Высокоскоростной интерконнект NVLink
Содержание
NVLink является новой технологией высокоскоростного интерконнекта NVIDIA для ускоряемых GPU вычислений. NVLink в настоящее время реализован в платах ускорения Tesla P100 и в GPU Pascal GP100, и она значительно увеличивает производительность как взаимодействия GPU-с-GPU, так и для доступа GPU к системной памяти.
Множество GPU обычно используются в узлах высокопроизводительных вычислительных кластеров. Сегодня типично наличие до восьми GPU на узел, а в системах с множеством процессоров мощный интерконнект чрезвычайно значителен. Наше предвидение в NVLink состояло в создании интерконнекта для GPU, который мог бы предложить более высокую полосу пропускания чем PCI Express Gen 3 (PCIe), и при этом был бы совместим с GPU ISA для поддержки рабочих нагрузок множества процессоров совместно используемой памяти.

При объединённых NVLink GPU программы могут выполняться непосредственно в памяти, которая подключена к другому GPU точно так же как в локальной оперативной памяти, при этом ваши операции с памятью остаются правильными (например, предоставляя полную поддержку для атомарных операций Pascal).
NVLink использует новый высокоскоростной интерконнект передачи сигналов (NVHS, High-Speed Signaling interconnect) NVIDIA. NVHS передаёт данные по дифференциальным парам работая со скоростью 20 Гб/с. Восемь из этих дифференциальных соединений формируют Sub-Link, который отправляет данные в одном направлении, а два Sub-Link - по одному для каждого направления - формируют Link, который соединяет два процессора (GPU-с-GPU или GPU-с-ЦПУ). Отдельный Link поддерживает до 40ГБ/с двунаправленной полосы пропускания между вашими терминалами. Множество Link могут быть собраны для образования Gang (группировки) для ещё большей связности между процессорами. Реализация NVLink в Tesla P100 поддерживает до четырёх Link, делая возможными конфигурации с агрегированием максимальной двунаправленной полосы пропускания в 160 ГБ/с, как это показано на Рисунке 14 и Рисунке 15.
Конфигурации NVLink
Возможны различные топологии, причём различные конфигурации могут быть оптимизированы для различных приложений. В данном разделе мы обсудим следующие конфигурации NVLink:
-
Связность NVLink GPU-c-GPU
-
Связность NVLink GPU-c-ЦПУ
Рисунок 14 отображает сетку гибридного куба (Hybrid Cube Mesh) с 8 GPU, которая две полностью соединённые четвёрки GPU с NVLink соединениями между этими четвёрками, причём GPU в пределах каждой четвёрки соединены со своими соответствующими ЦПУ напрямую через PCIe. Применение отдельных соединений NVLink для заполнения промежутка между этими двумя четвёрками облегчает давление на восходящие к ЦПУ соединения PCIe и к тому же избавляет от обменов с маршрутизацией через системную память и через соединения между ЦПУ.
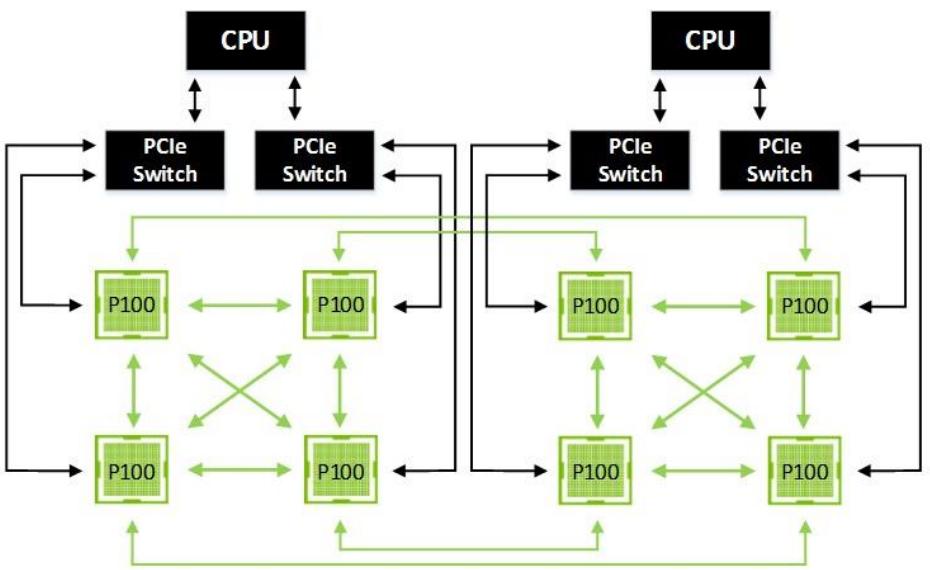
Отметим, что каждая половина сетки гибридного куба может работать как мультипроцессор с совместно используемой оперативной памятью, в то время как удалённые узлы могут также разделять оперативную память при помощи DMA через одноранговую сеть (peer). При всём обмене GPU-с-GPU идущем по NVLINK, PCIe теперь полностью доступна для соединения либо с NIC (не показанными на схеме) или для доступа к обмену с системной памятью. Эта конфигурация обычно рекомендуется для универсальных приложений Глубинного обучения и реализована в новом сервере NVIDIA DGX-1.
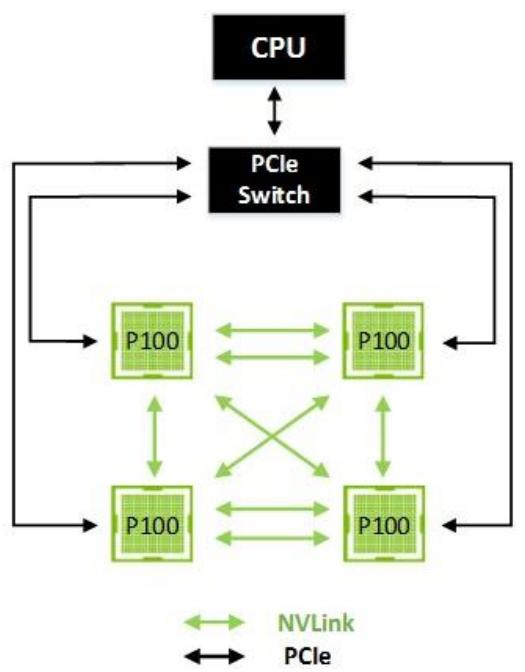
Рисунок 15 показывает кластер с четырьмя GPU, причём каждое из этих GPU соединено с каждым в одноранговую сеть (peer) отдельным NVLink. В этом случае одноранговая сеть может осуществлять взаимодействие в двух напрвлениях на скорости 40 ГБ/с (80 ГБ/с в двух направлениях для двойных Link), делая доступным надёжный обмен данными между вашими GPU.
Хотя NVLink изначально сосредоточен на соединении множества ускорителей Tesla P100 NVIDIA в единое целое, он также может применяться для интерконнекта ЦПУ-с-GPU. Например, ускорители Tesla P100 могут соединяться с POWER8 при помощи технологии NVLink NVIDIA. POWER8 c NVLink™ поддерживает четыре NVLink.
Рисунок 16 показывает один GPU соединённый с ЦПУ имеющим возможность обмена по NVLink. В этом случае GPU может осуществлять доступ к памяти системы с двунаправленной полосой пропускания 160 ГБ/с - что в 5 раз выше пропускной способности доступной в PCIe.
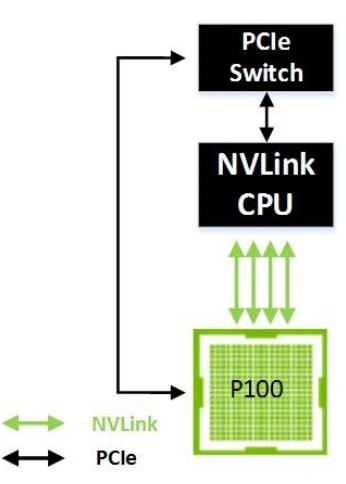
Рисунок 17 показывает систему с двумя NVLink от ЦПУ к каждому GPU. Остающиесядва link каждого GPU используются для однорангового (peer-to-peer) взаимодействия.
Рисунок 17
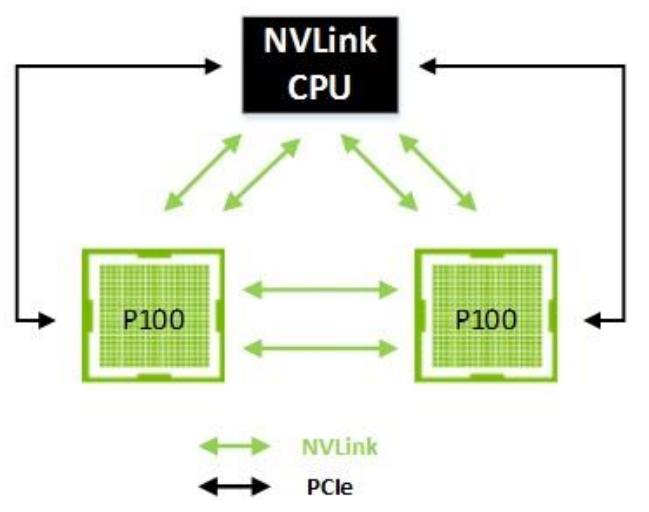
Два GPU и ЦПУ, соединяемые с использованием 80 ГБ/с двунаправленной полосы пропускания NVLink
Как уже описывалось в разделе архитектуры Tesla P100, интерконнект NVLink содержится в ускорителе P100. P100 содержит два 400-пиновых высокоскоростных коннектора. Один из этих коннекторов используется для модуля включения/ выключения сигналов NVLink, а другой для запитывания электричеством, управляющих сигналов и ввода/ вывода PCIe.
Ускоритель Tesla P100 может быть установлен в носитель GPU большего размера или в системную плату. Носитель GPU выполняет соответствующие соединения с другими ускорителями P100 или контроллерами PCIe. Благодаря меньшему размеру ускорителя P100 в сравнении с традиционными платами GPU, потребители легко могут строить серверы, которые упаковывают больше GPU, чем это было возможно ранее. Имея дополнительную полосу пропускания предоставляемую NVLink, взаимодействия GPU-с-GPU больше не будут узким местом при ограничении полосы пропускания PCIe, позволяя ранее не доступные возможности для кластеров GPU.
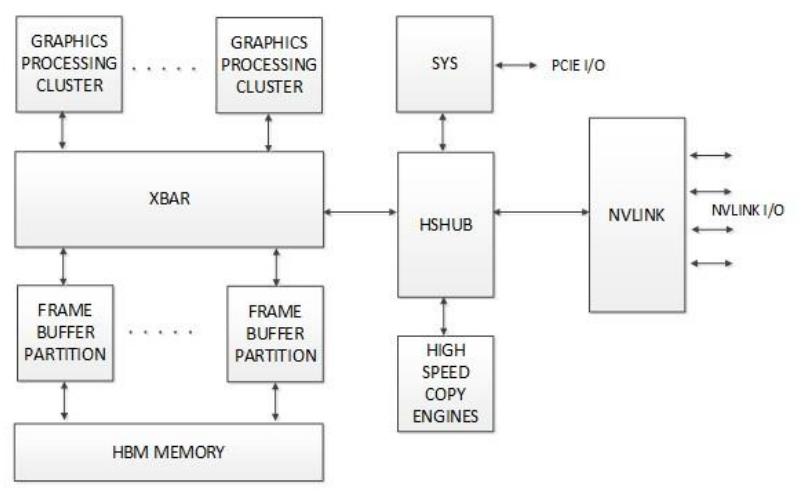
На уровне интерфейса архитектуры GPU контроллер NVLink внутренне взаимодействует с GPU посредством нового блока с названием HSHUB (High-Speed Hub). HSHUB имеет прямой доступ к общему для GPU матричному переключателю (crossbar) и прочим элементам системы, например, High-Speed Copy Engines (HSCE), который может использоваться для перемещения данных в- или из- GPU на пиковых скоростях NVLink. Рисунок 18 показывает как NVLink соотносится с HSHUB и некоторыми блоками более высшего уровня в GPU GP100.
С дополнительными подробностями можете ознакомиться в Приложении A: Технология передачи сигналов и протоколов NVLink.