Глава 2. Начало работы с Prometheus
Содержание
В этой главе я настрою и запущу Prometheus, Экспортёр узла и Alertmanager. Данный образец примера будет мониторить некую отдельную машину и даст вам слегка попробовать как выглядит некое полное развёртывание Prometheus. В последующих главах мы рассмотрим все аспекты данной настройки более подробно.
Данная глава требует запущенной машины с любой разумной современной версией Linux. Подойдут и голое железо и некая виртуальная машина. Вы будете пользоваться командной строкой и доступом к службам данной машины при помощи веб браузера. Для простоты я буду полагать, что всё запускается на localhost; если это не так, настройте необходимые URL надлежащим образом.
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Базовая настройка, аналогичная той, что я применяю в данной главе доступна в http://demo.robustperception.io/. |
Предварительно скомпилированная версия Prometheus и прочие компоненты доступны на сайте Prometheus по адресу: https://prometheus.io/download/. Пройдите на эту страницу и выгрузите самую последнюю версию Prometheus для ОС Linux с архитектурой фьв64; обшая страница загрузок будет выглядеть примерно как это показано на Рисунке 2-1.
Рисунок 2-1
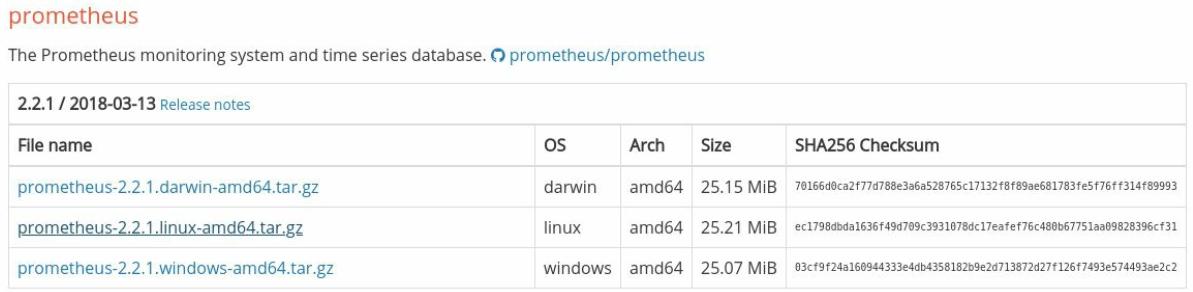
Часть страницы загрузок Prometheus. Необходимая нам архитектура Linux/amd64 расположена в середине.
Здесь я применяю Prometheus 2.2.1, поэтому нужным мне файлом является
prometheus-2.2.1.linuxamd64.tar.gz.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Гарантии стабильности Безопасность обновлений имеет тенденцию присутствовать между версиями с незначительными изменениями, например с 2.0.0 на 2.0.1, 2.1.0, или 2.3.1. Несмотря на это, как и для любого прочего программного обеспечения имеет смысл прочесть журнал изменений. Для данной главы должно быть достаточно любой версии 2.x.x Prometheus. |
Раскройте в командной строке выбранный tar- архив и перейдите в созданный каталог1:
hostname $ tar -xzf prometheus-*.linux-amd64.tar.gz
hostname $ cd prometheus-*.linux-amd64/
Теперь внесём изменения в файл с названием prometheus.yml с тем, чтобы он содержал следующий текст:
global:
scrape_interval: 10s
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
|
| Замечание |
|---|---|
|
YAML Prometheus применяет язык разметки YAML (Yet Another Markup Language) для своих файлов настроек, так как он подходит как для восприятия человеком, а также может обрабатываться инструментами. Данный формат, однако, чувствителен к пробелам, поэтому убедитесь что скопировали примеры в точности, с применением символов пробелов вместо символов табуляции2 . |
По умолчанию Prometheus запускается на TCP порте 9090, поэтому данная настройка указывает на необходимость Выуживать (scrape) себя каждые 10 секунд.
Теперь вы можете запустить исполняемый код Prometheus при помощи ./prometheus.
hostname $ ./prometheus
level=info ... msg="Starting Prometheus" version="(version=2.2.1, branch=HEAD,
revision=bc6058c81272a8d938c05e75607371284236aadc)"
level=info ... build_context="(go=go1.10, user=root@149e5b3f0829,
date=20180314-14:15:45)"
level=info ... host_details="(Linux 4.4.0-98-generic #121-Ubuntu..."
level=info ... fd_limits="(soft=1024, hard=1048576)"
level=info ... msg="Start listening for connections" address=0.0.0.0:9090
level=info ... msg="Starting TSDB ..."
level=info ... msg="TSDB started"
level=info ... msg="Loading configuration file" filename=prometheus.yml
level=info ... msg="Server is ready to receive web requests."
Как вы можете обнаружить, Prometheus регистрирует при запуске полезную информацию, содержащую его точную версию и подробности той машины, на которой он запущен. Теперь вы можете выполнить доступ к UI Prometheus в своём браузере по ссылке http://localhost:9090/, как это показано на Рисунке 2-2.
Это Браузер выражений (expression browser), из которого вы можете запускать запросы PromQL. В данном UI также имеются прочие страницы для того, чтобы помочь вам с пониманием что делает Prometheus, например, страница Targets под закладкой Status, которая показана на Рисунке 2-3.
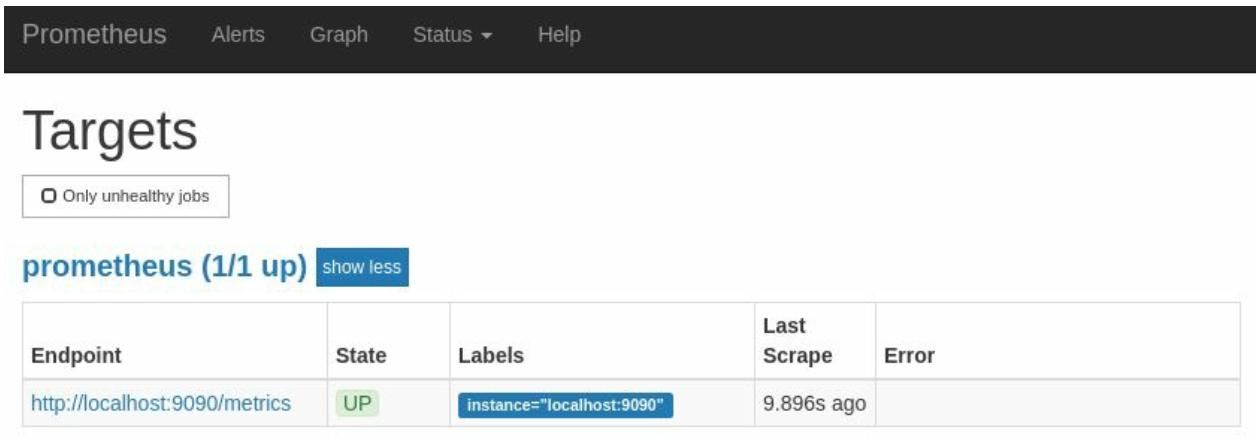
На данной странице имеется только один сервер Prometheus в состоянии UP, что означает, что самое последнее
Выуживание было успешным. Если бы самое последнее Выуживание столкнулось вс какой- то проблемой, в имеющемся поле Error имелось юы некое сообщение.
Другой страницей, на которую вам стоит обратить внимание, является страница /metrics инструментов самого
Prometheus с измерениями Prometheus. Все эти замеры доступны по ссылке http://localhost:9090/metrics и доступны для чтения человеком, что вы можете увидеть на
как это показано на Рисунке 2-4:

Обратите внимание, что здесь представлены не только показатели самого кода Prometheus, но также и сведения времени исполнения Go и самого процесса.
Браузер выражений полезен для выполнения специализированных запросов, разработки PromQL, выражений, а также отладки как PromQL, так и имеющихся внутри Prometheus данных.
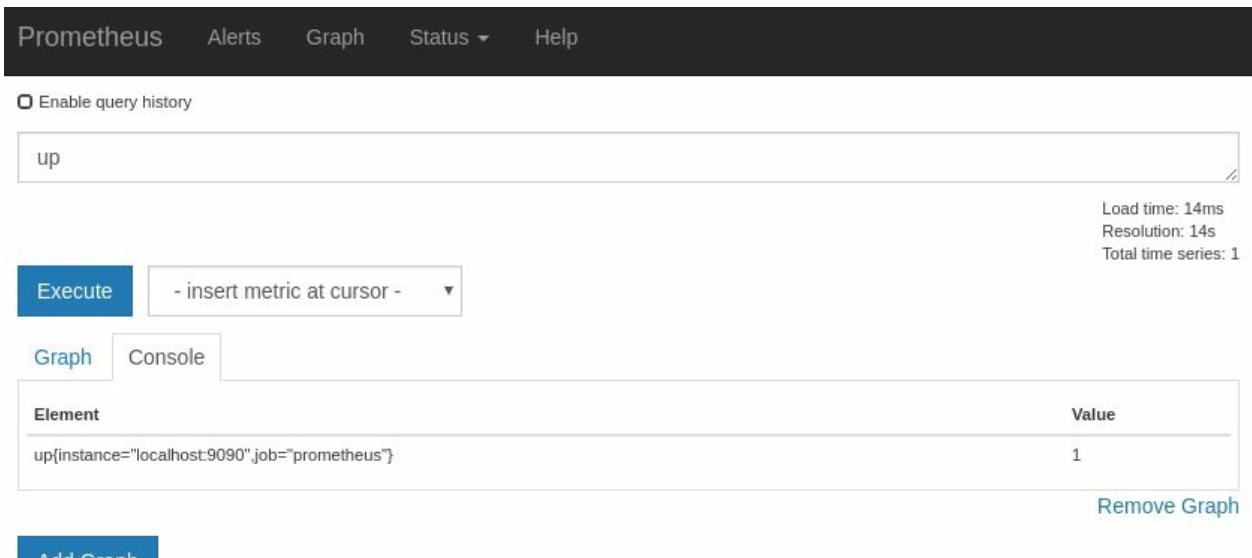
Для начала убедимся что вы находитесь в зоне просмотра Console, введём выражение
up и кликнем по Execute.
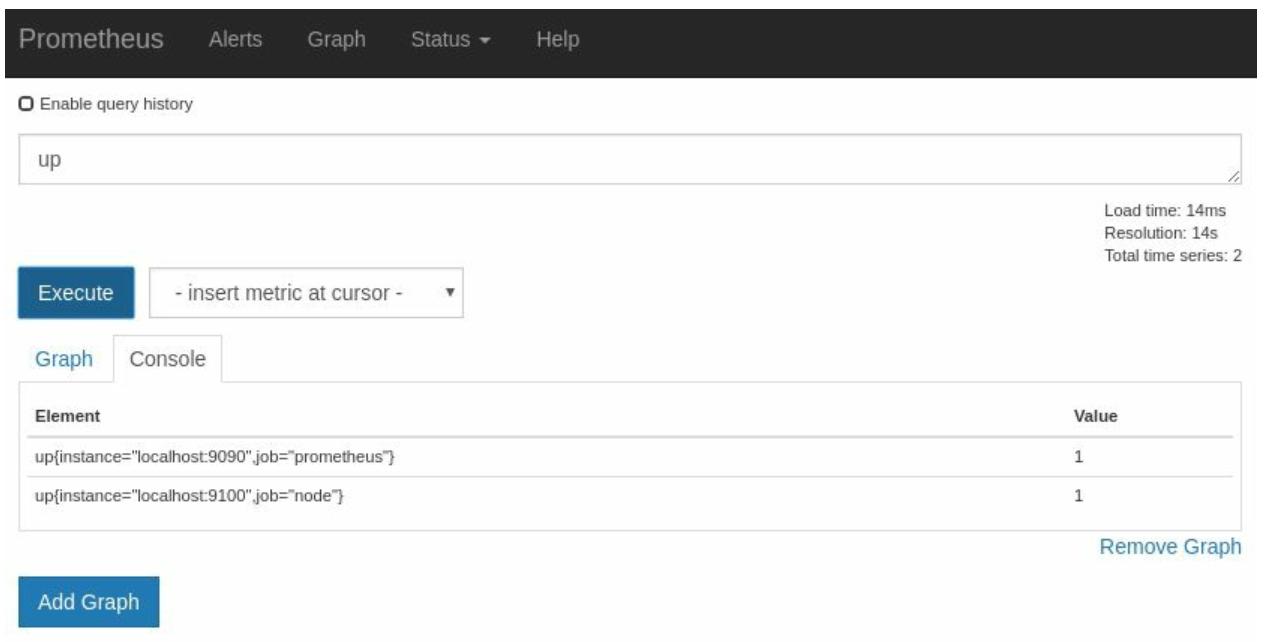
Как показывает Рисунок 2-5, существует единственный результат со значением 1 и его название
up{instance="localhost:9090",job="prometheus"}. up является специальным параметром, добавленным Prometheus
при выполнении Выуживания; 1 указывает что данное Выуживание было успешным. Значением instance является некая
метка, которая указывает значение Выуженной цели. В данном случае оно указывает на сам Prometheus.
Значение метки job в данном случает получается из job_name в
prometheus.yml. Prometheus не обладает магическим знанием того, что он Выудил именно prometheus и,
таким образом, что он должен применять некую метку job с установленным значением
prometheus. Скорее, данное соглашение треует установки со стороны конкретного пользователя. Сама метка
job указывает значение типа приложения.
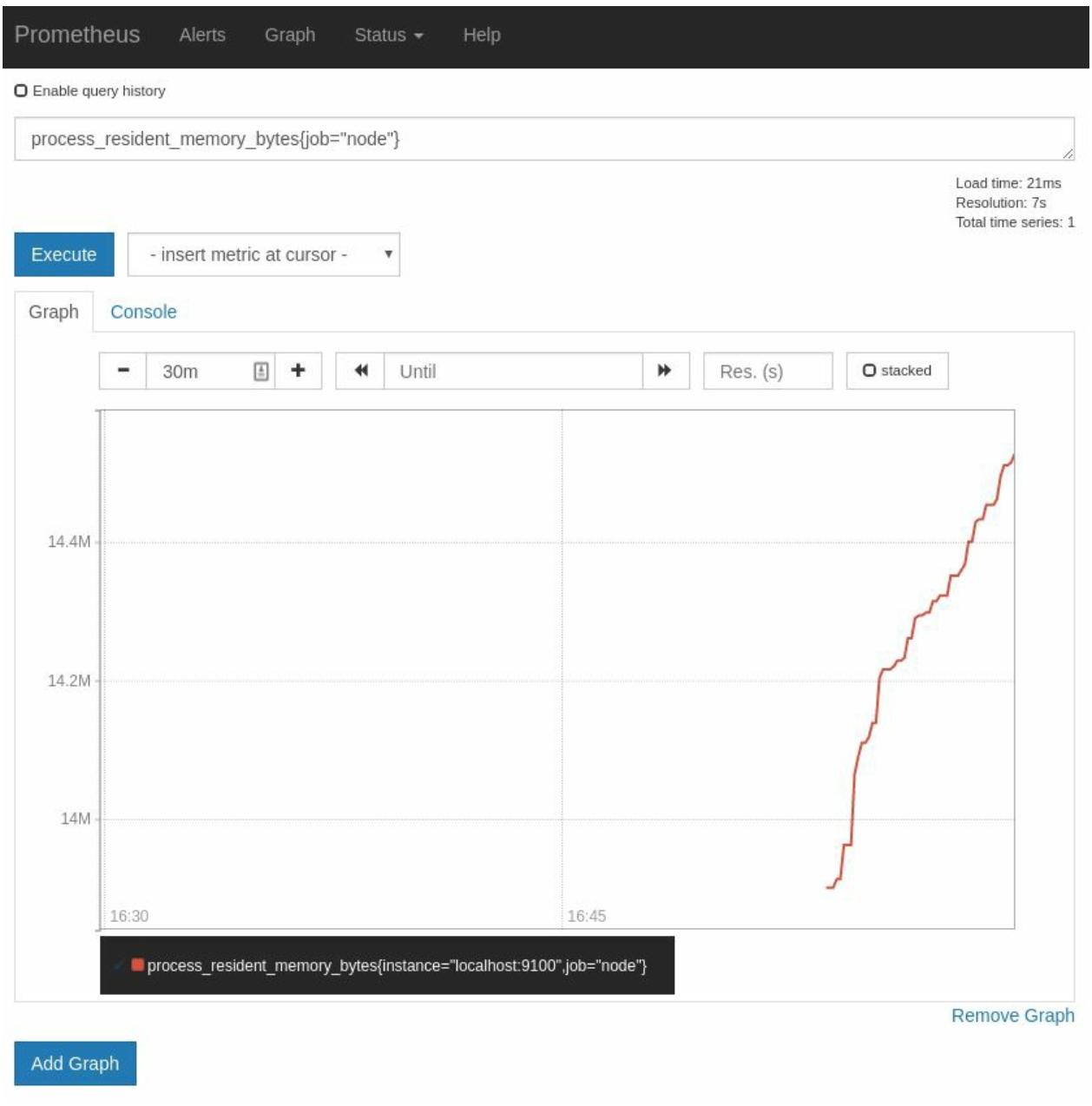
Заетм нам следует оценить process_resident_memory_bytes,
как это показано на Рисунке 2-6:
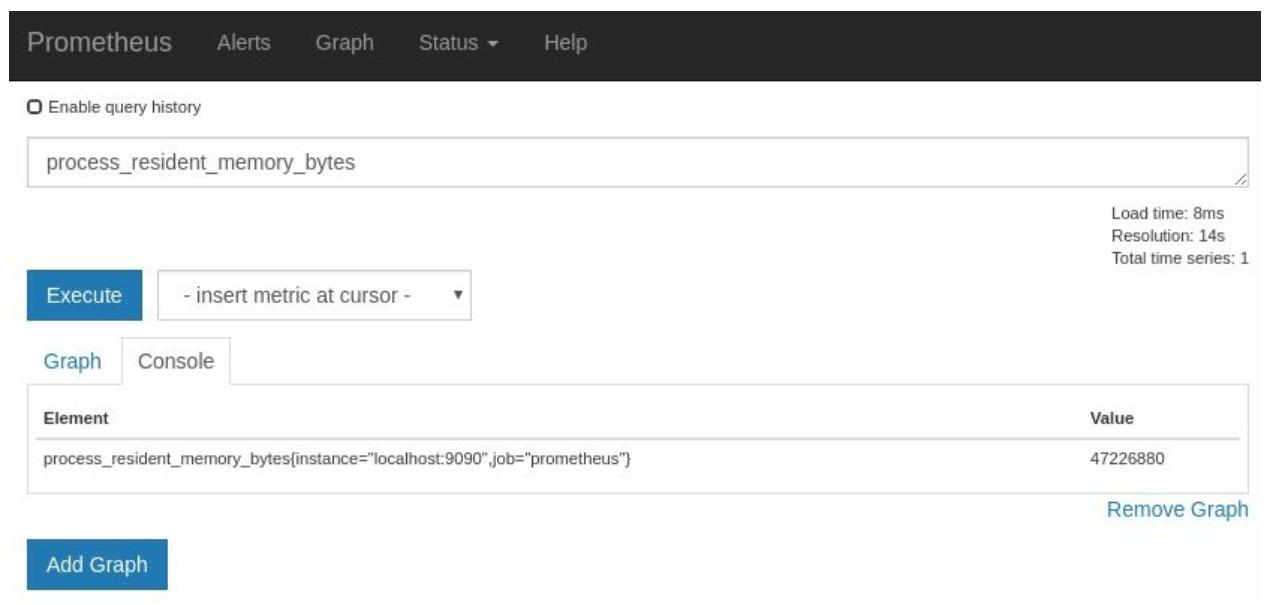
Мой Prometheus использует около 44Мбайт оперативной памяти. У вас может возникнуть вопрос почему данный параметр выставляется с применением байт вместо МегаБайт или ГигиБайт, что может иметь более простое восприятие. Ответ состоит в том, что лучшее восприятие сильно зависит от контекста и даже один и тот же исполняемый модуль в различных средах может иметь значения, отличающиеся на много порядков. Некий внутренний RPC может требовать микросекунд, в то время, как опрос продолжительного процесса может занимать часы и даже дни. Таким образом, установленное в Prometheus соглашение заключается в том, что он использует базовые единицы, такие как байты и секунды и избегает вывода улучшений информации в инструменты интерфейса, подобные Grafana3
Знание текущего значения использования памяти это чудесно, но вот то, что на самом деле может быть очень полезным, так это возможность отслеживания изменений во времени. Для того чтобы выполнить это, кликните Graph с тем, чтобы переключиться на просмотр диаграммы, как это отображено на Рисунке 2-7:
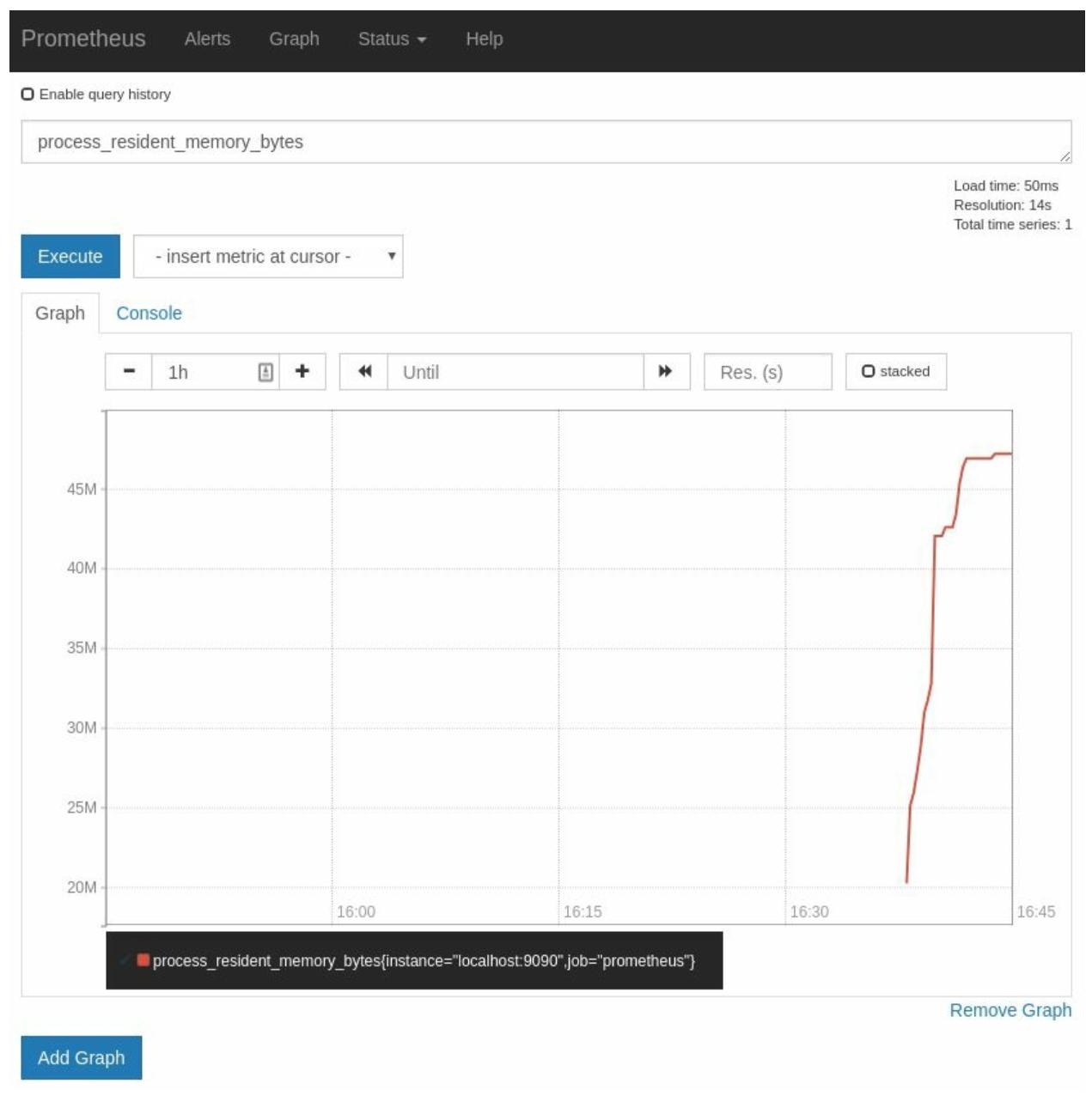
Измерения, подобные process_resident_memory_bytes именуются Шкалами
(gauges). Для некоторой Шкалы для вас является важным её текущее абсолютное значение. Существует и второй
центральный тип измерений, именуемый Счётчиком (counter).
Счётчики отслеживают сколько событий произошло, либо обший размер всех имеющихся событий. Давайте взглянем на некий счётчик на диаграмме
prometheus_tsdb_head_samples_appended_total, который поглощает общее число
образцов Prometheus, которые выглядят так,
как это показано на Рисунке 2-8:
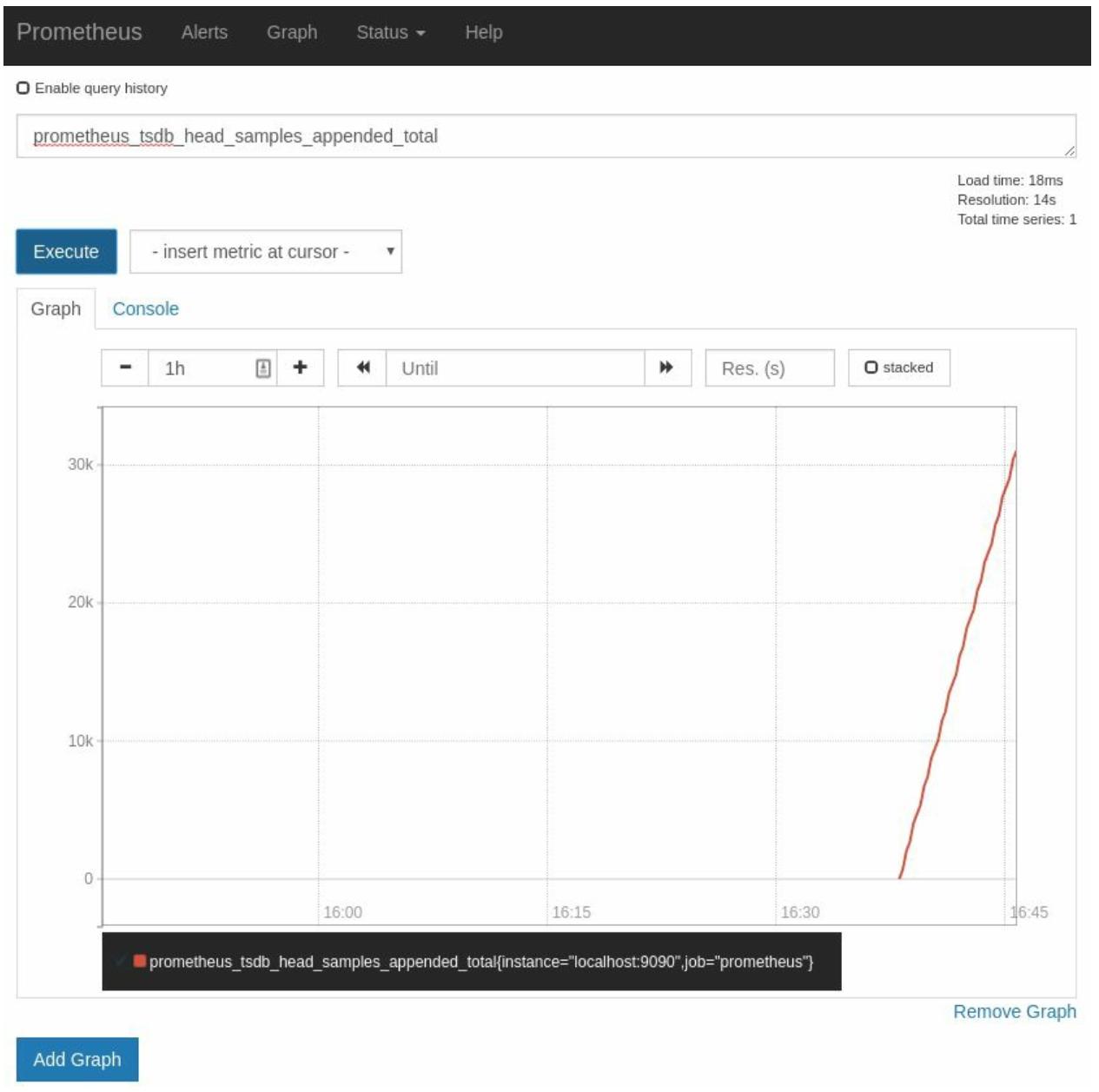
Счётчики всегда возрастают. Это создаёт хорошие и верные диаграммы, но отображаемые значения счётчиков слабо применимы сами по себе. То, что вы на
самом деле желаете знать - это насколько быстро растёт данный счётчик, и именно здесь приходит на помощь функция rate.
Эта функцияrate определяет насколько велик рост некоторого счётчика за секунду. Отрегулируйте своё выражение при помощи
rate(prometheus_tsdb_head_samples_appended_total[1m]), которая будет будет вычислять
сколько образцов Prometheus поглощается в секунду в среднем на протяжении одной минуты и предоставьте результат,
как это показано на Рисунке 2-9:
Рисунок 2-9
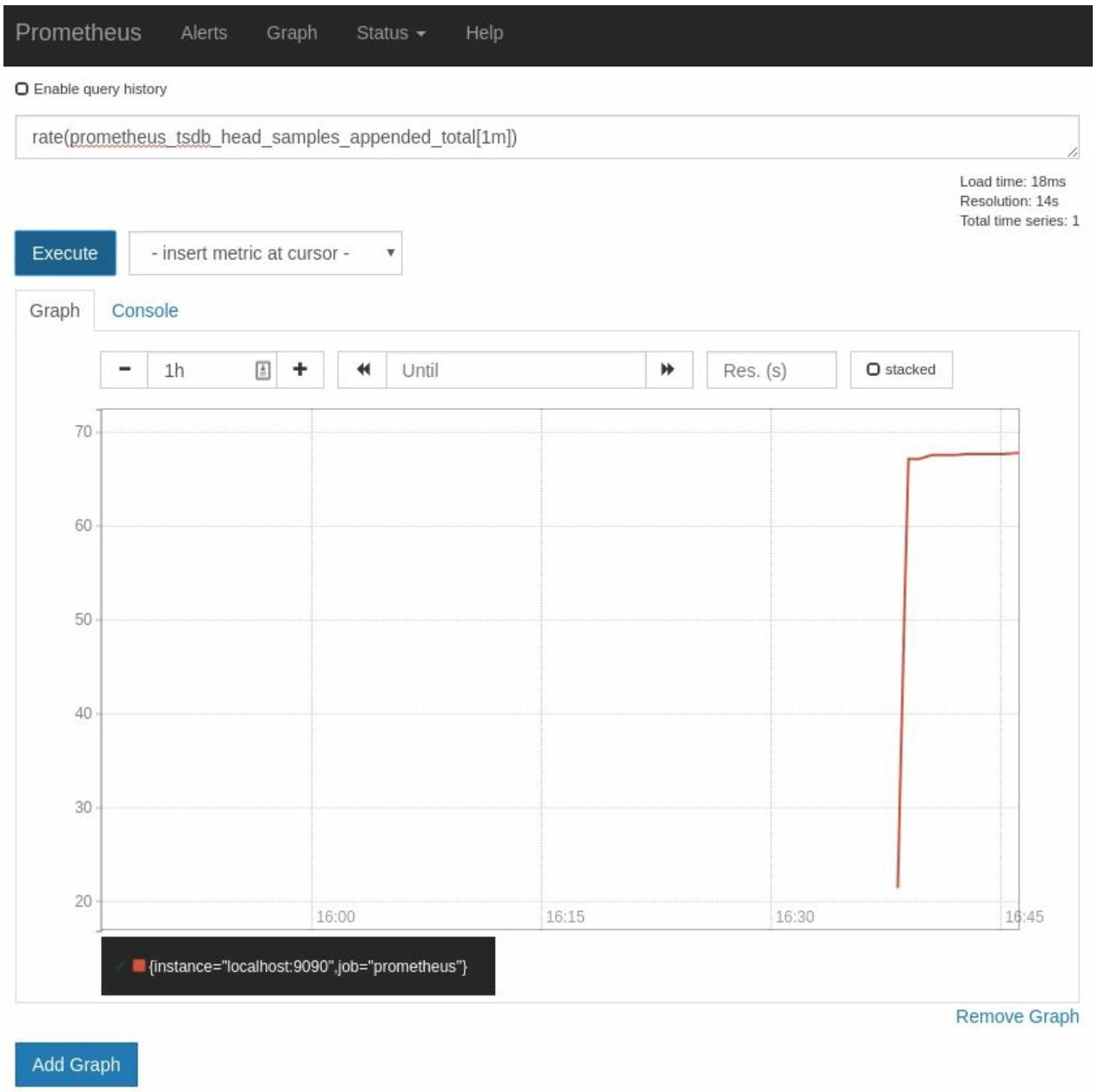
Диаграмма rate(prometheus_tsdb_head_samples_appended_total[1m]) в нашем Браузере выражений.
Теперь вы можете увидеть, что Prometheus потребляет в среднем 68 или около того образцов в секунду в среднем. Данная функция rate
автоматически обрабатывает сброс счётчиков из- за перезагрузки процессов, причём образцы не выравниваются
точно4.
Экспортёр узла (Node exporter) выставляет параметры уровня ядра и машины в Unix системах, подобных Linux5. Он предоставляет все стандартные измерения, такие как ЦПУ, оперативная память, дисковое пространство, ввод/ вывод диска и полоса пропускания сети. Кроме того он предоставляет мириады дополнительных параметров выставляемых имеющимся ядром, начиная со средней загрузки, вплоть до температуры материнской платы.
То что Экспортёр узла не выставляет, так это измерения относительно индивидуальных процессов, а также посреднические (прокси) показатели прочих экспортёров или приложений. В имеющейся архитектуре Prometheus вы мониторите приложения и службы напрямую, а не вплетаете их в общие метрики машин.
Некая предварительно скомпилированная версия необходимого Экспортёра узла может быть выгружена с https://prometheus.io/download/. Пройдите на эту страницу и выгрузите самую последнюю версию Экспортёра узла для ОС Linux с архитектурой amd64.
Вам вновь придётся раскрыть tar- архив, однако при этом не требуется никакой файл настроек, поэтому вы сможете сразу непосредственно его исполнить.
hostname $ tar -xzf node_exporter-*.linux-amd64.tar.gz
hostname $ cd node_exporter-*.linux-amd64/
hostname $ ./node_exporter
INFO[0000] Starting node_exporter (version=0.16.0, branch=HEAD,
revision=d42bd70f4363dced6b77d8fc311ea57b63387e4f)
source="node_exporter.go:82"
INFO[0000] Build context (go=go1.9.6, user=root@a67a9bc13a69,
date=20180515-15:52:42)
source="node_exporter.go:83"
INFO[0000] Enabled collectors: source="node_exporter.go:90"
INFO[0000] - arp source="node_exporter.go:97"
INFO[0000] - bacahe source="node_exporter.go:97"
...
various other collectors
...
INFO[0000] Listening on :9100 source="node_exporter.go:111"
Теперь вы можете выполнить доступ к полученному Экспортёру узла из своего браузера по адресу http://localhost:9100/ и посетить его оконечную точку /metrics.
Чтобы указать Prometheus на необходимость мониторинга нашего Экспортёра узла, нам следует внести изменения в имеющийся
prometheus.yml, добавив некие дополнительные настройки Выуживания:
global:
scrape_interval: 10s
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: node
static_configs:
- targets:
- localhost:9100
Перезапустите Prometheus, чтобы зацепить полученные только что настройки, воспользовавшись Ctrl-C для его останова и затем запустите
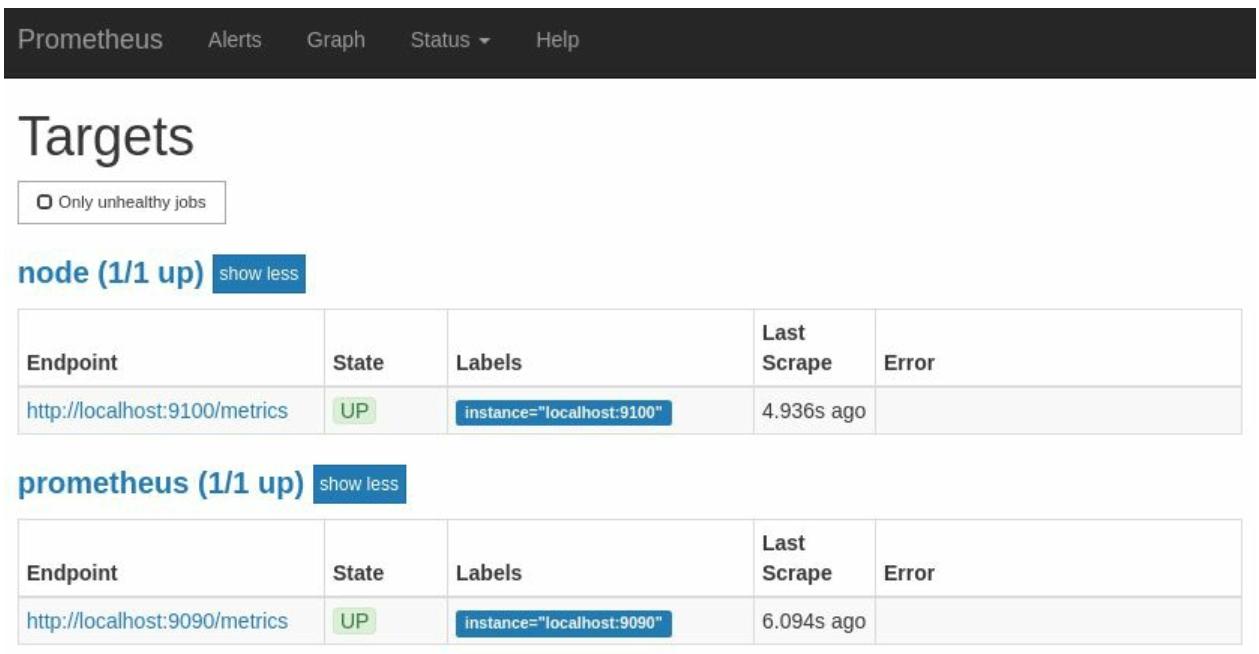
вновь6. Если вы загляните на свою страницу Targets, вы должны обнаружить
две цели, причём обе в состоянии UP?
как это показано на Рисунке 2-10:
Если вы теперь введёте up в просмотре Console своего браузера выражений,
вы обнаружите два записи,
как это показано на Рисунке 2-11:
Поскольку вы добавили дополнительные задания и настройки Выуживания, вряд ли вы пожелаете рассматривать эти самые параметры из различных заданий
одновременно. Значения использования памяти Prometheus и Экспортёра узла, например, очень сильно разнятся и посторонние данные делают отладку и
исследование сложнее. Вы можете отображать использование памяти только для Экспортёра узла при помощи
process_resident_memory_bytes{job="node"}. Значение
job="node" именуется пометкой совпадений
(label matcher). и он ограничивает те параметры, которые следует возвращать,
как это показано на Рисунке 2-12:
Здесь process_resident_memory_bytes это память, используемая самим процессом Экспортёра узла (как об этом можно
догадаться по префиксу process) а не соответствует всей машине целиком. Знание общего потребления ресурса вашего
Экспортёра узла удобно и так далее, но вы запукаете его не по этой причине.
В качестве последнего примера оценим rate(node_network_receive_bytes_total[1m])
в просмотре Graph для вывода диаграммы, аналогичной
отображаемой на Рисунке 2-13:
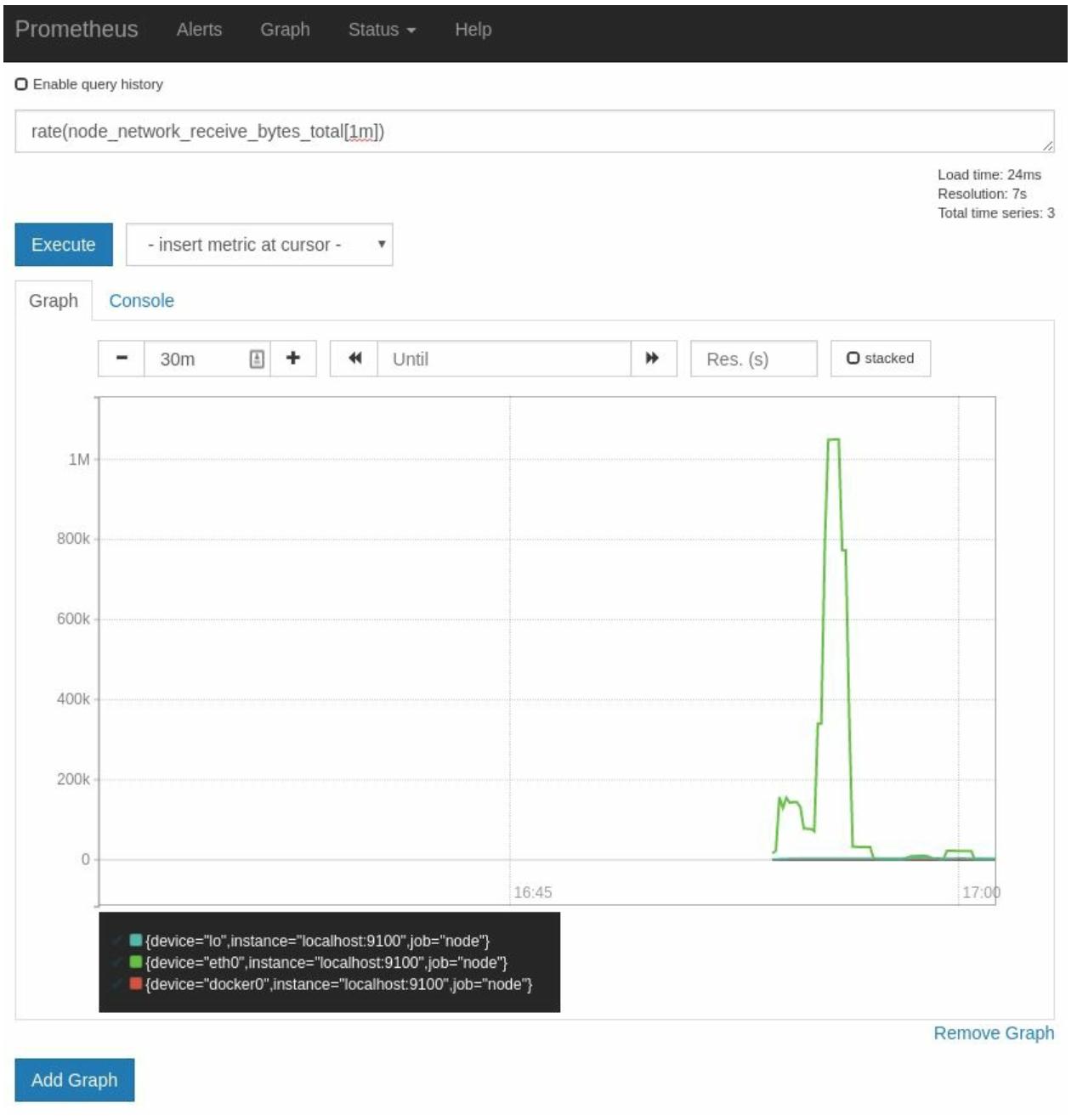
node_network_receive_bytes_total является неким счётчиком того, сколько байт было получено из сетевых интерфейсов.
Ваш Экспортёр узла автоматически цепляет все мои сетевые интерфейсы и они будут выступать в качестве некоторой группы в PromQL. Это полезно для оповещений,
так как позволяет избегать необходимости избыточно перечислять все отдельные вещи, о которых вы желаете получать оповещения.
Для оповещений существует две части. Во- первых, добавление правил оповещения в Prometheus, определение необходимой логики, которая составляет некое предупреждение. Во- вторых, имеющийся Alertmanager преобразовывает оповещения в уведомления, такие как отправления электронной почты, пейджинг, а также сообщения в чат.
Давайте начнём с создания некоего условия, согласно которому вы хотите получать предупреждение. остановите свой Экспортёр узла при помощи Ctrl-C.
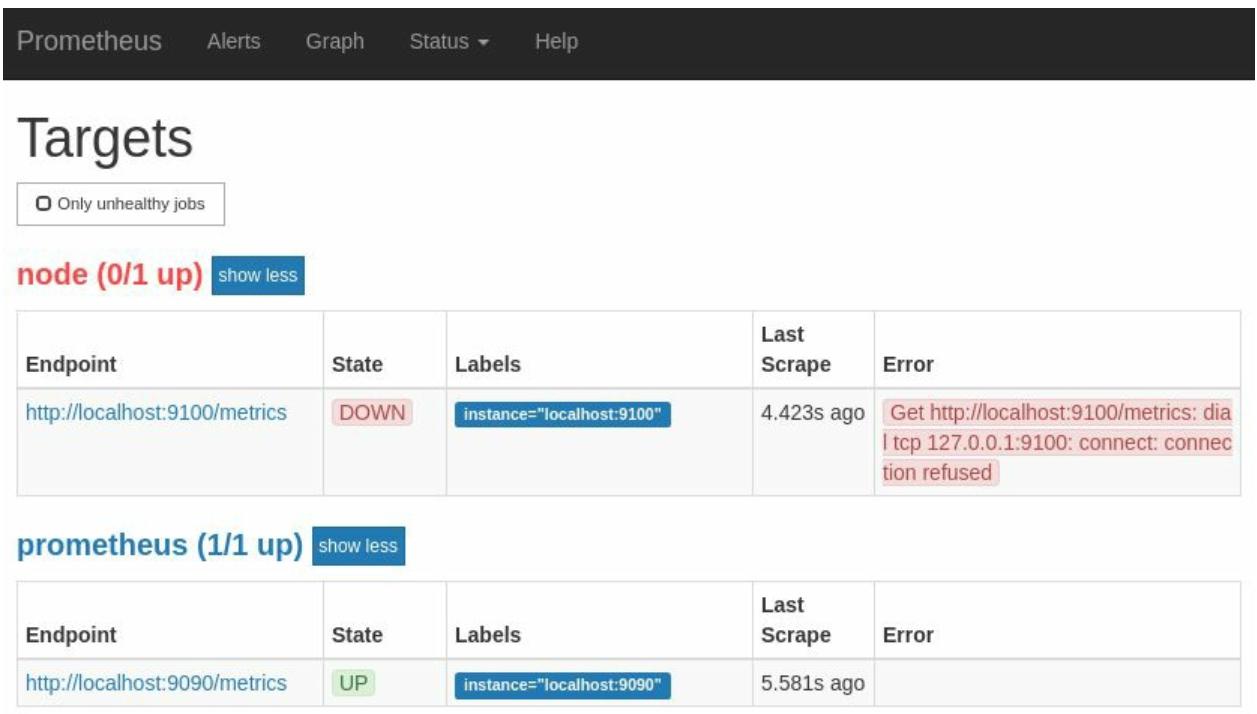
После следующего Выуживания, ваша страница Targets отобразит что ваш Экспортёр узла находится в состоянии Down,
что показано на Рисунке 2-14, с ошибкой
connection refused (потеря соединения), которая уведомляет, что ожидание по указанному порту TCP
и получение запросов HTTP отклоняется7.
|
| Совет |
|---|---|
|
Prometheus не включает отказы Выуживаний в свои журналы приложений, так как некий отказ Выуживания является ожидаемым событием, которое не указывает
на какие бы то ни было проблемы самого Prometheus. За пределами страницы Targets ошибки Выуживания также доступны в установленном журнале отладки (debug)
Prometheus, который можно включить передав флаг командной строки |
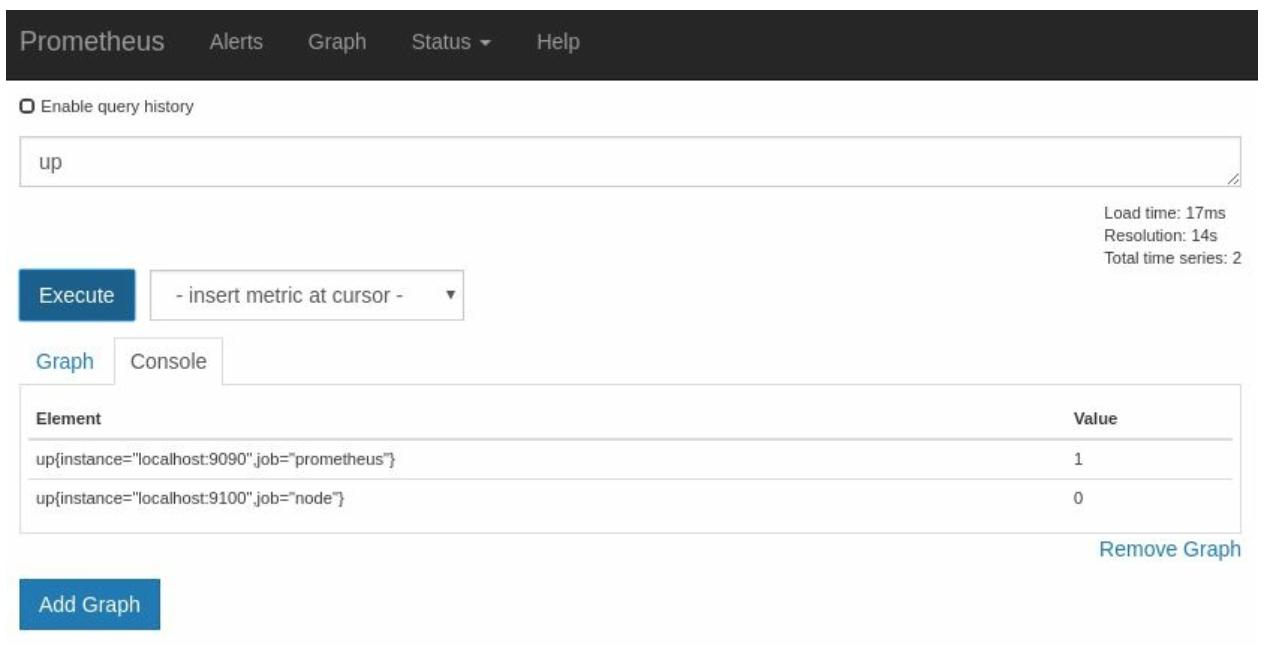
Просмотр вручную страницы Targets для остановленных экземпляров не самое лучшее времяпровождение для вас. К счастью, у вас в арсенале имеется
показатель up, а при исполнении up
в просмотре Console вашего браузера выражений вы видели, что он теперь имеет значение 0 для вашего Экспортёра узла,
как это показано на Рисунке 2-15:
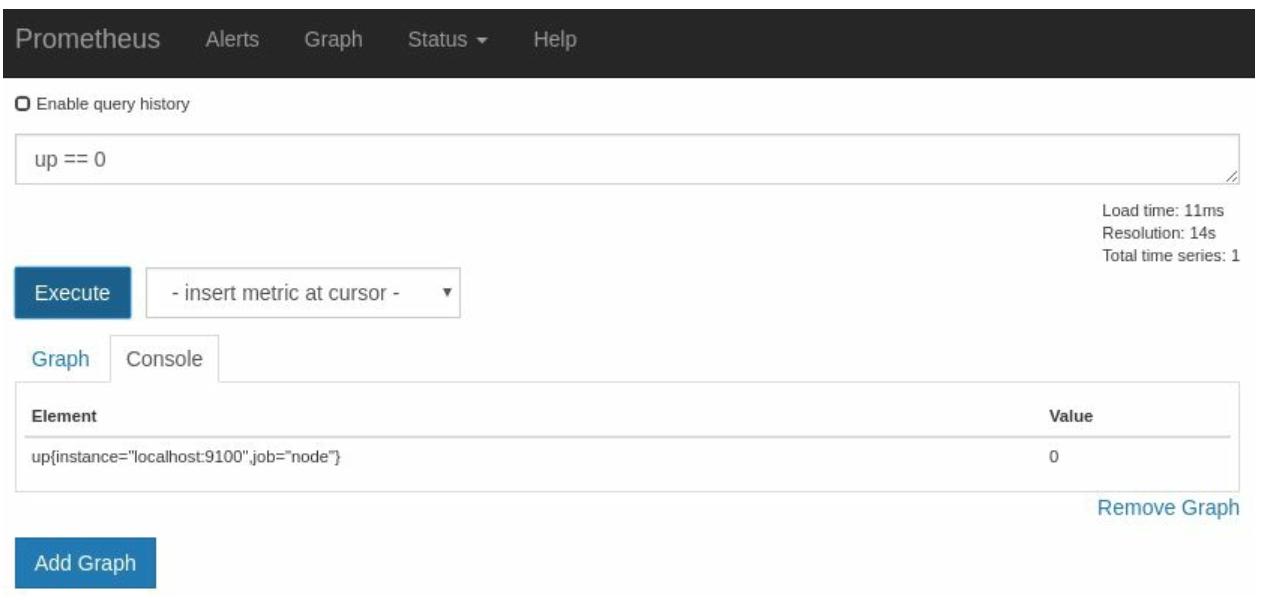
Для правил оповещения вам понадобится некое выражение PromQL, которое возвращает только те результаты, о который вы желаете выполнять оповещение.
В данном случае это просто сделать при помощи оператора ==. == будет
отфильтровывать8 все не совпадающие последовательности. Если вы
выполните оценку up == 0 в своём браузере выражений, вам будут возвращены
только остановленные экземпляры,
как это показано на Рисунке 2-16:
Затем вам понадобится добавить это выражение в некое правило оповещения в Prometheus. Я слегка забегаю вперёд, но вы сообщите Prometheus что ему
следует взаимодействовать с Alertmanager. Вам следует расширить свой prometheus.yml с тем, чтобы в нём
появилось содержимое Примера 2-1.
Пример 2-2. prometheus.yml Выуживает две цели, загружает некий файл правила и общается с Alertmanager
global:
scrape_interval: 10s
evaluation_interval: 10s
rule_files:
- rules.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: node
static_configs:
- targets:
- localhost:9100
После этого создайте новый файл rules.yml с содержимым из
Примера 2-2.
Пример 2-2. rules.yml с единственным правилом оповещения
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
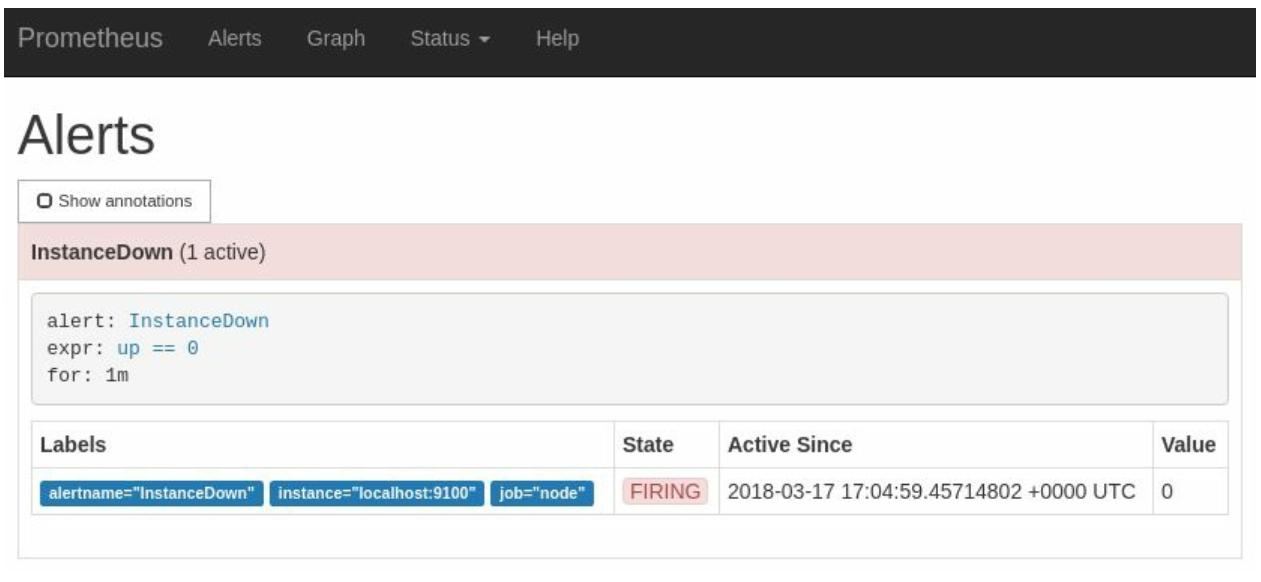
Оценка необходимости оповещения InstanceDown будет выполняться каждые 10 секунд в соответствии со
значением evaluation_interval. Если на протяжении по крайней мере
минуты9 (значение for)
возвращается эта последовательность, тогда будет рассмотрена возможность инициации соответствующего оповещения. Если на протяжении минуты не
появляется состояние up, данное оповещение будет установлено в состояние
pending (задержан). На своей странице Alerts вы можете кликнуть по этому предупреждению и рассмотреть
дополнительные подробности, включая и его метки,
как это видно на Рисунке 2-17:
Теперь, когда у вас имеется некое включённое предупреждение, вам необходим Alertmanager чтобы что- то предпринять. Со страницы https://prometheus.io/download/ выгрузите самую последнюю версию Alertmanager для ОС Linux с архитектурой amd64. Раскройте tar для Alertmanager и зайдите в полученный каталог.
hostname $ tar -xzf alertmanager-*.linux-amd64.tar.gz
hostname $ cd alertmanager-*.linux-amd64/
Теперь вам понадобится настроить свой Alertmanager. Существует множество возможностей с помощью которых Alertmanager может выполнять уведомления
для вас, однако большинство из нах при работе сразу после установки применяет коммерческих поставщиков и имеют инструкции, которые часто меняются со
временем. Поэтому я собираюсь сделать предположение, что у вас имеется доступным некий интеллектуальный хост
SMTP10. Вам следует выполнить установки в своём
alertmanager.yml из Примера 2-3,
настроив smtp_smarthost, smtp_from и
to в соответствии с имеющимися у вас настройками и адресами электронной почты.
Пример 2-3. alertmanager.yml отправляет все оповещения на электронную почту
global:
smtp_smarthost: 'localhost:25'
smtp_from: 'youraddress@example.org'
route:
receiver: example-email
receivers:
- name: example-email
email_configs:
- to: 'youraddress@example.org'
Теперь вы можете запустить Alertmanager выполнив ./alertmanager.
hostname $ ./alertmanager
level=info ... caller=main.go:174 msg="Starting Alertmanager"
version="(version=0.15.0, branch=HEAD,
revision=462c969d85cf1a473587754d55e4a3c4a2abc63c)"
level=info ... caller=main.go:175 build_context="(go=go1.10.3,
user=root@bec9939eb862, date=20180622-11:58:41)"
level=info ... caller=cluster.go:155 component=cluster msg="setting advertise
address explicitly" addr=192.168.1.13 port=9094
level=info ... caller=cluster.go:561 component=cluster msg="Waiting for
gossip to settle..." interval=2s
level=info ... caller=main.go:311 msg="Loading configuration file"
file=alertmanager.yml
level=info ... caller=main.go:387 msg=Listening address=:9093
level=info ... caller=cluster.go:586 component=cluster msg="gossip not settled"
polls=0 before=0 now=1 elapsed=2.00011639s
level=info ... caller=cluster.go:578 component=cluster msg="gossip settled;
proceeding" elapsed=10.000782554s
После чего вы можете получить доступ к установленному Alertmanager в своём браузере по адресу http://localhost:9093/, где вы обнаружите включённое предупреждение, которое должно выглядеть аналогично Рисунку 2-18:
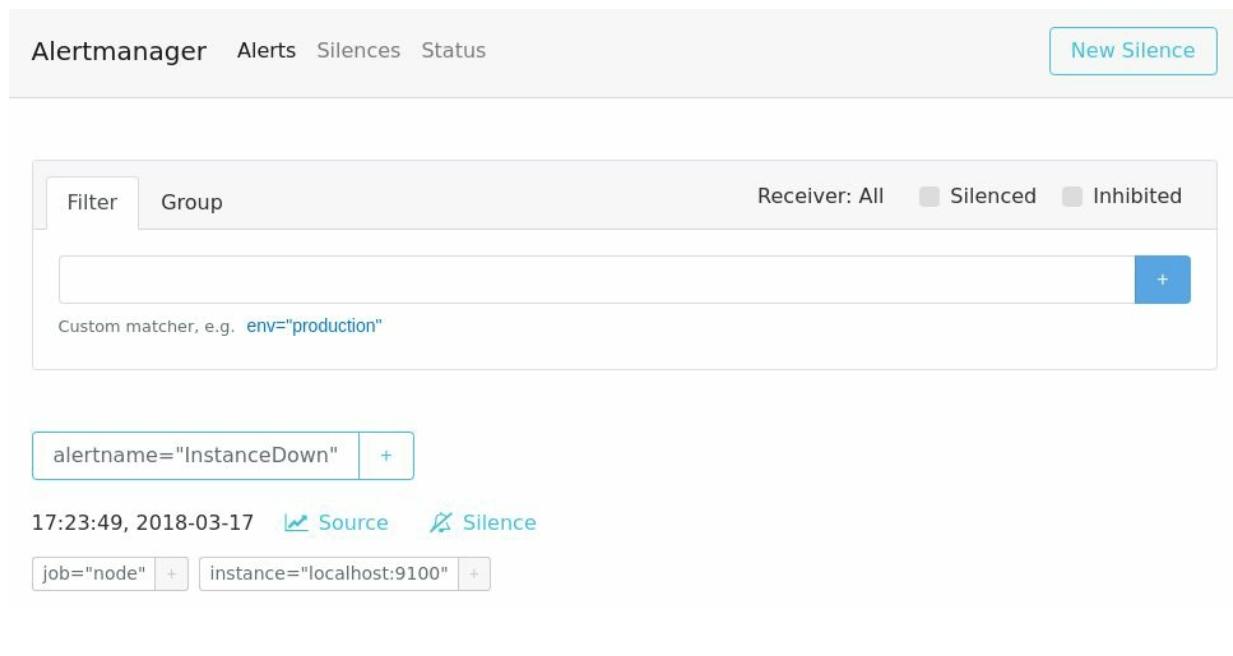
Если всё настроено и работает надлежащим образом, через минуту или две вы должны получить уведомление от Alertmanager в блоке своих входящих сообщений электронной почты, как это показано на Рисунке 2-19:
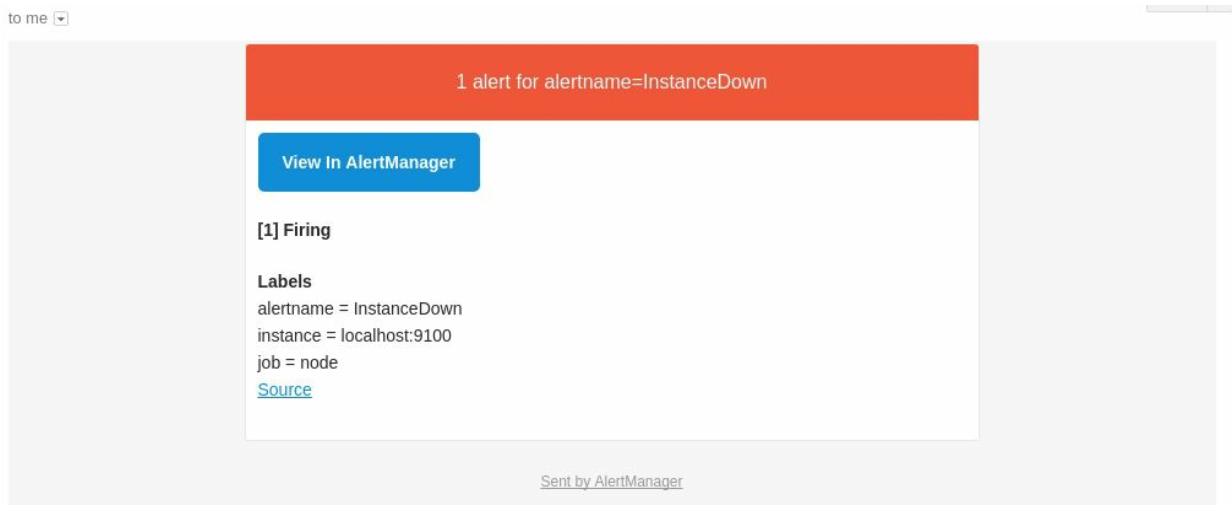
Базовые настройки позволяют вам попробовать что может делать Prometheus. Вы можете добавлять дополнительные цели в свой
prometheus.yml и установленные вами оповещения также должны выполняться.
В своей следующей главе я собираюсь сосредоточиться на одной из частей использования Prometheus- добавления инструментария в ваши собственные приложения.
1 Здесь применяется подстановка для номера версии, на тот случай если вы применяете версию, отличную от моей. Символ звёдочки будет соответствовать любой версии.
2 Вы можете удивиться почему Prometheus не использует JSON. У JSON имеются свои проблемы, например, разборчивость в отношении запятых и, в отличии от YAML, он не поддерживает комментарии. Так как JSON является подмножеством YAML, вы можете применять и JSON, если пожелаете.
3 Здесь применяется та же самая логика, согласно которой значения дат и времени лучше сохранять в UTC, а преобразования во временные зоны применяются только при показе персоналу..
4 Это может приводить к тому, что измеряемые в целых скорости возвращают не целочисленные значения, но в среднем результаты являются правильными. Для получения дополнительной информации обратитесь к разделу Счётчики.
5 Пользователям Windows следует применять wmi_exporter вместо Экспортёра узла.
6 Существует также возможность перегружать файл настроек Prometheus
без его перезапуска при помощи SIGHUP.
7 Другой распространённой ошибкой является
context deadline exceeded (превышен срок времени жизни контекста). Это указывает на некий таймаут, обычно
происходящий вследствие того, что другая сторона слишком медленная, либо в сетевой среде теряются пакеты.
8 Также имеется некий режим bool,
не подлежащий фильтрации, описываемый в разделе Модификатор bool.
9 Обычно рекомендуется устанавливать значение
for по крайней мере на 5 минут с тем, чтобы снизить уровень зашумления и смягчить различия в скоростях, наследуемые
мониторингом. Здесь я применяю значение одной минуты исключительно с той целью, чтобы вам не пришлось слишком долго ждать.
10 С учётом того, как за последние десятилетия эволюционировала защита электронной почты, это не является наилучшим предположением, но у вашего поставщика услуг, наверное, имеется хотя бы один.