Глава 1. Введение в систему хранения Ceph
В данной главе мы охватим:
-
Обзор Ceph
-
Историю и эволюцию Ceph
-
Ceph и будущее систем хранения
-
Портфолио совместимости
-
Ceph в противовес остальным
Содержание
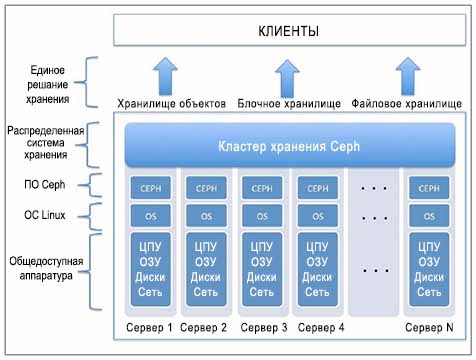
Ceph является проектом с открытым кодом, который предоставляет определяемые программным обеспечением унифицированные решения для хранения данных. Ceph является распределенной системой хранения, которая является массивно масштабируемой и высокопроизводительной и при этом не имеет единой точки отказа. С самого начала она разрабатывалась для высокой масштабируемости, до уровней эксабайт и выше, при работе на общеупотребимых аппаратных средствах.
Ceph получил наибольшее звучание в индустрии хранения благодаря своей природе открытости, масштабируемости и распределенности. Сегодня общедоступные, частные и гибридные облачные модели являются доминирующими стратегиями для целей обеспечения массивной инфраструктуры, и Ceph становится популярной в соответствующих решениях облачных систем хранения данных. Облака рассчитывают на общеупотребимых аппаратные средства и Ceph выполняет наилучшим образом использование таких рыночных аппаратных средств для предоставления вам отказоустойчивых и высоконадежной системы хранения корпоративного уровня.
Ceph вырос и впитал в себя архитектурные принципы которые включают в себя следующие свойства:
-
Все компоненты должны быть масштабируемыми
-
Историю и эволюцию Ceph
-
Не должно быть единой точки отказа
-
Решение должно быть основано на открытом и адаптируемом программном обеспечении
-
Программное обеспечение Ceph должно работать на общедоступных аппаратных средствах
-
Все должно быть самоуправляемым, где это возможно
Ceph обеспечивает предприятиям огромную производительность, неограниченную масштабируемость, мощность и гибкость, тем самым помогая им избавиться от дорогих фирменных бункеров хранения. Ceph является унифицированным решением для хранения данных уровня предприятия, определяемым программным обеспечением, которое работает на стандартных аппаратных средствах, что делает его наиболее экономически эффективной и многофункциональной системой хранения. Универсальная система хранения Ceph предоставляет блочные, файловые и объектные системы хранения под одной капотом, что позволяет клиентам использовать систему хранения так, как они хотят.
Основой Ceph являются объекты, которые являются основными строительными блоками. Любойформат данных, будь то блок, объект или файл сохраняется в виде объекта внутри группы размещения кластера Ceph. Хранилища объектов, подобные Ceph, являются ответом на потребности в хранении неструктурированных данных сегодня и в будущем. Объектно ориентированная система хранения имеет свое преимущества перед над традиционными решениями на основе файлов, поскольку с использованием хранения объектов мы можем достичь независимости от платформ и аппаратных средств. Ceph разумно обращается с объектами и реплицирует каждый объект по кластерам для повышения надежности. В Ceph объекты не привязаны к физическому пути, что делает их гибкими и не зависящими от местоположения. Это делает возможным линейное масштабирование от уровня петабайт до уровня эксабайт.
Ceph был разработан в Университете Калифорнии, Санта-Крус, Сейджем Вейлем в 2003 году как часть проекта его докторской диссертации. Первоначальный прототип проекта был файловой системой Ceph, написанной примерно в 40 000 строк кода на С++, который был сделан открытым в 2006 году с Lesser GNU Public License License (LGPL), чтобы для эталонной реализации и научно-исследовательской платформы. Ливерморская национальная лаборатория поддержала начальную разработку Сейджа. Период с 2003 по 2007 год был научно-исследовательским периодом для Ceph. К этому времени его основные компоненты были выявлены и началась ускоренная работа сообщества с проектом. Ceph не последовал модели двойного лицензирования, и не имеет ни одного набора свойств только для предприятий.
В конце 2007 Ceph достиг зрелости и ожидал инкубации. В этот момент в действие вошла компания DreamHost, поставщик услуг веб- хостинга и регистрации доменных имен из Лос Анджелеса. DreamHost растила Ceph с 2007 по 2011. В течение этого периода Ceph получила свою форму, существующие компоненты стали более стабильными и надежными, были реализованы различные новые функции, а также были разработаны будущие дорожные карты. Здесь Ceph обрела подлинные свойства и дорожные карты уровня предприятия. В этот период времени в проект Ceph начали вносить вклад многие разработчики, некоторыми из них были Иегуда Саде, Вейнрауб, Григорий Фарнум, Джорж Дургин, Сэмуэл Жюст, Вайдо ден Холландер и Лойк Дачари, которые присоединились к побеждающей партии Ceph.
В апреле 2012 Сейдж Вейль основал новую компанию, Inktank, которую финансировала DreamHost. Inktank была создана для широкого внедрения служб Ceph и поддержки. Inktank является компанией в поддержку Ceph, основной задачей которой является предоставление компетенций, технологических процессов инструментов и поддержки для своих корпоративных подписчиков, что позволяет им эффективно осваивать и управлять системами хранения Ceph. Сейдж был техническим директором и основателем Inktank. В 2013г Inktank привлекла для финансирования $13.5 млн. 30 апреля 2014г, Red Hat, Inc. — ведущий в мире поставщик решений с открытым кодом дал согласие на приобретение Inktank за примерно $175 млн. наличными. Некоторые клиенты Inktank включают Cisco, CERN и Deutsche Telekom, а также ее партнерами являются Dell и Alcatel-Lucent, которые все теперь стали партнерами Red Hat в области решений программно определяемых систем хранения Ceph. Для получения дополнительной информации, пожалуйста, посетите www.inktank.com
Термин Ceph является общим прозвищем, данным осьминогам; Ceph можно рассматривать как короткую форму для Cephalopod, которое относится к семейству морских животных моллюсков. Ceph имеет осьминогов в качестве своих талисмана, который представляет поведение Ceph сравнимое с осьминогом.
Слово Inktank в некотором роде связано с головоногими моллюсками. Рыбаки иногда называют головоногих моллюсков чернильными рыбами из-за их способности брызгаться чернилами. Это поясняет почему головоногие моллюски (Ceph, cephalopods), имеют какое-то отношение к чернильным рыбам (Inktank). Кроме того, Ceph и Inktank имеют много общего. Вы можете рассматривать Inktank как ThInkTank ("мозговой центр") для Ceph.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Сейдж Вейль является одним из соучредителей DreamHost. |
В конце 2007 года, когда начался проект Ceph, она сначала взращивался в DreamHost. 7 мая 2008 года, Сейдж выпустил редакцию Ceph 0.2 и после этого стадии развития стали быстро развиваться. Промежутки между новыми редакциями стали короткими и Ceph теперь имеет новые обновления версий каждый следующий месяц. 3 июля 2012 года, Сейдж объявил о редакции с кодовым названием Argonaut (v0.48).Ниже перечислены основные редакции Ceph, включающие в себя долгосрочную поддержку редакций (LTS, Long Term Support). Для получения более подробной информации, пожалуйста, посетите https://ceph.com/category/releases/.
| Название редакции Ceph | Версия редакции Ceph | Выпущена |
|---|---|---|
Argonaut (Аргонавт) |
v0.48 (LTS) |
3 июля 2012 |
Bobtail (Обрубок хвоста) |
v0.56 (LTS) |
1 января 2013 |
Cuttlefish (Каракатица) |
v0.61 |
7 мая 2013 |
Dumpling (Пельмень) |
v0.67 (LTS) |
4 августа 2013 |
Emperor (Император) |
v0.72 |
9 ноября 2013 |
Firefly (Светлячок) |
v0.80 (LTS) |
май 2014 |
Giant (Великан) |
v0.87 |
(будущая редакция) {Прим.пер.:29 октября 2014} |
|
| Замечание |
|---|---|
|
Названия редакций Ceph следуют в алфавитном порядке; название следующей редакции будет начинаться с I {Прим.пер.: так в оригинале, наверное, правильно H (Hummer?)}. |
Последние годы требования к системам хранения предприятий растут взрывообразным образом. Исследования показали, что данные крупных предприятий растут со скоростью от 40 до 60 процентов в год, и многие компании удваивают масштабы своих данных каждый год. По оценкам аналитиков IDC, во всем мире в 2000 году было 54.4 эксабайт общих данных в цифровом виде. В 2007 году эта величина достигла значения в 295 эксабайт, а к концу 2014 года ожидается, что она превысит 8`591 эксабайт.
Хранилища во всем мире требуют систем,которые являются единообразными, распределенными, надежными, обладающими высокой производительностью, и, что самое главное, массивно масштабируемые до уровня эксабайт и выше. Система хранения Ceph является правильным решением для растущего взрыва данных на этой планете. Причина, по которой Ceph развивается со скоростью молнии в его живом сообществе и пользователях, которые верят в мощность Ceph. Создание данных - процесс не имеющий конца. Мы не можем остановить генерацию данных, но мы должны преодолеть разрыв между созданием данных и их хранением.
Ceph заполняет именно этот зазор, его унифицированная, распределенная, экономически эффективная и масштабируемая природа является потенциальным решением для потребностей хранения данных сегодня и в будущем. Сообщество открытого кода Linux предвидело потенциал Ceph задолго, еще в 2008г оно добавило поддержку Ceph в основную ветвь ядра Linux. Это было важной вехой для Ceph, поскольку не существует его конкурента для присоединения к нему здесь.
Одной из самых проблематичных областей в развитии облачной инфраструктуры являются системы хранения. Облачная среда нуждается в хранилищах, которые могут масштабироваться и при этом иметь низкую стоимость, а также они могут быть легко интегрированы с другими компонентами структуры данной облачной среды. Необходимость такой системы хранения является жизненно важным аспектом для решения общей стоимости владения (TCO) всем проектом облака. Существует ряд традиционных производителей систем хранения, которые утверждают, что обеспечивают интеграцию в рамках облаков, однако сегодня нам нужны дополнительные функции помимо простой поддержки интеграции. Эти традиционные решения для хранения данных, возможно, казались успешными несколько лет назад, но в настоящее время они не являются хорошим кандидатом на унифицированное решение хранения для облака. Кроме того, традиционные системы хранения стоят слишком дорого для развертывания и поддержки в долгосрочной перспективе, а масштабирование вверх и наружу является для них серой зоной. Сегодня нам необходимо решение для хранения данных, которое было бы полностью пересмотрено для выполнения текущих и будущих потребностей, система, которая была бы создана на основе программного обеспечения с открытым исходным кодом и техническими средствами, которые могут обеспечить требуемую масштабируемость экономически эффективным способом.
Ceph быстро развивался в этом пространстве чтобы заполнить этот пробел для настоящего серверного облака хранения. Он занял центральное место во всех основных платформах облаков с открытым кодом, таких, как OpenStack, CloudStack и OpenNebula. Кроме того, Ceph выстроил партнерские отношения с Canonical, Red Hat и SUSE, гигантами в пространстве Linux. Эти компании уделяют много внимания Ceph — распределенным, надежным и масштабируемым кластерам хранения для их дистрибутивов Linux и программного обеспечения облаков. Ceph тесно сотрудничает с этими гигантами Linux для обеспечения надежного многофункционального серверного обеспечения систем хранения в своих облачных платформах.
Общедоступные и частные облака получают большой импульс благодаря реализации проекта OpenStack. OpenStack зарекомендовал себя как облачное решение полного цикла. Он имеет свои внутренние компоненты хранения с названием Swift для хранилища облака и Nova-Volume, также известного как Cinder, который поддерживает тома блочного хранилища для виртуальных машин.
В отличие от Swift, который ограничивается только хранением объектов, Ceph является универсальным решением для хранения блочных данных, файлов, а также объектов, и, таким образом приносит пользу OpenStack, предоставляя различные типы носителей в одном кластере хранения. Таким образом, вы можете легко и эффективно управлять хранением вашего облака OpenStack. Сообщества OpenStack и Ceph уже сотрудничали в течение многих лет в разработке полностью поддерживаемой облаком OpenStack системе хранения данных Ceph. Начиная с Folsom, который является шестой основной редакцией OpenStack, Ceph был полностью интегрирован с ним. Разработчики Ceph заверил, что Ceph хорошо работает с последней версией OpenStack, и одновременно способствуют появлению новых функций, а также корректировке ошибок. OpenStack использует одно из самых требовательных свойств Ceph, блочное устройство RADOS (RBD, RADOS block device), с применением своих компонентов cinder и glance. Ceph RBD помогает OpenStack c быстрой инициализации сотен экземпляров виртуальных машин, предоставляя тома- моментальные снимки и клоны, которые являются индивидуальной настройкой, и, следовательно, требуют менее требовательны к объему и чрезвычайно быстры.
Облачные платформы с Ceph в качестве механизма хранения данных обеспечивает столь необходимую гибкость для поставщиков услуг при построении решений системы хранения-как-службы и инфраструктуры-как-службы (IaaS), которые они не способны получить от других традиционных решений корпоративного уровня, поскольку они не предназначены для удовлетворения потребностей облаков. Используя Ceph в качестве механизма для платформ облаков, поставщики услуг могут предложить недорогие облачные службы для своих потребителей. Ceph позволяет им предоставлять относительно низкие цены для хранения данных при корпоративном функционале по сравнению с другими поставщиками услуг хранения, такими, как Amazon
Dell, SUSE и Canonical предлагают и предоставляют инструменты поддержки настройки и управления, такие как Dell Crowbar и Juju для автоматизированного и легкого развертывания систем хранения Ceph для своих корпоративных облачных решений OpenStack. Другие инструменты управления настройкой, такие как Puppet, Chef, SaltStack и Ansible являются довольно популярным для автоматизированного развертывания Ceph. Каждый из этих инструментов имеет открытый код, а также готовые модули Ceph, которые могут быть легко использованы для развертывания Ceph. В распределенной среде, такой как облачная, каждый компонент должен масштабироваться. Эти инструменты управления настройкой имеют важное значение для быстрого наращивания вашей инфраструктуры.
В настоящее время Ceph полностью совмести в этими инструментами, что позволяет пользователям мгновенно развертывать и расширять кластер Ceph.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Начиная с редакции OpenStack Folsom, компонента nova-volume стала называться cinder. |
Все клиенты, которые хотят сэкономить деньги на инфраструктуре хранения, скорее всего, очень скоро рассмотрят определяемую программным обеспечением систему хранения данных (SDS, Software-defined Storage). SDS может предложить хорошее решение для клиентов с крупными инвестициями в наследуемые системы хранения, которым пока еще не требуется гибкость и масштабируемость. Ceph является правильным решением SDS, которое является программным обеспечением с открытым исходным кодом, работает на любых доступных аппаратных средствах, что означает, что ни один производитель не может привязать только на себя, а также обеспечивает низкую стоимость в расчете на ГБайт. Решение SDS обеспечивает очень необходимую гибкость в отношении выбора оборудования. Пользователи могут выбрать любое доступное оборудование любого производителя и свободно проектировать гетерогенное аппаратное решение для собственных нужд. Определяемая программным обеспечением система хранения Ceph поверх этого оборудования обо всем позаботится. Она также предоставляет все свойства корпоративных систем хранения данных прямо на уровне программного обеспечения. Низкая стоимость, надежность и масштабируемость являются ее основные особенностями.
Определение единого решения для хранения с точки зрения поставщика системы хранения состоит из доступа на основе файлов и блоков с отдельной платформы. Окружение хранения уровня предприятие обеспечивает NAS плюс SAN с единой платформы, которая рассматривается в качестве единого решения для хранения данных. NAS и SAN технологии доказали свою успешность в конце 90-х и начале 20-х годов, но, если мы думаем о будущем, уверены ли мы, что NAS и SAN смогут управлять хранением, требующим в конечном итоге 50 лет? Имеется ли у них достаточный потенциал, чтобы управляться с многими эксабайтами данных? Вероятно нет.
В Ceph, термин унифицированные системы хранения данных является более значимым, чем то, на что претендуют существующие производители систем хранения. Ceph был разработан с нуля, чтобы быть в готовым к будущему; его строительные блоки сконструированы таким образом, что они работают с огромными объемами данных. Ceph является истинным унифицированным решение хранения данных, которое обеспечивает хранение объектов, блоков и файлов в одном едином программном уровне. Когда мы говорим о Ceph как готовой к будущему, мы прежде всего имеем в виду внимание к ее возможностям хранения объектов, которые лучше подходят для существующего сегодня замеса неструктурированных данных, чем блочные или файловые хранилища. Все в Ceph опирается на интеллектуальные объекты, будь то даже блочные или файловые хранилища.
Вместо того, чтобы управлять блоками и файлами на нижнем уровне, Ceph управляет объектами и поддерживает системы хранения на основе блоков и файлов поверх объектов. Если вы вспомните традиционную систему хранения на основе файлов, файлы адресуются с помощью пути к файлу, и таким же образом, объекты в Ceph адресуются уникальным идентификатором, и хранятся в однородном адресном пространстве. Объекты предоставляют безграничное масштабирование с повышенной производительностью за счет устранения операций с метаданными. Ceph использует алгоритм динамического вычисления того, где объект должен быть сохранен и откуда его извлечь.
Традиционные системы хранения не имеют интеллектуального способа управления метаданными. Метаданные информация (данные) о данных, которые решает, где будут записаны данные и откуда будут считаны. Традиционные системы хранения поддерживают центральную справочную таблицу для отслеживания своих метаданных; то есть, всякий раз, когда пользователь отправляет запрос на операцию чтения или записи, система хранения сначала выполняет поиск в огромной таблице метаданных, а уже после получения результатов, она выполняет операцию пользователя. Для небольших системы хранения данных вы можете не заметить падения производительности, но полагаю, что для большого кластера хранения при таком подходе Вы, несомненно, будете ограничены пределами производительности. Это также ограничивает вашу масштабируемость.
Ceph не следует за традиционными архитектурами хранения; она был создана заново с использованием архитектуры следующего поколения. Вместо того чтобы хранить метаданными и манипулировать ими, Ceph предлагает новый метод, алгоритм CRUSH. CRUSH является аббревиатурой для управляемых масштабируемым хешированием репликаций (Controlled Replication Under Scalable Hashing). Для получения более подробной информации, посетите http://ceph.com/resources/publications/. Вместо выполнении поиска в таблице метаданных для каждого клиентского запроса, алгоритм CRUSH, вычисляет по требованию где должны быть записаны данные или откуда их считывать. При наличии вычисляемых метаданных больше нет необходимости в управлении централизованной таблицей для них. Современные компьютеры удивительно быстрые и могут выполнять поиск CRUSH очень быстро. Кроме того, для уменьшения вычислительная нагрузка может быть распределена по узлам кластера, используя всю мощность распределенного хранения. CRUSH означает управление метаданными вчистую, что лучше, чем методы традиционных систем хранения.
В дополнение к этому, CRUSH имеет уникальное свойство осведомленности об инфраструктуре. Он понимает взаимодействия между различными компонентами инфраструктуры, начиная с системного диска, пула, узла, стойки, блоков распределения питания, коммутатора, и ряда в центре обработки данных, вплоть до помещения центра обработки данных и далее. Это зоны отказа для любой инфраструктуры. CRUSH сохраняет первичную копию данных и ее реплики таким образом, что данные будут доступны, даже если некоторые компоненты откажут в зоне отказа. Пользователи имеют полный контроль над определении таких зон отказа для своей инфраструктуры внутри карты CRUSH в Ceph. Это предоставляет администратору Ceph мощные средства эффективного управления данными об их собственной среде.
CRUSH придает Ceph самоуправляемсть и самовосстановливаемость. В случае отказа компоненты в зоне разрушения, CRUSH понимает какой компонент вышел из строя, и определяет эффект такого отказа в кластере.Без какого-либо административного вмешательства CRUSH осуществляет самоуправление и самовосстановление путем выполнения операции восстановления для утраченных в результате сбоя данных. CRUSH восстанавливает данные из поддерживаемых кластером копий репликаций. В каждой точке во времени кластер будет иметь более чем одну копию данных, которые будут распределены в нем.
С применением CRUSH, мы можем спроектировать весьма надежную инфраструктуру хранения не имеющей единой точки отказа. Это делает Ceph высоко масштабируемой и крайне надежной системой хранения, которая готова к будущему.
Raid технология была основным строительным блоком для систем хранения данных в течение многих лет. Она оказалась успешной почти для всех видов данных, которые создавались в течение последних 30 лет. Тем не менее, все эпохи должны иметь свой конец, и на этот раз пришло время для RAID. Системы хранения на основе RAID начали проявлять ограничения и не способны обеспечивать будущие потребности в хранении.
Технология производства дисков зрела на протяжении многих лет. Производители в настоящее время выпускают диски уровня предприятия большей емкости по более низким ценам. Мы больше не говорим о дисках 450 ГБ, 600 ГБ или даже 1 ТБ, поскольку существует много других вариантов дисков с большей емкостью, лучшей производительностью доступных сегодня. Новейшие технические характеристики дисков уровня предприятия предлагают диски с объемом до 4 ТБ и даже 6 ТБ. Емкость будет продолжать увеличивается из года в год.
Подумайте о RAID-системах хранения данных корпоративного класса, которые состоят из многочисленных 4 или 6 ТБ дисков. В случае сбоя диска, RAID может потребовать многих часов и даже до нескольких дней для восстановления одного неисправного диска. Между тем, если выйдет из строя другой диск, то это приведет к хаосу. Ремонт нескольких больших дисковых накопителей с использованием RAID является обременительным процессом.
Кроме того, RAID потребляет много дисков целиком в качестве резервных. Это опять-таки влияет на совокупную стоимость владения, а если вы работаете при недостаче запасных дисков, то вы снова в беде. Механизм RAID требует набор идентичных дисков в одной группе RAID; если вы измените размер диска, скорость вращения и тип диска, вы будете сталкиваться с штрафами. Такая замена отрицательно скажется на емкости и производительности вашей системы хранения.
Основанные на RAID системы уровня предприятия часто требуют дорогостоящих аппаратных компонентов, известных как RAID- адаптеры, что опять-таки увеличивает общие затраты. RAID может столкнуться с безвыходной ситуацией, при которой ему не удается увеличить свой размер в случае, когда по достижению определенного предела у него нет возможности ни внутреннего масштабирования, ни масштабирования наружу. Вы не можете добавить больше емкости, даже если у вас есть деньги. RAID 5 может отработать отказ одного диска, а RAID 6 обрабатывает отказ двух дисков, что является максимальным для любого уровня RAID. Во время операций по восстановлению RAID если клиенты выполняют операцию, они будут скорее всего испытывать недостаток в операциях ввода/вывода, пока не завершится процесс восстановления. Наиболее лимитирующим фактором в RAID является то, что он защищает только от сбоев диска; он не может защитить от сбоя сети, серверного оборудования, ошибок операционной системы, коммутатора или территориальной аварии. Максимальная защита, которую вы можете получить от RAID это продолжение работы в случае отказа двух дисков. Вы не можете продолжать работу в случае отказа более чем двух дисков при любых обстоятельствах.
Таким образом, нам нужна система, которая может преодолеть все эти недостатки с производительностью, причем экономически эффективным способом. На сегодняшний день система хранения Ceph является лучшим ответом для решения этих проблем. Чтобы обеспечить надежность хранения данных, Ceph использует метод репликации данных; то есть, она не использует RAID, и благодаря этому просто не встречает все проблемы, с которыми можно столкнуться в системе с RAID уровня предприятия. Ceph является определяемой программным обеспечением системой хранения, поэтому нам не требуются специализированного оборудования для репликации данных. Более того, уровень репликации глубоко и индивидуально настраивается с помощью команд. Таким образом, администратор системы хранения Ceph может легко управлять фактором репликации в соответствии со своими требованиями и имеющейся инфраструктурой. В случае сбоя одного или более дисков, репликация Ceph является лучшим процессом чем восстановление в RAID. Когда диск выходит из строя, все данные расположенные на этом диске в данный момент времени начинают восстанавливаться со дисков своего уровня. Поскольку Ceph является распределенной системой, все первичные копии, а также реплицированные копии данных разбросаны по всем дисков кластера, так что никакие основные и реплицированные копии не должны располагаться на одном и том же диске, а более того, должны находиться в различных зонах отказа определяемых картой CRUSH. Таким образом, все диски кластера участвуют в восстановлении данных. Это делает операцию восстановления удивительно быстрой, причем без узких мест производительности. Такая операция восстановления не требует каких-либо запасных дисков. Данные просто реплицируются на другие диски Ceph в кластере. Ceph использует механизм весов для своих дисков. Таким образом, различия в размерах дисков не являются проблемой. Ceph хранит основанные на весе диска данные, который используются для управляемой Ceph, а также ими можно управлять с помощью пользовательских карт CRUSH.
В дополнение к методу репликаций, Ceph также поддерживает другой современный способ сохранности данных при помощи техники кодирования очистки. Пулы кодирования очистки требуют меньше места для хранения данных по сравнению с пулами репликаций. В этом процессе данные восстанавливаются или регенерируются алгоритмически путем расчета кода стирания. Вы можете использовать обе техники обеспечения надежности, а именно, репликации и кодирование стирания в одном и том же кластере Ceph, но c разными пулами устройств хранения данных. Мы узнаем больше о технике кодирования стирания в последующих главах.
Ceph является законченной системой хранения данных корпоративного уровня, что обеспечивает поддержку для широкого диапазона протоколов и методов доступа. Единая системы хранения Ceph поддерживает блочный и файловый доступ, а также хранение объектов. Однако, во время написания данной книги, блочные хранилища и хранилища объектов Ceph рекомендуются для промышленного использования, в то время как файловая система Ceph находится этапе проверки качества (QA) и будет готова в ближайшее время. Рассмотрим каждую из них вкратце.
Блочные системы хранения является классом хранилищ, используемых для хранения данных в сети хранения данных. В этом типе, данные хранятся в виде томов, которые находятся в форме блоков и присоединяются к узлам. Это обеспечивает большую емкость хранения, требуемую приложениями с высокой степенью надежности и производительности. Такие блоки, в качестве томов отображаются в операционную систему и управляются ее структурой файловой системы.
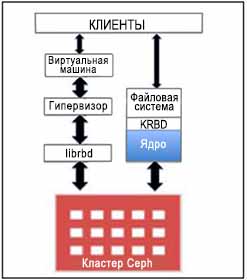
Ceph представила новый протокол RBD, который теперь известен как блочное устройство Ceph. RBD обеспечивает надежные, распределенные и высоко производительные диски хранения блоков для клиентов. RBD блоки чередуются с многочисленными объектами, которые по своей природе разбросаны по всему кластеру Ceph, тем самым обеспечивая клиентам надежность хранения данных и производительность. RBD имеет встроенную поддержку ядра Linux. Другими словами, драйверы RBD прошли хорошую интеграцию с ядром Linux за последние несколько лет. Почти все разновидности операционных систем Linux имеют встроенную поддержку RBD. В дополнение к надежности и производительности, RBD также обеспечивает такие функции уровня предприятия как полные и инкрементальные моментальные снимки, слабую инициализацию (динамическое выделение), клонирование копии при записи, а также ряд других свойств. RBD также поддерживает кэширование в памяти, что резко повышает его производительность.
Ceph RBD поддерживает образы с размером достигающим 16 эксабайт. Эти образы могут быть отображены как диски в машинах Bare Metal, виртуальных машинах или в обычных машинах хостов. Ведущие в отрасли гипервизоры с открытым кодом, такие как KVM и Zen обеспечивают полную поддержку RBD и используют ее возможности для своих гостевых виртуальных машин. Другие проприетарные гипервизоры, таких как VMware и Microsoft HyperV будут поддерживаться в ближайшее время. В сообществе проводится большая работа для поддержки этих гипервизоров.
Блочное устройство Ceph обеспечивает полную поддержку облачных платформ, таких как OpenStack, CloudStack, а также другие. Были продемонстрированы успешность и многофункциональность для таких облачных платформ. В OpenStack вы можете использовать блочное устройство Ceph с компонентами cinder (для блоков) и glance (для образов). Делая это, вы можете раскручивать тысячи виртуальных машин в очень сжатые сроки, воспользовавшись функциональностью блочного хранилища Ceph копирования при записи.
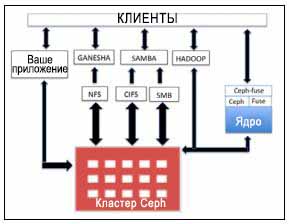
Файловая система Ceph, также имеющая название CephFS, является POSIX-совместимой файловой системой, которая использует кластерную систему хранения Ceph для хранения пользовательских данных. CephFS имеет поддержку собственного драйвера ядра Linux, что делает CephFS высоко адаптивный через любую разновидность ОС Linux. CephFS хранит данные и метаданные раздельно, обеспечивая тем самым увеличение производительности и надежности приложениям размещающимся поверх.
Внутри кластера Ceph библиотека файловой системы Ceph (libcephfs) работает поверх библиотеки RADOS (librados), который является протоколом кластера хранения Ceph, и является общей для файловых, блочных и объектных хранилищ. Чтобы использовать CephFS, вам потребуется, по крайней мере, один настроенный на любом из узлов кластера Ceph сервер метаданных (MDS, metadata server). Тем не менее стоит иметь в виду, что наличие только один сервер MDS будет единая точка отказа для файловой системы Ceph. После настройки MDS клиенты могут использовать CephFS различными способами. Для установки Ceph как файловой системы, клиенты могут использовать встроенные возможности ядра Linux или могут воспользоваться драйвером ceph-fuse (файловой системой в пространстве пользователя), поставляемым сообществом Ceph.
В дополнение к этому, клиенты могут воспользоваться программами с открытым исходным кодом сторонних производителей, такими как Ganesha для NFS и Samba для SMB/CIFS. Эти программы взаимодействуют с libcephfs для хранения данных пользователя в надежном и распределенном кластере хранения Ceph. CephFS также может быть использован в качестве замены для Apache Hadoop File System (HDFS). Это также выполняет компонент libcephfs для хранения данных в кластере Ceph. Для бесшовной реализации сообщество Ceph обеспечивает необходимый CephFS Java интерфейс для Hadoop и подключаемых программ (plugin) Hadoop. Компоненты libcephfs и librados очень гибкие, и вы можете даже создать свою собственную программу, которая взаимодействует с ними и хранит данные в оборудовании кластера хранения Ceph.
CephFS является единственным компонентом системы хранения Ceph, который на момент написания этой книги не готов для промышленного использования. Он улучшается в очень высоком темпе и, как ожидается, будет готов к промышленной эксплуатации очень скоро. В настоящее время он довольно популярен для тестирования, а также в качестве среды разработки, и был развит с функциями, необходимыми для корпоративного уровня, например, такими как динамическая ребалансировка и моментальный снимок подкаталога. Следующая диаграмма показывает различные способы использования CephFS:
Хранение объектов является подходом к хранению данных в виде объектов, отличающимся от традиционных файлов и блоков. Хранение на основе объектов получило значительное внимание со стороны промышленности. Организации, которые ищут гибкость для своих огромных данных быстро адаптируют решения для объектного хранения данных. Ceph, как известно, истинная система хранения на основе объектов.
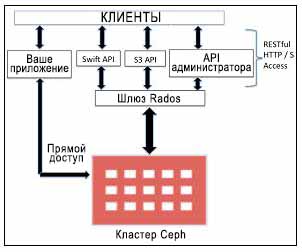
Ceph является распределенной системой хранения объектов, которая предоставляет интерфейс для хранения объектов через шлюз объектов Cepр, также известный как шлюз RADOS (radosgw). Шлюз RADOS использует библиотеки, такие как librgw (библиотеки шлюза RADOS) и librados, что позволяет приложению устанавливать соединение с хранилищем объектов Ceph. Ceph поставляет один из самых стабильных решений с многими владельцами для хранения объектных данных с доступом через RESTful API.
Шлюз RADOS обеспечивает интерфейс RESTful пользовательскому приложению для хранения данных в кластере хранения Ceph.
-
Интерфейсами шлюза Rados являются:
-
Совместимость с Swift: Это функциональность хранения объектов для OpenStack Swift API
-
Совместимость с S3: Это функциональность хранения объектов для API Amazon S3
-
API Администратора: Также известно как API управления или естественный API, который может быть использован непосредственно в приложении для получения доступа к системе хранения с целью управления
Для доступа к системе хранения объектов Ceph вы можете также обойти слой шлюза RADOS, что делает доступность более гибкой и быстрой. Библиотеки программного обеспечения librados позволяют пользовательским приложениям прямой доступ к хранилищам объектов Ceph через C, C ++, Java, Python и PHP. Хранилища объектов Ceph имеют многоузловые возможности. Таким образом, они предоставляют решения для аварийного восстановления. Многоузловая настройка хранилища объектов может быть достигнута с применением RADOS или шлюзов федерализации. Следующая диаграмма показывает различные системы API, которые могут быть использованы с Ceph:
Рынок систем хранения нуждается в переменах; проприетарные системы хранения не в состоянии обеспечить будущие потребности в хранении данных при относительно низком бюджете. После проведения закупок оборудования, лицензирования, поддержки и управления издержками проприетарные системы стоят очень дорого. В отличие от этого, технологии хранения с открытым исходным кодом хорошо зарекомендовали себя сприсущей им производительностью, надежностью, масштабируемостью и низкой совокупной стоимостью владения. Многочисленные организации с государственной собственностью, а также частные компании, университеты, научно-исследовательские и медицинские центры, а также системы высокопроизводительных вычислений уже используют некоторые решения систем хранения с открытым исходным кодом.
Тем не менее, Ceph получает потрясающую обратную связь и набирает популярность, оставляя позади другие решения для хранения данных как с открытым исходным кодом, так и проприетарные. Ниже приведены некоторые решения для хранения данных с открытым кодом {Прим. пер.: так в тексте, GPFS, например, является проприетарной файловой системой} в конкуренции с Ceph. Мы кратко обсудим недостатки этих решений для хранения данных, которые адресованы к Ceph.
General Parallel File System (GPFS) представляет собой распределенную файловую систему, разработанную и принадлежащую компании IBM. Это проприетарная система с закрытым кодом, что делает ее менее привлекательным и трудно адаптируемой. Лицензирование и стоимость поддержки после закупки оборудования для хранения делает ее очень дорогостоящей. Кроме того, она имеет очень ограниченный набор интерфейсов хранилищ данных. Она не обеспечивает ни блочное хранение, ни доступ RESTful к системе хранения, так что это является очень ограничительным. Даже максимальная репликация данных ограничивается только тремя экземплярами, что снижает надежность системы в случае более чем одного одновременного сбоя. {Прим. пер.: получить дополнительные сведения на русском языке вы можете, например, на нашем сайте http://www.mdl.ru/Solutions/Put.htm?Nme=GPFS }
iRODS является акронимом для интегрированной, ориентированной на правила системы хранения данных (Integrated Rule-Oriented Data System), которая является программным обеспечением управления данными с открытым исходным кодом, распространяемое согласно 3-й статье лицензии BSD. iRods не очень надежная система хранения, поскольку ее сервер метаданных iCAT является SPOF (единой точкой отказа) и это не допускает настоящей высокой доступности. Кроме того, она имеет очень ограниченный набор интерфейсов хранилищ данных. Она не обеспечивает ни блочные хранилища, ни RESTful доступ к системе хранения, что делает ее очень ограниченной. Она больше подходит для хранения небольшого количества крупных файлов, а не для одновременного хранения как файлов с малым, так и с большим размером. iRods работает в традиционном стиле, поддерживая индексы физического расположения, которое связаны с именем. Проблема возникает при множественных запросах клиентов к местоположению файла с сервера метаданных, накладывая большую вычислительную нагрузку на сервер метаданных, в результате чего возрастает зависимость от одной машины и узкие места в производительности.
HDFS является распределенной масштабируемой файловой системой написана на Java для платформы Hadoop. HDFS не полностью POSIX-совместимая файловая система и не поддерживает блочные храниилища, что делает ее менее удобной, чем Ceph. Надежность HDFS является вопросом для обсуждения, поскольку она не очень доступная файловая система. Отдельный NameNode в HDFS является основной причиной для ее единой точки отказа и узким местом для проблем производительности. Она больше подходит для хранения небольшого количества крупных файлов, а не для одновременного хранения как малых, так и больших файлов.
Lustre является параллельной распределенной файловой системой управляемой сообществом с открытым исходным кодом и доступно в соответствии с GNU General Public License. В Lustre один сервер отвечает за хранение и управление метаданными. Таким образом, запрос ввода/вывода от клиента полностью зависит от вычислительной мощности одного сервера, что является довольно плохим для использования на уровне предприятия. Как iRODS и HDFS, Lustre подходит для хранения небольшого количества крупных файлов, а не для одновременного хранения как малых, так и больших файлов. Как и iRODS, Lustre управляет индексным файлом, который поддерживает физические адреса, отображенные на именах файлов, что делает его архитектуру традиционной и склонной к узким местам производительности. Lustre не имеет никакого механизма для обнаружения и исправления сбоя узла. В случае отказа узла, клиенты должны подключаться к другому узлу самостоятельно. {Прим. пер.: получить дополнительные сведения на русском языке вы можете, например, на нашем сайте http://onreader.mdl.ru/Lustre/ru-lustre_manual-Part1.pdf }
GlusterFS была первоначально разработана Gluster, которая затем был приобретена Red Hat в 2011 году. GlusterFS является масштабно подключаемой к сети файловой системой. В Gluster администраторы должны определить, стратегию размещения, используемую для хранения данных реплик в различных географических стойках. Gluster не обеспечивает блочный доступ, файловую систему и удаленную репликацию в качестве собственных встроенных функций; скорее, она предоставляет эти возможности в виде дополнений.
Если мы сделаем сравнение между Ceph и другими решениями для хранения данных, доступными сегодня, Ceph явно выделяется из всего множества благодаря своему набору функций. Она была разработана, чтобы преодолеть ограничения существующих систем хранения, и она оказалось идеальной заменой для старых и дорогих проприетарных систем хранения данных. Она является определяемой программным обеспечением решением с открытым исходный кодом для хранения данных поверх любого доступного оборудования, что делает ее экономичным решением для систем хранения. Ceph предоставляет разнообразные интерфейсы для подключения клиентов к кластеру Ceph, тем самым увеличивая гибкость для клиентов. Для защиты данных Ceph не полагается на технологии RAID которые становятся ограниченными по различным причинам, упомянутым ранее в этой главе. Она более полагается на репликации и кодирование стирания что, как было доказано, является лучшим решением по сравнению с RAID.
Все компоненты Ceph является надежными и поддерживают высокую доступность. Если вы настроите компоненты Ceph сохраняя в виду резервирование, мы можем с уверенностью сказать, что Ceph не имеет никакой единой точки отказа, что является серьезной проблемой для других доступных сегодня решений хранения данных. Одним из самых больших преимуществ Ceph является единая природа, при которой она предоставляет встроенную функциональность решений для хранения блочных, файловых и объектных данных, в то время как другие системы хранения по-прежнему не в состоянии обеспечить такие возможности. Ceph подходит для хранения как малых, так и больших файлов без какой-либо сбоев производительности.
Ceph является распределенной системой хранения; клиенты могут выполнять быстрые транзакции с использованием Ceph. Она не следуют традиционным способам хранения данных, а именно, хранения метаданных, которые привязываются к физическому местоположению и имени файла. Она, скорее, вводит новый механизм, который позволяет клиентам динамически вычислять местоположение необходимых им данных. Это дает прирост производительности для клиента, поскольку ему больше не нужно ждать получения данные о местоположении и содержании с центрального сервера метаданных. Кроме того, размещение данных внутри кластера Ceph абсолютно прозрачно и при этом автоматическое. Ни клиент, ни администраторы не должны беспокоиться о размещении данных в другой зоне отказов. Об этом заботится интеллектуальная система Ceph.
Ceph предназначен для самоисцеления и самостоятельного управления. В случае стихийного бедствия, когда другие системы хранения не могут обеспечить надежность при множественных отказах, Ceph стоит как скала. Ceph обнаруживает и исправляет сбой в каждой зоне отказов, таких как диск, узел, сеть, стойки, ряд ЦОД, центр обработки данных и даже разных географических областях. Ceph пытается автоматически управлять ситуацией и устранять неполадки там, где это возможно, без отключения данных. Другие решения для хранения данных могут обеспечить надежность только на уровне до диска или при выходе из строя узла.
Когда дело доходит до сравнения, это лишь некоторые особенности Ceph для овладения представлением и выделением из всего множества.
Ceph является определяемым программным обеспечением решением для хранения данных с открытым исходным кодом, которое работает на стандартных аппаратных средствах, что позволяет предприятиям избавиться от дорогих ограничительных, проприетарных систем хранения данных. Она обеспечивает единое распределенное, масштабируемое и надежное решение для хранения объектов, которое столь необходимо современным и будущим потребностям для неструктурированных данных. Необходимость хранения в мире стремительно развивается, поэтому нам необходима система хранения данных, которая является масштабируемой до уровня многих эксабайт, и при этом не затрагивает надежность хранения данных и производительность. Ceph готова к будущему и обеспечивает решение всех этих проблем с данными. Ceph пользуется спросом, поскольку она является истинным решением облачных систем хранения данных с поддержкой для почти любых облачной платформ. С любой точки зрения, Ceph является великолепным решением для хранения доступное уже сегодня.