Глава 1. Обзор ZFS
Содержание
Для работы с ZFS важно понимать все основы его технической стороны и реализации. Я наблюдал множество провалов, которые имели стержнем тот факт, что люди, которые пытались выполнять администрирование или даже исправлять неисправности файловых систем ZFS, в действительности не понимали что они делают и почему. ZFS проделывает длинный путь для защиты ваших данных, но ничто в мире не остановит пытливого пользователя. Если вы на самом деле серьёзно этим займётесь, вы сломаете её. Именно поэтому неплохой мыслью будет начать с основ.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
В большинстве дистрибутивов Linux ZFS не доступна по умолчанию. Для информации о современном состоянии дел в отношении реализации ZFS в Linux, включая текущее сосотяние и дорожную карту, посетите домашнюю страницу проекта: http://zfsonlinux.org/. Начиная с Ubuntu Xenial Xerus, выпуска 16.04 LTS Ubuntu, Canonical сделал ZFS некоторой поддерживаемой на постоянной основе файловой системой. Хотя вы и не можете ещё пока применять её в процессе фазы установки, по крайней мере, простым способом, она готова в доступности для применения и является файловой системой по умолчанию для LXD (диспетчера контейнера системы следующего поколения). |
В этой главе мы рассмотрим что из себя представляет ZFS и осветим некоторые ключевые технологии.
ZFS является копируемой- записью (CoW, copy- on- write) файловой системой, которая соединяет файловую систему, диспетчер логических томов и программный RAID. Работа с еноторой файловой системой CoW означает, что для каждого изменения определённого блока данных эти данные записываются в совершенно новое место на данном диске. Либо запись завершается целиком, либо она не регистрируется как выполненная. Это помогает вам сохранять вашу файловую систему чистой и не разрушенной в случае отказа электропитания. Соединение инструментов диспетчера логических томов и файловой системы совместно с программным RAID означает, что вы легко можете создавать некий том хранения, который имеет желаемые вами настройки и содержит некую готовую к использованию файловую систему. {Прим. пер.: строго говоря, многие авторы настаивают на том, что применяемый в ZFS механизм избыточности данных содержит в себе технологии RAID, но является более объемлющим, но пропустим пока автору такую неточность.}
|
| Замечание |
|---|---|
|
Великолепные свойства ZFS не заменяют собой резервное копирование. Моментальные снимки, клоны, зеркала и т.п., всё это только защищает ваши данные на протяжении того времени пока данное хранилище доступно. Даже имея такие офигительные возможности в своей команде, вам всё ещё требуется выполнять резервное копирование и постоянно проверять его. |
Архитектура Cow (Copy on Write, копирование записью) оправдывает быстрое пояснение, поскольку она является основной концепцией, которая делает возможной существенные свойства ZFS. Рисунок 1.1 отображает графическое представление некоторого возможного пула; четыре диска составляют два vdev (по два диска в каждом vdev). vdev является виртуальным устройством (virtual device), строящимся поверх дисков, разделов, файлов или LUN. Внутри такого пула, поверх vdev, имеется некая файловая система. Данные автоматически балансируются по всем vdev, для всех дисков.
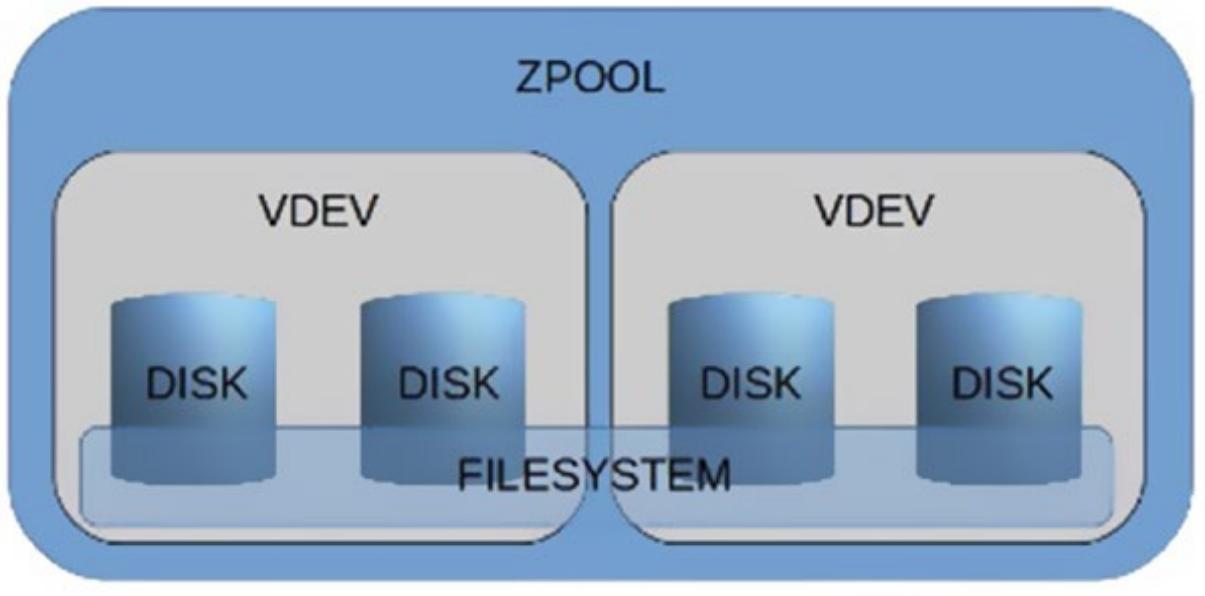
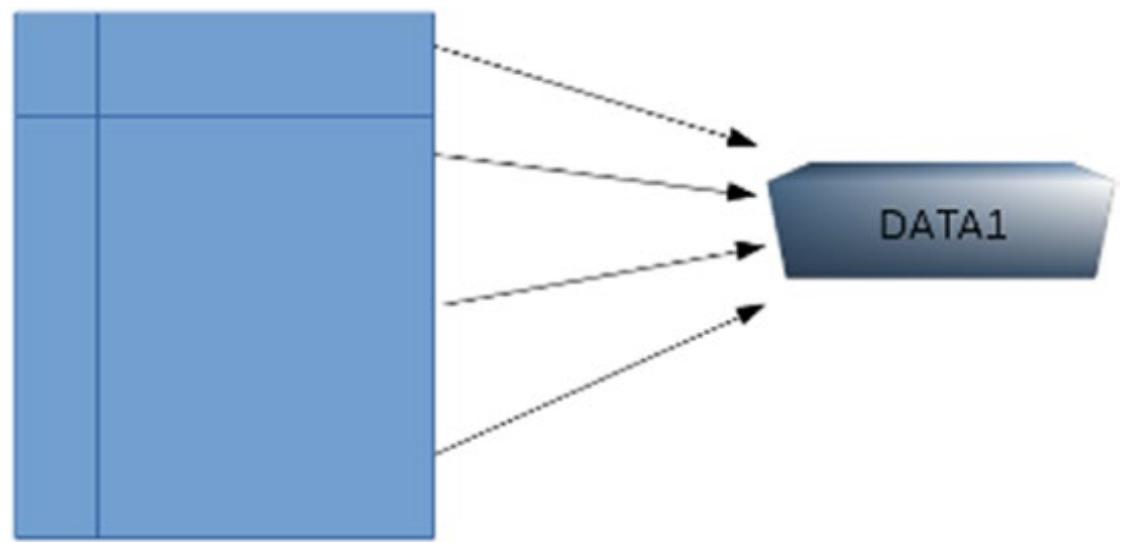
Рисунок 1.2 представляет некий отдельный блок только записанных данных.

Когда это блок впоследствии изменяется, он не перезаписывается. Вместо этого ZFS записывает его по новой, в новом месте на диске, как это показано на Рисунок 1.3. Старый блок всё ещё размещается на этом диске и при этом готов к повторному использованию, если потребуется свободное пространство.

Давайте предположим, что прежде чем эти данные были изменены, оператор данной файловой системы создаёт некий
моментальный снимок. Имеющийся блок DATA 1 SNAP помечается как
относящийся к такому моментальному снимку файловой системы. Когда данные изменяются и записываются в новое место,
имеющееся расположение старого блока записывается в таблице vnode моментального снимка. Всякий раз, когда некоей
файловой системе понадобится выполнить восстановление к моменту времени данного моментального снимка (при откате
назад или монтировании моментального снимка), имеющиеся данные восстанавливаются из vnode в текущей файловой
системе до те пор, пока необходимый блок данных также не будет записан в данной таблице моментального снимка
(DATA 1 SNAP), как это отображено на
Рисунке 1.4.

Дедупликация является совершенно отдельным сценарием. Имеющиеся блоки данных подлежат сравнению на предмет того, что уже имеется представленным в данной файловой системе и, если обнаружено дублирование, в присутствующую таблицу дедупликации добавляется некая новая запись. Сами реальные данные не записываются в этот пул. Смотрите это на Рисунке 1.5.
В дикой природе имеется множество решений хранения как для крупных корпораций, так и для сред SoHo. Их подробное рассмотрение выходит за рамки данного руководства, однако мы рассмотрим все основные за- и против- ZFS.
Благодаря слиянию воедино управления томами, RAID и файловой системы имеются всего лишь две команды, которые вам потребуются для создания томов, уровней избыточности, файловых систем, сжатия, точек монтирования и т.п. Это также упрощает мониторинг, так как имеется два или даже три меньших уровня, которые следует просматривать.
ZFS официально была выпущена в 2005 и на её основе было развёрнуто множество решений хранения. Я видел сотни больших хранилищ ZFS в крупных корпорациях и я уверен, что их общее число составляет сотни, если не тысячи. Я также видел небольшие массивы ZFS SoHo. Благодаря ZFS оба эти мира стали свидетелями великолепной стабильности и масштабируемости.
ZFS была разработана с прицелом в уме на целостность данных. Она пришла с проверками целостности данных, метаданными контрольных сумм, обнаружением отказов данных (и, в случае присутствия установок избыточности, возможности их устранения), а также автоматического замещения вышедших из строя устройств.
ZFS отлично масштабируется с возможностью добавления новых устройств, управления кэшем и тому подобного.
Как и у любой файловой системы, у ZFS также имеется своя доля слабых мест, которые вам следует иметь в виду для успешной работы с этим хранилищем.
Как и большинство прочих файловых систем, ZFS страдает от ужасной производительности при заполнении на 80% и более от своей ёмкости. Это общая проблема с файловыми системами. Запомните, что когда ваш пул начинает заполнять 80% ёмкости, вам необходимо либо расширить этот пул, либо выполнять миграцию на установку большего размера.
Вы не можете усекать данный пул, поэтому вы не можете удалять устройства или vdev из него после того как они были добавлены.
За исключением переключения пула отдельного диска в пул зеркалирования вы не можете изменять тип избыточности. Выбрав единожды тип избыточности, у вас есть единственный путь его разрушения и создания нового, восстанавливая данные из резервных копий или другого расположения.
В наших последующих разделах перечисляются ключевые термины, с которыми вы будете сталкиваться.
Пул хранения (storage pool) является комбинацией ёмкостей дисковых устройств. Некий пул может иметь одну или более файловых систем. Файловые системы создаются внутри конкретного пула, видящего всю ёмкость и могут расти вверх до достижения всего объёма данного пула. Любая из файловых систем способна получить всё доступное пространство, что сделает невозможным рост для прочих файловых систем в том же самом пуле и сохранение в них новых данных. Одним из способов обработки таких ситуаций состоит в применении резервирования и квот пространства.
vdev является неким виртуальным устройством, которое может состоять из одного или более физических устройств. vdev может быть неким пулом или быть частью какого- то пула большего размера. vdev может иметь уровень избыточности зеркала, тройного зеркала, RAIDZ, RAIDZ-2 или RAIDZ-3. Доступны даже более высокие уровни зеркальной избыточности, однако они не практичны и затратны. {Прим. пер.: на самом деле, имеется по крайней мере один вариант применения зеркалирования на большом числе дисков, а именно при решении задачи увеличения пропускной способности.}
Некая файловая система создаётся в рамках какого- то пула. Файловая система ZFS может относиться только к одному пулу, однако некий пул может содержать более одной файловой системы ZFS. Файловые системы ZFS могут иметь резервирования (минимально гарантированную ёмкость), квоты, сжатие и множество прочих свойств. Файловые системы могут быть встраиваемыми, что означает, что вы можете создавать одну файловую систему внутри другой. Пока вы не определите иное, файловые системы будут автоматически монтироваться внутри своих предков. Самая верхняя файловая система ZFS именуется также как сам пул и автоматически монтируется в своём корневом каталоге, если не определено иное.
Моментальные снимки (snapshots) являются снимками на момент- времени состояния определённой файловой системы. Благодаря семантике CoW они очень экономичны в терминах дискового пространства. Создание некоего моментального снимка означает регистрацию vnode файловой системы и их отслеживание. Когда имеющиеся данные в таком inode обновляются (записываются в новое место - помните, это CoW), имеющийся старый блок данных удерживается. Вы можете осуществлять доступ к просмотру старых данных, применяя обсуждавшиеся моментальные снимки и при этом применять только столько пространства, скольк было изменено между временем выполнения такого моментального снимка и текущим моментом.
Моментальные снимки доступны только для чтения. Если вы желаете смонтировать некий моментальный снимок и внести в него изменения, вам необходим моментальный снимок с доступом по чтению- записи, или клон. Клоны имеют множество применений, одним из величайших из которых являются клоны среды загрузки. При наличии некоторой операционной системы, способной загружаться из ZFS (дистрибутивов illumos, FreeBSD), вы можете создавать некий клон своей операционной системы и затем исполнять операции в текущей файловой системе или в некоем клоне с возможным обновлением такой системы или установкой хитроумного видео драйвера. Вы можете загрузиться обратно в свою первоначальную рабочую среду если вам это потребуется и это потребует только столько дискового пространства, сколько внесли данные изменения.
Набором данных (dataset) является некий пул ZFS, файловая система, моментальный снимок, том или клон. Именно это является тем уровнем ZFS, это именно тот уровень, на котором могут храниться данные и с которого они могут извлекаться.
Том (volume) является некоторой файловой системой, которая эмулирует определённое блочное устройство. Он не может применяться как какая- то обычная файловая система ZFS. Для всех намерений и целей он ведёт себя как некое блочное устройство. Некоторые из них применяются для их экспорта через протоколы iSCSI или FCoE с целью монтирования в качестве LUN в каком- то удалённом сервере с последующим применением их как дисков.
|
| Замечание |
|---|---|
|
Что касается меня самого, тома являются моими самыми не любимыми при применении ZFS. Многие из имеющихся свойств, которые мне больше всего нравятся в ZFS имеют ограничения в томах или вовсе не могут применяться к ним. Если вы применяете тома и выполняете их моментальные снимки, вы не сможете их монтировать простым способом локально для выемки файлов, как вы это могли бы делать при использовании некоторой простой файловой системы ZFS. |
Восстановление амальгамы (resilvering) является процессом восстановления избыточных групп после замены диска. Имеется множество причин почему вы можете пожелать заменить некий диск - возможно это устройство стало воспроизводить множество ошибок, либо вы решили перебросить этот диск по какой- либо иной причине - раз определённое новое устройство добавлено в имеющийся пул, ZFS запустит восстановление данных в нём. В этом состоит одно из очевидных преимуществ ZFS над традиционными RAID. Будут восстанавливаться только сами данные, не весь диск целиком.
|
| Замечание |
|---|---|
|
Восстановление амальгамы является низкоприоритетным процессом системы. В очень занятой системы оно потребует большего времени. |
Схема построения пула является тем способом, которым диски группируются в vdev, а vdev группируются вместе в определённый пул ZFS.
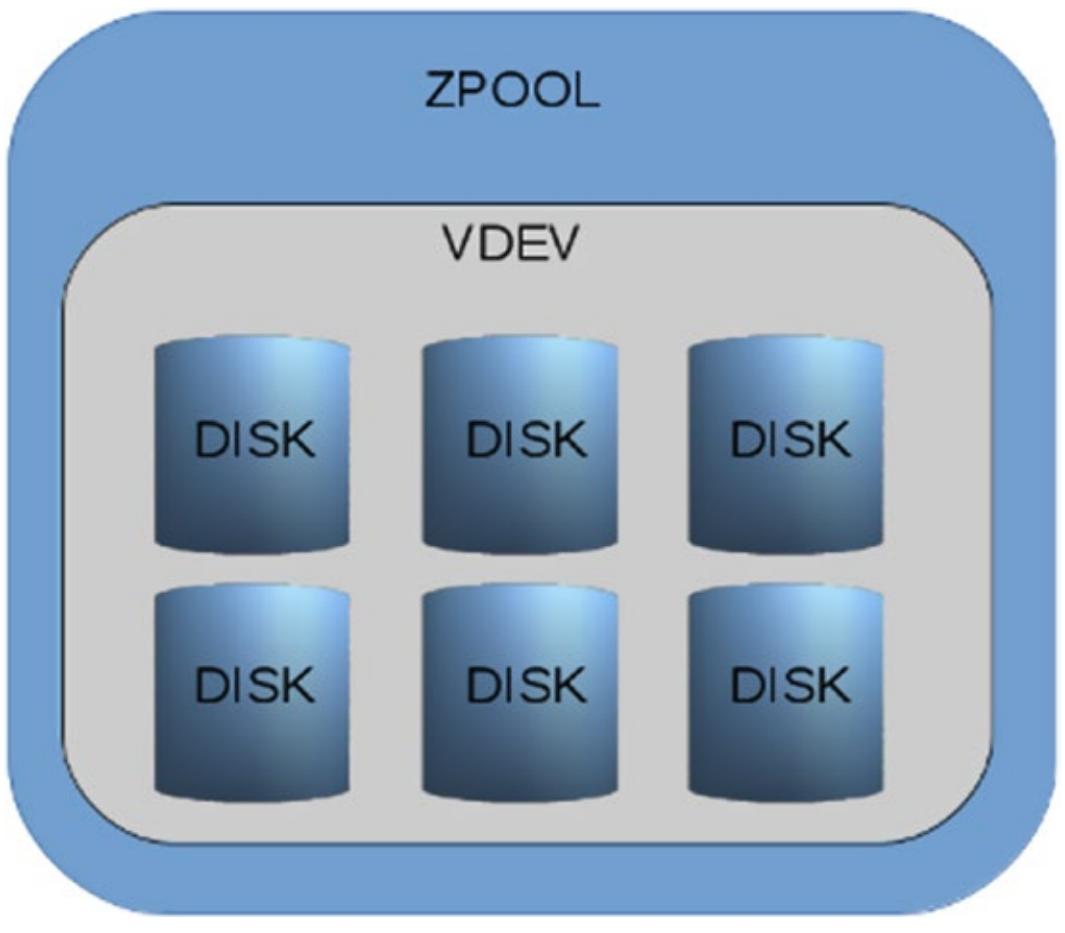
Предположим, что у нас имеется некий пул, состоящий из шести дисков, причём все они находятся в конфигурации RAIDZ-2 (грубо: эквивалент RAID-6). Четыре диска содержат данные в двух находятся суммы восстановления данных (parity data). Устойчивость данного пула делает возможной утрату до двух дисков. Любое значение выше этого невозвратимо разрушит имеющуюся файловую систему и как результат нам потребуются резервные копии.
Рисунок 1.6 представляет данный пул. Хотя технически возможно создать некий vdev из меньшего число дисков, причём с различными размерами, это практически обязательно отобразится в проблемах с производительностью.
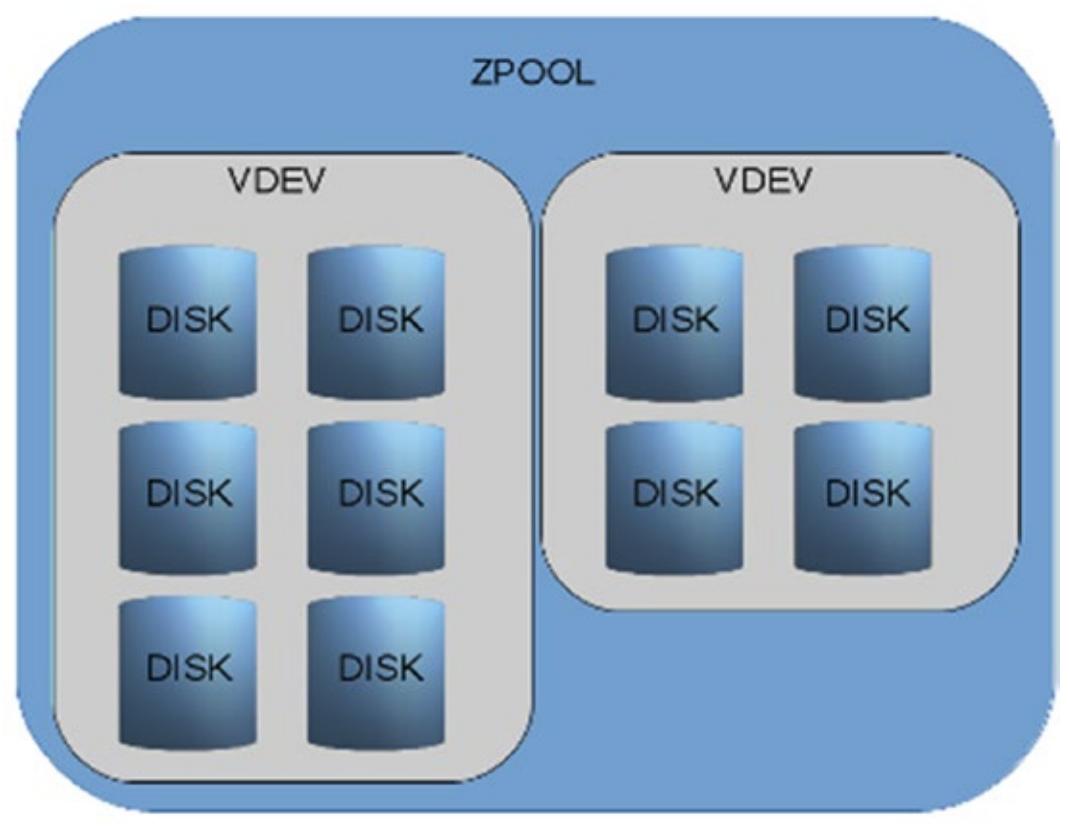
И запомните - вы не можете удалять диски из некоторого пула после того как добавлены vdev. Если вы вдруг добавите новый vdev, допустим, RAIDZ из четырёх дисков, как показано на Рисунке 1.7, вы нарушите целостность пула, введя vdev с меньшим уровнем отказоустойчивости.
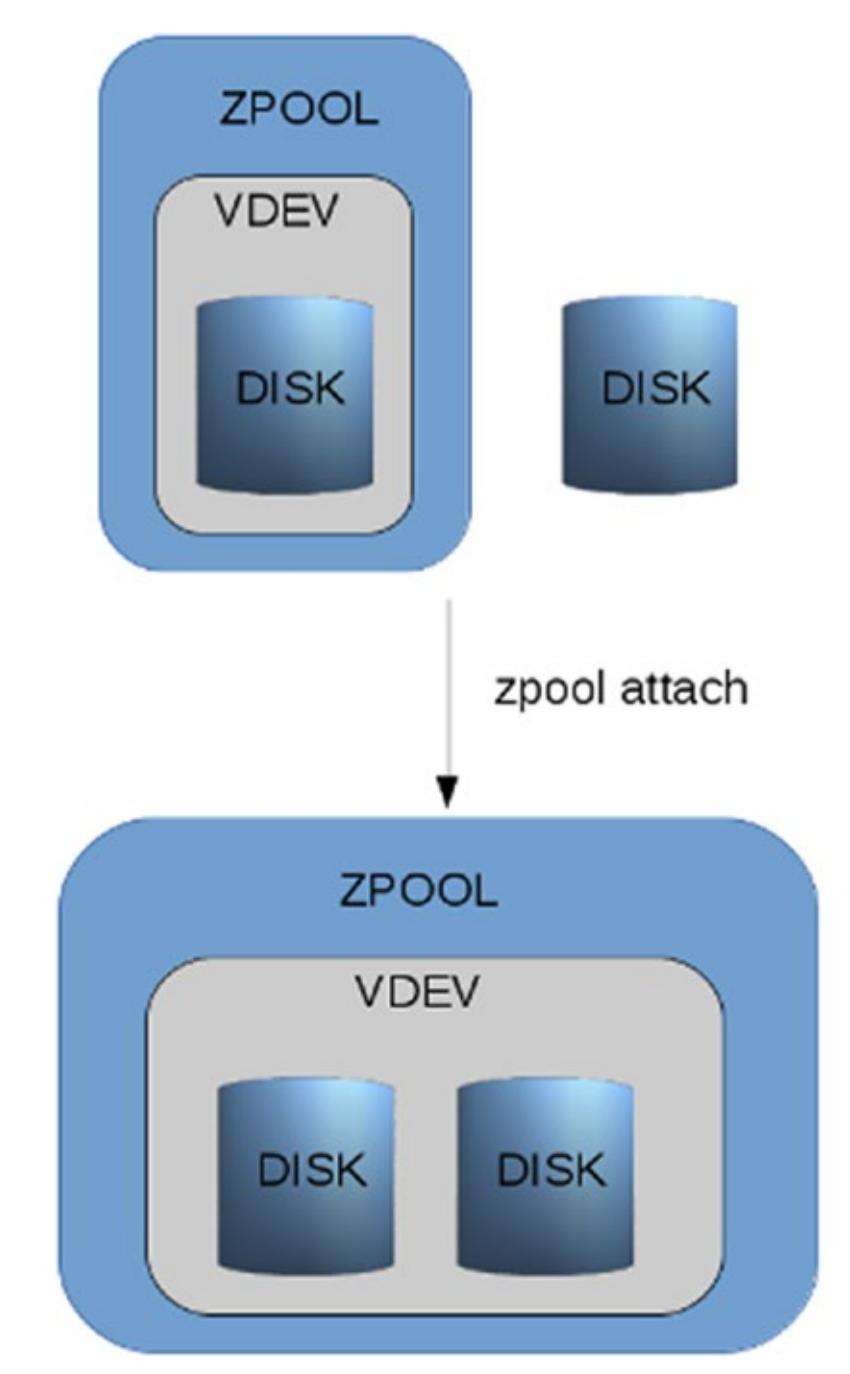
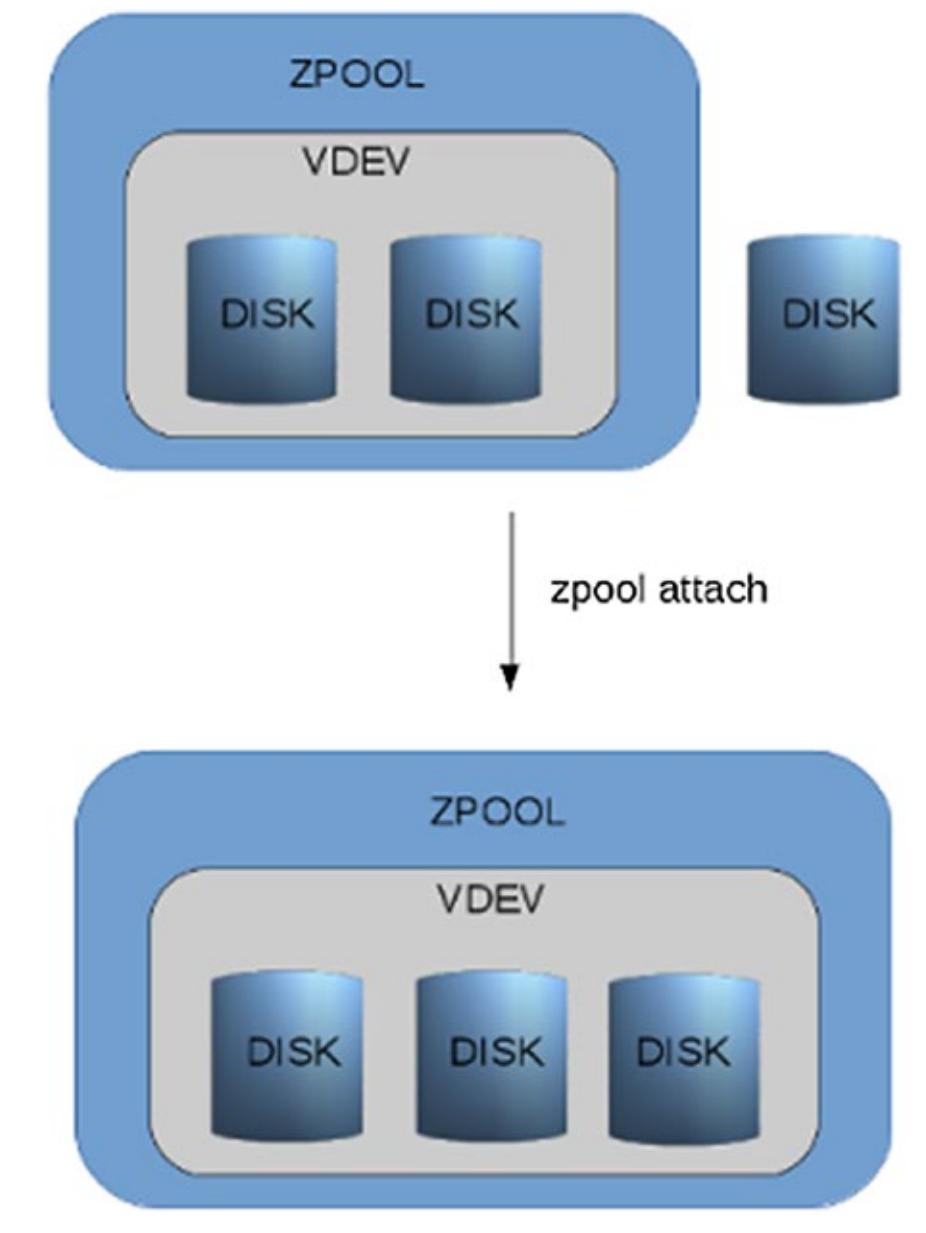
Единственным исключением из правила "вы не можете изменять уровень отказоустойчивости" является подключение диска единственного диска к отдельному vdev и это будет иметь результатом зераклированное vdev (см. Рисунке 1.8). Вы также можете подключить некий диск к зеркалу из двух устройств, создавая тем самым тройное зеркало. (см. Рисунке 1.9).
Множество руководств сообщают вам о предпочтительности настройки двух опций (одна уровня пула, а вторая
уровня файловой системы), которые, как предполагается, увеличат общую скорость. К сожалению, большинство из
них не объясняют что делают эти опции и почему они должны работать: ashift=12
и atime=off.
Хотя они и в самом деле могут предложить значительное увеличение производительности, их установка в слепую является существенной ошибкой. Как уже указывалось ранее, для надлежащего администрирования вашим сервером хранения вам необходимо понимать зачем вы применяете предлагаемые параметры.
Опция ashift позволяет вам настроить на диске схему физического блока.
По мере продолжающегося роста ёмкостей диска с определённой точки зрения сохранение имевшегося первоначально
размера блока в 512 байт становится не практичным и производители дисков изменили его на 4096 байт.
Однако, по причинам обратной совместимости диски всё ещё предлагают размеры блока в 512 байт. Это может оказывать
воздействие на производительность пула.
{Прим. пер.: подробнее см., например, Обзор технологии Расширенного формата жёстких
дисков Ильи Крутова.}
В ZFS был введён параметр ashift, чтобы разрешать вручную изменять
установку размера блока, осуществляемую ZFS. Поскольку это определяется как двоичный сдвиг, его значением
является величина степени, таким образом, 212 = 4096. Пропуск параметра
ashift делает возможным для ZFS определять это значение (сам диск может
врать о нём, {Прим. пер.: подробнее см., например, Обзор технологии Расширенного формата жёстких
дисков Ильи Крутова.}); применение значения 9 установит размер блока равным 512. Такой новый
размер блока диска имеет название Расширенной схемы (AL, Advanced Layout).
Данная опция ashift может применяться только в процессе установки пула
при добавлении нового устройства в некий vdev. Что привносит дополнительную проблему: если вы создали некий пул
установив ashift, а впоследствии добавляете некий диск, но не устанавливаете
параметр, ваша производительность может стать кривой благодаря смешению параметров
ashift. Если вы знаете что вы применяли данную опцию, или не уверены в этом,
всегда проверяйте это перед добавлением новых устройств:
trochej@madchamber:~$ sudo zpool list
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
data 2,72T 133G 2,59T - 3% 4% 1.00x ONLINE -
trochej@madchamber:~$ sudo zpool get all data
NAME PROPERTY VALUE SOURCE
data size 2,72T -
data capacity 4% -
data altroot - default
data health ONLINE -
data guid 7057182016879104894 default
data version - default
data bootfs - default
data delegation on default
data autoreplace off default
data cachefile - default
data failmode wait default
data listsnapshots off default
data autoexpand off default
data dedupditto 0 default
data dedupratio 1.00x -
data free 2,59T -
data allocated 133G -
data readonly off -
data ashift 0 default
data comment - default
data expandsize - -
data freeing 0 default
data fragmentation 3% -
data leaked 0 default
data feature@async_destroy enabled local
data feature@empty_bpobj active local
data feature@lz4_compress active local
data feature@spacemap_histogram active local
data feature@enabled_txg active local
data feature@hole_birth active local
data feature@extensible_dataset enabled local
data feature@embedded_data active local
data feature@bookmarks enabled local
Как вы можете заметить, я позволил ZFS автоматически определять установленные значения.
Если вы не уверены в состоянии AL для своих дисков, воспользуйтесь командой
smartctl:
[trochej@madtower sohozfs]$ sudo smartctl -a /dev/sda
smartctl 6.4 2015-06-04 r4109 [x86_64-linux-4.4.0] (local build)
Copyright (C) 2002-15, Bruce Allen, Christian Franke,
www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate Laptop SSHD
Device Model: ST500LM000-1EJ162
Serial Number: W7622ZRQ
LU WWN Device Id: 5 000c50 07c920424
Firmware Version: DEM9
User Capacity: 500,107,862,016 bytes [500 GB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5400 rpm
Form Factor: 2.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2, ACS-3 T13/2161-D revision 3b
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Fri Feb 12 22:11:18 2016 CET
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Вы можете заметить, что мой диск имеет строку:
Sector Sizes: 512 bytes logical, 4096 bytes physical
Она сообщает, что диск имеет физическую схему 4096 байт, однако сам диск предлагает 512 байт для обратной совместимости.
Возмите за правило: не применяйте дедупликацию. Просто никогда. Если вам на самом деле требуется отыскать дисковое пространство, применяйте прочие способы увеличения ёмкости. Некоторые мои былые потребители получали гигантские проблемы применяя дедупликацию.
ZFS имеет некую интересную опцию, которая вызвала достаточно большой интерес при её введении. Включение дедупликации сообщает ZFS о необходимости отслеживать блочные данные. Всякий раз когда данные записываются на диски, ZFS будет сравнивать их с теми блоками, которые уже имеются в данной файловой системе и, если обнаруживает некий идентичный блок, он не будет записывать физические данные, а вместо этого добавит некие метаданные и тем самым сбережёт очень и очень много дискового пространства.
Хотя эта функция и выглядит великолепно в теории, на практике она она превращается в достаточную хитроумность для гадкого применения. Прежде всего, дедупликация привносит стоимость по цене, в которую вам обойдётся оперативная память и ЦПУ. Для каждого юлока данных, который подвергается дедупликации, ваша система добавит некую запись в DDT (deduplication tables, таблицах дедупликации), которые присутствуют в вашей оперативной памяти. По иронии судьбы, для идеальной дедупликации данных получаемые в результате в оперативной памяти DDT приводили к тому, что система падала из- за нехватки памяти и мощности ЦПУ для работы операционной системы.
Нельзя сказать, что дедупликация не применяется. Однако, прежде чем устанавливать её, вы должны изучить насколько хорошо ваши данные будут дедуплицированы. Я могу представить себе хранилище резервных копий, которое позволит сэкономить место благодаря дедупликации. В таком случае, несмотря на размер DDT, во избежание проблем необходимо предусмотреть свободную оперативную память и предоставление ЦПУ.
Загвоздка в том, что DDT постоянно. Вы можете в некий момент отключить дедупликацию, но однажды дедуплицированные данные остаются дедуплицированными и если вы из- за этого столкнётесь с проблемами стабильности, отключение и перезагрузка вам не помогут. При следующем импорте (монтировании) пула DDT будут загружены в оперативную память вновь. Существует два способа избавиться от этих данных: удалить этот пул, создать его по новой, и восстановить все данные или запретить дедупликациюи переместить данные в этот пул с тем, чтобы они стали не дедуплицированными при своих следующих записях. Оба варианта требуют времени, которое определяется самим размером ваших данных. В случае, когда дедуплицирование способно сберечь дисковое пространство, тщательно изучите эту возможность.
Текущее соотношение дедупликации по умолчанию отображается с помощью команды zpool
list. Причём соотношение 1.00 означает, что никакой дедупликации вовсе нет:
trochej@madchamber:~$ sudo zpool list
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
data 2,72T 133G 2,59T - 3% 4% 1.00x ONLINE -
Вы можете проверить имеющиеся установки дедупликации опросив свойство дедупликации своей файловой системы:
trochej@madchamber:~$ sudo zfs get dedup data/datafs
NAME PROPERTY VALUE SOURCE
data/datafs dedup off default
Для файловой системы установлена дедупликация.
Опцией, которая сберегает дисковое пространство и добавляет скорость является сжатие (compression). Для применения в ZFS доступно несколько алгоритмов сжатия. Обычно вы можете просить имеющуюся файловую систему сжимать все блоки данных при их записи на диск. При современных ЦПУ вы обычно можете добавлять скорость при записи физических данных небольшого размера. Ваш процессор должен иметь возможность справляться с упаковкой и распаковкой данных на лету. Исключение могут составлять плохо пакуемые данные, такие как MP3, JPG или видео файлы. Текстовые данные (журналы регистрации приложений и т.п.) обычно хорошо проявляют себя при данной опции. Что касается моих личных предпочтений, я всегда включаю упаковку. Устновленным по умолчанию алгоритмом для ZFS является lzjb.
Сжатие может быть установлено на уровне файловой системы:
trochej@madchamber:~$ sudo zfs get compression data/datafs
NAME PROPERTY VALUE SOURCE
data/datafs compression on local
trochej@madchamber:~$ sudo zfs set compression=on data/datafs
Значение соотношения сжатия моно определить запросив свойство:
trochej@madchamber:~$ sudo zfs get compressratio data/datafs
NAME PROPERTY VALUE SOURCE
data/datafs compressratio 1.26x
Доступны различные алгоритмы сжатия. До недавнего времени если вы просто включали сжатие, применялся алгоритм
lzjb. Он рассматривается как хороший компромисс между производительностью
и сжатием. Прочие доступные алгоритмы сжатия перечислены на странице руководства zfs. Недавно добавленным новым
алгоритмом является lz4. Он может добавляться только для пулов, которые
имеют установленным флаг свойств функциональности feature@lz4_compress.
trochej@madchamber:~$ sudo zpool get feature@lz4_compress data
NAME PROPERTY VALUE SOURCE
data feature@lz4_compress active local
Если этот флаг включён, вы можете установить compression=lz4 для
дюбого выбранного набора данных (dataset). Вы можете вызвать его данной командой:
trochej@madchamber:~$ sudo zpool set feature@lz4_compress=enabled data
Теперь уже какое- то время lz4 является алгоритмом сжатия по
умолчанию.
сли вы вновь взглянете на перечень моего пула:
trochej@madchamber:~$ sudo zpool list
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
data 2,72T 133G 2,59T - 3% 4% 1.00x ONLINE -
вы заметите колонку с названием HEALTH. Это состояние пула ZFS.
Имеются также некоторые прочие индикаторы, которые вы тут можете обнаружить:
-
ONLINE: Данный пул жизнеспособен (нет выявленных ошибок) и он импортирован (смартирован, в смысле обычного жаргона файловых систем), а также готов к применению. Это не означает, что он в исключительно отличном состоянии. ZFS удерживает некий пул помеченным online даже при некотором небольшом количестве ошибок ввода/ вывода или при возникновении исправимых ошибок. Вам следуует выполнить мониторинг прочих индикаторов, также отвечающих за жизнеспособность диска (для контроллеров SAS LSIhdparm,smartctlиlsiutil). -
DEGRADED: Вероятно применим только для наборов с избыточностью, в которых были утрачены диски в зеркале, или RAIDZ, или в RAIDZ-2. Такой пул может потерять избыточность. Утрата дополнительных дисков приведёт к его разрушению. Имейте в виду, что тройное зеркалирование или RAIDZ-2 при утрате одного диска не приводит к отсутствию избыточности пула. -
FAULTED: Некий диск или vdev является недоступным. Это означает, что ZFS не может выполнятьс чтение с него или запись на него. При конфигурациях с избыточностью, некий диск может бытьFAULTED, однако его vdev может бытьDEGRADEDи всё ещё являться доступным. Это может произойтиесли наборе зеркала утрачен один диск. Если вы утратите некий верхний уровень vdev, то есть оба диска в зеркале, ваш пул целиком будет недоступным и станет испорченым. Поскольку не существует способа восстановления файловой системы, у вас на данном этапе имеются варианты восстановить этот пул с жизнеспособными дисками и воссоздать его из резервных копий, либо начать поиск экспертов по восстановлению данных ZFS {Прим. пер.: например, обратитесь к нам}. Последнее обычно достаточно затратный вариант. -
OFFLINE: устройство было отключено (выведено из рабочего сосотяния) администратором. Причины могут разниться, однако это не означает, что данный диск отказал. -
UNAVAIL: этот диск, или это vdev не могут быть открыты. На самом деле, ZFS не может их считывать или записывать в них. Вы можете отметить, что это звучит практически как состояниеFAULTED. Единственная разница состоит в том, что при наличии состоянияFAULTEDэто устройство отображает число ошибок, прежде чем помечается какFAULTEDсамой ZFS. ПриUNAVAILсистема не может общаться с данным устройством; возможно, оно пришло в полную негодность, либо электропитание слишком слабое чтобы запитать все ваши диски. Последний сценарий всегда надо иметь в виду, в особенности при использовании общедоступного оборудования. Я сталкивался с исчезающими дисками неоднократно, просто обнаруживая что имеющийся PSU слишком слаб. -
REMOVED: Если ваше оборудование поддерживает такое, когда некий диск физически удаляется без своего удаления перед этим из имеющегося пула при помощи необходимой для этого командыzpool, он будет помечен какREMOVED.
Вы можете проверять жизнеспособность пула в явном виде, применяя имеющиеся команды
zpool status и zpool status -x:
trochej@madchamber:~$ sudo zpool status -x
all pools are healthy
trochej@madchamber:~$ sudo zpool status
pool: data
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
data ONLINE 0 0 0
sdb ONLINE 0 0 0
errors: No known data errors
zpool status выведет подробное описание жизнеспособности и настрое
всех имеющихся пулов устройств. Когда данный пул состоит из сотен лисков, может оказаться проблематичным
отыскивать рыбку в мутной воде отказавшего устройтсва. Для такого случая вы можете воспользоваться
zpool status -x, которая выведе только общее состояние тех пулов,
которые испытывают проблемы.
trochej@madchamber:~$ sudo zpool status -x
pool: data
state: DEGRADED
status: One or more devices has been taken offline by the administrator.
Sufficient replicas exist for the pool to continue
functioning in a degraded state.
action: Online the device using 'zpool online' or replace the
device with 'zpool replace'.
scrub: resilver completed after 0h0m with 0 errors on Wed Feb
10 15:15:09 2016
config:
NAME STATE READ WRITE CKSUM
data ONLINE 0 0 0
mirror-0 DEGRADED 0 0 0
sdb ONLINE 0 0 0
sdc OFFLINE 0 0 0 48K resilvered
errors: No known data errors
ZFS был разработан для последовательно пошагового введения новых функций. Как часть данного механизма, в качестве отдельного номера были введены определённые версии ZFS. Отслеживая этот номер, конкретный оператор системы может определить, что его пул применяет самую последнюю версию ZFS, в том числе новые свойства и исправления ошибок. Обновления осуществляются прямо на месте и не требуют никакого времени простоя.
Эта философия достаточно хорошо работала когда ZFS разрабатывался исключительно Sun Microsystems. Когда в данное приключение ввязалось сообщество OpenZFS - illumos, Linux, OSX, а также миры FreeBSD - вскоре стало очевидным, что будет затруднительно, если не невозможно, приходить к согласию со всяким изменением форматом на диске по всему сообществу в целом. Таки м образом, номер версии остался самым последним из выпущенных Oracle Corp в качестве версии с открытым исходным кодом: 28. Начиная с этого момента была введена архитектура подключаемых модулей "флагов свойств" (features flags). Реализации ZFS совместимы если они реализуют один и тот же набор флагов свойств.
Если вы опять взглянете на вывод команды zpool в моём хосте:
trochej@madchamber:~$ sudo zpool get all data
NAME PROPERTY VALUE SOURCE
data size 2,72T -
data capacity 4% -
data altroot - default
data health ONLINE -
data guid 7057182016879104894 default
data version - default
data bootfs - default
data delegation on default
data autoreplace off default
data cachefile - default
data failmode wait default
data listsnapshots off default
data autoexpand off default
data dedupditto 0 default
data dedupratio 1.00x -
data free 2,59T -
data allocated 133G -
data readonly off -
data ashift 0 default
data comment - default
data expandsize - -
data freeing 0 default
data fragmentation 3% -
data leaked 0 default
data feature@async_destroy enabled local
data feature@empty_bpobj active local
data feature@lz4_compress active local
data feature@spacemap_histogram active local
data feature@enabled_txg active local
data feature@hole_birth active local
data feature@extensible_dataset enabled local
data feature@embedded_data active local
data feature@bookmarks enabled local
Вы можете отметить, что несколько последних свойств начинаются со строки
feature@. Именно эти флаги свойств вам необходимо разыскивать.
Для обнаружения всех поддерживаемых версий и флагов свойств выполните команды
sudo zfs upgrade -v и
sudo zpool upgrade -v , как это отображено в следующих примерах:
trochej@madchamber:~$ sudo zfs upgrade -v
The following file system versions are supported:
VER DESCRIPTION
--- --------------------------------------------------------
1 Initial ZFS file system version
2 Enhanced directory entries
3 Case insensitive and file system user identifier (FUID)
4 userquota, groupquota properties
5 System attributes
For more information on a particular version, including supported
releases, see the ZFS Administration Guide.
(Для получения дополнительной информации по определённой версии, включая поддерживаемые выпуски, обращайтесь к ZFS Administration Guide.)
trochej@madchamber:~$ sudo zpool upgrade -v
This system supports ZFS pool feature flags.
The following features are supported:
FEAT DESCRIPTION
-------------------------------------------------------------
async_destroy (read-only compatible)
Destroy file systems asynchronously.
empty_bpobj (read-only compatible)
Snapshots use less space.
lz4_compress
LZ4 compression algorithm support.
spacemap_histogram (read-only compatible)
Spacemaps maintain space histograms.
enabled_txg (read-only compatible)
Record txg at which a feature is enabled
hole_birth
Retain hole birth txg for more precise zfs send
extensible_dataset
Enhanced dataset functionality, used by other features.
embedded_data
Blocks which compress very well use even less space.
bookmarks (read-only compatible)
"zfs bookmark" command
The following legacy versions are also supported:
(Также поддерживаются следующие наследуемые версии:)
VER DESCRIPTION
--- --------------------------------------------------------
1 Initial ZFS version
2 Ditto blocks (replicated metadata)
3 Hot spares and double parity RAID-Z
4 zpool history
5 Compression using the gzip algorithm
6 bootfs pool property
7 Separate intent log devices
8 Delegated administration
9 refquota and refreservation properties
10 Cache devices
11 Improved scrub performance
12 Snapshot properties
13 snapused property
14 passthrough-x aclinherit
15 user/group space accounting
16 stmf property support
17 Triple-parity RAID-Z
18 Snapshot user holds
19 Log device removal
20 Compression using zle (zero-length encoding)
21 Deduplication
22 Received properties
23 Slim ZIL
24 System attributes
25 Improved scrub stats
26 Improved snapshot deletion performance
27 Improved snapshot creation performance
28 Multiple vdev replacements
For more information on a particular version, including
supported releases, see the ZFS Administration Guide.
(Для получения дополнительной информации по определённой версии, включая поддерживаемые выпуски, обратитесь к ZFS Administration Guide)
Обе команды выводят информацию о максимальном уровне пула ZFS и версиях файловой системы, а также перечень всех доступных флагов свойств.
Вы можете проверить текущее состояние версии своих пула и файловой системы воспользовавшись командами
zpool upgrade и zfs upgrade:
trochej@madchamber:~$ sudo zpool upgrade
This system supports ZFS pool feature flags.
All pools are formatted using feature flags.
Every feature flags pool has all supported features enabled.
trochej@madchamber:~$ sudo zfs upgrade
This system is currently running ZFS file system version 5.
All file systems are formatted with the current version.
Linux является доминирующей операционной системой в обасти серверов. ZFS является очень хорошей файловой системой
в большинстве сценариев. В сравнении с традиционными решениями RAID и управления томов, она привносит определённые
преимущества - простоту применения, возможности освидетельствования жизнеспособности данных, улучшенные способности
миграции между операционными системами, и многое другое. ZFS имеет дело с виртуальными устройствами
(vdev). Виртуальные устройства могут ставиться в соответствие либо напрямую
физическому диску, либо некоторой группе прочих vdev. Какая- то группа vdev, которая обслуживается как протранство
для файловых истем именуется пулом ZFS. Все файловые системы внутри него
называются файловыми системами. Файловые системы ZFS могут быть встраиваемыми. Администрирование такого пула
выполняется командой zpool. Администрирование файловыми системами осуществляется
командой zfs.