Часть 3. Оркестрация с применением Ansible
В этой части мы изучим применение Ansible в реальной жизни для координации систмемами и службами, а также управления ими, будь это на площадке или в определённом облачном решении.
В эту часть включены такие главы:
Глава 10, Минимизация времени простоя и накатывания развёртываний
Глава 11, Предоставление инфраструктуры
Глава 12, Автоматизация сетевой среды
Глава 10. Минимизация времени простоя и накатывания развёртываний
Ansible хорошо подходит для задач обновления или развёртывания приложений в средах обслуживания в реальном масштабе времени. Естественно, к разработке приложений и обновлениям могут применяться различные стратегии с широким разнообразием стратегий. Наилучший подход зависит от самого приложения, возможностей той инфраструктуры, в которой исполняется это приложение, а также всех обещанных соглашений уровня обслуживания для пользователей данного приложения. Какой бы подход не применялся, жизненно важно чтобы разработка или развёртывание данного приложения были бы контролируемыми, предсказуемыми и повторяемыми для гарантии предоставления практике пользователей стабильного обслуживания при автоматическом развёртывании в фоновом режиме. Самым последним моментом, который пожелал кто бы то ни было является простой, вызванный неожиданным поведением его автоматических инструментов: некое автоматизированное средство обязано заслуживать доверия, не внося никакого дополнительного фактора риска.
Хотя и имеются мириады возможностей, некоторые стратегии разработки являются более распространёнными чем иные и в этой главе мы пройдём парой общепринятых стратегий развёртывания и выставим те свойства Ansible, которые будут полезны в рамках таких стратегий. Мы также обсудим пару прочих соображений развёртывания, которые являются общими для тех стратегий развёртывания. Для достижения этого мы погрузимся в подробности следующих предметов в контексте раскрутки разhf,jnrb Ansible:
-
Выполнения обновления на площадке
-
Расширения вовне и заключение контрактов
-
Быстрого отказа
-
Минимизации разрушительных действия
-
Последовательного выполнения отдельных задач
Ознакомьтесь с видеоматериалами Code in Action.
Самым первым типом обсуждаемого нами развёртывания являются обновления на площадке. Этот стиль развёртывания работает в уже имеющейся инфраструктуре с целью обновления существующего приложения. Такая модель может рассматриваться как некая обычная схема, которая имеется, когда определённое создание новой инфраструктуры было бы затратным усилием и сточки зрения времени, и с точки зрения денег.
Для минимизации времени простоя на протяжении данного типа какого-то обновления неким общим шаблоном проектирования является развёртывание такого приложения по множеству хостов позади некоторого балансировщика нагрузки. Такой балансировщик нагрузки будет действовать как некий шлюз между пользователями данного приложения и теми серверами, которые исполняют само приложение. Запросы для этого приложения поступают на имеющийся балансировщик нагрузки и, в зависимости от настройки, этот балансировщик нагрузки принимает решение на какой сервер заднего плана направить данный запрос.
Для выполнения раскрутки обновления на месте некоторого развёрнутого приложения в соответствии с данным шаблоном, каждый сервер (или меньшее подмножество таких серверов) будет отключено от своего балансировщика нагрузки, обновлено и затем повторно включено для получения новых запросов. Этот процесс будет повторён для оставшихся серверов в общем пуле пока все серверы не будут обновлены. Поскольку только некая часть из всех доступных серверов приложения отключается для обновления, само приложение в целом остаётся доступным для запросов. Конечно, это предполагает что некое приложение может нормально исполняться на смеси версий работающих в одно и то же время.
Давайте построим некий плейбук для обновления какого- то выдуманного приложения. Наше фиктивное приложение
будет работать на серверах с foo-app01 по foo-app08,
которые присутствуют в группе foo-app. Эти серверы будут иметь в обслуживании
некий простой вебсайт посредством вебсервера nginx со своим
содержимым, поступающим из некоторого репозитория Git foo-app, определяемого
имеющейся переменной foo-app.repo. Некий сервер балансировки нагрузки,
foo-lb, работающий под управлением программного обеспечения
haproxy, будет передним фронтом данного приложения серверов.
Для работы некоторого подмножества наших серверов foo-app, нам
потребуется употребить имеющийся последовательный (serial) режим. Такой режим изменяет порядок исполнения
воспроизведений Ansible. По умолчанию Ansible будет выполнять задачи некоторого воспроизведения на каждом хосте в
том порядке как в нём перечислены все задачи. Всякая задача данного воспроизведения исполняется на каждом хосте
прежде чем будет осуществлён переход на следующий определённый хост. Если бы мы применили установленный по умолчанию
метод, наша первая задача удалила бы все серверы из имеющегося балансировщика заданий, что имело бы результатом
полный простой нашего приложения. Имеющийся последовательный метод вместо этого позволит нам работать на
некотором подмножестве с тем, чтобы наше приложение в целом оставалось доступным даже если некоторые участники
отключены. В своём примере мы воспользуемся количеством в последовательности равным двум для сохранения
основного числа участников данного приложения в рабочем состоянии:
---
- name: Upgrade foo-app in place
hosts: foo-app
serial: 2
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Ansible 2.2 вводит понятие |
Теперь мы можем начать создание своих задач. Первая задача будет отключать определённый хост от своего
балансировщика нагрузки. Сам балансировщик нагрузки исполняется на хосте foo-lb;
однако мы работаем на хостах foo-app. Вследствие этого нам необходимо
передать права определённой задаче с применением оператора задачи
delegate_to. Данный оператор выполняет перенаправление того места, откуда
Ansible подключится для выполнения данной задачи, однако сохранит весь контекст переменных своего первоначального
хоста. Мы воспользуемся модулем haproxy для отключения текущего хоста от
своего работающего пула заднего плана foo-app:
tasks:
- name: disable member in balancer
haproxy:
backend: foo-app
host: "{{ inventory_hostname }}"
state: disabled
delegate_to: foo-lb
После того, как этот хост отключён, мы теперь можем обновить своё содержимое foo-app.
Мы воспользуемся модулем git для обновления имеющегося пути содержимого с желаемой
версией, определяемой в foo-version. Мы добавим обработчик
notify в данную задачу для перезагрузки своего сервера
nginx если вступят в силу результаты обновления данного содержимого. Это можно
делать всякий раз, но мы применяем это в качестве некоторого примера использования notify
(уведомления):
- name: pull stable foo-app
git:
repo: "{{ foo-app.repo }}"
dest: /srv/foo-app/
version: "{{ foo-version }}"
notify:
- reload nginx
Нашим следующим шагом будет повторное включение данного хоста в его балансировщик нагрузки; однако, если мы
сделаем эту задачу следующей, мы поместим свою старую версий обратно на место, поскольку наш обработчик
уведомления ещё пока не выполнился. Поэтому нам необходимо включить свой обработчик с помощью вызова
meta: flush_handlers, который мы изучили в своей предыдущей главе:
- meta: flush_handlers
Теперь мы можем повторно разрешить данный хост в нашем балансировщике нагрузки. Мы можем просто включить его
непосредственно и положиться на то, что наш балансировщик нагрузки ожидает пока этот хост вернётся в
рабочеспособное состояние прежде чем отправлять на него запросы. Однако, поскольку мы работаем с уменьшенным
числом доступных хостов, нам необходимо быть уверенным, что все остающиеся хосты являются жизнеспособными.
Мы можем воспользоваться задачей wait_for для ожидания пока наша
служба nginx снова не вернётся к обслуживанию соединений. Этот модуль
wait_for будет ожидать некоторого условия либо в некотором порту, либо
в каком- то пути файла. В нашем примере мы будет ожидать свой порт 80
и само условие в том, что порт должен иметься. Если он запущен (значение по умолчанию), это означает, что он
принимает соединения:
- name: ensure healthy service
wait_for:
port: 80
Наконец, мы можем повторно разрешить участие внутри haproxy.
Опять же, мы передаём полномочия своей задачи в foo-lb:
- name: enable member in balancer
haproxy:
backend: foo-app
host: "{{ inventory_hostname }}"
state: enabled
delegate_to: foo-lb
Конечно, нам всё ещё необходимо определять свой обработчик reload nginx:
handlers:
- name: reload nginx
service:
name: nginx
state: restarted
Данный плейбук, по окончанию исполнения, теперь выполнил раскрутку обновления на месте своего приложения.
Некоторой альтернативой для представленной стратегии обновления на месте является стратегия раскрытия вовне и заключения контракта. Такая стратегия становится популярной в последнее время благодаря её природе самостоятельного обслуживания предоставляемой по запросу инфраструктуры, например облачных вычислений или пулов виртуализации. Такая возможность создавать серверы по запросу из некоторого большого пула доступных ресурсов означает, что каждое развёртывание некоторого приложения может происходить на совершенно новой системе. Данная стратегия избегает каких- либо проблем с хостами, таких как некоторое нарастание неприятных свойств программ в долгоиграющих системах, таких как:
-
Оставшиеся позади файлы настройки, которые больше не управляются Ansible
-
Быстрорастущие процессы потребляют ресурсы в фоновом режиме
-
Вручную изменяемые персоналом вещи при помощи доступа к серверу через оболочку
Постоянно осуществляемый запуск с нуля также удаляет различия между начальным развёртыванием и неким обновлением. Может применяться один и тот же код исправления ошибок, снижая риск неожиданностей при обновлении некоторого приложения. Такой способ установки может также быть чрезвычайно простым для отката обратно в случае, если новая версия не работает как ожидалось. Кроме того для данного варианта, поскольку новые системы создаются для замены старых систем, такое приложение не нуждается в переходе в ухудшенное состояние в процессе обновления.
Давайте применим новый подход к своему предыдущему плейбуку обновления для стратегии расширения вовне и контрактации. Наш шаблон будет состоять в создании новых серверов, развёртывании нашего приложения, проверки нашего приложения и добавлении новых серверов к имеющемуся балансировщику нагрузки, а также удалении старых серверов из этого балансировщика нагрузки. Вначале давайте запустим создание новых серверов. Для этого примера мы воспользуемся Вычислительным облаком OpenStack для запуска новых экземпляров:
---
- name: Create new foo servers
hosts: localhost
tasks:
- name: launch instances
os_server:
name: foo-appv{{ version }}-{{ item }}
image: foo-appv{{ version }}
flavor: 4
key_name: ansible-prod
security_groups: foo-app
auto_floating_ip: false
state: present
auth:
auth_url: https://me.openstack.blueboxgrid.com:5001/v2.0
username: jlk
password: FAKEPASSW0RD
project_name: mastery
register: launch
loop: "{{ range(1, 8 + 1, 1)|list }}"
В данной задаче мы проходим циклом со счётчиком 8, применяя новый
loop с синтаксисом range, который был
введён в Ansible 2.5. При каждом цикле его переменная item будет заменяться
неким числом. Это позволяет нам создать восемь экземпляров новых серверов с каким- то именем на основании номера версии
нашего приложения и номера данного цикла. Мы также предполагаем для применения некий предварительно подготовленный образ с
тем, чтобы нам не было нужды выполнять какую- либо ещё настройку этого экземпляра. Чтобы применять эти серверы в
последующих воспроизведениях, нам необходимо добавить их подробности в свой список учёта (inventory). Для осуществления
этого мы регистрируем все результаты своего исполнения в определённой переменной launch,
которая будет применена впоследствии для создания записей регистрации времени исполнения:
- name: add hosts
add_host:
name: "{{ item.openstack.name }}"
ansible_ssh_host: "{{ item.openstack.private_v4 }}"
groups: new-foo-app
with_items: launch.results
Данная задача создаст новые записи учёта с теми же самыми именами, которые имеют наши экзепляры сервера.
Чтобы помочь Ansible с информацией о том как осуществлять соединение, мы установим
ansible_ssh_host в тот IP адрес, который наш поставщик облака назначает
данному экземпляру (это предполагает, что данный адрес достижим самим исполняющим Ansible хостом). Наконец, мы
добавим все хосты в свою группу new-foo-app. По мере того как наша
переменная launch поступает из некоторой задачи в цикле, нам необходимо повторить итерацию по полученным
результатам этого цикла обратившись по полученным ключам результатов. Это позволит нам пройти циклом по каждому
действию launch чтобы получить доступ к специфичным для данной задачи данным.
Далее мы проверим свои новые серверы что их новые службы готовы для применения. Мы вновь воспользуемся
wait_for, в точности как мы делали это ранее, как некая часть какого- то
воспроизведения в нашей новой группе new-foo-app:
- name: Ensure new app
hosts: new-foo-app
tasks:
- name: ensure healthy service
wait_for:
port: 80
Раз они уже готовы к исполнению, мы можем повторно настроить свой балансировщик нагрузки чтобы применять наши
новые серверы. Для целей упрощения мы предположим наличие некого шаблона для настройки своего
haproxy, который ожидает хосты в группе
new-foo-app и окончательным результатом будет настройка, которая узнает
всё о наших новых хостах и забудет всё о старых хостах. Это означает, что мы можем просто вызвать некую
задачу шаблона в самой системе нашего балансирощика нагрузки вместо того чтобы пытаться манипулировать самим
состоянием исполнения этого балансировщика:
- name: Configure load balancer
hosts: foo-lb
tasks:
- name: haproxy config
template:
dest: /etc/haproxy/haproxy.cfg
src: templates/etc/haproxy/haproxy.cfg
- name: reload haproxy
service:
name: haproxy
state: reloaded
После того как данный новый файл настройки находится на своём месте, мы можем исполнить некий повторный запуск своей
службы haproxy. Это выполнит синтаксический разбор полученного нового
файла настройки и запустит новые процессы ожидания для новых входящих соединений. Все имеющиеся соединения будут
со временем закрыты и все старые процессы завершатся {Прим. пер.: такая процедура остановки
имеет название осушения/ дренажа}. Всем новым соединениям будут предоставляться маршруты к
полученным новым серверам, исполняющим нашу новую версию приложения.
Данный плейбук может быть расширен на списание всех старых версий наших серверов, либо на то, что это действие может происходить в некое другое время, когда будет принято решение что какой бы то ни было откат к возможностям нашей старой версии больше не требуется.
Данная стратегия расширения вовне и заключения контрактов может включать больше задач и даже отдельные плейбуки для создания некоторого набора золотого образа, однако преимущества свежей инфраструктуры для каждого выпуска намного перевешивают все дополнительные задачи или добавляемые усложнения создания за которым следует удаление.
При выполнении какого- то обновления некоторого приложения может быть желательным полный останов данного развёртывания при любом признаке ошибки. Частично обновлённая система со смесью версий может не работать вовсе, поэтому продолжение с частью имеющейся инфраструктуры при оставлении всех систем с оказами может повлечь крупные неприятности. К счастью, Ansible предоставляет некий механизм принятия решения когда доходить до варианта фатальной ошибки.
По умолчанию, когда Ansible осуществляет исполнение некоторого плейбука и встречает некоторую ошибку,
Ansible удалит такие отказавшие узлы из своего списка воспроизведения хостов и продолжит оставшиеся задачи
или воспроизведения. Ansible остановит исполнение когда либо отказали все запрошенные для некоторого
воспроизведения хосты, либо все воспроизведения были осуществлены. Для изменения такого поведения имеется пара
управлений воспроизведением, которые могут быть применены. Этими управлениями являются
any_errors_fatal и max_fail_percentage.
Эта установка указывает Ansible рассматривать всю операцию целиком как фатальную и немедленно останавливать
исполнение если любой хост сталкивается с некоторой ошибкой. Чтобы продемонстрировать это мы добавим некую новую
группу в свою инвентаризацию mastery-hosts при помощи некоторого
шаблона, который выполнит расширение до десяти новых хостов:
[failtest]
failer[01:10]
Затем мы создадим некое воспроизведение для этой группы с установленным в true значением
any_errors_fatal. Мы также отключим получение фактов, так как эти
хосты не существуют:
---
- name: any errors fatal
hosts: failtest
gather_facts: false
any_errors_fatal: true
Мы хотим чтобы некоторая задача выполнила отказ для одного из этих хостов, но не для всех остальных. Далее мы хотим выполнить также некую вторую задачу, просто чтобы продемонстрировать как она не исполнится:
tasks:
- name: fail last host
fail:
msg: "I am last"
when: inventory_hostname == play_hosts[-1]
- name: never ran
debug:
msg: "I should never be ran"
when: inventory_hostname == play_hosts[-1]
Теперь, когда мы осуществим исполнение, мы увидим что один хост отказал, однако всё воспроизведение остановится после своей первой задачи:
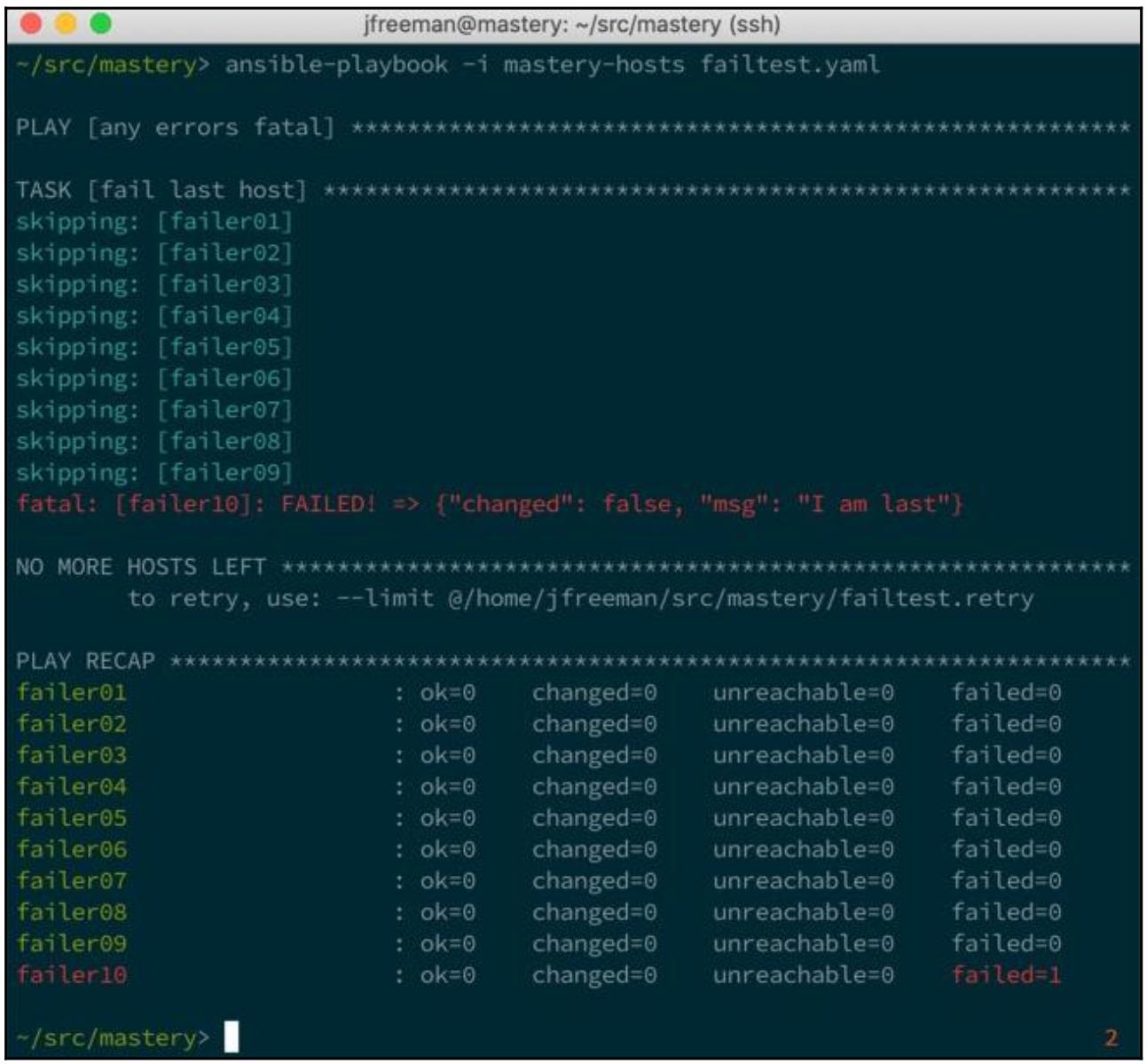
Мы можем видеть что только один хост отказал, однако Ansible сообщил, что все хосты должны выполнить отказа и прервал данный плейбук прежде чем получил своё следующее воспроизведение.
Данная установка позволяет разработчикам воспроизведений определять некое процентное соотношение
хостов, которые могут отказывать прежде чем вся операция будет прервана. В самом конце каждой задачи Ansible
выполнит некую математическую операцию для определения общего числа всех хостов, имеющих целью данное
воспроизведение, которые достигли состояния отказа и, если это число более допустимого значения, Ansible
прервёт данный плейбук. Это аналогично any_errors_fatal, по существу,
any_errors_fatal внутренне всего лишь выражает некий параметр
max_fail_percentage со значением 0,
при котором любой отказ рассматривается как фатальный. Давайте отредактируем своё воспроизведение из предыдущего
и заменим свой параметр max_fail_percentage на значение
20:
---
- name: any errors fatal
hosts: failtest
gather_facts: false
max_fail_percentage: 20
После выполнения такого изменения наше воспроизведение должно завершить обе задачи без прерывания:
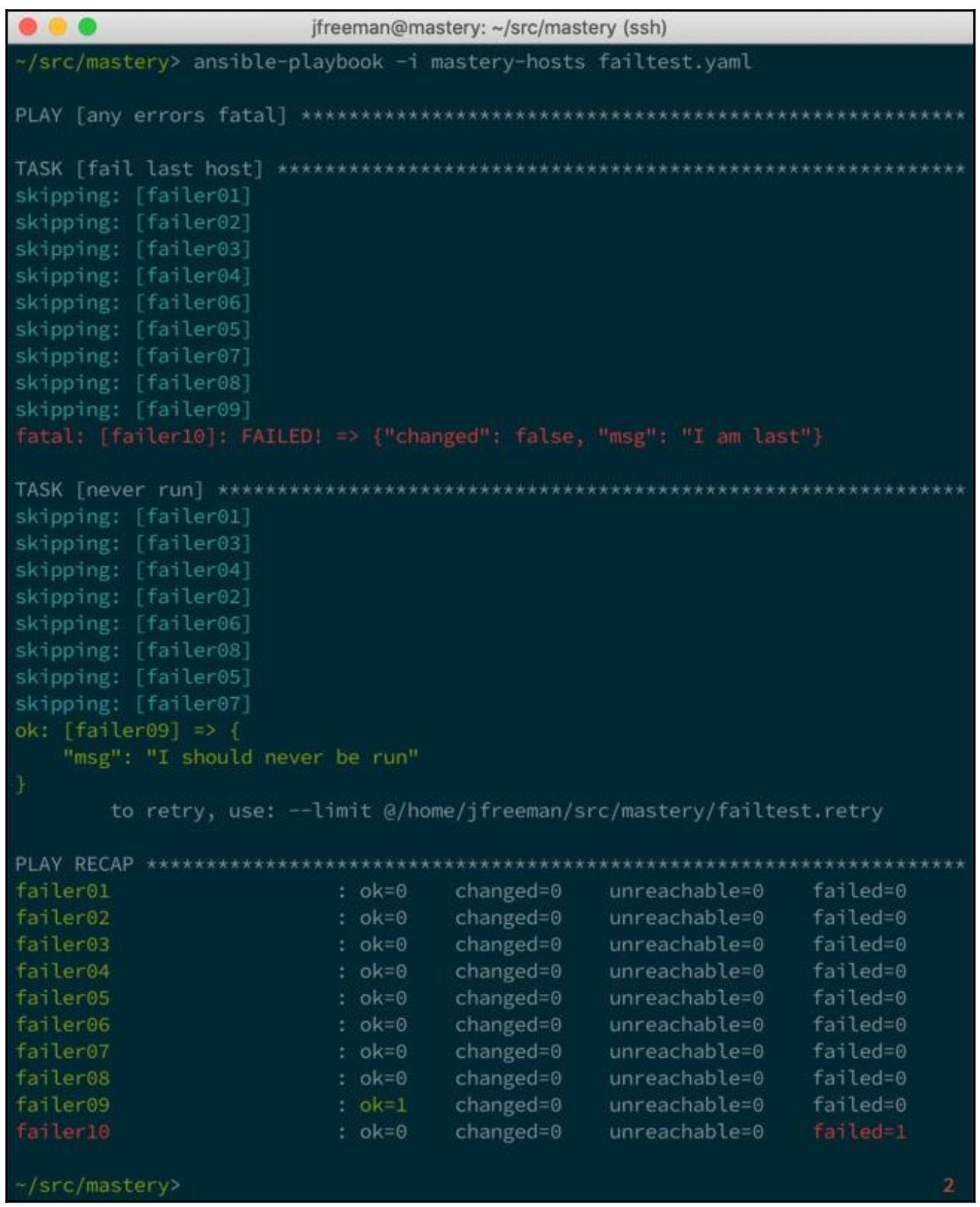
Теперь, если мы изменим свою условную зависимость с тем, чтобы мы получали отказ на более чем 20 процентах от всех хостов, мы обнаружим, что наш плейбук прервётся раньше:
- name: fail last host
fail:
msg: "I am last"
when: inventory_hostname in play_hosts[0:3]
Мы установили три хоста отказавшими, что даёт нам значение соотношение отказа превышающим 20 процентов.
Имеющаяся установка max_fail_percentage является максимально
допустимой, поэтому наша установка этого значения в 20 позволит нам отказ только 2 хостов из 10. При отказе
трёх хостов мы видим фатальную ошибку перед исполнением второй задачи:
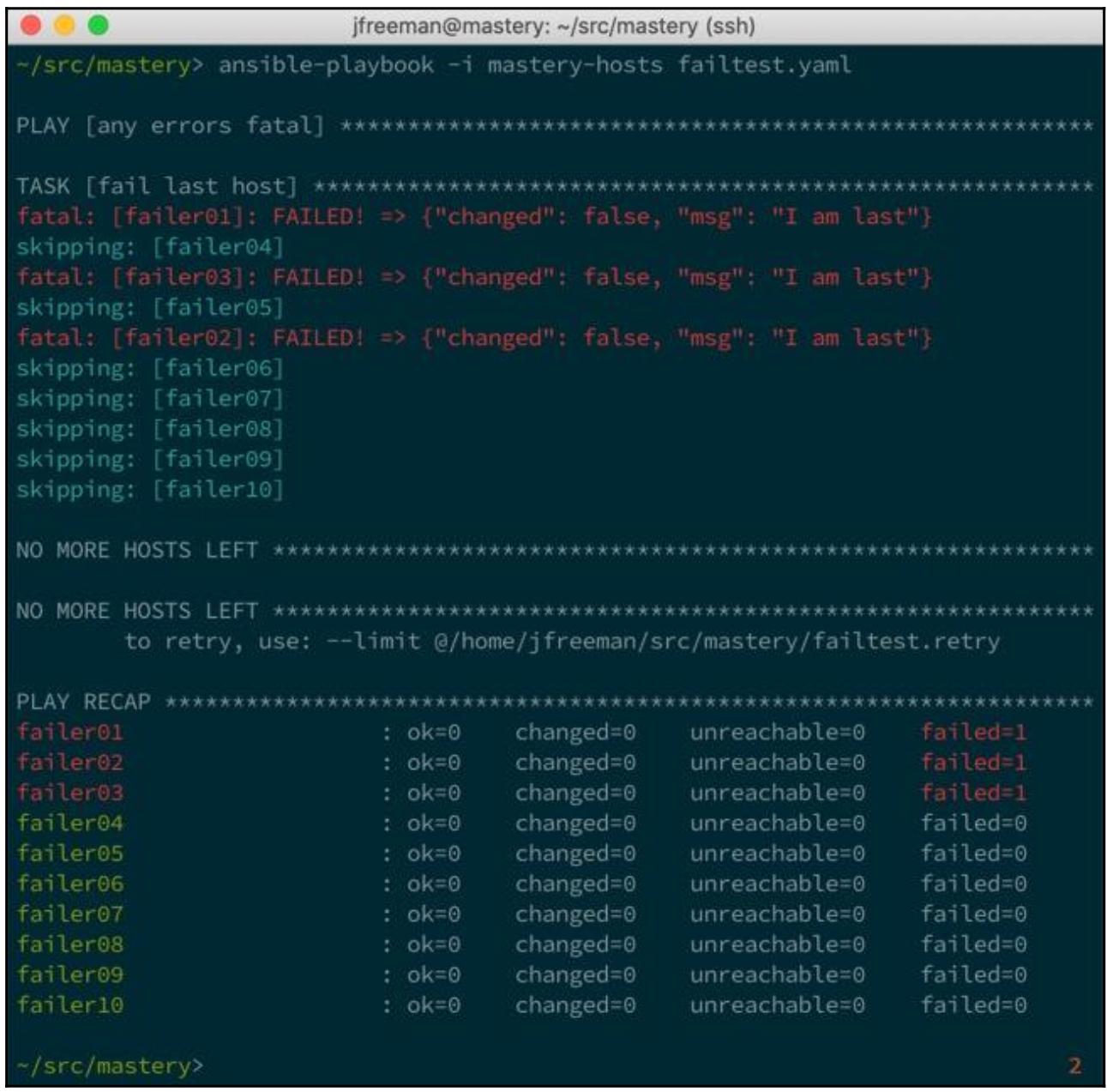
При таком сочетании параметров мы запросто можем настроить условие fail fast
и контролировать его в некой группе хостов, что является невероятно ценным для нашей установки поддерживать целостность
среды в процессе развёртывания Ansible.
Обычно, когда Ansible отказывает на некотором хосте, он прекращает исполнять что бы то ни было на этом
хосте. Это означает, что никакие отложенные обработчики не будут исполняться. Это может оказаться
нежелательным и имеется некое управление воспроизведением, которое принудит Ansible отработать нерешённые
обработчики для отказавших хостов. Этим управлением воспроизведения является
force_handlers, которое должно быть установлено в Булево значение
true.
Давайте слегка изменим свой предыдущий пример для демонстрации такой функциональности. Мы удалим свой
параметр max_fail_percentage, добавив новую задачу. Нам необходимо
создать некую задачу, которая успешно возвратится с неким изменением. мы можем сделать это при помощи модуля
debug воспользовавшись имеющимся управлением задачи
changed_when, даже хотя наш модуль
debug никогда не регистрирует некое изменение по умолчанию.
Также мы вернём условную зависимость своей отказавшей задачи в то, с чего мы первоначально стартовали:
---
- name: any errors fatal
hosts: failtest
gather_facts: false
tasks: - name: run first
debug:
msg: "I am a change"
changed_when: true
when: inventory_hostname == play_hosts[-1]
notify: critical handler
- name: change a host
fail:
msg: "I am last"
when: inventory_hostname == play_hosts[-1]
Наша третья задача остаётся без изменений, однако мы определим свой обработчик критических ситуаций:
- name: never ran
debug:
msg: "I should never be ran"
when: inventory_hostname == play_hosts[-1]
handlers:
- name: critical handler
debug:
msg: "I really need to run"
Давайте исполним это новое воспроизведение чтобы показать определённое по умолчанию поведение своего обработчика, который не выполнится. В интересах уменьшения вывода мы ограничили исполнение только одним из хостов:
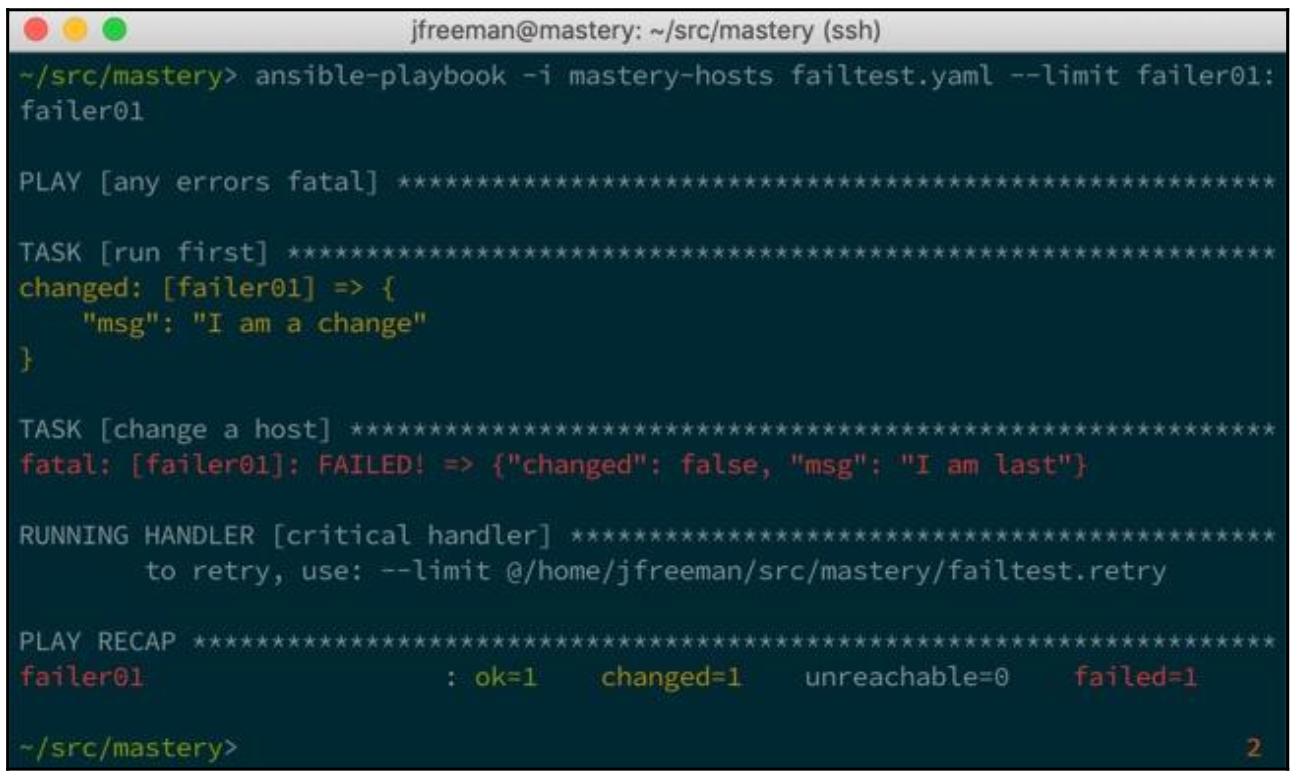
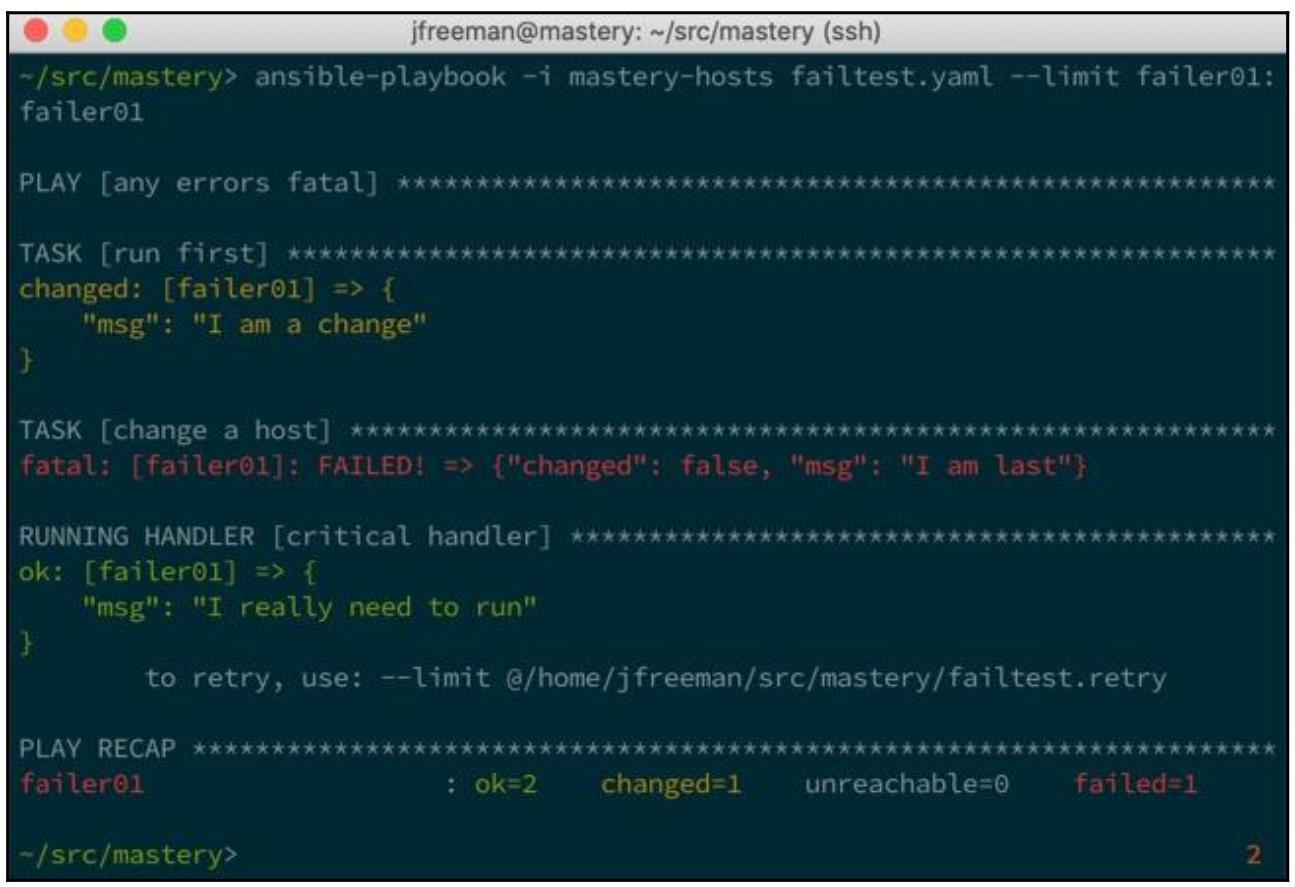
Теперь мы добавим управление воспроизведением force_handlers и
установим его значением true:
---
- name: any errors fatal
hosts: failtest
gather_facts: false
max_fail_percentage: 0
force_handlers: true
На этот раз, когда мы выполним этот плейбук, мы должны обнаружить что наш обработчик работает даже для испытавшего отказ хоста:
|
| Замечание |
|---|---|
|
Принудительное исполнение обработчиков может быть также решением времени исполнения при помощи аргумента
командной строки |
Принудительное исполнение обработчиков может быть на самом деле полезным для повторяющегося исполнения плейбука. Самое первое исполнение может приводить в результате к некоторым изменениям, однако если некоторая фатальная ошибка встретится прежде чем промелькнут имеющиеся обработчики, эти вызовы обработчиков могут быть утрачены. Повторные исполнения не приведут в результате к тем же самым изменениям, поэтому такой обработчик никогда не исполнится без вмешательства вручную. Принудительное исполнение обработчиков предпримет некую попытку, гарантируя что такие вызовы обработчиков не будут потеряны.
На протяжении разработки часто имеются задачи, которые могут рассматриваться как подрывные или разрушительные. Эти задачи могут содержать службы повторного запуска, осуществление миграций базы данных и тому подобное. Подрывающие задачи следует собирать в общий кластер для минимизации общего воздействия на некоторое приложение, хотя разрушительные задачи должны исполнится всего лишь один раз.
Перезапуск служб для некоторой новой версии кода достаточно распространённая потребность. При рассмотрении в изоляции, некоторая отдельная служба может повторно запускаться всякий раз, когда сам код или настройки для данного приложения были изменены, причём без рассмотрения общей работоспособности распределённой системы. Обычно, некая распределённая система будет иметь роли для каждой части всей системы, причём каждая роль будет в сущности работать в изоляции на тех хостах, которые предназначены для исполнения таких ролей. При развёртывании некоторого приложения в самый первый раз, не существует времени работы всей системы целиком до этого момента, о котором стоит позаботиться; поэтому службы могут повторно запускаться когда возникнет такое желание. Однако, в процессе обновления может быть желательно задержка перезапуска всех служб пока каждая служба не будет готова минимизировать прерывания.
Вместо того чтобы разрабатывать некий полностью отдельный путь кода обновления, настоятельно рекомендуется повторное применение кода роли. Для обеспечения согласованной перезагрузки имеющийся код роли для определённой службы необходимо защитить вокруг перезагрузки такой службы. Неким общим шаблоном является помещение какого- то выражения условной зависимости в таких подрывных задачах, которая проверит некое значение переменной. При выполнении некоторого обновления эта переменная может быть определена в реальном масштабе времени для переключения такого альтернативного поведения. Эта переменная также может включать некий скоординированный повторный запуск служб по окончанию своего основного плейбука когда завершатся все роли чтобы скоординировать все разрушения и минимизировать общее время простоя.
Давайте создадим некое вымышленное обновление приложения, которое содержит две роли с имитацией повторного
запуска служб. Мы назовём эти роли microA и
microB:
roles/microA
├── handlers
│ └── main.yaml
└── tasks
└── main.yaml
roles/microB
├── handlers
│ └── main.yaml
└── tasks
└── main.yaml
Для обеих этих ролей у нас есть некая простая задача отладки, которая имитирует процесс установки некоторого
пакета. Мы уведомим некий обработчик имитировать необходимы перезапуск какой- то службы. А чтобы гарантировать
что такой обработчик включится, мы принудим эту задачу всегда регистрироваться как изменённую. Ниже приводится содержимое
roles/microA/tasks/main.yaml:
roles/microA/tasks/main.yaml:
---
- name: install microA package
debug:
msg: "This is installing A"
changed_when: true
notify: restart microA
Содержимое roles/microB/tasks/main.yaml таково:
roles/microB/tasks/main.yaml:
---
- name: install microB package
debug:
msg: "This is installing B"
changed_when: true
notify: restart microB
Сами обработчики для этих ролей также будут отладочными действиями и мы подключим некое условие к
имеющейся задаче обработчиков чтобы выполнять перезапуск только если его переменная upgrade вычисляет
Булево значение false. Мы также применим установленный по умолчанию
фильтр чтобы предоставить этой переменной некое значение по умолчанию равным false.
Содержимое roles/microA/handlers/main.yaml следующее:
roles/microA/handlers/main.yaml:
---
- name: restart microA
debug:
msg: "microA is restarting"
when: not upgrade | default(false) | bool
А содержимое roles/microB/handlers/main.yaml таково:
roles/microB/handlers/main.yaml:
---
- name: restart microB
debug:
msg: "microB is restarting"
when: not upgrade | default(false) | bool
Для нашего плейбука верхнего уровня мы создадим четыре воспроизведения. Первые два воспроизведения применяют
каждую из имеющихся микро ролей, а два последних последующих воспроизведения выполнят необходимые повторные запуски.
Самые последние два воспроизведения будут исполняться только ели обновление произошло; поэтому мы применим свою
переменную upgrade в качестве условной зависимости. Давайте взглянем на следующий фрагмент кода (с названием
micro.yaml):
---
- name: apply microA
hosts: localhost
gather_facts: false
roles:
- role: microA
- name: apply microB
hosts: localhost
gather_facts: false
roles:
- role: microB
- name: restart microA
hosts: localhost
gather_facts: false
tasks:
- name: restart microA for upgrade
debug:
msg: "microA is restarting"
when: upgrade | default(false) | bool
- name: restart microB
hosts: localhost
gather_facts: false
tasks:
- name: restart microB for upgrade
debug:
msg: "microB is restarting"
when: upgrade | default(false) | bool
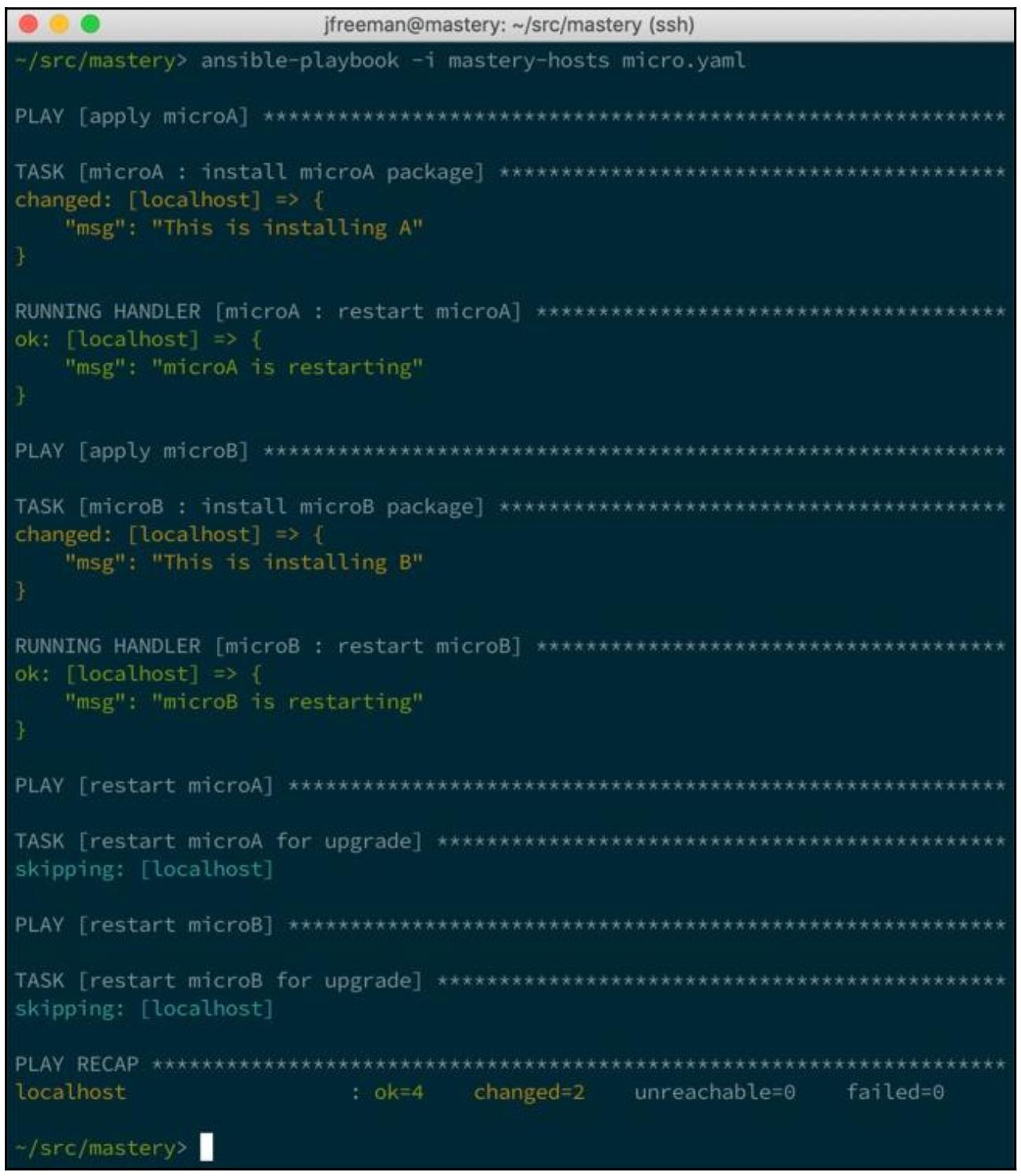
Если мы исполним этот плейбук без определения своего модуля обновления, мы увидим соответствующее исполнение каждой роли и её обработчиков внутри неё. Самые последние два воспроизведения будут иметь только пропущенные задачи:
Теперь давайте исполним этот плейбук снова, причём на этот раз мы определим свой переменную upgrade значением
true времени исполнения:
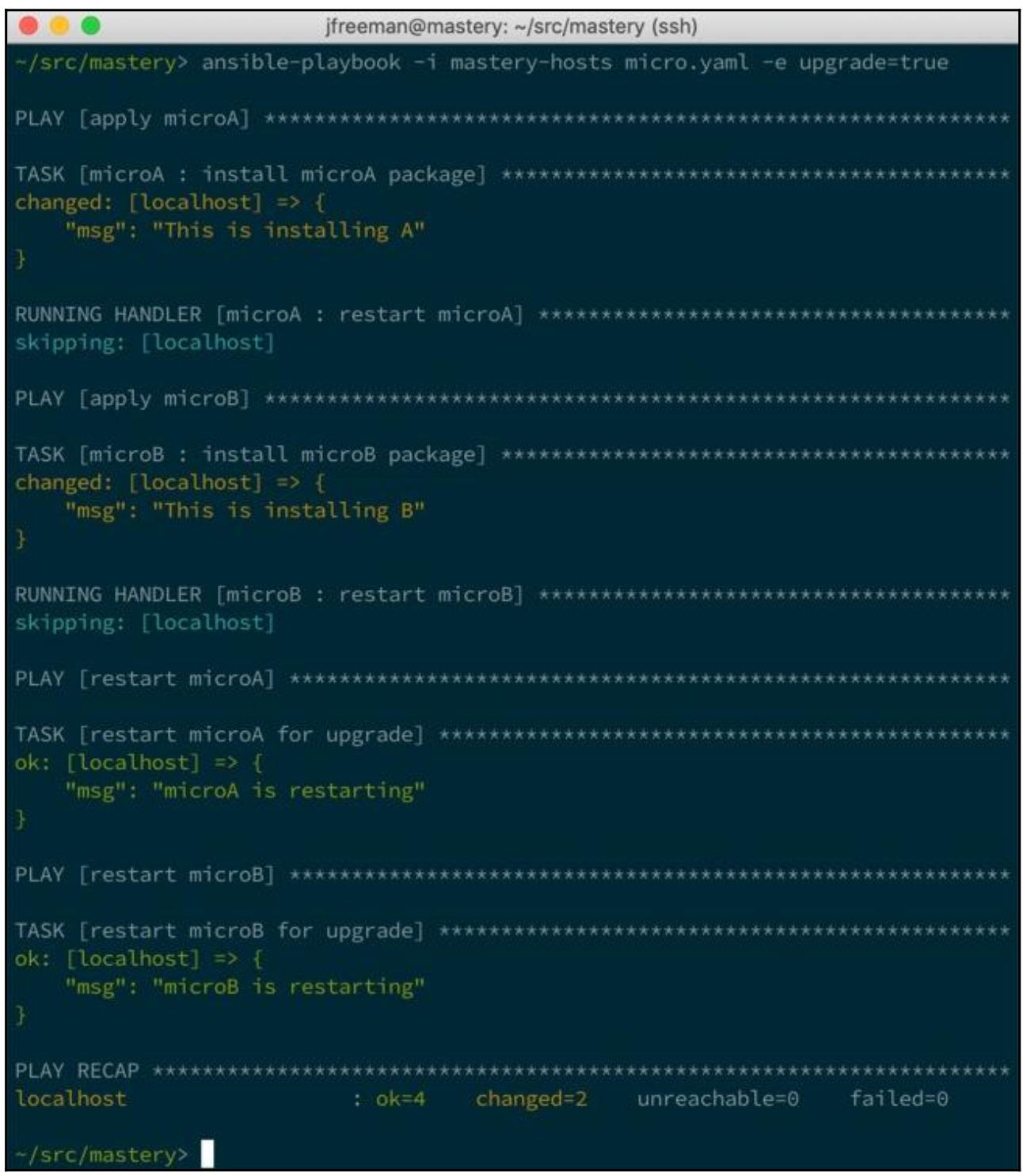
На этот раз мы можем видеть, что наши обработчики пропущены, однако наши два окончательных воспроизведения
получили задачи для исполнения. В сценарии реального мира, в котором имеется множество вещей, которые
происходят в таких ролях microA и
microB, а также потенциально имеются прочие роли микро- служб, имеющаяся
разница может составлять много минут и даже более. Сбор воедино всех перезапусков в самом конце может существенно
снизить такой период прерывания.
Разрушительные задачи возникают во многих проявлениях. Это могут быть однонаправленные задачи, которые чрезвычайно
сложно откатить обратно, одноразовые задачи, которые не так просто выполнить повторно, либо это могут быть
задачи состязания условий, которые при одновременном исполнении имеют результатом катастрофический отказ.
По этим причинам, или вследствие чего- либо ещё, существенным является то, что эти задачи выполняются только
единожды с отдельного хоста. Ansible предоставляет некий механизм для их выполнения посредством управления
задачами run_once.
Управление задачей run_once обеспечит что данная задача исполнится только
один раз на отдельном хосте вне зависимости от того сколько хостов может участвовать в некотором
воспроизведении. В то время как существуют прочие методы для выполнения этой цели, такие как использование некоторого
условия чтобы заставить данную задачу исполниться только однократно на самом первом хосте какого- то
воспроизведения, управление run_once является наиболее простым и
и прямым способом для выражения этого пожелания. Кроме того, любые переменные данные, зарегистрированные из
некоторой управляемой run_once задачи будут сделаны доступными для всех
хостов в данном воспроизведении, не только в том хосте, который был выбран Ansible для выполнения данного
действия. Это может упростить последующую выборку таких переменных данных.
Давайте создадим некий пример плейбука чтобы продемонстрировать данную функциональность. Мы повторно
воспользуемся своими хостами failtest, созданными в предыдущих примерах
чтобы иметь некий пул хостов и выбрать два из них с применением некоторого шаблона хостов. Мы сделаем некий набор задач
debug исполняющимся run_once и
зарегистрируем полученные результаты, затем осуществим доступ к этим результатам в различных задачах
разными хостами:
---
- name: run once test
hosts: failtest[0:1]
gather_facts: false
tasks:
- name: do a thing
debug:
msg: "I am groot"
register: groot
run_once: true
- name: what is groot
debug:
var: groot
when: inventory_hostname == play_hosts[-1]
Когда мы исполним данное воспроизведение, мы обратим особое внимание на те имена хостов, которые перечисляются для каждой операции задачи:

Мы можем видеть, что наша задача do a thing исполняется на хосте
failer01, в то время как задача
what is groot, которая изучает полученные данные от этой задачи
do a thing, работает на хосте
failer02.
Определённые приложения, которые исполняют множество копий служб, могут не отзываться должным образом на все те
службы, которые подлежат однократному перезапуску. Обычно при обновлении такого типа приложений применяется
воспроизведение serial. Однако, если данное приложение имеет достаточно
большой масштаб, упорядочение всего воспроизведения целиком может быть дико неэффективным. Могут применяться
различные подходы, которые состоят в упорядочении только чувствительных к этому задач, как правило определённые
обработчики для перезапуска служб.
Для упорядочения определённой задачи обработки мы можем воспользоваться встроенной переменной
play_hosts. Эта переменная содержит полный список хостов, которые должны быть
использованы этой задачей как частью общего воспроизведения. Он постоянно поддерживается в актуальном состоянии в
отношении отказавших или недостижимых хостов. Применяя эту переменную мы можем выстраивать некий цикл для итеративного
прохода по всем хостам, которые потенциально могут исполнять некую задачу обработчика. Вместо применения самого
item из имеющихся аргументов данного модуля мы будем применять элемент
item в условной зависимости when,
а также некую директиву delegate_to, таким образом мы можем исполнить данную
задачу обработчика если этот хост уведомил данный обработчик и представил данную задачу обработчика самому
хосту в исполняемом цикле вместо того чтобы выполнять её на первоначальном хосте. Однако, если мы применим это
только как список для некоторой директивы with_items, мы завершим
исполнение данной задачи для всех хостов, причём для каждого включившего некий обработчик хоста. Очевидно, что мы
хотим не этого, поэтому мы можем применить некую директиву задачи, run_once,
для изменения поведения. Такая директива run_once указывает Ansible необходимость
исполнять данную задачу только для одного хоста, вместо обычного целеуказания, которым являлось бы исполнение на
всех хостах. Сочетание run_once и нашего with_items
из play_hosts создаёт некий сценарий, при котором Ansible пройдёт по данному циклу
только один раз. Наконец, мы желаем выполнять некое непродолжительное ожидание между всеми проходами с тем, чтобы
все перезапускаемые службы могли стать работающими прежде чем мы выполним повторный запуск в следующий раз. Мы
можем воспользоваться неким loop_control из
pause (введённом в Ansible версии 2.2) чтобы вставлять паузу между
всеми последовательными исполнениями данного цикла.
Для демонстрации того как будет работать такое упорядочение, мы напишем некое воспроизведение применив несколько
хостов из своей группы failtest, причём некая задача, которая создаёт какое- то
изменение регистрирует свой вывод (поэтому мы можем выполнить проверку в своеё задаче обработчика) и упорядочивает
задачу обработчика:
---
- name: parallel and serial
hosts: failtest[0:3]
gather_facts: false
tasks:
- name: do a thing
debug:
msg: "I am groot"
changed_when: inventory_hostname in play_hosts[0:2]
register: groot
notify: restart groot
handlers:
- name: restart groot
debug:
msg: "I am groot?"
with_items: "{{ play_hosts }}"
delegate_to: "{{ item }}"
run_once: true
when: hostvars[item]['groot']['changed'] | bool
loop_control:
pause: 2
На протяжении исполнения данного плейбука мы можем видеть уведомления своего обработчика (благодаря удвоенной
многословности, -vv), а также в этой задаче обработчика мы можем видеть
определённый цикл, условную зависимость и делегирование. К сожалению, мы не можем видеть саму задержку, поскольку
эта информация не является частью нашего вывода:
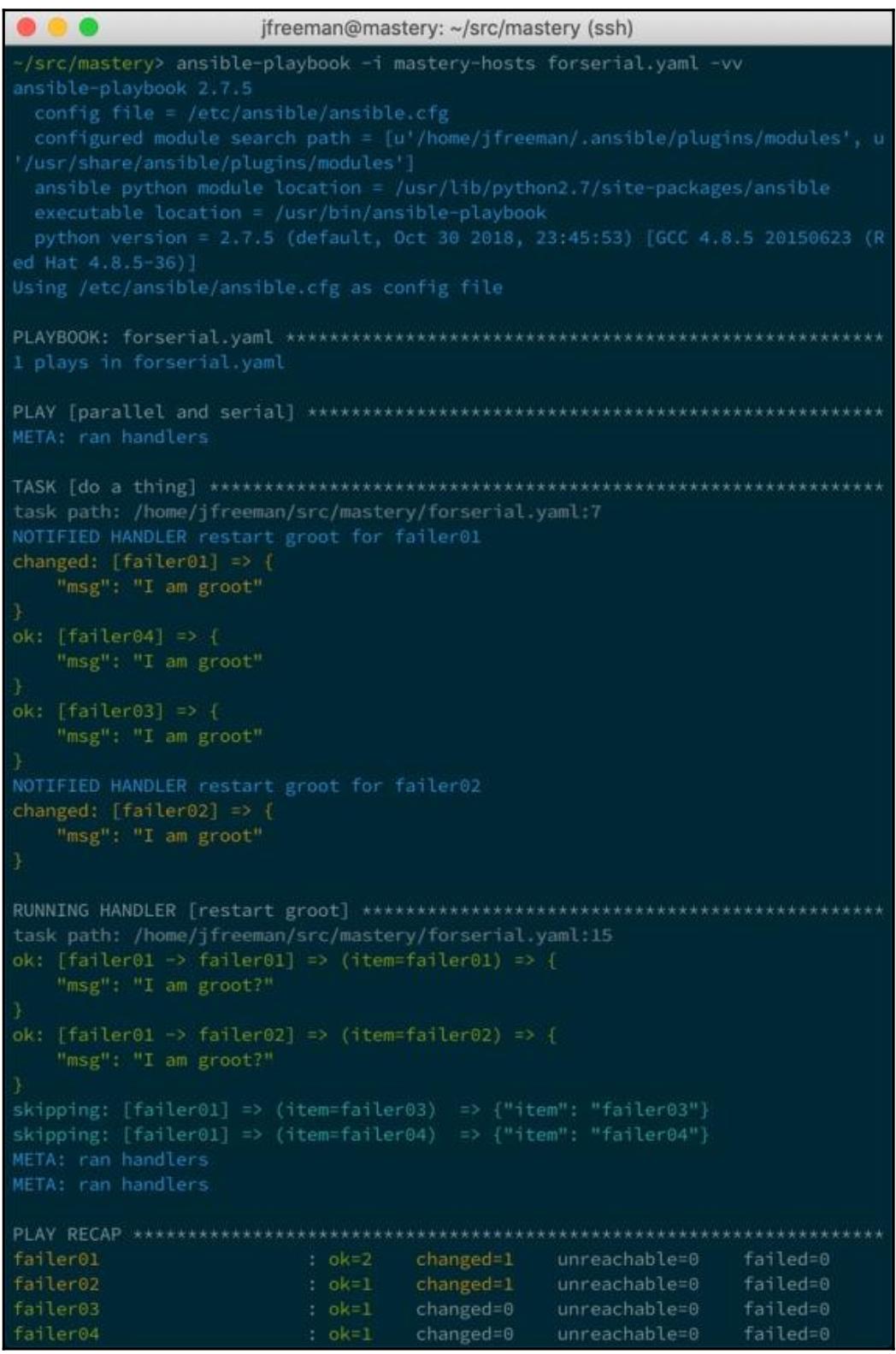
Если вы попробовали этот код для себя, вы заметите задержку между каждым запуском обработчика, как мы и указали на то в
части своей задачи loop_control.
Стратегии развёртывания и обновления - дело вкуса. Всякая привносит свои преимущества и недостатки. Ansible не заявляет некого мнения относительно того какая из них лучше и, тем самым, хорошо соответствует выполнению развёртываний и обновлений вне зависимости от принятой стратегии. Ansible предоставляет свойства и шаблоны разработки которые легко снаряжают некое разнообразие стилей. Понимание природы каждой стратегии и того, как Ansible может быть настроен под эту стратегию вооружит вас для решения и проектирования развёртываний любого вашего приложения. Управления задачами и встроенные переменные предоставляют методы эффективного обновления крупномасштабных приложений при тщательной отработке специфических задач.
В данной главе мы изучили как применять Ansible для выполнения обновлений на площадке, а также некие различные методологии для этого, включая такую технику как расширение и контрактные среды. Вы мзучили быстрый отказ для того чтобы гарантировать что плейбуки не вызывают значительных разрушений в случае когда начальная стадия некого воспроизведения пошла не так, а также как минимизировать и подрывающие и пагубные действия. Наконец, вы изучили упорядочение отдельных задач для основной цели минимизации разрушений от исполняемых служб путём выведения узлов из обслуживания неким минимально контролируемым образом. Это гарантирует что такие службы остаются работающими в о время как за сценой проводятся работы по сопровождению (например, обновление).
В своей следующей главе, мы вдадимся в подробности применения Ansible с поставщиками облачной инфраструктуры и систем контейнеров для создания некой инфраструктуры управления.