Глава 2. Построение сетевой среды Kubernetes
Содержание
Когда в неком кластере Kubernetes запущены тысячи микрослужб, вам может быть интересно как эти микрослужбы взаимодействуют друг с другом, а также с интернетом. В этой главе мы раскроем все пути взаимодействия в неком кластере Kubernetes. Мы бы хотели чтобы вы не только узнали как происходит это взаимодействие, но также рассмотрим и технические подробности в плане безопасности: обычный канал взаимодействия всегда может быть использован в качестве цепи убийств.
В этой главе мы рассмотрим следующие вопросы:
-
Обзор сетевой модели Kubernetes
-
Взаимодействие внутри пода
-
Взаимодействие между подами
-
Введение в службу Kubernetes
-
Введение в CNI и подключаемые модули CNI
Запускаемые в кластере Kubernetes подразумеваются доступными либо внутренним образом из самого кластера, либо извне, из- за пределов этого кластера. С точки зрения сетевой среды, подразумевается, что это может быть либо Uniform Resource Identifer (URI) или адрес Internet Protocol (IP), связанные с этим приложением. В одном и том же узле исполнителе Kubernetes может быть запущено множество приложений, однако как они могут сами выставлять их не конфликтуя друг с другом? Давайте рассмотрим эту задачу вместе, а затем погрузимся в собственно сетевую модель Kubernetes.
Обычно, если имеются запущенными в одной и той же машине два различных приложения, в то время когда значение IP адреса является общедоступно, а эти два приложения обладают открытым доступом, тогда два приложения не смогут одновременно выполнять ожидание по одному и тому же порту. Когда они оба пытаются выполнять ожидание по тому же самому порту в одной и той же машине, одно из приложений не будет запускаться поскольку этот порт задействован. Простая иллюстрация этого представляется на следующей схеме:
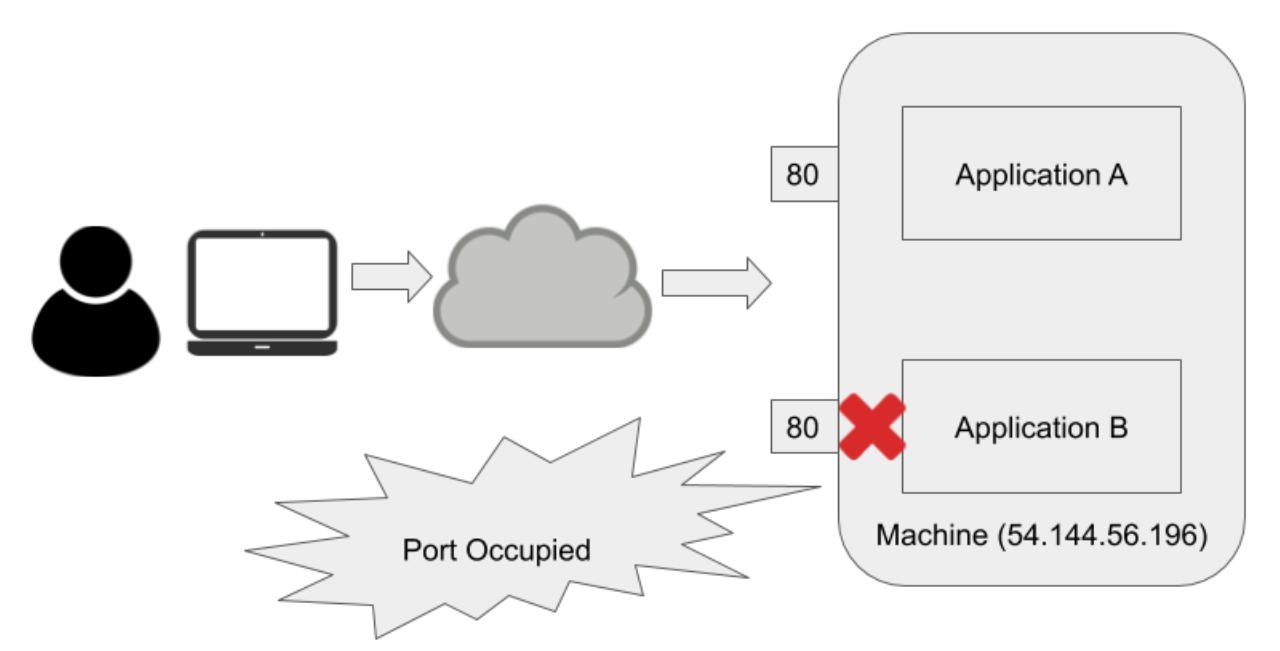
Для решения проблемы конфликта совместного использования порта, эти два приложения обязаны применять различные порты. Очевидно, основное ограничение здесь состоит в том, что такие два приложения обязаны совместно применять один и тот же адрес IP. Что ели бы они обладали своими собственными IP адресами, в то же самое время продолжая находиться в одной и той же самой машине? Это в чистом виде подход Docker. Это помогает когда такое приложение не должно выставлять себя само вовне, что иллюстрируется на следующей схеме:
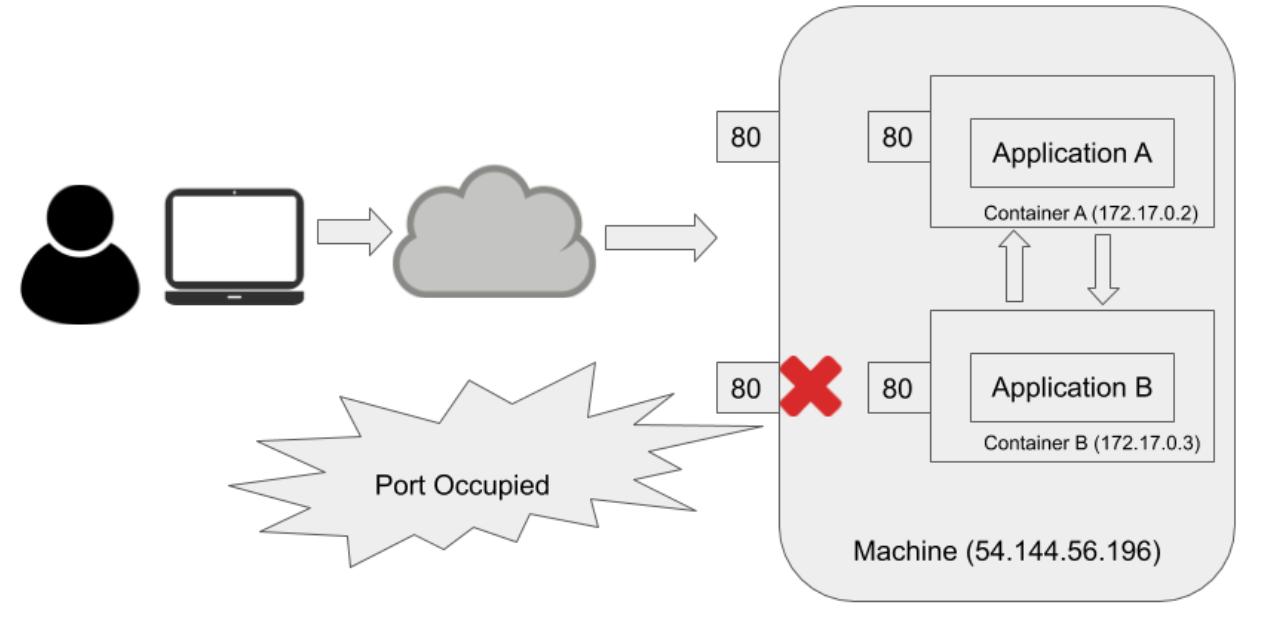
На нашей предыдущей схеме оба приложения имеют свои собственные IP адреса,а потому они оба способны выполнять
ожидание по порту 80. Они способны
взаимодействовать друг с другом, поскольку они пребывают в одной и той же подсети (например, мост Docker). Тем не
менее, если обоим приложениям требуется самостоятельно выставлять себя вовне через привязку значения порта контейнера
в порт своего хоста, они не смогут оба привязаться к тому же самому порту
80. По крайней мере одна из таких
привязок порта завершится неудачей. Как показано на нашей предыдущей схеме, контейнер
B не сможет привязаться к порту хоста
80, поскольку порт хоста
80 уже занят контейнером
A. Всё ещё присутствует проблема
еонфликта совместного применения порта.
Динамическая настройка порта привносит большое число осложнений в свою систему, относящихся к размещению порта и обнаружению приложения; тем не менее, Kubernetes не принмает такогй подход. Давайте же обсудим подход Rubernetes для решения данной задачи.
В кластере Kubernetes каждый под получает свой собственный IP адрес. Это означает, что приложения способны взаимодействовать друг с другом на уровне подов. Вся прелесть такой архитектуры состоит в том, что он предлагает чистую, обратно совместимую модель, в которой поды действуют как Виртуальные Машины (ВМ) или физические хосты с точки зрения выделения портов, именования, обнаружения службы, балансировки нагрузки, конфигурирования приложения и миграции. Контейнеры внутри одного и того же пода совместно используют один и тот же IP адрес. Маловероятно что аналогичные приложения, которые используют один и тот же порт (Apache и nginx) будут запущены внутри одного и того же самого пода. На практике, упакованные в одном и том же контейнере приложения обладают некой зависимостью или служат разным целям и именно разработчики приложения сверху собирают их воедино. Неким простым примером был бы такой, в котором в одном и том же поде имеется сервер HyperText Transfer Protocol (HTTP), либо некий контейнер nginx для обслуживания статических файлов и основное веб приложение для обслуживания динамического содержимого.
Для реализации выделения IP адресов, управления и взаимодействия подов Kubernetes получает усиление со стороны подключаемых модулей CNI. Тем не менее, всем таким подключаемым модулям необходимо следовать двум фундаментальным понятиям, приводимым здесь:
-
Поды в неком узле способны взаимодействовать со всеми подами во всех узлах не применяя Network Address Translation (NAT).
-
Такие агенты как
kubeletспособны взаимодействовать с полами в том же самом узле.
Эти два предыдущих требования усиливают простоту миграции приложений внутри соответствующей ВМ в некий под.
Назначаемые каждому поду IP адреса являются частными IP адресами или IP алресами кластера, которые не имеют открытого доступа. Следовательно, как же некое приложение становится общедоступным без конфликтов с прочими приложениями в этом кластере? Именно служба Kubernetes является тем, что выходит на поверхность из внутреннего приложения в общий доступ. В последующих разделах мы глубже погрузимся в рассмотрение понятия службы Kubernetes. На данный момент будет полезным суммировать всё содержимое этой главы в схеме следующим образом:
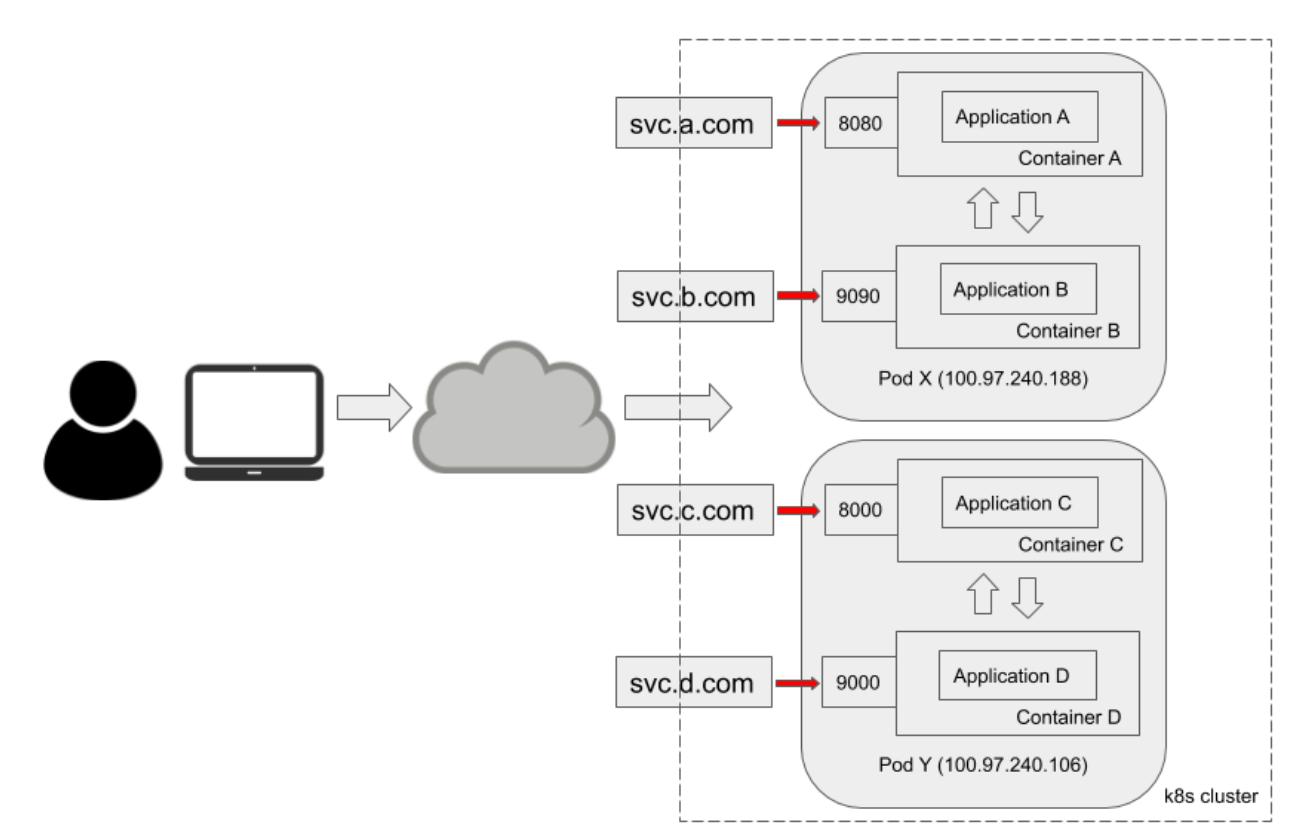
В нашей предыдущей схеме имеется k8s
cluster, в котором присутствуют четыре приложения, запущенные в двух подах:
Application A и
Application B исполняются в
Pod X и они совместно используют один
и тот же IP адрес пода - 100.97.240.188
- в то время как они выполняют ожидание соответственно по порту
8080 и
9090. Аналогично,
Application C и
Application D запущены в
Pod Y и выполняют ожидание, соответственно,
в портах 8000 и
9000. Все эти четыре приложения
общедоступны через следующие развёрнутые в открытый доступ службы Kubernetes:
svc.a.com,
svc.b.com,
svc.c.com и
svc.d.com. Такие поды
(X и
Y в данной схеме) могут быть развёрнуты
в одном и том же ухле исполнителя или реплицироваться в 1 000 узлов. Тем не менее, это не имеет отличий с точки зрения
пользователя или службы. Хотя такое приведённое на схеме развёртывание совершенно не обычно, всё ещё требуется
развёртывать более одного контейнера внутри одного и того же пода. Теперь настало время взглянуть на взаимодействие
контейнеров внутри одного и того же пода.
Контейнеры внутри одного и того же пода совместно применяют тот же самый IP адрес пода. Обычно именно разработчики приложения сверху пакуют соответствующие образы контейнеров воедино и разрешают все возможные конфликты использования ресурсов, например, ожидание по порту. В этом разделе мы окунёмся глубже в технические подробности того как проистекает взаимодействие между контейнерами внутри определённого пода, а также выделим те взаимодействия, которые имеют место позади имеющегося сетевого уровня.
Пространства имён Linux являются функциональной возможностью самого ядра Linux для разбиения на разделы ресурсов для целей изоляции. С выделенными им пространствами имён некий набор процессов видит одно множество ресурсов, в то время как другой набор процессов видит иное множество ресурсов. Пространства имён выступают главной фундаментальной стороной современной технологии контейнеров. Для читателей важно осознавать это понятие чтобы глубоко разобраться в Kubernetes. Итак, мы излагаем все пространства имён Linux с пояснениями. Начиная с версии ядра Linux 4.7 имеются семь видов пространств имён, перечисляемых далее:
-
cgroup: Выполняет изолирование cgroup и каталог корня. Пространства имён cgroup виртуализируют имеющееся представление cgroup некого процесса. Всякое пространство имён cgroup обладает собственными каталогами корня cgroup.
-
IPC: Изолирует объекты System V Interprocess Communication (IPC) или очереди сообщений Portable Operating System Interface (POSIX)
-
Network: Изолирует сетевые устройства, стеки протоколов, порты, таблицы маршрутизации IP, правила межсетевого экрана и тому подобного.
-
Mount: Изолирует точки монтирования. Тем самым, имеющиеся в каждом монтируемом экземпляре пространства имён процессы будут обладать отличающимися иерархиями отдельного каталога.
-
PID: Изолирует идентификаторы процесса (PID, process ID). Процессы из различных пространств имён PID могут обладать одними и теми же PID.
-
User: Изолирует идентификаторы пользователя и идентификаторы групп, корневой каталог, ключи и возможности. Некий процесс способен иметь различные идентификаторы пользователя и групп внутри и снаружи некого пространства имён пользователей.
-
Unix Time Sharing (UTS): Изолирует два системных идентификаторов: значения имени хоста и доменного имени Network Information Service (NIS).
Хотя каждое их этих пространств имён является мощным и служит целям изоляции в различных ресурсах, не все из них приспособлены для контейнеров внутри одного и того же пода. Контейнеры внутри одного и того же пода совместно используют по крайней мере одно и то же пространство имён IPC и сетевое пространство имён; в результате, K8S требуется разрешать потенциальные конфликты при использовании портов. Будет иметься созданным интерфейс обратной петли (loopback), а также интерфейс виртуальной сети, причём с неким IP адресом, назначенным этому поду. Более подробная схема будет выглядеть следующим образом:
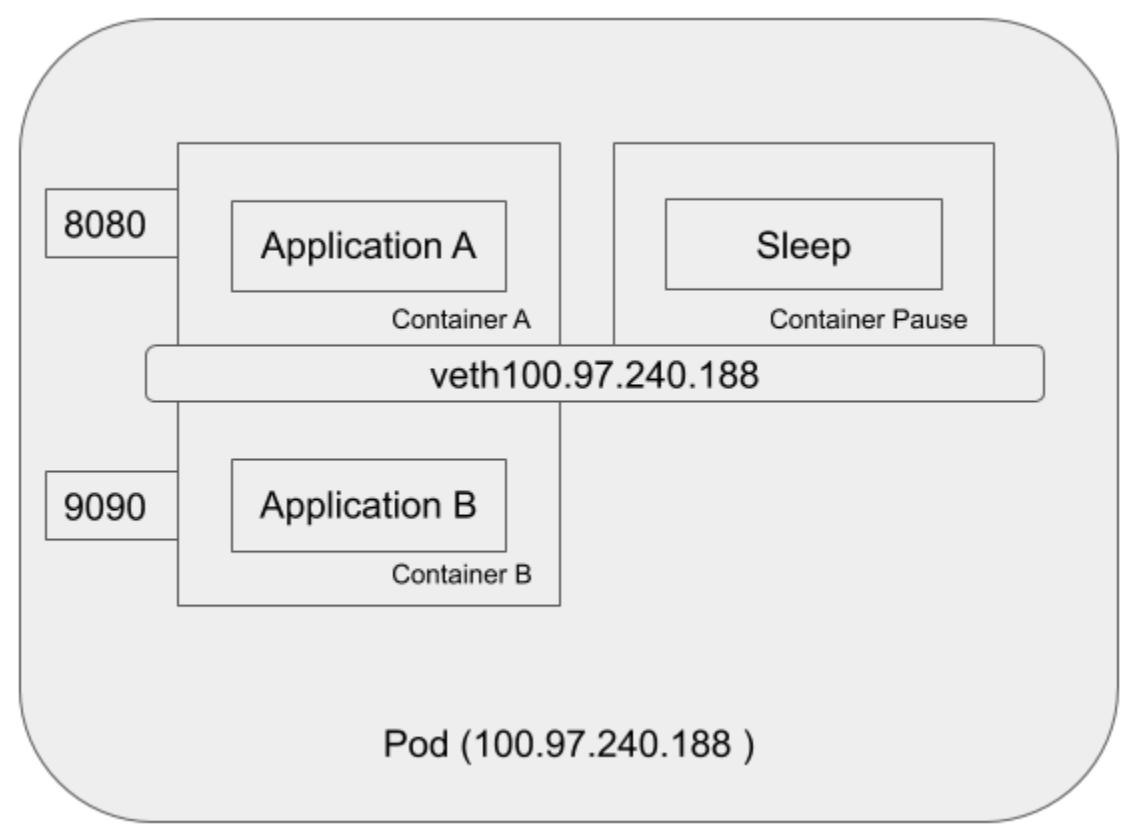
На этой схеме имеется один контейнер Pause,
запущенный внутри этого пода помимо контейнеров A
и B. Когда вы подключитесь через
Secure Shell
(SSH) к некому узлу кластера Kubernetes,
и запустите внутри этого узла команду docker ps, вы обнаружите по крайней
мере один контейнер, который был запущен при помощи команды pause. Эта
команда pause приостанавливает данный текущий процесс вплоть до получения
некого сигнала. В целом этот контейнер не выполняет ничего кроме пребывания в спящем состоянии. Несмотря на
отсутствие активности этот контейнер Pause
играет важную роль в своём поде. Он служит заполнителем для удержания пространства сетевых имён под все прочие
контейнеры в одном и том же поде. Тем временем, контейнер Pause
получает IP адрес для своего виртуального сетевого интерфейса, который будет применяться всеми прочими контейнерами
для связи друг с другом и с внешним миром.
Мы решили слегка выйти за рамки сетевого взаимодействия между контейнерами в одном поде. Основная причина этого состоит в том, что сам путь взаимодействия порой может становиться частью цепи уничтожения Тем самым, очень важно знать все возможные способы взаимодействия между логическими элементами. Более подробно об этом вы узнаете в Главе 3, Моделирование угроз.
Внутри некого пода все контейнеры совместно используют одно и то же пространство имён IPC с тем, чтобы контейнеры
были способны взаимодействовать через объект IPC или очередь сообщений POSIX. Помимо такого канала IPC, контейнеры
внутри одного и того же пода также имеют возможность взаимодействия через совместно используемый смонтированый том.
Такой смонтированный том может быть некой временной памятью, файловой системой хоста или облачным хранилищем. Когда
такой том смонтирован контейнерами внутри их Пода, тогда контейнеры способны считывать и записывать в этом томе одни и
те же файлы. И последнее, хотя и не в отношении важности, в бета, начиная с выпуска 1.12 Kubernetes, функциональная
возможность shareProcessNamespace наконец вышла в стабильную в 1.17.
Чтобы позволить контейнерам внутри некого пода разделять общее пространство имён PID, пользователи могут установить в
Podspec вариант shareProcessNamespace. В результате этого
Application A из
Container A имеет возможность видеть
Application B из
Container B. Поскольку они оба пребывают
в одном и том же пространстве имён PID, они способны взаимодействовать при помощи сигналов, таких как SIGTERM,
SIGKILL и тому подобных. Такое взаимодействие можно увидеть на следующей схеме:
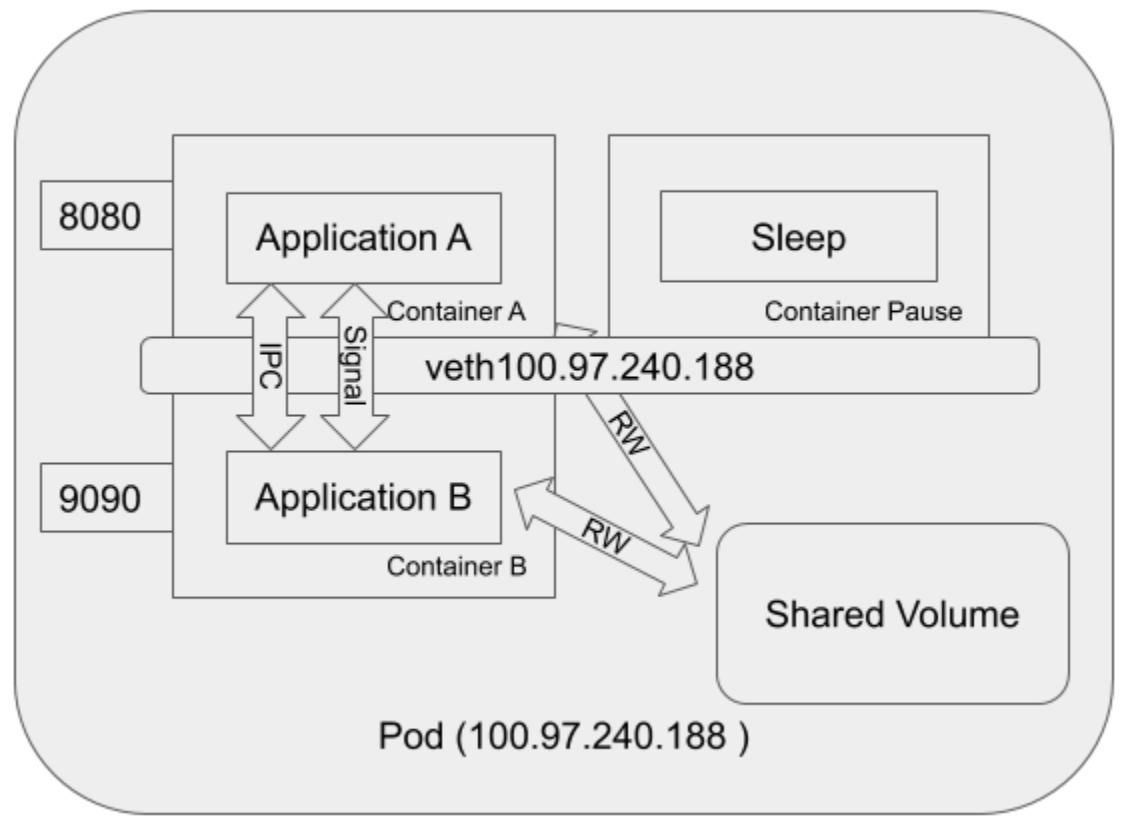
Как показывает предыдущая схема, контейнеры внутри одного и того же пода способны взаимодействовать друг с другом через сетевую среду, некий канал IPC, совместный том и посредством сигналов.
Поды Kubernetes это динамические и эфемерные существа. После создания некого набора подов из развёртывания или DaemonSet каждый под получает свой собственный IP адрес, однако, когда происходит исправление или подуль погибает и перезапускается, поды могут получить назначенным новый IP адрес. Это приводит к двум фундаментальным проблемам связи с учётом того, что некому набору подов (интерфейсу) требуется взаимодействовать с другим набором подов (серверной частью), которые подробнее приводятся ниже:
-
С учётом того, что IP адреса могут изменяться, какие именно IP адреса будут допустимыми адресами необходимых целевых подов?
-
Зная значения допустимых IP адресов, с каким именно подом нам надлежит взаимодействовать?
Теперь давайте перейдём к службе Kubernetes, ибо именно она является решением этих двух задач.
Служба Kubernetes это некая абстракция группировки наборов подов определением того как выполнять доступ к этим подам. Такой набор подов имеет целеуказание от некой службы, которое обычно определяется неким селектором на основе меток подов. Эта служба Kubernetes также получает назначенным ей некий IP адрес, однако он виртуальный. Основная причина вызова его виртуального IP адреса кроется в том, что с точки зрения узла не существует никакого пространства имён, ни сетевого интерфейса, привязанных к службе, как это имеет место в случае с подом. Кроме того, в отличии от подов, такая служба более стабильна и её IP адрес с меньшей степенью вероятности будет часто изменяться. Звучит так, словно мы будем способны решить те две задачи, которые были упомянуты ранее. Прежде всего, определим некую службу для своих целевых наборов подов с настроенным селектором; затем позволим некой ассоциированной с этой службой магии решить какой целевой под должен получать соответствующий запрос. Итак, когда мы взглянем снова на взаимодействие пода с подом, мы будем фактически обсуждать взаимодействие пода со службой (и далее с подом).
Итак, что это за магия, стоящая за конкретной службой? Теперь мы представим самую великую сетевую магию:
компонент kube-proxy.
Вы можете предсказать то, чем занимается kube-proxy, по его названию.
В целом, то чты выполняет этот посредник (не инвертированный посредник), так это передача обмена между
определённым клиентом и его серверами по двум соединениям: входящим от этого клиента и исходящим для необходимых
серверов. Итак, то что выполняет kube-proxy для решения двух упомянутых
ранее задач, это передача всего обмена, предназначенного (значением виртуального IP) для его целевой службы тем
подам, которые сгруппированы (значением реального IP) соответствующей службой; тем временем,
kube-proxy отслеживает панель управления Kubernetes на предмет добавлений
или удалений соответствующих служб и терминальных объектов (подов). Для хорошего исполнения такой простой задачи
kube-proxy несколько раз эволюционировал.
Режим посредника пространства пользователя
Компонент kube-proxy в режиме посредника установленного пространства
пользователя действует как реальный прокси (посредник). Прежде всего kube-proxy
будет ожидать по некому случайно выбранному в своём узле порту в качестве порта посредника для определённой
службы. Все входящие в это порт посредника соединения будут переправляться в надлежащие серверные поды данной службы.
Когда kube-proxy требуется принять решение в какой именно серверный под
отправлять запросы, он принимает во внимание установки SessionAffinity
данной службы. Затем kube-proxy установит
iptables rules (правила iptables) для переправления
всякого обмена, чьим назначением является данная целевая служба (виртуальный IP) в надлежащий порт посредника,
который выступает посредником соответствующего серверного порта. Наша приводимая ниже из документации Kubernetes
схема также иллюстрирует это:
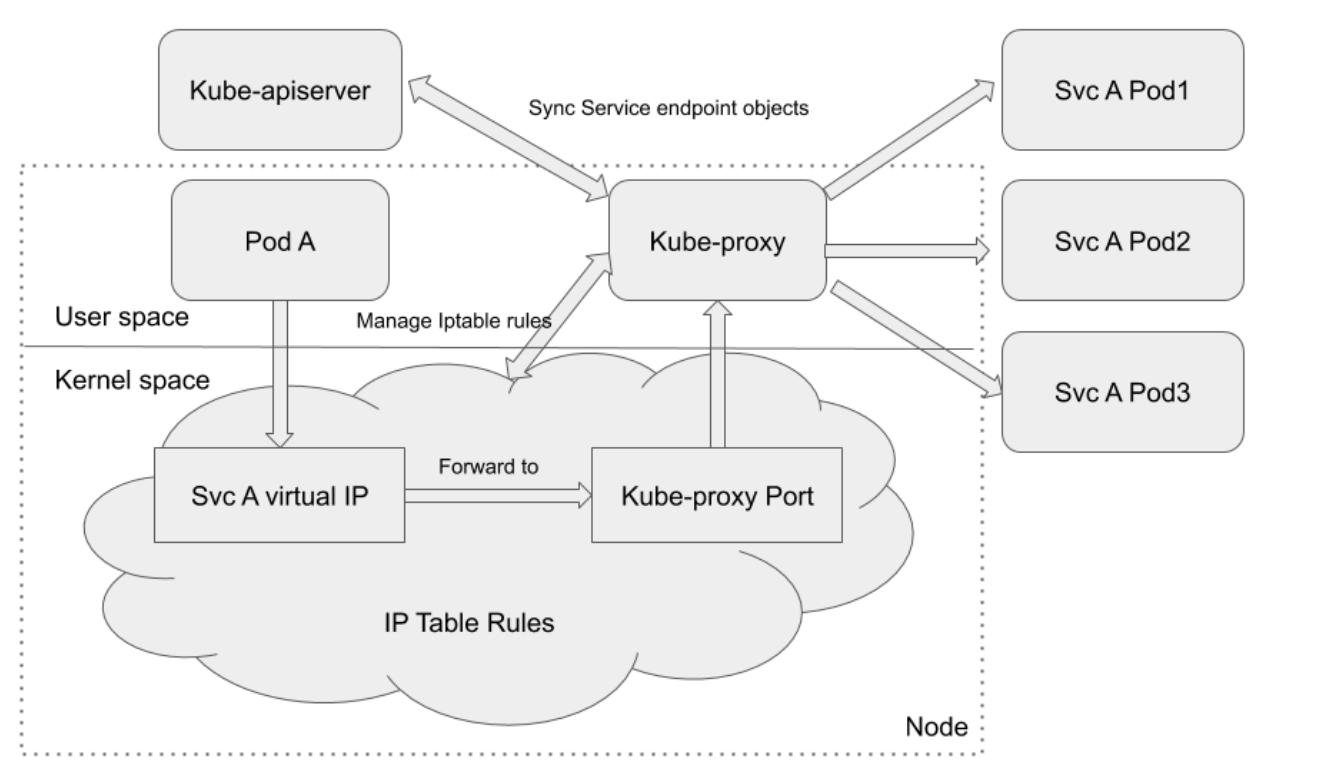
По умолчанию, kube-proxy в режиме пространства пользователя применяет
карусельный алгоритм для выбора того в какой серверный под отправлять соответствующие запросы. Теневая сторона
этого режима очевидна. Перенаправление обмена выполняется в самом пространстве пользователя. Это подразумевает,
что пакеты выстраиваются в самом пространстве пользователя и затем выстраиваются обратно в пространство ядра
при каждом прохождении через данного посредника. Такое решение нельзя назвать идеальным с точки зрения
производительности.
Режим посредника iptables
В режиме посредника iptables, компонент kube-proxy выгружает
задание передачи обмена в netfilter при помощи правил iptables.
kube-proxy в режиме посредника iptables отвечает лишь за сопровождение
и обновление устанавливаемых правил iptables. Весь имеющий целью IP службы обмен будет переправляться в
надлежащие серверные поды через netfilter на основании управляемых
kube-proxy правил iptables. Следующая схема из документации Kubernetes
иллюстрирует это:
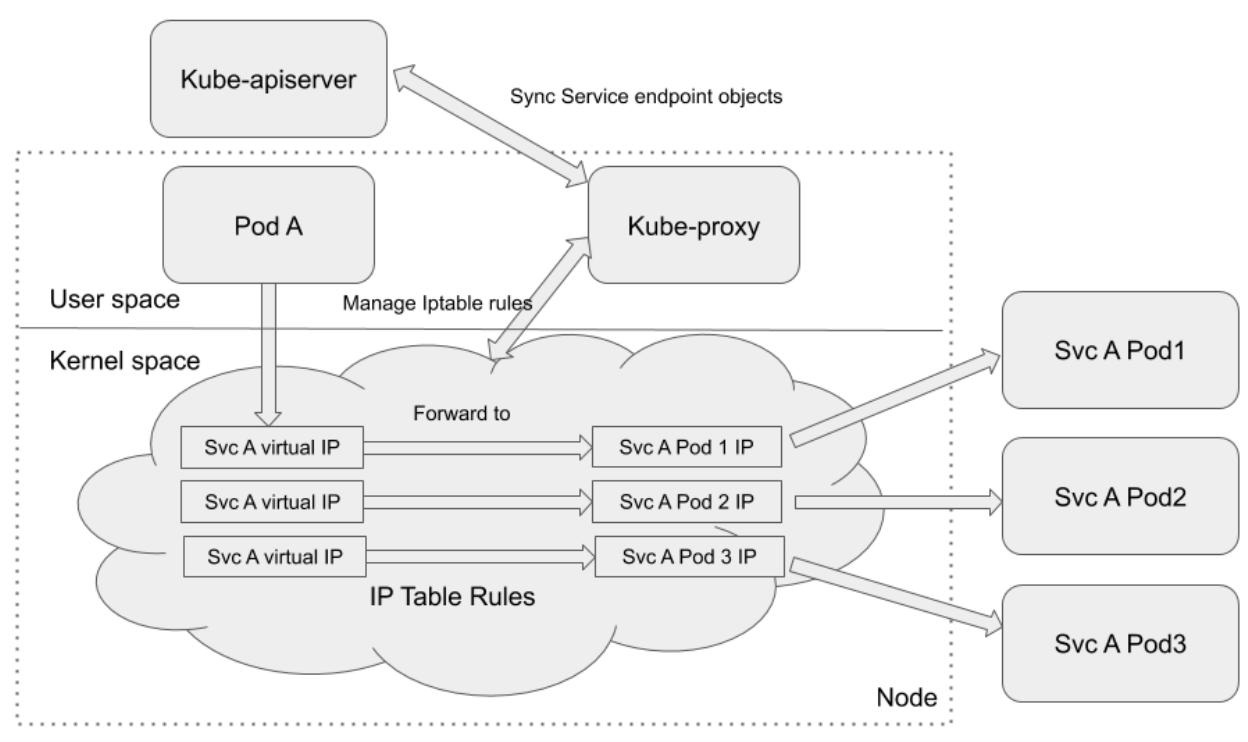
По сравнению с режимом посредника пространства пользователя, основное преимущество данного ражима iptables
очевидно. Весь обмен больше не проходит из пространства ядра в соответствующее пространство пользователя и затем
обратно в пространство ядра. Вместо этого, он будет переправляться напрямую в пространство ядра. Накладные расходы
намного ниже. Недостатком этого режима выступает необходимость обработки ошибок. Для того случая, когда
kube-proxy исполняется в режиме посредника iptables, когда самый первый
выбранный под не отвечает, такое соединение завершается отказом. В то время как в режиме пространства пользователя,
тем не менее, kube-proxy выявил бы отказ в подключении к самому первому поду
и затем автоматически выполнил бы повтор с другим серверным подом.
Режим посредника IPVS
Компонент kube-proxy в режиме посредника
IP Virtual Server
(IPVS) управляет и применяет правила IPVS для
перенаправления обмена необходимой целевой службы в соответствующие серверные поды. Также как и для правил
iptables, правила IPVS также выполняются в самом ядре. IPVS собирается поверх
netfilter. Он реализует балансировку нагрузки транспортного уровня
в качестве части самого ядра Linux, будучи частью Linux Virtual
Server (LVS). LVS запускается в
хосте и действует в качестве балансировщика нагрузки спереди от кластера реальных серверов и весь обмен
Transmission Control Protocol
(TCP) или
User Datagram Protocol
(UDP) в надлежащую службу IPVS будет переправляться
в имеющиеся реальные серверы. Это заставляет службу IPVS установленных реальных серверов проявляться в качестве
виртуальных служб по некому отдельному IP адресу. IPVS исключительно подходит для службы Kubernetes. Приводимая
далее схема из документации Kubernetes иллюстрирует это:
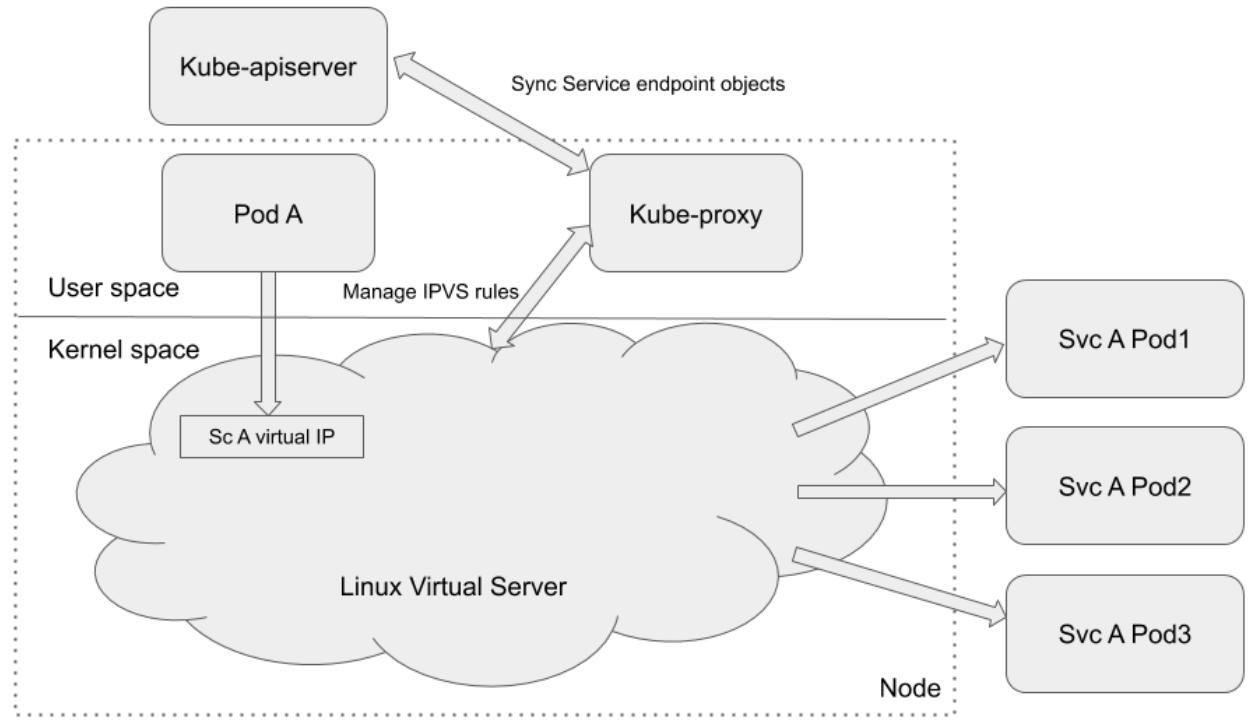
Сопоставляя с режимом посредника iptables, и правила IPVS, и правила iptables выполняются в пространстве
ядра. Тем не менее, правила iptables вычисляются последовательно для каждого приходящего пакета. Чем больше правил
установлено, тем длиннее весь процесс. Реализация IPVS отличается от iptables: она применят для хранения
получателей пакетов таблицы хэшей , а потому она обладает меньшими задержками и более быстрой синхронизацией
правил, нежели правила iptables. Режим IPVS также предоставляет больше возможностей балансировки нагрузки.
Единственным ограничением для применения режима IPVS является то, что вам следует обладать в соответствующем узле
доступным IPVS Linux для его употребления kube-proxy.
Развёртывания Kubernetes создают и уничтожают поды динамически. Для общей трехуровневой веб архитектуры когда интерфейсная и серверная части являются разными подами, это может оказаться проблемой. Поды интерфейса не знают как подключаться к соответствующим серверным. Абстракция сетевой службы в Kubernetes разрешает эту проблему.
Определённая служба Kubernetes включает сетевой доступ для некого логического набора подов. Такой логический набор подов обычно определяется с применением меток. Когда выполняются некий сетевой запрос для какой- то службы, он выбирает все поды с заданной меткой и переправляет эти сетевые запросы в один из выбранных подов.
Служба Kubernetes определяется при помощи некого файла YAML (YAML Ain't Markup Language) следующим образом:
apiVersion: v1
kind: Service
metadata:
name: service-1
spec:
type: NodePort
selector:
app: app-1
ports:
- nodePort: 29763
protocol: TCP
port: 80
targetPort: 9376
В этом YAML файле применяется следующее:
-
Свойство
typeопределяет как данная служба выставляется в установленной сетевой среде. -
Свойство
selectorопределяет значение метки для своих Подов. -
Свойство
portприменяется для задания значения порта, выставляемого вовнутрь своего кластера. -
Свойство
targetPortзадаёт значение порта в котором данный контейнер выполняет ожидание.
Обычно службы определяются неким селектором, который является некой меткой, подключаемой к подам, которым необходимо пребывать в одно и той же службе. Служба может быть определена без селектора. Это обычно выполняется для доступа к внешним службам или к службам в различных пространствах имён. Службы без селекторов ставятся в соответствие сетевым адресам и портам при помощи терминального объекта следующим образом:
apiVersion: v1
kind: Endpoints
subsets:
- addresses:
- ip: 192.123.1.22
ports:
- port: 3909
Этот терминальный объект будет направлять обмен для 192.123.1.22:3909
для подключённой службы.
Для поиска служб Kubernetes разработчики либо используют переменные среды, либо соответствующую Domain Name System (DNS), приводим подробности:
-
Переменные среды: При создании некой службы в соответствующем узле создаются переменные среды в виде
NAME]_SERVICE_HOSTи[NAME]_SERVICE_PORT. Эти переменные среды могут применяться прочими подами или приложениями для достижения соответствующей службы, что демонстрируется следующим фрагментом кода:DB_SERVICE_HOST=192.122.1.23 DB_SERVICE_PORT=3909 -
DNS: Соответствующая служба DNS добавляется в Kubernetes в качестве надстройки. Kubernetes поддерживает два дополнения: CoreDNS и Kube-DNS. Службы DNS содержат соответствие значения имени службы IP адресам. Поды и приложения применяют такое соответствие для подключения к необходимой службе.
Клиенты могут определять место IP необходимой службы из переменных среды, а также через некий DNS запрос и существуют различные типы служб для обслуживания различных типов клиентов.
Служба может иметь четыре следующих различных типа:
-
ClusterIP: Это задаваемое по умолчанию значение. Эта служба доступна только внутри самого кластера. Для внешнего доступа к службам ClusterIP могут применяться некий посредник Kubernetes. Применение посредника
kubectlпредпочтительно для отладки, но не рекомендуется в промышленных службах, поскольку требуется запускkubectlпользователем с аутентификацией. -
NodePort: Такая служба доступна через некий статический порт в каждом узле. NodePort выставляют по одной службе для порта и требует управления вручную изменениями IP адреса. Это также превращает NodePort в не подходящие для промышленных сред.
-
LoadBalancer: Данная служба доступна через некий балансировщик нагрузки. Балансировщик узла для службы обычно некий затратный вариант.
-
ExternalName: Эта служба обладает неким связанным с ней Canonical Name Record (CNAME), которое и применяется для доступа к этой службе.
Имеется несколько типов служб для использования и они работают на 3 и 4 уровнях модели OSI. Ни одна из них не способна переправлять сетевой запрос на уровне 7. Для запросов маршрутизации в приложения было бы идеально если бы такая служба Kubernetes поддерживалась как некая функциональная возможность. Давайте рассмотрим далее как здесь может поспособствовать некий объект ingress (вход доступа).
Ingress это не тип службы, но о нём стоит упомянуть. Ingress это интеллектуальный маршрутизатор, который обеспечивает внешний HTTP/ HTTPS (сокращение для безопасного HTTP, HyperText Transfer Protocol Secure) доступ к некой службе в кластере. Отличающиеся от HTTP/ HTTPS службы могут выставляться только для служб с типами NodePort или LoadBalancer. Некая служба Ingress определяется при помощи файла YAML, примерно так:
apiVersion: extensions/v1beta1
kind: Ingress
spec:
rules:
- http:
paths:
- path: /testpath
backend:
serviceName: service-1
servicePort: 80
Такая минимальная спецификация переправляет весь обмен из маршрута testpath
в маршрут service-1.
Объекты Ingress обладают пятью вариациями, перечисляемыми здесь:
-
Single-service Ingress: Выставляет единственную службу определяя устанавливаемый по умолчанию сервер и никаких правил, что иллюстрируется следующим блоком кода:
apiVersion: extensions/v1beta1 kind: Ingress spec: backend: serviceName: service-1 servicePort: 80Этот ingress (вход доступа) предоставляет для
service-1выделенный IP адрес. -
Simple fanout: Веерная конфигурация отправляет обмен из отдельного IP во множество служб на основе значения Uniform Resource Locator (URL), что иллюстрируется следующим блоком кода:
apiVersion: extensions/v1beta1 kind: Ingress spec: rules: - host: foo.com http: paths: - path: /foo backend: serviceName: service-1 servicePort: 8080 - path: /bar backend: serviceName: service-2 servicePort: 8080Данная конфигурация разрешает запросам к
foo.com/fooдостигатьservice-1, аfoo.com/barподключаться кservice-2. -
Name-based virtual hosting: Данная конфигурация использует множество имён хоста для некого отдельного IP для достижения различных служб, что иллюстрируется следующим блоком кода:
apiVersion: extensions/v1beta1 kind: Ingress spec: rules: - host: foo.com http: paths: - backend: serviceName: service-1 servicePort: 80 - host: bar.com http: paths: - backend: serviceName: service-2 servicePort: 80Эта конфигурация разрешает запросы
foo.comподключаться кservice-1и запросамbar.comподключаться кservice-2. В этом случае обеим службам выделяется одно и то же значение IP адреса. -
Transport Layer Security (TLS): Для безопасности соответствующих терминалов в их спецификацию ingress может добавляться некий секрет:
apiVersion: extensions/v1beta1 kind: Ingress spec: tls: - hosts: - ssl.foo.com secretName: secret-tls rules: - host: ssl.foo.com http: paths: - path: / backend: serviceName: service-1 servicePort: 443В этой конфигурации значение секрета
secret-tlsпредоставляет соответствующий частный ключ и сертификат для определяемого терминала. -
Load balancing: Некий ingress балансировки нагрузки предоставляет политику балансировки нагрузки, которая содержит соответствующий алгоритм балансировки нагрузки и схему весов для всех объектов ingress.
В этом разделе мы ввели необходимые базовые понятия службы Kubernetes, включая объекты ingress. Это всё
объекты Kubernetes. Тем не менее, реальная сетевая магия взаимодействия осуществляется определёнными компонентами,
например, kube-proxy. Далее мы введём CNI и подключаемые методы CNI, которые
выступают основой для сетевого взаимодействия кластера Kubernetes.
В Kubernetes CNI это сокращение для Container Network Interface. CNI является проектом Cloud Native Computing Foundation (CNCF) - вы можете обнаружить дополнительные сведения на GitHub. В целом, в этом проекте имеется три момента: некая спецификация, библиотеки для написания подключаемых модулей конфигурирования сетевых интерфейсов в контейнерах Linux и некоторые поддерживаемые подключаемые модули. Когда люди обсуждают CNI, они обычно ссылаются либо на его спецификацию, либо на подключаемые модули CNI. Основное взаимодействие между CMI и подключаемыми модулями CNI заключается в том, что такие подключаемые модули CNI являются исполняемыми двоичными файлами, которые реализуют соответствующую спецификацию CNI. Теперь давайте рассмотрим не неком верхнем уровне саму спецификацию CNI и подключаемые модули, а затем предоставим краткое введение в один из подключаемых модулей, Calico.
Спецификация CNI сосредоточена только на сетевых подключениях контейнеров и удалении выделенных ресурсов при удалении контейнеров. Позвольте мне более тщательно рассмотреть это. Во- первых, с точки зрения контейнера времени исполнения, обсуждаемая спецификация CNI определяет некий интерфейс для соответствующего компонента Container Runtime Interface (CRI, например, Docker) для взаимодействия - например, добавлять некий контейнер к какому- то сетевому интерфейсу при создании контейнера, или удалять такой сетевой интерфейс при гибели контейнера. Во- вторых, с точки зрения сетевой модели Kubernetes, поскольку подключаемые модули CNI являются ещё одной изюминкой сетевых подключаемых модулей Kubernetes, они должны следовать представленным далее требованиям сетевой модели Kubernetes:
-
Полы в неком узле способны взаимодействовать со всеми прочими подами во всех имеющихся узлах без применения NAT.
-
Такие агенты, как
kubeletспособны взаимодействовать с подами в том же самом узле.
Имеется доступными несколько подключаемых модулей CNI на выбор - просто перечислим некоторые из них: Calico, Cilium, WeaveNet, Flannel и так далее. Реализации подключаемых модулей CNI разнятся, однако в целом, то что выполняют подключаемые модули совпадает. Они осуществляют следующие задачи:
-
Управление сетевыми интерфейсами для контейнеров
-
Выделение IP адресов для подов. Обычно это выполняется через вызовы прочих подключаемых модулей IP Address Management (IPAM), например,
host-local -
Реализует сетевые политики (не обязательно)
В спецификации CNI реализация сетевой политики не требуется, но когда DevOps выбирает какой подключаемый модуль CNI применять, важно принимать во внимание вопросы безопасности. Статья Алексиса Дукастела предоставляет хорошее сопоставление находящихся в основном потоке подключаемых модулей CNI с самым последним обновлением в апреле 2019. Такое сопоставление безопасности примечательно, что можно увидеть на следующем снимке экрана:
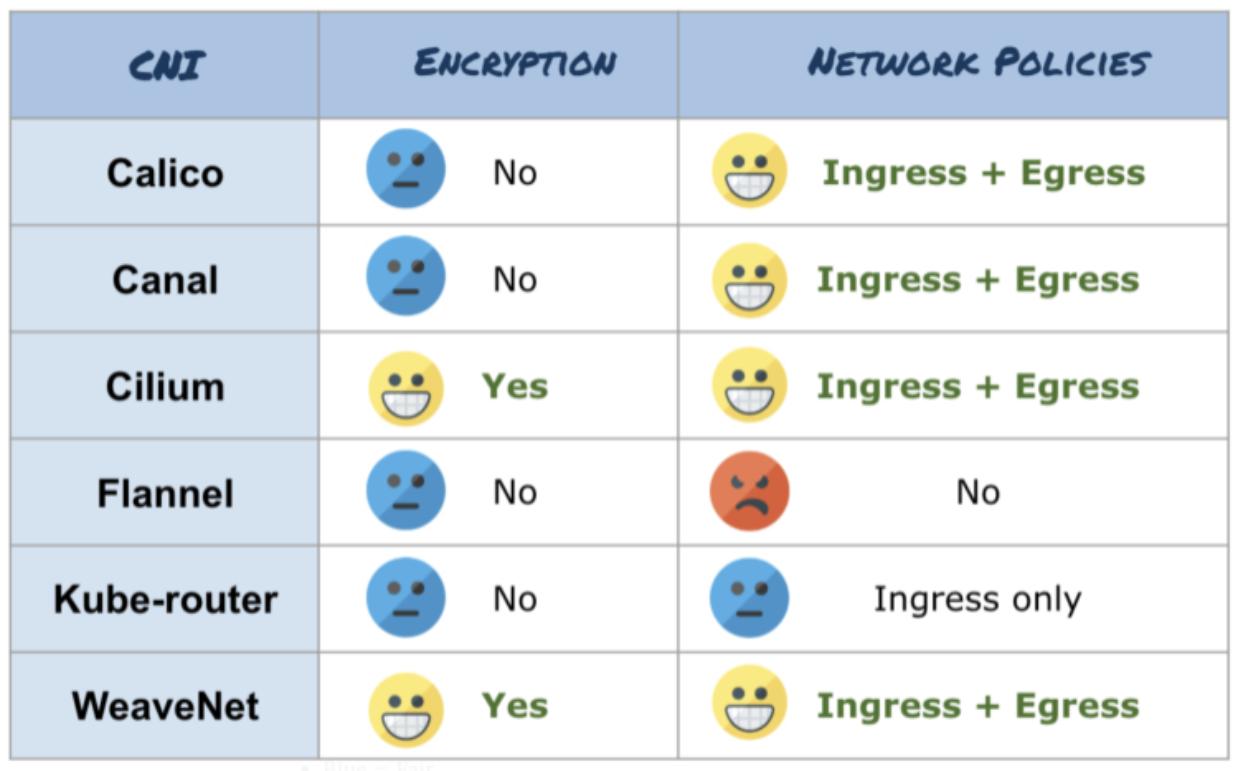
Вы можете видеть, что основная масса перечисленных в списке подключаемых модулей CNI не поддерживает
шифрование. Flannel не поддерживает сетевые политики Kubernetes, в то время как
kube-router поддерживает только сетевые политики ingress.
{Прим. пер.: на момент перевода доступны результаты тестирования, проведённого в августе 2020 процитируем итоги:}
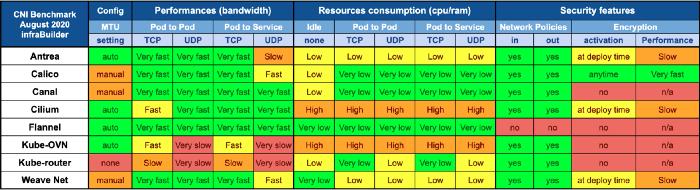
Kubernetes поставляется с установленным по умолчанию подключаемым модулем kubenet,
для применения подключаемых модулей CNI в кластере Kubernetes пользователи должны передавать параметр командной
строки --network-plugin=cni и определять некий файл настроек черезфлаг
--cni-conf-dir в каталоге значений по умолчанию
/etc/cni/net.d . Ниже приводится некий образец настроек, определяемый внутри
кластера Kubernetes с тем, чтобы kubelet знал с каким подключаемым модулем
CNI взаимодействовать:
{
'name': 'k8s-pod-network',
'cniVersion': '0.3.0',
'plugins': [
{
'type': 'calico',
'log_level': 'info',
'datastore_type': 'kubernetes',
'nodename': '127.0.0.1',
'ipam': {
'type': 'host-local',
'subnet': 'usePodCidr'
},
'policy': {
'type': 'k8s'
},
'kubernetes': {
'kubeconfig': '/etc/cni/net.d/calico-kubeconfig'
}
},
{
'type': 'portmap',
'capabilities': {'portMappings': true}
}
]
}
Этот файл настроек CNI сообщает kubelet о необходимости применения
Calico в качестве подключаемого модуля CNI и использовать host-local для
выделения IP адресов подам. В общем списке имеется и другой подключаемый модуль с названием
portmap, который применяется для поддержки
hostPort и который позволяет выставлять порты контейнеров в соответствующий
IP хоста.
При создании некого кластера при помощи Kubernetes Operations (kops) вы также можете определять какой из имеющихся подключаемых модулей CNI вы бы хотели применять, что иллюстрирует следующий блок кода:
export NODE_SIZE=${NODE_SIZE:-m4.large}
export MASTER_SIZE=${MASTER_SIZE:-m4.large}
export ZONES=${ZONES:-'us-east-1d,us-east-1b,us-east-1c'}
export KOPS_STATE_STORE='s3://my-state-store'
kops create cluster k8s-clusters.example.com \
--node-count 3 \
--zones $ZONES \
--node-size $NODE_SIZE \
--master-size $MASTER_SIZE \
--master-zones $ZONES \
--networking calico \
--topology private \
--bastion='true' \
--yes
В этом примере наш кластер создаётся с применением подключаемого модуля CNI
calico.
Calico это проект с открытым исходным кодом, который делает возможными взаимодействие имеющих облачную природу приложений и сопровождение политик. Он интегрирован основными системами оркестрации, такими как Kubernetes, Apache Mesos, Docker и OpenStack. По сравнению с прочими подключаемыми модулями CNI вот некоторые моменты, которые следовало бы выделить:
-
Calico предоставляет плоскую сетевую среду IP, что означает, что не будет иметься никакой инкапсуляции, добавляемой в конец сообщения IP (отсутствие перекрытий). Кроме того, это означает, что каждый назначаемый I соответствующему поду IP адрес полностью готов к маршрутизации. Возможность работы без перекрытий предоставляет исключительные характеристики пропускной способности.
-
Calico обладает лучшей производительностью и меньшим потреблением ресурсов в соответствии с экспериментами Алексиса Дукастела.
-
Calico предлагает более выразительные сетевые политики по сравнению со встроенными в Kubernetes сетевыми политиками. Сетевые политики Kuberneted способны задавать только правила белых списков, в то время как сетевые политики Calico могут определять и правила чёрного списка (deny - отказа в доступе).
при интеграции Calico в Kubernetes вы обнаружите внутри своего кластера Kubernetes запущенными три компонента, вот они:
-
calico/nodeэто некая служба DaemonSet, что подразумевает, что она запускается во всех узлах общего кластера. Она отвечает за программирование и отправку маршрутов ядра в локальные рабочие потоки и усиливает правила локальной фильтрации, требующиеся для текущих сетевых политик в этом кластере. Она также отвечает за широковещательное распространение таблиц маршрутизации в прочие узлы для удержания маршрутов IP в синхронном состоянии по всему кластеру. -
Исполняемый код подключаемого модуля CNI. Содержит два исполняемых файла (
calicoиcalico-ipam), а также файл настроек, которые интегрируются напрямую с процессомkubeletKubernetes в каждом узле. Он отслеживает событие создания пода и затем добавляет поды в установленную сетевую среду Calico. -
Контроллеры Calico Kubernetes, запускаемые как обособленные поды, выполняют мониторинг API (application programming interface) Kubernetes для удержания Calico в синхронном состоянии.
Calico это популярный подключаемый модуль CNI и к тому же определяемый по умолчанию подключаемый модуль CNI в GKE (Google Kubernetes Engine). Администраторы Kubernetes имеют полную свободу выбирать именно тот подключаемый модуль CNI, который лучше подходит под их требования. Просто отметьте для себя, что безопасность существенна и является одним из подлежащих обсуждению сторон. Мы уже много обсуждали сетевые среды Kubernetes в предыдущих разделах. Давайте быстро сделаем заключительный обзор их снова чтобы вы не забыли о них.
В кластере Kubernetes каждый под получает назначенным ему некий IP адрес, однако этот внутренний IP адрес недоступен извне. Контейнеры внутри одного пода могут взаимодействовать друг с другом через свои названия в сетевом интерфейсе, поскольку они совместно используют одно и то же сетевое пространство имён. Контейнерам внутри одного пода также требуется решать проблему конфликта ресурсов портов: однако она крайне маловероятна, поскольку различные контейнеры группируются в одном поде для некой определённой цели. Кроме того, не лишним будет отметить, что контейнеры внутри одного пода могут взаимодействовать помимо сетевой среды через совместный том, канал IPC и сигналы процессов.
Служба Kubernetes помогает стабильности взаимодействия пода с подом, поскольку поды обычно эфемерны. Такая
служба также получает назначенным некий IP адрес, однако он виртуален, что означает, что никакой сетевой интерфейс
не создаётся для такой службы. В действительности маршрутизацию всего обмена к необходимой целевой службе в
соответствующем серверном поде выполняет сетевая магия kube-proxy. Имеются
три различных режима kube-proxy: посредник пространства пользователя, посредник
iptables и посредник IPVS. Служба Kubernetes не только предоставляет поддержку для взаимодействия пода с подом,
но также делает возможным взаимодействие с внешними источниками.
Существует несколько способов выставления служб с тем, чтобы они становились доступными из внешних источников, такие как NodePort, LoadBalancer и ExternalName. Кроме того, вы также можете создавать объект Ingress (вход доступа) для достижения той же цели. Наконец, хотя это и тяжело, мы воспользуемся следующей схемой чтобы консолидировать большую часть знаний, которые мы бы хотели выделить в этой главе:
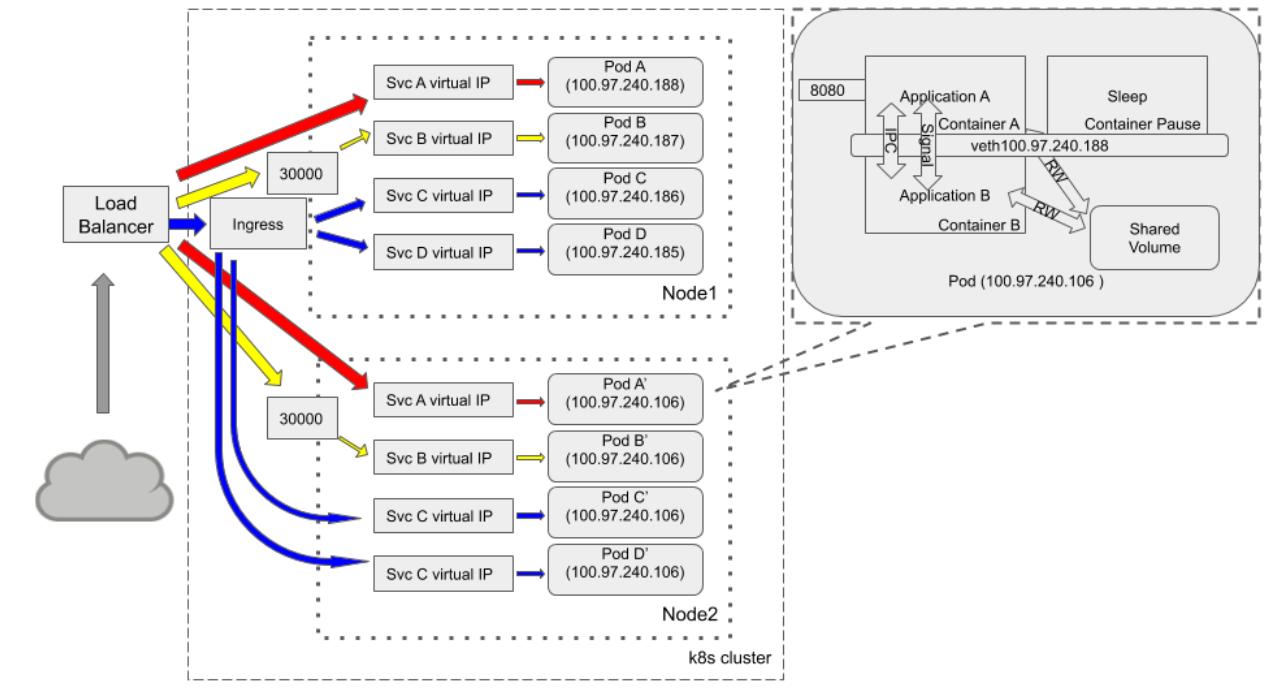
Почти постоянно перед кластером Kubernetes располагается балансировка нагрузки. При упомянутых нами ранее
различных типах служб это может быть отдельная служба, которая выставляется через определённый балансировщик
нагрузки (а именно, службы A), или
же она может выставляться через NodePort. Такая служба B
использует порт узла 30000 в обоих
узлах для приёма внешнего обмена. Хотя ingress и не выступает типом службы, он мощен и эффективен в стоимостном
отношении по сравнению со службами типа балансировщиков нагрузки. Маршрутизация службы
C и службы
D контроллируется одним и тем же объектом
ingress (входом доступа). Каждый под в общем кластере способен обладать некой внутренней топологией взаимодействия,
показанной на сноске в предыдущей схеме.
В этой главе мы начали с обсуждения типичной задачи конфликта ресурсов портов и того как сетевая модель Kubernetes пытается обходить её, в то же время поддерживая хорошую совместимость для миграции приложений из определённой ВМ в поды Kubernetes. Затем мы обсудили имеющееся внутри некого пода взаимодействие, связь между подами и подключение к подам из внешних источников.
И последнее, но не в отношении значимости, мы рассмотрели базовые понятия CNI и сделали введение в то, как Calico выполняет работу в среде Kubernetes. После наших первых двух глав мы надеемся, вы получили базовое представление того, как работают компоненты Kubernetes и как вещи взаимодействуют друг с другом.
В своей следующей главе мы собираемся поговорить о моделировании угроз в кластере Kubernetes.
-
В кластере Kubernetes IP адрес назначается поду или контейнеру?
-
Какие пространства имён Linux совместно используются контейнерами внутри одного и того же пода?
-
Что представляет собой контейнер паузы и зачем он нужен?
-
Каковы типы служб Kubernetes?
-
В чём состоят преимущества использования Ingress вместо служб с типом балансировки нагрузки?
Если вы желаете собрать свой собственный подключаемый модуль CNI или выполнить дополнительную оценку Calico, проверьте следующие ссылки:
-
https://docs.projectcalico.org/v3.11/reference/architecture/
-
https://docs.projectcalico.org/v3.11/getting-started/kubernetes/installation/integration
-
{Прим. пер.: наш перевод некоторых глав 2 издания Полного руководства Kubernetes Джиджи Сэйфана}