Глава 8. Параллельная обработка изображений
Содержание
Эта глава анализирует собственно процесс обработки и манипуляции изображениями при помощи параллельного программирования, в частности с применением множества процессов. Так как изображения обрабатываются независимо друг от друга, параллельное программирование может предоставлять для обработки изображений значительное ускорение. Данная глава обсуждает те основы, которые стоят за технологией обработки изображений, иллюстрируя те улучшения, которые предоставляет совместная обработка, а в конце обозревает некоторые наилучшие практические приёмы, применяемые в приложениях обработки изображений.
В этой главе будут рассмотрены следующие темы:
-
Основная идея стоящая за обработкой изображений и ряд основных технологий обработки изображений
-
Как применять одновременность при обработке изображений, а также как анализировать те улучшения, которые она предоставляет
-
Наилучшие практические приёмы при одновременной обработке изображений
Вот перечень предварительных требований для данной главы:
-
Убедитесь что на вашем компьютере уже установлен Python 3
-
Вам следует иметь установленными OpenCV и NumPy для вашего дистрибутива Python 3
-
Выгрузите необходимый репозиторий из GitHub
-
На протяжении данной главы мы будем работать с вложенной папкой, имеющей название
Chapter08 -
Ознакомьтесь со следующими видеоматериалами Code in Action
Цифровая/ вычислительная обработка изображений (которую мы с этого момента будем именовать просто как обработку изображений) стала настолько популярной в современную эпоху, что она присутствует во множестве сторон нашей повседневной жизни. Обработка изображений и манипуляция ими вовлечена в процесс при фотографировании вашей камерой или телефоном с применением различных фильтров или при более совереном редактировании изображений, например, в с применением Adobe Photoshop или даже просто когда вы просто редактируете изображения с помощью Microsoft Paint.
Многие из технологий и алгоритмов, применяемых при обработке изображений были разработаны в начале 1960-х для различных целей, например, медицинские изображения, анализ снимков со спутников, распознавание личностей и тому подобное. Однако такие технологии обработки изображений требуют значительных вычислительных мощностей и тот факт что доступное вычислительное оборудование, которое было доступно в компьютерах того времени, было неспособно удовлетворять потребностям быстрого численного перемалывания, замедлял применение обработки изображений.
Быстрое развитие со временем, когда были разработаны мощные компьютеры с быстрыми, многоядерными процессорами, постепенно сделало более доступной технику обработки изображений, а исследования в области обработки изображений существенно ускорились. В наши дни активно разрабатываются и изучаются множество приложений обработки изображений, в том числе распознавание шаблонов, классификация, выделение свойств и тому подобное. Особые технологии обработки изображений, которые овладевают преимуществами совместного и параллельного программирования и в противном случае были бы чрезвычайно потребляющими вычислительное время, в том числе скрытые модели Маркова, анализ независимых компонентов, и даже появившиеся в наши дни модели нейронных сетей:
Рисунок 8-1
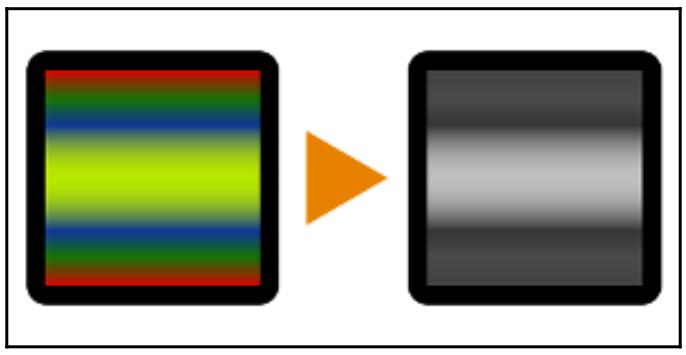
Один из примеров обработки изображений: формирование полутонового изображения с различными градациями серого
Как мы уже неоднократно упоминали на протяжении данной книги, язык программирования Python на своём пути стал наиболее популярным языком программирования. Это в особенности справедливо в области вычислительной обработки изображений, которая в большинстве случаев требует быстрого прототипирования и проектирования, а также значительных возможностей автоматизации.
Как мы увидим в своём следующем разделе, цифровые изображения представлены двумерными и трёхмерными матрицами с тем чтобы компьютерам можно было бы их проще обрабатывать. В конечном счёте, большую часть времени цифровая обработка изображений в основном привлекает матричные вычисления. Многие библиотеки и модули Python не только предоставляют эффективные возможности матричных вычислений, но также и бесшовное взаимодействие с прочими библиотеками, которые обрабатывают чтение/ запись изображений.
Как мы уже знаем, и задачи автоматизации, и превращение их в совместно обрабатываемые, и то и другое являются сильными комплектами Python. Это делает Python первейшим кандидатом для реализации ваших приложений обработки изображений. В этой главе мы будем работать с двумя основными библиотеками Python: OpenCV (что является сокращением от Open Source Computer Vision), которая является библиотекой, предоставляющей возможности обработки изображений и компьютерного видения в C++, Java и Python, а также NumPy, который, как мы уже знаем, является одним из самых популярных модулей Python и осуществляет действенные и готовые к параллельному перемалыванию чисел вычисления.
Установка OpenCV и NumPy
Для установки NumPy в вашем дистрибутиве Python при помощи диспетчера пакетов pip запустите такую команду:
pip install numpy
Если, однако, вы применяете для управления своими пакетами Anaconda/Miniconda, выполните следующую команду:
conda install numpy
Установка OpenCV может оказаться более сложной, в зависимости от вашей операционной системы. Самым простым вариантом является наличие Anaconda для обслуживания процесса установки следуя за этим руководством после установки в качестве вашего основного диспетчера пакетов Python. Если тем не менее вы не применяете Anaconda, основным вариантом будет последовать за её официальной руководящей документацией. После успешной установки OpenCV откройте интерпретатор Python и попобуйте импортировать необходимую библиотеку следующим образом:
>>> import cv2
>>> print(cv2.__version__)
3.1.0
Мы импортировали OpenCV, воспользовавшись соответствующим названием cv2, которое является псевдонимом
OpenCV в Python. Успешно полученное сообщение указывает номер версии моей выгруженной библиотеки OpenCV (3.1.0).
Прежде чем мы окунёмся в обработку и манипуляцию файлами цифровых образов,нам вначале необходимо обсудить самые основы этих файлов и то как компьютеры интерпретируют данные из них. В частности, нам требуется понимать как данные соотносятся с цветами и координатами отдельных пикселей в в некотором представленном файле образа и как выделять их с помощью Python.
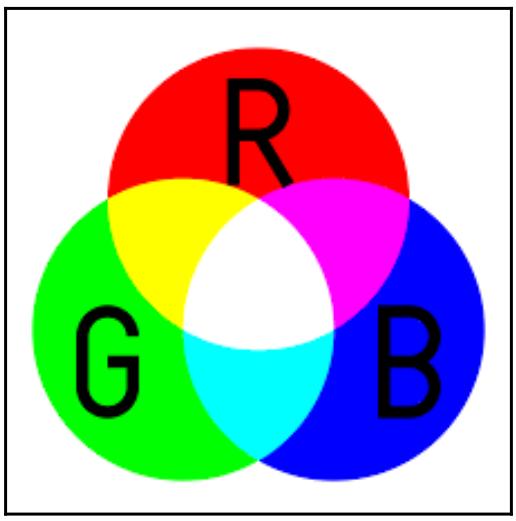
Значения RGB
Значения RGB являются той основой, как численно представлять цвета. Выступая сокращением от Red, Green и Blue, значения RGB конструируются на основе того факта, что все цвета вырабатываются из некоторой определённой комбинации красного, зелёного и голубого. Таким образом, некое значение RGB является кортежем каких- то трёх целочисленных значений, каждое из которых находится в диапазоне от 0(что указывает на полное отсутствие цвета) до 255 (что указывает на самый глубокий оттенок данного конкретного цвета).
Например, красный цвет соответствует кортежу (255, 0, 0); в этом кортеже имеется только самое высокое значение для красного и никаких значений для всех остальных цветов, поэтому наш кортеж целиком представляет самый чистый красный цвет. Аналогично синий представлен (0, 0, 255), а зелёный (0, 255, 0). Жёлтый цвет представлен смешением эквивалентных количеств красного и зелёного, а следовательно представляется (255, 255, 0) (максимальным количеством красного и зелёного, но совсем без синего). Белый, который представлен всеми тремя цветами, это (255, 255, 255), в то время как чёрный, который является противоположностью белого и тем самым полного отсутствия цветов, представлен (0, 0, 0).
Пиксели и файлы изображения
Итак, значение RGB указывает некий определённый цвет, но как мы связываем его с неким компьютерным изображением? Если мы просматривали какое- то изображение на своём компьютере и попытались бы расширит его зумом настолько много, насколько это возможно, мы бы наблюдали, что по мере всё более и более глубокого увеличения наше изображение начинает распадаться на всё возрастающе различимые цветные квадраты - такие квадраты именуются пикселями, которые являются самыми маленькими элементами цвета в некотором компьютерном дисплее или каком- то цифровом изображении:

Некий набор различных пикселей, выравниваемых в некий табличный формат (строки и колонки пикселей) составляют некое компьютерное изображение. Каждый пиксель, в свою очередь, является неким значением RGB; иными словами, некий пиксель является каким- то кортежем из трёх целых чисел. Это означает, что некое компьютерное изображение это просто двумерный массив кортежей, причём его стороны соответствуют самому размеру такого изображения. Например, изображение 128 x 128 имеет 128 строк и 128 колонок кортежей для своих данных.
Координаты внутри изображения
Аналогично индексации двумерных массивов, координатами для некоторого пикселя изображения является некая пара двух целых, представляющих x- и y- координат этих пикселей; значение x- координаты указывает расположение данного пикселя относительно горизонтальной оси, начиная слева, а y- координаты указывают вертикально местоположение пикселя, начиная сверху.
Здесь мы можем видеть как обычно вовлекаются тяжёлые вычислительные процессы перемалывания численных значений когда дело доходит до обработки изображений, поскольку всякое изображения является некоторой матрицей целочисленных кортежей. это также предполагает, что при помощи знаменитой библиотеки NumPy и совместного программирования мы можем реализовывать значительное улучшение времени исполнения для приложений обработки изображений на Python.
Следуя соглашению об индексации двумерных массивов в NumPy, рассматриваемое местоположение пикселя всё ещё оста1тся парой целых, однако значение первого числа указывает значение индекса для содержимого строки пикселей, что соответствует y- координате и аналогично второе число указывает значение x- координаты данного пикселя.
Существует поразительное число методов для считывания, выполнения обработки изображения и отображения некоего файла цифрового изображения в Python. Тем не менее OpenCV предоставляет для этого некий самый простой и наиболее понятный интуитивно API. Один из существенных моментов, который следует отметить относительно OpenCV состоит в том, что она на самом деле инвертирует значения RGB в значения BGR при интерпретации своих изображений, поэтому вместо красного, зелёного и синего по порядку, соответствующие кортежи в некоторой матрице изображения будут представлять синий, зелёный и красный именно в таком порядке.
Давайте рассмотрим некий образец взаимодействия с OpenCV из Python. Для этого давайте рассмотрим свой файл
Chapter08/example1.py:
# Chapter08/example1.py
import cv2
im = cv2.imread('input/ship.jpg')
cv2.imshow('Test', im)
cv2.waitKey(0) # press any key to move forward here
print(im)
print('Type:', type(im))
print('Shape:', im.shape)
print('Top-left pixel:', im[0, 0])
print('Done.')
Имеется несколько применяемых нами методов из OpenCV, которые нам следует обсудить:
-
cv2.imread(): Этот метод получает некий путь к какому- то файлу образа (обычно расширения файла содержат.jpeg,.jpg,.pngи тому подобное и возвращает некий объект изображения который, как мы это обнаружим далее, представлен массивом NumPy. -
cv2.imshow(): Данный метод получает некую строку и какой- то объект массива и отображает его в отдельном окне. Сам заголовок такого окна определяется в значении передаваемой строки. За данным методом всегда должен следовать соответствующий методcv2.waitKey(). -
cv2.waitKey(): Метод получает некое численное значение и блокирует свою программу на соответствующее число миллисекунд, если только не получит на вход значение0, и в таком случае будет заблокирован неограниченно, пока его пользователь не нажмёт какую бы то ни было клавишу со своей клавиатуры. Это метод всегда следует заcv2.imshow().
После вызова cv2.imshow() с файлом ship.jpg внутри надлежащей подпапки
для отображения его из вашего интерпретатора Python, наша программа остановится вплоть до нажатия клавиши и после него она исполнит оставшуюся часть
программы. При своём правильном исполнении наш сценарий отобразит следующее изображение:

После нажатия какой- то клавиши для закрытия отображаемой картинки вы должны также получить следующий вывод от оставшейся части своей программы:
> python example1.py
[[[199 136 86]
[199 136 86]
[199 136 86]
...,
[198 140 81]
[197 139 80]
[201 143 84]]
[...Truncated for readability...]
[[ 56 23 4]
[ 59 26 7]
[ 60 27 7]
...,
[ 79 43 7]
[ 80 44 8]
[ 75 39 3]]]
Type: <class 'numpy.ndarray'>
Shape: (1118, 1577, 3)
Top-left pixel: [199 136 86]
Done.
Этот вывод подтверждает несколько обсуждавшихся нами ранее моментов:
-
В- первых, при выводе на печать своего объекта изображения, возвращаемого из нашей функции
cv2.imread()мы получаем некую матрицу численных значений. -
Воспользовавшись в Python методом
type(), мы обнаруживаем, что на самом деле значением класса дляэтой матрицы является некий массив NumPy:numpy.ndarray. -
Вызвав соответствующий атрибут
shapeданного массива, мы можем обнаружить, что наше изображение является каким- то видом трёхмерной матрицы(1118, 1577, 3), что соответствует таблице из1118строк и1517колонок, причём каждый элемент является неким пикселем (кортежем из трёх чисел). Значение числа соответствующих строк и колонок также соответствует имеющемуся размеру нашего изображения. -
Рассмотрев подробнее самый левый верхний пиксель в нашей матрице (самый первый пиксель в самой первой строке, то есть
im[0, 0]), мы получим его значение BGR(199, 136, 86)-199синего,136зелёного и86красного. Просматривая значение данного BGR в каком- нибудь интернет- преобразователе, мы можем обнаружить, что это светло- голубой, который соответствует цвету неба, которое расположено в самой верхней части нашего изображения.
Мы уже видели кое- какой API Pithon, который предоставляется OpenCV для считывания данных из файлов изображений. Прежде чем мы сможем применять OpenCV для выполнения различных задач обработки изображений, давайте обсудим теоретические основы ряда технологий, которые обычно применяются при обработке изображений.
Формирование полутонового изображения
Ранее в этой главе мы уже видели некий пример формирования полутонового изображения с различными градациями серого. Возможно одна из самых используемых технологий обработки изображений, формирование градаций серого является процессом снижения размерности матрицы пикселей изображения путём рассмотрения исключительно информации интенсивности каждого пикселя, которая представляется количеством доступного цвета.
Как результат, пиксели изображения с градацией серого больше не содержат информацию трёх измерений (красного, зелёного и синего), а вместо этого представляют только одномерные данные белого- и- чёрного. Такие изображения составляются исключительно из полутонов серого, причём чёрный указывает на самую слабую интенсивность света, в то время как белый наиболее интенсивную.
Формирование полутонов обслуживает ряд важных целей в обработке изображений. Во- первых, как уже упоминалось, оно понижает число размерностей имеющейся матрицы пикселей изображения устанавливая соответствие трёхмерных цветных данных одномерным данным серого. Таким образом, вместо анализа трёх уровней цветов данных программам обработки изображения приходится иметь дело всего с одной третью общего задания для изображений только с градациями серого. Кроме того, предоставляя применение цветов только одного спектра, важные шаблоны в этом изображении более вероятно будут распознаны только при помощи данных чёрного и белого.
Существует много алгоритмов преобразования цветов в полутона серого: колориметрическое преобразование, кодирование яркости, отдельный канал и тому
подобные. Скорее всего нам не придётся реализовывать их самостоятельно, поскольку библиотека OpenCV предоставляет некий метод в одну строку для преобразования
обычного изображения в их аналоги полутонов серого. Всё ещё пользуясь своим изображением корабля, из нашего последнего примера, давайте рассмотрим свой
файл Chapter08/example2.py:
# Chapter08/example2.py
import cv2
im = cv2.imread('input/ship.jpg')
gray_im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
cv2.imshow('Grayscale', gray_im)
cv2.waitKey(0) # press any key to move forward here
print(gray_im)
print('Type:', type(gray_im))
print('Shape:', gray_im.shape)
cv2.imwrite('output/gray_ship.jpg', gray_im)
print('Done.')
В этом примере мы воспользовались методом cvtColor() из OpenCV для преобразования своего первоначального
изображения в изображение только с тонами серого. После исполнения данного сценария в вашем компьютере должно отобразиться следующее
изображение:

Нажав на любую клавишу для снятия блокировки с вашей программы, вы должны получить такой вывод:
> python example2.py
[[128 128 128 ..., 129 128 132]
[125 125 125 ..., 129 128 130]
[124 125 125 ..., 129 129 130]
...,
[ 20 21 20 ..., 38 39 37]
[ 19 22 21 ..., 41 42 37]
[ 21 24 25 ..., 36 37 32]]
Type: <class 'numpy.ndarray'>
Shape: (1118, 1577)
Done.
Мы можем видеть, что получаемая структура нашего объекта с полутонами серого отличается от того, что мы видели в своём первоначальном объекте
образа. Даже несмотря на то, что он всё ещё представлен неким массивом NumPy, он теперь является двумерным массивом целых, каждое из которых
является представителем диапазона от 0 (для чёрного) до 255 (для белого). Данная таблица пикселей, тем не менее, всё ещё состоит из
1118 строк и 1577 колонок.
В этом примере мы также воспользовались методом cv2.imwrite(), который сохранил полученный объект изображения
в вашем локальном компьютере. Обсуждаемое изображение полутонов серого также можно найти в той подпапке из папки для этой главы, в которой находится
и сам пример.
Установление пороговых значений
Другой важной технологией при обработке изображений является применение пороговых значений. Имея целью разбиения по категориям всех пикселей в некотором цифровом изображении на различные группы (что также имеет название сегментации изображения), работа с пороговыми значениями предоставляет некий быстрый и интуитивно понятный способ создания двоичных образов.
Основная идея, стоящая за работой с пороговыми значениями, состоит в замене каждого пикселя в некотором изображении на белый пиксель если интенсивность данного пикселя выше чем предварительно заданное пороговое значение и на чёрный пиксель когда интенсивность этого пикселя меньше данного порогового значения. Аналогично основной цели формирования полутонов серого, работа с пороговыми значениями усиливает имеющуюся разницу между пикселями с высокой и низкой интенсивностью, а отсюда можно распознать и извлечь важные признаки и шаблоны изображения.
Напомним, что преобразование в полутона серого преобразовывает полностью цветные изображения в некую версию, которая имеет лишь полутона серого; в этом случае каждый пиксель имеет некое целое значение в диапазоне от 0 до 255. Из некого образа с полутонами серого работа с пороговыми значениями способна преобразовать его в полностью чёрно- белое изображение, каждый пиксель которого теперь будет либо 0 (чёрный), либо 255 (белый). Таким образом, после обработки пороговым значением некоего изображения, каждый из пикселей этого изображения может поддерживать только два возможных значения, что также значительно снижает сложность наших данных изображения.
Основным ключом к действенному процессу работы с пороговым значением является таким образом поиск соответствующего порога с тем, чтобы пиксели из
изображения сегментировались таким образом, чтобы делать возможным установление более очевидного разделения областей в заданном изображении. Наиболее простым
видом работы с пороговым значением является применение некоего постоянного порогового значения для обработки всех пикселей по изображению в целом. Давайте
рассмотрим пример данного метода из файла Chapter08/example3.py:
# Chapter08/example3.py
import cv2
im = cv2.imread('input/ship.jpg')
gray_im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
ret, custom_thresh_im = cv2.threshold(gray_im, 127, 255, cv2.THRESH_BINARY)
cv2.imwrite('output/custom_thresh_ship.jpg', custom_thresh_im)
print('Done.')
В данном примере, после преобразования данного изображения корабля, которое мы применяли для преобразования в градации серого, мы вызываем функцию
threshold(src, thresh, maxval, type) из OpenCV, которая получает такие аргументы:
-
src: Этот аргумент принимает значение изображения на входе/ в источнике. -
thresh: Данная константа порогового значения должна применяться для всего изображения. В этом случае мы применяем127, поскольку это просто середина между 0 и 255. -
maxval: Пиксели с первоначальными значениями которые выше значения константы порогового значения принимают данную величину по завершению обработки пороговым значением. Мы передаём 255 чтобы для определения того, что такие пиксели должны быть совершенно белыми. -
type: Это значение указывает на тип порогового значения, применяемого в OpenCV. мы применяем простое бинарное разложение пороговым значением, поэтому мы передаёмcv2.THRESH_BINARY.
После исполнения данного сценария вы должны иметь возможность обнаружить следующее изображение в своём выводе с его названием
custom_thresh_ship.jpg:

Мы можем видеть, что при простейшем пороговом значении (127), мы получаем некое изображение, которое
выделяет отдельные области в нашем изображении: небо, корабль и море. Тем не менее, остаётся целый ряд проблем того, что формулирует данный метод,
причём наиболее общая состоит в том, какую именно константу выбрать для порогового значения. Поскольку различные изображения имеют разные цветовые
тона, условия освещённости и так далее, нежелательно применять какое- то статическое значение для различных изображений в качестве их порогового
значения.
Данная проблема разрешается различными адаптивными методами порогового значения, которые вычисляют текущее динамическое значение порога для небольших
областей некоторого изображения. Данный процесс позволяет выравнивать необходимое пороговое значение для соответствующего подаваемого на вход изображения,
а не зависит исключительно от некоторого статического значения. Давайте рассмотрим два примера таких адаптивных методов порогового значения, а именно
Адаптивного медианного порогового значения и Адаптивного Гауссова порогового значения. Перейдите к нашему файлу
Chapter08/example4.py:
# Chapter08/example4.py
import cv2
im = cv2.imread('input/ship.jpg')
im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
mean_thresh_im = cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
cv2.imwrite('output/mean_thresh_ship.jpg', mean_thresh_im)
gauss_thresh_im = cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)
cv2.imwrite('output/gauss_thresh_ship.jpg', gauss_thresh_im)
print('Done.')
Аналогично тому, как мы использовали соответствующий метод cv2.threshold() ранее, в данном случае мы опять- таки
преобразовываем своё первоначальное изображение в его версию с полутонами серого, а затем мы передаём это в метод
adaptiveThreshold() из OpenCV. Данный метод получает аргументы аналогично применявшемуся ранее методу
cv2.threshold(), за исключением того, что вместо получения значения константы в качестве порогового значения, он
принимает некий аргумент для своего адаптивного метода. Мы применяем соответственно cv2.ADAPTIVE_THRESH_MEAN_C
и cv2.ADAPTIVE_THRESH_GAUSSIAN_C.
Второй с конца аргумент определяет значение размера окна для осуществления работы с пороговым значением; это число должно быть нечётным положительным числом. В частности, мы применяем в своём примере значение 11, следовательно для каждого пикселя в полученном изображении наш алгоритм будет рассматривать соседние пиксели (из квадрата 11 x 11 вокруг своего первоначального пикселя). Самый последний аргумент определяет величину выравнивания для каждого пикселя в окончательном выводе. Эти два аргумента, снова таки, помогают делать локальным пороговое значение для различных областей заданного изображения, тем самым делая процесс определения порогового значения динамическим и, как это следует из его названия, адаптивным.
После исполнения данного сценария вы должны иметь возможность обнаружить следующие изображения в качестве вывода с названиями
mean_thresh_ship.jpg и gauss_thresh_ship.jpg. Вывод для
mean_thresh_ship.jpg таков:

А вывод для gauss_thresh_ship.jpg следующий:

Как мы можем понять, при адаптивной установке порогового значения подробности определённых областей будут обрабатываться пороговым значением и выделяться в окончательном изображении на выходе. Такая технология полезна в том случае, когда нам требуется распознавать небольшие подробности в каком- то изображении, в то время как простейшая работа с пороговым значением полезна только когда мы желаем выделять большие области некотрого изображения.
Мы достаточно обсудили основы обработки изображения и некоторые общие технологии процессинга. Мы также понимаем почему обработка изображений является тяжёлой задачей перемалывания чисел, а также что для ускорения независимая обработки задач могут применяться совместное и параллельное программирование. В данном разделе мы будем рассматривать некий особый пример того как реализовывать приложение совместной обработки изображения, которое способно обрабатывать большое число изображений на входе.
Вначале проследуем в свою текущую папку для кода этой главы. Внутри соответствующей папки input имеется
некая вложенная папка с названием large_input, которая содержит 400 изображений которые будут применяться в
данном примере. Эти картинки являются различными областями нашего первоначального изображения корабля, которые были вырезаны из него при помощи опция
индексации массивов и расслоения, которые предоставляет NumPy для рассечения объектов изображений OpenCV. Если вам любопытно как были созданы данные
изображения, проверьте соответствующий файл Chapter08/generate_input.py.
Целью данного раздела является реализация некоторой программы, которая сможет совместно обрабатывать эти изображения при помощи пороговых значений.
Для того чтобы осуществить это давайте рассмотрим свой файл example5.py:
from multiprocessing import Pool
import cv2
import sys
from timeit import default_timer as timer
THRESH_METHOD = cv2.ADAPTIVE_THRESH_GAUSSIAN_C
INPUT_PATH = 'input/large_input/'
OUTPUT_PATH = 'output/large_output/'
n = 20
names = ['ship_%i_%i.jpg' % (i, j) for i in range(n) for j in range(n)]
def process_threshold(im, output_name, thresh_method):
gray_im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
thresh_im = cv2.adaptiveThreshold(gray_im, 255, thresh_method,
cv2.THRESH_BINARY, 11, 2)
cv2.imwrite(OUTPUT_PATH + output_name, thresh_im)
if __name__ == '__main__':
for n_processes in range(1, 7):
start = timer()
with Pool(n_processes) as p:
p.starmap(process_threshold, [(
cv2.imread(INPUT_PATH + name),
name,
THRESH_METHOD
) for name in names])
print('Took %.4f seconds with %i process(es).
' % (timer() - start, n_processes))
print('Done.')
В этом примере мы пользуемся классом Pool из имеющегося модуля
multiprocessing для управления своими процессами. Чтобы освежить в памяти, напомним, что объект
Pool поддерживает удобные варианты установки соответствия некоторой последовательности на входе
отдельных процессов при помощи своего метода Pool.map(). В нашем примере мы используем однако метод
Pool.starmap() для передачи множества аргументов в свою целевую функцию.
В самом начале нашей программы мы сделаем ряд хозяйственных назначений: тот метод порогового значения, которым мы будем исполнять адаптивную
обработку пороговым значением при обработке своих изображений, пути для папок входящих и исходящих данных, а также названия тех изображений,
которые предстоит обрабатывать. Наша функция process_threshold() является именно тем местом, в котором мы
на самом деле выполняем обработку изображений; она получает некий объект изображения, название для версии обработки данного изображения, а также какой
именно метод пороговой обработки применять. пять же, именно по этой причине мы применяем метод
Pool.starmap() вместо метода Pool.map().
В своей основной программе с целью демонстрации имеющихся отличий между последовательной и параллельной обработкой изображений мы хотим запускать
свою программу с различным числом процессов, в частности от одного отдельного процесса до шести различных процессов. При каждой итерации своего
цикла for мы инициализируем какой- то объект Pool и устанавливаем
соответствие всех необходимых аргументов каждого изображения для своей функции process_threshold(), причём
в то же самое время отслеживаем сколько времени занимает эта обработка и сохраняем все получаемые изображения.
После запуска данного сценария полученные в процессе обработки изображения можно найти во вложенной папке
output/large_output/ в папке нашей текущей главы. Вы должны получить вывод похожий на такой:
> python example5.py
Took 0.6590 seconds with 1 process(es).
Took 0.3190 seconds with 2 process(es).
Took 0.3227 seconds with 3 process(es).
Took 0.3360 seconds with 4 process(es).
Took 0.3338 seconds with 5 process(es).
Took 0.3319 seconds with 6 process(es).
Done.
Мы можем обнаружить большую разницу времени исполнения при переходе от одного процесса к двум отдельным процессам. Тем не менее, имеется незначительное или даже отрицательное ускорение после перехода от двух к большему числу процессов. Обычно это происходит по причине значительных накладных расходов, которые производятся при реализации большого числа отдельных процессов по сравнению со сравнительно небольшим числом входных данных. Даже смотря на то, что мы не реализуем такое сравнение с целью простоты, при растущем числе операций ввода мы увидели бы улучшение производительности от большего числа работающих процессов.
До сих пор мы наблюдали что совместное программирование может предоставлять значительное ускорение для приложений обработки изображений. Однако, если мы взглянем на свою предыдущую программу, мы можем обнаружить что существуют дополнительные регулировки, которые мы можем сделать для ещё большего улучшения времени исполнения. В частности, в своей предыдущей программе мы считываем изображения неким последовательным образом, применяя охватывающий список в следующих строках:
with Pool(n_processes) as p:
p.starmap(process_threshold, [(
cv2.imread(INPUT_PATH + name),
name,
THRESH_METHOD
) for name in names])
Теоретически, если бы мы сделали свой процесс считывания различных файлов одновременным, мы также смогли бы получить дополнительное ускорение для своей
программы. Это в особенности справедливо для неких приложений обработки изображений, имеющих дело с большими файлами входных данных, при котором
значительная часть времени тратится на чтение входных данных. Имея это в виду, давайте рассмотрим следующий пример, в котором мы реализуем одновременную
обработку ввода/ вывода. Перейдите к нашему файлу example6.py:
from multiprocessing import Pool
import cv2
import sys
from functools import partial
from timeit import default_timer as timer
THRESH_METHOD = cv2.ADAPTIVE_THRESH_GAUSSIAN_C
INPUT_PATH = 'input/large_input/'
OUTPUT_PATH = 'output/large_output/'
n = 20
names = ['ship_%i_%i.jpg' % (i, j) for i in range(n) for j in range(n)]
def process_threshold(name, thresh_method):
im = cv2.imread(INPUT_PATH + name)
gray_im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
thresh_im = cv2.adaptiveThreshold(gray_im, 255, thresh_method, cv2.THRESH_BINARY, 11, 2)
cv2.imwrite(OUTPUT_PATH + name, thresh_im)
if __name__ == '__main__':
for n_processes in range(1, 7):
start = timer()
with Pool(n_processes) as p:
p.map(partial(process_threshold, thresh_method=THRESH_METHOD), names)
print('Took %.4f seconds with %i process(es).' % (timer() - start, n_processes))
print('Done.')
Основная структура этой программы аналогична представленной ранее. Тем не менее, вместо подготовки подлежащих обработке необходимых изображений
и прочей относящейся к ним информации, мы реализуем это в внутри своей функции process_threshold(), которая
теперь получает лишь название своего изображения на ввод и самостоятельно выполняет считывание.
В качестве заметки в отступе, мы применяем в своей основной программе встроенный метод functools.partial()
для передачи некоторого частного аргумента (здесь собственно названия), в частности thresh_method, для
своей функции process_threshold(), так как этот аргумент фиксирован для всех изображений и процессов.
Дополнительную об этом инструментарии можно отыскать на
https://docs.python.org/3/library/functools.html.
После исполнения своего сценария мы должны получить вывод похожий на такой:
> python example6.py
Took 0.5300 seconds with 1 process(es).
Took 0.4133 seconds with 2 process(es).
Took 0.2154 seconds with 3 process(es).
Took 0.2147 seconds with 4 process(es).
Took 0.2213 seconds with 5 process(es).
Took 0.2329 seconds with 6 process(es).
Done.
По сравнению с нашим последним выводом, данная реализация нашего приложения в действительности предоставляет нам намного лучшие значения времени исполнения.
К настоящему моменту вы скорее всего осознали, что обработка изображений достаточно запутанный процесс, а реализация совместного и параллельного программирования в некотором приложении обработки изображения может добавить в нашу работу ещё больше осложнений. Существуют, тем не менее, хорошие практические приёмы, которые будут служить нам руководством при разработке своего приложения обработки изображения. Наш следующий раздел обсуждает некоторые наиболее распространённые практические приёмы, которые нам следует иметь в виду.
Мы вкратце пользовались этой уловкой при изучении работы с пороговыми значениями. То как некое приложение обработки изображения управляется и обрабатывает данные своего изображения в сильной степени зависит от тех задач, которые предполагается решать, и того вида данных, которыми оно будет подпитываться. Тем самым имеется значительное разнообразие при выборе определённых параметров для обработки вашего изображения.
К примеру, как мы уже видели ранее, имеются различные способы установки пороговых значений для некоторого изображения, причём каждый из них будет иметь результатом очень отличающийся вывод: если вы желаете сосредоточиться только на крупных, индивидуальных областях некоторого изображения, простое пороговое значение с константой докажет вам свои преимущества относительно работы с адаптивными пороговыми значениями; ели однако вы желаете выделять небольшие изменения в деталях какого- то изображения, адаптивные пороговые значения будут значительно более предпочтительными.
Давайте рассмотрим другой пример, в котором мы рассмотрим как применять некую простую модель Каскадного висячего дождя (Haar Cascade) для выявления лиц в некотором изображении. Мы не будем глубоко копаться в том как эта модель справляется со своими данными и обрабатывает их, так как она уже встроена в OpenCV; опять же, мы применяем эту модель только на самом верхнем уровне, изменяя её параметры для получения различных результатов.
Перейдите к нашему файлу example7.py из папки для этой главы. Данный сценарий разработан для выявления лиц
в изображениях obama1.jpeg и obama2.jpeg из нашей папки входных данных:
import cv2
face_cascade = cv2.CascadeClassifier('input/haarcascade_frontalface_default.xml')
for filename in ['obama1.jpeg', 'obama2.jpg']:
im = cv2.imread('input/' + filename)
gray_im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(im)
for (x, y, w, h) in faces:
cv2.rectangle(im, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('%i face(s) found' % len(faces), im)
cv2.waitKey(0)
print('Done.')
Во- первых, данная программа загружает предварительно обученную модель Haar Cascade из нашей папки input
с применением класса cv2.CascadeClassifier. Для каждого из изображений на входе данный сценарий выполняет
преобразование в полутона серого и запитывает ими нашу предварительно натренированную модель. Этот сценарий затем очерчивает зелёные прямоугольники
вонруг каждого обнаруженного на этом рисунке изображения и наконец отображает его в отдельном окне.
Запустите данную программу и вы увидите следующее изображений с пятью обнаруженными лицами :

Кажется что до сих пор наша программ работает как подобает. Для продолжения нажмите на любую клавишу и вы должны обнаружить следующую фотографию с
семью обнаруженными лицами:

На этот раз наша программа допустила ошибку на неких иных объектах определив их как реальные лица, что привело к двум фальшивым обнаружениям. Причина стоящего за этим состоит в том как создавалась данная предварительно обучаемая модель. В частности, данная модель Haas Cascade применялась для тренировки с изображениями особых (в пикселях) размеров, и поэтому когда некое изображение на входе содержит лица различного размера - что достаточно распространено при получении групповых фотографий с некоторыми людьми, располагающимися ближе к камере, в то время как прочие находятся на некотором удалении - запитывает данную модель, это приводит к фальшивым обнаружениям в выводе.
Для решения этой проблемы служит параметр scaleFactor в соответствующем методе
detectMultiScale из класса cv2.CascadeClassifier. Этот параметр будет
уменьшать масштаб областей в вашем изображении на входе перед тем как предсказать содержат ли эти области некое лицо или нет - выполнение этого
нивелирует потенциальную разницу в размерах лиц. Чтобы реализовать это измените ту строку, в которой мы передаём свои изображения на входе в
соответствующую модель следующим образом, определяя параметр scaleFactor равным
1.2:
faces = face_cascade.detectMultiScale(im, scaleFactor=1.2)
Запустив данную программу, вы можете видеть, что на это раз наше приложение способно верно распознавать все имеющиеся лица в наших воодимых изображениях без создания неких ложных срабатываний.
На данном примере мы можем убедиться что важно знать о потенциальных вызовах, которые могут представлять наши изображения на входе при исполнении вашего приложения обработки изображения и пробовать различные методы или параметры в рамках одного метода обработки для достижения наилучших результатов.
Один из моментов в нашем примере для совместной обработки изображений состоит в том, что сама задача порождения процессов занимает существенное количество времени. По этой причине, если общее число процессов доступных для анализа наших данных слишком велико при сопоставлении с объёмом ввода, значение улучшения времени исполнения достигаемое за счёт увеличения общего числа рабочих процессов будет уменьшаться, а иногда даже становится отрицательным.
Тем не менее, не существует конкретного способа сказать будет ли определённое число отдельных процессов соответствующим в некоторой программе пока вы также не учтёте их ввод изображений. Например, если вводимые изображения являются достаточно большими файлами, и вашей программе требуется существенное время для их ввода из хранилища, наличие большого числа процессов может сулить преимущества; когда часть процессов дожидаются загрузки своих изображений, прочие могут продолжать обрабатывать то что имеют. Иными словами, наличие большего числа процессов позволит выполнять перекрытие между временем загрузки и обработки, что в результате приведёт к лучшему ускорению.
Короче говоря, важно проверять различные доступные процессы в своём приложении обработки изображений для определения оптимального числа при масштабировании.
Мы наблюдали, что загрузка входных изображений последовательным образом может иметь отрицательное воздействие на общее время исполнения некоторого приложения обработки изображений. вместо того чтобы допускать отдельным процессам загружать их собственные входные данные. Это в особенности верно когда ваши файлы изображений существенны в размере так как время загрузки может перекрываться с временем загрузки/ обработки другого процесса. То же самое относится и для записи изображений вывода в файлы.
Обработка изображений является существенной задачей анализа и манипуляции файлами цифровых изображений для создания новых версий этих изображений или выделения важной информации из них. Такие цифровые изображения представляются таблицами пикселей, являющихся значениями RGB или, по существу, кортежами чисел. Таким образом, цифровые изображения это просто многомерные матрицы чисел, которые фактически имеют результатом то, что задачи обработки изображений обычно сводятся к тяжёлому численному перемалыванию.
Так как в некотором приложении обработки изображений образы могут анализироваться и обсчитываться независимо друг от друга, совместное и параллельное программирование - в частности многопроцессность - предоставляют некий путь достижения значительного улучшения времени исполнения для такого приложения. Помимо этого существует целый ряд практических приёмов, которым стоит следовать при реализации вашей собственной программы совместной обработки изображений.
До сих пор в данной книге мы рассматривали два основных вида параллельного программирования: многопосточность и многопроцессность. В своей следующей главе мы перейдём к теме асинхронного ввода/ вывода, которая также является одним из ключевых элементов совместной обработки и параллелизма.
-
Что такое задача обработки изображений?
-
Что является наименьшим элементом цифрового изображения? как он представляется в компьютере?
-
Что такое формирование полутонов серого? Какую цель преследует данная техника?
-
Что представляет из себя обработка пороговым значением? Какую цель ставит перед собой такая методология?
-
Зачем следует выполнять совместную обработку изображений?
-
Назовите некоторые достойные практические приёмы совместной обработки изображений.
Для получения дополнительных сведений вы можете воспользоваться следующими ссылками:
-
Automate the Boring Stuff with Python: Practical Programming for Total Beginners, Эл Свейгард, No Starch Press, 2015
-
Learning Image Processing with OpenCV, Глория Гарсия Буэно и пр., Packt Publishing Ltd, 2015
-
A Computational Introduction to Digital Image Processing, Эйлайсдэйр МакЭндрю, Chapman and Hall/CRC, 2015.
-
OpenCV: Computer Vision Projects with Python, Хоузе, Дж., П. Джоши и М. Бэйелер, Packt Publishing Ltd, 2016
-
{Прим. пер.: Computer Vision Projects with OpenCV and Python 3, Мэттью Ривер, Packt Publishing Ltd, декабрь 2018}
-
{Прим. пер.: Mastering OpenCV 4, - Third Edition, Рой Шилкрот, Дейвид Мильян Ескривай, Packt Publishing Ltd, декабрь 2018}
-
{Прим. пер.: Learn OpenCV 4 By Building Projects - Second Edition, Дейвид Мильян Ескривай, Вайнайсиус Мендонса, Прэйтик Джоши, Packt Publishing Ltd, ноябрь 2018}
-
{Прим. пер.: Hands-On GPU-Accelerated Computer Vision with OpenCV and CUDA Бхомик Вайдья, Packt Publishing Ltd, сентябрь 2018}