Глава 2. Развёртывание Ceph в контейнерах
Содержание
Раз уж вы спланировали свой проект Ceph и готовы развернуть некий тестовый или промышленный кластер, вам понадобится рассмотреть тот метод, который вы пожелаете применить как для его развёртывания, так и для его сопровождения. Данная глава продемонстрирует как быстро развернуть тестовую среду для проверок и разработок при помощи Vagrant. Она также пояснит те причины, по которым вы могли бы захотеть рассмотреть применение инструментов оркестровки для развёртывания Ceph вместо того, чтобы применять включённые в поставку Ceph инструменты. В качестве одного из популярных средств оркестровки, Ansible будет применён для демонстрации как быстро и надёжно может быть развёрнут кластер Ceph и те преимущества, которые он может привнести.
В данной главе вы изучите следующие вопросы:
-
Как подготовить некую тестовую среду при помощи Vagrant и VirtualBox
-
Изучение различий между
ceph-deployи инструментами оркестровки -
Как устанавливать и применять Ansible
-
Как настроить модули Ansible Ceph
-
Как развёртывать некий тестовый кластер с помощью Vagrant и Ansible
-
Идеи по поводу того как управлять вашей настройкой Ceph
-
Что представляет из себя проект Rook и что он позволяет делать оператору Ceph
-
Как развернуть некий базовый кластер Kubernetes
-
Как применять Rook для развёртывания Ceph в Kubernetes
Чтобы быть способным запускать ту среду Ceph, которую мы позднее описываем в данной главе, важно чтобы ваш компьютер соответствовал ряду требований чтобы обеспечить достаточность ресурсов предоставляемым ВМ. Эти требования таковы:
-
Совместимую с Vagrant и VirtualBox операционную систему, включая Linux, macOS и Windows
-
ЦПУ с 2 ядрами
-
8 ГБ оперативной памяти
-
Включённые в BIOS инструкции виртуализации
Хотя некий тестовый кластер может быть развёрнут на любом оборудовании или VM (virtual machine - ВМ, виртуальной машине), для целей данной книги будет применяться некая комбинация Vagrant и VirtualBox. Это позволит нам быстро предоставлять необходимые ВМ и гарантировать согласованное окружение.
VirtualBox является свободно распространяемым гипервизором с открытым исходным кодом, который в настоящее время разрабатывается Oracle; хотя его производительность и свойства могут быть недостаточными по сравнению с высококлассными гипервизорами, однако его лёгкий вес и поддержка множества OC выдвигают его в первые кандидаты для тестирования.
Vagrant выступает помощником в предоставлении некой среды, которая может содержать множество быстро и действенно создаваемых машин. Он работает с концепцией ящиков (boxes), которые являются предварительно определёнными шаблонами для их применения с гипервизорами и их Vagrantfile, которые определяют среду для построения. Они поддерживают большое число гипрвизоров и делают возможным переносить между ними некий Vagrantfile.
Посетите веб сайт VirtalBox по адресу https://www.virtualbox.org/wiki/Downloads и выгрузите те пакеты, которые соответствуют используемой вами ОС.
Следуйте инструкциям установки с веб сайта Vagrant https://www.vagrantup.com/downloads.html для получения установки Vagrant в выбранной вами ОС:
-
Создайте некий новый каталог для своего проекта Vagrant, например
ceph-ansible. -
Перейдите в этот каталог и выполните следующие команды:
vagrant plugin install vagrant-hostmanager
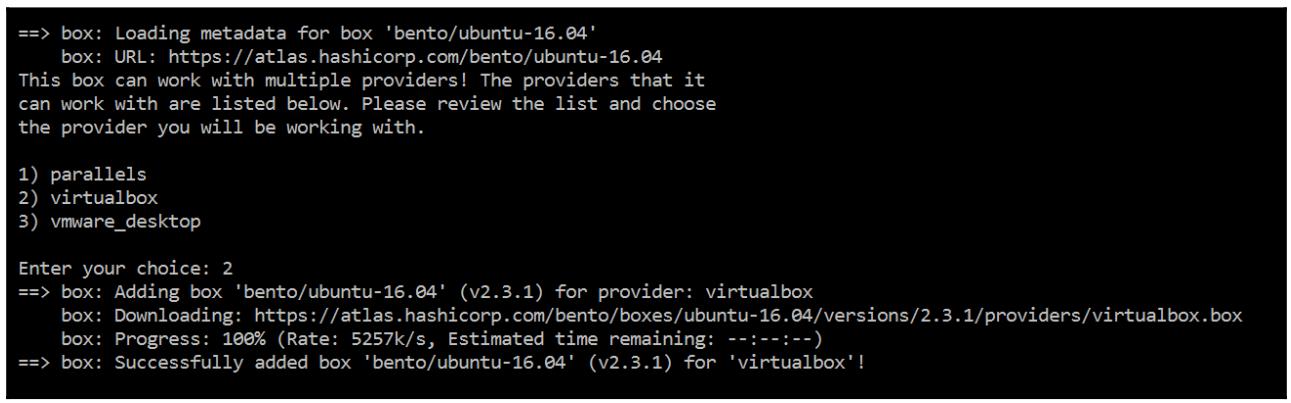
vagrant box add bento/ubuntu-16.04
-
Теперь создайте некий пустой файл с названием
Vagrantfileи поместите в него следующее:nodes = [ { :hostname => 'ansible', :ip => '192.168.0.40', :box => 'xenial64' }, { :hostname => 'mon1', :ip => '192.168.0.41', :box => 'xenial64' }, { :hostname => 'mon2', :ip => '192.168.0.42', :box => 'xenial64' }, { :hostname => 'mon3', :ip => '192.168.0.43', :box => 'xenial64' }, { :hostname => 'osd1', :ip => '192.168.0.51', :box => 'xenial64', :ram => 1024, :osd => 'yes' }, { :hostname => 'osd2', :ip => '192.168.0.52', :box => 'xenial64', :ram => 1024, :osd => 'yes' }, { :hostname => 'osd3', :ip => '192.168.0.53', :box => 'xenial64', :ram => 1024, :osd => 'yes' } ] Vagrant.configure("2") do |config| nodes.each do |node| config.vm.define node[:hostname] do |nodeconfig| nodeconfig.vm.box = "bento/ubuntu-16.04" nodeconfig.vm.hostname = node[:hostname] nodeconfig.vm.network :private_network, ip: node[:ip] memory = node[:ram] ? node[:ram] : 512; nodeconfig.vm.provider :virtualbox do |vb| vb.customize [ "modifyvm", :id, "--memory", memory.to_s, ] if node[:osd] == "yes" vb.customize [ "createhd", "--filename", "disk_osd-#{node[:hostname]}", "--size", "10000" ] vb.customize [ "storageattach", :id, "--storagectl", "SATA Controller", "--port", 3, "--device", 0, "--type", "hdd", "--medium", "disk_osd-#{node[:hostname]}.vdi" ] end end end config.hostmanager.enabled = true config.hostmanager.manage_guest = true end endВыполните
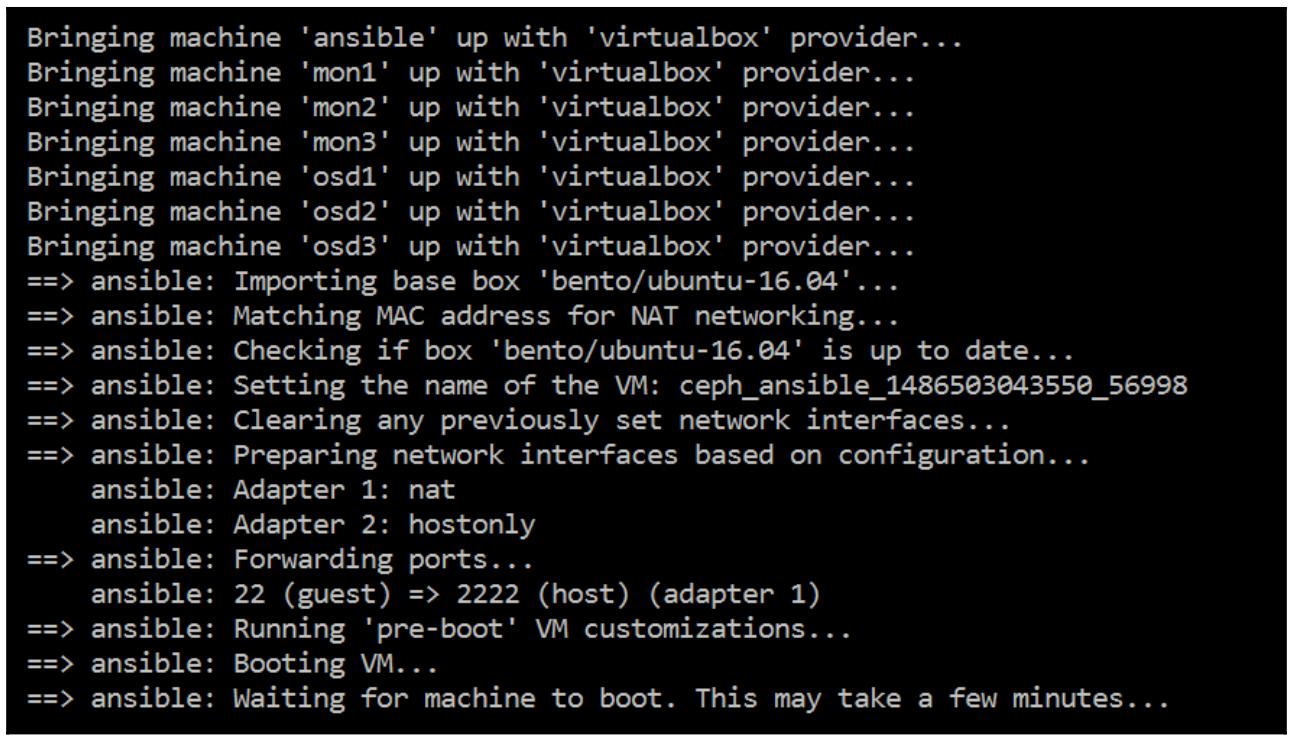
vagrant upчтобы поднять все определённые вVagrantfileВМ:
![[Совет]](/common/images/admon/tip.png)
Совет На всякий случай, если вы встретите на данном этапе с ошибкой, вам необходимо запретить Hyper-V.
-
Теперь давайте соединимся со своей ВМ
ansibleс применениемssh:vagrant ssh ansible
![[Замечание]](/common/images/admon/note.png)
Замечание Если вы исполняете Vagrant под Windows, тогда команда
sshпроинформирует вас что вам нужно воспользоваться неким клиентом SSH по вашему выбору и предоставит некоторые подробности по его использованию.{Прим. пер.: с января 2018 Windows 10 и Server 2016 располагают встроенным OpenSSH, который не включён по умолчанию. Для включения клиента/ сервера OpenSSH вам следует пройти в Пуск > Приложения и возможности > Управление дополнительными возможностями > Клиент OpenSSH/ Сервер OpenSSH}.
И имя пользователя, и пароль оба имеют значение
vagrant. После регистрации вы обнаружите себя находящимся в оболочке Bash вашей ВМansible:
Просто наберите
exitчтобы вернуться в машину своего хоста.Наши поздравления! Вы только что развернули три сервера для применения их в качестве мониторов Ceph, три сервера для их использования в качестве OSD Ceph, а также некий сервер Ansible.
Vagrantfileможет также содержать дополнительные шаги для исполнения команд на всех серверах для их настройки, однако на текущий момент давайте остановим все серверы при помощт показанной ниже команды, мы сможем поднять их вновь когда этого потребуют позже примеры в данной главе.vagrant destroy --force

ceph-deploy является официальным инструментом для развёртывания
кластеров Ceph. Он работает основываясь на принципе
наличия некоторого узла администратора с доступом через SSH (без пароля) для всех машин в вашем кластере Ceph;
он также содержит некую копию всего файла настройки Ceph. Всякий раз когда вы выполняете действие некоторого
развёртывания, он применяет SSH для соединения с вашими узлами Ceph для осуществления всех необходимых
шагов. Хотя данный инструментарий ceph-deploy и является полностью
поддерживаемым методом, который оставит вас с прекрасно работающим кластером Ceph, предоставляемое в настоящее
время управление со стороны Ceph не будет настолько простым, как того бы хотелось.
Кластеры большого размера также вызовут массу накладных расходов в случае применения
ceph-deploy. По этой причине рекомендуется ограничиться применением
ceph-deployдля целей тестирования или в промышленных кластерах небольшого
масштаба, несмотря на то, что как вы увидите, инструменты оркестровки позволяют быстрое развёртывание Ceph и вероятно
лучше приспособлены для сред проверки, в которых вам может требоваться постоянная сборка кластеров.
Одним из решений для выполнения более простым образом установки и управления Ceph является выбор инструмента оркестровки. Имеются различные доступные инструменты, например, Puppet, Chef, Salt и Ansible, причём все они имеют доступными модули Ceph. Если вы уже применяли некий инструментарий координации в своей среде, тогда мы бы порекомендовали вам продолжать его использование. Для целей данной книги будет применяться Ansible, причём для этого имеется целый ряд причин:
-
Это предпочитаемый метод развёртывания в Red Hat, которая является владельцем обоих проектов, и Ceph, и Ansible
-
Он имеет хорошо проработанный и зрелый набор ролей и плейбуков Ceph
-
Ansible имеет склонность быть более простым в изучении в случае, если вы никогда ранее не применяли средств оркестровки
-
Он не требует установки некоего центрального сервера, что означает, что демонстрации более сосредоточены на применении самого инструмента, вместо применения инструментов его установки
Все инструменты следуют одному и тому же принципу того, что вы предоставляете им некий реестр хостов и множество задач, подлежащих исполнению над этими хостами. На эти задачи часто ссылаются как на переменные, что делает возможной персонализацию данной задачи во время её исполнения. Инструменты оркестровки разработаны для исполнения по некому расписанию с тем, чтобы если по какой- либо причине данное состояние или настройка некоторого хоста изменится, она будет корректно возвращена обратно в предназначенное для неё состояние при следующем исполнении.
Другим преимуществом применения средств оркестровки является документирование. Хотя они и не заменяют хорошую документацию, факт состоит в том, что они ясно определяют вашу среду, включая роли и параметры настройки, что означает, что ваша среда начинает становиться самостоятельно документируемой. Если вы обеспечите чтобы все установки или изменения осуществлялись через ваши инструменты оркестровки, тогда этот файл настроек вашего инструмента оркестровки будет чётко описывать текущее состояние вашей среды. Если это соединено с чем- то типа некоего репозитория git для сохранения всех настроек оркестровки, у вас имеются задания системы управления изменениями. Всё это будет рассмотрено более подробно позднее в данной главе. Единственное неудобство состоит в некотором дополнительном времени которое требует сама начальная установка и настройка данного инструмента.
Итак, применение средств оркестровки не только даёт вам возможность более быстрого и менее подверженного ошибкам развёртывания, но также бесплатно предоставляет документирование и управление изменениями. Если вы пока не получали данной подсказки, именно это является тем, на что на самом деле стоит обратить своё внимание.
Как уже было отмечено, именно Ansible будет инструментом оркестровки, выбранным для данной книги. Давайте взглянем на него слегка более подробно.
Ansible является неким инструментом оркестровки свободным от агента, написанном на Python, который применяет SSH для выполнения задач настройки на удалённых узлах. Он был выпущен впервые в 2012 и получил широкое распространение, причём он славится простотой освоения и невысокой траекторией изучения. Red Hat приобрела коммерческую компанию Ansible, Inc. в 2015 и по этой причине имеет очень хорошо разработанную и тесную интеграцию для развёртывания Ceph.
Именуемые плейбуками файлы применяются в Ansible для
описания перечня команд, действий и настроек для обслуживания определённых хостов или групп хостов и сохраняются в
файловом формате YAML. Вместо наличия больших неуправляемых плейбуков, могут
создаваться роли Ansible, позволяющие некому плану содержать какую- то обособленную задачу, которая может впоследствии
осуществлять целый ряд задач, связанных с данной ролью.
Применение SSH для соединения с удалёнными узлами и исполнение плейбуков означает, что этот инструмент имеет очень малый вес и не требует никакого агента или некоторого централизованного сервера.
Для целей тестирования Ansible также хорошо интегрирован с Vagrant, некий плейбук Ansible может быть определён как часть самого Vagrant, предоставляющая настройки и будет автоматически создавать некий файл учёта (inventory) из создаваемой ВМ Vagrant и исполнять данный плейбук при загрузке данных серверов. Это позволяет некому содержащему ОС кластеру Ceph развёртываться всего одной командой.
Поднимите свою созданную ранее среду Vagrant опять и соединитесь через SSH со своим сервером Ansible. Для
данного примера будут необходимы только ansible,
mon1 и osd1:
vagrant up ansible mon1 osd1
Добавьте Ansible ppa следующим образом:
$ sudo apt-add-repository ppa:ansible/ansible-2.6
Обновите исходные файлы apt-get и установите
Ansible:
$ sudo apt-get update && sudo apt-get install ansible -y
Файл учёта ресурсов (inventory) Ansible применяется Ansible для справочной информации по всем известным хостам и тому, к каким группам они относятся. Некая группа определяется помещением её названия в квадратные скобки; причём группы могут встраиваться внутри прочих групп путём применения дочерних определений.
Прежде чем мы добавим хосты в свой файл учёта ресурсов, мы вначале должны настроить все свои удалённые узлы для работы с SSH (без паролей); в противном случае всякий раз, когда Ansible попытается соединиться с некоторой удалённой машиной, нам придётся вводить некий пароль.
-
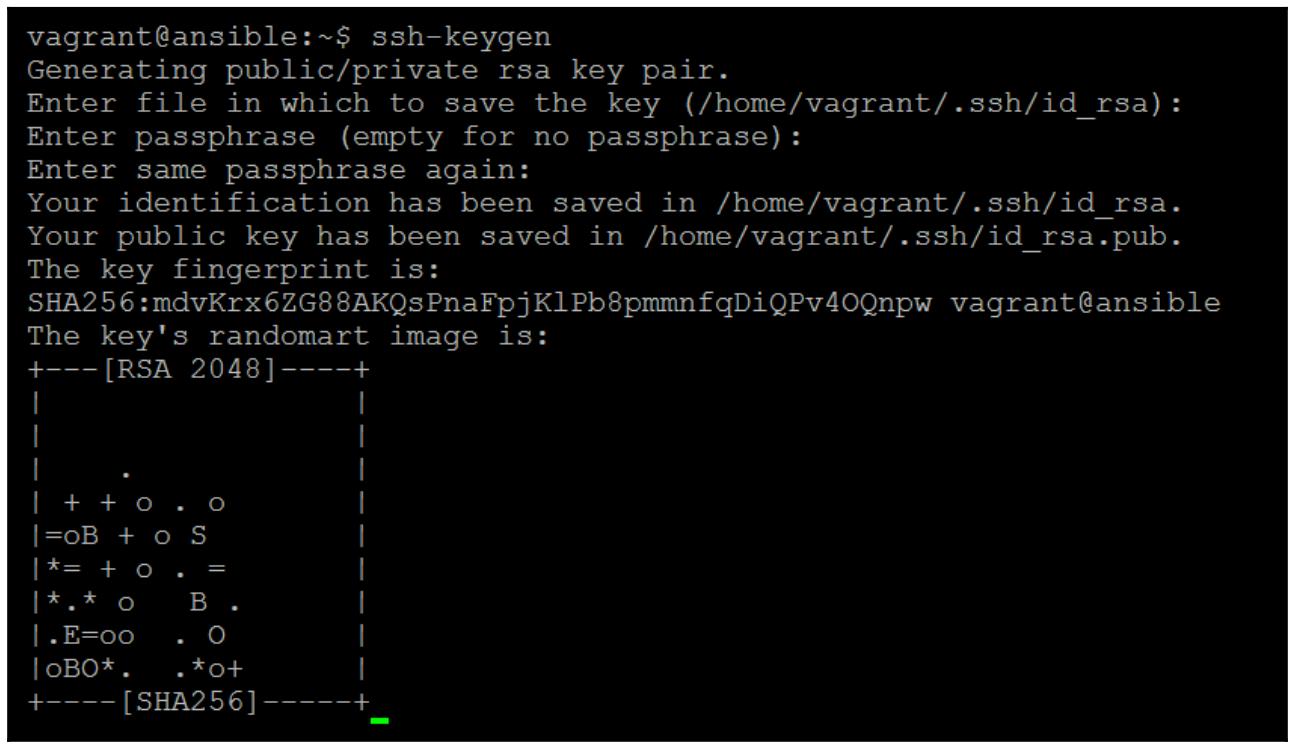
Создайте следующим образом некий ключ SSH:
$ ssh-keygen
-
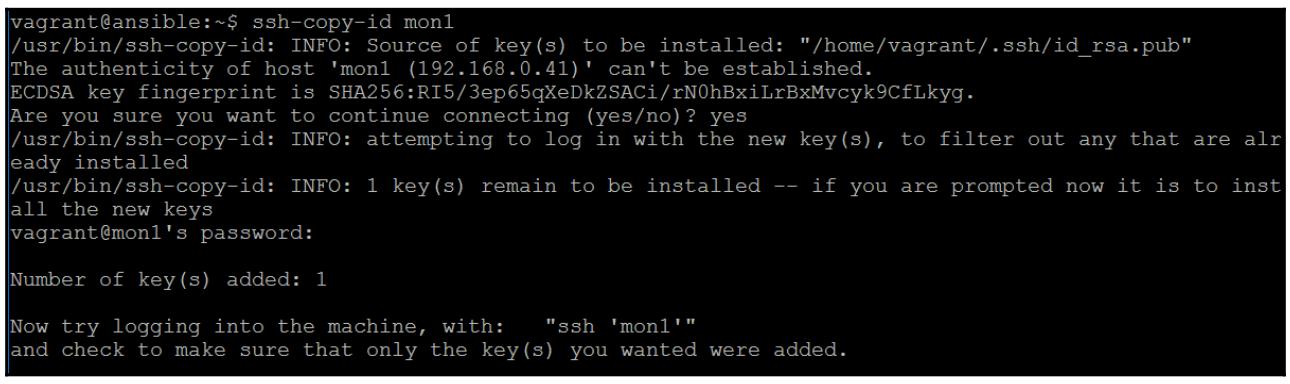
Скопируйте этот ключ на все удалённые хосты:
$ ssh-copy-id mon1
Это необходимо повторить для всех хостов. Обычно вы включаете этот этап в стадию предоставления своего Vagrant, однако полезно первые пару раз выполнить эти задачи вручную с тем, чтобы понять весь изучаемый процесс.
-
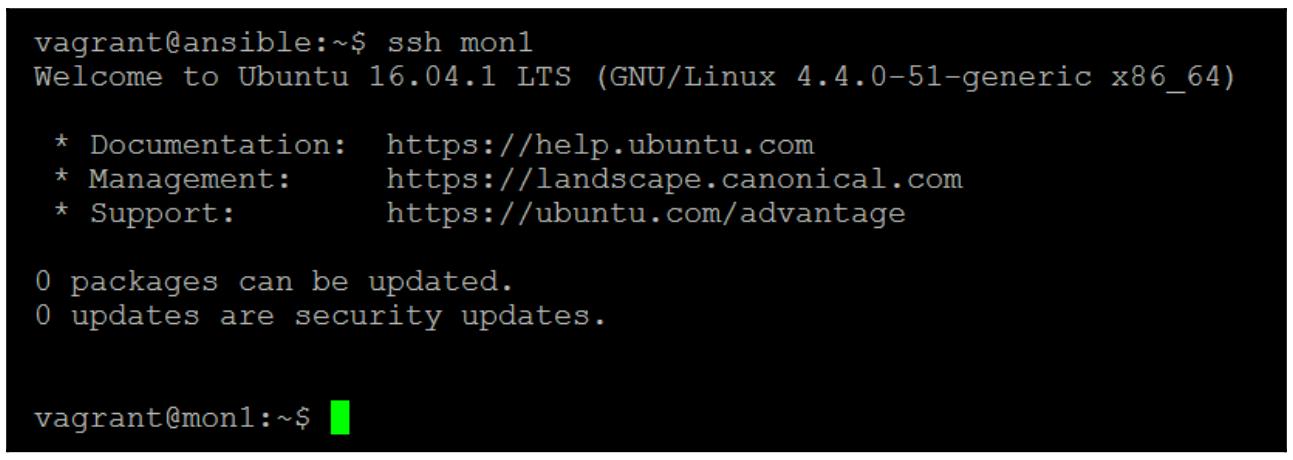
Теперь попытаемся зарегистрироваться в этой машине при помощи
ssh mon1:
-
Для возврата в свою ВМ Ansible наберите
exit. Теперь давайте создадим необходимый нам файл учёта ресурсов Ansible. Измените файл с названиемhostsв/etc/ansible:$ sudo nano /etc/ansible/hostsСоздайте три группы с названиями
osds,mgrsиmons, а также наконец третью группу с именемceph. Эта четвёртая группа будет содержать в качестве своих потомков созданные группыosds,mgrsиmons.Введите некий список хостов в правильные группы следующим образом:
[mons] mon1 mon2 mon3 [mgrs] mon1 [osds] osd1 osd2 osd3 [ceph:children] mons osds mgrs
Большинство плейбуков и ролей будут применять переменные; такие переменные могут переназначаться
различными способами. Простейший из них состоит в создании файлов в соответствующих папках
host_vars и groups_vars,
что позволяет вам перекрывать значения переменных либо на основании участия в хостах, либо в группах соответственно.
-
Создайте некий каталог
/etc/ansible/group_vars. -
В
group_varsсоздайте некий файл с названиемmons. Вmonsдобавьте следующее:a_variable: "foo" -
В
group_varsсоздайте некий файл с названиемosds. Вosdsдобавьте следующее:a_variable: "bar"
Переменные следуют некому порядку старшинства; вы можете также создать некий файл
all, который будет применяться ко всем группам. Однако, некая
переменная в точности с таким же названием, которая находится в более конкретной группе соответствия
перепишет её. Модули Ansible Ceph используют это чтобы иметь некий набор определённых по умолчанию переменных и
далее позволяют вам определять другие значения для заданных ролей.
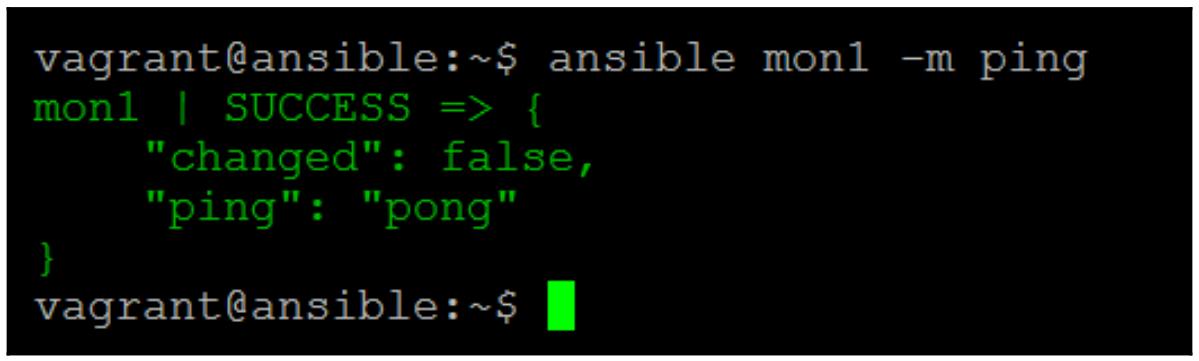
Чтобы убедится что Ansible работает правильно, и что мы можем успешно делать соединения и удалённо
исполнять команды, давайте воспользуемся командой Ansible ping для
проверки одного из наших хостов. Отметим, что она не похожа некий сетевой ping.
ping Ansible подтверждает что он способен взаимодействовать через
SSH и удалённо выполнять команды:
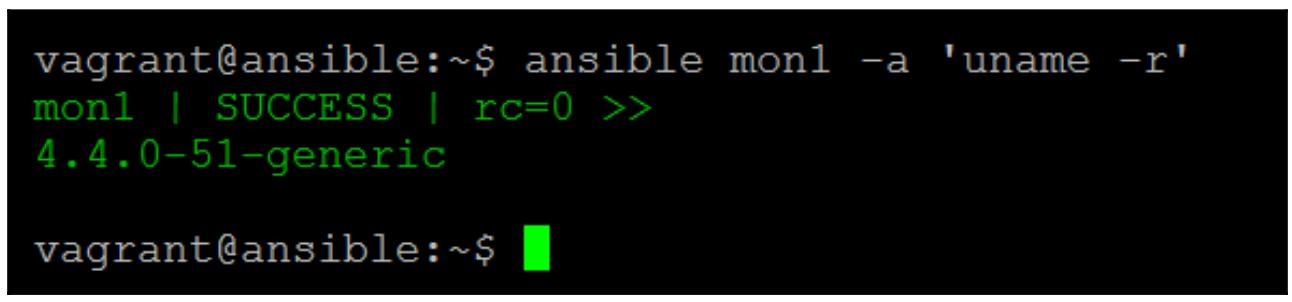
Замечательно, это работает, теперь давайте исполним удалённо некую простую команду чтобы продемонстрировать всю мощность Ansible. Следующая команда получит текущую версию работающего ядра в определённом удалённом узле:
$ ansible mon1 -a 'uname -r'
Чтобы продемонстрировать как работают планы (playbooks), приводимый ниже пример покажет некий небольшой план, который также применяет те переменные, которые мы настроили ранее:
- hosts: mon1 osd1
tasks:
- name: Echo Variables
debug: msg="I am a {{ a_variable }}"
Теперь выполним этот план. Обратите внимание что команда выполнения плейбука отличается в этом специальном случае от обычно применяемых команд Ansible.
$ ansible-playbook /etc/ansible/playbook.yml
Предыдущая команда предоставит вам следующий вывод:
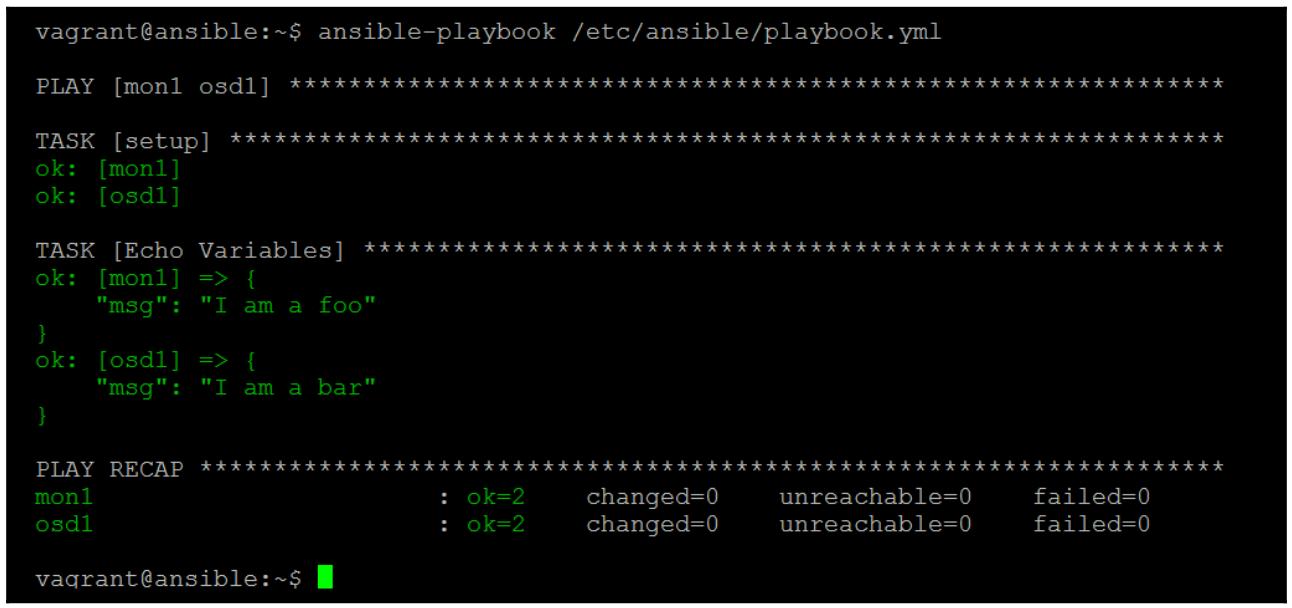
Данный вывод показывает исполнение нашего плейбука и на mon1,
и на osd1, поскольку они состоят в группах, которые являются дочерними
для нашей родительской группы ceph. Также отметим как этот вывод
различается между данными двумя серверами, поскольку они выхватываются теми переменными, которые вы установили
ранее в своём каталоге group_vars.
Наконец, самая последняя пара строк отображает общее состояние исполнения работы данного плейбука. Теперь вы можете вновь уничтожить свою среду Vagrant, чтобы подготовить её к работе в следующем разделе:
vagrant destroy --force
Это завершает наше введение в Ansible, однако это далеко не полное руководство. Рекомендуем вам изучить прочие ресурсы, чтобы получить более глубокое знание Ansible прежде чем применять его в промышленной среде. {Прим. пер.: мы частично перевели увидевшую свет в марте 2017 второй редакции Mastering Ansible, а теперь рассматриваем возможности перевода увидевшей свет в марте 2019 третьей редакции Mastering Ansible!}
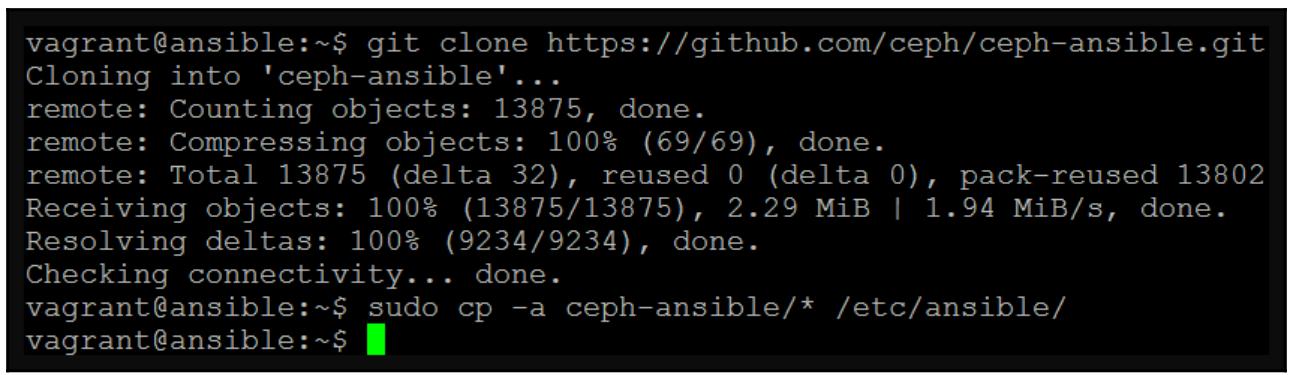
Мы можем воспользоваться git для клонирования своего репозитория
Ansible Ceph:
git clone https://github.com/ceph/ceph-ansible.git
git checkout stable-3.2
sudo cp -a ceph-ansible/* /etc/ansible/
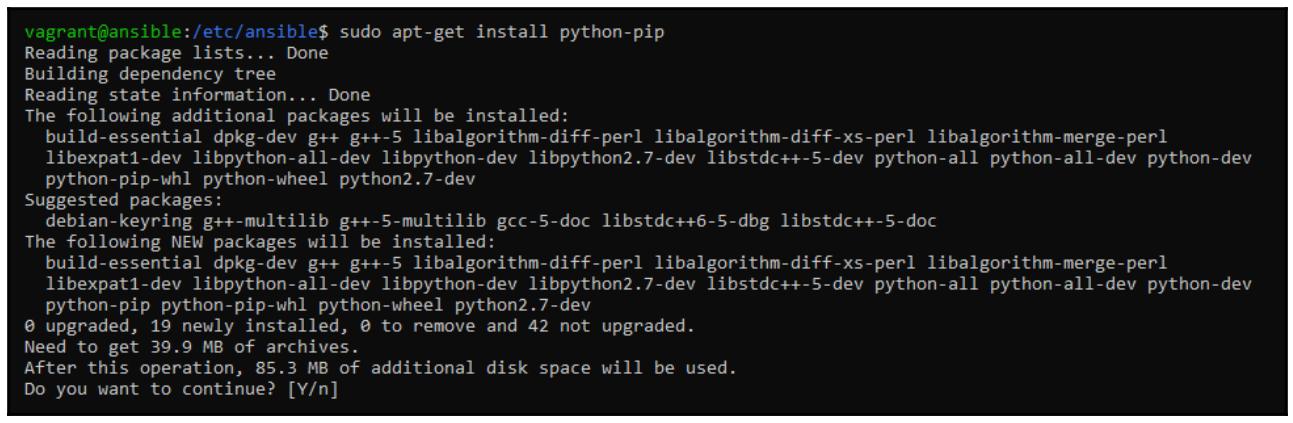
Также нам требуется установить ряд дополнительных необходимых для ceph-ansible
пакетов:
sudo apt-get install python-pip
sudo pip install notario netaddr
Давайте исследуем некоторые из основных папок в своём репозитории git:
-
group_vars: мы уже обсуждали что здесь располагается и позже более подробно изучим все возможные опции настройки. -
infrastructure-playbooks: Этот каталог содержит предварительно написанные плейбуки для осуществления некоторых стандартных задач, таких как развёртывание кластера или добавления OSD в некий уже имеющийся. Имеющийся в верхней части каждого плана комментарий даёт хорошую идею о том, что он должен делать. -
roles: Этот каталог содержит все роли, которые составляют все модули Ansible Ceph. Вы увидите, что для каждого из компонентов Ceph имеется некая роль и именно они вызываются через планы для установки, настройки и сопровождения Ceph.
Чтобы иметь возможность развернуть некий кластер Ceph при помощи Ansible необходимо установить целый ряд ключевых
переменных в вашем каталоге group_vars. Приводимые далее переменные
требуются либо для установки, либо предлагаются к изменению установленных для них по умолчанию значений. Для
всех остальных переменных предполагается, что вы прочтёте комментарии во всех файлах переменных.
Приводимые ниже переменные являются ключевыми в global:
#mon_group_name: mons
#osd_group_name: osds
#rgw_group_name: rgws
#mds_group_name: mdss
#nfs_group_name: nfss
...
#iscsi_group_name: iscsigws
Они управляют какие имена групп данных модулей применяются для идентификации всех типов хостов Ceph.
Если вы будете применять Ansible в более широких установках, можно предложить присоединить к ним спереди
ceph-, чтобы начать представлять более отчётливо что эти группы
относятся к Ceph:
ceph_origin: 'upstream' # or 'distro' or 'local'
Употребляйте upstream для применения тех пакетов, которые создаются
вашей командой Ceph, или distro для пакетов, создаваемых вашей
группой поддержки дистрибутивов. Установка upstream рекомендуется
если вы собираетесь иметь возможность обновлять Ceph независимо от своего дистрибутива.
По умолчанию для вашего кластера будет сгенерирован fsid и сохранён в некотором файле, на который можно будет ссылаться снова:
#fsid: "{{ cluster_uuid.stdout }}"
#generate_fsid: true
Вам не следует прикасаться к этому, если только вы не желаете управлять своим fsid
или захотите жёстко закодировать этот fsid в своём файле групповой переменной.
#monitor_interface: interface
#monitor_address: 0.0.0.0
Один из них следует определить. Если вы используете некую переменную в group_vars,
тогда вы вероятно пожелаете воспользоваться monitor_interface, которая
является именем того интерфейса, как он виден самой ОС, так как он вероятно будет одним и тем же во всех группах
mons. В противном случае, если вы определите
monitor_address в host_vars, вы
можете определить конкретный IP данного интерфейса, который очевидно будет различным во всех ваших трёх или
большем числе групп mons.
#ceph_conf_overrides: {}
Не все переменные Ceph напрямую управляются Ansible, однако все предыдущие переменные представлены с той целью,
чтобы позволить вам передавать любые дополнительные переменные в ваш файл
ceph.conf и его соответствующие разделы. Вот некий пример как это могло бы
выглядеть (обратите внимание на отступы):
ceph_conf_overrides:
global
variable1: value
mon:
variable2: value
osd:
variable3: value
Ключевые переменные в файле переменных OSD:
copy_admin_key: false
Если вы хотите иметь возможность управления вашим кластером со своих узлов OSD вместо того, чтобы делать
это только с мониторов, установите это значение в true, что скопирует
имеющийся ключ администратора в ваши узлы OSD.
#devices: []
#osd_auto_discovery: false
#journal_collocation: false
#raw_multi_journal: false
#raw_journal_devices: []
Это вероятно критически самый важный набор переменных во всей настройке Ansible. Они управляют тем какие диски применяются как OSD, а какие помещаются под журналы. Вы даже можете вручную определить те устройства, которые вы бы хотели применять в качестве OSD или вы можете использовать автоматическое выявление. Примеры в данной книге будут применять статические настройки устройств.
Переменная journal_collocationустанавливает желаете ли вы хранить сам
журнал на том же самом диске, что и сами данные OSD; для него будет создан отдельный раздел.
Переменная raw_journal_devices позволяет вам определить те
устройства, которые вы хотите применять для журналов. Достаточно часто некий отдельный SSD будет журналом
для различных OSD, в этом случае включите raw_multi_journal и
просто определите данное устройство журнала множество раз, никакие номера разделов не нужны если вы желаете
чтобы Ansible проинструктировал ceph-disk создать их для вас.
Имеются главные переменные которые вам необходимо рассмотреть. Рекомендуется чтобы вы прочли все комментарии в своих файлах переменных чтобы просмотреть имеются ли ещё какие- то другие, которые вам может понадобиться изменить для своей среды.
Во Всемирном Интернете имеется ряд примеров, которые содержат полностью настроенные Vagranfile и связанные
с ними плейбуки Ansible, которые позволят вам поднять полностью функциональную среду Ceph всего лишь
одной командой. Насколько это удобно, настолько это и не может помочь вам изучить как правильно настроить и
применить модули Ceph Ansible, в сравнении с тем, как если бы вы разворачивали некий кластер Ceph на реальном
оборудовании в некоторой промышленной среде. Таким образом, данная книга послужит вам руководством по настройке
Ansible с нуля, хоть и работает на серверах, предоставляемых Vagrant. Важно отметить, что как и сам Ceph, плейбуки
Ansible постоянно изменяются и следовательно вам рекомендуется просматривать документацию
ceph-ansible на предмет каких- либо прекращающих изменений.
На данный момент ваша среда Vagrant должна быть поднятой и находиться в рабочем состоянии, а Ansible должен иметь возможность связи со всеми шестью вашими серверами. Вы также должны иметь некую клонированную копию своего модуля Ansible Ceph:
-
Создайте некий файл с названием
/etc/ansible/group_vars/ceph:ceph_origin: 'repository' ceph_repository: 'community' ceph_mirror: http://download.ceph.com ceph_stable: true # use ceph stable branch ceph_stable_key: https://download.ceph.com/keys/release.asc ceph_stable_release: mimic # ceph stable release ceph_stable_repo: "{{ ceph_mirror }}/debian-{{ ceph_stable_release }}" monitor_interface: enp0s8 #Check ifconfig public_network: 192.168.0.0/24 -
Создайте некий файл с названием
/etc/ansible/group_vars/osds:osd_scenario: lvm lvm_volumes: - data: /dev/sdb -
Создайте папку
fetchи измените её владельца на своего пользователяvagrant:sudo mkdir /etc/ansible/fetch sudo chown vagrant /etc/ansible/fetch -
Выполните плейбук развёртывания своего кластера Ceph:
cd /etc/ansible sudo mv site.yml.sample site.yml ansible-playbook -K site.ymlПараметр
Kсообщает Ansible что ему следует запросить у вас пароль дляsudo.
Теперь присядьте поудобнее и наблюдайте как Ansible разворачивает ваш кластер:

Когда всё завершится, в предположении что Ansible исполнится без ошибок, соединитесь через SSH с
mon1 и выполните приведённый ниже код.
vagrant@mon1:~$ sudo ceph -s:
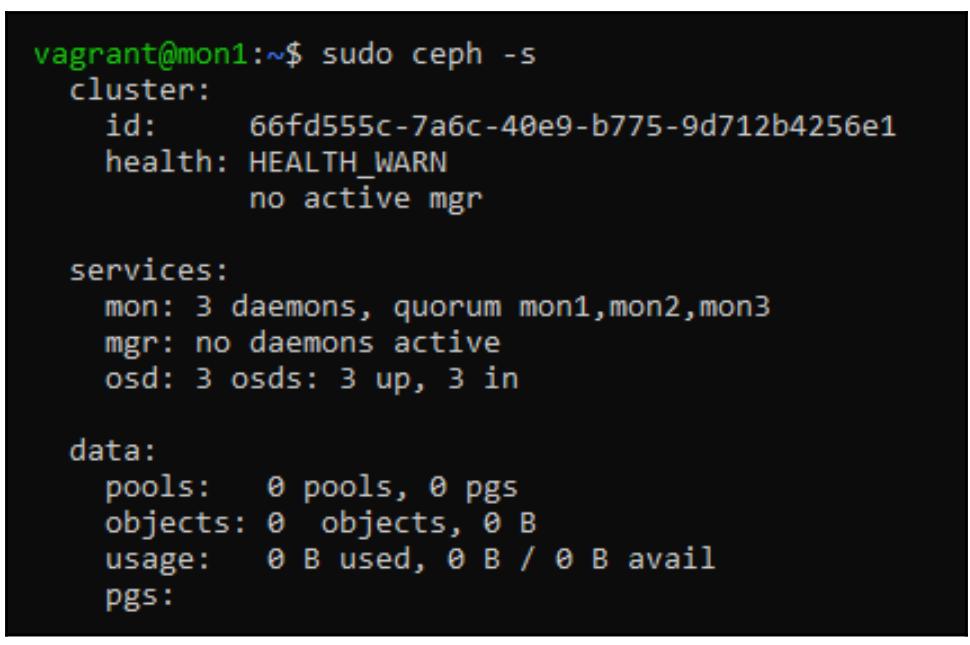
И это завершает всё развёртывание полностью работающего кластера Ceph при помощи Ansible.
Если вы желаете иметь возможность остановить данный кластер Ceph Vagrant без утраты той работы, которую вы выполнили на данный момент, вы можете исполнить следующую команду:
vagrant halt
Это переведёт в состояние паузы все ваши ВМ в их текущем состоянии:
vagrant suspend
Следующая команда включит все ваши ВМ и восстановит их исполнение с того состояния, в котором вы их оставили:
vagrant resume
Если вы развернули свою инфраструктуру при помощи инструмента оркестровки подобного Ansible, важным становится управление плейбуками Ansible. Как мы уже видели, Ansible позволяет вам быстро разворачивать как некий начальный кластер Ceph, так к тому же далее со временем и настраивать обновления. Следует иметь в виду, что такая мощность может иметь и разрушительные последствия при развёртывании неправильных настроек или операций. Внедряя некий вид управления настройками администраторы Ceph смогут чётко видеть какие изменения были внесены в плейбуки Ansible, прежде чем исполнить их.
Рекомендуемым подходом было бы сохранение ваших настроек Ansible Ceph в репозитории git, что позволило бы вам отслеживать изменения и предоставило бы возможность реализации некоторого вида управления изменениями либо посредством наблюдения за фиксациями git, или заставляя персонал выставлять запросы слияния в свою основную ветвь.
Ранее мы видели, что применяя инструменты оркестровки, такие как Ansible, мы можем снижать ту работу, которая необходима для развёртывания, управления и сопровождения кластера Ceph. Мы также видели как эти инструменты помогают нам выявлять доступные ресурсы оборудования и развёртывать в них Ceph.
Тем не менее, использование Ansible для настройки серверов голого железа всё ещё в результате приводит к очень статичному развёртыванию, возможно не лучшим образом подходящим для более динамичных нагрузок сегодняшних дней. Проектируя плейбуки Ansible также следует принимать во внимание некоторые различные дистрибутивы Linux, а также те отличия, которые могут происходить при смене выпусков; великолепным примером этого является systemd. Более того, большую часть развёртывания в инструментах оркестровки для выявления, развёртывания и управления Ceph необходимо настраивать индивидуально. Это распространённая тема, которую вынуждены обсуждать разработчики; применяя контейнеры Linux и связанные с ними платформы оркестровки, они надеются улучшить практику развёртывания Ceph.
Один из таких подходов, который был выбран в качестве предпочтительного, состоит в объединении усилий в проекте с названием Rook. Rook работает совместно с платформой управления Kubernetes над автоматизацией развёртывания, настройки и употребления хранилища Ceph. Если вы набросаете некий перечень требований и свойств, которые требуются для реализации индивидуальных оркестровки Ceph и инфраструктуры управления, вы скорее всего разработаете нечто с функциями, аналогичными манере Kubemnetes. Следовательно, имеет смысл собрать функциональность поверх хорошо устоявшегося проекта Kubernetes, и Rook в точности это и делает.
Одно из основных преимуществ исполения Ceph в контейнерах является то, что это позволит сочетать службы в одном и том же оборудовании. Обычно в кластерах Ceph ожидалось что мониторы Ceph будут запущены на некотором выделенном оборудовании; при использовании контейнеров это требование удаляется. Для кластеров меньшего размера это может исчисляться большими сбережениями стоимости работы и приобретения серверов. Если это позволяют ресурсы, также могут допускаться прочие рабочие нагрузки на основе контейнеров для исполнения на оборудовании Ceph, дополнительно увеличивая Возвраты на Инвестиции (RoI, Return on Investment) при приобретении оборудования. Такое использование контейнеров резервирует необходимые ресурсы оборудования с тем, чтобы рабочие нагрузки не могли воздействовать друг на друга. {Прим. пер.: дополнительные возможности также предоставляет обработка доставляемыми в сами узлы хранения контейнерами для больших данных прямо на месте, что может быть экономичнее транспортировки данных для их обработки в специализированных вычислительных узлах, подробнее в Главе 7. Распределённые вычисления при помощи классов RADOS Ceph.}
Для лучшего понимания того как эти две технологии работают с, нам для начала требуется рассмотреть более подробно Kubernetes и сами реальные контейнеры.
Хотя контейнеры в их текущем виде относительно новая технология, сам принцип изоляции наборов процессов друг от друга присутствовал на протяжении длительного времени. В чём сегодня расширились современные наборы технологий, так это в законченности их изоляции. Предыдущие технологии возможно изолировали лишь части применяемой файловой системы, в то время как самые последние технологии контейнеров также изолируют определённые области своей операционной системы и могут предоставлять квоты для аппаратных ресурсов. В частности, одна технология, Docker, становится наиболее популярной когда речь заходит о контейнерах, поэтому зачастую эти два слова многими применяются как взаимозаменяющие. Само слово контейнер описывает некую технологию, которая осуществляет операции виртуализации системного уровня. Docker является программным продуктом, который управляет первичными свойствами Linux, такими как группы и пространства имён, для изоляции наборов процессов Linux.
Важно отметить, что в отличие от полноценных решений для виртуализации, таких куак VMware, Hyper-V и KVM, которые предоставляют виртуальное оборудование и требуют отдельного экземпляра ОС, контейнеры используют саму операционную систему своего хоста. Полные требования к ОС для виртуальных машин могут приводить к утрате до десятков ГБ хранилища при установке самой операционной системы и, возможно, нескольких ГБ ОЗУ. Контейнеры же, как правило, потребляют дополнительные ресурсы хранения и оперативной памяти, измеряемые в МБ, а это означает что на одном и том же оборудовании можно ужать гораздо больше контейнеров по сравнению с технологиями полной виртуализации.
С контейнерами к тому же гораздо проще выполнять оркестровку, поскольку они целиком настраиваются из имеющейся операционной системы; это, в сочетании с их возможностью запускаться за миллисекунды, означает что они очень удобны для динамичного изменения окружений. В частности, в средах DevOps, они становятся чрезвычайно популярными там, где начинает стираться граница между инфраструктурой и приложением. Управление инфраструктурой, которое как правило, обладает медленным передвижением в сравнении с разработкой приложений, означает что в некой Гибкой среде разработки команда инфраструктуры почти всегда находится в состоянии догоняющей. Применяя DevPos и контейнеры имеющаяся команда инфраструктуры может сосредоточиться на предоставлении надёжной основы, в то время как разработчики могут поставлять свои приложения в сочетании с ОС и программным обеспечением промежуточного уровня, которые требуются для работы.
Сама возможность быстро и действенно раскручивать десятки контейнеров в считанные секунды позволяет вам осознать что, раз уж разрастание виртуальными машинами было достаточно плохим, при использовании контейнеров такая проблема может запросто стать ещё хуже. С приходом в современную ИТ- инфраструктуру Docker возникла необходимость управлять всеми этими контейнерами. Введём Kubernetes.
Хотя существует несколько технологий оркестровки контейнеров, наиболее широким успехом пользуется Kubernetes, а, поскольку это именно тот продукт, на котором строится Rook, в данной книге мы сосредоточимся на нём.
Kubernetes является системой оркестровки контейнеров с открытым исходным кодом для автоматизации необходимых развёртывания, масштабирования и управления контейнерными приложениями. Первоначально он был разработан Google для исполнения своих внутренних систем, однако с тех пор получил статус открытого исходного кода и его популярность расцвела.
Хотя в этой главе будет рассказано о развёртывании чрезвычайно простого кластера Kubernetes для оснащения некого кластера Ceph с помощью Rook, это не означает что такой рассказ будет полным руководством и читателю предлагается обратиться к прочим ресурсам для более подробного изучения Kubernetes.
Развёртывание кластера Ceph при помощи Rook
Для развёртывания некого кластера Ceph при помощи Rook и Kubernetes, для создания трёх ВМ которые будут исполнять сам кластер Kubernetes мы воспользуемся Vagrant.
Самой первой задачей будет чтобы вы целиком выполнили развёртывание трёх ВМ через Vagrant. Если вы прошли те шаги, которые мы указывали в самом начале данной главы, и применяли Vagrant для построения некой среды под Ansible, тогда вы уже должны иметь всё что вам требуется для развёртывания ВМ под необходимый кластер Kuberneytes.
Ниже приводится соответствующий Vagrantfile для привнесения трёх ВМ; как и ранее,
поместите его содержимое в некий файл с названием Vagrantfile в новом
каталоге и затем запустите vagrant up:
nodes = [
{ :hostname => 'kube1', :ip => '192.168.0.51', :box => 'xenial64', :ram => 2048, :osd => 'yes' },
{ :hostname => 'kube2', :ip => '192.168.0.52', :box => 'xenial64', :ram => 2048, :osd => 'yes' },
{ :hostname => 'kube3', :ip => '192.168.0.53', :box => 'xenial64', :ram => 2048, :osd => 'yes' }
]
Vagrant.configure("2") do |config|
nodes.each do |node|
config.vm.define node[:hostname] do |nodeconfig|
nodeconfig.vm.box = "bento/ubuntu-16.04"
nodeconfig.vm.hostname = node[:hostname]
nodeconfig.vm.network :private_network, ip: node[:ip]
memory = node[:ram] ? node[:ram] : 4096;
nodeconfig.vm.provider :virtualbox do |vb|
vb.customize [
"modifyvm", :id,
"--memory", memory.to_s,
]
if node[:osd] == "yes"
vb.customize [ "createhd", "--filename", "disk_osd-#{node[:hostname]}", "--size", "10000" ]
vb.customize [ "storageattach", :id, "--storagectl", "SATA Controller", "--port", 3, "--device", 0, "--type", "hdd", "--medium", "disk_osd-#{node[:hostname]}.vdi" ]
end
end
end
config.hostmanager.enabled = true
config.hostmanager.manage_guest = true
end
end
Через SSH зайдите в свою первую ВМ, Kube1:
Обновите её ядро до новейшей версии; это требуется для правильной работы определённых свойств Ceph в Rook:
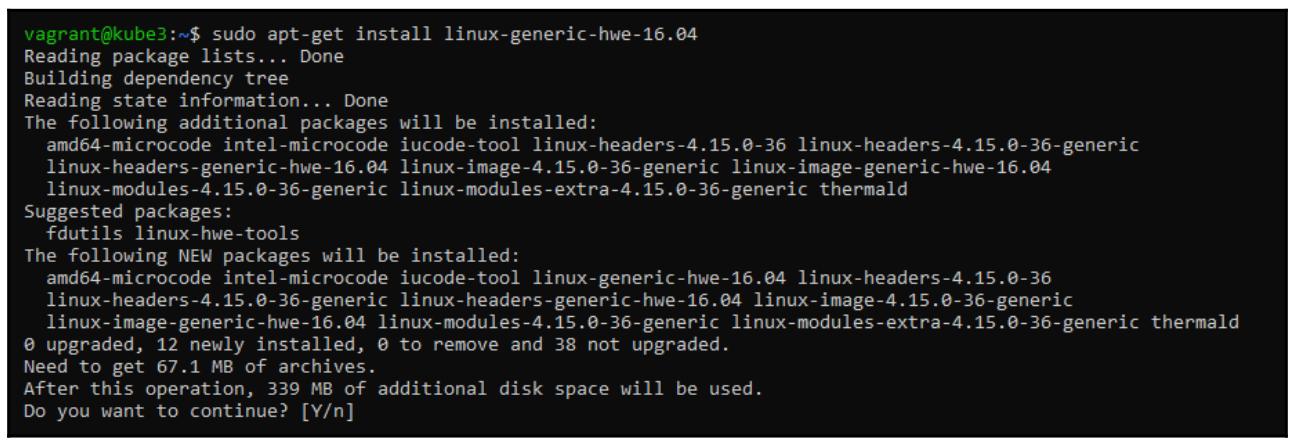
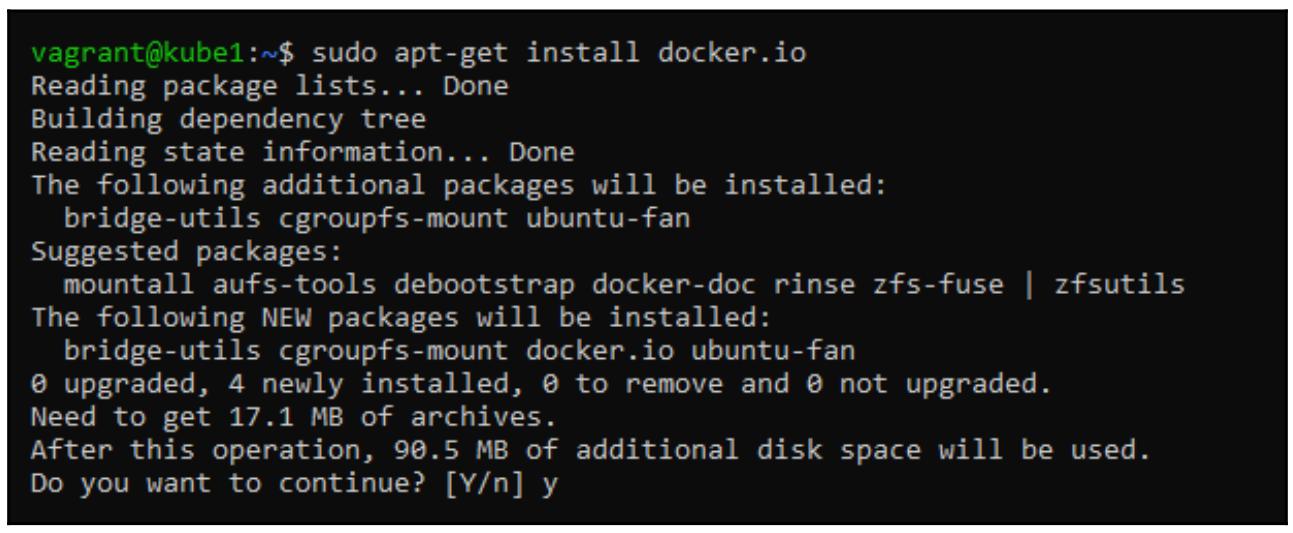
Установите Docker следующим образом:
sudo apt-get install docker.io
Включите полученную службу Docker и запустите её так:
sudo systemctl start docker
sudo systemctl enable docker

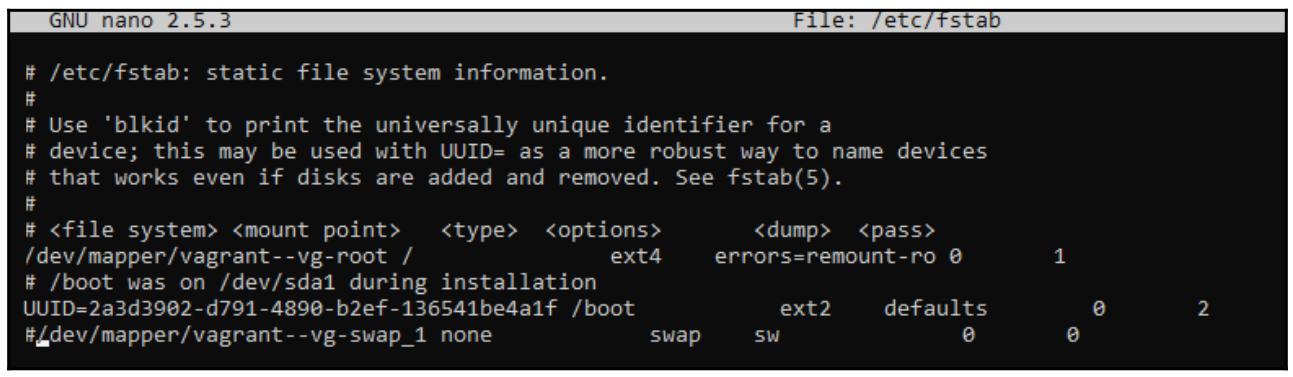
Отключите подкачку страниц для последующих загрузок изменив /etc/fstab
и снабдив комментарием строку с подкачкой страниц (swap):
А также отключите подкачку страниц сейчас следующим образом:
sudo swapoff -a

Добавьте необходимый репозиторий Kubernetes:
sudo add-apt-repository “deb http://apt.kubernetes.io/ kubernetes-xenial main”

Добавьте ключ GPG Kubernetes:
sudo curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add

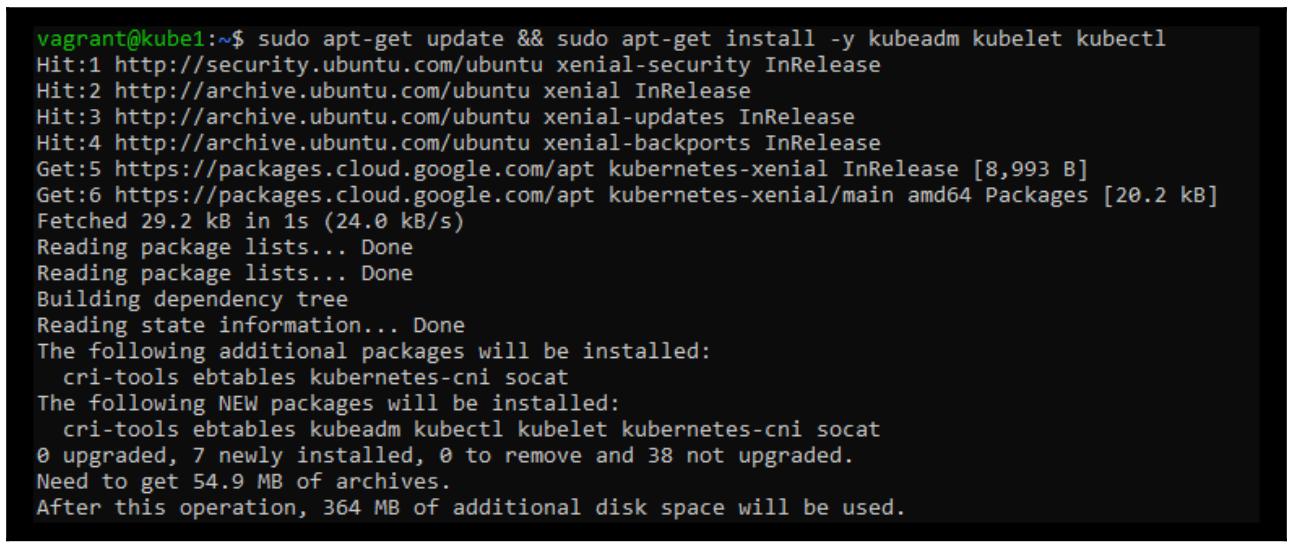
Установите Kubernetes:
sudo apt-get update && sudo apt-get install -y kubeadm kubelet kubectl
Повторите выполненные шаги установки для Docker и Kubernetes на обеих ВМ kube2
и kube3.
Когда все ВМ получат рабочие копии Docker и Kubernetes мы можем после этого инициализировать свой кластер Kubernetes:
sudo kubeadm init --apiserver-advertise-address=192.168.0.51 --pod-network-cidr=10.1.0.0/16 --ignore-preflight-errors=NumCPU

А по окончанию этого процесса выводится командная строка; обратите на неё внимание, поскольку она потребуется для соединения наших дополнительных узлов в общий кластер. Пример вывода может быть таким:
Теперь, когда у нас имеются установленными на всех наших узлах Docker и Kubernetes и мы инициализировали их хозяина, давайте добавим в создаваемый кластер остающиеся два узла. Помните ту строку, на которую мы советовали обратить внимание? Теперь мы можем запустить её для двух оставшихся узлов:
sudo kubeadm join 192.168.0.51:6443 --token c68o8u.92pvgestk26za6md --discovery-token-ca-cert-hash sha256:3954fad0089dcf72d0d828b440888b6e97465f783bde403868f098af67e8f073
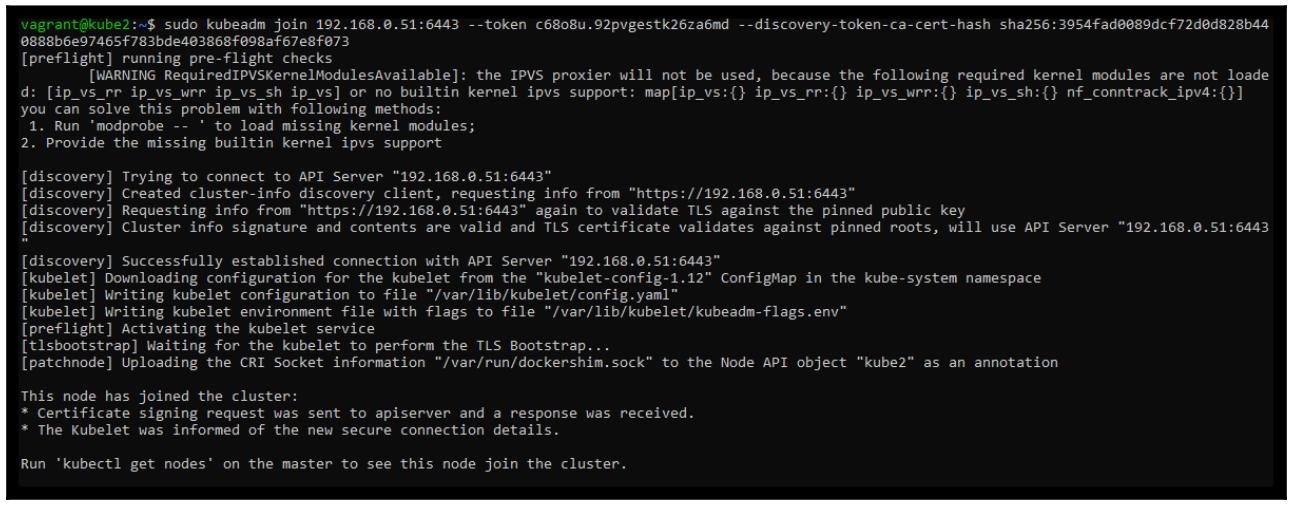
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Теперь мы можем ус тановить некую дополнительную поддержку сетевой среды контейнеров. Flannel, простое добавление
сетевой среды Kubernetes, применяющее в качестве наложения (оверлея) VXLAN для включения сетевой среды контейнер- к-
контейнеру. Для начала выгрузим с GitHub соответствующий файл yaml:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml

Прежде чем мы установим сетевой компонент Flannel, нам потребуется внести ряд изменений в свой файл определений
yaml:
nano kube-flannel.yml
|
| Совет |
|---|---|
|
Не применяйте в отступах символ табуляции, используйте пробелы. |
Нам требуется отыскать строки, подобные приводимым ниже и внести в них необходимые изменения, например:
"Network": "10.1.0.0/16":
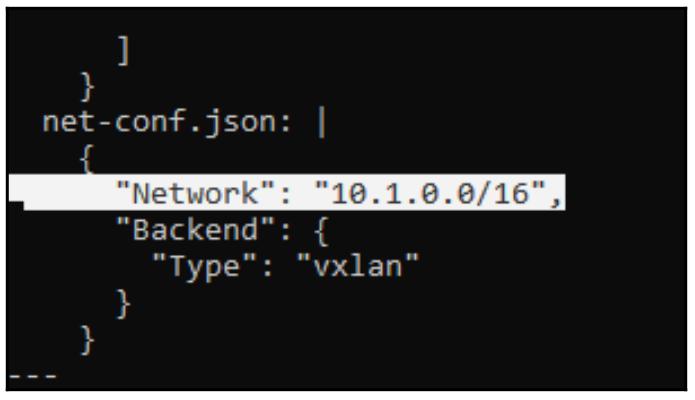
- --iface=eth1:
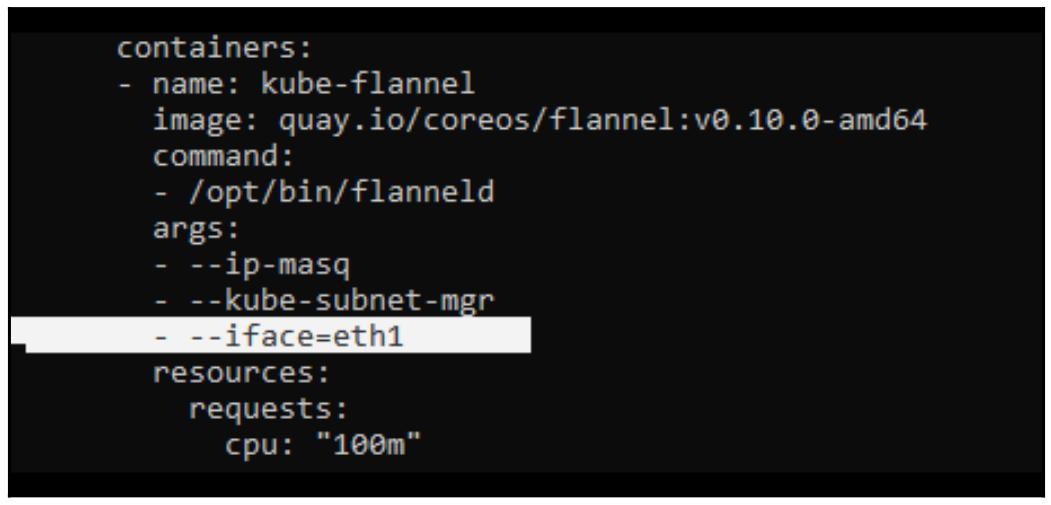
|
| Совет |
|---|---|
|
{Прим. пер.: вы даже можете здесь настроить обмен RDMA, как это объясняется в переводе статьи Mellanox Как создать контейнер Docker с ускорением RDMA приложений поверх сетевой среды 100Gb InfiniBand}. |
Теперь мы можем вызвать важную команду Kubernetes для применения своего файла определений и установки сетевой среды Flannel:
kubectl apply -f kube-flannel.yml
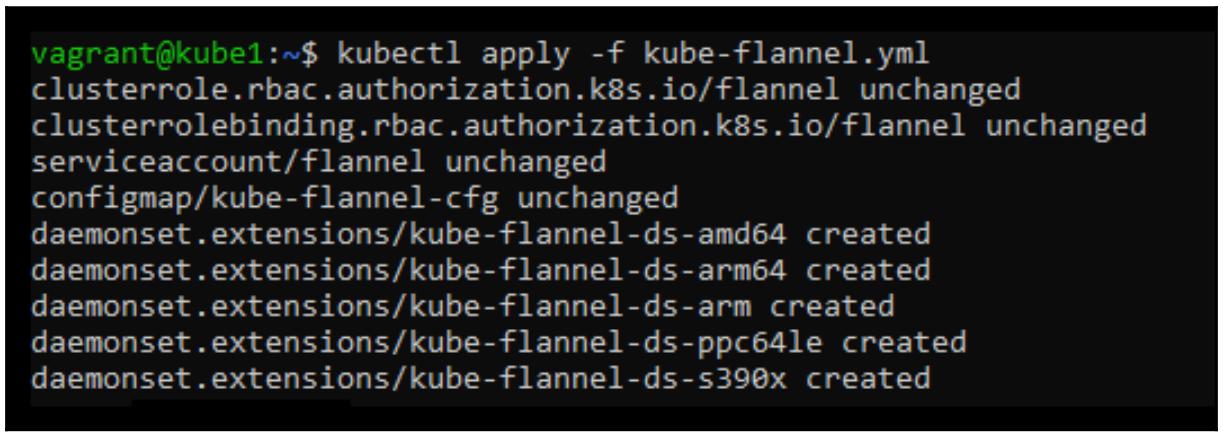
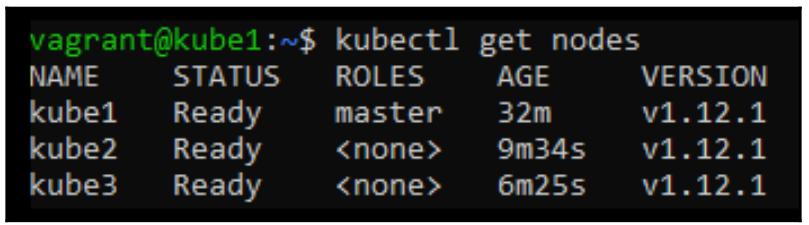
После установки сетевой среды мы можем удостовериться что всё работает и что наши узлы исполнителей Kubernetes готовы к выполнению рабочих нагрузок:
$ kubectl get nodes
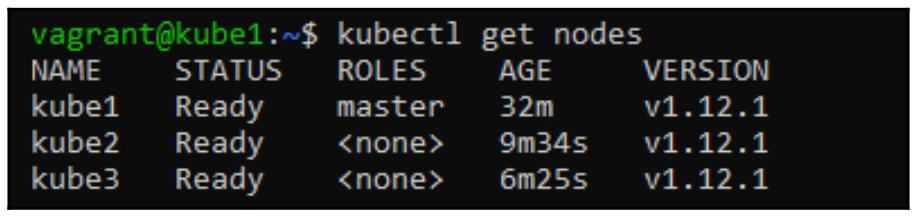
Теперь давайте проверим что запущены все все контейнеры, которые поддерживают внутренние службы Kubernetes:
$ kubectl get pods --all-namespaces –o wide
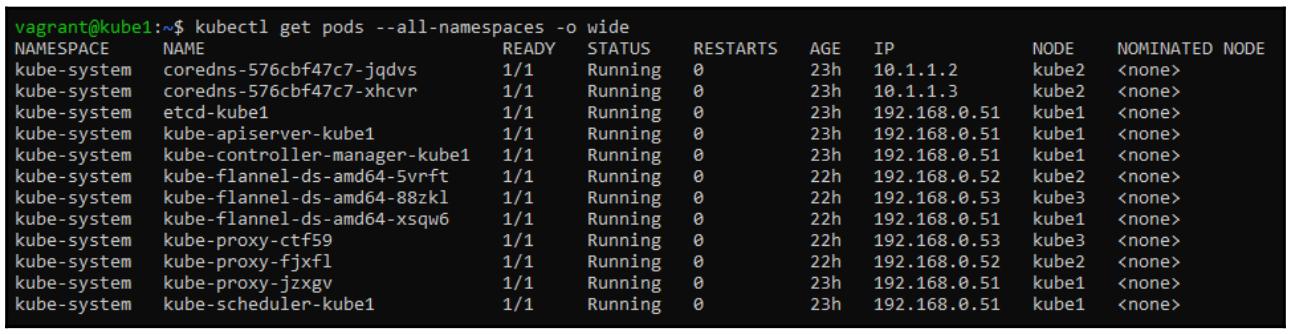
Обратите внимание, что установленная нами на предыдущем этапе сетевая служба наших контейнеров (Flannel) была автоматически развёрнута на всех трёх узлах. На данный момент у нас имеется полностью рабочий кластер Kubernetes для запуска любых контейнеров, которые мы пожелаем исполнять в нём.
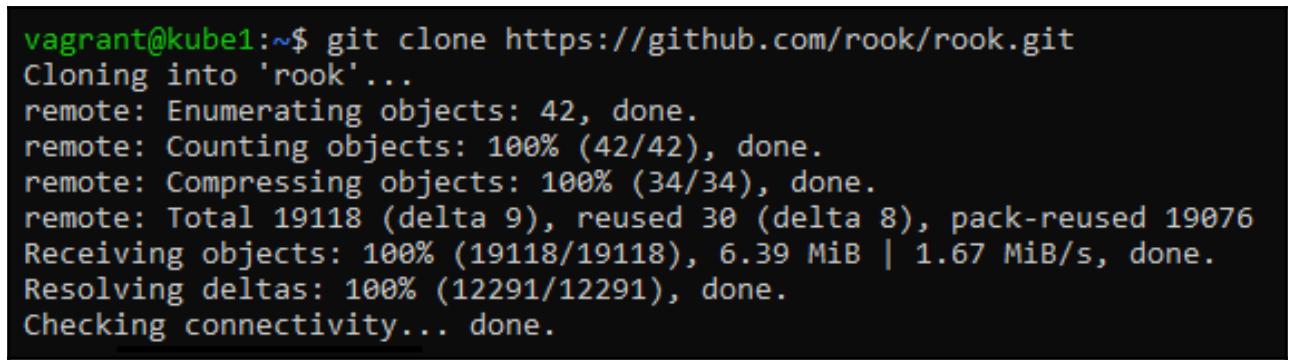
Теперь в полученном кластере Kubernetes мы можем развернуть Rook. Прежде всего клонируем сам проект Rook с GitHub:
$ git clone https://github.com/rook/rook.git
Перейдите в каталог examples:
$ cd rook/cluster/examples/kubernetes/ceph/

А теперь, наконец, создайте кластер Ceph воспользовавшись силой Rook выполнив две следующие команды:
$ kubectl create -f operator.yaml
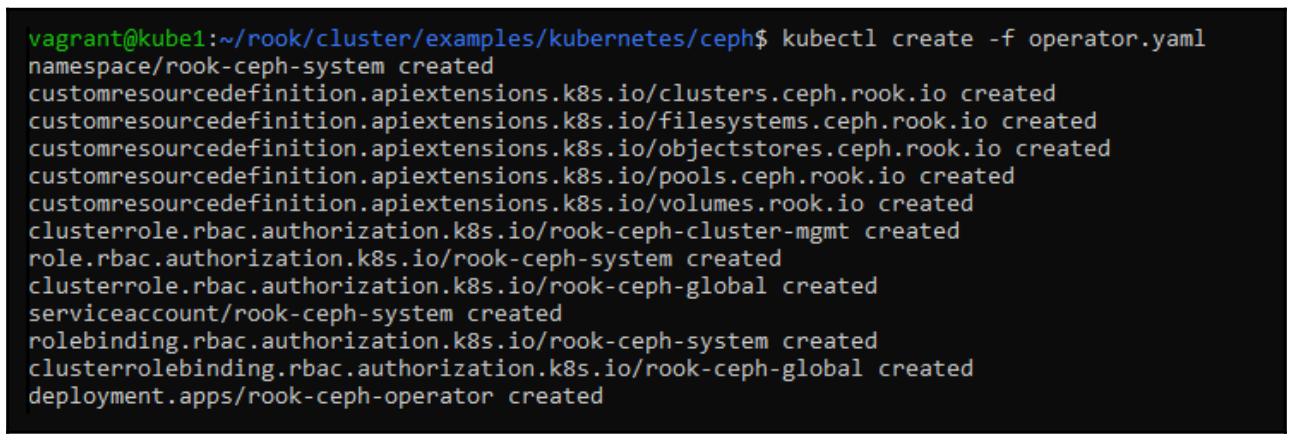
$ kubectl create -f cluster.yaml

Чтобы убедиться что наш кластер Rook теперь запущен, давайте проверим что контейнеры исполняются в нашем пространстве имён Rook:
$ kubectl get pods --all-namespaces -o wide

Как вы можете видеть, Rook развернул пару mons а также запустил некие контейнеры
обнаружения. Эти обнаруживающие контейнеры исполняют сценарий выявления локальных устройств хранения, подключённых к
нашему физическому хосту Kubernetes. После завершения данного процесса обнаружения в первый раз Kubernetes затем
запустит одноразовый контейнер для подготовки соответствующего OSD отформатировав такой диск и добавив полученный
OSD в общий кластер. Если вы подождёте несколько минут и повторно исполните команду get pods ,
вы, надеемся, должны увидеть что Rook выявил два диска подключёнными к kube2 и
kube3 и создал для них контейнеры osd:
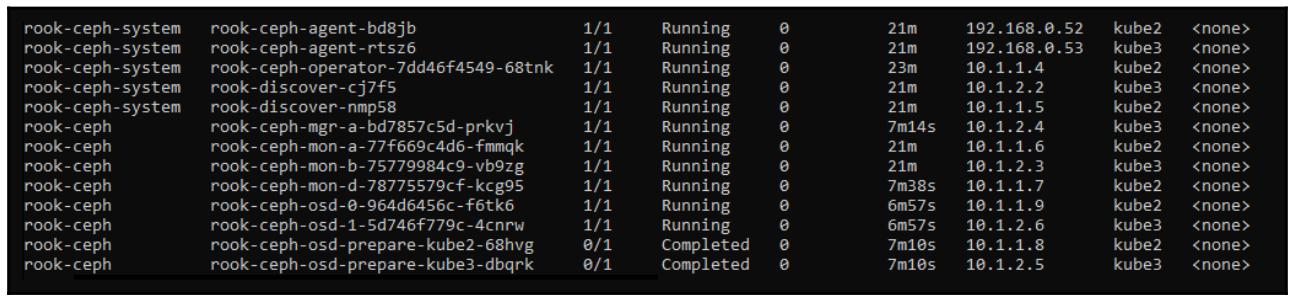
Для взаимодействия с нашим кластером давайте развернём соответствующий контейнер инструментария; это некий простой контейнер, содержащий саму установку Ceph и все необходимые кластеру ключи:
$ kubectl create -f toolbox.yaml

Теперь запустите в этом инструментальном контейнере bash:
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Это предоставит нам некую оболочку root, запущенную внутри соответствующего инструментального контейнера Ceph,
в которой мы можем проверить текущее состояние нашего кластера Ceph исполнив ceph –s
и просмотрев текущие OSD при помощи ceph osd tree:
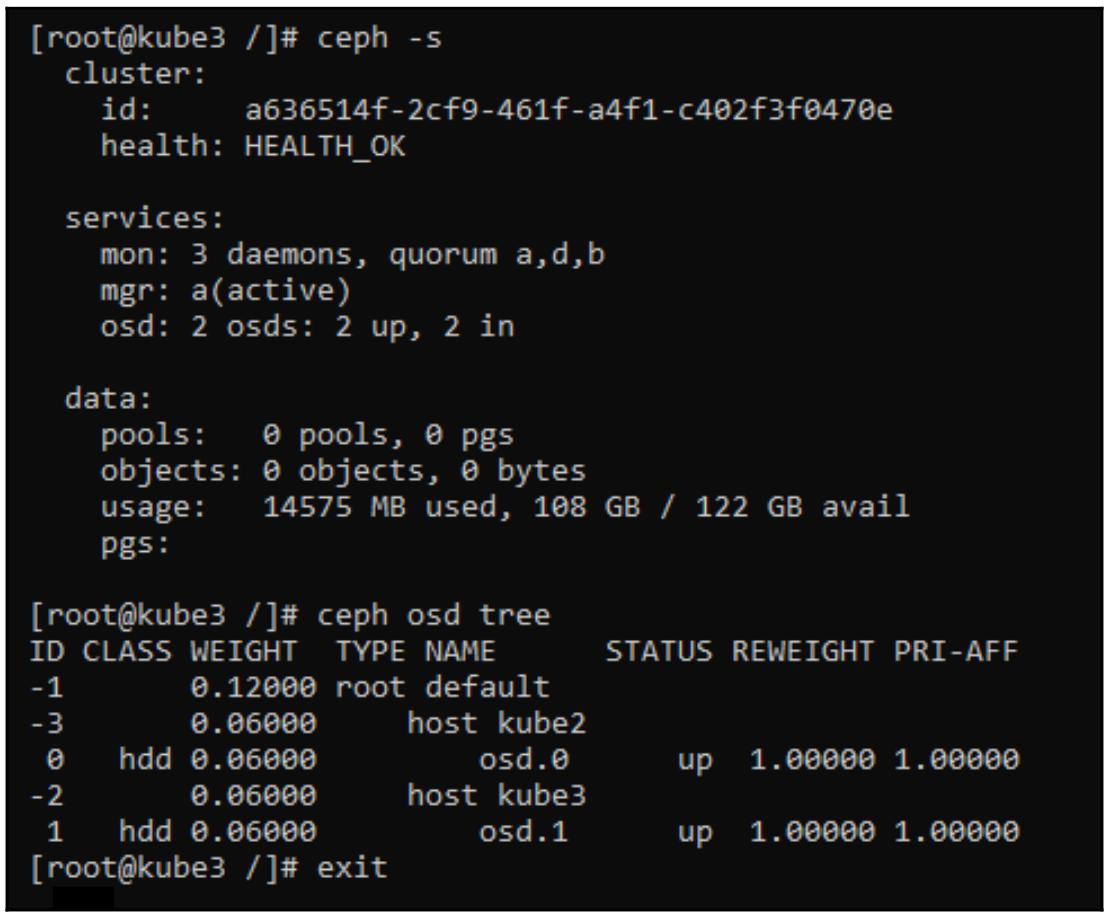
Вы можете обратить внимание, что хотя мы построили три ВМ, Rook развернул OSD только в kube2
и kube3. Это происходит потому, что по умолчанию Kubernetes не планирует запускать
контейнеры в своём узле хозяина; в промышленном кластере именно это является желательным поведением, но для целей проверки
мы можем избавиться от такого ограничения.
Вернитесь обратно в узел хозяина Kubeernetes и выполните следующее:
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
Вы можете обратить внимание, что Kubernetes развернёт пару новых контейнеров в kube1,
но он не развернёт никакие новые OSD; это происходит по причине текущего ограничения, связанного с тем что компонент
rook-ceph-operator развёртывает новые OSD только при первом запуске. Требуется
удалить этот компонент rook-ceph-operator для выявления новых доступных дисков и
их подготовки под OSD.
Выполните приведённую ниже команду, но не забудьте заменить имя контейнера на то, которое было получено вами в
вашей команде get pods:
kubectl -n rook-ceph-system delete pods rook-ceph-operator-7dd46f4549-68tnk
Kubernetes теперь автоматически раскрутит новый контейнер rook-ceph-operator
и сделав это запустит развёртывание нашего нового osd; в этом можно
убедиться взглянув снова на перечень исполняемых контейнеров:
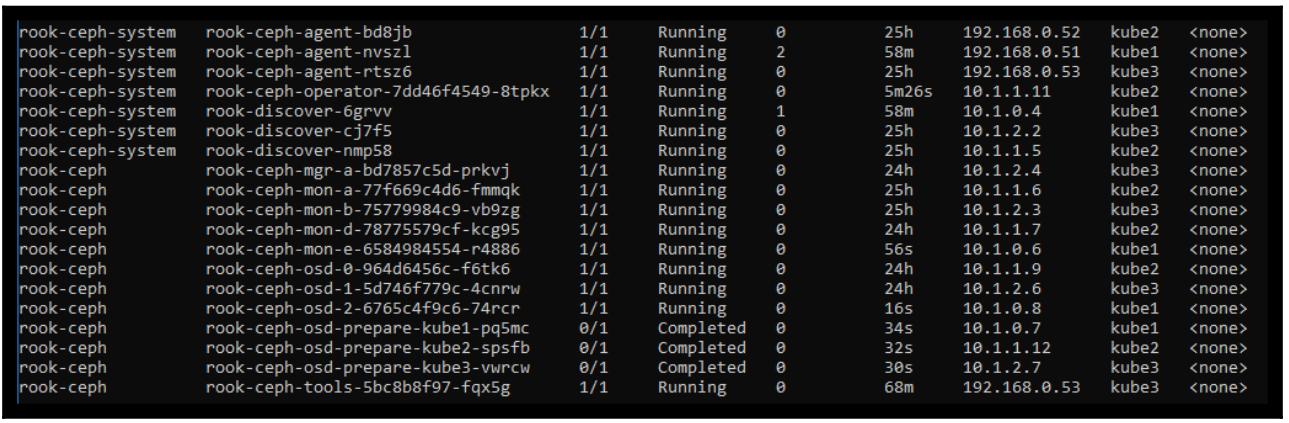
Вы можете видеть, что в kube1 имеются запущенными контейнеры
rook-discover, rook-ceph-osd-prepare и,
наконец, rook-ceph-osd, которым в данном случае является
osd с номером 2.
При помощи своего инструментального контейнера мы также можем убедиться что наш новый
osd успешно присоединился к общему кластеру:
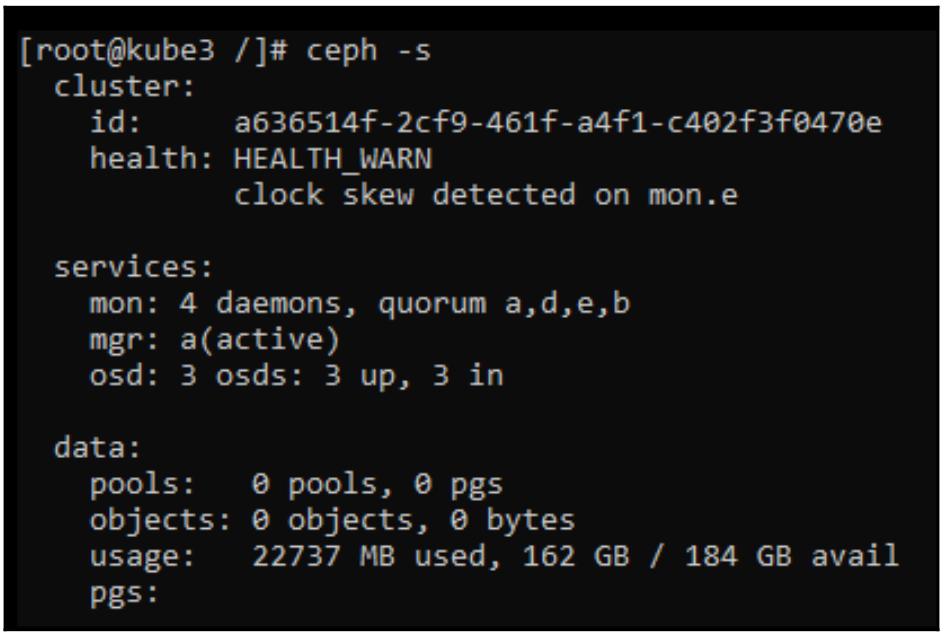
Теперь, когда Rook развернул наш кластер Ceph целиком, нам необходимо воспользоваться им и создать некие пулы RADOS, а также занять некое пространство хранения контейнером клиента. Для демонстрации этого процесса мы развернём файловую систему CephFS.
Прежде чем мы прыгнем в пучину развёртывания самой файловой системы, давайте вначале рассмотрим соответствующий пример
файла yaml, который мы будем развёртывать. Проверьте что вы всё ещё в каталоге
~/rook/cluster/examples/kubernetes/ceph и воспользуйтесь текстовым редактором
для просмотра этого файла filesystem.yaml:
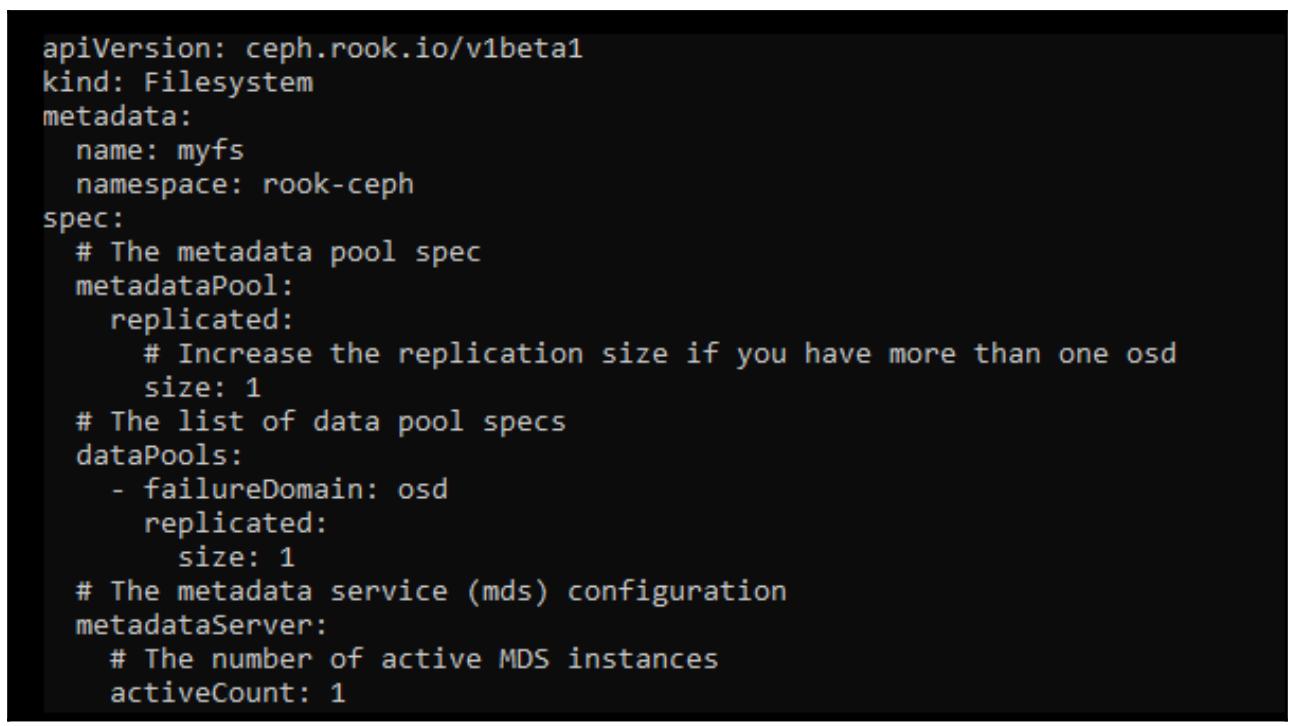
Вы можете увидеть, что данный файл содержит описание тех пулов RADOS, которые мы создали, а также соответствующие экземпляры MDS, которые требуются для данной файловой системы. В жтом примере будут развёрнуты три пула, два снабжённые репликами и один с удаляющим кодированием для наших реальных данных. Будут развёрнуты два сервера MDS, причём один будет выступать в качестве активного, а другой работающий в режиме готовности к замене.
Выйдите из своего текстового редактора и теперь разверните конфигурацию CephFS в данном файле
файла yaml:
$ kubectl create -f filesystem.yaml

Теперь давайте перескочим обратно в свой инструментальный контейнер, проверим значение состояния и рассмотрим что было создано:
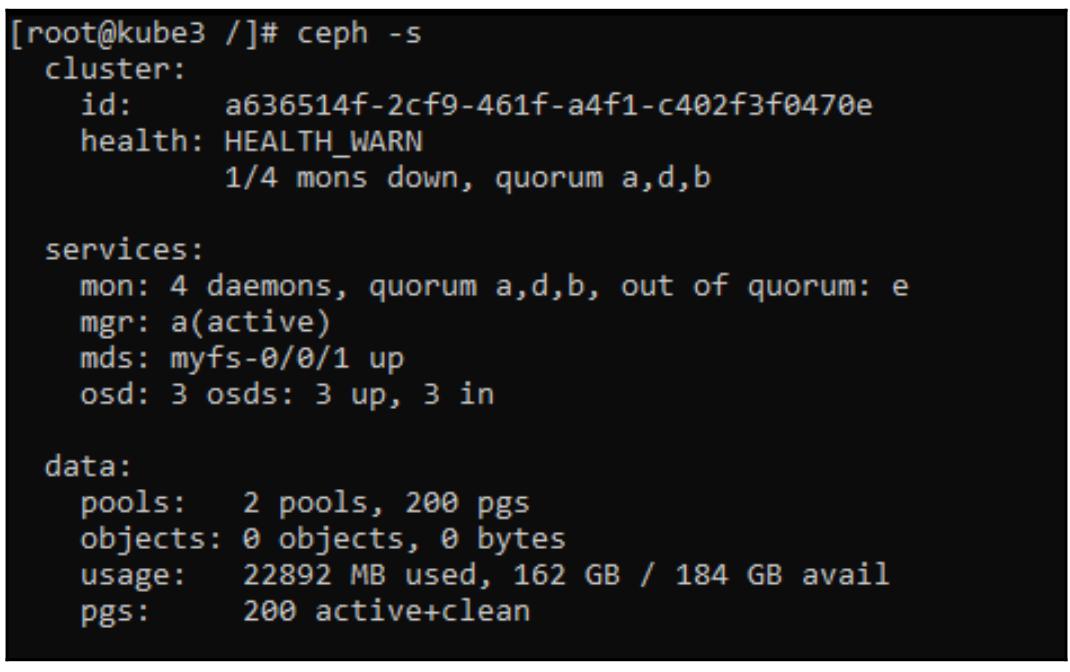

Мы можем видеть, что было создано два пула, один для имеющихся метаданных CephFS, а второй для реальных данных, хранимых в самой файловой системе CepFS.
Чтобы представить некий пример того как Rook затем может употребляться контейнерными приложениями, мы теперь развернём некий небольшой контейнер веб сервера NGINX, который хранит своё содержимое HTML в данной файловой системе CephFS.
Поместите приведённое ниже содержимое в файл с названием nginx.yaml:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumes:
- name: www
flexVolume:
driver: ceph.rook.io/rook
fsType: ceph
options:
fsName: myfs
clusterNamespace: rook-ceph
А теперь применим команду kubectl для создания
pod/nginx:

После небольшого ожидания данный контейнер будет запущен и войдет в состояние исполняемого; чтобы убедится в этом,
воспользуйтесь командой get pods:

Теперь мы можем быстро запустить в этом контейнере оболочку Bash чтобы проверить что смонтированая CephFS работает:
$ kubectl exec -it nginx bash
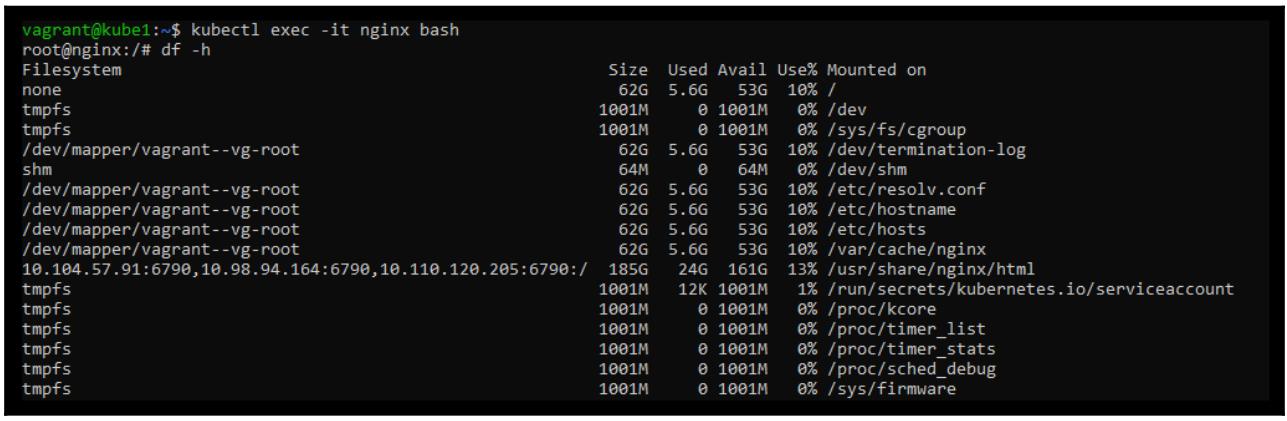
Мы можем видеть, что наша файловая система CephFS была смонтирована в /usr/share/nginx/html.
Это было сделано без необходимости установки в этом контейнере каких бы то ни было компонентов Ceph и без выпонения
каких бы то ни было настроек и копирования колец ключей. Обо всём этом позаботился Rook за сценой; можно осознать всю мощь
Rook только поняв и приняв всё это. Когда данный образец простого пода NGINX расширяется и становится автоматически
масштабируемой службой, которая раскручивает множество контейнеров в зависимости от нагрузки, становится очень полезной та
гибкость, которую предоставляет под Ceph Rook автоматически предоставляя одно и то же совместно применяемое хранилище под
веб ферму.
В данной главе мы изучили различные доступные методы развёртывания Ceph, а также различия между ними. Теперь вы также имеете основы понимания того как работает Ansible и как с его помощью развёртывать кластер Ceph. Было бы целесообразным в данный момент продолжить практиковаться в развёртывании и настройке Ceph при помощи Ansible с тем, чтобы вы с уверенностью смогли применять его в промышленных средах. Оставшаяся часть книги также исходит из того, что вы имеете полное понимание содержания данной главы для манипуляций с имеющимися настройками Ceph.
Вы также изучили имеющиеся исключительные разработки в развёртывании Ceph в контейнерах, исполняющихся в платформе Kubernetes. Хотя обсуждаемый проект Rook всё ещё в ранней стадии разработки, совершенно ясно, что это уже достаточно мощный инструмент, который позволит Ceph работать в меру его возможностей, одновременно упрощая необходимые развёртывание и администрирование. Благодаря продолжающейся успешности Kubernetes в качестве рекомендуемой платформы управления контейнерами, интеграция Ceph при помощи Rook приводит к идеальному сочетанию технологий.
Читателю настоятельно рекомендуется продолжить изучение Kubernetes, так как в этой главе лишь поверхностно рассмотрены предлагаемые им функциональные возможности. В данной отрасли имеются чёткие признаки того, что контейнеризация станет основной технологией для развёртывания приложений и управления ими, а также настоятельно рекомендуется наличие представления как о Kubernetes, так и о том как Ceph интегрируется с Rook.
-
Какое программное обеспечение можно применять для быстрого развёртывания сред проверки?
-
Следует ли применять Vagrant для развёртывания промышленной среды?
-
Какой проект позволяет развёртывать Ceph поверх Kubernetes?
-
Что такое Docker?
-
Как называется файл Ansible, применяемый для исполнения последовательности команд?