Глава 2. Гипервизоры
Содержание
В своей предыдущей главе мы обсудили что представляет из себя виртуализация и рассмотрели основные типы виртуализации - основанную на ВМ и основанную на контейнерах. В основанной на ВМ виртуализации мы кратко обсудили собственно роль т важность имеющегося гипервизора, который содействует созданию виртуальных машин.
В этой главе мы глубже окунёмся в гипервизоры. Основная часть этой главы поясняет виртуализацию с применением таких компонентов, как Linux Kernel Virtual Machine (KVM) и Quick Emulator (QEMU). Основываясь на этих компонентах, мы далее рассмотрим как создаются ВМ и как содействует потоку данных между самим гостем и его хостами.
Linux предоставляет функциональные возможности гипервизора при помощи QEMU в соответствующем пространстве
пользователей и особом модуле ядра с названием KVM (Kernel Virtual Machine Linux). Этот KVM применяет набор
инструкций расширения vt-x Intel для изолирования ресурсов на соответствующем
аппаратном уровне. Поскольку QEMU является процессом в пространстве пользователя, имеющееся ядро трактует его с точки
зрения планирования аналогично прочим процессам.
Прежде чем мы обсудим QEMU и KVM, давайте коснёмся vt-x Intel и
особенного для него набора инструкций.
Технология виртуализации Intel (VT) представляется в двух разновидностях:
-
Vt-x(для архитектур Intel x86 IA-32 и 64-бит) -
Vt-i(для линейки процессора Itanium)
По функциональности они схожи. Чтобы понять необходимость поддержки виртуализации на уровне ЦП, давайте по быстрому рассмотрим как программы и ОС взаимодействуют с ЦПУ, а также как как с ЦПУ взаимодействуют программы в ВМ.
В случае запускаемых в хосте обычных программ его ОС транслирует инструкции программ в инструкции ЦПУ которые и выполняются самим ЦПУ.
В случае виртуальной машины для запуска программ внутри соответствующей виртуальной машины, ОС этого гостя транслирует инструкции программы в инструкции виртуального ЦПУ, а её гипервизор затем конвертирует их в инструкции для своего физического ЦПУ.
Как мы можем видеть, для ВМ такие инструкции программ транслируются дважды - инструкции программ транслируются в инструкции виртуального ЦПУ, а инструкции виртуального ЦПУ транслируются в инструкции физического ЦПУ.
Это в результате приводит к большим накладным расходам и замедляет такую виртуальную машину. Виртуализация ЦПУ,
такая как функциональность vt-x, делает возможным полное абстрагирование
всего мастерства ЦПУ целиком в соответствующую виртуальную машину с тем, чтобы всё такое программное обеспечение
в этой ВМ могло запускаться без потерь в производительности; оно запускается так, как если бы оно исполнялось в
выделенном ЦПУ.
Функциональность vt-x также разрешает ту проблему, когда инструкции
архитектуры x86 не могут превращаться в виртуальные. Согласно принципу
виртуализации Поупека и Голдберга, все секретные инструкции также должны быть и привилегированными.
Привилегированные инструкции приводят к их перехвату в режиме пользователя. В x86 ряд инструкций являются
конфиденциальными, но не привилегированными. Это означает, что их запуск из пространства пользователя может не
приводить их перехвату. По сути, это означает что они не подлежат виртуализации. Неким примером такой инструкции
выступает POPF.
vt-x упрощает построение программного обеспечения VMM закрывая прорехи
виртуализации разработкой:
-
Сжатием колец: Вплоть до введения
vt-xсоответствующая ОС гости исполнялась бы в Кольце 1, а прикладные приложения этой гостевой ОС запускались бы в Кольце 3. Для выполнения имеющихся привилегированных инструкций в такой гостевой ОС нам бы требовались более высокие полномочия, которые по умолчанию не доступны этому гостю (по причинам безопасности). Тем самым, для исполнения таких инструкций нам требуется отлавливать их в своём гипервизоре (который запущен в Кольце 0 с большими полномочиями), который способен исполнять эти привилегированные инструкции от имеют соответствующего гостя. Это носит название сжатия колец или депривилегиризации.vt-xобходит это запуская соответствующую гостевую ОС прямо в Кольце 0. -
не перехватываемые инструкции: Подобные
POPFинструкции в x86, которые в идеале подлежат отлову со стороны установленного гипервизора, поскольку они являются чувствительными инструкциями, на самом деле не перехватываются. Именно это является проблемой, ибо нам необходим программируемый контроль над сдвигом в свой гипервизор всех конфиденциальных инструкций.vt-xрешает это запуская соответствующую гостевую ОС в Кольце 0, в котором такие инструкции какPOPFмогут отлавливаться установленным гипервизором, который выполняется в Кольце -1. -
Чрезмерный перехват: В отсутствии
vt-xвсе конфиденциальные и привилегированные инструкции отлавливаются установленным в Кольце 0 гипервизоре. При помощиvt-xэто становится настраиваемым и именно от VMM зависит какие инструкции вызывают перехват, а какие могут быть безопасно обработаны в Кольце 0. Подробности этого процесса выходят за рамки данной книги.
vt-x добавляет два дополнительных режима - режим вне корня (non-root, в
Кольце -1), в котором выполняется VMM и режим корня (root, в Кольце 0), именно там запускается гостевая ОС.
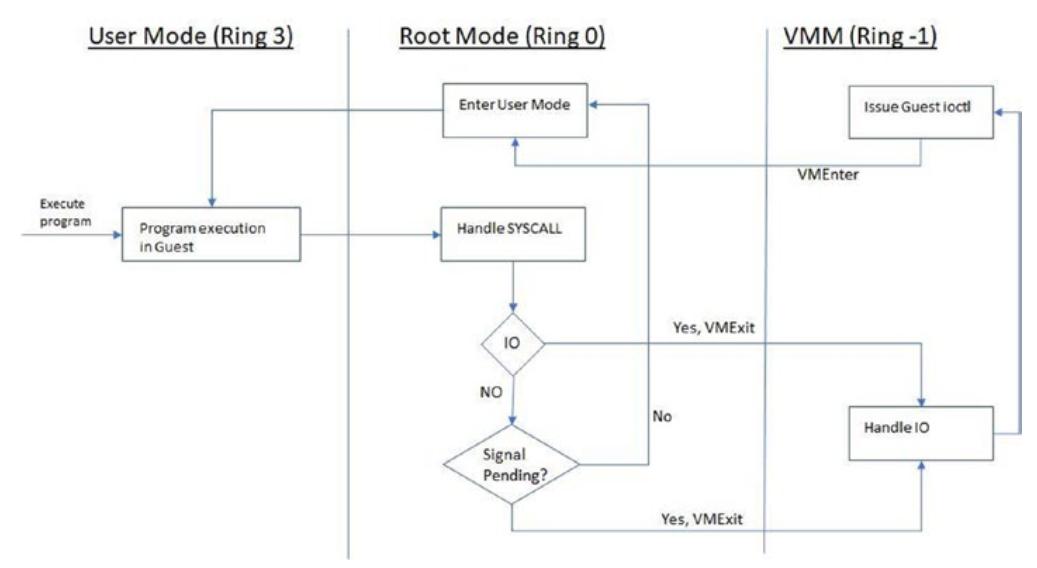
Чтобы понять как эти два режима вовлекаются в исполнение программы, давайте рассмотрим некий пример. Скажем, какая- то программа выполняется в ВМ и, на протяжении этого исполнения, она осуществляет системный вызов для ввода/ вывода. Как это уже обсуждалось в нашей предыдущей главе, гостевые программы из пространства пользователя исполняются в Кольце 3. Когда программа делает некий вызов ввода/ вывода (который является системным вызовом), эти инструкции исполняются на уровне ядра гостевой ОС (Кольцо 0). Такая гостевая ОС сама по себе не способна обрабатывать вызовы ввода/ вывода, а потому она делегирует их установленному VMM (Кольцо -1). Когда исполнение передаётся из Кольца 0 в Кольцо -1, это носит название Выхода ВМ (VMexit), а когда соответствующее выполнение возвращается обратно из Кольца -1 в Кольцо 0, это именуется ВМ входом (VMEntry). Это отображено на Рисунке 2-1.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Прежде чем мы углубимся в QEMM, в качестве пометки на полях, мы бы хотели привлечь ваше внимание к неким интересным проектам в виртуализации, таким как Dune, которые запускают некий процесс внутри среды собственно ВМ, вместо некой завершённой ОС. В режиме корня именно VMM запускает это. Именно в этом режиме запускается KVM. |
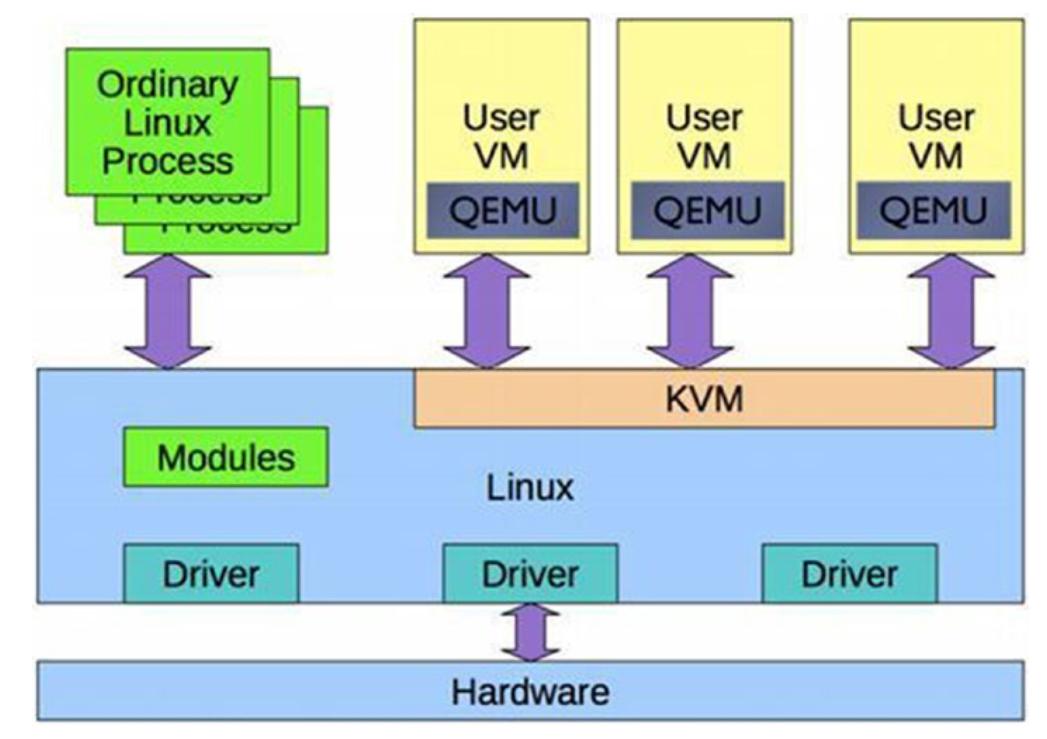
QEMU запускается как процесс пользователя и обрабатывается имеющимся модулем ядра KVM. Он применяет расширения
vt-x для предоставления своему гостю некой изолированной среды с точки зрения
памяти и ЦПУ. Этот процесс QEMU владеет оперативной памятью своего гостя и либо отображается в памяти через файл,
либо является анонимным. Виртуальные ЦПУ планируются на имеющихся физических ЦПУ.
Самое основное отличие между обычным процессом и процессом QEMU является тот код, который выполняется в этих потоках (thread). В случае своего гостя, поскольку он является соответствующей виртуальной машиной, его код выполняет программный BIOS и соответствующая операционная система.
Рисунок 2-2 отображает как QEMU взаимодействует со своим гипервизором.
QEMU также выделяет некий обособленный поток для ввода/ вывода. Этот поток запускает некий цикл событий на основе
не блокируемого механизма Он регистрирует необходимые файловые дескрипторы для ввода, вывода. Для снабжения гостей
устройствами virtio, QEMU может пользоваться такими паравиртуальными драйверами, как virtio, например,
virtio-blk для блочных устройств и
virtio-net для сетевых устройств.
Рисунок 2-3
показывает те специфические компоненты, которые обеспечивают взаимодействие между соответствующим гостем и его хостом
(гипервизором).
Рисунок 2-3
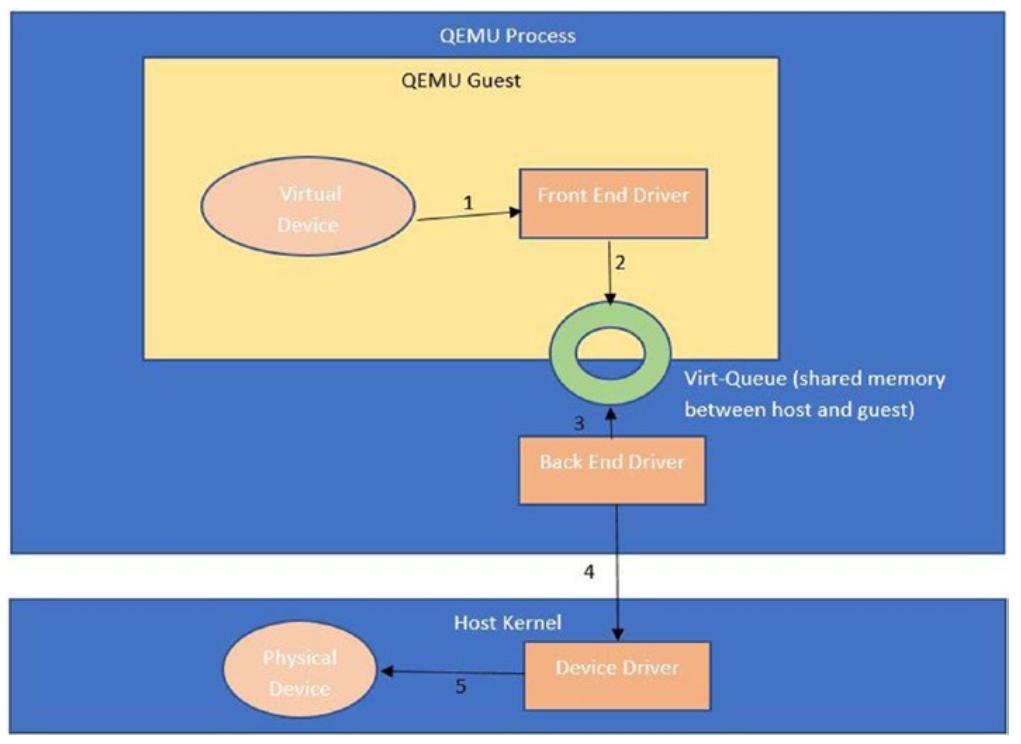
Как некое виртуальное устройтсво из гостевой ОС взаимодействует со своим физическим устройством на уровне своего гипервизора. Такой гость обладает неким интерфейсным драйвером устройства, в то время как его хост обладает каким- то серверным драйвером устройства и они оба совместно обеспечивают взаимодействие между ОС гостя и хоста.
На Рисунке 2-3 вы видите, что соответствующий гость внутри имеющегося процесса QEMU реализует свой драйвер интерфейса, в то время как его хост реализует необходимые серверные драйверы. Всё взаимодействие между драйверами интерфейса и сервера происходит через особые структуры данных с названием виртуальные очереди virtqueues. Все возникающие у соответствующего гостя пакеты сначала помещаются в такую виртуальную очередь драйвер стороны его хоста получает оповещение через некий гипервызов для опустошения соответствующего пакета под его реальную обработку в надлежащем устройстве. Может присутствовать два варианта потока таких пакетов, а именно:
-
Пакеты из соответствующего гостя получаются установленным QEMUи затем выполняется их активная доставка в надлежащий драйвер сервера в самом хосте. Одним из примеров является
virtio-net. -
Соответствующий пакет из своего гостя напрямую появляется в их хосте через то, что носит название драйвера vhost. Таким образом обходится уровень QEMU и он относительно быстрее.
Для создания некой ВМ, надлежит выполнить некий набор вызовов ioctl
в имеющийся модуль ядра KVM, который выставляет для такого гостя некое устройство
/dev/kvm. Упрощённо говоря, это именно те вызовы из пространства пользователя,
которые создают и запускают ВМ:
-
KVM CREATE VM: Данная команда создаёт некую новую ВМ, которая не имеет никаких виртуальных ЦПУ и никакой памяти. -
KVM SET USER MEMORY REGION: Эта команда устанавливает соответствие для необходимой памяти пространства пользователя под создаваемую ВМ. -
KVM CREATE IRQCHIP / KVM CREATE VCPUТакая команда создаёт некий аппаратный компонент, такой как виртуальный ЦПУ и устанавливает его соответствие с функциональными возможностямиvt-x. -
KVM SET REGS / SREGS / KVM SET FPU / KVM SET CPUID / KVM SET MSRS / KVM SET VCPU EVENTS / KVM SET LAPIC: Эти команды выполняют настройку оборудования. -
KVM RUN: Данная команда запускает созданную ВМ.
KVM RUN запускает созданную ВМ и внутренне это соответствующая инструкция
VMLaunch, вызываемая установленным модулем ядра KVM, который помещает необходимый код исполнения этой ВМ в не
корневой режим. Это всё слегка чуть упрощённо, поскольку этот модуль выполняет намного больше для настройки
соответствующей ВМ, в том числе установку необходимого VMCS (VM Control Section, Управляющего раздела ВМ) и тому
подобного.
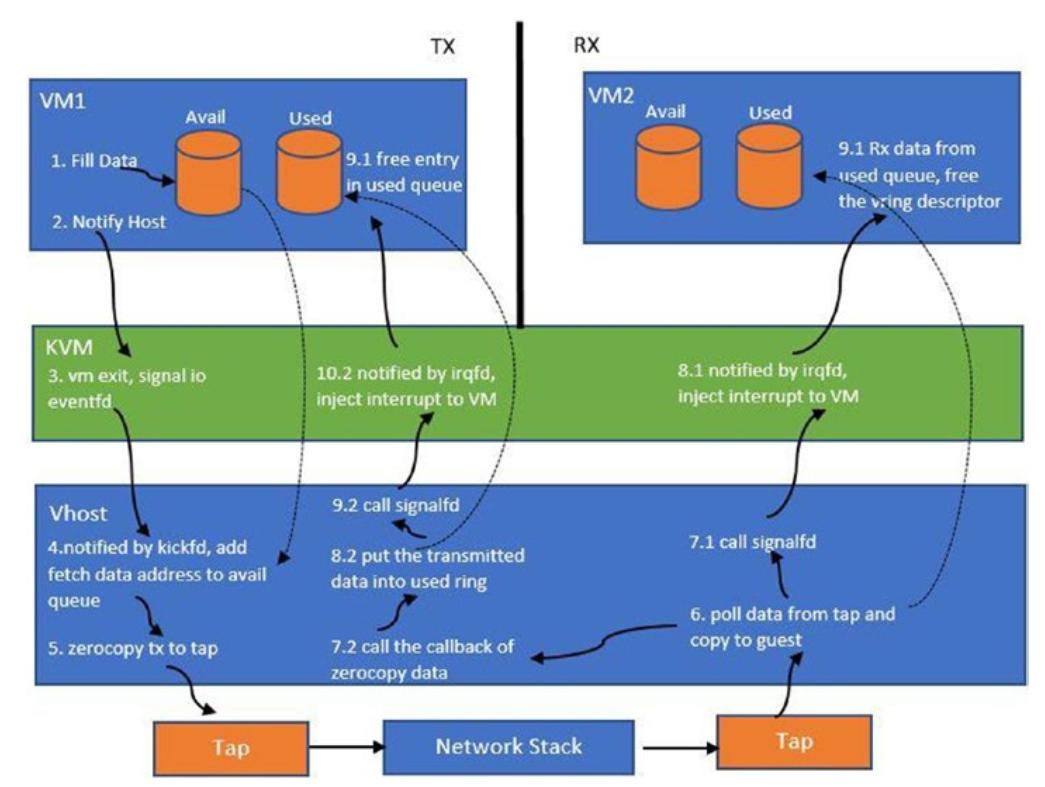
Любые рассуждения относительно гипервизоров были бы несовершенными без демонстрации конкретного примера. Вы
рассмотрим некий пример потока сетевых пакетов (изображённый на
Рисунке 2-4)
в контексте соответствующих драйверов устройств vhost-net. Когда мы
применяем механизм vhost, соответствующий QEMM уходит с переднего плана данных и между конкретным гостем и хостом
имеется непосредственное взаимодействие. QEMM остаётся в плоскости управления, где он настраивает устройство
vhost в самом ядре при помощи команды ioctl:
/dev/vhost-net device
Когда это устройство проинициализировно, для этого конкретного процесса QEMM создаётся некий поток ядра.
Этот поток обрабатывает соответствующий ввод/ вывод для этого конкретного гостя. Этот поток ожидает сообщений на
стороне самого хоста, в соответствующей виртуальной очереди. Когда возникает некое событие для опустошения
данных (в терминологии virtio это носит название толчка, kick), этот
поток ввода/ вывода потребляет соответствующий пакет из очереди tx
(передачи) своего гостя. Этот поток затем передаёт эти данные в соответствующее устройство ответвления, которое
делает его доступным для лежащего в основе моста/ коммутатора для передачи его вниз по потоку в механизм
перекрытия (оверлея) или маршрутизации.
Установленный модуль ядра KVM для такого гостя регистрирует соответствующий
eventfd. Это файловый дескриптор, который регистрируется для этого гостя
(со стороны QEMU) при помощи модуля ядра KVM. Этот FD регистрируется для события выхода из гостевого ввода/
вывода (толчка), которое опустошает эти данные.
Итак, что же такое eventfd? Это механизм взаимодействия
между процессами (IPC, interprocess communication), который предлагает механизм ожидания- уведомления между
программами пространства пользователя или между самим ядром и имеющимся пространством пользователя. Основная идея
проста. Точно так же как мы имеем FD для файлов, мы можем создавать файловые дескрипторы для событий. Основное
преимущество здесь состоит в том, что такой FD может затем трактоваться как и прочие FD и способен регистрироваться
при помощи таких механизмов как poll,
select и epoll.
Эти механизмы могут затем обеспечивать систему уведомлений после записи в эти FD.
Соответствующий потребляющий поток может быть выполнен для ожидания в неком объекте epoll через
epoll_wait. После того как производящий поток выполняет запись в
надлежащем FD, обсуждаемый механизм epoll оповестит своего потребителя (снова в зависимости от переключаемого фронтом или уровнем)
соответствующего события.
Переключение фронтом означает, что вы только уведомляетесь об обнаружении соответствующего события (которое имеет место, допустим, в некотором экземпляре), в то время как переключение уровнем подразумевает что вы извещаетесь при наличии такого события (что будет справедливым в течении некого промежутка времени).
Например, в некой переключаемой фронтом системе, когда вы желаете получать уведомления сигналом когда ваши данные доступны для считывания, вы получите такое уведомление только тогда, когда данные не были доступны ранее, а теперь стали доступными. Если вы считываете доступные данные (а потому некоторые из этих данных всё ещё доступны для считывания), вы не будете получать другого уведомления. Когда вы считаете все доступные данные, вы получите другое уведомление когда новые данные снова станут доступными. В системе, переключаемой уровнем, вы будете получать такое уведомление всякий раз, когда данные доступны для считывания.
Сам хост использует eventfd применяя
ioeventfd для отправки данных из соответствующего гостя и
irqfd для получения некого прерывания из своего хоста в этого гостя.
Другим вариантом применения eventfd выступает нехватка памяти
(OOM, out of memory) cgroup. Это работает следующим образом: всякий раз, когда соответствующий процесс превосходит
установленный предел memcg, уничтожитель OOM может решать уничтожать ли его,
или, если такое поведение отключено, его ядро может выполнить следующее:
-
Создать необходимый
eventfd. -
Записать соответствующее событие OOM в этот
eventfd.
Поток этого процесса будет заблокирован до тех пор пока не будет сгенерировано такое событие. После выработки такого события, этот поток пробуждается для реакции на такое уведомление OOM.
Основное отличие между eventfd и конвейером Linux является то, что для
конвейера требуются два файловых дескриптора, в то время как для eventfd
нужен один.
Соответствующий поток ввода/ вывода vhost отслеживает такой
eventfd. Всякий раз, когда в соответствующем госте происходит событие
ввода/ вывода, уведомляется надлежащий поток ввода/ вывода что ему надлежит опустошить свой буфер из
очереди tx.
Аналогично ioeventfd имеется и некий
irqfd. Установленный QEMM пространства пользователя также регистрирует
этот FD (irqfd) для своего гостя. Драйвер этого гостя ожидает изменений
в таких FD. Основная причина их применения состоит в передачи прерываний обратно в соответствующего гостя для
уведомления драйвера стороны этого гостя для обработки своих пакетов. Возвращаясь к предыдущему примеру, когда
такие пакеты следует отправлять обратно соответствующему гостю, поток ввода/ вывода заполняет буферы своей очереди
rx (очередь получения, receive) для гостя и вставка необходимого
прерывания выполняется в гостя через irqfd. На обратном пути потока пакетов,
эти получаемые самим хостом через имеющийся физический интерфейс пакеты помещаются в соответствующее ответвляющее
устройство. Тот поток, который взаимодействует с соответствующим ответвляющем устройстве получает пакеты для
заполнения буферов rx для своего гостя. Затем он уведомляет драйвер этого
гостя через irqfd. Смотрите на
Рисунок 2-4.
После тоо как мы рассмотрели виртуализацию через механизмы на основе ВМ, настало время вкратце взглянуть на прочие возможности виртуализации, которые выходят за рамки изоляции контейнера, такие как механизмы на основе пространства имён/ cgroup, которые мы имеем в Docker. Мотивы чтобы разобраться с тем как это можно сделать таковы:
-
Снижение взаимодействий, выставляемых различными уровнями, такими как VMM для снижения направлений атак. Такие направления атак могут иметь форму применения в своих интересах, например, использования памяти, когда устанавливается вредоносное программное обеспечение или контроль над всей системой путём повышения полномочий.
-
Применение аппаратных средств изоляции для изолирования различных запускаемых нами контейнеров/ процессов.
Суммируя, можем ли мы получать уровни изолированности ВМ при снижении или минимизации выставляемых машинных интерфейсов с предоставлением скорости, аналогичной имеющейся у контейнеров.
Мы уже обсуждали как ВМ при помощи VMM, изолируют такие рабочие потоки. Этот VMM выставляет модель машины
(интерфейс x86), в то время как контейнер выставляет интерфейс POSIX. Устанавливаемый VMM, при помощи
аппаратной виртуализации, способен изолировать ЦПУ, память и ввод/ вывод (vt-d,
SRIOV и IOMMU). Разделяющие
своё ядро контейнеры предоставляют эту функциональность через пространства имён и cgroup, но всё ещё
рассматриваются как более слабая альтернатива технологиям изоляции на основе оборудования.
Итак, имеется ли некий способ сблизит эти два понятия? Одна из основных целей будет состоять в снижении вектора атак при использовании подхода минимизации взаимодействия. Что это означает, так это то, что вместо выставления в прикладные приложения полного POSIX или полного машинного интерфейса в соответствующую гостевую ОС, мы предоставляем лишь то, что необходимо такому прикладному приложению/ ОС. Именно здесь мы начинаем видеть ту эволюцию, при которой начали появляться юникёрны и библиотечные ОС.
Юникёрны (Unikernel) предоставляют свой механизм, через необходимый набор инструментария, для подготовки какой- то минимальной ОС. Это означает, что если её приложению требуется лишь сетеые API, тогда устройства клавиатуры, мыши и их драйверы не вкллючаются в пакет. Это значительно снижает вектор атак.
Одной из основных проблем для юникёрнов является то, что их приходится собирать для различных моделей драйверов устройств. С появлением виртуализации ввода/ вывода и драйверов virtio эта задача до некоторой степени решена, поскольку теперь юникёрны могут собираться в точности с теми устройствами virtio и их драйверами, необходимыми таким прикладным приложениям в соответствующем госте. Это означает, что такой гость может быть неким юникёрном (Библиотечной ОС), сидящим поверх, допустим, какого- то гипервизора, например, KVM. Это всё ещё имеет ограничения, поскольку QEMU или часть пространства пользователя всё ещё имеет порядочный объём базового кода, причём он весь является предметом применения.
Для достижения дальнейшей минимизации, одним из предложений было упаковка самого VMM вместе с его юникёрном. Такой код VMM ограничен до необходимой функциональности и содействует взаимодействию на основе памяти между самим гостем и его VMM. При такой модели в основном гипервизоре может располагаться множество VMM. Основная роль VMM состоит в обеспечении ввода/ вывода и создании гостевого юникёрна при помощи возможностей аппаратной изоляции.
Сам по себе юникёрн представляет некий отдельный процесс с возможностью множества потоков, как это показано на Рисунке 2-5.
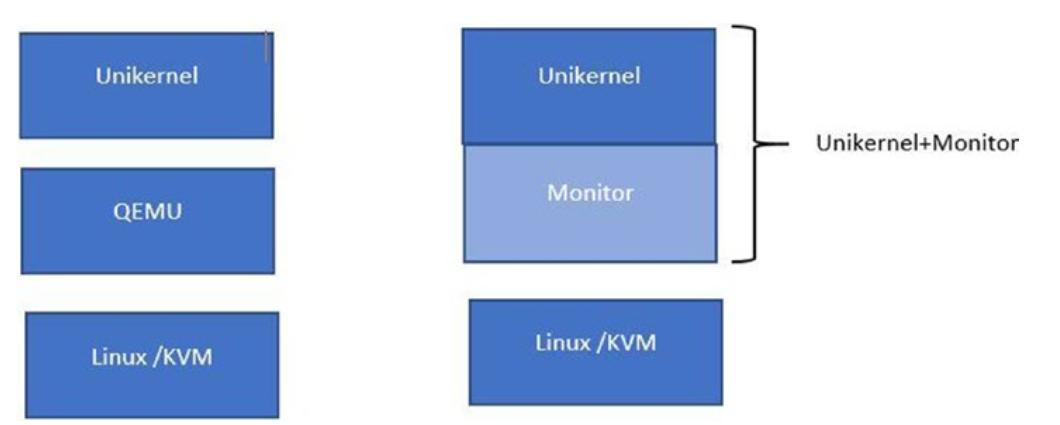
На Рисунке 2-5 мы можем наблюдать что на изображении слева запущена комбинация VMM и QEMU для исполнения поверх юникёрнов, в то время как изображение справа показывает VMM (монитор), такой как UKVM, упакованный вместе с его юникёрном. Итак, в целом мы имеем снижение необходимого кода (соответствующего QEMU) и тем самым получаем устранение значительного вектора атак. Именно это соответствует подходу с минимальным интерфейсом, о котором мы говорили ранее.
Внимательный читатель легко поймёт, что изоляция vt-x в основной
памяти и ЦПУ не предполагает в его гостевой памяти только кода гостевой ОС. Технически мы можем предоставлять
различные механизмы песочницы поверх такой аппаратной изоляции. Именно этим и занимается Проект Dune. Помимо
аппаратной изоляции vt-x, Dune раскручивает не некую гостевую ОС, а
процесс Linux. Это означает, что такой процесс запускается в Кольце 0 своего ЦПУ и обладает доступ к
выставляемому в него машинному интерфейсу. Такой процесс можно поместить в песочнице через:
-
Запуск доверенного кода такого процесса в Кольце 0. Именно он в основном та библиотека, которая в Dune именуется
libdune. -
Запуск не доверенного кода в Кольце 3.
Архитектура Dune показана на Рисунке 2-6.
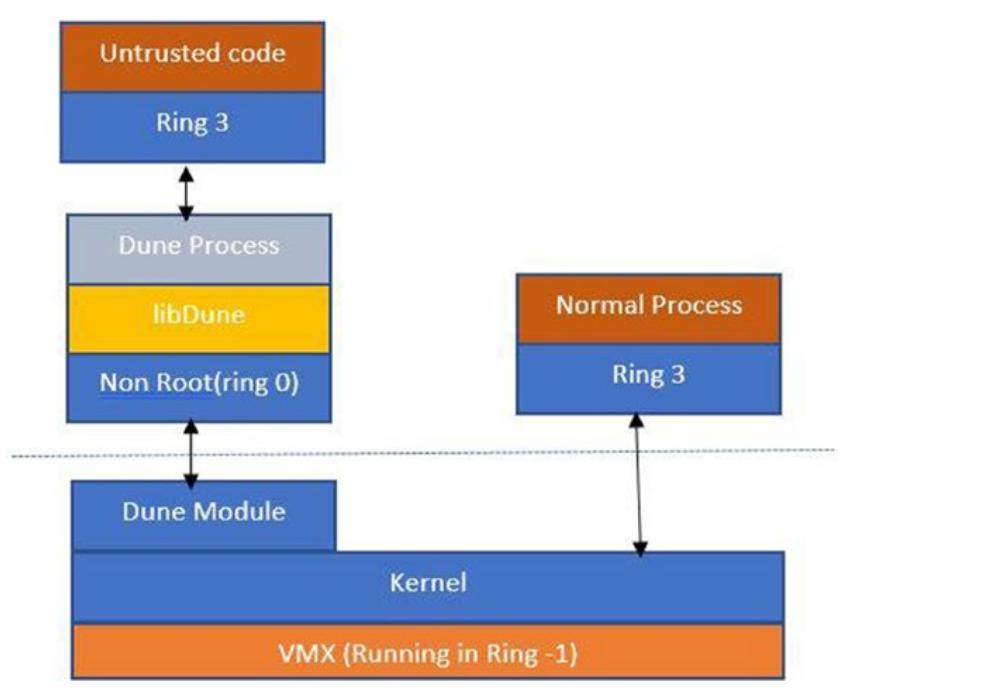
Для самораскрутки своего процесса Dune создаёт некую операционную среду, которая влечёт за собой установку необходимых таблиц страниц (значение регистра CR3 указывает на значение корня). Она также устанавливает значение IDT для соответствующих исключительных ситуаций оборудования. И доверенный и не обладающий доверенностью код работают в одном и том же адресном пространстве, в то время как страницы таблиц доверенного кода защищаются битами супервизора в записях таблицы страниц. Необходимые ловушки системных вызовов в том же самом процессе вставляются при помощи гипервызовов в соответствующий VMM. Для получения дополнительных сведений по Dune обратитесь к http://dune.scs.stanford.edu/.
novm это другой тип аппаратного контейнера применяемого в этом проекте. (Он также применяет API KVM для
создания соответствующей ВМ путём применения соответствующего файла устройства
/dev/kvm.) Вместо предоставления какого- то дискового интерфейса в эту ВМ,
novm представляет в свою ВМ интерфейс некой файловой системы (9p). Это делает возможным упаковку того
программного обеспечения, которое мы пожелаем для предоставления в качестве некого контейнера. Нет никакого
BIOS и необходимый VMM просто помещается в такую ВМ в 32- битном защищённом режиме напрямую. Это делает такой
процесс предоставления более быстрым, потому как не требуются такие шаги как зондирование устройства.
Таким образом, данная глава рассмотрела три подхода: один подход содержит юникёрнел с минимальным интерфейсом ОС, второй подход избавляется от взаиможействия ОС и запускает процесс напрямую в Кольце 0, а третий подход вместо этого предоставляет некую файловую систему в соответствующую ВМ вместо блочных устройств напрямую и оптимизированные вопросы запуска.
Эти подходы предоставляют хорошую изоляцию на аппаратном уровне и очень быстрое время раскрутки и могут отлично соответствовать для запуска без серверных рабочих нагрузок и прочих облачных рабочих потоков.
Это всё? Естественно нет. Теперь у нас имеются такие компании как Cloudflare и Fastly, которые пытаются решить задачи виртуализации предлагая изоляцию внутри некого процесса. Основное намерение состоит в том, чтобы воспользоваться возможностями определённых языков программирования чтобы получить:
-
Изоляцию потока кода через управление целостностью потока
-
Изоляцию памяти
-
Безопасновть на основе возможностей
Далее мы можем применять эти примитивы для сборки песочниц внутри каждого из процессов. Таким образом мы способны получать даже более быстрые времена запуска необходимого кода, который мы желаем выполнить.
В этом пространстве лидером выступает WebAssembly. Основная идея состоит в запуске WebAssembly, кратко модулей Wasm, внутри того же самого процесса (среда времени исполнения WASM). Все модули изолированы друг от друга, а потому мы получаем по одной песочнице для арендатора. Это отлично соответствует парадигмам безсерверного вычисления и возможно предотвращает такие проблемы как запуск по холодному.
Стоит отметить, что имеется новая функциональная возможность с названием способности
подключения в горячем режиме, которая делает доступными динамически необходимые устройства для
соответствующих гостей. Это позволяет разработчикам, например, динамически изменять размеры их блочных устройств без
перезапуска соответствующего гостя. Также имеется модуль hotplug-dimm,
который позволяет разработчикам изменять размер доступной соответствующему гостю оперативной памяти.