Глава 2. Управление памятью
Содержание
- Глава 2. Управление памятью
Управление памятью это часть операционной системы, ответственная за администрирование памятью. В данной главе мы обсудим некоторые технологии управления памятью. Эти технологии разнятся от примитивного подхода голого железа до страничной организации и техник сегментации. Всякий подход обладает собственными преимуществами и недостатками. Выбор наиболее подходящей технологии управления памятью зависит от большого числа факторов, в частности от аппаратной архитектуры самой системы. Как мы обсудим далее, многие технологии требуют аппаратной поддержки,хотя самые последние архитектуры обладают тесной интеграцией оборудования и операционной системы.
В современных операционных системах сама операционная система располагается как некая часть в основной памяти, а всё остальное используется различными процессами. Основная задача организации такой памяти между различными процессами носит название управления памятью. Управление памятью это метод, которым сама операционная система управляет операциями в основной памяти и диске на протяжении исполнения процесса.
Сама операционная система отвечает за следующие активности в отношении управления памятью:
-
Выделение и отзыв памяти перед и выполнением процесса и после него.
-
Отслеживание использования памяти процессами.
-
Минимизация проблем сегментации.
-
Достижение эффективного и безопасного использования памяти.
-
Поддержка целостности данных при выполнении процесса.
Выбор стратегии управления памятью это критически важное решение, которое необходимо разрешать в зависимости от самой системы. Некоторые из этих алгоритмов требуют аппаратной поддержки и ведут к тесной интеграции среды между имеющимися аппаратными средствами и управлением памятью операционной системой. Управление памятью это важная задача, которая требует решения со стороны различных частей вычислительной системы: оборудования, операционной системы, служб и приложений.
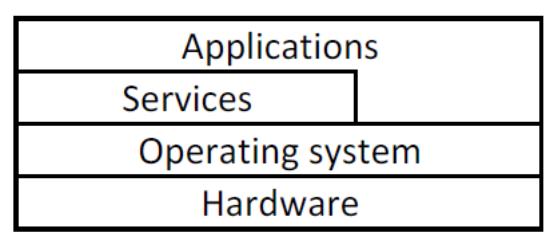
Каждый отображённый на Рисунке 2.1 уровень предоставляет различный набор служб для более верхнего уровня.
Процесс Привязки адресов это механизм ассоциации субъектов из двух различных адресных пространств. сопоставление одного адресного пространства другому [7]. Вычислительные системы хранят программы на диске в виде двоичных исполняемых файлов. Однако, для исполнения процессором с архитектурой фон Неймана, такая программа должна быть загружена в память и помещена вовнутрь некого процесса для надлежащего управления со стороны своей операционной системой. Такие процессы дожидаются на диске своего исполнения. Когда они готовы к исполнению, их операционная система загружает их в память некой программой и проходит ряд этапов перед выполнением. Адреса в самой исходной программе обычно символические. Компилятор, как правило, связывает такие символические адреса в перемещаемые адреса. Компоновщик (linker) или загрузчик (loader) в конечном итоге превращает такие перемещаемые адреса в абсолютные.
Существует возможность связывания инструкций и данных на одном из следующих шагов:
-
Время компиляции: Если сам компилятор знает где данный процесс будет расположен в памяти, он способен вырабатывать абсолютный код.
-
Время загрузки: Выработка перемещаемого кода соответствующим компилятором откладывает связывание до времени загрузки. В случае изменения начального адреса, самому коду пользователя требуется повторная загрузка для отражения такого изменения.
-
Время исполнения: Когда данный процесс может быть перемещён в процессе его исполнения из одного сегмента памяти в другой, тогда соответствующая привязка должна быть отложена до самого времени исполнения. Привязка времени исполнения требует специализированных аппаратных средств.
Как уже утверждалось в разделе Главы 1, устройство памяти способно безопасно игнорировать то как какой- либо процесс вырабатывает передаваемый на вход памяти адрес. Тем не менее, для надлежащего управления памятью необходимо различать логическое и физическое адресные пространства. Вырабатываемый ЦПУ адрес носит название логического адреса, тогда как физический адрес ссылается на наблюдаемый из устройства памяти адрес. Логический адрес также носит название виртуального адреса.
Технологии связывания времени компиляции и времени загрузки вырабатывают одни и те же логические и физические адреса. Схема связывания времени исполнения, тем не менее, имеет результатом различные логические и физические адреса [1]. Установление соответствия виртуальных адресов физическим осуществляется аппаратным устройством, носящим название блока управления памятью (MMU, memory management unit) [7].
Среди разнообразных методов мы можем выбирать выполнение следующего соответствия:
-
Непрерывное выделение памяти.
-
Страничную организацию.
-
Сегментацию.
-
Сегментацию со страничной организацией.
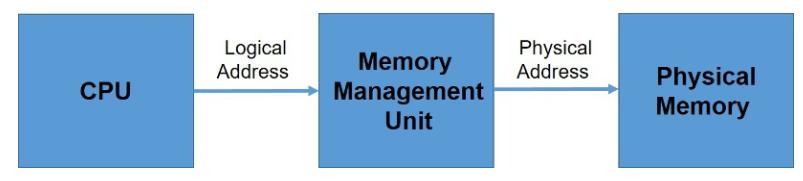
Для правильного управления памятью понятие привязанного к обособленному физическому адресному пространству логического адресного пространства является центральным. На Рисунке 2.2 показан процесс, который должен проходить создаваемый центральным процессором адрес для достижения соответствующего места в памяти. В MMU имеется регистр перераспределения. Значение этого регистра добавляется к каждому вырабатываемому пользовательским процессом адресу при его отправке в память. Например, если базовый адрес это 15000, то попытка адресации пользователем адреса 36 динамически перемещается в местоположение 15036.
Программа пользователя никогда не обращается к физическим адресам [1]. При применении в качестве адреса памяти (возможно, при косвенной загрузке или сохранении) программа пользователя лишь перемещается относительно регистра перераспределения. Сама программа пользователя имеет дело лишь с логическими адресами. Имеющиеся аппаратные средства отображения памяти выполняют преобразование логических адресов памяти в физические адреса. Значение окончательного расположения адреса памяти, на который ссылается адрес памяти, не определяется до тех пор пока не будет выполнена такая ссылка.
Если для исполнения процесса компьютерная система требует чтобы вся программа и данные находились в физической памяти, сама система обладает аппаратным ограничением на такие способные выполняться в этой системе программы, поскольку размер процесса никогда не должен превышать имеющийся размер физической памяти. Динамическая загрузка способна преодолевать это ограничение при том что значение времени загрузки подпрограммы равно первому времени её активности. Операционная система хранит все подпрограммы на диске в перемещаемом формате; затем, когда программа вызывает подпрограмму, такая вызывающая подпрограмма для начала проверяет находится ли эта другая подпрограмма в памяти. Когда это не так, для загрузки нужной подпрограммы в память вызывается загрузчик компоновки перемещаемого кода для отражения необходимого изменения. Наконец, только что загруженная подпрограмма получает от системы управление.
Основное преимущество динамической загрузки состоит в том, что подпрограмма загружается только в случае когда она требуется. Данный метод полезен когда для обработки редко возникающих ситуаций, например, процедур ошибок, требуются большие объёмы кода. В подобной ситуации, несмотря на то, что общий размер программы может быть большим, её применяемая часть (а следовательно загружаемая) может быть намного меньше.
Динамическая загрузка не требует особой поддержки от своей операционной системы. Она целиком пребывает в ответственности разрабатывающего её пользователя для получения преимуществ своего метода. Тем не менее, операционная система способна оказывать такому программисту содействие, предоставляя для реализации динамической загрузки процедуры библиотек.
Библиотеки динамической компоновки (DLL, Dynamically linked libraries) это системные библиотеки, которые компонуются с программами пользователя в процессе исполнения [1]. Некоторые операционные системы поддерживают только статическую компоновку, при которой системные библиотеки трактуются как прочие модули объектов и комбинируются своим загрузчиком в двоичный образ соответствующей программы. В противоположность этому динамические библиотеки аналогичны динамической загрузке. В них компоновка откладывается до времени исполнения. Такая функциональная возможность обычно применяется с системными библиотеками, например, со стандартной библиотекой языка программирования C. Без такой функциональности всякая программа в системе обязана содержать в своём исполняемом образе копию библиотеки своего языка программирования (или, по крайней мере, тех процедур, на которые ссылается её программа). Такое требование не только увеличивает значение размера исполняемого модуля, но также может впустую тратить основную память. Другим преимуществом DLL является то, что такие библиотеки способны совместно использоваться множеством процессов, а потому в основной памяти может пребывать лишь один экземпляр такой DLL. По этой причине DLL также носят название общих (разделяемых, shared) библиотек и они широко применяются в системах Windows и Linux.
Когда программа ссылается на процедуру из динамической библиотеки, её загрузчик определяет местоположение в такой DLL, загружая в случае необходимости её в память. Затем он регулирует значения адресов на такую функцию по ссылке в её динамической библиотеке для определения её места в памяти, по которому загружена данная DLL.
DLL могут расширяться обновлениями библиотеки (например, исправлениями ошибок). Кроме того, некая библиотека может заменяться новой версией и все программы, которые ссылаются на такую библиотеку будут автоматически пользоваться её новой версией. Без динамической компоновки всем таким программам необходимо было бы выполнять компоновку повторно для получения доступа к своей новой библиотеке. Итак, чтобы данная программа внезапно не стала исполнять новые, несовместимые версии библиотек, и в саму программу и в библиотеку включаются сведения о версии. В памяти может быть загружено более одной версии библиотеки и каждая программа для определения того какой копией пользоваться применяет свои сведения о версии. Версии с незначительными изменениями остаются с тем же самым номером версии, в то время как весрсии с основательными изменениями увеличивают свой номер. Таким образом, только те программы, которые скомпилированы с новой версией библиотеки подвержены любым несовместимостям включённых в неё изменений. Прочие программы, скомпонованные до установки новой версии продолжат пользоваться более старой библиотекой.
В отличие от динамической загрузки, динамической компоновке и совместным библиотекам обычно требуется помощь со стороны её операционной системы. Если имеющиеся в памяти процессы защищены друг от друга, тогда лишь сама операционная система является тем субъектом, который способен проверять потребуется ли процедуре в ином процессе пространство памяти или же он способен разрешать доступ по одним и тем же адресам в памяти множеству процессов.
Вплоть до этого момента в данной Главе для своего исполнения процессу было необходимо пребывать в памяти. Тем не менее, он может временно выгружаться из памяти и возвращаться обратно в память для продолжения выполнения когда он не является единственной запущенной в своей системе программой. Такая техника допускает размеру физического адресного пространства превышать значение реальной физической памяти в своей системе. Эта техника носит название подкачки (swapping) [1].
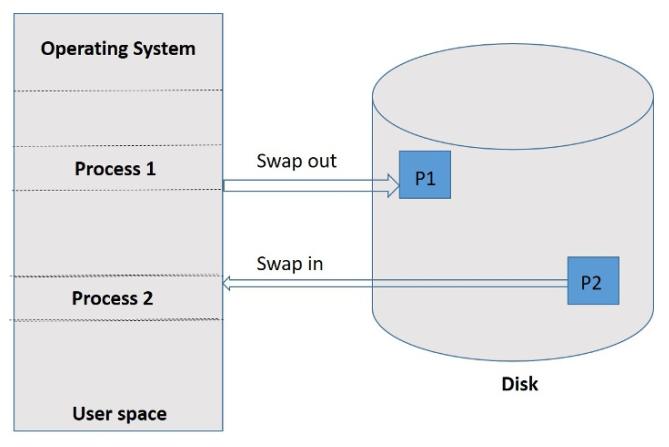
Стандартная подкачка вовлекает в себя процесс перемещения между основной памятью и достаточно большим лежащим в её основе хранилищем. Подкачку иллюстрирует Рисунок 2.3.
Сама система поддерживает готовой очередь, состоящей из всех процессов, чьи образы в памяти пребывают в хранилище основы или в памяти и готовы к исполнению. Всякий раз когда планировщик соответствующего ЦПУ принимает решение выполнять процесс, тот вызывается диспетчером. Этот диспетчер проверяет пребывает ли такой следующий процесс из очереди в памяти. Если это не так, и в памяти нет свободной области, данный диспетчер выгружает (swap out) находящийся в настоящее время в памяти процесс и подгружает (swap in) тот процесс, который желателен. Затем он перезагружает все регистры и передаёт управление подгруженному процессу.
Значение времени переключения контекста при такой подкачке системы относительно высокое. Современные операционные системы не пользуются подкачкой, поскольку она требует слишком много времени и обеспечивает слишком малое время исполнения. Подкачка сдерживается и прочими факторами. Если мы хотим выполнить выгрузку процесса, нам следует быть уверенными что он действительно простаивает. Особое беспокойство вызывает любой отложенный ввод/ вывод.
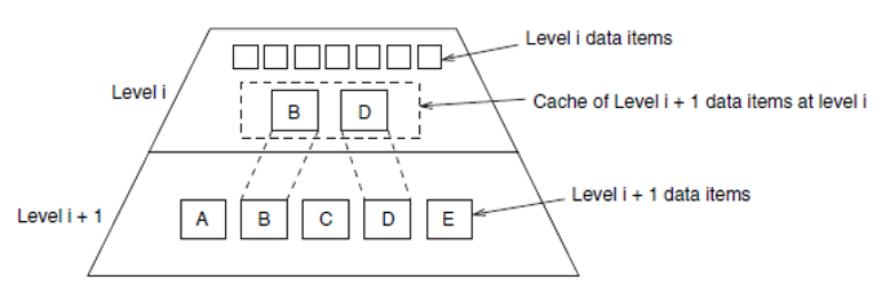
Кэш это название, присвоенное представлению уровня иерархии памяти между основной памятью и процессором в первой коммерчески доступной системе с таким дополнительным уровнем. Данный термин также используется для обозначения любого управления хранилищем с применением принципа локальности для повышения производительности [7].
При применении кэша ответа требуют два основополагающих вопроса: Как узнать находится ли элемент в кэше? Как отыскать в кэше этот элемент? Самый простой способ ответа на эти вопросы - назначать место в кэше для каждого слова в памяти на основе его адреса, например, в виде простой хэш- структуры без поддержки конфликтов [2]. Такой метод носит название кэша с прямым отображением. Рисунок 2.4 показывает образец соответствия кэша с прямым отображением.
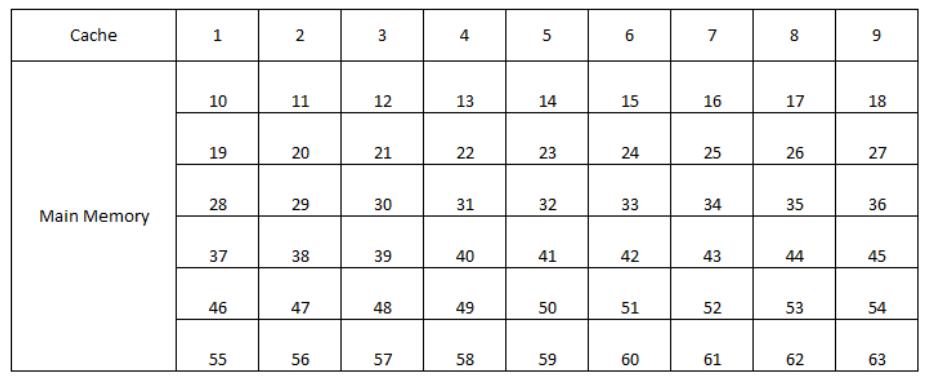
Поскольку каждое местоположение способно содержать множество адресов памяти, рассматриваемый кэш требует некое множество тегов. Теги содержат сведения, которые указывают является ли данное слово в кэше запрашиваемым словом из памяти. Бит действительности к тому же помечает информацию, что сведения кэш всё ещё достоверны. Для поиска уникальной записи в кэше, с которой способен сопоставляться данный адрес, могут применяться младшие биты. Значение индекса блока кэша совместно с содержимым тэга блока однозначно идентифицируют адрес памяти содержащегося в кэше слова.
Общее число необходимых для кэша битов это функция размера кэша и адресов, поскольку кэш содержит в себе как хранилище для данных, так и теги [2]. Блоки большего размера применяют пространственное расположение для снижения частоты промахов. Увеличение размера блока, как правило, снижает значение промахов. В конечном итоге частота промахов увеличится когда размер блока станет значительной долей размера кэша. Такое увеличение происходит из-за того, что сам кэш слишком мал и количество содержащихся в нём блоков также мало. Следующая глава разъясняет эту проблему. Другая проблема с увеличением размера блока состоит в том, что это также увеличивает временные затраты на промах. Такая стоимость может быть частично снижена когда обмен с памятью будет более действенным для больших фрагментов памяти. Применяемая для этого техника называется ранним перезапуском, когда соответствующий процесс восстанавливает управление сразу после того, как пропущенное попадание уже присутствует в кэше и тем самым данному процессу не требуется дожидаться полной передачи памяти.
Имеющийся блок управления должен выявлять промахи кэша и обрабатывать такой промах, извлекая запрошенные данные из памяти. Когда кэш сообщает о попадании, компьютер продолжает применять имеющиеся данные как ни в чём не бывало [7].
Обработка промаха кэша приводит к остановке конвейера вместо прерывания, которое потребовало бы сохранения состояния всех регистров. Более искушённые в идущих не по порядку инструкциях процессоры могут допускать инструкции в ожидании промахов. Если доступ к инструкции приводит к промаху, тогда содержимое этой инструкции не действительно. Для получения верной инструкции мы обязаны указывать нижнему уровню иерархии памяти выполнение считывания.
В случае промаха кэша соответствующему оборудованию надлежит предпринять следующие шаги [2]:
-
Отправить в свою память желаемый адрес памяти.
-
Проинструктировать свою основную память в выполнении считывания и дождаться его выполнения прежде чем осуществить доступ.
-
Выполнить запись элемента кэша, помещая необходимые данные из памяти в соответствующую порцию данных, записать значение верхней части обрабатываемого адреса в своё поле тега и установить бит действительности.
-
Перезапустить цикл исполнения инструкций.
Предположим, в инструкции сохранения мы записали данные только в кэш данных, тогда после такой записи сам кэш и его память будут обладать разными значениями. Они именуются несовместимыми [2]. Один из способов избегать этого - всегда выполнять запись и в кэш, и в память. Такая схема носит название сквозной записи (write-through). Это просто, но не предоставляет значительной производительности. Для решения данной задачи мы могли бы воспользоваться буфером записи. Буфер записи отвечает за ожидание поступления данных в память. После того как соответствующий процессор записал необходимые данные и в кэш, и в буфер, он может продолжать выполнение.
Другая схема именуется обратной записью (write-back): когда происходит запись, новое значение записывается только в блок кэша, а изменённый блок записывается на нижний уровень только при его замене [7]. С учётом промаха реализация сохранения в кэше, применяющем стратегию обратной записи, более сложна, чем в кэше со сквозной записью, поскольку процессор, когда данные в кэше изменены, обязан сначала записать блок обратно в память, а затем промах кэша. Если бы процессор только перезаписал блок, он бы уничтожил содержимое блока, для которого нет резервной копии на следующем более низком уровне иерархии памяти. Кэши с обратной записью обычно включают буферы записи, которые используются для уменьшения штрафа за промах, когда промах заменяет изменённый блок.
С одной стороны имеется метод прямого отображения, который ставит в соответствие любому блоку одно место на самом верхнем иерархии памяти. Противоположной крайностью выступает схема при которой любое место в кэше способно содержать любой заданный блок. Такая схема носит название полностью ассоциативной, потому как любой блок памяти ассоциируется с любой иной записью в кэше. Такая схема также означает, что для поиска блока в своём кэше процессор обязан просматривать все записи. Такой поиск выполняется одновременно с применением аппаратного компаратора, что превращает полностью ассоциативное размещение пригодным для кэширования исключительно с небольшим числом блоков [2].
Другая схема носит название множества ассоциаций и при ней блок может относиться только к фиксированному числу местоположений.
Имеющийся кэш делится на n наборов. Преимущество увеличения числа уровней ассоциативности
состоит в том, что обычно снижается частота промахов. Конкретный выбор между прямым отображением, набором ассоциаций и полностью
ассоциативным соответствием в любой иерархии памяти будет зависеть от стоимости промаха по сравнению со стоимостью реализации
ассоциативности как во времени, так и в дополнительном оборудовании и многими прочими относящимися к этому сторонами [7].
При ассоциативном кэше у нас имеется выбор для того куда помещать запрашиваемый блок и, тем самым, какой именно блок заменять. Наиболее распространённой схемой является схема последнего применяемого (LRU, least recently used). Она продолжает отслеживать применение истории каждого элемента набора относительно прочих элементов в этом наборе.
Современные процессоры пользуются большим числом кэшей для закрытия имеющегося зазора между быстрыми тактовыми частотами и временами доступа к памяти. Второй уровень кэширования обычно располагается в той же самой микросхеме и к нему выполняется доступ при каждом промахе в своём первичном кэше; это иллюстрирует Рисунок 2.5.
Когда ни первичный, ни вторичный кэш не содержит необходимых данных, требуется один дополнительный доступ к памяти и это влечёт за собой дополнительные штрафы [7].
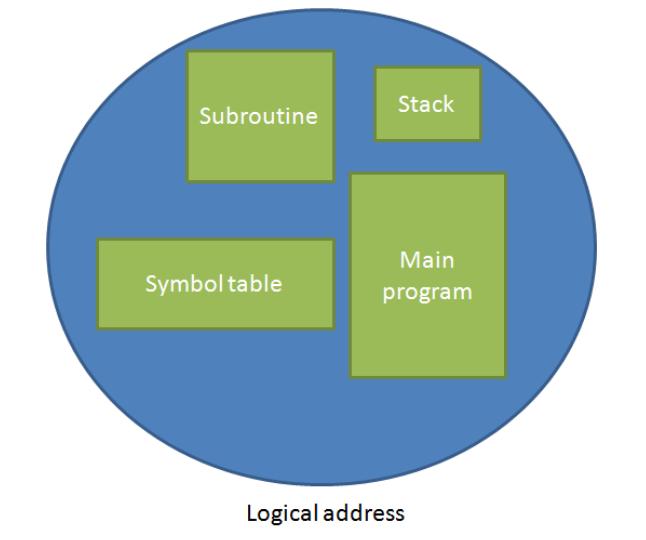
Основная память должна размещать свою операционную систему и процессы пользователя когда различные процессы совместно применяют в данной системе соответствующий ЦПУ.
Эта операционная система может помещаться либо в нижнюю, либо в верхнюю часть памяти. Единственным существенным фактором, оказывающим влияние на это решение выступает необходимый вектор прерываний, поскольку гораздо удобнее когда карта памяти операционной системы содержит и такой вектор прерываний. Обычно операционная система располагается в нижних адресах памяти, как и вектор прерываний. При распределении непрерывной памяти каждый процесс пребывает в одном разделе памяти, который является смежным для раздела, содержащего следующий процесс [1]. Такое поведение является частным случаем общей задачи динамического распределения памяти и имеется два основных подхода к управлению непрерывными областями памяти:
-
Схемой с фиксированным разделом.
-
Схемой с переменным разделом.
При схеме с разделами фиксированного размера всякий раздел содержи один процесс и:
-
При свободном разделе процесс выбирается из установленной входной очереди и загружается в такой свободный раздел.
-
Когда процесс завершается, его раздел становится свободным.
При переменной схеме сама операционная система отслеживает некую таблицу, указывая какие части памяти доступны.
-
Изначально доступна вся память. Когда процесс запускается, он загружается в память и после этого он соперничает за время соответствующего ЦПУ.
-
В любой определённый момент времени существует список размеров доступных блоков и входная очередь. Операционная система способна запрашивать свою входную очередь в соответствии с алгоритмом планирования.
-
Имеющиеся блоки памяти содержат разбросанным по памяти набором дырок различного размера.
-
Когда процессу требуется память, имеющаяся система отыскивает достаточно большой блок. Когда получаемая дырка слишком велика, тогда он делится пополам: один для данного процесса, а другой для набора доступных блоков. После завершения процесса он освобождает свои блоки в памяти и возвращает их к доступным блокам.
-
Когда соответствующая операционная система выполняет поиск необходимых доступных блоков для назначения блоков памяти некому процессу, она способна предпринимать три основных подхода первого подходящего, наилучшего подходящего, наихудшего подходящего.
Обычно операционные системы выделяют память со множеством размеров блоков. Такое отличие между значением размера выделения и величиной запрашиваемого размера носит название внутренней фрагментации.
Существует также и внешняя фрагментация, при которой существует достаточное общее пространство памяти для удовлетворения запроса, однако эти доступные пространства не непрерывны. От внешней фрагментации страдают схемы первого подходящего и наилучшего подходящего [1]. Неким решением внешней фрагментации выступает подход с названием уплотнения. Однако, оно не всегда возможно. В качестве примера, когда перераспределение статическое (осуществляется во время сборки или загрузки), выполнять уплотнение невозможно. Когда перераспределение динамическое и откладывается до времени исполнения, уплотнение может быть осуществлено. Другим решением для внешней фрагментации является допуск необходимому логическому адресному пространству соответствующего процесса иметь разрывы.
Сегментирование это способ соответствия представления памяти программистом реальной физической памяти [7]. Логическое адресное пространство это набор сегментов. Каждый сегмент обладает названием и длиной. Адреса определяют и название сегмента и значение смещения внутри данного сегмента. Рисунок 2.6 показывает представление логического адресного пространства.
Сам программист определяет всякий адрес двумя значениями: названием сегмента и неким смещением. При применении сегментирования ссылки на объекты представляются двумерными адресами, однако имеющаяся реально память это одномерный массив. Для решения данной задачи таблица с названием таблицы сегментов осуществляет соответствие между пространством объектов и пространством памяти. Каждая запись в такой таблице сегментов содержит значение базы сегмента и значение предела сегмента, которые представляют значение начального физического адреса и значение размера этого сегмента при размещении этого сегмента в памяти [2].
Разбиение на страницы это другой метод управления памятью, который допускает разрывы в физическом адресном пространстве. Таким образом, разбиение на страницы обладает гигантскими преимуществами в отношении исключения внешней фрагментации и потребности в уплотнении.
При отселении фрагментов в лежащее в основе подкачки хранилище, такое хранилище также становится фрагментированным, однако доступ к нему намного более медленный, что превращает его уплотнение в невозможное [1].
Разбиение на страницы вовлекает в себя разбиение физической памяти на фиксированные блоки с названием кадров и разбивает логическую память на блоки с тем же размером, именуемые страницами. Когда загружается некий процесс, его страницы загружаются в любые доступные кадры памяти перед запуском исполнения такого процесса.
Всякий логический адрес делится на две части: номер страницы и смещение страницы (как это отображено на Рисунке 2.7). Соответствующая таблица страниц применяет значение номера страницы в качестве индекса. Эта таблица страниц содержит значение базового адреса для всех страниц в физической памяти. Применяемое оборудование определяет значение размера страниц и оно является степенью 2 [7].
Обратите внимание, что величина размера памяти в системе с разбиением на страницы отличается от значения максимального логического размера процесса.
Большинство современных компьютеров позволяет своим таблицам страниц быть гигантскими (вплоть до 1 миллиона записей). Их память содержит такую таблицу страниц и некий регистр указывает на значение базы этой таблицы страниц. К сожалению, такая схема замедляет доступ в два раза.
Стандартное решение той задачи состоит в применении специального, небольшого и быстрого аппаратного кэша поиска (или буфера предыстории трансляции, TBL - translation look-aside bufer). Такой TBL получает на вход номер страницы от соответствующего логического адреса и сравнивает его одновременно со всеми ключами.
-
Когда искомый номер страницы соответствует некому ключу, тогда возвращается его номер кадра и доступ к памяти возможен немедленно.
-
Когда искомый номер страницы отсутствует в TBL, в этой таблице страниц необходимо сделать ссылку на память.
-
Если имеющаяся TBL уже заполнена записями, для замещения может быть выбрана некая имеющаяся запись. Политики замещения находятся в диапазоне от самой последней использованной через карусельной до произвольной.
Значение соотношения попаданий соотносится с величиной процентов тех раз когда эта TBL содержала представляющий интерес номер страницы [1].
Неким преимуществом страничной организации является возможность совместного применения общего кода. Такой вариант особенно важен в средах с разделением времени.
Повторно применяемый код не является кодом с самостоятельным изменением. Он никогда не изменяется в процессе выполнения, а потому два или более процессов способны исполнять тот же самый код одновременно.
Каждый процесс обладает собственной копией регистров и данных для содержания данных под исполнение процесса; тем не менее, самой операционной системе необходимо принуждать природу разделяемого кода для доступа исключительно на чтение [1].
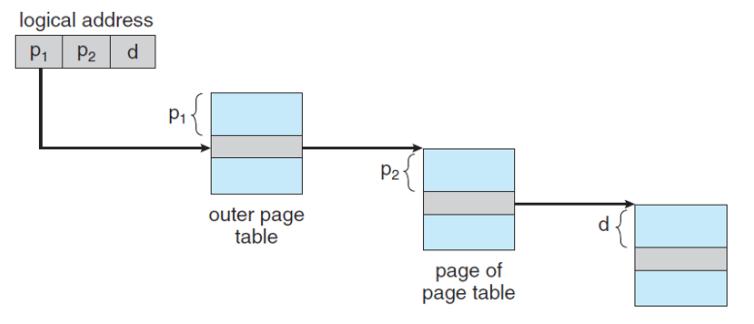
Наиболее современные вычислительные системы поддерживают значительное, 64- битное, логическое адресное пространство. В такой среде имеющаяся таблица страниц становится исключительно большой. По этой причине превращается в невыполнимое выделение непрерывной таблицы страниц в основной памяти.
Один из способов решения данной задачи состоит в алгоритме двухуровневого разбиения на страницы, при котором сама по себе
таблица страниц разбивается на страницы. Такая схема также носит название таблицы страниц с прямым отображением. Номер страницы
делится дополнительно и при этом p1 это индекс для внешней таблицы
страниц, а p2 сдвиг внутри соответствующей страницы соответствующей
внутренней таблицы (Рисунок 2.8.

Такая внешняя таблица также может разбиваться на страницы, что в результате приводит к схеме с тремя уровнями разбиения на страницы (Рисунок 2.9). Для архитектур с 64 битами иерархические таблицы страниц рассматриваются как неуместные по причине увеличения числа обращений к памяти [1].
Когда мы рассматриваем значение номера страницы как некое хэшируемое значение, каждое значение в такой хэшированной таблице содержит некий связный список кадров, которые соответствуют тому же самому номеру страницы. Каждый элемент состоит из следующих трёх полей:
-
Номера страницы
P1 -
Номера кадра
P2 -
Следующего узла
P3в его связном списке
Соответствующие "кластеризованные таблицы страниц" это предлагаемая вариация, в которой каждая запись соответствующей хэшированной таблицы ссылается на несколько страниц вместо одной страницы [1].
Обратные таблицы страниц это другой способ решения данной задачи. Для каждого кадра в памяти существует в точности одна запись и каждая запись составляется из значения логического адреса той страницы, которая хранится в точности по этому адресу. Таким образом, с систем имеется только одна отдельная таблица страниц и она обладает только одной записью для каждой страницы физической памяти.
К сожалению, те системы, которые пользуются обратными таблицами страниц обладают большими сложностями в реализации совместной памяти, поскольку разделяемая память обычно реализуется с применением нескольких логических адресов, которые соответствуют одному физическому адресу. Внутри обратных страниц такой метод не может применяться, поскольку для всякой физической страницы существует только одна запись виртуальной страницы [1].
Другим вводимым совместной памятью в операционной системе требованием является защита памяти. Для надлежащей операционной системы, такая Операционная система обязана защищать различные процессы друг от друга. То есть, область самой операционной системы должна быть доступна только самой операционной системе, а всякий процесс пользователя обязан обладать доступом только к своей области. Такую защиту своего процессора должно предоставлять оборудование; в противном случае самой операционной системе придётся взаимодействовать между своим процессором и каждым из его доступов к памяти [2].
Существуют различные методы, коими такая операционная система может применяться для защиты памяти. Например, для разделения областей памяти нам потребуется возможность выявления диапазона допустимых адресов для каждого процесса и убеждаться что каждый процесс имеет доступ только в разрешённым адресам.
Такая защита может быть предоставлена с применением двух регистров: базы и предела [6]. Такая защита некой области памяти потребует от аппаратных средств своего ЦПУ сравнения каждого вырабатываемого в режиме пользователя адреса с данными двумя регистрами. Имеющаяся операционная система способна загружать только значения регистров базы и предела с применением привилегированных инструкций, которые допустимы лишь для выполнения в режиме ядра. Данная стратегия к тому же позволяет своей операционной системе обладать неограниченным доступом к пространству процессов и загружать 2 или более процессов в перекрывающиеся области памяти для целей отладки [1].
Поскольку области памяти непрерывны, для имеющейся операционной системы критически важно гарантировать что только некий процесс способен выполнять доступ к своей памяти. Для осуществления этого когда имеющийся планировщик выбирает для исполнения процесс, его диспетчер загружает необходимое перераспределение и ограничивает регистры правильными значениями как часть переключения его контекста. Поскольку для защиты памяти используются перераспределение и ограничения регистров, такой метод защищает саму операционную систему и процессы пользователя друг от друга.
Данная схема регистра перераспределения предоставляет действенный способ разрешения самой операционной системе динамического изменения её размера. Данный регистр особенно полезен для драйверов устройств. Такой код является перемещаемым кодом операционной системы, поскольку он появляется и исчезает по мере необходимости [1].
При разделённой на страницы среде всякий кадр обладает набором специально предлагаемых битов защиты для осуществления защиты памяти. Обычно эти биты хранятся в самой таблице страниц. Один бит может означать что данный кадр обладает полномочиями чтений- записи или только чтения. Поскольку каждая ссылка на память обязана проходить через такую таблицу страниц для поиска ей номера кадра, установленные биты защиты могут проверяться для гарантии того что не предполагается никакой недопустимый доступ [7].
Существует одна таблица страниц для исполнения процесса и другая для установленной операционной системы, поэтому подобная схема позваляет её операционной системе обладать доступом к таблицам страниц и страницам процессов пользователей, а также не позволять процессам выполнять доступ к кадрам и таблицам страниц других процессов.