Глава 6. Условия управления задачами
Содержание
Ansible является некоторой системой для исполнения задач в одном или более хостов и гарантии того что операторы
осознают произойдут ли изменения (и на самом ли деле возникли ли какие- то проблемы). В результате задачи Ansible
имеют результатом четыре возможных состояния задачи: ok,
changed, failed
или skipped. Эти состояния выполняют ряд важных
функций.
С точки зрения некого оператора исполняющего какой- то плейбук Ansibl, они обеспечивают надзор за выполнением Ansible
независимо от того изменилось ли что- то или нет, а также были ли каккие- то сьои, которые требуют своего устранения.
Кроме того, они определяют сам поток определённого плейбука - например, если какая- то результаты какой- то задачи пребывают
в состоянии changed, в этом плейбуке может быть включён какой- то обработчик.
Аналогично, если некая задача имеет результатом failed, установленное по
умолчанию поведению Ansible состоит в том чтобы не пытаться в этом хосте выполнять задачи далее. Задачи также могут
применять условия, которые проверяют значение состояние предыдущих задач для контроля за действиями. Как результат, эти состояния,
или условия задач являются центром практически всего что выполняет Ansible и важно понимать как с ними работать, а тем самым
как как управлять имеющимся потоком некого плейбука - в особенности, например, при возникновении сбоя.
В данной главе мы изучим эти подробности, в частности сосредоточившись на следующих темах:
-
Управление в случае, когда определён некий отказ
-
Аккуратное восстановление из состояния отказа
-
Контроль того, что определило некое изменение
-
Выполнение итераций по некому набору задач с применением циклов
Ознакомьтесь с видеоматериалами Code in Action.
Большинство поставляемых с Ansible модулей имеют некую опцию, которая устанавливает некую ошибку. Ошибочное
условие сильно зависит от самого модуля и того, что пытается осуществлять данный модуль. Когда какой- то
модуль возвращает некую ошибку, данный хост будет удалён из имеющегося набора доступных хостов, что
предотвращает все последующие задачи или исполнения обработчиков для такого хоста. Далее, определённая
функция ansible-playbook или исполнение Ansible выйдет с не нулевым значением,
которое указывает отказ. Однако, мы не ограничены неким мнением модуля что имеется какая- то ошибка. Мы можем
игнорировать ошибки или повторно определять такое условие ошибки.
Для игнорирования ошибок применяется некое условие задачи, именуемое ignore_errors.
Это условие является Булевым, что означает, что его значение должно быть чем- то, что Ansible понимает как
true, например, yes,
on, true или
1 (строковое или целое).
Для демонстрации применения ignore_errors, давайте создадим некий
плейбук с названием errors.yaml, в котором мы попытаемся запросить некий
несуществующий вебсервер. Обычно это будет некоторой ошибкой и если мы не определили
ignore_errors, мы получим установленное по умолчанию поведение, то есть
данный хост будет помечен как отказавший и никакие последующие задачи не будут предпринимать свои попытки на
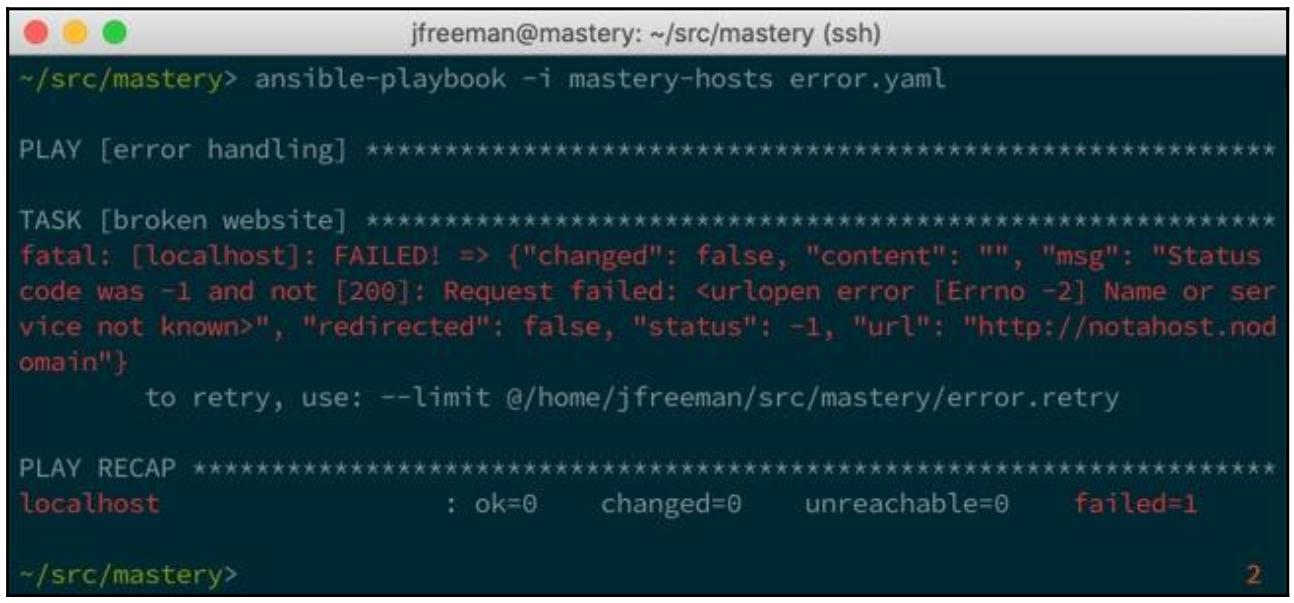
этом хосте. Давайте посмотрим на следующий кусочек кода:
-name: broken website
uri:
url: http://notahost.nodomain
Исполнение такой задачи в том виде, как она представлена, выдаст нам некую ошибку:
Теперь давайте представим себе, что мы не желаем остановки Ansible в данном месте и вместо этого мы хотим
продолжить его. Мы можем добавить своё условие ignore_errors в нашу задачу
как-то так:
- name: broken website
uri:
url: http://notahost.nodomain
ignore_errors: true
На этот раз, котгда мы исполним этот плейбук, наша ошибка будет проигнорирована, как мы можем увидеть здесь:
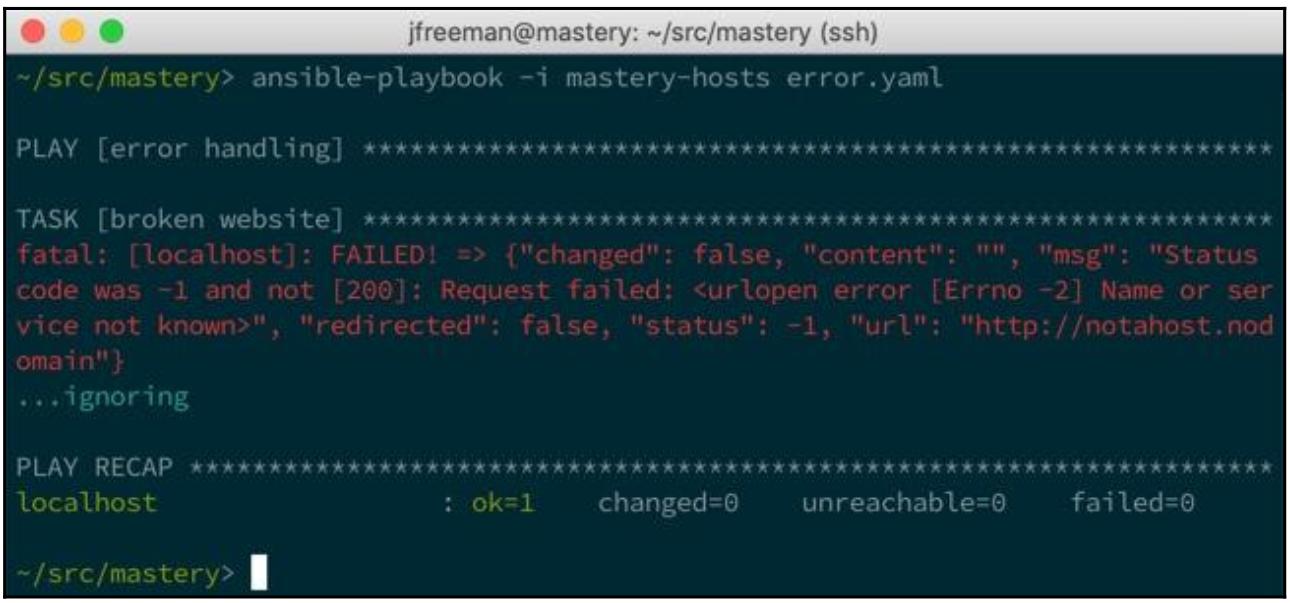
Ошибка нашей задачи игнорируется. Все дальнейшие задачи для этого хоста всё ещё будут предприниматься и данный плейбук не зарегистрирует никакие отказавшие хосты.
Условие ignore_errors является достаточно грубым молотом. Все
вырабатываемые в этом применяемом данной задачей модуле ошибки будут проигнорированы. Далее, полученный вывод,
на первый взгляд, всё ещё выглядит как некая ошибка и может смутить некоторого оператора, пытающегося выяснить
истинную причину отказа. Более аккуратным инструментом является условие failed_when.
Это условие работает как скальпель и позволяет некоторому автору плейбука быть очень точным в отношении того,
что составляет некую ошибку для какой- то задачи. Это условие выполняет некую проверку Булева результата, во
многом схоже с условием when. Если результаты этого условия в Булевом
выражении истинны, тогда эта задача будет рассматриваться как отказавшая. В противном случае данная задача
будет трактоваться как успешная.
Такое условие failed_when очень полезно когда применяется совместно с
модулем command или shell и
регистрирует свой результат данного исполнения. Многие исполняющиеся программы могут иметь подробные
ненулевые коды выхода, которые обозначают различные моменты, однако, все данные модули рассматривают некий
отличающийся от нуля код выхода как какой- то отказ. Давайте рассмотрим утилиту определённую
iscsiadm. Эта утилита может применяться для многих целей, относящихся к
iSCSI. Ради целей нашей демонстрации мы применим её для обнаружения любых активных сеансов
iscsi:
- name: query sessions
command: /sbin/iscsiadm -m session
register: sessions
Если это исполнить в некоторой системе, в которой отсутствуют активные сеансы, мы увидим вывод подобный такому:
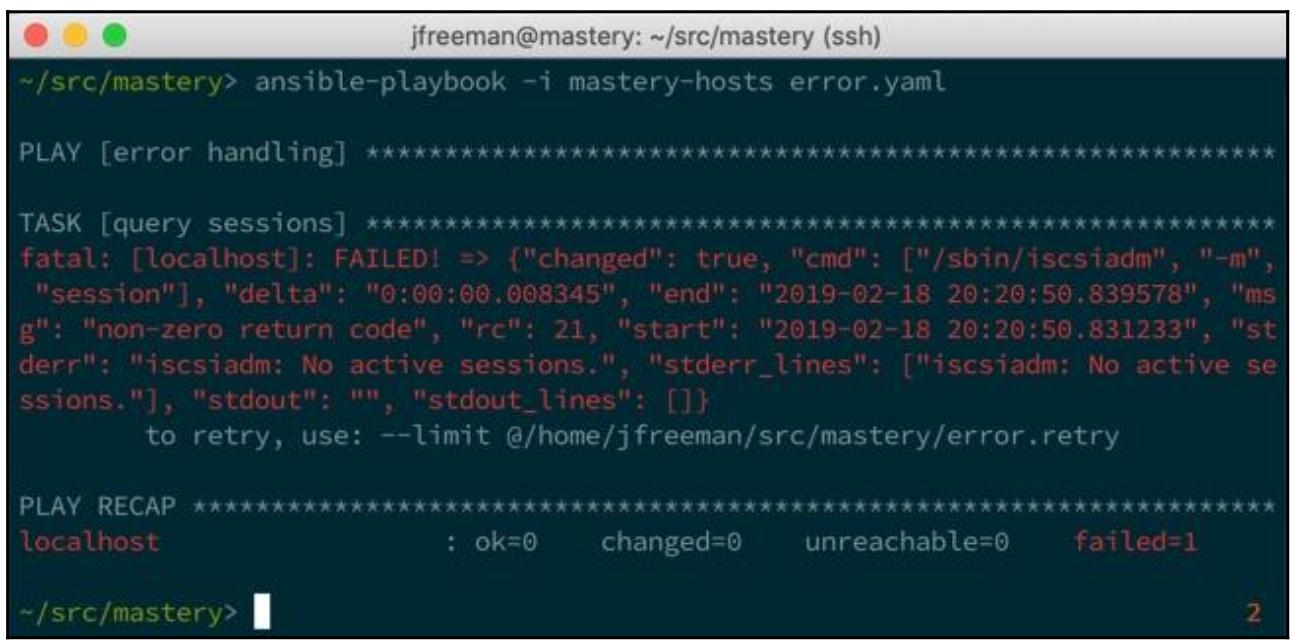
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Инструмент |
Мы можем просто применить своё условие ignore_errors, однако оно бы
маскировало прочие проблемы с iscsi; поэтому, вместо него мы желаем
указать Ansible что некий код выхода 21 является допустимым.
При таком окончании мы можем применить свою зарегистрированную переменную для доступа к определённой переменной
rc, которая содержит код возврата. Вы воспользуемся этим в некотором
выражении failed_when:
- name: query sessions
command: /sbin/iscsiadm -m session
register: sessions
failed_when: sessions.rc not in (0, 21)
Мы просто устанавливаем, что любой иной код кроме 0 или
21 должен рассматриваться как некий отказ. Давайте рассмотрим свой
новый вывод после такого изменения:
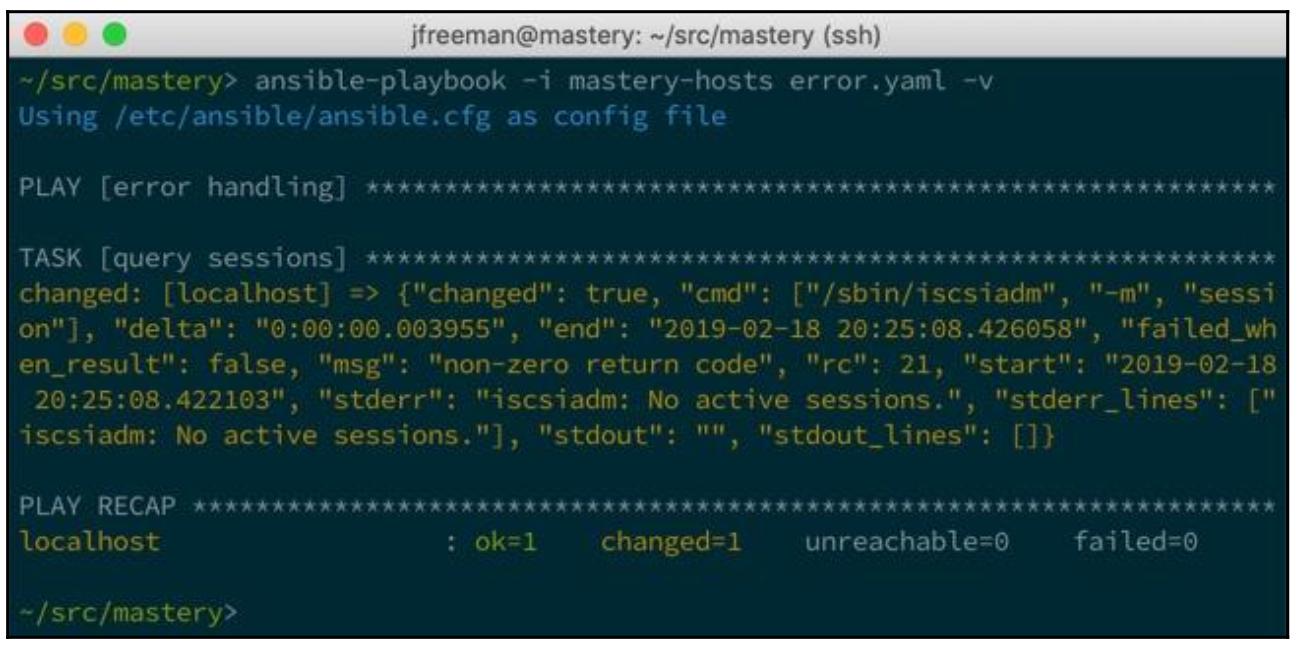
Данный вывод не показывает никаких ошибок и, на самом деле, мы видим некий новый ключ данных в своём
результате - failed_when_result. Это показывает будет ли наше выражение
failed_when вычислено как
true или как false, причём в
данном случае у нас имеется false.
Многие инструменты командной строки не имеют подробностей возвращаемых кодов. На самом деле, наиболее
обычным применением является ноль для успеха и какое- либо отличающееся от нуля значение для всех типов отказа.
К счастью, выражение failed_when не ограничено только значением
кода возврата определённого приложения; оно является свободной формой Булева выражения, которое может получать
доступ к любому виду необходимых данных. Давайте рассмотрим некую другую проблему, связанную с
git. Мы представим себе какой- то сценарий, при котором мы желаем
быть уверенными, что некое определённое подразделение не присутствует в каком- то сверке
git. Данная задача предполагает, что некий репозиторий
git проводит сверку в своём каталоге
/srv/app. Та команда, которая удалит некое подразделение
git, это git branch -D.
Давайте взглянем на следующий фрагмент кода:
- name: delete branch bad
command: git branch -D badfeature
args:
chdir: /srv/app
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Модули |
Если мы запустим только эту команду, мы получим некую ошибку с кодом возврата
1 если данное подразделение не существует:
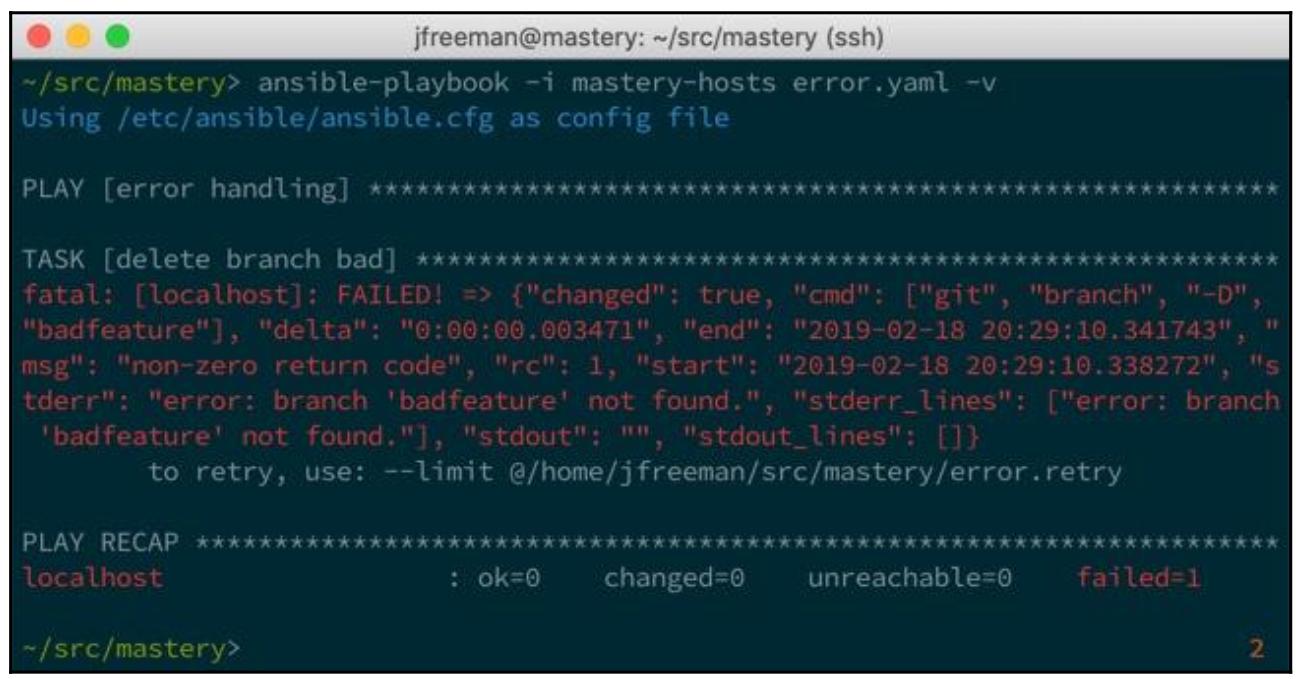
Как вы можете видеть, эта ошибка была аккуратно обработана и воспроизведение для локального хоста было прервано.
|
| Замечание |
|---|---|
|
Мы применяем модуль |
Без наличия условий failed_when и
changed_when, нам бы пришлось создать двухступенчатую комбинированную
задачу чтобы уберечься от ошибок:
- name: check if branch badfeature exists
command: git branch
args:
chdir: /srv/app
register: branches
- name: delete branch bad
command: git branch -D badfeature
args:
chdir: /srv/app
when: branches.stdout | search('badfeature')
В том случае, когда данное подразделение не существует, исполнение данных задач выглядит следующим образом:
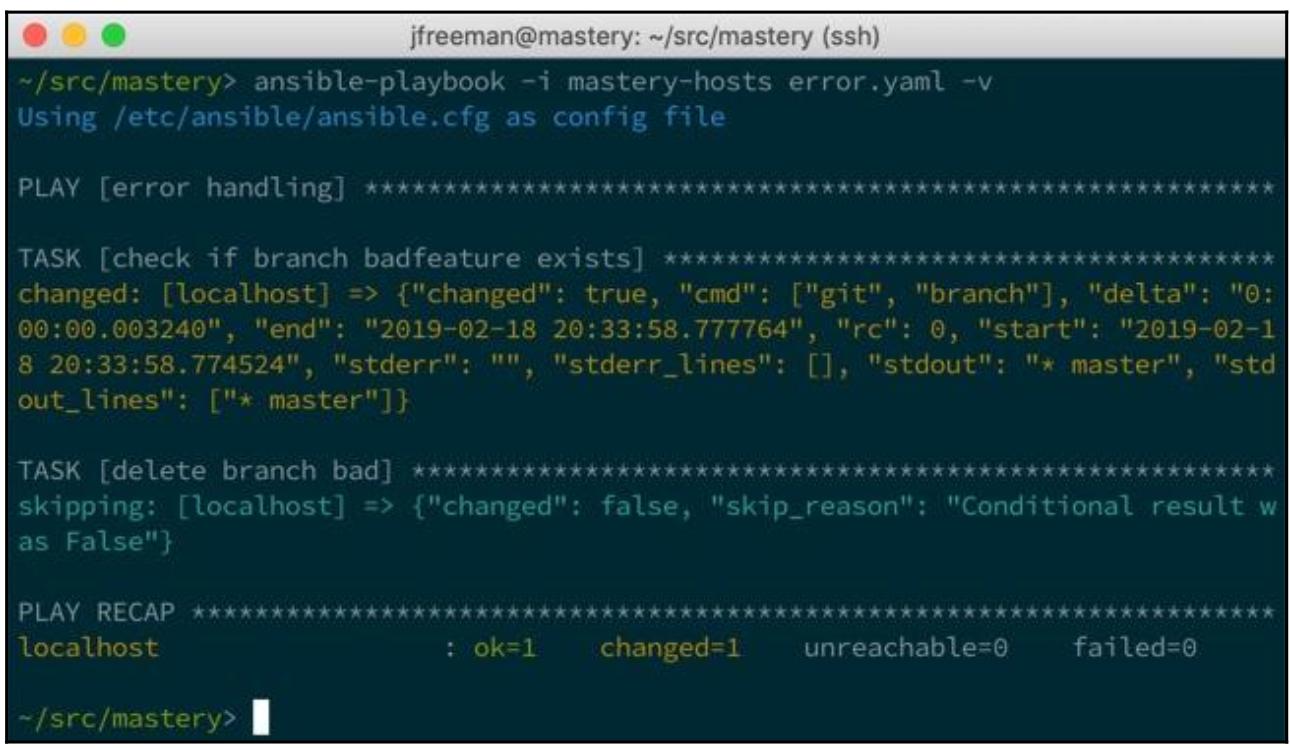
Хотя данный набор задач и работает, он не эффективен. Давайте улучшим его и усилимся имеющейся функциональность
failed_when для уменьшения двух задач до одной:
- name: delete branch bad
command: git branch -D badfeature
args:
chdir: /srv/app
register: gitout
failed_when:
- gitout.rc != 0
- not gitout.stderr | search('branch.*not found')
|
| Замечание |
|---|---|
|
Множество условий, которые обычно соединяются неким |
Мы проверим код возврата данной команды на что- либо отличное от 0
и затем применим фильтр поиска чтобы отыскать необходимое значение stderr
с каким- то regex branch.*not found. Мы воспользовались логикой
Jinja2 для соединения двух данных условий, которые будут оцениваться на вхождение неких вариантов
true или false:
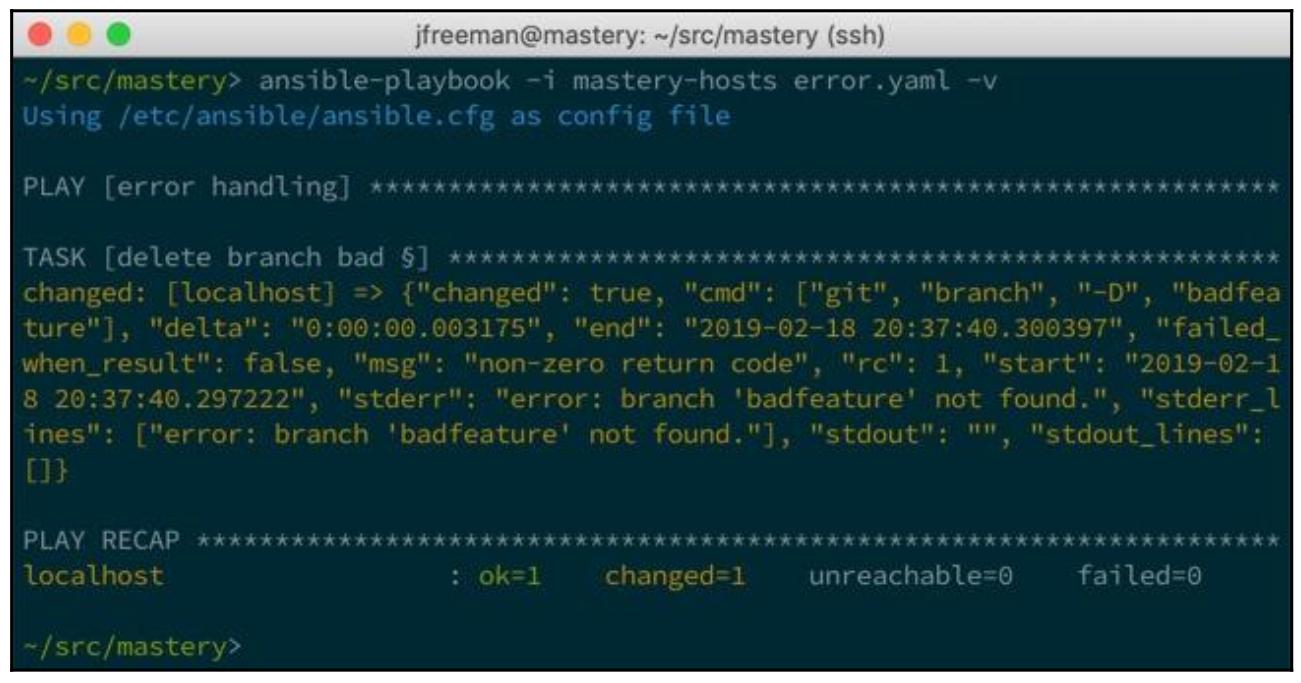
Это демонстрирует как мы способны переопределять отказ в некотором плейбуке Ansible и аккуратно обрабатывать условия, которые в противном случае нарушали бы воспроизведение. Мы также можем переопределять что Ansible наблюдает как какое- то изменение и мы рассмотрим это следующим.
Аналогично определению некоторого отказа задачи, также имеется и возможность определения что представляет
собой некоторое результат изменённой задачи. Эта возможность в особенности полезна с семейством модулей
command (command,
shell, raw и
script). В отличии от большинства прочих модулей, все модули
этого семейства не имеют встроенных данных или некоторой неотъемлемого представления о том каким может быть
изменение. На самом деле, пока не определено иное, эти модули могут иметь результатом
только failed,
changed или
skipped. Просто не существует никакого
способа для этих модулей допустить некое изменённое условие взамен не изменённого.
Условная зависимость changed_when делает возможным для некоторого автора
плейбука указывать модулю как интерпретировать какое- то изменение. В точности как и для
failed_when, changed_when
выполняет некую проверку для выработки какого- то Булева результата. Зачастую те задачи, которые используются с
changed_when являются командами, которые завершатся с ненулевым результатом
для указания того, что никакой работы не должно выполняться, поэтому часто авторы будут соединять
changed_when и failed_when
для тонкой настройки оценки результата такой задачи.
В нашем предыдущем примере определённое условие failed_when отлавливало тот случай,
при котором не должно было исполняться никаких действий, однако сама задача всё же показывала некоторое изменение. Мы хотим
зарегистрировать некоторое изменение при коде завершения 0, но ни для каких других
кодов возврата. Давайте расширим свой пример для выполнения этого:
- name: delete branch bad
command: git branch -D badfeature
args:
chdir: /srv/app
register: gitout
failed_when:
- gitout.rc != 0
- not gitout.stderr | search('branch.*not found')
changed_when: gitout.rc == 0
Теперь, если мы исполним свою задачу когда данное подразделение всё ещё не существует, мы увидим следующий вывод:
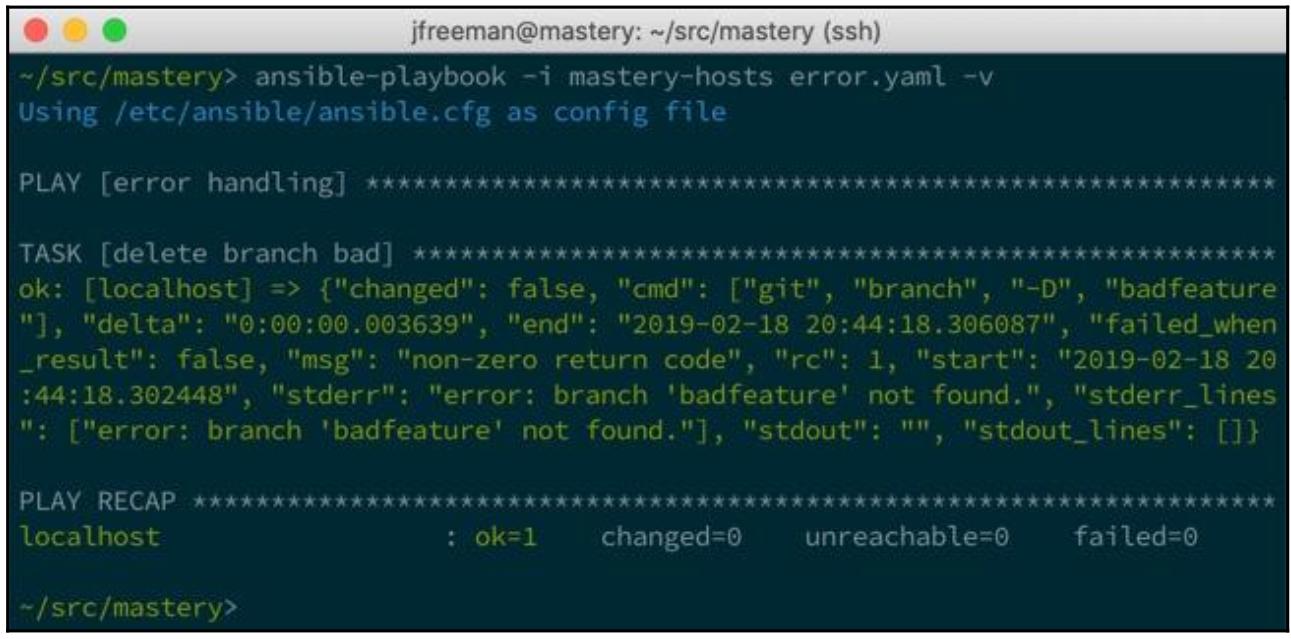
Отметим, что теперь наш ключ changed имеет своим значением
false.
Просто для завершённости, давайте изменим свой сценарий таким образом, чтобы это подразделение имелось в
наличии и выполним его вновь. Для создания своего подразделения просто исполните
git branch badfeature в своём каталоге
/srv/app. Теперь мы можем исполнить наш плейбук вновь для просмотра
вывода который будет таким:
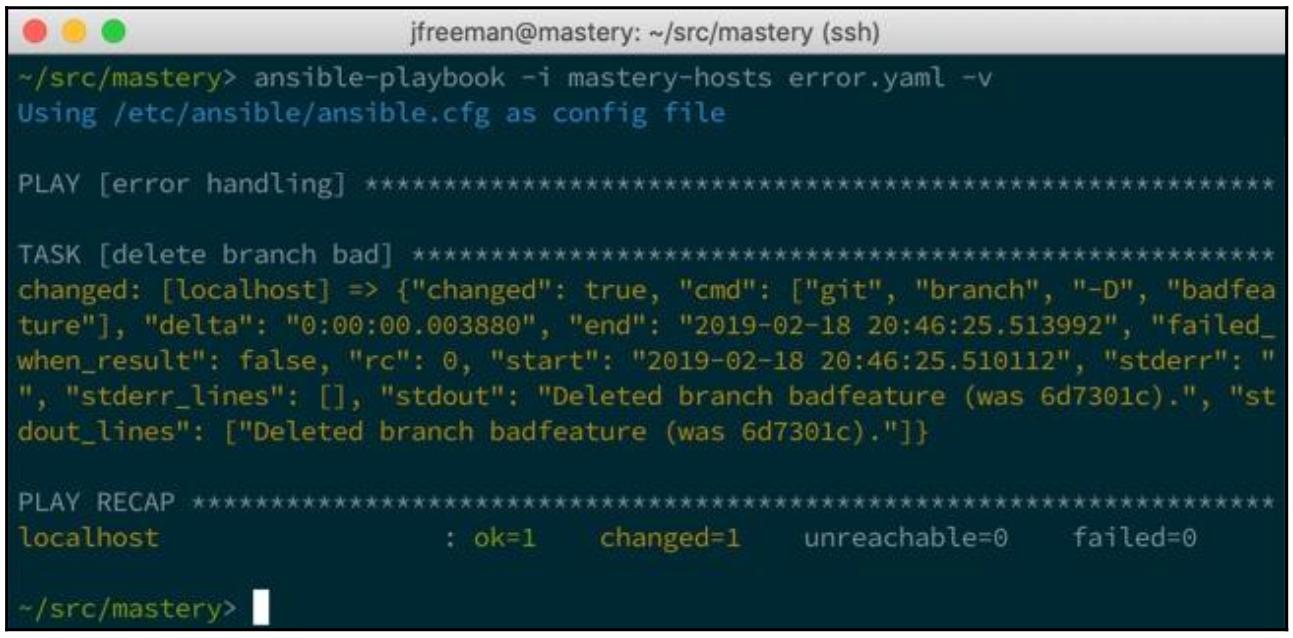
На этот раз наш вывод отличается; имеется зарегистрированное изменение, причём полученные в
stdout данные отображают то подразделение, которое подлежит удалению.
Некое подмножество имеющегося семейства модулей command
(command, shell и
script) имеет некую пару особых параметров, которые повлияют на то, была
ли уже выполнена определённая работа данной задачи, следовательно, будет ли некая задача приводить к какому- то
изменению. Именно такими аргументами и являются creates и
removes. Эти два аргумента ожидают в качестве значения некий путь файла.
Когда Ansible предпринимает попытку исполнить какую- то задачу с определёнными аргументами
creates и removes, он вначале
проверит существуют ли указанные пути к файлу и это будет первая проверка того, существует ли путь к файлу для данной
ссылки.
Если такой путь имеется и был применён аргумент creates, Ansible будет считать
что данная работа уже выполнена и возвратит Ok. Наоборот, если данный путь не
существует и применяется аргумент removes, тогда Ansible снова сочтёт что работа
выполнена и вернёт Ok. Все прочие комбинации вызовут реальное выполнение работы.
Ожидается, что любая работа которую выполнит данная задача, будет иметь результатом либо создание, либо удаление того
файла, на который имеется ссылка.
Само устройство creates и removes
уберегает разработчиков от необходимости выполнять две задачи в одной. Давайте создадим некий вариант, при котором
мы желаем выполнить свой сценарий frobitz из некоторого подкаталога нашего
корня проекта. Для нашего случая мы знаем, что наш сценарий frobitz
создаст некий путь /srv/whiskey/tango. Фактически, исходный код
frobitz таков:
#!/bin/bash
rm -rf /srv/whiskey/tango
mkdir /srv/whiskey/tango
Мы не хотим чтобы этот сценарий исполнялся дважды, поскольку это может разрушить все существующие данные.
Заменим имеющиеся задачи в своём плейбуке error.yaml и сочетание двух задач
будет выглядеть примерно так:
- name: discover tango directory
stat: path=/srv/whiskey/tango
register: tango
- name: run frobitz
script: files/frobitz --initialize /srv/whiskey/tango
when: not tango.stat.exists
Допустим, что этот файл уже имеется, тогда вывод будет таким:
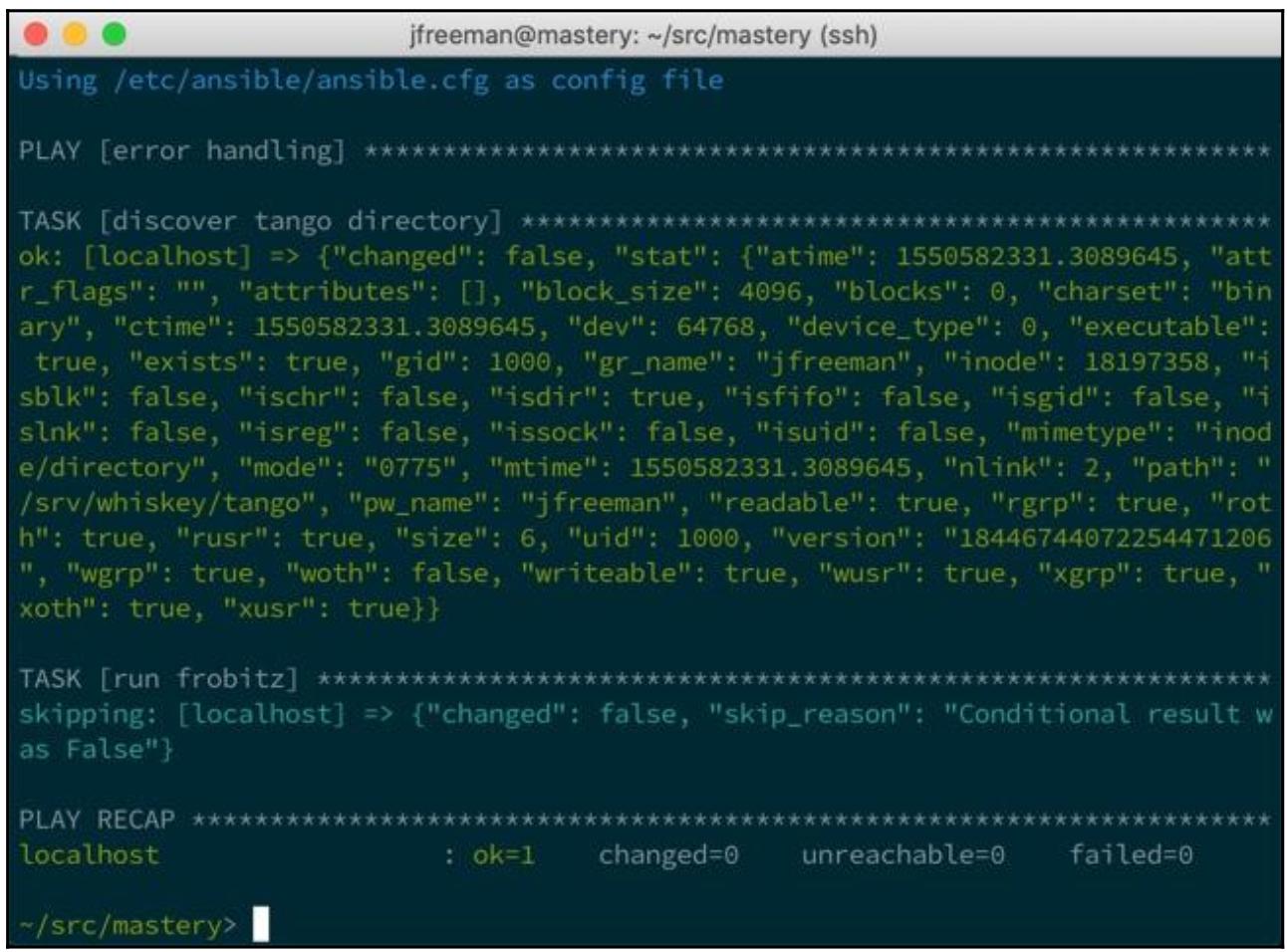
Если же запрошенный путь /srv/whiskey/tango не существует, наш модуль
stat возвратил бы намного меньше данных и результат ключа exists имел
бы значение false. Таким образом, был бы исполнен наш сценарий
frobitz.
Теперь мы применим creates для уменьшения всего до единственной
задачи:
- name: run frobitz
script: files/frobitz
args:
creates=/srv/whiskey/tango
|
| Замечание |
|---|---|
|
Наш модуль |
На это раз наш вывод будет слегка отличаться:
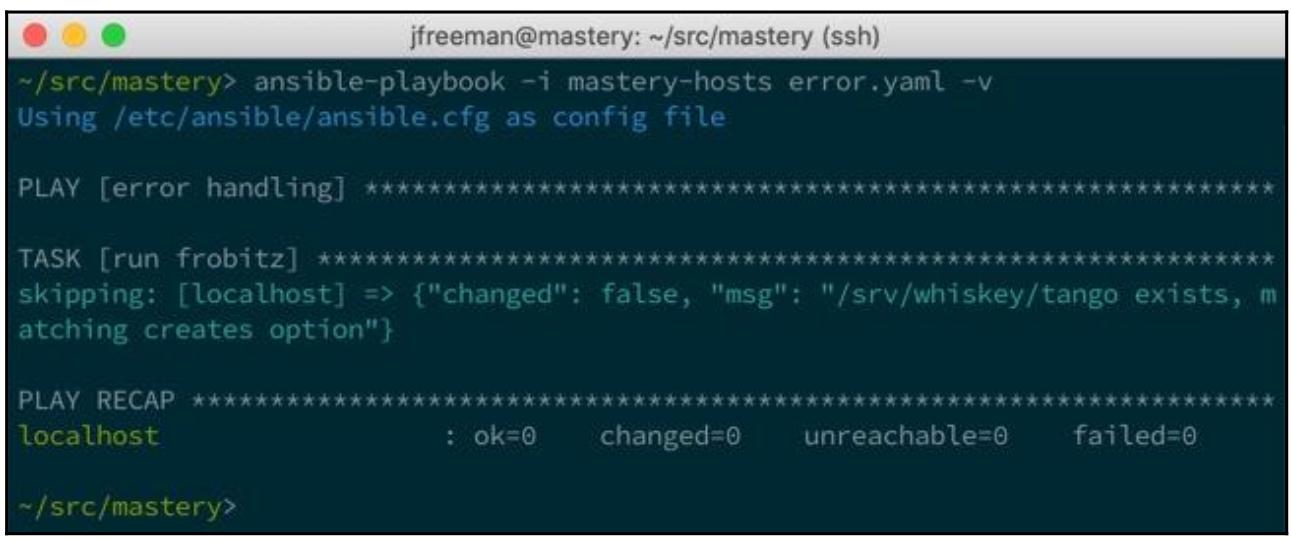
На этот раз мы просто пропустили выполнение данного сценария совсем, так как этот каталог уже имеется даже до того как был запущен этот плейбук. Это сберегает время во время исполнения плейбука, а также предотвращает от люьых разрушительных действий, которые могли бы произойти при исполнении некого сценария.
|
| Совет |
|---|---|
|
Надлежащее применение |
Порой бывает желательно полностью подавить изменения. Это часто применяется когда исполняется некая
команда чтобы получать данные. Такое исполнение команды на самом деле ничего не изменяет; вместо этого она только
извлекает информацию, например, как модуль setup. Подавление
изменений в таких задачах может быть полезным для быстрого определения того привело ли исполнение плейбука в
результате к некому реальному изменению на борту.
Для подавления изменений просто воспользуйтесь false в качестве
некоторого аргумента для имеющегося ключа задачи changed_when.
Давайте расширим один из наших предыдущих примеров по обнаружению активных сеансов
iscsi чтобы подавить изменения:
- name: discover iscsi sessions
command: /sbin/iscsiadm -m session
register: sessions
failed_when:
- sessions.rc != 0
- not sessions.stderr |
search('No active sessions')
changed_when: false
Теперь, вне зависимости от возвращаемых результатов Ansible будет рассматривать данную задачу как
Ok вместо внесения изменений:
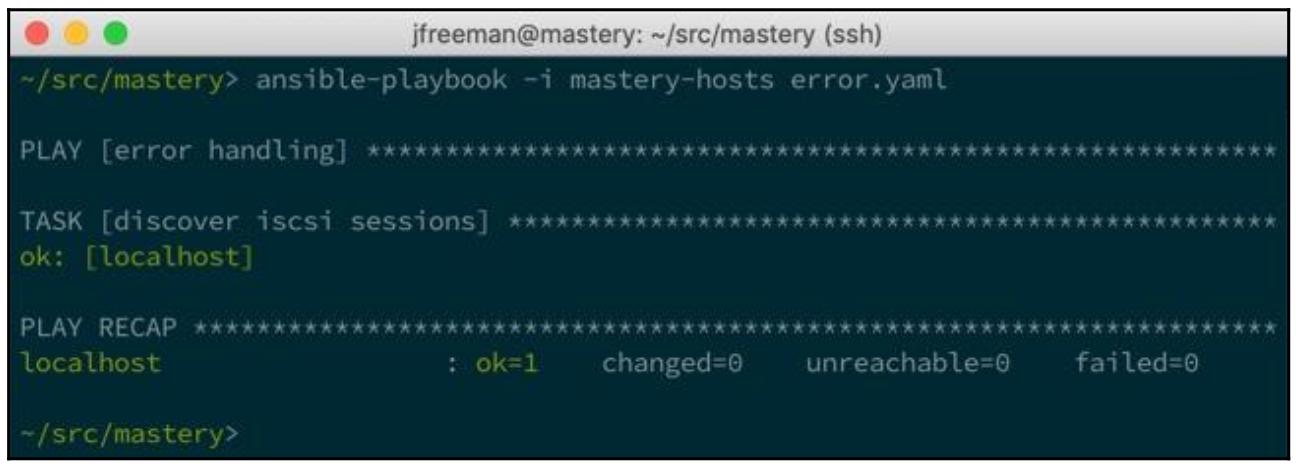
Таким образом, для данной задачи в настоящее время имеется лишь два возможных состояния - failed
и ok. Наам настоятельно требуется возможность в результате задачи
changed.
Хотя условия ошибки могут быть тщательно заданы, всё же могут возникать ситуации при которых на самом деле происходят
ошибки. Ansible предоставляет некий подход для реакции на действительно возникающие ошибки, метод, который выполняется
всегда, даже когда произошла одна, а то и две. Данный метод является функциональностью объединения в блоки
(blocks). Данная функциональность создания блоков была введена в версии Ansible 2.0 и
она предоставила дополнительную структуру для её воспроизведения при задаче ожидания (listining). Блоки способны группировать
задачи воедино в некий логический элемент, который способен выполнять контроль задач, применяемых к этому блоку целиком. Кроме
того некий block задач может иметь необязательные разделы
rescue и always.
Раздел rescue некого block определяет
какой- то логический элемент задачи, который будет исполняться если внутри какого- то block
на самом деле происходит сбой. Так как Ansible выполняет все задачи внутри некоторого
block сверху вниз, когда встретится истинный отказ, исполнение перескочит
на самую первую задачу имеющегося раздела rescue данного
block, если она имеется. Затем задачи выполняются сверху вниз пока не будет
достигнут самый конец этого раздела или не произойдёт новая ошибка.
После завершения такого раздела rescue, задача продолжит исполнение с тем,
что поступает после данного block, как если бы не было никакой ошибки. Это
предоставляет некий способ тщательной обработки ошибок, позволяя определять задачи очистки с тем, чтобы система не
оставалась в полностью разрушенном состоянии и оставшееся воспроизведение могло бы продолжиться. Это намного яснее чем
некий сложный набор зарегистрированных задачей результатов и задач условных зависимостей на основании состояния ошибки.
Для демонстрации такого решения, давайте создадим некий новый набор задач внутри некоторого
block. Этот набор задач будет иметь внутри некую не обрабатываемую ошибку,
которая вызовет переключение исполнения в имеющийся раздел rescue,
в котором мы выполним некую задачу cleanup.
Мы также предоставим некую задачу после такого block, чтобы обеспечить
продолжение исполнения. Мы повторно используем свой плейбук errors.yaml:
---
- name: error handling
hosts: localhost
gather_facts: false
tasks:
- block:
- name: delete branch bad
command: git branch -D badfeature
args:
chdir: /srv/app
- name: this task is lost
debug:
msg: "I do not get seen"
Эти две перечисленные в нашем разделе block задачи исполняются в том порядке, в
котором они определены. В случае возникновения в одной из них результата failed,
будет исполнен следующий код rescue из block.
rescue:
- name: cleanup task
debug:
msg: "I am cleaning up"
- name: cleanup task 2
debug:
msg: "I am also cleaning up"
Наконец, данная задача выполняется независимо от более ранних задач. Обратите внимание на его самый нижний уровень
отступа, который означает что он запускается на том же самом уровне, что и сам block,
вместо того чтобы выступать частью структуры этого block.
- name: task after block
debug:
msg: "Execution goes on"
Когда это воспроизведение исполнится, первая задача получит результатом некую ошибку и наша вторая задача будет обойдена стороной. Исполнение продолжится с имеющейся задачи очистки, как мы это можем наблюдать в данном снимке экрана:
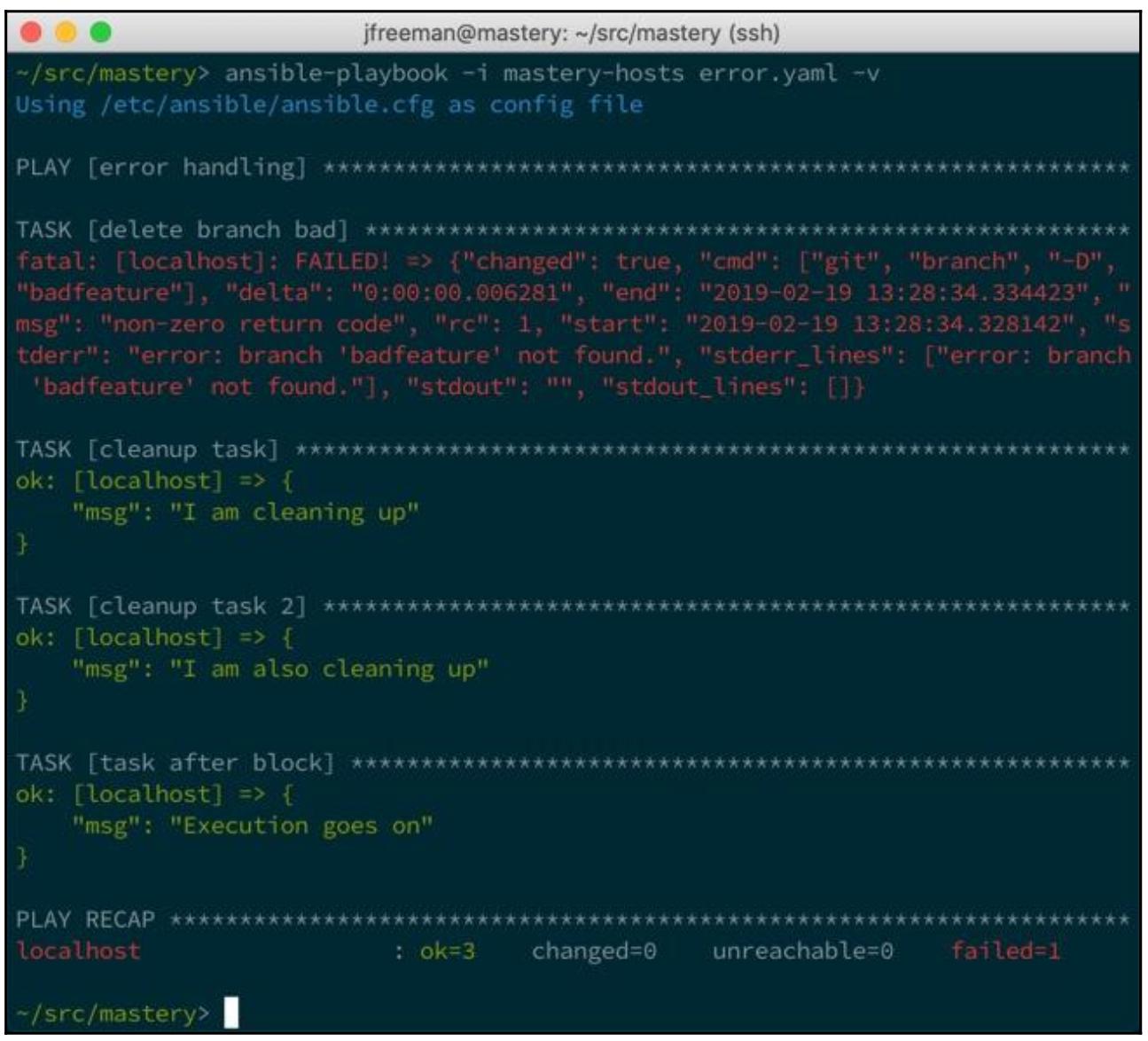
Но не только имеющийся раздел rescue будет исполнен, также выполнится
и оставшаяся часть данного воспроизведения и всё исполнение ansible-playbook
было рассмотрено как успешное.
Помимо раздела rescue доступен и другой раздел с названием
always. Этот раздел некоторого block будет
всегда исполняться были ли ошибки, или нет. Такая функциональность удобна чтобы обеспечить текущее состояние некоторой
системы всегда остающееся рабочим, будь некий block задач успешен или нет.
Поскольку некоторые задачи какого- то block могут быть пропущены из- за ошибок,
а некий раздел rescue исполняется только когда имеется какая- то ошибка, именно
раздел always предоставляет обязательное гарантированное исполнение
задачи в любом случае.
Давайте расширим наш предыдущий пример и добавим некий раздел always
в наш block:
always:
- name: most important task
debug:
msg: "Never going to let you down"
Повторно исполнив свой плейбук мы увидим отображённой свою дополнительную задачу:
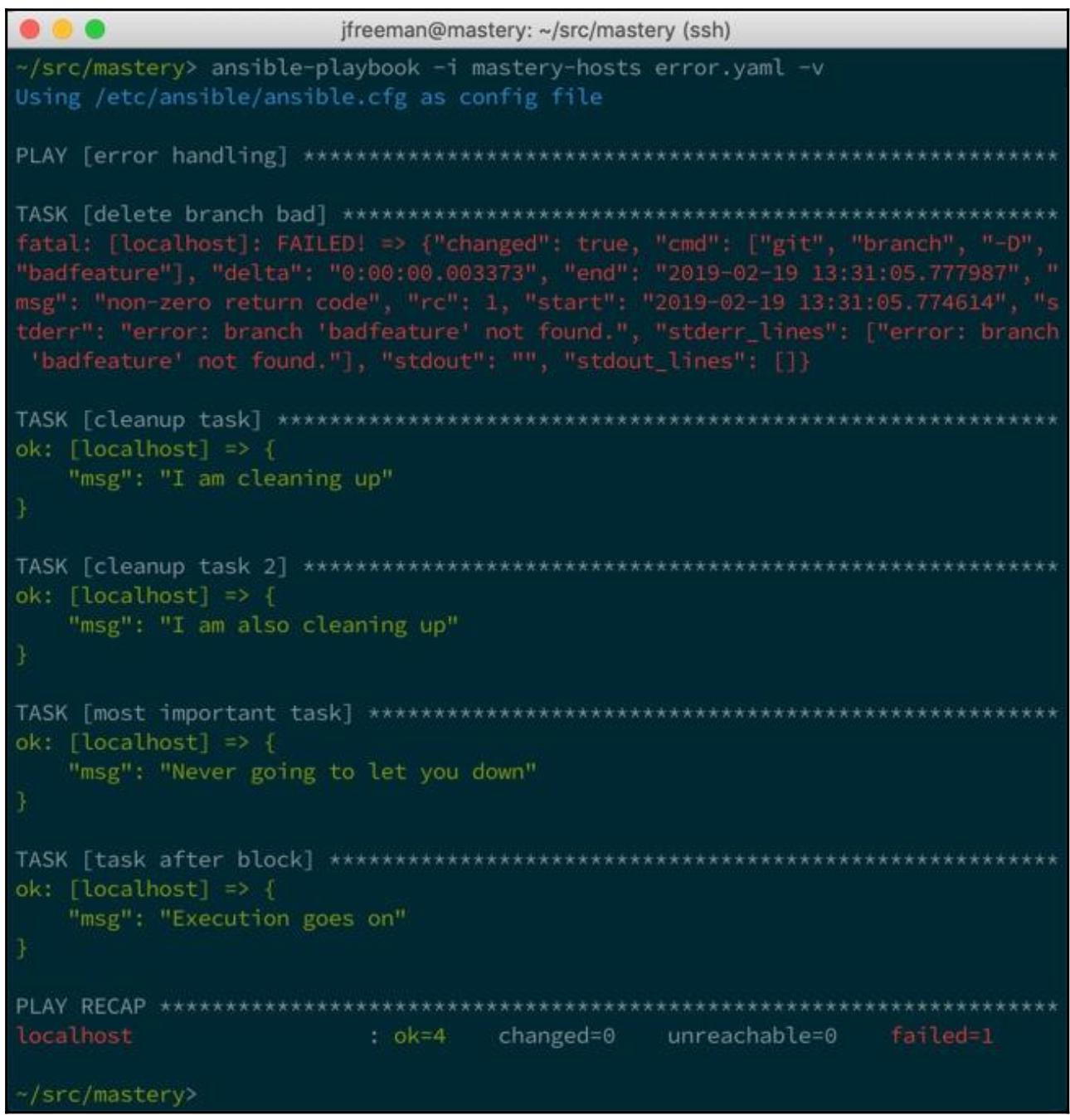
Чтобы проверить что данный раздел always на самом деле всегда
исполняется, мы можем поменять своё воспроизведение с тем чтобы наша задача git рассматривалась как успешная.
В следующем фрагменте кода отображена самая первая его часть, подвергшаяся изменению:
---
- name: error handling
hosts: localhost
gather_facts: false
tasks:
- block:
- name: delete branch bad
command: git branch -D badfeature
args:
chdir: /srv/app
register: gitout
failed_when:
- gitout.rc != 0
- not gitout.stderr | search('branch.*not found')
Обратите внимание на изменённое условие failed_when, которое делает возможным
запуск команды git без рассмотрения отказа. Оставшаяся часть данного плейбука
(которую теперь следует собрать из предыдущих примеров) остаётся без изменений.
На этот раз, когда мы исполняем свой плейбук, наш раздел rescue
пропускается, наша маскированная в прошлый раз задача исполняется, а наш always из
block всё равно при этом получает управление:
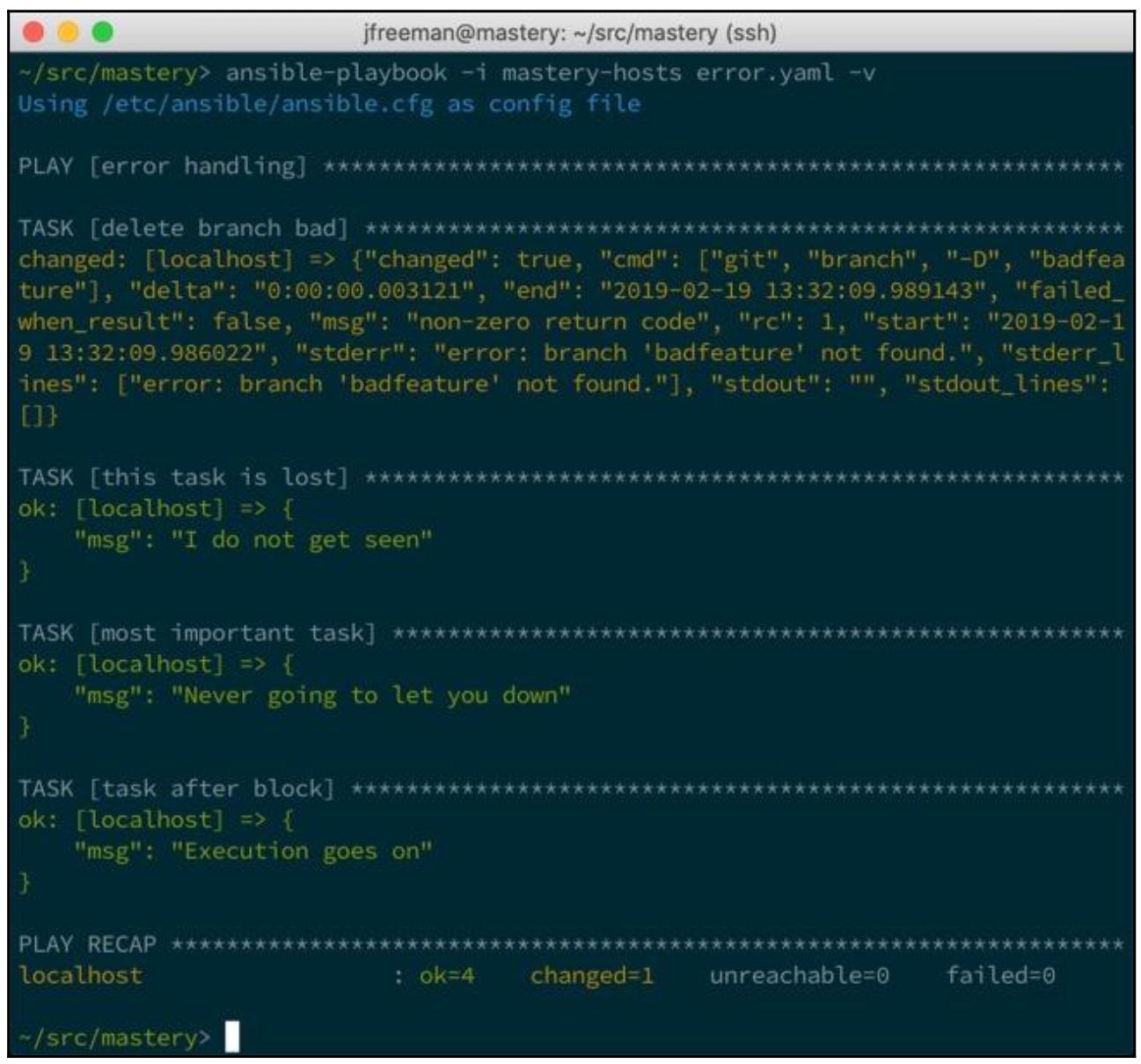
Обратите внимание, что наша утраченная в прошлый раз задача теперь выполняется, ибо само условие отказа для задачи
delete branch bad было изменено так чтобы оно более не претерпевало отказов в
данном воспроизведении. Аналогичным образом наш раздел rescue более не требуется, а
все прочие задачи (включая раздел always) выполняются ожидаемым образом.
До сих пор в этой главе мы сосредотачивались на аккуратной обработке ошибок, а также на изменении установленного по умолчанию поведения Ansible в соответствии с изменениями и отказами. Это всё хорошо подходит для задач, но что если вы запускаете Ansible в некой ненадёжной среде? Например, для достижения управляемых хостов может применяться плохая или имеющаяся лишь временно связь, либо хосты могут постоянно отключаться по какой- либо причине. Этот последний пример может быть динамически масштабируемой средой, которая способна увеличивать размеры при высокой нагрузке и отыгрывать обратно при более низких запросах для сбережения ресурсов.
К счастью, для обработки именно таких ситуаций было введено новое ключевое слово плейбука, ignore_unreachable,
и оно гарантирует будут испробованы все задачи из нашей описи даже для хостов, которые помечены как недостижимые при самом исполнении
некой задачи. Это лучше пояснит неким примером, а потому давайте опять воспользуемся своим плейбуком
error.yaml для создания такой ситуации:
---
- name: error handling
hosts: all
gather_facts: false
tasks:
- name: delete branch bad
command: git branch -D badfeature
args:
chdir: /srv/app
- name: important task
debug:
msg: It is important we attempt this task!
Мы теперь намерены попытаться удалить подразделение badfeature из некого
репозитория Git в двух удалённых хостах, определённых в нашей описи. Эти два хоста не существуют, естественно; они
вымышленные, а потому мы знаем что они будут помечены как unreachable после попытки
самой первой задачи. Несмотря на это, существует вторая задача, которая точно должна предпринять попытку если это
вообще возможно. Давайте запустим этот плейбук и посмотрим что произойдёт:
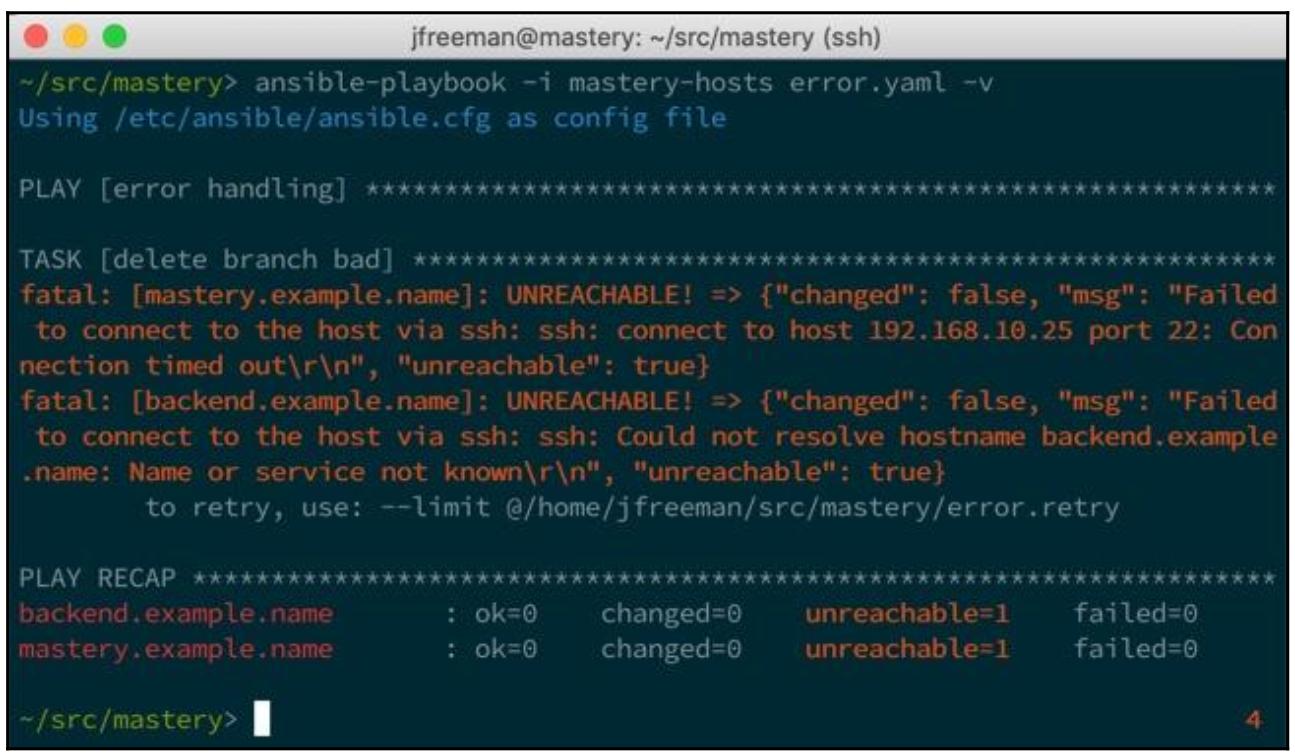
Обратите внимание, что никогда не осуществлялась попытка important task - наше
воспроизведение обрывалось после самой первой задачи, так как эти хосты вне досягаемости. Тем не менее, давайте
воспользуемся нашим вновь выявленным флагом для изменения такого поведения. изменим свой код с тем, чтобы она выглядит как
приведённый здесь код:
---
- name: error handling
hosts: all
gather_facts: false
tasks:
- name: delete branch bad
command: git branch -D badfeature
args:
chdir: /srv/app
ignore_unreachable: true
- name: important task
debug:
msg: It is important we attempt this task!
На этот раз отметим, что даже хотя наши хосты и не достижимы при самой первой попытке, наша вторя задача всё же выполняется:
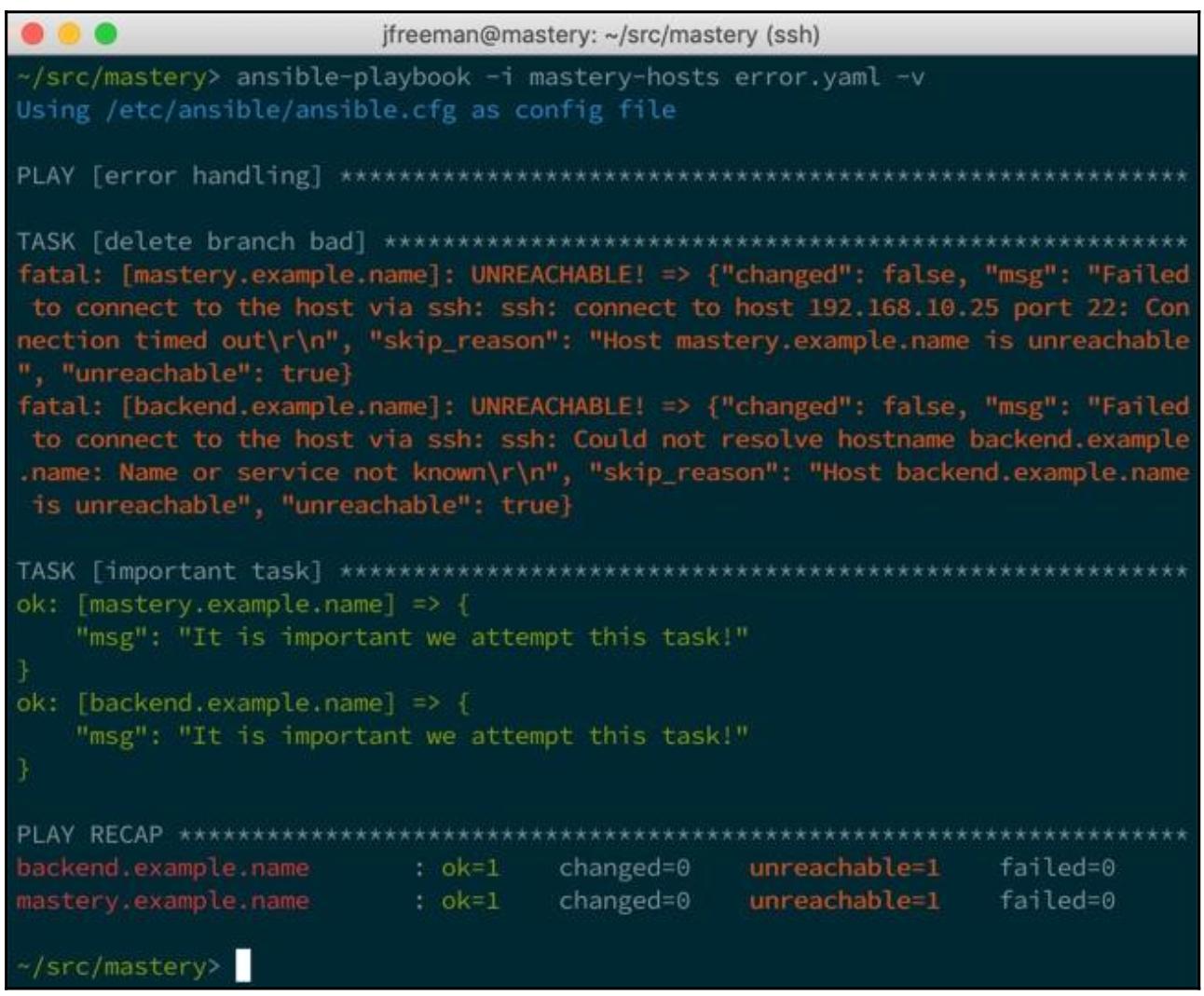
Это полезно когда, как в случае с нашей командой debug, это может выполняться
локально или, может быть, это является жизненно важным попытаться даже в случае отказа в подключении при первой попытке.
До сих пор в данной главе вы изучали инструменты Ansible, предоставляемые для аккуратной обработки разнообразных условий
ошибок. Далее мы продолжим рассмотрение управления потоком задач при помощи циклов - в особенности важного инструмента для
создания компактного кода и предотвращения его повторов.
Циклы заслуживают особого упоминания в данной главе. До сих пор мы были сосредоточены на упралвении самим потоком некого плейбука в стиле его прохождения сверху вниз - мы изменяли различные условия, которые можно было вычислять по мере исполнения плейбука, а также нам приходилось сосредотачиваться на создании компактного действенного кода. Что же произойдёт, тем не менее, если у нас имеется отдельная задача, но её требуется исполнять для некого перечня данных; например, создание определённых учётных записей пользователей, или каталогов, а то и ещё нечто более сложное.
Циклы были изменены в Ansible 2.5 - вплоть до этого циклы обычно создавались такими ключевыми словами как
with_items. Хотя и остаётся некая обратная совместимость, имеется также возможность
перехода вместо этого к новому ключевому слову loop.
Давайте рассмотрим простой пример - нам требуется создать два каталога. Создадим loop.yaml
следующим образом:
---
- name: looping demo
hosts: localhost
gather_facts: false
tasks:
- name: create a directory
file:
path: /srv/whiskey/alpha
state: directory
- name: create another directory
file:
path: /srv/whiskey/beta
state: directory
После его исполнения, как и ожидалось, будут созданы два каталога:

Однако мы можем видеть что этот код повторяется и неэффективен. Вместо него мы можем внести изменения как- то так:
---
- name: looping demo
hosts: localhost
gather_facts: false
tasks:
- name: create a directory
file:
path: "{{ item }}"
state: directory
loop:
- /srv/whiskey/alpha
- /srv/whiskey/beta
Обратите внимание на применение специальной переменной item, которая теперь
применяется для задания значения пути из элементов loop внизу каждой задачи. Теперь,
когда мы запустим этот код, вывод будет выглядеть иначе:

Эти два каталога создаются всё ещё как и ранее, но на этот раз внутри некой отдельной задачи. Это делает наш плейбук намного
более компактным и эффективным. Ansible предлагает намного больше мощных вариантов циклов, включая вложенные циклы и саму
возможность создания циклов, которые будут отслеживать соответствие некому критерию пока он имеет место (часто именуемые
как циклы do until), в противоположность некому ограниченному набору данных.
Все подробности относительно этого доступны в документации Ansible.
В этой главе мы узнали что имеется возможность определять как конкретно Ansible воспринимает некий отказ или изменение
при исполнении данной задачи, как применять блоки для аккуратной обработки ошибок и выполнения
cleanup и как писать плотный эффективный код с применением циклов.
Как результат, вы теперь должны быть способными изменять любую определённую задачу для предоставления особых условий после отказа Ansible в ней или рассматривать изменение как успешное. Это в особенности ценно когда выполняются команды оболочки, как мы уже продемонстрировали это в данной главе, а также при задании особых вариантов применения для имеющихся модулей. Теперь вы также должны иметь возможность организовывать свои задачи в блоки, гарантируя что при возникновении сбоев можно предпринять действия по восстановлению, которые в противном случае не стоило бы вовсе запускать. Наконец, теперь вы сможете писать компактные, эффективные плейбуки Ansible с применением циклов, устраняя необходимость в повторяющемся коде и длинных неэффективных плейбуках.
В своей следующей главе мы изучим применение ролей для организации задач, файлов, переменных и прочего содержимого.