Глава 8. Множество уровней в Ceph
{Прим. пер.: рекомендуем сразу обращаться к нашему переводу 2 издания вышедшего в феврале 2019 Полного руководства Ceph Ника Фиска}
Содержание
Функциональность множества уровней в Ceph делает возможным перекрытие одним пулом RADOS поверх другой и позволяет Ceph интеллектуально продвигать и исключать объекты между ними. В большинстве конфигураций пул самого верхнего уровня будет компромиссом между быстрыми устройствами, такими как SSD (Solid State Drives), а сам основной пул будет составлен из более медленных устройств навроде дисков SATA (Serial ATA) или SAS (Serial Attached SCSI). Если имеющийся у вас рабочий набор данных относительно мал в процентном отношении, тогда это позволит вам применить Ceph для предоставления хранения с высокой ёмкостью, но всё ещё снабжать неким хорошим уровнем производительности для часто используемых данных.
В данной главе мы обсудим следующие темы:
-
Как работает функциональность множества уровней Ceph
-
Какие варианты применения более всего подходят под множество уровней
-
Как настроить два пула в многоуровневую структуру
-
Рассмотрим различные доступные для многоуровневости опции тонкой настройки
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Настоятельно рекомендуется чтобы у вас в работе была по крайней мере редакция Jewel Ceph, если вы хотите применять имеющуюся функциональность множества уровней. Предыдущие версии упускают целый ряд необходимых свойств, которые делают многоуровневость жизнеспособной. |
Хотя её часто и называют многоуровневым кэшированием, лучше всё же представлять себе данную функциональность как технологию множества уровней, нежели как некое кэширование. Очень важно, чтобы вы учли этот момент прежде чем приступите к дальнейшему чтению, поскольку жизненно важно осознавать имеющуюся между ними двумя разницу.
Некий кэш обычно разрабатывается для ускорения доступа к некому набору данных, если только это не кэш отложенной записи; он будет содержать только копии имеющихся данных и обычно присутствуют дополнительные накладные расходы для представления данных в кэше.
Решение со множеством уровней также проектируется для ускорения доступа к некоторому набору данных; однако оно предлагает стратегию обычной работы в течение длительного периода времени и более избирательно в отношении предлагаемых данных, в основном благодаря тому, что само действие представления имеет малое воздействие на общую производительность хранилища. Кроме того, для технологий множества уровней достаточно распространено то, что только один уровень поддерживает правильное состояние имеющихся данных и, следовательно, все уровне и вашей системе требуют одинаковой защиты от утраты данных.
Когда вы настраиваете некий пул RADOS для перекрытия им другого пула RADOS, функциональность многоуровневости Ceph работает на основе базового принципа, что если объект отсутствует в имеющемся самом верхнем уровне, тогда он должен присутствовать в основном уровне. Все запросы к объектам от клиентов отправляются в самый верхний уровень; если его OSD не имеют запрашиваемого объекта, тогда в зависимости от установленного режима многоуровневости может быть представлен вниз к основному уровню запрос на чтение или запись, либо принудительное представление. Затем имеющийся основной уровень представляет такой запрос обратно через самый верхний уровень к осуществившему запрос клиенту. Важно отметить, что имеющаяся функциональность многоуровневости прозрачна для клиентов и не требует никакой специалной настройки клиента.
В многоуровневости имеются три основных действия, которые перемещают объекты между уровнями. Представления (promotions) копируют объекты с базового уровня вверх на топовый уровень. Если многоуровневость настроена в режиме с отложенной записью (writeback), действие Сброса (flushing) применяется для обновления имеющегося в основном уровне содержимого объекта с расположенного выше уровня. Наконец, когда имеющийся верхний уровень достигает предела ёмкости, объекты отселяются действием Вытеснения (eviction).
Чтобы принимать решения как перемещать объекты между имеющимися двумя уровнями, Ceph применяет наборы попаданий (HitSet) для отслеживания доступов к объектам. Некий Набор попаданий (HitSet) является некоторой коллекцией запросов ко все объектам и выступает в качестве консультанта для определения того имелись ли запросы чтения или записи с момента создания этого HitSet. Применяемый Набор попаданий использует фильтр bloom для статистики отслеживания доступов к объектам вместо сохранения всех доступов ко всем объектам, которые бы создавали значительные накладные расходы. Фильтр bloom сохраняет только двоичные состояния; некий объект может быть помеченным как имевший доступ, либо нет; причём не существует концепции для сохранения общего числа доступов в некоторому объекту в каком- то отдельном HitSet. Если некий объект возникает в некотором числе самых последних HitSets и при этом находится в имеющемся базовом пуле, тогда он будет Представлен.
И наоборот, если объекты более не появляются в последних HitSet,они станут кандидатами для Сброса или Вытеснения в случае, если самый верхний уровень начинает интенсивно использоваться. Общее число HitSet и того как часто создаётся некий новый могут настраиваться, в соответствии с имеющимся требуемым числом самых последних HitSet, должны возникать некие операции ввода/ вывода для записи или чтения с тем, чтобы имело место некое Представление. Также можно настраивать размер самого верхнего уровня, а также отключаться от имеющейся доступной ёмкости того пула RADOS, поверх которого он расположен.
Имеется целый ряд опций настройки и тонкой регулировки, которые определяют как Ceph реагирует на создаваемые HitSet и пороговые значения при которых происходят Представления, Сбросы и Отселения. Они будут рассмотрены более подробно далее в этой главе.
Фильтр bloom применяется в Ceph для предоставления эффективного способа отслеживания того является ли объект участником HitSet без необходимости индивидуального хранения состояния доступа к каждому из объектов. Он по своей природе является вероятностным и, хотя он и может возвращать ошибочные срабатывания (false positives), он никогда не вернёт ошибочного отказа (false negative). Это означает, что при запросе фильтра bloom он может сообщить что некий элемент присутствует в нём, хотя его там нет, однако он никогда не сообщит, что некий элемент отсутствует в то время как он имеется.
Применение Ceph фильтров bloom позволяет вам эффективно отслеживать все доступы к миллионам объектов без существенных накладных расходов хранения каждого отдельного доступа. В случае ошибочного отказа это может означать, что некий объект Представлен не верно; однако наличие вероятности возникновения такого события в сочетании с минимальным воздействием не представляет существенной озабоченности.
Имеется целый ряд режимов множества уровней, которые определяют частоту действий того, как Ceph реагирует на содержимое своих HitSet. Однако в большинстве случаев будет применяться режим отложенной записи. Доступными режимами для применения многоуровневости являются отложенная запись (writeback), упреждение (forward), заблаговременное чтение (read-forward), посредничество (proxy) и посредническое чтение (read-proxy). Приведём краткое описание всех доступных режимов и того, как они действуют.
В режиме отложенной записи данные Представляются в самый верхний уровень и операциями чтения, и операциями записи, в зависимости от того насколько часто осуществляется доступ к этому объекту. Объекты в имеющемся верхнем уровне могут изменяться, причём изменённые (dirty) объекты будут Сбрасываться в соответствующий пул позднее. Если требуется операция чтения или записи некоторого объекта из нижнего уровня, и имеющийся нижний уровень поддерживает её, тогда Ceph попытается напрямую представлять ту операцию, которая имеет минимальное воздействие на латентность.
Режим упреждения просто выполняет упреждение на имеющемся основном уровне для всех запросов к своему верхнему уровню без выполнения каких либо Представлений. Следует отметить, что некое упреждение заставляет OSD сообщать своему клиенту повторить сам запрос к правильному OSD и таким образом имеет большее воздействие на задержки чем в случае с простым его посредничеством.
Упреждающее чтение
Упреждающее чтение заставляет Представлять все записи и, как и описанный ранее режим упреждения перенаправляет всех клиентов для всех чтений в свой основной пул. Это может быть полезным если вы желаете применять имеющийся пул верхнего уровня исключительно для ускорения записи. Использование SSD с интенсивной записью поверх SSD с интенсивным чтением является одним из таких примеров.
Аналогичен режиму упреждения, за исключением того что посредничество происходит для всех операций чтения и записи без выполнения каких- либо Представлений. Выполняя посредничество определённого запроса, OSD самостоятельно получает данные с OSD базового уровня и затем возвращает их назад своему клиенту. Это Снижает накладные расходы в сравнении с использованием упреждения.
Посредническое чтение
Аналогично режиму упреждающего чтения, за исключением того что он выступает посредником (proxy) чтения, но всегда осуществляет Представление при запросах записи. Следует отметить, что режимы отложенной записи и посреднического чтения являются исключительными режимами, получающими тщательное тестирование, поэтому при использовании прочих режимов следует проявлять осторожность. Кроме того, скорее всего они будут постепенно отменяться в последующих редакциях.
Как уже упоминалось в начале главы, функциональности множества уровней следует воспринимать именно как различные уровни, а не некое кэширование. Причина этого утверждения состоит в том, что действие Представления имеет пагубное воздействие на производительность кластера при сравнении с большей частью решений кэширования, которые обычно не приводят к деградации производительности если разрешены рабочие нагрузки без кэширования. Такое воздействие на производительность Представлений вызывается двумя основными причинами. Первая состоит в том, что данное Представление происходит в имеющемся пути ввода/ вывода, причём весь объект целиком должен быть прочтён со своего основного уровня и затем записан в имеющийся верхний уровень прежде чем результат операции ввода/ вывода будет возвращён данному клиенту.
Во- вторых, такое действие Представления скорее всего вызовет некие Сброс и Вытеснение, которые повлекут даже ещё больше операций чтения и записи в обоих уровнях. Если оба уровня применяют тройные репликации, это начнёт вызывать большое значение коэффициентов увеличений записей даже для просто отдельного Представления. В случае наихудшего сценария некий отдельный доступ к 4кБ, который вызывает некое Представление может вызвать 8МБ операций ввода/ вывода на чтение и 24 МБ операций ввода/ вывода на запись по имеющимся двум уровням. такое увеличенное значение операций ввода/ вывода вызовет увеличение задержек; по данной причине Представление должно рассматриваться как затратная операция и регулировки должны быть направлены на их минимизацию.
имея это в виду, многоуровневость Ceph следует применять так, где горячая или активная часть всех данных умещается в имеющемся верхнем уровне. рабочие нагрузки с единообразной случайностью скорее всего не получат преимуществ и во многих случаях на самом деле могут повлечь деградацию производительности, либо из за того, что нет подходящих объектов доступных к Представлению, либо по причине слишком большого числа происходящих Представлений.
Большая часть рабочих нагрузок, которые вовлечены в производство хранилища для обычных виртуальных машин имеют тенденцию выступать в роли хороших претендентов, так как обычно только небольшое процентное соотношение ВМ имеют тенденцию получения запросов на доступ.
Базы данных с OLTP (Online transaction processing, оперативной отработкой транзакций) обычно демонстрируют улучшение в случае, когда применяется либо кэширование, либо многоуровневость, так как их горячий набор данных обычно не очень велик, а шаблоны данных обосновано согласованы. Однако базы данных для составления отчётов или пакетной обработки обычно не очень хорошо соответствуют им, так как достаточно часто требуют доступа к большим диапазонам данных без какого- либо предварительного прогревочного промежутка.
Рабочие нагрузки RBD (RADOS Block Devices), которые вовлечены в случайный доступ без каких либо определённых шаблонов или рабочие нагрузки, которые осуществляют большие потоковые чтения или записи должны обходиться стороной, так как скорее всего пострадают при их добавлении некоторого уровня кэширования.
Чтобы проверить функциональность множества уровней Ceph требуются два пула RADOS. Если вы выполняете эти примеры на оборудовании ноутбука или настольного компьютера, хотя бы OSD на основе шпиндельного диска может применяться для создания таких пулов, настоятельно рекомендуются SSD, если имеется некое стремление читать и записывать данные. Если у вас имеется доступным множество типов дисков, тогда ваш базовый уровень может присутствовать на шпиндельных дисках, в то время как верхний уровень может быть помещён на SSD.
Давайте создадим уровни при помощи приводимых ниже команд, причём все онипользуются командой Ceph
tier:
-
Создадим два пула RADOS:
ceph osd pool create base 64 64 replicated ceph osd pool create top 64 64 replicatedПредыдущая команда предоставит вам следующий вывод:
-
Создайте некие уровни из двух пулов:
ceph osd tier add base topПредыдущая команда предоставит вам следующий вывод:
-
Настройте необходимый режим кэширования:
ceph osd tier cache-mode top writebackПредыдущая команда предоставит вам следующий вывод:
-
Сделайте верхний уровень и перекройте им имеющийся основной:
ceph osd tier set-overlay base topПредыдущая команда предоставит вам следующий вывод:
-
Теперь, когда многоуровневость настроена, нам необходимо установить некие простые значения чтобы убедиться что агент множества уровней может работать. Без этого весь механизм многоуровневости не будет работать должным образом. Отметим, что эти команды всего лишь устанавливают переменные в данном пуле:
ceph osd pool set top hit_set_type bloom ceph osd pool set top hit_set_count 10 ceph osd pool set top hit_set_period 60 ceph osd pool set top target_max_bytes 100000000Предыдущая команда предоставит вам следующий вывод:
Перечисленные выше команды просто сообщают Ceph что его HitSet следует создавать с применением bloom фильтра. Следует создавать некий новый HitSet каждые 50 секунд и так, чтобы сохранялось 10 из них перед тем как начнут разрушаться старые. Наконец, пул верхнего уровня не должен сохранять белее 100 МБ; если он достигает этого предела, все операции ввода/ вывода будут заблокированы. Дополнительные подробности данных установок будут приведены в идущем следующим разделе.
-
Далее нам необходимо настроить различные варианты для того, чтобы управлять тем как Ceph Сбрасывает и Вытесняет объекты из самого верхнего в базовый уровень:
ceph osd pool set top cache_target_dirty_ratio 0.4 ceph osd pool set top cache_target_full_ratio 0.8Предыдущая команда предоставит вам следующий вывод:
Предыдущая команда сообщает Ceph что ему следует начинать Сброс записанных (dirty) объектов из самого верхнего уровня вниз в основной уровень когда этот верхний уровень становится заполненным на 40%. А также что объекты должны вытесняться из самого верхнего уровня когда верхний уровень становится заполненным на 80%.
-
И, наконец, са мые последние две команды инструктируют Ceph что никакие объекты не должны пребывать в самом верхнем уровне в течение по крайней мере 60 секунд прежде чем их можно начать рассматривать кандидатами на Сброс или Вытеснение:
ceph osd pool set top cache_min_flush_age 60 ceph osd pool set top cache_min_evict_age 60Предыдущая команда предоставит вам следующий вывод:




В отличие от основной части свойств Ceph, которые со значениями по умолчанию выполняются неплохо для большей части рабочих нагрузок, функциональность множества уровней Ceph требует тщательной настройки различных своих параметров чтобы гарантировать хорошую производительность. Вам следует иметь основы понимания профилей операций ввода/ вывода своих рабочих нагрузок; множество уровней будет хорошо работать только если ваши данные имеют некое небольшое процентное соотношение горячих данных. Те рабочие нагрузки, которые являются единообразно случайными или влекут за собой множество последовательных шаблонов доступа либо не будут показывать никакого улучшения, либо в некоторых случаях могут оказаться на самом деле медленнее.
Основными параметрами регулировки, которые необходимо просматривать в первую очередь являются те, которые определяют пределы установленного размера для самого верхнего уровня когда он должен начинать Сбрасываться или когда его следует Вытеснять.
Следующие два параметра настройки устанавливают максимальный размер тех данных, которые должны храниться в пуле самого верхнего уровня
target_max_bytes
target_max_objects
Этот размер либо определяется в байтах, или в общем числе объектов и не должен иметь тот же самый размер, что и реальный пул, однако не может превышать его. Этот размер также основывается на общей доступной ёмкости после выполнения репликаций имеющегося пула RADOS, поэтому, в случае с пулом, имеющим установку на 3 репликации, это будет одна треть от вашей сырой ёмкости. Если общее число байт или объектов в данном пуле выходит за такой предел, все операции ввода/ вывода будут заблокированы; вследствие этого важно чтобы вы задумались на другие параметры настройки позже с тем, чтобы этот предел не был достигнут. Также важно чтобы было установленным, так как без него никакие Сбросы или Вытеснения не будут осуществляться и данный пул будет просто заполнять OSD до их полного предела и затем блокировать операции ввода/ вывода.
Основная причина наличия такой установки вместо того чтобы Ceph просто применял весь размер лежащей в основе ёмкости всех дисков в данном пуле RADOS состоит в том, что определяя такой размер вы можете, если пожелаете, иметь множество пулов верхнего уровня на одном и том же наборе дисков.
Как вы уже изучили ранее, target_max_bytes устанавливает
максимальный размер предназначенных для представления множественными уровнями данных в данном пуле и если
достигается данный предел, операции ввода/ вывода блокируются. Чтобы проверить что определённый пул RADOS не
достиг такого предела, cache_target_full_ratio предписывает Ceph
попытаться и сохранить данный пул в процентном соотношении target_max_bytes
путём Вытеснения объектов, когда эта финишная ленточка будет прорвана. В отличии от Представлений и Сбросов,
Вытеснения являются достаточно недорогими операциями:
cache_target_full_ratio
<Данное значение определяется в пределах от 0 до
1 и выступает в роли процентного соотношения. Следует заметить, что
хотя target_max_bytes и cache_target_full_ratio
устанавливаются для самого пула, во внутренних операциях Ceph применяет вместо этого данные значения для вычисления
пределов на PG (группы размещения). Это может означать, что в определённых обстоятельствах некоторые PG могут достичь
вычисленных значений максимума ранее других и это порой может повлечь неожиданные результаты. По этой причине
рекомендуется не устанавливать cache_target_full_ratio в верхнее значение
и оставлять немного свободной высоты, значение 0.8 будет работать
хорошо. У нас имеется следующий код:
cache_target_dirty_ratio
cache_target_dirty_high_ratio
<Две данные опции настройки управляют тем, когда Ceph Сбрасывает записанные (dirty) объекты из самого верхнего уровня в свой основной уровень если данная многоуровневость была настроена на режим отложенной записи. Некий объект полагается записанным (dirty) если он был изменён при его нахождении в самом верхнем уровне, причём изменённые в своём базовом уровне объекты не помечаются как записанные (dirty).
Сброс включает в себя копирование всех объектов из самого верхнего уровня в их основной уровень, также как это происходит при полной записи объекта, причём такой базовый уровень может быть неким пулом с удаляющим кодированием. Такое поведение является асинхронным и располагается в стороне от увеличения операций ввода/ вывода в данном пуле RADOS, причём не связано напрямую с каким бы то ни было воздействием на ввод/ вывод клиента. Обычно объекты Сбрасываются на некоторой более низкой скорости, чем это происходит при Вытеснении. Так как Сбрасывание является затратной операцией в сравнении с Вытеснением, это означает, что если это требуется, большие объёмы объектов могут при необходимости быть Вытесненными.
Те два управляющих соотношения, которые делают возможным Сброс OSD ограничивая общее число параллельных
потоков Сброса, который допускаются к одновременному исполнению. Этим можно управлять через настройку опций
конкретного OSD osd_agent_max_ops и
osd_agent_max_high_ops, соответственно. В определениях по умолчанию
эти установки установлены на 2 и 4
параллельных потока (threads).
Теоретически процентное соотношение записанных (dirty) объектов должно зависать вокруг самого низкого значения этого соотношения в процессе обычного применения кластера. Это будет означать, что объекты Сбрасываются с низким уровнем одновременности для минимизации воздействия задержек кластера. Как только обычная вспышка записей накрывает данный кластер, общее число записанных (dirty) объектов может вырасти, однако со временем, эти записи Сбрасываются обратно в свой базовый уровень.
Однако, если имеются периоды непрерывной записи, которая опережает имеющиеся низкоскоростные возможности Сброса, тогда общее число записанных (dirty) объектов начнёт расти. Надеемся, такой период повышенного ввода/ вывода не продлится достаточно длительное время чтобы заполнить весь уровень такими записанными (dirty) объектами и тем самым вернётся назад к самым низким пороговым значениям. Однако, если общее число записанных (dirty)объектов продолжит свой рост, тогда одновременность Сброса повысится и, надеемся, будет иметь возможность остановить общее число записанных (dirty) объектов от роста в дальнейшем. Раз имеющийся обмен записи снижен, общее число записанных (dirty) объектов вновь вернётся обратно к более низким соотношениям. Эта последовательность событий проиллюстрирована на представленном далее графике:
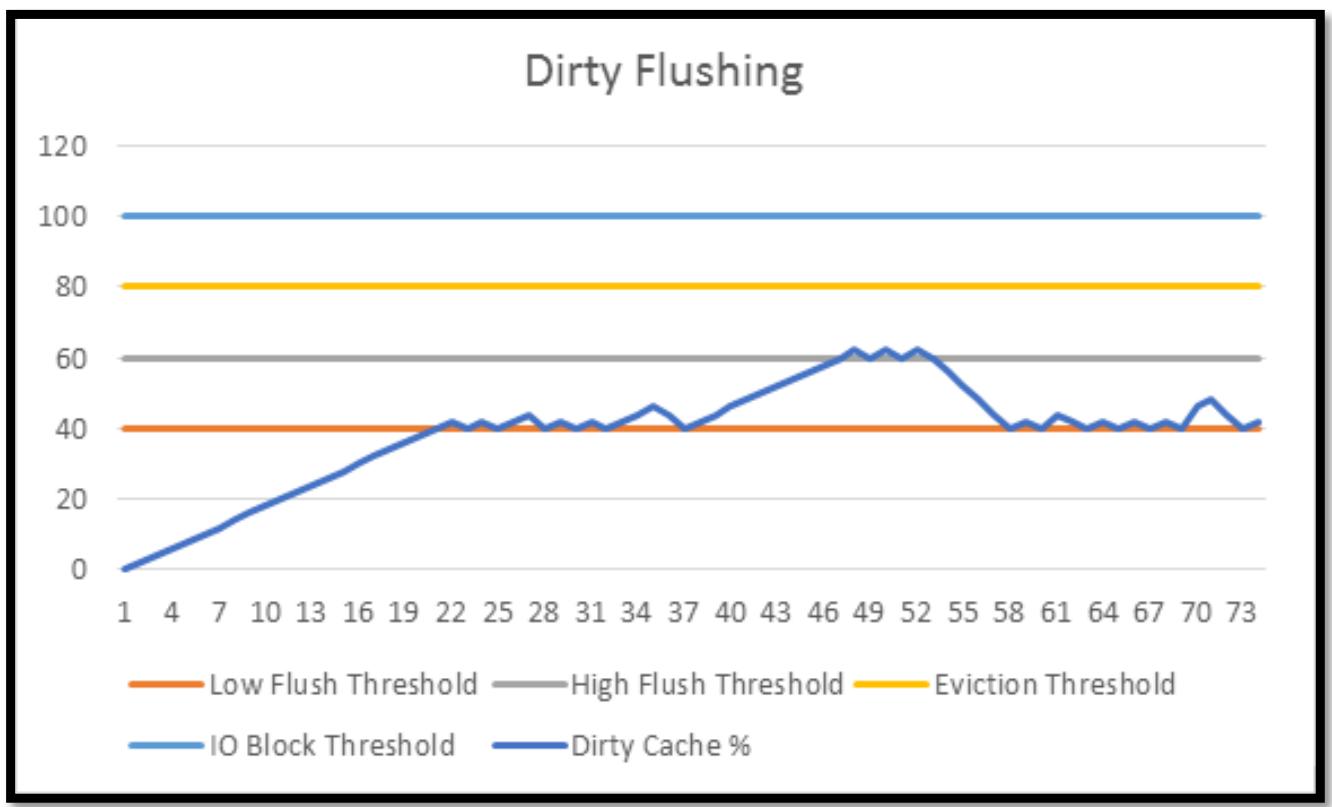
Данные два соотношения записей (dirty) должны иметь достаточные различия между ними с тем, чтобы обычные всплески записей могли поглощаться без высоких соотношений тычков. О таком высоком соотношении следует думать как о некотором предохранительном пределе.
Установка настройки osd_agent_max_high_ops должна быть отрегулирована
с тем, чтобы при обычных условиях обшее число записанных (dirty) объектов зависало или всего немного превосходило
самое низкое соотношение записанных (dirty) объектов. Не так легко порекомендовать некое значение, так как оно
во многом зависит от соотношения общих размеров и производительности от самого верхнего уровня к основному.
Однако, начните с установки osd_agent_max_high_ops в
1 и увеличивайте по мере необходимости при этом установите значение
osd_agent_max_high_ops, по крайней мере, вдвое большим.
Если вы видите сообщения о состоянии в экране состояний Ceph, которые отображают тот факт, что происходит
высокоскоростной Сброс, тогда вы пожелаете увеличить osd_agent_max_ops.
Если когда либо обнаружите самый верхний оказавшийся заполненным и блокирует ввод/ вывод, тогда вам либо
потребуется рассмотреть снижение имеющегося значения переменной cache_target_dirty_high_ratio,
либо увеличить имеющиеся установки osd_agent_max_high_ops чтобы остановить
наполнение данного уровня записанными (dirty) объектами.
Представления
Следующими опциями регулировки, которые необходимо рассмотреть, являются те, которые определяют сами HitSet и требующуюся их новизну для переключения Представления:
hitset_count
hitset_period
<Установка hitset_count управляет тем сколько HitSet может иметься
прежде чем самые старые начнут вычищаться. Установка hitset_period
управляет тем как часто должны создаваться HitSet. Если вы проверяете многоуровневость в лабораторной среде,
следует заметить, что операции ввода/ вывода с PG должны происходить с тем, чтобы создавались HitSet; в
простаивающем кластере никакие HitSet не будут создаваться и вычищаться.
Наличие корректного числа и управление тем насколько часто создаются HitSet являются ключом для того, чтобы
быть способным надёжно управлять тем, когда Представляется объект. Запомните, что HitSet содержат только
сведения о том осуществлялся ли доступ к некоторому объекту или нет; они не содержат некоторого значения числа
раз обращений к объекту. Если hitset_period слишком велик, тогда даже
объекты, к которым относительно редко происходят обращения появятся в большинстве HitSet. Например, при
hitset_period установленном на 2 минуты, некий содержащий определённые
дисковые блоки с фалом журнала объект RBD и обновляющийся раз в минуту, будет во всех тех же самых HitSet, что
и объект, обращения к которому происходят 100 раз в секунду.
И наоборот, если данный промежуток времени слишком мал, тогда даже горячие объекты могут получать отказ на появление в достаточном числе HitSet чтобы они стали кандидатами для Представления и ваш самый верхний уровень скорее всего не будет полностью использоваться. Отыскав правильный промежуток времени для HitSet, вы должны получить возможность фиксировать правильный обзор своих операций ввода/ вывода с тем, чтобы подходящая доля горячих объектов стала кандидатами для Представления.
min_read_recency_for_promote
min_write_recency_for_promote
<Эти две установки определяют сколько HitSet из последних только что произошедших некоторого объекта должно
возникнуть, чтобы он стал Представленным. Благодаря наличию вероятностного эффекта, имеющаяся зависимость между
почти горячими объектами и настройками новизны не является линейной. После того как настройки повторяемости
устанавливаются в значения от 3 до 4, общее число подходящих для Представления объектов падает логарифмически.
Следует отметить, что хотя решения Представления для чтения и записи могут выполняться по раздельности, оба они
пользуются одними и теми же данными HitSet, которые не имеют способа определения был ли доступ произведён на
чтение или на запись. В качестве удобной функции, если вы установите значение обновляемости выше установки
hitset_count, тогда он никогда не будет Представляться. Это можно
применять, например, чтобы убедиться в том, что некоторая операция ввода/ вывода на запись никогда не
приведёт к Представлению объекта, установив обновляемость записи выше чем установка
hitset_count.
Как уже описывалось ранее, Представления являются очень затратными операциями при многоуровневости и следует принимать меры предосторожности с тем, чтобы они происходили только когда необходимо. Большая часть из них выполняется тщательной настройкой HitSet и установок обновляемости. Однако, чтобы ограничить воздействие Представлений, дополнительно имеется дросселирование, которое ограничивает общее число предложений до определённой скорости. такой предел может либо определяться как число байт, либо как число объектов в секунду посредством двух опций настроек OSD:
osd_tier_promote_max_bytes_sec
osd_tier_promote_max_objects_sec
<Установленными по умолчанию являются значения 4 MBps или пять объектов в секунду. Хотя эти значения могут показаться низкими, особенно в сравнении со значениями производительности самых последних SSD, их первичным предназначением является минимизация воздействия Представлений на задержки. Чтобы определить хороший баланс в вашем кластере, необходимо провести тщательные регулировки. Следует отметить, что это значение настраивается для каждого OSD и, следовательно, общая скорость Представлений будет суммой по всем OSD.
Наконец, следующие опции настроек делают возможной регулировку самого выбора процесса для Сброса объектов:
hit_set_grade_search_last_n
<Данная опция управляет тем, сколько HitSet подлежит запросу для определения температуры объекта в предположении, что температура объекта отражается тем, насколько часто происходит к ним доступ. К холодным объектам доступ осуществляется редко, а некий горячий объект имеет достаточно высокую частоту обращений чтобы быть кандидатом для Вытеснения. У нас имеется следующий код:
hit_set_grade_search_last_n
<Он работает в сочетании с установкой hit_set_grade_search_last_n и
разрушает результаты HitSet по мере их устаревания. Получающие более частые запросы по сравнению с остальными
объекты имеют более горячий рейтинг и гарантируют что те объекты, которые являются более посещаемыми не будут
неверно Сброшены. Следует отметить, что установки min_flush и
evict_age могут перезаписывать значение температуры некоторого объекта
когда он подлежит Сбросу или Вытеснению.
cache_min_flush_age
cache_min_evict_age
<Данные установки cache_min_evict_age и
cache_min_flush_age просто определяют как долго некий объект не должен
изменяться прежде чем ему будут разрешены Сброс или Вытеснение. Их можно применять для того чтобы прекратить
для только что Представленных объектов застревание в некотором цикле перехода между уровнями. Его установка в
значение между 10 и 30 минутами вероятно является хорошим подходом, хотя необходимо принять меры, чтобы самый
верхний уровень не переполнялся если нет подходящих кандидатов для Сброса или Вытеснения.
Чтобы отслеживать текущие производительность и характеристики уровней кэширования в некотором кластере Ceph, имеется целый ряд счётчиков производительности, за которыми вы можете производить наблюдение. Мы предположим на момент что вы уже собрали все счётчики производительности Ceph со своего административного разъёма, как это обсуждается в следующей главе.
Самый важный момент, о котором надо помнить когда вы просматриваете свои счётчики производительности состоит в том, что когда вы настроили некую многоуровневость в Ceph , все запросы клиентов проходят через самый верхний уровень. По этой причине только счётчики операций чтения и записи в составляющих самый верхний уровень OSD будут отображать какие бы то ни было запросы в предположении что OSD основного уровня не применяются ни для каких других пулов. Чтобы понять общее число обрабатываемых имеющимся базовым уровнем запросов, существуют счётчики операций посредников (proxy), которые отобразят эти значения. Такие счётчики посреднических операций также вычисляются в OSD самого верхнего уровня и поэтому для наблюдения за неким кластером Ceph со множеством уровней необходимо вовлечение в вычисления OSD только с самого верхнего уровня.
Для наблюдения за многоуровневостью в Ceph могут применяться следующие счётчики, причём все они мониторятся в OSD самого верхнего уровня:
| Счётчик | Описание |
|---|---|
|
Обработанные данным OSD операции чтения |
|
Обработанные данным OSD операции записи |
|
Операции чтения, которые были передоверены базовому уровню |
|
Операции записи, которые были передоверены базовому уровню |
|
Общее число операций, Представленных самому верхнему уровню |
|
Общее число операций, Сброшенных из самого верхнего уровня на базовый |
|
Общее число операций, Вытесненных с самого верхнего уровня на базовый |
На текущий момент Ceph не поддерживает операции перезаписи в пулах удаляющего кодирования и поэтому он не может применяться напрямую для сохранения образов RBD. Однако, применяя многоуровневость, некий пул с удаляющим кодированием может применяться в качестве основного пула, в то время как пул с тремя репликами используется в качестве пула самого верхнего уровня. Это делает возможным для горячих активных наборов данных, которые будут относительно часто запрашиваться в отношении своих данных, располагаться в самом верхнем уровне, а холодные данные с редкими обращениями к ним размещать в имеющемся базовом уровне с удаляющим кодированием.
При данном подходе необходимо принять меры предосторожности; хотя в теории это звучит как бриллиантовая идей, не следует забывать, что при данной конфигурации передоверенные (proxy) записи не поддерживаются в базовом пуле с удаляющим кодированием. Следовательно, все операции записи в имеющийся базовый уровень должны Представляться вначале вверх, в самый топовый уровень. Даже если некий малый процент операций записи начинает иметь целью ваш базовый уровень, тогда производительность быстро рухнет, так как постоянные операции Представления и Сбросов засыплют имеющиеся в вашем кластере диски. Такой подход рекомендуется для применения только в тех случаях, когда операции записи редки или содержат малое количество объектов.
Хотя внутренняя функциональность многоуровневости RADOS предоставляет множество преимуществ со стороны гибкости и позволяет управление теми же самыми наборами инструментов Ceph, однако нельзя отрицать, что производительность многоуровневости RADOS в чистом виде отстаёт от прочих технологий кэширования, которые обычно работают на уровне блочных устройств.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Bcache является неким кэшированием блочных устройств в самом ядре Linux, который может применять SSD для кэширования более медленных блочных устройств, таких как шпиндельные диски. |
Bcache является одним из примеров популярного способа увеличения производительности Ceph в SSD. В отличии от многоуровневости RADOS, которая может выбирать какой пул пожелать кэшировать, при использовании bcache кэшируется весь OSD. Данный метод кэширования привносит ряд преимуществ для производительности. Первое заключается в том, что OSD сам по себе имеет более согласованный отклик латентности благодаря такому кэшированию SSD. Файловое хранение добавляет некое увеличенное число случайных операций ввода/ вывода в каждый запрос Ceph вне зависимости от того имеет ли данный запрос Ceph случайную или последовательную природу. Bcache может впитывать такие случайные операции ввода/ вывода и позволять шпиндельным дискам выполнять большее число последовательных операций ввода/ вывода. Это может быть очень полезным для промежутков высокой загруженности когда OSD обычного шпиндельного диска начнёт демонстрировать высокие задержки. Во- вторых, когда многоуровневость RADOS работает с размерами имеющихся в пуле объектами, они по умолчанию для рабочих нагрузок RBD составляют 4 МБ. Bcache кэширует данные блоками гораздо меньшего размера; это позволяет ему лучше применять доступное пространство SSD а также меньше страдать от перегрузок Представлений.
Вся назначаемая bcache ёмкость SSD будет также применяться в качестве кэширования чтения для горячих данных; это помимо операций записи также улучшит и операции чтения. Так как только bcache будет применять эту ёмкость для кэширования чтения, он будет хранить только одну копию данных и, следовательно, будет иметь в три раза больше ёмкости для кэширования чтения в сравнении с применением того же самого SSD в некотором многоуровневом пуле RADOS.
Однако имеется и ряд недостатков применения bcache которые делают использование пулов кэширования RADOS по- прежнему выглядящими привлекательно. Как уже упоминалось ранее, bcache будет кэшировать весь OSD целиком. В некоторых случаях, когда множество пулов может располагаться в одном и том же OSD, такое поведение может быть нежелательным. Кроме того, раз bcache настроен с SSD и HDD, более сложно расширять общий объём кэширования, если это понадобится впоследствии. Это также применимо к случаю, когда ваш кластер в настоящее время не имеет никакого кэширования; в таком случае введение bcache было бы разрушающим. При многоуровневости RADOS вы можете просто прибавлять дополнительные SSD или намеренно проектировать узлы SSD для добавления или расширения своего верхнего уровня по мере необходимости.
Другой подход состоит в помещении имеющихся шпиндельных дисков под некий контроллер RAID с имеющимся кэшированием отложенной записи, снабжённым батареей. Такой RAID контроллер выполняет аналогичную bcache роль и впитывает множество случайных операций ввода/ вывода на запись для файлового хранения дополнительных метаданных. В результате улучшаются и латентность и производительность записи, однако производительность чтения вряд ли увеличится из за относительно небольшого размера кэша имеющихся RAID контроллеров. При использовании некоего RAID контроллера, имеющийся у OSD журнал может также быть размещён напрямую на самом диске вместо применения отдельного SSD. При данном подходе журнальные записи впитываются контроллерами RAID и улучшают производительность случайных операций такого журнала, так как большую часть времени содержимое этих журналов будет находиться в имеющемся в контроллере кэше. Однако следует соблюдать осторожность, так как если входящий обмен записи превышает имеющуюся ёмкость кэша контроллеров, содержимое журнала начнёт Сбрасываться на диск и производительность будет ухудшаться. Для достижения наилучшей производительности для журнала файлового хранения следует использовать отдельный SSD или NVMe, хотя следует обратить внимание на стоимость применения и некоторого RAID контроллера с достаточными производительностью и кэшем в дополнение к стоимости SSD.
Оба метода имеют свои заслуги и подлежат рассмотрению перед реализацией вашего кластера.
В данной главе мы изучили теоретические вопросы основы функционирования множества уровней Ceph и просмотрели все доступные операции настройки и регулировки чтобы сделать лучшей работу при ваших рабочих нагрузках. Не следует забывать что наиболее важным аспектом является понимание ваших рабочих нагрузок и уверенность что их структура операций ввода/ вывода и распределения дружественны к кэшированию. Следуя примерам данной главы, вы также должны понять все необходимые шаги для реализации многоуровневых пулов и того как применять все параметры настроек.