) в современных интеллектуальных сетевых картах интерфейса (SmartNIC). способно полностью выгружать задачи вычисления Удаляющего кодирования в свою SmartNIC (Shi and Lu, 2019, 2020), что способно минимизировать применение WGE и достигать наилучшего перекрытия. Технология SHARP от Mellanox способна дополнительно разгружать коллективные операции из ЦПУ в сетевую среду коммутаторов, что способно повышать производительность коллективных операций MPI (Graham et al., 2016).
Имеющиеся тенденции сетевого вычисления делают возможной действенную реализацию в своей сетевой среде различных типов операций взаимодействия и вычислений, таких как однонаправленные точка- точка, групповую передачу один- ко- многим, сбор от многих- к- одному, операций кодирования и декодирования. Все упомянутые выше технологии становятся существенными при достижении пиковой производительности. Такие возможности, а также способности ПО промежуточного уровня по использованию этих схем будут существенными для стимулирования научных приложений и приложений Больших данных к производительности свыше экза- масштабов. По мере увеличения сетевого взаимодействия, с целью минимизации сетевых разногласий превращается в критически важную насущная необходимость "осведомлённости о сетевой топологии" протоколов взаимодействия и синхронизации.
Интегрированная поддержка ускорителей: Как уже обсуждалось во втором разделе этой главы, системы HEC следующего поколения будут широко применять ускорители и компоненты на основе FPGA/ ASIC, поэтому для обеспечения интегрированной поддержки таких устройств в неоднородной среде необходимо также перерабатывать и механизмы связи. Такие протоколы надлежит разрабатывать для обеспечения высокопроизводительного взаимодействия при высокой производительности. Например, фундаментальной задачей является поддержка типов данных в библиотеках взаимодействия. Обмен фрагментированными данными зачастую реализуется простой упаковкой данных в непрерывные буферы на стороне отправителя, в то время как выполняет распаковку полученных данных в буфер пользователя с применением большого числа библиотек или инфраструктур обработки Больших данных. Такой подход отнимает у своего приложения циклы ЦПУ и предоставляет худшую производительность, в особенности для сообщений большой длины, поскольку требует многократного копирования данных. Для решения задачи ненужных копий в памяти и отсутствия возможностей перекрытия при обработке типов данных, требуются архитектуры, в которых существенной является разгрузка упаковки/ распаковки данных в FPGA и интеллектуальные адаптеры. Прекрасными образцами тенденций в подобных новых технологий выступают такие решения как BlueField (Mellanox, 2018). Кроме того, появление новых отраслей, таких как Глубинное обучение, выдвинуло экстремальные и индивидуальные требования к взаимодействию/ вычислениям, которым необходимо принимать во внимание такие среды исполнения. Графические процессоры, FPGA и прочие ASIC, способные выражать такие сложные требования взаимодействия и вычислений при высокой производительности рассматриваются в качестве идеально подходящих для подобных потребностей.
Отказоустойчивость и поддержка QoS: Поскольку системы HEC и системы с масштабом выше экзаFOPS будут массивными и состоящими из миллионов компонентов, частые сбои будут обычным явлением. Таким образом, для возможности проектирования ПО верхнего уровня с целью превращения такой программной инфраструктуры в отказоустойчивую, сетевые среды на всех уровнях обязаны обеспечивать механизмы отказоустойчивости. Зарождающиеся приложения (такие как Глубинное обучение и обработка в потоках) носят итеративный характер. Кроме того, требуется учитывать взаимодействие между рядом различных приложений, которые потенциально способны пользоваться одной и той же сетевой средой интерконнекта. Например, когда операция контрольной точки выполняется одновременно с с операцией плотного взаимодействия, скорее всего, они будут мешать друг другу, что приведёт к снижению производительности обоих приложений. В данном контексте важное значение будет иметь предоставление качества обслуживания (QoS, quality of service) различным приложениям, а также различным операциям в одном и том же приложении. Для сетевых технологий следующего поколения также будет крайне важно поддерживать механизмы QoS на самом нижнем уровне, чтобы имелась возможность предоставления решения с учётом QoS для изоляции между потоками взаимодействия и заданиями. Системы HEC следующего поколения будут обладать набором разнородных сетевых сред. Несмотря на то, что каждая сетевая среда способна достойно обеспечивать поддержку QoS, достижения QoS по всей среде в разнородных сетях будет сложной задачей и потребует инновационных решений.
Схемы и протоколы взаимодействия с учётом энергопотребления: Высокий уровень энергопотребления превратится в серьёзную проблему для систем HEC следующего поколения.В данном контексте сетевые технологии обязаны предоставлять механизмы энергосбережения (например, автоматическое понижение скорости при отсутствии данных, переменные скорости с различными компромиссами по энергопотреблению). Кроме того, протоколы верхнего уровня коммуникации и синхронизации, применяемые моделями программирования и их средами исполнения, которые фактически и перемещают необходимые данные по системам HEC, обязаны разрабатываться с учётом энергоэффективности в качестве одной из своих основных целей. Этого невозможно достигать при помощи имеющихся подходов, которые рассматривают среду выполнения в качестве чёрного ящика и пользуются такими методами как дросселирование и масштабирование частоты ЦПУ на основе замеров энергопотребления на верхнем уровне. Целостный подход, который содержит тщательное понимание характеристик мощности этапа перемещения данных, интегрированный в архитектуру различных протоколов взаимодействия и, наконец, важное значение будут иметь совместное проектирование среды выполнения и приложений. К тому же, важно чтобы различные программные компоненты в такой среде HEC (планировщик, приложение и среда выполнения) обладали взаимодополняющими и адаптивными стратегиями энергосбережения для достижения максимальной экономии при минимальном воздействии на производительность.
Программно определяемые сети: На протяжении ряда последних лет в отрасли облачных вычислений всё большее значение приобретает область SDN (software-defined networking, программно- определяемых сетевых сред). По мере того, как современные системы HEC переходят к поддержке интерактивных рабочих нагрузок с анализом данных и визуализацией, всё большее значение приобретают требования к непрерывной связности (доступному, например, в SDN с OpenFlow). Высокопроизводительный интерконнект текущего поколения, такой как InfiniBand, включает в себя некоторые функциональные возможности SDN (в случае с InfiniBand через диспетчер подсети OpenSM). Однако управление ресурсами для каждого потока отсутствует. Исследователи изучают как внедрить в InfiniBand такое управление ресурсами. Для систем HEC следующего поколения технология SDN будет развиваться на протяжении ближайшего десятилетия и превратится в критически важную. Это позволит приложениям работы с Большими данными применять способности и функциональные возможности SDN. Однако предоставление функциональности SDN в неоднородных сетевых средах будет сложной задачей и потребует инновационных решений.
Масштабируемые протоколы взаимодействия с неоднородными памятью и хранилищами: Поскольку системы HEC будут применять не только оперативную память (DRAM), но и прочие новые типы памяти и технологии хранения, такие как NVM и NVMeSSD, расширенные функциональные возможности NVM открывают большие возможности при разработке новых высокопроизводительных подсистем взаимодействия и ввода/ вывода с высокой полосой пропускания для приложений Больших данных. Такие технологии как NVMeoF (NVMe Express, 2016) позволяют выгружать в сетевую среду различные вычислительные задачи, относящиеся к операциям ввода/ вывода. Рождение стандарта NVMe изменило имеющийся ландшафт хранения. Предлагаемые этим стандартом меньшая латентность и высокая степень масштабируемости обеспечивают беспрецедентно высокую производительность. Зарождающийся стандарт NVMeoF обеспечивает удалённый доступ к удалённым устройствам флеш- памяти с малой задержкой через команды NVMе, что позволяет коренным образом повторно проектировать системы хранения. Среда осуществления взаимодействия и ввода/ вывода следующего поколения должна быть переработана с учётом технологий NVM и NVMe. Мы полагаем, что протоколы взаимодействия и ввода/ вывода с поддержкой RDMA в NVM и NVMe способны коренным образом изменить весь ландшафт архитектуры подсистем взаимодействия и ввода/ вывода в системах HEC следующего поколения.
Для решения многих из этих задач взаимодействия и перемещения данных мы дополнительно обсудим в Главе 7 различные современные разработки для ускорения ПО промежуточного слоя и библиотек Больших данных в сетевых средах с поддержкой RDMA для достижения высокопроизводительных вычислений Больших данных.
Во многих последних разработках программного обеспечения (ПО) промежуточного уровня обработки Больших данных и управления ими для достижения высокой производительности применялись технологии работы в оперативной памяти (in- memory) (Li, Ghodsi, et al., 2014; Zaharia et al., 2012). Тем не менее, для большинства таких построений сами данные располагаются в оперативной памяти, а операции ввода/ вывода будут считывать/ записывать данные в/ из оперативной памяти (DRAM). Хотя такая архитектура улучшит производительность ПО промежуточного уровня Больших данных, она к тому же привносит дополнительные проблемы проектирования, вытекающие из непостоянства данных по причине природы нестабильности оперативной памяти. Для преодоления этого ПО промежуточного слоя Больших данных обычно должно "сбрасывать" (spill) данные из оперативной памяти в SSD или HDD, что вызывает дополнительные накладные расходы ввода/ вывода. С другой стороны, новая технология NVM (энергонезависимой памяти) способна предлагать побайтовую адресацию с аналогичной оперативной памяти производительностью при сохранности данных.
Аналогично, большинство современных центров обработки данных (ЦОД) предоставляют NVMe-SSD. NVMe-SSD обеспечивают низкое значение задержки и высокую одновременность обработки ввода/ вывода, а также хорошую производительность произвольного считывания. Более того, NVMe-oF (NVMe Express, 2016) предоставляют собственную возможность непосредственного доступа к удалённым SSD при помощи стандарта NVMe. Чтобы подчеркнуть потенциальное воздействие технологий NVM на проектирование стеков аналитики Больших данных следующего поколения, мы можем сопоставить производительность произвольно записи на твердотельном (SSD) накопителе Intel NVMe с применением POSIX, NVMe и NVMe-oF. Мы выявили, что POSIX демонстрирует низкую производительность по сравнению с NVMe и NVMe-oF, даже несмотря на то, что в нём применяется протокол NVMe, что ещё раз доказывает необходимость непосредственного применения протокола NVMe. К сожалению, стеки Больших данных текущего поколения по- прежнему активно применяют подсистемы ввода- вывода на основе POSIX, что приводит к не оптимальным производительности и масштабируемости. Эти тенденции производительности и особенности технологий NVMe открывают большие возможности для разработки новых высокопроизводительных подсистем взаимодействия и ввода/ вывода с высокой пропускной способностью для приложений с Большими данными. Некоторые недавние исследования (Pelley et al., 2013; Huang et al., 2014; Arulraj et al., 2015; Apache Software Foundation, 2019) показали, что их первоначальные проекты с NVM и NVMe-SSD могут принести пользу базам данных, хранилищам KV, распределённым файловым системам и тому подобному.
Тем не менее, эти недавние исследования по- прежнему не смогли целиком охватить всю доступную в новых архитектурах NVM функциональность и предложить построения с высокой оптимизацией, соединяющие NVM с высокоскоростными технологиями и ускорителями. К примеру, многие из имеющихся проектов, например, (см. обсуждения в Pelley et al. 2013; Huang et al. 2014; Arulraj et al. 2015), по- прежнему сосредоточены на том как применять NVM для обеспечения неизменности при локальном хранении данных. Эти типы проектов не способны полностью применять все устройства NVM во всём кластере для решения задач Больших данных. Для эффективного применения всех устройств NVM в ЦОД существующие построения должны обеспечивать высокую производительность и масштабируемость за счёт применения всех возможностей новых технологий NVM и NVMe, а также высокопроизводительных интерконнектов и ускорителей.
Все обсуждаемые выше тенденции поднимают две основные задачи: (1) Какие архитектурные революции произойдут для ориентированных на NVMe проектов в стеках аналитики Больших данных в ближайшие годы? (2) Способны ли такие революционные изменения извлечь выгоду из масштабируемых и устойчивых схем обработки данных при проектировании обработки Больших данных следующего поколения с поддержкой NVMe? Мы предполагаем, что совместное проектирование появляющихся технологий NVM и NVMe одновременно с возможностями высокоскоростных сетевых сред и ускорителей, предоставляемых системами HEC следующего поколения, позволит стекам Больших данных текущего поколения больше не применять традиционный стек ввода/ вывода на основе POSIX. Вместо этого протоколы взаимодействия и ввода/ вывода с поддержкой NVM и NVMe способны коренным образом изменить структуру подсистем коммуникации и ввода/ вывода в системах Больших данных следующего поколения. Наше видение основывается на том, что поддерживающие энергонезависимую память (NVM) проекты с высокопроизводительны интерконнектом способны не только повышать производительность таких стеков, но также наращивать показатели отказоустойчивости и масштабируемости таких стеков.
С целью дополнительного обсуждения таких исследовательских задач в Главе 9 мы представим большое число передовых проектов ускорения систем и библиотек Больших данных при помощи высокопроизводительных технологий хранения для достижения высокой производительности вычислений Больших данных.
Чтобы применять обеспечиваемые современными аппаратными компонентами высокопроизводительные возможности в системах HEC следующего поколения, будет жизненно важно совместно разрабатывать приложения Больших данных и ИИ верхнего уровня и соответствующие системы с лежащими в их основе средствами времени исполнения следующего поколения вычисления, коммуникации и ввода/ вывода. Архитектуры вычислений, взаимодействия и ввода/ вывода времени исполнения, также как и совместные системы и приложения Больших данных зависят друг от друга. Процесс исследований и разработок такого совместного проектирования систем HEC следующего поколения обязан следовать спиральной модели. Например, наряду с разработкой необходимых современных функциональных возможностей высокой производительных и энергосберегающих протоколов взаимодействия и синхронизации, неоднородной памяти и поддержки хранения, критически важно будет разобраться и определиться с шаблонами, определяющими производительность конечных приложений, что предоставит лучшее понимание характерных для таких приложений узких мест при их выполнении в системах HEC следующего поколения. Скажем, отслеживание и профилирование перемещения данных между различными компонентами (такими как ЦПУ, ускорители, неоднородная память, а также FPGA/ ASIC) будут применяться при разработке высокопроизводительных и энергосберегающих схем коммуникации. Кроме того, как только предсказуемые характеристики станут понятными сообществу, оценка времени выполнения для различных моделей вычислений и доступа к памяти станет основой для разработки методов размещения данных, а также, соответственно, и для схем управления данными.
Как мы можем себе представить, существует множество прочих типов открытых задач, которые необходимо тщательно решать, когда, как это обсуждалось в предыдущих разделах мы совместно разрабатываем системы и приложения для Больших данных и компоненты. В следующих главах, в особенности в главах 7–10, мы представим множество различных тематических исследований, для демонстрации того, как сообщество может предлагать большое сисло передовых проектов и совместных разработок для решения этих задач.
Для действенного совместного проектирования систем и приложений Больших данных, как это обсуждалось ранее, необходимо хорошо разбираться в их внутренних характеристиках производительности. Несмотря на то, что имеются сторонние инструменты, которые помогают разбираться с поведением работы некоторых систем Больших данных, не так много работ было осуществлено для целостного понимания их взаимодействия со своей системой, приложениями и лежащими в их основе аппаратными архитектурами. Для устранения такого недопонимания сообществу требуется предлагать новые структуры или инструменты определения характеристик производительности, которые будут способны изучать взаимодействие между различными компонентами с Рисунка 5.2, особое внимание уделяя их вычислительным и коммуникационным характеристикам, а также характеристикам ввода/ вывода. Соответствующие платформы и инструменты должны разрабатываться для сбора жизненно важных показателей как на уровне самой системы, так и на уровнях программного обеспечения, таких как шаблоны взаимодействия между процессами, счётчики запросов ввода/ вывода на уровне блоков, загруженность физической оперативной памяти, запросы к файловой системе и поведение кэширования, использование сетевых ресурсов, загруженность совместной памяти и тому подобное.
Дополнительно к статической характеристике вычислений, обмена данными и поведения ввода/ вывода таких приложений для автономного анализа, соответствующие среды или инструменты должны иметь возможность динамического обеспечения обратной связи с системами и приложениями обработки и управления Большими данными в виде советов, которые способны оказывать содействие принятию решения по оптимизации времени исполнения. Скажем, такие советы можно применять для динамической настройки числа рабочих потоков внутри систем Больших данных или для динамического выбора пороговых значений переключения между различными сетевыми транспортными протоколами на основе шаблонов связи приложений Больших данных. Знакомство с такими характеристиками рабочей нагрузки будет руководить и управлять соответствующими проектами и оптимизациями. Подобные инструменты описания рабочей нагрузки могут быть интегрированы в описанную в разделе 5 этой главы спиральную модель разработки. Это обеспечит учёт и постепенную оценку взаимодействия между различными компонентами системы, а также постоянное увеличение получаемых преимуществ.
Для содействия в осуществлении осмысленных задач по выработке характеристик рабочей нагрузки Больших данных и оценки производительности, сообществу требуются более добротно разработанные эталонные тесты и наборы данных. Существует большое число тестов, которые пытаются зафиксировать поведение различных вычислительных сред и интенсивным применением данных. Но большинство подобных эталонных тестов предлагается для комплексной оценки всей системы, а это означает, что даже для запуска такого простого эталонного теста, скажем, Hadoop TeraSort, нам всё равно требуется развернуть тяжёлый стек и для завершения такого эталонного тестирования заставить совместно работать все имеющиеся компоненты. В таком случае на получаемые в результате подобного эталонного тестирования влияет множество компонентов, что может помешать нам выполнять анализ отдельных компонентов. Мы полагаем, что сообществу Больших данных требуется больше микротестов, которые могут обладать очень конкретными целями, а такие микротесты должны работать изолированно с отдельными компонентами. Некоторые предварительные микротесты (Islam et al., 2012) уже были предложены в сообществе в попытке достижения такой цели. Те не менее, в сообществе всё ещё имеется большое число возможностей для проведения дополнительных исследований сопоставительного анализа Больших данных.
В помощь пониманию того какие именно тесты доступны в сообществе Больших данных, мы суммируем на систематической основе многие разнообразные типы тестов в Главе 6.
Типичная среда обработки Больших данных и управления ими обладает достаточно большим стеком, который обычно содержит множество отдельных или сторонних компонентов. Такие компоненты могут содержать составляющие приложений, платформы анализа Больших данных, планировщики ресурсов, распределения системы хранения и многие прочие вспомогательные библиотеки и среды исполнения. Чтобы развернуть полностью работающую систему Больших данных, нам требуется решать большое число задач, связанных с зависимостями ПО, что требует больших инженерных усилий. Существуют различные системные ограничения для развёртывания приложений Больших данных и управления ими в высокопроизводительных и облачных средах. Нам необходимо развёртывать в таких средах системы и приложения Больших данных и, как можно скорее, превратить в доступные их службы. Нам также необходимо убедиться, что развёрнутые системы и приложения способны работть с максимальной эффективностью. Во многих ситуациях непросто выполнять эти задачи, поскольку в разных компонентах или уровнях может возникать большое число вероятных проблем. Для систематического решения подобных задач кажутся многообещающими методы прикладных приложений на основе контейнеров или виртуальных машин (то есть инкапсуляция стека ПО в виде образов контейнеров или виртуальных машин). Однако, при подобном уровне виртуализации, может оказываться воздействие на производительность времени исполнения. Всё ещё большой задачей остаётся то, как развёртывать системы и приложения Больших данных в современных платформах HEC и платформах следующего поколения, а также управлять ими. Для этого требуется большое число новых инструментов и архитектур для превращения систем Больших данных в простые при развёртывании и управлении ими.
В отношении производительности, такие системы и приложения Больших данных также должны автоматически определять среды размещения и корректировать своё поведение при работе для обеспечения действенного выполнения в различных платформах. Наряду с этим направлением исследований, в Главе 11 мы представим большое число относящихся к облачным технологиям изысканиям для систем Больших данных, которые пребывают в настоящее время в литературе и в сообществе, уделяя особое внимание обсуждению того, как достигать высокопроизводительных архитектур при помощи облачных технологий HPC.
В данной главе мы сосредоточились на обсуждении некоторых конкретных исследовательских задач достижения высокопроизводительных вычислений Больших данных с точки зрения вычислений, взаимодействия, памяти/ хранилищ, совместного проектирования, уточнения характеристик рабочих нагрузок и эталонного тестирования, а также развёртывания системы и управления ею. Эти задачи будут очень важны для сообщества при проектировании или совместной разработке сред времени выполнения Больших данных с высокой производительностью следующего поколения, а также систем и приложений поверх HEC систем следующего поколения. В последующих главах мы обсудим более конкретные изучения архитектур для демонстрации того как сообщество пытается решать эти задачи с разных точек зрения.