Глава 1. Развёртывание Zabbix
Содержание
Если вы читаете эту книгу, скорее всего, у вас имеется уже применяемый и установленный Zabbix. Наиболее вероятно, вы сделали это в небольшом/ среднем окружении, но теперь ситуация изменилась, а ваша настоящая среда является достаточно большой с новыми регулярно поступающими вызовами. В наши дни среды быстро растут или изменяются, а быть готовым к поддержке и предоставлению надёжного решения мониторинга является сложной задачей.
Обычно, при начальном развёртывании системы, настройка системы мониторинга осуществляется согласно руководству или рекомендациям "как сделать", а это распространённая ошибка. Такой вариант подхода правилен для необльших сред, в которых время простоя не является критичным, где нет необходимости обработки восстановления при несчастных случаях, или, короче говоря, там, где всё просто.
Скорее всего, такая наладка не выполнена с заглядыванием на будущее за возможным новым объёмом элементов, спусковых механизмов и событий, которые должен тщательно обрабатывать ваш сервер. Если у вас уже имеется установленный Zabbix и у вас имеется потребность в планировании и разработки новой инфраструктуры мониторинга, данная глава поможет вам.
Данная глава также поможет вам выполнить трудную задачу наладки/ обновления Zabbix в больших и очень сложных средах. Эта глава охватит все стороны подобной задачи, начиная с определения большой среды, вплоть до применения Zabbix в качестве ресурса планирования ёмкости. Настоящая глава обозначит все возможные решения Zabbix, включая практические примеры с готовой к обработке большой среды установкой, а также готовой к будущему для возможных усовершенствований.
К концу данной главы мы поймём как работает Zabbix, какие таблицы должны находиться под особенным наблюдением, а также как улучшать действия по обслуживанию системы в большом окружении, при наличии необходимости обработки тенденций в несколько лет, что на самом деле является сложной задачей.
Данная глава охватывает следующие темы:
-
Понимание того, когда вы находитесь на пороге большой среды и определение того, когда некое окружение может рассматриваться как большая соеда
-
Наладка/ обновление Zabbix в большой среде и очень большой среде
-
Установка Zabbix в системе с тремя уровнями и получение предварительно подготовленного решения для обработки большой среды
-
Определение размера базы данных и окончательное понимание общего объёма пространства, потребляемого приобретаемыми нами данными
-
Осознание самых интенсивно используемых таблиц и задач базы данных
-
Улучшение обслуживания компьютерной системы в плане уменьшения нагрузки на реляционную СУБД и повышение эффективности всей системы в целом
-
Изучение фундаментальных основ планирования ёмкости, принимая во внимание, что Zabbix является интсрументом планирования ёмкости
Так как данная книга сосредоточена на больших средах, нам необходимо определить или, по крайней мере, предоставить основные фиксированные положения для идентификации больших окружений. В данном определении присутствуют различные вещи, которые необходимо принимать во внимание; в основном мы можем определять окружение как большое когда:
-
Присутствует более одного отличающегося местоположения
-
Количество подлежащих мониторингу устройств большое (сотни или тысячи)
-
Количество извлекаемых в секунду проверок и элементов высоко (больше 500)
-
Присутствует много элементов, спусковых механизмов и подлежащих обработке данных (ваша база данных превоходит 100ГБ)
-
Критически важны как доступность, так и производительность
Все предыдущие положения определяют большую среду; при наличии подобной среды ваша установка и сопровождение инфраструктуры Zabbix играют критически важную роль.
Установка, естественно, является задачей, которая хорошо определяется на своевременной основе и, вероятно, является одной из наиболее критичных задач; на самом деле важно начинать работу с сильной и надёжной инфраструктурой мониторинга. Кроме того, поскольку мы приступаем к выполнению задач с уже находящейся в работе системой мониторинга, будет не так просто перемещать/ мигрировать её части ьез какой- бы то ни было потери данных. Также существуют и другие вещи, подлежащие рассмотреню: мы будем иметь множество связанных с мониторингом нашей системы задач, причём большинство из них являются ежедневными, однако в большой среде они требуют особенного внимания.
В небольшой среде с незначительной по размеру базой данных, резервное копирование вызовет вашу занятость в несколько минут, однако, если база данных большая, эта задача будет потреблять подлежащее принятию во внимание объёму времени на своё завершение.
Ваши планы восстановления и относительного восстановления должны рассматртваться и проверяться периодически с тем, чтобы иметь представление о времени, необходимом для выполнения данной задачи, в случае возникновения подобной катастрофы или отказа критически важного оборудования.
В промежутках между задачами сопровождения мы должны проверять и размещать в производство обновления с минимальным воздействием, помимо ежедневных задач и каждодневных проверок.
Zabbix можно определить как распределённую систему мониторинга с централизованным веб- интерфейсом (в котором мы можем управлять практически всем). Наряду с основными функциями, мы выделим следующие:
-
Zabbix имеет централизованный веб- интерфейс
-
Его сервер может выполняться на большинстве Unix= подобных операционных систем
-
Система мониторинга имеет внутренне присутствующих агентов для большинства опреационных систем Unix, Unix- подобных и Microsoft Windows
-
Данная система легко интегрируется в другие системы благодаря своему API, доступному во многих различных языках программирования и параметрах, поддерживаемых Zabbix самой по себе
-
Zabbix может осуществлять мониторинг через SNMP (v1, v2 и v3), IPMI, JMX, ODBC, SSH, HTTP(s), TCP/UDP, а также Telnet
-
Эта система мониторинга даёт нам возможность создания индивидуальных элементов и графиков, а также интерпретации данных
-
Система просто настраивается под персональные требования
Следующая схема показывает систему из трёх слоёв архитектуры Zabbix:
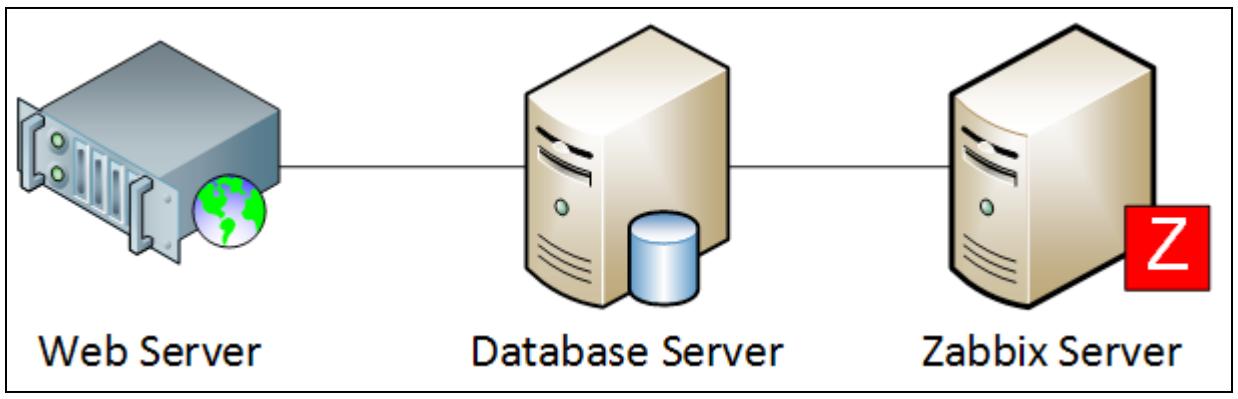
Архитектура Zabbix для масштабных сред собирается из трёх различных серверов/ компонентов (которые к тому же должны быть настроены на высокую доступность, HA). Этими тремя компонентами являются:
-
Веб- сервер
-
Сервер базы данных
-
Сервер Zabbix
Вся инфраструктура Zabbix в крупных средах позволяет нам иметь два других действующих компонента, которые играют фундаментальную роль. Такими персонажами являются агенты Zabbix и прокси Zabbix. Некий пример представляет следующий рисунок:
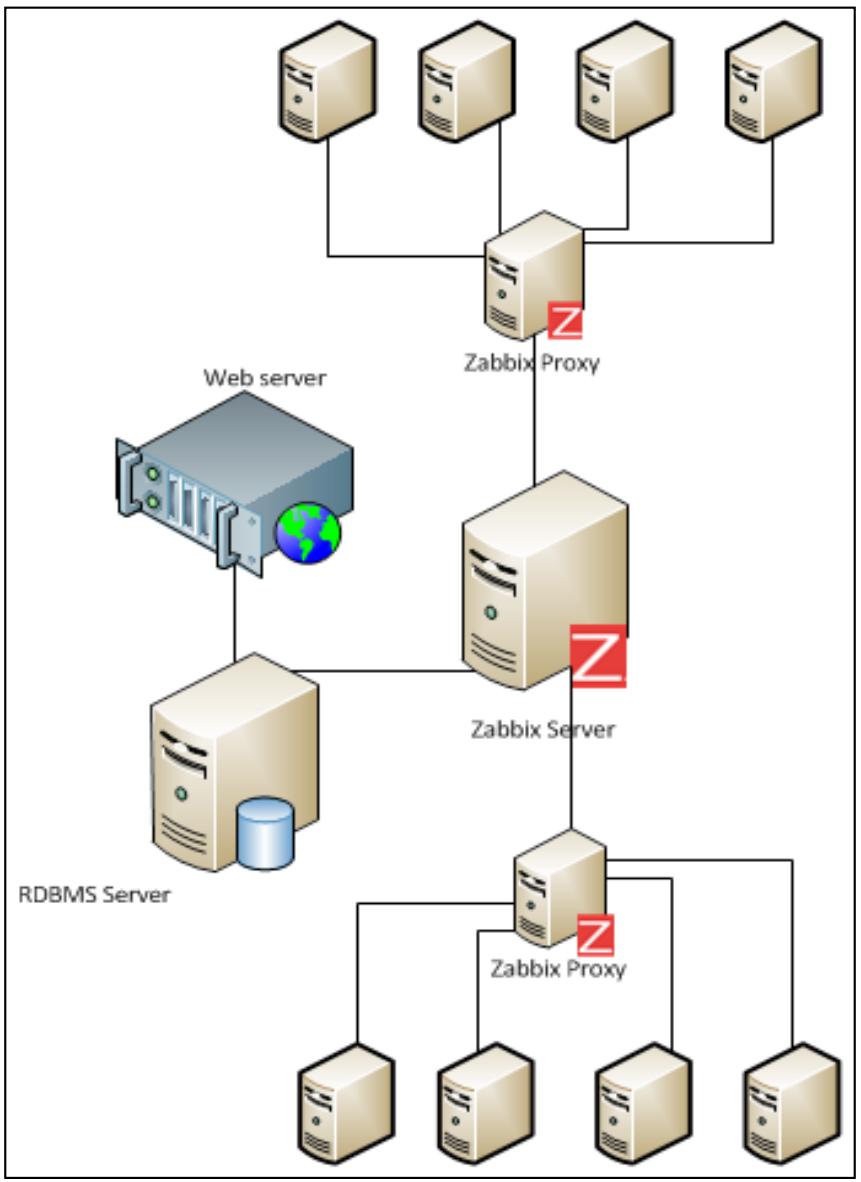
В данной инфраструктуре у нас имеется центральный сервер Zabbix, который соединён с различными прокси, как правило, по одному на каждую ферму серверов или подсеть.
Сервер Zabbix будет получать данные от прокси Zabbix, а прокси будут получать данные от своих агентов Zabbix, присоединённых к ним, все эти данные будут сохраняться на выделенной реляционной СУБД (RDBMS), а клиентское представление будет представляться пользователю через веб- интерфейс. Рассматривая используемые технологии, мы видим, что данный веб- интерфейс написан на PHP, а наш сервер, прокси и агенты написаны на C.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Ниши сервер, прокси и агенты написаны на C для получения наилучшей производительности при наименьшем возможном потреблении ресурсов. Все эти компоненты глубоко оптимизированы для достижения наилучшей производительности. |
При помощи прокси мы можем реализовывать различные виды архитектур. Существует несколько типов архитектур и, в порядке их сложности мы находим следующие:
-
Установка с одним сервером
-
Один сервер и множество прокси
-
Распределённая установка (доступна только вплоть до 2.3.0)
Установка с одним сервером не рекомендуется в крупных средах. Именно базовая установка, в которой единственный сервер выполняет мониторинг, может рассматриваться как хорошая отправная точка.
Наиболее вероятно, что в нашей инфраструктуре мы уже можем иметь установку Zabbix. Zabbix является очень гибким, а это позволяет нам обновлять такую установку до следующего этапа: мониторинга на основании прокси.
Мониторинг на базе прокси реализуется при помощи сервера Zabbix и нескольких прокси, то есть по одному прокси на подразделение или центр обработки данных. Такую конфигурацию легко сопровождать и предлагать преимущество наличия централизованного решения мониторинга. Такой вид настройки является верным балансом между мониторингом большой среды и сложностью. Отталкиваясь от такой позиции мы можем (приложив немало усилий) расширить нашу установку до завершённой и распределённой архитектуры мониторинга. Установка, состоящая из одного сервера и множества прокси представлена на нашей предыдущей схеме.
Начиная с версии Zabbix 2.4.0, все распределённые сценарии, которые включали узлы, больше не являются возможными настройками. На самом деле, если вы загрузите исходный код дистрибутива обсуждаемого в данной книге Zabbix, а затем Zabbix 2.4.3, вы увидите, что ветвь кода, которая управляла узлами, была удалена.
Все возможные архитектуры Zabbix будут подробно обсуждаться в Главе 2, Распределённый мониторинг.
Рассматриваемая в данной главе установка состоит из установки серверов для каждой из следующих компонентов:
-
Веб- интерфейса
-
Сервера Zabbix
-
Базы данных Zabbix
Мы начнём объяснять эту установку потому что:
-
Это базовая установка, которая готова к расширению при помощи прокси и узлов
-
Каждый компонент является выделенным сервером
-
Такой вид настройки является отправной точкой для мониторинга больших сред
-
Она широко применяется
-
Скорее всего, она будет отправной точкой вашего обновления и расширения своей инфраструктуры мониторинга
Действительно, этот первый этап для большого окружения, как объясняется здесь, может быть полезен если вы собираетесь улучшить существующую инфраструктуру мониторинга. Если ваше используемое в настоящее время решение не реализовано таким образом, первой вещью, которую необходимо сделать, будет планирование миграции на три выделенных сервера.
Когда ваша среда настраивается на трёх уровнях, но всё ещё выдаёт плохую производительность, вы можете планировать и размышлять какой вид настройки большого окружения будет наилучшим образом соответствовать вашей инфраструктуре.
Когда вы осуществляете мониторинг своей большой среды, существует несколько моментов подлежащих рассмотрению:
-
Применение выделенного сервера для сохранения вещей простыми для расширения
-
Придерживаться простых решений для расширения и реализации высокой доступности
-
Придерживаться простых решений для расширения и реализации отказоустойчивой архитектуры
При такой трёхуровневой установке, использование ЦПУ вашей серверной компоненты не будет действительно критичным по крайней мере для сервера Zabbix. Потребление ЦПУ напрямую связано с общим числом подлежащих сохранению элементов и частотой обновлений (число сэмплов в минуту) больше чем с вашей оперативной памятью.
Тем не менее, сервер Zabbix не будет потреблять непомерно ЦПУ, однако слегка более жаден к памяти. Мы можем считать, что четыре ядра ЦПУ с 8ГБ ОЗУ может применяться для более чем 1000 четвёрок хостов не испытывающих каких= либо проблем.
Обычно рассматриваются два способа установки Zabbix:
-
Загрузка самых последних исходных кодов и их компиляция
-
Установка из пакетов
Существует также другой способ иметь сервер Zabbix в наличии работающим, это загрузка виртуальных приложений, однако мы не рассматриваем этот случай, так как лучше иметь полный контроль над нашей установкой и быдь в курсе всех её этапов. Кроме того, главное соображение о виртуальных приложениях состоит в том, что Zabbix сам по себе определяет виртуальные приложения, которые пока не готовы к промышленному применению напрямую на странице загрузки по адресу http://www.zabbix.com/download.php.
Установка из пакетов предоставляет следующие преимущества:
-
Она делает процесс обновления и изменения более простым
-
Зависимости автоматически сортируются
Компиляция из исходных кодов также предоставляет преимущества:
-
Мы можем компилировать только необходимые свойства
-
Мы можем статично строить своего агента и разворачивать его в различных реализациях Linux
-
Мы можем осуществлять полный контроль в процессе обновления
Совершенно обычное дело иметь в большой среде различные версии Linux, Unix и Microsoft Windows. Такие виды сценариев широко распространены в гетерогенной инфраструктуре и если мы будем использовать распространение своего агента в виде пакета для каждого сервера Linux, мы несомненно будем иметь различные версии этого агента и различные местоположения для его файлов настроек.
Чем более стандартны мы по всем серверам, тем проще будет сопровождать и обновлять нашу
инфраструктуру. --enable-static предоставляет нам способ
стандартизации своего агента по всем различным версиям и выпускам Linux, а это сильное преимущество.
Агент, будучи статически скомпилированным, может быть легко развёрнут где угодно, и, несомненно, мы
будем иметь одно и то же местоположение (и мы сможем применять один и тот же файл настройки, не говоря уж
об имени узла) для этого агента и его файла настройки. Развёртывание будет стандартизовано; однако,
единственный момент, который может изменяться это сценарий запуска/ останова и порядок регистрации его в
правильном уровне работы (runlevel) init.
Аналогичный подход может быть применён для коммерческого Unix, принимая во внимание его компиляцию производителем, таким образом один и тот же агент может быть развёрнут в различных версиях выпусков Unix одного и того же производителя.
Необходимые условия
Перед компиляцией Zabbix нам необходимо рассмотреть предварительные требования. Веб интерфейс нуждается по крайней мере в следующих версиях:
-
Apache (1.3.12 или последующих)
-
PHP (5.3.0 или старше
Помимо этого вашему серверу Zabbix понадобятся:
-
СУБД: Альтернативами с открытым исходным кодом являются PostgreSQL и MySQL
-
zlib-devel: {Прим. пер.: сжатие/ декомпрессия} -
mysql-devel: применяется для поддержки MySQL (не нужна для нашей установки) -
postgresql-devel: используется для поддержки PostgreSQL -
glibc-devel: {Прим. пер.: библиотека системных вызовов} -
curl-devel: применяется для веб- мониторинга -
libidn-devel:curl-develзависит от неё -
openssl-devel:curl-develзависит от неё -
net-snmp-devel: используется для поддержки SNMP -
popt-devel:net-snmp-develзависит от неё -
rpm-devel:net-snmp-develзависит от неё -
OpenIPMI-devel: применяется для поддержки IPMI -
iksemel-devel: используется для протокола Jabber -
Libssh2-devel:{Прим. пер.: поддержка SSH2} -
sqlite3: необходима в случае, когдя SQLite применяется в качестве сервера базы данных (обычно в прокси)
Чтобы установить все эти зависимости дистрибутива Linux Red Hat Enterprise мы можем воспользоваться
yum (с правами root),
однако прежде всего нам необходимо вкючить репозиторий EPEL воспользовавшись следующей командой:
# yum install epel-release
Применив yum install установите следующие пакеты:
# yum install zlib-devel postgresql-devel glibc-devel curl-devel gcc automake postgresql libidn-devel openssl-devel net-snmp-devel rpm-devel OpenIPMI-devel iksemel-devel libssh2-devel openldap-devel
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Пакет |
Для работы Zabbix необходим пользователь и непривилегированная учётная запись. В любом случае, если ваш демон запускается с правами root, он автоматически переключится на учётную запись Zabbix если таковая присутствует:
# groupadd zabbix
# useradd –m –s /bin/bash -g zabbix zabbix
# useradd –m –s /bin/bash -g zabbix zabbixsvr
|
| Замечание |
|---|---|
|
Ваш сервер никогда не должен работать с правами root, так как это подвергнет ваш сервер риску безопасности. |
Предыдущие строки позволяют вам усилить безопасность вашей установки. Ваши сервер и агент должны работать
с двумя различными учётными записями; в противном случае ваш агент сможет осущетвлять доступ к настройкам
вашего сервера Zabbix. Теперь, используя учётную запись пользователя Zabbix, мы можем загрузить необходимые
исходные коды из файла tar.gz:
# wget http://sourceforge.net/projects/zabbix/files/ZABBIX%20Latest%20Stable/2.4.4/zabbix-2.4.4.tar.gz/download -O zabbix-2.4.4.tar.gz
# tar -zxvf zabbix-2.4.4.tar.gz
Чтобы настроить источник для нашего сервера мы можем применить следующие параметры:
# ./configure --enable-server --enable-agent --with-postgresql --withlibcurl --with-jabber --with-net-snmp --enable-ipv6 --with-openipmi --with-ssh2 --with-ldap
|
| Замечание |
|---|---|
|
Команды |
Если настройка выполнена без каких- либо ошибок, мы должны увидеть что- то подобное этому:
config.status: executing depfiles commands
Configuration:
Detected OS: linux-gnu
Install path: /usr/local
Compilation arch: linux
Compiler: gcc
Compiler flags: -g -O2 -I/usr/include -I/usr/include/rpm -I/usr/local/include -I/usr/lib64/perl5/CORE -I. -I/usr/include -I/usr/include -I/usr/include -I/usr/include
Enable server: yes
Server details:
With database: PostgreSQL
WEB Monitoring: cURL
Native Jabber: yes
SNMP: yes
IPMI: yes
SSH: yes
ODBC: no
Linker flags: -rdynamic -L/usr/lib64 -L/usr/lib64 -L/usr/lib -L/usr/lib -L/usr/lib
Libraries: -lm -ldl -lrt -lresolv -lpq -liksemel -lnetsnmp -lssh2 -lOpenIPMI -lOpenIPMIposix -lldap -llber -lcurl
Enable proxy: no
Enable agent: yes
Agent details:
Linker flags: -rdynamic -L/usr/lib
Libraries: -lm -ldl -lrt -lresolv -lldap -llber -lcurl
Enable Java gateway: no
LDAP support: yes
IPv6 support: yes
***********************************************************
* Now run 'make install' *
* *
* Thank you for using Zabbix! *
* <http://www.zabbix.com> *
***********************************************************
Теперь не выполним make install целиком, а только компиляцию
при помощи # make. Чтобы определить различные местоположения для
вашего сервера Zabbix нам необходимо применять префикс --prefix
в опциях настройки, например, --prefix=/opt/zabbix. Теперь
следуйте инструкциям, описанным в разделе Установка
и создание пакета.
Наладка агента
Чтобы настроить источники для создания вашего агента, нам необходимо выполнить следующую команду:
# ./configure --enable-agent
# make
|
| Совет |
|---|---|
|
При помощи команды |
Установка и создание пакета
В обоих предыдущих разделах наша командная строка завершалась прямо перед началом инсталляции; тем не менее, мы не выполняем следующую команду:
# make install
Я предлагаю вам не выполнять команду make install, а вместо неё
применять программу checkinstall.
Вы можете загрузить это программное обеспечение по ссылке ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/ikoinoba/CentOS_CentOS-6/x86_64/checkinstall-1.6.2-3.el6.1.x86_64.rpm.
{Прим. пер.: воспроизведена ссылка автора, она не работае, причём ни внешняя, ни вложенная.
Для поиска пакета checkinstall можно воспользоваться предлагаемым автором
сервером, например: http://rpm.pbone.net/index.php3?stat=3&search=checkinstall&srodzaj=3, или, что
кажется более логичным воспользоваться единственный раз make install для
создания нужного пакета из исходного кода, предлагаемого его разработчиком:
http://checkinstall.izto.org/.}
Отметим, что checkinstall является единственная из возможная
имеющаяся у вас альтернатива создания системного пакета для распространения.
|
| Замечание |
|---|---|
|
Мы также можем использовать предварительно построенный Нам также необходимо создать требующиеся каталоги: |
Данный пакет делает вещи более простыми; он лёгок для распространения и обновления вашего программного
обеспечения, плюс мы можем создавать пакет для различных версий управления пакетами:
rpm, deb и
tgz.
|
| Замечание |
|---|---|
|
|
Теперь нам необходимо перейти к root или применить команду sudo checkinstall
с идущими за ней опциями:
# checkinstall --nodoc -R --install=no -y
Если вы не столкнётесь ни с какими проблемами, вы должны получить следующее сообщение:
******************************************************************
Done. The new package has been saved to
/root/rpmbuild/RPMS/x86_64/zabbix-2.4.4-1.x86_64.rpm
You can install it in your system anytime using:
rpm -i zabbix-2.4.4-1.x86_64.rpm
******************************************************************
Теперь, чтобы установить этот пакет от имени root, вам необходимо выполнить следующую команду:
# rpm -i zabbix-2.4.4-1.x86_64.rpm
Наконец, Zabbix установлен. Двоичные файлы вашего сервера будут установлены в
<prefix>/sbin, утилиты будут в
<prefix>/bin, а страницы руководств (man pages) будут в
местоположении <prefix>/share.
Установка из пакета
Для представления полной картины всех наших возможных методов установки, вы должны быть осведомлены
об этапах, необходимых для установки Zabbix с применением предварительно построенных пакетов
rpm.
Для начала необходимо установить соответствующий репозиторий:
# rpm -ivh http://repo.zabbix.com/zabbix/2.4/rhel/6/x86_64/zabbix-2.4.4-1.el6.x86_64.rpm
Эта команда создаст ваш файл yum repo, /etc/yum.repos.d/zabbix.repo
и сделает доступным необходимый репозиторий.
|
| Совет |
|---|---|
|
Если вы взглянете на репозиторий Zabbix, вы сможете увидеть, что внутри "не поддерживаемого"
дерева: http://repo.zabbix.com/non-supported/rhel/6/x86_64/ вы имеете в наличии следующие
пакеты: |
Теперь достаточно просто установить наш сервер Zabbix и веб- интерфейс, вы просто можете на своём сервере выполнить такую команду:
# yum install zabbix-server-pgsql
Имейте в виду, что на своём веб- сервере вы также вначале добавить репозиторий
yum:
# yum install zabbix-web-pgsql
Для установки агента вам всего лишь нужно воспользоваться следующей командой:
# yum install zabbix-agent
|
| Совет |
|---|---|
|
Если вы решите использовать пакеты RPM, пожалуйста, держите в памяти что ваши файлы настройки
расположены в |
Кроме того, если у вас имеется локальный межсетевой экран, активный в том месте, где вы разворачиваете
своего агента Zabbix, вам необходимо должным образом настроить iptables
чтобы разрешить обмен с портом агента Zabbix при помощи следующей команды, которую вам необходимо
выполнить от имени root:
# iptables -I INPUT 1 -p tcp --dport 10050 -j ACCEPT
# iptables-save
Настройка сервера
Чтобы настроить ваш сервер, нам понадобится только проверить и отредактиоать один файл:
/usr/local/etc/zabbix_server.conf
Наши файлы настройки расположены внутри следующего каталога:
/usr/local/etc
Нам необходимо изменить упомянутый файл /usr/local/etc/zabbix_server.conf
и записать ваши имя пользователя, соответствующий пароль и имя вашей базы данных; отметим, что настройка самой
базы данных будет выполнена позже в данной главе и что на текущий момент вы можете записать планируемые
имена username/password/database. Затем, в своей учётной записи zabbix
вам необходимо сделать изменения:
# vi /usr/local/etc/zabbix_server.conf
Замените следующие параметры:
DBHost=localhost
DBName=zabbix
DBUser=zabbix
DBPassword=<write-here-your-password>
|
| Замечание |
|---|---|
|
Теперь наш сервер Zabbix настроен и практически готов к работе. |
Местоположение ваших внешних сценариев по умолчанию будет следующим:
/usr/local/share/zabbix/externalscripts
Оно определяется значением переменной установки времени компиляции datadir.
Каталог alertscripts будет иметь следующее расположение:
usr/local/share/zabbix/alertscripts
|
| Совет |
|---|---|
|
Это может быть изменено в процессе компиляции и зависит от значения переменной установки
|
Теперь нам необходимо настроить нашего агента. Именно файл настройки является те местом, где мы должны записать IP адрес нашего сервера Zabbix. Выполнив это, важно добавить две новые службы на верный уровень исполнения (runlevel) чтобы быть уверенным, что они запустятся когда ваш сервер войдёт в свой правильный уровень исполнения.
Для завершения этой задачи нам необходимо установить сценарии старта/ останова следующим образом:
-
/etc/init.d/zabbix-agent -
/etc/init.d/zabbix-proxy -
/etc/init.d/zabbix-server
Внутри вашей папки misc присутствует ряд предварительно
сделанных сценариев, расположенных в следующем месте:
zabbix-2.4.4/misc/init.d
Эта папка содержит различные сценарии запуска для различных вариантов Linux, однако это дерево не является активно поддерживаемым и протестированным и может оказаться не соответствующим текущему моменту с наиболее последними версиями дистрибутивов Linux, поэтому лучше позаботиться о выполнении теста перед выпуском их в свет.
Когда сценарий старта/ останова добавлен вовнутрь вашей папки /etc/init.d,
нам необходимо добавить его в свой перечень служб:
# chkconfig --add zabbix-server
# chkconfig --add zabbix-agentd
Теперь всё что осталось, так это сообщить системе с каким уровнем исполнения (runlevel) они должны запускаться; мы собираемся применить уровни исполнения 3 и 5:
# chkconfig --level 35 zabbix-server on
# chkconfig --level 35 zabbix-agentd on
Помимо этого, в случае, если у нас имеется активный локальный межсетевой экран на нашем сервере Zabbix,
вам необходимо надлежащим образом настроить iptables чтобы сделать
доступным обмен с портом сервера Zabbix при помощи следующей команды, которую необходимо выполнить от имени
root:
# iptables -I INPUT 1 -p tcp --dport 10051 -j ACCEPT
# iptables-save
В настоящий момент мы не можем запустить свой сервер; перед запуском нашего сервера нам необходимо настроить свою базу данных.
Раз уж мы завершили предыдущий этап, мы можем пройтись по установке нашего сервера базы данных. Все эти шаги будут выполнены на выделенном сервере базы данных. Первое что необходимо сделать, это установить наш сервер PostgreSQL. Это дегко может быть выполнено при помощи пакета предлагаемого в дистрибутиве, однако вам рекомендуется применять самую последнюю стабильную версию 9.x. {Прим. пер.: На момент перевода это 9.6.}
Red Hat всё ещё распространяет версию 8.x в своём RHEL6.4. Кроме того, его клоны, такие как CentOS и ScientificLinux поступают аналогично. {Прим. пер.: согласно http://distrowatch.com/http://distrowatch.com/, на момент перевода последние поддерживаемые версии PostgreSQL таковы: для Red Hat 7.2, а также для CentOS и ScientificLinux 7.1511 это 9.2.13.} PostgreSQL 9.x имеет много полезных свойств; на момент написания книги самой стабильной, готовой к промышленному применению является версия 9.2.
Для установки PostgreSQL 9.4 существуют некоторые простые этапы, они таковы:
-
Определите местоположение файлов
.repo:-
Red Hat: они представлены в
/etc/yum/pluginconf.d/rhnplugin.conf [main] -
CentOS: они представлены в
/etc/yum.repos.d/CentOS-Base.repo,[base]и[updates]
-
-
Добавьте в конец раздела определённого на предыдущем шаге следующую строку:
exclude=postgresql* -
Пройдитесь по http://yum.postgresql.org и найдите верный RPM. Например, для установки PostgreSQL 9.4 в RHEL 6 перейдите в http://yum.postgresql.org/9.4/redhat/rhel-6-x86_64/pgdg-redhat94-9.4-1.noarch.rpm.
-
Установите repo посредством:
yum localinstall http://yum.postgresql.org/9.4/redhat/rhel-6-x86_64/pgdg-centos94-9.4-1.noarch.rpm -
Теперь для отображения перечня всего пакета
postgresqlвыполните такую команду:# yum list postgres* -
Когда вы отыщите наш пакет в этом списке, установите его при помощи следующей команды:
# yum install postgresql94 postgresql94-server postgresql94-contrib -
После установки этих пакетов нам необходимо инициализировать свою базу данных:
# service postgresql-9.4 initdbВ качестве альтернативы мы можем инициализировать эту базу данных таким образом:
# /etc/init.d/postgresql-9.4 initdb -
Теперь нам необходимо изменить некоторые вещи в файле настроек
/var/lib/pgsql/9.4/data/postgresql.conf. Нам необходимо изменить адрес прослушивания и соответствующий порт:listen_addresses = '*' port = 5432Нам также необходимо добавить пару элементов для прав
zabbix_dbпосле следующих строк:# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all trust in /var/lib/pgsql/9.4/data/pg_hba.conf # configuration for Zabbix local zabbix_db zabbix md5 host zabbix_db zabbix >CIDR-address> md5Ключевое слово
localсоответствует всем соединениям выполненным сокетами домена Unix. За этой строкой следуют имя базы данных (zabbix_db), имя пользователя (zabbix), а также метод аутентификации (в нашем случаеmd5).Ключевое слово
hostсоответствует всем соединениям, которые доступны через TCP/IP (которые включают как SSL, так и соединения без SSL), за которым следуют имя базы данных (zabbix_db), имя пользователя (zabbix), сетевая среда и маска всех ваших разрешённых хостов, а также метод аутентификации (в нашем случаеmd5). -
Сетевая маска разрешённых хостов в нашем случае должна быть именно сетевой маской, потому что нам необходимо сделать доступным веб интерфейс (поддерживаемый нашим веб- сервером), а также наш сервер Zabbix который расположен на другом выделенном сервере, например,
10.6.0.0/24(маленькая подсеть) или даже большой сетевой средой. Скорее всего, ваш веб интерфейс, а также ваш сервер Zabbix будут в различных сетевых средах, поэтому убедитесь, что вы отображаете здесь все свои сетевые среды и соответствующие маски. -
Наконец, мы можем запустить свой сервер PosgreSQL воспользовавшись такой командой:
# service postgresql-9.4 startВ качестве альтернативы мы можем применить и такую:
vfs.zfs.vdev.cache.size="10M"
Чтобы создать базу данных нам необходимо быть пользователем postgres
(или пользователем, который в вашем дистрибутиве выполняет PostgreSQL). Создайте пользователя для этой
базы данных (наш пользователь Zabbix) и зарегистрируйтесь в качестве этого пользователя для импорта вашей
схемы с соответствующими данными.
Код для импорта этой схемы таков:
# su - postgres
Когда мы стали пользователем postgres, мы можем создать
нашу базу данных (в нашем примере это zabbix_db):
-bash-4.1$ psql
postgres=# CREATE USER zabbix WITH PASSWORD '<YOUR-ZABBIX-PASSWORDHERE>';
CREATE ROLE
postgres=# CREATE DATABASE zabbix_db WITH OWNER zabbix ENCODING='UTF8';
CREATE DATABASE
postgres=# \q
Наши сценарии создания базы данных расположены в папке /database/postgresql
развёрнутых исходных файлов. Они должны быть установлены в точности в следующем порядке:
# cat schema.sql | psql –h <DB-HOST-IP-ADDRESS> -W -U zabbix zabbix_db
# cat images.sql | psql –h <DB-HOST-IP-ADDRESS> -W -U zabbix zabbix_db
# cat data.sql | psql –h <DB-HOST-IP-ADDRESS> -W -U zabbix zabbix_db
|
| Совет |
|---|---|
|
Применяемый в команде |
Теперь, наконец, настало время запуска сервера Zabbix и тестирования всей настройки для наших сервера и базы данных Zabbix:
# /etc/init.d/zabbix-server start
Starting Zabbix server: [ OK ]
Беглая проверка файла журнала может предоставить нам дополнительную информацию о том что в настоящее
время проиходит в нашем сервере. Мы должны иметь возможность получать следующие строки из файла протокола
(его местоположение по умолчанию /tmp/zabbix_server.log):
26284:20150114:034537.722 Starting Zabbix Server. Zabbix 2.4.4 (revision 51175).
26284:20150114:034537.722 ****** Enabled features ******
26284:20150114:034537.722 SNMP monitoring: YES
26284:20150114:034537.722 IPMI monitoring: YES
26284:20150114:034537.722 WEB monitoring: YES
26284:20150114:034537.722 VMware monitoring: YES
26284:20150114:034537.722 Jabber notifications: YES
26284:20150114:034537.722 Ez Texting notifications: YES
26284:20150114:034537.722 ODBC: YES
26284:20150114:034537.722 SSH2 support: YES
26284:20150114:034537.722 IPv6 support: YES
26284:20150114:034537.725 ******************************
26284:20150114:034537.725 using configuration file: /usr/local/etc/zabbix/zabbix_server.conf
26284:20150114:034537.745 current database version (mandatory/optional): 02040000/02040000
26284:20150114:034537.745 required mandatory version: 02040000
26284:20150114:034537.763 server #0 started [main process]
26289:20150114:034537.763 server #1 started [configuration syncer #1]
26290:20150114:034537.764 server #2 started [db watchdog #1]
26291:20150114:034537.764 server #3 started [poller #1]
26293:20150114:034537.765 server #4 started [poller #2]
26294:20150114:034537.766 server #5 started [poller #3]
26296:20150114:034537.770 server #7 started [poller #5]
26295:20150114:034537.773 server #6 started [poller #4]
26297:20150114:034537.773 server #8 started [unreachable poller #1]
26298:20150114:034537.779 server #9 started [trapper #1]
26300:20150114:034537.782 server #11 started [trapper #3]
26302:20150114:034537.784 server #13 started [trapper #5]
26301:20150114:034537.786 server #12 started [trapper #4]
26299:20150114:034537.786 server #10 started [trapper #2]
26303:20150114:034537.794 server #14 started [icmp pinger #1]
26305:20150114:034537.790 server #15 started [alerter #1]
26312:20150114:034537.822 server #18 started [http poller #1]
26311:20150114:034537.811 server #17 started [timer #1]
26310:20150114:034537.812 server #16 started [housekeeper #1]
26315:20150114:034537.829 server #20 started [history syncer #1]
26316:20150114:034537.844 server #21 started [history syncer #2]
26319:20150114:034537.847 server #22 started [history syncer #3]
26321:20150114:034537.852 server #24 started [escalator #1]
26320:20150114:034537.849 server #23 started [history syncer #4]
26326:20150114:034537.868 server #26 started [self-monitoring #1]
26325:20150114:034537.866 server #25 started [proxy poller #1]
26314:20150114:034537.997 server #19 started [discoverer #1]
В действительности, местоположение вашего журнала по умолчанию не является наилучшим местом, так как
/tmp будет очищен при наступлении события перезагрузки и,
наверняка, журналы не будут подвергаться надлежащим ротации и управлению.
Мы можем изменить это местоположение по умолчанию простой заменой записи в
/etc/zabbix_server.conf. Вы можете изменить этот файл
таким образом:
### Option: LogFile
LogFile=/var/log/zabbix/zabbix_server.log
Создайте структуру каталога при помощи следующей команды от имени root:
# mkdir –p /var/log/zabbix
# chown zabbixsvr:zabbixsvr /var/log/zabbix
Другой важной вещью подлежащей изменению является logrotate,
так как лучше будет иметь автоматизированную ротацию нашего файла протокола. Это может быть быстро
реализовано добавлением соответствующей настройки в ваш каталог logrotate
/etc/logrotate.d/.
Чтобы выполнить это, создайте следующий файл выполнив приводимую ниже команду из учётной записи root:
# vim /etc/logrotate.d/zabbix-server
Воспользуйтесь следующим содержимым:
/var/log/zabbix/zabbix_server.log {
missingok
monthly
notifempty
compress
create 0664 zabbix zabbix
}
После выполнения данных изменений вам необходимо перезапустить ваш сервер Zabbix при помощи следующей команды (исполняемой с правами root):
# /etc/init.d/zabbix-server restart
Shutting down Zabbix server: [ OK ]
Starting Zabbix server: [ OK ]
Другим подлежащим проверке моментом является необходимость удостовериться, что наш сервер работает с нашим пользователем:
# ps aux | grep "[z]abbix_server"
502 28742 1 0 13:39 ? 00:00:00 /usr/local/sbin/zabbix_server
502 28744 28742 0 13:39 ? 00:00:00 /usr/local/sbin/zabbix_server
502 28745 28742 0 13:39 ? 00:00:00 /usr/local/sbin/zabbix_server
...
Предыдущие строки отображают, что zabbix_server работает с
пользователем 502. Мы забежим вперёд и проверим, что
502 это пользователь, которого мы создали ранее:
# getent passwd 502
zabbixsvr:x:502:501::/home/zabbixsvr:/bin/bash
Предыдущие строки показывают, что всё прекрасно. Обычно наиболее распространённая проблема сопровождается следующей ошибкой:
28487:20130609:133341.529 Database is down. Reconnecting in 10 seconds.
Существуют различные действующие факторы, вызывающие данную проблему:
-
Межсетевой экран (локальный на нашем сервере или межесетевой экран инфраструктуры)
-
Настройка
postgres -
Неверные данные в
zabbix_server.conf
|
| Совет |
|---|---|
|
Мы можем попытаться локализовать эту проблему, выполнив следующую команду на своём сервере базы данных: Если у нас имеется соединение, мы можем попробовать ту же самую команду с сервера Zabbix;
если она откажет, то лучше проверить настройки своего межсетевого экрана. Если мы получаем
неизбежную (fatal) ошибку отказа идентификации- аутентификации, лучше будет проверить свой
файл |
Теперь, второй подлежащий проверке момент заключается в локальном межсетевом экране и последующей
iptables. Вам необходимо убедиться, что порт PostgreSQL
открыт на вашем сервере базы данных. Если этот порт не открыт, вам необходимо добавить правило
межсетевого экрана воспользовавшись учётной записью root:
# iptables -I INPUT 1 -p tcp --dport 5432 -j ACCEPT
# iptables-save
Теперь самое время проверить как стартует и останавливается ваша установка Zabbix. Приводимый ниже сценарий слегка подправлен для управления различными нашими пользователями для наших же сервера и агента.
|
| Замечание |
|---|---|
|
Следующий сценарий запуска хорошо работает при стандартной компиляции без использования префикса
|
Для zabbix-server создайте файл
zabbix-server в /etc/init.d со
следующим содержимым:
#!/bin/sh
#
# chkconfig: - 85 15
# description: Zabbix server daemon
# config: /usr/local/etc/zabbix_server.conf
#
### BEGIN INIT INFO
# Provides: zabbix
# Required-Start: $local_fs $network
# Required-Stop: $local_fs $network
# Default-Start:
# Default-Stop: 0 1 2 3 4 5 6
# Short-Description: Start and stop Zabbix server
# Description: Zabbix server
### END INIT INFO
# Source function library.
. /etc/rc.d/init.d/functions
exec=/usr/local/sbin/zabbix_server
prog=${exec##*/}
lockfile=/var/lock/subsys/zabbix
syscf=zabbix-server
Следующий параметр, zabbixsvr, определяется внутри вашей
функции start() и он определяет какой пользователь будет
использован для выполнения нашего сервера Zabbix:
zabbixsrv=zabbixsvr
[ -e /etc/sysconfig/$syscf ] && . /etc/sysconfig/$syscf
start()
{
echo -n $"Starting Zabbix server: "
В предыдущем коде наш пользователь (который будет владеть процессом нашего Zabbix) определяется
внутри нашей функции start:
daemon --user $zabbixsrv $exec
Не забудьте изменить владельца файла протокола своего сервера и файла настройки Zabbix. Это
послужит предотвращению доступа обычного пользователя к чувствительным данным, которые могут
быть извлечены в Zabbix. Logfile определяется
следующим образом:
/usr/local/etc/zabbix_server.conf
On 'LogFile''LogFile' properties rv=$?
echo
[ $rv -eq 0 ] && touch $lockfile
return $rv
}
stop()
{
echo -n $"Shutting down Zabbix server: "
В этом месте, внутри функции stop, у нас нет необходимости
определять своего пользователя, так как сценарий запуска/ останова исполняется от имени root, поэтому
мы просто применим killproc $prog следующим образом:
killproc $prog
rv=$?
echo
[ $rv -eq 0 ] && rm -f $lockfile
return $rv
}
restart()
{
stop
start
}
case "$1" in
start|stop|restart)
$1
;;
force-reload)
restart
;;
status)
status $prog
;;
try-restart|condrestart)
if status $prog >/dev/null ; then
restart
fi
;;
reload)
action $"Service ${0##*/} does not support the reload
action: " /bin/false
exit 3
;;
*)
echo $"Usage: $0 {start|stop|status|restart|try-restart|forcereload}"
exit 2
;;
esac
|
| Замечание |
|---|---|
|
Следующий сценарий запуска хорошо работает при стандартной компиляции без использования префикса
|
Для zabbix_agent создайте следующий файл
zabbix-agent в /etc/init.d/zabbix-agent:
#!/bin/sh
#
# chkconfig: - 86 14
# description: Zabbix agent daemon
# processname: zabbix_agentd
# config: /usr/local/etc/zabbix_agentd.conf
#
### BEGIN INIT INFO
# Provides: zabbix-agent
# Required-Start: $local_fs $network
# Required-Stop: $local_fs $network
# Should-Start: zabbix zabbix-proxy
# Should-Stop: zabbix zabbix-proxy
# Default-Start:
# Default-Stop: 0 1 2 3 4 5 6
# Short-Description: Start and stop Zabbix agent
# Description: Zabbix agent
### END INIT INFO
# Source function library.
. /etc/rc.d/init.d/functions
exec=/usr/local/sbin/zabbix_agentd
prog=${exec##*/}
syscf=zabbix-agent
lockfile=/var/lock/subsys/zabbix-agent
Приводимый ниже параметр zabbix_usr определяет вашу учётную запись,
которая будет использоваться для выполнения агента Zabbix:
zabbix_usr=zabbix
[ -e /etc/sysconfig/$syscf ] && . /etc/sysconfig/$syscf
start()
{
echo -n $"Starting Zabbix agent: "
Следующая команда использует значение вашей переменной zabbix_usr
и позволяет нам иметь двух различных пользователей, одного для нашего сервера и другого для нашего
агента, предотвращая доступ нашему агенту Zabbix к файлу zabbix_server.conf,
который содержит пароль нашей базы данных:
daemon --user $zabbix_usr $exec
rv=$?
echo
[ $rv -eq 0 ] && touch $lockfile
return $rv
}
stop()
{
echo -n $"Shutting down Zabbix agent: "
killproc $prog
rv=$?
echo
[ $rv -eq 0 ] && rm -f $lockfile
return $rv
}
restart()
{
stop
start
}
case "$1" in
start|stop|restart)
$1
;;
force-reload)
restart
;;
status)
status $prog
;;
try-restart|condrestart)
if status $prog >/dev/null ; then
restart
fi
;;
reload)
action $"Service ${0##*/} does not support the reload action:" /bin/false
exit 3
;;
*)
echo $"Usage: $0 {start|stop|status|restart|try-restart|forcereload}"
exit 2
;;
esac
При такой настройке у нас имеется агент который работает с zabbix_usr
и сервер с учётными записями Unix zabbixsvr:
zabbix_usr_ 4653 1 0 15:42 ? 00:00:00 /usr/local/sbin/zabbix_agentd
zabbix_usr 4655 4653 0 15:42 ? 00:00:00 /usr/local/sbin/zabbix_agentd
zabbixsvr 4443 1 0 15:32 ? 00:00:00 /usr/local/sbin/zabbix_server
zabbixsvr 4445 4443 0 15:32 ? 00:00:00 /usr/local/sbin/zabbix_server
Zabbix использует интересный способ сохранения своей базы данных в одних и тех же размерах на протяжении всего времени. Тем не менее, общий размер базы данных зависит от:
-
Общего числа обрабатываемых в секунду значений
-
Установок по уборке
Zabbix применяет два варианта хранения собираемых данных:
-
История
-
Обобщённые динамики (trends)
В то время, как в истории мы находим все свои собранные данные (вне зависимости от того какой тип данных будет храниться в истории); обобщённые динамики (trends) собирают только численные данные. Их мимнимальные, максимальные и средние значения объединяются по часам (чтобы сохранять для таких обобщённых значений процессы с малым весом).
|
| Совет |
|---|---|
|
Любые элементы имеющие значения строк, такие как символ, регистрация, а также текст, не соответствуют обобщённым динамикам (trends), так как они сохраняют только знчения. |
Существует процесс, называемый уборкой (housekeeper), который отвечает за обработку удержания нашей базы данных в размерах. Вам настоятельно рекомендуется хранить свои данные в истории настолько небольшой, насколько это возможно с тем, чтобы не перегружать вашу базу данных громадными объёмами данных и хранить обобщённые динамики столько вам необходимо.
Итак, поскольку Zabbix также будет применяться для целей планирования ёмкости, нам необходимо учитывать использование основного направления и по крайней мере хранить весь бизнес- период. Обычно минимальным периодом является один год, однако настоятельно рекомендуется чтобы вы сохраняли свои обобщённые динамики истории, по крайней мере, за последние два года. Такие исторические тенденции будут использоваться в процессе открытия и закрытия дел для наличия основной линии и количества выхода за пределы в описанный период.
|
| Замечание |
|---|---|
|
Если в качестве обобщённых динамик (trens) мы укажем значение |
Наиболее распространённая проблема с которой мы сталкиваемся при объединении данных состоит в наличии значений, подверженных воздействию положительных всплесков или быстрых падений в наших почасовых обобщённых динамиках, что не является верным.
Обобщённые динамики в Zabbix реализуются интеллектуальным образом. Создание вашего сценария для таблицы обобщённых динамик (trends) выглядит следующим образом:
CREATE TABLE trends(
itemid bigin NOT NULL, clock integer DEFAULT '0'
NOT NULL, num integer DEFAULT '0'
NOT NULL, value_min numeric(16, 4) DEFAULT '0.0000'
NOT NULL, value_avg numeric(16, 4) DEFAULT '0.0000'
NOT NULL, value_max numeric(16, 4) DEFAULT '0.0000'
NOT NULL, PRIMARY KEY(itemid, clock));
CREATE TABLE trends_uint(
Itemid bigint NOT NULL, Clock integer DEFAULT '0'
NOT NULL, Num integer DEFAULT '0'
NOT NULL, value_min numeric(20) DEFAULT '0'
NOT NULL, value_avg numeric(20) DEFAULT '0'
NOT NULL, value_max numeric(20) DEFAULT '0'
NOT NULL, PRIMARY KEY(itemid, clock));
Как вы можете увидеть, внутри вашей базы данных Zabbix присутствуют две таблицы, показывающие обобщённые динамики:
-
Trends -
Trends_uint
Наша первая таблица, Trends используется для хранения численных
значений в виде с плавающей запятой. А наша вторая таблица, Trends_uint,
применяется для хранения целых значений без знака. Обе таблицы обладают понятием для сохранения следующего
для каждого часа:
-
Минимальное значение (
value_min) -
Максимальное значение (
value_max) -
Среднее значение (
value_avg)
Это свойство позволяет нам находить и отображать наши тенденции графически используя воздействие всплесков и быстрых падений помимо среднего значения и понимать как и насколько эти значения оказывали своё влияние. Оставшиеся таблицы применяемые для целей истории таковы:
-
history: применяется для хранения численных данных (с плавающей запятой) -
history_log: применяется для хранения регистраций (например, текстовое поле в значении переменной PostgreSQL имеет неограниченную длину) -
history_str: используется для хранения строк (длиной до 255 символов) -
history_text: применяется для хранения текстовых значений (опять же, это текстовае поле поэтому оно имеет неограниченную длину) -
history_unit: используется для хранения численных значений (целое без знака)
Вычисление окончательного размера базы данных не является простой задачей, потому что тяжело предсказать сколько элементов и с какой относительной частотой в секунду мы будем их получать в своей инфраструктуре, а также сколько событий будет генерироваться. Для упрощения этого мы рассмотрим наихудший случай, когда у нас имеется генерируемое каждую секунду событие.
Суммируя, на размер вашей базы данных оказывают воздействие:
-
Элементы: в частности, общее число элементов
-
Частота обновления: средняя скорость обновления
-
Пространство для хранения значений: это значение определяется СУБД
Используемое для хранения данных пространство может меняться от одной базы данных к другой, однако мы упростим свою работу, рассматривая средние значения, которые определяют максимальный объём потребляемого вашей базой данных пространства. Мы также можем рассматривать общий объём пространства для хранения значений в истории равным примерно 50 байтам на значение, а объём пространства для значения в таблице обобщённых динамик (trends) примерно 128 байт, в то время как пространство, используемое для одного события обычно составляет около 130 байт.
Общий объём используемого пространства может быть вычислен по следующей формуле:
Настройки + История + Тренды + События
Теперь давайте заглянем в каждую из компонент:
-
Настройки: это относится к конфигурации Zabbix для вашего сервера, веб- интерфейса и всем параметрам, которые хранятся в вашей базе данных; обычно это около 10МБ
-
История: компонента истории вычисляется по следующей формуле:
Число хранимых дней истории *(элементы/ частота обновления) *24 *3600 *50байт (среднее используемое историей число байт) -
Обобщённые динамики: компонента тренда вычисляется по следующей формуле:
Число дней *(элементы/ 3600) *24 *3600 *128байт (среднее используемое обобщённой динамикой число байт) -
События: компонента событий вычисляется по следующей формуле:
Число дней *число событий *24 *3600 *130байт (среднее используемое событием число байт)
Теперь, вернувшись к нашему конкретному примеру мы можем предполагать что 5000 элементов будут обновляться каждую минуту при том, что мы хотим иметь 7 сохраняемых дней; потребляемое нами пространство будет определено следующим образом:
История: (общее число хранимых дней) *(элементы/скорость обновления)
*24 *3600 *50байт (среднее используемое историей число байт)
|
| Замечание |
|---|---|
|
50 являются средним числом байт потребляемых значением в истории пространства. |
Рассматривая вариант истории 30 дней, мы получим следующий результат:
-
История вычисляется так:
30 *5000 /60 *24 *3600 *50 = 10.8ГБ -
Как мы уже говорили ранее, для простоты, мы рассмотрим наихудший сценарий (одно событие в секунду) а также рассмотрим сохранение событий на протяжении 5 лет
-
События вычисляются с применением следующей формулы:
Число хранимых дней *число событий *24 *3600 *число используемых байт (среднее)Когда мы вычислим события, мы получим:
5 *365 *24 *3600 *130 = 15.7ГБЗамечание 130 являются средним объёмом потребляемого значением хранимого события.
-
Обобщённые динамики вычисляются при помощи такой формулы:
Число хранимых дней *(число элементов /3600) *24 *3600 *число используемых в тренде байт (среднее)Когда мы вычислим обобщённые динамики, мы получим:
5000 *24 *365 *128 = 5.3ГБ в год, или 26.7ГБ за 5 лет.Замечание 128 являются средним числом байт потребляемых значением хранимого тренда.
Приводимая ниже таблица отображает число хранимых дней и общий объем требуемого пространства для наших измерений:
| Тип измерения | Число дней хранения | Необходимое пространство |
|---|---|---|
|
30 |
10.8ГБ |
|
1825 (5 лет) |
15.7ГБ |
|
1825 (5 лет) |
26.7ГБ |
|
- |
53.2ГБ |
Вычисленный размер не является начальным размером нашей базы данных, однако нам необходимо иметь в виду, что это значение будет нашим окончательным размером после 5 лет. Мы также рассматриваем историю 30 дней, поэтому будем помнить, что эта продолжительность может быть уменьшена если возникнут проблемы, так как наши обобщённые динамики будут хранить наши основные линии почасовых тенденций.
Политика истории и обобщённых динамик может быть легко изменена для каждого элемента. Это означает, что мы можем создавать шаблоны с элементами, которые имеют различную историческую протяжённость по умолчанию. Обычно история устанавливается на 7 дней, однако для некоторых видов измерений, таких как используемые в веб- сеансах или ещё какие- нибудь измерения, нам может понадобиться хранить все свои значения на протяжении более одной недели. Это позволит нам изменять значение продолжительности хранения для каждого элемента.
В нашем примере мы рассматриваем наихудший сценарий с сохранением 30 дней, однако существует хорошая
заготовка с предложением хранить историю 7 дней или даже меньше в больших средах. Если мы выполним
основные вычисления для элемента, обновляемого каждые 60 секунд и имеющего историю в 7 дней, мы
получим (интервал обновлений) *(часов в дне) *(число дней в истории)
= 60 *24 *7 =10080.
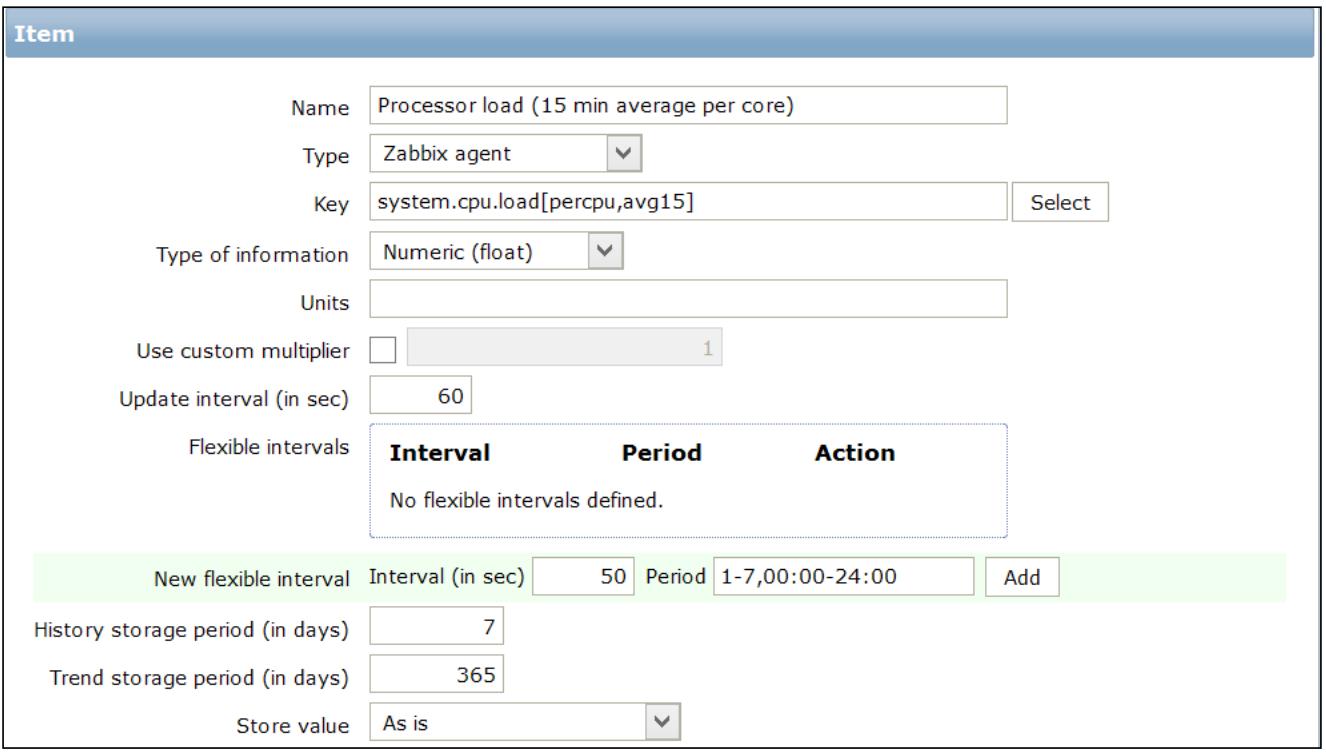
Это означает, что для каждого элемента мы будем иметь 10080 строк в неделю, что даёт нам понимание общего числа строк, производимых в нашей базе данных.
Следующий экранный снимок представляет подробности отдельного элемента:
Очистка может быть достаточно тяжёлым процессом. По мере роста базы данных очистка требует всё больше и больше
времени для выполнения своей работы. Эта проблема может быть разобрана с применением функции базы данных
delete_history().
Существует способ глубинного улучшения производительности очистки и фиксации этого падения производительности.
Самыми нагруженными таблицами являются history,
history_uint, trends
и trends_uint.
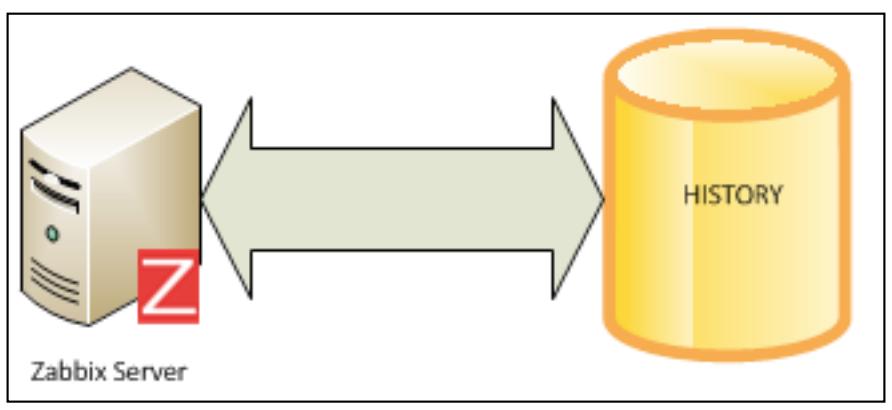
Решение состоит в разделении таблицы PostgreSQL и разбиении всей вашей таблицы на основе месяцев. Приводимый ниже рисунок отображает стандартную и нераздельнкю таблицу истории вашей базы данных:
Следующий рисунок показывает как разбитая на разделы таблица истории будет храниться в вашей базе данных:
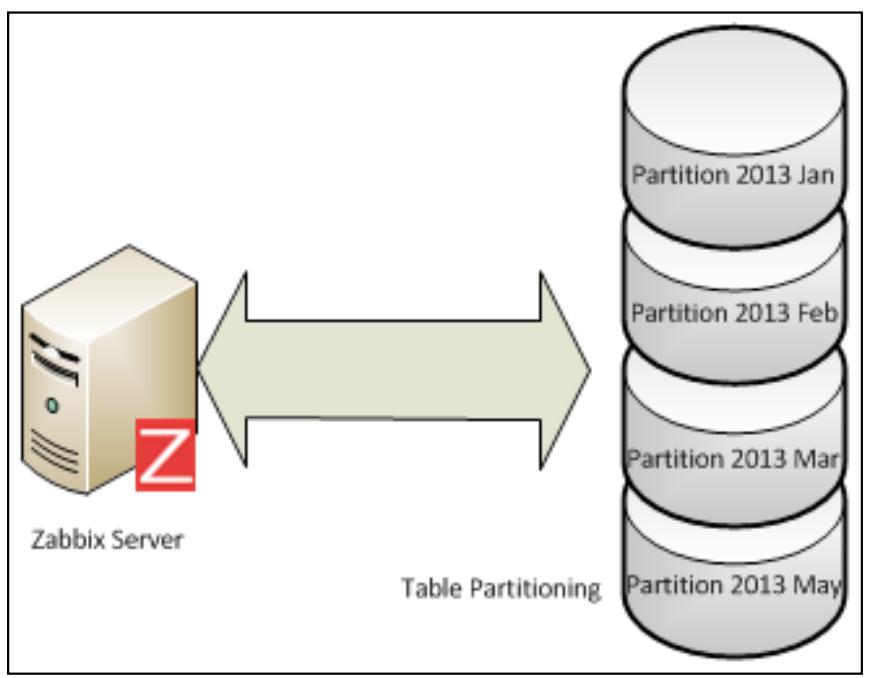
Разбиение на разделы (partitioning) в основном состоит в расщеплении большой логической таблицы на физические части меньшего размера. Это свойство может предоставить определённые преимущества:
-
В случаях, когда присутствует нагруженный доступ к строкам таблицы в отдельном разделе производительность очередей может быть кардинально улучшена.
-
Разбиение на разделы уменьшает размер индексации, делая более вероятным размещение в оперативной памяти тех частей, которые используются наиболее интенсивно.
-
Массовые удаления могут сопровождаться уничтожением разделов, незамедлительно снижая выделяемое под вашу базу данных пространство без введения фрагментации и интенсивной нагрузки по перестроению индекса. Команда
delete partitionтакже целиком избегаетвакуумнойперегрузки вызываемой массовымdelete. -
Когда запрос обновляет ли запрашивает доступ большого процентного соотношения всего раздела, применение последовательного сканирования часто более эффективно чем использование имеющегося индекса со случайным доступом или разрозненных чтений по этому индексу.
Все эти преимущества приносят результат только когда некая таблица очень велика. Сильной стороной архитектуры такого рода является то, что СУБД будет иметь прямой доступ к нужному разделу, а удаление будет просту удалять раздел. Удаление раздела быстрый процесс, требующий незначительных ресурсов.
К сожалению, Zabbix не в состоянии управлять такими разделами, поэтому нам необходимо запретить его очистку и применять внешний процесс для выполнения всей очистки.
Описываемый здесь подход на основании разделов имеет несомненный преимущества в сравнении с прочими решениями разбиения на разделы:
-
Он не требует от вас подготовки к разбиению вашей базы данных на разделы при помощи Zabbix
-
Он не требует от вас создавать/ выполнять расписание задания cron по ваших таблиц в будущем
-
Он проще в реализации чем остальные решения
Данный метод подготовит разделы для необходимых вам схем разделов при учёте следующего соглашения:
-
Ежедневные разделы представляются в виде
partitions.tablename_pYYYYMMDD -
Ежемесячные разделы представляются в виде
partitions.tablename_pYYYYMM
Все приводимые здесь сценарии доступны по ссылке https://github.com/smartmarmot/Mastering_Zabbix.
Чтобы наладить эту функциональность, нам потребуется создать схему, в которой мы можем размещать
все свои таблицы разделов; затем, внутри секции psql, нам необходимо
выполнить следующую команду:
CREATE SCHEMA partitions AUTHORIZATION zabbix;
Теперь нам понадобится функция, которая создаст наш раздел. Поэтому, чтобы соединиться с Zabbix, вам необходимо выполнить следующий код:
CREATE OR REPLACE FUNCTION trg_partition()
RETURNS TRIGGER AS
$BODY$
DECLARE
prefix text:= 'partitions.';
timeformat text;
selector text;
_interval INTERVAL;
tablename text;
startdate text;
enddate text;
create_table_part text;
create_index_part text;
BEGIN
selector = TG_ARGV[0];
IF selector = 'day'
THEN
timeformat:= 'YYYY_MM_DD';
ELSIF selector = 'month'
THEN
timeformat:= 'YYYY_MM';
END IF;
_interval:= '1 ' || selector;
tablename:= TG_TABLE_NAME || '_p' || TO_CHAR(TO_TIMESTAMP(NEW.clock), timeformat);
EXECUTE 'INSERT INTO ' || prefix || quote_ident(tablename) || ' SELECT ($1).*'
USING NEW;
RETURN NULL;
EXCEPTION
WHEN undefined_table THEN
startdate:= EXTRACT(epoch FROM date_trunc(selector, TO_TIMESTAMP(NEW.clock)));
enddate:= EXTRACT(epoch FROM date_trunc(selector, TO_TIMESTAMP(NEW.clock) + _interval));
create_table_part:= 'CREATE TABLE IF NOT EXISTS ' || prefix || quote_
ident(tablename) || ' (CHECK ((clock >= ' || quote_literal(startdate) || ' AND clock < ' || quote_literal(enddate) || '))) INHERITS (' || TG_TABLE_NAME || ')';
create_index_part:= 'CREATE INDEX ' || quote_ident(tablename) || '_1on ' || prefix || quote_ident(tablename) || '(itemid,clock)';
EXECUTE create_table_part;
EXECUTE create_index_part;
--insert it again
EXECUTE 'INSERT INTO ' || prefix || quote_ident(tablename) || ' SELECT
($1).*'
USING NEW;
RETURN NULL;
END;
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100;
ALTER FUNCTION trg_partition()
OWNER TO zabbix;
|
| Замечание |
|---|---|
|
Убедитесь, пожалуйста, что ваша база данных была настроена на работу с пользователем Zabbix. Если вы применяете другую роль/ учётную запись, будьте любезны изменить соответствующим образом последнюю строку данного сценария: |
Теперь нам необходим запускающий механизм (trigger), подключённый к каждой таблице, которую мы хотим
отделить. Этот триггер будет выполнять оператор INSERT и, если
данный раздел ещё не создан, данная функция создаст такой раздел сразу перед оператором
INSERT:
CREATE TRIGGER partition_trg BEFORE INSERT ON history
FOR EACH ROW EXECUTE PROCEDURE trg_partition('day');
CREATE TRIGGER partition_trg BEFORE INSERT ON history_sync
FOR EACH ROW EXECUTE PROCEDURE trg_partition('day');
CREATE TRIGGER partition_trg BEFORE INSERT ON history_uint
FOR EACH ROW EXECUTE PROCEDURE trg_partition('day');
CREATE TRIGGER partition_trg BEFORE INSERT ON history_str_sync
FOR EACH ROW EXECUTE PROCEDURE trg_partition('day');
CREATE TRIGGER partition_trg BEFORE INSERT ON history_log
FOR EACH ROW EXECUTE PROCEDURE trg_partition('day');
CREATE TRIGGER partition_trg BEFORE INSERT ON trends
FOR EACH ROW EXECUTE PROCEDURE trg_partition('month');
CREATE TRIGGER partition_trg BEFORE INSERT ON trends_uint
FOR EACH ROW EXECUTE PROCEDURE trg_partition('month');
На данный момент мы упустили только функцию очистки которая заменит уже построенную в Zabbix и запретит имеющуюся в самом Zabbix. Функция отработки очистки для нас такова:
CREATE OR REPLACE FUNCTION delete_partitions(intervaltodelete
INTERVAL, tabletype text)
RETURNS text AS
$BODY$
DECLARE
result RECORD ;
prefix text := 'partitions.';
table_timestamp TIMESTAMP;
delete_before_date DATE;
tablename text;
BEGIN
FOR result IN SELECT * FROM pg_tables WHERE schemaname = 'partitions' LOOP
table_timestamp := TO_TIMESTAMP(substring(result.tablename FROM '[0-9_]*$'), 'YYYY_MM_DD');
delete_before_date := date_trunc('day', NOW() - intervalToDelete);
tablename := result.tablename;
IF tabletype != 'month' AND tabletype != 'day' THEN
RAISE EXCEPTION 'Please specify "month" or "day" instead of %', tabletype;
END IF;
--Check whether the table name has a day (YYYY_MM_DD) or month (YYYY_MM) format
IF LENGTH(substring(result.tablename FROM '[0-9_]*$')) = 10 AND tabletype = 'month' THEN
--This is a daily partition YYYY_MM_DD
-- RAISE NOTICE 'Skipping table % when trying to delete "%" partitions (%)', result.tablename, tabletype, length(substring(result.tablename from '[0-9_]*$'));
CONTINUE;
ELSIF LENGTH(substring(result.tablename FROM '[0-9_]*$')) = 7 AND tabletype = 'day' THEN
--this is a monthly partition
--RAISE NOTICE 'Skipping table % when trying to delete "%" partitions (%)', result.tablename, tabletype, length(substring(result. tablename from '[0-9_]*$'));
CONTINUE;
ELSE
--This is the correct table type. Go ahead and check if it needs to be deleted
--RAISE NOTICE 'Checking table %', result.tablename;
END IF;
IF table_timestamp <= delete_before_date THEN
RAISE NOTICE 'Deleting table %', quote_ident(tablename);
EXECUTE 'DROP TABLE ' || prefix || quote_ident(tablename) || ';';
END IF;
END LOOP;
RETURN 'OK';
END;
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100;
ALTER FUNCTION delete_partitions(INTERVAL, text)
OWNER TO zabbix;
Теперь у нас имеется готовая к работе очистка (housekeeping). Чтобы включит её, мы можем воспользоваться crontab, добавив следующие записи:
@daily psql –h<your database host here> -d zabbix_db -q -U zabbix -c
"SELECT delete_partitions('7 days', 'day')"
@daily psql –h<your database host here> -d zabbix_db -q -U zabbix -c
"SELECT delete_partitions('24 months', 'month')""
Эти две задачи должны будут выполняться по расписанию в crontab вашего сервера базы данных. В данном примере мы храним свою историю 7 дней и обобщённые динамики 24 месяцев.
Теперь мы можем наконец запретить очистку самого Zabbix. Для выключения очистки в Zabbix 2.4 лучше всего применит веб- интерфейс выбрав Administration | General | Housekeeper, а уже в нём мы можем выключить очистку для таблиц Trends и History, как это показано на следующем снимке экрана:
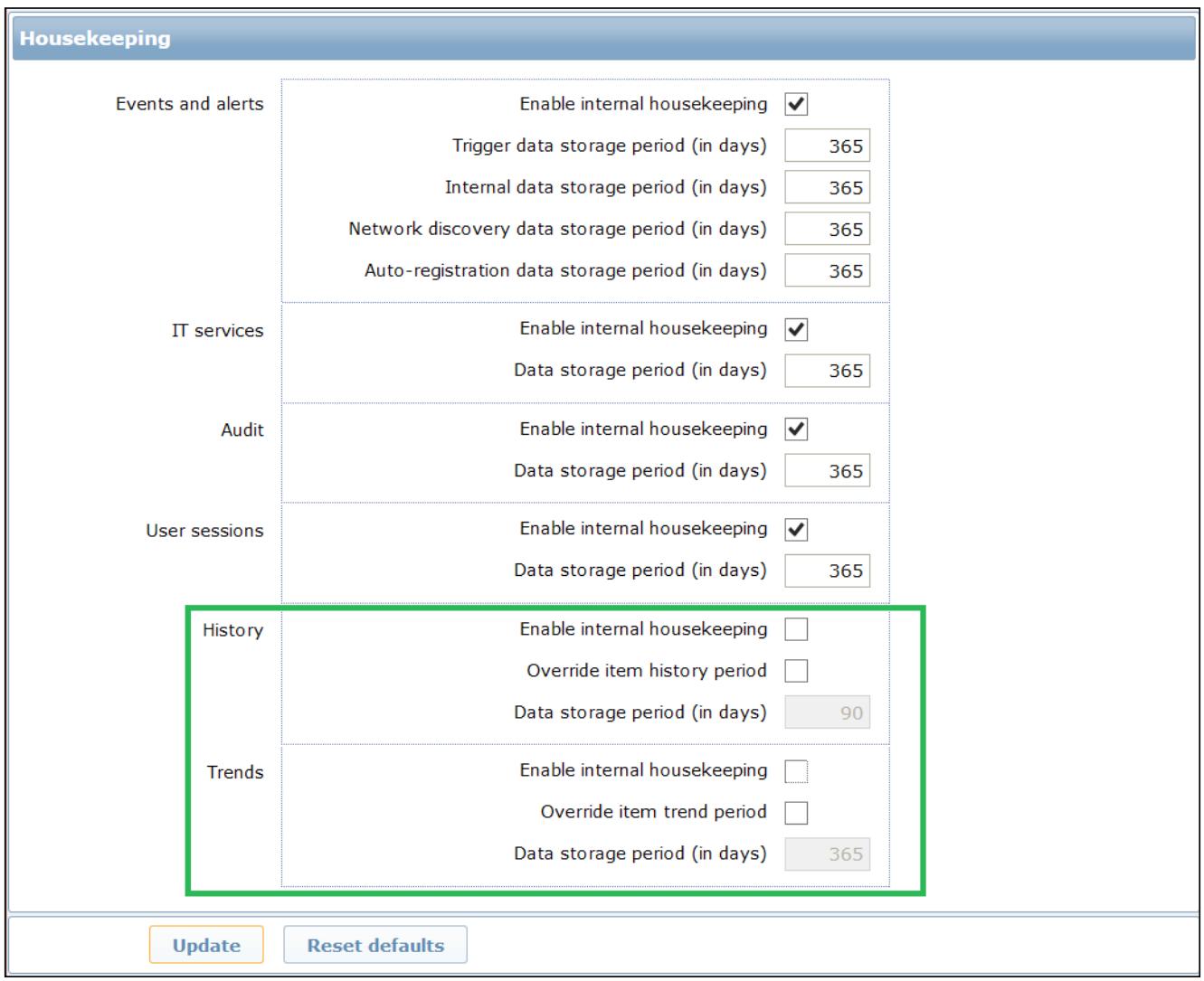
Теперь встренная очистка выключена и вам следует наблюдать целый ряд улучшений производительности. Чтобы сохранять вашу базу данных легковесной насколько это возможно, вы можете очищать следующие таблицы:
-
acknowledges -
alerts -
auditlog -
events -
service_alarms
Когда вы выберите свои значения длительности, вам необходимо добавить политику длительности;
например, в нашем случае, это будет продолжительность в 2 года. При помощи следующих записей crontab мы
можем удалять все записи старше 63072000 (2 года выраженные в
секундах):
@daily psql -q -U zabbix -c "delete from acknowledges where clock < (SELECT (EXTRACT( epoch FROM now() ) - 63072000))"
@daily psql -q -U zabbix -c "delete from alerts where clock < (SELECT (EXTRACT( epoch FROM now() ) - 63072000))"
@daily psql -q -U zabbix -c "delete from auditlog where clock < (SELECT (EXTRACT( epoch FROM now() ) - 62208000))"
@daily psql -q -U zabbix -c "delete from events where clock < (SELECT (EXTRACT( epoch FROM now() ) - 62208000))"
@daily psql -q -U zabbix -c "delete from service_alarms where clock < (SELECT (EXTRACT( epoch FROM now() ) - 62208000))"
Чтобы запретить очистку, нам необходимо отбросить созданные нами запускающие механизмы:
DROP TRIGGER partition_trg ON history;
DROP TRIGGER partition_trg ON history_sync;
DROP TRIGGER partition_trg ON history_uint;
DROP TRIGGER partition_trg ON history_str_sync;
DROP TRIGGER partition_trg ON history_log;
DROP TRIGGER partition_trg ON trends;
DROP TRIGGER partition_trg ON trends_uint;
Все эти изменения необходимо проверить и изменить/ модифицировать чтобы они отвечали вашим настройкам. Кроме того, позаботьтесь о резервных копиях своей базы данных.
Установка веб- интерфейса достаточно проста; существуют определённые основные этапы, которые необходимо выполнить. Веб- интерфейс полностью написан на PHP; в нашем случае мы будем применять Apache со включённой поддержкой PHP.
Весь веб интерфейс целиком содержится внутри папки php в
frontends/php/, которую мы должны скопировать в нашу папку
htdocs:
/var/www/html
Воспользуйтесь следующими командами для копирования необходимых папок:
# mkdir <htdocs>/zabbix
# cd frontends/php
# cp -a . <htdocs>/zabbix
|
| Замечание |
|---|---|
|
Будьте внимательны - вам могут понадобиться соответствующие права и полномочия, так как все эти
файлы находятся во владении Apacheи они также зависят от ваших настроек
|
Веб мастер - настройка пользовательского интерфейса
Теперь вам необходимо открыть в своём браузере следующий URL:
http://<server_ip_or_name>/zabbix
Первый экран, который вы увидите, будет экраном приветствия; в нём вам не нужно ничего делать кроме нажатия
на Next. Порой вы можете увидеть на своей первой
странице предупредительное сообщение, в котором ваш браузер информирует, что не установлена зона ваших даты/
времени. Это параметр внутри файла php.ini Все возможные временные зоны
описаны на официальном веб- сайте PHP по ссылке http://www.php.net/manual/en/timezones.php.
Подлежащий изменению параметр зоны даты/ времени расположен внутри файла php.ini.
Если вы не знакомы с текущими настройками вашего PHP или где расположен ваш файл php.ini,
а вам нужна подробная информация о том, какие модули исполняются или текущие настройки, тогда вы можете написать
файл, например, php-info.php, внутри своего каталога Zabbix со следующим
содержимым:
<?phpphpinfo();phpinfo(INFO_MODULES);
?>
Теперь укажите в своём браузере этот файл: http://your-zabbix-web-frontend/zabbix/phpinfo.php.
Вы получите распечатку всех настроек на веб- странице. Следующий снимок экрана более важен; он отображает проверку необходимых начальных условий и, как вы можете видеть, присутствует по крайней мере одна не соответствующая требованиям предпосылка:
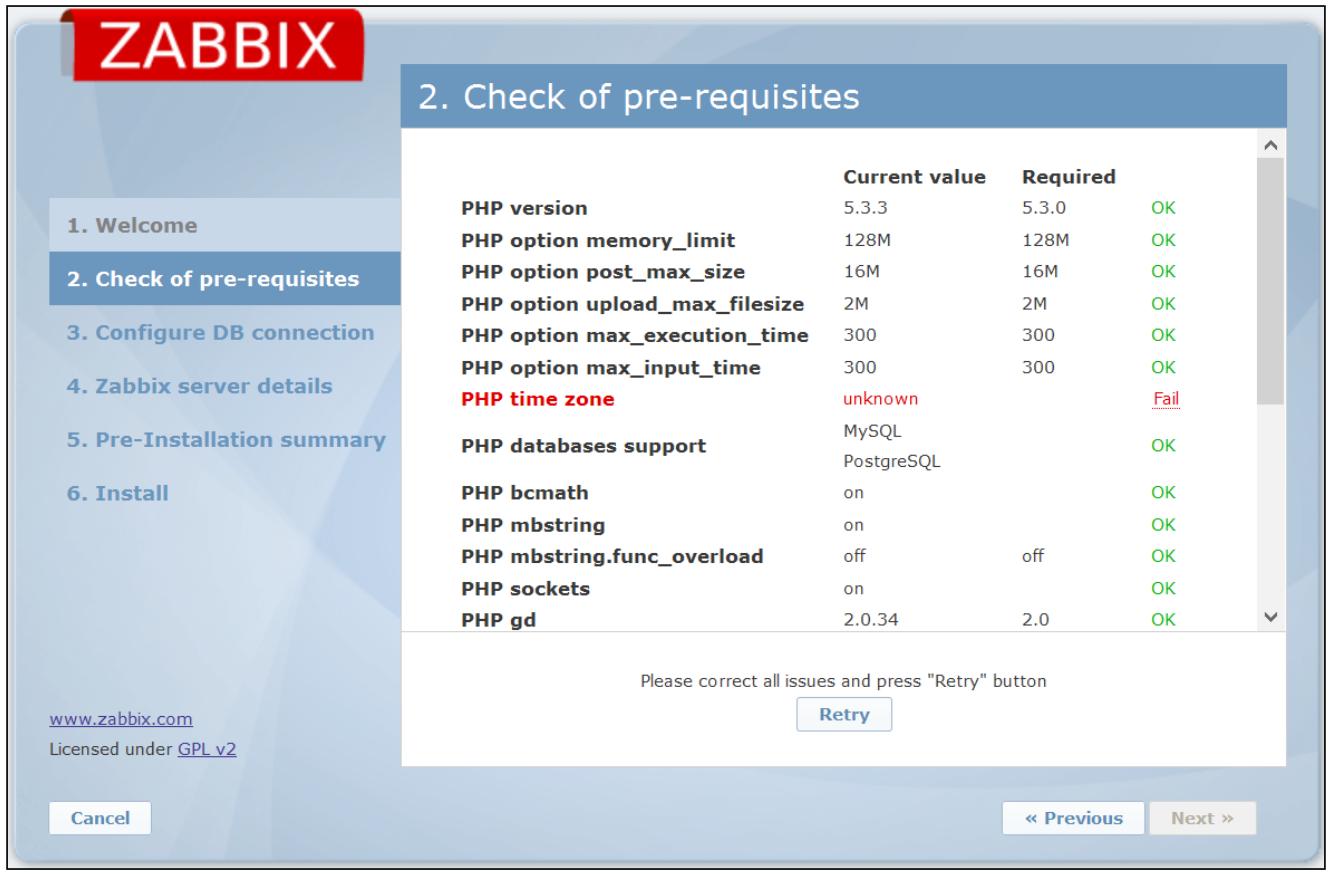
В стандартных Red-Hat/CentOS 6.6 вам необходимо только установить временную зону; в противном случае, если вы приеняете более старую версию, вам может понадобиться изменить следующие предварительные условия, которые скорее всего не удовлетворяют требованиям:
PHP option post_max_size 8M 16M Fail
PHP option max_execution_time 30 300 Fail
PHP option max_input_time 60 300 Fail
PHP bcmath no Fail
PHP mbstring no Fail
PHP gd unknown 2.0 Fail
PHP gd PNG support no Fail
PHP gd JPEG support no Fail
PHP gd FreeType support no Fail
PHP xmlwriter no Fail
PHP xmlreader no Fail
Большинство из этих параметров содержится внутри вашего файла php.ini.
Чтобы поправить их просто измените следующие параметры внутри своего файла
/etc/php.ini:
[Date]
; Defines the default timezone used by the date functions
; http://www.php.net/manual/en/datetime.configuration.php#ini.date.
timezone
date.timezone = Europe/Rome
; Maximum size of POST data that PHP will accept.
; http://www.php.net/manual/en/ini.core.php#ini.post-max-size
post_max_size = 16M
; Maximum execution time of each script, in seconds
; http://www.php.net/manual/en/info.configuration.php#ini.maxexecution-time
max_execution_time = 300
; Maximum amount of time each script may spend parsing request data.
It's a good
; idea to limit this time on productions servers in order to eliminate
unexpectedly
; long running scripts.
; Default Value: -1 (Unlimited)
; Development Value: 60 (60 seconds)
; Production Value: 60 (60 seconds)
; http://www.php.net/manual/en/info.configuration.php#ini.max-inputtime
max_input_time = 300
; Maximum amount of time each script may spend parsing request data.
It's a good
; idea to limit this time on productions servers in order to eliminate
unexpectedly
; long running scripts.
; Default Value: -1 (Unlimited)
; Development Value: 60 (60 seconds)
; Production Value: 60 (60 seconds)
; http://www.php.net/manual/en/info.configuration.php#ini.max-inputtime
max_input_time = 300
Чтобы решить возможные упущенные проблемы, нам необходимо установить следующие пакеты:
-
php-xml -
php-bcmath -
php-mbstring -
php-gd
Для установки этих пакетов мы воспользуемся следующей командой:
# yum install php-xml php-bcmath php-mbstring php-gd
Полный список необходимых начальных условий приводится в следующей таблице:
| Элемент | Вид информации | Введённое значения |
|---|---|---|
Версия PHP |
|
|
PHP |
|
В |
PHP |
|
В |
PHP |
|
В |
Опция PHP |
|
В |
Опция PHP |
|
В |
PHP |
Выключена |
В |
|
|
Примените расширение |
|
|
Примените расширение |
PHP |
Должно быть выключено |
В |
PHP |
Должно быть установлено |
В |
|
|
Это расширение требуется для поддержки сценариев пользователя:
|
|
|
Расширение PHP GD должно поддерживать изображения PNG
( |
|
2.6.15 |
Используйте |
|
|
Используйте |
|
|
Используйте |
|
|
Используйте |
|
|
Используйте |
|
|
Используйте |
При каждом изменении файла php.ini или установке расширения PHP
необходим перезапуск службы httpd для того, чтобы изменения вступили
в силу. Когда все необходимые предварительные условия соблюдены, мы можем кликнуть по
Next и двинуться вперёд. На следующей
странице нам необходимо настроить своё соединение с базой данных. Нам просто необходимо заполнить свою
форму именем пользователя, паролем, IP адресом или именем хоста, а также определить вид используемого
нами сервера базы данных, как это отображено на снимке экрана внизу:
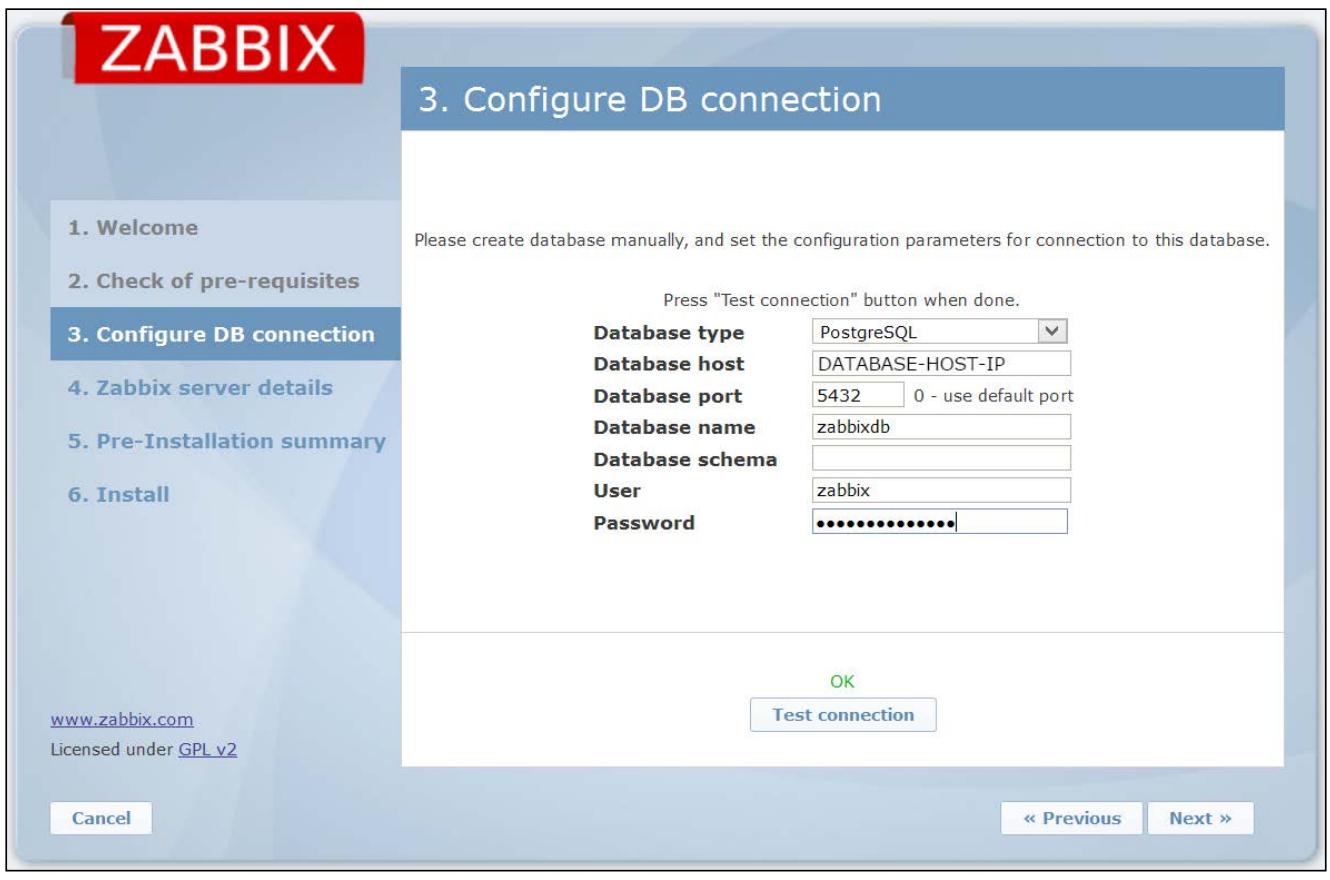
Если соединение успешно (это можно проверить при помощи тестового соединения), мы можем продолжить со следующим этапом. В нём нам всего лишь нужно установить соответствующие параметры базы данных для включения веб GUI чтобы создать корректное соединение, как это показано на следующем снимке экрана:
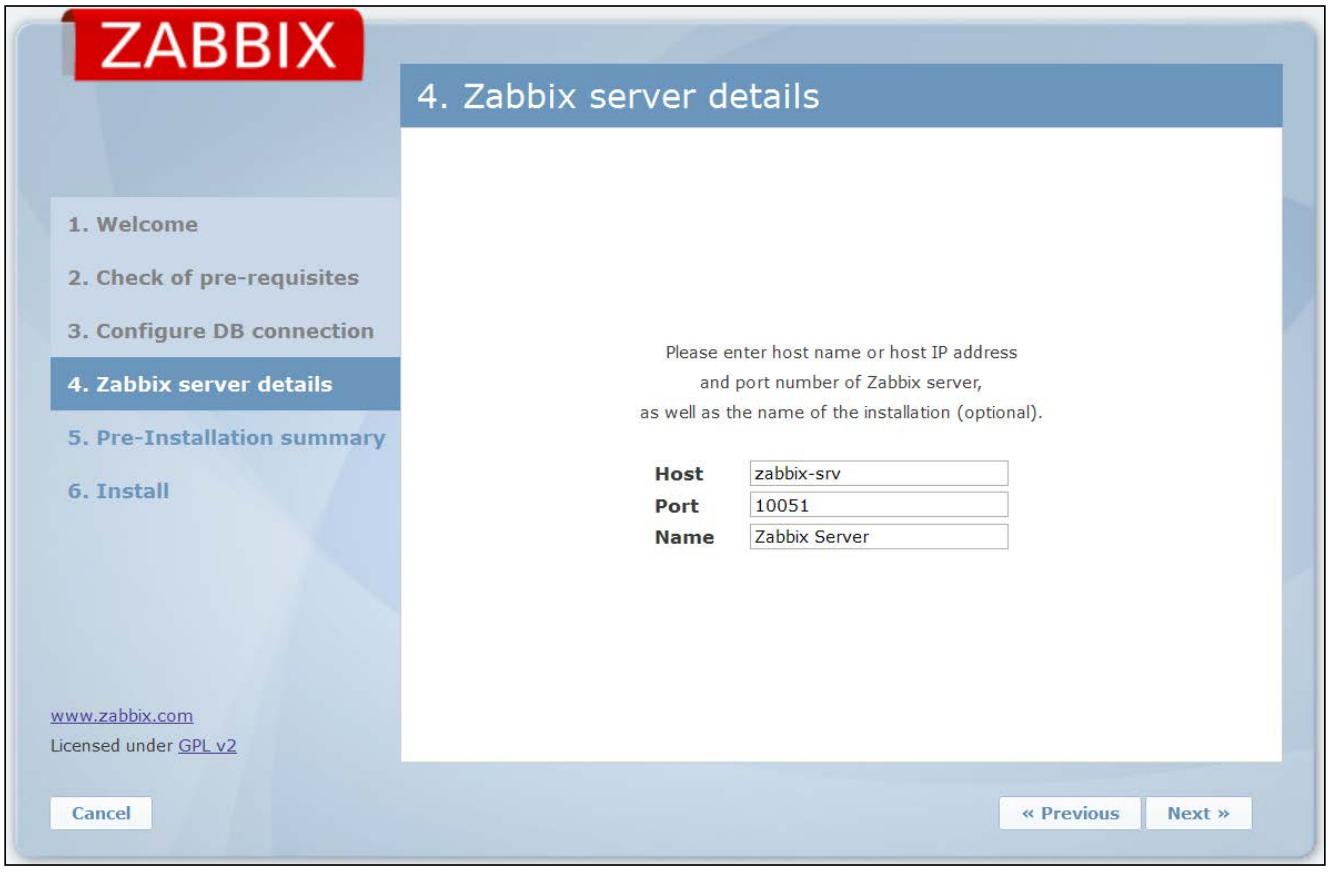
Не существует проверки для такого соединения на данной странице, поэтому лучше будет убедиться что вы можете достичь сервера в своей сетевой среде. В данной форме необходимо заполнить Host (или адрес IP) нашего сервера Zabbix. Так как мы устанавливаем инфраструктуру трёх различных серверов, нам необходимо определить все параметры и убедиться что порт нашего сервера Zabbix доступен за пределами этого сервера.
По заполнению этой формы мы можем кликнуть по Next.
После этого мастер установки пригласит нас просмотреть Pre-Installation summary,
в котором приводится полный перечень всех параметров нашей настройки. Если всё хорошо, просто кликните по
Next; в противном случае мы можем вернуться
назад и поправить свои параметры. Когда мы продвинемся вперёд, мы увидим, что наш файл настройки создан
(например, в данной установке ваш файл был создан в
/usr/share/zabbix/conf/zabbix.conf.php).
Может случиться, что мы получим ошибку вместо уведомления об успехе и, скорее всего, это из- за полномочий
на ваш каталог с нашей папкой conf в
/usr/share/zabbix/conf. Не забудьте сделать этот каталог доступным
для записи пользователю httpd (обычно Apache является открытым на
запись) по крайней мере на время, необходимое для создания этого файла. Когда этот этап завершён,
ваш интерфейс готов и мы можем выполнить свою первую регистрацию.
Очень часто люди путают разницу между планированием ёмкости и настройкой производительности. Хорошо, сферой настройки производительности является оптимизация вашей системы, которую вы уже имеете, для достижения лучшей производительности. Отталкиваясь от текущей производительности в качестве основного уровня, планирование ёмкости определяет что нужно и когда ей это необходимо. Здесь вы ознакомитесь с тем, как организовать нашу инфраструктуру мониторинга для достижения такой цели и снабжения нас полезным базовым уровнем. К сожалению, данная глава не может охватить все стороны этой дискуссии; нам понадобится целая книга о планировании ёмкости, однако в данном разделе мы взглянем на Zabbix с различных точек зрения и получим сведения о том, что с этим делать.
Эффект обозревателя
Zabbix является хорошей системой мониторинга так как она действительно имеет малый вес. К сожалению, каждая наблюдаемая система отнимает часть её ресурсов из операционной системы для исполнения агента, который собирает и измеряет данные и метрики. Это называется эффектом наблюдателя. Мы можем только принимать это бремя на своём сервере и принимать во внимание то, что это вносит некоторое искажение в сбор данных, имея в виду что нам следут удерживать его на минимальном уровне по возможности пока выполняется мониторинг данного процесса и наша индивидуальная проверка.
Принятие решения о предмете мониторинга
Задание агента Zabbix состоит в периодическом сборе данных с подлежащих мониторингу машин и отправке измерений на сервер Zabbix (который будет нашим сервером агрегации и разработки). Теперь по нашему сценарию присутствуют определённо подлежащие рассмотрению моменты:
-
Что мы собираемся получать?
-
Как мы намереваемся получать эти измерения (в чём состоит способ или метод)?
-
Какова частота с которой выполняются эти измерения?
Рассматривая первый момент, важно подумать о том что должно подвергаться мониторингу на нашем хосте и тот вид работы, который наш хост должен выполнять; или, другими словами, каую функцию он будет обслуживать.
Существует несколько основных замеров операционной системы которые, на сегодняшний день, более или менее стандартизованы, и это: загруженность ЦПУ, процентное соотношение свободной оперативной памяти, подробности использования оперативной памяти, использование подкачки, время ЦПУ для процесса, и всё это семейство замеров, все они встроены в нашего агента Zabbix.
Наличие набора элементов со встроенными замерами означает, что они оптимизированы для осуществления минимальной рабочей нагрузки на подлежащем мониторингу хосте, насколько это возможно; весь код агента Zabbix написан таким образом.
Все остальные измерения могут быть подразделены на службы, которые должен предоставлять наш сервер.
|
| Замечание |
|---|---|
|
В данном случае действительно полезны шаблоны! (Кроме того, это эффективный способ агрегирования наших измерений по типу.) |
Выполняя практический пример и рассматривая мониторинг своей СУБД будет фундаментальным получать:
-
Все метрики операционной системы
-
Различные индивидуальные метрики СУБД
Наши различные персональные измерения СУБД могут быть: общим числом присоединённых пользователей, общее использование систем кеширования, общее число полного сканирования таблицы и тому подобное.
Все эти виды замеров будут действительно полезны и могут быть легко интерполированы и сравнены с аналогичными измерениями за тот же период времени графически. Графики имеют ряд сильных сторон:
-
Они полезны для понимания (к тому же и со стороны бизнеса)
-
Они зачастую прекрасны для представлений и интеграции в слайдах для усиления наших выступлений
Возвращаясь назад к практическому примеру, хорошо, в настоящий момент мы получаем данные от своих СУБД и операционной системы. Мы можем сравнивать загруженность своей СУБД и видеть как это отражается на рабочей нагрузке нашей ОС. Что теперь?
Скорее всего, наш основной бизнес состоит в доходе от вебсайта, торгового сайта или веб- приложения. Мы пердполагаем, что нуждаемся в сохранении вебсайта под управлением в трёхуровненвой среде, так как это наиболее распространённый вариает. Наша инфраструктура будет состоять из следующих действующих представителей:
-
Веб- сервера
-
Сервера приложений
-
СУБД
Наиболее вероятно, что в реальной жизни именно в таком виде будет настроена среда Zabbix. Нам необходимо быть в курсе всех частей и каждого компоенента, которые могут оказывать воздействие на нашу подлежащую измерениям службу и сохранение внутри нашей системы мониторинга Zabbix. Обычно мы можем ожидать это совершенно обыденно видеть опытных в системном администрировании людей, сосредоточенных на подробностях операционной системы и всего что с нею связано. Мы также встерчались с людьми, пишущими Java код который необходим для концентрации на некотором другом виде замеров, например, на общем числе потоков (threads). Такого же рода аргументация может быть осуществлена в случае обсуждения планирования ёмкости с администратором базы данных или конкретным парнем из любого подразделения.
Это абсолютно важный момент, так как реализующий Zabbix должен иметь общее видение и должен помнить, что при приобретении новых аппаратныз средств, скорее всего, их посредником будет организационное подразделение (business unit).
Такое организационное подразделение очень часто ничего не знает о числе потоков, которые может поддерживать наша система, однако будет понимать только удовлетворённость пользователей, связанные с пользователями проблемы и как много одновременных пользователей мы можем успешно обслуживать.
Мы уже сказали, что это действительно очень важно быть готовым разговаривать на языке такого подразделения, и мы можем сделать это только если у нас имеются несомненно эффективные элементы для графического представления.
Определение базового уровня
Теперь, когда мы бросим взгляд на всю инфраструктуру с точки зрения клиента, мы можем подумать, что если се наши страницы могут обслуживаться за разумное время, то опыт наблюдения будет удовлетворительным.
Наша цель состоит в том, чтобы сделать наших клиентов счастливыми, а всю инфраструктуру надёжной. Теперь нам необходимо иметь два вида измерений:
-
Одни производятся со стороны пользователя (общее время отклика наших веб страниц)
-
Элементы инфраструктуры связанные с ними
Нам необходимо количественно описывать время отклика связанное с конкреной навигацией пользователя и нам необходимо знать сколько пользователь может ожидать в интерфейсе веб- страницы получения отклика, имея в виду что весь опыт просмотра в браузере должен быть приятным. Мы можем измерять и разделять на категории свои замеры при помощи трёх таких уровней времени отклика:
-
0.2 секунды: это даёт ощущение немедленного отклика. Пользователь чувствует реакцию своего браузера вызванную им/ ею, а не сервером с его бизнес- логикой.
-
1-2 секунды: здеь пользователь что браузер непрерывен, без каких либо прерываний. Пользователь может свободно перемещаться, не ожидая загрузки страниц.
-
10 секунд: любовь к нашему сайту упадёт. Пользователь будет хотеть лучшей производительности и может определённо быть растроен прочими моментами.
Теперь у нас имеются собственные пороговые значения и мы можем выполнять замеры общего откликака веб страниц в процессе обычного их просмотра, а тем временем, мы можем установить уровень запускающего механизма (trigger) для предупреждения нас о том, когда время нашего отклика превысит две секунды для какой- либо страницы.
Теперь нам необходимо установить это для всех наших прочих измерений: общего числа присоединённых пользователей, общего числа сеансов в нашем сервере приложений, а также общего числа соединений с нашей базой данных. Нам также необходимо увязать все свои замеры с их временем отклика и числом подключённых пользователей. Теперь нам необходимо измерить как наша система обслуживает страницы для пользователей в процессе их обычного просмотра.
Это может быть определено как базовый уровень. Это то, где мы находимся в настоящее время и замер того как наша система работает при обычной нагрузке.
Нагрузочное тестирование
Теперь, когда мы знаем то, как мы поживаем, и мы определили пороговые уровни для своей цели, соответствующей приятному опыту просмотра, давайте двинемся вперёд.
Нам необходимо знать что является пределом и, что ещё более важно, как система должна отвечать на наши запросы. Так как мы не можем нанять комнату наполенную людьми, которые будут как бешенные кликать по нашему веб сайту, нам необходимо применять программное обеспечение для имитации такого вида поведения. Существует интересное программное обеспечение с открытым исходным кодом, которое в точности выполняет это. Присутствуют различные адьтернативы для выбора - одной из них является Seige (https://www.joedog.org/2013/07/siege-3-0-3-url-encoding/).
Seige позволяет нам эмулировать сохранённую историю браузера и загружать её на наш сервер. Нам необходимо иметь в виду, что пользователи, реальные пользователи, никогда не будут синхронно работать. Поэтому важно ввести задержку между всеми такими запросами. Помните, что если у нас имеется регистрация, то нам нужно использовать базу данных пользователей, так как серверы приложений кешируют свои объекты, а мы не желаем измерять насколько хорошо данный процесс работает при кэшировании его. Основное правило состоит в создании реальных сценариев просмотра нашего веб сайта, поэтому способные выполнять регистрацию пользователи могут завершать работу простым кликом и при этом без каких- либо случайных задержек.
Такие сохранённые сценарии должны повторяться x раз
с нарастающим числом пользователей, что означает, что Zabbixбудет сохранять наши измерения и, в определённый
момент, мы преодолеем свой первый порог (1-2 секунды на веб страницу). Мы можем двигаться вперёд пока время
отклика не достигнет величины нашего второго порога. Не существует способа посмотреть какую нагрузку может
выдержать наш сервер, однако хорошо известно, что аппетит приходит во время еды, поэтому я не буду
удивлён, если вы двинитесь дальше и не будете грузить свой сервер до полного краха одной из компонент
его инфраструктуры.
Прорисовывка графиков, которые связывают время отклика с общим числом пользователей сервера, поможет нам увидеть будут ли наши три уровня веб- архитектуры линейными или нет. Скорее всего, они будут расти линейным образом до определённого момента. Этот сегмент является тем, где наша система работает прекрасно. Мы также можем наблюдать внутри Zabbix за компонентами и с этой точки мы можем вводить некоторый вид задержки и производить некоторые умозаключения.
Теперь мы в точности знаем чего нам ожидать от своей системы и как наша система может обслуживать наших клиентов. Мы можем увидеть какая компонента первой пострадает от загрузки и где нам необходимо планировать тонкую настройку.
Планирование ёмкости может быть выполнено без закапывания и погружения в то что оптимизировать. Как мы уже сказали ранее, существует две различные задачи - настройка производительности и планирование ёмкости - которые, конечно же, связаны, но являются различными. Мы можем просто пересмотреть нашу производительность и спланировать расширение своей производительности.
|
| Совет |
|---|---|
|
Планирование аппаратного расширения всегда экономичнее чем внезапное, вызванное катастрофой улучшение оборудования. |
Мы также можем выполнить тонкую настройку производительности, однако имейте в виду, что существует связь между общим затраченным временем и получаемой производительностью, поэтому нам необходимо понимать когда самое время прекратить нашу настройку производительности, что отражается на следующем рисунке:
Предсказание тенденций
Одно из наиболее важных свойств Zabbix состоит в его ёмкости для хранения данных истории. Это свойство является жизненно важным в процессе предсказания тенденций. Предсказание наших тенденций не является простой задачей и является важным для рассмотрения того бизнеса, который мы обслуживаем, а когда мы рассматриваем историю данных, нам следует увидеть будут ли присутствовать повторяющиеся периоды, либо существует некоторая формула, которая может описать нашу тенденцию.
Например, может оказаться, что наблюдаемый нами онлайн веб магазин требует всё больше и больше ресурсов в процессе определённого времени года, в частности, влизи общественных праздников, если мы продаём поездки. Выполняя практическое упражнение, вы можете рассматривать пространство, используемое на определённом диске сервера. Zabbix снабжает нас экспортируемой функциональностью для получения наших исторических данных, поэтому очень просто импортировать их в электронные таблицы. Exel имеет опции построения кривых, которые вполне помогут нам. Очень просто определить линии тенденций с помощью Exel, который сообщит нам когда мы можем исчерпать всё своё дисковое пространство. Чтобы добавть линию тенденции в Exel, вначале нам необходимо создать "поточечный график" (scatter graph) с нашими данными; в нашем случае также важно нанести на график размер диска. После этого мы можем попытаться найти математическое уравнение, которое наиболее близко к нашей тенденции. Существуют различные виды формул из которых можно выбирать; в нашем примере я применяю линейные уравнения, потому что наши графики растут с линейной зависимостью.
|
| Замечание |
|---|---|
|
Процесс построения линии тенденции также называется подбором аппроксимирующей кривой (curve fitting process). |
Получающийся в данном процессе график позволяет нам узнать, с определённой степенью точности, где мы выйдем за пределы своего пространства.
Теперь совершенно ясно насколько важно обладать значительным объёмом исторических данных, имея в виду промежуток бизнеса и то, как он влияет на данные.
|
| Совет |
|---|---|
|
Важно сохранять отслеживание используемых линий тенденций/ регрессий и соответствующие формулы при помощи значений R- квадрата, так как существует возможность точно вычислять его и, если нет никаких изменений в тенденциях, определить когда будет исчерпано пространство. {Прим. пер.: R-квадрат характеристика линейной связи в рамках регрессионного анализа; R-квадрат принимает значение между нулём и единицей, причем ноль означает отсутствие линейной связи, а единица - тесную функциональную зависимость; R-кадрат часто используется в финансовых приложениях в качестве характеристики тесных связей двух переменных, например как коэффициент соответствия между доходностью портфеля ценных бумаг и рыночным индексом; значение коэффициента, равное единице, означает, что доходность портфеля полностью определяется рынком; ноль означает, что между ними нет никакой зависимости.} |
Полученный график отображён на экранном снимке внизу, и из этого графика просто увидеть, что если тенденция не изменится, мы выйдем за пределы имеющегося пространства 25 июня 2015:
В данной главе мы выполнили настройку Zabbix в среде с тремя уровнями. Это окружение является хорошей отправной точкой для обработки всех событий, генерируемых большими и очень большими средами.
В нашей следующей главе мы окунёмся глубже в узлы, прокси и все возможные эволюции и, как мы увидим, все они улучшают нашу начальную настройку. Это не означает, что такие описываемые в следующей главе расширения просты в реализации, однако все улучшения инфраструктуры применяют такую трёхуровневую настройку в качестве отправной точки. В следующей главе вы, в основном, изучите как расширять и развивать эту настройку, а также увидите как в нашу установку могут быть интегрированы распределённые сценарии. Наша следующая глава также содержит важную дискуссию о безопасности в распределённых средах, осведомляя вас о возможных рисках безопасности, которые могут вознкать в распределённых средах.