Глава 12. Атака на протоколы маршрутизации
Содержание
- Глава 12. Атака на протоколы маршрутизации
- Стандартные протоколы IGP - поведения RIP (кратко), OSPF и IS - IS
- Фальсификация, превышение прав и отказ от заявления
- DDOS, плохое обращение и атаки на уровень управления
- Отравление таблицы маршрутизации и атаки на плоскость управления
- Генерация обмена и атаки на плоскость данных
- Как настраивать ваши маршрутизаторы для защиты
- BGP - протокол и операции
- Угон BGP
- Облегчение условий BGP
- Выводы
- Вопросы
В своей предыдущей главе мы изучили протоколы шифрования беспроводных сред, беспроводную архитектуру, атаки на беспроводные сетевые среды и безопасности беспроводных сетей. Данная глава рассмотрит различные, но тем не менее весьма занимательные и важные сетевые протоколы: протоколы маршрутизации, в частности, IGP (Interior Gateway Protocol, протокол внутреннего шлюза).
IGP используется для совместного применения сведений маршрутизации в виде таблиц маршрутизации внутри имеющейся анонимной системы для перенаправления обмена и сетевых протоколов, таких как IP (Internet Protocol).
Эта глава начинается с объяснения собственно протокола IGP, различных протоколов маршрутизации, неверных настроек и мер противодействия, которые можно реализовывать для безопасности протокола маршрутизации относительно разнообразных атак.
В данной главе мы охватим следующие вопросы:
-
Стандартные протоколы IGP - поведение RIP (вкратце), OSPF, а также IS-IS
-
Фальсификацию, завышенные требования и отказ в признании
-
DDoS, ненадлежащая обработка и атаки плоскости контроля
-
Отравление таблицы маршрутизации и атаки плоскости управления
-
Выработка обмена и атаки плоскости данных
-
Как настраивать ваши маршрутизаторы для защиты
-
BGP - протокол и операции
-
Взлом BGP
-
Ослабление BGP
Как нам теперь известно, весь Интернет целиком представляет собой очень большое единое целое, состоящее из большого числа более мелких сетевых сред. Эти сети меньшего размера связаны друг с другом посредством неких протоколов маршрутизации. Тем самым, это означает, что когда всякий компьютер подключён к Интернету, такая вычислительная система выступает частью сети меньшего размера - эта меньшая сеть с точки зрения построения сетевых сред носит название автономной системы (Autonomous System, AS -АС).
Эти AS подключаются через EGP (Exterior Gateway Protocol, протокол внешнего шлюза), а потому, скажем, если компьютер из, допустим, AS-1 желает взаимодействовать с другим компьютером в AS-2, этот обмен происходит через соответствующий EGP. Неким примером EGP выступает BGP (Border Gateway Protocol, протокол пограничного шлюза).
Таким образом, когда, следуя аналогичной концепции, компьютерам внутри AS-1 необходимо взаимодействовать друг с другом, они пользуются соответствующим IGP. Образцами IGP являются RIP (Routing Information Protocol), OSPF (Open Shortest Path First), IGRP (Interior Gateway Routing Protocol), EIGRP (Enhanced Interior Gateway Protocol) и IS-IS (Intermediate System-Intermediate System).
Итак, прежде чем погружаться глубже в протоколы маршрутизации, давайте разберёмся с EGP и IGP при помощи следующей простой схемы:

Как это показано на Рисунке 12.1, две автономные системы взаимодействуют друг с другом через протокол маршрутизации EGP, а имеющиеся между ними маршрутизаторы подключаются через протоколы маршрутизации IGP.
Следовательно, теперь, когда мы разобрались с собственно AS и архитектурой маршрутизации, давайте перейдём для начала к пониманию того, как соответствующие протоколы IGP работают в промышленных средах.
IGP применяется для передачи сведений о маршрутизации в виде таблиц маршрутизации для взаимодействующих маршрутизаторов. В данном случае IGP отвечают исключительно за передачу сведений в сторону верных получателей (в сетевых средах это IP адреса). Когда протоколы маршрутизации не заданы надлежащим образом, такие сообщения в соответствующих сетевых каналах будут либо путать пункт назначения, либо будут отбрасываться в своём подключённом следом сетевом устройстве. Таким образом, злоумышленники также пользуются неверными настройками таких протоколов маршрутизации для перехвата или подделки имеющихся сообщений.
Ладно, давайте разберёмся с поведением некоторых из главным образом применяемых в организациях протоколами маршрутизации.
RIP это один из наиболее широко применяемых видов IGP во внутренних сетевых средах. RIP пользуется методологией счётчика скачков (hop) для выявления изменений в сети, а также для распознавания того как далеко может доставать это взаимодействие в сетевой среде.
Технология счётчика скачков определяется как значение числа соединений (здесь перенаправлений), которые имеются между самим источником и его получателем. Данная технология помогает RIP выявлять наиболее лучшие и самые короткие пути между пунктом возникновения данного сообщения и целью получения такого сообщения.
RIP работает по UDP
(User Datagram Protocol) и пользуется портом 520.
Итак, давайте при помощи Packet Tracer разберёмся как работает RIP.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Единственной целью данной главы выступает анализ имеющихся неверных настроек в применяемых протоколах маршрутизации. Следовательно, мы ожидаем, что наши читатели знакомы с основами необходимых установок маршрутизации и обладают базовыми знаниями по различным сетевым устройствам. |
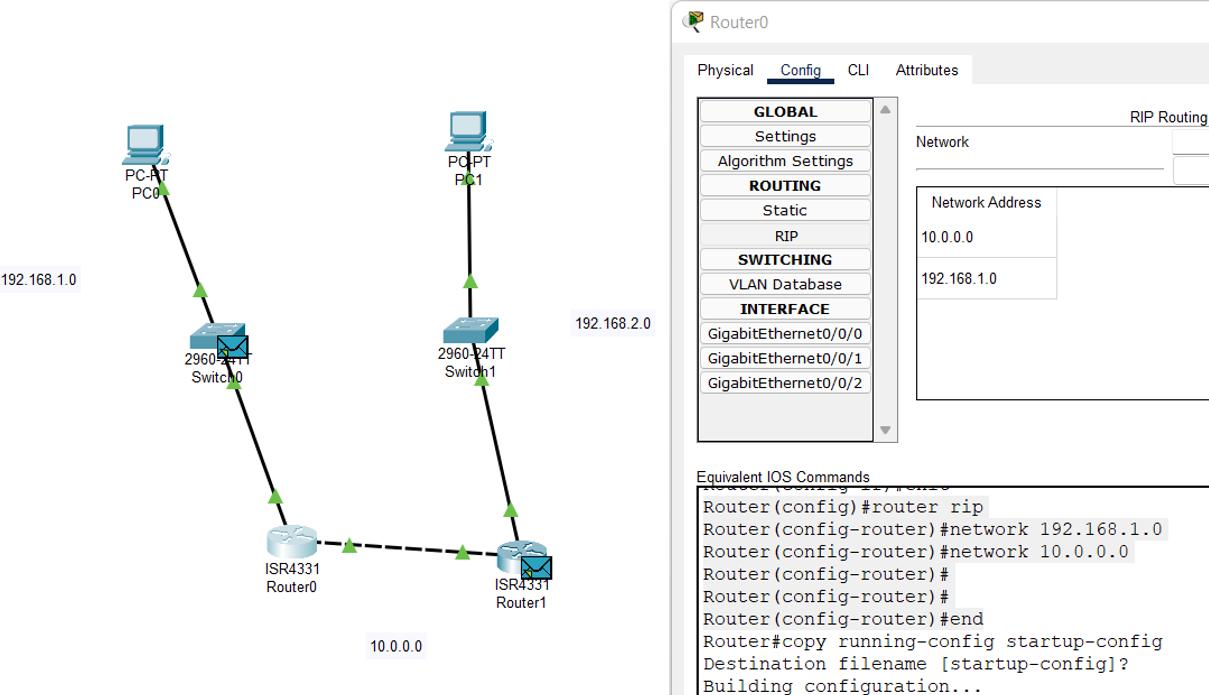
Как показано на Рисунке 12.2, RIP сконфигурирован и все пакеты запросто выполняют обмен из сети
192.168.2.0 в 192.168.1.0.
Давайте воспользуемся встроенными средствами наблюдения Packet Tracer и проанализируем RIP:
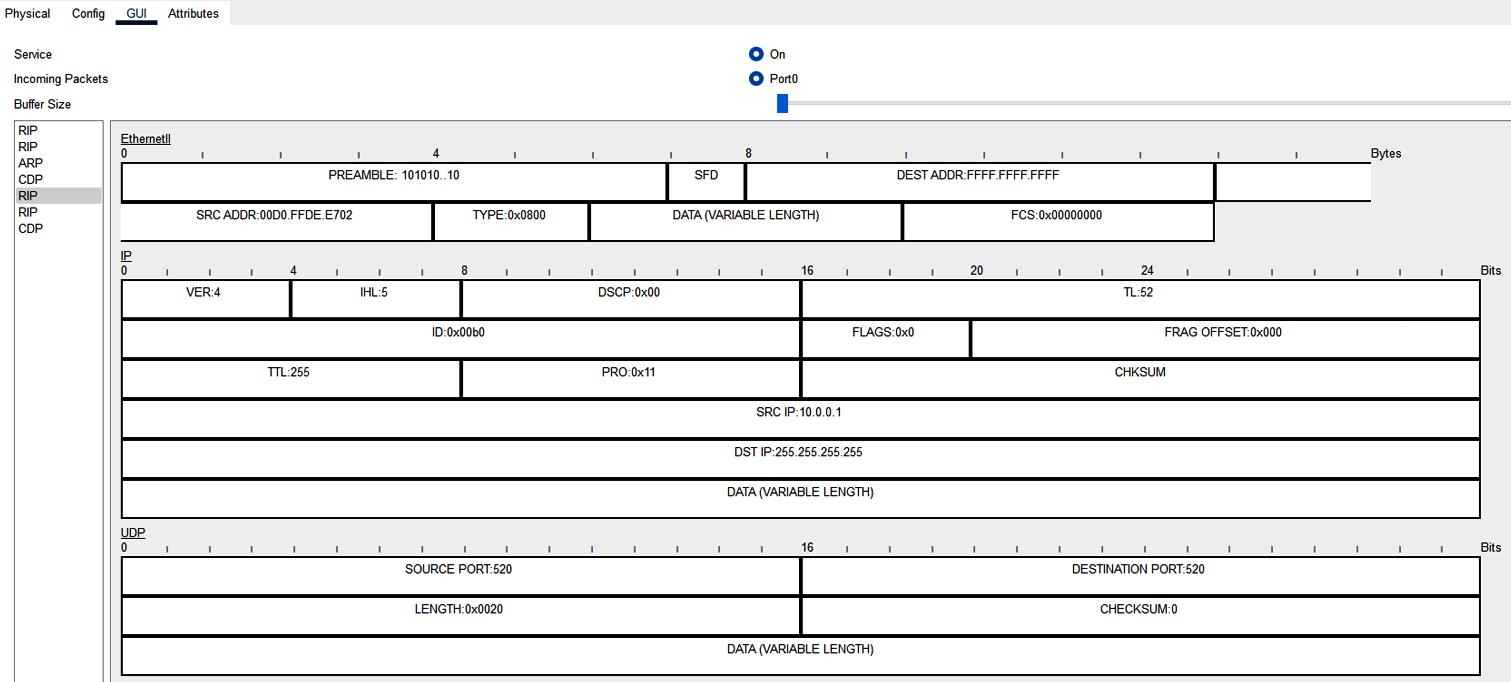
Как это отражено на Рисунке 12.3, при помощи средства наблюдения Packet Tracer успешно отслежено представление пакета.
|
| Замечание |
|---|---|
|
В промышленных средах реального масштаба времени для анализа имеющихся пакетов мы можем также применять в качестве средства наблюдения Wireshark. Однако просто для демонстрации поведения единственного пакета мы воспользовались встроенной в Packet Tracer функциональной возможностью. |
Итак теперь, раз мы поняли собственно поведение протокола RIP, давайте разберёмся с другим протоколом маршрутизации - OSPF.
Протокол OSPF, как и предполагает его название {Open Shortest Path First}, это протокол маршрутизации состояния канала IGP, применяемый для обмена пакетами посредством фильтрации кратчайших путей в AS {автономной системе}. В наши дни OSPF очень популярен в организациях, поскольку он передаёт пакеты с очень высокой скоростью, причём даже в AS большого размера.
Способ, коим работает OSPF, достаточно прямолинеен. Все имеющиеся в его AS маршрутизаторы будут совместно пользоваться LSA (Link-State Advertisements, уведомлениями о состоянии каналов) при помощи соседнего или смежного с ним маршрутизатора, а все имеющиеся маршрутизаторы будут поддерживать LSD (Link-State Databases, базы данных состояния канала). Затем, на основании этого, вычисляется кратчайший путь между соответствующими маршрутизаторами. Следовательно, всякий раз, когда отправителю приходится выполнять обмен каким бы то ни было пакетом в некой AS из одной машины в другую, имеющиеся в данной топологии маршрутизаторы выявляют самый короткий путь и затем осуществляют обмен такими пакетами.
Когда OSPF был представлен, он был очень успешен для сетевых сред меньшего размера, однако когда данный алгоритм маршрутизации вводился для организаций большего размера с большим числом маршрутизаторов в AS, OSPF начинал отказывать, поскольку он требовал большого времени на вычисление кратчайших каналов между всеми маршрутизаторами. Однако даже после подобного неудобства, OSPF всё ещё один из основных реализуемых в организациях алгоритмов маршрутизации по причине большого числа его преимуществ. Вот перечисление некоторых из таких преимуществ протокола OSPF:
-
Данный протокол позволяет имеющимся маршрутизаторам повторно вычислять подходящие каналы при всяких даже незначительных изменения внутри своей AS.
-
OSPF предоставляет некий дополнительный уровень защиты, носящий название маршрутизации области, который подразумевает реализацию внутри своей AS многоступенчатой иерархии с тем, чтобы сведения относительно топологии данной сетевой среды являлись неизвестными всеми прочими располагающимися вне этой AS маршрутизаторами.
-
Лишь обладающим доверием маршрутизаторам позволяется выполнять обмен имеющимися сведениями маршрутизации, ибо сам протокол обмена выполняет аутентификацию перед тем как подлежит совместному использованию.
OSPF работает по порту 89 и поддерживает как IPv4, так и IPv6. Текущая поддерживаемая версия для IPv4 это v2, а для
IPv6 v3.
Итсак, давайте разберёмся с OSPF по следующему снимку экрана:
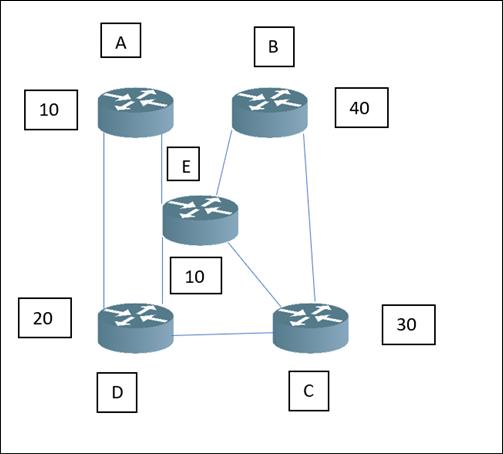
Как отображено на Рисунке 12.4, рассмотрим очень небольшую AS с пятью наборами маршрутизаторов - теперь предположим что маршрутизатор A пожелал бы создать свою LSD, а потому отправит необходимые LSA обновления каждому подключённому маршрутизатору для обновления своей таблицы. Затем эти маршрутизаторы будут отправлять такое LSA другому подключённому маршрутизатору, а когда все присоединённые маршрутизаторы обновят свои таблицы, они отправят обновление маршрутизатору A, а маршрутизатор A обновит свою LSD.
Однако тут возникает вопрос - как маршрутизатор A или любые иные подключённые маршрутизаторы вычисляют значение кратчайшего или самого быстрого пути?
Таким образом, ответ очень прост. Сам протокол OSPF вычисляет длину пути через имеющееся назначенным значение COST (стоимости), а затем добавляет величину общей стоимости достижения такого маршрутизатора. Это показывается следующим образом.
Итак, допустим, маршрутизатор A пожелает отправить пакет маршрутизатору C, а потому давайте вычислим значение общей стоимости по множеству путей:
-
A + E + C = 10 + 10 + 30 = 50
-
A + E + D + C = 10 + 10 + 20 + 30 = 70
-
A + D + C = 10 + 20 + 30 = 60
-
A + E + B + C = 10 + 10 + 40 + 30 = 90
Следовательно, из произведённых вычислений дин путей, самый короткий (или наибыстрейший) путь это A + E + C = 50. Отсюда, когда некая подключённая к маршрутизатору A машина захочет отправить сообщение подключённой к маршрутизатору C машине, кратчайшим путём будет A + E + C. Аналогичная методика применяется также и для всех прочих маршрутизаторов в матрице.
Тем самым, давайте разберёмся с этим путём простой демонстрации, выглядящей так:
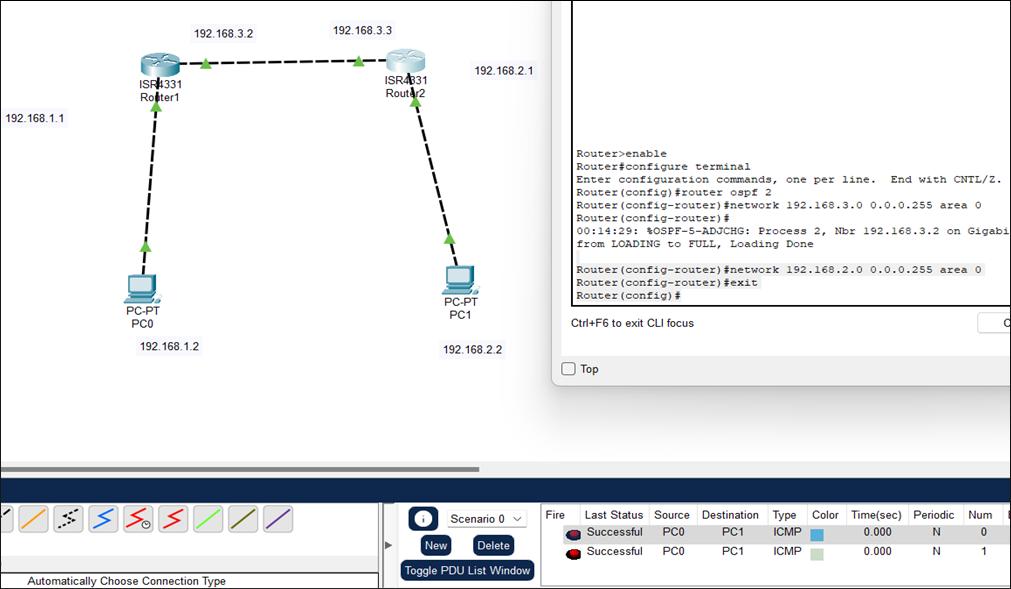
Как отображено на Рисунке 12.5, два смежных маршрутизатора настроены друг на друга, а также соединены со своими соответствующими компьютерами. Теперь
PC0 отправил сообщение к PC1 и это сообщение успешно доставлено при помощи
протокола маршрутизации OSPF.
Значит, мы подробно разобрались с RIP и OSPF, давайте поймём поведение протокола IS-IS.
IS-IS это протокол маршрутизации состояния канала, который был намеренно разработан для модели OSI (Open Systems Interconnect) самой ISO (International Standards Organization). IS-IS намеренно применяется всеми ISP (Internet Service Provider, поставщиками Интернет услуг) по причине его глубокого масштабирования.
Вот некоторые характеристики протокола IS-IS:
-
Это протокол состояния канала.
-
Он работает по принципу SPF.
-
IS-IS это некий протокол IGP.
-
Это не обладающий классами маршрутизации протокол.
-
IS-IS поддерживает подчинённые сети и VLSM (Variable Length Subnet Mask, маской подсети изменяемой длины).
-
IS-IS это протокол 2 Уровня - следовательно, он пользуется адресами MAC (Media Access Control) для отправки сообщений в качестве группового обмена и индивидуальной рассылки.
-
Величиной значения AD (Administrative Distance, показателя надёжности маршрута) протокола IS-IS равно
115. -
В целом, аналогично OSPF, IS-IS поддерживает три таблицы, а именно, neighbor table (таблицу соседей), topology table (таблицу топологии) и routing table (таблицу маршрутизации).
-
Основным преимуществом протокола IS-IS является то, что он свободен от длины метрики полосы пропускания состояния канала. По умолчанию, установленным значением метрики данного канала является
10, однако мы можем определять значение своей метрики от0до63.
Теперь, когда мы ознакомились с поведением самого протокола IS-IS, давайте разберёмся с IS-IS поглубже.
Когда IS-IS был первоначально обнародован, он применялся в качестве EGP на соответствующем уровне OSI, однако по мере развития данной технологии IS-IS был изменён на поддержку протокола TCP/IP, а потому он получил название Дуального IS-IS или Интегрированного IS-IS.
Дуальный IS-IS был разработан для поддержки:
-
Его работы так же, как и всякого прочего вида IGP, например, OSPF.
-
IS-IS более стабилен нежели прочие протоколы.
-
IS-IS очень действенно задействует полосу пропускания, потребление памяти и ресурсов.
-
IS-IS работает очень быстро - величина пакета hello по умолчанию составляет 10 секунд.
Теперь давайте перейдём к другой концепции в IS-IS, именуемой CLNP (Connectionless Network - Address - Protocol, протоколом передачи данных без предварительного установления соединения).
Некий адрес CLNP, также носящий название сетевого адреса, если коротко, используется для назначения некого адреса соответствующему маршрутизатору на Уровне 3 в качестве замены для его адреса IP. Тем самым, CLNP превратился в чрезвычайно популярный усилиями CISCO и был адаптирован в компаниях крупного размера. Адрес CLNP составляется тремя основными полями, определяемыми следующим образом:
-
AFI (Authority Format Identifier, идентификатор формата полномочий) - данное значение закреплено на
49, что указывает на то, что данный адрес частный:-
AreaID - значение величины минимально устанавливается равной 1 байту и представляется как
0001.
-
-
SystemID - Это значение составляет 48 бит, то есть 6 байт.
-
NSAP (Network Service Access Point Address, адрес точки доступа к сетевым услугам) - это значение всегда установлено в
00, что указывает на то, что это устройство является маршрутизатором.
Таким образом, комбинируя эти значения, соответствующий адрес CLNP будет представлен следующим образом:
49.0001.1111.1111.1111.00 -- CLNP или Net Address
IS-IS поддерживает два уровня иерархии:
-
Level-2 (L2): Когда данный маршрут соответствующего обмена будет вне пределов области, проще говоря, определяет магистраль (backbone).
-
Level-1 (L1): Это означает, что маршрут данного обмена будет внутри свои областей. Уровень 1, короче говоря, определяет сами области.
IS-IS способен работать также на обоих уровнях одновременно. Мы можем определять значение соответствующих уровней в IS-IS вручную, но когда оно не задано, значением по умолчанию будет L1/L2.
Теперь давайте настроим IS-IS:

Как показано на Рисунке 12.6, два маршрутизатора успешно соединены и готовы к взаимодействию друг с другом с применением протокола IS-IS. Поэтому давайте настроим соответствующий протокол IS-IS в обоих маршрутизаторах:
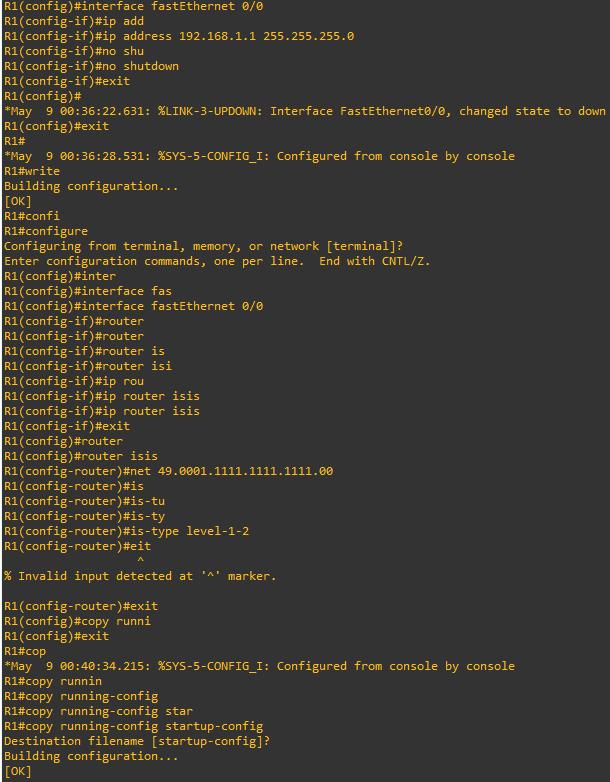
Как отображено на Рисунке 12.7, конфигурация IS-IS успешно построена и наши маршрутизаторы теперь начнут взаимодействовать друг с другом.
Итак, теперь, когда мы изучили работу и поведение различных сетевых протоколов маршрутизации, давайте сейчас рассмотрим некоторые лазейки таких протоколов маршрутизации.
Подделка (фальсификация) маршрутизатора это атака в которой злоумышленник отправляет поддельные или фальшивые сведения маршрутизации в атакуемую сеть. После того как все промежуточно подключённые узлы (в данном случае маршрутизаторы) принимают такую фальшивую информацию маршрутизацию, такую как поддельные LSA (в варианте OSPF), маршрутизаторы обладают тенденцией обновлять свои таблицы маршрутизации. Такие атаки могут оказаться опасными, ибо они влекут за собой фишинг вебсайтов, атаки MITM, прослушиванию и мистификацию DNS.
Для выполнения атак фальсификации требуется достичь некоторых предположений в их цели. Самое первое предположение состоит в том, что сам злоумышленник не может быть получателем, однако он должен выступать первоисточником. Это означает что машина злоумышленника обязана быть способной быть порождающей необходимые фальшивые сведения маршрутизации и должна действовать в качестве ретранслятора таких фальсифицированных данных маршрутизации вместо того чтобы просто обладать возможностью получения такой информации.
Действующий в качестве инициатора фальсификации злоумышленник описывается так:
-
Превышение прав - Атака с превышением прав происходит когда подключённый к соседнему маршрутизатору злоумышленник утверждает, что наилучший путь маршрута для достижения другой стороны сети обеспечивается эти заявляемым злоумышленником маршрутизатором, что не соответствует действительности реального масштаба времени или когда такое объявление злоумышленника не обладает авторизацией для приёма в данной сетевой среде. Давайте рассмотрим это воспользовавшись приводимым ниже рисунком:
Как это отражено на Рисунке 12.8, маршрутизатор A (RA) подключается в Интернету через маршрутизатор B (RB) - маршрутизатор C (RC) подключён к интернету и своей внутренней сети точно так же как и RA. Теперь, давайте предположим что в настоящем сценарии RA способен представить свой канал в Интернет через RB, а RC авторизован на представление любого канала для данной сети. Согласно данному сценарию RA не обладает авторизацией на представление какого бы то ни было канала в данной сетевой среде, что означает что RA не способен контролировать свои каналы в этой сети, однако всё ещё обладает подключённым к ней каналом.
Давайте допустим, что RA выступает маршрутизатором злоумышленника, что подразумевает, что этот злоумышленник целиком контролирует состояния этого канала, собственно сведения протокола, такие как идентификаторы маршрутизатора, идентификаторы состояния канала и собственно представление маршрутизатора. Теперь, RA будет представлять эти каналы с поддельной маршрутизацией, выставляя требование того что это кратчайший путь достижения необходимой сетевой среды заключается через RA в RB и собственно в Интернет. Раз RB принимает и изменяет свою таблицу маршрутизации и выполняет авторизацию этого потока обмена, тогда весь поток сетевого обмена начнёт следовать через наш RA и злоумышленник будет обладать возможностью контроля данного потока обмена.
Тепер могут происходить два момента - либо основываясь на авторизации весь обмен в сеть назначения начнёт следовать через RA, либо этот обмен никогда не достигнет своего назначения. Однако в обеих ситуациях RA будет способен контролировать весь сетевой обмен.
Итак, теперь мы разобрались с основами превышения прав и давайте проследуем далее к другому понятию - отказу от заявления или неверное заявление.
-
Неверное заявление - Атака неверного заявления происходит когда маршрутизатор злоумышленника представлен в сетевой среде с некоторыми правами авторизации и пользуется этой авторизацией, такой злоумышленник начинает отправлять фальшивые сведения маршрутизации, однако такая авторизация не является фактической или предполагаемой представленной сетевым администратором.
Давайте поймём это при помощи некого образца, как это отображает следующий снимок экрана:
Как показано на Рисунке 12.9, давайте предположим, что RA авторизован некими полномочиями в нашей сетевой среде, однако не контролирует всю сеть целиком. RA начинает отправлять фальшивые сообщения LSA во всю сетевую среду через RB. Раз такой поддельное LSA маршрутизации принят, RA будет способен контролировать весь сетевой обмен.
Теперь мы разобрались с такими типами фальсификации при помощи примеров. Давайте взглянем на то как мы можем воспользоваться этим при помощи примера из реальной практики, что отображено на следующем снимке экрана:
Как это показано на на Рисунке 12.10, давайте допустим, что в нашей сети имеется некая интеграция нового серверного сегмента и для интеграции этой маршрутизации существует новый маршрутизатор, RC, который вводится в нашу сетевую среду посредством маршрутизации OSPF.
Теперь, в соответствии с устанавливаемым по умолчанию поведением маршрутизации, RC, для выстраивания доверительного отношения с прочими маршрутизаторами в этой сети, приступит к отправке сведений о маршрутизации - скажем интеграцию
10.1.1.1/24- к другим маршрутизаторам. Прочие подключающиеся маршрутизаторы начнут обновлять свои соответствующие таблицы не проверяя целостность таких сведений маршрутизации.Предположим, имеется некий злоумышленник с поддельным маршрутизатором, который также часть этой сетевой среды, причём он пребывает в режиме MITM, и он также будет получать эту информацию. Теперь, как только этот маршрутизатор злоумышленника получает данные сведения, наш злоумышленник также отправляет в эту сеть поддельный пакет LSA о том, что сеть
10.1.1.1/24больше не поддерживается, а новой подсетью должна выступать192.168.1.1/24.Как только прочие маршрутизаторы получают это поддельное LSA, они также приступят к обновлению своих сведений таблицы маршрутизации для выстраивания доверительного отношения с этим новым интегрированным маршрутизатором и сетевой средой. После того как все таблицы маршрутизации обновлены, наш злоумышленник начнёт получать обмен от прочих подключённых устройств для такой вновь интегрированной сетевой среды.


Таким образом, именно это является фальсификацией маршрутизации OSPF через отправку поддельных LSA. Теперь у нас имеется понимание о подобных атаках на протоколы маршрутизации и давайте взглянем на некоторые иные атаки на протоколы маршрутизации.
Сейчас, перед более глубоким погружением в собственно этап атаки, давайте сначала поймём некоторые из основ построения сетей для определения DDoS (Distributed Denial-of-Service, распределённого отказа в обслуживании) на плоскости контроля.
Плоскости в сетевой среде просто определяются как те измерения, которые определяют как будет передаваться от своего источника к его получателю пакет данных, а также как он будет обрабатываться в процессе передачи данных и собственно методы отслеживания такой передачи данных.
Теперь, эти плоскости, в терминологии построения сетей, подразделяются на три категории:
-
Плоскость контроля
-
Плоскость данных
-
Плоскость управления
Плоскость контроля
Плоскость контроля принимает решения о том как переправлять соответствующие данные, что подразумевает как эти данные будут передаваться от источника к получателю. Сам процесс создания таблицы маршрутизации при котором соответствующий маршрутизатор сохраняет необходимые пути маршрутизации это часть такой плоскости контроля.
Плоскость данных
Теперь, когда имеющаяся плоскость контроля приняла решение относительно перемещения данных, имеющаяся плоскость данных будет ответственной за обмен пакетами данных. Такая плоскость данных также именуется плоскостью продвижения.
Плоскость управления
Плоскость управления это то место, в котором инженеры настраивают и отслеживают имеющиеся сетевые устройства. Такая плоскость управления запущена на том же самом процессоре что и её плоскость контроля.
Итак, когда теперь мы разобрались с сетевыми плоскостями, давайте взглянем на атаки на плоскость контроля.
Атака DoS (Denial-of-Service, отказа в обслуживании) это попытка отправлять большое число пакетов, которые отсекут соединение между пользователями и имеющимися сетевыми устройствами путём увеличения текущей нагрузки на сетевую среду или использования машинных ресурсов. В таком случае пользователи не будут способны получать доступ к чему бы то ни было в своей сетевой среде.
Теперь, DDoS, с другой стороны, выполняет такую же атаку, но в распределённом виде. Многие Боты будут отправлять гигантское число пакетов дабы задействовать все ресурсы, что в конечном счёте приведёт к отключению данного устройства и пользователи в его сетевой среде не смогут получать к нему доступ.
Тогда, в случае DDoS атаки уровня контроля, злоумышленники отправят гигантское число пакетов контроля к плоскости управления такого устройства, что приведёт к исчерпанию ресурсов и чрезмерной нагрузке на такой маршрутизатор и нарушит сетевое взаимодействие.
Атаки отражения на имеющийся уровень контроля - это ещё один вид DoS атак, который обычно отличается от оригинальной DoS или DDoS атаки. Подобная атака отражения осуществляется в два этапа:
-
Пробная фаза - На данном этапе злоумышленник сперва отправляет пакеты синхронизации, тестовые пакеты и пакеты плоскости данных. Эти пакеты помогают злоумышленнику узнать о настройках имеющихся приложений уровня контроля, которые вовлечены в плоскость данных.
-
Фаза переключения - Теперь, когда злоумышленник получил достаточно сведений с пробного этапа, он далее создаст вручную шаблоны для инициации сообщения об обновлении за очень короткое время, что повлечёт сбои в сетевом обмене, а в некоторых ситуациях может быть парализована вся сеть.
Итак, на данный момент мы изучили различные атаки на уровне контроля, давайте взглянем на некоторые существующие атаки в плоскости управления.
|
| Замечание |
|---|---|
|
Следует избегать выполнения DoS и DDoS атак в сетях реальной практики, так как это может обрушать всю сетевую среду целиком - утрата подключённых к сети одного маршрутизатора или коммутатора способно в результате приводить к потере всех сетевых подключений. Таким образом, для данного раздела невозможна демонстрация атак DoS или DDoS. |
Таблицы маршрутизации определены как устанавливаемый набор правил и сведений, представляемых в табличной форме, которые задают собственно маршрут необходимого обмена в данной сетевой среде. Такая таблица маршрутизации выступает наиболее важной частью всякого протокола маршрутизации, ибо представляет ту конфигурацию своих маршрутизаторов, которая относится ко всем IP адресам и напрямую подключается к соседним маршрутизаторам.
Подобная таблица маршрутизации обычно составлена из IP адресов получателей, масок подсетей и интерфейсов. Это отображается следующим образом:
| Адрес назначения | Маска подсети | Интерфейс |
|---|---|---|
|
|
FastEthernet0/0 |
|
|
FastEthernet0/1 |
|
|
FastEthernet0/1 |
Соответствующая запись шлюза по умолчанию к адресу получателя в таблице маршрутизации это всегда 0.0.0.0, а значение
его маски всегда установлено в 255.255.255.255.
Теперь, как нам известно, пакет маршрутизации содержит полные сведения относительно адресов своих источника и получателя. Эта информация помогает построению надлежащей таблицы маршрутизации, поскольку такой протокол маршрутизации способен принимать решение относительно наилучшего пути, как мы это уже наблюдали для протокола OSPF, а после выбора такого наилучшего и кратчайшего пути эти сведения также сохраняются в данной таблице маршрутизации.
Тем самым, при отправке соответствующих пакетов от любого источника к его получателю, наша таблица маршрутизации инструктирует своё устройство отправлять пакеты к следующему скачку. При помощи каждой записи в своей таблице маршрутизации сохраняются такие записи:
-
Сетевой идентификатор - Значение адреса получателя, который соотносится со сведениями данного маршрута.
-
Маска подсети - Соответствующее адресу сети получателя значение маски.
-
Следующий скачок - Ближайшее соседнее подключённое устройство в которое будет отправлен данный пакет.
-
Интерфейс - Исходящий порт, из которого уйдёт данный пакет для достижения своего получателя.
-
Метрика - Значение минимального числа скачков или маршрутизаторов, которое данный пакет пересечёт до достижения необходимого адреса получателя.

Как показано на Рисунке 12.11, команда show IP route применяется для выставления сведений своей таблицы маршрутизации.
Давайте взглянем на непосредственно подключённые устройства, как это отображено на приводимом ниже снимке экрана:

Как отображено на Рисунке 12.12, команда show IP route connected показывает значением следующего скачка непосредственно
подключённого к Router0, в который и последует передача данного пакета.
Теперь, прежде чем изучать отравление таблицы маршрутизации, давайте поймём сначала основную проблему в протоколе DVR (Distance Vector Routing, дистанционной векторной маршрутизации).
Основная проблема с DVR заключается в том, что когда какой- то из маршрутизаторов отказывает, прочим маршрутизаторам потребуется некоторое время для получения уведомления о подобном отказе, и между тем, прочие имеющиеся маршрутизаторы начнут отправлять соответствующие пакеты данных, что в конечном счёте создаст бесконечный цикл. Давайте разберёмся с этим при помощи некого образца:

Как отображено на Рисунке 12.13, имеется три подключённых маршрутизатора (R0 -> R1 -> R2). Теперь воспользуемся этим образцом - от R1 к R2 общая стоимость пакета равна 1, а от R0 к R2 это 2.
Через какое- то время R2 падает, а соединение между R1 и R2 разъединяется. Теперь, раз R1 знает о данном отказе, он автоматически удалит данный путь из своей таблицы. Однако прежде чем отправить обновление к R0, R1 получает обновление от R0. Теперь R1 отправит обратно некое обновление, которое составит общую стоимость достижения R2 равной 3, а затем, раз R0 получит обновление, он отправит свой следующий пакет со стоимостью 4 и данный цикл продолжится. Это носит название Проблемы счётчика бесконечности, при которой все маршрутизаторы продолжают отправлять друг другу фальшивые сведения относительно значения стоимости и путей в не имеющем окончания цикле.
Данная проблема имеет перечисленные ниже два решения:
-
Расщепление перспективы - При применении данного метода в случае сбоя какого бы то ни было маршрутизатора принимающий пакеты маршрутизатор не будет отправлять никаких сведений обратно маршрутизатору- отправителю. Тем самым, если маршрутизатор R2 откажет, а R1 получит обновление от R0, R1 не будет сообщать никаких сведений R0 и тем самым можно избежать зацикливания.
-
Отравление маршрутизации - С помощью данной технологии, если некий маршрутизатор в сетевой среде выходит из строя, подключённый соседний маршрутизатор приступит к отправке отрицательных сведений об этом отказе с весьма специфичным значением метрики, имеющим название бесконечности, которая будет информировать прочие маршрутизаторы что с определённой стороны присутствует отказ в соединении. У всякого протокола маршрутизации имеется заданное значение бесконечности - к примеру, для RIP оно равно 16.
Теперь, когда соответствующие маршрутизаторы получают значение бесконечности, все эти маршрутизаторы получают эту информацию и вносят изменение в свою таблицу маршрутизации. Однако основная проблема отравления маршрута заключается в том, что значение числа объявлений увеличивается, что может повлечь наводнение в данной среде.
На данный момент мы разобрались с самой таблицей маршрутизации, её проблемами и тем почему может вводиться отравление маршрутизации. Сейчас задумайтесь о перспективе злоумышленника ка если бы негодяй начал отправлять фальшивые объявления в свою сетевую среду и мог бы изменять имеющиеся таблицы маршрутизации, это в конечном итоге вызвало бы неверную работу такой сети или её полную компрометацию.
В таком случае мы можем создавать такие пакеты и маршруты для фальшивых записей таблицы маршрутизации - для этого существует некое написанное Frederico средство автоматизации. Вы можете найти его здесь.
Приводимый далее рисунок показывает атаку таким инструментом автоматизации:
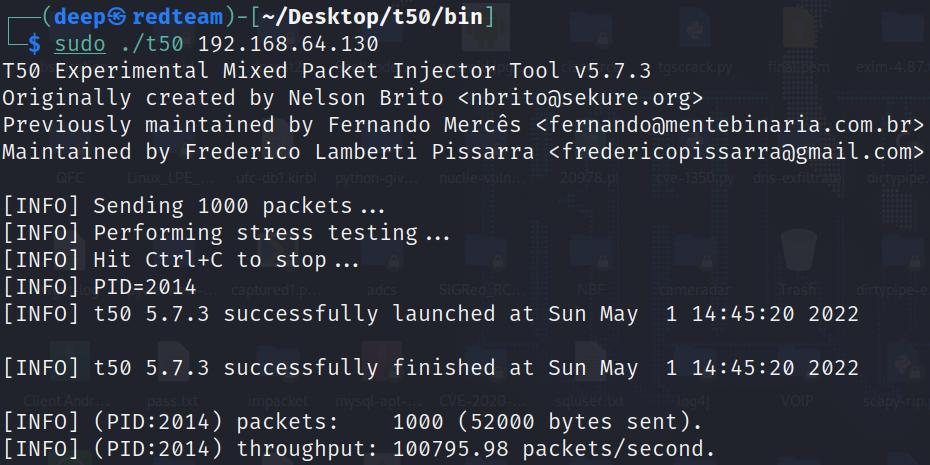
Как это отражено на Рисунке 12.14, 1 000 фальшивых пакетов осуществляют затопление и будут отравлять имеющиеся таблицы маршрутизации поддельными записями.
Теперь, атаки аналогичного типа могут осуществляться на уровне управления и в них злоумышленник атакует и контролирует имеющиеся коммутаторы:
-
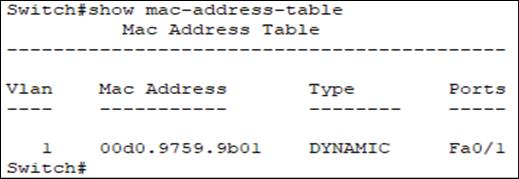
Отравление таблицы CAM - Таблица CAM (Content Addressable Memory, ассоциативной памяти) создаётся коммутаторами в своей сети для хранения сведений относительно имеющихся MAC адресов, причём совместно с их соответствующими параметрами VLAN. Приводимый ниже снимок экрана отображает записи таблицы CAM в таком коммутаторе:
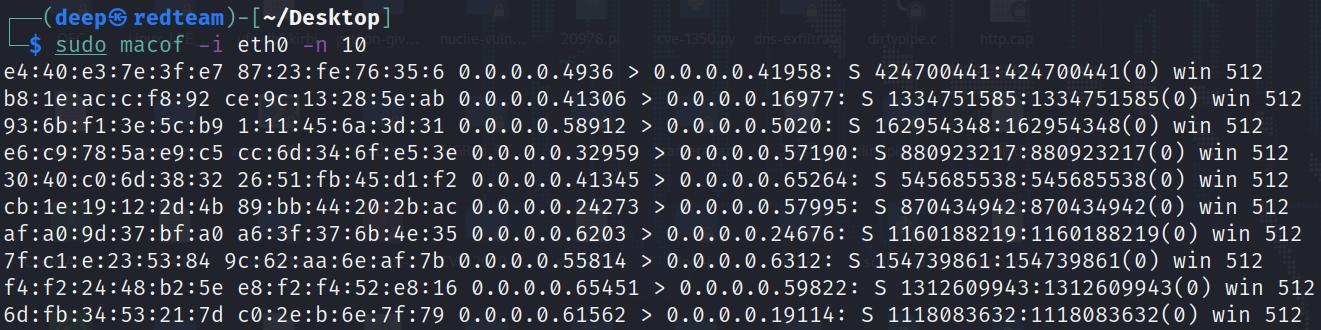
Как показано на Рисунке 12.15, команда
show mac-address tableпредставляет значения записей таблицы CAM в выбранном коммутаторе.Теперь злоумышленник способен затопить эту таблицу CAM фальшивыми записями при помощи инструментария macof, который является предустановленным в Kali Linux. Приводимый далее снимок экрана отображает это средство
macof:
Как показано на Рисунке 12.16, для отравления данной таблицы MAC подключённого к
eth0коммутатора было отправлено 10 записей. -
Address Resolution Protocol (ARP) - Мы подробно представляли отравление ARP в разделе Подмена ARP, угон сеанса а также инструменты, сценарии и методы захвата данных из Главы 8, Анализ и подслушивание сетевого обмена. В данной главе мы взглянем на некие иные способы атаки коммутаторов на Уровне 2.
-
Атаки на основе протокола - Также имеются атаки на протоколы SNMP (Simple Network Management Protocol) или SSH (Secured Shell), которые не охватывает данная глава, однако не чувствуйте себя ограниченными также и на их изучение.
На текущий момент мы рассмотрели атаки на коммутаторы и маршрутизаторы, давайте бросим взгляд на конфигурации безопасности для маршрутизаторов.
В наши дни построение сетевых сред намного сложнее чем раньше. Выполнение относящихся к сети тестов является более сложной задачей для сетевых администраторов, в особенности с точки зрения проверки пропускной способности, всяких сбоев, которые влекут за собой отключение промежуточных сетевых устройств от этой сетевой среды или отслеживания потери пакетов между хостом и сервером.
Таким образом, для устранения неполадок в сетевой среде жизненно важную роль играет генерация пакетов. Таким образом, выработка пакетов это некий вид производства обмена, который определяет собственно поток необходимых пакетов и источников данных между исследуемыми клиентом и сервером в сети коммутации пакетов. Например, в случае веб служб обмен отправляется в виде веб- пакетов, которые подлежат получению и отправляются браузером пользователя.
Следовательно выработка обмена определяет сам поток конкретного обмена между отправителем и получателем в заданных формате и сетевой среде, таких как сотовые сети или вычислительные сети.
Теперь, для данной книги и главы, мы сосредоточимся на вычислительных сетевых средах, однако не запрещаем вам также изучать и сотовый обмен.
Для анализа производительности обмена в реальном масштабе времени существует великое множество присутствующих в Интернете средств, таких как Bwping или iperf. Тем не менее, согласно моим наблюдениям, в целом, сетевые администраторы предпочитают применять iperf, поскольку он очень дружественен пользователям, поставляется со множеством опций, совместим с Windows и Linux (обоих предпочтений), предоставляет точные подробности и, что наиболее важно, способен производить пакеты и для TCP, и для UDP.
Итак, давайте анализировать полосу пропускания обмена вырабатывая определённое число пакетов между своими клиентом и сервером.
На данный момент, для генерации обмена между двумя хостами, нам потребуется создать с одной из сторон пребывающий в ожидании сервер, что показано на следующем снимке экрана:

Как это отображено на Рисунке 12.17, ожидающий элемент это установка с одной из сторон нашей сетевой среды. Теперь давайте установим с другой стороны своей сети клиента, как это демонстрирует приводимый ниже снимок экрана:
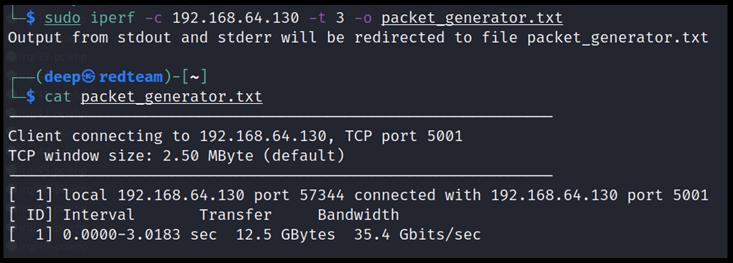
Как видно из Рисунка 12.18, эта машина с другого конца соединена с машиной, в которой открыто ожидание и, как мы можем наблюдать, имеется обмен сообщениями с полосой пропускания 35.4Гбит/с.
Мы можем отслеживать те же самые моменты в окне системного монитора, в котором достигается пик графика использования памяти в процессе обмена сообщениями или выработки обмена:

Как это наблюдается на Рисунке 12.19, прежде чем наш клиент соединится с машиной в ожидании, наш обмен был обычным, а использование ЦПУ низким, однако как только наш клиент подключается к своему серверу, имеется обмен сообщениями, вызывающий немедленный рост использования ЦПУ и проявляющийся как заметный пик в этой сетевой среде.
Вот, атаки на уровне данных аналогичны тем типам атак, которые мы наблюдали исполняющимися на уровне управления, однако сама природа такой атаки будет совершенно иной.
Итак, как нам изветсно, плоскость данных это носитель пакетов данных - таким, ниже приводятся уровни атак, которые могут здесь осуществляться:
-
Подслушивание - Подслушивание, это механизм, при помощи которого злоумышленник отслеживает и изменяет текущий обмен между двумя узлами. Данная атака обычно зависит от самого типа пакетов, но, как правило, злоумышленники осуществляют ретрансляцию ARP для перехвата всего обмена целиком. Мы подробно обсуждали это в Главе 8, Анализ и подслушивание сетевого обмена.
-
DoS - Другая основная атака, которая очень распространена на уровне данных, это атака DoS, в основном выполняемая по двум причинам:
-
Прерывание соединения полностью между обеими частями взаимодействия
-
Отправка испорченного обмена для перенаправления имеющихся запросов обычно осуществляется в процессе беспроводных атак
-
Итак, давайте взглянем на атаку DoS в плоскости данных:
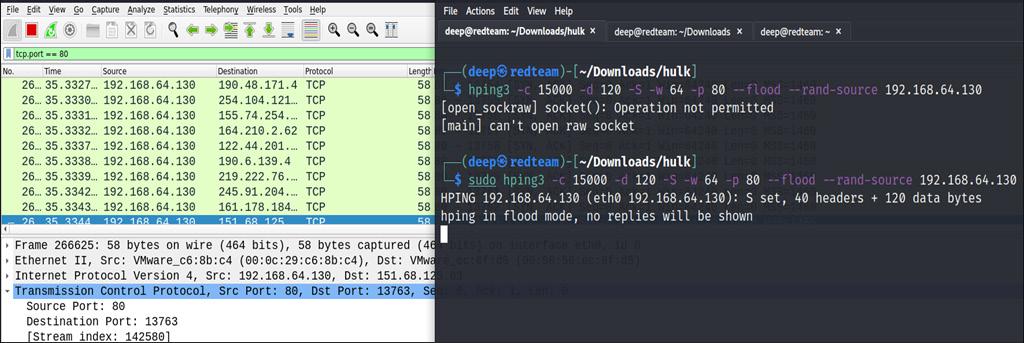
Как показано на Рисунке 12.20, эта атака запускается по порту 80 в сервере, который исполняется в
192.168.64.130. Через некоторое время этот сервер недоступен:

Как показывает Рисунок 12.21, данная служба упала. На данный момент мы рассмотрели множество атак на на марщрутизаторы и протоколы маршрутизации, давайте бросим взгляд на конфигурации безопасности со стороны самого маршрутизатора.
На данный момент мы рассмотрели разнообразные типы атак на маршрутизаторы, теперь давайте взглянем на рекомендации безопасности верхнего уровня, которые можно применять к вашим маршрутизаторам для защиты от различных уровней нападений:
-
Инфраструктура аутентификации, Авторизации, Ведения учётных записей - Эта структура AAA (Authentication, Authorization, Accounting) предоставляет централизованный подход, который предоставляет механизмы для аутентификации сеансов управления пользователями. Данная структура AAA также также производит безопасную конфигурацию для ограничения того числа команд, которое будет допускаться администраторами, а также поможет выполнять регистрацию всех разрешённых пользователям команд.
-
Настройка безопасности уровня управления - Как уже определялось ранее, сама плоскость управления отвечает за мониторинг и управление имеющимися устройствами и сетевыми операциями в которых она развёрнута. Такой уровень управления обязан быть безопасно настроенным, ибо имеющиеся данные с плоскости контроля напрямую воздействуют на все операции данного положения управления. В плоскости управления надлежит безопасно настраивать следующие протоколы:
-
SNMP
-
SSH
-
Terminal Access Controller Access Control System (TACACS+)
-
Radius
-
Telnet
-
File Transfer Protocol (FTP)
-
Network Time Protocol (NTP)
-
-
Централизованные мониторинг и безопасность операций - Мониторинг обязательно должен быть включён во всех сетевых устройствах. Он будет отслеживать входящий и исходящий обмены целиком, что предотвратит оповещения о несанкционированном доступе или атаках. Этого можно достигать посредством мониторинга SIEM и NetFlow.
NetFlow это применяемая сетевыми администраторами технология для отслеживания потока обмена к маршрутизаторам и от них.
-
Управление паролями - Учётные данные играют ключевую роль во всякой машине, которая способствует аутентификации таких машин. Точно так же, для аутентификации маршрутизаторов сетевые администраторы обычно для взаимодействия включают SSH. Как правило, на этапе проникновения злоумышленники способны взламывать такие учётные данные, поскольку администраторы, как правило, придерживаются ненадёжных или распространённых паролей, скажем,
Admin@123, чего следует избегать на практике.
Таким образом, для SSH должен быть настроен сильный пароль регистрации. Дополнительно к этому, все администраторы должны пользоваться сильным механизмом
шифрования для аутентификации самих администраторов на уровне настроек IOS маршрутизатора. Этого можно достигать посредством применения команды
enable secret.
Другой реализацией безопасности, о которой надлежит побеспокоиться, это реализация сервера управления паролями TACACS+ или Radius. Они включают запросы аутентификации для первоначальной проверки значения уровня доступа, предоставляемого соответствующим пользователям или группам, а затем основываются на установках допущений для предоставления или отказа в доступе.
Сетевым администраторам к тому же следует настраивать функциональность запреа входа в маршрутизаторы нежелательных пользователей. Именно это воспрепятствует и заблокирует всякого пользователя после трёх- пяти неудачных попыток:
-
Отказ в обслуживании пароля восстановления - Эта функциональная возможность No Service Password Recovery препятствует доступу для модификации NVRAM и изменения значения реестра конфигурации.
-
Централизованная регистрация - Регистрация в журнале помогает всем администраторам, а так же профессионалам по вопросам безопасности, при просмотре таких журналов в процессе отказов сетевого взаимодействия или в случае взломов безопасности.
-
Ограничение простаивающих служб - В процессе начальной реализации маршрутизаторов также будут разрешены в большом количестве множество служб без ограничения. Это может оказывать содействие злоумышленникам в использовании их и получении доступа к маршрутизаторам, к примеру, через SNMP - злоумышленники не только смогут изменять имеющиеся параметры маршрутизатора, но также модифицировать его конфигурации. Следовательно, отключайте не применяемые службы и ограничивайте существенные протоколы.
-
Access Control Lists (ACL) - Списки контроля доступа играют в среде жизненно важную роль. Такие ACL носят название ACL инфраструктуры. ACL принимают решение о потоке сетевого обмена, например, когда ограничивать или допускать любые пакеты обмена из одной области в другую. Основной пример этого подобен разрешению обмена только через SSH или SNMP.
Помимо инфраструктуры ACL существуют и прочие виды ACL, имеющие название VLAN ACL (VACL). Эти VACL усилят правила обмена передаваемые к- или из- внутренних VLAN или внешних VLAN. Такие VACL защищают имеющуюся среду применяя как сегментацию, так и разделение. Например, среды SWIFT зачастую помещаются в некую изолированную зону и она отделяется от всей среды при помощи VACL:
-
NTP - NTP это всегда некая простая цель для всякого злоумышленника. Таким образом, NTP должен быть защищён при помощи аутентификации NTP.
-
Безопасные протоколы - Другой очень важной стороной является настройка безопасных протоколов, таких как SSHv2, SNMPv3 и фильтрация обмена таких протоколов как ICMP (Internet Control Message Protocol).
-
Реализация DoS или DDoS - Атаки DoS или DDoS очень распространены в сетевых средах. Следовательно существует большое число предоставляемых CISCO и прочими субъектами, такими как Juniper, доступных решений для защиты против DoS или DDoS атак..
|
| Замечание |
|---|---|
|
Имеются некоторые важные конфигурации, которые защищают от проникновения через сеть. Для получения исчерпывающих сведений CISCO опубликовала законченный документ безопасных конфигураций маршрутизатора. С полными сведениями, пожалуйста, обратитесь к ссылке. |
BGP это некий EGP, представленный в качестве v1 в 1984 году для направления сетевых пакетов путём выбора наилучшего пути маршрутизации. Тем самым, BGP также носит название протокола динамической маршрутизации.
Итак, по мере развития во времени, Интернет начал расти и сетевой обмен в конечном счёте начал помещать в имеющиеся коммуникационные каналы нагрузки большего размера. Таким образом сам BGP подвергался изменениям и было введено множество версий. Текущей версией BGP является v4.
На данный момент, как нам известно, для осуществляющих взаимодействие вне собственной AS (автономной системы) маршрутизаторов, им требуются настройки BGP. Администратору локальной сети не будет известно под какой номер AS им следует выполнять настройку. А потому, для разрешения всех необходимых AS и проблем конфигурации BGP все организации берут необходимые конфигурации AS от своих ISP (поставщиков сетевых услуг). Следовательно, этот ISP помещает маршрутизатор такой сетевой среды под свою собственную автономную систему, превращая её в единственную AS для направления обмена от этой организации в глобальный Интернет.
Итак, как и в случае с OSPF, BGP также передаёт необходимые данные выбирая наилучший для передачи путь, однако не тем способом, которым это делают параметры OSPF. BGP работает с параметрами пути для выбора наилучших, например, на основе значения числа скачков (hops), что в терминологии сетевых сред носит название значения расстояния вектора протокола. Таким образом, данный протокол маршрутизации будет вычислять значение числа скачков между своими источником и получателем. Это отображается следующим образом:

Как отражено на Рисунке 12.22, наша AS источника, A100, отправляет запросы и собирает получаемые отклики от обоих векторов расстояния. Теперь, на основании вычисления расстояния вектора, BGP выберет в качестве наилучшего пути Distance vector 2, так как он обладает лишь двумя скачками AS для достижения своего получателя.
Далее, в BGP имеется другое очень важное понятие - он не настроен на умную работу во избежание перспективы зацикливания. Это означает, что когда AS источника получает зацикливание автономных систем своим собственным номером, замыкая цикл, тогда она просто отвергает такой путь и выбирает после этого второй наилучший путь. Давайте разберёмся с этим при помощи приводимой далее схемы:
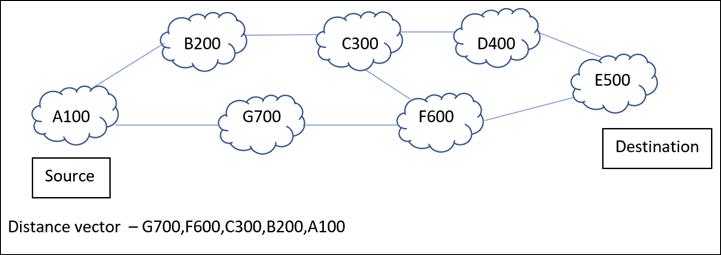
Как показано на Рисунке 12.23, самый первый вектор расстояния, который получает BGP формирует цикл, а следовательно, BGP просто отбросит этот путь. Итак, давайте сейчас взглянем на таблицы и сообщения BGP.
BGP создаёт три таблицы:
-
Таблицы соседей - Эта таблица содержит все записи непосредственно подключённых AS.
-
Таблицы BGP - Данная таблица размещает все необходимые сведения относительно имеющихся маршрутах BGP, таких как все выявленные пути и префиксы.
-
Маршруты BGP - Здесь заключены сведения относительно выбора наилучших путей для передачи данных.
BGP пользуется четырьмя различными типами сообщений:
-
OPEN -
UPDATE -
KEEPALIVE -
NOTIFICATION
Итак, теперь мы рассмотрели все операции BGP. Давайте теперь бросим взгляд на то, как работает BGP в реальном масштабе времени посредством имитации в Packet Tracer:

Как отражено на Рисунке 12.24, наш BGP сконфигурирован для Router1 и та же самая настройка осуществлена в Router0 и Router2. Теперь, раз всем маршрутизаторам известно обо всех подключённых узлах, тогда наш источник способен приступать к передаче данных.
На данном этапе мы глубоко ознакомились с BGP. Давайте взглянем на некоторые из имеющихся изъянов BGP.
Угон BGP по простому определяется как перенаправление исходящего обмена от одной автономной системы (AS) в другую AS, которая целиком во власти злоумышленников. Угон BGP также именуется угоном префикса, маршрута или IP.
Давайте разберёмся с этим на простом примере. Представим себе, что каждый день все получают утром различные маршруты из дома для достижения одного и того же пункта назначения, который обладает лишь одной дорогой для возврата к ним. Теперь, внезапно, в один из дней, угонщиками разрабатывается иная дорога и, в качестве извещения, устанавливается некий знак, который сигнализирует что именно это кратчайший путь до пункта назначения, а потому все сворачивают именно на эту вновь отстроенную дорогу. После этого, весь имеющийся обмен будет в конечном счёте угнан злоумышленником. Давайте сведём это в простую схему, как это показано на рисунке далее:

Как отражает Рисунок 12.25, злоумышленник или угонщик создаёт фальшивую дорогу просто параллельно другой дороге, а потому весь имеющийся обмен будет перенаправляться на эту поддельную дорогу.
Таким образом, аналогичная мысль может быть применена к угону BGP. Теперь, злоумышленники взламывают имеющуюся таблицу маршрутизации Интернета и незаконно забирают имеющиеся IP адреса. Для осуществления этого злоумышленники завладеют неким маршрутизатором и заявлять значение IP адресов, которые в настоящее время не назначены маршрутизатору злоумышленника. Такой запрос предложит прочим маршрутизаторам направить свой обмен по кратчайшему пути, а исходный маршрутизатор добавит идентификатор этого маршрутизатора в таблицу маршрутизации BGP, что в конечном счёте перенаправит весь обмен на собственный IP адрес злоумышленника. Полный шаблон атаки отображён на снимке экрана ниже:
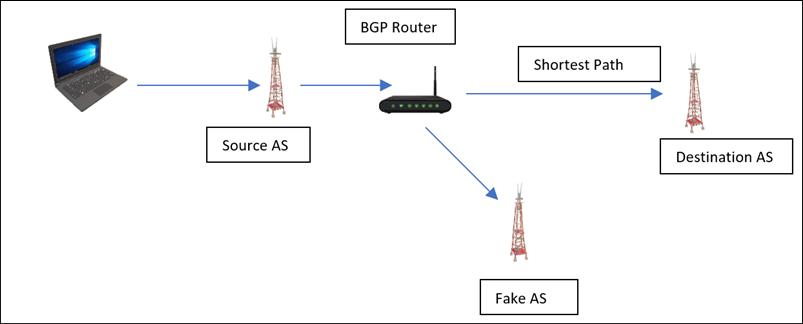
Как показано на Рисунке 12.26, злоумышленник заявляет IP адрес с кратчайшим маршрутом до заданного пункта назначения.
Далее, когда мы изучили угон BGP, давайте взглянем на то что бы произошло при угоне BGP:
-
Злоумышленник был бы способен отслеживать весь обмен с Интернетом и контролировать его.
-
Весь обмен с Интернетом может направляться в другую зону, например, на вредоносные площадки.
-
Спаммеры могут пользоваться угоном BGP для подделки допустимых IP адресов для незаконных действий.
-
Такие злоумышленники способны увеличивать значение задержки для всего обмена с Интернетом.
Тому будет множество примеров, например, как выполнившие в 2018 году захват BGP хакеры, которые смогли украсть около 152 000 долларов США в виде цифровых денег или криптовалюты.
Теперь давайте продемонстрируем угон BGP в ситуации реального масштаба времени, как это отражено на следующем рисунке:
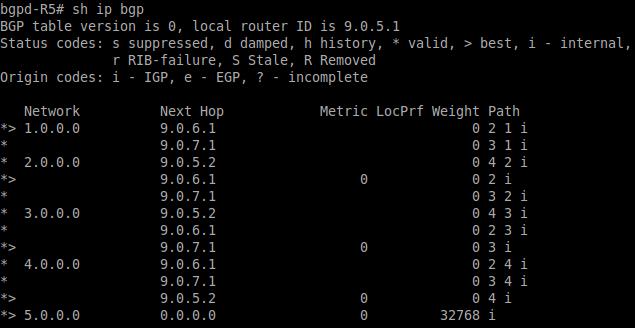
Как показано на Рисунке 12.27, ткущая конфигурация для соответствующего следующего скачка в маршрутизаторе R5 для его
сети 1.0.0.0 это 9.0.6.1/9.0.7.1 и аналогично также и для прочих сетей.
Теперь злоумышленник создаст неконтролируемую автономную систему (AS) и подделает сведения о маршруте для отправки всего обмена через такую поддельную AS, как это показано на следующем рисунке:
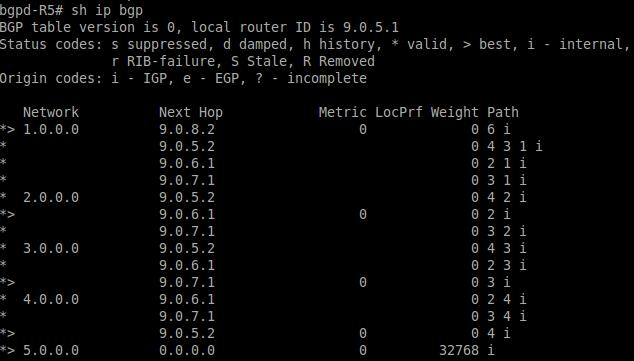
Как отображено на Рисунке 12.28, при помощи фальшивой AS имеется новая запись к сети 1.0.0.0 с соответствующим следующим
скачком, выполняемом через 9.0.8.2/9.0.5.2. Теперь весь обмен будет направляться через эти новые настройки сети.
На текущий момент мы разобрались с тем насколько опасен был бы угон протокола BGP. Итак, давайте поймём как мы можем защитить его.
Для предотвращения угона BGP могут применяться следующие методы:
-
Выявление угона BGP - Надлежащее отслеживание всего направляемого BGP обмена может помогать организациям избегать угона BGP. Этого можно достичь, когда в сетевом обмене существуют какие бы то ни было задержки по сравнению с нормальным значением латентности TTL (Time To Live).
-
Фильтрация префикса IP -
Сами сетевые администраторы или поставщик сетевых услуг должны объявлять только фиксированные IP адреса вместо всего Интернета целиком. Это воспрепятствует приёму имеющимися маршрутизаторами значений объявлений префикса поддельного IP адреса, а также поможет предотвращению непреднамеренному захвату маршрута. -
BGPSec - Реализует BGPSec, который воплощает иной уровень безопасности в самом протоколе BGP.
В данной главе мы глубоко изучили типы IGP и EGP, такие как OSPF, RIP, BGP и IS-IS, а также провели их соответствующий анализ с применением разнообразных средств наблюдения сети (снифферов) и имитаций сетевой среди на основе графического интерфейса, таких как Packet Tracer и GNS3. Далее мы изучили BGP. Помимо протоколов маршрутизации, мы выполнили различные практические демонстрации атак, таких как отравление таблицы маршрутизации и угон BGP, а также ознакомились с различными методиками облегчения условий протоколов маршрутизации и того как мы можем безопасно настраивать свои маршрутизаторы.
Теперь, в своей следующей главе, мы ознакомимся с очень важным протоколом с точки зрения злоумышленника, а именно, DNS (Domain Name Service ), анализом его поведения с применением средств наблюдения сети, а также с практическими демонстрациями различных атак на DNS в реальном масштабе времени.
-
Что является полным названием OSPF?
-
Open Shortest Path First
-
Open Small Path First
-
Open Shortest Payload First
-
Ни одно из перечисленных
-
-
Что является полным названием BGP?
-
Bi Gate Protocol
-
Border Gateway Protocol
-
Border Gate Protocol
-
Ни одно из приведённых
-
-
Что включает в себя EGP?
-
OSPF
-
RIP
-
BGP
-
Всё указанное
-
-
Что входит в IGP?
-
OSPF
-
RIP
-
Static
-
И A, и B
-
-
Как разрешается проблема счётчика до бесконечности?
-
BGPSec
-
Расщепление перспективы
-
Шлюз к последнему обращению
-
Ничто из перечисленного
-
-
От чего выполняет защиту BGPsec?
-
Захват BGP
-
Зацикливание маршрута
-
Подсчёт скачков
-
Всё приведённое
-
-
Какое из средств используется для отравления таблицы маршрутизации?
-
macof
-
Kali
-
T50
-
Всё указанное
-