Глава 4. Пространство адресов и маршрутизация транзакций
Содержание
- Глава 4. Пространство адресов и маршрутизация транзакций
- Мне требуется некий адрес
- Регистры базового адреса (BAR)
- Регистры базы и предела
- Проверка корректности: регистры, применяемые для маршрутизации адресов
- Основы маршрутизации TLP
- Применение механизмов маршрутизации
- Отсутствие маршрутизации DLLP и Упорядоченных наборов
Предыдущая глава представила некое введение в настройку в имеющейся среде PCI Express. Она содержала в себя то пространство, в котором настройка некоторой Функции регистрируется и реализуется, как некая Функция обнаруживается, как создаются и маршрутазируются настройки транзакций, имеющиеся различия между совместимым с PCI пространством настроек и расширенным PCIe пространством настроек, а также как программное обеспечение различает некую Конечную точки и Мост.
Данная глава объясняет цели и методы функций запроса адресного пространства (либо адресного пространства в памяти, либо адресного пространства IO) через BAR (Base Address Registers, Регистры базового адреса) и как программное обеспечение должно устанавливать регистры базы/ предела во всех мостах чтобы осуществлять маршрутизацию TLP от порта источника к правильному порту назначения. Также обсуждаются самые основные положения маршрутизации TLP в PCI Express, в том числе маршрутизацию на основе адреса, маршрутизацию по идентификатору и неявную маршрутизацию.
Следующая глава подробно описывает содержимое TLP (Transaction Layer Packet, Пакета уровня транзакции). Мы объясняем его применение, формат и назначение всех типов пакета TLP, а также подробности относящихся к ним полей.
Почти все устройства имеют внутренние регистры или местоположения для хранения, которые требуются программному обеспечению (а потенциально и прочим устройствам) доступными для доступа. Эти внутренние расположения могут управлять самим поведением устройства, сообщать о состоянии данного устройства, или же может являться расположением для хранения данных, обрабатываемых данным устройством. Вне зависимости от имеющейся цели таких внутренних регистров/ хранилищ важно иметь возможность осуществлять доступ к ним извне самого данного устройства. Это означает, что данное внутреннее расположение должно иметь адресацию. Программное обеспечение обязано иметь возможность операций чтения или записи по какому- то адресу, который осуществит доступ к соответствующему внутреннему расположению внутри служащего целью устройства. Для выполнения данной работы подобные внутренние расположения нуждаются в назначении адресов из одного из поддерживаемых в данной системе адресных пространств.
PCI Express поддерживает в точности те же самые три адресных пространства, которые поддерживались в PCI:
-
Настройки
-
Памяти
-
IO
Как мы уже видели в Главе 1, Основы, пространство настройки было ведено в PCI чтобы сделать возможным программному обеспечению осуществлении управления и проверки текущего состояния устройств неким стандартизованным образом. PCI Express был разработан с учётом обратной совместимости с PCI, поэтому пространство настройки всё ещё поддерживается и применяется по той же самой причине, которая имелась в PCI. Дополнительная информация о пространстве настройки (его назначении, тому, как осуществлять доступ к нему, размере, содержимом и т.п.) можно отыскать в Главе 3, Обзор настройки.
Даже хотя пространство настройки первоначально подразумевалось для хранения стандартизованных структур (заголовков определения PCI, структур возможностей и т.п.), для устройств PCIe является очень распространённым иметь особые для устройства регистры в их пространстве настройки. В таком случае все соответствующие пространству настройки регистры зачастую являются регистрами управления, состояния или указателей в противоположность местам хранения данных.
Общие понятия
На начальном этапе ПК все внутренние регистры/ хранилища в устройствах ввода/ вывода имели доступ через пространство адресов IO (обычно именуемому отображаемым в памяти вводом/ выводом - MMIO - memory- mapped IO). Однако, поскольку применяемое вначале программное обеспечение было написано с применением пространства адресов IO для доступа к внутренним регистрам/ хранилищам в устройствах ввода/ вывода, стало распространённой практикой ставить в соответствие один и тот же набор особых для устройства регистров в адресном пространстве памяти наряду с адресным пространством IO. Это позволяет новому программному обеспечению осуществлять доступ к имеющимся внутренним расположениям некоторого устройства с применением адресного пространства памяти (MMIO), и в то же время делая возможным для наследуемого (старого) программного обеспечения продолжать свою работу, так как оно всё ещё может продолжать выполнять доступ к необходимым внутренним регистрам устройств с применением адресного пространства IO.
Более новые устройства, которые не полагаются на наследование или имеют проблемы с наследуемой совместимостью обычно устанавливают соответствие к внутренним регистрам/ хранилищам исключительно через адресное пространство памяти (MMIO) без какого бы то ни было запроса адресного пространства IO. На самом деле, спецификация PCI Express не одобряет применение адресного пространства IO, указывая, что оно применяется исключительно исходя из причин наследования и может быть упразднено в последующих версиях данной спецификации.
Соответствие общей памяти и IO отображено на Рисунке 4-1. Общий размер имеющегося соответствия адресам памяти является некоей функцией от того диапазона адресов, который данная система может применять (обычно выделяется самим диапазоном адресов ЦПУ). Весь размер карты IO в PCIe ограничен 32 битами (4ГБ), хотя во многих компьютерах с применением совместимых с Intel процессоров (x86), используются только самые нижние 16 бит (64кБ). PCIe может поддерживать адресацию памяти с размером до 64 бит.
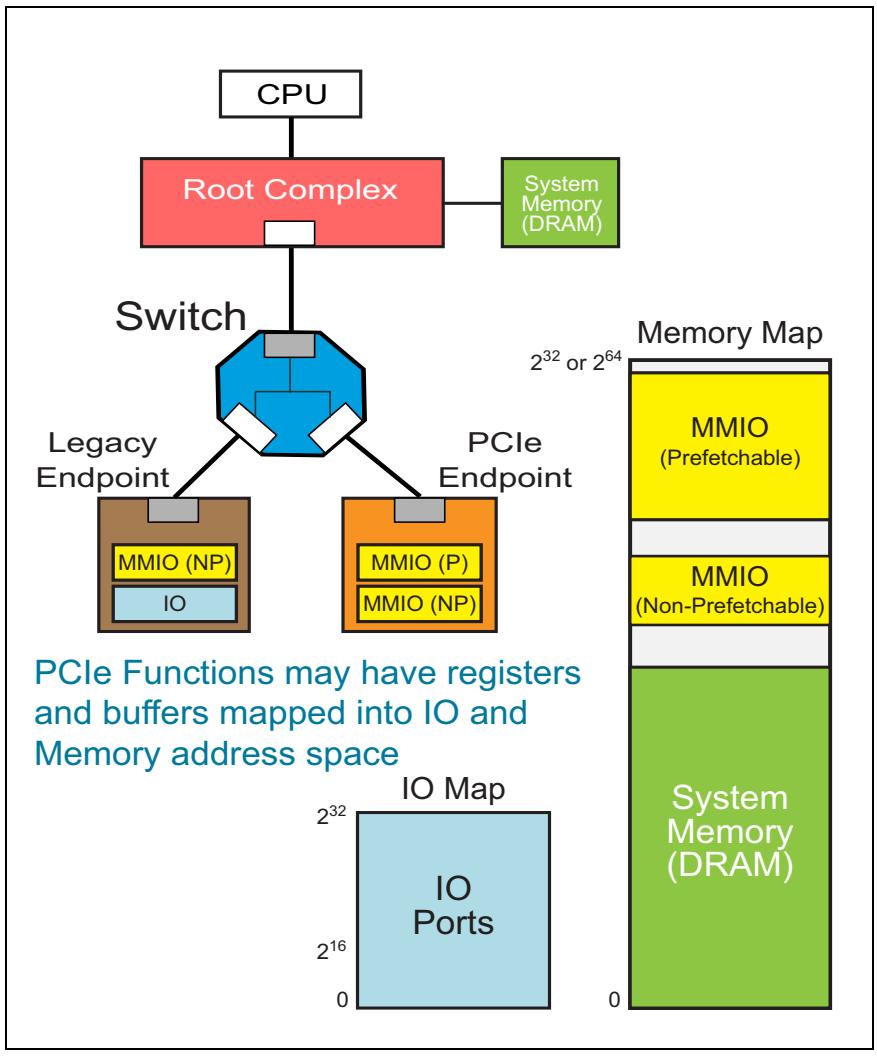
Пример соответствия на Рисунке 4-1 отображает только пространства MMIO и IO, заявляемые только Оконечными устройствами (Endpoints), однако данная возможность не является исключительной только для Оконечных устройств. Очень распространённым также является осуществление доступа к Комплексам Коммутаторов и Корня (Switches и Root Complexes) также иметь доступными через адресации MMIO и IO специфичные для них регистры.
Сопоставление пространств памяти с упреждающей выборкой и без неё
Рисунок 4-1 также показывает два различных заявляемых устройствами PCIe типа MMIO: MMIO с упреждающей выборкой (P-MMIO, Prefetchable MMIO) и MMIO без упреждающей выборки (NP-MMIO, Non-Prefetchable MMIO). Важно обозначить имеющееся различие между пространствами памяти с упреждающей выборкой и без неё. Пространства с упреждающей выборкой имеют две очень хорошо определённых отличительных особенности:
-
Считывания не имеют последствий
-
Допускаются слияния записей
Определение области MMIO как имеющей упреждающую выборку делают возможной для всех данных из такой области теоретически опрашиваться заранее в предположении, что некоей Запрашивающей стороне может потребоваться больше данных в недалёком будущем в сравнении с уже запрошенными. Основная причина безопасности такого незначительного кэширования заключается в том, что чтение данных не изменяет информацию о состоянии на целевом устройстве. Именно это подразумевается под тем, что мы назвали "Считывание не имеет последствий" в имеющемся местоположении. Например, если Запрашивающая сторона просит считать 128 байт по некоему адресу, имеющаяся Выполняющая сторона может считать с упреждением также и следующие 128 байт с тем, чтобы улучшить производительность, имея данные на руках когда они будут запрошены. Однако, если Запрашивающая сторона никогда не запросит эти дополнительные данные, Исполняющей стороне в конце концов придётся очистить их чтобы освободить имеющееся пространство буфера. Если данное действие считывания изменяет текущее значение по данному адресу (либо имеет некий иной эффект на другой стороне), не будет никакой возможности восстановить все отвергаемые данные. Однако, для пространства с упреждающей выборкой любое считывание не имеет никакого эффекта на стороне, поэтому всегда имеется возможность забежать вперёд и получить их впоследствии, так как все первоначальные данные уже имеются здесь.
Возможно, вам будет интересно знать какое пространство памяти может иметь побочные эффекты? Одним из примеров может быть регистр состояния отображения памяти, который был разработан для автоматической своей очистки после считывания для сбережения программисту времени дополнительного шага очистки всех бит после считывания их состояния.
Присутствие данного отличия было более важным для PCI, нежели для PCIe, поскольку транзакции в этой шине не содержали размера обмена. Не имелось никаких проблем, когда все устройства обменивались данными, находясь в одной и той же шине, так как имелось рукопожатие в реальном времени для указания того, когда Запрашивающая сторона завершила операцию и более не нуждается в данных, таким знание общего числа байт не было важным. Однако, когда обмен осуществляется через некий мост, это не так просто, поскольку для считываний такой мост нуждается в знании общего числа байт при получении данных из другой шины. Неверное предположение об имеющемся размере обмена добавило бы латентность и снизило бы производительность, поэтому наличие возможности упреждающей выборки может быть очень полезной. Именно поэтому понятие пространства памяти с упреждающей выборкой было полезным в PCI. Так как запросы PCIe содержат размер обмена, оно менее привлекательно чем прежде, но переносится для обратной совместимости.
Каждое устройство в некоторой системе может иметь различные требования в терминах необходимых общего объёма и типа адресного пространства. например, одно устройство может нуждаться в значимых 256 байтах внутренних регистров/ хранилищ, которые должны быть доступными через адресное пространство IO, а другому устройству может требоваться 16кБ внутренних регистров/ хранилищ, доступ к которым следует осуществлять через MMIO.
Устройствам на основе PCI не позволялось самостоятельно принимать решение о том какие адреса следует применять для доступа к их внутренним местоположениям, именно это составляло задание для системного программного обеспечения (т.е. BIOS и ядра ОС). Таким образом, данные устройства обязаны предоставлять некий способ для системного программного обеспечения определять необходимое данному устройству адресное пространство. Раз программное обеспечение знает каковы требования данного устройства в терминах адресного пространства, тогда предполагаемый запрос может быть заполнен, программное обеспечение просто выделяет некий доступный диапазон адресов надлежащего типа (IO, NP‐MMIO или P‐MMIO) данному устройству.
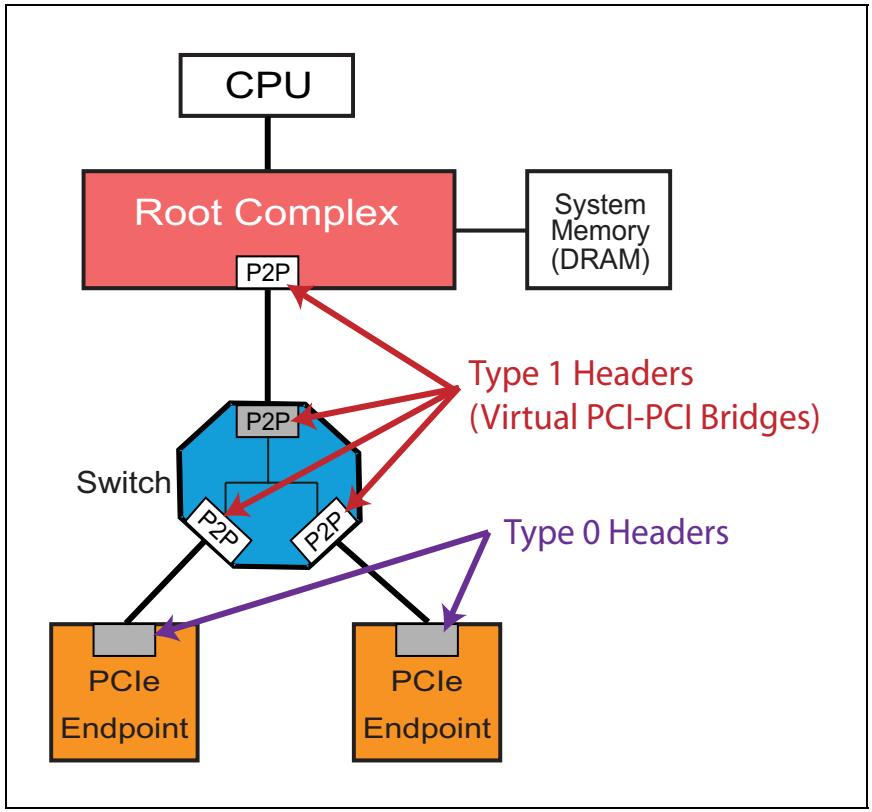
Всё это выполняется через имеющиеся в заголовке пространства настройки Регистры базового адреса (BAR, Base Address Registers). Как показано на Рисунке 4-2, заголовок типа 0 имеет доступными шесть BAR (каждый имеет длину 32 бита), в то время как заголовок типа 1 имеет только два BAR. Заголовки типа 1 можно обнаружить на всех устройствах моста, что означает, что каждый порт коммутатора и комплекса корня имеет заголовок 1 типа. Заголовки 0 типа имеются в устройствах, не связанных с мостами, таких как оконечные устройства. Некий их пример можно увидеть на Рисунке 4-3.

Системное программное обеспечение должно вначале определить необходимые размер и тип запрашиваемого устройством адресного пространства. Сам разработчик устройства знает общий размер всех внутренних регистров/ хранилищ, которые должны быть доступными через IO или MMIO. Этот разработчик устройства также знает как данное устройство поведёт себя при доступе к данным регистрам (т.е. имеется ли побочное воздействие считывания или нет). Это определяет то, будет ли запрашиваться MMIO с упреждающей выборкой (считывания не имеют побочного эффекта) или MMIO без упреждающей выборки (считывание имеет побочный эффект). Зная данную информацию, разработчик устройства жёстко кодирует самые нижние биты имеющихся BAR для определённых значений, указывающих на необходимые тип и размер запрашиваемого адресного пространства.
Все верхние биты имеющихся BAR записываются программным обеспечением. После того, как системное программное обеспечение проверит все нижние биты имеющихся BAR для определения необходимых размера и типа запрашиваемого адресного пространства, системное программное обеспечение затем запишет необходимый базовый адрес требуемого для выделения диапазона адресов в верхние биты данного устройства. Поскольку отдельное оконечное устройство (с типом заголовка 0) имеет шесть BAR, может быть выполнено до шести различных запросов адресного пространства. Однако, это не очень распространено в нашем реальном мире. Большинство устройств запрашивает 1- 3 различных диапазонов адресов.
Подлежат реализации не все BAR. Если некоторому устройству требуются не все BAR для установления соответствия его внутренним регистрам, все дополнительные BAR аппаратно кодируются всеми 0, что указывает программному обеспечению, что эти BAR не реализованы.
После того как все BAR были запрограммированы, все внутренние регистры или локальная память внутри этого устройства могут получать доступ через те диапазоны адресов, которые запрограммированы в BAR. Всякий раз, когда данное устройство обнаруживает некий запрос с каким- то адресом, который соответствует одному из его BAR, оно получит этот запрос, поскольку оно является целью.
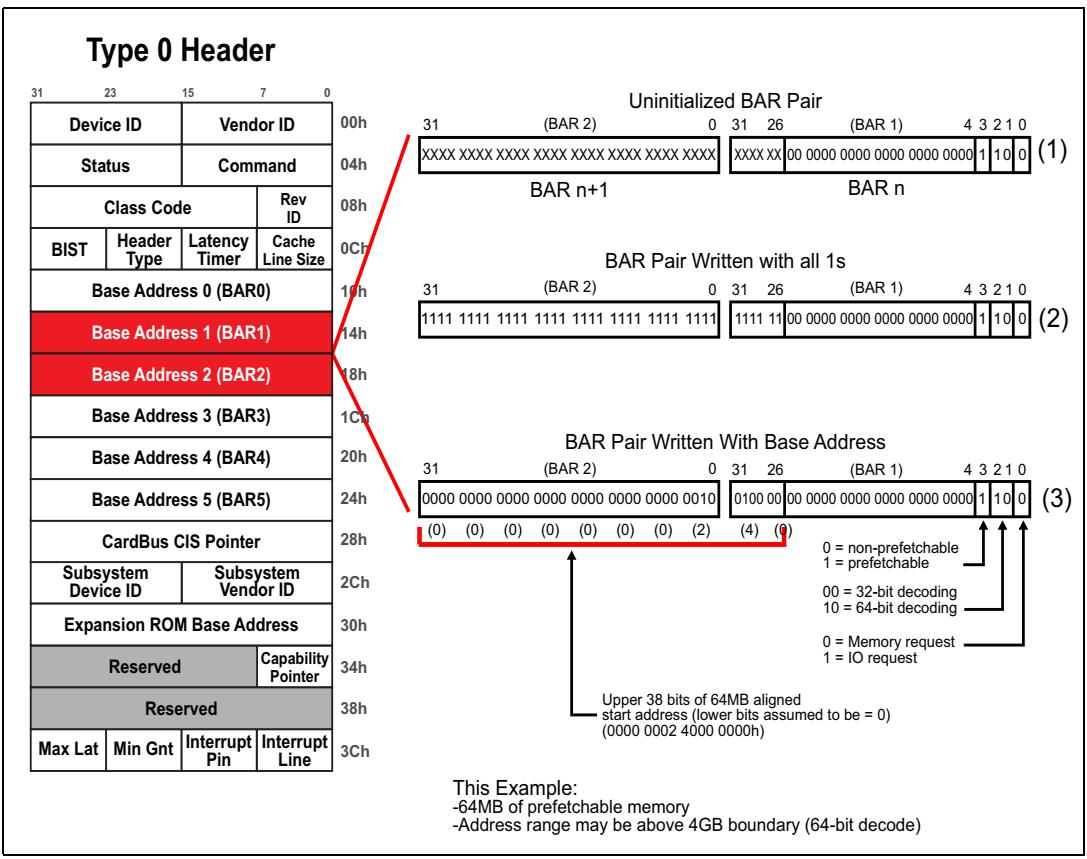
Рисунок 4-4 отображает основные этапы в установке BAR, который в данном примере запрашивает блок памяти без предварительной выборки 4кБ (NP-MMIO). На данном рисунке рассматриваемый BAR показан в трёх пунктах процесса настройки:

-
В (1) Рисунка 4-4 мы наблюдаем наличие не инициализированного состояния данного BAR. Разработчик данного устройства зафиксировал самые нижние биты для указания необходимых размера и типа, однако имеющиеся верхние биты (которые доступны на чтение- запись) показаны как Xs, чтобы указать, что их значение не известно. Системное программное обеспечение вначале заполнит всеми 1-цами все BAR (с применением записей настройки) для установления всех записываемых битов. (Естественно, те нижние биты, которые прописаны аппаратно не подлежат изменению ни при каких записях настроек.) Второй просмотр данного BAR, отображаемый в (2) на Рисунка 4-4, показывает как он выглядит после того как программное обеспечение настройки прописало в нём все 1-цы.
Запись во все биты единиц выполняется для определения того, какой записываемый пит является последним значащим. Это положение бита указывает тот размер адресного пространства, который будет запрошен. В данном примере последним значащим битом является 12, поэтому данный BAR запрашивает 212 (или 4кБ) адресного пространства. Если бы самым последним значащим записываемым битом был бы бит 20, тогда BAR запрашивал бы 220 (или 1МБ) адресного пространства.
-
После записи всех единиц в данный BAR, программное обеспечение пройдёт по всем BAR и считает их значения, начиная с BAR0 для определения указанного типа и размера данного запрашиваемого адресного пространства. Таблица 4-1 суммирует полученные результаты такого чтения настройки BAR0 для данного примера.
-
Завершающим этапом в данном процессе для системного программного обеспечения является выделение некоего диапазона запрошенных адресов. Третий просмотр данных BAR в (3) Рисунка 4-4 показывает как он выглядит после того, как программное обеспечение прописало начальный адрес для выделенного блока адресов. В данном примере начальным адресом является
F900_0000h.
| Биты BAR | Значение |
|---|---|
|
Считан как |
|
Считывание |
|
Считывание |
|
Считывание всех как |
|
Все считываются как |
На данный момент настройка BAR0 завершена. Как только программное обеспечение разрешит декодирование адреса памяти в
своём регистре Команд (смещение 04h), это устройство будет принимать любые запросы
к памяти, попадающие в указанный диапазон F900_0000h -
F900_0FFFh (с размером 4кБ).
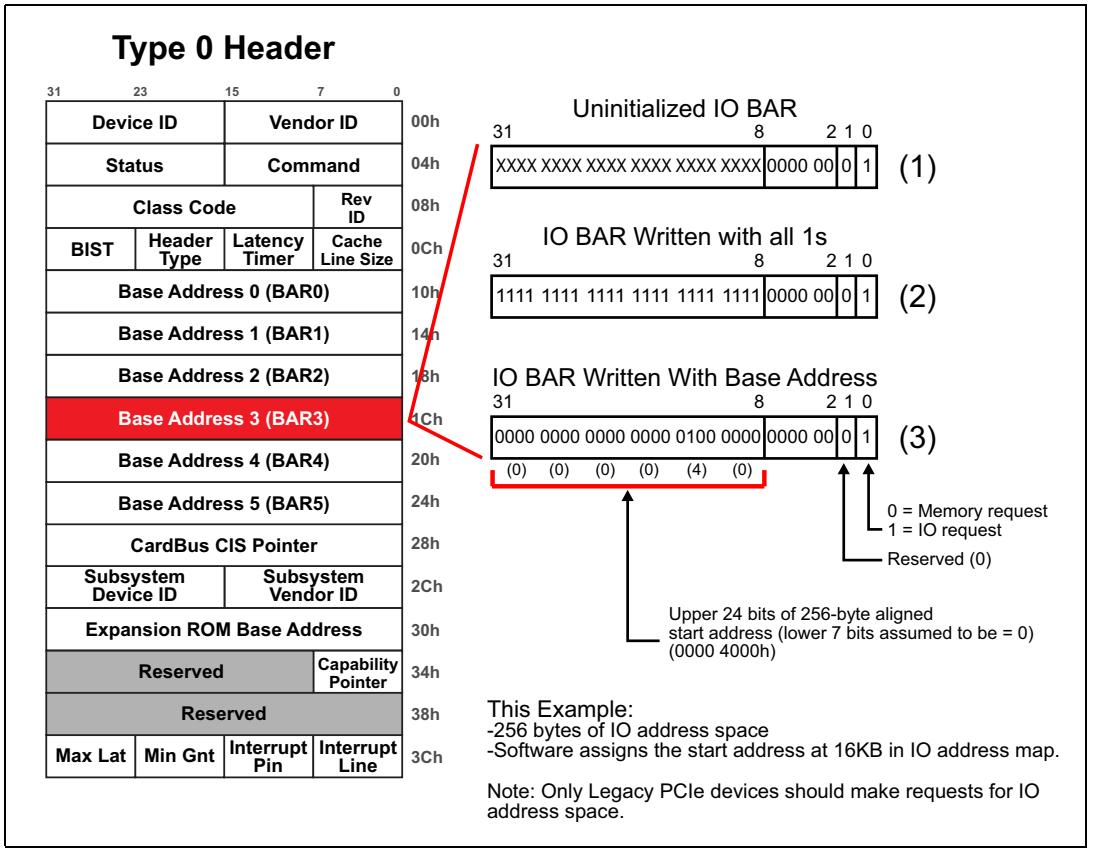
В своём предыдущем примере мы видели BAR0 применяемый для запроса пространства адресов памяти без предварительной выборки (NP-MMIO). В данном примере, который показан на Рисунка 4-5, BAR1 и BAR2 применяются для запроса некоторого 64МБ блока адресного пространства памяти с предварительной выборкой, что означает, что программное обеспечение может выделять запрашиваемое адресное пространство выше границы адресации в 4ГБ, если в нём имеется потребность (однако это не является неким требованием). Поскольку данный адрес может быть неким 64- битным адресом, два последовательных BAR должны применяться совместно.
Как и ранее, данные BAR показаны в трёх моментах нашего процесса настройки:
-
В (1) Рисунка 4-5 мы видим не инициализированное состояние данной пары BAR. Разработчик данного устройства аппаратно закодировал самые нижние биты нижнего BAR (в нашем примере, BAR1) для указания типа и размера запроса, в то время как все биты верхнего BAR (в нашем примере BAR2) все доступны на чтение- запись. Первым этапом системного программного обеспечения было прописывание всех битов единицами во всех BAR. В (2) Рисунка 4-5 мы наблюдаем эти BAR после того как они все получили запись единиц.
-
Как это уже описывалось в предыдущем примере, системное программное обеспечение уже вычислило BAR0. Таким образом, следующим шагом программного обеспечения является считывание следующего BAR (BAR1) и его вычисление для просмотра того, запрашивает ли данное устройство дополнительное адресное пространство. Когда BAR1 считан, программное обеспечение понимает, что запрошено дополнительное адресное пространство и что данный запрос предназначен для адресного пространства памяти с упреждающей выборкой, которое может быть выделено где- то в имеющемся диапазоне 64- битных адресов. Поскольку он запрашивает некий 64- битный адрес, следующий в последовательности BAR (в данном случае BAR2) рассматривается как верхние 32 бита BAR1. Поэтому программное обеспечение теперь также считывает имеющееся содержимое BAR2. Однако, программное обеспечение не осуществляет оценку нижних битов BAR2 таким образом, как оно это делало для BAR1, поскольку оно знает, что BAR2 это просто верхние 32 бита 64- битного адреса запроса, начинающегося в BAR1. Таблица 4-2 суммирует все результаты такого считывания.
-
Завершающий шаг данного процесса состоит в выделении теперь системным программным обеспечением адресного пространства в эти BAR, когда программное обеспечение знает требуемые размер и тип необходимого запрашиваемого адресного пространства. Третий просмотр наших BAR в (3) Рисунка 4-5 отображает полученные результаты после того, как программное обеспечение воспользовалось двумя записями настройки чтобы запрограммировать необходимый начальный 64- битный адрес для выделяемого диапазона. В данном примере бит 1 нашего верхнего BAR (бит с адресом 33 в нашей паре BAR) установлен и бит 30 нашего нижнего BAR (бит с адресом 30 в нашей паре BAR) также установлен, что указывает на некий начальный адрес
2_4000_0000h. Все прочие записываемые биты в обоих BAR очищены.
| BAR | Биты BAR | Значение |
|---|---|---|
|
|
Считан как |
|
|
Считывание |
|
|
Считывание |
|
|
Все считываются как |
|
|
Все считываются как |
|
|
Все считываются как |
На данный момент выполнена настройка данной пары BAR (BAR1 и BAR2). Как только программное обеспечение разрешит декодирование
в имеющемся регистре команд (смещение 04h), это устройство будет принимать все запросы
к памяти, которые попадают в указанный диапазон
2_4000_0000h - 2_43FF_FFFFh
(с размером 64МБ).
Продолжает два предыдущих примера такая же функция запрашивающая пространство IO, которая показана на Рисунке 4-6. В данной схеме, запрашивающей BAR (в данном примере BAR3) отображены три момента в описываемом процессе настройки:
-
В (1) Рисунка 4-6 мы видим не инициализированное состояние данного BAR. Системное программное обеспечение ранее прописало всеми единицами все BAR и определило BAR0, а затем BAR1 и BAR2. Теперь программное обеспечение собирается просмотреть запрашивает ли данное устройство дополнительное адресное пространство с помощью BAR3. Позиция (2) Рисунка 4-6 отображает состояние BAR3 после того прописывания его целиком единицами.
-
Программное обеспечение теперь считывает BAR3 для определения требуемых размера и типа данного запроса. Таблица 4-3 суммирует все результаты такого настроечного считывания.
-
Теперь, когда программное обеспечение знает этот запрос на 256 байт адресного пространства IO, окончательный этап состоит в выделении программировании данного BAR необходимым базовым адресом пространства адресов IO, специально для этого BAR. Положение (3) Рисунка 4-6 показывает получаемое состояние этого BAR после данного шага. В нашем примере назначаемым начальный адрес данного устройства составляет 16кБ, поэтому бит 14 записывается как результат в некотором базовом адресе как
4000h; все прочие биты выше очищены.
| BAR | Биты BAR | Значение |
|---|---|---|
|
|
Считан как |
|
|
Считывание |
|
|
Считывание |
|
|
Все считываются как |
|
|
Все считываются как |
|
|
Все считываются как |
На данный момент выполнена настройка BAR3. Как только программное обеспечение разрешит декодирование адресов IO
в имеющемся регистре команд (смещение 04h), это устройство будет принимать все запросы
и отвечать на них внутри диапазона
4000h - 40FFh
(с размером 256 байт).
После просмотра трёх предыдущих примеров становится ясным, что программное обеспечение обязано вычислять BAR последовательным образом.
В большинстве случаев функции не нуждаются во всех шести BAR. Даже в приведённых примерах, которые мы изучили, использовались только четыре из шести доступных BAR. Если данная функция в нашем примере не нуждается в запросе какого бы то ни было дополнительного адресного пространства, разработчик такого устройства закодирует аппаратно все биты BAR4 и BAR5 нулями. Таким образом, даже хотя программное обеспечение пропишет в эти BAR все биты единицами, такая запись не будет иметь воздействия. После определения BAR3 программное обеспечение перейдёт к вычислению BAR4. Когда оно определит, что никакие из его битов не настраиваются, программное обеспечение будет знать, что это BAR не используется и перейдёт к вычислению своего следующего BAR.
Должна вычисляться все BAR, даже если программное обеспечение определило BAR, который не используется. Не существует никаких правил в PCI или PCIe, которые постулируют, что BAR0 обязан быть самым первым BAR, применяемым для запросов адресного пространства. Если некий разработчик устройства выберет такое, он может воспользоваться BAR4 для запроса некоего адресного пространства и аппаратно заполнить всеми нулями BAR0, BAR1, BAR2, BAR3 и BAR5. Это означает, что программное обеспечение обязано вычислять все BAR в имеющемся заголовке.
Версия 2.1 спецификации PCI Express дополнена поддержкой для изменения установленного размера запрашиваемого пространства адресов в рассматриваемом BAR определением новой структуры возможностей в расширенном пространстве настройки. Эта новая структура делает возможной функцию для объявления того, с каким размером адресного пространства она может работать и после этого получать разрешение программного обеспечения одного из имеющихся размеров на основании доступных ресурсов системы. Например, если некая функция в идеале предпочла бы иметь 2ГБ адресного пространства с предварительной выборкой, но она также всё ещё может продолжать работать только с 1ГБ, 512МБ или 256МБ P-MMIO, системное программное обеспечение может разрешить данной функции запрашивать только 256МБ адресного пространства если оно не имеет возможности удовлетворять запросам на большие размеры.
Когда некая функция BAR запрограммирована, эта функция знает каким диапазоном адресов она владеет, что означает, что функция будет заявлять о своих правах на любые обнаруживаемые ею транзакции, которые имеют целью тот диапазон адресов, которым она владеет, неким диапазоном адресов, запрограммированных в одном из её BAR. Это хорошо, однако важно понимать, что единственный способ, которым данная функция собирается "видеть" те транзакции, на которые она должна заявлять свои права, это если имеющийся выше неё мост (мосты) пересылает эти транзакции вниз по потоку в соответствующее соединение, к которому подключена соответствующая функция назначения. Более того, каждый мост (то есть порты коммутатора или порты комплекса корня) должны знать те адреса, которые располагаются под ними с тем, чтобы они могли определять какие из запросов следует направлять далее из их первичного интерфейса (с восходящей стороны) на их вторичный интерфейс (в нисходящую сторону). Если данный запрос имеет целью некий адрес, который находится во владении какого- то BAR в расположенной под этим мостом функцией, этот запрос следует направить во вторичный интерфейс такого моста.
Именно регистры базы и предела в заголовках 1 типа программируются теми диапазонами адресов, которые расположены ниже данного моста. Существует три вида необходимых регистров, поскольку может иметься три отдельных вида диапазонов адресов, располагающихся ниже какого- то моста:
-
Пространство памяти с упреждающей выборкой (P-MMIO)
-
Пространство памяти без упреждающей выборки (NP-MMIO)
-
Пространство IO (IO)
Чтобы пояснить как работают эти регистры базы и предела, давайте продолжим наш пример из предыдущего раздела и поместим такую программируемую функцию (некую конечную точку) ниже показанного на Рисунке 4-7 коммутатора. Данный рисунок также перечисляет все диапазоны адресов, которыми владеют BAR данной функции.

Регистры вазы и предела каждого восходящего моста данной конечной точки подлежат программированию, однако для того чтобы начать, давайте сосредоточимся на том мосте, который подключён к рассматриваемой конечной точке (порт B).
Заголовки 1 типа имеют две пары регистров базы/ предела памяти с упреждающей выборкой. Данные регистры базы/ предела памяти
с упреждающей выборкой сохраняют информацию адреса для нижних 32 бит диапазона адресов с упреждением. Если этот мост поддерживает
декодирование 64- битных адресов, тогда имеющиеся регистры верхних 32- бит базы/ предела памяти с упреждающей выборкой
также применяются и содержат верхние 32 бита (биты [63:32]) применяемого диапазона адресов.
Рисунок 4-8 показывает имеющиеся значения, которые программное обеспечение
будет программировать в эти регистры чтобы указывать тот диапазон адресов с упреждающей выборкой
2_4000_0000h - 2_43FF_FFFFh, который
расположен под данным мостом (Порт B). Значения каждого поля в этих регистрах суммируются в
Таблице 4-4.

| Регистр | Значение | Использование |
|---|---|---|
База памяти с упреждающей выборкой |
|
Верхние 12 бит этого регистра содержат верхние 12 бит имеющегося адреса BASE (биты [31:20]). Нижние 20 бит данного базового адреса в неявном виде подразумеваются заполненными нулями, что означает что такой базовый адрес всегда выравнивается на границу 1МБ. Самые нижние 4 бита данного регистра указывают поддерживает ли данный мост декодирование 64- битной адресации, что означает применение верхних регистров базы/ предела. |
Предел памяти с упреждающей выборкой |
|
Аналогично, верхние 12 бит данного регистра содержат верхние 12 бит имеющегося адреса LIMIT (биты [31:20]). Нижние 20 бит данного адреса предела в неявном виде подразумеваются заполненными Fh. Самые нижние 4 бита данного регистра имеют то же самое значение, что и самые нижние 4 бита регистра базы. |
Верхние 32 бита базы памяти с упреждающей выборкой |
|
Содержит верхние 32 бита 64- битного адреса BASE памяти с упреждающей выборкой для нисходящего потока данного порта. |
Верхние 32 бита предела памяти с упреждающей выборкой |
|
Содержит верхние 32 бита 64- битного адреса LIMIT памяти с упреждающей выборкой для нисходящего потока данного порта. |
В отличии от диапазона памяти с упреждающей выборкой, диапазон памяти без упреждающей выборки может поддерживать только 32- битные адреса. Поэтому имеется только один для базы и один регистр для предела. Вслед за примером Рисунка 4-7 регистры базы/ предела памяти без упреждающей выборки порта B будут запрограммированы отображёнными на Рисунке 4-9 значения. Объяснение имеющихся значений суммируются в Таблице 4-5.

| Регистр | Значение | Использование |
|---|---|---|
База памяти без упреждающей выборки |
|
Верхние 12 бит этого регистра содержат верхние 12 бит имеющегося 32- битного адреса BASE (биты [31:20]). Нижние 20 бит данного базового адреса в неявном виде подразумеваются заполненными нулями, что означает что такой базовый адрес всегда выравнивается на границу 1МБ. Самые нижние 4 бита данного регистра должны быть нулями. |
Предел памяти без упреждающей выборки |
|
Аналогично, верхние 12 бит данного регистра содержат верхние 12 бит имеющегося адреса LIMIT (биты [31:20]). Нижние 20 бит данного адреса предела в неявном виде подразумеваются заполненными Fh. Самые нижние 4 бита данного регистра должны быть нулями. |
Данный пример отображает некий интересный вариант, когда имеющийся диапазон адресов без упреждающей выборки программирующий настраиваемое пространство порта B указывает намного больший диапазон (1МБ), чем тот диапазон NP-MMIO (4кБ), которым владеет та конечная точка, которая расположена ниже. Это происходит из- за того, что имеющиеся в заголовке 1 типа регистры базы/ предела памяти могут применяться только для определения битов выше 20 ([31:20]). Нижние 20 бит адреса, [19:0] имеют значения по умолчанию. Поэтому самым наименьшим диапазоном адресов, который может быть определён регистрами базы/ предела памяти является 1МБ.
В нашем примере, имеющаяся конечная точка запросила и получила 4кБ NP-MMIO (F900_0000h
- F900_0FFFh). Порт B был запрограммирован значением, указывающим 1МБ, или 1024кБ
расположенных ниже этого порта NP-MMIO (F900_0000h - F900_FFFFh).
Это подразумевает пустую трату 1020кБ (F900_1000h - F90F_FFFFh)
адресного пространства памяти. Такое адресное пространство НЕ МОЖЕТ быть выделено другой конечной точке, поскольку
маршрутизация таких пакетов не будет работать.
Как и в случае с диапазоном памяти с предварительной выборкой, заголовки 1 типа имеют две пары регистров базы/ предела IO.
Эти регистры базы/ предела IO содержат информацию для нижних 16 бит имеющегося диапазона адресов IO. Если данный мост
поддерживает декодирование 32- битных адресов IO (что редко встречается среди устройств реального мира), тогда регистры
верхних 16 бит базы/ предела IO также применяются и содержат верхние 16 бит (биты [31:16]) имеющегося диапазона адресов IO.
Следуя нашему примеру,
Рисунок 4-10 отображает те значения, которые программное обеспечение
закодирует в этих регистрах чтобы указывать, что имеющийся диапазон 4000h -
4FFFh располагается ниже данного моста (порт B). Значения всех полей в этих регистрах
суммируются в Таблице 4-6.
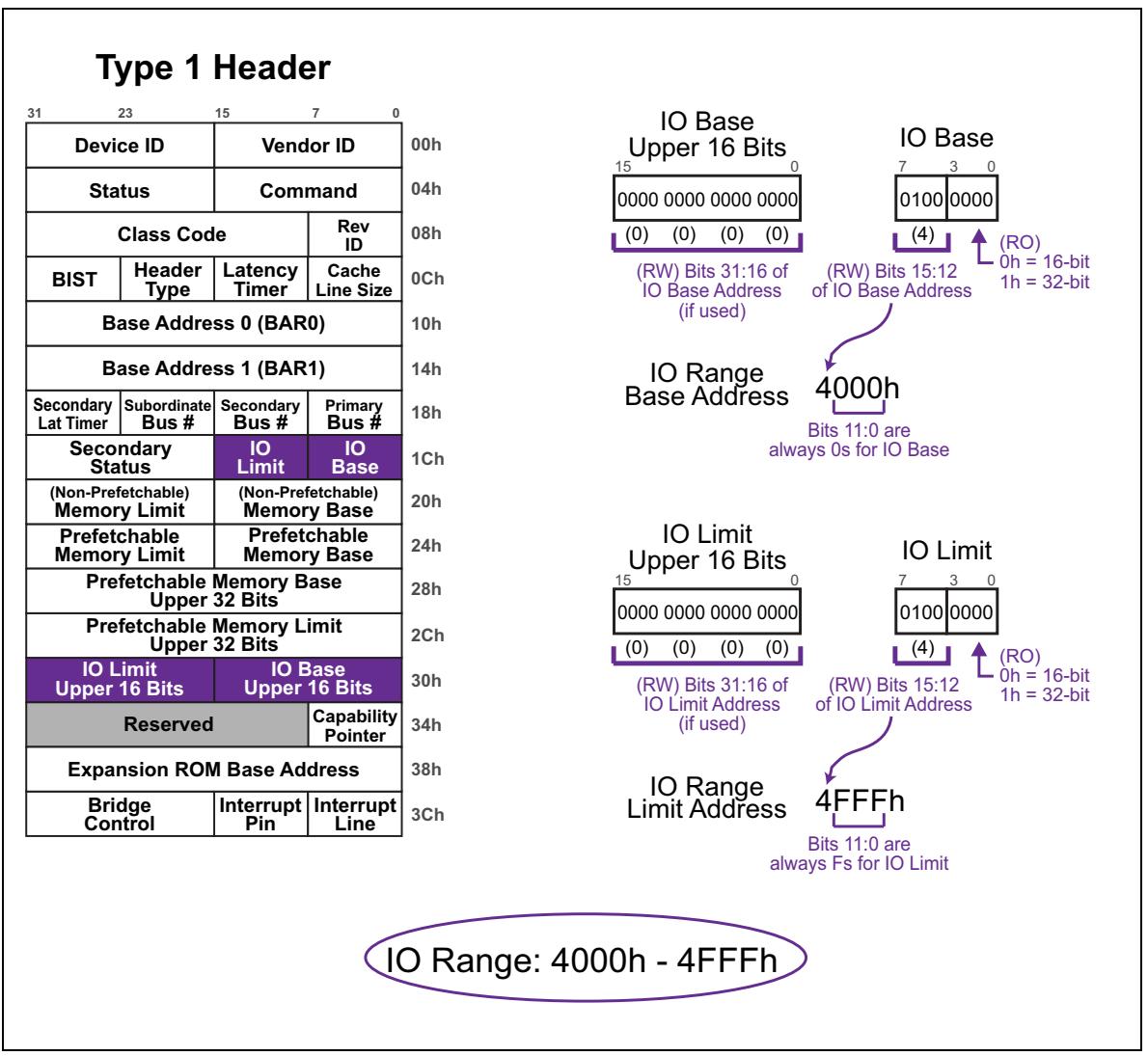
| Регистр | Значение | Использование |
|---|---|---|
База IO |
|
Верхние 4 бита этого регистра содержат верхние 4 бита имеющегося 16- битного адреса BASE (биты [15:12]). Нижние 12 бит данного базового адреса в неявном виде подразумеваются заполненными нулями, что означает что такой базовый адрес всегда выравнивается на границу 4кБ. Самые нижние 4 бита данного регистра указывают поддерживается ли 32- битное декодирование адресов в этом мосту, что означает применение верхних регистров базы/ предела. |
Предел IO |
|
Аналогично, верхние 4 бита этого регистра содержат верхние 4 бита имеющегося 16- битного адреса LIMIT (биты [15:12]). Нижние 12 бит данного базового адреса в неявном виде подразумеваются заполненными Fh. Самые нижние 4 бита данного регистра имеют то же самое значение, что и самые нижние 4 бита регистров базы. |
Верхние 16 бит базы IO |
|
Содержит верхние 16 бита 32- битного адреса BASE IO для нисходящего потока данного порта. |
Верхние 16 бит предела IO |
|
Содержит верхние 16 бита 32- битного адреса LIMIT IO для нисходящего потока данного порта. |
В данном примере мы видим другой случай при котором имеющийся диапазон адресов программирует в восходящем потоке моста
адресное пространство, намного превосходящее реальное, которым обладает имеющаяся внизу функция. Конечная точка в нашем
примере владеет 256 байтами адресного пространства IO (а именно, 4000h -
4FFFh). Порт B программируется значениями, указывающими, что под ним расположено
адресное пространство IO 4кБ (адреса 4000h -
4FFFh). Опять же, это просто ограничение заголовков 1 типа. Для пространства адресов
IO самые нижние 12 бит ([11:0]) имеют подразумеваемые значения, поэтому наименьший определяемый диапазон адресов IO
составляет 4кБ. Это ограничение является более существенным чем имеющееся минимальное окно в 1МБ для диапазонов памяти. В
на основе x86 (Intel- совместимых), все процессоры поддерживают только 16 бит адресного пространства IO, что означает,
что в некоторой системе может иметься только 16 (24) различных диапазонов адресов IO.
Не все устройства PCIe будут использовать все три типа адресного пространства. На самом деле, имеющаяся спецификация PCI Express в действительности предостерегает от применения адресного пространства IO, указывая, что оно применяется исключительно по причине наследования и может быть отклонено в последующих редакциях спецификации.
В том случае, когда некая конечная точка не нуждается во всех трёх типах адресного пространства, какие именно регистры базы и предела имеющегося восходящего моста таких устройств следует программировать? Они не могут быть закодированы всеми нулями, так как имеющиеся нижние биты адресов всё ещё подразумеваются различными (для базы равны нулям, а для предела единицами -Fh), что представляло бы некий допустимый диапазон. Поэтому, чтобы обрабатывать такие варианты, имеющийся регистр предела должен кодироваться неким более высоким адресом, нежели имеющаяся база. Например, если некая конечная точка не запрашивает адресное пространство IO, тогда тот мост, который расположен непосредственно над такой функцией будет иметь её базовый регистр запрограммированным на 00h и её регистр предела IO запрограммированным значением F0h. Так как имеющийся адрес предела выше своего адреса базы, этот мост понимает что это неверная установка и считает что под владельцем такого адресного пространства IO нет никакой расположенной ниже функции.
Такой метод указания неверных регистров базы и предела допустим для всех трёх типов пар базы и предела, а не только для регистров базы/ предела IO.
Чтобы убедиться, что вы понимаете все правила и методы установки BAR и регистров базы/ предела, взгляните, пожалуйста, на Рисунок 4-11 для проверки вещей по- существу. Мы просто расширили свой пример системы с тем, чтобы он содержал дополнительные запросы адресного пространства от иных оконечных устройств, а также ещё из одного из имеющихся портов коммутатора (порта A). Помните, что заголовки 1 типа также имеют BAR (а именно два, если быть точными) и могут также запрашивать пространство адресов. Имеющиеся регистры базы/ предела НЕ содержат те адреса, которыми владеют BAR того же самого моста. Регистры базы/ предела представляют исключительно те адреса, которые расположены ниже этого моста.
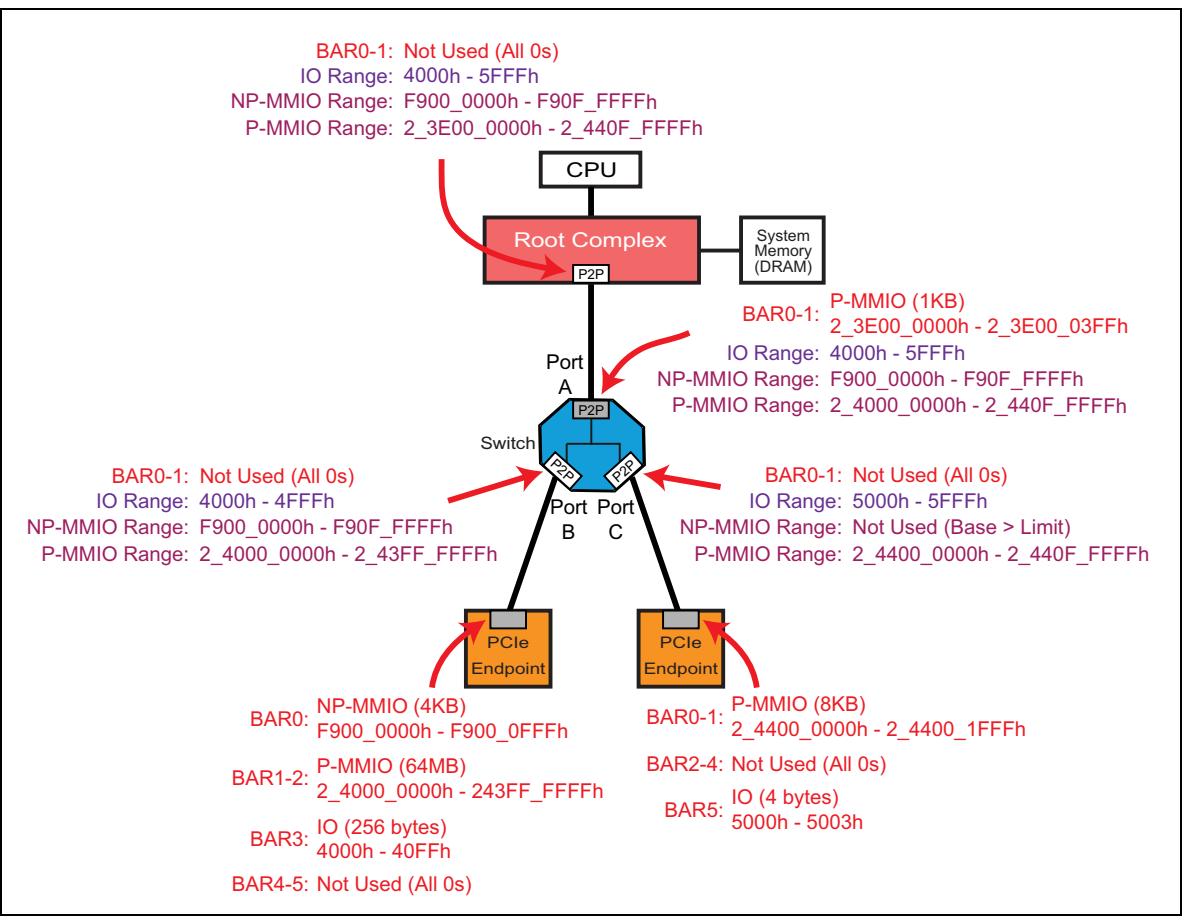
Целью установки имеющихся BAR и регистров базы/ предела, как это было описано в предыдущих разделах, является гарантия того, что обмен с некоторой функцией назначения будет правильно снабжаться маршрутами с тем чтобы такая целевая функция могла видеть все транзакции и заявлять на них свои права. В архитектурах с совместно используемой шиной, таких как PCI, весь обмен виден всем устройствам. Единственным вариантом, когда происходит маршрутизация, является случай, при котором целевое устройство расположено в другой шине и должно пересекать некий мост. Так как PCIe соединения относятся к соединениям точка- точка, для транспортировки транзакций между устройствами требуется дополнительная маршрутизация.
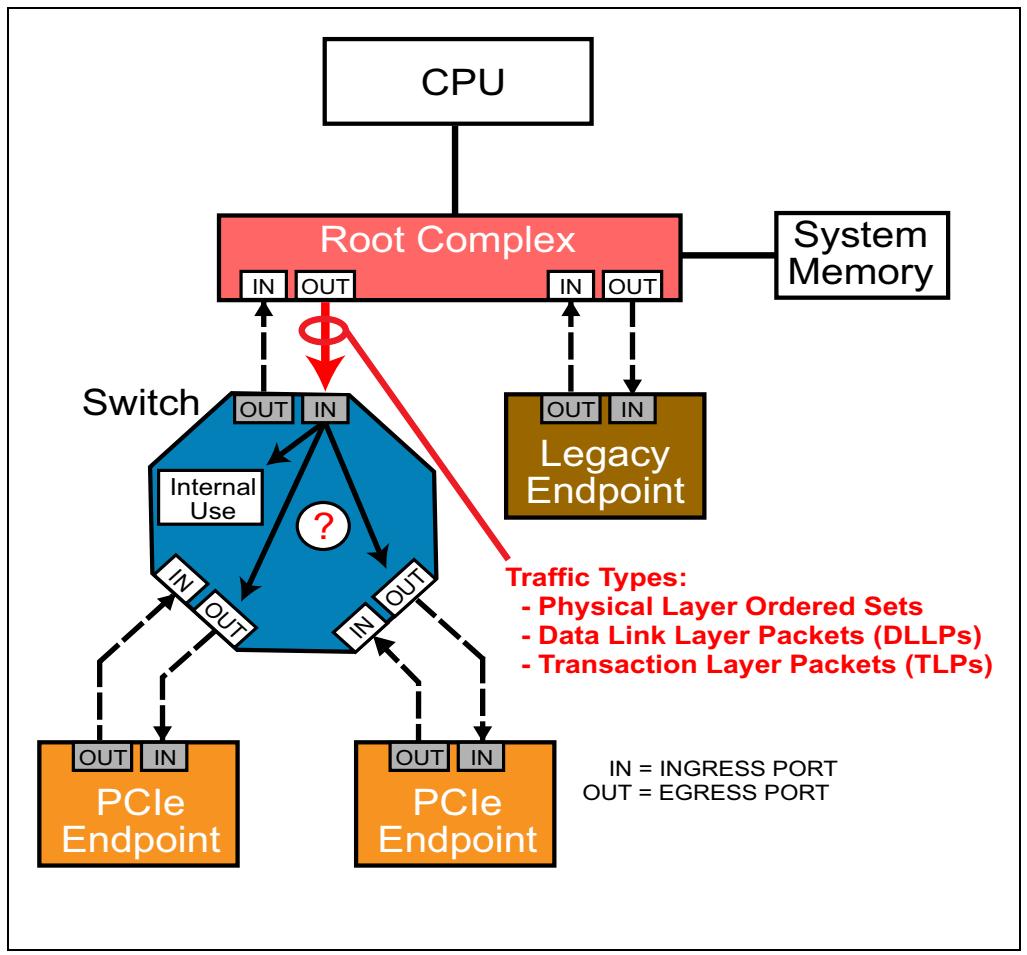
Как это отображено на Рисунке 4-12, некая топология PCI Express состоит из независимых связей точка- точка, соединяющих каждое устройство с одним или более соседями. При возникновении обмена с входной стороны какого- то интерфейса соединения (имеющего название порта доступа - ingress port), этот порт проверяет наличие ошибок, после чего принимает одно из трёх решений:
-
Принять полученный обмен и использовать его внутри
-
Переслать этот обмен в соответствующий исходящий порт (порт исхода - egress)
-
Отклонить этот обмен, поскольку он не является ни намеченной целью, ни неким интерфейсом к ней (отметим, что имеются прочие причины отклонения обмена).
В предположении, что некое соединения является полностью рабочеспособным, определённый интерфейс получателя каждого устройства (порт доступа) обязан определять и оценивать получение трёх типов обмена по соединению: Упорядоченных наборов (Ordered Sets), Пакетов уровня передачи данных (DLLP, Data Link Layer Packets) и Пакетов уровня транзакций (TLP, Transaction Layer Packets). Упорядоченные наборы и DLLP являются локальными для некоторого соединения и по этой причине никогда не маршрутизируются в другое соединение. TLP же на самом деле перемещаются от соединения к соединению на основании информации о маршрутизации, содержащейся в самих заголовках пакетов.
Устройства со множеством портов, такие как Комплексы корня (Root Complexes) и Коммутаторы (Switches), могут переправлять TLP между своими портами и иногда именуются Агентами маршрутизации (Routing Agents) или Элементами маршрутизации (Routing Elements). Они принимают TLP, которые имеют целью внутренние ресурсы и переправляют TLP между портами доступа и исхода.
Интересно, что в Коммутаторах требуется поддержка одноранговой маршрутизации, однако для Комплекса корня это не является обязательным. Одноранговый обмен обычно присутствует там, где Конечные точки (Endpoint) отправляют пакеты, имеющие целью другие Конечные точки.
Конечные точки имеют только одни Соединение (Link) и никогда не ожидают обнаружения обмена на доступ, отличного от того, в котором они являются получателем. Они просто принимают или отвергают входящие TLP.
Общие понятия
TLP могут осуществлять маршрутизацию на основании адреса (либо в памяти, либо IO), на основании идентификатора (подразумевающего Шину - Bus, Устройство - Device, номер Функции - Function number), либо выполнять маршрутизация неявным образом. Конкретный метод маршрутизации основывается на заданном типе TLP. Таблица 4-7 резюмирует все виды TLP и методы маршрутизации, применяемые для каждого из них.
| Тип TLP | Используемый метод маршрутизации |
|---|---|
Чтение памяти [с блокировкой], Запись в память, Атомарная операция |
Маршрутизация по адресу |
Чтение и запись IO |
Маршрутизация по адресу |
Чтение и запись настроек |
Маршрутизация по идентификатору |
Обмен сообщениями, сообщения с данными |
Маршрутизация по адресу, Маршрутизация по идентификатору или Маршрутизация в неявном виде |
Завершение, завершение с данными |
Маршрутизация по идентификатору |
Обмен сообщениями является единственным типом TLP, который поддерживает более одного метода маршрутизации. Большинство имеющихся сообщений TLP, определяемых в спецификации PCI Express применяют неявную маршрутизацию, хотя, если он того пожелает, конкретный производитель может определять сообщения,которые могут использовать маршрутизацию адресов или маршрутизацию идентификаторами.
Назначение маршрутизации в неявном виде и обмена сообщениями
При маршрутизации в неявном виде не применяется никакой адрес или идентификатор; вместо этого все пакеты маршрутизируются на основании некоторого кода в самом заголовке такого пакета, указывающего некоторого получателя с известным расположением в имеющейся топологии, например, Комплекс корня. Это упрощает маршрутизацию сообщений в тех случаях, когда применяется некий тип неявной маршрутизации.
Зачем нужен обмен сообщениями?
Транзакции обмена сообщениями не были определены в PCI или PCI-X, однако были представлены в PCIe. Основной причиной добавления Обмена сообщениями как некоего типа состояла в преследовании цели проектирования такого PCIe, который мог бы впечатляющим образом уменьшить общее число сигналов вспомогательной полосы, реализуемых в PCI (то есть, контактов прерываний, контактов ошибок, сигналов управления питанием и тому подобных). В конце концов большинство сигналов вспомогательной полосы было заменено встроенными пакетами в виде TLP сообщений.
Как помогает маршрутизация в явном виде
Применение внутриполосного обмена сообщениями вместо сигналов вспомогательной полосы требует средств их маршрутизации до соответствующего получателя в топологии, которая состоит из значительного числа соединений точка- точка. Неявная маршрутизация получает преимущества из того факта, что Коммутаторы и прочие элементы маршрутизации понимают наличие концепции восходящих и нисходящих потоков, а также того, что сам Комплекс корня обнаруживается в вершине топологии, в то время как Конечные точки расположены в самом низу. Как результат, некое Сообщение может применять какой- то простой код для отображения того, как как оно должно следовать к имеющемуся Комплексу корня, например, или быть отправленным ко всем устройствам вниз по потоку. Эта возможность избавляет от необходимости определять диапазоны адресов или перечни идентификаторов применяемых специально применяемых в качестве цели различных транзакций сообщений.
С различными видами неявной маршрутизации можно ознакомиться в разделе Неявная маршрутизация.
Как и большинство прочих последовательных технологий, PCI Express применяет протокол расщепления транзакции, который делает возможным некоторому целевому устройству принимать один или более запросов и затем отвечать каждому запросу неким отдельным завершением. Это является значительным улучшением в сравнении с имевшимся протоколом шины PCI, который применял состояния ожидания или задерживаемых транзакций (повторов) для обработки задержек в получающих доступ назначениях. Вместо проверок того, чтобы определять когда эта цель станет готовой выполнить обмен со значительной задержкой, такая цель инициирует необходимый отклик всякий раз по достижению готовности. Это имеет результатом по крайней мере два отдельных TLP на транзакцию - сам Запрос (Request) и его Завершение (Completion) - как мы обсудим позже, некий одиночный запрос на чтение может в результате получить множество TLP завершения, отосланных обратно. Рисунке 4-13 отображает программное чтение данных из некоторой конечной точки.

Для снижения получаемых штрафов от имеющихся задержек Запросов- Завершений, транзакции записи в память отсылаются (posted), что означает, что такая транзакция рассматривается как завершённая с точки зрения её Запрашивающей стороны как только данный запрос покидает эту Запрашивающую сторону. Если это полезно, вы можете представлять себе ассоциацию с термином "посылки" в почтовой системе, где отсылка записи в память аналогична отправке какого- то письма по почте. После того как вы поместили письмо в имеющийся почтовый ящик вы имеете полную уверенность в том, что данная система доставит его и не ожидаете его проверки и доставки. Такой подход может быть гораздо более быстрым чем ожидание всей передачи Запроса- Завершения, однако - как и во всех почтовых системах - имеется неопределённость когда (и произошла ли) такая транзакция с её успешным завершением у конечного получателя.
В PCIe небольшая неопределённость, связанная с созданием отправок всех записей в памяти, рассматривается как приемлемая в обмен на получаемую производительность. Напротив, записи в IO и пространствах настроек почти всегда воздействуют на поведение устройства и имеют временную взаимосвязь с ними. Следовательно, всегда необходимо знать когда (и были ли) эти запросы на запись завершены. Из- за этого Записи IO и записи настроек всегда выполняются без отсылки и некое завершение всегда будет возвращаться в виде отчёта о получаемом состоянии данной операции.
Суммируя, транзакции без отправки требуют некоего завершения. Отсылаемые транзакции не требуют завершения и никогда не должны его получать. Таблице 4-8.
| Запрос | Как обрабатывается запрос |
|---|---|
Запись в память |
Все запросы записи в память отправляются. Никакие завершения не ожидаются и не отсылаются. |
Чтение памяти Чтение памяти с блокировкой |
Все запросы чтения памяти не отправляются. Завершение с данными (выполняемые одним или более TLP) будут возвращаться Завершающей стороной для доставки как самих запрошенных данных, так и получаемого состояния данного чтения памяти. В случае возникновения некоторой ошибки, будет возвращено завершение без данных с отчётом о полученной ошибке. |
Атомарная операция |
Все Атомарные операции не отправляются. Завершение с данными возвращаются Завершающей стороной с содержанием первоначального значения самого местоположения цели. |
Чтение IO Запись IO |
Все запросы IO не отправляются. Завершение без данных возвращаются для записей и отказанных считыванияй, в то время как для успешного чтения будут возвращаться завершения с данными. |
Чтение настроек Запись настроек |
Все настроечные запросы не отправляются. Завершение без данных возвращаются для записей и отказанных считыванияй, в то время как для успешного чтения будут возвращаться завершения с данными. |
Обмен сообщениями |
Все обмены сообщениями отправляются. Метод маршрутизации зависит от самого типа Обмена сообщениями, однако все они рассматриваются как отправляемые запросы. |
Общие понятия
Как показано на Рисунке 4-14, каждый TLP содержит три или четыре заголовка из двух слов (12 или 16 байт). Это включает в себя поля Format и Type, которые определяют само содержимое оставшейся части данного заголовка и указывают применяемый метод маршрутизации для данного TLP при его прохождении в имеющейся топологии.

Кодирование поля формат/ тип заголовка
Приводимая ниже Таблице 4-9 суммирует то кодирование, которое применяется в полях Format и Type заголовка TLP.
| TLP | FMT[2:0] | TYPE[4:0] |
|---|---|---|
Запрос чтения памяти ( |
|
|
Запрос чтения памяти с блокировкой ( |
|
|
Запрос записи в память ( |
|
|
Запрос чтения IO ( |
|
|
Запрос записи IO ( |
|
|
Запрос чтения настройки типа 0 ( |
|
|
Запрос записи настройки типа 0 ( |
|
|
Запрос чтения настройки типа 1 ( |
|
|
Запрос записи настройки типа 1 ( |
|
|
Запрос обмена сообщениями ( |
|
|
Запрос обмена сообщениями с данными ( |
|
|
Завершение ( |
|
|
Завершение с данными ( |
|
|
Завершение блокируемое ( |
|
|
Завершение с данными блокируемое ( |
|
|
Запрос выборки и добавления Атомарной операции ( |
|
|
Запрос безусловного обмена Атомарной операции ( |
|
|
Запрос сравнения и обмена Атомарной операции ( |
|
|
Префикс локальных TLP ( |
|
|
Префикс TLP End-to-End ( |
|
|
Когда TLP принимаются портом доступа, вначале они проверяются на наличие ошибок на Физическом уровне и уровне Канала передачи данных. При отсутствии ошибок этот TLP исследуется на уровне Транзакций на предмет изучения того какой метод маршрутизации необходимо применять. Основными этапами являются:
-
Поля Format и Type определяют текущий размер заголовка, формат и тип данного пакета.
-
В зависимости от того метода маршрутизации, который связан с данным типом пакета, данное устройство определяет является ли оно тем получателем, которому предназначен данный пакет. Если так, оно принимает (потребляет) данный TLP, однако если нет, оно перенаправит такой TLP в соответствующий порт исхода - в соответствии с имеющимися для такого порта исхода правилами упорядочения и управления потоком.
-
Если же данное устройство не является ни надлежащим получателем и не находится в том пути, который ведёт к необходимому получателю, оно обычно отвергает данный пакет как Не поддерживаемый запрос (UR, Unsupported Request).
После того, как адреса системы были настроены, а транзакции разрешены, устройства исследуют поступающие TLP и применяют соответствующие поля настроек для маршрутизации этих пакетов. Последующие разделы описывают основные свойства/ функциональности всех применяемых TLP механизмов маршрутизации через имеющуюся структуру PCI Express.
Маршрутизация по идентификатору применяется для указания цели его логического местоположения - Номера шины (Bus Number), Номера устройства (Device Number) и Номера функции (Function Number) - обычно именуемого как BDF - для некоторой Функции в пределах имеющейся топологии. Она совместима с методами маршрутизации, применяемыми в протоколах PCI и PCI-X для настройки транзакций. В PCIe она всё ещё применяется для маршрутизации пакетов настройки, а также используется для маршруизации завершений и некоторых обменов сообщениями.
Номер шины, номер устройства, пределы номера функции
PCI Express применяет те же самые пределы топологии, что и PCI с PCI-X:
-
Восемь бит применяются для задания необходимого номера шины, следовательно в системе возможно максимум 256 шин. Они включают и внутренние шины, создаваемые Коммутаторами.
-
Пять бит задают определённый номер устройства, таким образом, в каждой шине допускается максимум в 32 устройства. Некие более ранние шины PCI или какие- либо внутренние шины в коммутаторе или комплексе корня могут размещать более одного устройства ниже себя. Однако, внешние соединения PCIe всегда являются соединениями точка- точка и в таком соединении имеется только одно подлежащее устройство. Номер такого устройства для любого внешнего соединения принудительно устанавливается для расположенного ниже порта всегда как Device 0, поэтому все внешние Конечные точки всегда будут Device 0 (если только не применяется Альтернативная интерпретация идентификатора маршрутизации - ARI, Alternative Routing‐ID Interpretation - в этом случае номера устройств отсутствуют; дополнительные сведения об ARI можно найти в разделе IDO - упорядочение на основе идентификатора).
-
Три бита задают конкретный номер функции, стало быть для устройства имеется возможность максимум в 8 внутренних функциях.
Ключевые поля заголовка TLP в маршрутизации ID
Если значение поля Type в полученном TLP указывает, что необходимо применять маршрутизацию по идентификатору, тогда для проверки этой маршрутизации используются поля идентификаторов из полученного заголовка (Bus, Device, Function). Имеется два варианта: маршрутизация по идентификатору с заголовком 3DW и маршрутизация по идентификатору с заголовком 4DW (которые могут быть только доступными в обмене сообщениями). Рисунок 4-15 иллюстрирует маршрутизацию по идентификатору с применением 3DW заголовка, в то время как Рисунок 4-16 отображает заголовок 4DW для маршрутизации по идентификатору.

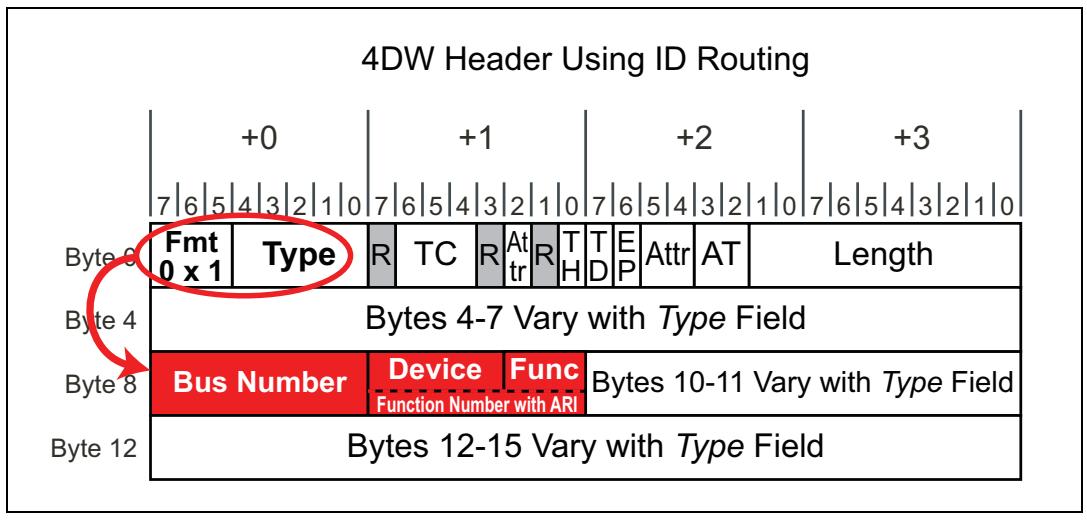
Конечные точки: одна проверка
Для маршрутизации по идентификатору некая Конечная точка просто проверяет само поле идентификатора в данном заголовке пакета относительно его собственного BDF. Все функции "перехватывают" свои собственные номера Bus и Device всякий раз, когда обнаруживают в своём соединении запись настройки с типом 0 из байтов 8-9 в полученном Заголовке TLP. Где обязана храниться перехваченная информация номеров Bus и Device не определено, определяется только что функции обязаны сохранять их. Хранимые номера Bus и Device применяются как сам идентификатор Запрашиваемой стороны в запросах TLP, которые инициируют данную конечную точку, поэтому соответствующий Завершитель такого запроса может содержать такое значение идентификатора Запрашиваемой стороны в соответствующем пакете (пакетах) завершения. Такой идентификатор Запрашиваемой стороны в пакете завершения применяется для маршрутизации данного завершения.
Коммутаторы (мосты): две проверки на порт
Для некоторого TLP с маршрутизацией по идентификатору порт коммутатора вначале выполняет проверку не является ли он сам целью, сравнивая полученный идентификатор назначения в этом заголовке TLP со своим собственным BDF, как это отображено на Рисунке 4-17. Так же, как это было справедливо и для Конечной точки, всякий порт коммутатора перехватывает свои собственные номера Bus и Device при каждой записи настройки (с типом 0) при её обнаружении в своём собственном Восходящем порте. Если полученное поле идентификатора назначения в данном TLP соответствует с самим идентификатором данного порта коммутатора, он потребляет такой пакет. Если данное поле идентификатора не совпадает, он затем проверяет не указывает ли полученный TLP на некое расположенное ниже данного порта устройство. Он осуществляет это проверяя имеющиеся регистры Вторичного и подчинённого номера шины (Secondary and Subordinate Bus Number) чтобы убедиться, что имеющийся в полученном TLP номер шины присутствует в таком диапазоне (включительно). Если это так, тогда данный TLP подлежит отправке по направлению вниз. Такая провекра указывается как (2) на Рисунке 4-17. Если данный пакет перемещён вниз (появившись в Восходящем порте) и при этом не соответствует BDF данного Восходящего порта или не попадает в диапазон Вторичной- Подчинённой шины, он будет обработан как в данном Восходящем порте как Не поддерживаемый запрос (Unsupported Request).
Рисунок 4-17
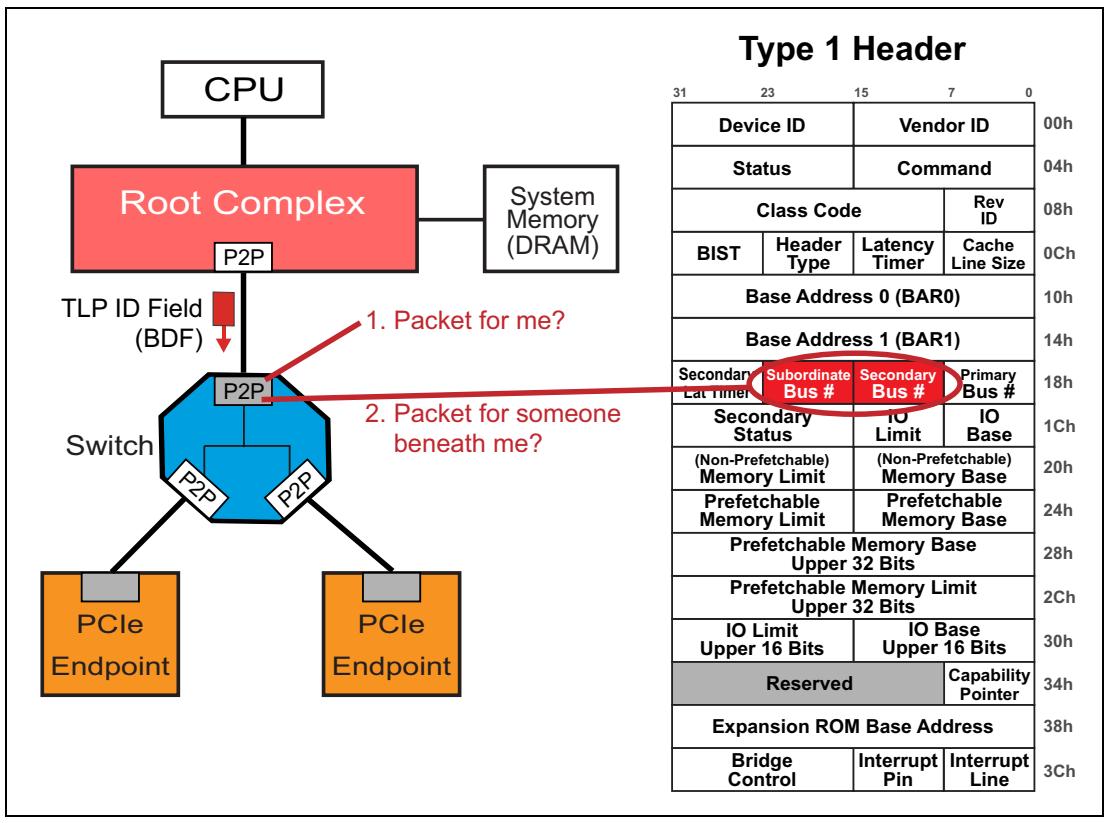
Проверки Коммутатором маршрутизации некоторого полученного TLP с применением маршрутизации по идентификатору
Если рассматриваемый Восходящий порт определяет, что некий полученный TLP предназначен для расположенных ниже него устройств (так как его номер шины назначения находится в том же диапазоне, который имеется в его диапазоне номеров Вторичных- Подчинённых шин), тогда он переправляет его вниз и все все расположенные ниже порты соответствующего коммутатора выполняют такие же проверки. Все расположенные ниже порты проверяют не указывает ли данный TLP на них. Если это так, соответствующий порт получателя потребит данный TLP, а прочие порты его игнорируют. Если нет, проверяются все лежащие ниже порты на предмет того, что этот TLP имеет целью порт под ними. Тот порт, который возвращает истину для такой проверки переправит получаемый TLP в свою Вторичную шину, а все прочие расположенные ниже порты проигнорируют этот TLP.
В данном разделе важно помнить, что каждый порт в некотором коммутаторе является Мостом (Bridge) и, тем самым, имеет своё собственное пространство настроек с заголовком 1 типа. Даже несмотря на то, что Рисунок 4-17 отображает только один заголовок 1 типа, на самом деле каждый порт (все Мосты P2P) имеет свой собственный заголовок 1 типа и выполняет такие же две проверки для TLP когда они обнаруживаются в этом порте.
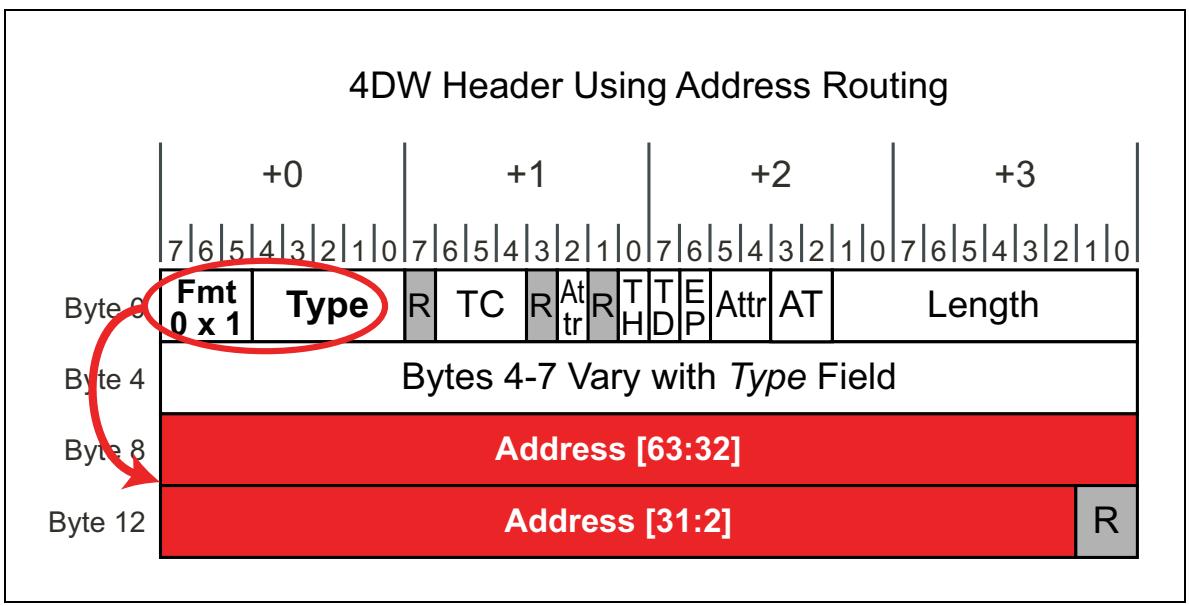
TLP, которые применяют маршрутизацию по адресу ссылаются на ту же самую память (системную память и соответствующий памяти IO - MMIO), а также адреса соответствия IO, как это делают транзакции PCI и PCI-X. Запросы к памяти, имеющие целью адреса ниже 4ГБ (т.е. с 32- битной адресацией) должны применять некий заголовок 3DW, а запросы, имеющие целью адреса выше 4ГБ (т.е. с 64- битной адресацией) обязаны использовать заголовок 4DW. Запросы IO ограничены 32- битной адресацией и реализуются исключительно для поддержки наследования функциональности.
Ключевые поля заголовка TLP в маршрутизации адреса
Если поле Type указывает, что для некоего TLP следует применять маршрутизацию адреса, тогда в его заголовке применяются Поля адреса для осуществления проверки маршрутизации. Это может быть адресация с 32- битами или 64- битная адресация.
TLP с 32- битным адресом
Для запросов IO или к 32- битной памяти применяется заголовок 3DW, как это отображается на Рисунке 4-18. Целевые регистры соответствия памяти для таких TLP, вследствие этого, будут располагаться ниже границы в 4ГБ памяти или ограничиваться адресом IO.

TLP с 64- битным адресом
Для запросов к 64- битной памяти применяется заголовок 4DW, показанный на Рисунке 4-19. Все целевые регистры соответствия памяти для этих TLP способны выполнять адресацию свыше границы памяти в 4ГБ.
Проверка адреса конечной точки
Если некоторая конечная точка получает какой- то TLP, который применяет маршрутизацию по адресу, тогда она проверяет такой адрес в его заголовке, сравнивая его со всеми её реализациями BAR (Регистров базового адреса) в своём заголовке настройки, как это отображено на Рисунке 4-20. Поскольку Конечные точки имеют только один интерфейс соединения, они либо принимают данный пакет, либо отвергают его. Данная конечная точка примет полученный пакет, если его целевой адрес в полученном TLP соответствует одному из диапазонов, закодированных в её BAR. Дополнительные сведения о том, как эти BAR применяются, можно получить в разделе Регистры базового адреса (BAR).

Переключение маршрутизации
Когда некий получаемый TLP применяет маршрутизацию по адресу, Порт Коммутатора вначале проверяет не соответствует ли такой адрес его локальному для самого Порта, сравнивая полученный в заголовке этого пакета адрес со своими двумя BAR в его заголовке настройки с типом 1, как это отображено в этапе 1 на Рисунке 4-21. Если он соответствует одному из этих BAR, данный порт коммутатора является целью такого TLP и потребляет полученный пакет. Если нет, данный порт затем проверяет свои пары регистров базы/ предела с тем, чтобы убедиться что полученный TLP имеет целью некую функцию под (в исходящем потоке) данным мостом. Если полученный Запрос имеет целью пространство IO, он проверит все регистры базы и предела IO, как это отображается шагом 2a. Однако, если полученный Запрос имеет целью пространство памяти, он проверит свои регистры базы/ предела памяти без упреждающей выборки и регистры базы/ предела памяти с упреждающей выборкой, как это указано в шаге 2b на Рисунке 4-21. Дополнительные сведения о том, как исчисляются пары регистров базы/ предела, можно получить в разделе Регистры базы и предела.
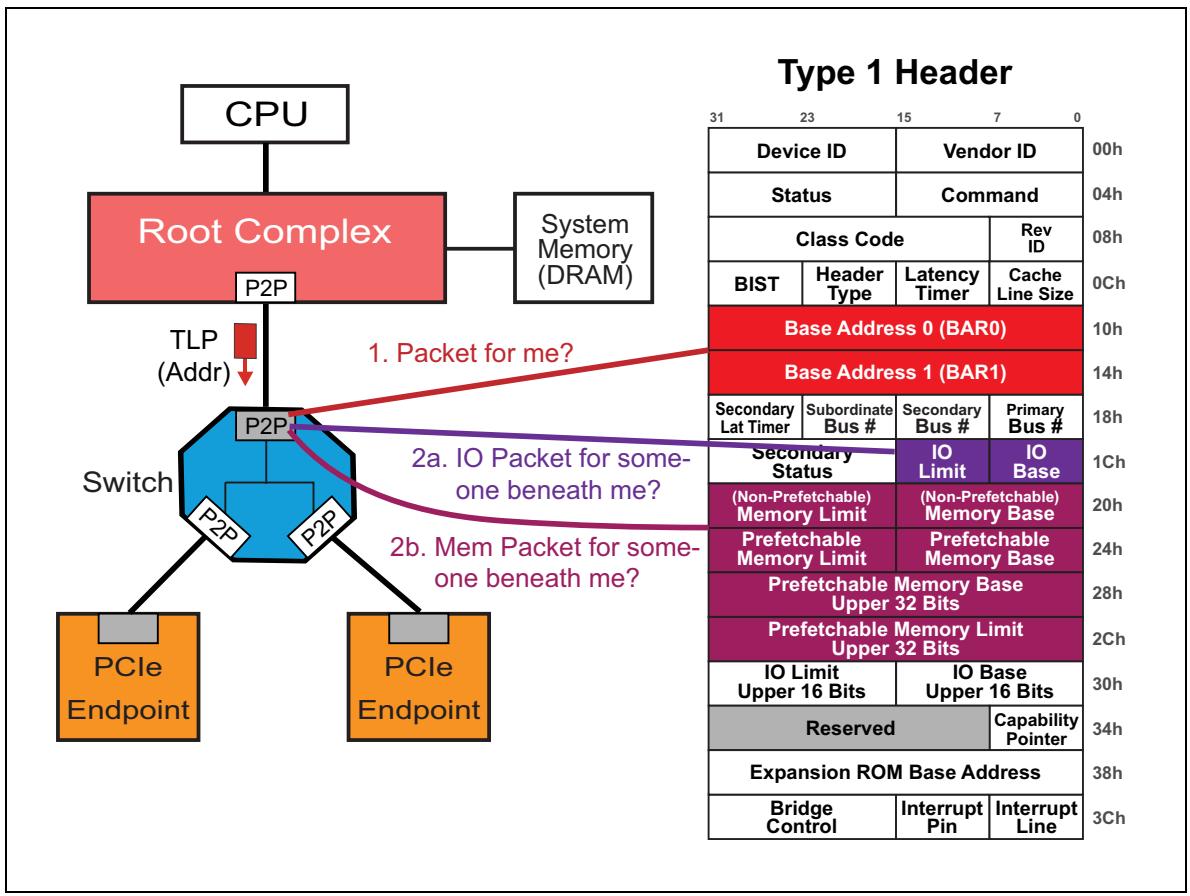
Для понимания маршрутизации TLP на основе адреса в коммутаторе, хорошо помнить о том, что какждый порт коммутатора является сам по себе мостом. Далее приводятся этапы того, что некий мост (порт коммутатора) предпринимает получив какой- то TLP:
Перемещающиеся вниз TLP (получаемые на первичном интерфейсе)
-
Если полученный адрес назначения в данном TLP соответствует одному из имеющихся BAR, тогда данный мост (порт коммутатора) потребляет этот TLP, поскольку именно он является целью данного TLP.
-
Если полученный адрес назначения в данном TLP не попадает в имеющийся диапазон ни одного из своих наборов регистров базы/ предела, такой пакет будет направлен в его вторичный интерфейс (вниз по потоку).
-
В ПРОТИВНОМ СЛУЧАЕ данный TLP будет обработан как Не поддерживаемый запрос в своём первичном интерфейсе. (Это верно если никакой прочий мост в таком первичном интерфейсе также не заявит свои права на данный TLP.)
Перемещающиеся вверх TLP (получаемые на вторичном интерфейсе)
-
Если полученный адрес назначения в данном TLP соответствует одному из имеющихся BAR, тогда данный мост (порт коммутатора) потребляет этот TLP, поскольку именно он является целью данного TLP.
-
Если полученный адрес назначения в данном TLP не попадает в имеющийся диапазон ни одного из своих наборов регистров базы/ предела, такой TLP будет обработан как Не поддерживаемый запрос в его вторичном интерфейсе. (Это верно только если данный порт не является восходящим портом в данном коммутаторе. В таких случаях полученный пакет может быть какой- то одноранговой транзакцией и будет направлен вниз по потоку в другой порт вниз, отличный от того, из которого он был получен.
-
В ПРОТИВНОМ СЛУЧАЕ данный TLP будет направлен в его первичный интерфейс (восходящий поток) определяя, что адрес данного TLP не предназначен для такого моста и подлежащих ниже него функций.
Возможности множественной адресации
Версия 2.1 спецификации PCI Express добавила поддержку для определения некоторого диапазона адресов, которые предоставляют функциональность множественной адресации. Любой получаемый пакет, который попадает в диапазон адресов, определяемый как диапазон с множественной адресацией подлежит маршрутизации/ приёму в соответствии с установленными правилами множественной адресации. Такой диапазон адресов может не быть зарезервирован в неких BAR функций и может не попадать в пары регистров базы/ предела, однако всё ещё нуждается в надлежащих приёме/ перенаправлении. Дополнительную информацию о функциональности множественной адресации можно найти в разделе Регистры возможностей множественной адресации.
Неявная маршрутизация, используемая в некоторых пакетах обмена сообщениями, основывается на осведомлённости об элементах маршрутизации, которые данная топология имеет в направлениях вверх по потоку и вниз по потоку, а также о Комплексе корня в своей вершине. Это допускает некоторые простые методы маршрутизации без необходимости назначения некоего адреса назначения или идентификатора. Так как Комплекс корня (Root Complex) обычно интегрирует управление питанием, прерывания и логику обработки ошибок, он является либо источником, либо получателем большей части сообщений PCI Express.
Только для обмена сообщениями
Некоторые сообщения применяют маршрутизацию по адресам или идентификаторам вместо неявной маршрутизации и для них применяется тот механизм маршрутизации и в точности тем же самым образом, как мы описали это в предыдущих разделах. Однако большинство сообщений применяют неявную маршрутизацию. Основной целью неявной маршрутизации является имитация поведения дополнительной полосы сигналов, так как одной из целей архитектуры PCIe было по возможности исключить множество сигналов PCI из дополнительной полосы. Эти сигналы дополнительной полосы в PCI были либо уведомлениями хоста всех устройств в некотором событии, либо уведомлениями устройств хоста в каких -то событиях. В PCIe у нас имеется Обмен сообщениями TLP для переправления этих событий. Теми типами событий, для которых PCIe определило обмен сообщениями это:
-
Управление питанием
-
Наследуемые сигналы INTx
-
Сгналы ошибок
-
Поддержка блокируемых транзакций
-
Сигналы подключения в горячем режиме
-
Специфичные для производителя сигналы
-
Установки предела питания слота
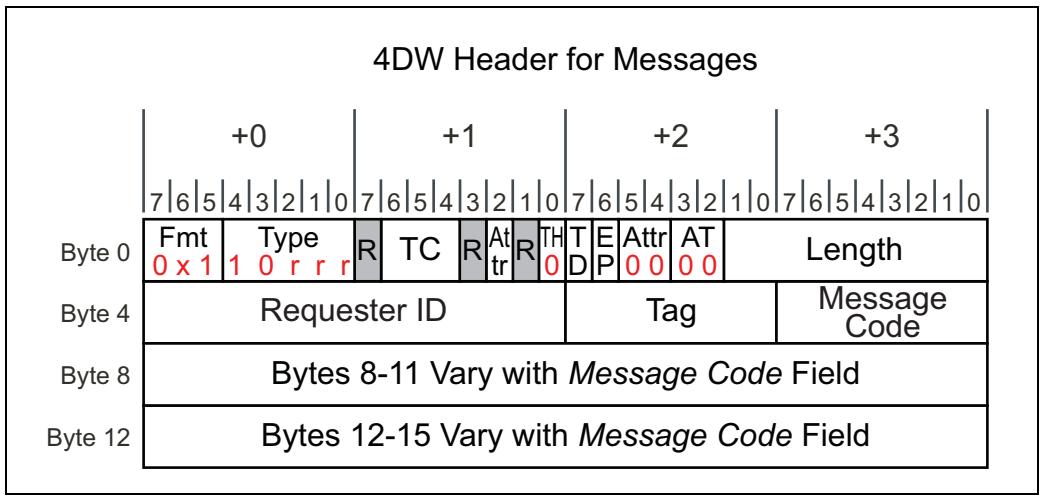
Ключевые поля заголовка TLP в неявной маршрутизации
Для неявной маршрутизации для определения необходимого получателя сообщения применяются соответствующие подполя маршрутизации в используемом заголовке. Рисунок 4-22 отображает некий TLP, применяющий неявную маршрутизацию.
Суммарные сведения о поле типа сообщения
Таблица 4-10 показывает как интерпретируются все поля Type для Обмена сообщениями в соответствующем заголовке TLP. Как отображено, самые верхние два бита указывают, что данный пакет является пакетом Обмена сообщениями, в то время как самые последние три бита определяют применяемый метод маршрутизации. Отметим, что TLP Обмена сообщениями всегда применяют заголовок 4DW вне зависимости от выбранного варианта маршрутизации. Для маршрутизации по адресам байты 8-15 содержат до
| Биты поля Type | Описание |
|---|---|
Бит |
Подполя маршрутизации обмена сообщениями R[2:0]:
|
Обработка конечной точки
При неявной маршрутизации некая Конечная точка просто проверяет соответствует ли ей полученное подполе маршрутизации. Например, любая Конечная точка примет какое- то Широковещательное сообщение или некое Сообщение, которое завершается на получателе; однако при этом не примет никаких сообщений, которые неявно имеют целью Комплекс корня.
Обработка коммутатора
Элементы маршрутизации, такие как коммутаторы, рассматривают тот порт, в котором появился TLP и соответствует ли ему полученный код подполя маршрутизации. Например:
-
Восходящий порт коммутатора может оправданно принимать Широковещательное сообщение. Он будет дублировать его и отправлять во все свои Нисходящие порты. Некое Широковещательное сообщение с неявной маршрутизацией, принимаемое в Нисходящем порте Коммутатора (что подразумевает, что данное сообщение перемещается вверх) будет являться некоторой ошибкой, которая будет обработана как Malformed TLP.
-
Коммутатор может получать Сообщения с неявной маршрутизацией для своего Комплекса корня в Нисходящем порте и направляет их в свой Восходящий порт, так как местоположение имеющегося Комплекса корня понимается как находящееся вверх по потоку. Он не будет принимать Сообщения получаемые в его Восходящем порте (что подразумевает, что такое сообщение перемещается вниз), которые неявно маршрутизируются к его Комплексу корня.
-
Если некое неявно маршрутизируемое Сообщение указывает, что оно должно быть прекращено на его получателе, тогда данный порт коммутатора потребит это сообщение вместо того чтобы переправлять его.
-
Для маршрутизируемых сообщений, применяющих маршрутизацию по адресу или идентификатору, Коммутатор просто выполнит обычную проверку адреса или идентификатора чтобы принять решения по его приёму или перенаправлению.
Обмен DLLP и Упорядоченного набора (Ordered Set) не маршрутизируется с порта доступа на исходящие порты коммутатора или Комплексов корня. Эти пакеты перемещаются с порта на порт по соединениям с Физического уровня на Физический уровень.
Возникающий на Канальном уровне какого- то порта PCI Express DLLP пробрасывается через Физический уровень, покидает этот порт, перемещается по имеющемуся Соединению и появляется на соседнем порте. В данном порте это пакет пробрасывается через Физический уровень и прибывает на Канальный уровень, в котором он обрабатывается и потребляется. DLLP не продвигаются далее в этом порте на его уровень Транзакции и, следовательно не маршрутизируются.
Аналогично, возникающие на данном Физическом уровне пакеты Упорядоченного набора покидают это порт, перемещаются по установленному Соединению и появляются на его соседнем порте. В этом порте такой пакет возникает на его Физическом уровне, где он обрабатывается и потребляется. Упорядоченные наборы не обрабатываются далее в этом порте на его Канальном уровне и уровне транзакций и, таким образом, не подлежат маршрутизации.
Как уже было обсуждено в данной главе, через коммутаторы и комплексы корня маршрутизируются только TLP. Они возникают на своём уровне Транзакции в порте источника и завершаются на уровне Транзакций порта назначения.