Приложение B: Архитектура Ceph
Содержание
Содержание
Данное руководство является переводом материалов Architecture официальной документации Ceph на дату публикации 06.06.2017.


Введение в CRUSH
Карта кластера
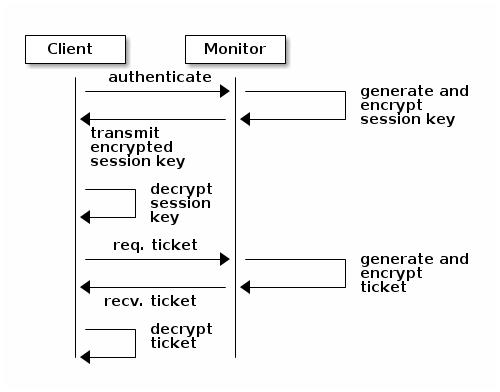
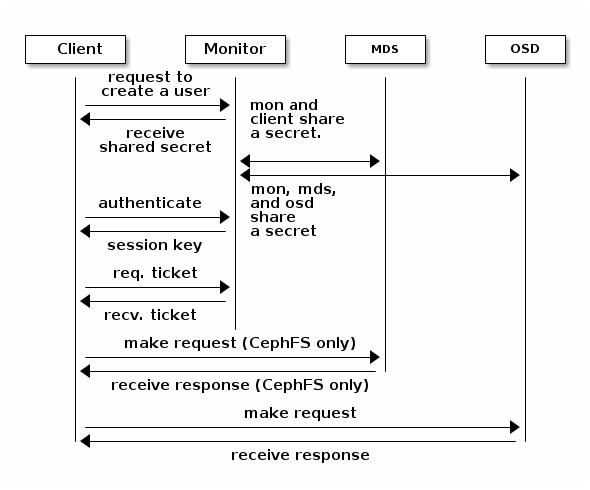
Мониторы с высокой доступностью
Аутентификация с высокой доступностью
Разрешение гипермасштабирования интеллектуальных демонов
Обзор пулов
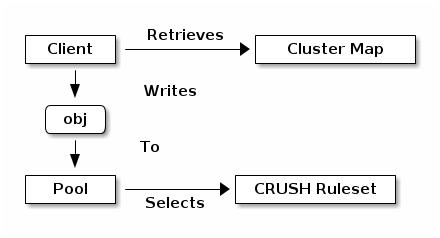
Установление соответствия PG для OSD
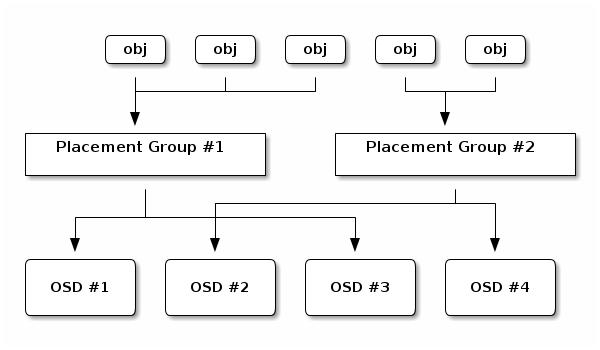
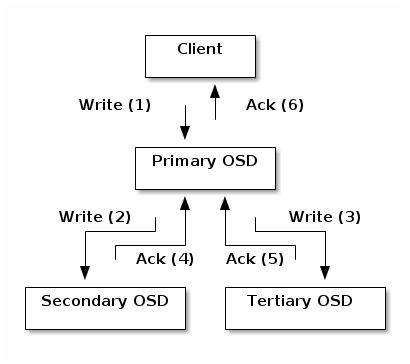
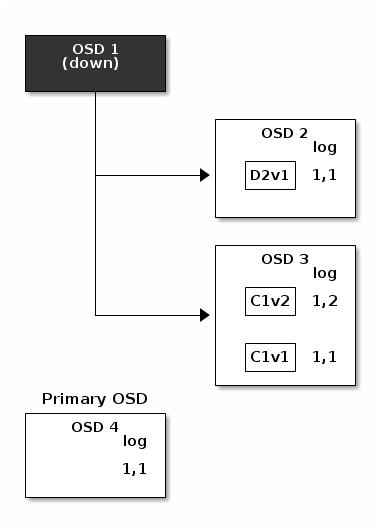
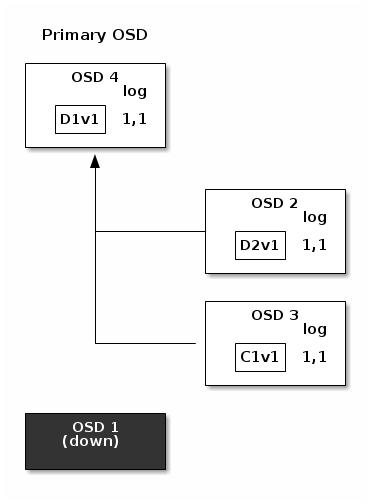
Одноранговость и множества
Повторная балансировка
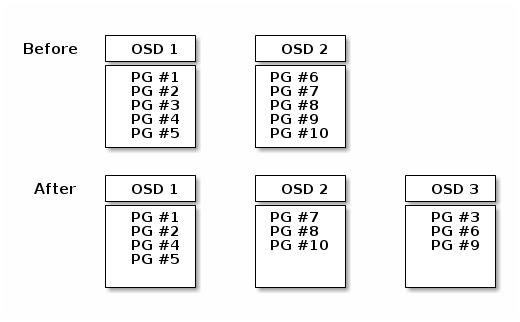
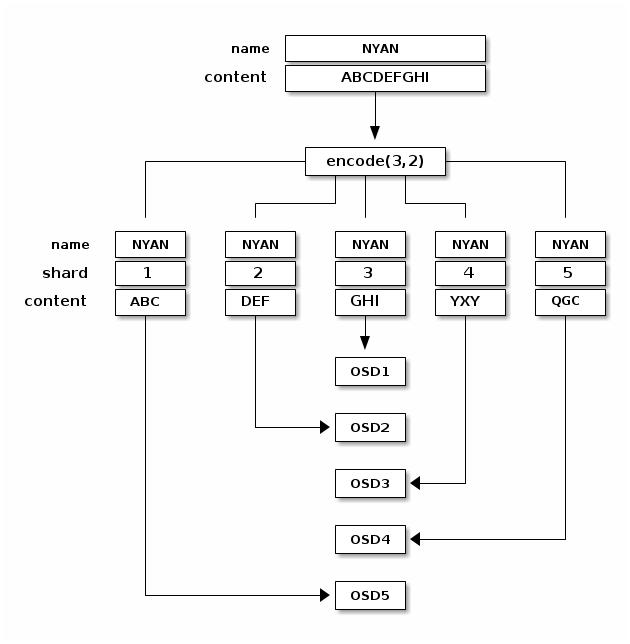
Согласованность данных
Чтение и запись кодированных фрагментов
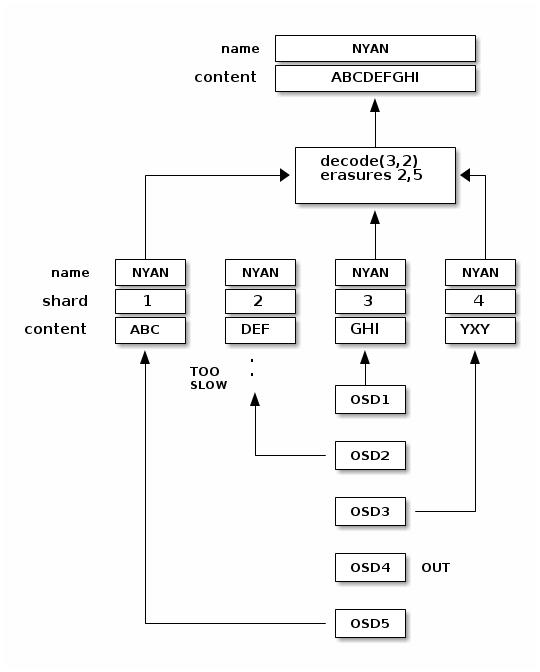
Прерванные полные записи
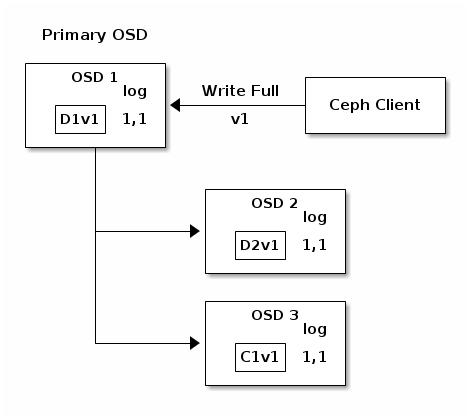
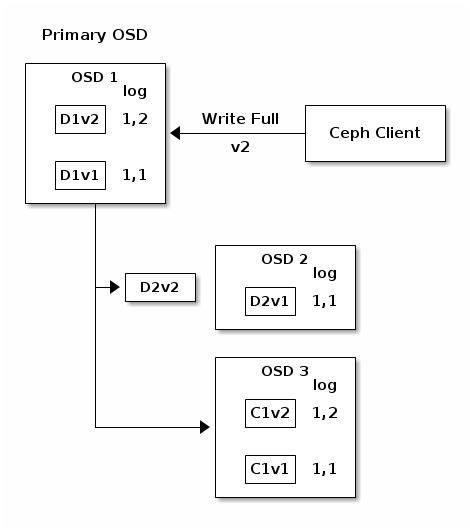
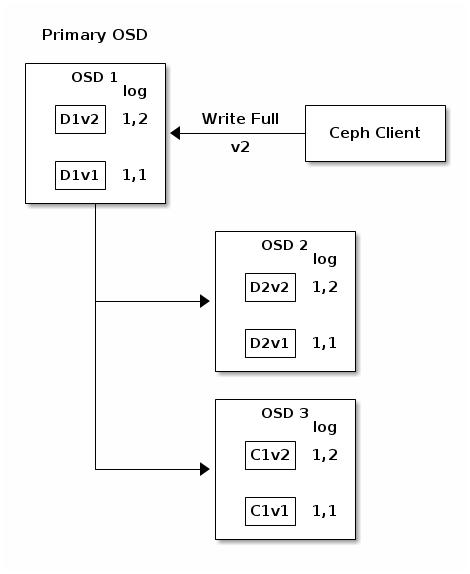
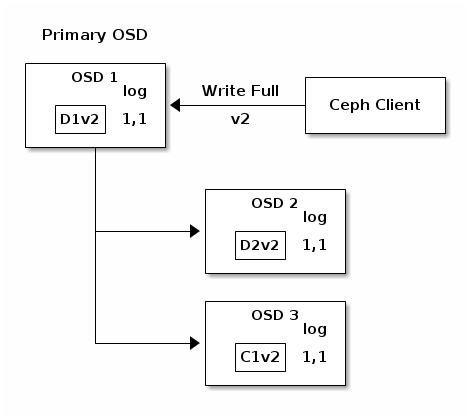
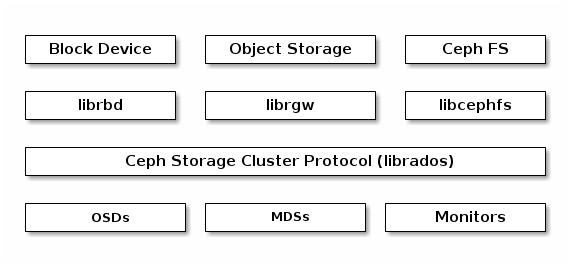
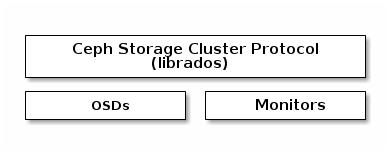
Клиенты Ceph используют родной имеющийся у них протокол для взаимодействия с кластером хранения Ceph.
Ceph упаковывает эту функциональность в свою библиотеку librados
с тем, чтобы вы могли создавать своих собственных персональных клиентов. Следующая схема изображает
основу архитектуры.
Современным приложениям необходим некий простой интерфейс хранения объектов с асинхронными возможностями взаимодействия. Имеющийся кластер хранения Ceph предоставляет некий простой предоставляет некий простой интерфейс хранения объектов с асинхронными возможностями взаимодействия. Данный интерфейс предоставляет прямой, одновременный доступ к объектам через имеющийся кластер.
-
Операции пула
-
Моментальные снимки и клонирование Копирования-при-Записи (COW, Copy-on-Write)
-
Чтение/ Запись объектов - Создание или удаление - Целого объекта или Диапазона байт - Добавление или Усечение
-
Создание/ Установка/ Получение/ Удаление XATTR
-
Создание/ Установка/ Получение/ Удаление пар Ключ/ Значение
-
Операции составления и семантики дублированного подтверждения
-
Классы объектов
Клиент может зарегистрировать некий постоянный интерес к некоторому объекту и сохранять сеанс с открытым первичным объектом. Такой клиент может отправлять уведомляющие сообщения всем кто просматривает и получать уведомления когда просматривающие получают его уведомление. Это позволяет некоторому клиенту использовать любой объект какого- то канала синхронизации/ взаимодействия.
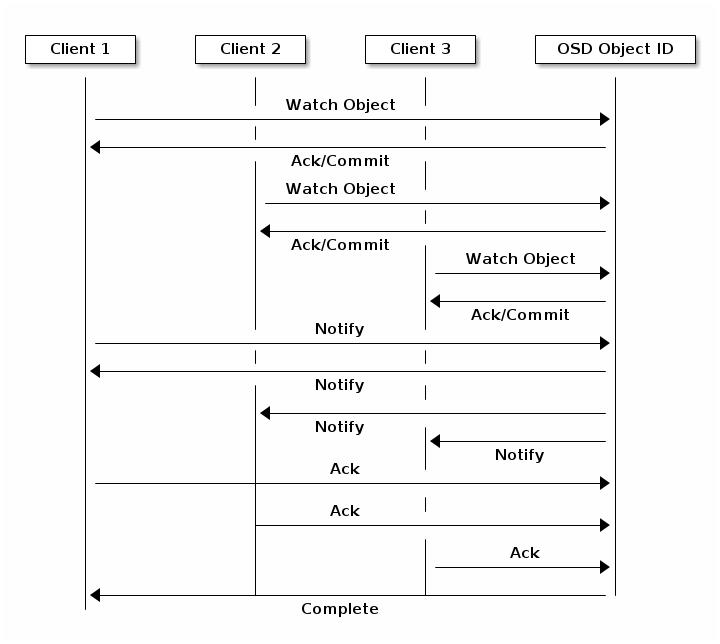
Устройства хранения имеют ограничения пропускной способности, которые оказывают воздействие на производительность и масштабируемость. Поэтому системы хранения зачастую поддерживают последовательность расщепления - сохраняя части информации по множеству устройств хранения - для увеличения пропускной способности и производительности. Наиболее общий вид разделения данных восходит к RAID. Наиболее подходящим для аналогии с расщеплением Ceph является RAID 0, или некий "чередующийся том". Расщепление Ceph предлагает пропускную способность чередования RAID 0, наличие возможности зеркалирования по n- путям и более быстрого восстановления.
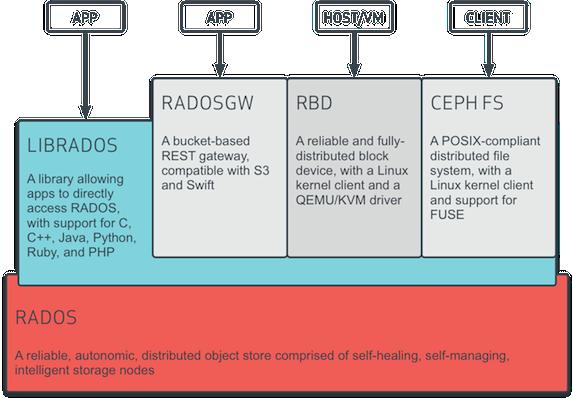
Ceph предоставляет три вида клиентов: блочное устройство Ceph, файловую систему Ceph и хранилище объектов Ceph. Любой клиент преобразовывает свои данные из формата собственного представления своим пользователям (некий образ блочного устройства, объект RESTful, каталоги файловой системы CephFS) в объекты для хранения в имеющемся кластере хранения Ceph.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Все хранящиеся в кластере хранения Ceph объекты не расщеплены. Блочное устройство Ceph и файловая
система Ceph разделяют свои данные по множеству объектов кластера хранения Ceph. Клиенты Ceph, которые
выполняют прямую запись в кластер хранения через |
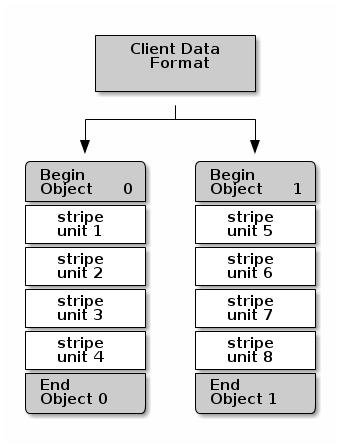
самый простой формат расщепления Ceph влечёт некоторое число чередований одного объекта. Клиенты Ceph записывают чередующиеся элементы в некоторый объект кластера хранения Ceph пока этот объект не достигнет своей максимальной ёмкости, а затем создают другой объект для дополнительных полос данных. Самая простейшая форма чередования может быть достаточной для малых образов блочного устройства, объектов S3 или Swift, а также файлов CephFS. Однако, самая простая форма не получает максимального преимущества от возможности Ceph распределять данные по группам размещения и в конечном итоге не очень сильно улучшает производительность. Следующая схема изображает самый простой вид чередования:
Если вы ожидаете большие размеры образов, большие объекты S3 или Swift (т.е. видео) или большие каталоги CephFS, вы можете увидеть значительные улучшения производительности чтения/ записи при чередовании данных клиентов по множеству объектов внутри некоторого набора объектов. Значительная производительность записи имеет место когда клиент записывает свои чередующиеся элементы в их соответствующие объекты одновременно. Так как объекты соответствуют различным группам размещения и в дальнейшем соответствуют различным OSD, все записи происходят одновременно с максимальной скоростью записи. Некая запись на какой- то отдельный диск будет ограничена имеющимся перемещением головок (т.е. 6мс на перевод головки - seek) и полосой пропускания такого отдельного устройства (т.е. 100МБ/с). разделяя такие записи по множеству объектов (которые соответствуют различным группам размещения и различным OSD), Ceph может уменьшать общее число перемещений головок на устройство и сочетать общую пропускную способность множества устройств для достижения более быстрой скорости записи (или чтения).
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Чередование не зависит от репликации объектов. так как CRUSH реплицирует объекты по имеющимся OSD, полосы данных автоматически получают реплицирование. |
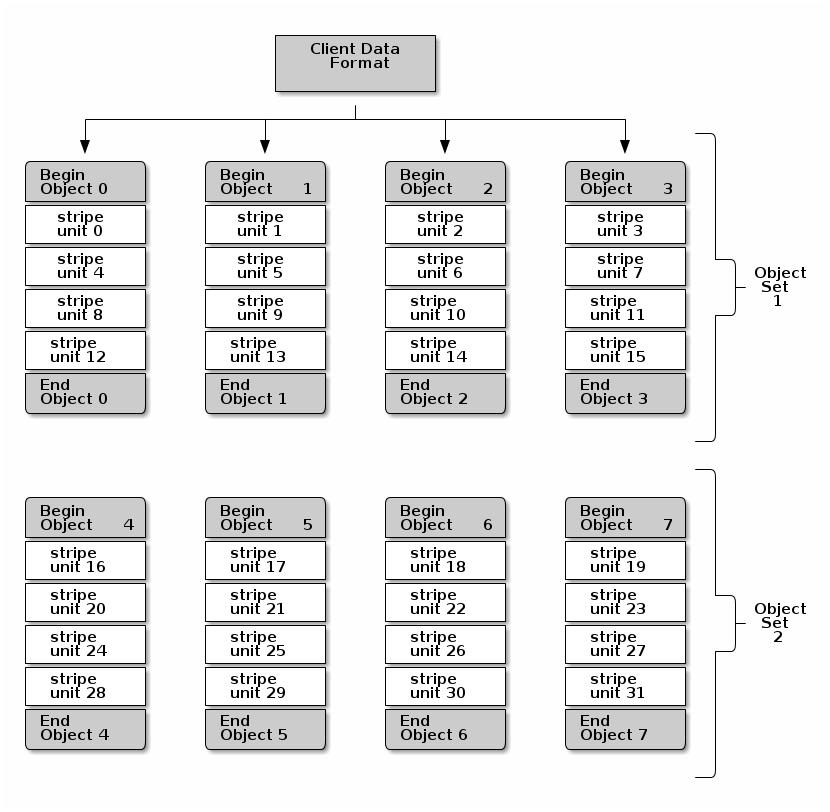
На следующей схеме клиентские данные подвергаются расщеплению по некоторому набору объектов (на приводимой
ниже схеме object set 1), состоящей из 4 объектов, причём самый первый
элемент чередования это stripe unit 0 в object
0, а последний четвёртый элемент это stripe unit 3 в
object 3. После записи последнего четвёртого элемента, наш клиент
определяет не заполнился ли набор объектов. Если данный набор объектов не заполнен, такой клиент снова начинает
запись некоторого элемента в самый первый объект (object 0 на схеме внизу).
Если же данный набор объектов заполнен, данный клиент создаёт некий новый набор объектов
(object set 2 на приводимой ниже схеме) и начинает запись в самый первый
элемент (stripe unit 16) в самом первом объекте в таком новом наборе
объектов (object 4 на схеме внизу).
Три важных переменных определяют как расщеплять данный Ceph:
-
Object Size: Объекты в имеющемся кластере хранения Ceph имеют некий максимальный настраиваемый размер (например, 2МБ, 4МБ и т.д.). Такой размер объекта должен быть достаточно большим для размещения множества элементов полосы и должен быть неким произведением таких элементов полос.
-
Stripe Width: Полосы имеют некий настраиваемый размер элемента (например, 64кБ). Конкретный клиент Ceph делит имеющиеся данные, которые он будет записывать в объект на элементы полосы равного размера, за исключением самого последнего элемента полосы. Ширина полосы (Stripe Width), должна быть дробной частью имеющегося размера объекта (Object Size) с тем, чтобы некий объект мог содержать много элементов полосы.
-
Stripe Count: Определённый клиент Ceph записывает некую последовательность элементов полосы в какую- то последовательность объектов, определённых данным числом полос (Stripe Count). такие последовательности объектов называются неким набором объектов (object set). После того как данный клиент Ceph запишет самый последний объект в текущий набор объектов, он возвращается к самому первому объекту в этом наборе объектов.
![[Предостережение]](/common/images/admon/warning.png) | Предостережение |
|---|---|
|
Проверьте общую производительность своих настроек чередования перед тем как разместите свой кластер в промышленную эксплуатацию. Вы НЕ МОЖЕТЕ изменять такие параметры чередования после того как вы чередуете имеющиеся данные и записываете их в объекты. |
Когда все клиенты Ceph чередуют данные по элементам полос и устанавливают соответствие таких элементов полос объектам, алгоритм CRUSH Ceph устанавливает соответствие всех объектов группам размещения для демонов OSD Ceph прежде чем все объекты сохранятся в виде файлов в некотором диске хранения.
|
| Замечание |
|---|---|
|
Так как некий клиент пишет в какой- то отдельный пул, все чередующиеся по объектам данные ставятся в соответствие группам размещения в одном и том же пуле. Поэтому они применяют одну и ту же карту CRUSH и одни и те же управления доступом. |