Приложение A: Ceph поверх RDMA
Содержание
Данное руководство является переводом материалов HowTo Configure Ceph RDMA с обновлениями от 27.03.2017 5:19.
Основной целью данного документа является описание того как поднять кластер Ceph с RDMA. Данные инструкции предназначаются искушённым пользователям Ceph.
На всех своих серверах примените следующее:
-
Убедитесь что у вас в наличии работающие
pingиrpingмежду всеми узлами Ceph.{Прим. пер.: Убедитесь что у вас установлена последняя версия OFED и после установки перезагружен драйвер
openibd.
Проверкаrpingвыполняется так:
Сервер:rping –s –v server_ip
Клиент:rping –c –v –a server_ip}} -
Откройте
/etc/security/limits.confи добавьте следующие строки для выполнения ping к оперативной памяти. RDMA тесно связан с выделенными адресами физической памяти.* soft memlock unlimited * hard memlock unlimited root soft memlock unlimited root hard memlock unlimited -
Для выполнения процесса развёртывания вы должны разрешить регистрацию ssh без применения пароля, как это требуется Ceph. Подробнее Preflight Checklist — Ceph Documentation.
-
Установите Ceph-deploy
sudo rpm -Uvh https://download.ceph.com/rpm-kraken/el7/noarch/ceph-deploy-1.5.36-0.noarch.rpm;
Данная настройка основана на repo — ceph-deploy 1.5.37 documentation и Storage Cluster Quick Start — Ceph Documentation.
-
Создайте некий рабочий каталог.
mkdir my_cluster cd my_cluster -
Установите Ceph:
-
Создайте
ceph.confи установите ceph на все узлы:$ceph-deploy new --cluster-network=11.130.1.0/24 --public-network=11.130.1.0/24 "list of monitors" $ceph-deploy --overwrite-conf install --repo-url=ftp://user:password@ftpsupport.mellanox.com/rpm-v11.1.0-6639-gb304df1 --gpg-url=ftp://user:password@ftpsupport.mellanox.com/rpm-v11.1.0-6639-gb304df1/release.asc "list all nodes"![[Замечание]](/common/images/admon/note.png)
Замечание Если пользователь или пароль имеют особые символы, такие как "@", зарезервированные символы, тогда такой символ должен быть заменён "зарезервированным символом, закодированным после символа процента", например %40.
![[Совет]](/common/images/admon/tip.png)
Совет Помните, что общее число мониторов Ceph должно быть нечётным числом.
-
В
my_cluster/ceph.confдобавьте следующие строки:[global] ... ms_type=async+rdma ms_async_rdma_device_name=mlx5_0Замечание "
ms_async_rdma_device_name" должен быть активным устройствомДля определения активных устройств вы можете исполнить следующее:
$ ifconfig ... ens4: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 >------------ Это то устройство, которое вы проверили rping на этапе предварительной подготовки inet 11.1.1.14 netmask 255.255.255.0 broadcast 11.1.1.255 inet6 ffff::ffff:ffff:ffff:ffff prefixlen 64 scopeid 0x20 ether ff:ff:ff:ff:ff:ff txqueuelen 1000 (Ethernet) RX packets 10104263288 bytes 646758740138 (602.3 GiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 13 bytes 2410 (2.3 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 $ cat /sys/class/net/ens4/device/infiniband/mlx5_0/ports/*/state 4: ACTIVE ----------> mlx5_0 - это ваше активное устройство -
Выполните:
ceph-deploy --overwrite-conf mon create-initial ceph-deploy --overwrite-conf admin "list_all_nodes"Для каждого узла из перечня
list_all_nodesвыполните:sudo chmod +rx /etc/ceph/ceph.client.admin.keyring
-
-
Настройте все демоны OSD Ceph.
Выполните для каждого диска на всех узлах:
ceph-deploy --overwrite-conf disk zap node1:sdb ceph-deploy ---overwrite-conf osd prepare node1:sdb ceph-deploy osd activate node1:"sdb"1Замечание Имеющийся минимум числа узлов OSD должен быть то же значение, которое имеет число, определённое для реплик. Значение реплик по умолчанию равно 3.
-
Для проверки состояния исполните
ceph -s. Вы должну увидеть в качестве откликаHEALTH_OKили нечто подобное.# ceph -s health *HEALTH_OK* monmap e1: 1 mons at {r-aa-zorro002=2.2.68.102:6789/0} election epoch 7, quorum 0 r-aa-zorro002 *osdmap e26: 3 osds: 3 up, 3 in* flags sortbitwise,require_jewel_osds pgmap v57: 64 pgs, 1 pools, 0 bytes data, 0 objects 101 MB used, 1381 GB / 1381 GB avail 64 active+clean
Поздравляем! Ваш RDMA Ceph кластер поднят и работает!
|
| Замечание |
|---|---|
|
Если вы обнаружили некоторое предостережение
|
Данный материал является переводом материалов Ceph Async Messenger с обновлениями от 28.12.2016.
Исходный код Ceph имеет три вида реализации сетевого взаимодействия. В самой ранней реализации
SimpleMessenger для каждой пары взаимодействия между
имеющимися равноправными участниками создавалось четыре потока (thread) чтобы поддерживать соответствующее
состояние соединения (два потока на каждой стороне несут ответственность за чтение и запись). Таким образом,
по мере роста кластера это приводит к созданию большого числа потоков. Благодаря реализации Linux
epoll на помощь приходит высокое распараллеливание сетевого
ввода/ вывода за счёт таких системных вызовов epoll, как библиотека
libevent. Исходный код также реализует на основе
epoll систему AsyncMessenger,
которая помогает снизить общее число потоков, необходимое для сетевого обмена в имеющемся кластере. Имеющаяся
в настоящее время {Прим. пер.: 28 декабря 2016} ещё пока не стабильная
и не является компонентой взаимодействия по умолчанию, однако в будущем заменит
SimpleMessenger.
Для прослушивания порта, ожидания поступления запросов на соединение и последующего приёма запросов на установление некоторого соединения для взаимодействия необходим соответствующий сервер.
Инициализация
Рассмотрим в качестве примера OSD. При запуске его процесса будет создан некий объект
Messenger , применяемый для управления текущим сетевым соединением,
прослушивания порта и получения всех запросов, его исходный код находится в соответствующем файле
/ceph_osd.cc:
int main(int argc, const char **argv)
{
......
// public --используется для взаимодействия с клиентом
Messenger *ms_public = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "client", getpid());
// cluster --применяется для внутреннего взаимодействия кластера
Messenger *ms_cluster = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::OSD(whoami), "cluster",
getpid());
......
}
// src/msg/Messenger.cc
Messenger *Messenger::create(CephContext *cct, const string &type,
entity_name_t name, string lname,
uint64_t nonce)
{
......
// в исходном файле /common/config_opts.h вам необходимо настроить связанные асинхронным доступом опции, чтобы они вступили в действие
// OPTION(enable_experimental_unrecoverable_data_corrupting_features, OPT_STR, "ms-type-async")
// OPTION(ms_type, OPT_STR, "async")
else if ((r == 1 || type == "async") &&
cct->check_experimental_feature_enabled("ms-type-async"))
return new AsyncMessenger(cct, name, lname, nonce);
......
return NULL;
}
Конструкторы класса AsyncMessenger должны быть осведомлены о том, что
хотя все шесть систем обмена сообщения создаются в процессе начального запуска процесса OSD, однако все они
совместно используют некий WorkerPool, причём функция
lookup_or_create_singleton_object гарантирует что создаётся только один
пул, так как её имя во входных параметрах, WorkerPool::name является
одним и тем же:
AsyncMessenger::AsyncMessenger(CephContext *cct, entity_name_t name,
string mname, uint64_t _nonce)
: SimplePolicyMessenger(cct, name,mname, _nonce),
processor(this, cct, _nonce),
lock("AsyncMessenger::lock"),
nonce(_nonce), need_addr(true), did_bind(false),
global_seq(0), deleted_lock("AsyncMessenger::deleted_lock"),
cluster_protocol(0), stopped(true)
{
ceph_spin_init(&global_seq_lock);
cct->lookup_or_create_singleton_object<WorkerPool>(pool, WorkerPool::name); // создаём объект pool,
// отметим, что второй аргумент является статической константой в WorkerPool
// Создаём некий объект локального соединения для отправки сообщения самому данному процессу
local_connection = new AsyncConnection(cct, this, &pool->get_worker()->center);
init_local_connection(); // инициализируем необходимый локальный объект
}
template<typename T>
void lookup_or_create_singleton_object(T*& p, const std::string &name) {
ceph_spin_lock(&_associated_objs_lock);
if (!_associated_objs.count(name)) { // name определяет некий процесс, который будет иметь только какой-то pool
p = new T(this); // new некий объект, здесь это WorkerPool
_associated_objs[name] = reinterpret_cast<AssociatedSingletonObject*>(p); // присоединить map
} else {
p = reinterpret_cast<T*>(_associated_objs[name]);
}
ceph_spin_unlock(&_associated_objs_lock);
}
Также отметим что в таком конструкторе данной системы сообщений размещается только единственный пул данного
процесса, причём деструктор не отвечает за высвобождение его памяти, так как множество систем сообщений являются
использующими его совместно и то что некая система сообщений удалена не означает что прочие системы сообщений
будут также несомненно удалены. Основной указатель на пул хранится как участник
CephContext в переменной _associated_objs,
поскольку данный процесс демона имеет некий глобально уникальный CephContext,
который высвобождает имеющуюся память основного указателя на пул при деструкции его
CephContext.
Все процессы OSD будут иметь только какой- то WorkerPool во время
инициализации чтобы сделать некую работу? Как предполагает его имя, WorkerPool
несомненно используется для управления конкретным Worker, именно
конструктором несомненно нового класса объектов Worker и причём наследуемый
из имеющегося класса thread класс Worker
несомненно является неким отодельным рабочим потоком. В исходном коде
src/msg/async/AsyncMessenger.[h|c]:
WorkerPool::WorkerPool(CephContext *c): cct(c), seq(0), started(false),
barrier_lock("WorkerPool::WorkerPool::barrier_lock"),
barrier_count(0)
{
assert(cct->_conf->ms_async_op_threads > 0);
for (int i = 0; i < cct->_conf->ms_async_op_threads; ++i) {
Worker *w = new Worker(cct, this, i); // Новый класс объектов Worker
workers.push_back(w); // Хранится в данном контейнере вектора, применяется для отслеживания всех workers
}
......
}
class Worker : public Thread { // Наследует класс Thread, отображает тот факт, что самм класс Worker содержит потоки
static const uint64_t InitEventNumber = 5000; // Общее число событий
static const uint64_t EventMaxWaitUs = 30000000; // Значение максимального времени ожидания события, 30 секунд
CephContext *cct;
WorkerPool *pool;
bool done;
int id;
public:
EventCenter center; // Центр обработки событий
Worker(CephContext *c, WorkerPool *p, int i)
: cct(c), pool(p), done(false), id(i), center(c) {
center.init(InitEventNumber); // Инициализация выполняется событиями,
// на самом деле служит для инициализации относящейся к epoll структуре
}
void *entry();
void stop();
};
Для общности всего кода здесь присутствует некий отдельный уровень абстракции, а именно
EventCenter, который применяется для управления различными событиями в
имеющемся драйвере, такими как epoll,
kqueue, select и
тому подобными. Исходный код в src/msg/async/Event.[h]c]:
class EventCenter {
......
FileEvent *file_events; // Все события ввода/ вывода
EventDriver *driver; // Определённый драйвер
map<utime_t, list<TimeEvent> > time_events; // Все события времени
......
};
// Интерфейс EventDriver
// epoll Данный драйвер наследует этот интерфейс,
// причём реализация данного интерфейса является тремя системными вызовами epoll
// epoll_create, epoll_ctl,epoll_wait данного пакета
class EventDriver {
public:
virtual ~EventDriver() {} // мы хотим иметь виртуальный деструктор!!!
virtual int init(int nevent) = 0;
virtual int add_event(int fd, int cur_mask, int mask) = 0;
virtual void del_event(int fd, int cur_mask, int del_mask) = 0;
virtual int event_wait(vector<FiredFileEvent> &fired_events, struct timeval *tp) = 0;
virtual int resize_events(int newsize) = 0;
};
class EpollDriver : public EventDriver {
int epfd; // epoll fd
struct epoll_event *events; // Ожидаем появления определения структуры данного указателя на событие,
// вы можете просмотреть соответствующую информацию Epoll
ephContext *cct;
int size;
......
};
Функция конструктора Worker, вызывает
center функции init чтобы просмотреть что делает
center.init?
int EventCenter::init(int n)
{
......
driver = new EpollDriver(cct); // Создаём некий новый объект драйвера
int r = driver->init(n); // Инициализируем определённый драйвер
int fds[2]; // pipe Применяется для пробуждения данного потока worker, далее мы проанализируем это
if (pipe(fds) < 0) {
lderr(cct) << __func__ << " can't create notify pipe" << dendl;
return -1;
}
notify_receive_fd = fds[0];
notify_send_fd = fds[1];
......
create_file_event(notify_receive_fd, EVENT_READABLE, EventCallbackRef(new C_handle_notify())); // Наблюдает за событием чтения конвейера
return 0;
}
// Инициализация epoll
int EpollDriver::init(int nevent)
{
events = (struct epoll_event*)malloc(sizeof(struct epoll_event)*nevent); // nevent является значением InitEventNumber в определённом классе Worker
memset(events, 0, sizeof(struct epoll_event)*nevent);
epfd = epoll_create(1024); // Получить fd epoll
fd size = nevent; return 0;
}
От самого первого процесса OSD к классу AsyncMessenger, затем
ко всем совместно использующим WorkerPool системам сообщений и затем
инициализируя определённый процесс единственного пула для всех Worker,
а потом worker при помощи универсального обработчика всех событий
EventCenter и инициализирует данный определённый механизм обработки
события, например, epoll. Вся работа выполнена? В действительности, во- первых данный поток
worker не запущен, а во- вторых, процесс системы сообщений не
связан с неким определённым портом для наблюдения, поэтому OSD запускает тот процесс, который должен
предпринять прочие шаги.
Привязка и ожидание
После создания системы сообщений установите стратегию и текущие пределы всех параметров, следующими будут
привязка адреса, обработка имеющегося сетевого уровня сокета, например
socket/bind/listen/accept, причём в основном с управлением через
класс Processor.
// Продолжение кода ceph_osd.cc
int main(int argc, const char **argv)
{
......
// Устанавливаем протокол
ms_cluster->set_cluster_protocol(CEPH_OSD_PROTOCOL);
......
// Устанавливаеем все политики и вс текущие пределы
ms_public->set_default_policy(Messenger::Policy::stateless_server(supported, 0));
ms_public->set_policy_throttlers(entity_name_t::TYPE_CLIENT,
client_byte_throttler.get(),
client_msg_throttler.get());
......
// Связываем имеющийся адрес
r = ms_public->bind(g_conf->public_addr);
if (r < 0)
exit(1);
r = ms_cluster->bind(g_conf->cluster_addr);
if (r < 0)
exit(1);
......
ms_public->start(); // Запускаем поток (thread)
......
err = osd->init(); // Это ключ, анализ далее
......
ms_public->wait(); // Ожидание окончания потока
......
}
int AsyncMessenger::bind(const entity_addr_t &bind_addr)
{
......
// привязываемся к некоторому сокету
set<int> avoid_ports;
int r = processor.bind(bind_addr, avoid_ports); // Вызов для обработки объекта processor
......
}
// processor --Действие происходит прямо в API socket пакетов: socket, bind, listen
// Создаём некий сокет, привязываем его к определённому порту и переходим в ожидание (listen)
int Processor::bind(const entity_addr_t &bind_addr, const set<int>& avoid_ports)
{
......
listen_sd = ::socket(family, SOCK_STREAM, 0);
......
rc = ::bind(listen_sd, (struct sockaddr *) &listen_addr.ss_addr(), listen_addr.addr_size());
......
rc = ::listen(listen_sd, 128);
......
msgr->init_local_connection(); // Обновляем имеющийся адрес, однако поскольку отсутствует объект координации,
// данное соединение не обрабатывается
return 0;
}
void init_local_connection() {
Mutex::Locker l(lock);
_init_local_connection();
}
void _init_local_connection() {
assert(lock.is_locked());
local_connection->peer_addr = my_inst.addr;
local_connection->peer_type = my_inst.name.type();
ms_deliver_handle_fast_connect(local_connection.get());
}
void ms_deliver_handle_fast_connect(Connection *con) {
for (list<Dispatcher*>::iterator p = fast_dispatchers.begin(); // fast_dispatchers в настоящее время пуст
p != fast_dispatchers.end();
++p)
(*p)->ms_handle_fast_connect(con);
}
Обработка события
При привязке адреса для мониторинг порта будет выполняться ожидание момента когда соединение начнёт дело с
запросом на такое соединение. Обязательно ли необходимо создать поток
worker для решения данной задачи?
// ceph_osd.cc --Продолжим вызывать messenger->start(), см. предыдущий код
int AsyncMessenger::start()
{
lock.Lock();
......
pool->start(); // Запускаем все потоки (thread)
lock.Unlock();
return 0;
}
void WorkerPool::start()
{
if (!started) {
for (uint64_t i = 0; i < workers.size(); ++i) {
workers[i]->create(); // Создаём некий поток
}
started = true;
}
}
// Функция элемента потока
void *Worker::entry() {
......
center.set_owner(pthread_self());
while (!done) { // Потоки зацикливаются по событиям
int r = center.process_events(EventMaxWaitUs); // При обслуживании событий центр обработки событий,
// отметим, что максимальное время ожидания 30 секунд
}
return 0;
}
// Возвращаем все готовые fd через epoll_wait, а затем сразу вызываем его callback
int EventCenter::process_events(int timeout_microseconds)
{
......
vector<FiredFileEvent>
fired_events;
next_time = shortest;
numevents = driver->event_wait(fired_events, &tv); // Получить текущее событие ввода/ вывода
for (int j = 0; j < numevents; j++) {
int rfired = 0;
FileEvent *event;
{
Mutex::Locker l(file_lock);
event = _get_file_event(fired_events[j].fd);
}
if (event->mask & fired_events[j].mask & EVENT_READABLE) {
rfired = 1;
event->read_cb->do_request(fired_events[j].fd); // Обработка доступных на чтение событий
}
if (event->mask & fired_events[j].mask & EVENT_WRITABLE) {
if (!rfired || event->read_cb != event->write_cb)
event->write_cb->do_request(fired_events[j].fd); // Дело с доступными для записи событиями
}
}
......
}
int EpollDriver::event_wait(vector<FiredFileEvent> &fired_events, struct timeval *tvp)
{
int retval, numevents = 0; retval = epoll_wait(epfd, events, size,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1); // epoll_wait
// --некий системный вызов, событие готовности ожидания или таймаут
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = events + j;
if (e->events & EPOLLIN) mask |= EVENT_READABLE;
if (e->events & EPOLLOUT) mask |= EVENT_WRITABLE;
if (e->events & EPOLLERR) mask |= EVENT_WRITABLE;
if (e->events & EPOLLHUP) mask |= EVENT_WRITABLE;
// Записываем что произошло
fired_events[j].fd = e->data.fd;
fired_events[j].mask = mask;
}
return numevents;
}
Функция Process_events, стоит отметить, что здесь мы имеем дело с тремя
событиями, а также относящимися к данным событиям чтения и записи fd, относящимися ко времени событиями по установленному
времени, а также всеми дополнительными внешними событиями в связи с fd, если нет fd готовых к ожиданию таймаута
(максимальный тайаут не превышает имеющегося значения для следующего события по времени). Однако, при данном процессе
имеются две ситуации, которые должны пробуждаться, а именно, первая состоит в добавлении некоторого меньшего
интервала времени (только что произошедшего), а другая состоит в добавлении некоторого внешнего события.
Добавление ожидания fd
Поток (thread) worker в цикле обрабатывает события, фактически,
вызывает epoll_wait, возвращает определённому готовому событию fd, а
затем вызывает соответствующий fd обратный вызов read_cb или
write_cb. Совершенно ясно, что чтобы epoll_wait
мог вернуть готовому событию fd, такой fd должен быть добавлен заранее. Когда же его добавить? Также запомните,
что на втором шаге, связывания, для управления epoll, чтобы ожидать необходимый запрос от такого fd должен
быть добавлен listen_fd, созданный классом
Processor.
Однако, похоже, из подлежащего здесь для исполнения кода OSD не добавляется действие? Вызываемый в OSD
messenger->start() приводит к:
err = osd->init();
Необходимый трюк тут:
int OSD::init()
{
......
// я готов!
client_messenger->add_dispatcher_head(this);
cluster_messenger->add_dispatcher_head(this);
......
}
void add_dispatcher_head(Dispatcher *d) {
bool first = dispatchers.empty(); // Самое начало курса, пусто, для истинности first
dispatchers.push_front(d);
if (d->ms_can_fast_dispatch_any())
fast_dispatchers.push_front(d);
if (first) ready(); // Готов добавить fd к epoll
}
void AsyncMessenger::ready()
{
ldout(cct,10) << __func__ << " " << get_myaddr() << dendl;
Mutex::Locker l(lock);
Worker *w = pool->get_worker(); // Получить один worker для работы
processor.start(w); // listen_sd если внутри Processor
}
int Processor::start(Worker *w)
{
ldout(msgr->cct, 1) << __func__ << " " << dendl; // Запуск потока (thread)
if (listen_sd > 0) {
worker = w; // Создаём доступные для чтения события и, со временем, вызываем epoll_ctl чтобы listen_sd добавил epoll для управления
w->center.create_file_event(listen_sd, EVENT_READABLE,
EventCallbackRef(new C_processor_accept(this))); // Обратите внимание на происходящий со временем обратный вызов (callback)
}
return 0;
}
Приём соединения
После всего процесса инициализации добавляется ожидание (Listen) fd, даже если всё завершено. Когда появится
новый запрос на соединение, как уже упоминалось ранее, поток worker
вызовет необходимую функцию process_event и выполнится обратный
вызов:
// listen fd --Обратный вызов (callback)
class C_processor_accept : public EventCallback
{
Processor *pro;
public:
C_processor_accept(Processor *p): pro(p) {}
void do_request(int id) {
pro->accept(); // Обратный вызов
}
};
void Processor::accept()
{
while (errors &дt; 4) {
entity_addr_t addr;
socklen_t slen = sizeof(addr.ss_addr());
int sd = ::accept(listen_sd, (sockaddr*)&addr.ss_addr(), &slen); // Принять запрос на соединение
if (sd >= 0) {
msgr->add_accept(sd); // Принять системой сообщений тот сокет sd, который обрабатывается этой системой (messenger)
continue;
} else {
......
}
}
}
AsyncConnectionRef AsyncMessenger::add_accept(int sd)
{
lock.Lock();
Worker *w = pool->get_worker();
AsyncConnectionRef conn = new AsyncConnection(cct, this, &w->center); // Создать некое соединение
w->center.dispatch_event_external(EventCallbackRef(new C_conn_accept(conn, sd))); // Распространение события, новое внешнее соединение, поэтому вызов внешний
accepting_conns.insert(conn); // Записываем то соединение, которое вступит в силу и будет удалено из собрания после окончательного завершения
lock.Unlock();
return conn;
}
void EventCenter::dispatch_event_external(EventCallbackRef e)
{
external_lock.Lock();
external_events.push_back(e); // Помещаем данную функцию обратного вызова события в имеющуюся очередь центра обработки событий и ожидаем исполнения
external_lock.Unlock();
wakeup(); // Пробуждаем поток (thread) worker
}
Не очень понятно зачем нужно помещать эту очередь, ожидать следующего вызова worker
process_event, когда это может быть реализовано напрямую?
В любом случае, что касается данной очереди и необходимости реализовать обратный вызов очереди, когда
он будет реализованы? Очевидно, что в потоке worker для функции
process_event, но поток worker
может заснуть в epoll_wait (управление epoll всеми fd не готово,
может лишь ожидать тайм-аута), если имеется некое новое соединение, вам нужно немедленно получать запросы
на соединение, поэтому возбуждаем пробуждение. Данный поток записывается в имеющейся функции
EventCenter :: init (), так что другая сторона доступна для чтения,
т.е. Notify_receive_fd готов,
epoll_wait будет записан в конец канала.
Верните его доступное доя читаемое событие, а затем выполните его обратный вызов (обратный вызов - это простое
чтение канала) с тем, чтобы поток worker продолжал обработку, а
после этого просто помещался в обратный вызов очереди.
void EventCenter::wakeup()
{
ldout(cct, 1) << __func__ << dendl;
char buf[1];
buf[0] = 'c'; // wake up "event_wait"
int n = write(notify_send_fd, buf, 1); // Прбудить поток worker
// FIXME ? -- Исправить?
assert(n == 1);
}
int EventCenter::process_events(int timeout_microseconds)
{
......
numevents = driver->event_wait(fired_events, &tv); // Первоначально поток worker может находиться здесь в спящем состоянии и будет тут пробуждён со стороны wakeup
// На данный момент имеется готовым по крайней мере один fd, а именно, notify_receive_fd
// Данная реализация всего обратного вызова fd, причём для notify_receive_fd, как вы можете обнаружить, обратный вызов, является неким простым чтением, что не витеевато
for (int j = 0; j < numevents; j++) {
......
event->read_cb->do_request(fired_events[j].fd);
.....
}
......
// Немедленно следуем за данной очередью, именно она является поставленной целью для пробуждения worker
external_lock.Lock();
while (!external_events.empty()) {
EventCallbackRef e = external_events.front();
external_events.pop_front();
external_lock.Unlock();
if (e) e->do_request(0); // Вызов запоса на обратный вызов
external_lock.Lock();
}
external_lock.Unlock();
}
......
}
Добавление приёма fd
Из данного анализа заключаем, что такой запрос вызова обратного вызова исполнится быстро.
В передней части такого запроса получается приём fd, теперь необходимо добавить такую структуру
fd epoll, управление, и после этого вы можете осуществлять взаимодействие, обратные вызовы со временем
выполнят все эти вещи:
// Определение типа обратного вызова в данной очереди
class C_conn_accept : public EventCallback {
AsyncConnectionRef conn;
int fd;
public: C_conn_accept(AsyncConnectionRef c, int s): conn(c), fd(s) {}
void do_request(int id) {
conn->accept(fd);
}
};
void AsyncConnection::accept(int incoming)
{
ldout(async_msgr->cct, 10) << __func__ << " sd=" << incoming << dendl;
assert(sd < 0);
sd = incoming;
state = STATE_ACCEPTING;
center->create_file_event(sd, EVENT_READABLE, read_handler); // Sd является успешным подключением fd, добавлено управление epoll
process(); // Запускает своё исполнение машина состояния серверной стороны и вначале отправляет сообщение BANNER обратившемуся клиенту
}
Взаимодействие
Отметим, что самым начальным состоянием машины состояния AsyncConnection
данного сервера является STATE_ACCEPTING и это состояние данного сервера
является самым первым для отправки сообщения BANNER своему клиенту.
Позже, приняв данное сообщение, поток (thread) worker вызовет
обработку read_handler, а после этого вызовет процесс,
причём машина состояния не остановит преобразование состояний:
// Зарегистрированный класс обратного вызова
class C_handle_read : public EventCallback {
AsyncConnectionRef conn;
public:
C_handle_read(AsyncConnectionRef c): conn(c) {}
void do_request(int fd_or_id) {
conn->process(); // Вызов обработки соединения
}
};
void AsyncConnection::process()
{
int r = 0;
int prev_state = state;
Mutex::Locker l(lock);
do {
prev_state = state;
// Машина состояний соединения
switch (state) {
case STATE_OPEN:
......
default:
{
if (_process_connection() < 0)
goto fail; break;
}
}
}
return 0;
fail:
......
}
// Отдельная обработка информации о соединении
int AsyncConnection::_process_connection()
{
int r = 0;
switch(state) {
case STATE_WAIT_SEND:
......
}
......
}
AsyncConnection отвечает за имеющийся класс
communication, чтобы понять все принципа этой машины состояний,
вы должны понимать имеющийся прикладной уровень коммуникационного протокола Ceph, с которым вы можете
ознакомиться в официальном поясняющем документе.
Инфраструктура AsyncMessenger, даже если вся вводная часть
завершена, в случае поступления некоторого нового запроса будет повторять следующие этапы:
-
принять соединение (accept connection)
-
добавить принятие fd (add accept fd)
-
взаимодействие (communication)
Как можно увидеть, общее число потоков не растёт линейным образом одновременно с числом соединений,
только в самом начале первичного запуска когда определённое число worker
принимает решение стартовать.
Операции клиента в основном инициируют выполнение соединения, само установление соединения для взаимодействия.
Все клиенты основаны на библиотеке librados
и тогда могут соединяться со всем кластером через RadosClient:
int librados::Rados::connect()
{
return client->connect();
}
int librados::RadosClient::connect()
{
......
// Создать систему сообщений --messenger
messenger = Messenger::create(cct, cct->_conf->ms_type, entity_name_t::CLIENT(-1),
"radosclient", nonce);
......
// Создать систему объектов --objecter
// Отправлять сообщения, например, код librbd, который обрабатывается objecter
// Для системы объектов требуются отправки системой сообщений, поэтому необходимо создать
// определённую систему сообщений, переданную в имеющийся класс objecter
objecter = new (std::nothrow) Objecter(cct, messenger, &lmonclient,
&finisher,
cct->_conf->rados_mon_op_timeout,
cct->_conf->rados_osd_op_timeout);
// Аналогично, наблюдение за соединением также необходимо чтобы иметь дело с приёмом сообщений
monclient.set_messenger(messenger);
objecter->init();
messenger->add_dispatcher_tail(objecter);
messenger->add_dispatcher_tail(this);
messenger->start();
......
messenger->set_myname(entity_name_t::CLIENT(monclient.get_global_id())); // ID является глобально уникальным, поэтому вам необходимо получить его для наблюдения
......
}
Операция соединения только инициализирует имеющийся объект системы сообщений, для необходимого в действительности
взаимодействия в качестве примера будет установлено некое соединение к
op_submit objecter.cc:
ceph_tid_t Objecter::_op_submit(Op *op, RWLock::Context& lc)
{
......
int r = _get_session(op->target.osd, &s, lc);
......
}
int Objecter::_get_session(int osd, OSDSession **session, RWLock::Context& lc)
{
......
// session --Не существует, создаст некий один новый сеанс.
s->con = messenger->get_connection(osdmap->get_inst(osd));
......
}
ConnectionRef AsyncMessenger::get_connection(const entity_inst_t& dest)
{
......
conn = create_connect(dest.addr, dest.name.type());
......
}
AsyncConnectionRef AsyncMessenger::create_connect(const entity_addr_t& addr, int type)
{
// create connection
Worker *w = pool->get_worker();
AsyncConnectionRef conn = new AsyncConnection(cct, this, &w->center); // Создать connection
conn->connect(addr, type); // Cоединение
assert(!conns.count(addr));
conns[addr] = conn;
return conn;
}
void connect(const entity_addr_t& addr, int type)
{
set_peer_type(type);
set_peer_addr(addr);
policy = msgr->get_policy(type);
_connect();
}
void AsyncConnection::_connect()
{
state = STATE_CONNECTING; // Это инициализирующее состояние является кртитчески важным и является отправной точкой машины состояний данного клиента
stopping.set(0);
center->dispatch_event_external(read_handler); // Помещает в очередь ожидания данный обработчик worker
}
Здесь в точности так же как и раньше, worker
будет иметь дело с такими внешними событиями, а read_handler
вызовет функцию процесса, за чам последует исполнение
_process_connection:
int AsyncConnection::_process_connection()
{
int r = 0;
switch(state) {
case STATE_CONNECTING: // Начальное состояние
{
......
sd = net.connect(get_peer_addr()); // Через данный класс сетевой функции, в действительности,
// вызывается системный вызов соединения, который устанавливает взаимодействие сокета
// После успешного соединения fd данного сокета будет добавлен в имеющийся epoll для управления
center->create_file_event(sd, EVENT_READABLE, read_handler);
state = STATE_CONNECTING_WAIT_BANNER;
break;
}
}
}
Следующий этап состоит во взаиодействии саого клиента с имеющейся серверной стороной, осуществляемое
через выполнение имеющейся машины состояний AsyncConnection.
Аналогично, даже если данный клиент создаёт множество систем сообщений (messenger), они всё ещё совместно
используют некий рабочий пул, и общее число потоков (thread) определяется инициализацией такого пула, а не
растёт линейно по мере роста числа соединений.
Все AsyncMessenger в данном процессе совместно применяют некий
workerpool для управления имеющимися
worker.
Потоки worker отвечают за определённую обработку событий в
имеющемся EventCenter (центре обработки событий).
Весь обмен сетевого уровня приложений обрабатывается машиной состояний
AsyncConnection.
Данный материал является переводом материалов Ceph Asyncmessenger Stack с обновлениями от 12.01.2017.
С быстрым развитием аппаратных средств и оборудования узкие места системы хранения постепенно перемещаются в само программное обеспечение такой системы хранения, что приводит к проявлению роли DPDK / SPDK, таким компонентам разработки, которые помогают системным разработчикам развивать программное обеспечение систем хранения с применением самых последних технологий для улучшения производительности.
Для Ceph это многократно усиливается благодаря разработчиками открытого исходного кода распределённых систем хранения направленных на то, чтобы логично воспользоваться такой новой технологией, лежащей в основе автономного механизма хранения, последней версии BlueStore, которая поддерживает SPDK. Для сетевого уровня Ceph AsyncMessenger это уровень, который добавляет абстракцию NetworkStack для поддержки различных протоколов стеков (Posix/ DPDK/ RDMA).
В своей более ранней статье мы подробно анализировали AsyncMessenger для такой рабочей нагрузки, когда имелся эталонный код Hummer, в целом, с той поры структура AsyncMessenger не изменилась и эта статья анализирует как ввести NetworkStack, некоторого уровня абстракции для поддержки различных протоколов стека, в основном, в качестве примера PosixStack. Для главного кода зафиксировано значение is5b97cce360fe1f6b15dfad0866d90c85262f8253.
Для начала запустите конструктор:
AsyncMessenger::AsyncMessenger(CephContext *cct, entity_name_t name,
string mname, uint64_t _nonce)
: SimplePolicyMessenger(cct, name,mname, _nonce),
......
{
ceph_spin_init(&global_seq_lock);
StackSingleton *single;
cct->lookup_or_create_singleton_object<StackSingleton>(single, "AsyncMessenger::NetworkStack&qout;); // Относящийся к некоторому уникальному стеку процесс, который присутствует до WorkerPool
stack = single->stack.get();
stack->start(); // запускаем поток (thread)
......
}
struct StackSingleton {
std::shared_ptr<NetworkStack> stack;
StackSingleton(CephContext *c) {
stack = NetworkStack::create(c, c->_conf->ms_async_transport_type); // создать другой stack, зависящий от типа
}
~StackSingleton() {
stack->stop();
}
};
NetworkStack::NetworkStack(CephContext *c, const string &t): type(t), started(false), cct(c)
{
......
for (unsigned i = 0; i < num_workers; ++i) {
Worker *w = create_worker(cct, type, i); // создать worker
w->center.init(InitEventNumber, i); // инициализировать обработчик событий
workers.push_back(w);
}
......
}
Ранее в конструкторе создавался только один WorkerPool, который
применялся для управления всеми worker, а класс
worker наследовался из класса потока (thread), который теперь
замещён абстракцией NetworkStack, а сам thread перемещён во владельца
stack для его достижения, и только соответствующий класс
worker развит во всего один
oneEventCenter, соответствующий каждому
stack для реализации одного собственного
worker. Ниже приводится взаимосвязь наследований:
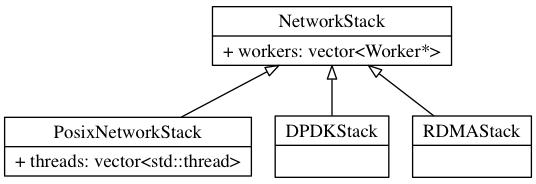
Следующий шаг состоит в инициализации наших worker и потоков:
void NetworkStack::start()
{
......
for (unsigned i = 0; i < num_workers; ++i) {
if (workers[i]->is_init())
continue;
std::function<void ()> thread = add_thread(i); // Получает анонимную функцию данного элемента потока
spawn_worker(i, std::move(thread)); // Запускаем поток
} started = true;
......
}
// Создаём реализацию своего потока PosixNetworkStack
virtual void spawn_worker(unsigned i, std::function<void ()> &&func) override {
threads.resize(i+1);
threads[i] = std::thread(func); // Создаём некий поток с применением cli библиотеки thread
}
// Точка входа в поток
std::function<void ()> NetworkStack::add_thread(unsigned i)
{
Worker *w = workers[i];
return [this, w]() {
const uint64_t EventMaxWaitUs = 30000000;
w->center.set_owner();
w->initialize();
w->init_done();
while (!w->done) {
int r = w->center.process_events(EventMaxWaitUs); // Обработка событий
}
}
w->reset();
w->destroy();
};
Здесь представлен конструктор класса AsyncMessenger, который будет
перенаправлять первоначально выполненный готовый к обработке событий поток stack,
в то время как имеющаяся точка входа данного обработчика событий worker
влечёт за собой реализацию различных worker. Упомянутый ранее
worker, относящийся к EventCenter, при
том что сам EventCenter внутри соответствует некоторому
EventDriver для DPDK, так как данный
пользователь устанавливает определённый интерфейс опроса в котором он обращается к
DPDKDriver (который всё ещё наследует
EventDriver) и в свой EventCenter,
добавляющий относящуюся к опросу структуру.
Реализация класса абстракции worker достаточно проста и наиболее
важными являются два интерфейса listen и
connect, причём первый применяется для создания некоторого сокета с
заданным адресом и данный сокет может обрабатывать следующий запрос контроллера, который применяется для создания
некоторого успешно подключённого сокета и может через него читать и записывать данные.
class Worker {
unsigned id; // идентификатор worker
EventCenter center; // обработка события
......
virtual int listen(entity_addr_t &addr,
const SocketOptions &opts, ServerSocket *) = 0;
virtual int connect(const entity_addr_t &addr,
const SocketOptions &opts, ConnectedSocket *socket) = 0;
......
};
Для выполнения различных протоколов стека, несомненно, реализация socket
не одна и та же, вся разница оформляется здесь, таким образом, абстрагируемся двумя обычными
обёртками классов ServerSocket и
ConnectedSocket:
class ConnectedSocket {
std::unique_ptr<ConnectedSocketImpl> _csi; // зависит от реализации определённого стека протокола
ssize_t read(char* buf, size_t len) { // считать данные
return _csi->read(buf, len);
}
ssize_t send(bufferlist &bl, bool more) { // записать данные
return _csi->send(bl, more);
}
};
class ServerSocket {
std::unique_ptr<ServerSocketImpl> _ssi; // зависит от реализации определённого стека протокола
int accept(ConnectedSocket *sock, const SocketOptions &opt, entity_addr_t *out, Worker *w) { // Принимает запрос на соединение после того как первый параметр успешно подключился к необходимому сокету
return _ssi->accept(sock, opt, out, w);
}
};
Взгляните, как и ранее, на реализацию posix:
int PosixWorker::listen(entity_addr_t &sa, const SocketOptions &opt,
ServerSocket *sock)
{
int listen_sd = net.create_socket(sa.get_family(), true); // создаём сокет
r = ::bind(listen_sd, sa.get_sockaddr(), sa.get_sockaddr_len()); // привязываем его адрес
r = ::listen(listen_sd, 128); // начинаем ожидание
*sock = ServerSocket(
std::unique_ptr<PosixServerSocketImpl>(
new PosixServerSocketImpl(net, listen_sd))); // создать вернуть исполнение пользователю, вы можете принимать запрос на данный сокет
return 0;
}
int PosixWorker::connect(const entity_addr_t &addr, const SocketOptions &opts, ConnectedSocket *socket)
{
int sd; sd = net.connect(addr); // инициализируем соединение
// создаём connectedsocket,возвращаем его пользователю, теперь вы можете применять этот сокет для send/read
*socket = ConnectedSocket(std::unique_ptr<PosixConnectedSocketImpl>(new PosixConnectedSocketImpl(net, addr, sd, !opts.nonblock)));
return 0;
}
Различные режимы взаимодействия реализуют различные абстракции интерфейса сокета, наследуемые как это отображено ниже:

В качестве примера возьмём реализацию posix:
int PosixServerSocketImpl::accept(ConnectedSocket *sock, const SocketOptions &opt, entity_addr_t *out, Worker *w)
{
int sd = ::accept(_fd, (sockaddr*)&ss, &slen); // Принять запрос на соединение
std::unique_ptr<PosixConnectedSocketImpl> csi(new PosixConnectedSocketImpl(handler, *out, sd, true)); // создать некий сокет с успешным соединением
*sock = ConnectedSocket(std::move(csi)); // вернуть исполнение пользователю
return 0;
}
Реализация ConnectedSocket в основном является интерфейсом
read/send, сооттветствующие
read и sendmsg, а также прочие
системные вызовы реализуются не здесь.
Теперь мы понимаем, что для некоторых различных worker
создаются различные стеки, причём worker через
listen и connect создаёт
поток ожидания (listen), который может отслеживать данный serversocket
и может отправлять и принимать данные для connectedsocket, причём
различные реализации соответствуют различным сокетам. Прочие модули async
messenger достигаю надлежащую работу сетевого взаимодействия прочими модулями через реализацию
двух абстракций сокета для ожидания данных, а также чтения и записи.
Для иллюстрации того привязать определённый процесс к некоторому конкретному адресу, ссылаемся на предыдущую статью: AsyncMessenger.bind -> Processor.bind()
int Processor::bind(const entity_addr_t &bind_addr,
const set<int>& avoid_ports,
entity_addr_t* bound_addr)
{
......
// Представить некое внешнее событие соответствующему центру событий worker в случае, когда
// реализация этого события является реализацией второго параметра анонимного объекта функции,
// т.е. вызов ожидания worker
worker->center.submit_to(worker->center.get_id(), [this, &listen_addr, &opts, &r]() {
r = worker->listen(listen_addr, opts, &listen_socket); // после обработки данного события listen_socket обновляется и может использоваться для приёма
}, false);
......
}
И аналогично предыдущему имеется определённый сокет для наблюдения, тем не менее не присоединённый к центру обработки событий управления fd, либо вынужденный ожидать время инициализации osd: OSD.init() -> AsyncMessenger.ready() -> Processor.start()
void Processor::start()
{
// Представляет некое внешнее событие центру обработки событий worker. Когда такое событие обработано,
// имеется некий асинхронный объект функции, который исполняет имеющийся второй аргумент,
// т.е. добавляет fd в центр обработки событий для управления
if (listen_socket) {
worker->center.submit_to(worker->center.get_id(), [this]() {
worker->center.create_file_event(listen_socket.fd(), EVENT_READABLE, listen_handler); }, false);
}
}
// В случае наступления описанного выше события обратным вызовом является listen_handler,
// таким образом, ниже приводится его реализация
void Processor::accept()
{
.......
while (true) {
int r = listen_socket.accept(&cli_socket, opts, &addr, w); // Данная реализация ожидания сокета приёма
// после успешного выполнения первого значения параметра для надлежащего типа connectedsocket
// может применяться для отправки и приёма данных
}
......
}
Давайте взглянем на некий пример клиентского соединения, рассмотренного в предыдущей статье: AsyncMessenger.create_connect() -> AsyncConnection.connect() -> AsyncConnection._process_connection()
ssize_t AsyncConnection::_process_connection()
{
......
case STATE_CONNECTING: {
......
r = worker->connect(get_peer_addr(), opts, &cs); // вызов соединения с worker
center->create_file_event(cs.fd(), EVENT_READABLE, read_handler); // соединяется для управления
// с успешно созданным в центре обработки событий connectedsocket
state = STATE_CONNECTING_RE;
break;
}
}
Последующим этапом является чтение и отправки данных через ConnectedSocket,
сам основной кадр данных не изменяется.
Итак, суммируем, введение некоторого уровня NetworkStack и
соответствующего стека worker, основное применение которых состоит в
интерфейсе ожидания и приёма, используются для создания неких абстрактов ServerSocket
и ConnectedSocket, причём первый служит ожиданию входящих запросов, а второй
применяется для чтения и записи данных. Основное изменение с AsyncMessenger
состоит в вызове со стороны worker двух абстрактных интерфейсов для режима
опроса DPDK, для соответствующих EventCenter
DPDKDriver определённого worker
добавляется специальный обработчик.