Дополнение A. Zonefs
Содержание
- Дополнение A. Zonefs
- Что представляют собой Зонированные хранилища и Инициатива Зонированных хранилищ?
- Файловая система Zonefs стартовала в Linux® 5.6
- ZoneFS - Файловая система зон для Зонированных блочных устройств
- Инструменты Пространства пользователя Zonefs
{Прим. пер.: перевод WesternDigital blog What is Zoned Storage and the Zoned Storage Initiative? Джорджа Кампелло Де Суза, 14 июня 2019.}
Ранее на этой недели мы анонсировали Инициативу Зонированного хранилища, некого почина, сосредоточенного на инфраструктуре данных , более конкретно, на инфраструктуре открытых данных, разработанной для извлечения преимуществ из Устройств Зонированного хранения (ZSD, Zoned Storage Devices).
Зонированные хранилища это новый экземпляр в хранилищах, мотивированный невероятным взрывом данных. Наше движимое данными сообщество всё возрастающим образом зависит от сведений для повседневной жизни, а управление данными в экстремальноых масштабах превращается в необходимость. Уже сегодня инфраструктуры данных большого масштаба применяют десятки тысяч жёстких шпиндельных и твердотельных дисков. Компании сверхкрупного размера имеют потребность тщательного управления ими с глобальной точки зрения и при этом действенным в отношении стоимости способом. Технологии Зонированных блочных устройств были представлены с целью нашего продвижения к эффективному управлению данными в развёртываниях инфраструктур крупного масштаба.
В данном блоге я пройдусь по:
-
Что представляют собой Устройства Зонированного хранения и зачем следует приспосабливаться к этим технологиям.
-
Жёсткие диски SMR и Зонированные пространства имён твердотельных устройств.
-
Инфраструктура данных - что они получают от приспособления к Зональным хранилищам.
-
Инициатива Зонированных хранилищ.
В своей сердцевине, Устройства Зонированного хранения (ZSD, Zoned Storage Devices) это устройства блочного хранения, которые обладают своими адресными пространствами, поделёнными на зоны. ZSD накладывают нетрадиционные правила записи: записи в зоны могут выполняться только последовательно и начинаться с самого начала конкретной зоны. Кроме того, сведения в рамках зоны не могут перезаписываться произвольным образом.

Единственный способ перезаписи уже записанной зоны состоит в сбросе указателя записи зоны (zone write pointer), действенно удаляющего все имеющиеся сведения в этой Зоне и перезапускающего запись с самого начала данной зоны. Считывание данных же, с другой стороны, по большей части не ограничено и имеющиеся данные могут считываться тем же самым образом, что и с обычных устройств хранения.
Понятия Устройств Зонированного хранения стандартизированы для таких устройств хранения как:
-
ZBC: Блочные зонные команды (Zoned Block Commands) в T10/SAS
-
ZAC: Набор команд Зонированных устройств ATA (Zoned Device ATA Command Set) в T13/SATA
-
ZNS: Зонированные пространства имён в NVMe (Zoned Namespaces in NVMe™) - Техническое предложение в разработке
Основным мотивом для технологии Зонированных блочных устройств выступает эффективность инфраструктуры данных крупного масштаба. Благодаря данной технологии устройства большей ёмкости могут использоваться более действенным в отношении стоимости способом, который делает возможным эффективное управление производительностью по всей системе.
Вариант SMR
На протяжении нескольких последних лет с целью возрастающей плотности в области и большей ёмкости, а также экономической эффективности в отношении жёстких шпиндельных дисках (HDD), в них была введена технология драночной (черепичной) магнитной записи (SMR, Shingled Magnetic Recording). Это делает возможной более плотную упаковку дорожек, а следовательно достигает более высокую плотность записи.
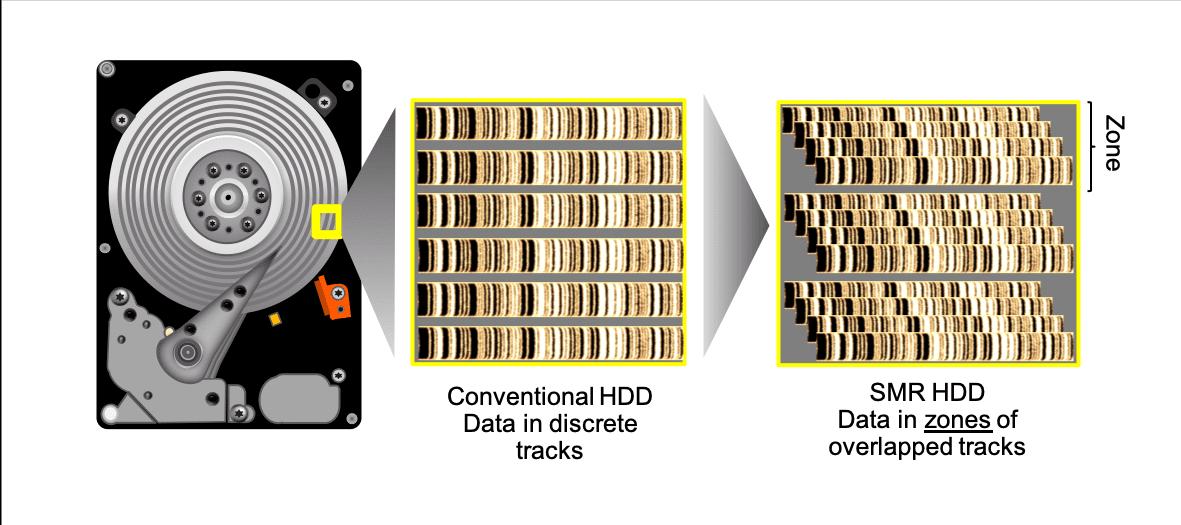
Однако, раз дорожки обладают записью внахлёст, они не имеют возможности независимой записи. Для управления необходимой записью имеющаяся поверхность диска делится на Зоны с неим оставляемым между Зонами зазором. Это делает возможным независимые запись и удаление в каждой из Зон. Установившийся традиционный подход предполагает что устройства внутренним образом обрабатывают имеющиеся ограничения на запись, а в свой хост выставляют некое обобщённое взаимодействие. Тем не менее, в системах крупного масштаба, в которых необходимо тщательно управлять производительностью и использованием пространства, локальное управление на стороне устройства обладает недостатками. Управление имеющейся сложностью со стороны хоста является практически обязательным требованием для большинства систем хранения и выступает наилучшим выбором для центров обработки данных сверхкрупного масштаба.
Для SAS и SATA, соответственно, Host Managed SMR (управляемые хостом SMR) стандартизованы в INCITS T10/T13 в качестве Зонированных блочных команд (ZBC, Zoned Block Commands), а Набор команд Зонированныйх устройств ATA (ZAC, Zoned Device ATA Command Set).
NVMe и Зонированные пространства имён в Твердотельных устройствах
С другой стороны для Твердотельных устройств (SSD, Solid-State Drives) ограничение на присутствие областей, которые обладают способностью исключительно последовательной записи и требуют удаления перед тем как будут способны записать у себя новые данные это врождённое свойство того как именно работают флеш хранилища.
Когда SSD представлялись изначально, они реализовывали некую внутреннюю систему управления, которая имела название FTL (Flash Translation Layer, уровня трансляции сброса), которому и надлежало управлять этим ограничением на запись. Такой FTL делал возможным применение SSD вместо HDD без какой либо потребности в немедленном переписывании имеющегося стека программного обеспечения хранения. Тем не менее, локальное упралвение внутри соответствующего SSD создаёт некую неэффективность внутри самого SSD. В частности это:
-
Рост времени записи: Для управления ограничением на перезапись данных соответствующее SSD обязано внутренним образом перемещать внутри себя данные для возвращения себе неиспользуемых местоположений данных, что носит название Сборки мусора (GC, Garbage Collection). Такой процесс сборки мусора вызывает множество записей одних и тех же данных (отсюда и термин Роста времени записи - Write Amplification), создающего дополнительный износ для Флеш- носитля и снижающего время службы своего SSD.
-
Сверхзапасы (Over-Provisioning): Для повсеместного перемещения данных под сборку мусора и для увеличения его действенности приходится резервировать дополнительное пространство (в некоторых случаях это достигает 28%).
-
Высокие требования к оперативной памяти: Для сопровождения соответствия логической адресации физической в самом устройстве требуется большой объём оперативной памяти. Обратите внимание на то, что объём оперативной памяти растёт по мере роста размера самого устройства.
-
Изменчивость QoS, обусловленная ударом со стороны сборки мусора в любой момент при отсутствии контроля в явном виде со стороны программного обеспечения самого хоста.
Такая неудача с эффективностью при представлении первых SSD была принята по той причине, что имеющиеся стеки SSD и их взаимодействие разрабатывались под шпиндельные диски, а их времена отклика были намного выше. Повышение производительности выступало достойным компромиссом.
Однако со временем, наша отрасль продвинулась к созданию более действенных интерфейсов и стеков программного обеспечения, которые способны получать преимущества от внутренне присущих низких задержек и более высоких полос пропускания Флеш- памяти. В частности, была создана спецификация NVMe (Non-Volatile Memory Express) и были разработаны соответствующие стеки программного обеспечения с более низкими накладными расходами.
Современное состояние отрасли в наши дни состоит в том, что та локальная оптимизация, которая участвует в FTL SSD теперь превращается в причиняющую ущерб при развёртывании инфраструктур данных крупного масштаба; в частности, многие потребители выразили пожелание включение выравнивания управления последовательными рабочими потоками в соответствии с удалениями блоков Флеш- памяти. В ответ на это организация NVMe выполняет стандартизацию ZNS (Zoned Namespaces, Зонированных пространств имён), которые посзволят самому хосту направлять ввод/ вывод в обособленные рабочие потоки и улучшать латентность, пропускную способность и экономическую эффективность перемещая весь пакет управления в сам хост.
Рисунок A-3
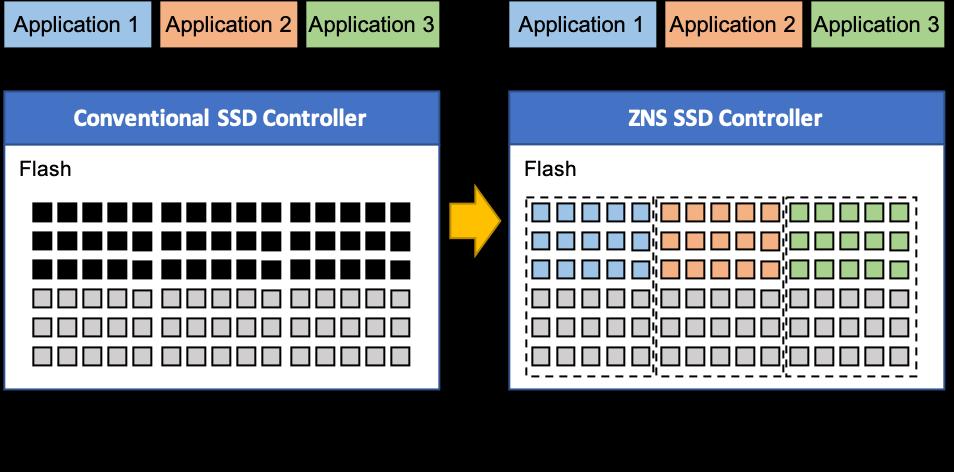
Слева, обычное SSD: Устройство управляет размещением данных
Справа, ZNS SSD: Размещением данных по зонам управляют приложения
Инфраструктура данных - и Адаптивные Зонированные хранилища
Зонированные блочные устройства предоставляют крупномасштабную эффективность, однако применение преимуществ таких новых устройств требует серьёзной поддержки, поскольку они не обладают обратной совместимостью. В то время как традиционные устройства хранения не имеют ограничений на запись, Зонированные блочные устройства имеют ограничение, согласно которому выполнение записей в пределах некой Зоны обязаны быть последовательными. Основное следствие этого состоит в том, что требуется обновить имеющийся стек программного обеспечения!
Самый первый компонент, подлежащий обновлению это собственно операционная система. Это нетривиальная задача для современных многозадачных операционных систем, исполняемых в серверах мо множеством ядер и множеством сокетов, обычных для развёртываний центров обработки данных. Сообщество Linux® приложило значительные усилия для поддержки Зонированные блочных устройств в целом и, в частности, в SMR.
Помимо поддержки собственно ядром Linux, существует целый ряд утилит и приложений, которые сопровождают Зонированные блочные устройства, такие
как fio, blktests и util-linux.
Ядро Linux работает с Зонированными хранилищами начиная с далёкого 2014 с минимальной поддержкой встроенной в ядро 3.18. Самым первым выпуском с функциональностью команд ZBC/ ZAC стало ядро 4.10 в начале 2017. Это сопровождение продолжило улучшаться, а самые последние ядра обладают поддержкой device-mapper (механизм соответствия устройств), а также некоторой поддержкой файловой системы.
Приводимая ниже схема показывает изображение на верхнем уровне собственно структуры ядра Linux и того как Зонированные блочные устройства могут интегрироваться совместно с наследуемыми блочными устройствами. Такая поддержка в имеющемся ядре Linux была введена посредством определённого изменения некоторых имеющихся компонентов, вводя новые интерфейсы, такие как интерфейс ZBD на Блочном уровне, а также вводит некоторые новые компоненты, такие как механизм соответствия устройств (device mapper) с зонированием dm (dm-zoned).
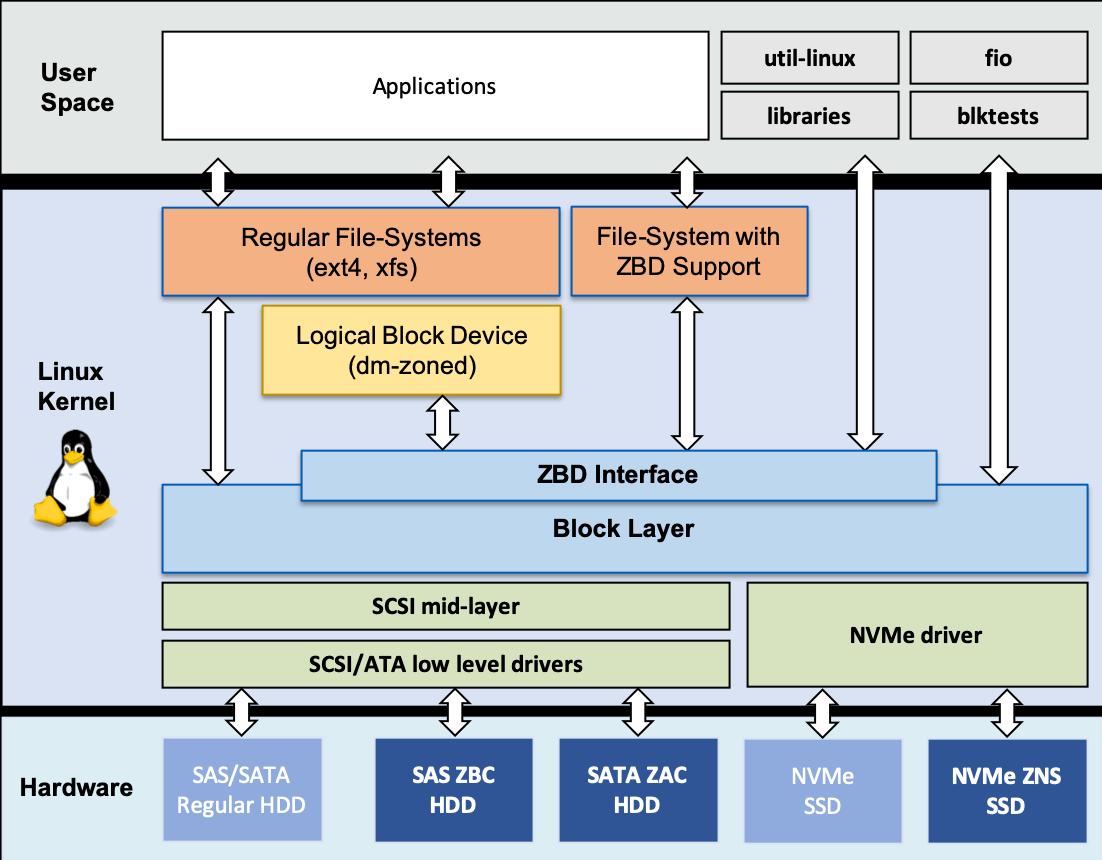
Как показывает эта схема, существует множество путей, которыми развёртываемая инфраструктура данных может пользоваться Зонированными
блочными устройствами. Например: (i) С применением наследуемой файловой системы при помощи механизма соответствия устройств с зонированием dm,
(ii) Используя файловую систему с естественной поддержкой ZBC, (iii) При помощи осведомлённых о ZBD приложений, которые напрямую общаются с
Зонированными блочными устройствами через библиотек пространства пользователя, таких как libzbc и т.п..
Несмотря на достигнутые сообществом с открытым исходным кодом успехи в поддержке Зонированных блочных устройств, инженерам инфраструктуры данных и разработчикам приложений по- прежнему требуются некоторые усилия для применения данной технологии, например, выяснять какой уровень поддержки имеется в каждом из выпусков ядра Linux или какие версии приложений обладают необходимой поддержкой и какая версия ядра необходима для его работы.
Отчасти для решения этой проблемы и облегчения более широкой поддержки приложений для технологий Зонированного хранения и была запущена Инициатива Зонированного хранилища. Для того чтобы узнать больше о технологиях Зонированных хранилищ и приспособлении к ZNS SSD и ZBC/ZAC SMR HDD вы можете ознакомиться с ZonedStorage.io. Здесь вы найдёте сведения о:
-
Зонированных блочных устройствах
-
Руководства для начала работы
-
Поддержка ядра Linux и его функциональные возможности
-
Приложения и библиотеки
-
Эталонные тесты
-
Тесты на совместимость с системой
При помощи данной платформы инженеры инфраструктуры и разработчики приложений хранения теперь обладают неким централизованным местом для получения всех необходимых сведений и ресурсов, требуемых для использования технологий Зонированного хранилища.
Посетите ZonedStorage.io
Прочтите об Активировании Эры зеттабайтов при помощи хранилищ зеттабайтов.
{Прим. пер.: перевод WesternDigital blog Zonefs File-System Will Land with Linux® 5.6 Дэмиен Ле Моаля, 24 февраля 2020.}
Файловая система zonefs для зонированных устройств хранения запускается в выпуске Linux 5.6. Здесь приводится то, что вам следует знать.
В этом блоге:
-
Ещё одна файловая система?
-
Зонированные блочные устройства
-
Про Zonefs
-
Ссылки на файлы документации
На протяжении последних нескольких лет мы были чрезвычайно заняты работой над ядром Linux. Будь то поддержка архитектуры RISC-V, вплоть до расширений стека хранения и поддержки SMR, а теперь и новой файловой системы Linux - Zonefs!
Это последнее достижение является важной вехой не только потому что внедрять новую файловую систему в ядро Linux сложно, но и потому что оно открывает новые возможности для разрабочиков, которые желают применять преимущества зонированных блочных устройств.
Итак, для начала давайте подготовим почву. Zonefs не является файловой системой общего назначения, такой как широко известные XFS или ext4. Наследуемые приложения без изменений не смогут воспользоваться преимуществами zonefs.
Если точнее, Zonefs это узкоспециализированная файловая система для зонированных устройств хранения (жёсткие диски SMR и твердотельные накопители ZNS). ZNS позволяет упростить реализацию поддержки зонированных блочных устройств в приложениях, заменяя доступ к файлам сырого блочного устройства более богатым набором обычных вызовов файловой системы. Это означает, например, что разработчикам нет нужды полагаться на непосредственное управление операциями ввода/ вывода файла блочного устройства, которые могут быть гораздо более невразумительными.
Zonefs экспонирует каждую зону некого зонированного блочного устройства в виде обычного файла, аналогично традиционным файловым системам и устанавливает для такого файла прямое соответствие ограничения записи соответствующей зоны устройства. Представляющие зоны файлы подлежащие последовательной записи необходимых зон такого устройства обязаны выполнять запись последовательно. Приводимый далее рисунок иллюстрирует принцип работы zonefs.
Рисунок A-5

Слева: Непосредственный доступ к блочному устройству
Всё устройство целиком представляется неким отдельным файлом, требуется множество дополнительных действий для выявления, идентификации и доступа к зонам.
Справа: Zonefs
Каждая зона данного устройства представляется неким полностью изолированным от прочих файлов зон файлом, упрощая управление такой зоной.
Движущей силой технологии Зонированных блочных устройств выступают крупномасштабные центры обработки данных, которым требуется максимальная эффективность, в особенности компаниям, которые предоставляют облачные службы и облачные приложения. По мере быстрого продвижения нашего мира к зеттабайтовому масштабу, мы будем наблюдать, что всё большее число компаний будет нуждаться во внедрении такой технологии чтобы идти в ногу с ростом объёмов данных и действенно управлять ёмкостью и производительностью системы.
Да, зонированные хранилища это не просто игра с ёмкостью.
С одной стороны, шпиндельные жёсткие диски были приняты компаниями облачных служб для достижения наилучшего соотношения стоимости/ ёмкости при масштабировании. Это происходит по причине того, что устройства SMR способны хранить несоизмеримо больше данных по сравнению с обычными дисками. В масштабах экзабайт это означает значительную укономию оборудования, мощности, отвода тепла и сложности в управлении. Dropbox является отличным образцом долгосрочной отдачи от технологии SMR. Он оказался способным добавлять сотни петабайт новой ёмкости при значительной экономии стоимости, причём даже при обновлении ЦПУ и увеличении пропускной способности сетевой среды.
По другую сторону в своём уравнении мы имеем SSD Зонированного пространства имён (ZNS) NVMe™. Хотя они работают в принципе аналогично тому, как это происходит ы устройствах SMR, они предлагают иные преимущества, обусловленные самой природой технологии Флеш- памяти.
SSD ZNS не содержат ничего лишнего. Перемещая большую часть управления с FTL в имеющийся стек программного обеспечения вы получаете дополнительное пространство (в некоторых случаях до 28%), меньшие затраты (поскольку таким дискам требуется меньше оперативной памяти) и более высокую производительность, которая делает возможным получение преимуществ присущих Флеш- памяти низкой латентности и более высокой полосы пропускания.
Аналогично прямому доступу к зонированным блочным устройствам, zonefs требует от своих приложений последовательной записи данных в файлы. Такое базовое ограничение зонированных блочных устройств не обрабатывается прозрачно самой zonefs, как это происходило бы в обычной файловой системе. Сила zonefs состоит в упрощённом управлении дисковым пространством и в предоставляемой ею защите от повреждения данных по причине ошибок приложений.
-
Упрощение взаимодействия: После исключения необходимого ограничения на последовательную запись, многие стороны управления зонированными блочными устройствами интегрированы ы zonefs. Это делает возможным более простой код приложения, которому нет нужды, например, реализовывать сложную процедуру восстановления при ошибках ввода/ вывода (к примеру, проверок условия зонированности и положения указателя записи при ошибках чтения или записи).
-
Управление в явном виде открытием/ закрытием, которое предоставляет некоторое улучшение некоторым устройствам также может быть автоматизировано через связывание таких действий с операциями открытия/ закрытия файла, выполняемого соответствующим приложением.
-
Наконец, новая команда записи в конец, определяемая ZNS может прозрачно поддерживаться при помощи стандартного
write()или асинхронных системных вызовов ввода/ вывода. Хотя первоначальная версия zonefs пока ещё не реализовала добавление в конец зоны и управление открытием/ закрытием зоны, значительное выявление ошибок ввода/ вывода и реализация обработки уже имеются.
-
-
Изоляция: Устанавливаемая неким файлом абстракция каждой зоны зонированного блочного устройства создаёт изолированность между зонами,поскольку некая операция ввода/ вывода файла может выдаваться лишь для представляемой ею зоны. Ошибки приложений, приводящие к неверным смещениям для экземпляра не могут разрушать другие зоны. Такая изоляция также применима и к таким разрушающим действиям как сброс зоны, которые связаны с системным вызовом обычного файла
truncate().
В целом файловое взаимодействие zonefs позволяет упрощать внесение изменений в приложения для поддержки зонированных блочных устройств. Типичным примером этого являются базы данных хранилищ ключ- значение, полагающихся на журнально структурированные конструкции данных деревьев слияния (LSM- деревьев). Примерами таких приложений служат хорошо известные хранилища ключей- значений RocksDB и LevelDB. Поскольку таблицы хранилищ ключ- значение дерева LSM всегда записываются последовательно, файлы zonefs можно применять для замены обычной файловой системы без необходимости внесения обильных изменений в приложение. Производительность также улучшается, поскольку накладные расходы zonefs значительно ниже чем у полностью POSIX совместимой файловой системы, такой как ext4 или XFS.
В целом, принятие шпиндельных дисков SMR и твердотельных накопителей ZNS позволяет снижать действенность операций на всех уровнях. Поскольку объём данных будет продолжать взрывной рост, такой способ упрощения имеющегося стека будет иметь решающее значение для управления данными при их масштабировании. Мы прилагаем все усилия чтобы упростит переход на зонированные хранилища. Zonefs - это шаг вперёд в данном направлении.
{Прим. пер.: перевод материалов ZoneFS - Zone filesystem for Zoned block devices, kernel.org, по сотсоянию на 16 апреля 2021.}
zonefs это очень простая файловая система, выставляющая в качестве файла каждую зону зонированного блочного устройства. В отличии от обычной POSIX- совместимой файловой системы с естественной поддержкой зонированного блочного устройства (например, f2fs), zonefs не скрывает установленное ограничение последовательной записи зонированных блочных устройств для своего пользователяПредставляемые самим устройством зон последовательной записи файлы обязаны выполнять последовательную запись начиная с конца такого файла (записи исключительно в конец).
По существу, zonefs ближе к интерфейсу доступа сырых блочных устройств, нежели к полнофункциональной файловой системе POSIX. Основная цель zonefs - упростить реализацию сопровождения зонированных блочных устройств в приложениях путём замены доступа к файлу сырого блочного устройства более богатым файловым API, избегая непосредственного управления вводом/ выводом файла блочного устройства, что может быть более обескураживающим для разработчиков. Одним из примеров такого подхода является реализация конструкций деревьев LSM (log-structured merge - слияния структурированных журналов, например, RocksDB и LevelDB) в зонированных блочных устройствах, позволяя сохранять SSTable в зонированных файлах аналогично обычной файловой системе вместо некого диапазона секторов всего диска целиком. Введение конструкции верхнего уровня "один файл это одна зона" может способствовать снижению общего числа требующихся в приложении изменений, а также обеспечивает сопровождение для различных языков программирования приложений.
Зональные устройства хранения относятся к некому классу устройств хранения с адресным пространством, которое делится на зоны. Некая зона это группа следующих друг за другом LBA {Logical Block Address - адресов логических блоков} и все зоны непрерывны (нет никаких промежутков LBA). Зоны обладают разными типами:
-
Обычные (conventional) зоны: нет никаких ограничения доступа к LBA, принадлежащим обычноым зонам. Любой доступ для считывания или записи может выполнятьчя аналогично обыкновенному блочному устройству.
-
Последовательный (sequential) зоны эти зоны принимают произвольные считывания, но записи в них должны выполняться последовательно. Каждая последовательная зона обладает указателем записи, поддерживаемым самим устройством, который отслеживает обязательную начальную позицию LBA следующей записи в данное устройство. В результате такого ограничения на операцию записи, LBA в последовательной зоне не могут перезаписываться. Перед повторной записью последовательные зоны должны быть сначала удалены при помощи специальной команды (сброс зоны, zone reset).
Зональные устройства хранения могут реализовываться при помощи различных технологий записи и носителей. Наиболее общими видами зонированных хранилищ сегодня применяют интерфейсы ZBC (SCSI Zoned Block Commands) и ZAC (Zoned ATA Commands) в шпиндельных дисках SMR (Shingled Magnetic Recording - с черепичной магнитной записью).
Твердотельные (SSD, Solid State Disks) устройства хранения также способны реализовывать зонированный интерфейс для, например, снижения роста числа записей (write amplification) по причине сборки мусора. ZNS (Zoned NameSpace) NVMe является технологией, предлагаемой основным комитетом стандарта NVMe с целью добавления интерфейса зонированного хранения в имеющийся протокол NVMe.
Zonefs экспонирует все зоны зонированного блочного устройства в качестве файлов. Такие представляющие зоны файлыгруппируются по типу зон, которые сами по себе представляются подкаталогами. Такая структура файла строится целиком с применением сведений зоны, предоставляемых самим устройством, а потому не требует никакой сложной структуры размещаемых на диске метаданных.
Записанные на диске метаданные
Размещаемые на диске метаданные zonefs сокращаются до неизменного суперблока, который постоянно хранит некое магическое число, а также флаги и
значения необязательных функциональных возможностей. При монтировании zonefs пользуется blkdev_report_zones()
для получения конфигурации зон своего устройства и заполняет свою точку монтирования статическим деревом файлов исключительно на основании этих сведений.
Размеры файлов зависят от типа зоны устройства и положения указателя записи, управляемого самим устройством.
Суперблок всегда записывается на диск в сектор 0. Самая первая зона устройства, хранящая суперблок, никогда не выставляется в качестве зоны
самой zonefs в качестве файла зоны. Когда содержащая суперблок зона является последовательной зоной, соответствующий инструмент форматирования
mkzonefs всегда "завершает" эту зону, то есть переводит эту зону в заполненное состояние для
превращения её в доступную исключительно для считывания, предотвращая любую запись данных.
Подкаталоги типа зон
Представляющие одним и тем же типом зоны файлы совместно группируются в одном и том же подкаталоге, автоматически создаваемом при монтировании.
Для обычных зон применяется подкаталог "cnv". Такой каталог, тем не менее, создаётся тогда и только тогда, когда данное устройство обладает используемыми обычными зонами. Когда это устройство обладает единственной обычной зоной в секторе 0, такая зона не экспонируется в качестве файла, поскольку она будет использоваться под хранение суперблока самой zonefs. Для подобного устройства подкаталог "cnv" не создаётся.
Для последовательно записываемых зон применяется подкаталог "seq".
В zonefs имеются только каталоги этих двух каталогов. Пользователи не могут создавать прочие каталоги и не могут ни переименовывать, ни удалять имеющиеся подкаталоги "cnv" и "seq".
Значение размера соответствующего каталога указывается значением поля st_size, получаемого системными
вызовами stat() или fstat(), указывающими значение числа файлов, имеющихся в
соответствующем каталоге.
Зонированные файлы
Зонированные файлы именуются при помощи значения номера той зоны, которую они представляют внутри соответствующего набора зон определённого типа. То есть, оба имеющихся каталога "cnv" и "seq" содержат файлы с названиями "0", "1", "2", ... . Номера соответствующего файла также представляют собой увеличивающийся стартовый сектор зоны на самом устройстве.
Все операции чтения и записи в зонированные файлы не допустимы за пределами максимального размера такого файла, то есть вне пределов ёмкости
соответствующей зоны. Все выходящие за рамки ёмкости соответствующей зоны попытки доступа завершаются неудачей со значением ошибки
-EFBIG.
Недопустимы создание, удаление, переименование или изменение любых атрибутов файлов и подкаталогов.
Общее число блоков файла представляется stat() и fstat(), указывающими
значение ёмкости файла соответствующей зоны или, иначе говоря, значение максимального размера файла.
Обычные зонированные файлы
Значение размера обычных зонированных файлов фиксируется значением размера тех зон, которые они представляют. Обычные зонированные файлы не могут усекаться.
Такие файы могут произвольным образом считываться и выполнять запись при помощи любого типа операций ввода/ вывода: буферированного ввода/ вывода, непосредствееного ввода/ вывода, поставленного в соответствие в памяти ввода/ вывода (mmap, memory mapped) и т.п.. Не существует никаких ограничений для таких файлов з исключением упомянутого выше предела на значение размера файла.
Последовательные зонированные файлы
Значение размера группирующихся в подкаталоге "seq" последовательных зонированных файлов представляют собой значение позиции указателя записи зоны относительно начального сектора этой зоны.
Последовательные зонированные файлы могут выполнять запись только последовательно, начиная с самого кнца файла, то есть, операции записи могут добавляться только в конец всех записей. Zonefs не предпринимает никаких попыток по получению выполняемых случайным образом записей и будут отказывать всем запросам на запись, которые обладают начальным смещением, не соответствующем значению конца данного файла., либо значению онца самой последней выданной и всё ещё исполняющейся записи (для асинхронных операций ввода/ вывода).
Поскольку обратная запись недействительных страниц из установленного кэша страниц не гарантирует последовательной записи, zonefs предотвращает
буферированное выполнение записи, а также записываемые совместные сопоставления в последовательные файлы. Для таких файлов допускается только
непосредственный ввод/ вывод выполнения записей. Zonefs полагается на последовательную доставку запросов ввода/ вывода на запись к своему устройству,
реализуемую подъёмником своего блочного уровня. Необходимо применять подъёмник, реализующий функциональную возможность последовательной записи для
зонированного блочного устройства (функциональная возможность подъёмника ELEVATOR_F_ZBD_SEQ_WRITE).
Такой тип подъёмника (например, mq-deadline) устанавливается по умолчанию для зонированных блочных устройств при
инициализации устройства.
Не существует никаких ограничений на значение типа ввода/ вывода, применяемого для операций считывания в последовательных зонированных файлах. Допускаются буферированный ввод/ вывод, непосредственный ввод/ вывод и совместно используемые считывания соответствий.
Усечение последовательных зонированных файлов допускается исключительно вниз до 0, причём в этом случае данная зона сбрасывается для переустановки
значения полоения указателя файла этого файла зоны в самое начало данной зоны, либо вверх до значения ёмкости этой зоны и в таком случае этот файл зоны
переводится в состояние FULL (заполненного, завершающего работу с зоной).
Варианты форматирования
Во время форматирования могут быть включены некоторые необязательные функциональные возможности zonefs.
-
Обычное объединение зон диапазоны смежных обычных зон могут соединяться в один файл большого размера вместо одного файла по умолчанию для каждой зоны.
-
Владение файлом: UID и GID соответствующих зонированных файлов по умолчанию устанавливается равным 0 (
root), но может быть изменено на любой допустимый UID/ GID. -
Права доступа к файлам: Установленные по умолчанию права доступа
640могут быть изменены.
Обработка ошибок ввода/ вывода
Зонированные блочные устройства могут отказывать запросам ввода/ вывода по причинам, аналогичным для обычных блочных устройств, например, из- за сбойного сектора. Тем не менее, дополнительно к подобным известным шаблонам отказов ввода/ вывода определённые стандарты поведения зонированных блочных устройств определяют дополнительные условия, которые в результате приводят к ошибкам ввода/ вывода.
-
Некая зона может быть переведена в положение доступной только на чтение (
BLK_ZONE_COND_READONLY): Хотя все записанные в этой зоне данные всё ещё доступны для считывания, в эту зону больше невозможно выполнять запись. Никакие действия пользователя в этой зоне (команды управления зоной или доступ на чтение/ запись) не способны изменить данное положение зоны в нормальное состояние чтения/ записи. Хотя сами причины для перевода некой зоны в состояние доступности только для чтения и не определены в имеющихся стандартах, типичным случаем такого перевода могла бы быть дефектная головка записи в неком шпиндельном диске (все зоны под этой головкой изменяются на доступные только для считывания). -
Некая зона мжт переходить в положение отключённой (
BLK_ZONE_COND_OFFLINE). Отключённая зона не может выполнять ни считывание, ни запись. Никакие действия пользователя не способны перевести отключённую зону обратно в хорошее рабочее состояние. Аналогично перемещению в доступную только на чтение зону, собственно причины для устройства по переводу некой зоны в отключённое состояние не определено. Типичным вариантом могли бы служить дефектные головки чтения- записи в шпиндельном диске, вызывающие отсутствие доступа ко всем зонам на такой пластине под сломавшейся головкой. -
Ошибки не выровненной записи: Такие ошибки возникают в результате выдачи хостом запросов на запись с начальным сектором, который не соответствует положению указателя записи зоны при выполнении записи самим устройством. Несмотря на то, что zonefs принуждает к последовательной записи файлов в последовательных зонах, ошибки не выровненной записи всё же могут возникать в случае частичного отказа очень большой операции ввода/ вывода, расщепляемой на множество запросов блочного ввода/ вывода или асинхронных операций ввода/ вывода. Когда один из таких запросов на запись в рамках набора выданных в соответствующее устройство последовательных запросов на запись испытывает отказ, все находящиеся после него в очереди запросы на запись превращаются в не выровненные и получают отказ.
-
Запаздывающие ошибки записи: аналогично обычным блочным устройствам, когда включено кэширование на стороне устройства, в диапазонах выполненных ранее записей могут происходить ошибки при сбросе кэша записи, например при
fsync(). Аналогично предыдущему варианту непосредственно не выровненной ошибки записи, запаздывающие ошибки записи могут распространяться в потоке кэшированных последовательных записей для некой зоны, вызывая сброс всех данных после того сектора, который привёл к данной ошибке.
Обо всех выявляемых zonefs ошибки ввода/ вывода соответствующий пользователь получает уведомление с неким кодом ошибки для того системного вызова, который включил или выявил такую ошибку. Необходимые восстанавливающие действия, предпринимаемые zonefs для ошибок ввода/ вывода, зависят от типа соответствующего ввода/ вывода (чтения или записи) и от причины для данной ошибки (сбойный сектор, не выровненные записи или изменение положения зоны).
-
Для ошибок ввода/ вывода считывания zonefs не осуществляет никаких восстанавливающих действий, однако только тогда, когда этот файл зоны всё ещё в хорошем положении и нет никакого несоответствия между размером inode этого файла и положением указателя записи его зоны. Когда выявляется некая проблема, выполняется восстановление после ошибки ввода/ вывода (см. приводимую ниже таблицу).
-
Для ошибок ввода/ вывода выполнения записи всегда выполняется восстановление zonefs после ошибок ввода/ вывода.
-
Изменение положения зоны в доступность только на чтение или в отключение всегда включает восстановление после ошибок ввода/ вывода.
Минимальное восстановление после ошибки ввода/ вывода способно изменить размер некого файла и полномочия на доступ к файлу.
-
Изменения размера файла: Непосредственные или задержанные ошибки записи в последовательном зонированном файле способны вызывать несогласованность размера inode этого файла с успешно записанными в этом зонированном файле данных. Например, частичный отказ множественного блочного ввода/ вывода большой операции на запись вызовет частичное продвижение вперёд указателя записи этой зоны, даже хотя вся операция на запись сообщит об отказе своему пользователю. В таком случае должно быть продвинуто вперёд значение размера inode чтобы отражать изменение указателя записи своей зоны и в конечном счёте позволить своему пользователю повторно запустить запись с самого конца этого файла. Размер некого файла также может быть понижен для отражения некой задержанной ошибки записи выявленной в
fsync():: в таком случае значение объёма действенно записанных данных в этой зоне может быть меньше чем первоначально указанное в размере inode этого файла. После подобной ошибки ввода/вывода zonefs всегда исправляет значение размера inode файла чтобы отражать то количество данных, которое было записано на постоянное хранения в этом файле зоны. -
Изменение прав доступа: Изменение положения зоны на доступную только для считывания указывает на изменения в полномочиях на доступ к соответствующему файлу для перевода в состояние этого файла доступного только на чтение. Это отключает изменения в атрибутах такого файла и изменения данных. Для отключённых зон отключаются все полномочия (чтение и запись) к такому файлу.
Последующие действия, предпринимаемые восстановлением после ошибок ввода/ вывода могут управляться самим пользователем при помощи варианта монтирования
"errors=xxx". Приводимая ниже таблица суммирует все результаты обработки ошибок ввода/ вывода
в зависимости от вариантов монтирования и положения рассматриваемой зоны:
+--------------+-----------+-----------------------------------------+
| | | Post error state |
| "errors=xxx" | device | access permissions |
| mount | zone | file file device zone |
| option | condition | size read write read write |
+--------------+-----------+-----------------------------------------+
| | good | fixed yes no yes yes |
| remount-ro | read-only | as is yes no yes no |
| (default) | offline | 0 no no no no |
+--------------+-----------+-----------------------------------------+
| | good | fixed yes no yes yes |
| zone-ro | read-only | as is yes no yes no |
| | offline | 0 no no no no |
+--------------+-----------+-----------------------------------------+
| | good | 0 no no yes yes |
| zone-offline | read-only | 0 no no yes no |
| | offline | 0 no no no no |
+--------------+-----------+-----------------------------------------+
| | good | fixed yes yes yes yes |
| repair | read-only | as is yes no yes no |
| | offline | 0 no no no no |
+--------------+-----------+-----------------------------------------+
Последующие замечания:
-
Вариант монтирования
"errors=remount-ro"является установленным по умолчанию поведением обработки ошибок ввода/ вывода zonefs когда не определены никакие варианты монтирования. -
При варианте монтирования
"errors=remount-ro"изменение полномочий доступа к файлам на доступность только для чтения применяется ко всем файлам. Вся файловая система монтируется повторно доступной только на считывание. -
Изменения полномочий доступа и размера файла, обусловленные перемещением данным устройством зон в отключённое положение является неизменным. Повторное монтирование или повторное форматирование данного устройства при помощи
mkfs.zonefs(mkzonefs) не изменит обратно отключённые зонированные файлы в некое приемлемое состояние. -
Изменения полномочий доступа к файла на доступность только для считывания, по причине перевода зон его устройства в положение только для считывания неизменно. Повторное монтирование или повторное форматирование данного устройства не вернёт обратно доступ на запись к файлу.
-
Изменение прав доступа к файлам напрямую вариантами монтирования
remount-ro,zone-roиzone-offlineявляется временным для зон в хорошем положении. Размонтировани и повторное монтирование всей файловой системы восстановит установленное ранее значение по умолчанию (значения времени форматирования) прав доступа к подвергшемуся такому воздействию файлам. -
Само по себе восстановление варианта монтирования включает лишь минимальный набор восстанавливающих действий после ошибок ввода/ вывода, то есть исправляет размер файла для зон в хорошем положении. Зоны, указанные как доступные только для считывания или как отключённые своим устройством всё ещё подразумевают изменения полномочий на доступ в соответствующим зонированным файлам как это было указано выше.
Варианты монтирования
zonefs определяет значения вариантов монтирования "errors=<behavior>" чтобы позволить
своему пользователю определять поведение zonefs в ответ на ошибки ввода/ вывода, несостоятельность размера inode или изменения положения зоны.
Определённые поведения таковы:
-
remount-ro(по умолчанию) -
zone-ro -
zone-offline -
repair
Сами действия опо ошибкам ввода/ вывода времени исполнения для каждого варианта поведения подробно описаны в предыдущем разделе. Ошибки
ввода/ вывода времени монтирования вызовут отказ в самой операции монтирования. Действия обработки доступных только для чтения зон также
разнятся для времени монтирования и времени исполнения. Когда доступная только для чтения зона обнаруживается во время монтирования, такая зона
всегда рассматривается точно так же как отключённые зоны, то есть отключается весь доступ и значение размера этой зоны устанавливается равным 0.
Это обусловлено тем, что значение указателя записи доступных только для чтения зон определено стандартами ZBC и ZAC как
invalib, делая невозможным выявление того количества данных, которое было записано в данной зоне. В случае
выявления доступной только на чтение зоны во время исполнения, как это было указано в нашем предыдущем разделе, значение размера соответствующего
зонированного файла остаётся без изменений с его последнего обновлённого значения.
Зонированное блочное устройство (например, устройство Зонированного пространства имён NVMe) может обладать пределами на значение числа зон, которые способны быть активными, то есть зон, которые в положении неявно открытых, явно открытых или закрытых. Такие потенциальные ограничения транслируются в некую степень риска приложениям обнаружить ошибки ввода/ вывода на запись по причине преодоления такого предела в процессе выполнения когда соответствующая зона файла уже не открыта при выданным пользователем запросе на запись.
Чтобы избежать подобных потенциальных ошибок вариант монтирования "explicit-open" принуждает
зоны стать активными с применением команды открытия зоны при открытии файла на запись в самый первый раз. Когда такая команда открытия зоны
успешна, само приложение впоследствии обеспечивает что могут осуществляться запросы на запись. И наоборот, вариант монтирования
"explicit-open" для выданной в соответствующее устройство самой последней команды
close() некого зонированного файла будет иметь результатом команду закрытия зоны, когда такая зона не заполнена,
а также не пуста.
Инструмент mkzonefs применяется для форматирования зонированных блочных устройств под использование с
zonefs. Этот инструмент доступен в Github.
zonefs-tools также содержат комплект тестирования, который может запускаться для любого зонированного
блочного устройства, включая блочное устройство null_blk block, создаваемое в зонированном режиме.
Примеры
Приводимое ниже отформатирует 15ТБ шпиндельный диск SMR, управляемый хостом с 256 зонами при включённой функциональности обычного объединения зон:
# mkzonefs -o aggr_cnv /dev/sdX
# mount -t zonefs /dev/sdX /mnt
# ls -l /mnt/
total 0
dr-xr-xr-x 2 root root 1 Nov 25 13:23 cnv
dr-xr-xr-x 2 root root 55356 Nov 25 13:23 seq
Значение размера подкаталогов зонированных файлов указывает общее число файлов, присутствующих для каждого типа зон. В данном примере имеется лишь один обычный зонированный файл (все обычные зоны объединены в одном файле):
# ls -l /mnt/cnv
total 137101312
-rw-r----- 1 root root 140391743488 Nov 25 13:23 0
Такой объединённый обычный зонированный файл может использоваться в качестве обычного файла:
# mkfs.ext4 /mnt/cnv/0
# mount -o loop /mnt/cnv/0 /data
Приводимый подкаталог "seq" группирует файлы для последовательно записываемых зон обладает в данном примере 55356 зонами:
# ls -lv /mnt/seq
total 14511243264
-rw-r----- 1 root root 0 Nov 25 13:23 0
-rw-r----- 1 root root 0 Nov 25 13:23 1
-rw-r----- 1 root root 0 Nov 25 13:23 2
...
-rw-r----- 1 root root 0 Nov 25 13:23 55354
-rw-r----- 1 root root 0 Nov 25 13:23 55355
Для последовательно записываемых зонированных файлов значение размера файла изменяется по мере добавления в его конец данных, аналогично любой обычной файловой системе:
# dd if=/dev/zero of=/mnt/seq/0 bs=4096 count=1 conv=notrunc oflag=direct
1+0 records in
1+0 records out
4096 bytes (4.1 kB, 4.0 KiB) copied, 0.00044121 s, 9.3 MB/s
# ls -l /mnt/seq/0
-rw-r----- 1 root root 4096 Nov 25 13:23 /mnt/seq/0
Такой записанный файл может быть обрезан до размера своей зоны, предотвращая все последующие операции записи:
# truncate -s 268435456 /mnt/seq/0
# ls -l /mnt/seq/0
-rw-r----- 1 root root 268435456 Nov 25 13:49 /mnt/seq/0
Усечение до 0 размера позволяет освобождать пространство соответствующего файла зоны и перезапускать записи в конец этого файла:
# truncate -s 0 /mnt/seq/0
# ls -l /mnt/seq/0
-rw-r----- 1 root root 0 Nov 25 13:49 /mnt/seq/0
Поскольку файлам статически поставлены в соответствие зоны самого диска, общее число блоков некоторого файла, выдаваемое в отчёте
stat() и fstat() указывает значение ёмкости такого файла зоны:
# stat /mnt/seq/0
File: /mnt/seq/0
Size: 0 Blocks: 524288 IO Block: 4096 regular empty file
Device: 870h/2160d Inode: 50431 Links: 1
Access: (0640/-rw-r-----) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-11-25 13:23:57.048971997 +0900
Modify: 2019-11-25 13:52:25.553805765 +0900
Change: 2019-11-25 13:52:25.553805765 +0900
Birth: -
Общее число блоков такого файла ("Blocks") в единицах по 512 байт в блоках даёт максимальный размер файла в
524288 * 512 Б = 256 МБ, что соответствует ёмкости зоны данного устройства в этом примере.
Следует отметить, что поле "IO block" всегда указывает минимальный размер ввода/ вывода для записи и соответствует размеру
физического сектора данного устройства.