Глава 8. Регулировка ядра KVM для повышения производительности
Содержание
В данной главе мы собираемся рассмотреть следующие рецепты регулировки производительности:
-
Настройку самого ядра для низкой латентности операций ввода/ вывода
-
Регулировку оперативной памяти для гостевых KVM
-
Опции производительности ЦПУ
-
Регулировка NUMA при помощи libvirt
-
Регулировка самого ядра в отношении сетевой производительности
В данной главе мы собираемся изучить различные варианты настройки и инструменты, которые могут помочь улучшить имеющуюся производительность ОС определённого хоста и всех работающих на нём экземпляров KVM.
При исполнении виртуальных машин KVM важно понимать, что с точки зрения самого хоста все они являются обычными процессами. Мы можем увидеть, что гости KVM являются процессами Linux опросив его дерево процессов в имеющемся гипервизоре:
root@kvm:~# virsh list
Id Name State
----------------------------------------------------
16 kvm running
root@kvm:~# pgrep -lfa qemu
19913 /usr/bin/qemu-system-x86_64 -name kvm -S -machine pc-i440fx-trusty,accel=kvm,usb=off -m 1024 -realtime mlock=off -smp 1,sockets=1,cores=1,threads=1 -uuid 283c6653-9981-9396-efb4-fb864d87f769 -no-user-config -nodefaults -chardev socket,id=charmonitor,path=/var/lib/libvirt/qemu/domain-kvm/monitor.sock,server,nowait -mon chardev=charmonitor,id=monitor,mode=control -rtc base=utc -no-shutdown -boot strict=on -device piix3-usb-uhci,id=usb,bus=pci.0,addr=0x1.0x2 -drive file=/tmp/debian.img,format=raw,if=none,id=drive-ide0-0-0 -device ide-hd,bus=ide.0,unit=0,drive=drive-ide0-0-0,id=ide0-0-0,bootindex=1 -netdev tap,fd=26,id=hostnet0 -device rtl8139,netdev=hostnet0,id=net0,mac=52:54:00:2f:df:93,bus=pci.0,addr=0x3 -chardev pty,id=charserial0 -device isa-serial,chardev=charserial0,id=serial0 -vnc 0.0.0.0:0 -device cirrus-vga,id=video0,bus=pci.0,addr=0x2 -device virtio-balloon-pci,id=balloon0,bus=pci.0,addr=0x4 -msg timestamp=on
root@kvm:~#
Все виртуальные ЦПУ, выделенные всем гостям KVM, являются потоками (threads), управляемые планировщиком самого хоста:
root@kvm:~# ps -eLf
UID PID PPID LWP C NLWP STIME TTY TIME CMD
...
libvirt+ 19913 1 19913 0 3 14:02 ? 00:00:00 /usr/bin/qemu-system-x86_64 -name kvm -S -machine pc-i440fx-trusty,accel=kvm,usb=off -m 1024 -realtime mlock=off -smp 1,sockets=1,cores=1,threads=1 -uuid 283c6653-9981-9396-efb4-fb864d87f769 -no-user-config -nodefaul
libvirt+ 19913 1 19914 0 3 14:02 ? 00:00:08 /usr/bin/qemu-system-x86_64 -name kvm -S -machine pc-i440fx-trusty,accel=kvm,usb=off -m 1024 -realtime mlock=off -smp 1,sockets=1,cores=1,threads=1 -uuid 283c6653-9981-9396-efb4-fb864d87f769 -no-user-config -nodefaul
libvirt+ 19913 1 19917 0 3 14:02 ? 00:00:00 /usr/bin/qemu-system-x86_64 -name kvm -S -machine pc-i440fx-trusty,accel=kvm,usb=off -m 1024 -realtime mlock=off -smp 1,sockets=1,cores=1,threads=1 -uuid 283c6653-9981-9396-efb4-fb864d87f769 -no-user-config -nodefaul
...
root@kvm:~#
В зависимости от самого типа планировщика операций ввода/ вывода, сетевого драйвера имеющейся
libvirt, а также настроек оперативной памяти общая производительность
всех виртуальных машин может очень значительно варьироваться. Прежде чем вносить какие- либо изменения во все
упомянутые ранее компоненты, важно понимать тот тип деятельности ОС конкретного гостя, который будет выполняться
на нём. Регулировки самого хоста и ОС гостя для нагрузок с интенсивным использованием памяти будут отличаться
от нагрузок, связанных с вводом/ выводом или ЦПУ.
Поскольку все экземпляры KVM всего лишь обычные процессы Linux, можно применять драйвер QEMU к любым их
следующих контроллеров cgroup
(Control Group, Групп управления):
cpuset, cpu,
memory и blkio, а также к
еонтроллерам устройств. Использование контроллеров cgroup предоставляет более гранулированное управление
над доступными ЦПУ, оперативной памятью, а также ресурсами ввода, что мы и собираемся более подробно
рассмотреть в последующих рецептах.
Возможно наиболее важный момент при регулировки и оптимизации любой системы состоит в определении имеющегося базового уровня производительности, прежде чем приступать к каким- либо корректировкам. Начните с измерения такого базового уровня производительности некоторой подсистемы, например оперативной памаяти или операций ввода/ вывода, выполните небольшие корректировки приращения, затем снова измерьте полученное воздействие выполненных изменений. Повторяйте по мере необходимости, пока не достигните желаемого эффекта.
Все рецепты в данной главе предназначены для предсоставления читатель некоторой отправной точки для того что можно регулировать в имеющемся хосте и его виртуальных машинах для улучшения производительности либо учитывать побочные эффекты запуска различных рабочих нагрузок на одном и том же хосте/ выиртуальной машине и получать выгоду от увеличения числа арендаторов. Все ресурсы следует корректировать на основе имеющегося типа рабочей нагрузки, установок аппаратных средств и прочих переменных.
В данном рецепте мы собираемся рассмотреть некоторые методики оптимизации производительности имеющихся дисков посредством выбора некоторого расписания операций ввода/ вывода и регулирования блочного ввода/ вывода с применением Групп управления (cgroup) Linux для всех виртуальных гостей и самого хоста.
Существуют три планировщика ввода/ вывода для выбора его в ОС самого хоста или в определённом экземпляре KVM:
-
noop: Это один из самых простых планировщиков ядра; она работает посредством помещения всех поступающих операций ввода/ вывода в простую очередь FIFO (First In, First Out, Первый пришёл, первый исполнен). Данный планировщик полезен когда ОС данного хоста не пытается переупорядочивать запросы операций ввода/ вывода при работе множества виртуальных машин. -
deadline: Данный планировщик накладывает ограничение времени жизни на все операции ввода/ вывода для предотвращения блокировок запросов на неопределённое время, выставляя приоритеты на запросы чтения, поскольку блокируемыми обычно являются процессы операций чтения. -
cfq:Основной целью CFQ (Completely Fair Queuing, Полностью справедливой очереди) является максимальное общее использование ЦПУ при разрешении наилучшей производительности взаимодействия.
Выбор правильного планировщика операций ввода/ вывода на данном хосте и гостях сильно зависит от имеющихся рабочих нагрузок и лежащего в основе оборудования хранения данных.
В качестве основного правила, выбирайте планировщик noop для всех
гостевых ОС, что позволит гипервизору их хоста лучше оптимизировать все запросы операций ввода/ вывода, так
как он осведомлён обо всех запросах, поступающих от своих виртуальных гостей. Однако, если используемое
машинами KVM хранилище это тома iSCSI или любое другое удалённое хранилище, такое как GlusterFS, применение
планировщика deadline может дать лучшие результаты.
В самых современных ядрах Linux планировщиком по умолчанию является
deadline и этого может быть достаточно для хостов, на которых исполняется
множество виртуальных машин KVM. Как и с любой другой регулируемой системой, при изменении своих планировщиков на
основном хосте и в гостевых ОС необходимы выполнять тестирование.
Для данного рецепта нам понадобится следующее:
-
Некий хост Ubuntu с установленными и настроенными на нём libvirt и QEMU
-
Какая- то работающая виртуальная машина KVM
Чтобы изменить свой планировщик операций ввода/ вывода на самом хосте и в определённом экземпляре KVM, а также установить веса операций ввода/ вывода выполните следующие шаги:
-
В ОС самого хоста укажите используемый в настоящее время планировщик операций ввода-вывода, подставив то блочное устройство, которое соответствует вашей системе:
root@kvm:~# cat /sys/block/sda/queue/scheduler noop deadline [cfq] root@kvm:~# -
Измените текущий планировщик ввода вывода на требуемый и убедитесь что он применяется и работает:
root@kvm:~# echo deadline > /sys/block/sda/queue/scheduler root@kvm:~# cat /sys/block/sda/queue/scheduler noop [deadline] cfq root@kvm:~# -
Чтобы сделать эти изменения постоянными между перезагрузками сервера добавьте следующие строки в свои настройки GRUB по умолчанию и обновите их:
root@kvm:~# echo 'GRUB_CMDLINE_LINUX="elevator=deadline"' >> /etc/default/grub root@kvm:~# tail -1 /etc/default/grub GRUB_CMDLINE_LINUX="elevator=deadline" root@kvm:~# update-grub2 Generating grub configuration file ... Found linux image: /boot/vmlinuz-3.13.0-107-generic Found initrd image: /boot/initrd.img-3.13.0-107-generic done root@kvm:~# cat /boot/grub/grub.cfg | grep elevator linux /boot/vmlinuz-3.13.0-107-generic root=/dev/md126p1 ro elevator=deadline rd.fstab=no acpi=noirq noapic cgroup_enable=memory swapaccount=1 quiet linux /boot/vmlinuz-3.13.0-107-generic root=/dev/md126p1 ro elevator=deadline rd.fstab=no acpi=noirq noapic cgroup_enable=memory swapaccount=1 quiet linux /boot/vmlinuz-3.13.0-107-generic root=/dev/md126p1 ro recovery nomodeset elevator=deadline root@kvm:~# -
Для выбранного экземпляра KVM установите на постоянной основе планировщик операций ввода/ вывода
noop:root@kvm:~# virsh console kvm1 Connected to domain kvm1 Escape character is ^] root@kvm1:~# echo 'GRUB_CMDLINE_LINUX="elevator=noop"' >>>> /etc/default/grub root@kvm1:~# tail -1 /etc/default/grub GRUB_CMDLINE_LINUX="elevator=noop" root@kvm1:~# update-grub2 Generating grub configuration file ... Found linux image: /boot/vmlinuz-3.13.0-107-generic Found initrd image: /boot/initrd.img-3.13.0-107-generic done root@kvm1:~# cat /boot/grub/grub.cfg | grep elevator linux /boot/vmlinuz-3.13.0-107-generic root=/dev/md126p1 ro elevator=noop rd.fstab=no acpi=noirq noapic cgroup_enable=memory swapaccount=1 quiet linux /boot/vmlinuz-3.13.0-107-generic root=/dev/md126p1 ro elevator=noop rd.fstab=no acpi=noirq noapic cgroup_enable=memory swapaccount=1 quiet linux /boot/vmlinuz-3.13.0-107-generic root=/dev/md126p1 ro recovery nomodeset elevator=noop root@kvm1:~# -
Установите некий вес
100для данного экземпляра KVM, воспользовавшись контроллером cgroupblkio:root@kvm:~# virsh blkiotune --weight 100 kvm root@kvm:~# virsh blkiotune kvm weight : 100 device_weight : device_read_iops_sec: device_write_iops_sec: device_read_bytes_sec: device_write_bytes_sec: root@kvm:~# -
Найдите необходимую иерархию каталога
cgroupв данном хосте:root@kvm:~# mount | grep cgroup none on /sys/fs/cgroup type tmpfs (rw) systemd on /sys/fs/cgroup/systemd type cgroup (rw,noexec,nosuid,nodev,none,name=systemd) root@kvm:~# -
Убедитесь что данная cgroup для текущего экземпляра KVM содержит тот вес, который мы установили ранее на своём контроллере
blkio:root@kvm:~# cat /sys/fs/cgroup/blkio/machine/kvm.libvirt-qemu/blkio.weight 100 root@kvm:~#
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Для более подробного объяснения того, как работают cgroups Linux обратитесь к книге Packt publishing Containerization with LXC {Прим. пер.: или её переводу у нас Контейнеризация при помощи LXC}. |
Мы можем увидеть какой планировщик операций ввода/ вывода нашего ядра в настоящее время применяется, опросив
имеющийся файл scheduler в данной виртуальной файловой системе
/sys. На шаге 1 мы обнаружили, что это планировщик
cfq. Затем, на шаге 2, мы осуществили замену данного планировщика
ввода/ вывода в работающей системе. Имейте в виду, пожалуйста, что изменение данного планировщика по запросу
как в этом случае, не сохранится после перезагрузки сервера. На шагах 3 и 4 мы изменили свои настройки GRUB
путём добавления о новом планировщике для операций загрузчика самого ядра. Перезапуск данного сервера или
конкретной виртуальной машины теперь выберет этот новый планировщик ввода/ вывода.
При работе множества виртуальных машин в одном и том же хосте может оказаться полезным предоставление большего
приоритета некоторым из них на основе определённого критерия, такого как время дня и загруженность ВМ. На шаге
5 мы воспользовались контроллером cgroup blkio для установки веса данной
гостевой KVM. Меньший вес даст лучший приоритет операций ввода/ вывода. На шагах 6 и 7 мы можем обнаружить,
что была создана правильная иерархия cgroup, а файл
blkio.weight содержит новое значение веса, которое мы установили с
помощью команды virsh.
Когда дело доходит до регулировок оперативной памяти гостевых KVM имеются доступными несколько вариантов в зависимости от имеющихся на данной виртуальной машине рабочей нагрузки. Одной из таких опций является HugePage.
Большинство хостов Linux по умолчанию для адресации памяти применяют сегменты по 4кБ, имеющие название страниц (pages). Однако, имеющееся ядро в состоянии применять страницы большего размера. использование HugePage (страниц более 4кБ) может улучшить производительность за счёт роста попаданий в имеющийся кэш ЦПУ в сравнении с TLB (Transaction Lookaside Buffer, буфером быстрого преобразования адреса). Такой TLB является кэшированием памяти, в котором сохраняются последние трансляции виртуальной памяти в физические адреса для быстрой выборки.
В данном рецепте мы собираемся разрешить и установить HugePage в своём гипервизоре определённой гостевой
KVM, а затем проверим все отрегулированные опции, которые предоставит команда
virsh.
Для данного рецепта нам понадобится следующее:
-
Некий хост Ubuntu с установленными и настроенными на нём libvirt и QEMU
-
Какая- то работающая виртуальная машина KVM
Чтобы разрешить и установить в своём гипервизоре и определённой гостевой KVM HugePages, а также
применить команду virsh для установки различных опций памяти выполните
приводимую ниже последовательность:
-
Проверьте текущие установки HugePage в ОС данного хоста:
root@kvm:~# cat /proc/meminfo | grep -i huge AnonHugePages: 509952 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB root@kvm:~# -
Подключитесь к гостевой KVM и проверьте её текущие установки HugePage:
root@kvm1:~# cat /proc/meminfo | grep -i huge HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB root@kvm1:~# -
Увеличьте соответствующий размер имеющегося пула HugePage с
0на25000в данном гипервизоре и проверьте следующим образом:root@kvm:~# sysctl vm.nr_hugepages=25000 vm.nr_hugepages = 25000 root@kvm:~# cat /proc/meminfo | grep -i huge AnonHugePages: 446464 kB HugePages_Total: 25000 HugePages_Free: 24484 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB root@kvm:~# cat /proc/sys/vm/nr_hugepages 25000 root@kvm:~# -
Проверьте поддерживает ли ЦПУ данного гипервизора размеры HugePage 2МБ и 1ГБ {Прим. пер.: см. Флаги /proc/cpuinfo}:
root@kvm:~# cat /proc/cpuinfo | egrep -i "pse|pdpe1" | tail -1 flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm arat epb xsaveopt pln pts dtherm tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid root@kvm:~# -
Установите размер HugePage 1ГБ изменив настройку GRUB по умолчанию и перезагрузившись:
root@kvm:~# cat /etc/default/grub ... GRUB_CMDLINE_LINUX_DEFAULT="rd.fstab=no acpi=noirq noapic cgroup_enable=memory swapaccount=1 quiet hugepagesz=1GB hugepages=1" ... root@kvm:~# update-grub Generating grub configuration file ... Found linux image: /boot/vmlinuz-3.13.0-107-generic Found initrd image: /boot/initrd.img-3.13.0-107-generic done root@kvm:~# cat /boot/grub/grub.cfg | grep -i huge linux /boot/vmlinuz-3.13.0-107-generic root=/dev/md126p1 ro elevator=deadline rd.fstab=no acpi=noirq noapic cgroup_enable=memory swapaccount=1 quiet hugepagesz=1GB hugepages=1 linux /boot/vmlinuz-3.13.0-107-generic root=/dev/md126p1 ro elevator=deadline rd.fstab=no acpi=noirq noapic cgroup_enable=memory swapaccount=1 quiet hugepagesz=1GB hugepages=1 root@kvm:~# reboot -
Установите необходимый пакет HugePages:
root@kvm:~# apt-get install hugepages -
Проверьте текущий размер HugePage:
root@kvm:~# hugeadm --pool-list Size Minimum Current Maximum Default 2097152 25000 25000 25000 * root@kvm:~# -
Разрешите поддержку HugePage для KVM:
root@kvm:~# sed -i 's/KVM_HUGEPAGES=0/KVM_HUGEPAGES=1/g' /etc/default/qemu-kvm root@kvm:~# root@kvm:~# /etc/init.d/libvirt-bin restart libvirt-bin stop/waiting libvirt-bin start/running, process 16257 root@kvm:~# -
Смонтируйте виртуальную файловую систему HugeTable в ОС данного хоста:
root@kvm:~# mkdir /hugepages root@kvm:~# echo "hugetlbfs /hugepages hugetlbfs mode=1770,gid=2021 0 0" >> /etc/fstab root@kvm:~# mount -a root@kvm:~# mount | grep hugepages hugetlbfs on /hugepages type hugetlbfs (rw,mode=1770,gid=2021) root@kvm:~# -
Измените имеющиеся настройки для данной гостевой KVM и разрешите HugePages:
root@kvm:~# virsh destroy kvm1 Domain kvm1 destroyed root@kvm:~# virsh edit kvm1 ... <memoryBacking> <hugepages/> </memoryBacking> ... Domain kvm1 XML configuration edited. root@kvm:~# virsh start kvm1 Domain kvm1 started root@kvm:~#![[Совет]](/common/images/admon/tip.png)
Совет Если при запуске данного экземпляра KVM вы обнаруживаете такую ошибку:
error: internal error: hugetlbfs filesystem is not mounted or disabled by administrator config(файловая система hugetlbfs не смонтировалась или запрещена в настройках администратора), проверьте что данная виртуальная файловая система успешно смонтировалась на шаге 9.Совет Если при запуске данного экземпляра KVM вы обнаруживаете такую ошибку:
error: internal error: process exited while connecting to monitor: file_ram_alloc: can't mmap RAM pages: Cannot allocate memory(выход процесса при подключении к монитору ... нет возможности выделения памяти), на шаге 3 вам необходимо увеличить рахмер пула HugePages. -
Обновите жёсткий предел памяти для данного экземпляра KVM и выполните проверку следующим образом:
root@kvm:~# virsh memtune kvm1 hard_limit : unlimited soft_limit : unlimited swap_hard_limit: unlimited root@kvm:~# virsh memtune kvm1 --hard-limit 2GB root@kvm:~# virsh memtune kvm1 hard_limit : 1953125 soft_limit : unlimited swap_hard_limit: unlimited root@kvm:~#
Libvirt и KVM выполняют поддержку и получают преимущество от HugePages. Но вам стоит быть осведомлённым о том, что не все рабочие нагрузки выиграют при наличии страниц с размером, большим чем установлен по умолчанию. Те экземпляры, которые исполняют базы данных и связанные с памятью экземпляры KVM являются хорошими вариантами применения. Как и всегда, прежде чем разрешить данное свойство, замерьте производительность вашего приложения внутри данной виртуальной машины чтобы гарантировать что он выиграет от HugePages.
В данном рецепте мы разрешаем HugePages в своём хосте и определённой гостевой ОС и устанавливаем некий жёсткий предел на используемую этим гостем память. Давайте пройдём по эти шагам более внимательно.
На шагах 1 и 2 мы проверяем текущее состояние HugePages. Из вывода мы можем увидеть, что в настоящее время нет
выделенного пула для размещения HugePages, о чём сообщает поле HugePages_Total
На шаге 3 мы увеличиваем размер пула HugePages до 25000. Это изменение осуществляется по запросу и не
сохраняется при перезагрузке сервера. Чтобы сделать его неизменным, вы можете добавить его в свой файл
/etc/sysctl.conf.
Чтобы применять данное свойство HugePage, нам необходимо удостовериться, что данный ЦПУ нашего сервера хоста
имеет аппаратную поддержку для них, что отображается флагами pse и
pdpe1, как это показывается на шаге 4.
На шаге 5 мы настраиваем начальный загрузчик GRUB на запуск своего ядра с поддержкой HugePages и устанавливаем для них размер 1ГБ.
Хотя мы можем работать напрямую с файлами, выставляемыми нашей виртуальной файловой системой
/proc, на шаге 6 мы устанавливаем пакет HugePages, который
предоставляет несколько полезных инструментов пространства пользователя для просмотра и управления различными
установками памяти. Мы применяем команду hugeadm на шаге 7 для
просмотра размера своего пула HugePages.
Чтобы включить поддержку HugePages для KVM, мы обновляем файл /etc/default/qemu-kvm
на шаге 8, монтируем необходимую файловую систему для них на шаге 9 и, наконец, перенастраиваем данную виртуальную
машину KVM на применение HugePages добавив строфу <hugepages/>
для своего объекта <memoryBacking>.
Libvirt предоставляет удобный способ управления объёмом выделяемой памяти для гостевых KVM. На шаге 11 мы
устанавливаем жёсткий предел в 2ГБ для своей виртуальной машины
kvm1.
Существует несколько методов для управления ЦПУ и всеми доступными частотами ЦПУ для машин KVM с применением cgroups, а также для libvirt с предоставлением прикрепления ЦПУ и функций родства (affinity), которые мы собираемся исследовать в данном рецепте. Родство (affinity) ЦПУ является свойством планировщика, которое подключает некий процесс к заданному множеству ЦПУ на данном хосте.
При предоставлении виртуальных машин с помощью libvirt, поведение по умолчанию состоит в предоставлении гостей
на все доступные ядра ЦПУ. В некоторых случаях NUMA
(Non-Uniform Memory Access , архитектура
Неоднородного доступа к памяти) является хорошим примером того, что когда нам необходимо назначить некоторое
Неоднородного доступа к памяти) является хорошим примером того, что когда нам необходимо назначить некоторое
ядро для экземпляра KVM (как мы это собираемся увидеть в следующем рецепте), тогда будет лучше назначать эту
виртуальную машину некоторому определённому ядру ЦПУ. Так как каждая виртуальная машина KVM является неким
процессом ядра, (конкретно для наших примеров qemu-system-x86_64),
мы можем сделать это при помощи таких инструментов как команда taskset
или virsh. Также мы можем воспользоваться подсистемеой ЦПУ cgroups для
управления выделением частот ЦПУ, которые производят более гранулированное управление для ресурсов использования
на каждую виртуальную машину.
Для данного рецепта нам понадобится следующее:
-
Некий хост Ubuntu с установленными и настроенными на нём libvirt и QEMU
-
Какая- то работающая виртуальная машина KVM
Чтобы прикрепить некую виртуальную машину KVM к определённому ЦПУ и изменить все доли ЦПУ (shares) сделайте следующее:
-
Получите информацию обо всех доступных ядрах ЦПУ в данном гипервизоре:
root@kvm:~# virsh nodeinfo CPU model: x86_64 CPU(s): 40 CPU frequency: 2593 MHz CPU socket(s): 1 Core(s) per socket: 10 Thread(s) per core: 2 NUMA cell(s): 2 Memory size: 131918328 KiB root@kvm:~# -
Извлеките информацию о выделении ЦПУ для данной гостевой KVM:
root@kvm:~# virsh vcpuinfo kvm1 VCPU: 0 CPU: 2 State: running CPU time: 9.1s CPU Affinity: yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy root@kvm:~# -
Прикрепите ЦПУ экземпляра KVM (
VCPU: 0) к соответствующему первому ЦПУ гипервизора (CPU: 0) и отобразите результат:root@kvm:~# virsh vcpupin kvm1 0 0 --live root@kvm:~# virsh vcpuinfo kvm1 VCPU: 0 CPU: 0 State: running CPU time: 9.3s CPU Affinity: y--------------------------------------- root@kvm:~# -
Выдайте список всех долей времени исполнения, которые назначены некоторому экземпляру KVM:
root@kvm:~# virsh schedinfo kvm1 Scheduler : posix cpu_shares : 1024 vcpu_period : 100000 vcpu_quota : -1 emulator_period: 100000 emulator_quota : -1 root@kvm:~# -
Измените вес текущего ЦПУ исполняющейся виртуальной машины:
root@kvm:~# virsh schedinfo kvm cpu_shares=512 Scheduler : posix cpu_shares : 512 vcpu_period : 100000 vcpu_quota : -1 emulator_period: 100000 emulator_quota : -1 root@kvm:~# -
Проверьте эти доли ЦПУ в соответствующей подсистеме cgroups ЦПУ:
root@kvm:~# cat /sys/fs/cgroup/cpu/machine/kvm1.libvirt-qemu/cpu.shares 512 root@kvm:~# -
Проверьте и обновите определение XML экземпляра:
root@kvm:~# virsh dumpxml kvm1 ... <vcpu placement='static'>1</vcpu> <cputune> <shares>512</shares> <vcpupin vcpu='0' cpuset='0'/> </cputune> ... root@kvm:~#
Мы начали с получения информации об имеющихся ресурсах ЦПУ, доступных в данном гипервизоре. Из вывода на шаге 1 мы можем видеть, что ОС данного хоста имеет 40 ЦПУ в одном сокете.
На шаге 2 мы собираем информацию о всех ЦПУ виртуальных машин и их сходству с ЦПУ данного хоста. В данном
примере наша гостевая KVM имеет один виртуальный ЦПУ, обозначаемый как запись VCPU: 0
и родство со всеми 40 процессорами гипервизора, что отображено полем
CPU Affinity: yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy.
На шаг 3 м прикрепляем/ привязываем данный виртуальный ЦПУ к определённому первому физическому процессору в
своём гипревизоре. Отметим изменение вывода соответствующего родства:
CPU Affinity: y---------------------------------------..
Из вывода команды virsh на 4 шаге мы можем ознакомиться с тем, что
все выделенные данному экземпляру KVM доли ЦПУ установлены в значение 1024. Это назначение является
соотношением, которое означает что если другой гость имеет 512 долей, он будет иметь вдвое меньше времени
исполнения ЦПУ чем экземпляр с 1024 долями. Мы уменьшаем это значение на шаге 5.
На шагах 6 и 7 мы подтверждаем что все доли ЦПУ были верно установлены в соответствующих подсистемах
cgroups в их ОС хоста. Как уже упоминалось ранее, доли ЦПУ настроены при помощи cgroups и могут регулироваться
напрямую или предоставляемой libvirt функциональностью через её команду
virsh.
NUMA является некоторой технологией, которая позволяет имеющейся системной памяти подразделяться на зоны, также именуемые узлами. Эти узлы NUMA затем выделяются определённым ЦПУ или сокетам. В противовес обычному монолитному подходу к оперативной памяти, при котором всякий ЦПУ/ всякое ядро могут осуществлять доступ ко всей оперативной памяти вне зависимости от её расположения, что обычно выражается в больших задержках, ограниченные NUMA процессы могут осуществлять доступ к памяти которая является локальной для конкретно того ЦПУ, на котором она будет исполняться. В большинстве случаев это намного быстрее чем для памяти, подключаемой к удалённому ЦПУ в данной системе.
Libvirt применяет библиотеку libnuma чтобы включить функциональность
NUMA для виртуальных машин, что мы можем увидеть так:
root@kvm:~# ldd /usr/sbin/libvirtd | grep numa
libnuma.so.1 => /usr/lib/x86_64-linux-gnu/libnuma.so.1 (0x00007fd12d49e000)
root@kvm:~#
Libvirt NUMA поддерживает следующие политики выделения памяти для размещения виртуальных машин в узлах NUMA:
-
strict: Размещение будет оклонено если данная память не может быть выделена на данном целевом узле
-
interleave: Страницы памяти выделяются карусельным (round- robin) образом
-
preferred: Данная политика позволяет гипервизору предоставлять память из других узлов в случае, когда для определённого узла недостаточно доступной памяти
В данном рецепте мы собираемся разрешить доступ NUMA для некоторого экземпляра KVM и изучить его воздействие на общую производительность системы.
Для данного рецепта нам понадобится следующее:
-
Некий хост Ubuntu с установленными и настроенными на нём libvirt и QEMU
-
Какая- то работающая виртуальная машина KVM
-
Утилита
numastat
Чтобы разрешить некоторой виртуальной машине KVM исполняться в некотором заданном узле NUMA, а ЦПУ применять строгую политику NUMA выполните следующие шаги:
-
Установите пакет
numactlпроверьте свою настройку оборудования данного гипервизора:root@kvm:~# apt-get install numactl ... root@kvm:~# numactl --hardware available: 2 nodes (0-1) node 0 cpus: 0 1 2 3 4 5 6 7 8 9 20 21 22 23 24 25 26 27 28 29 node 0 size: 64317 MB node 0 free: 3173 MB node 1 cpus: 10 11 12 13 14 15 16 17 18 19 30 31 32 33 34 35 36 37 38 39 node 1 size: 64509 MB node 1 free: 31401 MB node distances: node 0 1 0: 10 21 1: 21 10 root@kvm:~# -
Отобразите текущее размещение NUMA для определённой гостевой KVM:
root@kvm:~# numastat -c kvm1 Per-node process memory usage (in MBs) for PID 22395 (qemu-system-x86) Node 0 Node 1 Total ------ ------ ----- Huge 0 0 0 Heap 1 1 2 Stack 2 2 4 Private 39 21 59 ------- ------ ------ ----- Total 42 23 65 root@kvm:~# -
Измените определение XML данного экземпляра, установите его режим памяти в
strictи выберите конкретно второй узел NUMA (индексация начинается с 0, поэтому наш второй узел NUMA помечен как 1), затем перезапустите своего гостя:root@kvm:~# virsh edit kvm1 ... <vcpu placement='static' cpuset='10-11'>2</vcpu> <numatune> <memory mode='strict' nodeset='1'/> </numatune> ... Domain kvm1 XML configuration edited. root@kvm:~# virsh destroy kvm1 Domain kvm1 destroyed root@kvm:~# virsh start kvm1 Domain kvm1 started root@kvm:~# -
Получите все параметры NUMA для данного экземпляра KVM:
root@kvm:~# virsh numatune kvm1 numa_mode : strict numa_nodeset : 1 root@kvm:~# -
Выведите все текущее родство виртуальных ЦПУ:
root@kvm:~# virsh vcpuinfo kvm1 VCPU: 0 CPU: 11 State: running CPU time: 8.4s CPU Affinity: ----------yy---------------------------- VCPU: 1 CPU: 10 State: running CPU time: 0.3s CPU Affinity: ----------yy---------------------------- root@kvm:~# -
Выведите размещение данного узла NUMA для нашего экземпляра KVM:
root@kvm:~# numastat -c kvm1 Per-node process memory usage (in MBs) for PID 22395 (qemu-system-x86) Node 0 Node 1 Total ------ ------ ----- Huge 0 0 0 Heap 0 3 3 Stack 0 2 2 Private 0 174 174 ------- ------ ------ ----- Total 0 179 179 root@kvm:~#
Мы начинаем с опроса установок NUMA в ОС своего хоста. Из вывода команды numactl
на 1 шагу мы можем обнаружить, что наш гипервизор имеет два узла NUMA: узел 0 и узел 1. Каждый узел
управляет неким списком ЦПУ. В данном случае узел 1 NUMA содержит ЦПУ с 10 по 19 и с 30 по 30, а также содержит
64ГБ памяти. Это означает, что 64ГБ оперативной памяти предназначено для локалбного использования этими ЦПУ
и доступ к этой памяти с этих ЦПУ предполагается намного более быстрым чем с ЦПУ, которые являются частью узла 0.
Чтобы улучшить показатели задержек памяти для некоторой гостевой KVM, нам необходимо прикреплять те виртуальные
ЦПУ, которые назначены данной виртуальной машине на ЦПУ, которые являются частью одного и того же узла NUMA.
На шаге 2 мы можем увидеть что все экземпляры KVM применяют память из обоих узлов NUMA, что далеко от идеальности.
На шаге 3 мы изменяем определение XML данного гостя и прикрепляем этогогостя к 10му и 11му ЦПУ, которые являются
частью единого узла 1 NUMA, применяя параметр cpuset='10-11'.
Мы также определяем режим strict узла NUMA и свой второй узел NUMA в общем параметре
<memory mode='strict' nodeset='1'/>.
После перезапуска этого экземпляра, на шаге 4, мы убеждаемся что данная гостевая KVM теперь работает с применением в узле 1 режима NUMA strict. Мы также убеждаемся, что прикрепление этого ЦПУ именно такое, как мы на самом деле указали на шаге 5. Отметим, что имеющееся родство ЦПУ отмечено 10м и 11м элементами из всех элементов родства ЦПУ.
Из вывода на шаге 6 мы можем увидеть, что данная гостевая KVM теперь использует память только из узла 1 NUMA, чего мы и добивались.
Если вы исполняете приложения с интенсивно используемой памятью до и после данных регулировок NUMA и выполните тестирование, вы скорее всего обнаружите серьёзный прирост производительности когда осуществите доступ к большим объёмам памяти внутри данной гостевой KVM благодаря локальности самого ЦПУ и оперативной памяти, предоставляемых NUMA.
В данном рецепте мы увидели примеры того как вручную назначать некий процесс KVM какому- то узлу NUMA путём
изменения соответствующего XML определения данного гостя. Некоторые дистрибутивы Linux, такие как RHEL/CentOS 7
и Ubuntu 16.04 предоставляют службу numad (демон NUMA), целью которой является
автоматическая балансировка процессов между узлами NUMA путём мониторинга текущей топологии памяти:
-
Чтобы установить эту службу в Ubuntu 16.04 выполните:
root@kvm:~# lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 16.04.2 LTS Release: 16.04 Codename: xenial root@kvm2:~# apt install numad ... root@kvm:~# -
Для запуска этой службы исполните такоой код:
root@kvm:~# service numad start root@kvm2:~# pgrep -lfa numad 12601 /usr/bin/numad -i 15 root@kvm:~# -
Для управления определённой гостевой KVM при помощи
numadпередайте идентификатор процесса данного экземпляра KVM:root@kvm:~# numad -S 0 -p $(pidof qemu-system-x86_64) root@kvm:~# -
Данная служба зарегистрирует все попытки ребалансировки NUMA:
root@kvm:~# tail /var/log/numad.log Thu May 25 21:06:42 2017: Changing THP scan time in /sys/kernel/mm/transparent_hugepage/khugepaged/scan_sleep_millisecs from 10000 to 1000 ms. Thu May 25 21:06:42 2017: Registering numad version 20150602 PID 12601 Thu May 25 21:09:25 2017: Adding PID 4601 to inclusion PID list Thu May 25 21:09:25 2017: Scanning only explicit PID list processes root@kvm:~#Данная служба
numadможет оказаться полезной в узлах OpenStack {Прим. пер.: а также Proxmox и т.п.}, в которых ручная балансировка NUMA может оказаться слишком запутанной.
Большинство современных ядер Linux снабжены достаточными регулировками для различных сетевых рабочих
нагрузок. Некоторый дистрибутивы предоставляют предварительно определённые службы регулировок (хорошим примером
является tuned для Red Hat/CentOS), которые включают некий набор профилей на
основе роли данного сервера.
Давайте пошагово пройдём весь процесс, происходящий при передаче и приёме данных в обычном хосте Linux, прежде чем мы зароемся в то как регулировать сам гипервизор:
-
Определённое приложение вначале записывает свои данные в некий сокет, который по очереди помещается в имеющиеся буферы передачи.
-
Само ядро инкапсулирует эти данные в некий PDU (Protocol Data Unit , Протокольный блок данных).
-
Этот PDU затем перемещается в соответсвующую очередь передачи для каждого устройства.
-
Имеющийся драйвер NIC (Network Interface Cards, Плат сетевого интерфейса) затем извлекает этот PDU из очереди передачи и копирует его в NIC.
-
NIC отправляет эти данные и возбуждает аппаратное прерывание.
-
С другой стороны данного коммуникационного канала соответствующая NIC получает этот кадр, копирует его в свой буфер приёма и возбуждает аппаратное прерывание.
-
Соответствующее ядро по очереди обрабатывает все прерывания и возбуждает некое программное прерывание для обработки данного пакета.
-
Наконец, это ядро обрабатывает данное программное прерывание и перемещает данный пакет верх по имющемуся стеку TCP/IP для его деинкапсуляции и помещения результата в буфер прийма для процесса считывания из нго.
В данном рецепте мы собираемся обследовать несколько практических приёмов для регулировок имеющегося ядра Linux, как правло, имеющих результатом лучшую сетевую производительность для хостов KVM со множеством арендаторов.
|
| Замечание |
|---|---|
|
Убедитесь, пожалуйста, что вы определили некий базовый уровень прежде чем приступите к выполнению каких бы то ни было изменений, предварительно измерив производительность данного хоста. Делайте небольшие изменения приращениями, затем замеряйте полученное воздействие вновь. Все примеры в данном рецепте не подразумевают того что вы просто скопирует и вставите их без предварительного осмысления возможных положительных или отрицательных воздействий, которые они могут сделать. Применяйте представленные примеры как некое руководство к тому что может быть настроено - реальные значения необходимо тщательно рассматривать в каждом конкретном случае, основываясь на типе имеющегося у вас сервера и всём окружении. |
Для данного рецепта нам понадобится следующее:
-
Некий хост Ubuntu с установленными и настроенными на нём libvirt и QEMU
-
Какая- то работающая виртуальная машина KVM
Для регулировки имеющегося ядра с целью улучшения сетевой производительности осуществите следующие этапы (для дополнительной информации о том что регулируется в самом ядре прочтите раздел Как это работает...):
-
Увеличьте размер буфера сокета приёма и отправки TCP:
root@kvm:~# sysctl net.core.rmem_max net.core.rmem_max = 212992 root@kvm:~# sysctl net.core.wmem_max net.core.wmem_max = 212992 root@kvm:~# sysctl net.core.rmem_max=33554432 net.core.rmem_max = 33554432 root@kvm:~# sysctl net.core.wmem_max=33554432 net.core.wmem_max = 33554432 root@kvm:~# -
Увеличьте пределы своих буферов TCP: минимальное, значение по умолчанию, а также максимальное число байт. Установите максимум в 16МБ для 1GE NIC и 32МБ или 54МБ для 10GE NIC:
root@kvm:~# sysctl net.ipv4.tcp_rmem net.ipv4.tcp_rmem = 4096 87380 6291456 root@kvm:~# sysctl net.ipv4.tcp_wmem net.ipv4.tcp_wmem = 4096 16384 4194304 root@kvm:~# sysctl net.ipv4.tcp_rmem="4096 87380 33554432" net.ipv4.tcp_rmem = 4096 87380 33554432 root@kvm:~# sysctl net.ipv4.tcp_wmem="4096 65536 33554432" net.ipv4.tcp_wmem = 4096 65536 33554432 root@kvm:~# -
Убедитесь что масштабирование окна TCP разрешено:
root@kvm:~# sysctl net.ipv4.tcp_window_scaling net.ipv4.tcp_window_scaling = 1 root@kvm:~# -
Чтобы помочь увеличению пропускной способности TCP для 1G NIC и выше, увеличьте имеющуюся длину своей очереди передачи этого сетевого интерфейса. Для путей с более чем 50 мс RTT рекомендуется значение 5000 - 10000:
root@kvm:~# ifconfig eth0 txqueuelen 5000 root@kvm:~# -
Снизьте установленное значение
tcp_fin_timeout:root@kvm:~# sysctl net.ipv4.tcp_fin_timeout net.ipv4.tcp_fin_timeout = 60 root@kvm:~# sysctl net.ipv4.tcp_fin_timeout=30 net.ipv4.tcp_fin_timeout = 30 root@kvm:~# -
Уменьшите имеющееся значение
tcp_keepalive_intvl:root@kvm:~# sysctl net.ipv4.tcp_keepalive_intvl net.ipv4.tcp_keepalive_intvl = 75 root@kvm:~# sysctl net.ipv4.tcp_keepalive_intvl=30 net.ipv4.tcp_keepalive_intvl = 30 root@kvm:~# -
Разрешите быстрый повтор циклов сокетов
TIME_WAIT. Установленным по умолчанию значением является 0 (отключено):root@kvm:~# sysctl net.ipv4.tcp_tw_recycle net.ipv4.tcp_tw_recycle = 0 root@kvm:~# sysctl net.ipv4.tcp_tw_recycle=1 net.ipv4.tcp_tw_recycle = 1 root@kvm:~# -
Разрешите повторное использование сокетов в их состоянии
TIME_WAITдля новых соединений. Установленным по умолчанию значением является 0 (отключено):root@kvm:~# sysctl net.ipv4.tcp_tw_reuse net.ipv4.tcp_tw_reuse = 0 root@kvm:~# sysctl net.ipv4.tcp_tw_reuse=1 net.ipv4.tcp_tw_reuse = 1 root@kvm:~# -
Начиная с версии ядра 2.6.13, Linux поддерживает встраиваемые алгоритмя управления перегруженностью. Применяемый определённый алгоритм управления перегруженностью устанавливается с использованием переменной
sysctlnet.ipv4.tcp_congestion_control, которая по умолчанию в Ubuntu установлена в значения bic/cibic. Для получеия списка доступных в вашем ядре алгоритмов управления перегруженностью (если вы применяете 2.6.20 или выше), выполните следующее:root@kvm:~# sysctl net.ipv4.tcp_available_congestion_control net.ipv4.tcp_available_congestion_control = cubic reno root@kvm:~# -
Чтобы сделать доступными дополнительные подключаемые алгоритмы управления перегруженностью загрузите следующие доступные модули ядра:
root@kvm:~# modprobe tcp_htcp root@kvm:~# modprobe tcp_bic root@kvm:~# modprobe tcp_vegas root@kvm:~# modprobe tcp_westwood root@kvm:~# sysctl net.ipv4.tcp_available_congestion_control net.ipv4.tcp_available_congestion_control = cubic reno htcp bic vegas westwood root@kvm:~# -
Для длинных, быстрых путей обычно лучше применять алгоритмы cubic или htcp. Cubic является установленным по умолчанию для целого ряда дистрибутивов Linux, однако если он не является значением по умолчанию в вашей системе, вы можете сделать следующее:
root@kvm:~# sysctl net.ipv4.tcp_congestion_control net.ipv4.tcp_congestion_control = cubic root@kvm:~# -
Если ваш гипервизор перенасыщен соединениями SYN, следующие опции могут помочь уменьшить воздействие этого:
root@kvm:~# sysctl net.ipv4.tcp_max_syn_backlog net.ipv4.tcp_max_syn_backlog = 2048 root@kvm:~# sysctl net.ipv4.tcp_max_syn_backlog=16384 net.ipv4.tcp_max_syn_backlog = 16384 root@kvm:~# sysctl net.ipv4.tcp_synack_retries net.ipv4.tcp_synack_retries = 5 root@kvm:~# sysctl net.ipv4.tcp_synack_retries=1 net.ipv4.tcp_synack_retries = 1 root@kvm:~# -
Наличие достаточного числа доступных дескрипторов файлов крайне важно, так как достатосно многое из всего что есть в Linux является неким файлом. Каждое сетевое соединение применяет некий файловый дескриптор/ сокет. Чтобы проверить ваши текущие максимаольное и доступное значения файловых дескрипторов исполните такой код:
root@kvm:~# sysctl fs.file-nr fs.file-nr = 1280 0 13110746 root@kvm:~# -
Чтлбы увеличить значение максимума файловых дескрипторов выполните это:
root@kvm:~# sysctl fs.file-max=10000000 fs.file-max = 10000000 root@kvm:~# sysctl fs.file-nr fs.file-nr = 1280 0 10000000 root@kvm:~# -
Если ваш гипервизор применяет правила iptables с учётом состояния соединения, тогда ваш модуль ядра
nf_conntrackможет исчерпывать память для отслеживания соединений и будет зарегистрирована некая ошибка:nf_conntrack: table full, dropping packet(таблица переполнена, пакет отвергнут). Чтобы поднять этот предел и тем самым выделить болше памяти, вам необходимо вычислить сколько каждое соединение использует оперативной памяти. Вы можете получить эту информацию из файла proc/proc/slabinfo. Значение записиnf_conntrackпоказывает число активных записей, насколько велик каждый объект и сколько умещается в листе (slab, каждый лист умещается в одной или более страниц ядра, которая обычно 4кБ, если не используется HugePage). Ведя учёт накладных расходов имеющегося размера страниц ядра, вы можете увидеть изslabinfo, что каждый объектnf_conntrackпотребляет примерно 316 байт (это значение может быть разным в разных системах). Поэтому для отслеживания 1М соединений вам понадобится выделить премерно 316 МБ памяти:root@kvm:~# sysctl net.netfilter.nf_conntrack_count net.netfilter.nf_conntrack_count = 23 root@kvm:~# sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 65536 root@kvm:~# sysctl -w net.netfilter.nf_conntrack_max=1000000 net.netfilter.nf_conntrack_max = 1000000 root@kvm:~# echo 250000 > /sys/module/nf_conntrack/parameters/hashsize # hashsize = nf_conntrack_max / 4 root@kvm:~#
На шаге 1 мы увеличили максимальное значение буферов сокетов отправки и приёма. Это выделит больше памяти для имеющегося стека TCP, однако в серверах с большим объёмом памяти и значительным числом соединений TCP это будет гарантировать, что данные размеры буферов будут достаточными. Хорошей начальной точкой для выбора значения по умолчанию является BDP (Bandwidth Delay Product, Произведение полосы пропускания и задержки), основывающийся на измерении задержки, например, умножьте значение полосы пропускания данного соединения на среднее время пути с возвратом до некоторого хоста.
На шаге 2 мы увеличиваем минимальное, по умолчанию и максимальное значения байт, используемых TCP для регулировки размерами буфера отправки. TCP динамически выравнивает этот размер своего буфера отправки от установленного по умолчанию значения.
На шаге 3 мы убеждаемся что разрешено окно масштабирования. Окно масштабирования TCP автоматически увеличивает соответствующий размер окна приёма.
|
| Замечание |
|---|---|
|
Для получения дополнительной информации по окну масштабирования, пожалуйста, обратитесь к https://en.wikipedia.org/wiki/TCP_window_scale_option {Прим. пер.: см. также Какие параметры влияют на производительность приложений? Часть 1. TCP Window Size.} |
На шаге 5 мы понижаем значение tcp_fin_timeout, которое определяет
сколько секунд ждать некий окончательный пакет FIN прежде чем данный сокет будет принудительно закрыт. На шагах
6 и 7 мы уменьшаем значение в секундах между пробами TCP keep-alive и быстрым повтором циклов сокетов в
соответствующем состоянии TIME_WAIT.
Чтобы освежить в памяти.ю приводимая ниже схема отображает различные состояния соединения TCP, в котором оно может находиться:
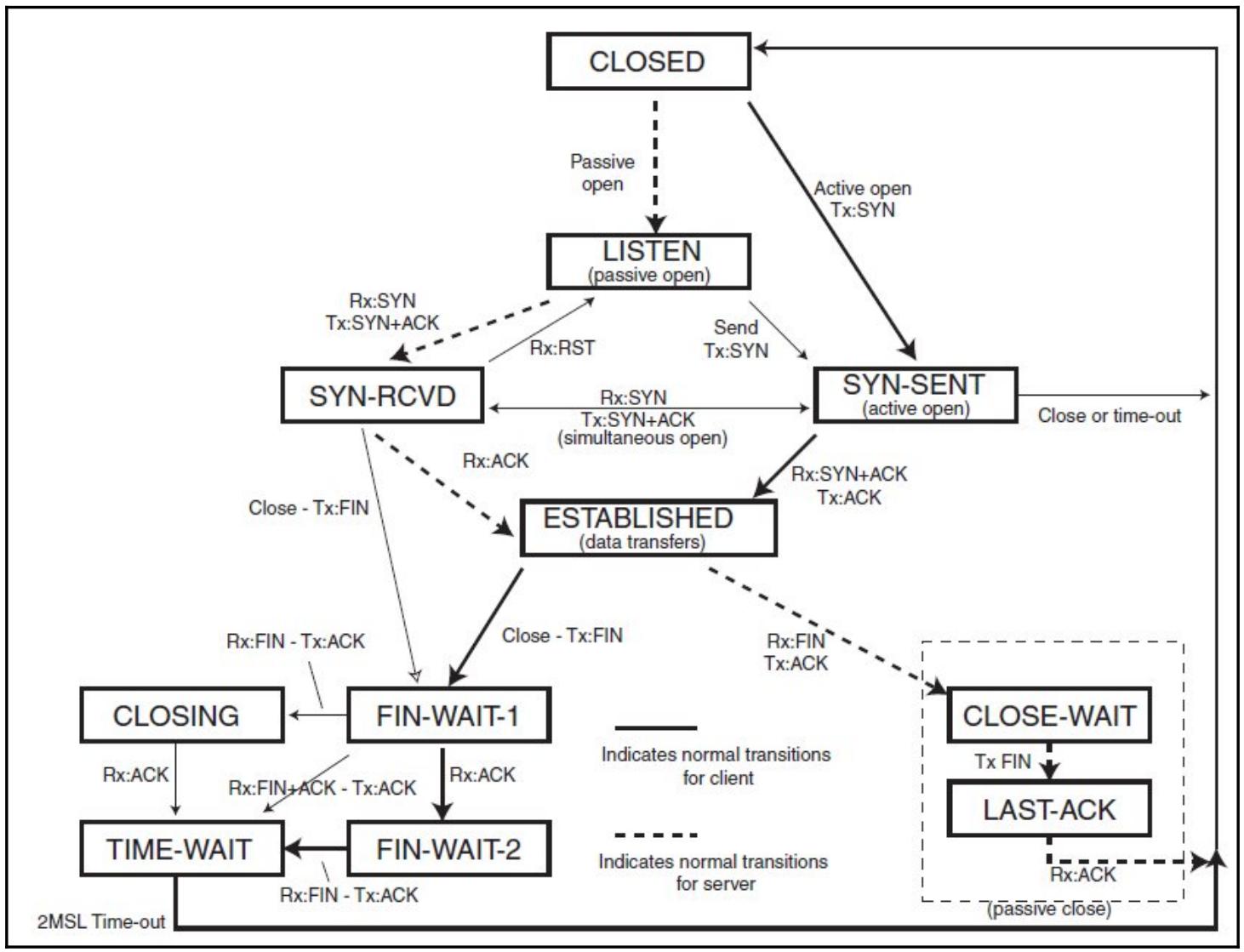
На шаге 8 мы разрешаем повторное использование сокетов в состоянии TIME_WAIT
только для новых соединений. В хостах с большим числом экземпляров KVM это может иметь существенное
воздействие на то, насколько быстро может устанавливаться новое соединение.
На шагах 9 и 10 мы разрешаем различные алгоритмы управления перегрузкой (заторами: congestion control algorithms). Сам выбор алгоритмов управления перегруженностью выполняется при построении ядра системы. На шаге 11 мы выбираем алгоритм cubic, при котором данное окно является некоторой кубической зависимостью от времени с последнего события затора, причём точка перегиба устанавливается на то окно, которое предшествовало этому событию.
|
| Замечание |
|---|---|
|
Для получения дополнительной информации по сетевым алгоритмам заторов- предотвращения обратитесь, пожалуйста к https://en.wikipedia.org/wiki/TCP_window_scale_option {Прим. пер.: см. также Какие параметры влияют на производительность приложений? Часть 1. TCP Window Size.} |
В системах испытывающих перенасыщение количество имеющихся запросов SYN может помочь регулирование значения
максимального число запросов соединений в очереди, которые всё ещё не получили подтверждения от клиента
соединения, с применением опций tcp_max_syn_backlog и
tcp_synack_retries. Мы делаем это на шаге 12.
На шагах 13 и 14 мы увеличиваем значение максимального числа дескрипторов файлов во всей системе. Это помогает, когда присутствует большое число сетевых соединений, так как каждое соединение требует некоторого файлового дескриптора.
На самом последнем шаге мы имеем дело с опцией nf_conntrack_max.
Это полезно если мы отслеживаем соединения в своём гипервизоре при помощи модуля ядра
nf_conntrack.