Глава 5. Одновременные веб запросы
Содержание
Эта глава сосредоточится на конкретном приложении совместной обработки при выполнении веб запросов. Интуитивно понятно, что выполнение запросов к некоторой веб странице для сбора информации по ней независимо от применения той же самой задачи к другой веб страницы. Совместная обработка, в частности в данном случае обработка в потоках, таким образом может оказаться мощным инструментом, который предоставляет значительное ускорение в таком процессе. В этой главе мы изучим необходимые основы веб запросов и как взаимодействовать с вебсайтами при помощи Python. Мы также увидим как совместная обработка может помочь нам делать множество запросов неким действенным образом. Наконец, мы рассмортрим ряд практических приёмов при выполнении веб запросов.
В этой главе мы охватим следующие понятия:
-
Основы веб запрсов
-
Модуль requests
-
Совместная обработка веб запросов
-
Проблема таймаутов
-
Положительные практические приёмы веб запросов
Вот перечень предварительных требований для данной главы:
-
Убедитесь что на вашем компьютере уже установлен Python 3
-
Выгрузите необходимый репозиторий из GitHub
-
На протяжении данной главы мы будем работать с вложенной папкой, имеющей название
Chapter05 -
Ознакомьтесь со следующими видеоматериалами Code in Action
Способность генерации данных по всему миру оценивается удвоением в каждые два года. Даже несмотря на то, что существует междисциплинарная область, именуемая наукой о данных, которая полностью посвящена изучению данных, почти любая задача программирования при разработке программного обеспечения также имеет отношение к сбору и анализу данных. Значительная часть этого, конечно же, сбор данных. Однако те данные, которые нам требуются нашим приложениям, порой не хранятся надлежащим образом и аккуратно в какой- то базе данных - иногда нам требуется собирать нужные нам данные с веб-страниц.
Например выборка веб информации (веб скрапинг) является методом выделения данных, который автоматически выполняет запросы к веб страницам и выгружает определённую информацию. Веб выборка позволяет нам прочёсывать большое число вебсайтов и собирать все требующиеся нам данные систематическим и согласованным образом - такие собираемые данные могут анализироваться позднее нашими приложениями или просто сохраняться в наших компьютерах в различных форматах. Неким примером может служить Google, который программирует и запускает множество выборщиков веб информации в себе самом с целью поиска и индексирования веб страниц для своего поискового механизма.
Язык программирования Python сам по себе предоставляет некоторое число достойных вариантов для приложений такого рода. В этой главе мы будем в основном
работать с имеющимся модулем requests с целью создания веб запросов стороны клиента из ваших программ Python.
Однако, прежде чем мы более подробно рассмотрим этот модуль, нам требуется разобраться в некоторой вб терминологии чтобы иметь возможность действенно
разрабатывать свои приложения.
HTML (Hypertext Markup Language,
язык разметки гипертекста) является наиболее распространённым языком разметки для разработки веб страниц и веб приложений. Некий файл HTML представляет
из себя простой текстовый файл с расширением .html. В некотором HTML документе тексты окружены и ограничены
тегами, записываемыми в угловых скобках, <p>, <img>
<i> и тому подобными. Такие теги обычно составляют пары - некий открывающий тег и какой- то закрывающий
тег - указывающие стилизацию или природу самих заключённых в них данных.
Также имеется возможность включения прочих видов форм носителей информации в код HTML, таких как картинки иди видео- материалы. Существует также
множество прочих тегов, применяемых в обычных документах HTML. Некоторые определяют какую- то группу элементов, которые совместно используют некие
общие характеристики, например, <id></id> и
<class></class>.
Вот некий образец кода HTML:
К счастью, для того чтобы иметь возможность осуществлять действенные веб запросы, нам нет нужды в подробных знаниях того что осуществляет каждый тег HTML. Как мы обнаружим позднее в этой главе, наиболее существенная часть выполнения веб запросов состоит в возможности эффективного взаимодействия с веб страницами.
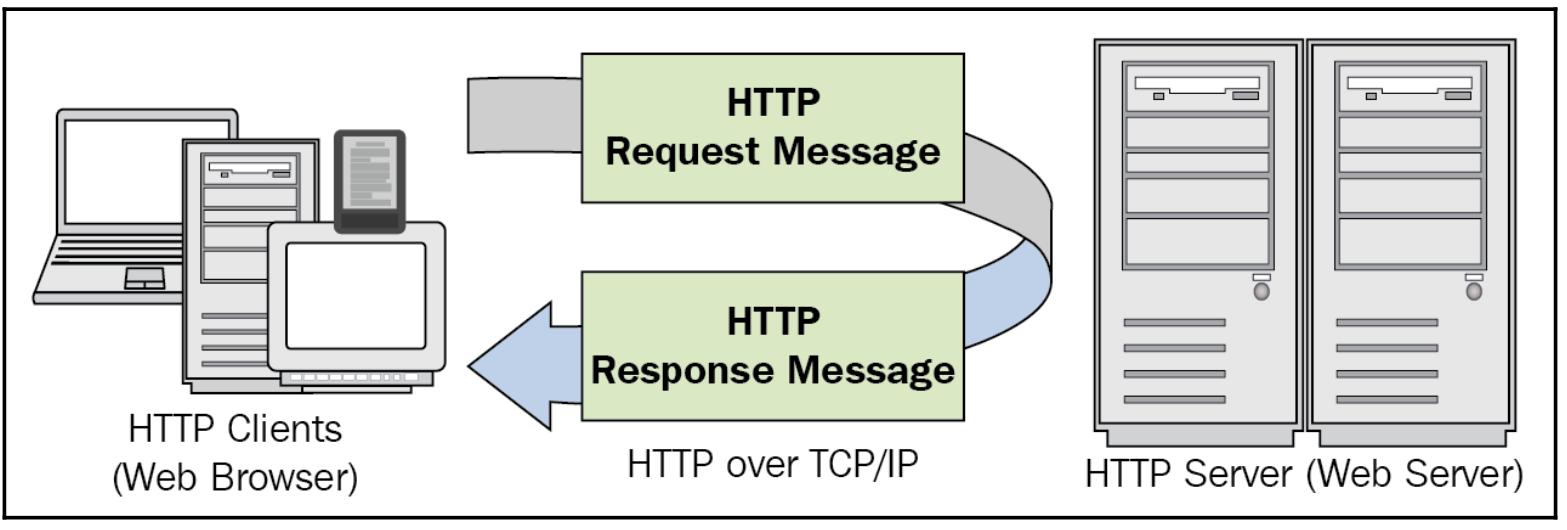
В типичном процессе взаимодействия в веб тексты HTML являются данными, которые подлежат сохранению и/ или дальнейшей обработке. Эти данные вначале требуется собрать с веб страниц, но как нам позаботиться о выполнении этого? Большая часть взаимодействий выполняется через Интернет - более определённо, World Wide Web - а он использует HTTP (Hypertext Transfer Protocol, гипертекстовый транспортный протокол). В HTTP для перемещения необходимой информации или тех данных, которые были запрошены и подлежат отправке обратно с некоторого сервера, применяются методы запросов.
Например, когда вы набираете в своём браузере packtpub.com, ваш браузер отправляет некий метод запроса через
HTTP в соответствующий основной сервер вебсайта Packt, запрашивая данные обратно с этого вебсайта. Теперь, если и ваше подключение к Интернет, и
сервер Packt работают как положено, ваш браузер получит обратно некий отклик от своего сервера, как это показано на приводимой ниже схеме. Данный отклик
будет в виде некоего документа HTML, который будет интерпретирован вашим браузером и ваш браузер отобразит соответствующий вывод HTML на соответствующем
экране.
В целом, методы запросов определяются как глаголы, которые указывают нужное действие, которое следует выполнить в процессе взаимодействия друг с
другом клиента HTTP (веб браузера) и его сервера: GET, HEAD,
POST, PUT, DELETE и так далее.
В приложениях веб- извлечения из всех этих методов наиболее часто применяются два метода GET и
POST; их функции описываются в следующем списке:
-
Метод
GETделает некий запрос для получения определённых данных от своего сервера. Этот метод просто извлекает данные и не имеет никакого другого воздействия на свой сервер и его базы данных. -
Метод
POSTотправляет данные в определённом виде, которые принимается его сервером. Этими данными, к примеру, может быть некое сообщение на доску объявлений, в список рассылки или в группу новостей; информация подставляется в некую веб форму; или же в какую- то базу данных добавляется некий элемент.
Все серверы общего назначения, которые мы как правило наблюдаем в Интернета самом деле требуют реализации по крайней мере метода
GET (и POST), хотя метод POST и
рассматривается как необязательный.
Мы не всегда имеем тот случай, когда выполняется веб запрос и отправляется в свой веб сервер, а этот веб сервер обработает данный запрос вернёт запрошенные данные без отказа. Порой этот сервер может быть полностью остановлен, или уже оказаться занятым взаимодействием с прочими клиентами и по этой причине не способным отвечать на некий новый запрос; иногда клиент сам по себе делает неверные запросы в какой- то сервер (к примеру, неверно отформатированные или вредоносные запросы).
В качестве способа разбить эти проблемы на категории, а также предоставить как столько информации, сколько возможно, на протяжении того взаимодействия, которое явилось результатом некоторого веб запроса, HTTP требует от серверов окликаться на каждый запрос от своих клиентов неким HTTP response status code (кодом состояния отклика HTTP). Некий код состояния обычно это число из трёх цифр, которое указывает особые характеристики того отклика, который данный сервер отправляет обратно клиенту.
В общей сложности имеется пять больших категорий откликов HTTP, обозначаемых самой первой цифрой данного кода. Вот они:
-
1xx (информационный код состояния): Данный запрос был получен сервером и обработан им. Например, 100 означает что соответствующий запрос заголовка был получен и этот сервер ожидает самого тела данного запроса; 102 указывает что соответствующий запрос в настоящее время обрабатывается (он применяется для больших запросов и служит предотвращению выхода клиентов по тайм- ауту.
-
2xx (код состояния успеха): Данный запрос был успешно получен, распознан и обработан ответившим сервером. Например, 200 означает что данный запрос был успешно выполнен; 202 указывает что данный запрос был принят в обработку, но само его обслуживание ещё не завершено.
-
3xx (код состояния перенаправления): Для того чтобы этот запрос был успешно выполнен, необходимо предпринять дополнительные действия. Скажем, 300 означает, что имеется множество вариантов, относящихся к тому как конкретный отклик от данного сервера следует обработать (например, предоставляя данному клиенту множество возможных видео форматов при вызгрузке некоторого видео файла); 301 указывает что данный сервер был временно перемещён и все запросы следует перенаправлять по другому адресу (предоставляемому в соответствующем отклике от этого сервера).
-
4xx (код состояния ошибки для соответствующего клиента): Данный запрос был неверно сформирован отправившим его клиентом и не может быть обработан. К примеру, 400 означает что данный клиент отправил плохой запрос (допустим, с синтаксической ошибкой или размер данного запроса слишком велик); 404 (вероятно, наиболее знаменитый код состояния) указывает что данный метод запроса не поддерживается вызванным сервером.
-
5xx (код состояния ошибки для соответствующего сервера): Данный запрос, хотя и верный, не может быть обработан этим сервером. Например, 500 означает что имеется некая внутренняя ошибка сервера, при которой возникло некое непредвиденное обстоятельство; 504 (Таймаут шлюза) обозначает что указанный сервер, который действовал в качестве некоторого шлюза или посредника (прокси), вовремя не получил отклика от самого последнего сервера.
Много чего ещё можно сказать о данных кодах состояния, но нам уже достаточно и того, что мы имеем в виду пять упомянутых ранее основных больших категорий при выполнении веб запросов из Python. Если у вас имеется желание отыскать более определённую информацию о перечисленных выше или прочих кодах состояния, IANA (Internet Assigned Numbers Authority) сопровождает официальный реестр кодов состояния HTTP.
Модуль requests позволяет своим пользователям выполнять и отправлять методы запросов HTTP. В тех приложениях,
которые мы будем рассматривать, именно он в основном будет применяться для осуществления контакта с тем сервером веб страниц, с которого мы бы желали
выделить данные и получить соответствующий отклик для этого сервера.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Согласно официальной документации данного модуля, для |
Для установки этого модуля на вашем компьютере запустите следующее:
pip install requests
Если вы применяете в качестве своего диспетчера пакетов pip, вам следует воспользоваться указанным кодом.
Если же вы вместо этого применяете Anaconda, просто примените такое:
conda install requests
Данные команды должны установить requests и все прочие необходимые для вас зависимости
(idna, certifi, urllib3 и тому
подобное), если ваша система их пока не имеет. После этого запустите в интерпретаторе Python import requests
для подтверждения того, что данный модуль был успешно установлен.
Давайте рассмотрим некий образец применения данного модуля. Если у вас уже имеется необходимый для данной книги код, выгруженный с нашей страницы
GitHub, пройдите далее и переместитесь в папку Chapter05. Давайте рассмотрим файл
example1.py, который отображён в следующем коде:
# Chapter05/example1.py
import requests
url = 'http://www.google.com'
res = requests.get(url)
print(res.status_code)
print(res.headers)
with open('google.html', 'w') as f:
f.write(res.text)
print('Done.')
В этом примере мы применяем обсуждаемый модуль requests для выгрузки кода обозначенной веб страницы,
www.google.com. Соответствующий метод requests.get() отправляет некий
метод запроса GET в url, а мы сохраняем полученный отклик в своей
переменной res. После проверки значения состояния и заголовков отклика через их вывод на печать, мы создаём
некий файл с названием google.html и записываем тот код HTML, который хранится в самом тексте отклика в данный
файл.
После запуска данной программы (в предположении что ваш Интернет работает, а сервер Google не лёг), вы должны получить такой вывод:
200
{'Date': 'Sat, 17 Nov 2018 23:08:58 GMT', 'Expires': '-1', 'Cache-Control': 'private, max-age=0', 'Content-Type': 'text/html; charset=ISO-8859-1', 'P3P': 'CP="This is not a P3P policy! See g.co/p3phelp for more info."', 'X-XSS-Protection': '1; mode=block', 'X-Frame-Options': 'SAMEORIGIN', 'Content-Encoding': 'gzip', 'Server': 'gws', 'Content-Length': '4958', 'Set-Cookie': '1P_JAR=2018-11-17-23; expires=Mon, 17-Dec-2018 23:08:58 GMT; path=/; domain=.google.com, NID=146=NHT7fic3mjBO_vdiFB3-gqnFPyGN1EGxyMkkNPnFMEVsqjGJ8S0EwrivDBWBgUS7hCPZGHbosLE4uxz31shnr3X4adRpe7uICEiK8qh3Asu6LH_bIKSLWStAp8gMK1f9_GnQ0_JKQoMvG-OLrT_fwV0hwTR5r2UVYsUJ6xHtX2s; expires=Sun, 19-May-2019 23:08:58 GMT; path=/; domain=.google.com; HttpOnly'}
Done.
Полученный отклик имеет код состояния 200 что, как мы знаем, означает что данный запрос был успешно
выполнен. Соответствующий заголовок полученного отклика, сохранённый в res.headers, дополнительно содержит
дальнейшую конкретную информацию относительно полученного отклика. Например, мы можем обнаружить соответствующие дату и время когда этот запрос был
выполнен или что самим содержимым данного отклика является текст и HTML, а общая длина содержимого составляет
4958.
Полные данные, отправленные опрошенным сервером были также записаны в файле google.html. Когда вы откроете
этот файл в каком- то текстовом редакторе, у вас будет возможность увидеть весь код HTML с той вебстраницы, который был выгружен при помощи запросов.
С другой стороны, если вы воспользуетесь неким веб браузером для открытия этого файла, вы обнаружите как
большая часть этой информации со своей первоначальной веб страницы теперь отображается через
выгружаемый в отключённом режиме файл.
В качестве примера ниже приводится то как Google Chrome в моей системе интерпретирует этот файл HTML:
Имеется также и прочая информация, которая хранится в самом сервере, на которую ссылаются веб страницы данного сервера. Это означает, что не вся
информация, которую предоставляет в реальном режиме веб страница может быть выгружена при помощи некоего запроса GET,
и именно по этой причине код HTML в отключённом режиме порой отказывает в поддержке всей той информации, которая доступна с веб страницы в реальном
времени, как это было при выгрузке отображаемой страницы. (Например, наш выгруженный код HTML в предыдущем снимке экрана не отображает должным образом
соответствующую иконку Google).
Вооружившись базовыми знаниями запросов HTTP и имея в виду соответствующий модуль Python requests,
мы на протяжении оставшейся части данной главы ознакомимся с центральной задачей: запуском теста ping. Некий тест ping является процессом, при котором
вы проверяете взаимодействие между вашей системой и определёнными веб серверами, просто делая запросы к каждому из серверов в опросе. Рассматривая
код состояния полученного отклика HTTP (потенциально) возвращаемого соответствующим сервером, этот тест применяется для оценки того имеется ли интернет
соединение у вашей собственной системы или доступность таких серверов.
Ping тестирование достаточно распространено у веб администраторов, которым обычно приходится управлять большим числом веб сайтов одновременно. Ping тесты являются хорошим инструментом для быстрого выявления страниц, которые внезапно перестали отвечать или отключились. Существует множество инструментов, которые предоставляют вам мощные возможности для ping тестирования, и в этой главе мы разработаем некое приложение ping теста, которое сможет одновременно отправлять множество совместных веб запросов.
Для имитации различных кодов состояния отклика HTTP, подлежащих отправке обратно в нашу программу, мы воспользуемся
httpstat.us, вебсайтом, который способен вырабатывать различные коды состояния и обычно применяется для проверки
того как вырабатывающие веб запросы приложения могут обрабатывать различные отклики. В частности, чтобы применить некий запрос, который возвратит в
программу код состояния 200, мы можем просто выполнить некий запрос на httpstat.us/200 и то же самое применимо
и к прочим кодам состояния. В своей программе проверки ping у нас будет иметься некий список URL httpstat.us
с различными кодами состояния.
Давайте рассмотрим свой файл Chapter05/example2.py, который показан в следующем коде:
# Chapter05/example2.py
import requests
def ping(url):
res = requests.get(url)
print(f'{url}: {res.text}')
urls = [
'http://httpstat.us/200',
'http://httpstat.us/400',
'http://httpstat.us/404',
'http://httpstat.us/408',
'http://httpstat.us/500',
'http://httpstat.us/524'
]
for url in urls:
ping(url)
print('Done.')
В этой программе наша функция ping() получает некий URL и пытается выполнить запрос
GETк этому сайту. Затем она выведет на печать полученное содержимое соответствующего отклика,
возвращаемого вызывавшимся сервером. В нашей основной программе у нас имеется перечень различных кодов состояния, которые мы уже
упоминали ранее, причём все они будут подвергнуты обходу и будут вызваны этой функцией ping().
Наш окончательный вывод будет следующим:
http://httpstat.us/200: 200 OK
http://httpstat.us/400: 400 Bad Request
http://httpstat.us/404: 404 Not Found
http://httpstat.us/408: 408 Request Timeout
http://httpstat.us/500: 500 Internal Server Error
http://httpstat.us/524: 524 A timeout occurred
Done.
Мы видим, что наша программа тестирования ping способна получать соответствующие отклики от своего сервера.
В контексте совместного программирования мы можем обнаружить, что определённый процесс выполнения какого- то запроса к веб серверу и получению соответствующего возвращаемого отклика независим от той же самой процедуры для какого- то другого веб сервера. Это говорит о том, что мы можем применить совместную обработку и параллелизм в своём приложении ping для ускорения нашего исполнения.
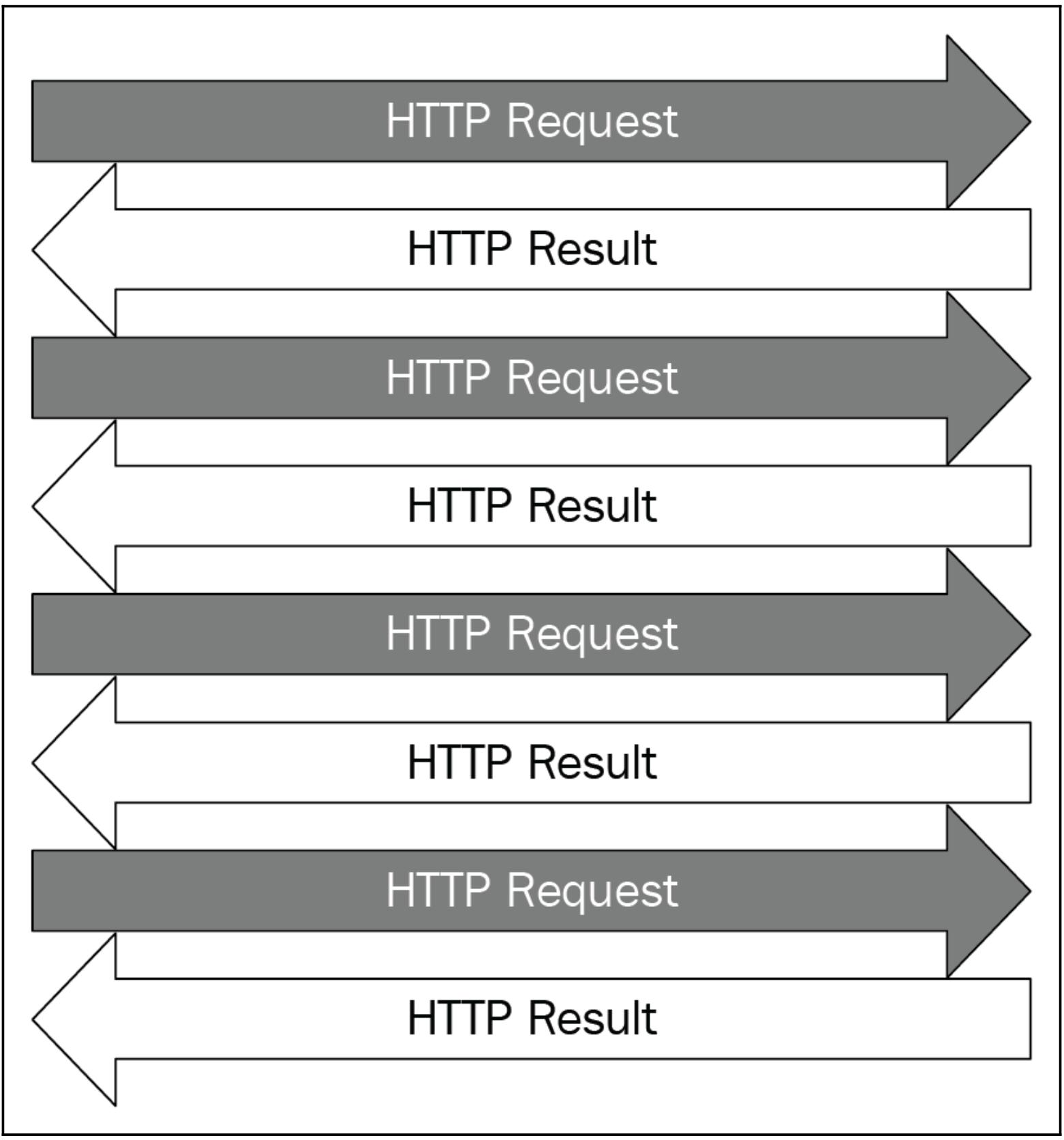
При надлежащих совместных приложениях проверки ping, которые мы проектируем, множество запросов HTTP будет выполняться к необходимому серверу одновременно и соответствующие отклики будут отправляться обратно в нашу программу, как это отображено на приводимом далее рисунке. Как уже обсуждалось ранее, совместная обработка и параллелизм имеют знаменательные приложения при веб разработке, причём большинство серверов в наши дни имеют способность обработки большого числа запросов в одно и то же время.
Для применения одновременности мы просто воспользуемся модулем threading, который мы уже обсуждали при
создании отдельных потоков для обработки различных веб запросов. Давайте взглянем на свой файл Chapter05/example3.py,
который отображён в приводимом ниже коде:
# Chapter05/example3.py
import threading
import requests
import time
def ping(url):
res = requests.get(url)
print(f'{url}: {res.text}')
urls = [
'http://httpstat.us/200',
'http://httpstat.us/400',
'http://httpstat.us/404',
'http://httpstat.us/408',
'http://httpstat.us/500',
'http://httpstat.us/524'
]
start = time.time()
for url in urls:
ping(url)
print(f'Sequential: {time.time() - start : .2f} seconds')
print()
start = time.time()
threads = []
for url in urls:
thread = threading.Thread(target=ping, args=(url,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
print(f'Threading: {time.time() - start : .2f} seconds')
В этот пример мы включили ту последовательную логику, которую мы приводили в своём предыдущем примере, чтобы обрабатывать своё список URL с тем,
чтобы мы имели возможность сравнить улучшения в скорости при применении потоков в своей программе проверки ping. Мы также создали некий поток для
выполнения ping с каждым имеющемся URL из своего перечня URL воспользовавшись модулем threading; эти потоки
будут обрабатываться независимо друг от друга. Также с помощью методов из модуля time отслеживается время,
затрачиваемое на обработку URL последовательно и одновременно.
Выполните свою программу и ваш вывод должен быть похож на такой:
http://httpstat.us/200: 200 OK
http://httpstat.us/400: 400 Bad Request
http://httpstat.us/404: 404 Not Found
http://httpstat.us/408: 408 Request Timeout
http://httpstat.us/500: 500 Internal Server Error
http://httpstat.us/524: 524 A timeout occurred
Sequential: 0.82 seconds
http://httpstat.us/404: 404 Not Found
http://httpstat.us/200: 200 OK
http://httpstat.us/400: 400 Bad Request
http://httpstat.us/500: 500 Internal Server Error
http://httpstat.us/524: 524 A timeout occurred
http://httpstat.us/408: 408 Request Timeout
Threading: 0.14 seconds
Хотя конкретное время, которое последовательная логика и логика потоков требуют для обработки всех URL-адресов, может отличаться в зависимости от системы, между ними должно иметься чёткое различие. В частности, здесь мы можем видеть, что логика потоков была почти в шесть раз быстрее, чем последовательная логика (что соответствует тому факту, что у нас было шесть потоков, обрабатывающих шесть URL параллельно). Таким образом, нет никаких сомнений в том, что параллелизм может значительно ускорить работу нашего приложения ping-теста и в целом процесса веб-запросов.
Наша текущая версия приложения проверки ping работает как и предполагалось, но мы можем улучшить его читабельность перестроив ту логику,
в которой мы выполняем веб запросы к некому классу потоков. Рассмотрим файл Chapter05/example4.py, в
частности, обсуждаемый класс MyThread:
# Chapter05/example4.py
import threading
import requests
class MyThread(threading.Thread):
def __init__(self, url):
threading.Thread.__init__(self)
self.url = url
self.result = None
def run(self):
res = requests.get(self.url)
self.result = f'{self.url}: {res.text}'
В данном примере MyThread наследуется из соответствующего класса
threading.Thread и содержит два дополнительных атрибута: url и
result. Первый атрибут url содержит тот URL, который надлежит обработать
его потоку, а получаемый отклик от соответствующего веб сервера в этом потоке будет записан в атрибут result
(в имеющейся функции run()).
Вне данного класса мы теперь можем просто выполнить цикл по всему списку URL, а также создавать надлежащие потоки и управлять ими соответствующим образом, и в то же самое время не беспокоиться о логике самого запроса в своей основной программе:
urls = [
'http://httpstat.us/200',
'http://httpstat.us/400',
'http://httpstat.us/404',
'http://httpstat.us/408',
'http://httpstat.us/500',
'http://httpstat.us/524'
]
start = time.time()
threads = [MyThread(url) for url in urls]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
for thread in threads:
print(thread.result)
print(f'Took {time.time() - start : .2f} seconds')
print('Done.')
Отметим, что теперь мы сохраняем получаемые отклики в своём атрибуте result в имеющемся классе
MyThread, вместо того чтобы выводить их на печать, как это было в нашей старой функции
ping() в наших предыдущих примерах. Это означает, что после того как мы убедились что все наши потоки
завершились, нам потребуется обойти в цикле все эти потоки ещё раз и вывести на печать эти отклики.
Переделка данной логики запросов не должна сильно сказаться на имеющейся производительности нашей текущей программы; мы отслеживаем общую скорость исполнения чтобы увидеть что это в действительности так. Выполните данную программу и вы получите свой вывод, похожий на приводимый ниже:
http://httpstat.us/200: 200 OK
http://httpstat.us/400: 400 Bad Request
http://httpstat.us/404: 404 Not Found
http://httpstat.us/408: 408 Request Timeout
http://httpstat.us/500: 500 Internal Server Error
http://httpstat.us/524: 524 A timeout occurred
Took 0.14 seconds
Done.
В точности как и ожидалось, мы всё ещё достигаем значительного ускорения относительно своей версии последовательной данной программы и при таком
перестроении логики запроса. И опять же, наша основная программа теперь более читабельна и последующие регулировки имеющейся логики запроса
как мы обнаружим в своём следующем разделе) может быть просто направлено в наш класс MyThread без воздействия на
оставшуюся часть нашей программы.
В данном разделе мы изучим потенциальные улучшения, которые следует осуществить в нашем приложении тестирования ping: обработке таймаута. Таймауты периодически возникают когда определённому серверу требуется неожиданно длительное время для обработки какого- то конкретного запроса, а соответствующее соединение между этим сервером и его клиентом прервалось.
В соответствующем контексте приложения проверки ping мы реализуем некий настраиваемый индивидуально порог для значения таймаута. Повторный вызов теста ping применяется для определения того продолжает ли отвечать конкретный сервер, с тем чтобы мы могли в своей программе определять, раз некий запрос требует больше времени чем наше пороговое значение для отклика соответствующего сервера, мы будем относить этот конкретный сервер к категории с неким таймаутом.
Дополнительно к различным возможностям для кодов состояния, уже упоминавшийся вебсайт httpstat.us дополнительно
предоставляет некий способ имитации какой- то задержки со своим откликом когда мы отправляем запросы. В частности, мы можем настраивать
индивидуально значение времени задержки (в миллисекундах) при помощи некоторого аргумента обращения в своём запросе
GET. К примеру, httpstat.us/200?sleep=5000 возвратит некий отклик
по прошествии пяти секунд задержки.
Теперь давайте рассмотрим как некая подобная указанной задерка воздействует на исполнение нашей программы. Рассмотрим свой файл
Chapter05/example5.py, который содержит обсуждавшуюся текущую логику запроса нашего прложения тестирования
ping, но имеет иной перечень URL:
# Chapter05/example5.py
import threading
import requests
class MyThread(threading.Thread):
def __init__(self, url):
threading.Thread.__init__(self)
self.url = url
self.result = None
def run(self):
res = requests.get(self.url)
self.result = f'{self.url}: {res.text}'
urls = [
'http://httpstat.us/200',
'http://httpstat.us/200?sleep=20000',
'http://httpstat.us/400'
]
threads = [MyThread(url) for url in urls]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
for thread in threads:
print(thread.result)
print('Done.')
Здесь у нас имеется некий URL, который потребует примерно 20 секунд для возврата некоего отклика. Учитывая, что мы заблокируем свою основную
программу пока все потоки не завершат своё исполнение (при помощи соответствующего метода join()), наша
программа скорее всего будет казаться повисшей на 20 секунд прежде чем будет выведен на печать какой бы то ни было отклик.
Запустите эту программу чтобы прочувствовать это на своей собственной шкуре. Возникнет задержка на 20 секунд (что потребует это исполнение значительно продолжительнее для завершения) и мы получим следующий вывод:
http://httpstat.us/200: 200 OK
http://httpstat.us/200?sleep=20000: 200 OK
http://httpstat.us/400: 400 Bad Request
Took 22.60 seconds
Done.
Некое действенное приложение проверки ping не должно ожидать откликов от своих вебсайтов слишком долго; следует иметь некое установленное пороговое значение для таймаута с тем, чтобы когда некий сервер отказывает в возврате кокого- то отклика более этого порогового значения, наше приложение полагало бы что такой сервер не отвечает. Таким образом, нам следует реализовать некий способ отслеживания как много времени прошло с тех пор как некий запрос был отправлен в сервер. Мы будем выполнять это через обратный отсчёт от величины порогового значения таймаута и, когда это пороговое значение истекает, все отклики (будь они уже возращены, либо ещё нет) будут выведены на печать.
Кроме того мы также будем отслеживать сколько запросов всё ещё задержаны и не получили свои отклики возвращёнными. Мы будем применять метод
isAlive() из своего класса threading.Thread для непосредственного
определения был ли возвращён некий отклик для какого- то определённого запроса: если в определённый момент обрабатывающий определённый запрос
данный поток всё ещё жив, мы можем заключить, что этот конкретный запрос всё ещё задерживается.
Перейдите к нашему файлу Chapter05/example6.py и для начала рассмотрите функцию
process_requests():
# Chapter05/example6.py
import time
UPDATE_INTERVAL = 0.01
def process_requests(threads, timeout=5):
def alive_count():
alive = [1 if thread.isAlive() else 0 for thread in threads]
return sum(alive)
while alive_count() > 0 and timeout > 0:
timeout -= UPDATE_INTERVAL
time.sleep(UPDATE_INTERVAL)
for thread in threads:
print(thread.result)
Эта функция получает некий список потоков, которые мы использовали для выполнения веб запросов в своих предыдущих примерах, а также некий необязательный
параметр, определяющий величину порогового значения таймаута. Внутри этой функции у нас имеется вложенная функция,
alive_count(), которая возвращает значение счётчика тех потоков, которые всё ещё живы на момент вызова данной
функции.
В своей функции process_requests(), раз уж имеются потоки, которые в настоящий момент присутствуют и
обрабатывают запросы, мы позволим этим потокам продолжить их исполнение (это выполняется в нашем цикле while
с его двойным условием). Значение переменной UPDATE_INTERVAL, как вы можете видеть, определяет как часто мы проверяем
данное условие. Если любое из условий отказывает (если нет никаких живых потоков или если пройдено пороговое значение таймаута), тогда мы продолжим
выводом на печать всех откликов (даже если некоторые могут быть ещё не возвращены).
Давайте обратим свои взоры на класс MyThread:
# Chapter05/example6.py
import threading
import requests
class MyThread(threading.Thread):
def __init__(self, url):
threading.Thread.__init__(self)
self.url = url
self.result = f'{self.url}: Custom timeout'
def run(self):
res = requests.get(self.url)
self.result = f'{self.url}: {res.text}'
Этот класс почти идентичен тому, что мы рассматривали в своём предыдущем примере, за исключением того, что самым изначальным значением для нашего
атрибута result является некое сообщение, указывающее о каком- то таймауте. В том случае, который мы уже обсудили
ранее, при котором истекает величина порогового значения таймаута, определённая в нашей функции process_requests(),
именно это первоначальное значение будет использовано при выводе на печать соответствующих откликов.
В конце концов, давайте рассмотрим свою основную программу:
# Chapter05/example6.py
urls = [
'http://httpstat.us/200',
'http://httpstat.us/200?sleep=4000',
'http://httpstat.us/200?sleep=20000',
'http://httpstat.us/400'
]
start = time.time()
threads = [MyThread(url) for url in urls]
for thread in threads:
thread.setDaemon(True)
thread.start()
process_requests(threads)
print(f'Took {time.time() - start : .2f} seconds')
print('Done.')
Здесь, в нашем перечне URL, у еас имеется некий запрос, который потребовал бы 4 секунды и другой, который занял бы 20 секунд, помимо ещё одного, который отвечает незамедлительно. Что касается порогового значения таймаута, в качестве которого мы применяем 5 секунд, теоретически мы должны иметь возможность увидеть, что наш второй запрос с 4-х секундной задержкой успешно получит некий отклик, в то время как запрос с 20-ти секундной задержкой не получит своего отклика.
Имеется ещё один момент, который следует отметить в данной программе: потоки демонов. В своей функции
process_requests(), если пройдена величина порогового значения таймаута в то время как всё ещё имеется по
крайней мере один обрабатываемый поток, в этом случае наша функция продолжит выод на печать значения атрибута result
каждого из потоков:
while alive_count() > 0 and timeout > 0:
timeout -= UPDATE_INTERVAL
time.sleep(UPDATE_INTERVAL)
for thread in threads:
print(thread.result)
Это означает, что мы не блокируем свою программу пока все её потоки не завершили своё исполнение при помощи функции
join(), и наша программа тем самым может просто продолжится в случае достижения порогового значения.
Однако, это подразумевает, что такие потоки сами по себе не завершились в этот момент. В частности, наш запрос с 20-ти секундной задержкой
скорее всего всё ещё исполнятся после выхода из нашей программы из своей функции process_requests().
Если тот поток, который обрабатывает данный запрос не является неким потоком демона (как мы знаем, потоки демонов исполняются в фоновом режиме и никогда не завершаются), он заблокирует нашу основную программу на её завершение пока такой поток не завершится сам по себе. Сделав такой поток, как и все прочие потоки потоками демонов, мы позволим своей основной программе завершиться как только она исполнит самую последнюю строку своих инструкций, даже если е1 потоки всё ещё исполняются.
Давайте посмотрим на эту программу в действии. Запустите её код и ваш вывод должен оказаться похожим на такой:
http://httpstat.us/200: 200 OK
http://httpstat.us/200?sleep=4000: 200 OK
http://httpstat.us/200?sleep=20000: Custom timeout
http://httpstat.us/400: 400 Bad Request
Took 5.70 seconds
Done.
Как вы можете видеть, на завершение нашей программы потребовалось около 5 секунд. Это обусловлено тем, что мы потратили 5 секунд для тех потоков,
которые всё ещё исполнялись, а также поскольку было передано 5-ти секундное пороговое значение, прежде чем данная программы вывела на печать полученные
результаты. здесь мы наблюдаем тот факт, что для нашего запроса с 20-ти секундной задержкой результатом было просто установленное по умолчанию
значение атрибута result из класса MyThread, в то время как остальные
запросы имели возможность получить правильные отклики от соответствующего сервера (в том числе и запрос с 4-х секундной задержкой, так как у них
было достаточно времени для получения такого отклика).
Если вы желаете увидеть соответствующий эффект потоков, не являющихся демонами, которые мы только что обсудили, просто закройте комментарием соответствующие строки кода в нашей основной программе, а именно:
threads = [MyThread(url) for url in urls]
for thread in threads:
#thread.setDaemon(True)
thread.start()
process_requests(threads)
Вы обнаружите, что ваша основная программа повиснет на 20 секунд, так как обработка не являющимся демоном потоком запроса с 20-ти секундной задержкой всё ещё продолжается, прежде чем получить возможность завершить своё исполнение (даже несмотря на то, что выводимые на печать результаты идентичны).
Существует несколько сторон при выполнении совместных веб запросов, которые требуют тщательного рассмотрения и реализации. В этом разделе мы рассмотрим эти аспекты и некоторые наилучшие практические приёмы, которым надлежит следовать при разработке ваших приложений.
Несанкционированный сбор данных являлся ведущей темой обсуждения в мире технологий на протяжении последних лет и он будет продолжаться долгие годы - и для этого также имеются веские основания. Поэтому для разработчиков выполняющих автоматизированные веб запросы в своих приложениях чрезвычайно важно просматривать политики вебсайтов по сбору данных. Вы можете найти эти политики в их условиях служб или аналогичных документах. При наличии сомнений, высеченным в камне правилом является обращение к такому вебсайту напрямую за подробной информацией.
Ошибки являются чем- то, чего просто нельзя избежать в области программирования, и это в особенности справедливо в отношении выполнения веб
запросов. Ошибки в таких программах могут включать в свой состав выполнение плохих запросов (неверные запросы или даже плохие соединения Интернет),
нерациональная выгрузка кода HTML, или не успешный синтаксический разбор кода HTML. Тем более важно применять блоки
try...except и прочие инструменты обработки ошибок в Python во избежание крушений ваших приложений.
Избежание крушений в особенности важно если ваши код/ приложения используются в промышленном применении и более крупных приложениях.
В частности, при совместной обработке веб извлечения, может оказаться что некоторые потоки успешно собирают данные, в то время как прочие завершают дело неудачно. Посредством реализации свойств обработки ошибок в многопоточных частях ваших программ, вы сможете гарантировать что какой- то отказавший поток не будет иметь возможности обрушить всю вашу программу целиком и обеспечить всё же возврат результатов тех потоков, которые завершились успешно.
Тем не менее, важно отметить, что слепое улавливание ошибок всё ещё нежелательно. Это условие указывает на ту практику, при которой у нас в нашей
программе имеется некий обширный блок try...except, который будет отлавливать все и всякие ошибки,возникающие
при исполнении данной программы и не принимать в расчёт никакую дополнительную информацию относительно тех ошибок, которая может быть получена;
такая практика также может именоваться как поглощение ошибок. Настоятельно рекомендуется иметь в программе специализированный код обработки ошибок,
стем чтобы не просто соответствующие действия можно было бы предпринять в отношении такой конкретной ошибки, но также и прочие ошибки, которые могли бы
не приниматься во внимание также могли бы проявлять себя.
Для вебсайтов достаточно распространённой практикой является изменение их логики обработки запросов, а также их регулярного отображения данных. Если некая программа, которая выполняет запросы к какому- то вебсайту имеет относительно негибкую логику взаимодействия со своим сервером этого вебсайта (например, структурирование его запросов в особом формате, обработке только одного вида отклика), тогда если и когда этот вебсайт изменяет тот способ, которым он обрабатывает запросы своих клиентов, данная программа может прекратить свою правильную работу. Такая ситуация часто происходит с программами веб выборки которые отыскивают данные в определённых тегах HTML; когда такие теги HTML изменяются, эти программы перестают отыскивать свои данные.
Такая практика используется для предотвращения функционирования программ автоматизации сбора данных. Единственный способ продолжать применять некий вебсайт который только что изменил свою логику обработки запросов состоит в анализе самих протоколов обновлений и соответствующего изменения наших программ.
Всякий раз, когда запускается одна из тех программы, которые мы обсуждали, она делает HTTP запросы к некому серверу, который управляет тем сайтом, с которого вы бы желали выделить данные. Такой процесс происходит значительно чаще и на протяжении более короткого промежутка времени в совместной программе, в которой множество запросов подлежат отправке к такому серверу.
Как уже упоминалось ранее, в наши дни серверы имеют возможность запросто обрабатывать множество запросов одновременно. Тем не менее, во избежание перегрузок и чрезмерного потребления ресурсов, серверы также проектируются так, чтобы прекращать отвечать на запросы, которые приходят слишком часто. Вебсайты крупных технологических компаний, таких как Amazon или Twitter следят за большими количествами автоматизированных запросов, которые выполняются в одних и тех же IP адресов и реализуют различные ответные протоколы; некоторые запросы могут задерживаться, некоторые могут получать отказ в ответе или такой IP адрес может быть даже получить запрет (banned) на дальнейшее выполнение запросов на определённое время.
Занимательно, что повторяющиеся запросы к серверам с большой загруженностью фактически являются неким видом взлома какого- то вебсайта. При атаках DoS (Denial of Service, Отказа в обслуживании) или DDoS (Distributed Denial of Service, Распределённых атак отказа в обслуживании), к атакуемому серверу одновременно выполняется очень большое число запросов, переполняя полосу пропускания атакуемого сервера обменом и как результат, обычно, не вредоносные запросы от прочих клиентов отклоняются, так как такие серверы заняты обработкой одновременных запросов, что иллюстрируется на следующей схеме:
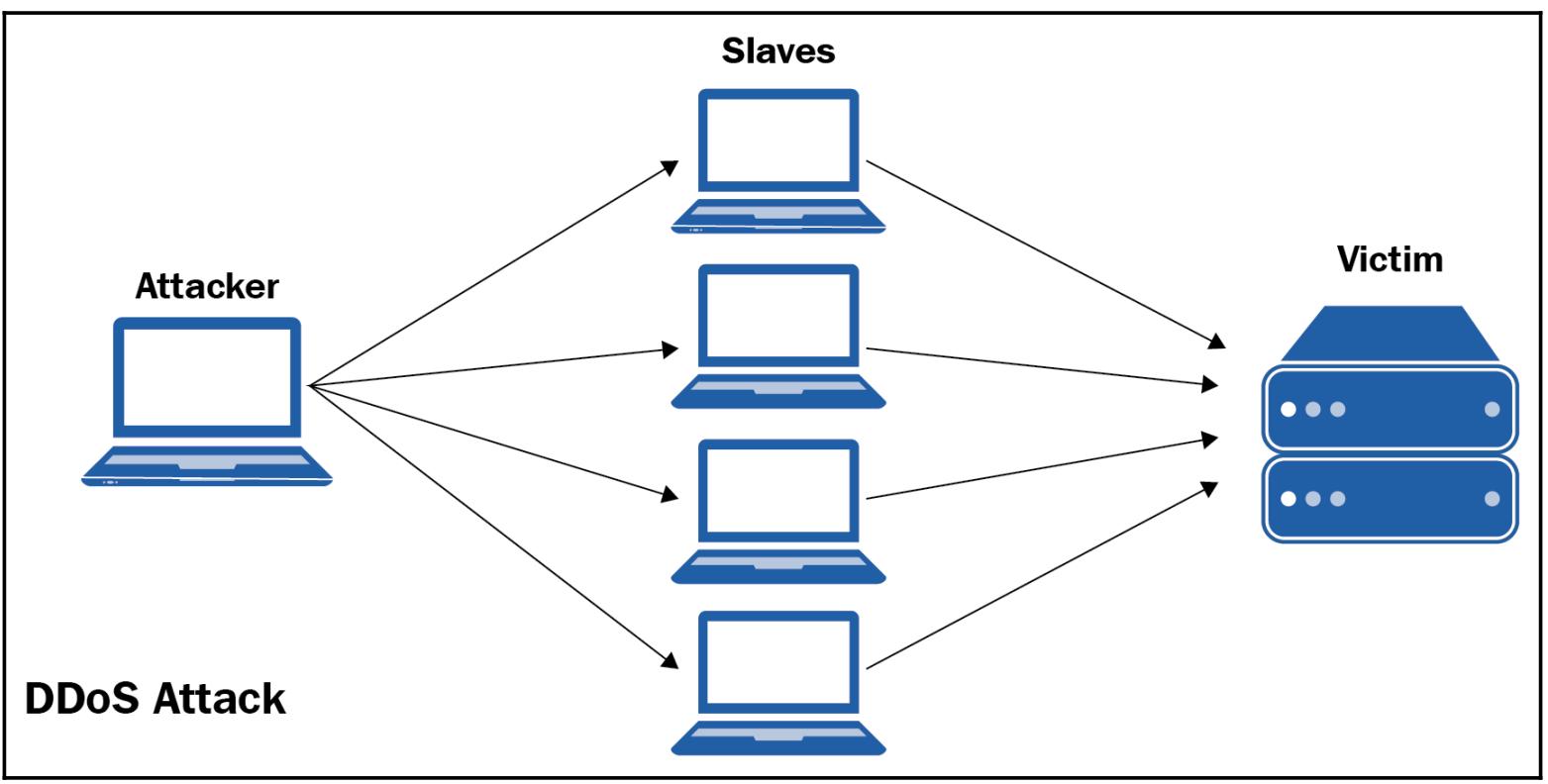
Таким образом важно разносить ваши совместные запросы, которые ваше приложение осуществляет к некому серверу с тем, чтобы ваше приложение не рассматривалось
бы как некое осуществляющее атаку и потенциально получило бы запрет или трактовалось бы как некий вредоносный клиент. Это можно запросто сделать
ограничивая максимальное число потоков/ запросов в определённый промежуток времени (например, применяя функцию time.sleep())
прежде чем выполнить некий запрос к такому серверу.
В этой главе мы изучили основы HTML и веб запросов. Двумя наиболее распространёнными запросами являются GET
и POST. Существует пять основных категорий для кодов состояния HTTP откликов, причём каждая указывает на некую
отличительную концепцию относительно самого взаимодействия между данным сервером и его клиентом. Рассматривая значения кодов состояния, получаемых
от различных вебсайтов, мы можем написать некое приложение ping тестирования, которое действенно проверяет способность к отклику таких вебсайтов.
Совместная обработка может применяться к задачам одновременного выполнения множества веб запросов через потоки для предоставления значительного улучшения в скорости приложения. Однако, важно иметь на уме, что при выполнении совместных веб запросов следует принимать во внимание ряд обстоятельств.
В своей следующей главе мы начнём обсуждать другого важного игрока в совместном программировании: процессы. Мы рассмотрим основные понятия и основные идеи стоящие за неким процессом, а акже те варианты, которые предоставляет нам Python для работы с процессами.
-
Что такое HTML?
-
Что такое запрос HTTP?
-
Что такое код состояния отклика HTTP?
-
Как модуль
requestsпомогает с выполнением веб запросов? -
Что из себя представляет тестирование ping и как он обычно проектируется?
-
Зачем нужна совместная обработка в применении к выполнению веб запросов?
-
Что необходимо принимать во внимание при разработке приложений, которые осуществляют одновременные веб запросы?
Для получения дополнительных сведений вы можете воспользоваться следующими ссылками:
-
Automate the boring stuff with Python: practical programming for total beginners, Эл Свигарт, No Starch Press, 2015
-
Web Scraping with Python, Ричард Лоусон, 2е изд., Packt Publishing Ltd, 2017
-
Instant Web Scraping with Java, Райан Митчел, Packt Publishing Ltd, 2013
-
{Прим. пер.: Скрапинг веб- сайтов с помощью Python, Райан Митчел, перевод 1го изд., ДМК-пресс, апрель 2016. Прим. пер.: Web Scraping with Python, 2nd Edition Collecting More Data from the Modern Web, Райан Митчел, O'Reilly Media, апрель 2018}
-
{Прим. пер.: Python Web Scraping Cookbook, Микаэль Хейдт, Packt Publishing Ltd, февраль 2018}