Глава 5. Развертывание Ceph - дорога, которую вы обязаны знать
На текущий момент у вас уже достаточно сведений о Ceph, включая некоторые практические навыки. В данной главе мы узнаем следующие интересные материалы о Ceph:
-
Планирование аппаратных средств Ceph
-
Подготовка к вашей установке Ceph
-
Развертывание кластера Ceph вручную
-
Расширение кластера Ceph
-
Развертывание кластера Ceph с помощью инструментария ceph-deploy
-
Модернизация кластера Ceph
Содержание
- Планирование аппаратных средств для кластера Ceph
- Настройка вашей среды VirtualBox - еще раз
- Подготовка к установке вашей Ceph
- Развертывание кластера Ceph вручную
- Масштабирование вашего кластера
- Развертывание кластера Ceph с использованием инструмента ceph-deploy
- Модернизация вашего кластера Ceph
- Заключение
Ceph является системой хранения на базе программного обеспечения, которая разработана для работы на обычном доступном у любого производителя оборудовании. Такая доступность Ceph делает ее экономичной, расширяемой и не привязанной к определенному производителю решению для систем хранения.
Настройка оборудования Ceph требует планирования на основании ваших потребностей. Тип аппаратных средств, а также проект кластера являются факторами, которые необходимо проанализировать на начальной стадии проекта. Тщательное планирование на начальном этапе может занять длинный путь для того, чтобы избежать узких мест и помочь с лучшей надежностью кластера. Выбор аппаратных средств зависит от различных факторов, таких как бюджет, том, есть ли необходимость сосредоточиться на производительности или емкости, либо на том и другом сразу, уровне отказоустойчивости, а также на вариантах окончательного использования. В данной главе мы обсудим мы обсудим общие соображения относительно аппаратных средств и проектирования кластера.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
| За дополнительными сведениями о рекомендациях в отношении аппаратных средств вы можете обращаться к официальной документации Ceph на http://ceph.com/docs/master/start/hardware-recommendations/ {Прим. пер.: или на русскоязычной странице http://www.mdl.ru/Solutions/Put.htm?Nme=CephHW, для корпоративных клиентов трепетно относящихся к стоимости торговой марки: Fujitsu Storage ETERNUS CD10000, Dell and Nexenta SDS Solutions, ... } |
Мониторы Ceph заботятся о работоспособности всего кластера, поддерживая его карты. Они не участвуют в хранении данных кластера. Следовательно, им не требуются мощные процессоры и большая память и у них довольно низкие запросы к системным ресурсам. В большинстве случаев для узла монитора вполне достаточно экономичного сервера начального уровня с одноядерным процессором и несколькими гигабайтами оперативной памяти.
Если у вас уже есть сервер с приличным количеством доступных системных ресурсов, вы можете выбрать такой узел для дополнительных обязанностей запуска мониторов Ceph. В этом случае вы должны быть уверены, что прочие службы, работающие на данном узле оставляют достаточные ресурсы для демонов монитора Ceph. В не промышленных средах, когда у вас есть бюджетные или аппаратные ограничения, вы можете рассмотреть возможность запуска мониторов Ceph на физически выделенных виртуальных машинах. Однако в производственной практике следует запускать монитор Ceph на нетребовательных к ресурсам, экономичных физических серверах.
Если вы настроили кластер на хранение журналов на локальном узле монитора, убедитесь, что у вас есть достаточное дисковое пространство на этом узле монитора для хранения таких журналов. Для кластера в рабочем состоянии журналы могут расти в объеме до нескольких гигабайт, однако для столкнувшегося с проблемами кластера, при включенном режиме отладки, они быстро потребляют гигабайты. Пожалуйста, регулярно проверяйте, что кластер не остается в проблемном состоянии в течении длительного времени при наличии любого пространства для журналов. В промышленной среде вы должны выделить достаточно большой раздел для журналов и выработать политику ротации журналов, чтобы всегда оставалось свободное пространство.
Сеть для узла монитора должна иметь резервирование., поскольку монитор не является участником автоматического восстановления кластера. Достаточно будет дополнительного сетевого адаптера с 1Gbps. Избыточности на сетевом уровне будет вполне достаточно, поскольку монитор устанавливает кворум с другими мониторами и отказ более 50 процентов узлов мониторов создаст проблемы при подключении к кластеру. В не промышленном окружении вы можете осуществлять управление и с одним сетевым адаптером узла монитора, но для промышленной установки избыточность на сетевом уровне является важным фактором.
Типичная реализация кластера Ceph создает одно OSD (устройство хранения объектов) для каждого физического диска на узле кластера, что является рекомендованной практикой. Однако, OSD поддерживают гибкое развертывание одного OSD на диск или одного OSD на том RAID. Большинство реализаций кластера Ceph в среде JBOD использует одно OSD на физическое устройство. Для OSD Ceph необходимы:
-
Процессор и оперативная память
-
Журнал OSD (блочное устройство или файл)
-
Файловая система поддержки (XFS, ext4 или Btrfs)
-
Отдельная отказоустойчивая (рекомендуется) сетевая среда OSD или кластера
Рекомендуемая конфигурация процессора и оперативной памяти, которую вам необходимо иметь, состоит из процессора 1 ГГц и оперативной памяти 2 ГБ на OSD. Этого должно быть достаточно для большинства кластерных сред; однако, важно отметить, что в случае происшествий процесс восстановления требует больших системных ресурсов, чем при обычной работе.
|
| Замечание |
|---|---|
|
Как правило, экономически эффективно выделить избыточные ресурсы процессора и памяти на ранней стадии планирования вашего кластера, поскольку мы сможем в любое время добавить дополнительные физические диски JBOD- подобным образом в тот же хост, если он имеет достаточно системных ресурсов, вместо покупки целиком нового узла, что является более дорогостоящим решением. |
OSD является основной единицей хранения в Ceph; вы должны иметь достаточно жестких дисков в соответствии с вашими потребностями к емкости хранилища. Для дисковых устройств обычно чем выше их емкость, тем ниже стоимость в терминах стоимости за гигабайт. Вам следует воспользоваться преимуществом стоимости гигабайта и использовать OSD довольно большого размера. Однако следует иметь в виду, что чем больше размер диска, тем больше оперативной памяти необходимо для работы. {Прим. пер.: при операциях балансировки и восстановления для OSD рекомендуется наличие оперативной памяти из расчета 1 ГБ на 1 ТБ.}
С точки зрения производительности, вам следует рассмотреть возможность выделения отдельных дисков ведения журналов для OSD. Отмечается повышение производительности при создании журналов OSD в разделах SSD диска при хранении данных на отдельном шпиндельном диске. Когда для журналов используются твердотельные диски, это улучшает производительность кластера и управляет рабочей нагрузкой быстро и эффективно. Тем не менее, недостатком твердотельного диска является то, что он увеличивает стоимость хранения одного гигабайта в вашем кластере. Эффективным способом инвестирования в SSD является назначение одного SSD диска в качестве журнального для более чем одного OSD. Компромиссом здесь является то, что если вы потеряете твердотельный диск ведения журналов, который является общим для нескольких OSD, вы потеряете ваши данные на всех этих дисках, следовательно, попытайтесь избегать перегруженности SSD журналами. Достойным количеством журналов должно быть от двух до четырех на SSD.
В отношении конфигурации сетевой среды рекомендуется, чтобы кластер имел по крайней мере две отдельные сети, по одной для сети передачи данных передней стороны или общедоступной сети и другой для сетевой среды тыльной стороны или кластерной сети. Две различные сети рекомендуются для того, чтобы разделять сети данных клиентов и обмена данных кластера Ceph. БОльшую часть времени сетевой обмен в среде кластера Ceph превосходит по объему обмен данными клиентов, поскольку Ceph использует сеть кластера для выполнения репликаций для всех объектов, а также для восстановления после сбоев {Прим. пер.: и для балансировки OSD}. Если у вас обе сети содержатся в одной физической среде, вы можете столкнуться с некоторыми проблемами производительности. Опять же, рекомендуется иметь две различные сети, но вы всегда можете запустить свой кластер Ceph в одной физической сети. Эти отдельные сети должны иметь пропускную способность не менее 1Gbps. Тем не менее, всегда будет лучше иметь сеть 10Gbps основываясь на вашей рабочей нагрузке или требуемой производительности. Елси вы проектируете кластер Ceph, который планируется расширять в ближайшем будущем, и можете рассчитывать на хороший объем рабочей нагрузки, старт с 10Gbps физически разделенных сетей и для данных и для кластера будет правильным выбором если вас беспокоят отдача на инвестиции и производительность.
Желательно также иметь избыточность на каждом уровне конфигурации сети, а именно: сетевых контроллеров, портов, коммутаторов и маршрутизаторов. Сеть передачи данных передней стороны или общедоступная сеть обеспечивает взаимосвязь между клиентами и кластером Ceph. Каждая операция ввода/вывода между клиентами и кластером Ceph будет проходить через этот интерконнект. Вы должны убедиться, что у вас существует достаточно пропускной способности для каждого клиента. Второй интерконнект, который является серверной кластерной сетью, используется внутри узлов Ceph OSD. Поскольку Ceph обладает распределенной архитектурой, для каждой клиентской операции записи, данные реплицируются N раз и хранятся в кластере. Таким образом, для одной операции записи кластер Ceph должен выполнить N* значений одной операции записи. Все это копии данных перемещаются по одноранговым связям узлов во внутрикластерной сети. Помимо начальной репликации записи, сеть кластера также используется при балансировке и восстановлении данных. Поэтому она играет жизненно важную роль для определения производительности вашего кластера.
Учитывая потребности вашего бизнеса, рабочей нагрузки и общей производительности вы всегда должны пересматривать конфигурацию своей сети и можете выбрать отдельные интерконнекты 40Gbps как для общедоступной, так и для кластерной сетевой среды. Это может сделать существенные улучшения для очень больших кластеров с размерами в сотни терабайт. Большинство реализаций кластеров основано на Ethernet, однако, InfiniBand также набирает популярность в качестве высокоскоростной сетевой среды для сетей переднего и заднего плана. В качестве дополнительной опции, исходя из вашего бюджета, вы также можете рассмотреть отдельную сеть для управления, а также аварийную сеть для обеспечения дополнительного уровня резервирования сети в вашем промышленном кластере.
По сравнению с монитором (MON) Ceph и OSD, Ceph MDS (сервера метаданных) является слегка более ресурсоемкими. Они требуют значительно больших мощностей процессоров с четырьмя ядрами и более. Поскольку серверы метаданных должны быстро обслуживать данные, они сильно зависят Ceph от кешируемых данных, поэтому им требуется много оперативной памяти. Чем выше объем оперативной памяти для Ceph MDS, тем лучше будет производительность CephFS. Если у вас существует большая нагрузка на CephFS, вы должны выделить для серверов метаданных Ceph отдельные физические машины с относительно большим количеством ядер и оперативной памяти. Сетевой интерфейс с резервированием со скоростью 1Gb или выше будет работать в большинстве случаев для MDS Ceph.
|
| Замечание |
|---|---|
|
Вам рекомендуется для операционной системы использовать отдельные диски в RAID- массиве для MON, ODS и MDS. Вам не следует использовать диски/ разделы операционной системы для данных кластера. |
В Главе 2. Моментальное развертывание Ceph мы создали три виртуальные машины VirtualBox, которые мы использовали для развертывания первого мгновенного кластера Ceph. Теперь вы должны удалить этот кластер Ceph и деинсталлировать пакеты Ceph или удалить эти виртуальные машины. В данной главе мы опять установим Ceph, однако используем другой способ. Вы должны следовать указаниям раздела Создание среды песочницы с использованием VirtualBox в Главе 2. Моментальное развертывание Ceph для повторного создания виртуальных машин,которые мы будем использовать в данной главе.
{Прим. пер.: Хорошие новости для совсем ленивых: VSM делает процесс установки Ceph исключительно простым. В качестве бонуса вы получаете очень ээфективное средство мониторинга и сопровождения.}
Ранее в данной главе мы обсудили некоторые особенности выбора правильного оборудования в зависимости от ваших потребностей и вариантов использования. Вы должны соответствующим образом организовать ваши аппаратные средства, включая компоненты сетевой среды. Оборудования кластера должно быть смонтировано, соединено кабелями, запитано, а также должно иметь действующую сеть для своих узлов. Как только вы завершите с подготовкой аппаратных средств, вы будете готовы к выполнению настройки программных средств вашего кластера.
Ceph является определяемой программным обеспечением системой хранения, которая работает поверх операционной системы на
основе Linux. Все узлы Ceph должны быть установлены с поддерживающей Ceph операционной системой. В настоящее время допустимым
выбором операционных систем для работы Ceph является RHEL, CentOS, Fedora, Ubuntu, Debian и OpenSuse. Более подробную информацию
о поддерживаемых платформах вы можете проверить на
http://ceph.com/docs/master/start/os-recommendations/
|
| Замечание |
|---|---|
|
Вам рекомендуется использовать одни и те же дистрибутив, редакцию и версию ядра на всех узлах кластера Ceph. |
Ceph является проектом с открытым исходным кодом; существует несколько способов получения его программного обеспечения через интернет.
Получение пакетов через интернет является одним из наиболее распространенных вариантов получения Ceph. Опять же, существует два различных способа получения пакетов:
-
Первый метод состоит в загрузке Ceph и соответствующих пакетов вручную в необходимом формате. Если по соображениям безопасности ваши узлы Ceph не имеют доступа в интернет, это будет возможным вариантом для вас. Вы можете скачать Ceph и все связанное с ним на любую из машин в вашей сети и скопировать их на каждый узел, после чего выполнить установку.
Для получения пакетов RPM вы можете посетить
http://ceph.com/rpm-<ceph-release-name>иhttp://ceph.com/debian-<ceph-release-name>для пакетов на основе Debian. Допустимыми именами редакций {на момент издания книги} являются Argonaut, Bobtail, Cuttlefih, Dumpling, Emperor, Firefl и Giant.Помимо этого вам также могут понадобиться сторонние библиотеки, которые должны быть установлены перед установкой Ceph. Вы можете проверить список дополнительных двоичных файлов в документации Ceph на
http://ceph.com/docs/master/install/get-packages/#download-packages. -
Второй метод состоит в использовании инструментов управления пакетами путем добавления репозиториев пакетов Ceph либо Advanced Package Tool (APT) для дистрибутивов на основе Debian, либо Yellowdog Updater Modifier (YUM) для дистрибутивов на основе RHEL. Для пакетов RPM вы должны создать новый файл репозитория
/etc/yum.repos.d/ceph.repo, Добавьте приводимый ниже код в этот файл; замените{ceph-release}допустимой редакцией Ceph, а{distro}дистрибутивом Linux, например, el6 или rhel6. Для получения дополнительной информации по получению пакетов Ceph, ознакомьтесь сhttp://ceph.com/docs/master/install/get-packages/.[ceph] name=Ceph packages for $basearch baseurl=http://ceph.com/rpm-{cephrelease}/{distro}/$basearch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=http://ceph.com/rpm-{ceph-release}/{distro}/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [ceph-source] name=Ceph source packages baseurl=http://ceph.com/rpm-{ceph-release}/{distro}/SRPMS enabled=0 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc
Вы можете загрузить исходный код с http://ceph.com/download/,
а затем откомпилировать его и построить версию из исходного кода.
Вы можете клонировать главную ветвь исходного кода Ceph в интерактивном репозитории Ceph GitHub. Для этого вам понадобится установленный на вашем локальном компьютере инструментарий Git. Если вы являетесь разработчиком, это будет вам полезно при построении Ceph и внесения вашего вклада в проект с открытым исходным кодом. Если вам нужна самая последняя версия разработки Ceph или необходимо исправить ошибку в стабильной версии, вы можете выполнить клонирование и построить специальные исправления ошибок до выпуска их официальной редакции.
Мы можем устанавливать Ceph либо с использованием инструментария ceph-deploy, либо методом ручного развертывания. В данном разделе мы ознакомимся с процессом установки Ceph вручную.
{Прим. пер.: Отдавая должное методологической важности данного раздела, рады сообщить: у нас есть хорошие новости для совсем ленивых: VSM делает процесс установки Ceph исключительно простым. В качестве бонуса вы получаете очень ээфективное средство мониторинга и сопровождения.}
Ceph требует дополнительные библиотеки сторонних производителей. Для дистрибутивов на основе RHEL Linux вы можете получить дополнительные пакеты из репозитория EPEL. Выполните следующие действия, чтобы установить Ceph.
-
Установите репозиторий EPEL. Проверьте, чтобы параметр
baserulбыл разрешен в файле/etc/yum.repos.d/epel.repo. Параметрbaserulопределяет URL для дополнительных пактов Linux. Также убедитесь, что параметрmirrorlistдолжен быть запрещен (помещен в комментарий) в этом файле. При включенном параметреmirrorlistв файлеepel.repoво время установки наблюдались проблемы. Выполните этот шаг на всех трех узлах.{Прим. пер.: Для RHEL/CentOS: }
# rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epelrelease-6-8.noarch.rpm
{Прим. пер.: Для Ubuntu/Debian списки пакетов дополнений, основного репозитория (
echo deb http://ceph.com/debian-{release-name}/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list), Apache/FastCGI устанавливаются, например, так:~$ echo deb http://ceph.com/packages/ceph-extras/debian $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph-extras.list ~$ echo deb http://ceph.com/debian-hammer/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list ~$ echo deb http://gitbuilder.ceph.com/apache2-deb-$(lsb_release -sc)-x86_64-basic/ref/master $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph-apache.list ~$ echo deb http://gitbuilder.ceph.com/libapache-mod-fastcgi-deb-$(lsb_release -sc)-x86_64-basic/ref/master $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph-fastcgi.list} -
Установите необходимые Ceph двоичные файлы сторонних разработчиков:
{Прим. пер.: Для RHEL/CentOS:}
# yum install -y snappy leveldb gdisk python-argparse gperftools-libs
{Прим. пер.: Для Ubuntu/Debian:
~$ sudo apt-get install -y libaio1 libsnappy1 libcurl3 curl libleveldb1 libgoogle-perftools4 google-perftools} -
Создайте файл репозитория для редакции Emperor как показано на следующей копии экрана:
[root@ceph-node1 ~]# cat /etc/yum.repos.d/ceph.repo [ceph] name=Ceph packages for $basearch baseurl=http://ceph.com/rpm-emperor/el6/$basearch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=http://ceph.com/rpm-emperor/el6/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [ceph-source] name=Ceph source packages baseurl=http://ceph.com/rpm-emperor/el6/SRPMS enabled=0 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [root@ceph-node1 ~]#
-
Установите пакеты Ceph:
{Прим. пер.: Для RHEL/CentOS:}
# yum install ceph -y --disablerepo=epel
{Прим. пер.: Для Ubuntu/Debian:
~$ sudo apt-get install ceph -y}В этой команде {Прим. пер.: для RHEL/CentOS} мы добавили параметр
--disablerepo=epel, поскольку мы не хотим устанавливать пакеты Ceph поддерживаемые EPEL, поскольку EPEL устанавливает самую последнюю версию Ceph, которой является Firefly. Мы хотим устанавливать Emperor, поэтому мы запрещаем репозиторий epel и, следовательно, Ceph должен устанавливаться с использованием файлаceph.repo -
Когда пакеты установятся, проверьте: установились они или нет (не обязательно):
{Прим. пер.: Для RHEL/CentOS:}
# rpm -qa | egrep -i "ceph|rados|rbd"
{Прим. пер.: Для Ubuntu/Debian:
~$ sudo apt list | egrep -i "ceph|rados|rbd"}Предыдущая команда {Прим. пер.: для RHEL/CentOS} выдаст результат подобный показанному на следующем снимке экрана:
[root@ceph-node1 ~]# rpm -qa | egrep -i "ceph|rados|rbd" ceph-0.72.2-0.el6.x86_64 libcephfs1-0.72.2-0.el6.x86_64 python-ceph-0.72.2-0.el6.x86_64 librbd1-0.72.2-0.el6.x86_64 librados2-0.72.2-0.el6.x86_64 [root@ceph-node1 ~]#
-
Повторите шаги с 1 по 5 на остальных двух узлах, т.е.
ceph-node2иceph-node3.
{Прим. пер.: Отдавая должное методологической важности данного раздела, рады сообщить: у нас есть хорошие новости для совсем ленивых: VSM делает процесс установки Ceph исключительно простым. В качестве бонуса вы получаете очень ээфективное средство мониторинга и сопровождения.}
Теперь мы установили пакеты Ceph на всех узлах и хорошо подготовлены к развертыванию Ceph ручную. Процесс ручной установки Ceph является основным для разработчиков, вовлеченных в создание сценариев развертывания Ceph для инструментария управления настройкой, такого как Ansible, Chef и Puppet, чтобы понять поток развертывания. Как администратор вы можете редко пользоваться установкой вручную, однако будет существенной добавкой к вашим навыкам Ceph. Большинство промышленных развертываний основываются на инструментах ceph-deploy. Наша текущая настройка развертывания выглядит следующим образом:
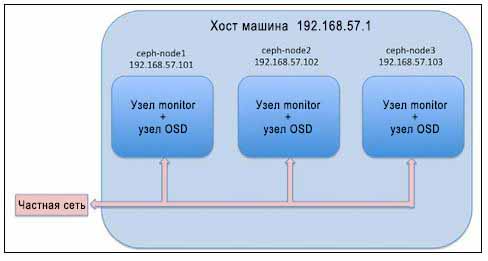
Для своей работы кластер хранения Ceph требует по крайней мере один узел монитора. Однако рекомендуется иметь нечетное число мониторов большее одного. В данном разделе мы ознакомимся с развертыванием узлов мониторов Ceph:
-
Создайте каталог для Ceph и заведите файл конфигурации кластера Ceph:
# mkdir /etc/ceph # touch /etc/ceph/ceph.conf
-
Создайте FSID для вашего кластера:
# uuidgen
-
Создайте свой файл конфигурации кластера; именем кластера по умолчанию будет
ceph. Файлом конфигурации будет/etc/ceph/ceph.conf. Вы должны использовать вывод командыuuidgenиз предыдущего шага в качестве параметраfsidв файле конфигурации.[root@ceph-node1 ceph]# cat /etc/ceph/ceph.conf [global] fsid = 07a92ca3-347e-43db-87ee-e0a0a9f89e97 public network = 192.168.57.0/24 osd pool default min size = 1 osd pool default pg num = 128 osd pool default pgp num = 128 osd journal size = 1024 [mon] mon initial members = ceph-node1 mon host = ceph-node1,ceph-node2,ceph-node3 mon addr = 192.168.57.101,192.158.57.102,192.168.57.103 [mon.ceph-node1] host=ceph-node1 mon addr = 192.168.57.101 [root@ceph-node1 ceph]#
-
Создайте кольцо для ключей (keyring) вашего кластера и секретный ключ для монитора следующим образом:
# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
-
Создайте пользователя
client.adminи добавьте этого пользователя в кольцо ключей:# ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --set-uid=0 --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow *'
-
Добавьте ключ
client.adminвceph.mon.keyring:# ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
Следующая копия экрана демонстрирует предыдущие команды в действии:
[root@ceph-node1 ceph]# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key n mon. --cap mon 'allow *' creating /tmp/ceph.mon.keyring [root@ceph-node1 ceph]# [root@ceph-node1 ceph]# ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --set-uid=0 -cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow' creating /etc/ceph/ceph.client.admin.keyring [root@ceph-node1 ceph]# [root@ceph-node1 ceph]# ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring importing contents of /etc/ceph/ceph.client.admin.keyring into /tmp/ceph.mon.keyring [root@ceph-node1 ceph]#
-
Создайте карту монитора для вашего первого монитора со следующим синтаксисом:
monmaptool --create --add {hostname} {ip-address} --fsid {uuid} /tmp/monmap.Взглянем на следующий пример:
# monmaptool --create --add ceph-node1 192.168.57.101 --fsid 07a92ca3-347e-43db-87ee-e0a0a9f89e97 /tmp/monmap
[root@ceph-node1 ceph]# monmaptool --create --add ceph-node1 192.168.57.101 --fsid 07a92ca3-347e-43db-87ee-e0a0a9f89e97 /tmp/monmap monmaptool: monmap file /tmp/monmap monmaptool: set fsid to 07a92ca3-347e-43db-87ee-e0a0a9f89e97 monmaptool: writing epoch 0 to /tmp/monmap (1 monitors) [root@ceph-node1 ceph]#
-
Создайте каталог для монитора как
/path/cluster_name-monitor_node:# mkdir /var/lib/ceph/mon/ceph-ceph-node1
-
Заселите первый демон монитора:
# ceph-mon --mkfs -i ceph-node1 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
-
Запустите службу монитора как показано на следующей копии экрана:
[root@ceph node1 ceph]# ceph-mon --mkfs -i ceph-node1 --monmap /tmp/monmap -keyring /tmp/ceph.mon.keyring ceph-mon: set fsid to 07a92ca3-347e-43db-87ee-e0a0a9f89e97 ceph-mon: created monfs at /var/lib/ceph/mon/ceph-ceph-node1 for mon.ceph-node1 [root@ceph-node1 ceph]# [root@ceph-node1 ceph]# service ceph start === mon.ceph-node1 = Starting Ceph mon.ceph-node1 on ceph-node1... Starting ceph-create-keys on ceph-node1... [root@ceph-node1 ceph]#
-
Проверьте состояние вашего кластера и найдите пулы по умолчанию:
[root@ceph-node1 ceph]# [root@ceph-node1 ceph]# ceph status cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_ERR 192 pgs stuck inactive; 192 pgs stuck unclean; no osds monmap e1: 1 mons at {ceph-nodel=192.168.57.101:6789/0}, election epoch 1, quorum 0 ccph-nodel osdmap e1: 0 osds: 0 up, 0 in pgmap v2: 192 pgs, 3 pools, 0 bytes data, 0 objects 0 kB used, 0 kB / 0 kB avail 192 creating [root@ceph-node1 cephJ# [root@ceph-node1 ceph]# ceph osd lspools 0 data,1 metadata,2 rbd, [root@ceph-node1 ceph]#
Вы должны проверить карту монитора. Вы увидите, что ваш первый узел правильно настроен в качестве узла монитора. Пока не стоит беспокоиться о работоспособности кластера. Нам нужно будет добавить несколько OSD, чтобы сделать ваш кластер работоспособным.
После того, как вы создали свой начальный монитор, вы должны добавить в свой кластер несколько OSD (устройств хранения объектов):
-
Проверьте доступные в вашей системе диски. В нашей тестовой установке каждая виртуальная машина имеет три диска (в идеале sdb, sdc и sdd):
# ceph-disk list
-
OSD Ceph работает с таблицей разделов GUID (GPT, GUID Partition Table). Если OSD еще не помечен как GPT, вы должны заменить метку раздела с любого другого типа на GPT:
# parted /dev/sdb mklabel GPT
[root@ceph-node1 ~]# parted /dev/sdb mklabel GPT warning: The existing disk label on /dev/sdb will be destroyed and all data on this disk will be lost, do you want to continue? Yes/No? yes Information: you may need to update /etc/fstab. [root@ceph-node1 ~]#
-
Таким же образом выполните маркировку остальных дисков:
# parted /dev/sdc mklabel GPT # parted /dev/sdd mklabel GPT
-
Подготовьте диск OSD, снабдив его информацией о кластере и файловой системе; используйте следующий синтаксис:
ceph-disk prepare --cluster {cluster-name} --cluster-uuid {fsid} --fs-type {ext4|xfs|btrfs} {data-path} [{journal-path}]:Рассмотрим следующий пример:
# ceph-disk prepare --cluster ceph --cluster-uuid 07a92ca3- 347e-43db-87ee-e0a0a9f89e97 --fs-type xfs /dev/sdb
Следующий снимок экрана отображает вывод предыдущей команды:
[root@ceph-node1 ~]# ceph-disk prepare —-cluster ceph —-cluster-uuid 07a92ca3-347e-43db-87ee-e0a0a9f89e97 --fs -type xfs /dev/sdb INFO:ceph-disk:will colocate journal with data on /dev/sdb Setting name! partNum is 1 REALLY setting name! The operation has completed successfully. Setting name! partNum is 0 REALLY setting name! The operation has completed successfully. meta-data=/dev/scbl isize=2048 agcount=4, agsize=589759 blks = sectsz=Sl2 attr=2, projid32bit=0 data = bsize=409G blocks=2359035, inaxpct=2S = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 log =Internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 The operation has completed successfully. [root@ceph-node1 ~]# -
Подготовьте остальные диски следующим образом:
# ceph-disk prepare --cluster ceph --cluster-uuid 07a92ca3-347e-43db-87ee-e0a0a9f89e97 --fs-type xfs /dev/sdc # ceph-disk prepare --cluster ceph --cluster-uuid 07a92ca3-347e-43db-87ee-e0a0a9f89e97 --fs-type xfs /dev/sdd
-
Наконец, активируем OSD:
# ceph-disk activate /dev/sdb1
Взглянем на следующий снимок экрана:
[root@ceph-node1 ~]# ceph-disk activate /dev/sdb1 INFO:ceph-disk:ceph osd.0 already mounted in position; unmounting ours. === osd.0 === Starting Ceph osd.O on ceph-node1...already running [root@ceph-node1 ~]# [root@ceph-node1 ~]# [root@ceph-node1 ~]# [root@ceph-node1 ~]# service ceph status osd === osd.0 === osd.0: running {"version":"0.72.2"} [root@ceph-node1 ~]# -
Активируем остальные диски:
# ceph-disk activate /dev/sdc1 # ceph-disk activate /dev/sdd1
-
Проверим состояние вашего кластера. Вы увидите три OSD в состояниях UP и IN:
[root@ceph-node1 ~]# ceph -s cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_WARN 63 pgs degraded; 192 pgs stuck unclean monmap e1: 1 mons at (ceph-node1=192.168.57.101:6789/0}, election epoch 1, quorum 0 ceph-node1 osdmap e16: 3 osds: 3 up, 3 in pgmap v26: 192 pgs, 3 pools, 0 bytes data, 0 objects 106 MB used, 27508 MB / 27614 MB avail 52 active 77 active+remapped 63 active+degraded [root@ceph-node1 ~]# -
Скопируем файлы
ceph.confиceph.client.admin.keyringсceph-node1наceph-node2иceph-node3выполнив команды кластера:# scp /etc/ceph/ceph.* ceph-node2:/etc/ceph # scp /etc/ceph/ceph.* ceph-node3:/etc/ceph
-
Даже после копирования
ceph.confиceph.client.admin.keyringнаceph-node2иceph-node3, если вы не можете выполнять команды кластера сceph-node2иceph-node3, и вы получаете сообщение об ошибке подобноеError connecting to cluster, вы должны настроить правила межсетевого экрана для всех трех демоновceph-monitorили выключить межсетевые экраны на всех трех узлах.
Расширение кластера Ceph является одной из самых важных задач для администратора Ceph. Она включает в себя добавление
дополнительных узлов мониторов и OSD (устройств хранения объектов).Мы рекомендуем использовать нечетное число узлов мониторов
для обеспечения высокой доступности и установления кворума; однако, это не является обязательным требованием. Операции
расширения и сворачивания для узлов мониторов и OSD являются абсолютно интерактивными и не требуют останова. В нашей
тестовой реализации у нас есть отдельный узел, ceph-node1,
который работает и как узел монитора, и как узел OSD. Теперь добавим еще два монитора в наш кластер Ceph.
Выполним следующие шаги:
-
Зарегистрируемся на
ceph-node2и создадим каталоги:# mkdir -p /var/lib/ceph/mon/ceph-ceph-node2 /tmp/ceph-node2
-
Исправим файл
/etc/ceph/ceph.confи добавим новую информацию о мониторе в раздел[mon]:[mon.ceph-node2] mon_addr = 192.168.57.102:6789 host = ceph-node2
-
Выделим информацию о кольце ключей из кластера Ceph:
# ceph auth get mon. -o /tmp/ceph-node2/monkeyring
[root@ceph-node2 ceph]# mkdir -p /var/lib/ceph/mon/ceph-ceph-node2 /tmp/ceph-node2 [root@ceph-node2 ceph]# [root@ceph-node2 ceph]# [root@ceph-node2 ceph]# [root@ceph-node2 ceph]# ceph auth get mon. -o /tmp/ceph-node2/monkeyring exported keyring for mon. [root@ceph-node2 ceph]#
-
Получим карту монитора из кластера Ceph:
# ceph mon getmap -o /tmp/ceph-node2/monmap
-
Построим новый монитор, fs, используя ключ и существующую monmap:
# ceph-mon -i ceph-node2 --mkfs --monmap /tmp/cephnode2/monmap --keyring /tmp/ceph-node2/monkeyring
-
Добавим новый монитор в кластер:
# ceph mon add ceph-node2 192.168.57.102:6789
[root@ceph-node2 ceph]# ceph mon getmap -o /trp/ceph-node2/monmap got latest monmap [root@ceph-node2 ceph]# [root@ceph-node2 ceph]# ceph-mon -i ceph-node2 --mkfs --monmap /tmp/ceph-node2/monmap --keyring /tmp/ceph-node2/monkeyring ceph-mon: set fsid to 07a92ca3-347e-43db-87ee-e0a0a9f89e97 ceph-mon: created monfs at /var/lib/ceph/mon/ceph-ceph-node2 for men.ceph-node2 [root@ceph-node2 ceph]# [root@ceph-node2 ceph]# [root@ceph-node2 ceph]# [root@ceph node2 ceph]# [root@ceph-node2 ceph]# ceph mon add ceph-node2 192.168.57.102:6789 added mon.ceph-node2 at 192.168.57.102:6789/0 [root@ceph-node2 ceph]#
-
После добавления монитора проверим состояние кластера. Вы заметите, что теперь у нас есть два монитора в нашем кластере Ceph. Вы можете продолжать игнорировать предупреждающее сообщение о расфазировке тактовых сигналов или можете настроить NTP на всех ваших узлах так, чтобы они были синхронизированы по времени. Мы уже обсуждали настройку NTP в разделе Увеличение вашего кластера Ceph в масштабах- добавление монитора и OSD Главы 2. Моментальное развертывание Ceph.
[root@ceph-node2 ceph]# ceph -s cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_WARN 63 pgs degraded; 192 pgs stuck unclean; clock skew detected on monn.ceph-node2 monmap e2: 2 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=l9?.168.57.102:6789/0}. election epoch 2, quorum 0.1 ceph-node1,ceph-node2 osdmap e27: 3 osds: 3 up, 3 in pgmap v43: 192 pgs, 3 pools, 0 bytes data, 0 objects 104 MB used. 27510 MB / 27614 MB avail 87 active+remapped 41 active+degraded 42 active+replay+remapped 22 active+replay+degraded -
Повторите пройденные шаги для добавления
ceph-node3в качестве вашего третьего монитора. После добавления третьего монитора проверьте состояние вашего кластера и вы заметите третий монитор в кластере:[root@ceph-node3 ceph]# ceph -s cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_WARN 63 pgs degraded; 192 pgs stuck unclean; 1 mons down, quorum 0.1 ceph-node1,ceph-node2; clock skew detected on mon.ceph- node2 monnap e3: 3 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=192.168.57.102:6789/0,ceph-node3=192.168.57.103:6789/0}. election epoch 4, quorum 0.1 ceph-node1,ceph-node2 osdmap e27: 3 osds: 3 up, 3 in pgmap v43: 192 pgs, 3 pools, 0 bytes data, 0 objects 104 MB used, 27510 MB / 27614 MB avail 87 active+remapped 41 active+degraded 42 active+replay+remapped 22 active+replay+degraded [root@ceph-node3 ceph]#
Расширять ваш кластер путем добавления OSD (устройств хранения объектов) на лету достаточно легко. Ранее в данной главе мы изучали создание OSD; этот процесс аналогичен масштабированию вашего кластера для добавления дополнительных OSD. Зарегистрируйтесь на узле, на котором требуется добавить диски в кластер и выполните следующие действия:
-
Выведите список доступных дисков:
# ceph-disk list
-
Пометьте диски в GPT
# parted /dev/sdb mklabel GPT # parted /dev/sdc mklabel GPT # parted /dev/sdd mklabel GPT
-
Подготовьте диски с необходимой файловой системой и снабдите их инструкцией подключения в кластер, предоставив
uuidкластера:# ceph-disk prepare --cluster ceph --cluster-uuid 07a92ca3-347e-43db-87ee-e0a0a9f89e97 --fs-type xfs /dev/sdb # ceph-disk prepare --cluster ceph --cluster-uuid 07a92ca3-347e-43db-87ee-e0a0a9f89e97 --fs-type xfs /dev/sdc # ceph-disk prepare --cluster ceph --cluster-uuid 07a92ca3-347e-43db-87ee-e0a0a9f89e97 --fs-type xfs /dev/sdd
-
Активируйте диск так, чтобы Ceph смогла запустить службы OSD и помочь присоединиться к кластеру:
# ceph-disk activate /dev/sdb1 # ceph-disk activate /dev/sdc1 # ceph-disk activate /dev/sdd1
-
Повторите эти действия для всех других узлов, для которых вы хотите добавить их диски в кластер. Наконец, проверьте состояние кластера; вы заметите, что диски будут в состояниях UP и IN:
[root@ceph-mode1 ceph]# ceph -» cluster 07a92ca3-347e-43db-87ee-e0a0a9f89e97 health HEALTH_OK monmap e3: 3 mons at {ceph-node1=192.168.57.101:6789/0,ceph-node2=192.168.57.102:6789/0,ceph-node3=192.168.57.103:6789/0}, election epoch 668, quorum 0,1,2 ceph-node1,ceph-node2,ceph-node3 osdmap e62: 9 osds: 9 up, 9 in pgmap v112: 192 pgs, 3 pools, 0 bytes data, 0 objects 338 MB used, 78409 MB / 78748 MB avail 192 active+clean [root@ceph-mode1 ceph]# -
Проверьте дерево OSD кластера; это снабдит вас информацией об OSD и физических узлах:
[root@ceph-node1 ceph]# ceph osd tree # id weight type name up/dewn reweight -1 0.08995 root default -2 0.02998 host ceph nodel 0 0.009995 osd.O up 1 1 0.009995 osd.1 up 1 2 0.009995 osd.2 up 1 -3 0.02998 host ceph node2 3 0.009995 osd.3 up 1 5 0.009995 osd.5 up 1 4 0.009995 osd.4 up 1 -4 0.02998 host ceph node3 6 0.009995 osd.6 up 1 7 0.00999S osd.7 up 1 5 0.009995 osd.8 up 1 [root@ceph-node1 ceph]#
Ceph поставляется с очень мощным инструментом развертывания, называемым ceph-deploy. Инструмент ceph-deploy полагается на SSH при развертывании программного обеспечения Ceph на узлах кластера, поэтому он имеет основное требование, что на узле должна быть предустановлена операционная система и он должен быть доступен в сети. Инструмент ceph-deploy не требует дополнительных системных ресурсов и он может хорошо работать на обычной рабочей станции, которая должна иметь доступ к узлам кластера.
{Прим. пер.: Отдавая должное методологической важности данного раздела, рады сообщить: у нас есть хорошие новости для совсем ленивых: VSM делает процесс установки Ceph исключительно простым. В качестве бонуса вы получаете очень ээфективное средство мониторинга и сопровождения.}
Вы также можете рассмотреть возможность использования любого вашего узла монитора в качестве узла ceph-deploy. Инструмент ceph-deploy делает развертывание Ceph легким с начальной конфигурацией по умолчанию, которая может быть изменена позже на основе вашего варианта использования. Инструмент ceph-deploy предоставляет такие возможности, как установка пакетов Ceph, создание кластеров, добавление мониторов и OSD (устройств хранения объектов), управление ключами Ceph, создание MDS (сервера метаданных), настройка хостов администрирования, а также демонтаж кластера Ceph.
Ранее вэтой книге в Главе 2. Моментальное развертывание Ceph мы уже видели как развертывать кластер с использованием инструментария ceph-deploy. Сейчас мы кратко пройдем по этапам развертывания кластера Ceph с применением ceph-deploy:
-
Настройте регистрацию на основе SSH для всех ваших узлов Ceph. Если это возможно, сделайте регистрацию на них свободной от ввода пароля. Вы всегда должны следовать практике безопасности вашего окружения при настройке регистрации свободной от ввода пароля.
-
Установите файл репозитория на ваш менеджер пакетов Linux. Этот файл репозитория должен присутствовать на всех узлах в вашем кластере.
-
Установите ceph-deploy на любом узле в кластере. Обычно это узел администратора, который используется для управления Ceph.
-
Создайте новый кластер, именем кластера по умолчанию будет
ceph:# ceph-deploy new ceph-node1
-
Установите программное обеспечение Ceph на узлы кластера:
# ceph-deploy install ceph-node1 ceph-node2 ceph-node3
Замечание По умолчанию
ceph-deployбудет устанавливать последнюю редакцию Ceph, если вы хотите установить некую особенную редакцию Ceph, воспользуйтесь параметром--release {Ceph-release-name}вceph-deploy. -
Создайте начальные мониторы и соберите ключи:
# ceph-deploy mon create ceph-node1 # ceph-deploy gatherkeys ceph-node1
Начиная с версии 1.1.3 ceph-deploy, вам больше не требуется несколько команд для создания начальных мониторов и сбора ключей. Это может быть достигнуто за один шаг с помощью следующей команды. Перед запуском этой команды в файле
ceph.confдолжны быть настроены начальные мониторы.# ceph-deploy mon create-initial
-
Для высокой доступности настройте больше машин мониторов. Рекомендуется нечетное число. Убедитесь, что вы добавили правила межсетевого экрана для монитора портов 6789 так, что они могут соединяться друг с другом. Если вы выполняете это только для целей тестирования, вы можете отключить межсетевой экран.
# ceph-deploy mon create ceph-node2 # ceph-deploy mon create ceph-node3
-
Если вы используете диски, которые имеют старую файловую систему, очистите разделы так, чтобы они могли использоваться с Ceph. Эта операция снесет все данные на диске.
# ceph-deploy disk zap ceph-node1:sdb ceph-node1:sdc cephnode1:sdd
Создайте OSD для вашего кластера Ceph. Повторите шаги для добавления дополнительных OSD. Для достижения чистого состояния для вашего кластера вы должны должны добавить OSD на машинах, которые разделены физически.
# ceph-deploy osd create ceph-node1:sdb ceph-node1:sdc cephnode1:sdd
-
Наконец, проверьте состояние вашего кластера Ceph. Он должен быть работоспособным.
Инструмент ceph-deploy это стабильное и удивительное средство для легкого развертывания кластера Ceph. Он быстро оснащается новыми свойствами и файлами исправления ошибок. В настоящее время большинство кластеров Ceph осуществляют развертывание с применением инструментария ceph-deploy.
Обновление вашей версии программного обеспечения кластера Ceph относительно простое. Вам нужно просто обновить пакет Ceph, затем перезапустить службу и все сделано. Процесс модернизации является последовательным и обычно не требует каких- либо остановов ваших служб хранения если вы настроили ваш кластер на высокую доступность, то есть с множеством OSD (устройств хранения объектов), мониторов, MDS (серверов метаданных) и RADOSGW (шлюзов RADOS, Безотказного автономного распределенного хранилища объектов - Reliable Autonomic Distributed Object Store). Обычно модернизация выполняется во внерабочее время (при отсутствии пиковых нагрузок). Процесс модернизации обновляет каждый демон Ceph один за другим. Рекомендуемая последовательность модернизации для кластера Ceph является следующей:
{Прим. пер.: Хорошие новости для совсем ленивых: VSM делает процесс обновления Ceph исключительно простым. Более того, процесс обновления с его применением полностью происходит в реальном масштабе времени, то есть не требует никаких перерывов обслуживания по расписанию для выполнения обновления. Стоит напомнить, однако, что VSM позволяет работать только с кластером, который он же и устанавливал (доступно для версий VSM начиная с 2.1)!}
-
Монитор
-
OSD (устройства хранения объектов)
-
Сервер метаданных (MDS)
-
Шлюз RADOS
Вы должны обновить все демоны одного типа, а потом приступить к модернизации следующего типа. Например, ваш кластер содержит три узла мониторов, 100 OSD, 2 MDS и RADOSGW. В начале вы должны обновить все ваши узлы мониторов один за другим, затем обновить по одному все узлы OSD, потом MDS и, наконец RADOSGW. Это позволит поддерживать один и тот же уровень редакции всех конкретных типов демонов.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Перед выполнением модернизации демонов Ceph, пожалуйста, прочитайте примечания к выпуску, а также любую другую информацию в официальной документации Ceph, связанные с модернизацией. После того, как вы обновите демон, вы не сможете понизить его версию. |
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Перед модернизацией вы всегда должны проверять требования клиента Ceph, такие как версия ядра или любые другие связанные компоненты. |
Для обновления монитора придерживайтесь следующих шагов:
-
Проверьте текущую версию ваших демонов:
[root@ceph-node1 ~]# service ceph status === osd.1 === osd.1: running {"version":"0.72.2"} === osd.0 === osd.0: running {"version":"0.72.2"} === osd.2 === osd.2: running {"version":"0.72.2"} mon.ceph-node1: running ["version":"0.72.2"} [root@ceph-node1 ~]#Поскольку наша установка тестового кластера имеет демоны MON и OSD, выполняющиеся на одной и той же машине, модернизация двоичных файлов Ceph на редакцию Firefly (0.80) повлечет обновление демонов MON и OSD за один шаг. Однако, в промышленных реализациях Ceph модернизация должна выполняться последовательно, один за другим. В противном случае вы можете столкнуться с проблемами.
-
Модернизируйте ваши репозитории Ceph на целевые репозитории Firefly. Обычно вам необходимо просто изменить имя вашей новой редакции в файле
/etc/yum.repos.d/ceph.repo, который уже имеется:[root@ceph-node1 ~]# cat /etc/yun.repos.d/ceph.repo [ceph] name=Ceph packages for $basearch baseurl=http://ceph.com/rpm-firefly/el6/$basearch enabled=l gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=http://ceph.com/rpm-firefly/el6/noarch enabled=1 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f-keys/re1ease.asc [ceph source] name=Ceph source packages baseurl-http://ceph.com/rpm-firefly/el6/SRPMS enabled=0 gpgcheck=1 type=rpm-md gpgkey=https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc [root@ceph-node1 ~]#
-
Модернизируйте ваше программное обеспечение Ceph:
# yum update ceph
-
После того как двоичные файлы программного обеспечения Ceph обновлены, вы должны перезапустить демон монитора, чтобы изменения вступили в силу:
# service ceph restart mon
-
Проверьте версию демона монитора; она должна измениться:
# service ceph status mon
[rootGceph-node1 ceph]# service ceph restart mon === mon.ceph-node1 === === mon.ceph-node1 === Stopping Ceph mon.ceph-node1 on ceph-node1...kill 2106...done === mon.ceph-node1 === Starting Ceph mon.ceph-node1 on ceph-node1... Starting ceph-create-keys on ceph-node1... [root@ceph-node1 ceph]# [root@ceph-node1 ceph]# service ceph status mon === mon.ceph-node1 === mon.ceph-node1: running {"version":"0.80.1"} [root@ceph-node1 ceph]# -
Проверьте состояния монитора:
# ceph mon stat
-
Повторите эти шаги для других мониторов в вашем кластере. Убедитесь, что все узлы мониторов имеют одну и ту же редакцию Ceph, прежде чем приступите к модернизации OSD, MDS или RGW.
Для обновления OSD (устройств хранения объектов) придерживайтесь следующих шагов:
-
Аналогично процессоу модернизации монитора, обновите репозитории Ceph на целевые хранилища Firefly.
-
Выполните модернизацию Ceph:
# yum update ceph
-
После успешного обновления программного обеспечения Ceph перезапустите демоны OSD:
# service ceph restart osd
-
Проверьте состояние OSD; вы должны обнаружить новую редакцию OSD:
# service ceph status osd
[root@ceph-node1 ceph]# service ceph status osd === osd.1 === osd.1: running {"version":"0.80.1"} === osd.O === osd.O: running {"version":"0.80.1"} === osd.2 === osd.2: running {"version":"0.80.1") [rootOceph-node1 ceph]# -
Повторите эти шаги для других узлов OSD в вашем кластере. Убедитесь, что все узлы в вашем кластере имеют одну и туже редакцию Ceph.
|
| Совет |
|---|---|
|
{Прим. пер.: чтобы полностью использовать полосу пропускания SSD, они должны расщепляться примерно между 5 OSD (по опыту Mirantis), для включения такой возможности вам необходимо удалить OSD, созданные на этих SSD при установке, разделить каждый SSD на пять разделов и создать на них OSD. см., например, раздел 6.1 Эталонной архитектуры для компактного облачного решения с применением Mirantis OpenStack 9.1 и оборудования Dell EMC.} |
Планирование ваших потребностей в хранении чрезвычайно важно для вашего кластера Ceph. Этап планирования является тем, что определяет емкость вашего кластера Ceph, его производительность и уровень отказоустойчивости. Вы знаете свои требования, потребности в хранении и рабочую нагрузку лучше, чем кто-либо другой. Следовательно вы должны принять решение о ваших конфигурациях аппаратуры и программного обеспечения Ceph имея в виду свои потребности. Следуя контексту развертывания, Ceph предоставляет способы как ручного, так и автоматизированного развертывания. Процедура развертывания вручную используется в основном инструментами управления конфигурации, такими как Puppet, Ansible и Chef.
Ручной процесс развертывания помогает этим инструментам реализовать ряд проверок во время развертывания, тем самым улучшая гибкость. Автоматизированный способ развертывания должен использовать инструментарий ceph-deploy, который является относительно простым и обеспечивает легкие в использовании наборы команд для различных связанных с кластером мероприятий. Кластер хранения Ceph можно масштабировать на лету; кроме того, модернизация с одной редакции на другую очень проста и не влияет ни на какие службы.