Глава 4. Cgroups
Содержание
В предыдущей главе мы изучили как кправлять видимостью процессов Linux применяя пространства имён и рассмотрели как они реализуются внутри самого ядра. В этой главе мы коснёмся другой важной стороны - контроля ресурсов - который позволяет нам применять квоты к различным ресурсам операционной системы.
Мы изучили пространства имён, поэтому мы можем ограничивать имеющуюся видимость ресурсов для процессов, что мы выполняем помещая такие процессы в обособленные пространства имён. Мы также рассмотрели вовлекаемые в это из ядра структуры данных чтобы разобраться как реализуется внутри своего ядра Linux некое пространство имён.
Теперь задайте себе вопрос, вполне ли достаточно для виртуализации ограничения видимости или же требуется нечто ешё.
Допустим, мы запустили процессы tenant1 в одном пространстве имён и
процессы tenant2 в отдельном пространстве имён. Хотя эти процессы и не имеют
возможности доступа к ресурсам друг друга (точкам монтирования, деревьям процессов и тому подобному), поскольку
такие ресурсы относятся к сфере действий своих персональных пространств имён, мы не достигаем истинной изоляции
только через такие сферы.
например, что воспрепятствует tenant1 от запуска некого процесса, который
способен сожрать весь ЦПУ в неком бесконечном цикле? Неудачный код может оставлять утечки памяти (скажем, к
примеру, он потребляет громадный кусок страниц кэша своей ОС). Неверно ведущий себя процесс может создавать тонны
процессов через ветвления, запуская некую бомбу ветвлений и сокрушая своё ядро.
Это означает, что нам требуется ввести некий способ контроля ресурсов для процессов в пределах заданного
пространства имён. Это достигается через механизм, носящий название групп
контроля (control groups), обычно именуемых cgroups.
cgroups работают под понятием контроллеров cgroup и представляются в файловой системе с названием
cgroupfs в самом ядре Linux.
В настоящее время применяется cgroup v2 версия cgroups. Мы изучим некоторые подробности того, как работают cgroups, а также некоторые контроллеры cgroup, которые можно обнаружить в коде ядра. Мы также рассмотрим как cgroups реализуются внутри ядра Linux. Но перед этим вкратце рассмотрим что являют собой cgroups.
Прежде всего, для применения cgroup нам требуется смонтировать соответствующую файловую систему
cgroup в некой точке монтирования следующим образом:
mount -t cgroup2 none $MOUNT_POINT
Основное отличие между cgroup версий v1 и v2 состоит в том, что при монтировании в v1 нам приходится определять параметры самого монтирования для задания включённых необходимых контроллеров, в то время как в cgroup v2 не могут передаваться никакие параметры.
Давайте создадим некий образец cgroup с названием mygrp. Для создания
cgroup нам вначале требуется создать некую папку, в которой будут храниться артефакты cgroup следующим образом:
mkdir mygrp
Теперь мы можем создать некую cgroup при помощи приводимой ниже команды (Обратите внимание:
cgroup2 поддерживается в ядре с версией 4.12.0-rc5 и далее. Я работаю
в Ubuntu 19.04, которая имеет ядро версии Ubuntu 19.04 с ядром Linux 5.0.0-13.)
mount -t cgroup2 none mygrp
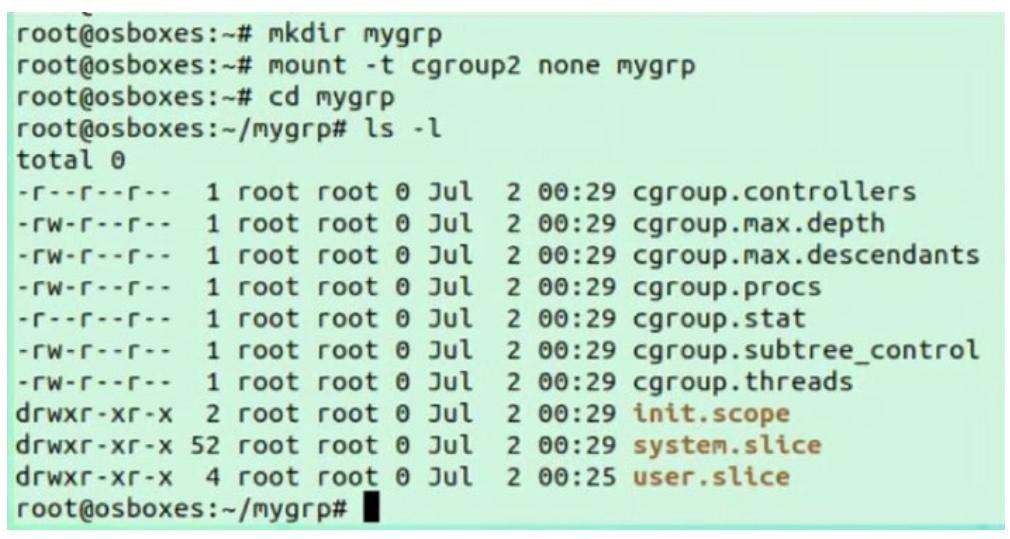
Мы создали каталог с названием mygrp, затем смонтировали в нём файловую
систему cgroup v2. При входе вовнутрь этого каталога mygrp мы можем
наблюдать там множество файлов:
-
cgroup.controllers: Этот файл содержит все поддерживаемые контроллеры. Появятся все контроллеры, которые не смонтированы в cgroup v1. В настоящий момент в своей системе я имею cgroup v1, смонтированный черезsystemd. Мы можем видеть, что все контроллеры пребывают там.
Только после размонтирования этих контроллеров из v1 v2 должна показать эти контроллеры. Иногда нам требуется добавить параметр запуска ядра
systemd.unified_cgroup_hierarchy=1и перезапустить само ядро для ввода в действие этих изменений. После внесения этих изменений в своей машине я вижу такие контроллеры:
-
Cgroup.procs: Этот файл содержит значения процессов внутри корня cgroup. Когда такая cgroup только что создана, там не будет никаких PID. Записывая соответствующие PID в этот файл они превращаются в часть данной cgroup. -
Cgroup.subtree_control: Содержит контроллеры, которые включены для имеющейся промежуточной подгруппы.Включая и отключая контроллеры в этой промежуточной подгруппе некого предка выполняется лишь записью в её файл
cgroup.subtree_control. Итак, к примеру, включение контроллера памяти выполняется следующим образом:echo "+memory" > mygrp/cgroup.subtree_controlА его отключение осуществляется так:
echo "-memory" > mygrp/cgroup.subtree_control -
cgroup.events: Это файл интерфейса сердцевины cgroup. Этот файл интерфейса уникален для не являющихся корневыми подгрупп. Такой файлcgroup.eventsотражает общее число подключённых к данной подгруппе процессов и он составляется единственным элементом -populated: value. Величинаvalueравна0когда нет подключённых к этой подгруппе или ей потомкам процессов и1, когда имеется один или более процессов, подключённых к этой подгруппе или её потомков.

Помимо этих файлов также создаются особые для контроллера файлы. Например, для контроллеров памяти
создаётся файл memory.events, который можно отслеживать на предмет таких
событий как OOM. Аналогично, контроллер PID имеет такие файлы как pids.max
во избежание ситуаций, подобных бомбе ветвлений.
В своём случае я создал некую дочернюю cgroup (child) под
mygrp. В этом каталоге child мы
можем наблюдать следующие файлы:

Мы можем наблюдать такие относящиеся к контроллерам файлы как memory.max.
Имеющийся файл взаимодействий с названием memory.events перечисляет
различные имевшие место события, например, oom, которые могут быть
включёнными и отключёнными:

Наш следующий раздел пояснит как реализуются cgroups внутри ядра и как они допускают контроль ресурсов.
Имеются различные типы cgroups, причём они основаны на тех ресурсах, которыми мы бы желали управлять. Вот те две cgroups, которые мы рассмотрим:
-
CPU: Предоставляет ограничения ЦПУ процессам пространства пользователя
-
Block I/O: Предоставляет ограничения ввода/ вывода блочных устройств процессов пространства пользователя
Давайте рассмотрим как реализованы cgroup с точки зрения ядра. Cgroup ЦПУ могут реализовываться поверх двух планировщиков:
-
Совершенно честный планировщик
-
Планировщик реального масштаба времени
В этой главе мы обсудим только Совершенно честный планировщик CFS (completely fair scheduler). Cgroup ЦПУ предоставляет два типа контроля ресурса ЦПУ:
-
cpu.shares: Содержит некое целое значение, которое определяет относительную долю времени ЦПУ, доступного имеющимся в этой cgroup задачам. Например, задачи в двух cgroups, которые имеют установленными в 100cpu.sharesполучат равное время ЦПУ, однако задачи в cgroups, которые обладаютcpu.shares, установленным в 200 получат в два раза больше времени ЦПУ чем те задачи, в cgroup которыхcpu.sharesустановлен равным 100. Залаваемое в файлеcpu.sharesзначение должно быть 2 или выше. -
cpu.cfs_quota_us: Определяет общее значение времени в микросекундах (μs, представляемое здесь как "us") на протяжении которого все задачи в cgroup способны работать за один период (который определяется черезcpu.cfs_period_us). Как только все задачи в некой cgroup использует всё заданное этой квотой время, они останавливаются на тот промежуток времени, который определяется значением периода и не допускается к исполнения в следующем периоде. -
cpu.cfs_period_us: Это период, из которого выделяются квоты ЦПУ для cgroup (cpu.cfs_quota_us), а значения параметров квоты и периода действуют на основе применения к каждому ЦПУ. Рассмотрим такие примеры:-
Чтобы позволить соответствующей cgroup быть способной выполнять доступ к отдельному ЦПУ на 0.2 секунды на протяжении каждой секунды, установите
cpu.cfs_quota_usв 200000, аcpu.cfs_period_usв 1000000. -
Чтобы позволить некому процессу задействовать отдельный ЦПУ на 100%, установите
cpu.cfs_quota_usв 1000000 иcpu.cfs_period_usравным 1000000. -
Чтобы допускать некому процессу использовать 100% два ЦПУ, установите
cpu.cfs_quota_usравной 2000000, в то время какcpu.cfs_period_usравным 1000000.
-
Чтобы разобраться с обоими этими механизмами контроля, мы можем рассмотреть основные стороны планировщика задач CFS Linux. Основная цель этого планировщика состоит в предоставлении справедливой доли имеющихся ресурсов ЦПУ всем запущенным в этой системе задачам.
Мы можем разбить эти задачи на два типа:
-
Задачи интенсивного ЦПУ: Такие задачи как шифрование, машинное обучение, обработка запросов и тому подобное
-
Задачи с интенсивным вводом/ выводом: Задачи, которые применяют дисковый и сетевой ввод/ вывод, такие как клиенты баз данных
Этот планировщик должен отвечать за планирование обоих видов задач. CFS применяет понятие
vruntime. vruntime является
участником структуры sched_entity, который в свою очередь выступает
участником структуры task_struct (каждый процесс процесс представляется
в Linux структурой task_struct):
struct task_struct {
int prio, static_prio, normal_prio; unsigned int rt_priority;
struct list_head run_list;
const struct sched_class *sched_class;
struct sched_entity se;
unsigned int policy; cpumask_t cpus_allowed; unsigned int time_slice;
}
struct sched_entity {
/* Для балансировки нагрузки: */
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
#ifdef CONFIG_FAIR_GROUP_SCHED
Int depth;
struct sched_entity *parent;
/* rq в которой (должен быть) поствлен в очередь этот логический элемент: */
struct cfs_rq *cfs_rq;
/* rq "владелец" этого логического элемента/группы: */
struct cfs_rq *my_q;
/* кэшированное значение my_q->h_nr_running */
unsigned long runnable_weight;
task_struct обладает ссылкой на
sched_entity, которая содержит ссылку на
vruntime.
vruntime вычисляется с применением следующих шагов:
-
Вычисляется значение времени, затрачиваемого этим процессом в своём ЦПУ.
-
Взвешивается значение вычисленного времени исполнения относительно значения исполняемых процессов.
Само ядро использует функцию update_curr, определяемую в файле
https://elixir.bootlin.com/linux/latest/source/kernel/sched/fair.c.
/*
* Обновить текущие статистики времени исполнения текущей задачи.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cgroup_account_cputime(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
Эта функция вначале вычисляет значение delta_exec, что является значением
времени, проводимое данной текущей задачей в своём ЦПУ.
Эта delta_exec затем передаётся в качестве параметра в другой вызов функции
с названием calc_delta_fair.
Этот вызов вернёт взвешенное значение данного процесса времени исполнения в отношении к общему числу исполняемых
процессов. После того как vruntime вычислен, он сохраняется как часть
структуры sched_entity.
Кроме того, выступая как часть обновления vruntime для данной задачи,
наша функция update_curr вызывает
update_min_vruntime. Она вычисляет наименьшее значение
vruntime по всем исполняемым процессам и добавляем его в красно чёрное
дерево в самый левый узел. Планировщик CFS сможет затем просмотреть своё красно чёрное дерево для планирования того
процесса, который обладает наименьшим vruntime.
В своей основе планировщик CFS составляет графики своих эврестических составляет расписание, причём в нём задачи с
интенсивным вводом/ выводом в нём более частые, но при этом предоставляет больше времени в единственном запуске для
задач с интенсивным потреблением ЦПУ. С этим также можно разобраться на основе обсуждённого ранее понятия
vruntime. Поскольку задачи ввода, вывода в основном ожидают сеть/ диск, их
vruntime имеет тенденцию иметь значение ниже чем у задач ЦПУ. Это означает,
что задачи ввода/ вывода будут планироваться более частыми. Соответствующие задачи с интенсивными задачами ЦПУ получат
большее время, раз уж они запланированы на выполнение своей работы. Тем самым, CFS пытается достигать справедливого
планирования задач.
Давайте прервёмся на минутку и задумаемся о потенциальных проблемах к которым может приводить такое планирование.
Допустим, у вас имеются два процесса, A и B, относящихся к различным пользователям. Каждый из этих процессов получает долю в 50% от своего ЦПУ. Теперь, скажем, владеющий процессом A пользователь запускает другой процесс, именуемый A1. Теперь CFS получит долю в 33% для каждого из процессов. На практике это означает что пользователи процессов A и A1 теперь получат 66% своего ЦПУ. Классическим примером является некая база данных, например, PotgreSQL, которая создаёт процессы для соединений. По мере роста соединений растёт и общее число процессов. Когда выполняется справедливое планирование, каждое соединение будет иметь тенденцию выбирать свою долю от прочих процессов не Postgre, запущенных в той же самой машине.
Эта задача приводит к тому что мы именуем групповым планированием. Чтобы разобраться с этим, давайте рассмотрим другую структуру данных ядра:
/* Относящиеся к CFS поля в очереди запуска */
struct cfs_rq {
struct load_weight load;
unsigned int nr_running;
unsigned int h_nr_running; /* SCHED_{NORMAL,BATCH,IDLE} */
unsigned int idle_h_nr_running; /* SCHED_IDLE */
u64 exec_clock;
u64 min_vruntime;
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root_cached tasks_timeline;
/*
* 'curr' указывает на исполняемый в данный момент логический элемент в этой cfs_rq.
* В противном случае он устанавливается в NULL (т.е. когда ничто в данный момент не исполняется).
*/
struct sched_entity *curr;
struct sched_entity *next;
struct sched_entity *last;
struct sched_entity *skip;
Эта структура удерживает значение числа запущенных задач в участнике
nr_running. Участник curr
является указателем на текущий исполняемый спланированный логический элемент или соответствующую задачу.
Кроме того, sched_entity теперь представляется как некая иерархическая
структура:
struct sched_entity {
/* Для балансировки нагрузки: */
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
#ifdef CONFIG_FAIR_GROUP_SCHED
Int depth;
struct sched_entity *parent;
/* rq в которую (должен) ставиться этот логический элемент: */
struct cfs_rq *cfs_rq;
/* rq "владелец" этого логического элемента/группы: */
struct cfs_rq *my_q;
/* кэшированное значение my_q->h_nr_running */
unsigned long runnable_weight;
#endif
#ifdef CONFIG_SMP
/*
* Отслеживание средней нагрузки для каждого логического элемента.
*
* Поместить в отдельную строку кэширования с тем, чтоб он не
* сталкивался с в основном считываемыми значениями, приведёнными выше.
*/
struct sched_avg avg;
#endif
};
Это означает, что теперь могут иметься sched_entities, которые не
ассоциированы с неким процессом (task_struct). Вместо этого, такие записи могут
представлять группу процессов. Каждая sched_entities теперь
сопровождает некую собственную очередь исполнения. Процесс может перемещаться в дочерний логический элемент
планирования, что означает, что он будет частью очереди исполнения, которая имеет эту дочернюю запись расписания.
Эта очередь исполнения может представлять все процессы в соответствующей группе.
Наш поток кода в расписании будет выполнять следующее.
Pick_next_entity вызывается для подбора наилучшего кандидата в расписании.
Мы предполагаем, что в данный момент имеется лишь одна исполняемая группа. Это означает, что ассоциированное с
процессом sched_entity красно чёрное дерево пустое. Этот метод теперь
попытается получить соответствующего потомка текущей sched_entity. Он
проверяет значение cfs_rq, который обладает всеми процессами
находящихся в очереди группы процессов. Эти процессы запланированы.
Значение vruntime основывается на весах процессов внутри определённой группы.
Это позволяет нам выполнять справедливое планирование предотвращать воздействие процессов внутри некой группы
на использование ЦПУ процессами внутри прочих групп.
После того как мы разобрались как процессы могут помещаться в группы, давайте рассмотрим как усиление
полосы пропускания способно применяться в такой группе. Свою роль играет другая структура данных с названием
cfs_bandwidth, которая определена в
sched.h:
struct cfs_bandwidth {
#ifdef CONFIG_CFS_BANDWIDTH
raw_spinlock_t lock;
ktime_t period;
u64 quota;
u64 runtime;
s64 hierarchical_quota;
u8 idle;
u8 period_active;
u8 distribute_running;
u8 slack_started;
struct hrtimer period_timer;
struct hrtimer slack_timer;
struct list_head throttled_cfs_rq;
/* Статистики: */
Int nr_periods;
Int nr_throttled;
u64 throttled_time;
#endif
};
Эта структура
продолжает отслеживать значения квот времени исполнения для соответствующей группы. Функция
cff_bandwith_used применяется для возврата некого Булева значения когда
проверка выполняется в методе account_cfs_rq_runtime файла реализации
справедливого планирования. Когда не остаётся никаких квот времени исполнения, активируется метод
throttle_cfs_rq. Он удаляет из очереди все задачи из очереди исполнения
sched_entity и устанавливает флаг дросселирования. Здесь отображена
реализация этой функции:
static void throttle_cfs_rq(struct cfs_rq *cfs_rq)
{
struct rq *rq = rq_of(cfs_rq);
struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);
struct sched_entity *se;
long task_delta, idle_task_delta, dequeue = 1;
bool empty;
se = cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))];
/* при дросселировании заморозить иерархию средних запущенных */
rcu_read_lock();
walk_tg_tree_from(cfs_rq->tg, tg_throttle_down, tg_nop, (void *)rq);
rcu_read_unlock();
task_delta = cfs_rq->h_nr_running;
idle_task_delta = cfs_rq->idle_h_nr_running;
for_each_sched_entity(se) {
struct cfs_rq *qcfs_rq = cfs_rq_of(se);
/* логический элемент дросселирования или throttle-on-deactivate */
if (!se->on_rq)
brea;
if (dequeue) {
dequeue_entity(qcfs_rq, se, DEQUEUE_SLEEP);
} else {
update_load_avg(qcfs_rq, se, 0);
se_update_runnable(se);
}
qcfs_rq->h_nr_running -= task_delta;
qcfs_rq->idle_h_nr_running -= idle_task_delta;
if (qcfs_rq->load.weight)
dequeue = 0;
}
if (!se)
sub_nr_running(rq, task_delta) ;
cfs_rq->throttled = 1;
cfs_rq->throttled_clock = rq_clock(rq);
raw_spin_loc(&cfs_b->lock);
empty = list_empty(&cfs_b->throttled_cfs_rq);
/*
* Добавляем в _head_ of данного списка, с тем, чтобы уже запущенные
* distribute_cfs_runtime не видели нас. Если disribute_cfs_runtime не
* запущен, добавьте его в хвост чтобы не оставались голодными последующие очереди.
*/
if (cfs_b->distribute_running)
list_add_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq);
else
list_add_tail_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq);
/*
* Когда мы впервые дросселируем задачу, убедитесь что запущен
* таймер имеющейся полосы пропускания.
*/
if (empty)
start_cfs_bandwidth(cfs_b);
raw_spin_unlock(&cfs_b->lock);
}
Это объясняет как наши cgroup ЦПУ делают возможным группирование задач процессов и могут применять механизмы долей ЦПУ для применения справедливого планирования внутри некой группы. Это также объясняет как внутри некой группы осуществляется квотирование и применение полос пропускания. Теперь мы обсудим иной тип cgroup, который принуждает к ограничению пределов блочного ввода/ вывода.
Основная цель cgroup блочного ввода/ вывода двоякая:
-
Доставлять справедливость в индивидуальные cgroup: применение планировщика вызывается полностью справедливыми очередями.
-
Выполнять дросселирование блочного ввода, вывода: принудительно устанавливает квоты на блочный ввод/ вывод (байты, а также iops) для cgroup.
Прежде чем погружаться в подробности того как реализуются cgroup для блочного ввода/ вывода, мы предпримем небольшой обход расследования того как работает блочный ввод/ вывод Linux. Рисунок 4-6 представляет собой схему на верхнем уровне того как протекает запрос блочного ввода/ вывода через пространство пользователя в его устройство.
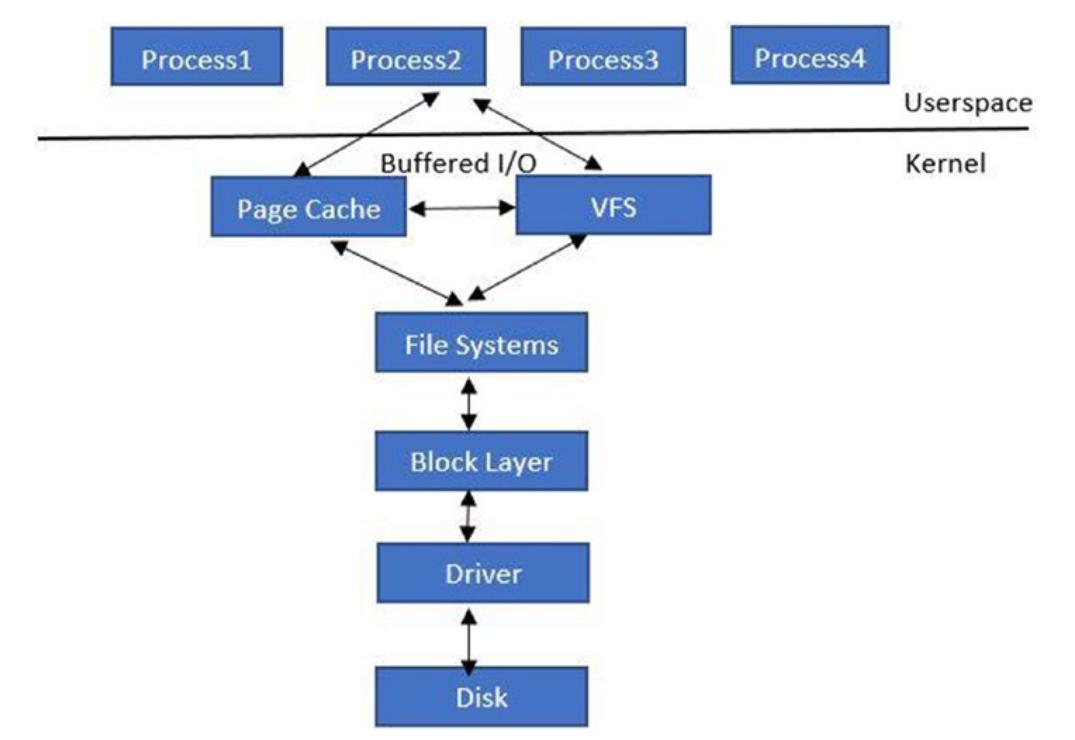
Соответствующее приложение осуществляет некий запрос на считывание/ запись либо через свою файловую систему, либо через файлы установления соответствия в памяти. При вызове на основе файловой системы, имеющаяся виртуальная файловая система (VFS, virtual file system) обрабатывает такой системный вызов и активизирует лежащую в её основе зарегистрированную файловую систему.
Следующим уровнем выступает блочный уровень, в котором и собираются реальные запросы ввода/ вывода. Внутри этого блочного уровня имеются три важных структуры данных:
-
Request_queue: Архитектура с единственной очередью это когда для каждого устройства имеется одна очередь запросов. Это именно та очередь, в которой сам блочный уровень в тандеме со своим планировщиком ввода/ вывода выстраивает очередь запросов. Имеющийся драйвер устройства осушает такую очередь запросов и представляет такие запросы в реальное устройство. -
Request: Самrequest(запрос) представляет отдельный запрос на ввод/ вывод , который надлежит доставить в соответствующее устройство ввода/ вывода. Этотrequestсостоит из списка структурbio. -
Bio: Структураbioявляется базовым контейнером для блочного ввода/ вывода. Такая структураbioрасполагается внутри своего ядра. Будучи определённой в файле<linux/bio.h>, эта структура представляет находящиеся на лету (активные) операции ввода/ вывода как список неких сегментов. Сегмент представляет собой фрагмент буфера, который непрерывен в памяти.
В виде диаграммы bio отражён на
Рисунке 4-7.
Рисунок 4-7
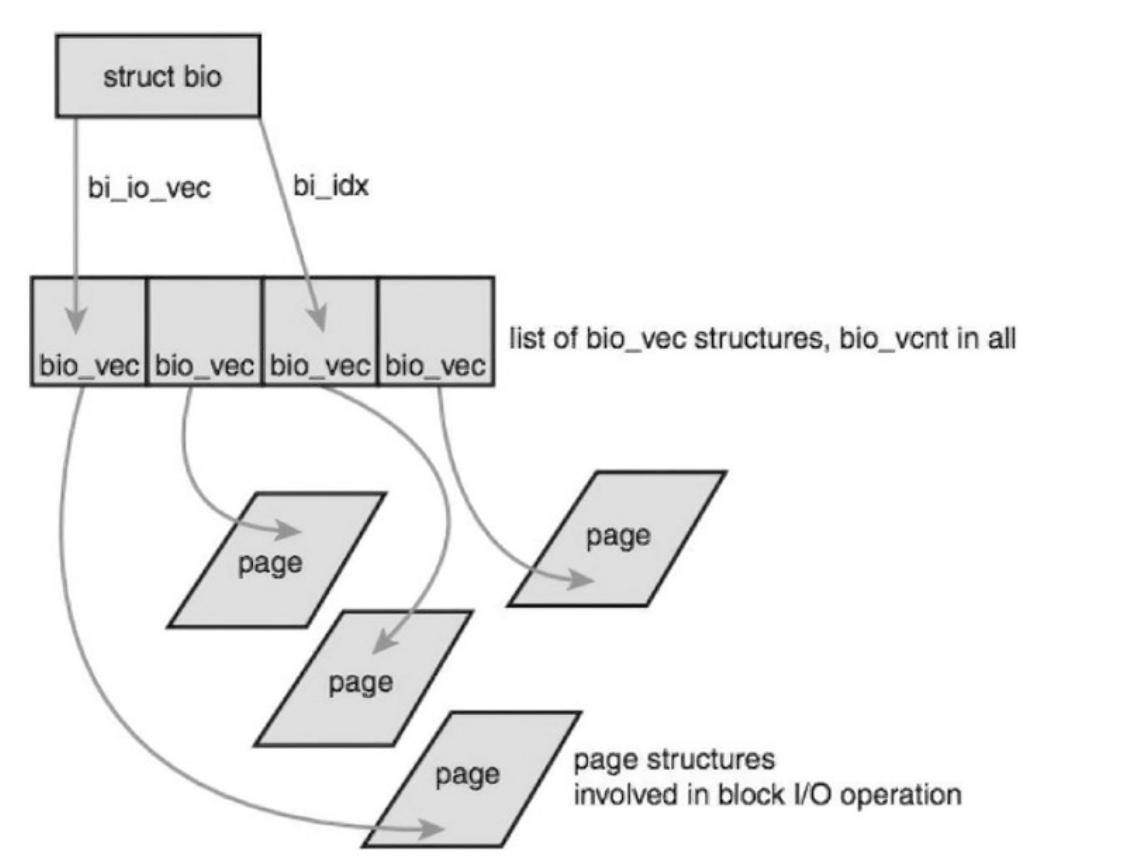
Структура bio, представляющая наход\щиеся на лету (активные) операции блочного ввода/ вывода как список сегментов
bio_vec представляет некий особый сегмент и обладает указателем на ту
страницу, которая содержит блочные данные по конкретному смещению.
Все запросы представляются в имеющуюся очередь запросов и осушаются соответствующим драйвером устройства. Здесь показаны важные структуры данных, вовлекаемые в реализацию обсуждаемой cgroup блочного ввода/ вывода ядра Linux:
struct blkcg {
struct cgroup_subsys_state css;
spinlock_t lock;
struct radix_tree_root blkg_tree;
struct blkcg_gq __rcu *blkg_hint;
struct hlist_head blkg_list;
struct blkcg_policy_data *cpd[BLKCG_MAX_POLS];
struct list_head all_blkcgs_node; #ifdef
CONFIG_CGROUP_WRITEBACK
struct list_head cgwb_list;
refcount_t cgwb_refcnt;
#endif
};
Эта структура представляет cgroup рассматриваемого нами блочного ввода/ вывода. Каждой cgroup блочного ввода/ вывода ставится в соответствие некая очередь запросов, как мы поясняли ранее.
/* ассоциация между cgroup blk и очередью запросов */
struct blkcg_gq {
/* Указатель на ассоциированную request_queue */
struct request_queue *q;
struct list_head q_node;
struct hlist_node blkcg_node;
struct blkcg *blkcg;
/*
* Каждая blkg переполняется по отдельности и такое состояние переполнения
* распространяется соответствующему bdi_writeback_congested.
*/
struct bdi_writeback_congested *wb_congested;
/* все не корневые blkcg_gq's гарантированно обязаны обладать доступом к предку */
struct blkcg_gq *parent;
/* запросить список выделения для этой пары blkcg-q */
struct request_list rl;
/* счётчик ссылок */
atomic_t refcnt;
/* доступна ли эта blkg? защищается и blkcg, и q locks */
Bool online;
struct blkg_rwstat stat_bytes;
struct blkg_rwstat stat_ios;
struct blkg_policy_data *pd[BLKCG_MAX_POLS];
struct rcu_head rcu_head;
atomic_t use_delay;
atomic64_t delay_nsec;
atomic64_t delay_start;
u64 last_delay;
int last_use;
};
Все очереди запросов ассоциируются с какой- то cgroup блочного ввода/ вывода.
Под справедливостью (fairness) мы имеем ввиду, что каждая cgroup получает справедливую долю значения выдачи ввода/ вывода в это устройство. Для осуществления этого следует настроить планировщик CFQ (Complete Fair Queuing). В отсутствии cgroup планировщик CFQ назначает каждому процессу некую очередь, а затем предоставляем расслоение по времени для каждой из очередей, тем самым обрабатывая справедливость.
Некое дерево обслуживания это список активных очередей/ процессов над которым работает планировщик. Итак, в своей основе, планировщик CFQ обслуживает запросы из всех очередей в дереве обслуживания.
При работе с cgroup вводится понятие CFQ групп. Теперь вместо планирования по процессам собственно планирование выполняется на уровне групп. Это означает,что каждая cgroup обладает множеством деревьев обслуживания в которых планируются очереди этих групп. Затем имеется некое глобальное дерево обслуживания в котором планируются сами группы CFQ.
Группа CFQ определяется следующим образом:
struct cfq_group {
/* должен быть самым первым участником */
struct blkg_policy_data pd;
/* участник группы service_tree */
struct rb_node rb_node;
/* ключ группы service_tree */
u64 vdisktime;
/*
* Значение числа cfqgs и сумма их весов под этой cfqg.
* Она покрывает эти leaf_weight cfqg е веса всех потомков,
* однако не покрывает веса всех последующих потомков.
*
* Когда cfqg присутствует в дереве обслуживания, она активна. Некая активная cfqg
* также активирует своих предков и вносит вклад в значение children_weight
* своего предка.
*/
int nr_active;
unsigned int children_weight;
/*
* vfraction это доля vdisktime которые озаглавлены в этой
* cfqg. Она определяется составлением значений отношений
* проходом вверх по этой cfqg к корню.
*
* Она пребывает в фиксированной точке с/ CFQ_SERVICE_SHIFT, а значение суммы всех
* vfractions в неком дереве обслуживания примерно равно 1. Сумма может слегка отличаться
* по причине ошибок округления и отклонений, вызванных входом и выходом
* cfqgs из дерева обслуживания.
*/
* unsigned int vfraction;
/*
* Имеются два веса - (внутренний) вес это вес всех этих
* cfqg относительно cfqgs одного уровня. leaf_weight это значение веса
* такой cfqg относительно всех дочерних cfqgs. Для значения корневой cfqg, оба
* веса выдерживаются синхронными для обратной совместимости.
*/
unsigned int weight;
unsigned int new_weight;
unsigned int dev_weight;
unsigned int leaf_weight;
unsigned int new_leaf_weight;
unsigned int dev_leaf_weight;
/* число cfqq находящихся в данный момент вэтой группе */
int nr_cfqq;
/*
* Среднее число занятых очередей в группе. Полезно при расчёте среза рабочей группы.
* Мы создаём массив для каждого класса prio, но во время выполнения он используется
* только для классов RT и BE, а слот для класса IDLE остаётся не использованным.
* Это в первую очередь сделано во избежание путаницы и предупреждающих сообщений gcc.
*/
unsigned int
busy_queues_avg[CFQ_PRIO_NR]; /*
*rr перечисляет все очереди с запросами. Мы поддерживаем деревья обслуживания для
*классов RT и BE. Эти деревья подразделяются на подклассы
* на базе SYNC, SYNC_NOIDLE и ASYNC в типе рабочей нагрузки. Для
* класса IDLE нет никаких подклассов и все имеющиеся очереди CFQ идут в
* некое отдельное дерево обслуживания service_tree_idle.
* Сч1тчики встраиваются в cfq_rb_root
*/
struct cfq_rb_root service_trees[2][3];
struct cfq_rb_root service_tree_idle;
u64 saved_wl_slice;
enum wl_type_t saved_wl_type;
enum wl_class_t saved_wl_class;
/* число запросов, которые пребывают в списке отправки или внутри драйвера */
int dispatched;
struct cfq_ttime ttime;
struct cfqg_stats stats; /* статистики для этой cfqg */
/* асинхронная очередь для каждого варианта приоритета */ struct
cfq_queue *async_cfqq[2][IOPRIO_BE_NR]; struct
cfq_queue *async_idle_cfqq;
};
Каждая группа CFQ содержит некое значение "веса ввода/ вывода", которое можно настраивать в
cgroup. Значения vdisktime CFQG (групп CFQG) определяются их положением в
"дереве обслуживания cfqg", а затем они изменяются в соответствии с "весом ввода/ вывода".
Дросселирование (throttling) предоставляет некое средство для применения ограничения ресурсов к имеющемуся блочному вводу/ выводу. Это делает возможным для ядра осуществлять контроль над значением максимального блочного ввода/ вывода, который может получать процесс пространства пользователя. Имеющееся ядро реализует его через cgroup блочного ввода/ вывода.
Дросселирование имеющегося блочного ввода/ вывода для cgroup выполняется с применением некого набора различных
функций. Самой первой функцией является blk_throttl_bio и она определена в
blk-throttle.c:
bool blk_throtl_bio(struct request_queue *q, struct blkcg_gq
*blkg, struct bio *bio)
{
struct throtl_qnode *qn = NULL;
struct throtl_grp *tg = blkg_to_tg(blkg ?: q->root_blkg); struct throtl_service_queue *sq; bool rw = bio_data_dir(bio);
bool throttled = false;
struct throtl_data *td = tg->td;
WARN_ON_ONCE(!rcu_read_lock_held());
/* см. throtl_charge_bio() */
if (bio_flagged(bio, BIO_THROTTLED) || !tg->has_rules[rw])
goto out;
spin_lock_irq(q->queue_lock);
throtl_update_latency_buckets(td);
if (unlikely(blk_queue_bypass(q)))
goto out_unlock;
blk_throtl_assoc_bio(tg, bio);
blk_throtl_update_idletime(tg);
sq = &tg->service_queue;
again :
while (true) {
if (tg->last_low_overflow_time[rw] == 0) tg->last_low_overflow_time[rw] = jiffies;
throtl_downgrade_check(tg);
throtl_upgrade_check(tg);
/* throtl выполнен как FIFO - если bios уже в очереди, он должен там присутствовать */
if (sq->nr_queued[rw])
break;
/* прерываем очередь в случае превышения предела */
if (!tg_may_dispatch(tg, bio, NULL)) {
tg->last_low_overflow_time[rw] = jiffies;
if (throtl_can_upgrade(td, tg)) {
throtl_upgrade_state(td);
goto again;
}
break;
}
/* находясь в рамках предела, давайте выполним начисление и отправим напрямую */
throtl_charge_bio(tg, bio);
/*
* Необходимо подрезать сечение, даже когда bio не были поставлен в очередь,
* в противном случае может получиться, что bio находится вне очереди
* длительное время и сечение продолжит расширяться, а обрезка не
* вызывается очень долго. Теперь, если пределы внезапно уменьшаются,
* мы принимаем во внимание все операции ввода/ вывода, отправленные до сих пор с новой
* низкой скоростью, а * вновь поставленные в очередь операции ввода/ вывода получают действительно
* продолжительное время отправки.
*
* Так что продолжайте подрезать сечение, даже если bio не стоит в очереди. */
throtl_trim_slice(tg, rw);
/*
* @bio передаётся через этот уровень без дросселирования.
* Идём вверх по лестнице. Если мы уже на самом верху,
* можно выполнять непосредственно.
**/
qn = &tg->qnode_on_parent[rw];
sq = sq->parent_sq;
tg = sq_to_tg(sq);
if (!tg)
goto out_unlock;
}
/* out-of-limit, ставим в очередь к @tg */
throtl_log(sq, "[%c] bio. bdisp=%llu sz=%u bps=%lluiodisp=%u iops=%u queued=%d/%d",
rw == READ ? 'R' : 'W',
tg->bytes_disp[rw], bio->bi_iter.bi_size,
tg_bps_limit(tg, rw),
tg->io_disp[rw], tg_iops_limit(tg, rw),
sq->nr_queued[READ], sq->nr_queued[WRITE]);
tg->last_low_overflow_time[rw] = jiffies;
td->nr_queued[rw]++;
throtl_add_bio_tg(bio, qn, tg);
throttled = true;
/*
* Обновите время отправки @tg и принудительно отправьте расписание если @tg
* был пуст до @bio. Принудительное планирование вряд ли
* вызовет неоправданную задержку, поскольку @bio, скорее всего, будет отправлен напрямую,
* если запланированное время @tg не пребывает в будущем.
*/
if (tg->flags & THROTL_TG_WAS_EMPTY) {
tg_update_disptime(tg);
throtl_schedule_next_dispatch(tg->service_queue.parent_sq, true);
}
out_unlock:
spin_unlock_irq(q->queue_lock);
out:
bio_set_flag(bio, BIO_THROTTLED);
#ifdef CONFIG_BLK_DEV_THROTTLING_LOW
if (throttled || !td->track_bio_latency) bio->
bi_issue.value |= BIO_ISSUE_THROTL_SKIP_LATENCY;
#endif
return throttled;
}
Следующий фрагмент кода проверяет может ли данный bio быть
отправлен для активной доставки в драйвер своего устройства:
if (!tg_may_dispatch(tg, bio, NULL)) { tg->last_low_overflow_time[rw] = jiffies;
if (throtl_can_upgrade(td, tg)) {
throtl_upgrade_state(td);
goto again;
}
break;
}
Здесь приводится определение tg_may_dispatch:
static bool tg_may_dispatch(struct throtl_grp *tg, struct bio *bio, unsigned long *wait)
{
bool rw = bio_data_dir(bio);
unsigned long bps_wait = 0, iops_wait = 0, max_wait = 0;
/*
* В настоящий момент вся машина состояний группы целиком зависит от первого bio
* находящегося в очереди в списке bio этой группы. Поэтому не следует вызывать
* эту функцию с другим bio когда в очереди имеются прочие bio.
* /
BUG_ON(tg-&service_queue.nr_queued[rw] &&
bio != throtl_peek_queued(&tg-&service_queue.queued[rw]));
/* Когда tg-&bps = -1, BW неограничен */
if (tg_bps_limit(tg, rw) == U64_MAX &&
tg_iops_limit(tg, rw) == UINT_MAX) {
if (wait)
*wait = 0;
return true;
}
/*
* Когда предыдущий срез закончился, начните новый, в противном случае
* обновите/расширьте уже имеющийся срез чтобы быть уверенным, что он по крайней мере пребывает в интервале
* throtl_slice достаточно давно. Новый срез запускается только для пустой группы
* дросселирования. Когда в очереди имеется bio, это означает, что должен иметься некий
* активный срез и вместо этого его надлежит расширить.
* /
if (throtl_slice_used(tg, rw) &&
!(tg-&service_queue.nr_queued[rw]))
throtl_start_new_slice(tg, rw);
else {
if (time_before(tg-&slice_end[rw],
jiffies + tg-&td-&throtl_slice))
throtl_extend_slice(tg, rw,
jiffies + tg-&td-&throtl_slice);
}
if (tg_with_in_bps_limit(tg, bio, &bps_wait) &&
tg_with_in_iops_limit(tg, bio, &iops_wait)) {
if (wait)
*wait = 0 ;
return true;
}
max_wait = max(bps_wait, iops_wait);
if (wait)
*wait = max_wait;
if (time_before(tg-&slice_end[rw], jiffies + max_wait))
throtl_extend_slice(tg, rw, jiffies + max_wait);
return false;
Фрагмент кода
if (tg_with_in_bps_limit(tg, bio, &bps_wait) &&
tg_with_in_iops_limit(tg, bio, &iops_wait)) {
if (wait)
*wait = 0;
return true;
}
определяет пребывает ли этот bio внутри установленных пределов данной
cgruop или нет. Как видно, он проверяет для данной cgroup как ограничение в байтах в секунду, так и предел числа
вводав/ выводов в секунду.
Когда предел не превышен, этот bio загружается в данную cgroup
первым:
/* находясь в рамках, давайте заполним и отправим непосредственно and dispatch directly */ throtl_charge_bio(tg, bio);
static void throtl_charge_bio(struct throtl_grp *tg, struct bio *bio) {
bool rw = bio_data_dir(bio);
unsigned int bio_size =
throtl_bio_data_size (bio);
/* Заносим этот bio в его группу */
tg->bytes_disp[rw] += bio_size;
tg->io_disp[rw]++;
tg->last_bytes_disp[rw] += bio_size;
tg->last_io_disp[rw]++;
/*
* BIO_THROTTLED применяется для предотвращения дросселирования того же самого bio
* более одного раза, поскольку дросселированный bio проследует через blk-throtl
* второй раз когда он в конечном счёте будет выдан. Установите его когда bio
* загружается до tg.
*/
if (!bio_flagged(bio, BIO_THROTTLED))
bio_set_flag(bio, BIO_THROTTLED);
}
Данная функция загружает этот bio (в bytes
и iops) в группу throttle. Затем
она передаёт этот bio вверх своему предку, что видно из приводимого
ниже кода:
/*
* @bio передаётся через этот уровень без дросселирования.
* Поднимаемся вверх по лестнице. Если мы уже на самом верху,
* Можно выполнять непосредственно.
*/
qn = &tg->qnode_on_parent[rw];
sq = sq->parent_sq;
tg = sq_to_tg(sq);
Если превышены ограничения, этот код принимает другой ход. Вызывается следующий фрагмент кода:
throtl_add_bio_tg(bio, qn, tg);
throttled = true;
Давайте взглянем на функцию throtl_add_bio_tg более внимательно:
/**
* throtl_add_bio_tg - добавить bio в предписанный throtl_grp
* @bio: подлежащий добавлению bio
* @qn: qnode для применения
* @tg: целевая throtl_grp
*
Добавить @bio в service_queue @tg при помощи @qn. Если @qn не задан,
применяется tg->qnode_on_self[].
*/
static void throtl_add_bio_tg(struct bio *bio, struct
throtl_qnode *qn,
struct throtl_grp *tg)
{
struct throtl_service_queue *sq = &tg->service_queue; bool rw = bio_data_dir(bio);
if (!qn)
qn = &tg->qnode_on_self[rw];
/*
* Если @tg в настоящий момент не обладает никакими очередями bio в том же самом
* направлении, устанавливаемая очередь @bio может измениться когда должен быть отправлен
* @tg. Отметьте что @tg был пустым. Это автоматически
* очищается при следующем tg_update_disptime().
*/
if (!sq->nr_queued[rw])
tg->flags |= THROTL_TG_WAS_EMPTY;
throtl_qnode_add_bio(bio, qn, &sq->queued[rw]);
sq->nr_queued[rw]++;
throtl_enqueue_tg(tg);
}
Данная функция добавляет полученный bio в очередь обслуживания
throttle. Такая очередь действует как механизм для дросселирования запросов
bio. Этот запрос на обслуживание затем позднее осушается.
/**
*blk_throtl_drain - осушить дросселированные bio
*@q: request_queue чтобы осушить дросселированные bio для
*отправки всех дросселированных в данный момент bio в @q через
- >make_request_fn().
*/
void blk_throtl_drain(struct request_queue *q)
__releases(q->queue_lock) __acquires(q->queue_lock)
{
struct throtl_data *td = q->td; struct blkcg_gq *blkg;
struct cgroup_subsys_state *pos_css;
struct bio *bio;
int rw;
queue_lockdep_assert_held(q);
rcu_read_lock();
/*
* Осушить все tg при выполнении проход в обратном порядке по дереву blkg с тем,
* чтобы все bio распространились в td->service_queue. Было бы лучше
* непосредственно пройти по дереву service_queue, но проход по blkg
* выполняется проще.
*/
blkg_for_each_descendant_post(blkg, pos_css, td->queue->root_blkg)
tg_drain_bios(&blkg_to_tg(blkg)->service_queue);
/* наконец, передаём bio из tg верхнего уровня в установленный td */
tg_drain_bios(&td->service_queue);
rcu_read_unlock();
spin_unlock_irq(q->queue_lock);
/* все bio теперь должны пребывать в td->service_queue, выдаём их
*/ for (rw = READ; rw <= WRITE; rw++)
while ((bio = throtl_pop_queued(&td->service_queue.queued[rw],
NULL)))
generic_make_request(bio);
spin_lock_irq(q->queue_lock) ;