Глава 1. Архитектура системы и проектирование Ansible
{Прим. пер.: рекомендуем сразу обращаться к нашему более полному переводу 3 издания вышедшего в марте 2019 существенно переработанного и дополненного Полного руководства Ansible Джеймса Фримана и Джесса Китинга}
Содержание
Данная глава предоставляет подробное исследование архитектуры и проектирования того, как Ansible занимается исполнением задач от вашего имени. Мы рассмотрим основные понятия синтаксического разбора учёта ресурсов и способов обнаружения данных, а затем погрузимся в синтаксический анализ плейбуков (планов). Мы предпримем ознакомление с подготовкой, транспортировкой и исполнением модулей. Наконец, мы подробно рассмотрим типы переменных и узнаем где могут располагаться переменные, области в которых они могут применяться, а также как определяется приоритет в случае, когда переменные определены более чем в одном месте. Все эти вопросы будут рассмотрены с целью создания основы для овладения Ansible!
В данной главе мы рассмотрим следующие вопросы:
-
Версии и настройка Ansible
-
Синтаксический анализ учёта ресурсов и источники данных
-
Синтаксический анализ плейбуков (планов)
-
Стратегии исполнения
-
Транспортировка и исполнение модулей
-
Типы и расположение переменных
-
Приоритетность переменных
{Прим. пер.: для тех, кто впервые сталкивается с Ansible или тех, кому необходимо вначале представить в своём сознании некую картинку того, во что мы собираемся погрузиться, советуем начать с Быстрого примера Ansible в нашем переводе вышедшей в июне 2017 книги Эрика Чоу "Полное руководство работы с сетями на Python".}
Предполагается что у вас имеется установленный Ansible в вашей системе. Имеется множество документации,
которая охватывает установку Ansible тем способом, который соответствует именно вашей операционной системе
и избранной вами версии. Данная книга предполагает что вы применяете версию Ansible 2.2.x.x. Чтобы узнать
версию, применяемую в системе с уже установленным Ansible, примените аргумент версии либо в
ansible, либо в ansible-playbook:
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Отметим, что |
Настройки Ansible могут присутствовать в нескольких различных расположениях, причём именно первый найденный файл будет применяться. Порядок поиска слегка изменён в версии 1.5, с таким новым порядком:
-
ANSIBLE_CFG: это переменная окружения -
ansible.cfg: находится в текущем каталоге -
~/ansible.cfg: расположено в домашнем каталоге пользователя -
./etc/ansible/ansible.cfg
Некоторые методы установки могут содержать помещение файла config
в одном из этих размещений. Посмотрите везде, чтобы проверить имеется ли такой файл и какие параметры имеются
в этом файле, чтобы получить представление о том, какое воздействие может оказать эта операция Ansible.
Данная книга предполагает отсутствие каких либо настроек в файле ansible.cfg,
который воздействует на работу Ansible заданными по умолчанию значениями.
В Ansible ничего не происходит без инвентаризации. Даже одноразовые действия выполняемые в локальном хосте
требуют учёта ресурсов, даже если такая инвентаризация состоит в учёте только на отдельном локальном хосте.
Такой учёт ресурсов является самым основным строительным блоком архитектуры Ansible. При выполнении
ansible или ansible-playbook
необходима ссылка на некую опись. Описи являются либо файлами, либо каталогами, которые присутствуют в той
же самой системе, которая исполняет ansible или
ansible-playbook. Расположение такой описи может быть объектом ссылки
в аргументе --inventory-file
(-i), либо посредством определения его пути в некотором файле Ansible
config.
Описи (inventory) могут быть статическими или динамическими, или даже комбинацией и того, и другого, причём Ansible не ограничивается единственной описью. Стандартным подходом является разделение описей по логическим ограничениям, таким как этапы сред для их ратификации, что делает возможной инженерам исполнять некий набор представлений именно в их средах для проверки правильности, а затем следовать именно такому воспроизведению, исполняемому уже для имеющегося набора описей в производстве.
Данные переменных, такие как определённые подробности того как подключаться к конкретному хосту из вашей описи, могут включаться повсеместно с помощью учёта ресурсов самыми разнообразными способами, и мы также изучим все доступные вам варианты.
Статический учёт ресурсов является наиболее основным из всех вариантов инвентаризации. Обычно некая статическая
опись будет состоять из отдельного файла в формате ini. Вот некий пример
какого- то статического файла описи, описывающего отдельный хост,
mastery.example.name:
mastery.example.name
Вот и всё. Просто список имён определённых систем в вашей описи. Конечно, это не в полной мере получает все
преимущества, которые предоставляет учёт ресурсов. Если бы все имена перечислялись так, все представления (play)
должны были бы ссылаться на определённое имя хоста, или на определённую группу all.
Это делало бы достаточно утомительной разработку плейбуков (планов), которые работают с различными наборами
вашей инфраструктуры. По крайней мере, хосты должны быть организованы в группы. Некий хорошо отлаженный шаблон
проекта должен выстраивать ваши системы в группы на основе ожидаемой функциональности. По началу это может
показаться трудным, если у вас имеется некая среда, в которой отдельные системы могут выполнять различные роли,
но это исключительно хорошо. Системы в некоторой описи могут присутствовать в более чем в одной группе, а группа
может даже состоять из других групп! Их следует вначале перечислять, прежде чем будут определены прочие группы.
Давайте построим наш предыдущий пример и расширим свою опись несколькими хостами и определёнными группировками:
[web]
mastery.example.name
[dns]
backend.example.name
[database]
backend.example.name
[frontend:children]
web
[backend:children]
dns
database
То, что мы здесь выполнили, это некий набор из трёх групп и по одной системе в каждой, а затем ещё две
дополнительные группы, которые логически собирают всё дерево воедино. Да, всё верно; вы можете иметь группу
групп. Здесь применяется синтаксис [groupname:children], который
указывает синтаксическому анализатору Ansible, что данная группа с названием
groupname является ничем иным как некоторой группировкой прочих
групп. Потомками (children) в этом случае являются приводимые имена прочих групп. Такая опись теперь
позволяет записывать представления (play) для определённых хостов, групп с определёнными ролями нижнего уровня,
либо логического группирования высокого уровня, или какой- то комбинации.
При применении общих имён групп, таких как dns или
database, представления Ansible могут ссылаться на эти общие группы вместо
того, чтобы в явном виде указывать находящиеся в них хосты. Некий инженер может создать один файл описи, который
заполнит эти группы хостами из некоторой среды на этапе подготовки к промышленному использованию и другой файл
описи с версиями такой группировки для своего промышленного решения. Сам плейбук (план) не потребует изменений при
его исполнении будь то стадия отработки, или промышленная среда, так как он ссылается на конкретные общие имена
групп, которые присутствуют в обеих описях. Просто сошлитесь на правильную опись для исполнения его в желаемом
окружении.
Описи предоставляют больше чем просто имена систем и группировок. Также могут передаваться данные об этих системах. Они могут содержать:
-
Специфические для хоста данные для их применения в шаблонах
-
Особые для групп данные для их использования в аргументах задач или в условиях
-
Параметры поведения для регулирования того как Ansible взаимодействует с некоторой системой
Переменные являются мощной конструкцией внутри Ansible и они могут применяться различными способами, причём не только описываемыми здесь. Почти все отдельные вещи, осуществляемые в Ansible могут включать некие переменные ссылки. Хотя Ansible и способен обнаруживать данные, описывающие некоторую систему в процессе фазы установки, не все данные могут обнаруживаться. Определение данных при помощи описи является способом как расширять имеющийся набор данных. Отметим, что переменные данные могут поступать из многих различных источников, причём один источник может перекрывать другой источник. Приоритет порядка следования описывается далее в этой главе.
Давайте улучшим имеющийся у нас пример описи и добавим в него некоторые переменные данные. Мы добавим немного данных, специфичных для хоста, а также данных, характерных для групп.
[web]
mastery.example.name ansible_host=192.168.10.25
[dns]
backend.example.name
[database]
backend.example.name
[frontend:children]
web
[backend:children]
dns
database
[web:vars]
http_port=88
proxy_timeout=5
[backend:vars]
ansible_port=314
[all:vars]
ansible_ssh_user=otto
В данном примере мы определили ansible_host для
mastery.example.name с IP адресом
192.168.10.25. Эта переменная
ansible_host является некоторой
переменной поведения учёта ресурсов, которая
предназначена для изменения того способа, которым Ansible ведёт себя при работе именно с этим хостом.
В этом случае данная переменная указывает Ansible необходимость подключиться к системе с применением
предоставленного IP, вместо того, чтобы выполнять некий просмотр DNS для обнаружения имени
mastery.example.name. Существует целый ряд других переменных поведения
описи, которые перечисляются в конце данного раздела совместно с их предназначением применения.
|
| Замечание |
|---|---|
|
Что касается версии 2.0, более длинная форма некоторых параметров поведения описи устарела. Часть
|
Наши новые данные описи также предоставляют переменные уровня групп для групп web и backend. Группа web определяет
http_port, который может быть использован в некотором файле настройки
nginx, а также
proxy_timeout, который может применяться для определения поведения
HAProxy. Ещё одна группа
backend применяет другие параметры поведения описи чтобы указать Ansible
необходимость соединения с имеющимися в этой группе хостами с применением порта 314
для SSH, вместо определяемого по умолчанию 22.
Наконец, вводится некоторая конструкция, которая предоставляет переменные данные для всех хостов в данном учёте
ресурсов при помощи некоторой встроенной группы all. Определённые в этой
группе переменные будут применены ко всем хостам в данном учёте ресурсов. В данном конкретном примере мы указываем
Ansible необходимость зарегистрироваться под именем пользователя otto при
подключении к данным системам. Это также некоторое поведенческое изменение, поскольку имеющееся по умолчанию
поведение Ansible заключается в регистрации под тем же самым пользователем, который исполняет
ansible или ansible-playbook
в данном хосте управления.
Приведём таблицу переменных поведения учёта ресурсов и то действие, которое они предназначены изменять:
| Параметры описи | Действие |
|---|---|
|
Это имя DNS или IP адрес, применяемые для соединения с данным хостом, если они отличаются от самого учётного имени, либо это название того контейнера Docker, к которому необходимо подключиться. |
|
Это номер порта SSH, если он не |
|
Это имя пользователя SSH по умолчанию или пользователя внутри контейнера Docker для его использования. |
|
Это пароль SSH для применения (в открытом, опасном виде; мы настоятельно рекомендуем применять
|
|
Это файл частного ключа, используемый SSH. Он полезен если вы используете множество ключей и вы не хотите применять агент SSH. |
|
Определяет аргументы SSH для добавления в конец к применяемым по умолчанию аргументам
|
|
Эти установки всегда добавляются в конец к применяемым по умолчанию аргументам командной строки
|
|
Эти установки всегда добавляются в конец к применяемым по умолчанию аргументам командной строки
|
|
Эти установки всегда добавляются в конец к применяемым по умолчанию аргументам командной строки
|
|
Эта установка применяют Булево значение для определения следует или нет применять конвейеризацию SSH для данного хоста. |
|
Эта установка переписывает имеющийся путь к исполняемому SSH для данного хоста. |
|
Определяет должна ли для данного хоста применяться эскалация привилегий
( |
|
Применяемый для эскалация привилегий метод. Один из
|
|
Тот пользователь, от имени которого применяется эскалация привилегий. |
|
Применяемый при эскалация привилегий пароль. |
|
Пароль для применения в |
|
Тип соединения с данным хостом. Претендентами являются
|
|
Это строка любых дополнительных аргументов, которые можно передать Docker. В основном применяется для определения некоторого удалённого использования демона Docker. |
|
Это тип оболочки для целевой системы. По умолчанию команды форматируются при помощи синтаксиса
|
|
Устанавливает те инструменты оболочки, которые будут применяться в целевой системе. Этим следует
пользоваться только в случае, если невозможно применять |
|
Пароль для применения в |
|
Путь к Python на целевом хосте. Это полезно для систем, в которых имеется более одного Python,
системах, которые не размещают его в |
|
Работает для любых интерпретаторов, таких как Ruby или Perl, причём в точности так же как
|
Исходный код динамического учёта ресурсов (или встраиваемый модуль) является неким исполняемым сценарием,
который Ansible может вызывать во время исполнения для обнаружения учитываемых данных в реальном времени.
Этот сценарий может осуществлять связь с источниками внешних данных и возвращать информацию, или же он может
просто делать синтаксический разбор локальных данных, которые уже имеются, но могут не находиться в формате
учётных данных Ansible ini. Хотя достаточно просто разработать ваш
собственный исходный код динамического учёта, и мы займёмся этим в одной последующих глав, Ansible
предоставляет примеры встраиваемых модулей учёта ресурсов, включающих в себя, но не ограничивающихся
следующие:
-
OpenStack Nova
-
Rackspace Public Cloud
-
DigitalOcean
-
Linode
-
Amazon EC2
-
Google Compute Engine
-
Microsoft Azure
-
Docker
-
Vagrant
Многие из этих встраиваемых модулей требуют некоторого уровня настроек, таких как полномочия пользователей
для EC2 или терминалы аутентификации для OpenStack Nova. Так как для Ansible невозможно настраивать передачу
дополнительных аргументов в такой сценарий учёта ресурсов, все настройки для этого сценария должны либо управляться
либо через некий файл ini config, считываемый из некоторого известного
расположения или из переменных среды, считываемых из окружения той оболочки, которая используется для выполнения
ansible или ansible-playbook.
Когда ansible или ansible-playbook
находятся непосредственно в некотором исполняемом файле для какого бы то ни было исходного кода, Ansible
будет исполнять этот сценарий с единственным аргументом --list. Это
означает, что Ansible может получить список всех своих учитываемых ресурсов чтобы построить свои внутренние
объекты для представления имеющихся данных. Как только эти данные будут созданы, Ansible затем исполнит данный
сценарий с отличными для каждого хоста аргументами чтобы обнаружить изменяемые данные. Применяемым при таком
выполнении аргументом является --host <hostname>, который будет
возвращать все переменный данные, являющиеся особенными для данного хоста.
В Главе 8, Расширение Ansible мы разработаем наш собственный пользовательский встраиваемый модуль учёта ресурсов, специфичный для такого хоста.
Так же как и в случае со статическими файлами учёта ресурсов, важно помнить, что Ansible будет выполнять
синтаксический анализ этих данных один единственный раз при исполнении
ansible или ansible-playbook.
Именно это часто становится камнем преткновения для пользователей облачных динамических исходных кодов,
когда часто некий плейбук (план) создаст некий новый облачный ресурс, а затем попытается использовать его так,
как если бы он был частью описи. Такая попытка потерпит неудачу, так как данный ресурс не был частью
имевшихся учитываемых ресурсов в момент запуска данного плейбука. Однако не всё ещё потеряно! Предоставляется
некий специализированный модуль, который позволяет какому- то плейбуку временно добавлять учитываемые ресурсы
в расположенный в оперативной памяти объект инвентаризации, а именно модуль
add_host.
Модуль add_host получает два параметра,
name и groups. Имя, что должно
быть очевидным, определяет конкретное название хоста, который Ansible будет применять при соединении с
этой определённой системой. Опция groups является разделяемым
запятой списком групп для добавления к этой новой системе. Все прочие опции, передаваемые в данный модуль
станут переменными данными хоста для данного хоста. Например, если мы желаем добавить некую новую систему,
присвоить её название newmastery.example.name, добавить её в группу
web и указать Ansible соединиться с ней с применением IP адреса
192.168.10.30, это создаст задачу аналогичную такой:
- name: add new node into runtime inventory
add_host:
name: newmastery.example.name
groups: web
ansible_host: 192.168.10.30
Такой новый хост будет доступен для применения через предоставляемое имя, либо через имеющуюся у нас группу
web для оставшейся части исполнения ansible-playbook. Однако, как
только исполнение завершится, этот хост уже не будет доступен, пока он не будет добавлен в определённый источник
учёта ресурсов сам по себе. Конечно, если это был некий новый созданный облачный ресурс, последующее исполнение
ansible или ansible-playbook,
которое получит исходный код описи из этого облака подхватят такого нового участника.
Как уже упоминалось ранее, всякое исполнение ansible или
ansible-playbook будет выполнять синтаксический разбор всей инвентаризации,
к которой он был направлен. Это будет даже справедливо при применении некоторого предела. Некий предел применяется
во время исполнения посредством использования аргумента времени исполнения --limit
к ansible или ansible-playbook.
Этот аргумент применяет некий шаблон, который обычно представляет некую маску для применения к имеющемуся списку
ресурсов. Производится синтаксический разбор всего перечня ресурсов, а при каждом воспроизведении (play)
предоставляемая маска ограничений будет в дальнейшем ограничивать шаблон хостов, перечисляемых для данного
воспроизведения.
Давайте возьмём наш предыдущий пример учёта ресурсов и продемонстрируем само поведение Ansible при наличии
некоторого предела и без него. Если вы помните, у нас имеется специальная группа all,
которую мы можем применять для ссылки на все свои хосты внутри некоторой описи ресурсов. Давайте предположим,
что наш учёт ресурсов записан в имеющемся у нас текущем каталоге в файле с названием mastery-hosts,
и мы будем строить некий плейбук (план) для демонстрации того хоста, на котором работает Ansible. Давайте
запишем этот плейбук как mastery.yaml:
---
- name: limit example play
hosts: all
gather_facts: false
tasks:
-name: tell us which host we are on
debug:
var: inventory_hostname
Данный модуль отладки применяется для вывода текста, или значений переменных. Мы будем применять этот модуль много раз в данной книге для эмуляции реальной работы, происходящей на некотором хосте.
Теперь давайте выполним этот простой плейбук без предоставления какого- либо предела. Ради простоты мы укажем Ansible использовать некий метод локального соединения, который исполнится локально вместо того, чтобы попытаться установить SSH к этому несуществующему хосту. Давайте взглянем на следующий снимок экрана:
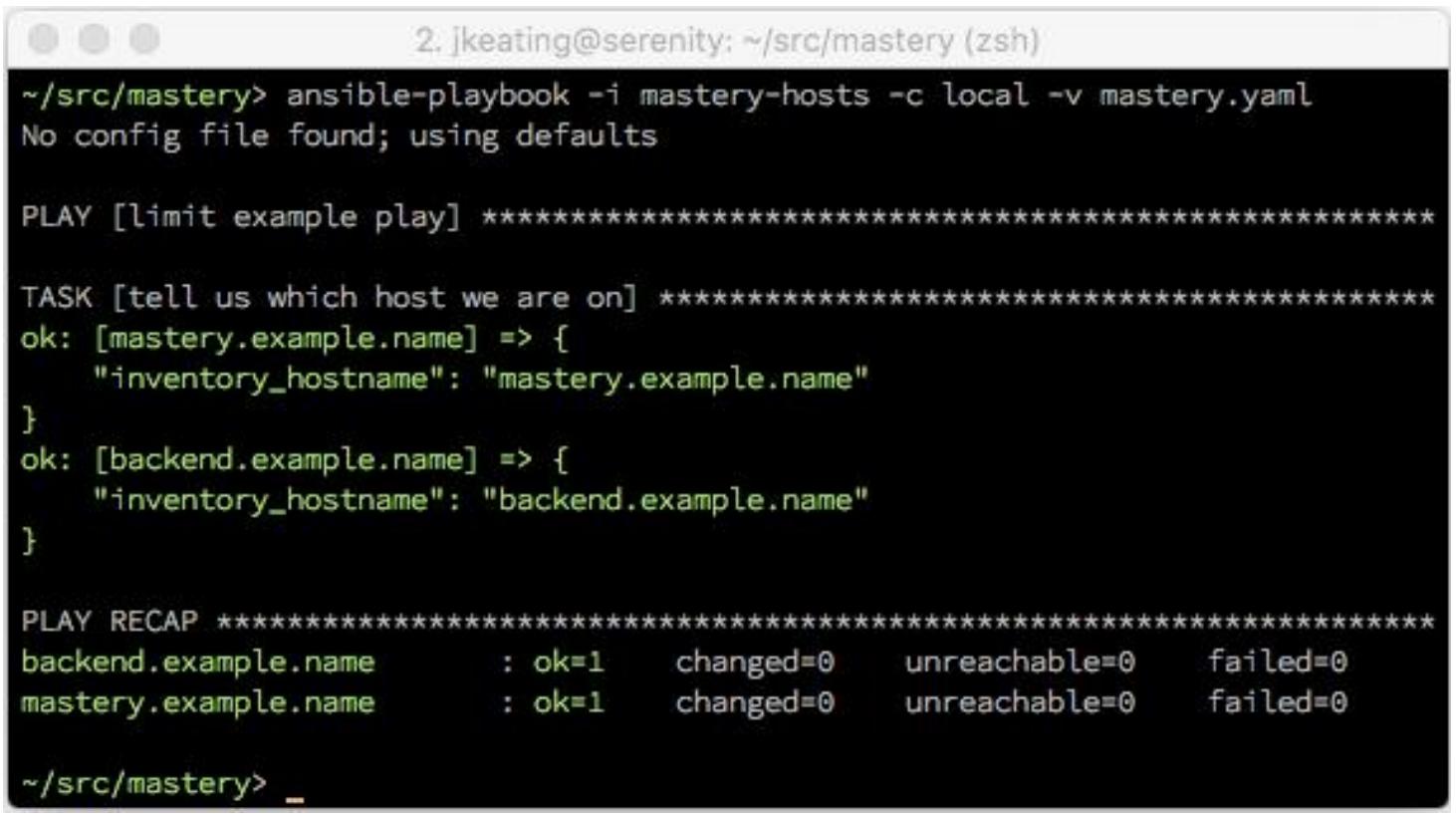
Как мы можем видеть, были обработаны оба хоста, backend.example.name и
mastery.example.name. Давайте посмотрим что произойдёт если мы
предоставим некое ограничение, определяющее ограничение нашего исполнения только на системы интерфейса:
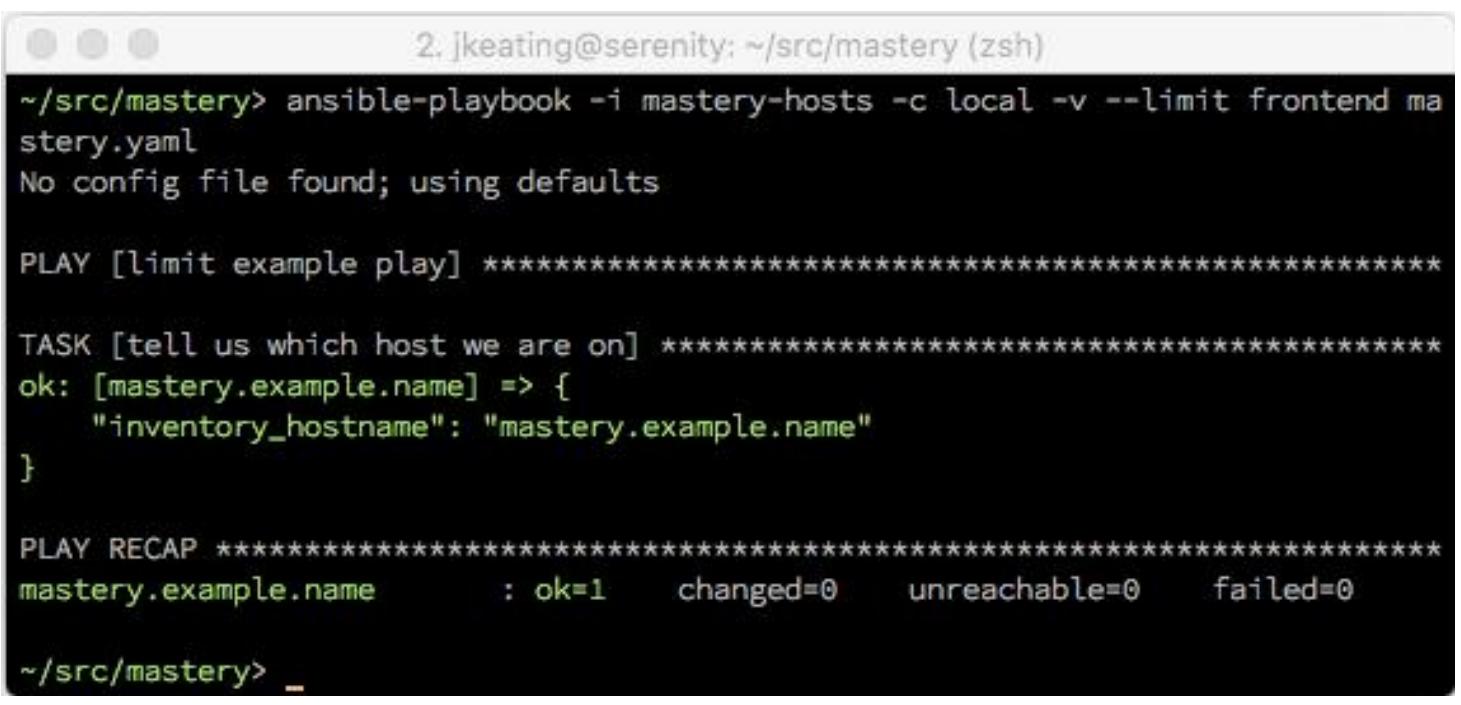
Мы можем видеть, что только mastery.example.name был обработан
на этот раз. Хотя нет никаких видимых ключей к тому что был произведён синтаксический разбор всей описи ресурсов,
если мы погрузимся глубже в имеющийся код Ansible и опросим имеющийся объект учёта ресурсов, мы действительно
обнаружим внутри все имеющиеся хосты, а также увидим как применяется предел всякий раз, когда этот объект
опрашивается для получения элементов.
Важно помнить, что в зависимости от применяемого в воспроизведении (play) шаблона хостов, или предоставляемого
на время исполнения предела, Ansible всё же осуществляет синтаксический разбор всего множества учёта ресурсов при
каждом исполнению На самом деле, мы можем подтвердить это попытавшись осуществить доступ к переменным данным
определённого хоста, который был бы в противном случае маскирован нашим пределом. Давайте слегка расширим наш
плейбук и попытаемся выполнить доступ к существующей переменной ansible_port
в backend.example.name:
---
- name: limit example play
hosts: all
gather_facts: false
tasks:
- name: tell us which host we are on
debug:
var: inventory_hostname
- name: grab variable data from backend
debug:
var: hostvars['backend.example.name']['ansible_port']
Мы всё ещё применяем свой предел, который ограничивает наши операции всего лишь до
mastery.example.name:
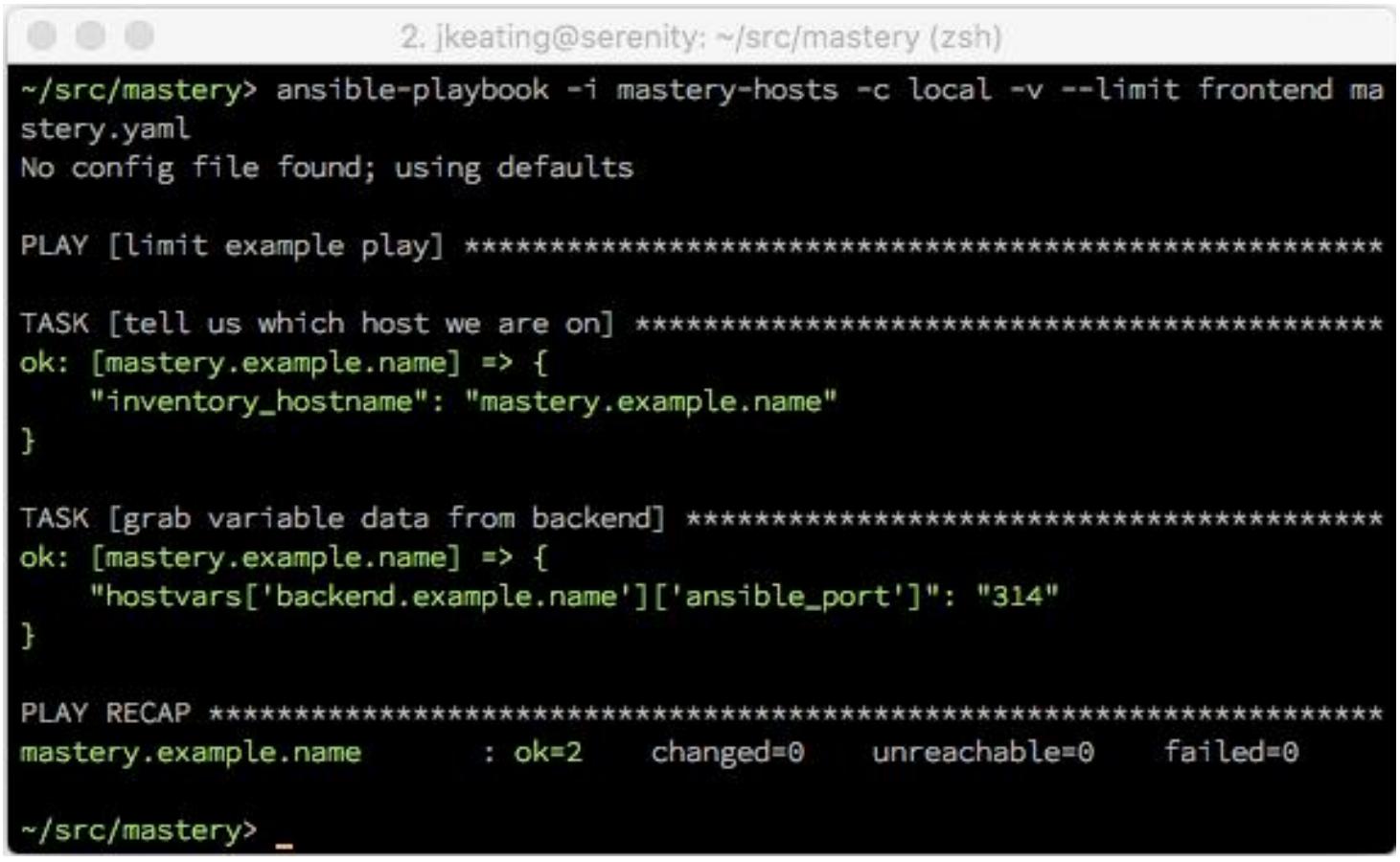
Но мы успешно осуществили доступ к переменным данным того хоста (через переменные группы) для некоторой системы, которая в противном случае была бы ограничена. Это некоторый ключевой навык для понимания, так как он делает возможными более расширенные сценарии, такие как направление некоторой задачи на какой- то хост, который в противном случае был бы ограничен. Делегирование может применяться для управления балансировщиком нагрузки для перевода системы в режим обслуживания при её обновлении, без необходимости включения такой системы балансировки нагрузки в вашу маску ограничения.
Вся цель некоторого источника учёта ресурсов состоит в наличии систем для их обработки. Такая обработка
поступает из плейбуков (или, в случае одноразового исполнения ansible,
простого воспроизведения единственной задачи). Вы уже должны иметь базовое представление строения плеубуков - планов-
поэтому мы не будем тратить много времени на их рассмотрение; однако, мы погрузимся в некоторые особенности того,
как осуществляется синтаксический разбор некоторого плейбука. В частности, мы рассмотрим следующее:
-
Порядок операций
-
Предположения об относительных путях
-
Ключевые поведения воспроизведения
-
Выбор хоста для воспроизведения и задач
-
Имена воспроизведений и задач
Ansible разработан с целью быть настолько простым для восприятия людьми, насколько это возможно. Разработчики стремились достичь наилучшего баланса между пониманием людьми и машинной эффективностью. Исходя из этого, почти всё в Ansible может рассматриваться как исполняемое в порядке сверху вниз, то есть, все операции, перечисленный в верхней части некоторого файла предполагаются исполняемыми до тех операций, которые располагаются в нижней части файла. Сказав это, необходимо отметить несколько предостережений и даже ряд способов повлиять на такой порядок операций.
Всякий плейбук имеет только две основные операции, которые он может исполнять. Он может либо выполнять воспроизведение (play), либо он может включать другой плейбук откуда-то ещё из имеющейся файловой системы. Тот порядок, который в котором это осуществляется это просто порядок, в котором они возникают в данном файле плейбука, от начала и до конца. Важно отметить, что хотя все операции выполняются о порядку, весь этот плейбук и все включаемые файлы плейбуков подвергаются полному синтаксическому разбору до какого бы то ни было исполнения. Это означает, что все включаемые в плейбук файлы должны существовать на тот момент времени, когда выполняется такой синтаксический разбор плейбука. Они не могут создаваться в какой- либо более ранней операции. Это является особенностью для включений плейбука и не является обязательным для включений задач, которые могут возникнуть внутри некоторого воспроизведения, что будет рассмотрено в следующей главе.
Внутри некоторого воспроизведения (play) имеется несколько больше операций. В то время, как некий плейбук (план) строго упорядочен сверху донизу, некое воспроизведение имеет более тонкий порядок операций. Вот некий список всех возможных операций и тот порядок, в котором они могут происходить:
-
Загрузка переменных
-
Получение фактов
-
Исполнение
pre_tasks -
Обработка уведомлений от исполненных
pre_tasks -
Исполнение ролей
-
Исполнение задач
-
Обработка уведомлений от исполненных ролей и задач
-
Исполнение
post_tasks -
Обработка уведомлений от исполненных
post_tasks
Вот некий пример воспроизведения с отображением большинства из этих операций:
---
- hosts: localhost
gather_facts: false
vars:
- a_var: derp
pre_tasks:
- name: pretask
debug:
msg: "a pre task"
changed_when: true
notify: say hi
roles:
- role: simple
derp: newval
tasks:
- name: task
debug:
msg: "a task"
changed_when: true
notify: say hi
post_tasks:
- name: posttask
debug:
msg: "a post task"
changed_when: true
notify: say hi
В зависимости от того порядка, в котором эти блоки перечисляются в некотором воспроизведении, тот порядок,
который был уточнён ранее является тем порядком, в котором они могут быть исполнены. Частным случаем являются
обработчики (те задачи, которые могут быть вызваны прочими задачами, приводящими к некоторому изменению).
Имеется некий модуль утилиты, meta, который может быть применён для
запуска исполнения обработчика в некоторый определённый момент:
- meta: flush_handlers
Это укажет Ansible на необходимость исполнения всякого находящегося в рассмотрении обработчика прежде чем
продолжить следующую определённую задачу или следующий блок действий внутри некоторого воспроизведения.
Понимание данного порядка и способность воздействовать на порядок посредством flush_handlers
является другим необходимым ключевым навыком в случае, когда имеется необходимость для координации сложных
действий, при которых такие вещи как перезапуски службы очень чувствительны к порядку. Рассмотрим конкретную
начальную раскрутку некоторой службы. Её воспроизведение будет иметь задачи которые изменяют файлы
config и указывают, что данная служба должна быть перезапущена когда эти
файлы изменены. Данное воспроизведение также будет указывать, что данная служба должна исполняться. При
первом возникновении данного воспроизведения данный файл config будет
изменён и обозначенная служба изменится с не исполняющейся на исполняемую. Затем будут запущены обработчики,
что вызовет немедленный перезапуск данной службы. Это может быть разрушительным для всякого потребителя данной службы.
Было бы лучше сбросить все обработчики перед некоторой завершающей операцией, чтобы обеспечить запуск этой
службы. Таким образом, перезапуск произойдёт до самого первого начального старта и тем самым данная служба
запустится один раз и останется поднятой.
Когда Ansible осуществляет синтаксический разбор некоторого плейбука (плана), имеется ряд предположений, которые могут быть сделаны обо всех относительных путях элементов, на которые ссылаются операторы в некотором плейбуке. В большинстве случаев, пути для таких вещей как подлежащие включению файлы переменных, файлы задач для включения, файлы плейбуков для включения, подлежащие копированию файлы, шаблоны для построения, сценарии для исполнения и тому подобное, всё является относительным к тому каталогу, в котором расположен тот файл, из которого исходит ссылка. Давайте исследуем это на некотором примере плейбука и перечисления каталога, в котором всё это происходит:
-
Структура каталога:
. ├── a_vars_file.yaml ├── mastery-hosts ├── relative.yaml └── tasks ├── a.yaml └── b.yaml -
Содержимое
a_vars_file.yaml:--- something: "better than nothing" -
Содержимое
relative.yaml--- - name: relative path play hosts: localhost gather_facts: false vars_files: - a_vars_file.yaml tasks: - name: who am I debug: msg: "I am mastery task" - name: var from file debug: var: something - include: tasks/a.yaml -
Содержимое
tasks/a.yaml--- - name: where am I debug: msg: "I am task a" - include: b.yaml -
Содержимое
tasks/b.yaml--- - name: who am I debug: msg: "I am task b"
Исполнение данного плейбука таково:
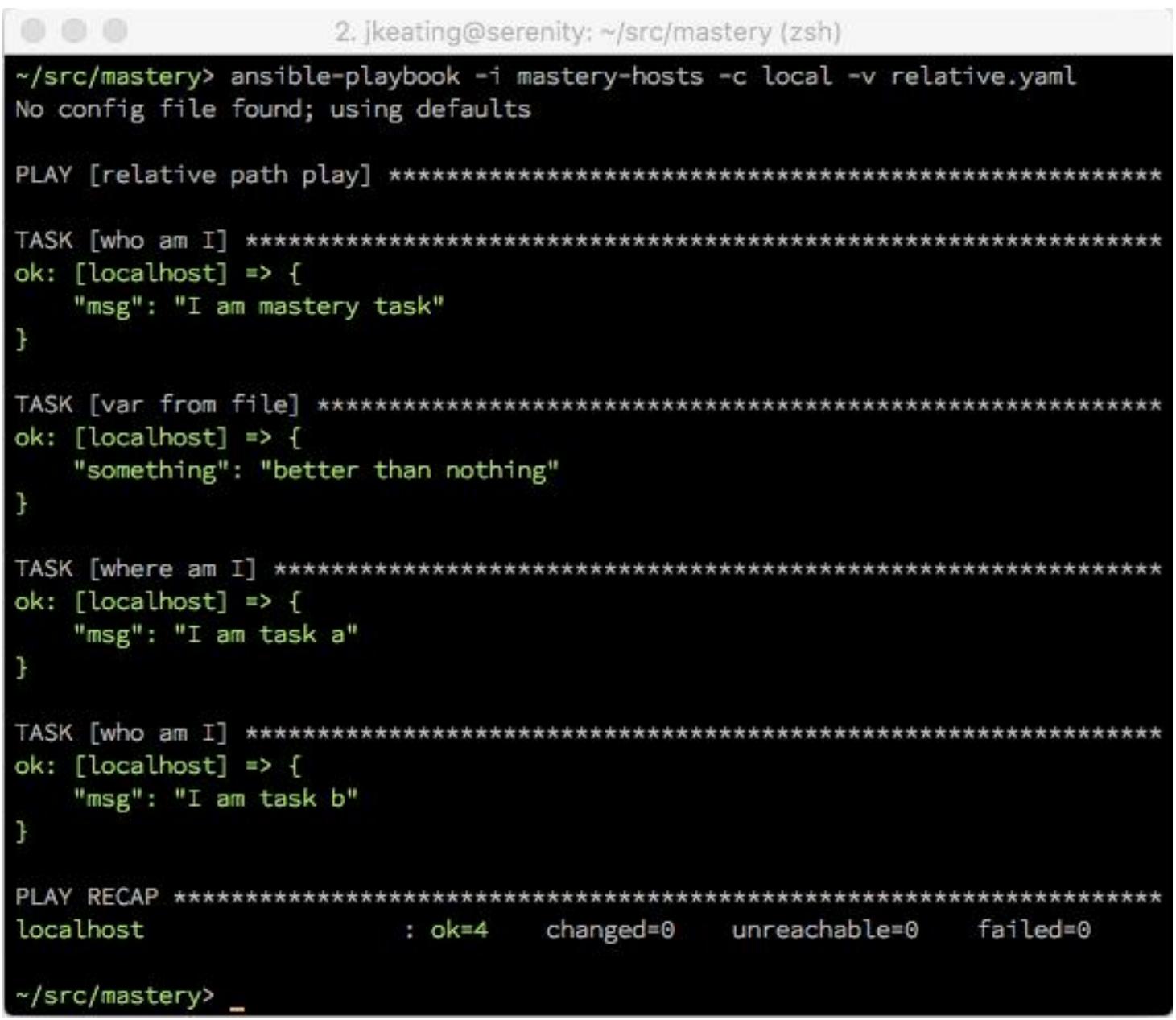
Мы можем отчётливо видеть все относительные ссылки на пути и как они соотносятся с теми файлами, которые ссылаются на них. При использовании ролей, имеются некоторые дополнительные предположения об относительных путях, однако мы подробно обсудим это в следующей главе.
Когда Ansible осуществляет синтаксический разбор воспроизведения (play), имеется ряд директив, поиск которых
он выполняет, чтобы определить различное поведение для некоторого воспроизведения. Эти директивы записываются
на том же самом уровне, что и директива hosts:. Вот подмножество из
ключевых, которые могут применяться описанным образом:
-
any_errors_fatal: Данная Булева директива применяется для указания Ansible рассматривать любой отказ как неустранимую ошибку для предотвращения любых попыток выполнения дальнейших задач. Она изменяет все значения по умолчанию, при которых Ansible продолжится пока все задачи не будут завершены или не откажут все хосты. -
connection: Эта строковая директива определяет какую систему соединения применять для данного воспроизведения. Обычным выбором здесь является local, что указывает Ansible на необходимость выполнять все операции локально, однако в контексте той системы, которая взята из учёта ресурсов. -
gather_facts: Эта Булева директива управляет тем, будет или нет Ansible выполнять свою фазу операций получения фактов, при которой некая особая задача исполняется на каком- то хосте для обнаружения различных фактов об этой системе. Пропуск получения фактов, когда вы уверены что вам не нужно никакого обнаружения данных, может стать значительным сохранением времени в некотором большом окружении. -
max_fail_percentage: Эта численная директива аналогичнаany_errors_fatal, однако более гранулирована. Она позволяет вам определить какой процент ваших хостов может отказать прежде чем выполнит останов вся операция. -
no_log: Эта Булева директива управляет тем, будет или нет Ansible выполнять регистрацию (на определённый экран и/или в некий настроенный файлlog) данной команды или всех полученных от некоторой задачи результатов. Это важно если ваша задача или вывод имеют отношение к секретной информации. Этот ключ также может быть применён к некоторой задаче напрямую. -
port: это ряд директив для определения того, какой порт SSH (или другого встраиваемого модуля соединения) необходимо применять для соединения пока другого не будет настроено в данных учёта ресурсов. -
remote_user: Данная строковая директива определяет какой пользователь регистрируется в этой удалённой системе. По умолчанию соединение производится от имени того пользователя, который запускалansible-playbook. -
serial: Эта директива принимает некоторое значение и контролирует сколько систем Ansible выполнит задачу прежде чем перейти к следующей задаче в воспроизведении. Это решительное изменение по сравнению с обычным порядком работы, при котором некоторая задача исполняется по всем системам при воспроизведении прежде чем перейти к следующей. Это очень полезно при сценариях накатывания обновлений, которые будут более подробно описаны в последующих главах. -
become: Эта Булева директива определяется для настройки того, следует ли применять эскалацию привилегий (sudo, или иного метода) на данном удалённом хосте для выполнения задач. Этот ключ также может определяться на уровне некоторой задачи. Связанные директивы включают в себяbecome_user,become_methodиbecome_flags. Может применяться для того, чтобы настраивать как должна происходить эскалация. -
strategy: Данная директива устанавливает какая тратегия будет применяться для воспроизведения.
Многие из этих ключей будут применяться в примерах плейбуков на протяжении всей книги.
|
| Замечание |
|---|---|
|
За полным списком доступных директив воспроизведения отсылаем вас к документации в интернет- ресурсах по адресу https://docs.ansible.com/ansible/playbooks_variables.html#play. |
Выпуск Ansible 2.0 ввёл новый способ управления поведением исполнения воспроизведения, стратегию. Некая стратегия определяет каким образом Ansible координирует все задачи по множеству хостов. Всякая стратегия является неким встраиваемым модулем, причём Ansible вводит два: линейный (linear) и свободный (free). Линейная стратегия, являющая стратегией по умолчанию, это то, как Ansible всегда себя ведёт. При исполнении некоторого воспроизведения все подлежащие этому воспроизведению хосты исполняют самую первую задачу. Когда все завершаются, Ansible переходит к следующей задаче. Директива serial может создавать пакеты хостов для работы последовательным образом, однако сама базовая стратегия остаётся той же самой. Все имеющиеся цели для для некоторого заданного пакета должны выполнить какую- то задачу прежде чем начать исполнение следующей. Новая свободная стратегия прерывает такое обычное поведение. При применении свободной стратегии, как только некий хост выполняет какую- то задачу, Ansible будет исполнять следующую задачу для этого хоста, не ожидая когда её не завершит ещё какой- нибудь хост. Это происходит со всеми хостами в данном наборе, для всех задач во всех воспроизведениях. Эти хосты завершат задачи настолько быстро, насколько смогут, минимизируя время исполнения для каждого конкретного хоста. Хотя большинство плейбуков будут применять определённую по умолчанию линейную стратегию, имеются случаи, в которых свободная стратегия будет более предпочтительной. Например, обновление некоторой службы по какому- то обширному набору хостов. Если такое воспроизведение имеет значительное число задач для исполнения такого обновления, которые начинаются с останова данной службы, тогда более важно для каждого хоста испытать настолько малое время простоя, насколько это возможно. Позволяя всем хостам независимо перемещаться по исполняемому ими воспроизведению настолько быстро, насколько это возможно, мы обеспечиваем останов каждого хоста только на тот промежуток, который ему необходим. Не применяя свободную стратегию, целый парк был бы остановлен на тот период, пока самый медленный хост во всём парке завершит все задачи.
|
| Замечание |
|---|---|
|
Так как свободная стратегия не осуществляет координацию выполнения задач в хостах, не возможно зависеть от тех данных, которые создаются на протяжении некоторой задачи для использования в последующих задачах на каком- то другом хосте. Нет никакой гарантии, что данный самым первым завершит ту задачу, которая вырабатывает необходимые данные. |
Стратегии исполнения реализуются в виде некоторого встраиваемого модуля и, таким образом, могут быть разработаны персональные стратегии для расширения поведения Ansible. Разработка таких встраиваемых модулей не входит в задачи данной книги.
Самый первый предмет, который определяют большинство воспроизведений (после именования, конечно), это шаблон хостов для воспроизведения. Это именно тот шаблон, который применяется для выбора хостов из объекта описи, на котором исполняются данные задачи. Обычно он прямолинеен; некий шаблон хостов содержит один или более блоков, указывающих некий хост, группу, символы подстановки или регулярное выражение применяемое для такого выбора. Блоки разделяются двоеточием, из символов подстановки применяется только звёздочка, а регулярное выражение начинается с символа тильды:
hostname:groupname:*.example:~(web|db)\.example\.com
Расширенное применение может включать выбор индекса группы или даже диапазон внутри какой- то группы:
Webservers[0]:webservers[2:4]
Все блоки рассматриваются как некий включаемый блок, то есть все обнаруженные в самом первом шаблоне хосты добавляются ко всем хостам, обнаруживаемым в последующем шаблоне, и так далее. Однако, можно оперировать при помощи управляющих символов для изменения их поведения. Применение амперсанада ("&") делает возможным некий включающий выбор (всех присутствующих в обоих шаблонах хостов). Использование восклицательного знака позволяет выбор с исключением (все хосты, имеющиеся в данном предыдущем шаблоне и НЕ находящиеся в указанном исключающем шаблоне):
Webservers:&dbservers
Webservers:!dbservers
Когда Ansible осуществляет синтаксический разбор данных шаблонов, он будет затем применять ограничения, если они
имеются. Ограничения поступают в виде пределов или отказавших хостов. Такой результат сохраняется на протяжении
данного воспроизведения и доступен через переменную с именем play_hosts.
По мере выполнения каждой задачи, эти данные опрашиваются и в процессе обработки последовательных операций могут
помещаться некие дополнительные ограничения. По мере возникновения отказов, будь то отказы в соединении или отказы
в исполнении задач, все отказавшие хосты помещаются в некий список ограничений с тем, чтобы такой хост был передан
в идущую следующей задачу. Если, в определённый момент, некая процедура выбора хостов получает падение ограничений
до нуля хостов, исполнение данного воспроизведения прекращается с некоторой ошибкой. Некая оговорка здесь состоит в
том, что если воспроизведение настроено на наличие некоторого параметра max_fail_precentage
ил any_errors_fatal, тогда исполнение данного воспроизведения прекращается
непосредственно после того как данная задача встречает такое условие.
Когда нет прямого ограничения, хорошей практикой является пометка ваших воспроизведений (play) и задач
именами. Такие имена будут отображаться в выводах командных строк ansible-playbook
и будут отображаться в файлах журнала если ansible-playbook
напрямую выполняет регистрацию в некотором файле. Имена задач также становятся удобными для прямого запуска
ansible-playbook в конкретной задаче и для ссылок в обработчиках.
Имеются два основных подлежащих рассмотрению момента при именовании воспроизведений и задач:
-
Имена воспроизведений и задач должны быть уникальными.
-
Избегайте какого- либо применения переменных в именах воспроизведений и задач
Наилучшей практикой будет использование уникальных имён воспроизведений и задач, что в целом поможет быстро идентифицировать где может размещаться проблемная задача в вашей иерархии плейбуков (планов), ролей, файлов задач, обработчиков и тому подобного. Уникальность является ещё более важной при уведомлении некоторого обработчика или при запуске некоторой определённой задачи. В случае, когда имена задач имеют дублирования, само поведение Ansible может стать непредсказуемым или по крайней мере не очевидным.
Имея в качестве некоторой цели уникальность, многие авторы плейбуков смотрят на переменные для удовлетворения данному сдерживающему фактору. Такая стратегия может хорошо работать, однако авторы вынуждены заботиться об источнике тех переменных данных, на которые они ссылаются. Переменные данные могут поступать из разнообразных расположений (которые мы обсудим позже в данной главе), а назначаемые этим переменным значения могут определяться в самое разное время. Ради имён воспроизведений и задач важно помнить, что правильно будут разбираться и обсчитываться только те параметры, для которых значения будут определены во время синтаксического разбора плейбука. Если эти данные, на которые ссылается переменная, обнаруживаются через некую задачу или прочие операции, такая строка переменной будет отображаться как не прошедшая синтаксический анализ в получаемом выводе. Давайте рассмотрим некий пример плейбука, который применяет переменные для имён воспроизведений и задач:
---
- name: play with a {{ var_name }}
hosts: localhost
gather_facts: false
vars:
- var_name: not-mastery
tasks:
- name: set a variable
set_fact:
task_var_name: "defined variable"
- name: task with a {{ task_var_name }}
debug:
msg: "I am mastery task"
- name: second play with a {{ task_var_name }}
hosts: localhost
gather_facts: false
tasks:
- name: task with a {{ runtime_var_name }}
debug:
msg: "I am another mastery task"
На первый взгляд можно ожидать, что по крайней мере var_name и
task_var_name вычисляются правильно. Мы можем отчётливо видеть, что
task_var_name определяется до её применения. Однако, вооружившись
знанием, что плейбуки целиком подвергаются синтаксическому анализу до исполнения, мы лучше понимаем:
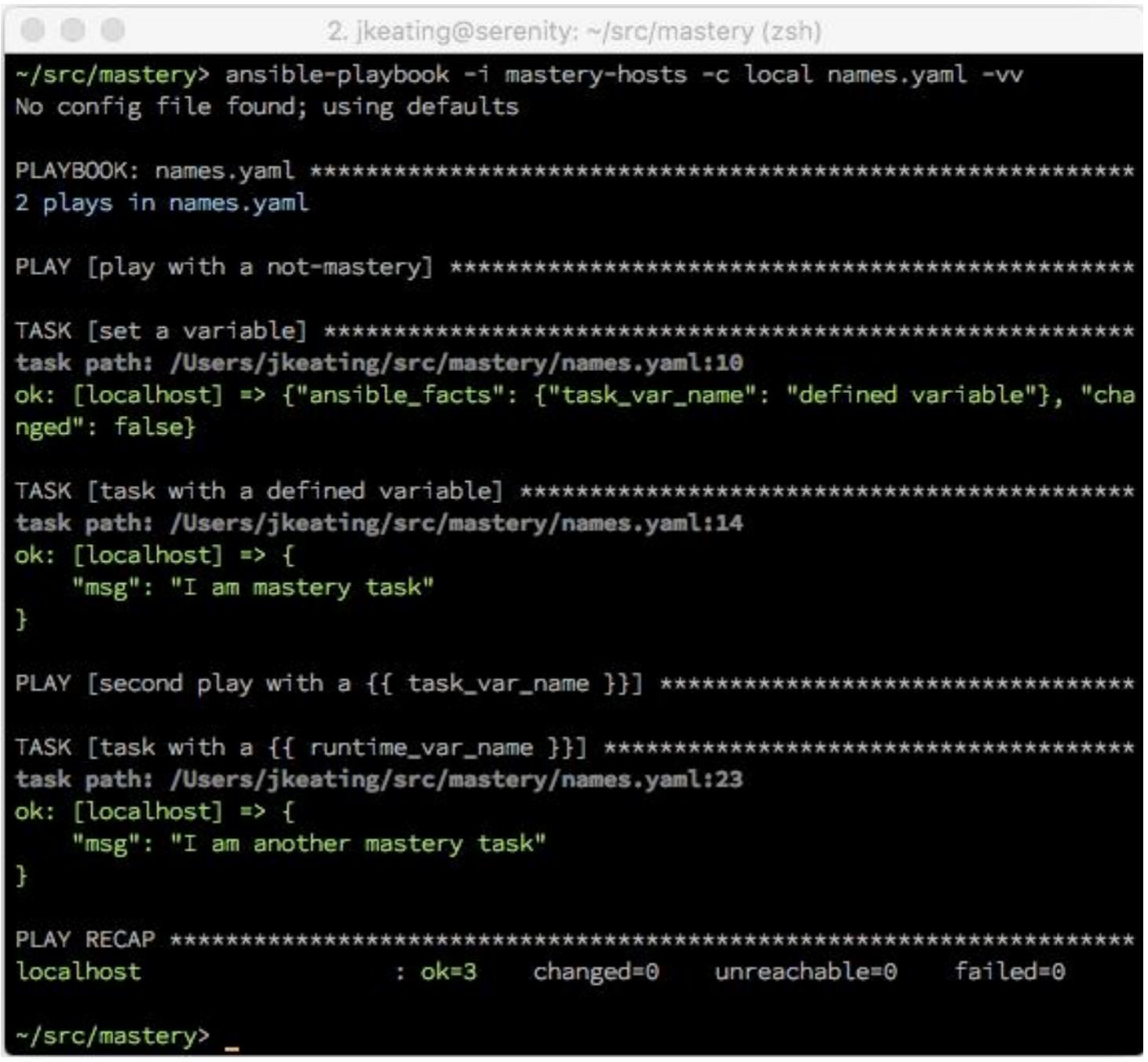
Как мы можем видеть, надлежащим образом обработан только одно имя переменной,
var_name , так как она была определена как некая статическая
переменная воспроизведения.
Когда некий плейбук (план) прошёл синтаксический разбор и определены все хосты, Ansible готов выполнить некую задачу. Задачи состоят из имени (необязательно, но, пожалуйста, не пропустите его), ссылки на модуль, аргументов модуля и директив управления задачей. Следующая глава подробно обсудит директивы управления задачей, поэтому мы рассмотрим только её ссылку на модуль и аргументы.
Все задачи имеют некую ссылку на модуль. Она сообщает Ansible какой вид работы выполнять. Ansible разработан с тем, чтобы сделать возможным присутствие в некотором плейбуке пользовательских модулей. Такие пользовательские модули могут быть целиком с новой функциональностью или они могут заменять поставляемые с самим Ansible модули. Когда Ansible выполняет синтаксический разбор накоторой задачи и обнаруживает то имя модуля, которое необходимо применять для какой- то задачи, он просматривает последовательности расположений чтобы определить все запрошенные модули. Где он осуществляет просмотр, также зависит и от того, где находится данная задача, является она ролью или нет.
Если некая задача является какой- то ролью, Ansible вначале просматривает наличие данного модуля в некотором
дереве каталога с названием library, где располагаются все роли и задачи.
Если там модуль не обнаружен, Ansible ищет каталог с названием library
на том же самом уровне где находится самый главный плейбук (тот, который обозначен при исполнении
ansible-playbook). Если модуль не обнаружен и там, Ansible наконец
выполняет просматр во том настроенном пути библиотек, который по умолчанию определён в
/usr/share/ansible/. Такой путь библиотеки может быть настроен в файле
config Ansible или через переменную окружения
ANSIBLE_LIBRARY.
Такое построение позволяет модулям быть упакованными в роли и плейбуки, что делает возможным добавление функций или очень просто и быстро устранять проблемы.
Не всякому модулю порой требуются аргументы; вывод подсказки модуля укажет каким модулям они нужны, а каким
нет. Доступ к документации модуля может быть выполнен при помощи команды
ansible-doc:
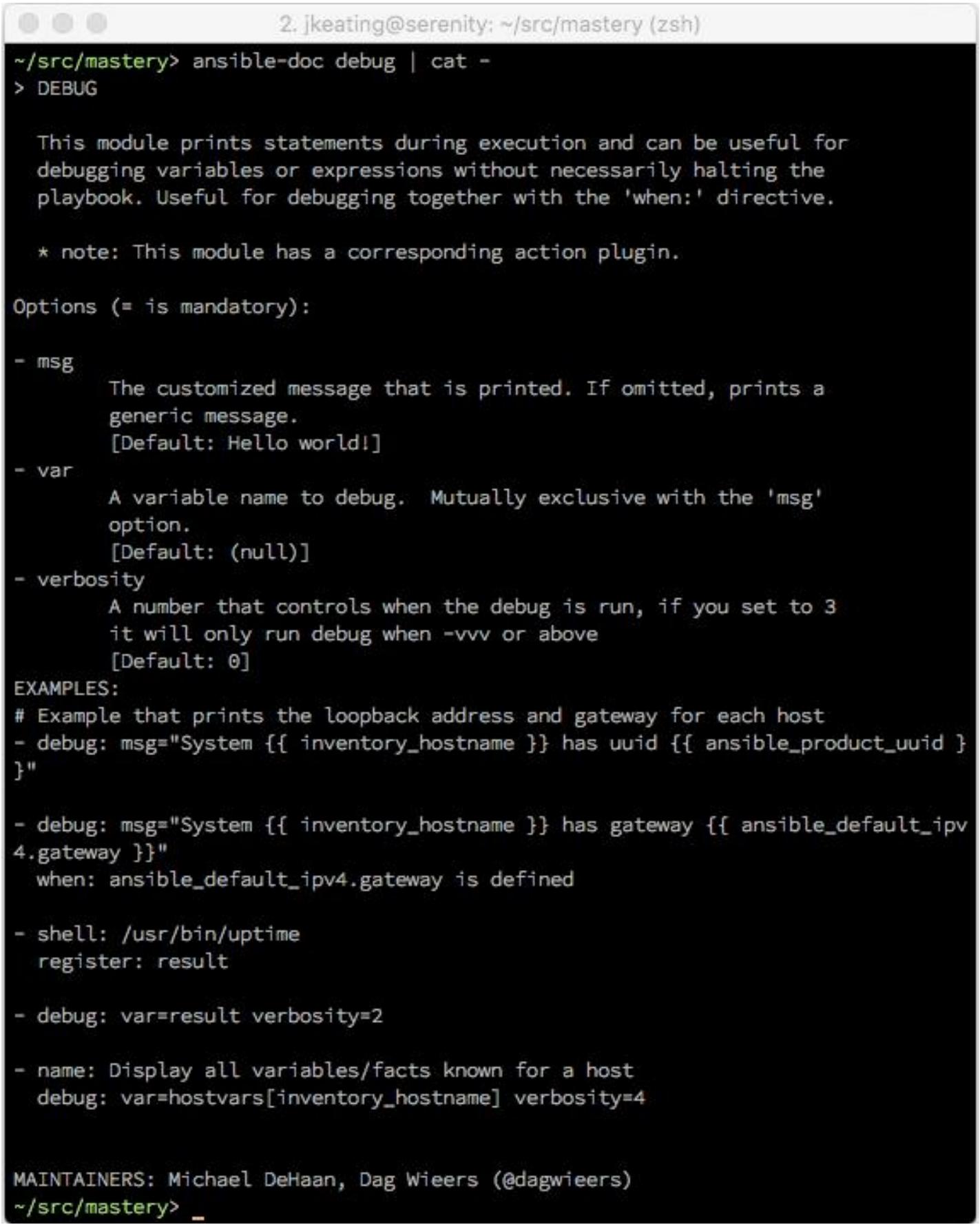
|
| Замечание |
|---|---|
|
Во избежание разбиения на страницы оболочкой данный вывод был перенаправлен в
|
Аргументы могут быть используемыми в Jinja2 шаблонами, которые будут подвергнуты синтаксическому разбору во время исполнения модуля, что позволяет обнаруженным некоторой предыдущей задаче данным применяться в последующих задачах; это очень мощный элемент разработки.
Аргументы могут предоставляться в виде key=value, или некотором более
сложном формате, который более привычен для YAML. Вот два примера передаваемых некому модулю аргументов, показывающих
два варианта формата:
- name: add a keypair to nova
os_keypair: cloud={{ cloud_name }} name=admin-key wait=yes
- name: add a keypair to nova
os_keypair:
cloud: "{{ cloud_name }}"
name: admin-key
wait: yes
Оба формата приводят к одному и тому же результату в данном примере; однако, именно сложный формат необходим, если вы желаете передавать сложные аргументы в некий модуль. Некоторые модули ожидают какого- то списка объектов или хэша данных для передачи в них; и только сложный формат позволяет это делать. Хотя для многих задач приемлемы оба формата, именно сложный формат является тем форматом, который применяется для большинства примеров данной книги.
Когда некий модуль обнаружен, Ansible должен исполнить его каким- то образом. Как этот модуль передаётся и выполняется зависит от ряда моментов; однако, обычный процесс состоит помещении данного файла модуля в определённую локальную файловую систему и его считывание в оперативную память, а затем добавления всех переданных такому модулю аргументов. После этого в данный объект файла в оперативной памяти добавляется из ядра Ansible стандартная вставка (boilerplate) кода модуля. Этот набор является сжатым zip и закодированным в base64, а затем завёрнутым в некий сценарий. Что происходит далее в действительности зависит от метода соединения и параметров времени исполнения (таких как оставление данного кода модуля в данной удалённой системе для просмотра).
Определённым по умолчанию методом соединения является smart,
который как правило разрешается в метод соединения ssh. При настройке
по умолчанию Ansible откроет некое соединение SSH с заданным удалённым хостом, создаст временный каталог и
закроет это соединение. Затем Ansible откроет другое соединение чтобы записать определённый ZIP файл в обёртке
из оперативной памяти (являющийся результатом локального файла модуля, аргументов модуля задачи и кода стандартной
вставки Ansible -boilerplate) в некий файл внутри того временного каталога, который мы только что создали и закрыли
данное соединение.
Наконец, Ansible откроет некое третье соединение чтобы исполнить данный сценарий и удалить весь временный каталог и
всё его содержимое. Все результаты модуля перехватываются из stdout в формате JSON, который Ansible разберёт
синтаксически и обработает надлежащим образом. Если некая задача имеет управление
async, Ansible закроет это третье соединение предле чем завершится данный
модуль и выполнит обратное соединение SSH со своим хостом чтобы проверить текущее состояние данной задачи после
предписанного периода пока данный модуль не завершится, либо достижения некоторого предписанного тайм-аута.
Производительность задачи
Приведённое выше описание того, как Ansible соединяется с хостами имея в результате три соединения с определённым хостом для каждой задачи. В маленьких парках с малым числом задач это может не иметь значения, однако, по мере роста набора задач а также роста в размере самого парка, общее время, необходимое для создания и разбора на части соединений SSH растёт. К счастью, существует пара способов для уменьшения этого.
Первым является свойство SHH, ControlPersist, который
предоставляет некий механизм создание постоянных сокетов при первом соединении с каким- то удалённым хостом,
который может повторно использоваться в последующих соединениях через передачу какого- то подтверждения
установленной связи при создании соединения. Это может впечатляюще снизить объём времени, которое Ansible
тратин на установление новых соединений. Ansible автоматически использует такую функциональность если та
платформа, где исполняется Ansible, поддерживает её. Чтобы проверить поддерживает ли ваша платформа данное
свойство, проверьте её страницы руководства SSH на предмет
ControlPersist.
Вторым расширением производительности, которое может применяться, является некое свойство Ansible, имеющее
название конвейеризации (pipelining). Конвейеризация доступна методам на основании соединений SSH и настраивается
в файле конфигураций Ansible внутри раздела ssh_connection:
[ssh_connection]
pipelining=true
Эта установка изменяет то, как выполняется передача модулей. Вместо открытия некоторого соединения SSH для создания какого- то каталога, другого для записи нашего собранного модуля и третьего для исполнения и очистки, Ansible вместо этого открывает некоторое SSH соединение с заданным удалённым хостом. Затем, поверх этого рабочего соединения, Ansible будет конвейерно передавать упакованный составной модуль кода и сценарий для исполнения. Это снижает число соединений с трёх до одного, что может быть в действительности пойти в сумму. По умолчанию конвейеризация отключена.
Применение комбинации двух этих трюков с производительностью может оставить ваши плейбуки прекрасными и
быстрыми, даже по мере масштабирования вашего парка. Однако имейте в виду, что Ansible будет за раз
адресоваться к тому числу хостов, какое число ветвлений Ansible настроено для исполнения. Ветвления являются
общим числом процессов Ansible, на которое будет поделены исполнители для взаимодействия с удалёнными хостами.
Значением по умолчанию является пять ветвлений, что будет разрешать до пяти хостов за раз. Увеличьте данное
значение на адресацию к большему числу хостов по мере роста своего парка выравнивая имеющийся параметр
forks= в файле настроек Ansible или применяя аргумент
--forks (-f) для
ansible или ansible-playbook.
Переменные являются ключевыми компонентами для конкретного плана Ansible. Переменные предусмотрены для динамического содержимого воспроизведения и повторно используемых воспроизведений по различным наборам учётов ресурсов. Всё за пределами самого базового использования Ansible будет применять переменные. Понимание различных типов переменных и того где они могут располагаться, а также изучение того как осуществлять доступ к внешним данным или приглашать пользователей заполнять переменные данные, всё это является ключом к освоению Ansible.
Прежде чем погрузиться в вопрос старшинства переменных мы вначале должны понять различные типы и подтипы доступных для Ansible переменных, их расположение и где они разрешены к применению.
Самым первым главным типом являются переменные учёта
ресурсов (inventory variables). Это те переменные, которые Ansible получает посредством
определённой инвентаризации. Они могут быть определены как переменные, которые являются особыми для
host_vars по отношению к индивидуальным хостам или применяться к целой
группе как group_vars.Эти переменные могут записываться напрямую в
имеющийся файл описи, доставляться определёнными динамическими встраиваемыми модулями инвентаризации или
загружаться из каталогов host_vars/<host> или
group_vars/<group>.
Эти типы переменных должны применяться для определения поведения Ansible при работе с данными хостами или
особыми для сайта данными, относящимися к тем приложениям, которые исполняют эти хосты. Когда некая переменная
поступает из host_vars или
group_vars, она назначается некоторой
hostvars и может применяться из плейбуков и временных файлов. Доступ
к некоторым собственным переменным хоста может быть выполнен просто путём ссылки на её название, например,
{{ foobar }}, а доступ к переменным другого хоста может быть выполнен
путём доступа к hostvars. Например, для доступа к переменной
foobar для examplehost:
examplehost: {{ hostvars['examplehost']['foobar'] }}. Эти переменные
имеют глобальную область действия.
Вторым основным типом переменных являются переменные
роли (role variables). Это переменные, особые для некоторой роли и они используются задачами данной
роли и имеют область действия только внутри той роли, для которой они определены, то есть их можно применять
только внутри данной роли. Эти переменные часто предоставляются в качестве
значений роли по умолчанию (role default), что
означает поставку некоторого значения по умолчанию для определённой переменной, однако легко может быть
переписано при применении данной роли. Когда выполняется ссылка на роль, имеется возможность предоставить
данные переменной в то же самое время, причём либо переписывая определённую по умолчанию роль, либо создавая
целиком новые данные. В следующей главе мы изучим глубже роли. Эти переменные применяются ко всем хостам
внутри данной роли и к ним можно осуществлять доступ напрямую во многом аналогично случаю с собственными
hostvars хоста.
Третьим главным типом переменных являются переменные
воспроизведения (play variables). Эти переменные определяются в управляющих ключах воспроизведения,
причём либо непосредственно через ключ vars, либо берутся из внешних
файлов чрез ключ vars_files . Кроме того, само воспроизведение может
интерактивно запрашивать у своего пользователя данные переменной при помощи vars_prompt.
Эти переменные предназначены для использования внутри самой области действия данного воспроизведения и в любых
задачах или включённых задачах данного воспроизведения. Эти переменные применяются ко всем хостам в рамках данного
воспроизведения и на них можно ссылаться как если бы они были hostvars.
Четвёртым типом переменных являются переменные
задачи (task variables). Переменные задачи создаются из данных, которые обнаруживаются при
исполнении задач или на фазе сбора фактов некоторого воспроизведения. Эти переменные являются специфичными для
хоста и добавляются в hostvars, а также могут применяться в качестве
таковых, что также означает, что они имеют глобальную область действия после
того момента, как они обнаружены или определены. Переменные данного типа могут обнаруживаться через
gather_facts и модули
фактов (fact modules, модули, которые не изменяют состояние, но вместо этого возвращают
данные), заполняемые возвращаемыми данными посредством определённого ключа задачи
register, либо определяются напрямую некоторой задачей, применяющей
модули set_fact или add_host.
Данные также могут получаться интерактивно из тех операторов, которые применяют аргумент
prompt для своего модуля pause
и регистрируют получаемый результат:
- name: get the operators name
pause:
prompt: "Please enter your name"
register: opname
Также имеется последний тип переменных, внешние
переменные (extra variables), или тип extra-vars.
Это переменные, поставляемые в командной строке при исполнении
ansible-playbook через --extra-vars.
Переменные данные могут поставляться как список пар key=value,
заключённые в кавычки данные JSON, или как некая ссылка на файл в формате YAML с определёнными в нём
переменными данными:
--extra-vars "foo=bar owner=fred"
--extra-vars '{"services":["nova-api","nova-conductor"]}'
--extra-vars @/path/to/data.yaml
Внешние переменные рассматриваются как глобальные переменные. Они применяются ко всем хостам и имеют область действия по всему плейбуку.
Данные для переменных роли, переменных воспроизведения, а также переменных задачи также могут поступать из
внешних источников. Ansible предоставляет некий механизм доступа и вычисления данных из своей
управляющей машины (control machine, машины,
исполняющей ansible-playbook). Данный механизм вызывается неким
встраиваемым модулем просмотра
(lookup plugin) и ряд из них приходят вместе с Ansible. Эти встраиваемые модули могут может применяться для просмотра
данных или доступа к ним посредством чтения файлов, создаваемых и хранимых локально паролей в данном хосте
Ansible для последующего повторного применения, вычисления переменных окружения, получаемых от исполняемых
заданий через конвейер данных, доступа к данным через системы Redis
или etcd, построения данных из временных файлов, запроса записей
dnstxt и тому подобного. Их синтаксис таков:
lookup('<plugin_name>', 'plugin_argument')
Например, чтобы воспользоваться имеющимся значением mastery из
etcd в некоторой задаче отладки:
- name: show data from etcd
debug:
msg: "{{ lookup('etcd', 'mastery') }}"
Просмотры вычисляются когда исполняется ссылающаяся на них данная задача, что делает возможным динамическое обнаружение данных. Чтобы повторно использовать определённый просмотр во множестве задач и повторно вычислять их всякий раз, может быть определена некая переменная плейбука с каким- то значением просмотра. Всякий раз когда выполняется ссылка на данную переменную плейбука, будет выполняться определённый просмотр, что потенциально предоставляет различные значения в разное время.
Как мы уже изучали в предыдущих разделах, имеется несколько различных типов переменных, которые могут определяться в мириадах расположений. Это подводит к очень важному вопросу: что происходит, когда одно и то же имя переменной применяется во множестве местоположений? Ansible имеет старшинство для загрузки переменных данных и тем самым он имеет некий порядок и какое- то определение для решения какая переменная будет победителем. Перезаписывание значения переменной является неким расширенным применением Ansible, поэтому важно полностью понимать его семантику, прежде чем предпринимать попытку такого сценария.
Ansible определяет своё старшинство следующим образом:
-
Внешние
vars(из командной строки) всегда побеждают. -
varsзадач (только для определённых задач). -
Блочные
vars(только для тех задач, которые находятся внутри определённого блока). -
varsролей и вложений. -
Создаваемые
set_factvars. -
vars, создаваемые при помощи директивregister. -
vars_filesвоспроизведения. -
vars_promptвоспроизведения. -
varsвоспроизведения. -
Факты хоста.
-
host_varsплейбука. -
group_varsплейбука. -
host_varsучёта ресурсов. -
group_varsучёта ресурсов. -
varsучёта ресурсов. -
Значения по умолчанию роли.
В предыдущем разделе мы были сосредоточены на том старшинстве, в котором переменные будут переписывать друг друга. Определённое по умолчанию поведение Ansible заключается в том, что любое переписывание определения для некоторого имени переменной полностью маскирует все предыдущие определения данной переменной. Однако, такое поведение может быть изменено для одного типа переменных, для хэшей. Некая переменная хэша (в терминах Python словарь, dictionary) является набором данных из ключа и значения. Значения могут иметь различные типы для каждого ключа и даже могут хэшировать сами себя в сложных структурах данных.
В некоторых расширенных сценариях желательно заменять всего лишь часть некого хэша или добавлять к
имеющемуся хэшу, вместо того, чтобы целиком замещать данный хэш. Чтобы разблокировать данную возможность, в файле
config Ansible необходимы некие изменения настроек. Именно
hash_behavior является тем элементом настройки, который принимает одно
из значений replace (замена) или
merge (слияние). Установка слияния
укажет Ansible на необходимость слияния или замеса двух хэшей при представлении в некотором сценарии перезаписи
вместо определённой по умолчанию замены, которая полностью замещает все старые данные имеющимися новыми.
Давайте пройдём по двум примерам двух поведений. Мы начнём с некоторого хэша, загруженного данными и симулирующего некий сценарий, при котором некоторое отличное значение для данного хэша предоставляется как какая- то переменная с более высоким приоритетом.
Начальные данные:
hash_var:
fred:
home: Seattle
transport: Bicycle
Новые данные загружаются через include_vars:
hash_var:
fred:
transport: Bus
Для данного определённого по умолчанию поведения получаемое значение для
hash_var будет таким:
hash_var:
fred:
transport: Bus
Однако, если мы включим поведение merge,
мы получим следующий результат:
hash_var:
fred:
home: Seattle
transport: Bus
Имеется даже больше нюансов и не определённых поведений при использовании слияний, а раз так, настоятельно рекомендуется применять эту установку только если она абсолютно необходима.
Хотя само проектирование Ansible и сосредоточено на простоте и лёгкости применения, его архитектура сама по себе очень мощна. В данной главе мы обсудили ключевые понятия проектирования и архитектуры Ansible, такие как версии и настройка, синтаксический разбор плейбуков (планов), передача модуля и его исполнение, типы переменных и их расположение, а также старшинство переменных.
Вы изучили, что плейбуки содержат переменные и задачи. Задачи присоединяют небольшой код с названием модули, имеющий аргументы, которые могут заполняться переменными данными. Такие комбинации передаются на выбранные хосты из предоставляемых источников учёта ресурсов. Полное фундаментальное понимание таких строительных блоков является основной платформой на которой вы можете выстраивать некое овладение всеми предметами Ansible!
В нашей следующей главе вы изучите как обезопасить секретные данные при работе с Ansible.