Глава 8. Мониторинг сетей при помощи Python - Часть 2
Содержание
Обычно мы классифицируем подход SNMP как метод pull (извлечения),
поскольку мы постоянно опрашиваем у своего устройства определённую информацию. Этот конкретный метод
добавляет обременённость самому устройству, поскольку теперь он нуждается во времени ЦПУ на его управляющей
панели для поиска ответа от определённой подсистемы и затем соответствующего ответа на управляющее состояние.
Со временем, если у нас имеется множество регистраторов SNMP, опрашивающих одно и то же устройство каждые 30 секунд
(вы будете удивлены насколько часто это происходит), такие накладные расходы управления станут значительными.
На примере человеческой практики, представьте себе что у вас имеется множество людей, прерывающих вас
каждые 30 секунд с тем, чтобы задать некий вопрос. Я знаю, что я буду раздражён, даже если это некий простой вопрос
(ил, что ещё хуже, если все они спрашивают одно и то же).
Другой способ, которым мы можем предоставлять сетевое управление состоит в смене соединения с такой станцией
управления с pull на push
(активную доставку). Другими словами, данная информация может выталкиваться с данного устройства на его
станцию управления в уже согласованном виде. Такая концепция является тем, на чём основывается мониторинг на
основе потока. В некоторой модели на основании потока, само сетевое устройство изливает трафик необходимой
информации, называемый потоком, на свою станцию управления. Такой формат может быть определённым частным Cisco
NetFlow (версии 5 или версии 9), отраслевым стандартом IPFIX, либо форматом открытого кода sFlow. В данной главе мы
потратим некоторое время на рассмотрение NetFlow, IPFIX и sFlow с помощью Python.
Не любое наблюдение осуществляется в виде временных последовательностей данных. Такая информация, как сетевая топология и системный журнал может быть представлена в виде временных последовательностей но, скорее всего, это не лучший вариант. Информация сетевой топологии проверяет не изменилась ли данная топология рассматриваемой сетевой среды со временем. Также мы можем применять такие инструменты как Graphviz с некоей оболочкой Python для иллюстрации имеющейся топологии. Как мы уже видели в Главе 6, Сетевая безопасность с помощью Python, системный журнал содержит информацию о безопасности. В данной главе мы взглянем на то, как воспользоваться стеком ELK (Elasticsearch, Logstash, Kibana) для сьора информации сетевого журнала.
В частности, мы рассмотри следующие темы:
-
Graphviz, являющийся программным обеспечением визуализации с открытым исходным кодом, которое помогает нам быстро и действенно отображать нашу сетевую среду.
-
Мониторинг на основании потока, такой как NetFlow, IPFIX и sFlow.
-
Применение ntop для визуализации информации определённого потока.
-
Elasticsearch для анализа собираемых нами данных.
Давайте для начала приступим к рассмотрению того, как применять Graphviz в качестве инструмента отслеживания изменений сетевой топологии.
Graphviz является программным обеспечением с открытым исходным кодом графического представления информации. Представим себе, что вы желаете описать свою топологию сетевой среды неким коллегам без определённых преимуществ какой бы то ни было картинки. Вы можете сказать: "Наша сетевая среда состоит из трёх уровней: ядра, распределения и доступа. Уровень ядра представлен двумя маршрутизаторами для избыточности и оба этих маршрутизатора целиком привязаны к четырём распределительным маршрутизаторам; они также полностью связаны со всеми маршрутизаторами доступа. Нашим внутренним протоколом маршрутизации является OSPF, а для внешнего мы применяем для своего поставщика услуг BGP." В то время как данное описание упускает некоторые подробности, его, скорее всего, достаточно вашим коллегам для достаточно хорошего представления высокоуровневой картинки вашей сетевой среды.
Graphviz работате аналогично данному процессу описания диаграммы в текстовом виде с последующим запросом имеющейся программы Graphviz для построения такой диаграммы нам. В данном случае такая описанная в виде текстового формата диаграмма имеет название DOT, а Graphviz на его основании рисует необходимую графическую диаграмму. Конечно, из- за того, что компьютер уступает человеческому воображению, данный язык должен быть точным и подробным.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Ознакомьтесь с http://www.graphviz.org/doc/info/lang.html для получения определений грамматики DOT в терминах Graphviz. |
В следующем разделе мы применим Протокол описания канального уровня (LLDP, Link Layer Discovery Protocol) для запросов к соседям устройства и создания некоей диаграммы сетевой топологии с помощью Graphviz. Выполнив этот внушительный пример, вы поймёте, как мы можем взять нечто новое, скажем, Graphviz, и объединить его с теми вещами, которые мы уже изучили, чтобы решать интересные задачи.
В своей лаборатории мы воспользуемся, как и в своих предыдущих главах, VIRL, так как наша цель состоит в иллюстрации сетевой топологии. Мы применим пять сетевых узлов IOSv совместно с двумя серверами хостов:
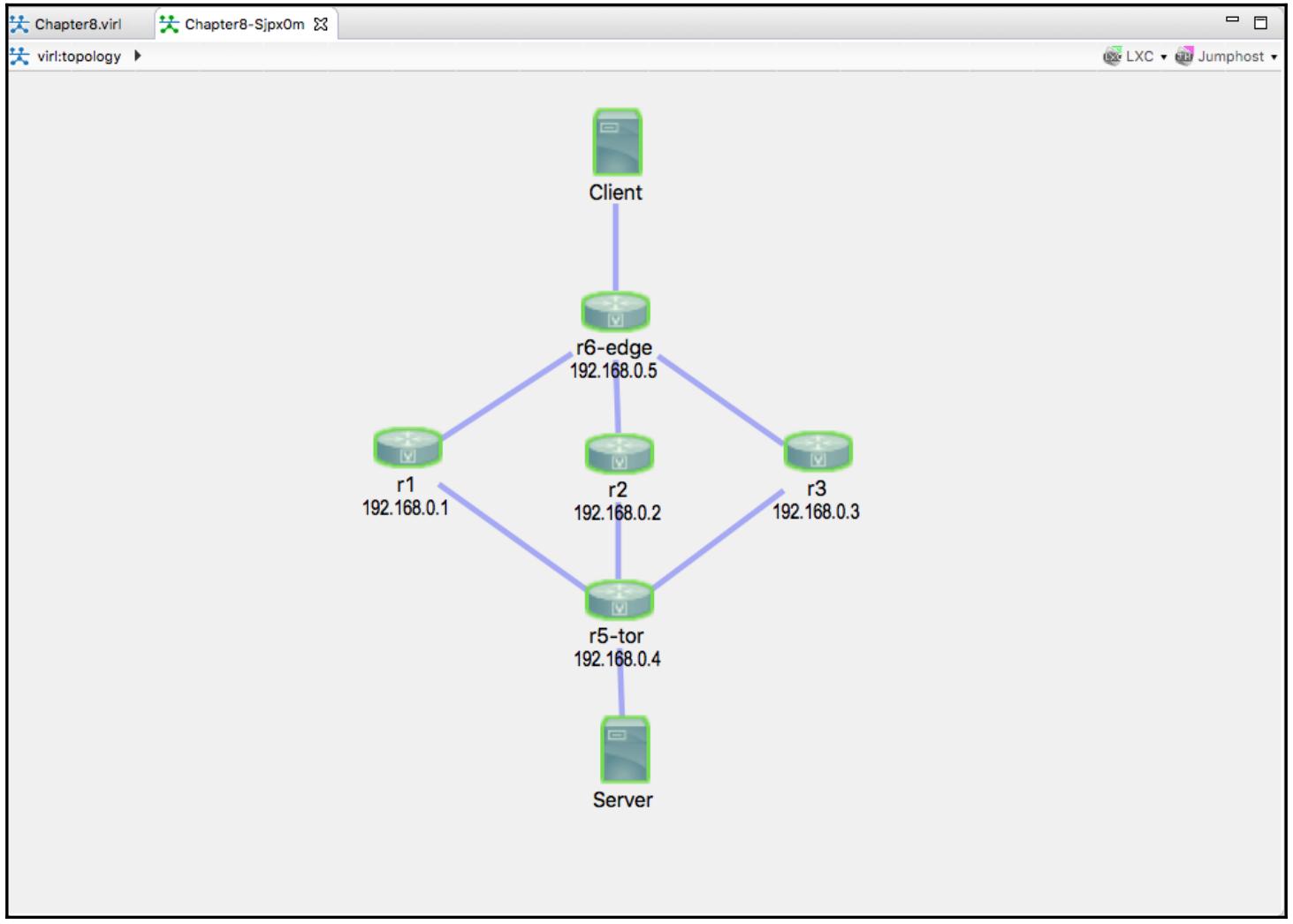
Если вы удивлены моим выбором IOSv вместо NX-OS или IOS-XR, а также общего числа устройств, вот некоторые моменты для вашего рассмотрения когда вы строите свою лабораторию:
-
Виртуализация узлов с помощью NX-OS и IOS-XR намного более затратна в отношении памяти в сравнении с IOS
-
Применяемый мной виртуальный диспетчер VIRL имеет 8ГБ ОЗУ, что кажется достаточным для того чтобы выдержать девять узлов, однако может быть слегка нестабильным (узлы меняются с достижимых на недосягаемые случайным образом)
-
Если вы желаете воспользоваться NX-OS, рассмотрите применение NX-API или других вызовов API, которые бы возвращали структурированные данные
Для нашего примера я намереваюсь воспользоваться протоколом LLDP для описания соседей канального уровня, так как он нейтрален в отношении производителя. Отметим, что VIRL предоставляет некий вариант для включения CDP, которой может сберечь вам некоторое время и аналогичен LLDP по функциональности; однако, он к тому же является собственностью Cisco:
Когда ваша лаборатория запущена и работает, перейдите к установке необходимых пакетов программного обеспечения.
Graphviz может быть получен с помощью apt:
$ sudo apt-get install graphviz
По завершению установки отметим, что определённым способом проверки является применение команды
dot:
$ dot -V
dot - graphviz version 2.38.0 (20140413.2041)
Мы будем применять обёртку Python для Graphviz, поэтому давайте установим её сейчас, пока мы в самом начале:
$ sudo pip install graphviz
$ sudo pip3 install graphviz
Давайте посмотрим как применять это программное обеспечение.
Как и у большинства проектов с открытым исходным кодом, Документация Graphviz очень обширна. Обычно является вызовом с чего начать. Для своей цели мы сосредоточимся на dot, которые напрямую рисует диаграммы в виде иерархии (не путать с уже упоминавшимся языком DOT).
Давайте начнём с основополагающих шагов:
-
Узлы представляют наши сетевые сущности, такие как маршрутизаторы, коммутаторы и серверы.
-
Рёбра представляют связи между имеющимися сетевыми сущностями.
-
Все диаграммы, узлы и рёбра, каждый из них имеет атрибуты, которые могут регулироваться.
-
После описания всей сетевой среды, выводится полученная диаграмма сети в одном из форматов - PNG, JPEG или PDF.
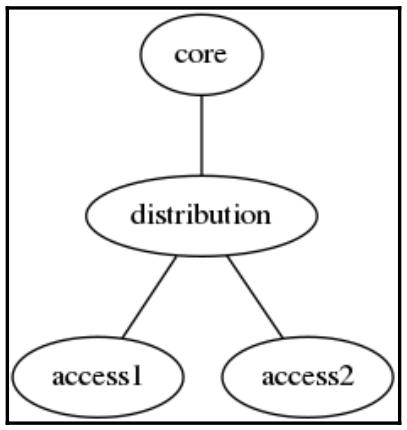
Наш первый пример заключается в неориентированном точечном графе, состоящим из четырёх узлов (ядра,
распределения, access1 и access2).
Имеющиеся рёбра соединяют узел ядра со своим узлом распределения, а узел распределения с обоими узлами
доступа:
$ cat chapter8_gv_1.gv
graph my_network {
core -- distribution;
distribution -- access1;
distribution -- access2;
}
Данная схема может быть отображена командной строкой
dot -T<format> source -o <output file>:
$ dot -Tpng chapter8_gv_1.gv -o output/chapter8_gv_1.png
Получаемая в результате диаграмма может быть просмотрена в следующем выводимом буклете:
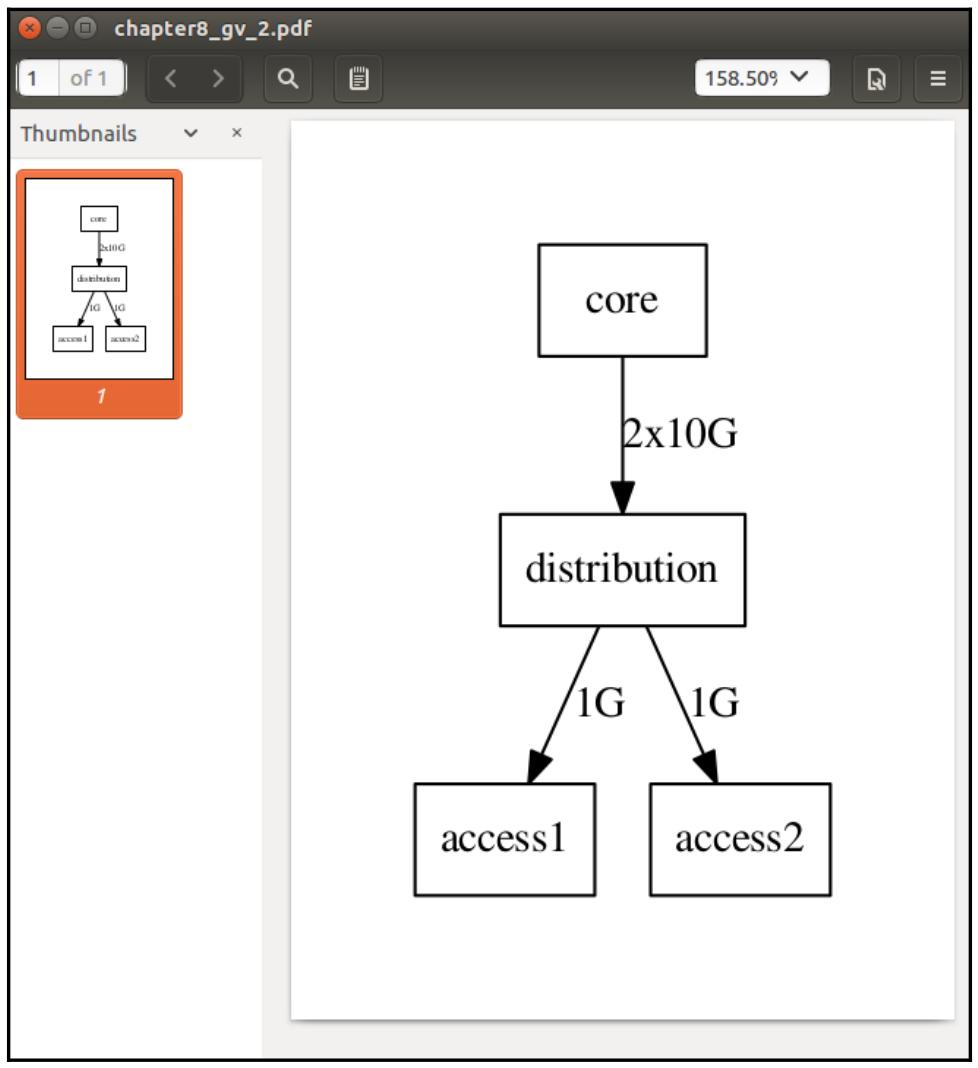
Отметим, что мы можем применять направленный граф, определяя его как некий ориентированный граф, вместо
обычного, также применяя символ стрелки направления (->) для
представления рёбер. Существуют различные атрибуты, которые мы можем изменять в случае узлов или рёбер,
например, форму, метки рёбер и тому подобное. Тот же самый граф может быть изменён следующим образом:
$ cat chapter8_gv_2.gv
digraph my_network {
node [shape=box];
size = "50 30";
core -> distribution [label="2x10G"];
distribution -> access1 [label="1G"];
distribution -> access2 [label="1G"];
}
На этот раз мы выведем свой файл в PDF:
$ dot -Tpdf chapter8_gv_2.gv -o output/chapter8_gv_2.pdf
Давайте взглянем на свой ориентированный граф в нашей новой диаграмме:
Теперь давайте рассмотрим свою обёртку Python вокруг Graphviz.
Мы можем повторить воспроизведение того жа самого графа топологии, что и рассматривали ранее, применив установленный нами пакет Python Graphviz:
$ python3
Python 3.5.2 (default, Nov 17 2016, 17:05:23)
>>> from graphviz import Digraph
>>> my_graph = Digraph(comment="My Network")
>>> my_graph.node("core")
>>> my_graph.node("distribution")
>>> my_graph.node("access1")
>>> my_graph.node("access2")
>>> my_graph.edge("core", "distribution")
>>> my_graph.edge("distribution", "access1")
>>> my_graph.edge("distribution", "access2")
Данный код в основном воспроизводит то, что мы бы обычно записали на языке определений DOT. Вы можете просмотреть его исходный код:
>>> print(my_graph.source)
// My Network
digraph {
core
distribution
access1
access2
core -> distribution
distribution -> access1
distribution -> access2
}
Данный граф может быть построен определённым файлом .gv;
его форматом является PDF:
>>> my_graph.render("output/chapter8_gv_3.gv")
'output/chapter8_gv_3.gv.pdf'
Пакет обёртки Python близко имитирует все имеющиеся параметры API для Grphviz. Вы можете найти документацию на его вебсайте. Вы также можете воспользоваться ссылкой на имеющиеся исходные коды на GitHub для получения дополнительной информации. Мы теперь можем воспользоваться имеющимися инструментами для построения карты своей сетевой среды.
В данном разделе мы воспользуемся своим примером установки соответствия LLDP соседей для иллюстрации неких шаблонов решения задач, которые помогали мне на протяжении многих лет:
-
По- возможности, разбивайте на модули каждую задачу более мелкими частями. В нашем примере мы можем объединять несколько этапов, однако, если мы разабъём их на меньшие куски, у нас будет лёгкая возможность повторно применять и улучшать их.
-
Пользуйтесь инструментами автоматизации для взаимодействия со своими сетевыми устройствами, однако оставляйте наиболее сложную логику на стороне своей управляющей станции. Например, маршрутизатор предоставил некий вывод LLDP соседей, который слегка беспорядочен. В данном случае мы останемся со своими рабочими командами и выводом и воспользуемся неким сценарием Python на своей станции управления для синтаксического разбора и получим тот вывод, который нам необходим.
-
Когда для одной и той же задачи представляется выбор, применяйте тот вариант, который можно использовать повторно. В нашем примере мы можем применять Pexpect, Paramiko или плейбук Ansible для опроса своих маршрутизаторов. По моему мнению, будет проще повторно применять в будущем Ansible, поэтому я выбираю именно его.
Чтобы начать, поскольку LLDP не включён на наших маршрутизаторах, нам потребуется вначале настроить его на
своих устройствах. На текущий момент, как мы знаем, у нас есть ряд вариантов из которых можно выбрать; я
останавливаюсь для данной задачи на плейбуке Ansible с имеющимся модулем ios_config.
Мой файл хостов состоит из пяти маршрутизаторов:
$ cat hosts
[devices]
r1 ansible_hostname=172.16.1.218
r2 ansible_hostname=172.16.1.219
r3 ansible_hostname=172.16.1.220
r5-tor ansible_hostname=172.16.1.221
r6-edge ansible_hostname=172.16.1.222
Наш плейбук cisco_config_lldp.yml состоит из одного воспроизведения
со встроенными в этот плейбук переменными для настройки необходимого LLDP:
<пропуск>
vars:
cli:
host: "{{ ansible_hostname }}"
username: cisco
password: cisco
transport: cli tasks:
- name: enable LLDP run
ios_config:
lines: lldp run
provider: "{{ cli }}"
<пропуск>
Через несколько секунд, необходимых для включения обмена LLDP, мы можем проверить что LLDP на самом деле активен в данном маршрутизаторе:
r1#show lldp neighbors
Capability codes: (R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable
Device (W) WLAN Access Point, (P) Repeater, (S) Station, (O) Other
Device ID Local Intf Hold-time Capability Port ID
r2.virl.info Gi0/0 120 R Gi0/0
r3.virl.info Gi0/0 120 R Gi0/0
r5-tor.virl.info Gi0/0 120 R Gi0/0
r5-tor.virl.info Gi0/1 120 R Gi0/1
r6-edge.virl.info Gi0/2 120 R Gi0/1
r6-edge.virl.info Gi0/0 120 R Gi0/0
Total entries displayed: 6
В своём выводе мы увидим что G0/0 настроен в виде интерфейса
MGMT; таким образом, вы можете видеть однораноговый LLDP, как если бы он был в некоторой сети управления
с единственным уровнем. Очём нам в действительности следует побеспокоиться, так это чтобы наши интерфейсы
G0/1 и G0/2 подключались к
другим одноранговым сетям. Это знание нам пригодится, поскольку мы готовимся выполнить синтаксический анализ
своего вывода и построить диаграмму своей топологии.
Получение информации
Мы можем теперь применить другой плейбук Ansible, а именно cisco_discover_lldp.yml,
чтобы выполнить свою команду LLDP для данного устройства и скопировать полученный вывод с каждого устройства в некий
каталог tmp:
<пропуск>
tasks:
- name: Query for LLDP Neighbors
ios_command:
commands: show lldp neighbors
provider: "{{ cli }}"
<пропуск>
Этот каталог ./tmp теперь содержит выводы всех маршрутизаторов
(отображающих LLDP соседей) в своих собственных файлах:
$ ls -l tmp/
total 20
-rw-rw-r-- 1 echou echou 630 Mar 13 17:12 r1_lldp_output.txt
-rw-rw-r-- 1 echou echou 630 Mar 13 17:12 r2_lldp_output.txt
-rw-rw-r-- 1 echou echou 701 Mar 12 12:28 r3_lldp_output.txt
-rw-rw-r-- 1 echou echou 772 Mar 12 12:28 r5-tor_lldp_output.txt
-rw-rw-r-- 1 echou echou 630 Mar 13 17:12 r6-edge_lldp_output.txt
Файл r1_lldp_output.txt содержит необходимую переменную
output.stdout_lines из нашего плейбука Ansible:
$ cat tmp/r1_lldp_output.txt
[["Capability codes:", " (R) Router, (B) Bridge, (T) Telephone, (C) DOCSIS Cable Device", " (W) WLAN Access Point, (P) Repeater, (S) Station, (O) Other", "", "Device ID Local Intf Hold-time Capability Port ID", "r2.virl.info Gi0/0 120 R Gi0/0", "r3.virl.info Gi0/0 120 R Gi0/0", "r5-tor.virl.info Gi0/0 120 R Gi0/0", "r5-tor.virl.info Gi0/1 120 R Gi0/1", "r6-edge.virl.info Gi0/0 120 R Gi0/0", "", "Total entries displayed: 5",""]]
Сценарий Python синтаксического анализа
Теперь мы можем воспользоваться неким сценарием Python для синтаксического анализа имеющегося вывода LLDP
соседей от каждого устройства и построить некий граф топологии сетевой среды из него. Цель состоит в
автоматической проверке устройства на предмет просмотра будет ли кто- либо из соседей LLDP пропадать из- за
отказов соединений или прочих проблем. Давайте взглянем на свой файл cisco_graph_lldp.py
и рассмотрим как он построен.
Мы начнём с необходимых импортов его пакетов - некоторого пустого списка, который мы будем пополнять
кортежами и взаимосвязями узлов. Мы также знаем, что Gi0/0 в наших
устройствах соединён с нашей управляющей сетью; таким образом, мы ищем только
Gi0/[1234] в качестве своего регулярного выражения для отображения вывода
LLDP соседей:
import glob, re
from graphviz import Digraph, Source
pattern = re.compile('Gi0/[1234]')
device_lldp_neighbors = []
Для обхода всех имеющихся файлов каталога ./tmp мы воспользуемся
своим методом glob.glob(), осуществим синтаксический анализ имён
устройств и обнаружим всех соседей, к которым подключено данное устройство. Имеется ряд встроенных выражений
печати в данном сценарии, которые были закрыты комментарием; если вы уберёте их, вы увидите то, чем мы хотели
завершить свои результаты синтаксического анализа:
device: r1
neighbors: r5-tor
neighbors: r6-edge
device: r5-tor
neighbors: r2
neighbors: r3
neighbors: r1
device: r2
neighbors: r5-tor
neighbors: r6-edge
device: r3
neighbors: r5-tor
neighbors: r6-edge
device: r6-edge
neighbors: r2
neighbors: r3
neighbors: r1
Полностью заполненный список рёбер содержит кортежи, которые состоят из самого устройства и его соседей:
Edges: [('r1', 'r5-tor'), ('r1', 'r6-edge'), ('r5-tor', 'r2'), ('r5-tor', 'r3'), ('r5-tor', 'r1'), ('r2', 'r5-tor'), ('r2', 'r6-edge'), ('r3', 'r5-tor'), ('r3', 'r6-edge'), ('r6-edge', 'r2'), ('r6-edge', 'r3'), ('r6-edge', 'r1')]
Теперь мы можем построить свой граф топологии, воспользовавшись имеющимся пакетом Graphviz. Наиболее важная часть состоит в распаковке всех кортежей, которые представляют эти взаимосвязи рёбер:
my_graph = Digraph("My_Network")
<пропуск>
# построение всех взаимосвязей рёбер
for neighbors in device_lldp_neighbors:
node1, node2 = neighbors
my_graph.edge(node1, node2)
Если бы вы распечатали свой результирующий исходный файл dot, он был бы точным представлением вашей сетевой среды:
digraph My_Network {
r1 -> "r5-tor"
r1 -> "r6-edge"
"r5-tor" -> r2
"r5-tor" -> r3
"r5-tor" -> r1
r2 -> "r5-tor"
r2 -> "r6-edge"
r3 -> "r5-tor"
r3 -> "r6-edge"
"r6-edge" -> r2
"r6-edge" -> r3
"r6-edge" -> r1
}
Однако, имеющееся размещение данных узлов будет слегка беспорядочным, поскольку они не упорядочиваются
автоматически. Приводимая ниже диаграмма иллюстрирует отрисовку в некоторой схеме по умолчанию, а также
определённую схему neato, а именно ориентированный граф
(My_Network, engine='neato'):
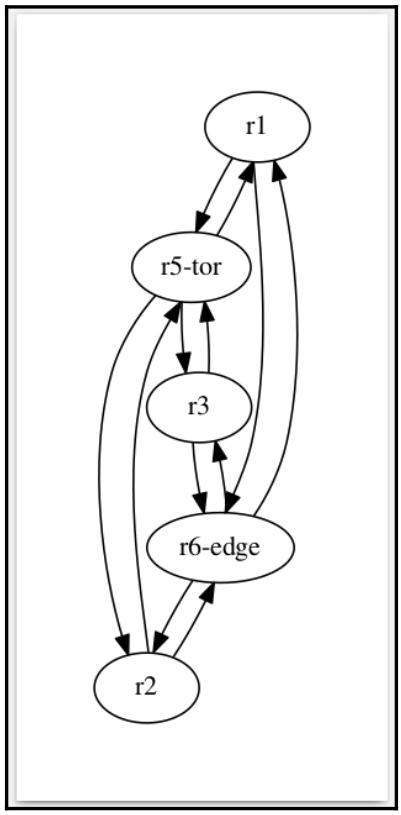
Схема neato представляет некую попытку нарисовать неориентированные
графы с даже меньшей иерархией:
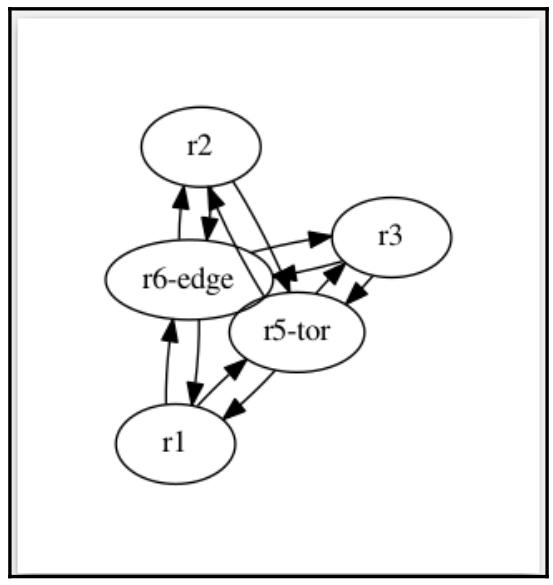
Иногда те схемы, которые предоставляют наши инструменты достаточно хороши, в особенности если ваша цель
состоит в определении отказа, а не в её визуализации. Однако ,в данном случае давайте рассмотрим как мы можем
вставить простые ручки управления языка DOT в свой исходный файл. По опыту мы знаем, что мы можем применять
команду уровня для определения того уровня, на котором могут находиться узлы. Однако, в API Python Graphviz
не представлены такие опции. К счастью, сам исходный файл dot является всего лиши строками, в которые можно
вставлять комментарии dot, применяя метод replace():
source = my_graph.source
original_text = "digraph My_Network {"
new_text = 'digraph My_Network {n{rank=same Client "r6-edge"}n{rank=same r1 r2 r3}n'
new_source = source.replace(original_text, new_text)
new_graph =
Source(new_source)new_graph.render("output/chapter8_lldp_graph.gv")
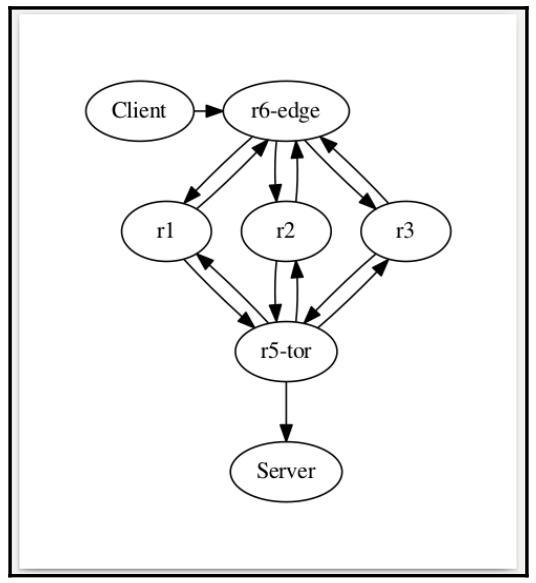
Окончательный результат состоит в новом исходном тексте, с которым мы можем нарисовать окончательный граф топологии:
digraph My_Network {
{rank=same Client "r6-edge"}
{rank=same r1 r2 r3}
Client -> "r6-edge"
"r5-tor" -> Server
r1 -> "r5-tor"
r1 -> "r6-edge"
"r5-tor" -> r2
"r5-tor" -> r3
"r5-tor" -> r1
r2 -> "r5-tor"
r2 -> "r6-edge"
r3 -> "r5-tor"
r3 -> "r6-edge"
"r6-edge" -> r2
"r6-edge" -> r3
"r6-edge" -> r1
}
Граф теперь достаточно хорош для представления:
Окончательный плейбук
Теперь мы готовы включить данный новый сценарий синтаксического разбора в наш плейбук. Мы можем сейчас
добавить определённые дополнительные задачи прорисовки нашего вывода с генерацией графа в
cisco_discover_lldp.yml:
- name: Execute Python script to render output
command: ./cisco_graph_lldp.py
Данный плейбук может в настоящее время управляться расписанием для регулярного исполнения посредством cron или прочими способами. Он будет автоматически опрашивать имеющиеся устройства на предмет LLDP соседей и выстраивать граф, а данный граф будет представлять текущую топологию известную вашим маршрутизаторам.
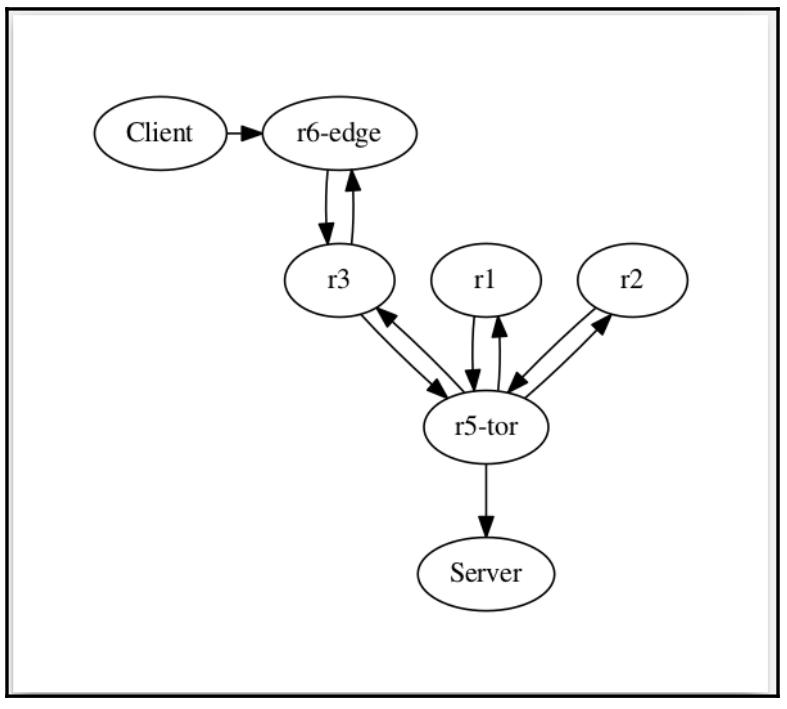
Мы можем проверить это, отключив свои интерфейсы Gi0/1 и
Gi0/2 на r6-edge, когда LLDP
соседство пройдёт время удержания и они исчезнут из имеющейся таблицы LLDP.
r6-edge#sh lldp neighbors
...
Device ID Local Intf Hold-time Capability Port ID
r2.virl.info Gi0/0 120 R Gi0/0
r3.virl.info Gi0/3 120 R Gi0/2
r3.virl.info Gi0/0 120 R Gi0/0
r5-tor.virl.info Gi0/0 120 R Gi0/0
r1.virl.info Gi0/0 120 R Gi0/0
Total entries displayed: 5
Полученный граф автоматически отобразит, что r6-edge соединён
только с r3.
Это достаточно продолжительный пример. Мы применили те инструменты, которые мы изучили на текущий момент в своей книге - Ansible и Python - чтобы делать модули и разбить задачи на повторно применяемые части. Затем мы воспользовались новым инструментом, а именно Graphviz, для помощи в мониторинге своей сетевой среды на предмет не являющихся последовательностями во времени данных, таких, как взаимоотношения в сетевой топологии.
Некий поток, как это определяет IETF, является некоторой последовательностью пакетов, перемещаемых от некоторого приложения, отправляющего нечто для того приложения, которое принимает их. Если мы вернёмся назад к модели OSI, некий поток это то, что составляет какой- то отдельный элемент взаимодействия между двумя приложениями. Каждый поток составляет некоторое число пакетов; некоторые потоки имеют много пакетов (например, видео- потоки), в то время как некоторые имеют всего несколько (например, какой- то запрос HTTP). Если вы задумаетесь на минутку о потоках, вы отметите, что маршрутизаторы и коммутаторы обязаны заботиться о пакетах и кадрах, однако сами приложение и пользователь обычно больше заинтересованы в потоках.
Основанный на потоках мониторинг, как правило, ссылается на NetFlow, IPFIX, and sFlow:
-
NetFlow: NetFlow v5 является технологией, при которой ваше сетевое устройство кэширует элементы потока и агрегирует пакеты соответствующим набором кортежей (интерфейс источника, IP/ порт источника, IP/ порт получателя и тому подобное). При этом, когда некий поток завершается, данное сетевое устройство экспортирует все характеристики этого потока, включая общее число байт и счётчик пакетов в таком потоке, на свою управляющую станцию.
-
IPFIX: IPFIX предлагается в качестве стандарта для структурированных потоков и аналогичен NetFlow v9, также имеющему называние Flexible NetFlow. По сути, именно он является тем определяемым экспортом потока, который позволяет определённому пользователю выполнять экспорт почти всего, о чём знает данное сетевое устройство. Однако, подобная гибкость зачастую достигается за счёт простоты; другими словами, это намного сложнее, нежели имеющийся обычный NetFlow. Дополнительная сложность делает его менее чем идеальным для первоначального обучения. Тем не менее, раз вы знакомы с NetFlow v5, вы будете способны выполнять синтаксический разбор IPFIX всякий раз, когда вы ставите в соответствие надлежащее определение шаблона.
-
sFlow: sFlow сам по себе, фактически, не имеет представления о каком бы то ни было потоке или агрегации пакетов. Он выполняет два типа выборки пакетов. Он случайным образом выбирает один из n пакетов/ приложений и имеет счётчики выборки на основании времени. Он отправляет получаемую информацию на свою управляющую станцию, а сама станция получает информацию о данном сетевом потоке, ссылаясь на тип образца пакета, получаемого совместно со счётчиками. Поскольку он не осуществляет агрегацию на самом сетевом устройстве, вы можете утверждать, что sFlow является более мосштабируемым в сравнении со всеми остальными.
Наиболее хорошим способом изучить каждый из них, скорее всего, заключается в том, чтобы погрузиться непосредственно в примеры.
МЫ можем воспользоваться Python для синтаксического разбора той дейтаграммы NetFlow, которая передаётся по нашему кабелю. Это снабдит нас неким способом более подробного рассмотрения пакета, а также отыскания любых возникающих в NetFlow проблем в случае, когда он не работает как ему полагается.
Для начала давайте выработаем какой- то обмен между нашими клиентом и сервером в своей сетевой среде VIRL. Мы можем воспользоваться имеющимся встроенным модулем сервера HTTP из Python для быстрого запуска простейшего сервера HTTP в своём хосте VIRL, выступающем в роли необходимого сервера:
cisco@Server:~$ python3 -m http.server
Serving HTTP on 0.0.0.0 port 8000 ...
|
| Совет |
|---|---|
|
Для Python 2 этот модуль имеет название |
Мы можем создать некий короткий цикл для непрерывной отправки HTTP GET на свой веб сервер с данного клиента:
sudo apt-get install python-pip python3-pip
sudo pip install requests
sudo pip3 install requests
$ cat http_get.py
import requests, time
while True:
r = requests.get('http://10.0.0.5:8000')
print(r.text)
time.sleep(5)
Наш клиент должен получить очень простую страницу HTML:
cisco@Client:~$ python3 http_get.py
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 3.2 Final//EN"><html>
<title>Directory listing for /</title>
<body>
...
</body>
</html>
Мы должны наблюдать определённые запросы, которые непрерывно повторяются с нашего клиента каждые 5 секунд:
cisco@Server:~$ python3 -m http.server
Serving HTTP on 0.0.0.0 port 8000 ...
10.0.0.9 - - [15/Mar/2017 08:28:29] "GET / HTTP/1.1" 200 -
10.0.0.9 - - [15/Mar/2017 08:28:34] "GET / HTTP/1.1" 200 -
Мы можем экспортировать NetFlow с любого из своих устройств, однако поскольку r6-edge
является самым первым прыжком для нашего хоста клиента, мы заставим этот хост экспортировать NetFlow на
свой хост управления по порту 9995.
|
| Совет |
|---|---|
|
В данном примере мы применяем только одно устройство для демонстрации, таким образом мы вручную настраиваем его при помощи необходимых команд. В следующем разделе, когда мы включим NetFlow на всех своих устройствах, мы воспользуемся плейбуком Ansible. |
!
ip flow-export version 5
ip flow-export destination 172.16.1.173 9995 vrf Mgmt-intf
!
interface GigabitEthernet0/4
description to Client
ip address 10.0.0.10 255.255.255.252
ip flow ingress
ip flow egress
...
!
Далее мы рассмотрим необходимый сценарий синтаксического анализа Python.
Сокет и структура Python
Наш сценарий netFlow_v5_parser.py был изменён в
посте
блога Брайана Рэка; это было сделано в основном для совместимости
с Python 3, а также для дополнительных полей NetFlow версии 5. Та причина, по которой применяется v5 вместо v9
состоит в большей сложности v9, поскольку он вводит шаблоны; тем самым, он предоставит очень трудное для
быстрого усвоения введение в NetFlow. Поскольку версия 9 NetFlow является неким расширенным форматом своей
первоначальной версии 5, все понятия, вводимые в данном разделе, приемлемы и для него.
Так как пакеты NetFlow представляются байтами в нашем кабеле, мы будем применять структурный модуль, содержащийся в имеющейся стандартной библиотеке для преобразования байт в натуральные типы данных Python.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Вы можете найти дополнительную информацию по двум применяемым модулям по ссылкам socket и struct. |
Сы также начнём применять данный модуль socket для привязке и ожидания своих дейтаграмм UDP. С помощью
socket.AF_INET мы намереваемся выполнять ожидание по определённому
IPv4 адресу; посредством socket.SOCK_DGRAM мы определяем, что мы будем
видеть все дейтаграммы UDP:
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
sock.bind(('0.0.0.0', 9995))
Мы запустим некий цикл и будем выбирать из своего кабеля информацию:
while True:
buf, addr = sock.recvfrom(1500)
Следующая строка является тем местом, в котором мы начнём перестраивать или распаковывать полученный пакет.
Самый первый аргумент !HH определяет имеющийся в сетевой среде обратный
(big-endian) порядок байт определяемым восклицательным знаком (big-endian), а также необходимый формат типа C
(H=2 короткое целое байт без знака):
(version, count) = struct.unpack('!HH',buf[0:4])
Если вы не помните структуру заголовка NetFlow версии 5 в верхушке свей головы (что, между прочим, является шуткой), вы всегда можете обратиться по ссылке чтобы быстро освежить её. Остающаяся часть данного заголовка может быть разобрана аналогично и зависит от местоположения определённого байта и типа данных:
(sys_uptime, unix_secs, unix_nsecs, flow_sequence) = struct.unpack('!IIII', buf[4:20])
(engine_type, engine_id, sampling_interval) = struct.unpack('!BBH', buf[20:24])
Последующий цикл while заполнит необходимый словарь nfdata
соответствующей записью потока, которая распаковывает полученные адрес и порт источника, адрес и порт получателя,
счётчик пакета и выводит эту информацию на экран:
for i in range(0, count):
try:
base = SIZE_OF_HEADER+(i*SIZE_OF_RECORD)
data = struct.unpack('!IIIIHH',buf[base+16:base+36])
input_int, output_int = struct.unpack('!HH', buf[base+12:base+16])
nfdata[i] = {}
nfdata[i]['saddr'] = inet_ntoa(buf[base+0:base+4])
nfdata[i]['daddr'] = inet_ntoa(buf[base+4:base+8])
nfdata[i]['pcount'] = data[0]
nfdata[i]['bcount'] = data[1]
...
Вывод данного сценария позволяет нам визуализировать сам заголовок, а также имеющееся в потоке содержимое для одного взгляда:
Headers:
NetFlow Version: 5
Flow Count: 9
System Uptime: 290826756
Epoch Time in seconds: 1489636168
Epoch Time in nanoseconds: 401224368
Sequence counter of total flow: 77616
0 192.168.0.1:26828 -> 192.168.0.5:179 1 packts 40 bytes
1 10.0.0.9:52912 -> 10.0.0.5:8000 6 packts 487 bytes
2 10.0.0.9:52912 -> 10.0.0.5:8000 6 packts 487 bytes
3 10.0.0.5:8000 -> 10.0.0.9:52912 5 packts 973 bytes
4 10.0.0.5:8000 -> 10.0.0.9:52912 5 packts 973 bytes
5 10.0.0.9:52913 -> 10.0.0.5:8000 6 packts 487 bytes
6 10.0.0.9:52913 -> 10.0.0.5:8000 6 packts 487 bytes
7 10.0.0.5:8000 -> 10.0.0.9:52913 5 packts 973 bytes
8 10.0.0.5:8000 -> 10.0.0.9:52913 5 packts 973 bytes
Отметим, что в NetFlow версии 5 сам размер его записи фиксирован в 48 байт; таким образом, приводимые цикл и сценарий относительно незатейливы. Однако, в случае с NetFlow версии 9 или IPFIX, сразу после заголовка, имеется некий шаблон FlowSet, который определяет необходимые счётчик поля, тип поля и длину поля. Это делает возможным определённому коллектору выполнять анализ полученных данных без предварительного знания самого формата данных.
Как вы можете себе представить, имеются прочие инструменты, которые уберегут нас от определённых проблем последовательного разбора записей NetFlow. Давайте взглянем на одно из таких средств с названием ntop в нашем следующем разделе.
Также как и в случае с SNMP в нашей предыдущей главе, мы можем воспользоваться сценариями Python и прочими инструментами для непосредственного опроса своего устройства. Однако существуют средства наподобии Cacti, которые представляют собой пакет с открытым исходным кодом всё- в- одном и содержат сбор данных (poller), хранение данных (RRD), а также веб интерфейс для визуализации.
В данном случае с NetFlow имеется целый ряд сборщиков NetFlow как с открытым исходным кодом, так и в коммерческом исполнении, которыми вы можете воспользоваться. Если вы выполните быстрый поиск для "top N open source NetFlow analyzer" (10 из самых распространённых анализаторов NetFlow с открытым исходным кодом), вы обнаружите целый ряд студий сравнения для различных инструментов. Каждая из них имеет свои собственные сильные и слабые стороны; какую именно применять, на самом деле зависит от предпочтений, платформы и вашего аппетита для персонализации. Я бы порекомендовал выбрать некий инструмент, который поддерживает и v5, и v9, а также потенциально и sFlow. Неким вторым моментом, подлежащим рассмотрению был бы тот факт как язык, на котором написано данное средство, который вы можете понимать; мне представляется, что наличие расширяемости под Python было бы неплохой штукой.
Двумя инструментами NetFlow с открытым исходным кодом, которые мне нравятся, и которые я применял ранее, это NfSen (с NFDUMP в качестве сервера коллектора) и ntop (или ntopng). Из этих двоих, ntop является более известным анализатором обмена; он работает как на платформах Windows, так и на платформах Linux и хорошо интегрирован с Python. Итак, давайте попробуем в качестве примера для данного раздела ntop.
Его установка на наш хост Ubuntu достаточно прямолинейна:
$ sudo apt-get install ntop2
Данный поцесс установки запросит необходимые интерфейс для ожидания и ваш пароль администратора. По
умолчанию сам веб интерфейс ntop прослушивает порт 3000, в то время как
имеющийся детектор отслеживает UDP порт 5556. В своём сетевом устройстве
нам понадобится определить необходимое местоположение самого проводника NetFlow:
!
ip flow-export version 5
ip flow-export destination 172.16.1.173 5556 vrf Mgmt-intf
!
|
| Замечание |
|---|---|
|
По умолчанию IOSv создаёт некий VRF с названием |
Нам также необходимо определить какое направление обмена экспортировать, например вход или выход (ingress или egress) в своей настройке интерфейса:
!
interface GigabitEthernet0/0
...
ip flow ingress
ip flow egress
...
В качестве справки для вас, я включил свой плейбук Ansible, cisco_config_netflow.yml,
в настройку своего лабораторного устройства для данного экспорта NetFlow.
|
| Замечание |
|---|---|
|
По умолчанию IOSv создаёт некий VRF с названием |
Когда всё настроено, вы можете проверить веб интерфейс ntop для локального обмена IP:
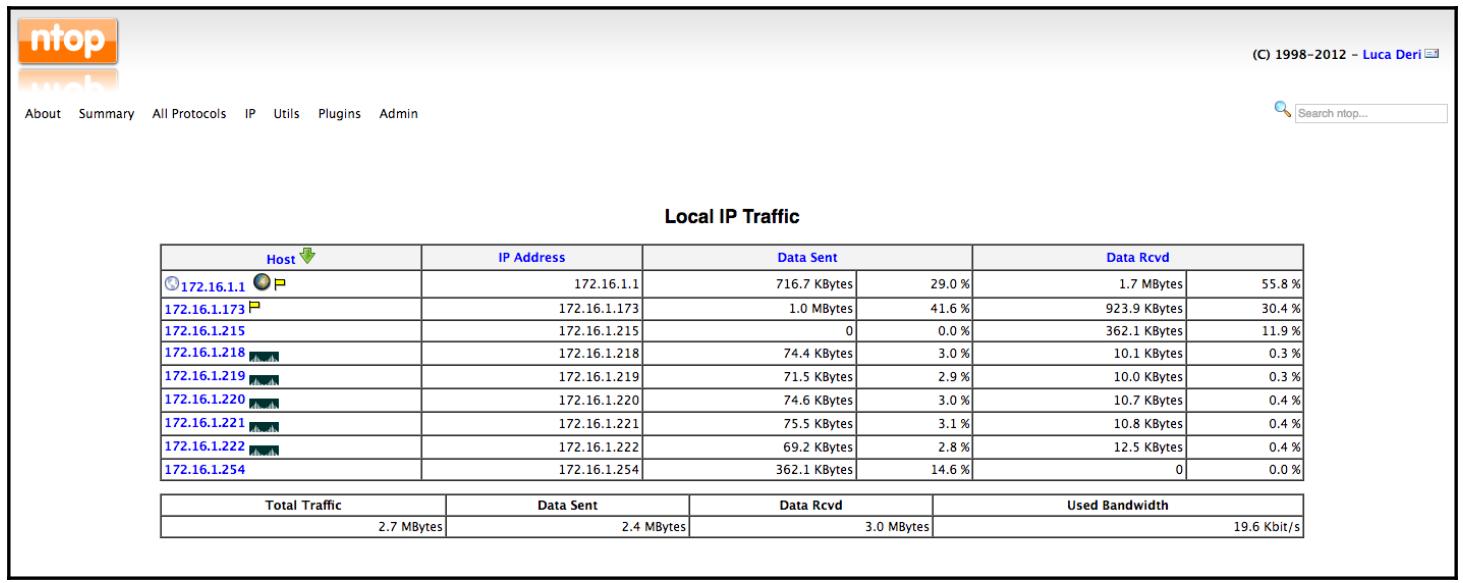
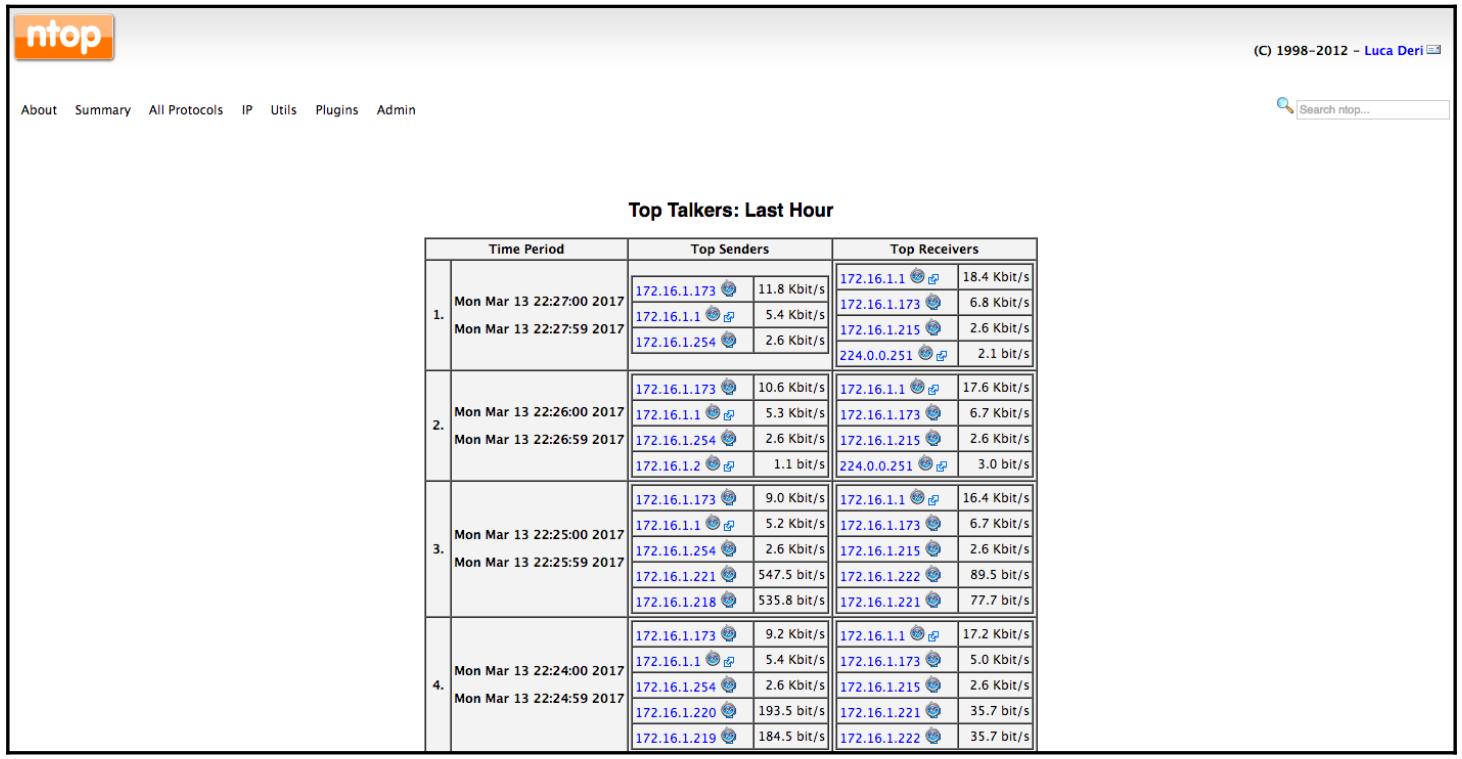
Одним из наиболее часто применяемых свойств ntop является его использование для просмотра самых востребованных графиков общения:
Механизм отчётов ntop написан на C; он быстрый и эффективный, однако потребность иметь соответствующие навыки C чтобы вносить правки в имеющийся веб интерфейс не отвечают современному динамичному складу ума разработчика. После нескольких неудачных стартов с Perl в середине 2000-х, основной честной народ в ntop, в конце концов закрепился на встроенном Python в качестве некоторого расширяющего механизма сценариев. Давайте рассмотрим его.
Расширение Python для ntop
Мы можем применять Python для расширения ntop через его веб сервер. Веб сервер ntop может исполнять сценарии Python. На некотором верхнем уровне, такой сценарий осуществляет следующее:
-
Методы для доступа к определённым состояниям ntop
-
Модуль CGI Python для обработки форм и параметров URL
-
Создание шаблонов, которые вырабатывают динамические страницы HTML
-
Каждый сценарий Python может считывать из
stdinи осуществлять вывод вstdout/stderr -
Сам
stdoutсценария является возвращаемой страницей HTTP
Имеется ряд ресурсов, которые пригодятся при интеграции с Python. В имеющемся веб интерфейсе вы кликаете по About | Show Configuration чтобы посмотреть версию интерпретатора Python, а также местоположение каталога для ваших сценариев Python:

Вы также можете проверить различные каталоги в которых должны располагаться необходимые сценарии Python:

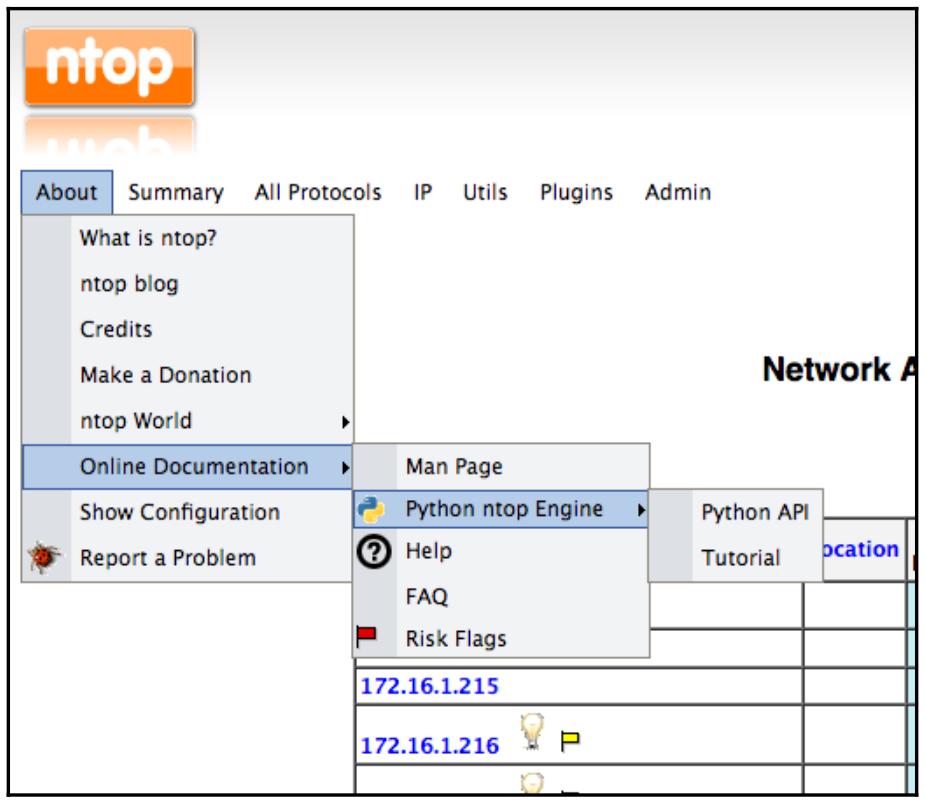
В About | Online Documentation | Python ntop Engine имеются ссылки на API Python, а также основное руководство:
Как уже упоминалось, имеющийся веб сервер ntop напрямую исполняет те сценарии Python, которые помещаются в обозначенный каталог:
$ pwd
/usr/share/ntop/python
Мы поместим в этот каталог свой первый сценарий, а именно chapter8_ntop_1.py.
Модуль CGI Python обработает формы и выполнит разбор параметров URL:
# Импорт модулей для обработки CGI
import cgi, cgitb
import ntop
# Разбор URL
cgitb.enable();
ntop реализует три модуля Python; каждый из них имеет свои определённые цели:
-
ntop: Взаимодействует с самим механизмом ntop
-
Host: Применяется для проникновения вглубь определённой для хоста информации
-
Interfaces: Это необходимая информация для экземпляров ntop
В нашем сценарии мы применим свой модуль ntop для выборки информации своего механизма ntop, а также
воспользуемся методом sendString() для отправки самого текста
тела HTML:
form = cgi.FieldStorage();
name = form.getvalue('Name', default="Eric")
version = ntop.version()
os = ntop.os()
uptime = ntop.uptime()
ntop.printHTMLHeader('Mastering Pyton Networking', 1, 0)
ntop.sendString("Hello, "+ name +"
")
ntop.sendString("Ntop Information: %s %s %s" % (version, os, uptime))
ntop.printHTMLFooter()
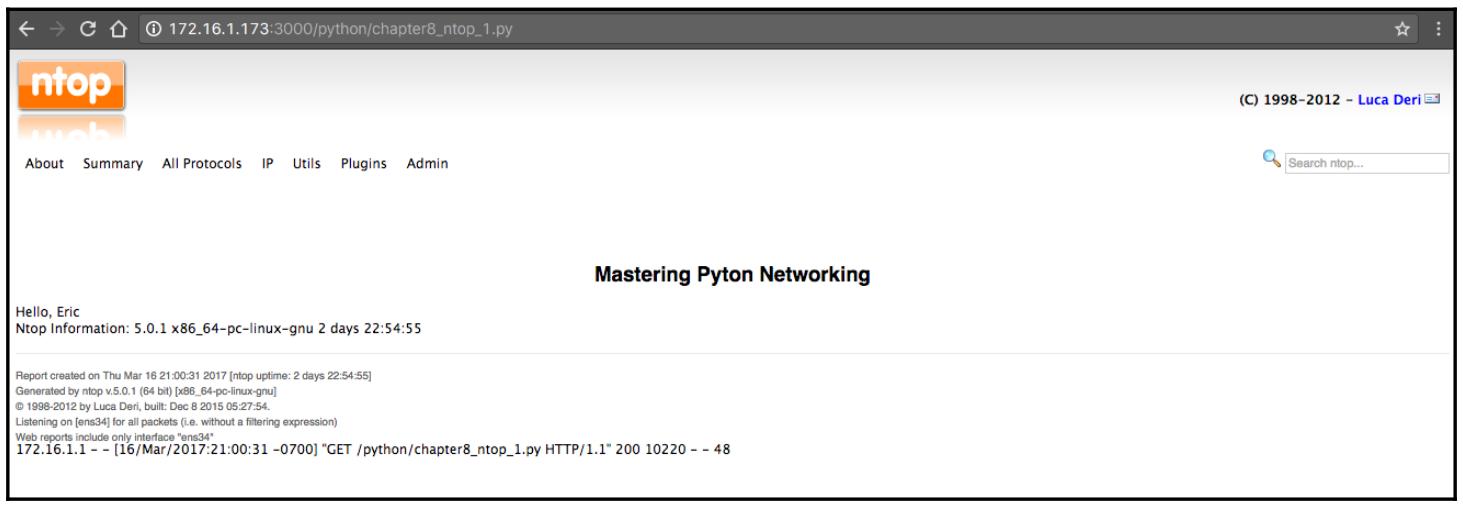
Мы будем исполнять свой сценарий Python при помощи http://<ip>:3000/python/<script name>.
Вот результат нашего сценария chapter8_ntop_1.py:
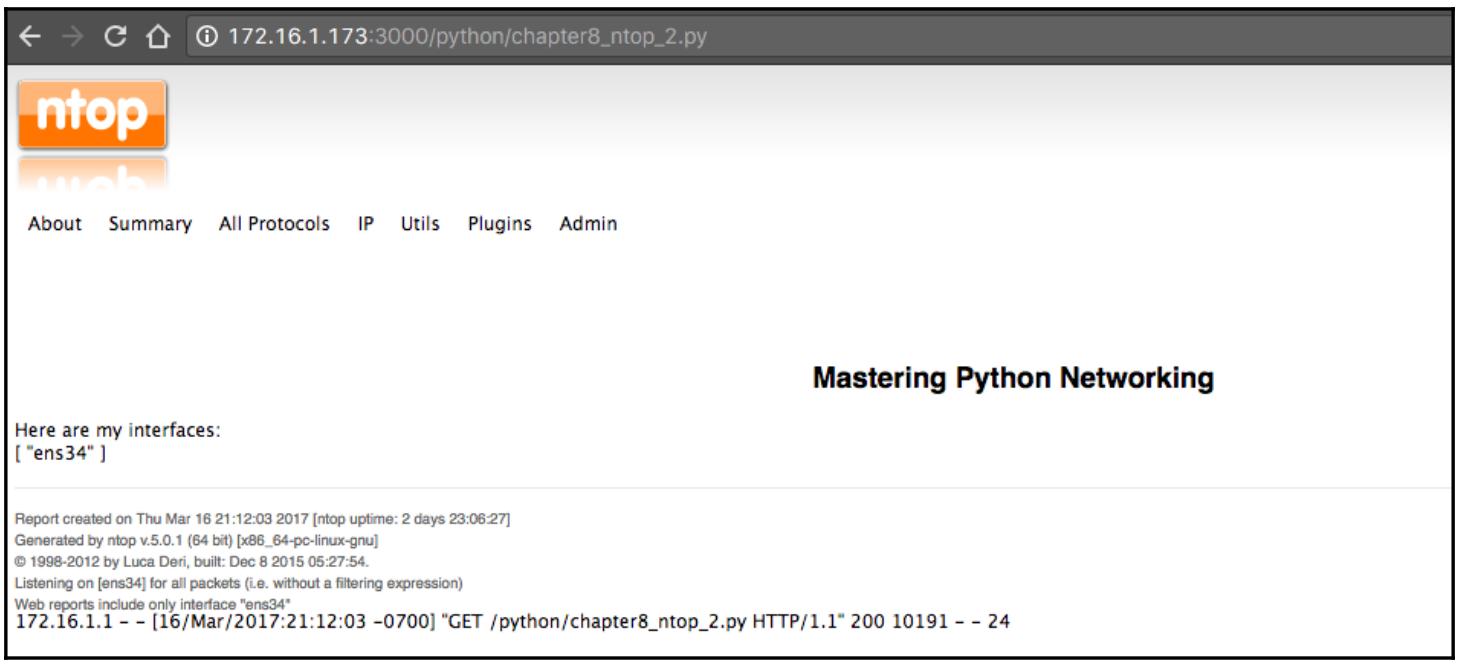
Мы можем взглянуть на другой пример, который взаимодействует с нашим модулем интерфейса chapter8_ntop_2.py.
Мы воспользуемся имеющимся API для итеративного прохода по всем интерфейсам:
import ntop, interface, json
ifnames = []
try:
for i in range(interface.numInterfaces()):
ifnames.append(interface.name(i))
except Exception as inst:
print type(inst) # the exception instance
print inst.args # arguments stored in .args
print inst # __str__ allows args to printed directly
...
Вот получаемая в результате страница, которая отображает все интерфейсы ntop:
Помимо распространяемой сообществом версии, также предоставляются коммерческие продукты, если вам необходима поддержка. Имея своё активное сообщество открытого исходного кода, коммерческую поддержку, а также расширения Python, ntop является хорошим выбором для ваших потребностей сетевого мониторинга NetFlow.
Далее давайте взгляним на кузена NetFlow: sFlow.
sFlow, позиционируемый для упрощённых потоков, первоначально был разработан InMon, а позже был стандартизован посредством RFC. Текущей является верия v5. Самым первым преимуществом для аргументации sFlow является масштабируемость. sFlow использует случайным образом один из n пакетов потока в качестве образца наряду с установкой интервала опроса счётчика образцов для извлечения некоторой оценки общего обмена; то есть менее интенсивный в отношении ЦПУ чем NetFlow. Статистическая выборка sFlow интегрируется совместно с имеющимся оборудованием и обеспечивает сырой экспорт в реальном масштабе времени.
По соображениям масштабируемости и большей конкурентности, sFlow обычно более предпочтителен, чем NetFlow для более новых производителей, таких как Arista Networks, Vyatta и A10 Networks. Хотя Cisco поддерживает sFlow в своей платформе Nexus 3000, sFlow обычно не поддеживается в платформах Cisco.
SFlowtool и sFlow-RT с применением Python
К нашему несчастью, на данный момент sFlow является чем- то, что не поддерживают наши лабораторные устройства VIRL. Вы может либо воспользоваться каким- то коммутатором Cisco Nexus 3000, или коммутатором другого производителя, например, Arista, который поддерживает sFlow. Други неплохим вариантом для нашей лаборатории является применение некоего виртуального диспетчера Arista vEOS. Мне посчастливилось иметь коммутатор Cisco Nexus 3048 под управлением 7.0 (3), котрый я буду использовать в данном разделе.
Настройка Cisco Nexus 3000 для sFlow является прямолинейной:
Nexus-2# sh run | i sflow
feature sflow
sflow max-sampled-size 256
sflow counter-poll-interval 10
sflow collector-ip 192.168.199.185 vrf management
sflow agent-ip 192.168.199.148
sflow data-source interface Ethernet1/48
Самый простой способ применения sFlow это воспользоваться sflowtool. Отсылаем к http://blog.sflow.com/2011/12/sflowtool.html, который предоставляет простые инструкции по его установке:
$ wget http://www.inmon.com/bin/sflowtool-3.22.tar.gz
$ tar -xvzf sflowtool-3.22.tar.gz
$ cd sflowtool-3.22/
$ ./configure
$ make
$ sudo make install
После такой установки вы можете запустить sFlow и взглянуть на те дейтаграммы, которые отправляет Nexus 3048:
$ sflowtool
startDatagram =================================
datagramSourceIP 192.168.199.148
datagramSize 88
unixSecondsUTC 1489727283
datagramVersion 5
agentSubId 100
agent 192.168.199.148
packetSequenceNo 5250248
sysUpTime 4017060520
samplesInPacket 1
startSample ----------------------
sampleType_tag 0:4
sampleType COUNTERSSAMPLE
sampleSequenceNo 2503508
sourceId 2:1
counterBlock_tag 0:1001
5s_cpu 0.00
1m_cpu 21.00
5m_cpu 20.80
total_memory_bytes 3997478912
free_memory_bytes 1083838464
endSample ----------------------
endDatagram =================================
В репозитории GitHub sflowtool
имеется целый ряд хороших примеров использования; один из них состоит в применении некоего сценария для
получения самого ввода sflowtool и синтаксического разбора его вывода. Для этой цели мы можем применить
некий сценарий Python. В своём примере chapter8_sflowtool_1.py мы будем
использовать sys.stdin.readline для приёма получаемого ввода и поиск
регулярным выражением для печати только тех строк, которые содержат слово
agent, когда мы видим своего агента sFlow:
import sys, re
for line in iter(sys.stdin.readline, ''):
if re.search('agent ', line):
print(line.strip())
Вывод может быть перенаправлен через конвейер в sflowtool:
$ sflowtool | python3 chapter8_sflowtool_1.py
agent 192.168.199.148
agent 192.168.199.148
Имеется множество прочих полезных примеров вывода, таких как tcpdump,
выводящий записи подобные NetFlow версии 5, а также некий компактный построчный вывод.
Ntop поддерживает sFlow, что означает, что вы можете напрямую экспортировать своих получаетелей sFlow в
определённый коллектор ntop. Если вашим коллектором является NetFlow, вы вожете воспользоваться параметром
-c для своего вывода в формате NetFlow врсии 5:
NetFlow output:
-c hostname_or_IP - (netflow collector host)
-d port - (netflow collector UDP port)
-e - (netflow collector peer_as (default = origin_as))
-s - (disable scaling of netflow output by sampling rate)
-S - spoof source of netflow packets to input agent IP
Как альернатива, вы таже можете применять sFlow-RT InMon в качестве своего механизма аналитики sFlow. Что отличает sFlow-RT от точки зрения оператора - это обширный APi REST, который можно настраивать индивидуально для поддержки ваших вариантов применения. Вы также легко можете осуществлять выемку всех измерений из такого API. Вы можете ознакомиться с его обширным API по ссылке.
Отметим, что для работы sFlow-RT требуется исполнить Java следующим образом:
$ sudo apt-get install default-jre
$ java -version
openjdk version "1.8.0_121"
OpenJDK Runtime Environment (build 1.8.0_121-8u121-b13-0ubuntu1.16.04.2-b13)
OpenJDK 64-Bit Server VM (build 25.121-b13, mixed mode)
После установки выгрузка и исполнение sFlow-RT получаются простыми:
$ wget http://www.inmon.com/products/sFlow-RT/sflow-rt.tar.gz
$ tar -xvzf sflow-rt.tar.gz
$ cd sflow-rt/
$ ./start.sh
2017-03-17T09:35:01-0700 INFO: Listening, sFlow port 6343
2017-03-17T09:35:02-0700 INFO: Listening, HTTP port 8008
Вы можете указать своему веб браузеру порт HTTP 8008 и проверить
выполнение установки:
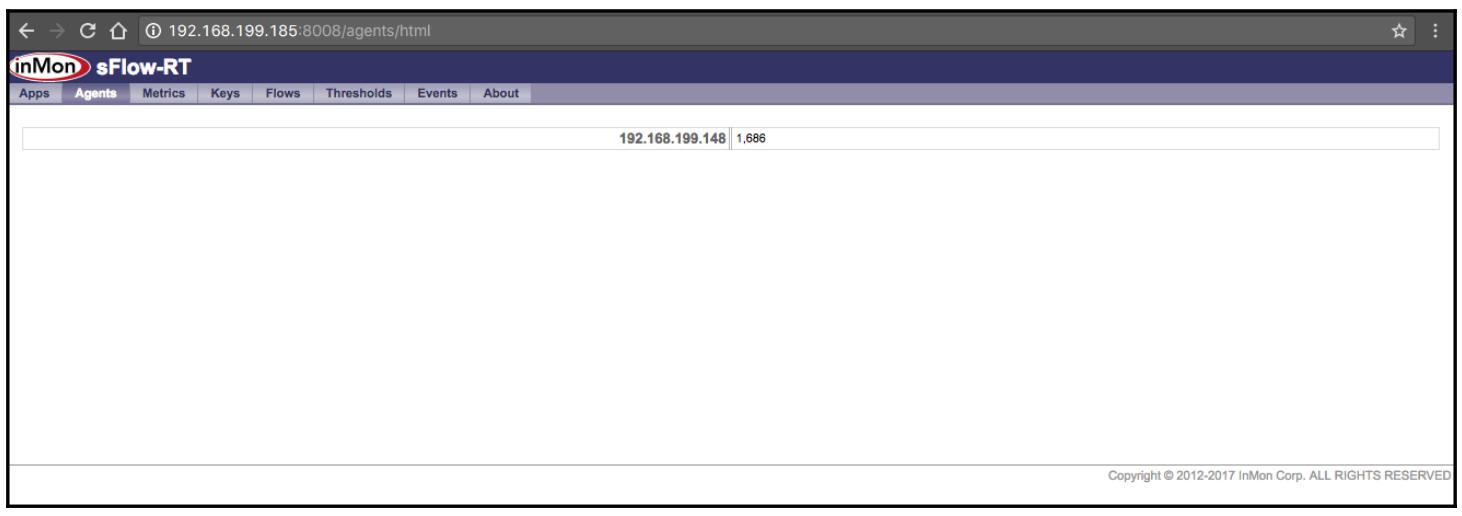
Поскольку sFlow получает пакеты sFlow, появятся сам агенти прочие измерения:
Вот два примера использования запросов для выборки информации из sFlow-RT:
>>> import requests
>>> r = requests.get("http://192.168.199.185:8008/version")
>>> r.text
'2.0-r1180'
>>> r = requests.get("http://192.168.199.185:8008/agents/json")
>>> r.text
'{"192.168.199.148": {n "sFlowDatagramsLost": 0,n "sFlowDatagramSource": ["192.168.199.148"],n "firstSeen": 2195541,n "sFlowFlowDuplicateSamples": 0,n "sFlowDatagramsReceived": 441,n "sFlowCounterDatasources": 2,n "sFlowFlowOutOfOrderSamples": 0,n "sFlowFlowSamples": 0,n "sFlowDatagramsOutOfOrder": 0,n "uptime": 4060470520,n "sFlowCounterDuplicateSamples": 0,n "lastSeen": 3631,n "sFlowDatagramsDuplicates": 0,n "sFlowFlowDrops": 0,n "sFlowFlowLostSamples": 0,n "sFlowCounterSamples": 438,n "sFlowCounterLostSamples": 0,n "sFlowFlowDatasources": 0,n "sFlowCounterOutOfOrderSamples": 0n}}'
Обратитесь к своей справочной документации по дополнительным терминальным пунктам REST, доступным для ваших потребностей. Далее мы рассмотрим другой инструмент, а именно Elasticsearch, который становится достаточно популярным как для индексации системного журнала, так и для общего сетевого мониторинга.
Как мы уже видели ранее в этой главе, простое применение имеющихся инструментов Python, которое мы выполняли, будет равносильно мониторингу вашей сетевой среды с достаточной масштабируемостью для любых типов сетевых сред, как крупных, так и небольших. Однако, я бы хотел ввести один дополнительный механизм с открытым исходным кодом для широкого применения, распространения, поиска и аналитики с названием Elasticsearch. Он также часто называется стеком Elastic или ELK для объединения с имеющимся интерфейсом и инструментами ввода.
Если вы рассмотрите сетевой мониторинг в целом, он в действительности занимается анализом сетевых данных и осуществлением вывода на его основании. Данный стек ELK состоит из Elasticsearch, Logstash и Kibana в виде полного стека для поглощения информации с помощью Logstash, индексации и анализа данных посредством Elasticsearch, а также представления её графического вывода через Kibana. Именно эти три проекта в одном представляют гибкость подстановки Logstashс прочими вводами, например, Beats. В качестве альтернативы вы можете применять для визуализации иные средства, такие как Grafana, вместо Kibana. Данный стек ELK от Elastic Co. также предоставляет множество добавляемых инструментов, которые называются X-Pack, для дополнительных свойств безопасности, уведомлений, мониторинга и тому подобного.
Как вы могли вероятно понять по его описанию, ELK (и даже Elasticsearch в отдельности) являются глубокой темой для изучения и имеется множество книг, написанных по этму предмету. Даже охват основных вариантов применения потребует намного больше места, чем мы можем выделить в данной книге. Порой я полагал оставить данный предмет за бортом данной книги из- за его глубины. Однако, ELK стал очень важным инструментом для многих проектов с которыми я работаю, включая и сетевой мониторинг. Я чувствую, что его исключение было бы гигантской проблемой для вас.
Итак, я собираюсь занять несколько страниц на краткое введение в этот инструментарий и несколько вариантов применения поимо той информации для вас как погрузиться глубже, если это необходимо. Мы пройдём следующие темы:
-
Установка некоторой хостинга службы ELK
-
Основной формат Logstash
-
Вспомогательный сценарий Python для форматирования Logstash
Весь полный стек ELK может быть установлен как некий отдельный сервер или распределяться по множеству серверов. Сами этапы установки доступны в https://www.elastic.co/guide/en/elastic-stack/current/installing-elastic-stack.html. По моему опыту, даже с минимальным объёмом данных некая отдельная ВМ, исполняющая стек ELK часто вытягивает все ресурсы. Моя первая попытка исполнения ELK в качестве некоторой одиночной ВМ длилась не более нескольких дней, причём всего лишь два или три сетевых устройства отправляли в неё информацию журнала. После ещё нескольких неудачных попыток запуска своего собственного кластера в качестве начинающего, я в конце концов решил запустить свой стек ELK как размещённую службу и именно с этого я бы рекомендовал вам начать.
Вы можете рассмотреть двух поставщиков в качестве службы размещения:
В настоящее время AWS предлагает некий свободный уровень, с которого просто начать и который тесно интегрирован с имеющимся в настоящее время комплексом набора ис=нструментария AWS, такого как службы идентификации и лямбда функции. Однако, Служба Elasticsearch AWS не имеет всех самых последних функций в сравнении с Elastic Cloud, а также не имеет такой интеграции, как X-Pack. Так как AWS предлагает некий бесплатный уровень, моей рекомендацией было бы начать со службы Elasticsearch AWS. Если впоследствии вы обнаружите, что вам требуется больш функциональности, чем то, что уже предоставляет AWS, вы всегда можете перейти в Elastic Cloud.
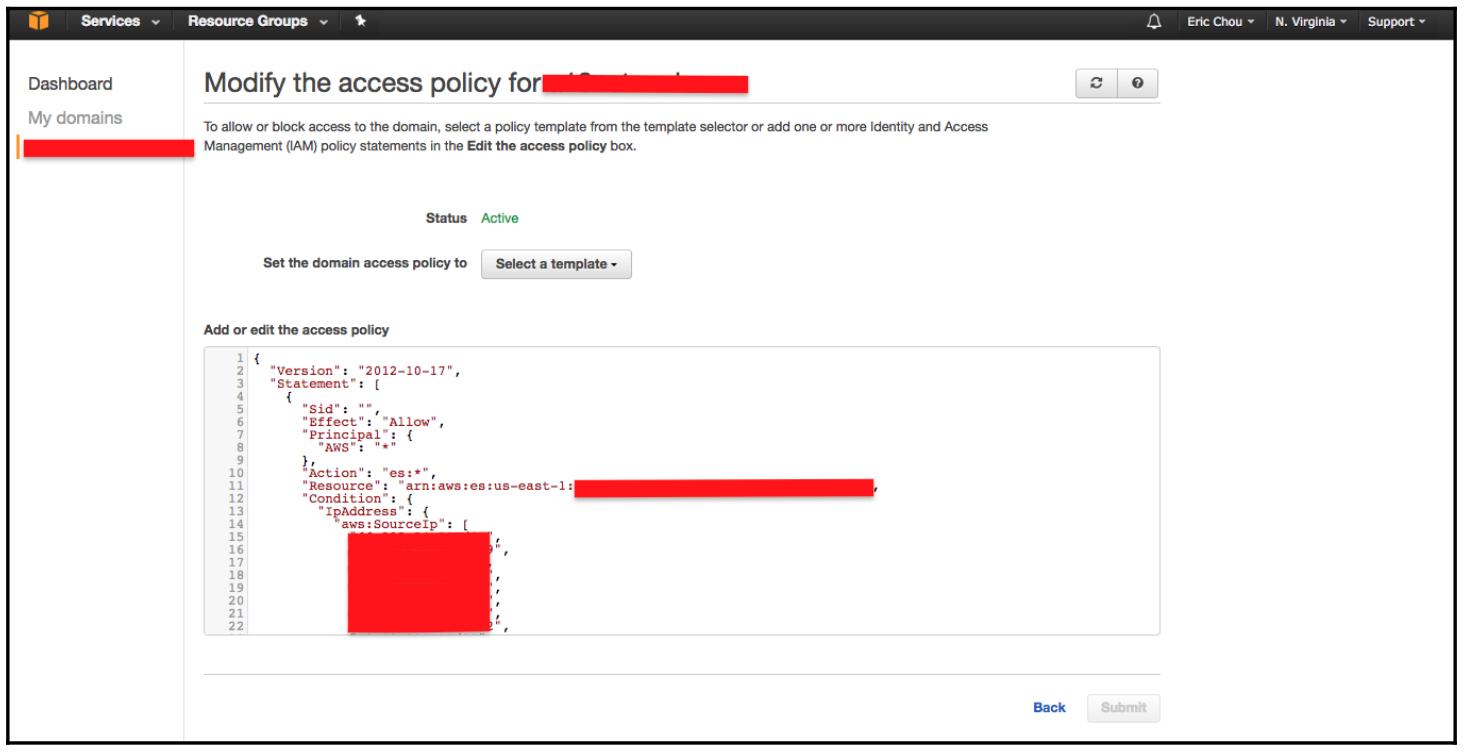
Установка этой службы достаточно непосредственна; вам всего лишь нужно выбрать свой регион и название вашего первого домена. После их установки вы можете применить имеющуюся политику для ограничения ввода посредством некого IP адреса; убедитесь, что именно этот IP видит AWS в качестве IP вашего источника (задайте свой общедоступный корпоративный IP, если IP адрес вашего хоста транслируется под NAT межсетевого экрана):
Logstash может быть установлен там, куда вам удобно отправлять свои сетевые журналы. Все шаги установки
доступны по ссылке. По умолчанию вы можете поместить основной файл настройки Logstash в
/etc/logstash/conf.d/. Этот файл представлен в формате ввод- фильтр- вывод
(подробнее). В приводимом далее примере мы определили свой ввод в качестве некоторого файла
сетевого журнала с неким держателем места для фильтрации ввода, а нашим выводом является и распечатка сообщений
на нашу консоль, а также наличие самого вывода, экспортируемого в наш экземпляр Службы Elasticsearch AWS:
input {
file {
type => "network_log"
path => "path to your network log file"
}
}
filter {
if [type] == "network_log" {
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
index => "logstash_network_log-%{+YYYY.MM.dd}"
hosts => ["http://Теперь давайте взглянем на то, что мы можем делать с Python и Logstash.
Предыдущая конфигурация Logstash позволит вам поглотить сетевые журналы и создать необходимый индекс в Elasticsearch. Ч то произойдёт, если тот текстовый формат, который мы попробуем поместить в ELK не является неким стандартным форматом журнала? Именно здесь нам на помощи приходит Python. В нашем следующем примере мы осуществим следующее:
-
Применим свой сценарий Python для выемки некоторого списка IP, который на проект Spamhaus рассматривает в качестве некоторого списка сброса (
https://www.spamhaus.org/drop/drop.txt). -
Воспользоваться модулем регистрации Python для форматирования всей информации неким способом, который может поглотить Logstash.
-
Изменить имеющийся файл настройки Logstash таким образом, чтобы любой новый ввод мог бы отправляться в Службу Elasticsearch AWS.
Наш сценарий chapter8_logstash_1.py содержит тот код, который мы
будем использовать. Помимо необходимого модуля импорта мы определим свою основную настройку журналирования:
#logging configuration
logging.basicConfig(filename='/home/echou/Master_Python_Networking/Chapter8/tmp/spamhaus_drop_list.log', level=logging.INFO, format='%(asctime)s %(message)s', datefmt='%b %d %I:%M:%S')
Мы определим несколько дополнительных переменных и сохраним свой список IP адресов из имеющихся запросов в некоторой переменной:
host = 'python_networkign'
process = 'spamhause_drop_list'
r = requests.get('https://www.spamhaus.org/drop/drop.txt')
result = r.text.strip()
timeInUTC = datetime.datetime.utcnow().isoformat()
Item = OrderedDict()
Item["Time"] = timeInUTC
Самый последний раздел данного сценария является неким циклом, предназначенным для синтаксического разбора всего вывода и его записи в имеющийся журнал:
for line in result.split('n'):
if re.match('^;', line) or line == 'r': # comments
next
else:
ip, record_number = line.split(";")
logging.warning(host + ' ' + process + ': ' + 'src_ip=' + ip.split("/")[0] + ' record_number=' + record_number.strip())
Вот некий пример такой записи файла журнала:
...
Mar 17 01:06:08 python_networkign spamhause_drop_list: src_ip=5.8.37.0
record_number=SBL284078
Mar 17 01:06:08 python_networkign spamhause_drop_list: src_ip=5.34.242.0
record_number=SBL194796
...
Затем мы можем изменить свой файл настройки Logstach соответствующим образом, начав с добавления необходимого местоположения файла ввода:
input {
file {
type => "network_log"
path => "path to your network log file"
}
file {
type => "spamhaus_drop_list"
path => "/home/echou/Master_Python_Networking/Chapter8/tmp/spamhaus_drop_list.log"
}
}
Мы можем добавить дополнительный фильтр настройки:
filter {
if [type] == "spamhaus_drop_list" {
grok {
match => [ "message", "%{SYSLOGTIMESTAMP:timestamp} %{SYSLOGHOST:hostname} %{NOTSPACE:process} src_ip=%{IP:src_ip} %{NOTSPACE:record_number}.*"]
add_tag => ["spamhaus_drop_list"]
}
}
}
Мы можем оставить свой раздел вывода без изменений, так как все дополнительные записи будут сохраняться в том же самом индексе. Теперь мы можем применять свой стек ELK для запроса, хранения и представления своего сетевого журнала, а также всей информации IP Spamhaus.
В данной главе мы рассмотрели дополнительные способы, которыми мы можем применять Python для расширения своих усилий по сетевому мониторингу. Мы начали с применения пакета Graphviz Python для создания графов сетевой топологии. Это позволило нам без усилий отображать всю текущую топологию, а также отмечать любые отказы соединений.
Далее мы применили Python для синтаксического анализа пакетов NetFlow версии 5 с целью расширить наше понимание NetFlow и обнаружения ошибок. Мы также взглянули на то как применять ntop и Python для расширения мониторинга NetFlow посредством ntop. sFlow является альтернативной технологией образцов пакетов, которую мы рассмотрели там, где мы применяем sflowtool и sFlow-RT для интерпретации полученных результатов. Мы закончили данную главу с инструментом анализа данных общего назначения, а именно Elasticsearch или стек ELK.
В нашей следующей главе мы исследуем как применять веб инфраструктуру Flask Python для построения сетевых веб служб.