Технический обзор процессоров Intel® Xeon® семейства Scalable
Copyright © 2017 Intel
Перевод редакции на английском языке с исправлениями от 22 Июня 2017.
Рекомендуемые розничные цены (РРЦ) на них вы можете найти по ссылке xls.

|
Данный документ предоставляется по лицензии Creative Commons Attribution 3.0 License, за исключением разделов со специальными оговорками. |
Дэйвид Маникс является инженером программного обеспечения, который работает в Intel Corporation на протяжении более 20 лет. Его области интересов включают автоматизацию программного обеспечения, энергоснабжение сервера, а также анализ производительности, а также он участвует в поддержке разработки Server Efficiency Rating ToolTM
- Аннотация
- Введение
- Обзор функций семейства Scalable процессоров Intel Xeon
- Архитектура Skylake Mesh
- Intel® Ultra Path Interconnect
- Агент кэширование и размещения UPI Intel®
- Кластеризация Sub-NUMA
- Когерентность на основе каталога
- Изменения иерархии кэширования
- Ключи защиты страниц
- Расширения защищённости памяти Intel
- Управление исполнением на основе режима
- Intel® AVX-512
- AVX512DQ
- AVX512BW
- AVX512VL
- Регистры маски
- Встроенное округление
- Встроенная широковещательность
- Целочисленная арифметика с четырьмя словами
- Поддержка Math
- Новые примитивы перестановки
- Развёртывание и сжатие
- Манипуляции битами
- Универсальные тройные логические операции
- Инструкции определения конфликта
- Поддержка трансцендентности
- Поддержка компилятора
- Расширения счётчика временного штампа для виртуализации
- Технология сдвига скорости Intel
- Определение PMax
- Архитектура Intel® Omni-Path
- Технология Intel® QuickAssist
- Протокол широкополосного интернет RDMA
- Новые и расширенные свойства RAS
- Виртуальный RAID Intel® в ЦПУ
- Охранник загрузки
- Охранник BIOS 2.0
- Трассировка процессора Intel®
- Диспетчер узла Intel®
- Ресурсы
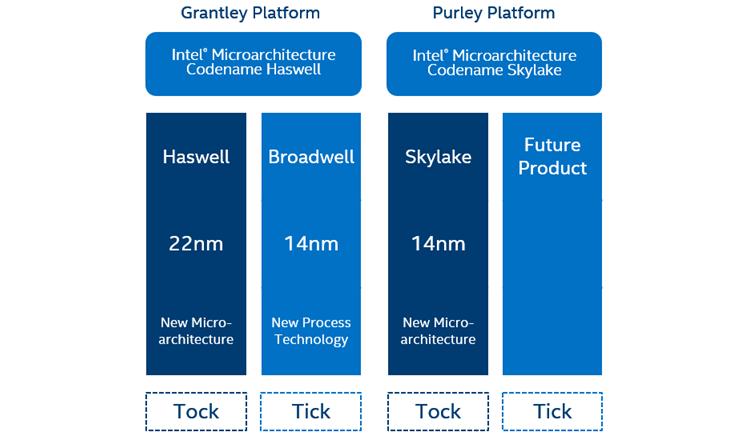
Intel применяет модель тик- так в связи со своими поколениями процессоров. Новое поколение, семейство Scalable процессоров Intel® Xeon® (первоначально именовавшееся как Skylake-SP), является тактом, основывающемся на процессе технологии 14-нм. Основные архитектурные изменения происходят при "тактовом" этапе, в то время как менее значительные изменения и сужение технологии случается на "тике".
Семейство Scalable процессоров Intel® Xeon® на платформе Purley является новой архитектурой со множеством дополнительных свойств в сравнении с предыдущим поколением процессоров E5-2600 v4 продуктового семейства Intel® Xeon® (изначально микроархитектура Broadwell). Эти свойства включают в себя увеличение ядер процессора, рост пропускной способности памяти, не включающее кэширование, Intel® Advanced Vector Extensions 512 (Intel® AVX-512, векторное расширение команд x86), Intel® Memory Protection Extensions (Intel® MPX, расширения защищённости памяти), Intel® Ultra Path Interconnect (Intel® UPI, интерфейс экстремального пути), а также кластеры sub-NUMA.
В предыдущих поколениях семейства для двух и четырёх процессоров были разделены на две различные продуктовые линейки. Одним из самых больших изменений в семействе процессоров Scalable Intel® Xeon® является то, что они включает в себя все имеющиеся модели процессоров, связанные с этим новым поколением. Все процессоры из семейства Scalable Intel® Xeon® масштабируются от двухсокетных конфигураций до конфигураций с восемью сокетами. Все они платформой Intel для наиболее масштабируемой и надёжной производительности с широчайшим разнообразием свойств и интеграцией, предназначенными для соответствия потребностям самого большого разнообразия рабочих нагрузок.
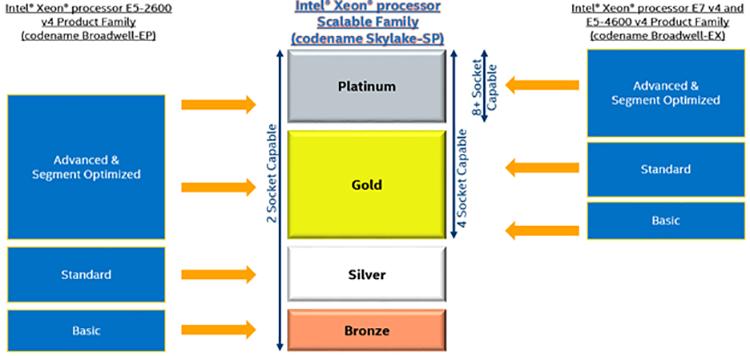
Конфигурации с двумя процессорами Intel® Xeon® могут отыскаться на всех уровнях начиная с бронзового вплоть до платинового, в то время как конфигурации с восемью сокетами могут быть обнаружены только на платиновом уровне. Бронзовый уровень имеет самое меньшее количество свойств, а по мере того как вы продвигаетесь в сторону платинового уровня добавляется всё больше функциональности. На платиновом уровне доступны все возможные функции для всего диапазона количества процессорных разъёмов (от двух до восьми).
Данная статья обсуждает все новые свойства и расширения, доступные в процессорах Intel Xeon семейства Scalable и то, что необходимо знать разработчикам об их преимуществах.
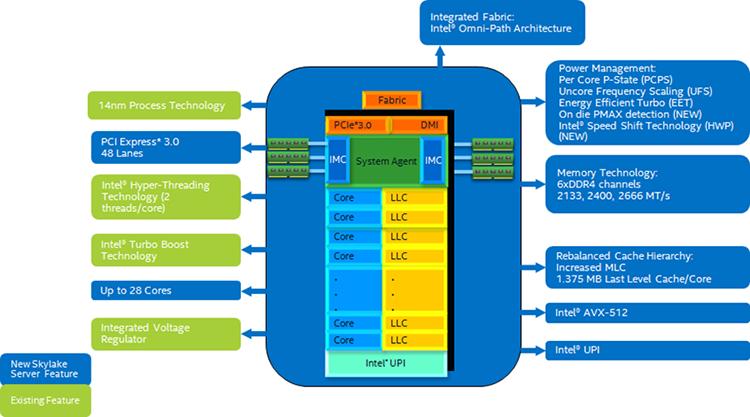
Процессор Intel Xeon семейства Scalable в своей платформе Purley предоставляет до 28 ядер, которые привносят на поверхность дополнительную вычислительную мощность в сравнении с 22 ядрами своих предшественников. Дополнительные улучшения содержат не включающее кэширование последнего уровня, кэш L2 большего размера 1МБ, более быструю оперативную память DDR4 2666МГц, увеличение до шести каналов памяти на ЦПУ, новые свойства защиты памяти, технологию Intel® Speed Shift, определение в кристалле PMAX, интегрированную архитектуру связи через Intel® Omni-Path (Intel® OPA), протокол iWARP (Internet Wide Area RDMA), Intel® Virtual RAID on CPU (Intel® VROC) и многое другое.
Таблица 1
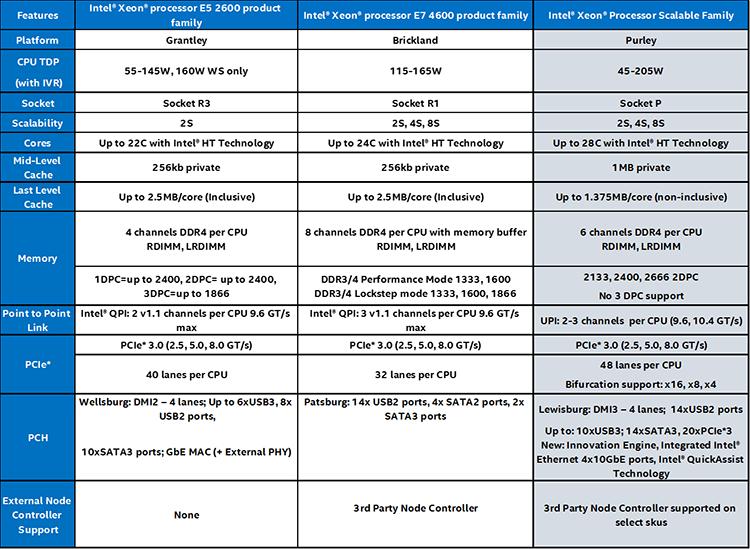
Сопоставление процессоров семейства Scalable Intel® Xeon® с продуктами семейств процессоров Intel® Xeon® E5-2600 и E7-4600
Оставшаяся часть данной статьи обсуждает все улучшения производительности, новые возможности, усовершенствования безопасности, а также расширения виртуализации в процессорах Intel Xeon семейства Scalable.
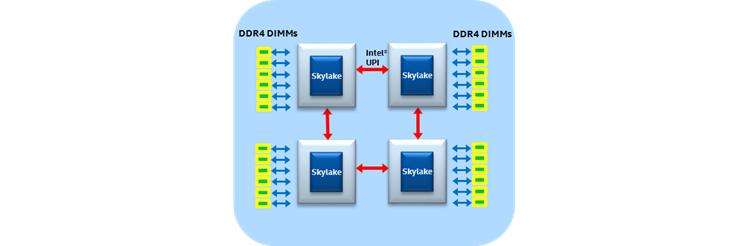
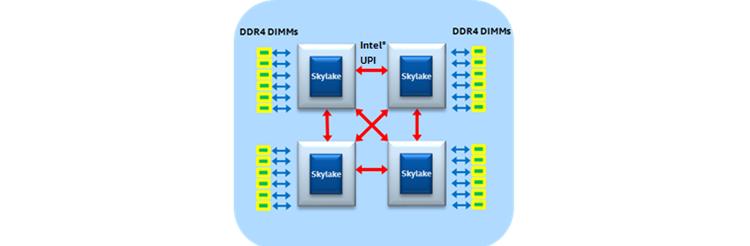
Во всех предыдущих поколениях семейств процессоров Intel® Xeon® (более ранних Haswell и Broadwell) в их платформе Grantley все процессоры, вся ядра, кэш последнего уровня (LLC, last-level cache), контроллер памяти, контроллер ввода/ вывода и порты межсокетного взаимодействия QuickPath Intel® (Intel® QPI) соединялись воедино с применением некоторой кольцевой архитектуры, которая находилась на своём месте вплоть до самых последних поколений многоядерных ЦПУ Intel®. По мере роста с каждым поколением общего числа ядер в имеющихся ЦПУ возрастали задержки доступа и снижалась доступная полоса пропускания на ядро. Эта тенденция мигрировала с момента деления имеющегося чипа на две половины и ввела некое второе кольцо для снижения расстояний и добавления дополнительной пропускной способности.
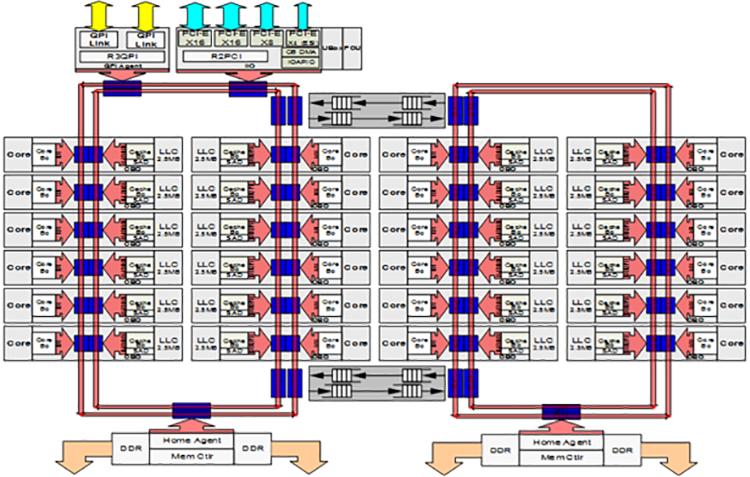
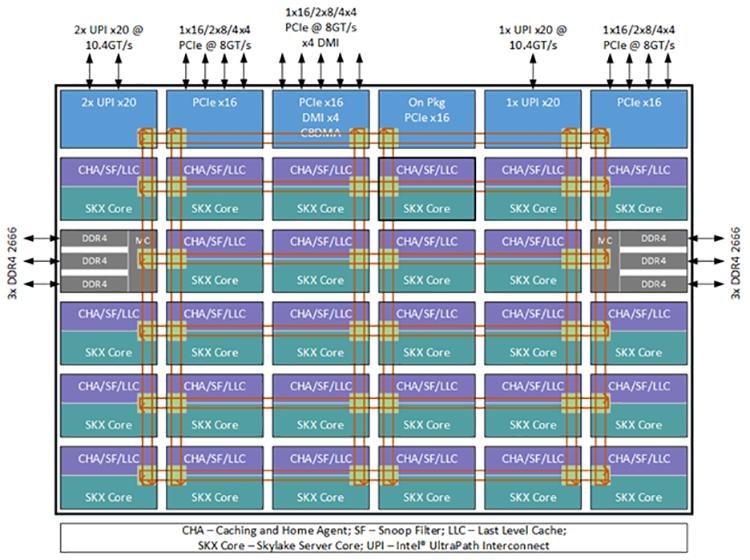
При наличии большего числа ядер на процессор и намного более высоких пропускных способностей памяти и ввода/ вывода в процессорах Intel® Xeon® семейства Scalable, дополнительные потребности во взаимодействии внутри чипа могут стать неким ограничителем при архитектуре на основе кольца. Вследствие этого семейство Scalable процессоров Intel® Xeon® вводит для миграции некую сеточную архитектуру для ограничения роста задержек и пропускной способности, вызываемых предыдущей архитектурой на основе кольца. Семейство Scalable процессоров Intel® Xeon® также интегрирует имеющихся агента кэширования, агента заплонения (home), а также подсистему ввода/ вывода в такую сетку интерконнекта модульным и распределённым образом для удаления узких мест при доступе к этим функциям. Каждое ядро и слой LLC имеют присоединённого агента кэширования и заселения (CHA, Caching and Home Agent), которые предоставляют масштабируемость ресурсов по всей имеющейся сетке для функциональности кэш- когерентного взаимодействия Intel® Ultra Path (Intel® UPI) без каких- либо перегретых участков.
Сеточная архитектура семейства Scalable процессоров Intel Xeon охватывает некий массив вертикальных и горизонтальных путей взаимодействия по всему маршруту от одного ядра до другого через кратчайшие маршруты (прыжок по вертикальному пути на правильную строку и скачок по горизонтальному пути на правильный столбец). Все CHA располагаются на тех срезах LLC, которые соответствуют адресам, связанными с определёнными банком LLC, контроллером памяти или подсистемой ввода/ вывода, а также предоставляют информацию маршрутизации, необходимую для достижения его получателя с применением сеточной взаимосвязи.
Кроме того, помимо ожидания улучшения в общих латентностях ядра-к-кэшу и ядра-к-памяти, мы также ожидаем увидеть улучшения в латентностях для инициируемого вводом/ выводом доступа. В предыдущем поколении процессоров, чтобы осуществить доступ к данным в LLC, памяти или вводе/ выводе некому ядру или вводу/ выводу понадобилось бы пройтись по кольцу и выдержать арбитраж имеющегося коммутатора между всеми кольцами если данные источник и получатель не находятся в одном и том же кольце. В семействе Scalable процессоров Intel Xeon некое ядро или ввод/ вывод могут осуществлять доступ к данным в LLC, памяти или вводе/ выводе по кратчайшему пути в имеющейся сетке.
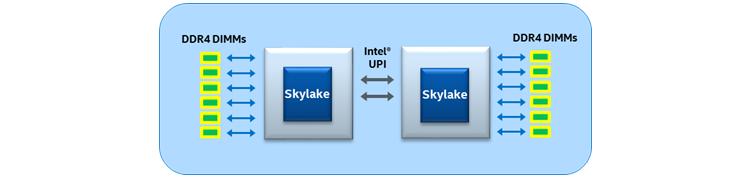
Предыдущее поколение процессоров Intel® Xeon® применяло Intel QPI, который был заменён в семействе Scalable процессоров Intel Xeon на Intel UPI. Intel UPI является неким когерентным интерконнектом для масштабируемых систем, содержащих множество процессоров в каком- то едином совместно используемом адресном пространстве. Поддерживающие Intel UPI процессоры Intel Xeon предоставляют либо два, либо три соединения Intel UPI для связи с другими процессорами Intel Xeon и осуществляют это с применением высокоскоростного пути с низкой латентностью в прочие сокеты ЦПУ. Intel UPI применяет когерентный протокол выискивания размещения на основе каталога (directory-based home snoop coherency protocol), который предоставляет рабочую скорость до 10.4GT/s, улучшая эффективность энергопотребления за счёт состояния L0p в состояниях с пониженным потреблением питания, предоставляет улучшенную эффективность обмена данными по имеющимся связям при помощи некоего нового формата упаковки в пакеты и имеет улучшения на уровне протокола такие как отсутствие предварительного размещения для удаления пределов масштабирования при Intel QPI.
Предыдущие реализации процессоров Intel Xeon предоставляли некоего агента распределённого кэширования Intel QPI, размещающегося в каждом ядре и централизуемого агентом размещения Intel QPI, располагающимся в каждом контроллере памяти. Процессоры семейства Scalable Intel Xeon реализуют некий комбинированный CHA, который является распределённым и размещается в каждом ядре и банке LLC и, тем самым, предоставляет ресурсы, которые масштабируются совместно с общим числом ядер и банков LLC. CHA отвечает за отслеживание запросов от определённого ядра и реагирует на выискивания (snoops) локальных и удалённых агентов, а также за разрешение когерентности по множеству процессоров.
Intel UPI удаляет требование предварительного размещения ресурсов в имеющемся агенте заполнения (home agent), что делает возможной распределённую реализацию такого агента заполнения. Имеющиеся распределённые агенты заполнения всё ещё логически представляют некий единый агент Intel UPI, который перемежает адреса по различным CHA, поэтому общее число видимых узлов Intel UPI всегда равно одному, вне зависимости от общего числа ядер, используемых контроллеров памяти или режима кластеризации sub-NUMA. Каждый CHA реализует некий слой получаемой агрегированной функциональности, ответственной за какую- то порцию имеющегося адресного пространства, соответствующего данному слою.
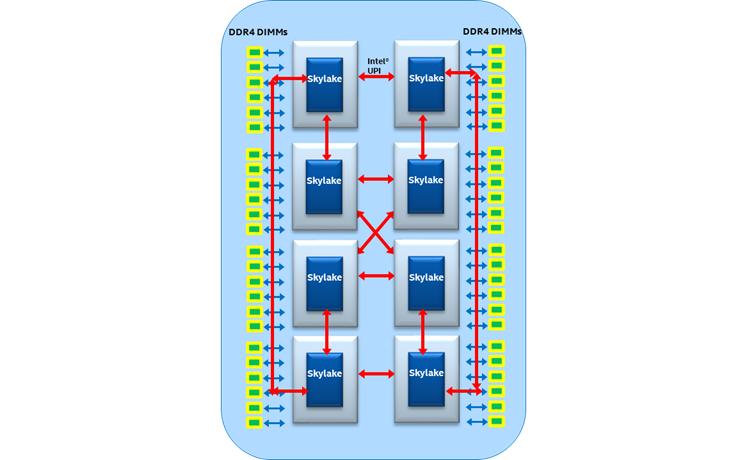
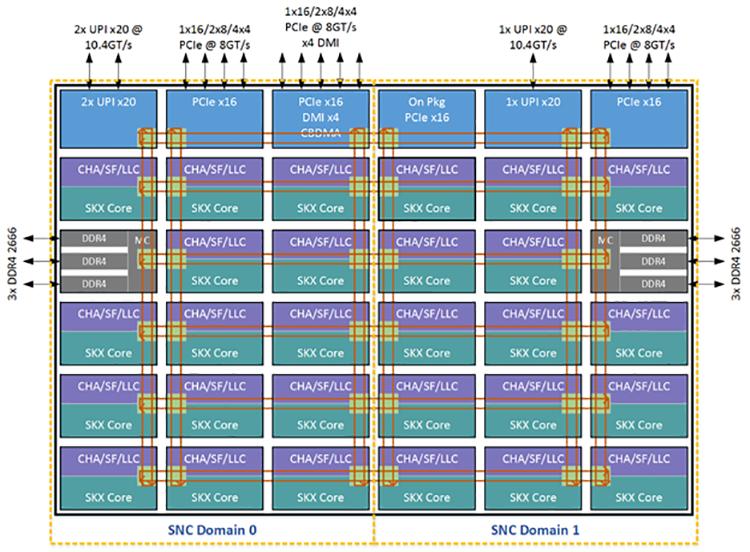
Кластер sub-NUMA (SNC, sub-NUMA cluster) аналогичен функциональности кластер- на- чипе (COD, cluster-on-die), который был введён в Haswell, хотя между ними и имеются некие различия. Некий SNC создаёт два домена локализации внутри некоторого процессора ставя в соответствие адреса из одного из имеющихся локальных контроллеров памяти в в одной половине более близких к этому контроллеру памяти имеющихся слоёв LLC и относящихся к другому контроллеру памяти адресам прочих слоёв LLC во второй половине. Благодаря данному механизму сопоставления адресов выполняемые на ядрах в одном из доменов SNC с применением памяти из имеющегося в том же самом домене SNC контроллера памяти процессы отмечают меньшую задержку LLC и памяти в сравнении с латентностью при доступе к соответствующим расположениям за пределами одного и того же домена SNC.
В отличии от механизма COD, при котором некая линия кэширования может иметь копии в имеющийся LLC каждого кластера, SNC имеют уникальное местоположение для каждого адреса в данном LLC и никогда не дублируются внутри всех банков LLC. Кроме того, расположение адресов внутри конкретного LLC для каждого домена SNC применяется только к адресам, соответствующим имеющимся внутри того же самого сокета контроллерам памяти. Все сопоставленные с памятью на удалённых сокетах адреса равномерно распределяются по всем банкам LLC независимо от установленного режима SNC. Таким образом вся ёмкость LLC в данном сокете целиком доступна каждому ядру даже в установленном режиме SNC, причём данная ёмкость LLC, сообщаемая через CPUID не зависит от самого режима SNC.
Рисунок 10 представляет некую конфигурацию с двумя кластерами, которая состоит из Доменов 0 и 1 SNC в добавление к своим связанными с ней ядрами, LLC и контроллерами памяти. Каждый домен SNC содержит половину всех процессоров в данном сокете, половину всех банок LLC и один из имеющихся контроллеров памяти с тремя каналами DDR4. Родственность ядер, LLC и памяти внутри некоторого домена выражается с применением имеющихся обычных параметров родственности (affinity) NUMA для данной ОС, которая может принимать в расчёт домены SNC при задачах планирования и выделения памяти некоторому процессу для оптимальной производительности. {Прим. пер.: подробнее о механизмах, например, см. Оптимизацию ресурсов виртуальных машин во 2-ои издании "Книги рецептов Windows Server 2016 Hyper-V", NUMA в переводе 1-й части 7-го издания "Внутреннего устройства Windows", Регулировки NUMA с применением libvirt в "Книгe рецептов виртуализации KVM", Тонкая настройка ЦПУ и памяти при помощи NUMA в "Полном руководстве Виртуализации KVM".}.
SNC требует чтобы память не перемежалась тонко гранулированным образом между контроллерами памяти. Кроме того, режим SNC должен быть разрешён BIOS чтобы представить два домена SNC для каждого сокета и установить родственность ресурсов и параметры латентности для применения с примитивами NUMA.
В отличие от более раннего поколения процессоров Intel Xeon, который поддерживает четыре различных режима отслеживания (nosnoop, early snoop, home snoop и directory), семейство Scalable процессоров Intel Xeon поддерживает только режим directory (каталога). С произошедшим изменением в иерархии кэширования на не включающий LLC, в зависимости от того где находится линия кэширования в данной иерархии кэширования латентность разрешения отслеживания может окаываться более длительной. Кроме того, при более высокой пропускной способности памяти имеющаяся пропускная способность Intel UPI между сокетами является более ценным ресурсом и может становиться узким местом в производительности системы если к удалённым сокетам отправляется не достаточный объём отслеживаний (snoops). В результате компромиссы оптимизации для различных режимов отслеживания отличаются для семейства Scallable процессоров Intel Xeon в сравнении с предыдущими процессорами Intel Xeon, и поэтому сложность поддержки множества режимов выслеживания не является преимуществом.
Семейство Scalable процессоров Intel Xeon переносит и далее некоторые из оптимизаций когерентности из предыдущих поколений и вводит некоторые новые для снижения действительной латентности памяти. Например, некоторые оптимизации кэширования имеющегося каталога, такие как кэширование каталога ввода/ вывода и кэширование HitME всё ещё поддерживаются и расширяются дополнительно в семействе Scalable процессоров Intel Xeon. Также поддерживается функция приспособляемой широкополосности (opportunistic broadcast), однако она применяется только для записи в локальную память во избежание доступа к памяти при просмотре каталога.
Для кэширования каталога ввода/ вывода (IODC, IO directory cache) семейство Scalable процессоров Intel Xeon предоставляет кэш каталога с восемью записями для каждого CHA для кэширования состояния записей ввода/ вывода из удалённых сокетов. Операции записи в вводе/ выводе обычно требуют множества транзакций для аннуляции состоятельности некоторой линии кэширования во всех агентах кэширования следующих отложенной записи (writeback) при размещении обновлённых данных в памяти или домашних сокетах LLC. Имея сохранённой в памяти такую информацию каталога для выборки и обновления состояния каталога может потребоваться множество доступов. IODC снижает число доступов к памяти для выполнения операций записи ввода/ вывода сохраняя кэшируемой в имеющейся структуре IODC такую информацию каталога.
Кэш HitME является другой возможностью в имеющемся CHA, которая кэширует информацию каталога для ускорения обмена кэш-в-кэш. При распределённой структуре агентов размещения (home agent) имеющегося CHA, все ресурсы кэширования HitME масштабируются согласно сичлу CHA.
Приспосабливаемое широкополосное отслеживание (OSB, Opportunistic Snoop Broadcast) является другим свойством, перенесённым из предыдущих поколений в семейство Scalable процессоров Intel Xeon. OSB выполняет широкополосное отслеживание когда соединение UPI загружено не сильно, тем самым избегая какого- то просмотра каталога из памяти и уменьшая полосу пропускания памяти. В семействе Scalable процессоров Intel Xeon OSB применяется только для локальных запросов InvItoE (создаваемых благодаря записям полной линии из самого ядра или ввода/ вывода) так как для данной операции не требуется чтение данных. Избежание просмотра каталога имеет непосредственное воздействие на сбережение полосы пропускания памяти.
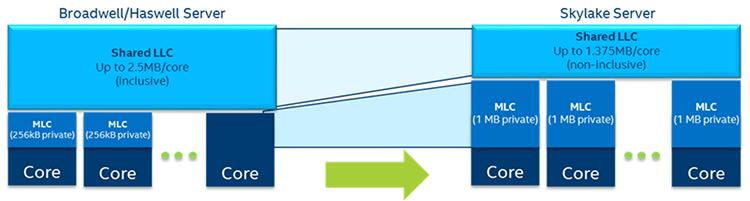
В предыдущем поколении кэш среднего уровня (MLC) имел 256кБ на ядро, а кэш последнего уровня был совместно используемым инклюзивным кэшем с 2.5МБ на ядро. В семействе Scalable процессоров Intel Xeon иерархия кэширования была изменена для предоставления MLC большего размера в 1МБ на ядро и меньшего не включающего (noninclusive) кэширования LLC в 1.375 МБ на ядро. MLC большего размера увеличивает частоту попаданий в MLC, что имеет результатом снижение реальной латентности памяти и также снижает запрос на имеющуюся сетку взаимодействия и LLC. Сдвиг в сторону не включающего кэширования для имеющегося LLC делает возможным более эффективное использование общего кэширования в самой микросхеме при сопоставлении с инклюзивным кэшированием.
Если данное ядро в семействе Scalable процессоров Intel Xeon получило промах во всех кэшах, оно выбирает эту линию из памяти и помещает её напрямую в MLC запрашивающего ядра, вместо того чтобы помещать некую копию и в MLC, и в LLC как это осуществлялось в предыдущем поколении. Когда данная линия кэширования вытесняется из имеющегося MLC, она помещается в свой LLC если ожидается её повторное использование.
Благодаря своей не включающей природе LLC, наличие отсутствия линии кэширования в LLC не указывает что данная линия отсутствует в частных кэшах любого из имеющихся ядер. Таким образом некий фильтр осмотра применяется для продолжения отслеживания имеющегося местоположения линий кэширования в имеющихся L1 или MLC ядер когда он не выделяется в LLC. Во всех ЦПУ предыдущих поколений сам по себе совместно используемый LLC заботился об этой задаче.
Даже вместе со всеми изменениями иерархии кэширования семейства Scallable процессоров Intel Xeon, действующий кэш, доступный из расчёта на ядро примерно тот же самый что и в предыдущих поколениях для некоторого сценария применения, при котором различние приложения исполняются на различных ядрах. Благодаря не включающей природе LLC имеющаяся реальная ёмкость для некоторого исполняемого в отдельном ядре приложения является комбинацией размера кэша MLC и некоторой части размера кэша LLC. Для прочих сценариев применения, таких как многопоточные приложения, исполняющиеся по множеству ядер с одним и тем же совместно используемым кодом и данными, или какой- то сценарий в котором используется только некое подмножество имеющихся ядер, общая реальная ёмкость кэша, видимая данным приложением может выглядеть отличной от того, что предоставляли ЦПУ предыдущего поколения. В некоторых случаях разработчикам приложений может потребоваться адаптация их кода для его оптимизации к данному изменению иерархии в процессорах семейства Scalable процессоров Intel Xeon.
Одной из проблем сложных многопоточных приложений, обусловленных паразитными записями, является разрушение памяти. Например, не каждой части имеющегося в приложении базы данных кода необходимо иметь один и тот же уровень полномочий. Тот кто ведёт протокол должен иметь полномочия записи в имеющийся буфер протокола, однако ему требуется иметь только полномочия на чтение на прочие страницы. Аналогично, в приложении с потоками производителя и потребителя для некоторых структур с критичными данными, потоки производителя могут получать дополнительные права в сопоставлении с потоками потребителей на определённых страницах.
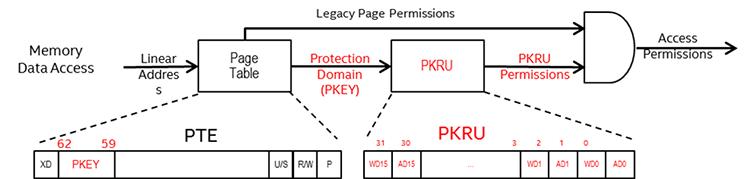
Для упрочнения приложений может применяться механизм защиты памяти на основе страниц. Однако, изменения таблицы страниц является затратным для производительности так как эти изменения требуют остановки буфера быстрого преобразования адреса (TLB, Translation Lookaside Buffer) и последующих промахов TLB. Ключи защиты предоставляют некий способ уровня пользователя с гранулированием до страниц для предоставления и отзыва полномочий доступа без изменения таблиц страниц.
Ключи защиты предоставляют 16 доменов для страниц пользователя и используют биты 62:59 имеющихся концевых
узлов таблицы страниц (например, PTE) для указания имеющегося защищённого
домена (PKEY). Каждый защищённый домен имеет два бита полномочий в
некотором новом частном регистре потока с названием PKRU. При доступе
к некоторой памяти для определения наличия доступа к определённому защищённому домену
(PKEY) применяется просмотр имеющейся таблицы страниц и соответствующие
специфичные для домена полномочия защиты определяются из содержимого регистра
PKRU для того чтобы определить предоставлены ли полномочия доступа и
записи для данного доступа. О нарушениях ключей защиты сообщается в отказах страниц с неким новым битом кода
ошибки отказа страницы. Ключи защиты не имеют воздействия на страницы супервизора, однако доступы супервизора к
страницам пользователя являются предметом в точности таких же проверок что и доступы пользователя.
Для получения преимуществ ключей защиты необходимы поддержка со стороны имеющегося диспетчера виртуальной машины, ОС и компилятора. Применение этой функциональности не должно оказывать ни какого воздействия на производительность, так как она является неким расширением имеющейся архитектуры управления памятью.
Арифметика указателей C/C++ является некоторой удобной языковой конструкцией, часто применяемой в качестве этапа для прохода по некому массиву структур данных. Если не принимаются во внимание некие имеющиеся границы самого получателя, некие итеративные операции могут повреждать записи смежных ячеек памяти. Такие непреднамеренные изменения смежных данных называются переполнением буфера. Известно, что переполнение буфера применяется и вызывает атаки отказа- в- обслуживании (DoS, denial-of-service) и крушения системы. Аналогично, неуправляемые чтения могут обнаруживать криптографические ключи и пароли. Более зловещие атаки, которые не сразу привлекают внимание самого пользователя или системного администратора изменяют путь исполнения текущего кода, например, изменяя имеющийся адрес возврата в части стека для исполнения вредоносного кода или сценария.
Бит запрета исполнения (Execute Disable Bit) Intel и аналогичные аппаратные свойства других производителей блокировали атаки переполнения буфера, которые перенаправляли имеющееся исполнение во вредоносный код, сохраняемый как данные. Технология Intel® MPXсостоит из новых инструкций и регистров архитектуры Intel®, которые могут применяться компиляторами для проверки границ некоторого указателя во время исполнения до его применения. Эта новая аппаратная технология поддерживается имеющимся компилятором.
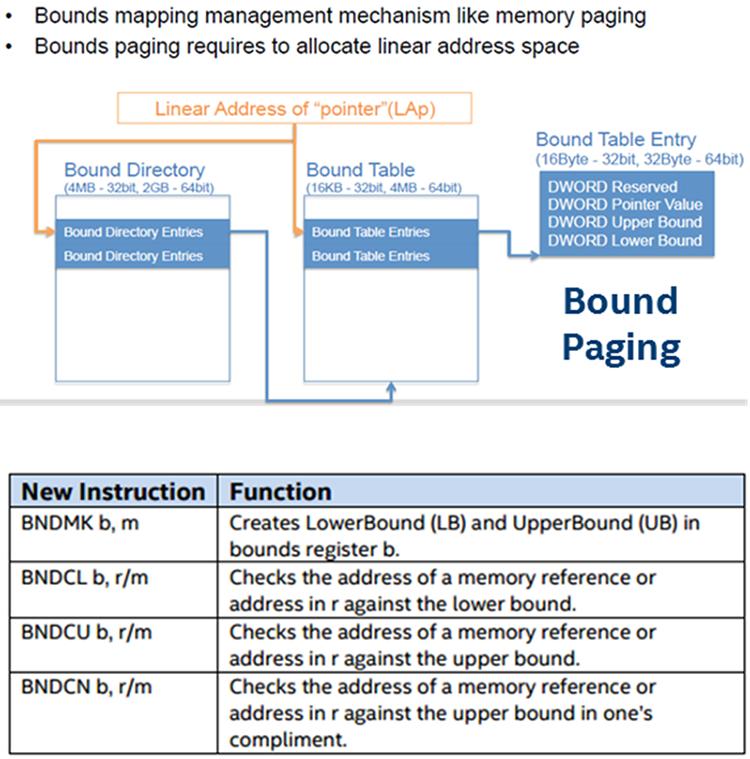
Для получения дополнительных подробностей обратитесь к Intel® Memory Protection Extensions Enabling Guide.
MBE предоставляет более тонкую грануляцию управления полномочиями исполнения в помощь защите целостности всего системного кода от вредоносных изменений. Оно предоставляет дополнительное улучшение внутри Расширенных таблиц страниц (EPT, Extended Page Tables) включением бита полномочий разрешения исполнения (Execute Enable - X) в два варианта:
-
XU: для страниц пользователя
-
XS: для страниц супервизора
Имеющийся ЦПУ выбирает один или другой на основании полномочий данной гостевой страницы и сопровождает
некую неизменность для всех страниц, что не позволяет им быть перезаписываемыми и исполнимыми супервизором в
одно и то же время. Преимущество данного подхода состоит в том, что некий гипервизор может более надёжно
выполнять проверку и усиливать имеющуюся целостность кода уровня ядра. Имеющиеся значения битов
XU/XS доставляются через работающий гипервизор, поэтому требуется
поддержка гипервизора.
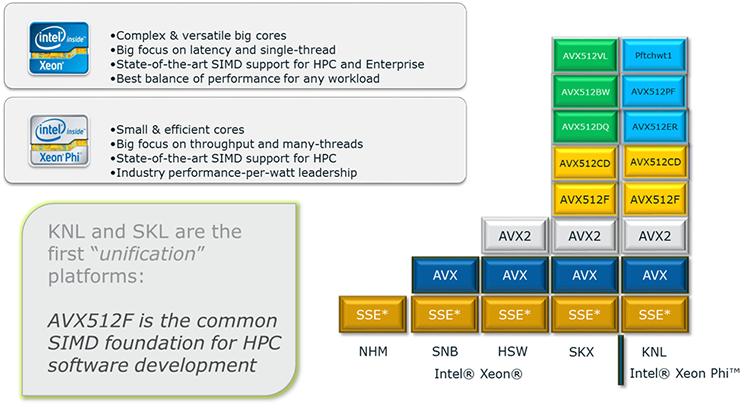
Intel® Advanced Vector Extensions 512 (Intel® AVX-512) было изначально введено в продуктовой линейке процессоров ntel® Xeon Phi™ (ранее Knights Landing). Имеются определённые группы инструкций AVX-512 (AVX512CD и AVX512F), которые являются общими для продуктовой линейки процессоров Intel® Xeon Phi™ и семейства Scalable процессоров Intel Xeon. Однако семейство Scalable процессоров Intel Xeon ввело новые группы инструкций (AVX512BW и AVX512DQ), а также некие новые возможности (AVX512VL) для расширения преимуществ имеющейся технологии. Группа инструкций AVX512DQ сосредоточена на новых добавлениях для преимуществ нагрузок высокопроизводительных вычислений (HPC, high-performance computing), таких как нефть и газ, моделирование сейсмики, отрасль обслуживания финансов, молекулярная динамика, отслеживание лучей, матричное умножение с двойной точностью, быстрые Фурье преобразования и свёртки, а также RSA криптография. Группа инструкций AVX512BW поддерживает операции с байтом/ словом (Byte/Word), которые могут дать преимущества некоторым корпоративным приложениям, медийным приложениям, а также HPC. AVX512VL не является некоторой группой операций, а только свойство связанное с отсутствием наложений длины вектора (vector length orthogonality).
Предыдущее поколение процессора, Broadwell, имело до двух FMA (Fused Multiple Add, Сплавленных множественных сложений) на ядро и это не изменилось в семействе Scalable процессоров Intel Xeon. Однако семейство Scalable процессоров Intel Xeon удвоило общее число элементов, которые могут обрабатываться в сравнении с Broadwell в качестве FMA в семействе Scalable процессоров Intel Xeon, которое было расширено с 256 бит до 512 бит.

Инструкции Intel AVX-512 предлагают самую высокую степень поддержки разработчикам программного обеспечения включая некий беспрецедентный уровень богатства в дизайне этих инструкций. Они включают 512- битные операции на упакованных данных с плавающей точкой или упакованные целочисленные данные, встроенное управление округлением (установки перезаписи глобальных настроек), встроенную широкую полосу, встроенное подавление отброса дробной части, встроенное подавление сброса памяти, дополнительную поддержку сборки/ разряжения, высокоскоростные математические операции, а также компактное представление больших значений смещения. Последующие разделы охватывают определённые подробности имеющихся новых свойств Intel AVX-512.
AVX512DQ
Флаг CPUID AVX512DQ расширения целочисленных операций и операций с плавающей запятой указывает на
операцию с двойными словами и учетверёнными словами, состоящими из дополнительных инструкций, которые работают
с 512- битными векторами, чьими элементами являются 16 32-битных элементов или 8 64-битных элементов. Некоторые
из этих инструкций предоставляют новую функциональность, такую как преобразование чисел с плавающей
запятой в 64-битные целые. Прочие инструкции предоставляют существующие инструкции, такие как инструкция
vxorps применения 512- битных регистров.
AVX512BW
Инструкции работы с байтами и словами, указываемые флагом CPUID AVX512BW, расширяют целочисленные операции, добавляя маскирование записи и маскирование нулём для поддержки элементов меньших размеров. Первоначально Учреждённые (Foundation) Intel AVX-512 инструкции поддерживали такое маскирование с векторными элементами размером 32 или 64 бита, поскольку 512-битный векторный регистр может содержать 16 32-битных элементов, запись маски размером в 16 бит была достаточной.
Некая инструкция, указываемая флагом CPUID AVX512BW требует какого- то размера маски записи до 64 бит, так
как некий 512- битный векторный регистр может содержать 64 8-битных или 32 16-битных элементов. Для поддержки
таких операций были введены два новых типа маски (_mmask32
и _mmask64) с дополнительными маскируемыми встроенными средствами.
AVX512VL
Некоторая новая дополнительная возможность отсутствия наложения (orthogonal), называемая Vector Length Extensions предоставляет для большинства инструкций Intel AVX-512 работу на 128 или 256 битах, вместо того чтобы работать только с 512. Vector Length Extensions могут в настоящее время применяться к большинству Учреждённых (Foundation) инструкций и инструкций обнаружения конфликта (Conflict Detection), а также к новым инструкциям с байтом, словом, двойным словом и учетверённым словом. Такие Intel AVX-512 Vector Length Extensions указываются флагом CPUID AVX512VL. Применение Vector Length Extensions расширяет большую часть операций Intel AVX-512 также на использование регистров XMM (128-bit, SSE) и регистров YMM (256-bit, AVX) вместо применимости только к регистрам ZMM.
Регистры маски
В предыдущих поколениях Intel® Advanced Vector Extensions и Intel® Advanced Vector Extensions 2
возможность маскирования бит была ограничена операциями загрузки и сохранения. В Intel AVX-512 эта функциональность
была значительно расширена восемью новыми регистрами opmask, применяемыми
для условного исполнения и действенного соединения операндов- получателей. Имеющаяся длина каждого регистра
opmask составляет 64 бита и они идентифицируются как
k0 - k7. Семь из восьми регистров
opmask (k1 - k7)
могут применяться для соединения с инструкциями кодирования EVEX Intel AVX-512 Foundation для предоставления
условной обработки, например, при остатка с векторизацией, которые только частично заполняют весь регистр.
Хотя регистр opmask k0
обычно и рассматривается как "не маскируемый" при безусловной обработке всех элементов данных, когда
это требуется. Кроме того, данные регистры opmask также применяются в
качестве уровня векторных флагов/ элемента векторного источника для введения новой функциональности SIMD, что
можно увидеть в новых инструкциях, таких как VCOMPRESSPS. Поддержка
для 512- битных регистров SIMD и регистров opmask управляется имеющейся
операционной системой с помощью инструкций XSAVE/
XRSTOR/ XSAVEOPT.
(см. Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 2B, and Intel® 64
and IA-32 Architectures Software Developer’s Manual, Volume 3A.)
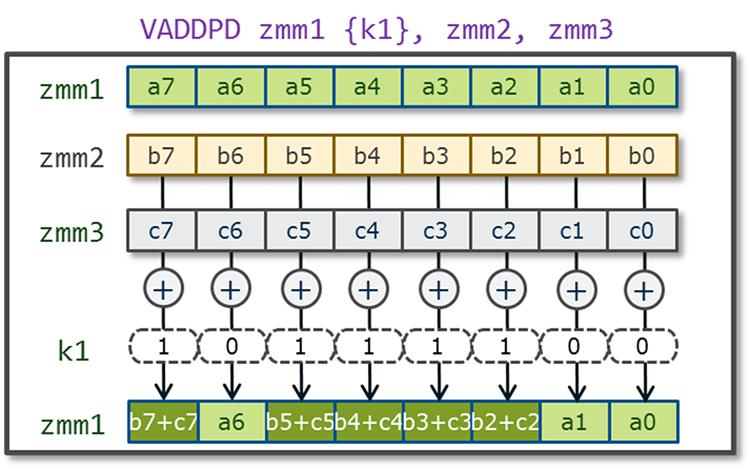
Встроенное округление
Встроенное округление (Embedded Rounding) предоставляет дополнительную поддержку для математических вычислений
делая возможным режим округления с плавающей точкой для его явного определения для некоторой персональной
операции без необходимости изменять имеющееся управление округлением в общем регистре управления
MXCSR для некоторой части инструкций предоставляя переназначение округления
для отдельной операции через поля кодирования внутри имеющегося операнда
imm8. Intel AVX-512 предлагает более гибкий атрибут кодирования для замены
управления округлением на основе MXCSR для операций с плавающей
точкой при помощи семантики округления. такой атрибут округления встроен в имеющемся префиксе
EVEX имеет название Режима статичного (на инструкцию) округления
(Static Rounding Mode) или Режима переопределения округления (Rounding Mode override). Статичное округление
также подразумевает запрет исключения (SAE) как если бы все исключения
плавающей точки отключены и не установлены никакие флаги. Статическое округление делает возможным управление
лучшей точностью в промежуточных шагах для операций деления и взятия квадратного корня для дополнительной
точности представления данных, в то время как режим округления MXCSR
по умолчанию применяется на самом последнем этапе. Это также может помочь в случае, когда необходима точность
минимально значимого бита, например при понижении диапазона в тригонометрических операциях.
Встроенная широковещательность
Встроенная широковещательность (Embedded broadcast) предоставляет некое битовое поле для кодирования
широковещательных данных при некоторых инструкциях load-op, таких
как инструкции, загружающие данные из памяти и выполняющие некоторые вычисления или операции перемещения
данных. Некий элемент источник из оперативной памяти может быть широковещательным (повторяемым) по всем
элементам определённого действующего операнда источника без требования некоторых дополнительных
инструкций. Это полезно когда мы желаем повторно применять один и тот же скалярный операнд для всех операций
в некоторой векторной инструкции. Встроенная широковещательность допустима только в операциях, имеющих размер
32 или 64 бита и не допускается в инструкциях с байтом или словом.
Целочисленная арифметика с четырьмя словами
Целочисленная арифметика учетверённого слова удаляет необходимость для затратных последовательностей
эмуляции. Эти инструкции включают сборку/ разряжение (gather/scatter) с индексами двойного/ учетверённого
слова, а также инструкции, которые могут исполняться частично, когда маска k-reg
применяется как маска исполнения.
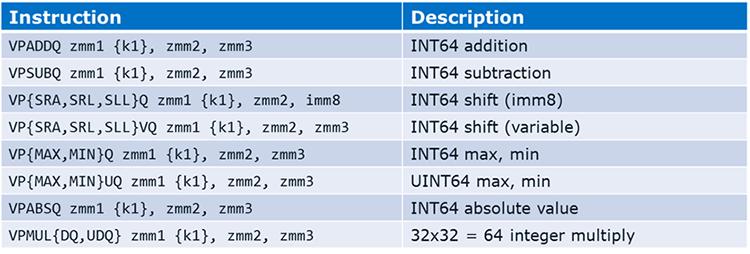
Поддержка Math
Поддержка Math разработана в помощь написанию математических библиотек и для преимуществ финансовых
приложений. Доступные типы данных включают PS,
PD, SS и
SD. Также включена IEEE форматов деления/ взятия квадратного
корня, трансцендентных примитивов DP, а также новой трансцендентной поддержки.
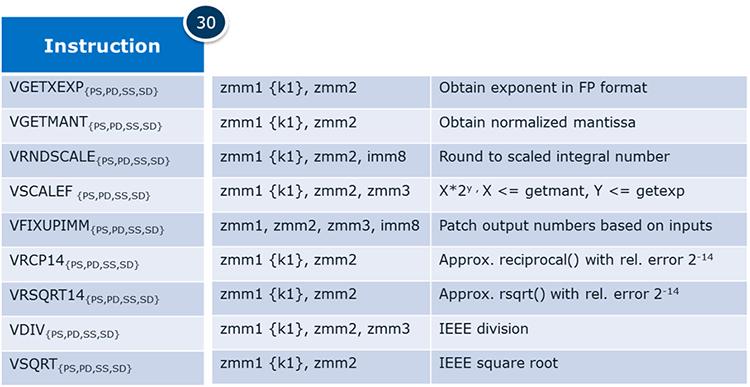
Новые примитивы перестановки
Intel AVX-512 вводит новые примитивы перестановки, такие как смешивание двух источников с 16/ 32 -элементным
просмотром таблицы при поддержке трансцендентности, транспонирования матриц и некоторой эмуляции переменной
VALIGN.

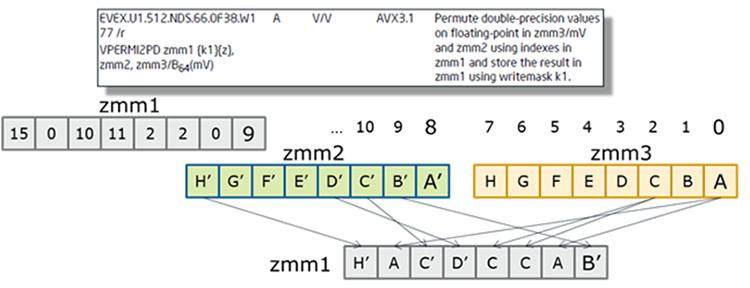
Развёртывание и сжатие
Развёртывание и сжатие (Expand and Compress) делает возможной векторизацию условных циклов. Аналогично внутреннему pack/unpack FORTRAN оно также обеспечивает подавление отказов памяти, может быть быстрее применения сборки/ разряжения (gather/scatter) и к тому же имеет обратную возможность операции сжатия. Рисунок ниже показывает некий пример какой- то операции развёртывания.
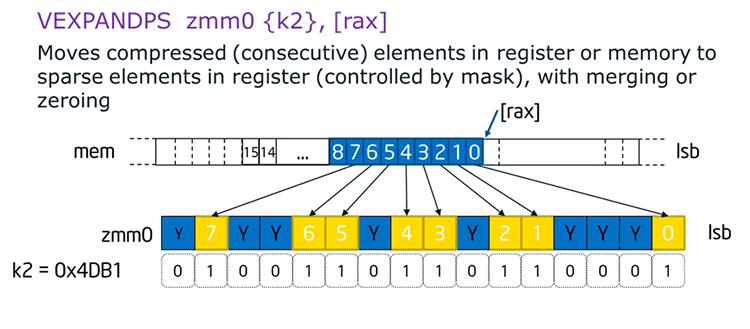
Манипуляции битами
Intel AVX-512 предоставляет поддержку для операций манипуляции с битами в операндах маски и вектора, включая вращение вектора. Эти операции могут применяться для манипуляции регистрами маски и они имеют некие применения в алгоритмах криптографии.
Универсальные тройные логические операции
Универсальные тройные логические операции являются другой функциональностью Intel AVX-512, которая
предоставляет некий способ подражания некоторой ячейке FPGA. Операции VPTERNLOGD
и VPTERNLOGQ работают с элементами двойных и учетверённых слов и
берут трёхбитные векторы соответствующих элементов входных данных для создания некоторого множества 32/ 64
индексов, причём каждое 3-битное значение предоставляет некий индекс для какой- то 8-битной таблицы
представляемой имеющимся байтом и imm8 в определённой инструкции.
Все возможные 256 значения данного байта imm8 строятся как логическая
Булева таблица 16x16, которая может быть заполнена простыми или составными Булевыми логическими
выражениями.
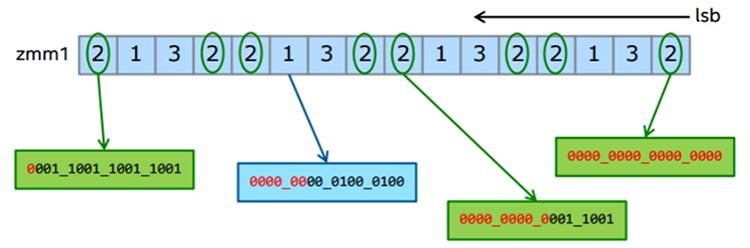
Инструкции определения конфликта
Intel AVX-512 предоставляет новые инструкции определения конфликта (CDI). Они включают в себя инструкцию
VPCONFLICT совместно с неким подмножеством поддерживаемых инструкций.
Такая инструкция VPCONFLICT позволяет определение элементов с
предыдущими конфликтами в некоторых векторных индексах. Она может создавать некую маску с подмножеством элементов,
которая гарантировано свободна от конфликтов. Данный цикл вычислений может повторно исполняться с остающимися
элементами пока не будут обработаны все имеющиеся индексы.

VPCONFLICT{D,Q} zmm1{k1}{z}, zmm2/B(mV), для каждого элемента в
ZMM2 сравниваем его со всеми и создаём некую маску, указывающую совпадения,
но игнорирующую элементы слева от текущего, которые являются "более новыми".
Для получения преимуществ CDI применяйте компиляторы Intel версии 16.0 в Intel® C++ Composer XE 2016,
который распознаёт потенциальные конфликты времени исполнения и автоматически вырабатывает циклы
VPCONFLICT.
Поддержка трансцендентности
Дополнительные 512-битные инструкции расширения были предоставлены для ускорения определённых
трансцендентных математических вычислений и могут быть отображены инструкциями
VEXP2PD, VEXP2PS,
VRCP28xx и VRSQRT28xx,
также именуемыми как Экспоненциальные инструкции и инструкции обратной величины AVX-512 (Exponential и
Reciprocal). Они могут предоставить преимущества в финансовых приложениях.
Поддержка компилятора
Оптимизации Intel AVX-512 включены в компиляторы Intel версии 16.0 в Intel C++ Composer XE 2016, а также в GNU* Compiler Collection (GCC) 5.0 (NASM 2.11.08 и binutils 2.25). Таблица 8 суммирует параметры компилятора для оптимизации микроархитектуры семейства Scalable процессоров Intel Xeon для Intel AVX-512.

Для получения дополнительной информации обратитесь к Intel® Architecture Instruction Set Extensions Programming Reference.
Данное семейство Scalable процессоров Intel Xeon вводит некое новое свойство масштабирования TSC для поддержки миграции некой виртуальной машины по различным системам. В предыдущих процессорах Intel Xeon TSC какой- то ВМ не мог автоматически регулировать себя самостоятельно, чтобы компенсировать некое различие частоты процессора при её миграции с одной платформы на другую. Семейство Scalable процессоров intel Xeon расширило поддержку TSC виртуализации добавив некоторое свойство масштабирования в добавление к свойству перемещения (offsetting), доступному в предыдущих поколнениях ЦПУ. Для получения дополнительных подробностей обратитесь к Intel® 64 SDM (ищите “TSC Scaling”, например, Vol 3A – Sec 24.6.5, Sec 25.3, Sec 36.5.2.6).
Broadwell ввёл Аппаратное управление энергопотреблением (HWPM, Hardware Power Management), некое новое необязательное свойство управления энергопотреблением процессора на аппаратном уровне, которое освобождает ОС от принятия решения о частоте процессора. HWPM позволяет данной платформе предоставлять информацию по всем доступным компонентам, делая возможным имеющемуся оборудованию выбирать оптимальные моменты работы. Выполняя независимую обработку, само оборудование использует информацию, которая не доступна программному обеспечению и способна выполнить более оптимальное решение относительно p- состояний и s- состояний. Семейство Scalable процессоров Intel Xeon в имеющейся платформе Purley расширилось в этой функциональности, предоставляя более широкий диапазон состояний, на которые оно может воздействовать, а также более тонкий уровень гранулярности и наблюдаемости микроархитектуры через Комплектное устройство управление (PCU, Package Control Unit). В Broadwell HWPM было автономным, что имело название режима Вне полосы (OOB, Out-of-Band) и не обращавшего внимания на имеющуюся операционную систему, семейство Scalable процессоров Intel Xeon также допускает это, но также предлагает определённый вариант для сотрудничества между имеющимися HWPM и операционной системой, называемое Естественным (native) режимом. имеющаяся операционная система может напрямую управлять тонкой настройкой производительности и профилем энергопотребления когда и где это желательно, в то время как имеющийся PCU может применять автономное управление в отсутствии размещаемых имеющейся операционной системой ограничений. В Естественном режиме семество Scalable процессоров Intel Xeon способно оптимизировать управление частотой для унаследованных операционных систем, и в то же время предоставлять новые модели применения для современных операционных систем. Конечный пользователь может устанавливать эти опции внутри BIOS; для получения дополнительной информации ознакомьтесь с руководством вашего OEM BIOS. Современные операционные системы, которые предоставляют полную интеграцию с Естественным режимом включают в себя Linux*, начиная с ядра 4.10, а также Windows Server* 2016. {Прим. пер.: в разделе Рекомендуемых регулировок нашего перевода "Полного руководства Ceph" Ника Фиска затрагивается тема недостаточной проработок планировщиков потоков и процессов в современных операционных системах, которые влекут за собой излишние задержки при выводе необходимых ядер из состояния сна.}
Процессор реализует схему обнаружения, предоставляющую более быстрое определение и отклик на события уровня Pmax. Изначально схемы обнаружения Pmax располагались либо в устройстве обеспечения питанием (PSU, power supply unit), либо в самой материнской плате, в то время как новая схема обнаружения семейства Scalable процессоров Intel Xeon расположена в самом процессоре. В общем, схема определения Pmax, предоставляемая семейством Scalable процессоров Intel Xeon делает возможным более быстрыми времена обнаружения и отклика в сравнении с методами выявления Pmax имеющихся предыдущих поколений. Определение Pmax позволяет самому процессору выполнять обратное дросселирование при выявлении достижения предела потребления мощности. Это может помочь со всплесками Pmax, связанными с вирусными приложениями при нахождении в режиме turbo до реакции со стороны блока питания. Более быстрое время отклика на события нагрузки Pmax потенциально делают возможным сохранение стоимости потребления электричества. Конечный пользователь может устанавливать определение Pmax внутри своего BIOS; ознакомьтесь с руководством OEM BIOS для получения дополнительной информации.
Архитектура Intel® Omni-Path (Intel® OPA), некий элемент Intel® Scalable System Framework, доставляет производительность для рабочих нагрузок HPC завтрашнего дня, а возможность масштабирования на десятки тысяч узлов - а со временем ещё больше - по конкурентной цене для современных связных архитектур. Продукты серии Intel OPA 100 является повсеместным решением адаптеров PCIe, микросхем, коммутаторов, кабелей и программного обеспечения управления. Будучи последователем Intel® True Scale Fabric, эта оптимизированная архитектура взаимодействия HPC строится поверх комбинации расширенного IP и технологии Intel®.
Для программных приложений Intel OPA будет сопровождать согласованность и совместимость с имеющимися Intel True Scale Fabric и API InfiniBand*, работая через стек программного обеспечения с открытым исходным кодом Альянса OpenFabrics (OFA, OpenFabrics OpenFabrics) в передовых выпусках дистрибутивов Linux. Потребители Intel True Scale Fabric будут иметь возможность мигрировать на Intel OPA путём некоторого обновления программ.
Семейство Scalable процессоров Intel Xeon на платформе Purley поддерживает Intel OPA в одном из двух видов: путём применения некоей карты Intel® Omni-Path Host Fabric Interface 100 Series или в виде некоторой определённой линейки моделей процессора (SKL-F), находящейся в рамках имеющегося семейства Scalable процессоров Intel Xeon, которые имеют встроенный в процессор интерфейс Host Fabric. Такая интеграция архитектуры взаимодействия в сам процессор имеет собственный выделенный путь в имеющихся материнских платах и не оказывает воздействия на доступные для дополнительных плат PCIe lane. данная архитектура способна предоставлять до 100Gb/s на процессорный сокет.
Intel работает с сообществом открытого исходного кода над предоставлением всем компонентам хоста изменений, которые находятся в восходящем потоке совместно с выпусками Delta Package. OSV работает совместно с Intel над включением в последующие дистрибутивы ОС. Хотя имеющиеся программы MPI (Message Passing Interface) и библиотеки MPI для Intel True Scale Fabric, которые применяют PSM будут работать как- есть с интерфейсом Intel Omni-Path Host Fabric без перекомпиляции, тем не менее, повторная компиляция может предоставить определённые преимущества.
Для поддержки программного обеспечения посетите Intel Download Center, а поддержка компилятора может быть найдена в Intel® Parallel Studio XE 2017.
Intel® QuickAssist Technology (Intel® QAT) ускоряет криптографические рабочие нагрузки и выполняет их сжатие, осуществляя разгрузку имеющихся данных для возможности оптимизации этих функций аппаратными средствами. Это делает более простой для разработчиков интеграцию встроенных криптографических ускорений в приложения сетевой среды, хранения и безопасности. В случае семейства Scalable процессоров Intel Xeon в платформе Purley Intel QAT интегрирована в имеющееся оборудование набора микросхем серии Intel® C620 (изначально Lewisburg) в самой платформе Purley и предлагает потрясающие возможности, включающие в себя 100 Gbs Crypto, 100Gbs Compression, 100kops RSA и 2k Decrypt. Следующие сегменты могут получить преимущества данной технологии:
-
Серверы: безопасный интернет- сёрфинг, электронная почта, аналитика больших данных (Hadoop), безопасное наличие множества арендаторов, IPsec, SSL/TLS, OpenSSL
-
Сетевые среды: межсетевые экраны, IDS/IPS, VPN, безопасная маршрутизация, веб- посредничество (proxy), оптимизация WAN (IP Comp), аутентификация 3G/4G
-
Системы хранения: сжатие данных в реальном масштабе времени, сжатие статических данных, безопасное хранение
Поддерживаемые алгоритмы включают в себя:
-
Алгоритмы шифрования: Null, ARC4, AES (с размером ключа 128, 192, 256), DES, 3DES, Kasumi, Snow3G и ZUC
-
Алгоритмы хэширования/ аутентификации с поддержкой: MD5, SHA1, SHA-2 (размер вывода 224,256,384,512), SHA-3 (размер вывода только 256), Advanced Encryption Standard (размер ключа 128, 192, 256), Kasumi, Snow 3G и ZUC
-
Алгоритм шифрованной аутентификации (AEAD): AES (размер ключа 128, 192, 256)
-
Алгоритмы криптографии с общедоступным ключом: RSA, DSA, Diffie-Hellman (DH), Large Number Arithmetic, ECDSA, ECDH, EC, SM2 и EC25519
ZUC и SHA-3 являются новыми алгоритмами, которые были включены в третье поколение технологии Intel QuickAssist, имеющейся в наборах микросхем серии Intel® C620.
Intel® Key Protection Technology (Intel® KPT) является неким новым добавочным свойством Intel QAT, которое можно обнаружить в семействе Scalable процессоров Intel Xeon в платформе Purley с набором микросхем серии Intel® C620. Intel KPT была разработана для помощи с безопасными криптографическими ключами на уровне программных и аппаратных атак на платформу в случае, когда данный ключ хранится и применяется в данной платформе. Это новое свойство сосредоточено на ключах защиты времени исполнения и воплощается внутри инструментов, технологий и имеющихся инфраструктур API.
Для получения более подробной информации обратитесь к Intel® QuickAssist Technology for Storage, Server, Networking and Cloud-Based Deployments. Руководства по программированию и оптимизации можно найти по адресу 01 Intel Open Source website.
iWarp (Internet Wide Area RDMA Protocol) является некоторой технологией, которая управлять сетевым обменом через имеющийся NIC, передавая его имеющемуся ядру что, тем самым, снижает воздействие на сам процессор из- за отсутствия вызываемых сетью прерываний. Это достигается за счёт взаимодействия имеющихся NIC друг с другом через пары очередей для предоставления обмена напрямую в приложения пользовательского пространства. Как правило, большие блоки хранимых данных и миграция виртуальных машин имеют тенденцию к созданию больших нагрузок на имеющийся ЦПУ из- за производимого ими сетевого обмена. Именно в этом случае могут быть получены преимущества iWARP. Благодаря применению пар имеющихся очередей уже известно куда следует отправлять данные и тем самым они могут помещаться непосредственно в пространство пользователя данного приложения. Это исключает дополнительное копирование данных между имеющимся пространством ядра и пространством пользователя приложения, что обычно имеет место в случае без iWARP.
Для получения дополнительной информации предлагаем вам видео Accelerating Ethernet with iWARP Technology.
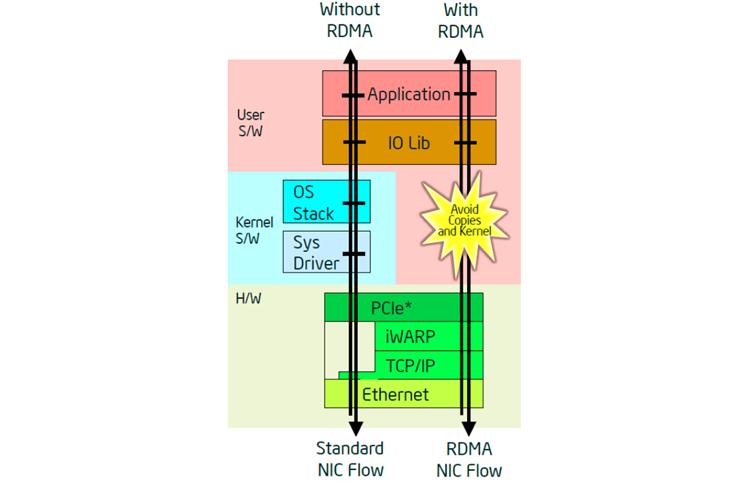
Платформа Purley имеет встроенное соединение X722 Intel Ethernet с общим числом до 4 портов 10 GbE/1 GbE с предоставлением поддержки iWARP. Эта новая функциональность может привносить преимущества в различные отрасли, включая сетевые функции виртуализации и программно- определяемую инфраструктуру. Она также может объединяться с Data Plane Development Kit для предоставления дополнительных преимуществ при дальнейшей передаче пакетов.
iWARP применяет VERB API для общения друг с другом вместо обычных сокетов. Для Linux* OFA OFED предоставляет VERB API, в то время как Windows* применяет Network Direct API.
Семейство Scalable процессоров Intel Xeon в своей платформе Purley предоставляет некоторые новые свойства, помимо улучшения некоторых уже имеющихся функций связанных с RAS (Reliability, Availability и Serviceability - Надёжностью, доступностью и возможностями обслуживания), а также Intel® Run Sure Technology. Семейством Scalable процессоров Intel Xeon предоставляются два уровня поддержки: Стандартная RAS и Расширенная RAS. Расширенная RAS помимо дополнительных свойств включает в себя все функции Стандартной RAS.
В предыдущих поколениях могли иметься ограничения в свойствах RAS, основанные на имеющемся количестве сокетов (2-8). Это было изменено и все имеющиеся свойства RAS доступны в некоторой версии с двумя сокетами и выше для имеющейся платформы в зависимости от уровня её процессоров (от Бронзового до Платинового). Ниже приводится перечисление обзора всех новых и расширенных в сравнении с предыдущим поколением свойств RAS.

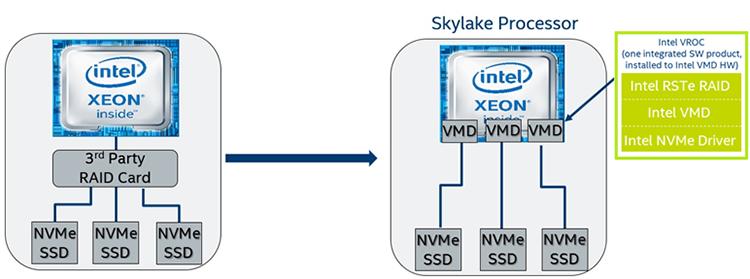
Intel VROC является программным решением, которое интегрировано с новой аппаратной технологией под названием Intel® Volume Management Device (Intel® VMD) для предоставления мощного решения гибридного RAID для твердотельных устройств NVMe* (Non-Volatile Memory Express* SSD). Все ЦПУ имеют на борту возможности, которые более тесно сотрудничают с самим набором микросхем для предоставления более быстрого доступа к непосредственно подключаемым NVMe SSDs на имеющихся в данной платформе lane PCIe. Основными свойствами, которые помогают сделать это возможным являются Intel® Rapid Storage Technology enterprise (Intel® RSTe) версии 5.0, Intel VMD, а также предоставляемый Intel драйвер NVMe
Intel RSTe является неким драйвером и пакетом приложения, которые делают возможным администрирование имеющихся свойств RAID. Они были обновлены для платформы Porley (версия 5.0) для получения преимуществ всех имеющихся новых свойств. Данный драйвер NVMe делает возможными ограничения, которые могут быть размещены в нём для передачи в некую операционную систему. Это означает, что подобные вставке в горячем режиме свойства могут быть доступны даже если сама ОС не предоставляет их, причём сам драйвер также может предоставлять поддержку для стороннего производителя SSD NVMe не- Intel.
Intel VMD является некоторой новой технологией, вводимой семейством Scalable процессоров Intel Xeon в первую очередь для улучшения самого управления высокоскоростными SSD. Изначально SSD подключались к некоторому SATA или другим типам интерфейса и управляли им посредством имевшегося программного обеспечения. Когда мы продвигаемся в сторону непосредственного подключения имеющихся SSD к некоторому интерфейсу PCIe для улучшения полосы пропускания, программное управление такими SSD вносит дополнительные задержки. Intel VMD применяет аппаратуру для переноса таких задач управления вместо того чтобы целиком полагаться на программное обеспечение.
Некоторые из основных свойств RAID, предоставляемых Intel VROC включают в себя защищённый кэш отложенной записи, изоляцию устройств хранения от самой ОС (обработка ошибок), а также защиту данных RAID 5 от некоторых проблем записи пустот RAID путём применения журналирования на программном уровне, что может исключать необходимость каких бы то ни было устройств буферирования батарей (bbu, battery backup unit). Напрямую подключаемые тома NVMe RAID являются RAID загружаемыми, имеют возможности горячей вставки (Hot Insert) и неожиданного удаления (Surprise Removal), предоставляют управляемые LED опции, поддержку естественных 4K NVMe SSD, а также варианты множественного управления, включая удалённый доступ через вебстраницы, взаимодействие на уровне UEFI для задач с неустановленной ОС, а также некий интерфейс GUI на уровне имеющейся ОС.
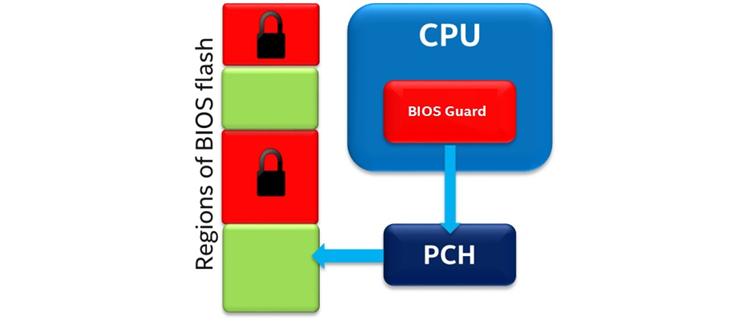
Boot Guard добавляет другой уровень защиты в платформу Purley путём выполнения некоторого криптографического корня прав для измерения (RTM, Root of Trust for Measurement) имеющегося более раннего встроенного ПО устройств хранения платформ, такого как модуль доверенной платформы или Intel® Platform Trust Technology (Intel® PTT). Он также может криптографически проверить более раннее встроенное ПО с применением предоставляемых OEM политик. В отличии от Intel® Trusted Execution Technology (Intel® TXT), Boot Guard не имеет каких бы то ни было требований программного обеспечения; он включается при производстве и не может быть отключён. Boot Guard работает независимо от Intel® TXT, но также имеет совместимость с ним. Boot Guard снижает вероятность эксплуатации вредоносным ПО имеющихся компонентов оборудования и программного обеспечения.

BIOS Guard является увеличением имеющихся возможностей защиты имеющейся в наборе микросхем флеш- памяти BIOS. Данная платформа Purley добавляет возможность обновления определённого устойчивого к отказам блока загрузки. Данный флеш BIOS разделяется на защищённую и не защищённую области. Purley обходит функцию top-swap и регистрации блокировки/ защиты диапазона флеш- памяти для явно активированных сценариев с подписью для облегчения обновления устойчивого к сбоям блока загрузки. Данное свойство защищает имеющийся флеш BIOS от изменения без определённой авторизации производителя платформы, а также в процессе обновления BIOS. Это может также помочь защитить данную платформу от DoS атак нижнего уровня.
Для получения дополнительных подробностей посетите Intel® Hardware-based Security Technologies for Intelligent Retail Devices.
Intel® Processor Trace (Intel® PT) является интригующим свойством улучшенной поддержки со стороны семейства Scalable процессоров Intel Xeon, которое может оказать значительную помощь при отладке, так как выделяет некие точные и подробные трассировки активности с возможностями переключения и фильтрации для поддержки с изолированием самого отслеживания как предмета.
Intel PT предоставляет контекст всех событий. Для изучения основных причин проблем "времени отклика" - осложнений производительности, которые воздействуют на качество исполнения, если даже не на общее время исполнения - могут применяться профили производительности.
Более того, полная трассировка, предоставляемая Intel PT, делает возможным более глубокий просмотр исполнения чем это было обычно возможно ранее; например, поведение цикла, начиная со входа и выхода, вплоть до определённых задних граней (back-edge) и счётчиков циклов легко выделяются и выдаются в сообщение.
Отладчики могут применять Intel PT для восстановления хода исполнения имеющегося кода, которое повлекло к текущему положению, будь то неким положением крушения, какой- то точкой прерывания или просто определённой инструкцией, за которой следует какой- то вызов функции, который мы просто перешагнули. Они могут даже допускать перемещение в имеющейся записанной истории исполнения через команды обратного пошагового прохода.
Другим важным вариантом применения является разрушения стека отладки. В случае разрушения имеющегося стека
вызовов обычное раскручивание участка кода может не предоставлять надёжного результата. Intel PT может
применяться для восстановления такого стека вновь из отслеженного на основе реальных инструкций
CALL и RET.
Операционные системы могут включать Intel PT в файлы ядра. Это позволило бы отладчикам не только инспектировать само состояние программы в момент её крушения, но также восстанавливать весь поток исполнения, который повлёк данный крах. Также имеется возможность расширить это на всю систему для отладки тревог ядра (kernel panic) и прочих зависаний системы. Intel PT может выполнять глобальную трассировку, поэтому если произошло некое крушение ОС, данное отслеживание может быть сохранено как некая часть какого- то механизма дампа крушения ОС, а затем использовано в последствии для восстановления данного отказа.
Intel PT может также содействовать сужению конкуренции данных в многопоточных операционных системах и кодах программ пользователей. Она может регистрировать всё исполнение всех потоков с некоторой грубой индикацией времени. Хотя она и не обладает достаточной точностью для автоматического определения конкуренции данных (data race), она может предоставить достаточный объём информации чтобы помочь с таким анализом.
Для применения Intel PT вам необходим Intel® Vtune™ Amplifier version 2017.
Для получения дополнительной информации изучите Debug and fine-grain profiling with Intel processor trace given by Beeman Strong, Senior и Processor tracing by James Reinders.
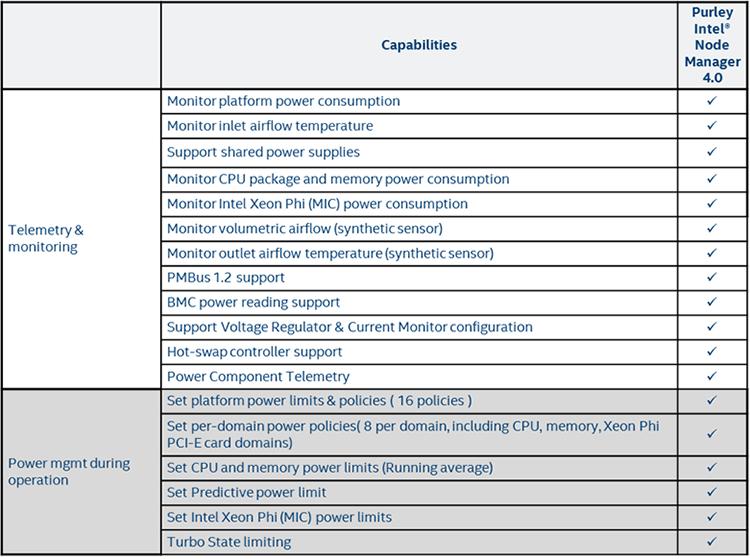
Intel® Node Manage ((Intel® NM) является центральным набором свойств управления энергопотреблением, которое предоставляет некий интеллектуальный способ оптимизации и управления питанием, охлаждением и вычислительными ресурсами в определённом центре обработки данных. Данная технология управления сервером расширяет инструментарий компонентов для имеющегося уровня платформы и может применяться чтобы использовать каждый потребляемый Ватт в этом ЦОД. Вначале Intel NM сообщает жизненно важную информацию, такую как мощность, температура, а также использование ресурсов стандартным образом, путём взаимодействия вне полосы. Во- вторых он предоставляет тонко гранулированное управление, такое как содействие в уменьшении общего энергопотребления или максимизации нагрузки на стойку для ограничения мощности платформы в соответствии с политикой ИТ. Данная функциональность может быть найдена по всем разделам продуктов Intel, включая семейство Scalable процессоров Intel Xeon, предоставляя единообразие в рамках данного ЦОД.
Семейство Scalable процессоров Intel Xeon на платформе Purley содержит четвёртое поколение Intel NM, которое расширяет управление и сообщения на некий более тонкий уровень гранулированности в сравнении с предыдущим поколением. Чтобы применить эту функциональность вы должны включить BMC LAN и связанные настройки пользователя BMC на уровне имеющегося BIOS, который может быть доступен в меню управления данным сервером. The Programmer’s Reference Kit является неким примером для применения и не требует никаких внешних библиотек для компиляции или исполнения. Всё что требуется, это некий компилятор C/C++ с последующими исполнением настройки и сценария компиляции.
Intel® 64 and IA-32 Architectures Software Developer’s Manual (SDM)
Intel® Architecture Instruction Set Extensions Programming Reference
Intel® Resource Director Technology (Intel® RDT)
Optimize Resource Utilization with Intel® Resource Director Technology
Intel® Memory Protection Extensions Enabling Guide
Intel® Scalable System Framework
Intel® Hardware-based Security Technologies for Intelligent Retail Devices
Processor tracing by James Reinders
Debug and fine-grain profiling with Intel processor trace given by Beeman Strong, Senior
Intel® Node Manager Programmer’s Reference Kit
Open Source Reference Kit for Intel® Node Manager
How to set up Intel® Node Manager
Intel® Performance Counter Monitor (Intel® PCM) a better way to measure CPU utilization
The Intel® Xeon® processor-based server refresh savings estimator
Для получения более полной информации по оптимизации компилятора обратитесь к Optimization Notice.
Рекомендуемые розничные цены (РРЦ) на них вы можете найти по ссылке xls.