Глава 6. Эталонное тестирование систем Больших данных
Содержание
Приложения Больших данных видоизменяют как сферу бизнеса. так и области научных исследований. С ростом доступной сырой вычислительной возможности каждый день разрабатываются всё новые и более совершенные системы обработки данных. Тем самым, изучение и оценка производительности, а также способности таких сред является неотъемлемой частью разработки нового программного обеспечения (ПО) промежуточного уровня для работы с Большими данными. В этой главе представлен обзор различных эталонных тестов, проектируемых и разрабатываемых для оценки существующих и появляющихся систем ПО промежуточного уровня работы с Большими данными. В Главах 7-11 будут обсуждаться результаты производительности новых проектов с применением таких эталонных тестов.
По мере того, как архитектура, среды обработки данных и разработчики приложений переключают своё внимание на инновационные аппаратные средства/ единую разработку Программного обеспечения (ПО) Больших данных и алгоритмов Машинного обучения, возникает потребность в систематическом способе оценки таких развивающихся аппаратных и программных систем. Средства для таких сред со сложными, разнообразными и динамичными нагрузками предоставляет эталонное тестирование (benchmarking). Такие эталонные тесты должны поддерживать исследования масштабируемости и переносимости, а также обеспечивать воспроизводимость и простую интерпретацию данных о производительности для различных наборов данных и рабочих нагрузок.
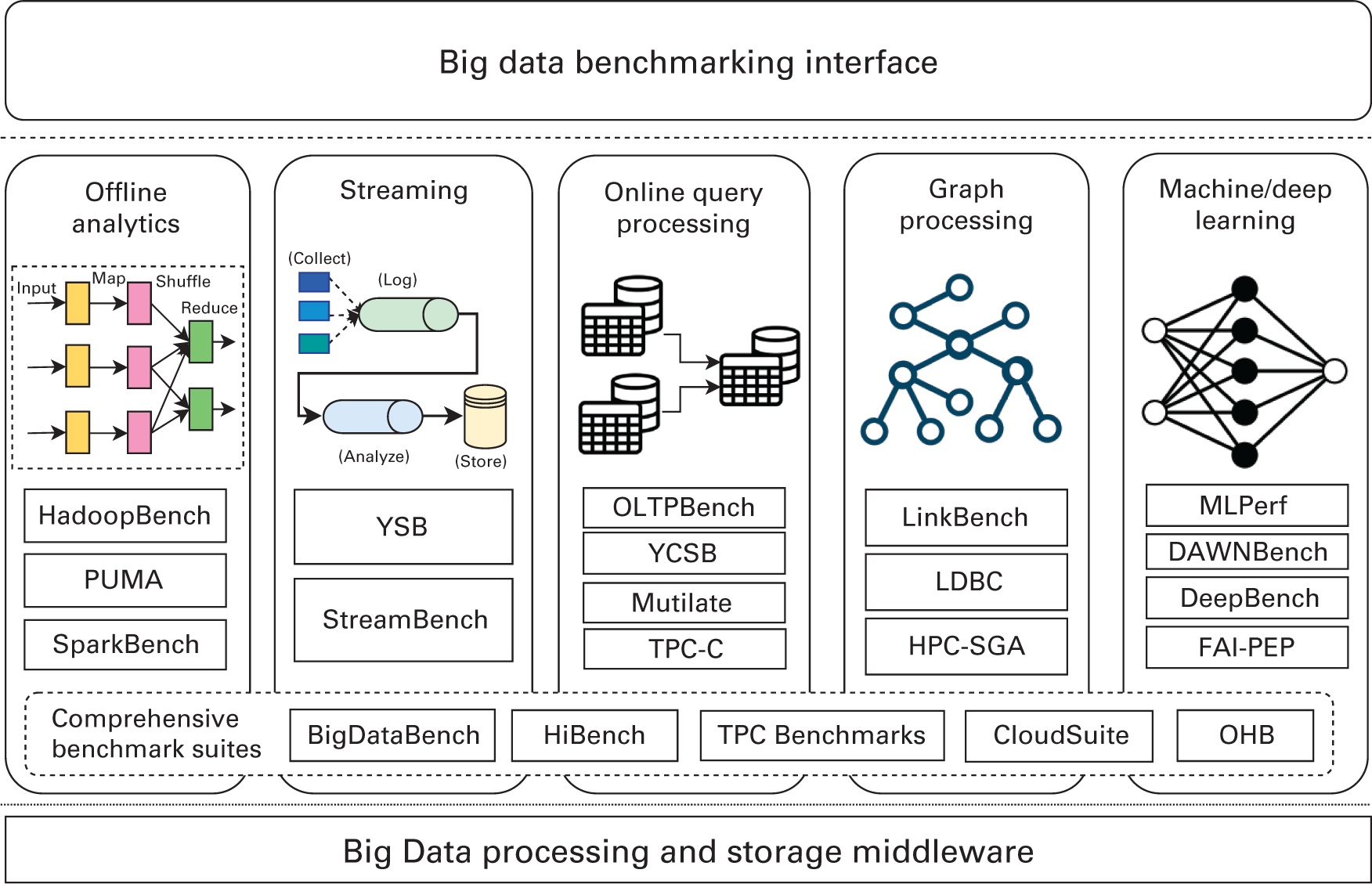
Рабочие нагрузки Больших данных охватывают различные области приложений, включая службы Интернета (такие как поисковые системы, социальные сети, электронную коммерцию), ИИ и медицинские науки. Как уже обсуждалось в Главе 2, эти рабочие нагрузки управляются и обрабатываются различными системами данных промежуточного ПО. Таким образом, как это отражено на Рисунке 6.1, эталонное тестирование Больших данных можно следующим образом классифицировать на пять типов сред обработки данных:
-
Эталонные тесты автономной аналитики данных
-
Эталонное тестирование в потоках
-
Сопоставительный анализ обработки данных в реальном времени
-
Эталонное тестирование в графах
-
Сравнительный анализ Машинного обучения и Глубинного обучения
В данной главе мы изучим эти разнообразные области эталонного тестирования Больших данных и обсудим распространённые эталонные тесты и их функциональные возможности помимо каждого из таких таких направлений и их свойств. Также мы изучим всесторонние комплекты эталонного тестирования для сравнительного анализа экосистем Больших данных в целом.
Автономная аналитика или обработка в пакетах вовлекает в себя итеративные вычисления над большими наборами данных. Как уже обсуждалось в Главе 2, это включает такие среды как Hadoop MapReduce and Spark. Некоторые популярные эталонные тесты для подобных сред обработки данных обсуждаются в последующих разделах.
Hadoop поставляется с предварительно упакованными наборами микротестов сопоставления, HadoopBench, которые могут применяться для тестов мелкомодульных функциональных возможностей различных компонентов (Apache Software Foundation, 2021e). Они содержат:
-
TestDFSIO: TestDFSIO это эталонное тестирование HDFS и он доступен в качестве всего дистрибутива Hadoop. Он замеряет производительность ввода/ вывода HDFS. Он реализуется в качестве задания MapReduce, в котором каждое задание сопоставления (map) открывает один файл на выполнение последовательной записи или считывания и замеров размера данных ввода/ вывода и времени исполнения такой задачи. Отдельная задача понижения (reduce) запускается по окончанию задач соответствия, которая собирает все результаты производительности со всех задач сопоставления.
-
Сортировка: Эталонный тест Sort пользуется средой MapReduce для сортировки каталога своих входных данных в соответствующий каталог вывода. Такие входные и исходящие данные должны быть последовательными файлами, в которых хранятся величины ключей и значений. В данном тесте сопоставления величины длин ключей и значений могут иметь от небольших размеров в 10 байт до больших в тысячи байт. Значения ввода для этого эталонного тестирования могут вырабатываться RandomWriter, который записывает в HDFS пары KV. Этот эталонный тест очень полезный инструмент для замера значений эффективности производительности кластеров MapReduce со случайными размерами KV.
-
TeraGen и TeraSort: TeraGen это эталонное тестирование интенсивного ввода/ вывода, который вырабатывает входные данные под TeraSort и сохраняет их в лежащей в своей основе файловой системе. С другой стороны, TeraSort выступает в роли интенсивного перемешивания. Он считывает данные из своей файловой системы и затем осуществляет сортировку и запись получаемого вывода обратно в эту файловую систему. Эти тесты сопоставления обладают реализациями и для Hadoop MapReduce, и для Spark.
-
WordCount and Grep: Микротест WordCount подсчитывает значение числа раз появления слов в своём входном наборе данных. Этот эталонный тест считывает текстовые файлы и подсчитывает частоту их слов. Каждое соответствие получает на вводе строку входного файла и разбивает её на слова. Затем он издаёт пару KV этих слов в виде
(word, 1)и каждое понижение суммирует значение счётчика для каждого слова и издаёт ключ/ значение с этим словом и суммой. Аналогично, микротетсирование Grep выделяет соответствие строк из файлов на входе и подсчитывает частоту их появления в этих строках.
Комплект эталонного тестирования Purdue MapReduce (PUMA), спроектированный Purdue MapReduce (PUMA), содержит тринадцать разработанных Purdue University тестов сопоставления. Они представляют широкий диапазон приложений MapReduce, демонстрирующих характеристики приложений с различными объёмами вычислений и перемешивания. Иначе говоря, набор эталонных тестов PUMA содержит смесь тестов сопоставления интенсивных вычислений, массового ввода/ вывода и напряжённого перемешивания. К тому же он содержит три эталонных теста из дистрибутива Hadoop.
PUMA содержит хорошо знакомые рабочие нагрузки поисковых систем, такие как Grep и SequenceCount, которые ищут шаблоны в
большом числе файлов и представляют собой класс программ, которые выделяют небольшое количество данных из большого набора
данных. Аналогично, для полнотекстового поиска применяется популярный алгоритм индексации поисковых систем Ranked Inverted
Index. Данный набор эталонных тестов к тому же содержит тест сопоставления Adjacency List, который вырабатывает степень
удалённости (смежности) и обращает списки смежности узлов графа для применения в алгоритмах, подобных PageRank-like, в то
время как Self Join вырабатывает ассоциации между k + 1 полями с учётом
набора k ассоциаций полей. MapReduce также применялся для распараллеливания
имеющихся алгоритмов интеллектуального анализа данных и Машинного обучения (например, библиотеки Машинного обучения Apache
Mahout на основе MapReduce Hadoop). Для оценки таких рабочих нагрузок PUMA содержит в себе такие рабочие нагрузки, как
алгоритм кластеризации K-средних, применяемый для выявления знаний при интеллектуальном анализе данных, а также алгоритмы
адаптивного машинного обучения, которые генерируют гистограммы для изучения тенденций данных (например, пользовательских
рейтингов для набора данных фильмов).
SparkBench, by (M. Li et al., 2015), это специфичный для Spark комплект эталонных тестов. Он выборочно охватывает набор представительных приложений для выявления различных узких мест производительности и показывает поведение ресурсов на этапах исполнения. Он охватывает четыре критически важных шаблона применения Spark, включая машинное обучение, обработку на графах, потоковые вычисления и обработку запросов SQL. Эо позволяет пользователям Spark изучать производительность, потребление ресурсов, поток данных и параметры конфигурации разнообразных шаблонов приложений Spark. SparkBench способен вырабатывать данные в соответствии со множеством различных настраиваемых генераторов и сохранять эти данные в различных распределённых или параллельных системах хранения, таких как HDFS, S3 и тому подобных. Рабочие нагрузки выполняются как отдельные задания Spark, которые можно запускать последовательно и одновременно.
AMPLab University of California–Berkeley представила Benchmark (AMPLab, 2021) для сравнения и противопоставления систем Больших данных, которые реализуют решения складирования данных поверх сред автономной аналитики, таких как Hadoop. К ним относятся аналитические базы данных, например, Impala (Apache Software Foundation, 2021i), SparkSQL (Apache Software Foundation, 2021s) и Apache Hive (Apache Software Foundation, 2021h). Этот эталонный тест замеряет производительность, применяя реляционные запросы, такие как сканирование, агрегирование, соединение и определяемые пользователем функции для разных размеров данных. Для простоты и воспроизводимости он выбирает для тестирования платформ применение простого метода хранения, например, сжатого SequenceFile.
С появлением Web 2.0 и Интернета вещей стало возможным отслеживать сведения, касающиеся мелкоформатных действий пользователей и данных датчиков с течением времени. Поскольку подобные сценарии приложений реального времени требуют обработки данных с учётом времени, пользователи и разработчики вышли за рамки традиционных ориентированных на пакетную обработку подходов. Это привело к появлению распределённых систем обработки данных, носящих название потоковых сред (streaming frameworks), таких как Apache Flink, Apache Storm и прочих, которые мы обсуждали в Главе 2. Соответственно, был разработан и выпущен ряд эталонных тестов для качественного сопоставления разнообразных претендентов. В идущих далее разделах мы обсудим несколько из таких популярных эталонных тестов потоковой обработки данных.
Yahoo! Streaming Benchmark (YSB) (Chintapalli et al., 2016, 2021) это тест сопоставления потоковой обработки, который позволяет платформам выполнять оценку реального варианта применения. Этот эталонный тест представляет собой простое рекламное приложение. Оно составлено из нескольких рекламных компаний и ряда объявлений для каждой из компаний. Задание этого эталонного теста состоит в считывании различных событий JSON из такого источника событий как Apache Kafka (Apache Software Foundation, 2021j), идентифицировать соответствующие события и сохранять количество подходящих событий в окне для каждой компании в сервере Redis. Эти шаги предпринимают попытку исследовать некие общие операции, осуществляемые с потоками поисковых данных. В настоящее время YSB поддерживает потоковую обработку Flink, Storm и Spark.
По мере роста сложности потоковых вычислений и разнообразия рабочих нагрузок, применяющих такие платформы, эталонное тестирование подобных систем выдвигает новые, более сложные задачи. В целях обеспечения стандартных критериев сопоставительного анализа современных сред распределённых потоковых данных (R. Lu et al., 2014) представил Stream Bench. Stream Bench предлагает систему сообщений, функционирующую как посредник между выработкой и потреблением потоковых данных. Он к тому же содержит семь тестов, предназначенных для решения типичных ситуаций потокового обмена. Помимо оценки производительности с различыми масштабами данных, он также учитывает отказоустойчивость и длительность хранения.
Обработка в реальном времени интерактивна, а следовательно она обеспечивает постоянное взаимодействие между пользователем и его системой. Такие системы содержат базы данных SQL транзакций и высокопроизводительные частично структурированные системы баз данных NoSQL. В приодимых ниже разделах представлены некоторые популярные эталонные тесты приложений обработки данных в реальном времени, выполняемых в данных системах.
Представленный Difallah et al. (2013) OLTPBench являет собой испытательный стенд "с батарейками в нём" для сопоставительного анализа систем управления базами данных. Он позволяет пользователю проводить эксперименты по анализу производительности под жёстким контролем над замесом, скоростью и распределением доступа транзакций для пятнадцать встроенных рабочих нагрузок. Рабочие нагрузки содержат синтетические микротесты, популярные тесты OLTP и реальные веб- приложения. К ним относятся такие рабочие нагрузки, как AuctionMark, Wikipedia, TPC Benchmark C (TPC-C), Telecom Application Transaction Processing Benchmark, Stonebraker Electronic Airline Ticketing System, Twitter, Epinions.com и многие иные.
OLTPBench разработан с многопоточным генератором нагрузки. Эта платформа способна создавать варьируемую скорость, переменную смешанную нагрузку для любой реляционной базы данных с поддержкой Java Database Connectivity. Она также предоставляет функции сбора данных, такие как задержку каждого типа транзакции и журналы пропускной способности.
Рабочие нагрузки облачных служб являются рабочими нагрузками интерактивной обработки данных, которые отдают высший приоритет масштабируемости, доступности и производительности в противовес согласованности данных. Yahoo! Cloud Serving Benchmark (YCSB) (Cooper et al., 2010) это типичный эталонный тест для подобных приложений облачной обработки данных. Эти службы часто развёртываются с применением подобных NoSQL распределённых KV и обслуживаемых облачным решением хранилищ. Он составлен из расширяемого генератора рабочих нагрузок, который моделирует различные системы обслуживания данных в виде пяти основных рабочих нагрузок. Клиенты YCSB вырабатывают и загружают данные на уровень удалённого хранения данных. Он создаёт некий шаблон доступа на основе избранной рабочей нагрузки или выбора входных параметров и оценивает лежащее в своей основе хранилище для сопоставления производительности и масштабируемости данной системы облачных служб. Данный комплексный набор стандартизованных эталонных тестов может применяться для оценки производительности разнообразных баз данных NoSQL, помимо прочего, включающих HBase, Cassandra и MongoDB. Он составлен из шести различных рабочих нагрузок пакетной обработки облачных систем, а именно:
-
Workload A: 50 процентов считывания, 50% записи
-
Workload B: 95 процентов считывания, 5% записи
-
Workload C: 100 процентов считывания
-
Workload D: Новые записи вставляются и считываются
-
Workload E: Опрашивается короткий диапазон записей вместо индивидуальных
-
Workload F: Считывается запись, изменяется и изменения записываются обратно
Mutilate (Jacob, 2021) это генератор нагрузки, предназначенный для высокой скорости запросов, хороших замеров задержек концов и создания реалистического потока запросов. Он применяется для оценки уровней созданного на основании KV, например, Memcached, распределённого кэширования. Mutilate выдаёт отчёты о значении задержки (среднем, минимальном и различных процентилей) для команд Get и Set Memcached, а также о достигаемых QPS (queries per second) и пропускной способности сетевой среды. Это позволяет имитировать и сопоставлять реальные развёртывания Memcached, которые зачастую обрабатывают тысячи запросов интерфейсов клиентов одновременно. Данный генератор рабочей нагрузки позволяет вырабатывать синтетические запросы на основе реальных наборов данных и трассировок Facebook (Atikoglu et al., 2012).
Задачи обработки данных на графах представляют собой фундаментальную сердцевину традиционных и появляющихся приложений с интенсивным применением данных, включая сложный анализ сетевых сред, интеллектуальный анализ данных, научные вычисления, вычислительную биологию, а также приложения в области безопасности. Такие как Интернет, всемирная паутина, социальные взаимодействия и транспортные сетевые среды реального мира анализируются путём их моделирования в виде графов. Для действенного решения задач крупного масштаба на графах требуется разрабатывать системы высокопроизводительных вычислений и новые параллельные алгоритмы, которые обсуждались в Главе 2. В этом разделе мы рассмотрим некоторые известные эталонные тесты обработки данных на графах и специализированных графовых систем баз данных.
Данные социальной сети могут моделироваться как некий социальный граф, в котором такие субъекты или узлы как люди, посты, комментарии и страницы связаны ссылками, моделирующими разнообразные отношения между этими узами. Различные типы ссылок могут представлять дружбу между двумя пользователями, пользователя, которому нравится другой объект, право собственности на публикацию или иные прочие отношения. Цель LinkBench (Armstrong et al., 2013) состоит в имитации подобной рабочей нагрузки базы данных социального графа и обеспечения реалистичного эталонного тестирования производительности базы данных социальных рабочих потоков.
LinkBench обладает широкими возможностями настройки и расширения, а также способен вырабатывать большой синтетический социальный граф с ключевыми свойствами, аналогичными реальному графу. Он содержит отслеживания промышленной базы данных социальных графов данных Facebook, а его генератор данных создаёт синтетические данные, которые обладают ключевыми свойствами рабочей нагрузки для соответствия промышленным рабочим потокам. Этот эталонный тест содержит стандартные операции вставки, обновления и удаления, а также поиска по ключу, запросов диапазона подсчётов.
Linked Data Benchmark Council (LDBC, Совет сравнительного анализа связанных данных)(LDBC, 2021) разработал два эталонных теста обработки графов: тест социальных сетей (SNB, Social Networks Benchmark) и тест семантики публикации (SPB, Semantic Publishing Benchmark). SNB представляет три различные рабочие нагрузки: (1) интерактивную рабочую нагрузку, которая тестирует пропускную способность системы с реальными образцами запросов при одновременном обновлении, (2) рабочую нагрузку бизнес- аналитики, состоящую из сложных структурированных запросов анализа поведения пользователей в Интернете в маркетинговых целях и затрагивающих прочие данные по мере роста размеров базы данных, а также (3) рабочей нагрузки аналитики на графах, которая обычно не может быть выражена при помощи языка запросов, например, SPARQL. Такие автономные рабочие нагрузки аналитики на графах охватывают алгоритмы, подобные PageRank, Clustering и Breadth-First Search, способные выдавать обширные промежуточные результаты. SPB выступает эталонным тестированием производительности механизмов Resource Description Framework (RDF, сред описания ресурсов), вдохновляемых средствами массовой информации или издательской отрасли. Значение производительности SPB измеряется путём создания рабочей нагрузки операций создания, считывания, обновления и удаления, которые осуществляются одновременно. Данный эталонный тест предлагает генератор данных, который пользуется реальными справочными сведениями для создания наборов различных размеров и проверяет соответствующую сторону масштабируемости RDF.
HPC Scalable Graph Analysis Benchmark (HPC-SGA) (Bader et al., 2021) составляется из четырёх операций на взвешенном ориентированном графе со степенями узлов, которые следуют степенному закону распределения. Этот эталонный тест основан на тесте анализа графов High Productivity Computing System Scalable Synthetic Compact Applications, который характеризуется целочисленными операциями, большим объёмом памяти и нерегулярными шаблонами доступа к памяти. Такой ориентированный на HPC эталонный тест теории графов представляет собой вычислительные ядра в вычислительной биологии, сложном сетевом анализе и тому подобных сферах и чрезвычайно отличается от типичных рабочих нагрузок графовых баз данных. Генератор данных эталонного тестирования создаёт узлы и рёбра с положительными значениями весов. Поддерживаемые четыре типа операций содержат массовые вставки, извлечение рёбер с наибольшим весом, извлечение пути k-hopиз заданного ребра в неком наборе рёбер, а также извлечение рёбер, которые идентифицируют ключевые вершины вдоль кратчайших путей своего графа.
Машинное обучение и Глубинное обучение в последнее время набирают популярность. С целью расширения знаний об ИИ в литературе было предложено большое число исследовательских проектов от области соответствующей микроархитектуры до пользовательских приложений верхнего уровня. Таким образом, эталонное тестирование Машинного и Глубинного обучения в наши дни выступает горячей точкой в компьютерном мире. Сообществу доступен ряд имеющихся и появляющихся эталонных тестов Машинного и Глубинного обучения. В этом разделе мы обсудим ряд популярных и важных тестов сопоставления.
MLPerf Inference Benchmark (Reddi et al., 2020) это эталонное тестирование Машинного обучения, которое замеряет насколько быстро любая система способна выполнять выводы Машинного обучения. Каждый тест в MLPerf определяется моделью, набором данных, целевым показателем, а также ограничением задержки. Они выполняются при помощи генератора нагрузки, который выдаёт запросы к установленной модели Машинного обучения по одному из нескольких шаблонов, включая автономный, серверный и потоковый режимы. Пакет MLPerf v0.5 состоит из пяти тестов, которые содержат англо- немецкий машинный перевод с англо- немецким набором данных Workshop on Statistical Machine Translation (WMT, мастерской статистического машинного перевода), двух тестов обнаружения объектов данных с набором данных Microsoft Common Objects in Context (COCO) (Lin et al., 2014) и два теста классификации с набором данных ImageNet. MLPerf также предлагает обучающие тесты (Mattson et al., 2020) для классификации изображений, обнаружения объектов (с большим весом), перевода (рекуррентного), перевода (одноразового), рекомендации и обучения с подкреплением. MLPerf теперь выступает частью ассоциации MLCommons (MLCommons, 2021).
MLBench (MLBench-Team, 2021) это среда для распределённого Машинного обучения. Она разработана и реализована для повышения прозрачности, воспроизводимости и надёжности, а также для предоставления средств справедливого сопоставления производительности эталонных реализаций. MLBench способствует внедрению Машинного обучения как в промышленном применении, так и в академическом сообществе. MLBench основана на Kubernetes (Kubernetes Team, 2021) для простого распределённого развёртывания как в общедоступных облачных решениях, так и в специально выделенных кластерах. Она поддерживает несколько стандартных платформ и алгоритмов стандартного Машинного обучения, включая деревья решений, Support Vector Machines (SVM - машины опорных векторов), логистическую регрессию, леса решений и т.п.
DAWNBench (Stanford DAWN Team, 2021) это эталонное тестирование и состязание для сквозного обучения Глубинному обучению и логическим выводам с открытым исходным кодом. Данный эталонный тест измеряет сквозную производительность обучения, например, время и стоимость, а также логические выводы, например, задержку. DAWNBench предоставляет исследователям стандарт объективной оценки различных вычислительных сред, оборудования, настроек гиперпараметров и алгоритмов оптимизации. DAWNBench способен измерять сквозное время и стоимости обучения модели Глубинного обучения с заданной точностью совместно с его временем вывода. В частности, DAWNBench измеряет время вывода с точностью достоверности 93% для различного оборудования, платформ и архитектур моделей.
DAWNBench изначально выпустил эталонные спецификации классификации изображений (ImageNet (Stanford Vision Lab, 2021) и CIFAR-10 (Canadian Institute for Advanced Research) (Krizhevsky, 2021)), а также ответов на вопросы (SQuAD (Rajpurkar et al., 2016)). Модели DAWNBench можно тестировать как в TensorFlow, так и в PyTorch, а также в различных аппаратных платформ ЦПУ- ЦПУ. Проект DAWNBench также позволяет пользователям состязаться, отправляя свои результаты сопоставительного анализа, в целях содействия его развитию.
Facebook AI Performance Evaluation Platform (FAI-PEP, Платформа Facebook оценки производительности ИИ) (Facebook AI Team, 2021) предоставляет средства сопоставления показателей производительности Машинного обучения или Глубинного обучения на наборе модулей в разных серверах. Эта платформа поддерживает как мобильные устройства, так и серверные платформы, включая ЦПУ, GPU, цифровую обработку сигналов, Android, iOS и прочие системы на основе Linux. В настоящее время FAI-PEP поддерживает две платформы, а именно, TensorFlow и Caffe2. Она содержит шестнадцать популярных моделей машинного обучения, в том числе MobileNet (Howard et al., 2017), SqueezeNet (Iandola et al., 2016), ShuffleNet (X. Zhang et al., 2018) и ряд других.
FAI-PEP предоставляет централизованную спецификацию модели/ эталонного тестирования, драйвер эталонного тестирования для распределённого исполнения и инструментарий потребления данных для сопоставления значений производительности. Данная платформа поддерживает два режима выполнения: автономное эталонное тестирование и непрерывное исполнение тестирования сопоставления. В автономном режиме эталонные тесты отображают результаты одного прогона тестов. Непрерывный режим исполнения эталонного тестирования многократно извлекает свою среду и запускает свои тесты сопоставления. Он также способен принимать любые предоставляемые пользователем модели Машинного обучения или Глубинного обучения и выдавать отчёты по любым определяемых пользователями метрикам.
Deep500 (Deep500-Team, 2021) это настраиваемая инфраструктура эталонного тестирования, которая позволяет справедливо сопоставлять множество сред, алгоритмов, библиотек и методов Глубинного обучения. Она поддерживает распределённое обучение TensorFlow, Caffe, а также PyTorch, причём пользователи обладают возможностью разработки различного кода при помощи API верхнего уровня. Точно так же, HPC AI500 (Jiang et al., 2019) представляет собой комплект эталонного тестирования сопоставления эталонных показателей Глубинного обучения в системах HPC. В качестве целевых сцен он выбирает несколько типичных научных отраслей, скажем, анализ экстремальных погодных условий, физику высоких энергий, а также космологию. Рабочие нагрузки в данном эталонном тестировании состоят из современных моделей Глубинного обучения и представительных наборов данных вместо стандартных моделей Глубинного обучения (например, Visual Geometry Group [VGG] and Long Short Term Memory [LSTM]) и наборов данных (скажем, Modified National Institute of Standards and Technology [MNIST] (LeCun et al., 2021) and ImageNet).
DeepBench (Baidu Research, 2021) от Baidu это эталонный тест с открытым исходным кодом, охватывающий как обучение, так и вывод. DeepBench сосредотачивается на производительности основных операций в библиотеках нейронных сетей. Он направлен на определение наиболее подходящего оборудования для конкретных операций и информирования производителей о требованиях к нему. Этот эталонный тест был приспособлен как для серверных, так и для оконечных платформ. Например, DeepBench способен работать поверх устройств GPU потребительского рынка, а также таких мобильных устройств как iPhone. DeepBench в целом сосредоточен на базовых операциях Глубинного обучения вместо полного вывода. Ключевым моментом, который он пытается определять выступает аппаратное обеспечение, которое способно обеспечивать наилучшую производительность основных применяемых в DNN операций.
DeepBench способен проводит измерения операций и слоёв, например, умножение плотных матриц, умножение разряженных матриц, свёртки (Lawrence et al., 1997), LSTM (Hochreiter and Schmidhuber, 1997), а также слои с рекуррентными блоками (Cho et al., 2014). Эти операции и слои широко применяются в таких приложениях как DeepSpeech (DeepSpeech Team, 2021), моделирование языков (Bengio et al., 2003), машинный перевод, идентификация говорящего (Reynolds and Rose, 1995) и прочих. По сравнению с эталонным тестом обучения, эталонный тест логического вывода обладает некими отличиями. Он представляет собой планировщик пакетной обработки для улучшения связанной с отдельными запросами производительности и предоставляет ядра с различной точностью для эталонного тестирования оптимизированных операций нейронной сети в мобильных устройствах.
Большинство современных усилий по сопоставительному анализу Больших данных, которые мы уже обсуждали, нацелены на оценку конкретных типов моделей программирования для системных стеков промежуточного ПО. Однако, если мы рассматриваем широкое применение систем Больших данных, наши эталонные тесты обязаны содержать широкое применение разнообразных данных и рабочих нагрузок. Тем самым, предварительным условием оценки систем и архитектуры Больших данных выступает "комплексный" набор тестов, который способен охватывать различные стороны сценариев приложений, алгоритмов, типов данных, источников данных, программных стеков и типов приложений. В приводимых далее разделах мы обсудим ряд популярных комплектов эталонных тестов для работы с Большими данными.
Среди самых современных комплексных наборов эталонного тестирования BigDataBench и HiBench это два тестовых комплекта, представленных с точки зрения систем. BigDataBench (L. Wang et al., 2014) от Institute of Computing Technology, Chinese Academy of Sciences представляет собой комплексный набор эталонных тестов Больших данных и Искусственного интеллекта. Основная концепция в BigDataBench носит название "мотивов данных" и она рассматривает любые Большие данные и рабочую нагрузку ИИ в качестве конвейера одного или нескольких вычислительных единиц, выполняемых на различных наборах входных данных. Команда BigDataBench определили восемь мотивов данных из широкого спектра рабочих нагрузок Больших данных и ИИ, включая Матрицу, Выборку, Логику, Преобразование, Набор, Граф, Сортировку и Статистические вычисления. Эти мотивы данных способны отражать шаблоны реальных рабочих нагрузок с точки зрения вычислений, доступа к памяти, взаимодействия и операций ввода/ вывода.
Текущая версия, BigDataBench 5.0, предоставляет тринадцать представительных реальных наборов данных и двадцать семь эталонных тестов Больших данных. Эти эталонные тесты охватывают шесть типов рабочей нагрузки, включая интернет службы, автономную аналитику, анализ на графах, складирование данных, NoSQL, а также потоковый обмен из трёх важных отраслей приложений (включая поисковые системы, социальные сети, электронную коммерцию), науки распознавания и медицинские науки. В частности, для ИИ BigDataBench способен работать поверх TensorFlow и Caffe, включая такие тесты моделей, как свёртки, полносвязные нейронные сети и т.п. Источниками данных включаю текст, графы, таблицы и данные изображений. Применяя в качестве начальных реальные наборы данных, генераторы данных в пакете генераторов Больших данных вырабатываю синтетические данные путём масштабирования начальных данных, сохраняя при этом характеристики сырых данных.
Intel HiBench (Intel, 2020a) это ещё один всеобъемлющий комплект эталонных тестов Больших данных, который способствует оценке различных сред Больших данных в плане скорости, пропускной способности и загруженности системных ресурсов. Этот комплект эталонного тестирования с открытым исходным кодом в общей сложности составлен из девятнадцати рабочих нагрузок. Они подразделены на шасть категорий: микро, Машинное обучение, SQL, граф, веб- поиск и обработка в потоках. Они представляют собой набор рабочих нагрузок Hadoop и Spark, включая Sort, WordCount, TeraSort, Sleep, SQL, PageRank, индексацию Nutch, Bayes, Kmeans, NWeight, а также расширенный DFSIO и ряд прочих. Он также содержит ряд потоковых рабочих нагрузок для Spark Streaming, Flink, Storm и Gearpump.
TPC Benchmarks (Transaction Processing Performance Council, Совета по производительности обработки транзакций) это золотой стандарт эталонного тестирования баз данных. Это торговая марка Transaction Processing Performance Council. Она представляет комплект эталонных тестов, охватывающих обработку транзакций в реальном времени и поддержку принятия решений, к тому же он был расширен для систем обработки Больших данных, таких как Hadoop и сред виртуальных систем. Ряд широко применяемых тестов TPC включают:
-
TPC-C имитирует полную вычислительную среду, в которой группа пользователей осуществляет транзакции базы данных. Он сосредоточен на основных транзакциях среды ввода предписаний и включает в себя сочетание пяти одновременных транзакций разного типа сложности, которые либо выполняются в реальном времени, либо ставятся в очередь для отложенного исполнения.
-
TPC-E рабочая нагрузка OLTP. Она пользуется базой данных для моделирования фирмы брокеров с клиентами, которые вырабатывают связанные со сделками, запросами счетов и исследованиями рынка транзакции. Она изучает масштабируемость по числу транзакций в секунду.
-
TPC-DS это стандартный эталонный тест отрасли для измерения производительности решений, помимо прочего, включающего системы Больших данных. Он моделирует сценарий поставщика розничных продуктов со схемой базы данных и правилами реализации, предназначенными для широкого представления современных систем принятия решений.
-
TPC-H это эталонное тестирование поддержки принятия решений. Он состоит из набора ориентированных на бизнес специальных запросов и одновременного изменения данных. Заполняющие его базу данных запросы и данные были отобраны так, чтобы они обладали широким значением для всей отрасли, сохраняя при этом достаточную степень простоты внедрения.
-
TPCx-BB Express Benchmark BB (TPCx-BB) измеряет производительность систем Больших данных на основе Hadoop. Он измеряет производительность как аппаратных, так и программных компонентов, исполняя часто выполняемые аналитические запросы SQL в контексте розничных продавцов, имеющих физические и интернет-магазины, для сопоставления систем на основе Hadoop, включая MapReduce, Apache Hive и Apache Spark MLlib.
Поскольку облачные вычисления превращаются в доминирующую вычислительную платформу для предоставления масштабируемых служб реального времени, они были направлены на обеспечение возможности работы с массивными рабочими наборами с высокой степенью одновременности и ограничениями реального масштаба времени. Для изучения ориентированных на данные облачных вычислений CloudSuite (CloudSuite Team, 2021; Palit et al., 2016) предлагает некий набор эталонного тестирования, основанный на реальных интернет- службах (таких как веб- поиск, социальные сети и аналитика дел). Он составлен из восьми приложений, выбранных по их популярности в современных ЦОД. К ним относятся тесты, представляющие собой манипуляции при жёстких ограничениях на задержки, например, анализ данных в памяти с применением Apache Spark, тест потокового видео в реальном времени, графическая аналитика и тесты веб-обслуживания, которые имитируют многоуровневые стеки программного обеспечения веб-сервера со слоем кэширования.
Ohio State High-Performance Big Data (HiBD) Benchmarks (OHB) (Network Based Computing Lab, 2021a) это комплексный пакет эталонного тестирования, предназначенный для детальной оценки производительности различных платформ обработки данных. Создаются синтетические рабочие нагрузки и, совместно с их уровнями приложений сопоставительного тестирования применяются для оценки автономной производительности различных сред обработки Больших данных. Оцениваемые платформы включают в свой состав Hadoop, Spark, Memcached и прочие.
Эталонное тестирование определяется как количественная основа любого исследования вычислительных систем. В данной главе представлен общий обзор современных эталонных тестов для работы с Большими данными, которые охватывают разнообразные предметные области и рабочие нагрузки. Она также предоставляет применяемые на практике эталонного тестирования для конкретных моделей программирования и обсуждает современные применяемые на практике комплексные наборы тестов. Многие из этих эталонных тестов применяются в Главах 7-11 для демонстрации сильных сторон и недостатков новых схем ускорения обработки Больших данных.