Глава 6. Создание простой контейнерной инфраструктуры
Содержание
- Глава 6. Создание простой контейнерной инфраструктуры
- Пространство имён UTS
- Установка Golang
- Сборка контейнера при помощи Пространства имён
- Добавление дополнительных пространств имён
- Запуск программы оболочки внутри контейнера
- Предоставление файловой системы Root
- Монтирование файловой системы Proc
- Включение сетевой среды для контейнера
- Включение Cgroup для контейнера
- Выводы
В своих предыдущих главах мы изучили пространства имён и cgroup. В этой главе мы прикоснёмся к другой интересной стороне экосистемы контейнеров, которой выступает многоуровневая файловая система. Мы обсудим как она делает возможным совместное использование файлов в своём хосте и как это способствует запуску большого числа контейнеров в таком хосте.
В своих предыдущих главах мы изучили важные строительные блоки инфраструктуры контейнеров, такие как пространства имён, cgroup и многоуровневые файловые системы. В этой главе вы применим эти знания для сборки простой инфраструктуры контейнеров и изучения того, как из этих строительных блоков составляется такая инфраструктура контейнеров.
Поскольку мы изучили основы, которые учреждают некий контейнер, настало время взглянуть на то, как написать свой собственный простой контейнер. К концу этой главы вы создадите свой собственный образец контейнера при помощи изоляции пространства имён.
Давайте приступим.
Я проверил упоминающиеся в этой главе команды на Ubuntu 19.04 с ядром Linux 5.0.0-13.
Самая первая изучаемая нами команда носит название unshare. Эта команда
позволяет нам перестать совместно использовать некий набор пространств имён в определённом хосте.
Мы введём новое пространство имён uts и изменим своё имя хоста внутри
этого пространства имён.
root@osboxes:~# unshare -u /bin/bash
root@osboxes:~# hostname test
root@osboxes:~# hostname
test
root@osboxes:~# exit
exit
root@osboxes:~# hostname
osboxes
Когда мы вводим новое пространство имён UTS, мы изменяем значение имени хоста на
test и это именно то что отражается внутри этого пространства имён. После
того как мы покидаем его и повторно входим в пространство имён host,
мы получаем значение пространства имён host.
Команда unshare -u /bin/bash создаёт пространство имён
uts и запускает наш процесс
(/bin/bash) внутри этого пространства имён. Внимательный читатель
может заметить, что когда мы не изменяем значение имени хоста после входа в это пространство имён, мы всё ещё
будем получать само имя хоста его хоста. Это не желательно, поскольку нам требуется некий способ устанавливать его
перед выполнением своей программы внутри такого пространства имён.
Именно здесь мы изучим написание некого контейнера при помощи Golang (также именуемого Go) и затем настроим пространства имён перед запуском своего процесса внутри этого контейнера. Мы будем писать свой контейнер на Golang, а потому нам потребуется иметь Golang установленным в своей ВМ или в той машине, в которой мы работаем. (Для установки Golang посетите https://golang.org/doc/install.)
Golang это самый распространённый язык системного программирования. Он применяется для создания сред исполнения контейнеров, таких как Docker, а также механизмов оркестровки контейнеров, например, Swarm и Kubernetes. Кроме того, он применялся в прочих настройках системного программирования. Перед тем как углубиться в код данной главы, неплохо составить пристойное представление о Golang.
Вот команды как по- быстрому установить Golang:
root@osboxes:~#wget https://dl.google.com/go/go1.12.7.linux-amd64.tar.gz
oot@osboxes:~# tar -C /usr/local -xzf go1.12.7.linux-amd64.tar.gz
Вы можете включить в root/.profile следующую строчку чтобы
добавить исполняемые файлы Golang в переменную PATH:
root@osboxes:~# export PATH=$PATH:/usr/local/go/bin
Затем в своём терминале исполните такую команду:
root@osboxes:~# source ~/.profile
Чтобы убедиться что Go (Golang) установился должным образом, вы можете запустить следующую команду:
root@osboxes:~# go version
Если установка была успешной, вы должны обнаружить такой вывод:

Теперь мы соберём некий контейнер с всего лишь с пространством имён и затем продолжим изменять свою программу
добавляя новые функциональные возможности, например, поддержку оболочки, rootfs,
сетевую среду и cgroups.
Давайте кратко повторим пространств имён Linux прежде чем мы построим свой контейнер. Пространства имён располагаются в самом ядре Linux, подобно ресурсам песочницы ядра, например, файловых систем, деревьев процессов, очередей сообщений и семафоров, а также сетевых компонентов, таких как устройства, сокеты и правила маршрутизации.
Пространства ядра изолируют процессы внутри их собственной песочницы исполнения с тем, чтобы они исполнялись полностью изолировано от прочих процессов в разных пространствах имён.
Имеются шесть пространств имён:
-
Пространство имён PID: Процессы внутри определённого пространства имён PID обладают различными деревьями процессов. У них имеется процесс
initс PID1. -
Пространство имён Mount: Это пространство имён управляет тем какие точки монтирования способен наблюдать процесс. Когда процесс пребывает в неком пространстве имён, он видит лишь точки монтирования внутри этого пространства имён.
-
Пространство имён UTS: Позволяет процессу видеть другое пространство имён нежели его реальное глобальное пространство имён.
-
Пространство имён Network: Это пространство имён даёт иное представление сетевой среды в пространстве имён. Такие сетевые конструкции как порты, iptables и тому подобное пребывает в рамках этого пространства имён.
-
Пространство имён IPC: Это пространство имён ограничивает структуры межпроцессного взаимодействия, такие как конвейеры внутри определённого пространства имён.
-
Пространство имён User: Данное пространство имён делает возможным обособление представления пользователя и группы внутри своего пространства имён.
Здесь мы не обсуждаем пространство имён cgroup, которое позволяет отделять сферы cgroup в свои собственные пространства имён.
Теперь давайте поработаем своими руками и создадим класс Go с названием myuts.go.
Скопируйте приводимый ниже фрагмент кода и воспользуйтесь go build myuts.go
для получения исполняемого файла myuts. Также запустите этот
исполняемый файл myuts от имени
пользователя root.
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("/bin/bash")
// Приводимые ниже операторы ссылаются на потоки input, output и error создаваемого процесса(cmd)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
//установка некой переменной среды
cmd.Env = []string{"name=shashank"}
// приводимая ниже команда создаёт пространство имён UTS для данного процесса
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
if err := cmd.Run(); err != nil {
fmt.Printf("Error running the /bin/bash command - %s\n", err)
os.Exit(1)
}
}
Это простая программа Go, которая запускает некую оболочку, настраивает необходимые потоки ввода/ вывода для
своего процесса и затем устанавливает одну переменную env. Затем она
применяет следующую команду:
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
Далее она передаёт флаги CLONE (в данном случае мы передаём лишь флаг
клонирования UTS). Такие флаги клонирования контролируют какие пространства
имён создаются для данного процесса.
После этого мы собираем и запускаем этот процесс Golang. Мы сможем увидеть было ли создано наше новое
пространство имён воспользовавшись своей файловой системой proc и проверив
значение proc/<<pid>>/ns:
root@osboxes:~/book_prep# ls -li /proc/self/ns/uts
60086 lrwxrwxrwx 1 root root 0 Apr 13 10:10 /proc/self/ns/uts – > 'uts:[4026531838]'
root@osboxes:~/book_prep# ./myuts
root@osboxes:/root/book_prep# ls -li /proc/self/ns/uts
60099 lrwxrwxrwx 1 root root 0 Apr 13 10:10 /proc/self/ns/uts – > 'uts:[4026532505]'
root@osboxes:/root/book_prep#exit
Вначале мы вывели на печать значение пространства имён данного хоста и далее мы напечатали значение пространства имён того контейнера, в котором мы находимся.
Мы можем обнаружить, что значения uts пространств имён различны.
В своём предыдущем разделе мы отобразили как может быть создано пространство имён UTS. В этом разделе мы добавим дополнительные пространства имён.
Прежде всего мы добавим больше флагов клонирования чтобы создать дополнительные пространства имён для того контейнера, который мы создаём.
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("/bin/bash")
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Env = []string{"name=shashank"}
//следующая команда создаёт UTS, PID и IPC, NETWORK и USERNAMESPACES
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWNS |
syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNET |
syscall.CLONE_NEWUSER,
}
if err := cmd.Run(); err != nil {
fmt.Printf("Error running the /bin/bash command - %s\n", err)
os.Exit(1)
}
}
Здесь мы при помощи флагов клонирования добавили дополнительные пространства имён. Мы собираем и запускаем свою программу следующим образом:
root@osboxes:~/book_prep# ./myuts
nobody@osboxes:/root/book_prep$ ls -li /proc/self/ns/ total 0
63290 lrwxrwxrwx 1 nobody nogroup 0 Apr 13 10:14 cgroup -> 'cgroup:[4026531835]'
63285 lrwxrwxrwx 1 nobody nogroup 0 Apr 13 10:14 ipc -> 'ipc:[4026532508]'
63289 lrwxrwxrwx 1 nobody nogroup 0 Apr 13 10:14 mnt -> 'mnt:[4026532506]'
63283 lrwxrwxrwx 1 nobody nogroup 0 Apr 13 10:14 net -> 'net:[4026532511]'
63286 lrwxrwxrwx 1 nobody nogroup 0 Apr 13 10:14 pid -> 'pid:[4026532509]'
63287 lrwxrwxrwx 1 nobody nogroup 0 Apr 13 10:14 pid_for_children -> 'pid:[4026532509]'
63288 lrwxrwxrwx 1 nobody nogroup 0 Apr 13 10:14 user -> 'user:[4026532505]'
63284 lrwxrwxrwx 1 nobody nogroup 0 Apr 13 10:14 uts -> 'uts:[4026532507]'
Мы получили те пространства имён, которые относятся к этому контейнеру. Теперь мы видим, что право владения не принадлежит никому (nobody). Это потому, что мы также воспользовались качестве флага клонирования и пространство имён пользователя. Теперь контейнер пребывает в новом пространстве имён пользователя. пространства имён пользователя требуют чтобы мы сопоставляли пользователя из пространства имён с его хостом. Поскольку мы ещё пока ничего не сделали, мы по- прежнему не видим никого в качестве пользователя.
Теперь мы добавим соответствие пользователя в свой код:
vfs.zfs.vdev.cache.size=<10M>package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("/bin/bash")
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Env = []string{"name=shashank"}
//command below creates the UTS, PID and IPC , NETWORK and
// USERNAMESPACES and adds the user and group mappings.
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWNS |
syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNET |
syscall.CLONE_NEWUSER,
UidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getuid(),
Size: 1,
} ,
},
GidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getgid(),
Size: 1,
},
},
}
if err := cmd.Run(); err != nil {
fmt.Printf("Error running the /bin/bash command - %s\n", err)
os.Exit(1)
}
}
Вы можете видеть, что у нас имеются UidMappings и
GidMappings. У нас есть поле с названием
ContainerID, которое мы установили в значение
0. Это означает, что устанавливаем внутри этого контейнера значения
uid и gid равными
0, в те значения uid и
gid пользователя, который запускает этот процесс.
Имеется один занимательный момент, который я бы хотел затронуть в контексте пространств имён пользователя. Нам нет необходимости быть пользователем root в своём хосте для создания пространств имён пользователя. Это предоставляет некий способ создания пространств имён и тем самым контейнеров без того чтобы пребывать в роли root в этой машине, что означает большой выигрыш в безопасности, поскольку предоставление доступа root некому процессу может быть рискованным. Когда программа запускается от имени root, любое компрометирование этой программы способно предоставить полномочия root атакующему злоумышленнику. И в свою очередь, становится скомпрометированной вся машина.
Технически мы можем выступать не root в своём хосте и затем создавать пространство имён пользователя и прочие пространства имён внутри такого пространства имён. Имейте в виду, что для всех прочих пространств имён, когда они запускаются без пространства имён пользователя, потребуется доступ с правами root.
Если мы возьмём свой предыдущий пример, когда мы передаём все свои флаги совместно, наша система сначала создаст некое пространство имён пользователя и поместит все прочие пространства имён внутри этого пространства имён пользователя.
Я не могу здесь целиком осветить тему пространства имён пользователя, но это занятная область для любознательных читателей. Одной из областей, которую я могу сразу упомянуть, это область сборок Docker, внутри которой нам требуется доступ с правами root для построения некого образа внутри контейнера. Это требуется по целому ряду причин, ибо нам требуется несколько многоуровневых файловых систем, причём смонтированными внутри своего контейнера, а для создания нового монтирования требуются привилегии root.
То же самое относится и к установке виртуальных сетевых устройств, например, пары veth
для подключения контейнеров к своему хосту. Сказав это, стоит отметить наличие продвижения в области контейнеров без root,
которые делают возможным для разработчиков запуск контейнеров без root. Если вы желаете прочитать подробности об
этом, вы можете изучить данную тему по следующим ссылкам:https://rootlesscontaine.rs/ и https://github.com/rootless-containers.
Чего мы достигли к данному моменту, так это возможности запускать некий процесс внутри набора пространств имён. Однако, несомненно, нам требуется больше. Нам необходим способ инициализации этих пространств имён до запуска их контейнера.
Вернёмся к созданной нами программе. Давайте соберём и запустим её:
root@osboxes:~/book_prep# ./myuts
root@osboxes:/root/book_prep# whoami
root
root@osboxes:/root/book_prep# id
uid=0(root) gid=0(root) groups=0(root)
Теперь мы видим, что пользователем внутри контейнера выступает root.
Наша программа проверяет самый первый аргумент. Когда самой первой командой выступает запуск, тогда эта программа
выполняет /proc/self/exe, что является просто запуском самой себя
(/proc/self/exe это копия того исполняемого образа, которым выступает
вызывающая сторона сама по себе).
Модно спросить зачем требуется выполнять /proc/self/exe. Когда мы выполняем
эту команду, она запускает тот же самый исполняемый файл с теми же самыми параметрами (в нашем случае мы передаём
в неё свой аргумент fork). Раз мы пребываем в разных пространствах имён, нам
необходимы некие настройки для своих пространств имён, например, значение имени хоста, прежде чем мы запустим этот
процесс внутри его контейнера.
Исполнение /proc/self/exe предоставляет нам такую возможность настройки
пространств имён подобно следующему:
-
Установит значение имени хоста.
-
Внутри пространства имён монтирования мы делаем некий основной корень, который позволит нам переключиться в эту корневую файловую систему. Это осуществляется путём копирования своего старого корня в некий иной каталог и превращая значения нового пути в новый корень. Этот опорный корень обязан изготавливаться в пределах пространства имён монтирования, ибо мы не желаем перемещать свою
rootfsпрочь из своего хоста. Мы также монтируем необходимую файловую системуproc. Это делается по причине того, что наше пространство имён монтирования наследует системуprocсвоего хоста, а мы желаем смонтироватьprocв пределах своего пространства имён монтирования. -
После того как наше пространство имён монтирования проинициализировано и настроено, мы осуществляем сам процесс контейнера (в нашем случае самого себя).
Исполнение этой программы запускает необходимую оболочку в некой песочнице, замкнутой в пространствах
имён proc, mount и
uts.
Теперь мы работаем в своём пространстве имён, проинициализированном до запуска самого процесса внутри его
контейнера. В своём следующем примере у нас будет друго имя хоста в его пространстве имён
uts. В свой приводимый дадее код мы внесём все необходимые изменения.
У нас имеется родительская функция, которая:
-
Клонирует необходимые пространства имён.
-
Запускает тот же самый процесс снова посредством
/proc/self/exeи передаёт некого потомка в качестве своего параметра.
Теперь этот процесс вызывается снова. Проверки из функции main приводят к осуществлению своей дочерней функции.
Теперь вы можете наблюдать, что мы клонировали свои пространства имён. Всё что мы делаем сейчас, так это меняем имя
хоста на myhost внутри пространства имён
uts. Выполнив это, мы запускаем необходимый исполняемый файл, переданный
в качестве параметра командной строки (в нашем случае, /bin/bash).
В своих предыдущих разделах мы объяснили как создавать различные пространства имён. В этом разделе мы поясним как входить в эти пространства имён. Вход в рамки определённого пространства имён может выполняться через запуск программы/ процесса внутри этого пространства имён. Наша следующая программа запускает программу оболочки внутри таких пространств имён.
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
func main() {
switch os.Args[1] {
case "parent":
parent()
case "child":
child()
default:
panic("help")
}
}
// эта родительская функция осуществляется из главной программы, которая устанавливает все необходимые пространства имён
func parent() {
cmd := exec.Command("/proc/self/exe",
append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Env = []string{"name=shashank"}
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWNS |
syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNET |
syscall.CLONE_NEWUSER,
UidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getuid(),
Size: 1,
},
},
GidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getgid(),
Size: 1,
},
},
}
must(cmd.Run())
}
// это дочерний процесс, который является копией своей родительской программы сам по себе.
func child () {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
//следующая команда устанавливает имя хоста в значение myhost. Основная идея состоит в демонстрации использования пространства имён UTS
must(syscall.Sethostname([]byte("myhost")))
// эта команда запускает оболочку, которая передаётся как аргумент программы
must(cmd.Run())
}
func must(err error) {
if err != nil {
fmt.Printf("Error - %s\n", err)
}
}
После выполнения этой программы мы можем запускать необходимый исполняемый файл внутри новых пространств
имён. Кроме того, обратите внимание, что имя хоста установлено в значение
myhost:
root@osboxes:~/book_prep# ./myuts parent /bin/bash
root@myhost:/root/book_prep# hostname
myhost
root@myhost:/root/book_prep#
После получения своего пространства имён uts пора пуститься во все
тяжкие. Сейчас мы проинициализируем своё пространство имён монтирований.
Здесь следует осознавать, что в пространстве имён монтирования наследуются все монтирования с самого хоста. Следовательно, нам требуется некий механизм очистки монтирований и сделать видимыми лишь монтировния для своего пространства монтирования.
Прежде чем мы двинемся далее, необходимо концептуально разобраться с системным вызовом
pivot_root. Этот системный вызов позволяет нам изменять корневую
файловую систему для своего процесса. Он монтирует свой старый корень в некий иной каталог (в нашем следующем
примере автор применяет для монтирования старого каталога каталог
pivot_root) else и монтирует
необходимый новый каталог в /. Это делает возможным для нас очистить все
монтирования своего хоста внутри своего пространства имён.
Опять же, нам требуется пребывать внутри пространства имён монтирования прежде чем мы выполним
pivot_root. Поскольку у нас уже имеется перехватчик для инициализации
пространства имён (применяя приём /proc/self/exe), нам требуется ввести
механизм опорного корня (pivot root).
Мы воспользуемся необходимым нам rootfs из busybox, которую вы можете
выгрузить с https://github.com/allthingssecurity/containerbook
(busybox.tar).
После выгрузки busybox.tar раскройте его в
/root/book_prep/rootfs в своей системе. На это местоположение ссылается
данный код как на местоположение rootfs. Как это отображено на
Рисунке 6-2,
содержимое /root/book_prep/rootfs в вашей системе должно выглядеть
таким же образом.
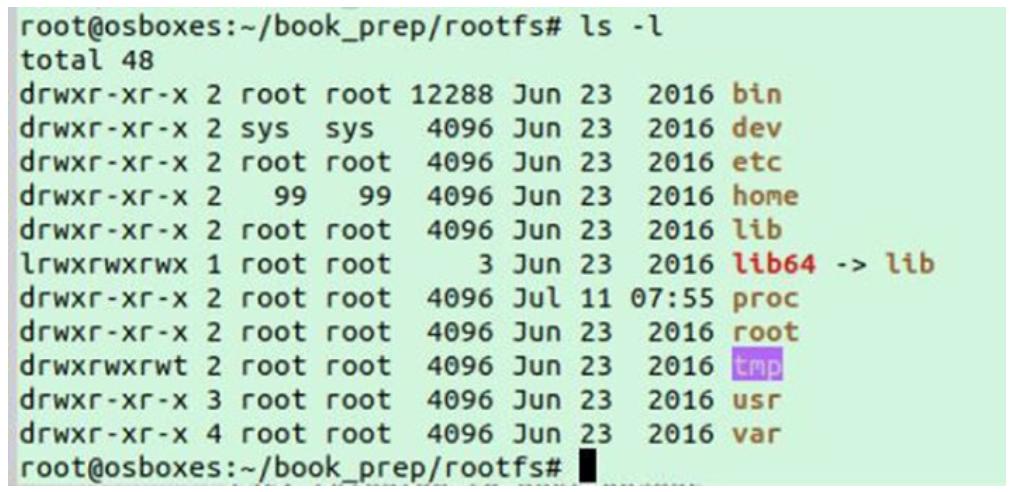
После раскрытия rootfs, мы можем наблюдать в
rootfs следующий каталог:

Приводимая ниже программа делает опорным корнем эту rootfs внутри
своего пространства имён монтирования.
Это пространство монтирования становится важным, что делает для нас возможным установить песочницу этих монтирований файловой системы. Именно это является способом получения изолированного представления необходимой файловой иерархии и наблюдения того, что присутствует в данном хосте или в различных запущенных в том же самом хосте песочниц.
В качестве примера предположим, что у нас имеются запущенными в одном и том же хосте две песочницы -
sandboxA и sandboxB. Когда
sandboxA получает свои собственные средства монтирования, её файловая
система наблюдает другое монтирование, отличающееся от того, что видит sandboxB
и ни одна из них не может отслеживать монтирования своего хоста. Это обеспечивает безопасность на уровне файловой
системы, поскольку отдельные песочницы не могут получать доступ к файлам других песочниц или из самого
хоста.
//providing rootfile system
package main
import (
"fmt"
"os"
"os/exec"
"path/filepath"
"syscall"
)
func main() {
switch os.Args[1] {
case "parent":
parent()
case "child":
child()
default:
panic("help")
}
}
func pivotRoot(newroot string) error {
putold := filepath.Join(newroot, "/.pivot_root")
//привязывает к самой себе монтирование newroot - именно это выступает небольшой уловкой, которая требуется для
//удовлетворения требования pivot_root в том, что newroot и putold не должны быть той же самой
//файловой системой что и текущий корень
if err := syscall.Mount(newroot, newroot, "", syscall.MS_BIND|syscall.MS_REC, ""); err != nil {
return err
}
// создаём каталог putold
if err := os.MkdirAll(putold, 0700); err != nil
{ return err
}
// вызываем pivot_root
if err := syscall.PivotRoot(newroot, putold); err != nil {
return err
}
// обеспечиваем установку нового текущего рабочего каталога
root if err := os.Chdir("/"); err != nil {
return err
}
//выполняем размонтирование putold, которая теперь пребывает в /.pivot_root putold = "/.pivot_root"
if err := syscall.Unmount(putold, syscall.MNT_DETACH); err !=
nil {
return err
}
// удаляем putold
if err := os.RemoveAll(putold); err != nil
{ return err
}
return nil
}
func parent() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Env = []string{"name=shashank"}
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWNS |
syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNET |
syscall.CLONE_NEWUSER,
UidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getuid(),
Size: 1,
},
},
GidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getgid(),
Size: 1,
},
},
}
must(cmd.Run())
}
func child () {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(syscall.Sethostname([]byte("myhost")))
if err := pivotRoot("/root/book_prep/rootfs"); err != nil
{ fmt.Printf("Error running pivot_root - %s\n",
err) os.Exit(1)
}
must(cmd.Run())
}
func must(err error) {
if err != nil {
fmt.Printf("Error - %s\n", err)
}
}
После выполнения этой программы:

Мы наблюдаем каталоги rootfs и видим, что имя хоста изменилось. Также
мы наблюдаем, что uid равен 0
(значение корня в контейнере).
У нас всё ещё присутствует проблема. Здесь отсутствует монтирование proc.
Для предоставления сведений относительно различных запущенных внутри этого пространства имён и в качестве
некого взаимодействия между различными процессами нам требуется монтирвоание
proc, как это пояснялось ранее в этой главе про псевдофайловые системы.
Внутри нашего пространства монтирвоания нам потребуется смонтировать файловую систему
proc.
Мы добавляем в свою программу новую функцию mountProc:
package main
import (
"fmt"
"os"
"os/exec"
"path/filepath"
"syscall"
)
func main() {
switch os.Args[1] {
case "parent":
parent()
case "child":
child()
default:
panic("help")
}
}
func pivotRoot(newroot string) error {
putold := filepath.Join(newroot, "/.pivot_root")
//привязывает к самой себе монтирование newroot - именно это выступает небольшой уловкой, которая требуется для
//удовлетворения требования pivot_root в том, что newroot и putold не должны быть той же самой
//файловой системой что и текущий корень
if err := syscall.Mount(newroot, newroot, "", syscall.MS_BIND|syscall.MS_REC, ""); err != nil {
return err
}
// создаём каталог putold
if err := os.MkdirAll(putold, 0700); err != nil {
return err
}
// вызываем pivot_root
if err := syscall.PivotRoot(newroot, putold); err != nil {
return err
}
// обеспечиваем установку нового текущего рабочего каталога
if err := os.Chdir("/"); err != nil {
return err
}
// выполняем размонтирование putold, которая теперь пребывает в /.pivot_root putold = "/.pivot_root"
if err := syscall.Unmount(putold, syscall.MNT_DETACH); err !=
nil {
return err
}
// удаляем putold
if err := os.RemoveAll(putold); err != nil
{ return err
}
return nil
}
func parent() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Env = []string{"name=shashank"}
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWNS |
syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNET |
syscall.CLONE_NEWUSER,
UidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getuid(),
Size: 1,
},
},
GidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getgid(),
Size: 1,
},
},
}
must(cmd.Run())
}
func child () {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
//выполняем вызов функции mountProc function которая смонтирует файловую систему proc в уже
//созданном пространстве имён монтирования
must(mountProc("/root/book_prep/rootfs"))
must(syscall.Sethostname([]byte("myhost")))
if err := pivotRoot("/root/book_prep/rootfs"); err != nil
{ fmt.Printf("Error running pivot_root - %s\n",
err) os.Exit(1)
}
must(cmd.Run())
}
func must(err error) {
if err != nil {
fmt.Printf("Error - %s\n", err)
}
}
// эта функция монтирует файловую систему proc внутри
// нового пространства имён монтирований
func mountProc(newroot string) error {
source := "proc"
target := filepath.Join(newroot, "/proc")
fstype := "proc"
flags := 0
data := ""
//выполняем системный вызов Mount для монтирования файловой системы proc внутри необходимого пространств имён монтирования
os.MkdirAll(target, 0755)
if err := syscall.Mount(
source,
target,
fstype,
uintptr(flags),
data,
); err != nil {
return err
}
return nil
}
Теперь когда мы выполняем ps внутри своего контейнера чтобы получить
список взех запущенных в нашей песочнице процессов, мы получим показанный здесь ниже вывод. Основной причиной
этого является то, что ps пользуется файловой системой
/proc.
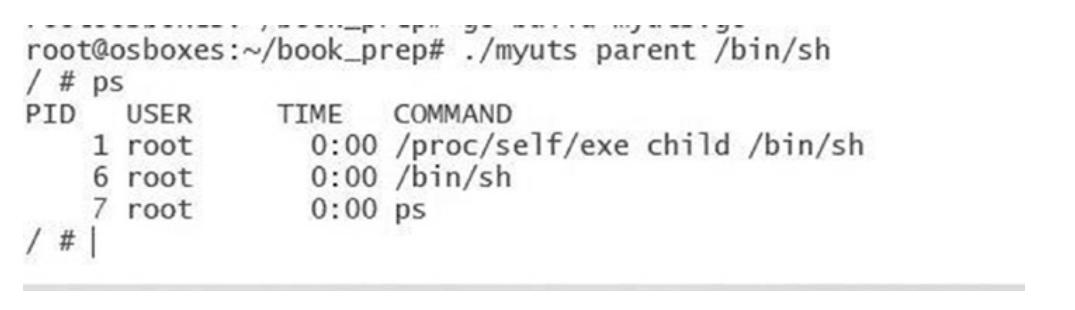
Мы можем воспользоваться другой командой nsenter для входа в созданное
пространство имён контейнера. Чтобы испробывать это, давайте создадим контейнер пребывающим в запущенном
состоянии и откроем другой терминал Linux. Затем выполните следующую команду:
ps -ef | grep /bin/sh
Вы должны обнаружить отражённый здесь вывод. В моём случае PID моего контейнера равен
5387. Пользователям следует применять PID их машин.
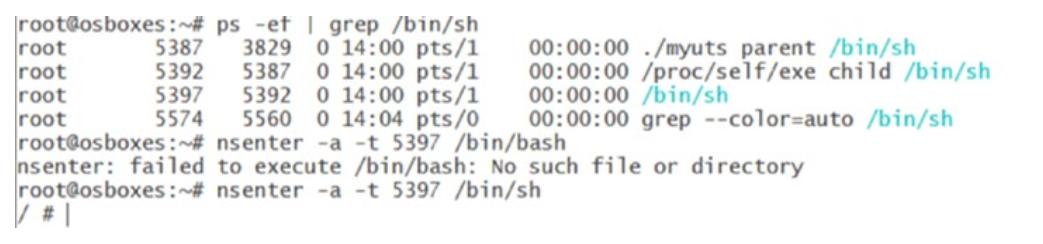
Выполнение nsenter -a -t 5387 /bin/sh делает возможным создание
этой оболочки внутри соответствующих пространств имён с PID 5387,
как это и отображено.
В предыдущих разделах мы создали контейнер с uts, PID и пространствами
имён монтирования. Мы не добавили необходимое сетевое пространство имён. В этом разделе мы обсудим как
настраивать сетевые пространства имён для своих контейнеров.
Прежде чем мы окунёмся в тему сетевых ресурсов, я предоставлю небольшое пособие для начинающих по виртуальным устройствам в Linux, который существенен для понимания сетевых сред на основе контейнеров или, раз уж на то пошло, любых виртуальных сетей.
В неком виртуальном мире имеется потребность отправки пакетов по виртуальным машинам в их реальные физические
устройства, между виртуальными машинами, либо между различными контейнерами. Таким образом, нам требуется некий
механизм применения виртуальных устройств. Linux предоставляет механизм создания виртуальных сетевых устройств,
именуемых tun и tap. Устройства
tun действуют на 3 уровне сетевого стека, что означает что они получают
необходимые пакеты IP. Устройства tap действуют на уровне, где они
получают сырые пакеты Ethernet.
Теперь может возникнуть вопрос: для чего используются эти устройства? Рассмотрим сценарий, при котором
containerA требуется отправить исходящие пакеты в другой контейнер. Все пакеты из одного
пакета передаются в машину своего хоста, который интеллектуально применяет устройство
tap для передачи этих пакетов в некий программный мост. Этот мост затем может
соединяться с другим контейнером.
Давайте на простом примере рассмотрим как работает это устройство tap.
Здесь я создаю два устройства tap, с названиями
mytap1 и mytap2:

Выдав перечень устройств tap, мы можем обнаружить что имеется два
сетевых интерфейса:
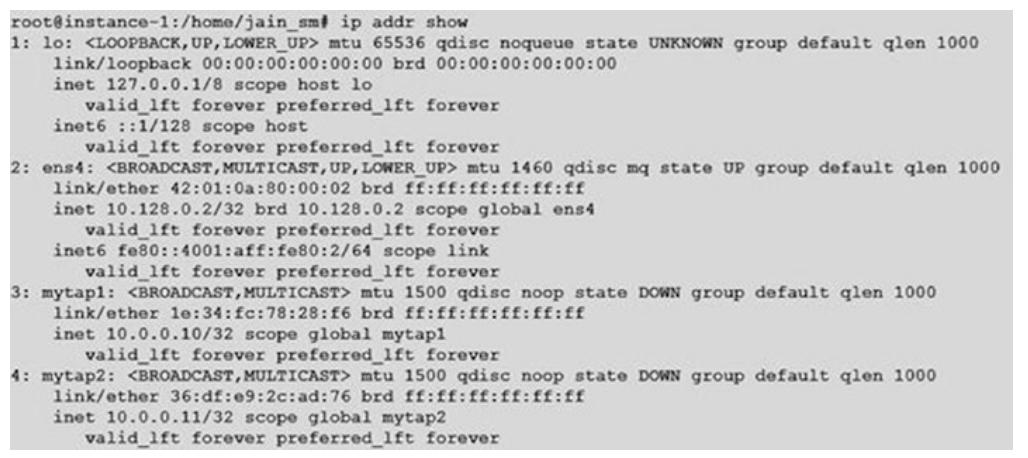
Мы выделяем IP адреса этим устройствам:
Запуск простого ping из одного устройства имеет результатом следующее:
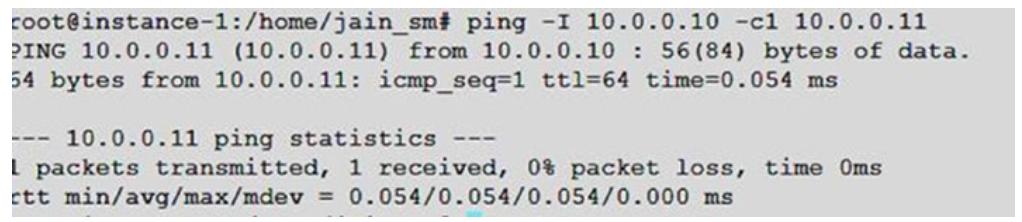
В этих примерах мы в явном виде создали два устройства tap и
выполнили попытку ping между ними двумя.
Мы также можем пользоваться парами veth, которые могут выступать чем- то навроде виртуальных кабелей,
которые соединяют виртуальные устройства. Они применяются в openstack
для соединения программных мостов.
Прежде всего создадим пару veth следующим образом:
Это создаст пару устройств tap с названиями
firsttap и secondtap.
Теперь мы добавим ip адреса в эти устройства tap и
запустим ping:

Вооружившись базовым пониманием устройств tun и
tap, давайте перейдём к тому как наша работать наша настройка сетевой
среды между создаваемым для контейнера сетевым пространством имён и соответствующим пространством имён хоста.
Для данного процесса мы следуем таким этапам:
-
Создаём в своём хосте мост.
-
Создаём пару veth.
-
Один конец veth обязан быть подключён к имеющемуся мосту.
-
Другой конец из этого моста должен соединяться с соответствующим сетевым интерфейсом в пространстве имён своего контейнера.
Эти этапы проиллюстрированы на Рисунке 6-13
Рисунок 6-13
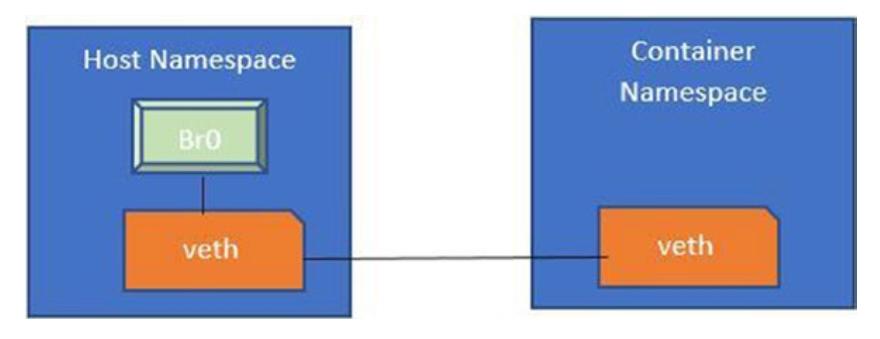
Построение сетевой среды между пространством имён контейнера и пространством имён его хоста
Теперь мы изменим свой код чтобы включить необходимое нам сетевое пространство имён:
package main
import (
"fmt"
"os"
"os/exec"
"path/filepath"
"syscall"
"time"
"net"
)
func main() {
switch os.Args[1] {
case "parent":
parent()
case "child":
child()
default:
panic("help")
}
}
func waitForNetwork() error {
maxWait := time.Second * 3
checkInterval := time.Second
timeStarted := time.Now()
for {
interfaces, err := net.Interfaces()
if err != nil {
return err
}
// довольно простая проверка ...
// > 1 в качестве уже имеющегося устройства lo
exist if len(interfaces) > 1 {
return nil
}
if time.Since(timeStarted) > maxWait {
return fmt.Errorf("Timeout after %s waiting for network", maxWait)
}
time.Sleep(checkInterval)
}
}
//Эта функция делает возможным монтирование файловой системы proc
func mountProc(newroot string) error {
source := "proc"
target := filepath.Join(newroot, "/proc")
fstype := "proc"
flags := 0
data := ""
os.MkdirAll(target, 0755)
if err := syscall.Mount(
source,
target,
fstype,
uintptr(flags),
data,
); err != nil {
return err
}
return nil
}
// Эта функция позволяет сделать опорной данную корневую файловую систему. Это делает для нас возможным
// обладать корневой файловой системой, доступной в нашей песочнице
func pivotRoot(newroot string) error {
putold := filepath.Join(newroot, "/.pivot_root")
//привязывает к самой себе монтирование newroot - именно это выступает небольшой уловкой, которая требуется для
//удовлетворения требования pivot_root в том, что newroot и putold не должны быть той же самой
//файловой системой что и текущий корень
if err := syscall.Mount(newroot, newroot, "", syscall.MS_BIND|syscall.MS_REC, ""); err != nil {
return err
}
// создаём каталог putold
if err := os.MkdirAll(putold, 0700); err != nil {
return err
}
// вызывпем pivot_root
if err := syscall.PivotRoot(newroot, putold); err != nil {
return err
}
// обеспечиваем установку нового текущего рабочего каталога
root if err := os.Chdir("/"); err != nil {
return err
}
// выполняем размонтирование putold, которая теперь пребывает в /.pivot_root putold = "/.pivot_root"
if err := syscall.Unmount(putold, syscall.MNT_DETACH); err != nil {
return err
}
// удаляем putold
if err := os.RemoveAll(putold); err != nil {
return err
}
return nil
}
func parent() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Env = []string{"name=shashank"}
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWNS |
syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNET |
syscall.CLONE_NEWUSER,
UidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getuid(),
Size: 1,
},
},
GidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getgid(),
Size: 1,
},
},
}
must(cmd.Start())
pid := fmt.Sprintf("%d", cmd.Process.Pid)
// Идущий далее код делает следующее:
// Создаёт в своём хосте необходимый мост
// Создаёт нужную нам пару veth
// Подключает один конец veth к мосту
// Другой конец подсоединяет к необходимому сетевому пространству имён. Именно это представляет интерес
// поскольку теперь мы обладаем доступом к стороне своего хостаи к необходимой стороне сетевой среды пока
// мы не блокированы.
netsetgoCmd := exec.Command("/usr/local/bin/netsetgo", "-pid", pid)
if err := netsetgoCmd.Run(); err != nil {
fmt.Printf("Error running netsetgo - %s\n", err)
os.Exit(1)
}
if err := cmd.Wait(); err != nil {
fmt.Printf("Error waiting for reexec.Command - %s\n", err)
os.Exit(1)
}
}
func child () {
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(mountProc("/root/book_prep/rootfs"))
//must(syscall.Mount("proc", "proc", "proc", 0, ""))
must(syscall.Sethostname([]byte("myhost")))
if err := pivotRoot("/root/book_prep/rootfs"); err != nil {
fmt.Printf("Error running pivot_root - %s\n", err)
os.Exit(1)
}
//must(syscall.Mount("proc", "proc", "proc", 0, ""))
if err := waitForNetwork(); err != nil {
fmt.Printf("Error waiting for network - %s\n", err)
os.Exit(1)
}
if err := cmd.Run(); err != nil {
fmt.Printf("Error starting the reexec.Command - %s\n", err)
os.Exit(1)
}
//must(cmd.Run())
}
func must(err error) {
if err != nil {
fmt.Printf("Error - %s\n", err)
}
}
Имеется пара моментов, которые будет не лишним рассмотреть здесь. В более раннем примере кода мы инициализировали
пространства имён (как и изменение имени своего хоста и опорный корень) в своём дочернем методе. Затем мы запускали
необходимую оболочку (/bin/sh) внутри этих пространств имён.
Этот механизм работал, потому как нам просто требовалось проинициализировть эти пространства имён и это осуществлялось внутри самих пространств имён. Когда дело доходит до нужных нам сетевых пространств имён, нам требуется позаботиться об определённых действиях, таких как:
-
Создании моста в своём хосте.
-
Создании пары veth и выполнения подключения одного конца к созданному мосту, и помещения другого конца вовнутрь необходимого пространства имён.
Основная задача в текущем подходе состоит в том, что когда мы запустим свою оболочку, мы останемся в её пространстве имён до тех пор, пока мы намеренно не покинем её. так, нам необходим способ вернуть свой код непосредственно в API с тем, чтобы мы были способны выполнить сетевую настройку в своём хосте и выполнить соединение своей пары veth.
К счастью, наша команда cmd.Run
может быть разбита на две части.
-
Cmd.Start()выполняет непосредственный возврат. -
Cmd.Wait()выполняет блокирование вплоть до выхода их оболочки.
Мы применяем это в своих целях в своём методе parent. Мы запускаем метод
Cmd.Start(), который выполняет немедленный возврат.
После этого метода start мы пользуемся библиотекой
netsetgo, созданной Эдом Кигом из Pivotal. Она выполняет следующее.
-
Создаёт в нашем хосте необходимый мост.
-
Создаёт нужную нам пару veth/
-
Подключает ожин конец созданного veth к имеющемуся мосту.
-
Другой её конец присоединяет к необходимому сетевому пространству имён. Это занимательно, ибо мы теперь обладаем доступом к стороне своего хоста и сетевой среде пока мы его не заблокируем.
Для выгрузки и установки netsetgo следуйте приводимым инструкциям:
wget "https://github.com/teddyking/netsetgo/releases/download/0.0.1/netsetgo"
sudo mv netsetgo /usr/local/bin/
sudo chown root:root /usr/local/bin/netsetgo
sudo chmod 4755 /usr/local/bin/netsetgo
На самом деле, многие из данных пояснений взяты из его примеров.
Здесь отображён соответствующий фрагмент кода:
must(cmd.Start())
pid := fmt.Sprintf("%d", cmd.Process.Pid)
netsetgoCmd := exec.Command("/usr/local/bin/netsetgo", "-pid", pid)
if err := netsetgoCmd.Run(); err != nil {
fmt.Printf("Error running netsetgo - %s\n", err)
os.Exit(1)
}
if err := cmd.Wait(); err != nil {
fmt.Printf("Error waiting for reexec.Command - %s\n", err)
os.Exit(1)
}
Когда это выполнено, мы применяем cmd.Wait(), который повторно запускает
нашу программу (/proc/self/exe). Затем мы выполняем свой дочерний процесс и следуем
далее со всеми прочими инициализациями. После этих инициализаций мы способны запустить необходимую оболочку внутри
установленных пространств имён.
Затем нам необходимо проверить сетевое взаимодействие от своего хоста к созданному контейнеру и от этого контейнера к его хосту. Прежде всего запустим эту программу:
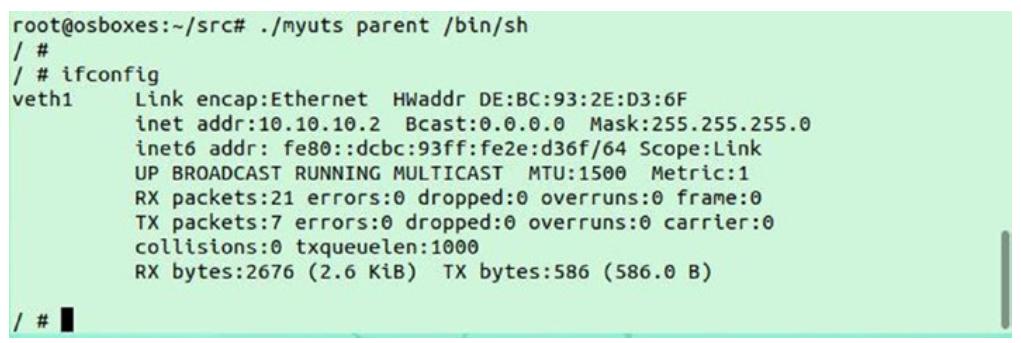
/myuts parent /bin/sh
Внутри запущенной оболочки выполните команду ifconfig. В должны обнаружить значение
IP адреса контейнера, как это отражено далее:
Оставьте этот контейнер запущенным и откройте другой терминал (оболочку bash) в своём хосте. Выполните следующую команду, которая осуществляет ping к IP нашего контейнера:
ping 10.10.10.2
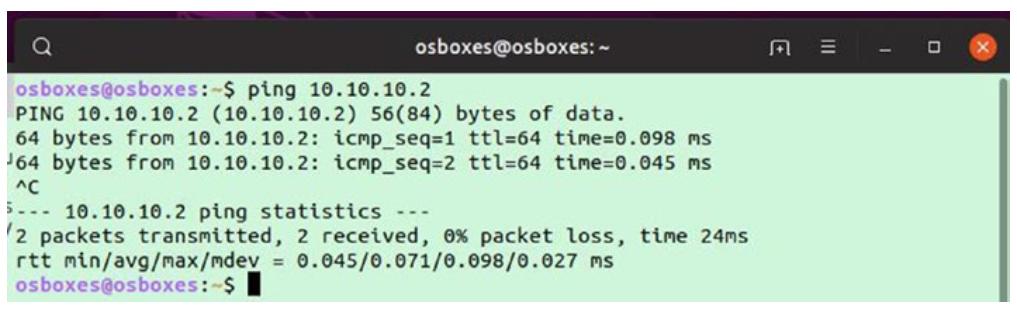
Заметьте, что теперь мы имеем возможность выполнения ping к IP адресу своего контейнера из его хоста.
Теперь мы попытаемся выполнить ping к IP адресу своего хоста из нашего контейнера. Прежде всего, заполучим IP адрес своего
хоста выполнив командуifconfig. Как вы можете здесь обнаружить, IP адресом моего хоста
является 10.0.2.15:
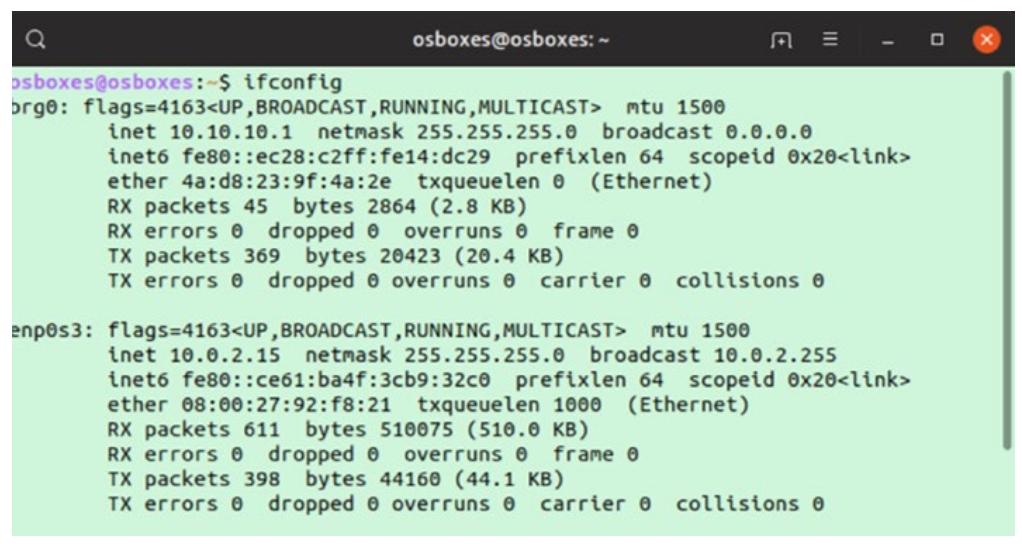
Теперь выполним ping этого IP хоста из своего контейнера:
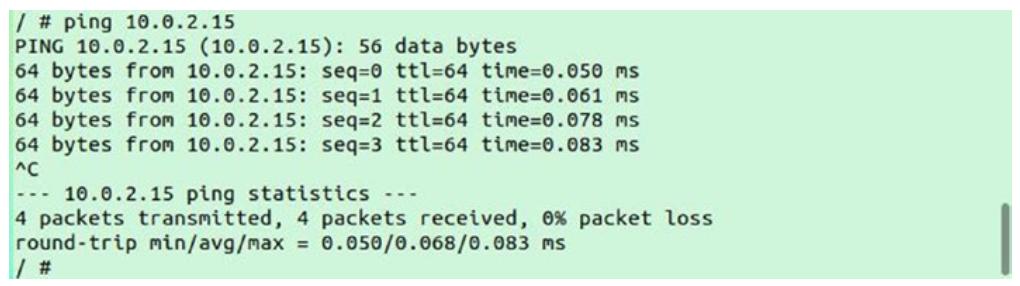
Как вы можете наблюдать, у нас имеется возможность выполнения ping из своего контейнера к его хосту, а также от самого хоста к этому контейнеру, поэтому взамиодействие работает в обоих направлениях.
Давайте резюмируем чего мы достигли к данному моменту:
-
при помощи
unshareмы создали контейнер и продемонстрировали его способность изменять имя своего хоста внутри пространства имёнuts. -
При помощи Golang мы создали некий контейнер с такими пространствами имён как UTS и пространство имён пользователя.UTS.
-
Мы добавили пространство имён монтирования и продемонстрировали как внутри этого пространства имён может быть смонтирована обособленная файловая система
proc. -
В соответствующее пространство имён мы добавили сетевые возможности, которые сделали для нас возможным взаимодействие между пространствами имён созданного контейнера и пространства имён его хоста.
Ранее мы смонтировали в /root/mygrp некую cgroup. Внутри неё мы создали дочерний каталог.
Теперь мы поместим свой процесс вовнутрь этой cgroup и ограничим его максимальную память.
Вот образец нашего фрагмента кода:
func enableCgroup() {
cgroups := "/root/mygrp"
pids := filepath.Join(cgroups, "child")
must(ioutil.WriteFile(filepath.Join(pids, "memory.max"), []byte("2M"), 0700))
must(ioutil.WriteFile(filepath.Join(pids, "cgroup.procs"), []byte(strconv.Itoa(os.Getpid())), 0700))
}
В этом фрагменте кода мы добавили значение PID того процесса, который мы создали внутри своего контейнера
(/bin/sh) в файл cgroup.procs и нахлобучили
максимальное значение памяти для него в 2 МБ.
Прежде чем мы выполним этот код, вам потребуется внести одно изменение в настройки своей ОС. Откройте файл
/etc/default/grub при помощи Nano или предпочитаемого вами редактора:
nano /etc/default/grub
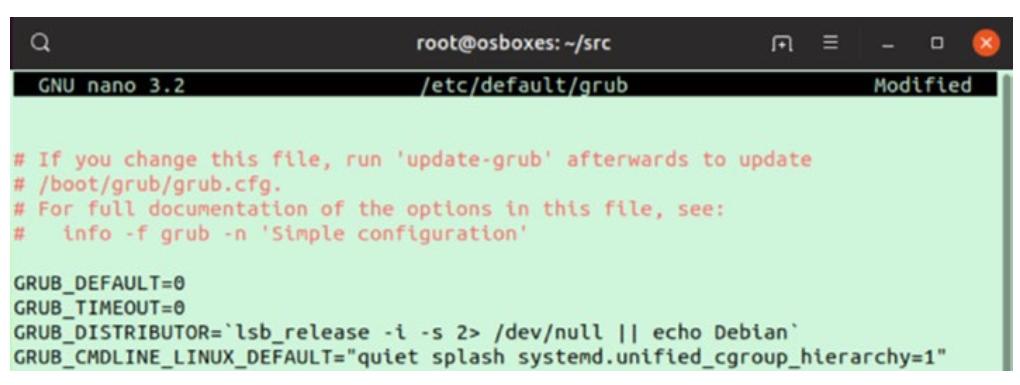
В этом файле вам придётся изменить значение ключа GRUB_CMDLINE_LINUX_DEFAULT, добавив
systemd.unified_cgroup_hierarchy=1. Для ясности отсылаем к следующему изображению.
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash systemd.unified_cgroup_hierarchy=1"
После этого обновления запустите следующую команду и перезагрузите свою систему:
sudo update-grub
После выполнения перезагрузки выполните такую команду:
cat /proc/cmdline

В /proc/cmdline вы должны наблюдать
systemd.unified_cgroup_hierarchy=1 равным
BOOT_IMAGE.
Для создания cgroup выполните в своём терминале следующую команду. Применяйте ту же папку, которую мы использовали в этой программе.
mkdir -p /root/mygrp
mount -t cgroup2 none /root/mygrp
mkdir -p /root/mygrp/child
Теперь вы можете выполнить эту программу:
package main
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path/filepath"
"strconv"
"syscall"
"time"
"net"
)
func main() {
switch os.Args[1] {
case "parent":
parent()
case "child":
child()
default:
panic("help")
}
}
func enableCgroup() {
cgroups := "/root/mygrp"
pids := filepath.Join(cgroups, "child")
must(ioutil.WriteFile(filepath.Join(pids, "memory.max"), []byte("2M"), 0700))
must(ioutil.WriteFile(filepath.Join(pids, "cgroup.procs"), []byte(strconv.Itoa(os.Getpid())), 0700))
}
func waitForNetwork() error {
maxWait := time.Second * 3
checkInterval := time.Second
timeStarted := time.Now()
for {
interfaces, err := net.Interfaces()
if err != nil {
return err
}
// довольно простая проверка ...
// > 1 в качестве уже имеющегося устройства lo
if len(interfaces) > 1 {
return nil
}
if time.Since(timeStarted) > maxWait {
return fmt.Errorf("Timeout after %s waiting
for network", maxWait)
}
time.Sleep(checkInterval)
}
}
func mountProc(newroot string) error {
source := "proc"
target := filepath.Join(newroot, "/proc")
fstype := "proc"
flags := 0
data := ""
os.MkdirAll(target, 0755)
if err := syscall.Mount(
source,
target,
fstype,
uintptr(flags),
data,
); err != nil {
return err
}
return nil
}
func pivotRoot(newroot string) error {
putold := filepath.Join(newroot, "/.pivot_root")
//привязывает к самой себе монтирование newroot - именно это выступает небольшой уловкой, которая требуется для
//удовлетворения требования pivot_root в том, что newroot и putold не должны быть той же самой
//файловой системой что и текущий корень if err := syscall.Mount(newroot, newroot, "", syscall.MS_BIND|syscall.MS_REC, ""); err != nil {
return err
}
// создаём каталог putold
if err := os.MkdirAll(putold, 0700); err != nil
{ return err
}
// вызывпем pivot_root
if err := syscall.PivotRoot(newroot, putold); err != nil
{ return err
}
// обеспечиваем установку нового текущего рабочего каталога
root if err := os.Chdir("/"); err != nil {
return err
}
// выполняем размонтирование putold, которая теперь пребывает в /.pivot_root putold = "/.pivot_root"
if err := syscall.Unmount(putold, syscall.MNT_DETACH); err != nil {
return err
}
// удаляем putold
if err := os.RemoveAll(putold); err != nil {
return err
}
return nil
}
func parent() {
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Env = []string{"name=shashank"}
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWNS |
syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNET |
syscall.CLONE_NEWUSER,
UidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getuid(),
Size: 1,
},
},
GidMappings: []syscall.SysProcIDMap{
{
ContainerID: 0,
HostID: os.Getgid(),
Size: 1,
},
},
}
must(cmd.Start())
pid := fmt.Sprintf("%d", cmd.Process.Pid)
netsetgoCmd := exec.Command("/usr/local/bin/netsetgo", "-pid", pid) if err := netsetgoCmd.Run(); err != nil {
fmt.Printf("Error running netsetgo - %s\n", err)
os.Exit(1)
}
if err := cmd.Wait(); err != nil {
fmt.Printf("Error waiting for reexec.Command - %s\n", err)
os.Exit(1)
}
}
Func child () {
//включаем функциональность cgroup
enableCgroup()
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(mountProc("/root/book_prep/rootfs"))
//must(syscall.Mount("proc", "proc", "proc", 0, ""))
must(syscall.Sethostname([]byte("myhost")))
if err := pivotRoot("/root/book_prep/rootfs"); err != nil
{ fmt.Printf("Error running pivot_root - %s\n",
err) os.Exit(1)
}
//must(syscall.Mount("proc", "proc", "proc", 0, ""))
if err := waitForNetwork(); err != nil {
fmt.Printf("Error waiting for network - %s\n", err)
os.Exit(1)
}
if err := cmd.Run(); err != nil {
fmt.Printf("Error starting the reexec.Command - %s\n", err)
os.Exit(1)
}
//must(cmd.Run())
}
func must(err error) {
if err != nil {
fmt.Printf("Error - %s\n", err)
}
}
Рисунок 6-20
показывает значение PID процесса, добавленного в нашу cgruop и то значение, которое сохранено в файле memory.max,
которые мы и определили в своей программе.
Рисунок 6-20
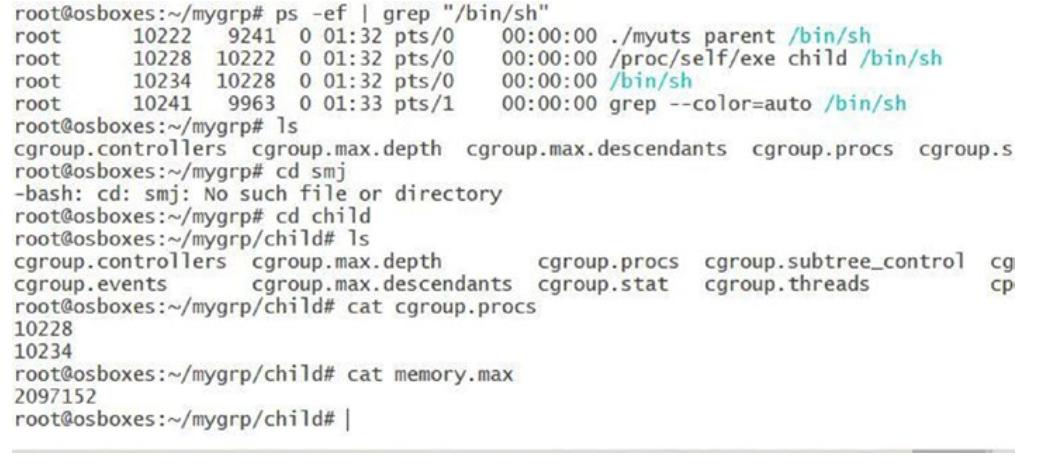
Добавленное в соответствующую cgroup значение PID процесса и то значение, которое сохранено в файле memory.max
В этой книге мы рассмотрели основы виртуализации. Мы погрузились в то как работает виртуализация и базовые методы связанные с ней. Мы рассмотрели различные сценарии протекания пакетов и как происходит взаимодействие от ВМ в сторону гипервизора.
Эта книга рассмотрела специфику контейнеров Linux (пространства имён, cgroup и единую файловую систему), а также как реализубтся контейнеры внутри ядра Linux. Мы предприняли попытку написать контейнер Linux и увидели как при помощи некого простого программирования мы способны создать простую среду исполнения контейнера подобную Docker.
Рекомендуется просмотреть все упражнения и попробовать разные сочетания кода. К примеру, вы можете предпринять следующее:
-
Попробовать новую
rootfsвместо busybox. -
Испытать взаимодействие контейнера с контейнером.
-
Поиграться с дополнительным контролем ресурсов.
-
Запустить HTTP сервер внутри одного контейнера и некого клиента HTTP внутри другого контейнера и установить взаимодействие поверх HTTP.
Теперь у вас должно иметься хорошее представление о том, что происходит под капотом внутри контейнера. Следовательно, когда вы применяете различные оркестраторы, такие как Kubernetes или Swarm, вам будет проще понимать что происходит на самом деле.