Глава 3. Виртуальная память
Содержание
В своей предыдущей главе мы обсудили некоторые применяемые в современных операционных системах методы управления памятью. Все эти методы служат одной и той же цели: поддерживать в памяти одновременно множество процессов для того чтобы допускать мультипрограммирование. Однако они требуют того, чтобы весь процесс целиком пребывал в памяти прежде чем такой процесс способен выполняться. Виртуальная память это технология, которая допускает исполнение тех процессов, которые могут не пребывать полностью в памяти. Одним из основных преимуществ такой схемы является то, что процессы могут быть больше доступной физической памяти. Данная методика абстрагирует основную память в очень большой, единообразный массив хранения, выделяя логическую память как представляемую своим пользователем от физической памяти. Данная методика освобождает программиста от заботы об ограничениях основной памяти. Виртуальная память также позволяет процессам разделять файлы и адресные пространства. Виртуальная память не столь проста в реализации, однако, и способна значительно понижать производительность при неаккуратном применении. В данной главе мы обсудим управление виртуальной памятью.
Кэш это специальный буфер быстрой памяти, обычно внутри микросхемы ЦПУ, применяемый для увеличения скорости доступа к основной памяти. Мы можем применять ту же методику для основной памяти и для вторичного хранилища с тем, чтобы основная память была способна действовать в качестве кэша для своего вторичного хранилища (жёстких дисков). Такая техника носит название виртуальной памяти. К несчастью, виртуальную память не просто реализовывать и может присутствовать существенное снижение производительности при её небрежном применении [2]. Для мотивации виртуальной памяти имеются различные основные мотивации:
-
Действенное и безопасное разделение памяти между множеством программ.
-
Допуск исполнения процессов, которые не помещаются целиком в памяти.
-
Разрешение процессам совместного использования файлов и простой организации разделяемой памяти.
Сама возможность исполнения программы, которая частично пребывает в памяти предлагает следующие преимущества:
-
Программа не будет ограничена на исполнение имеющимся объёмом физической памяти.
-
Увеличение одновременности, поскольку каждая программа может брать меньше памяти; следовательно больше программ может помещаться в памяти.
-
Изначально могло бы требоваться меньше ввода/ вывода для загрузки программ пользователя в память.
-
Во многих случаях вся программа целиком не нужна, например:
-
Код для обработки необычных условий ошибок.
-
Массивы, списки и таблицы обычно выделяют памяти больше чем им требуется.
-
Редко применяемые свойства.
-
Вся программа может не требоваться целиком в одно и то же время.
-
Принцип локальности допускает виртуальную память так же как и кэши. Виртуальная память обеспечивает действенное совместное использование процессора, а также основной памяти. Например:
-
Поведение совместно использующих память виртуальных машин изменяется динамически. По причине такого взаимодействия каждая программа компилирует в своё адресное пространство обособленный диапазон местоположений памяти, доступных только этой программе. Такое виртуальное адресное пространство процесса ссылается на соответствующее логическое представление того как процесс обозревает память.
-
Виртуальная память отвечает за реализацию собственно трансляции виртуального адресного пространства программы в имеющееся физическое адресное пространство.
-
Такая трансляция усиливает защиту адресного пространства программы от прочих виртуальных машин.
-
Виртуальная память вовлечена в отделение воспринимаемого пользователем логического адреса памяти от физической памяти.
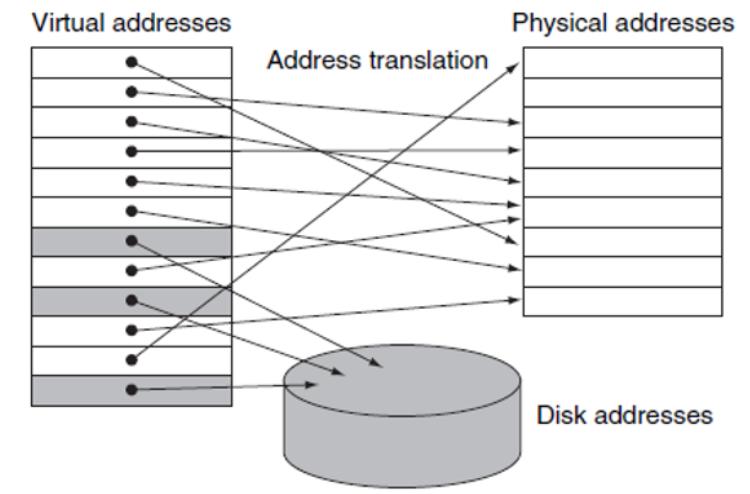
Хотя основные применяемые в виртуальной памяти и кэшировании понятия одни и те же, их различные исторические корни привели к применению разной терминологии. Страница - это название блока виртуальной памяти. Промах виртуальной памяти именуется ошибкой страницы. В виртуально памяти процессор создаёт виртуальный адрес, который при помощи сочетания аппаратных средств и программного обеспечения (ПО) преобразуется в физический адрес, который затем и можно использовать для доступа к памяти.
В виртуальной памяти (показанной на Рисунке 3.1) собственно адрес содержит значение номера виртуальной страницы и смещение страницы. Обладание большим числом виртуальных страниц нежели физических страниц и составляет основу иллюзии по существу неограниченного количества виртуальной памяти [7]. Виртуальная память к тому же упрощает загрузку самой программы для исполнения, предоставляя перераспределения и допуская более простую реализацию совместных библиотек.
Соответствия перераспределения значения виртуального адреса используется самой программой для различной физической адресации прежде чем такой адрес применяется для доступа к памяти. Они позволяют загрузку такой программы в любое место памяти вместо некого непрерывного блока.
Различные процессы могут совместно применять системные библиотеки через установление соответствия необходимого совместного объекта в их виртуальное адресное пространство. Совместные библиотеки позволяют вычислительной системе сберегать пространство диска и памяти.
Высокая стоимость отказа страниц (миллионы тактов) мотивируют многие выборы архитектуры в виртуальной памяти:
-
Страницы должны быть достаточно большими чтобы попытаться гасить высокое время доступа.
-
Привлекательны снижающие соотношение значения отказа страниц организации, например, полностью ассоциированное размещение страниц в памяти.
-
Отказы страниц могут обрабатываться на программном уровне, поскольку накладные расходы незначительны по сравнению с временем доступа к диску.
-
Сквозная запись (write- through) не срабатывает, поскольку записывание отнимает слишком длительное время на завершение. Системы виртуальной памяти пользуются методиками обратной записи (write- back).
Основная сложность использования полностью ассоциативного размещения состоит в локализации записи, так как она может быть где угодно на самом верхнем уровне установленной иерархии. Полный поиск не практичен. Страницы локализуются при помощи некой таблицы, которая индексирует используемую память: таблицу страниц. Такая таблица страниц, совместно со значением счётчика программы и соответствующим регистром определяют значение состояния виртуальной машины. Мы часто будем называть это состояние процессом [2].
Значение адреса виртуальной страницы само по себе не сообщает нам немедленно где находится эта страница на диске. Самой системе необходимо отследить значение местоположения на диске каждой страницы в виртуальном адресном пространстве. Когда бит разрешения для виртуальной страницы отключён, происходит отказ страницы. Поскольку сама система не знает наперёд то время, когда она заменит страницу в памяти, её операционная система обычно создаёт необходимое пространство во флэш памяти или на диске для всех необходимых страниц процесса при создании такого процесса. Это пространство носит название пространства подкачки (swap space). При этом также создаётся некая структура данных для записи того где сам диск сохраняет каждую виртуальную страницу [2].
Поскольку основная память хранит необходимые таблицы страниц, всякий доступ к памяти со стороны программы может отнимать по крайней мере вдвое больше времени. Соответственно, современные процессоры содержат уникальный кэш, который отслеживает только что применённые переводы (трансляции): буфер быстрого перевода (TLB, translation lookaside bufer). Поскольку при каждой ссылке вместо доступа к имеющейся таблице страниц мы осуществляем его для TLB, наша TLB будет обязана содержать все прочие биты состояния. На Рисунке 3.2 описан процесс, которым следует TLB.

Разработчики воспользовались широким разнообразием ассоциативности в TLB. В некоторых системах применяются небольшие полностью ассоциативные TLB, другие системы часто применяют большие TLB с незначительной ассоциативностью.
Операции ввода/ вывода наиболее сложная часть архитектуры виртуализации по причине разнообразия способных подключаться к системе устройств. Другим вызовом выступает собственно виртуализация виртуальной памяти. Чтобы она работала, VMM разделяет понятия реальной и физической памяти:
-
Реальная память это отдельный уровень, непосредственно находящийся между виртуальной и физической памятью.
-
Имеющаяся гостевая ОС устанавливает соответствие виртуальной памяти реальной памяти при помощи своих виртуальных таблиц.
-
Таблицы страниц VMM осуществляют отображение реальной памяти гостевой ОС в физическую память.
В виртуальной памяти со страницами по запросу страницы загружаются в кадры физической памяти только тогда, когда того требует исполнение программы. Таким образом, в основную память загружаются не все страницы, к которым осуществляется доступ. В некотором смысле система подкачки по запросу похожа на систему подкачки, при которой процессы находятся во вторичной памяти. Когда сама операционная система подкачивает некий процесс, соответствующая система страниц угадывает какие страницы она будет применять, прежде чем ОС снова выгрузит это процесс, но вместо того чтобы выполнять подкачку этого процесса целиком, управление страницами помещает в память только эти страницы.
Данная схема требует некой аппаратной поддержки чтобы различать находящиеся в памяти страницы и страницы, пребывающие на диске. По этой причине соответствующая таблица страниц содержит бит имеющей силу - недействительной (valid-invalid) [1]. Как обычно, когда страница загружается в память, система устанавливает запись в таблице страниц, но запись для страницы, которая отсутствует в памяти на данный момент либо помечается как недействительная, либо содержит значение адреса этой страницы на диске. Если система страниц угадывает верно и загрузит все необходимые страницы, данный процесс будет работать правильно, как если бы все его страницы находились в памяти. В противном случае, если процесс попытается получить доступ к странице, которую система не загрузила в память, произойдёт ошибка страницы. Аппаратное обеспечение подкачки отметит выполненную установку бита valid-invalid, что вызовет внутреннее прерывание (trap) для его операционной системы [7].
Операционная система обработает такой отказ страницы следующим образом.
-
Убедится квалифицируется ли данный доступ к памяти допустимым или не действительным.
-
Если данная ссылка не действительна, завершить данный процесс.
-
Отыскивает свободный кадр.
-
Считывает такой желаемый кадр с диска для соответствующего доступного кадра.
-
Изменяет свою таблицу страниц для указания того, что данная страница теперь в памяти.
-
Перезапустить ту инструкцию, которая была прервана внутренним прерыванием.
Истинная система подкачки страниц по запросу не привносит страницы в память до тех пор пока их не затребует исполнение программы. Однако, это в результате приводило бы к неприемлемой производительности системы.
Для подкачки страниц по запросу требуемой аппаратной поддержкой является: Таблица страниц и Вторичная память.
Подкачка страниц добавляется в вычислительную систему между ЦПУ и его памятью и должна быть прозрачной для процесса пользователя. Люди зачастую предполагают что применять подкачку страниц способна любая система. Это предположение верно только для сред без подкачки страниц по запросам, в которых отказ страницы представляет фатальную ошибку и никакие инструкции не требуют перезапуска операции.
Подкачка страниц по запросу способна оказывать существенное воздействие на значение производительности вычислительной системы, поскольку значение действительного времени доступа прямо пропорционально значению соотношения отказов страниц. Операции дискового ввода/ вывода для подкачки обычно быстрее чем у файловой системы. Он быстрее по причине того, что пространство подкачки выделяет блоки намного большего размера и не применяет поиск файла или методы косвенного выделения.
Мобильные операционные системы обычно не поддерживают подкачку. Вместо этого такие системы запрашивают страницы из своей файловой системы и возвращают страницы с доступом только на чтение из приложений при ограничениях памяти.
Когда мы увеличиваем степень многозадачности за пределы доступной системной памяти, мы выходим за рамки выделенной памяти. Если система выделяет памяти больше чем некое определённое пороговое значение, может происходить следующее:
-
При исполнении процесса пользователя могут происходить отказы страниц.
-
Его операционная система, таким образом, определяет что такие желаемые страницы расположены на диске и осознаёт, что нет никаких свободных кадров в его списке свободных кадров.
В таком случае данная операционная система имеет два варианта:
-
Завершить такой процесс пользователя.
-
Выгрузить другой процессор для освобождения всех его кадров и снижения значения уровня мультипрограммирования.
Легко ожидать, что предоставление большего объёма памяти процессу может улучшить его производительность. Однако, это не всегда вариант: Когда некий алгоритм не демонстрирует такого свойства, говорят, что он страдает аномалией Белади, и это нежелательно[1].
Замена страницы существенна для схемы страничного обмена по запросу. Она завершает разделение между логической памятью и физической памятью. В целом, замена страницы применяет следующий подход
-
Отыскивает значение местоположения запрашиваемой страницы на диске.
-
Находит свободный кадр.
Когда такой кадр имеется, пользуется им.
Если свободного кадра нет, для выбора приносимой в жертву (отселяемой) страницы применяется алгоритм замены страниц.
Записываем приносимую в жертву страницу на диск: изменяем саму страницу и таблицу кадров соответственным образом.
-
Считываем необходимую страницу во вновь освобождённый кадр, изменяем саму страницу и таблицы кадров.
-
Продолжаем свой процесс с того момента, в котором произошёл отказ кадра.
Обратите внимание, что если нет свободных кадров, требуется передача двух страниц. Соответствующая таблица страниц содержит бит для указания изменений с целью снижения накладных расходов. Имеющееся оборудование настраивает значение бита изменения для страницы при изменении любого байта соответствующей страницы в памяти [7].
Когда ваша система выбирает страницу для замены, она изучает значение бита изменения.
-
Когда соответствующий бит установлен, система понимает, что данная страница содержит отличия между своей версиями в памяти и на диске. Таким образом, система обязана записать данную страницу на диск.
-
Если бит изменения на взведён, данная страница не изменялась с того момента как она была считана в память, а потому мы можем сэкономить один доступ к памяти.
При реализации страничного обмена по запросу разработчик страничного обмена обязан решать две основные задачи:
-
Его система обязана принимать решение сколько кадров выделять каждому процессу: это носит название алгоритма выделения кадров.
-
Система обязана выбирать значения кадров на замену когда она необходима: алгоритм замены страниц.
Простейший алгоритм замены страниц это алгоритм FIFO (first-in, first-out - первым прибыл, первым обслужен). Он ассоциирует всякую страницу со временем загрузки данной страницы в память. Система применяет эту временную метку для выбора под замену самой старой страницы. Производительность алгоритма FIFO не всегда верна: Если мы выбираем страницу, которая активно используется исполняемым процессом, наш алгоритм замены выберет для замены некую иную страницу, и почти немедленно произойдёт новый отказ.
Паршивое решение замены увеличивает соотношение отказов и замедляет исполнение процесса; однако это не вызывает неверного исполнения [1].
Оптимальная замена страниц требует знаний о будущем. Тем не менее, когда они доступны, они предоставляют наинизшую вероятность частоты отказов для фиксированного числа раз. Основная идея алгоритмов OPT или MIN состоит в замене той страницы, которая не применяется длительное время.
Если мы применяем только что произошедшее для получения приблизительного представления о недалёком будущем, мы способны заменять ту страницу, которую данный процесс не применял длительное время. Замена LRU связывает каждую страницу с моментом времени последнего применения этой страницы. Когда ваша система выбирает страницу на замену, LRU выбирает наиболее длительно не применявшуюся страницу. Далее LRUстановится неким приближением для стратегии замены OPT [7]. Обычно LRU требует солидной аппаратной поддержки. Двумя возможными реализациями выступают:
-
Счётчики: связывают каждую запись поля времени применения таблицы страниц и добавляют логический таймер для своего ЦПУ.
Значение таймера увеличивается при каждой ссылке на память.
При всякой ссылке на страницу соответствующее оборудование копирует значение регистра таймера в поле времени применения записи таблицы страниц для этой страницы.
Значение страницы заменяется величиной наименьшего времени. Для этого необходим поиск по данной таблице страницы LRU и запись в память для каждого доступа к памяти.
-
Стек: Отслеживание стека номеров страниц и при каждой ссылке процесса на страницу её запись перебирается наверх данного стека.
Вершина стека всегда будет обладать самой последней применённой страницей, а страница LRU всегда будет внизу такого стека. И реализация 'счётчика' LRU, и реализация 'стека' LRU требуют содействия оборудования помимо регистров TLB [1].
LRU как и оптимальная замена относятся к множеству алгоритмов замены страниц с названием алгоритмов стека. Все алгоритмы стека разделяют такие характеристики:
-
Набор страниц в памяти для N кадров всегда выступает подмножеством набора страниц, которое бы пребывало в памяти при N+1 кадре.
-
Алгоритмы стека не проявляют аномалии Белади.
Ряд вычислительных систем предоставляют достаточно оборудования поддержки для истинной замены LRU. Тем не менее, многие системы пользуются битом ссылки, который устанавливается имеющимися аппаратными средствами при каждой ссылке на страницу [1]. Хотя они и не сообщают о своём порядке применения, многие алгоритмы замены используют такой бит ссылки. Эти алгоритмы аппроксимируют LRU по следующим причинам:
-
Всякая запись соответствующей таблицы страниц обладает собственными битами ссылки.
-
В процессе запуска программы эти биты очищаются самой операционной системой.
-
При каждом обращении к странице этого процесса соответствующий бит устанавливается имеющимся оборудованием.
Для реализации LRU при помощи такого бита ссылки требуются:
-
Оставлять байт для каждой страницы в таблице в памяти.
-
С определённой периодичностью сама операционная система сдвигает установленный бит ссылки каждой страницы в наивысший бит такого байта, двигая прочие биты вправо.
Сам регистр затем содержит всю историю тех страниц, которые применялись последние разы. Если мы представляем этот байт как целое без знака, страницей LRU выступает страница с наименьшим числом и она может быть заменена [1].
Алгоритм второй возможности
Алгоритм второй возможности это алгоритм замены FIFO. При своём выборе страницы на замену он инспектирует их бит ссылок.
-
Если значение бита страницы отключено, данная страница замещается.
-
Когда бит этой страницы взведён, данная страница получает второй шанс и выбирается следующая страница FIFO из списка LRU.
Когда страница получает вторую возможность, система отключает её бит ссылок и перезапускает её время доставки на значение текущего времени. Тем самым, когда страница получает вторую возможность, она не будет заменена пока не будут заменены или не получат своего второго шанса прочие страницы [7].
Алгоритм расширенной второй возможности
Данный алгоритм учитывает значение числа необходимых операций ввода/ вывода по замене страницы [1]. Алгоритм расширенной второй возможности принимает во внимание значение бита ссылок и изменение бита для предоставления возможности странице. Он строится с применением Таблицы 3.3:
| Ссылка | Изменение | Описание |
|---|---|---|
|
|
Никакого применения или изменения: наилучшая страница для замены. |
|
|
Не применялась недавно, но изменена. Такая страница должна быть записана повторно перед заменой. |
|
|
Только что применялась, но чистая: может применяться вскорости снова, но способна стать обновлённой. |
|
|
Только что применялась и изменена. Наихудшая страница для замены. |
Замена страницы на основе счётчика отслеживает счётчик числа ссылок, которым обладает каждая страница. Данный алгоритм способен применять любую из двух схем:
-
Наименее часто применяемой (LFU, Least frequently used). Заменяется такая страница с наименьшим значением счётчика.
-
Наиболее часто применяемой (MFU, Most frequently used). Страница с наименьшим значением счётчика, вероятно, только что заброшена в память и пока не применялась.
Данный алгоритм обладает отчётноостью о хорошей производительности для последовательного считывания файлов, такого как в складах данных [1].
Дополнительно к алгоритмам замены страниц ваша система может применять буферизацию страниц. Данное решение составляется из наличия пула свободных кадров. Такой пул свободных кадров выполняет считывание в свободный кадр прежде чем выполнена запись соответствующего отселения. Данный заполненный пул свободных кадров затем применяется для увеличения производительности системы при следующих обстоятельствах [7]:
-
В момент отказа страницы для замены выбирается отселяемый кадр вновь запрошенным кадром, однако необходимый новый кадр считывается в свободный кадр из имеющегося пула прежде чем будет записан вытесняемый.
-
Наконец, когда соответствующий вытесняемый кадр окончательно записан, его кадр перемещается в пул свободных кадров.
Производительность некоторых приложений при доступе через систему виртуальной памяти операционной системы хуже чем когда операционная система вовсе не предоставляет никакой буферизации. Типичным образцом этого выступает база данных, которая предоставляет собственные управление памятью и буферизацию ввода/ вывода. Операционные системы предоставляют `сырой диск`, который позволяет программам пользоваться разделом диска как обладающего размером последовательным массивом логических блоков, причём без какой бы то ни было файловой системы для адресации к ним [1].
Если мы теперь принимаем во внимание что вычислительная система способна обрабатывать исполняющиеся одновременно множество процессов, нам потребуется ответить на такой вопрос: "Как мы на практике выделим значение фиксированного объёма свободной памяти различным процессам?" [7]
Одной из причин для выделения по крайней мере минимального числа кадров выступает производительность:
-
По мере снижения значения числа выделяемых каждому процессу кадров соотношение отказов страниц растёт, замедляя исполнение процесса.
-
Процесс обязан обладать достаточным объёмом кадров для поддержки всех необходимых различных этапов на которые способны ссылаться любые инструкции в процессе полного цикла исполнения инструкций. В противном случае такое исполнение инструкций потребует повторного запуска.
Значение объёма доступной физической памяти определяется значением максимального числа кадров [1].
Самый простой способ расщепления M кадров по N процессам состоит в предоставлении всем некого равного совместного ресурса M x N кадров. Находящиеся слева кадры могут формировать буфер свободных кадров. Такая техника носит название равного выделения. Другим вариантом является пропорциональное выделение, когда вся доступная память выделяется каждому из процессов в зависимости от размера своего процесса. Таким образом, все процессы совместно применяют все доступные кадры в соответствии с собственными потребностями. Некими помехами равному и пропорциональному выделениям выступают:
-
Такое выделение может изменяться в соответствии со своим уровнем многопроцессности. Когда операционная система создаёт новый процесс, всякий новый процесс утрачивает какое- то число кадров для предоставления необходимой памяти для вновь создаваемого процесса.
-
Нет никакой приоритезации процессов. Процесс с высоким приоритетом рассматривается так же как и процесс с низким приоритетом.
Пропорциональное выделение обладает возможностью учёта размера программы и приоритета её процесса чтобы следовать приоритетам процессов [1].
Глобальная замена страниц позволяет процессу выбирать заменяемый кадр из имеющегося множества всех кадров, причём даже когда этот кадр получает иной процесс. Как альтернатива, локальная замена страниц требует чтобы всякий процесс выполнял выбор лишь из своего собственного набора выделенных кадров.
Также допустима схема выделения при которой процесс способен выбирать замену помимо собственных кадров также и кадры всех процессов с более низким приоритетом.
При глобальной замене страниц некий процесс способен столкнуться с выбором только кадров, которые выделены прочим процессам, тем самым увеличивая значения числа выделяемых ему кадров. Одной из проблем с глобальной заменой является то, что процесс не способен контролировать своё соотношение отказа страниц, что означает что тот же самый процесс может исполняться совершенно по- разному в соответствии с имеющимся уровнем многозадачности. Глобальная замена обычно имеет результатом более высокую пропускную способность системы и, тем самым, является более употребимым методом [1].
В системах со множеством ЦПУ конкретный ЦПУ обладает более быстрым доступом к некоторым разделам основной памяти, нежели он способен получать доступ к прочим. Такие отличия производительности вызываются тем как взаимодействуют через физические соединения ЦПУ и память. Системы NUMA медленнее систем, в которых ЦПУ совместно расположены на одной материнской плате. В системах NUMA оптимально расположенные кадры страниц способны оказывать значительное воздействие на производительность. Тот же самый тип управления исключениями также требуется для планирования систем для получения ведущих себя надлежащим образом систем NUMA. Необходимые изменения управлением состоят из отслеживания самого последнего ЦПУ на котором исполнялся каждый процесс. Такие исторические сведения применяются имеющимся планировщиком для расписания каждого процесса не его предыдущем ЦПУ. Далее имеющаяся система управления памятью выделяет наиболее близкие к тому ЦПУ, на котором будет выполняться данный процесс, кадры. Такая стратегия улучшает попадания в кэш и снижает значения времени доступа к памяти в подобной системе [1].
ОС Solaris решает данную задачу созданием в своём ядре lgroups (locality groups, групп локальности). Всякая lgroup совместно отслеживает ближайшие ЦПУ и память. Это создаёт некую иерархию lgroup на основе значений задержек между ними. Solaris пытается планировать все потоки процесса и выделять всю необходимую память процессу внутри его lgroup. Когда это не возможно, она пользуется наиболее близкой lgroup, применяя имеющуюся иерархию [10].
Буфер быстрого преобразования адреса (TBL, translation lookaside buffer) это кэш специального назначения в самом процессоре, применяемый для ускорения доступа к имеющейся таблице страниц в виртуальной памяти.
Такой TBL играет существенную роль в защите памяти для виртуальной памяти. Для осуществления этого когда операционная система принимает решение сменить исполняемый процесс с P1 на выполнение процесса P2, когда нет никакого загруженного в кэш своего процессора TBL, достаточно изменить значение регистра таблицы страниц на указание таблицы страниц P2 (вместо P1). Тем не менее, когда TLB уже загружен, тогда требуется очистить все записи P2. Иной распространённой альтернативой защите памяти выступает расширение на виртуальное адресное пространство добавлением идентификатора процесса или идентификатора задачи на данный адрес [2].
Когда процесс обладает высокой активностью подкачки страниц, его ЦПУ тратит бо́льшую часть своего времени в жонглировании страницами между своей оперативной памятью и имеющимся устройством подкачки страниц. Подобная ситуация носит название пробуксовки (trashing). Когда возникает ситуация пробуксовки, процесс способен тратить на подкачку страниц больше времени, нежели на исполнение.
Пробуксовка имеет результатом существенную деградацию производительности и может произойти коллапс возможности отклика самой системы. Операционной системе требуется предотвращать пробуксовку любой ценой [7]. Когда значение числа выделяемых процессу с низким приоритетом кадров падает ниже минимального необходимого для данной архитектуры компьютера уровня, сама операционная система обязана приостановить такой процесс с низким приоритетом, затем этот процесс освобождает страницы и его кадры могут быть освобождены.
Операционная система отслеживает оптимизацию ЦПУ в качестве способа контроля за значением уровня многозадачности. Когда её ЦПУ недогружен, её планировщик способен увеличит значение уровня многозадачности. Когда в момент создания процесса применяется глобальная замена страниц, при начале отказов страниц кадры берутся от прочих процессов. Данному процессу требуются подобные страницы, а потому он также получает отказы.
По мере роста очереди процессов к устройству подкачки страниц освобождается очередь готовности и снижается загруженность ЦПУ. Диспетчер ЦПУ наблюдает уменьшение загруженности ЦПУ и снова увеличивает степень многозадачности. В данный момент, для увеличение загруженности ЦПУ и остановки пробуксовки, операционная система обязана снижать степень многозадачности. К сожалению, планировщик ЦПУ делает ровно обратное.
Такое воздействие пробуксовки может ограничиваться только при помощи локальной замены страниц или замены с приоритетами. Во избежание пробуксовки следует применять исполнение процессов аналогичное модели локальности [1]. Локальность это множество страниц, которые активны совместно, а сама модель локальности постулирует, что по мере выполнения процесса он перемещается от одной локальности к другой. Тем самым, программа в целом составляется из некоторого числа различных локализаций. Сама структура программы и её структуры данных определяют локализации. Модель локальности устанавливает, что все программы будут проявлять подобную базовую структуру ссылок памяти [7].
Для определения окна рабочего набора эта модель применяет параметр дельты. Вычисление рабочего набора сложное [1].
-
Когда страница активна в исполняемом процессе, эта страница будет в рабочем наборе. Если страница более не активна, данный рабочий набор сбросит эту страницу после n единиц времени со своей последней ссылки.
-
Такой рабочий набор является неким приближением локальности своей программы.
-
Самым важным свойством такого рабочего набора является его размер, который может меняться со временем.
-
Общий запрос системной памяти компьютера это значение суммы размеров рабочих наборов всех процессов.
-
Когда запрос превышает общее число доступных кадров, происходит пробуксовка.
Имеющаяся операционная система отслеживает состояние рабочего набора каждого процесса. Когда имеется достаточное число дополнительных кадров, может запускаться дополнительный процесс. Если запрос к системе превосходит общее число доступных кадров, операционная система выбирает процесс для приостановки. Данная модель рабочего набора успешна, однако до некоторой степени неуклюжа в отношении контроля пробуксовки.
Одним из существенных свойств пробуксовки выступает высокая частота отказа страниц. Когда для некого процесса число отказов страниц слишком велико, нам ясно что ему требуется больше кадров. Если же они слишком низкое, этот процесс, вероятно, может обладать слишком большим числом кадров. Имеющаяся операционная система способна устанавливать верхнюю и нижнюю границы для соотношения отказов страниц.
-
Процесс получает новый кадр когда он переваливает за верхний край.
-
Процесс утрачивает кадр если он падает ниже нижней границы.
Если соотношение отказа страниц превосходит верхнюю границу, а свободных кадров нет, операционная система может приостановить процесс и распределить только что высвобожденные кадры по тем процессам, у которых соотношение отказов высокое.
В этом разделе мы обсудим общие альтернативы работы для управления памятью и то, как это определяет его поведение. Мы изучим эти политики как последовательности действий, которые применимы к любым двум уровням иерархии памяти, хотя для упрощения мы в первую очередь будем пользоваться терминологией кэширования.
Вот рассматриваемые действия:
-
Размещение блока
-
Доступ к блоку
-
Замена блока при промахе в кэше
-
Одновременность в иерархии памяти
Основное преимущество роста степени ассоциативности состоит в том, что это некий способ контроля соотношения промахов и его снижения. Улучшение достигается за счёт снижения промахов, происходящих при конкуренции за одно и то же место. Некие техники размещения блоков отражены в Таблице 3.4.
| Схема | Число наборов | Блоков в наборе |
|---|---|---|
Прямого соответствия |
Число блоков в кэше |
1 |
Ассоциативный набор |
(число блоков в кэше)/ ассоциативность |
Ассоциативность (обычно 2-16) |
Полная ассоциативность |
1 |
Число блоков в кэше |
Сам выбор между прямым соответствием, ассоциативным набором или полной ассоциативностью отражения в любой иерархии памяти будет зависеть от значения стоимости промахов по отношению к стоимости реализации ассоциативности, причём как в отношении времени, так и в дополнительном оборудовании. Как правило, кэширование с полной ассоциативностью запрещено, за исключением малых размеров. Тем не менее, для виртуальной памяти применяется подход с полной ассоциативностью, поскольку промахи обходятся дорого, а для снижения частоты промахов имеются изощрённые схемы замены. Некие методы доступа к блокам отражены в Таблице 3.5.
| Ассоциативность | Метод расположения | Требуемое число сравнений |
|---|---|---|
Прямое соответствие |
Индексный |
1 |
Ассоциативный набор |
Индексный для набора, поиск по элементам |
Степень ассоциативности |
Полная ассоциативность |
Поиск по всем записям в кэше |
Размер кэша |
Полная ассоциативность |
Обособленная таблица поиска |
0 |
Существуют две первичные стратегии замены при ассоциативном кэшировании: произвольная или LRU. Для некоторых рабочих нагрузок случайная замена способна оказываться лучшей, нежели LRU. Для кэша такой алгоритм кэширования это аппаратный модуль, что подразумевает, что соответствующая схема должна реализовываться просто. В виртуальной памяти, однако, система выполняет приближение LRU.
Промахи в кэше можно подразделить по их природе на следующие [2]:
-
Принудительные промахи: Это самые первые промахи, вызываемые самым первым доступом к блоку, который никогда не присутствовал в кэше (холодный старт).
-
Промахи по причине ёмкости: Вызваны тем, что кэш никогда не способен содержать все необходимые блоки в процессе исполнения своей программы.
-
Промахи конфликта: Когда множество блоков конкурируют за один и тот же набор (промахи соперничества).
Многопроцессность с большим числом ядер означает множество процессоров в отдельной микросхеме. Такие процессоры, скорее всего, совместно применяют общее физическое адресное пространство, что подразумевает разделение данных.
Кэширование совместных данных вводит новую задачу, поскольку имеющееся удерживаемое индивидуальными процессорами представление памяти происходит через кэширование. Такое поведение носит название задачи согласованности кэширования. Согласованность (когерентность) определяет то значение, которое может возвращать операция считывания. Непротиворечивость определяет когда считывание вернёт записанное значение. Система памяти согласована если она отражает следующие особенности:
-
Считывание процессором P в местоположение X, которое происходит вслед за записью P в X, причём в отсутствии прочих записях X другими процессорами между такими записью и считыванием, всегда возвратит записанное P значение.
-
Считывание процессором местоположения X, которое происходит вслед за записью в X другим процессором возвращает такое записанное значение, когда считывание и запись обладают достаточным временем на отделение и никакие прочие записи в X не происходят между этими двумя доступами.
-
Записи в одно и то же место упорядочиваются: Две записи любых двух процессоров для всех процессоров выглядят в одном и том же порядке.
Самое первое свойство сохраняет порядок программы, а второе свойство определяет понятие того что значит обладать согласованной памятью [2].
Основы соблюдения согласованности
При согласованной многопроцессности кэширования кэширование предоставляет как миграцию, так и реплицирование совместно используемых элементов данных:
-
Миграция: Элемент данных может быть перемещён в локальный кэш и применяться прозрачным образом. Миграция снижает задержки и потребности в полосе пропускания совместно используемой памяти для доступа к разделяемым элементам данных, которые поступают из удалённого местоположения.
-
Репликация: При одновременном считывании совместно применяемых данных кэширование выполняет копирование такого элемента данных в своём локальном кэше. Репликация снижает как задержку доступа, так и конкуренцию за считывание совместного элемента данных.
Протоколы поддержки согласованности для множества процессоров носят название протоколов согласованного кэширования. Ключевым моментом для протокола согласованного кэширования выступает отслеживание значения состояния всех совместных данных блока данных [2].
Протоколы слежения
Один из методов обеспечения согласованности состоит в том чтобы гарантировать процессору исключительный доступ к данным до того как он запишет этот элемент. такой стиль протоколов носит название протокола превращения записи в недействительную, поскольку при записи он аннулирует копии в прочих кэшированиях.
Рассмотрим один доступ на запись, за которым следует один доступ для чтения другим процессором: поскольку для записи требуется исключительный доступ, любая удерживаемая процессорами чтения копия, должна быть признана недействительной, а кэш вынужден получить новую копию данных. Одним из выводов является то, что важную роль в согласованности кэша играет размер блока, ибо большинство протоколов между процессорами обмениваются полными блоками, тем самым увеличивая требования к пропускной способности согласованности. Большие блоки могут вызвать то, что называется ложным разделением: когда один и тот же блок кэша содержит две независимые общие переменные, полный блок обменивается между процессорами, причём даже если процессоры обращаются к разным переменным. Ложное совместное применение следует учитывать во время программирования и в процессе компиляции.
Дополнительно к слежению за протоколом согласованности кэширования, когда он распределяет значение состояния совместно используемых блоков, протокол отслеживания согласованности на основе каталога удерживает значение состояния совместного применения соответствующего блока физической памяти всего в одном месте, носящем название его каталога.
Протоколы согласованности кэширования на основе каталога обладают слегка более высокими накладными расходами реализации, нежели следящие, тем не менее, они снижают обмен между кэшами и тем самым масштабируются на большее число процессоров [2].
Собственно выбор алгоритма замены и политики выделения памяти это самое основное решение, которое осуществляется для политики подкачки страниц. Тем не менее, в данном разделе мы обсудим также прочие подлежащие рассмотрению вопросы.
Предварительная выборка это некая попытка препятствия высокого уровня первоначальной подкачки страниц. Данная стратегия служит привнесению всех необходимых страниц памяти за раз. В применяющих модель рабочего набора системах, их операционная система хранит перечень всех страниц рабочего набора при приостановке соответствующего процесса и привносит его целиком обратно когда такой процесс может быть возобновлён.
При построении нового ЦПУ его проектировщик может рассматривать значение размера страницы. Размеры страниц неизменно остаются степенью двойки. Тем не менее, имеется некий набор факторов, поддерживающих различные размеры страниц:
-
Размер таблицы страниц: При фиксированном пространстве виртуальной памяти снижение величины размера страницы увеличивает значение числа страниц и величины размера самой таблицы страниц.
-
Поскольку таблица страниц необходима всем процессорам, желателен большой размер таблицы страниц.
-
Память лучше используется с применением страниц меньшего размера по причине снижения внутренней фрагментации.
-
Меньшие размеры страниц снижают значение числа операций ввода/ вывода по причине того, что лучшая грануляция памяти достигает лучшей локальности программы.
-
Большой размер страницы снижает значение числа отказов страниц.
Соотношение попаданий для TLB относится к процентному значению преобразований виртуальных адресов, которые разрешаются в этом TLB, а не в таблице страниц. Один из способов увеличить соотношение попаданий состоит в увеличении количества записей в TLB; однако это дорого. Рост TLB соотносится с объёмом доступной в TLB памяти и представляет собой количество записей, умноженное на размер страницы. Удвоение количества записей TLB также удваивает протяжённость TLB. Если размер страницы может увеличиваться, тогда увеличивается и протяжённость TLB. Такие приложения как базы данных, применяют гигантские страницы. Для увеличения размера страницы TLB должен управляться программным обеспечением, а не дорогостоящим аппаратным обеспечением; тем не менее, его цена зачастую превосходит прирост производительности, который достигается за счёт увеличения соотношения попаданий TLB [1].
Управление обратной таблицей страниц требует хранения сведений о кадрах для страниц в обособленной странице. Такая обособленная страница это просто другая обычная страница. Основная цель данного вида управления состоит в снижении объёма памяти, требующегося для отслеживания переводов адресов из виртуальных в физические. К несчастью отказ страницы способен вызывать от самого диспетчера виртуальной памяти выработку дополнительного отказа страниц [1].
Запрос страниц разрабатывается прозрачным для своего пользователя; тем не менее, когда пользователь имеет представление о лежащем в основе запросе страниц, можно существенно улучшить производительность системы.
Тщательный выбор структур данных способен увеличивать показатель локальности, а следовательно снижать количество отказов страниц и значение числа страниц в своём рабочем наборе.
-
Структуры стека данных обладают хорошей локальности, поскольку доступ к ним осуществляется исключительно через вершину.
-
Структуры хэшированных данных имеют плохую локализацию, поскольку они спроектированы под рассеивание ссылок.
Локальность выступает ещё одной мерой значения действенности структуры данных.
Существенное влияние на страничное разбиение способны оказывать компилятор и компоновщик. Отделение кода от данных и выработка повторно применяемого (реентерабельного) кода означает, что страницы кода доступны исключительно на считывание и никогда не будут изменяться. Сам загрузчик и относящиеся к нему подпрограммы могут умещаться в одной и той же странице. Данная стратегия являет собой воплощение задачи упаковки исполняемого кода исследования операций [1].
Когда система пользуется запросом страниц, её порой требуется допускать блокировку определённых страниц в памяти. По этой причине каждый кадр обладает битами блокировки. Когда такой кадр блокирован, он не допускает перемещения страницы. От битов блокировки способны получать преимущества различные ситуации:
-
Некоторые части самой операционной системы требуют блокировки в памяти (например её диспетчер памяти).
-
Фрагментом памяти может пожелать управлять некая база данных.
Закрепление или блокирование памяти это распространённое явление и большинство операционных систем обладают системным вызовом, позволяющим приложению закреплять некую область своего адресного пространства. К сожалению, это способно вызывать напряжение для применяемого алгоритма управления памятью. Блокирование памяти также может быть опасным; значение бита блокировки может быть взведено и никогда не сбрасываться. Когда происходит подобная ситуация, такой блокируемый кадр превращается в не используемый [1].
Файл соответствия памяти делает возможным логическую ассоциацию соответствующего виртуального адресного пространства некому файлу для получения преимуществ в производительности. Файл соответствия памяти выполняется установкой соответствия дискового блока странице в памяти (Рисунок 3.6). Первоначальный доступ к этому файлу происходит через обычный запрос страниц, являющийся результатом отказа страницы, тем не менее, часть этого файла размеров со страницу считывается из имеющейся файловой системы в физическую страницу. Записи в такой файл соответствий не обязаны быть синхронными с записями в сам файл на диске. Когда процесс закрывает данный файл, все относящиеся к соответствию в памяти данные записываются обратно на диск и удаляются из имеющейся виртуальной памяти данного процесса. Допускается одновременное соответствие множества процессов к одному и тому же файлу, что делает возможным совместное использование данных.

Системные вызовы соответствия памяти также способны поддерживать функциональности копирования записью (copy on write), позволяя процессам совместно применять файл в режиме доступа только на считывание, но при этом обладать своими копиями соответствующих данных, которые они способны изменять.
Совместная память зачастую реализуется при помощи файла соответствия памяти [1].
Всякий контроллер ввода/ вывода содержит регистры для содержания подлежащих обмену команд и данных. Многие архитектуры вычислительных систем предоставляют операции ввода/ вывода с соответствием в памяти для более удобного доступа к устройства ввода/ вывода. Таким регистрам устройств выделяются и ставятся в соответствие адреса диапазонов памяти. Считывание и запись в такие адреса памяти вызывает обмен соответствующих данных с регистрами подобного устройства [1].
Ядро само по себе выделяет память из пула свободной памяти отличную от того списка, который удовлетворяет процессам режима пользователя по следующим причинам:
-
Для минимизации бесполезных трат на фрагментацию. Такая оптимизация особенно важна поскольку сама операционная система не выполняет подкачку страниц своего кода или данных.
-
Выделения страниц процессам режима пользователя не обязано обладать непрерывной областью физической памяти; тем не менее, определённые аппаратные устройства могут требовать размещения памяти в физически непрерывных страницах.
Метод близнецов
Метод близнецов выделяет память из сегмента фиксированного размера, составленного из физически непрерывных страниц. Выделяемая из данного сегмента память применяет распределителями степени 2.
Преимуществом такого метода близнецов выступает то, что прилегающие друг к другу близнецы могут объединяться в виде сегментов большего размера с применением техники, носящей название слияния (coalescing). К недостаткам такой системы близнецов относится то, что округление до верхней степени 2, скорее всего, вызывает фрагментацию внутри выделяемых сегментов. Это не способно обеспечивать траты впустую по причине внутренней фрагментации менее 50% выделяемого элемента [1].
Выделение плит
Некая плита (сляб, slab) создаётся из одной или более физически непрерывных страниц, а кэш составляется из одной или более плит (Рисунок 3.7). Всякая уникальная структура данных ядра обладает собственным кэшем. Каждый кэш заполняется неким объектом, который выступает воплощением ассоциируемых этим кэшем структур данных ядра. Алгоритм выделения плит пользуется кэшированием для хранения объектов ядра. Когда операционная система создаёт некий кэш, она предварительно выделяет в этот кэш некоторые свободные объекты. Если требуется некий новый объект для какой- то структуры данных ядра, блок распределения способен назначать любой свободный объект из такого кэша и помечать его задействованным [11].
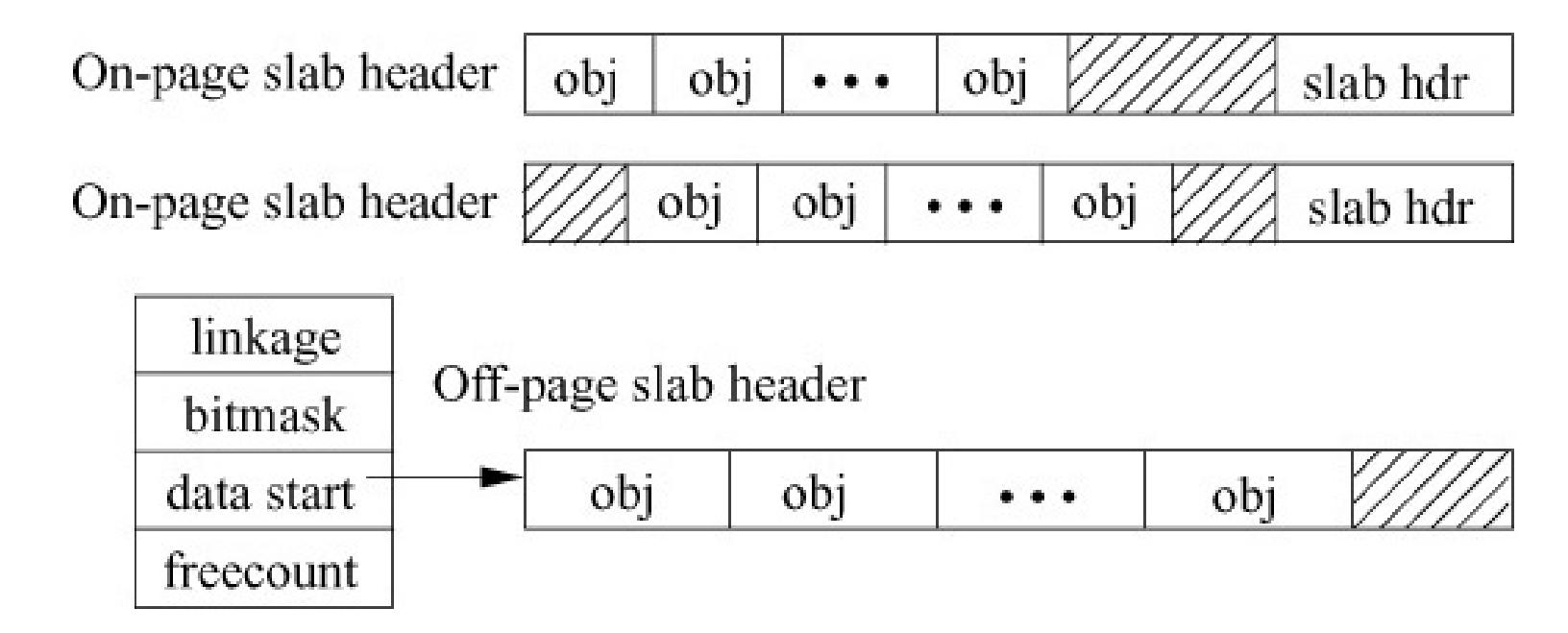
Блок выделения плит предоставляет два основных преимущества:
-
На фрагментацию не теряется никакая память.
-
Память может выделяться очень быстро. Такое поведение особенно эффективно для управления памятью при частом создании и уничтожении объектов.
Наиболее широкое определение ВМ содержит все методы имитации, которые предоставляют стандартный интерфейс программного обеспечения, например, ВМ Java. Виртуальная машина предоставляет по крайней мере два преимущества, представляющие значительный коммерческий интерес:
-
Управляемое программное обеспечение: Некую абстракцию для запуска завершённого программного стека.
-
Управление аппаратными средствами: Завершённый программный стек способен запускаться на независимых серверах, совместно применяющих оборудование.
Стоимость виртуализации процессора зависит от имеющейся рабочей нагрузки.
-
Ограниченные процессором программы уровня пользователя не обладают никакими накладными расходами виртуализации.
-
Программы с активным применением ОС имеют высокие накладные расходы виртуализации.
Качественными требованиями для монитора виртуальных машин (VMM) выступают:
-
Гостевое программное обеспечение обязано полагаться на некую ВМ в точности как на естественное оборудование.
-
Гостевое программное обеспечение не должно обладать возможностью изменения выделенных ресурсов системы напрямую.
Поскольку VMM обязан гарантировать что его гостевая система взаимодействует исключительно с виртуальными ресурсами, обычный гость запускается в качестве программы режима пользователя поверх имеющегося VMM. Затем, если гостевая ОС предпринимает попытку применения привилегированной инструкции, это отлавливается имеющимся VMM, который далее оказывает соответствующее необходимое действие с требующимися реальными ресурсами.
При отсутствии подобной поддержки VMM обязан предпринимать особые меры предосторожности для выделения всех проблемных инструкций, что увеличивает сложность самого VMM и снижает производительность его гостевого программного обеспечения [2].
Возможности управления памятью архитектуры IA-32 подразделяются на две части [49]: сегментацию и подкачку страниц. Сегментация производит механизм изоляции индивидуальных кода, данных и модулей стека с тем, чтобы множество программ (или задач) можно было запускать в одном и том же процессоре без взаимодействия друг с другом. ПАодкачка страниц предоставляет механизм реализации традиционных страниц по запросу, системы виртуальной памяти, в которой разделы среды исполнения программы по мере необходимости ставятся в соответствие физической памяти. Подкачка страниц также может применяться для предоставления изолированности между множеством задач. при работе в защищённом режиме необходимо применять некий вид сегментации. Не существует бита режима для запрета сегментации. Применение подкачки страниц, тем не менее, не обязательно.
Данные два механизма (сегментация и подкачка страниц) могут настраиваться для поддержки простых систем обособленных программ (или однозадачности), систем с многозадачностью или многопрецессорных систем, которые применяют разделяемую память. Как отражено на Рисунке 3.8 [49], сегментация предоставляет механизм для деления адресуемого пространства памяти процессора (носящего название линейного адресного пространства) на защищённые адресные пространства меньшего размера, именуемых сегментами. Сегменты могут применяться для содержания кода, данных и стека для программы или хранения структур данных системы (таких как TSS или LDT). Когда в процессоре исполняется более одной программы (или задачи), каждой программе может назначаться свой собственный набор сегментов. Их процессор затем устанавливает конкретные границы между такими сегментами и гарантирует что одна программа не воздействует на исполнение другой программы осуществлением записи в сегменты такой иной программы. Данный механизм сегментации также допускает типизацию сегментов с тем, чтобы можно было выполнять ограничение на те операции, которые способны выполняться в определённом сегменте.
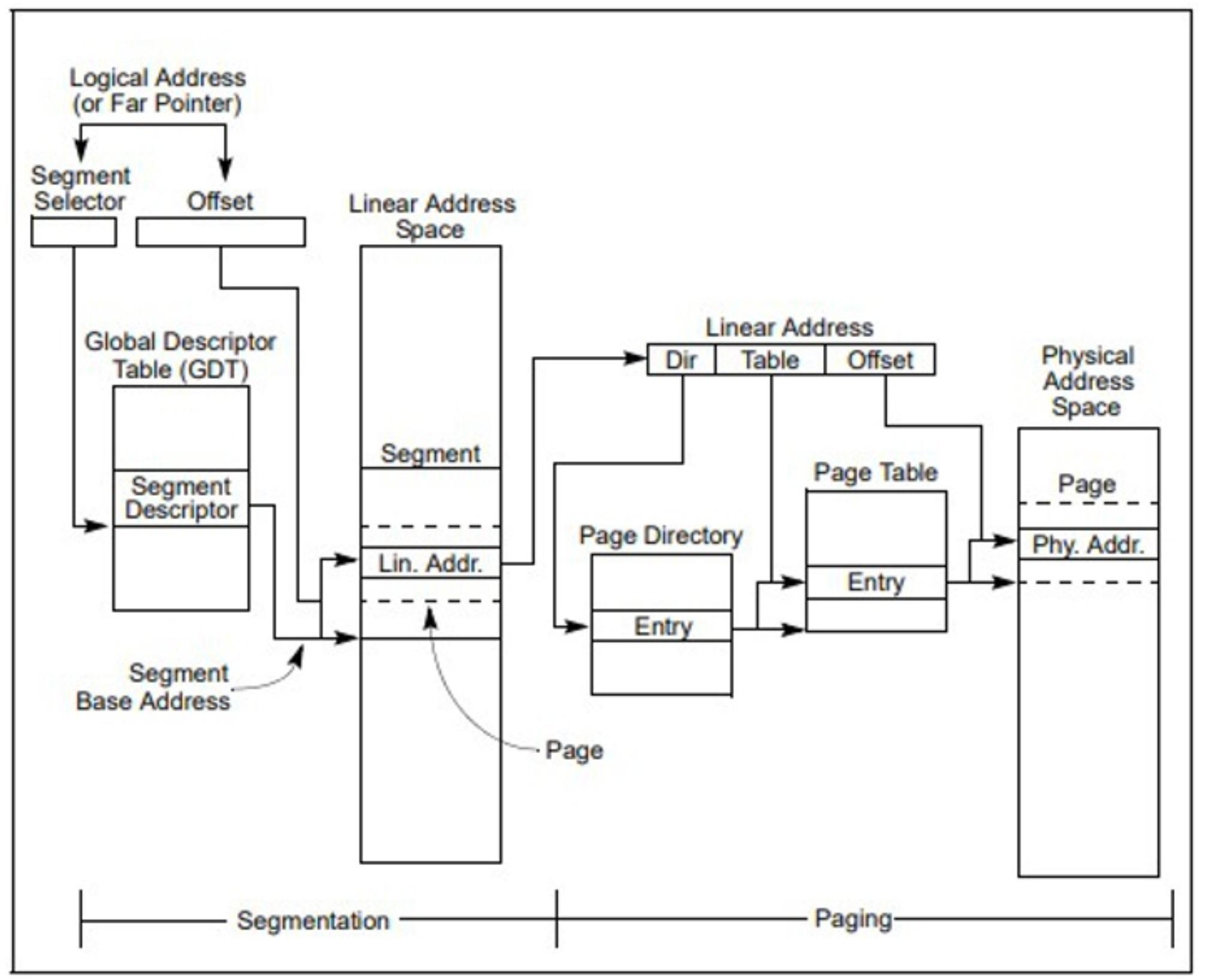
Все имеющиеся в системе сегменты содержатся в линейном адресном пространстве своего процессора. Для локализации некого байта в определённом сегменте, должен предоставляться некий логический адрес (также имеющем название дальнего указателя). Логический адрес составляется из переключателя сегмента и смещения. Переключатель сегмента это уникальный идентификатор для сегмента. Помимо всего прочего он предоставляет некое смещение в таблице дескрипторов (скажем, в глобальной таблице дескрипторов, GDT) к структуре данных с названием дескриптора сегмента. Каждый сегмент обладает дескриптором сегмента, который определяет значение размера этого сегмента, установленные права доступа и уровень привилегий для данного сегмента, значение типа сегмента и местоположение самого первого байта своего сегмента в установленном линейном адресном пространстве (также именуемого базовым адресом этого сегмента). Значение части смещения логического адреса добавляется к установленному базовому адресу для этого сегмента с целью локализации байта внутри своего сегмента. Значение базового адреса плюс величина смещения, таким образом, формируют линейный адрес в линейном адресном пространстве своего процессора.
Когда подкачка страниц не применяется, установленное линейное адресное пространство процессора непосредственно ставится в соответствие имеющемуся физическому адресному пространству процессора. Такое физическое адресное пространство определяется как тот диапазон адресов, который данный процессор способен вырабатывать в своей адресной шине.
Поскольку многозадачные вычислительные системы обычно определяют линейное адресное пространство намного большее нежели экономично реализуемое для содержания всей физической памяти за раз, требуется некий метод "виртуализации" имеющегося линейного адресного пространства. Подобная виртуализация имеющегося линейного адресного пространства обрабатывается через имеющийся механизм подкачки страниц процессора.
Подкачка страниц поддерживает среду "виртуальной памяти" в которой большое линейное адресное пространство имитируется меньшим объёмом физической памяти (RAM или ROM - оперативной или доступной только на чтение) и некого дискового хранилища. При применении подкачки страниц каждый сегмент делится на страницы (обычно размером в 4кБ каждая), которые хранятся либо в физической памяти, либо на своём диске. Сама операционная система или супервизор поддерживают каталог страниц и некий набор таблиц страниц для отслеживания таких страниц. Когда некая программа (или задача) пытается выполнить доступ к некому местоположению в его линейном адресном пространстве, её процессор пользуется этими каталогом страниц и таблицами страниц для перевода значения линейного адреса в некий физический адрес и затем выполняет запрашиваемую операцию (считывание или запись) в указанном месте памяти.
Когда подлежащая доступу страница в текущий момент времени не в физической памяти, её процессор прерывает исполнение данной программы (вырабатывая исключительную ситуацию отказа страницы). Имеющаяся операционная система или супервизор затем считывают эту страницу в физическую память с соответствующего диска и продолжает исполнение данной программы.
При надлежащей реализации подкачки страниц в операционной системе или супервизоре, такое переключение страниц между физической памятью и установленным диском прозрачны для корректного исполнения программы. Даже программа написанная для 16- битных процессоров IA32 может применять механизм подкачки страниц (прозрачно), когда она исполняется в режиме виртуального 8086.
В архитектуре AMD64 применяются методы управления сегментацией и/ или подкачкой страниц памяти. Обычно, управление памятью не видно прикладному программному обеспечению. Оно обрабатывается самим системным программным обеспечением и оборудованием процессора.
Сегментация AMD64
Архитектура AMD64 [50] спроектирована для поддержки всех форм наследуемой сегментации. Тем не менее, большинство системного программного обеспечения не пользуется функциональными возможностями сегментации, доступными в наследуемой архитектуре x86. Вместо этого системное программное обеспечение обычно обрабатывает изоляцию программы и данных применяя защиту уровня подкачки страниц. По этой причине имеющаяся архитектура AMD64 распределяется по множеству сегментов в 64- битном режиме и, вместо этого применяется модель плоской памяти. Имитация сегментации позволяет новому 64- битному системному программному обеспечению кодироваться более простым способом и она поддерживает более действенное управление многопроцессностью чем это возможно в наследуемой архитектуре x86.
Тем не менее, сегментация применяется в режиме совместимости и в режиме наследования. Здесь сегментация это некая форма адресации базовой памяти, которая позволяет программному обеспечению и данным быть перемещаемыми в виртуальном адресном пространстве относительно некого произвольного базового адреса. Программное обеспечение и данные могут перемещаться в виртуальном адресном пространстве пользуются одним или более сегментами памяти изменяемого размера. Такая наследуемая x86 архитектура предоставляет различные методы ограниченного доступа к сегментам из прочих сегментов с тем, чтобы такие программное обеспечение и данные могли быть защищены от взаимодействия друг с другом.
В режимах совместимости и наследования могут быть определены до 16 383 уникальных сегментов. Сами значение базового адреса, размер сегмента (носящий название предела), защита и прочие атрибуты для каждого из сегментов содержатся в структуре данных, которая именуется дескриптором сегмента. Коллекция дескрипторов сегментов содержится в таблицах дескрипторов. Конкретные дескрипторы сегментов применяются в качестве ссылки или выбираются из соответствующей таблицы дескрипторов при помощи регистра переключателя сегментов. Доступны шесть регистров переключателей сегмента для предоставления доступа за раз к шести сегментам.
Рисунок 3.9 [50] отображает некий образец сегментации памяти.

Одним особым случаем сегментации памяти является модель плоской памяти [50]. При модели наследуемой плоской памяти все адреса базовых сегментов обладают значением 0 и величина пределов сегмента фиксирована 4 ГБ. Сегментация не способна отключаться, но применение модели плоской памяти действенно отключает трансляцию сегментов. Получаемый результат заключается в виртуальном адресе, который эквивалентен действительному адресу. Рисунок 3.10 [50] отображает некий образец такой модели плоской памяти.

Исполняемое в 64- битном режиме программное обеспечение автоматически применяет такую модель плоской памяти. В 64- битном режиме значение базового сегмента трактуется как если бы оно было 0, а значение предела сегмента игнорируется. Это позволяет действенную адресацию для доступа к полному пространству виртуальных адресов, поддерживаемых данным процессором.
Подкачка страниц AMD64
Подкачка страниц позволяет программному обеспечению и данным перемещаться в физическом адресном пространстве при помощи блоков фиксированного размера с названием физических страниц. Наследуемая архитектура x86 поддерживает три различных размера физических страниц в 4 кБ, 2 МБ и 4 МБ [50]. Как и в случае с трансляцией сегментов, доступ к физическим страницам менее привилегированным программным обеспечением может быть ограничен.
Для перевода виртуальных страниц в физические страницы трансляция страниц пользуется иерархической структурой данных с названием таблицы трансляции страниц. Число уровней иерархии трансляции может составлять от одного до четырёх в зависимости от размера физической страницы и режима работы процессора. Таблицы трансляции выравниваются на границы в 4 кБ. Физические страницы, в зависимости от установленного размера физической страницы, должны выравниваться на границу в 4 кБ, 2 МБ или 4 МБ.
Всякая таблица в установленной иерархии трансляции индексируется некой порцией значений виртуальных битов. Имеющая ссылку на такой индекс таблицы запись содержит указатель на значение базового адреса таблицы следующего нижнего уровня в своей иерархии трансляции. В случае таблицы самого нижнего уровня, её записи указывают на базовые адреса соответствующей физической страницы. Сама физическая страница для достижения своего физического адреса далее индексируется самыми последними значащими битами своего виртуального адреса.
Рисунок 3.11 отображает пример разбитой на страницы памяти с тремя уровнями в своей иерархии таблиц трансляции.

Исполняемое в режиме долгого выполнения программное обеспечение требует обладания включённой трансляции страниц.
Смешанные сегментация и подкачка страниц AMD64
Программное обеспечение управления памятью способно сочетать применение сегментации памяти и разбиение памяти на страницы [50]. По причине того, что сегментация не может отключаться, управление подкачкой страниц требует некой минимальной инициализации имеющихся ресурсов сегментации. разбиение на страницы может быть отключено полностью, поэтому управление сегментацией не требует инициализации ресурсов подкачки страниц.
Сегменты могут находиться в диапазоне длины от одного байта до 4 ГБ. Таким образом, имеется возможность установки соответствия множества сегментов одной физической странице и выполнять соответствие множества физических страниц одному сегменту. Выравнивание между границами сегментов и физических страниц не требуется, однако программное обеспечение управления памятью при выравнивании границ сегментов и физических страниц упрощается.
Самым простым, наиболее действенным методом управления памятью выступает модель плоской памяти. При модели плоской памяти все базовые адреса сегментов обладают значением 0, а сам сегмент ограничен и фиксирован в 4 ГБ. Сам механизм сегментации всё ещё применяется при каждом выполнении ссылки на память, однако поскольку виртуальные адреса в данной модели идентичны действительным адресам, такой механизм сегментации действенно игнорируется. Трансляция виртуального (или действенного) адреса в физические адреса имеет место с применением лишь механизма подкачки страниц.
По причине того, что 64- битный режим отключает сегментацию, для управления памятью он применяет плоскую модель разбиения на страницы. В 64- битном режиме предел сегмента в 4 ГБ игнорируется. Рисунок 3.12 отображает пример данной модели.
