Глава 5. Многоуровневая файловая система
Содержание
В своих предыдущих главах мы изучили пространства имён и cgroup. В этой главе мы прикоснёмся к другой интересной стороне экосистемы контейнеров, которой выступает многоуровневая файловая система. Мы обсудим как она делает возможным совместное использование файлов в своём хосте и как это способствует запуску большого числа контейнеров в таком хосте.
В предыдущих главах мы решали вопросы изоляции процессов через пространства имён Linux и контроль ресурсов для индивидуальных процессов через cgroup. Теперь мы окунёмся в вопросы многоуровневых файловых систем, которые составляют третий строительный блок наших контейнеров Linux, после пространства имён и cgroup.
Давайте начнём с обсуждения того что представляет из себя файловая система.
Философия Linux трактует всё как файл. Например, сокет, конвейер и блочные устройства, все они в Linux представляются как файлы.
Файловые системы в Linux действует как контейнеры для абстрагирования лежащего в основе хранилища в случае блочных устройств. Для не блочных устройств, таких как сокеты и конвейеры, в памяти имеются файловые системы, которые обладают операциями, способными осуществляться при помощи API стандартной файловой системы.
Linux формализует все файловые системы при помощи некого уровня, носящего название VFS (Virtual File System). Все файловые системы регистрируются при помощи VFS. VFS обладает следующими важными структурами данных:
-
File: Представляет собой некий открытый файл и собранные в нём сведения, такие как смещение и тому подобное. Пространство пользователя обязано обрабатывать некий открытый файл через структуру с названием файловый дескриптор. Она выступает обработчиком, применяемым для взаимодействия с соответствующей файловой системой.
-
Inode: Это соответствие 1:1 к конкретному файлу. Такой inode является одной из наиболее критически важных структур и он содержит все метаданные относительно своего файла. Например, они содержат сведения о том, в каких блоках данных хранится информация файла и какие полномочия установлены для этого файла. Эти сведения являются частью такого inode. Inode также хранятся на диске особой файловой системой, однако они представляются в памяти как часть уровня своей VFS. За перечисление соответствующей структуры inode VFS ответственна сама файловая система.
-
Dentry: Это соответствие между именем файла и inode. Это размещаемая в памяти структура и она не хранится на диске. В основном она относится к поиску и проходу по пути.
-
Superblock: Эта структура удерживает все необходимые сведения относительно соответствующей файловой системы, в том числе, сколько в ней имеется блоков, значение имени устройства и тому подобное. Эта структура перечисляется и заносится в память во время операции монтирования.
Каждая из этих структур данных содержит указатели для своих специфических операций. Скажем,
file имеет file_ops для считывания
и записи, а superblock через super_ops
обладает операциями для монтирования, размонтирования и тому подобного.
Определённая операция монтирования создаёт некую структуру данных vfsmount,
которая содержит ссылки на новую структуру данных суперблока, создаваемую в той файловой системе, которая
подлежит монтированию на данном диске. dentry обладает ссылкой на
такую vfsmount. Именно этим VFS отличается от каталога и точки монтирования.
В процессе прохода, в dentry отыскивается
vfsmount, в смонтированном устройстве используется
inode номер 2 (inode 2 зарезервирован
для значения корневого каталога).
Итак, как эти части подгоняются друг к другу в случае блочного устройства? Допустим, определённый процесс
пространства пользователя выполняет вызов на считывание файла. Этот системный вызов выполняется в установленной
ядро. Его VFS проверяет значение пути и определяет имеются ли кэшированными dentry
в его корне. По мере прохода и поиска правильной dentry, она определяет
местоположение соответствующего inode для подлежащего открытию файла.
После нахождения местоположения inode, проверяются права доступа и загруженные
в кэш страниц ОС с соответствующего диска блоки данных. Эти же самые данные перемещаются в пространство пользователя
выполнившего запрос процесса.
Кэш страниц является занятной оптимизацией в ОС. Все считывания и записи (за исключением непосредственного
ввода/ вывода) происходят поверх такого кэша страниц. Этот кэш страниц сам по себе представляется некой структурой данных
с наименованием address_space. Это address_space
содержит некое дерево страниц памяти, а inode этого файла содержит некую ссылку
к этой структуре данных address_space.
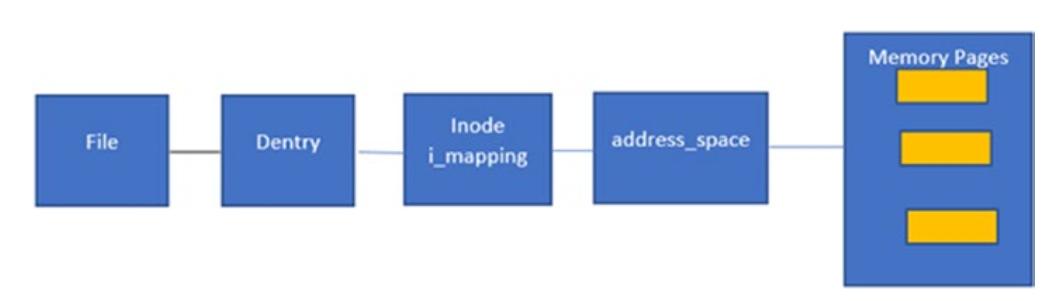
Рисунок 5-1
показывает как устанавливается соответствие файлу в имеющемся кэше страниц. Именно это также выступает основным
ключом к пониманию того, как работают такие операции как mmap для установки
соответствия файлам. Мы обсудим это когда будем рассматривать такую файловую систему как
tmpfs и совместное использование памяти примитивами IPC.
Когда запрашиваемый на считывание файл пребывает в установленном кэше страниц (что определяется через
соответствующую структуру address_space в
inode файла), эти данные обслуживаются оттуда.
Всякий раз, когда выполняется вызов на запись в соответствующем файле через его файловый дескриптор, эти записи
вначале выполняются в такой кэш страниц. Значения страниц памяти помечаются как грязные (dirty) и ядро Linux
применяет механизм кэширования с обратной записью, что означает, что имеются некие потоки в фоновом режиме
(с названиемpdflush), которые осушают этот кэш страниц и выполняют запись на
физический диск через надлежащий блочный драйвер. Этот механизм пометки страниц грязными не происходит на самом уровне
страниц. Страницы могут иметь в размере 4кБ и даже минимальное изменение затем вызовет запись страницы целиком.
Во избежание этого, имеются некие структуры, которые обладают более тонкой грануляцией и представляют в памяти дисковые блоки. Эти структуры носят название заголовков буфера (buffer heads). Например, когда значение размера блока равно 512 байт, имеется восемь заголовков буфера и одна страница в кэше страниц.
Таким образом, могут помечаться как грязные отдельные блоки и записываться часть данных.
Такие буферы могут в явном фиде сбрасываться на диск через следующие системные вызовы:
-
Sync(): Сбрасывает на диск все грязные записи. -
Fsync(fd): Сбрасывает на диск только грязные буферы данных соответствующего файла, включая сами изменения вinode. -
Fdatasync(fd): Сбрасывает на диск только грязные буферы данных соответствующего файла. Не выполняет сбросinode.
Вот некий образец того как работает процесс синхронизации:
-
Осуществляется проверка является ли грязным сам суперблок.
-
Выполняется обратная запись суперблока.
-
Выполняется итерация по всем
inodeиз имеющегося спискаinode:-
Если соответствующий
inodeгрязный, выполняется его обратная запись. -
Если соответствующий кэш страниц этого
inodeявляется грязным, выполняется обратная запись. -
Очищается значение флага dirty.
-
Рисунок 5-2 отображает различные уровни файловой системы под установленным ядром.
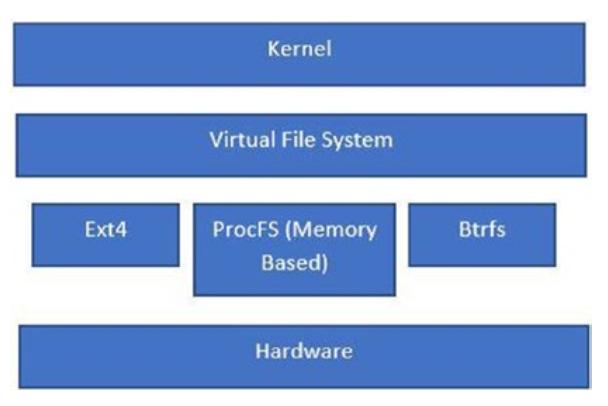
Примеры различных видов файловых систем включают:
-
Ext4: Эта файловая система применяется для доступа к лежащей в её основе блочным устройствам.
-
ProcFS: Это некая располагаемая в памяти файовая система и она используется для предоставления функциональных возможностей. Она также носит название псевдо файловой системы (pseudo file system).
-
Btrfs: Эта файловая система применяется для доступа к лежащей в её основе блочным устройствам.
Напомним, что общей философией Linux является то, что всё является файлами. Исходя из этого, имеются некоторые
файловые системы, которые предоставляют доступ к некоторым ресурсам ядра через файловый интерфейс. Мы называем их
псевдофайловыми системами. Одной из таких файловых систем выступает procfs.
Такая файловая система procfs монтируется в
rootfs в каталоге proc. Все
сведения в procfs не сохраняются на постоянной основе и все операции
происходят в памяти.
Некоторые выставляемые через procfs структуры поясняются в приводимой
ниже таблице:
| Структура | Описание |
|---|---|
|
Такие подробности ЦПУ как число ядер, размер ЦПУ, производитель и т.п. |
|
Сведения о физической памяти |
|
Сведения о прерываниях и обработчиках |
|
Статистики виртуальной памяти |
|
Активные в ядре фаловые системы |
|
Смонтированные в настоящее врмя устройства; они будут специфичными для своего монтируемого пространства имён |
|
Время, начиная с запуска ядра |
|
Статистики системы |
|
Сведения о физической памяти |
|
Относящиеся к сетевой среде структуры, такие как сокеты TCP, файлы и
т.п. |
|
Название командной строки данного процесса |
|
Переменные среды данного процесса |
|
Соответствие установленной виртуальной памяти |
|
Открытые файловые дескрипторы данного процесса |
|
Подробности его дочерних процессов |
Теперь, когда вы обладаете лучшим пониманием файловой системы в Linux, настало время рассмотреть многоуровневые файловые системы в Linux.
Многоуровневые файловые системы позволяют файлам совместно использовать диск, тем самым, сберегая пространство. Поскольку эти файлы совместно используются в памяти (загруженными в кэш страниц), многоуровневая файловая система делает возможным оптимальное применение пространства, а также более быстрый запуск.
Рассмотрим некий пример исполнения десяти баз данных Cassandra в одном и том же хосте, причём каждая база данных запускается в своём собственном пространстве имён. Когда у нас имеются отдельные файловые системы для всех различных inode баз данных, мы не пользуемся такими преимуществами:
-
Разделение памяти
-
Совместное использование диска
Поскольку в случае некой многоуровневой файловой системы все файлы разбиваются по уровням, каждый уровень является доступной только на чтение файловой системой. Так как эти уровни совместно применяются по имеющемся в одном и том же хосте контейнерам, они обладают тенденцией оптимально использовать хранилище. Кроме того, благодаря тому, что inode одни и те же, все они ссылаются на один и тот же кэш страниц ОС. Это превращает вещи в оптимальные во всех отношениях.
Сравним это с подготовкой на основе ВМ, когда всякая rootfs
предоставляется как некий диск. Это означает, что все они обладают различными представлениями inode в своём
хосте и нет никакого оптимального хранения по сравнению со случаем контейнеров.
Гипервизоры также обладают тенденцией достигать оптимальности при помощи подобных KSM (Kernel Same Page Merging Слияние одинаковых страниц ядра) чтобы они имели возможность выполнять дедупликацию одних и тех же страниц по виртуальным машинам.
Дадее мы обсудим понятие Объединённых файловых систем (union file systems)
Согласно Wikipedia, Единая файловая система это некая служба файловой системы для Linux, FreeBSD и NetBSD, которая реализует некое единое монтирование для прочих файловых систем. Она делает возможным прозрачное перекрытие файлов и каталогов отдельных файловых систем, именуемых ветвлениями (branches), формируя единую связную файловую систему. Всё содержимое каждого каталога, которое обладает одним и тем же путём внутри слитых ветвлений будут видны совместно в неком отдельном объединённом каталоге внутри своей новой виртуальной файловой системы (VFS).
Итак, в своей основе, единая файловая система позволяет вам брать различные файловые системы и создавать нечто единое из их содержимого, причём выставляя поверх некий уровень представления всех имеющихся в её основе файлов. Если будут обнаружены дублирующие файлы, их верхний уровень вытесняет все лежащие ниже уровни.
Этот раздел взглянет на OverlayFS как некий образец единой FS. OverlayFS выступала частью ядра Linux начиная с 3.18. Она перекрывает (как и предполагает её название) всё содержимое одного каталога другим. Исходными каталогами могут быть различные диски или файловые системы.
В OverlayFS v1 имелось лишь два уровня, и именно они применялись для создания некого единого уровня, отображаемого на Рисунке 5-3.
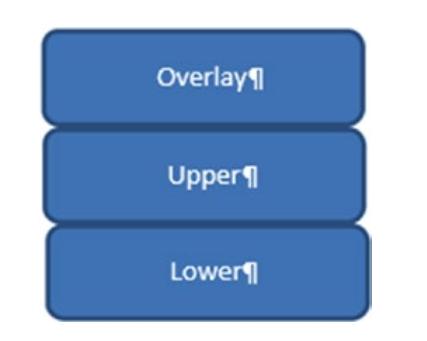
OverlayFS v2 обладает тремя уровнями:
-
Base: Это базовый уровень. В основном он доступен только на чтение.
-
Overlay: Этот уровень (перекрытия) предоставляет видимость с базового уровня и делает возможным добавление новых файлов, каталогов. Когда изменяются какие бы то ни было файлы с базового уровня, они сохраняются на своём следующем уровне.
-
Diff: Все сделанные на уровне перекрытия изменения сохраняются на этом уровне diff (приращений). Все изменения в файлах на своём базовом уровне влекут за собой копирование такого файла с этого базового уровня на уровень приращений. Все изменения затем записываются в этом уровне приращений.
Давайте рассмотрим пример того как работает OverlayFS v2:
root@instance-1: mkdir base diff overlay workdir
root@instance-1: echo "test data" > base/test1
root@instance-1: sudo mount \
> -t overlay \
> -o lowerdir=base,upperdir=diff,workdir=workdir \
> overlay \
> overlay
root@instance-1:-# I

Мы создаём некий файл в своём каталоге overlay и можем видеть что они
появляются в diff:
root@instance-1:/overlay# touch test2
root@instance-1:/overlay# ls
test1 test2
root@instance-1:-/overlay# cd ../diff
root@instance-1:-/diff# ls
test2

Теперь мы можем изменить свой файл test1:

Если мы проверим этот файл в каталоге diff, мы обнаружим уже
изменённый файл. Однако когда мы проследуем в каталог base, мы
будем наблюдать свой старый файл. Это означает, что мы изменили этот файл в своём каталоге
base, он был сначала скопирован в каталог
diff, после чего и были осуществлены изменения.
После выполнения этих примеров, когда пользователи пожелают выполнить очистку ресурсов, для размонтирования OverlayFS они могут выполнить такую команду:
root@instance-1: umount overlay
По завершению размонтирования, если пожелаете, эти каталоги также могут быть удалены.
Давайте теперь задумаемся о том как такие механизмы как Docker реализуют данный процесс. В Docker имеется драйвер хранилища Overlay2, о котором вы можете обнаружить дополнительные сведения в https://github.com/moby/moby/blob/master/daemon/graphdriver/overlay2/overlay.go.
Docker создаёт множество уровней чтения (базовые уровни) и один уровень чтения/ записи с названием уровня контейнера (в нашем случае уровня перекрытия, overlay).
Множество уровней чтения может совместно использоваться по различным контейнерам в одном и том же хосте, тем самым достигая очень высокой оптимизации. Как мы уже намекали ранее, поскольку мы обладаем одной и той же файловой системой и теми же самыми inode, наш кэш страниц ОС также совместно используется по всем контейнерам в одном и том же хосте.
В противовес этому, когда мы видим соответствие устройств некого драйвера Docker, так как он снабжает
каким- то виртуальным диском для каждого из уровней, мы можем не испытать того совместного использования, который
мы получаем при помощи OverlayFS. Но теперь даже применяя устройство сопоставления в Docker мы способны
передать параметр –shared-rootfs в этот демон для совместного использования
rootfs. Обычно это работает в виде создания некого устройства для самого
первого базового образа контейнера с последующей привязкой для последующих контейнеров. Такая привязка позволяет
нам сохранять одни и те же inode, а потому кэш страниц является общим.