Глава 4. Обмен сообщениями
Содержание
- Глава 4. Обмен сообщениями
- Технические требования
- Понимание структуры MPI
- Применение модуля Python mpi4py
- Реализация взаимодействия точка- точка
- Обход проблем взаимной блокировки
- Коллективное взаимодействие через широковещание
- Коллективное взаимодействие при помощи функции разброса
- Коллективное взаимодействие при помощи функции получения
- Коллективное взаимодействие с применением Всех-ко-всем
- Операция свёртки
- Оптимизация взаимодействия
В этой главе мы кратко рассмотрим MPI (Message Passing Interface, Интерфейс передачи сообщений), который является спецификацией обмена сообщениями. Самая первейшая цель MPI состоит в установлении некого действенного, гибкого и переносимого стандарта взаимодействия обмена сообщениями.
В основном мы покажем те функции имеющейся библиотеки, которые содержат синхронные и асинхронные примитивы взаимодействия, такие как (отправка/ получение - send/receive) и (широковещательный/ все- ко- всем - broadcast/all-to-all), имеющиеся операции сочетания параллельных результатов вычислений (сбор/ понижение - gather/ reduce) и, наконец, примитивы синхронизации между процессами (барьеры).
Более того, основные функции контроля сетевого взаимодействия будут представлены путём определения имеющихся топологий.
В этой главе мы рассмотрим такеи рецепты:
-
Применение модуля
mpi4pyPyhon -
Реализация взаимодействия точка- точка
-
Избежание проблем взаимной блокировки
-
Совместное взаимодействие через широковещательный обмен
-
Совместное взаимодействие при помощи функции
scatter -
Совместное взаимодействие с применением функции
gather -
Совместное взаимодействие за счёт
Alltoall -
Операция редуцирования
-
Оптимизация взаимодействия
Для данной главы нам потребуются библитотеки mpich и
mpi4py.
Библиотека mpich является переносимой реализацией MPI. Это свободно
распространяемое программное обеспечение для различных версий Unix (включая Linux and macOS), а также для
Microsoft Windows.
Для установки mpich воспользуйтесь тем установщиком, который
выгружается с основной страницы
выгрузки. Более того, убедитесь в правильности выбора между 32- битной и 64- битной версиями для получения
правильной для вашей машины.
Модуль библиотеки Python mpi4py предоставляет привязки Python для стандарта MPI. Он реализуется поверх спецификации
MPI-1/2/3 и выставляет некий API, который основывается на привязках MPI-2 C++.
Процесс установки mpi4py в машине Windows таков:
C:> pip install mpi4py
Пользователям Anaconda надо набрать следующее:
C:> conda install mpi4py
Обратите внимание, что во всех примерах в этой главе мы будем пользоваться mpi4py,
установленным с примененим установщика pip.
Это подразумевает, что та нотация, которая применятся для запуска примеров mpi4py
будет следующей:
C:> mpiexec -n x python mpi4py_script_name.py
Команда mpiexec является обычным способом для запуска параллельных заданий:
x является общим числом процессов для применения, в то время как
mpi4py_script_name.py выступает в качестве названия исполняемого сценария.
Стандарт MPI определяет основные примитивы для управления виртуальной топологией, синхронизацией и взаимодействием между процессами. Существует несколько реализаций MPI, которые различаются по версиям и свойствам от стандартной поддержки.
Мы будем придерживаться стандарта MPI через библиотеку Python mpi4py.
Вплоть до 1990-х, написание параллельных приложений для различных архитектур было намного более сложным заданием чем в наши дни. Сам процесс поддерживало множество библиотек, однако для них не существовало стандартного свособа. К этому времени большинство параллельных приложений предназначалось для сред научных исследований.
Та модель, которая в основном принималась всеми разнообразными библиотеками была моделью передачи сообщений, при которой само взаимодействие между процессами происходило через обмен сообщениями и без использования совместных ресурсов. Например, процесс хозяин мог назначать некое задание своим подчинённым просто отправляя некое сообщение, которое описывало подлежащую исполнению работу. Вторым, очень простым примером здесь является некое параллельное приложение, которое выполняет некую сортировку слиянием. Все сортируемые данные локальны для всех процессов, а получаемые результаты передаются прочим процессам, которые имеют дело с данным слиянием.
Так как все библиотеки в основном применяли одну и ту же модель, хотя и с незначительными отличиями друг от друга, основные авторы имевшихся разнообразных библиотек встретились в 1992 для определения некого стандартного интерфейса обмена сообщениями и, начиная с этого момента, был рождён MPI. Этот интерфейс позволил программистам писать переносимые параллельные приложения для большинства параллельных архитектур, причём применяя те же самые функциональные возможности и модели, кторые они уже использовали.
Изначально MPI был спроектирован для архитектур с распределённой памятью, которая начала свой рост популярности 20 лет тому назад:
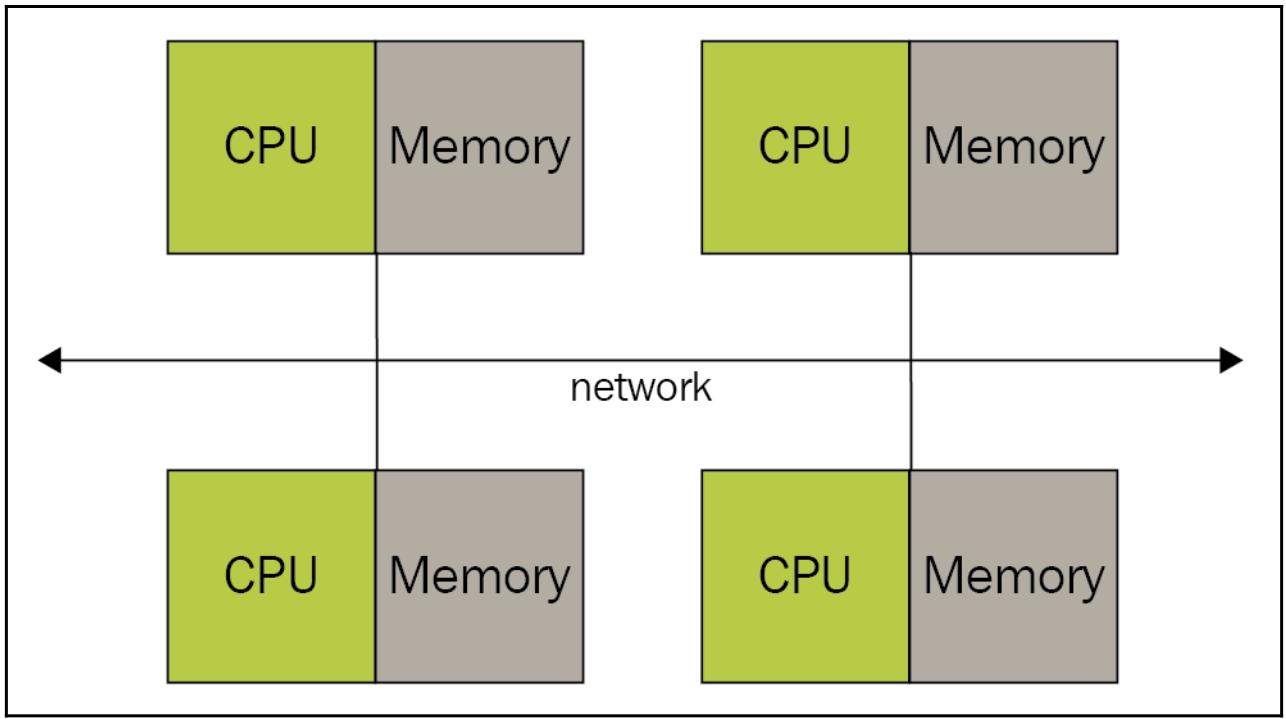
Со временем системы с распределённой памятью начали сочетаться друг с другом, создавая гибридные системы с распределённой/ разделяемой памятью:

В наши дни MPI работает с распределённой памятью, разделяемой памятью и в гибридных системах. Однако, сама модель программирования остаётся той же, что и для распределённой памяти, хотя сама реальная архитектура, на которой производятся вычисления и может быть иной.
Сильные стороны MOI можно суммировать так:
-
Стандартизация: Она поддерживается всеми платформами HPC (High-Performance Computing, Высокопроизводительных вычислений).
-
Переносимость: Все применяемые к самому исходному коду изменения минимальны, что полезно если вы принимаете решение использовать данное приложение на различных платформах, которые также поддерживают этот стандарт.
-
Производительность: Производители могут создавать реализации, оптимизированные под определённые виды оборудования и получать наилучшую производительность.
-
Функциональность: В MPI-3 определяется более 440 процедур, однако многие программы могут быть написаны с использованием менее 10 процедур.
В своих последующих разделах мы изучим саму основную библиотеку Python для передачи сообщений: библиотеку
mpi4py.
Язык программирования Python предоставляет различные модули MPI для написания параллельных программ. Наиболее
интересной из них является библиотека mpi4py. Она построена поверх спецификации
MPI-1/2 и предоставляет некий объектно- ориентированный интерфейс, который близко следует привязкам MPI-2 C++.
Некий пользователь C MPI может применять этот модуль без изучения нового интерфейса. Таким образом, он широко применяется
как почти полный пакте библиотеки MPI в Python.
Основными приложениями данного модуля, которые и описываются в данной главе, выступают следующие:
-
Взаимодействия точка- точка
-
Коллективные взаимодействия
-
Топологии
Давайте начнём наше путешествие по библиотеке MPI с изучения классического кода программы, который выводит на
печать фразу Hello, world! во всех создаваемых экземплярах процессов:
-
Импортируем библиотеку
mpi4py:from mpi4py import MPI![[Замечание]](/common/images/admon/note.png)
Замечание В MPI те процессы, которые вовлечены в само выполнение параллельной программы идентифицируются некой последовательностью неотрицательных целых, называемых порядками (ranks).
-
У нас имеется некое число (
p) процессов, в которых запущена некая программа, далее эти процессы имеютrank, который пробегает значения от0доp-1. В частности, чтобы получить значение порядка каждого процесса, мы должны воспользоваться функцией MPICOMM_WORLD. Эта функция имеет название communicator (средства связи), так как она определяет свой собственный набор всех процессов, которые могут совместно взаимодействовать:comm = MPI.COMM_WORLD -
Наконец, следующая функция
Get_rank()возвращаетrank(порядок) самого процесса при её вызове:rank = comm.Get_rank() -
После его вычисления,
rankвыводится на печать:print ("hello world from process ", rank)
В соответствии с имеющейся моделью исполнения MPI, наше приложение состоит из
N (в данном примере 5)
автономных процессов, причём каждый со своей собственной локальной памятью, способных взаимодействовать данными
через выполнение обмена сообщениями.
Наше средство связи (коммуникатор) определяет некую группу процессов, которые могут взаимодействовать друг с
другом. Применяемый здесь обработчик MPI.COMM_WORLD является устанавливаемым
по умолчанию средством связи и содержит все процессы.
Значение идентификатора процесса основывается на порядках. Каждому процессу назначается некий порядок от каждого
средства связи к которому он относится. Значением порядка является некое назначаемое ему целое, начинающееся с нуля и
указывающее на все индивидуальные процессы в контексте определённого средства связи (коммуникатора). Распространённой
практикой является определение того процесса, глобальный порядок которого 0,
в качестве процесса хозяина. Через значение порядка (rank) разработчик может определять кто именно выступает процессом
отправителем, а кто вместо этого являются процессами получателями.
Следует отметить, что исключительно для целей иллюстрации, вывод stdout не всегда
будет упорядочен, так как его одновременно могут применять множество процессов для вывода на экран, а ОС выбирает их
в произвольном порядке. Итак, мы готовы к основополагающему наблюдению: все участвующие в исполнении MPI процессы
запускают один и тот же скомпилированный исполняемый файл, а поэтому все процессы получают одинаковые инструкции для
исполнения.
Для выполнения данного кода наберите такую командную строку:
C:> mpiexec -n 5 python helloworld_MPI.py
Вот результат, полученный после выполнения данного кода (обратите внимание, что полученный порядок выполнения наших процессов не последовательный):
hello world from process 1
hello world from process 0
hello world from process 2
hello world from process 3
hello world from process 4
|
| Замечание |
|---|---|
|
Следует отметить, что значение числа применяемых процессов строго зависит от характеристик той машины, на которой должна выполняться эта программа. |
MPI относится к технологии программирования SPMD (Single Program Multiple Data, Одна программа со множеством данных).
SPMD это техника программирования, при которой все процессы выполняют одну и ту же программу, причём каждый для собственных данных. Основное отличие в исполнении между различными процессами происходит разделением самого потока данной программы на основе значения локального порядка (rank) данного процесса.
SPMD является техникой программирования при которой отдельная программа выполняется различными процессами в одно и то же время, но каждый процесс может обрабатывать различные данные. В то же самое время, эти процессы могут выполнять как одинаковые, так и различные инструкции. Очевидно, что данная программа будет содержать соответствующие инструкции, которые позволяют выполнять лишь части общего кода и/ или работать с подмножеством общих данных. Это может быть реализовано при помощи различных моделей программирования, причём все исполняемые файлы запускаются одновременно.
Полное руководство по библиотеке mpi4py можно найти по
ссылке.
Операции точка- точка состоят из обмена сообщениями между двумя процессами. В неком исключительном мире даже
операция отправки была бы исключительно синхронизована с соответствующей операцией приёма. Очевидно что это не так
и имеющаяся реализация MPI обязана предохранять отправляемые данные когда её процессы отправителя и получателя не
синхронны . Обычно это происходит с применением некого буфера, который прозрачен для разработчика и полностью
управляется самой библиотекой mpi4py.
Модуль Python mpi4py делает возможным взаимодействие точка- точка при
помощи двух функций:
-
Comm.Send(data, process_destination): Эта функция отправляет данные в процесс назначения, идентифицируемый его порядком в имеющейся группе средства связи. -
Comm.Recv(process_source): Эта функция получает данные от установленного процесса источника, который также идентифицируется его порядком в общей группе средств связи.
Значение параметра Comm, который является сокращением
communicator (средств связи), задаёт ту группу процессов, которая может
взаимодействовать через обмен сообщениями при помощи comm = MPI.COMM_WORLD.
В своём следующем примере мы применяем директивы comm.send и
comm.recv для обмена сообщениями между различными процессами.
-
Импортируем относящуюся к делу библиотеку
mpi4py:from mpi4py import MPI -
Затем мы определяем параметр средства связи, а именно
comm, через операторMPI.COMM_WORLD:comm=MPI.COMM_WORLD -
Значение параметра
rankприменяется для указания самого этого процесса:rank = comm.rank -
Будет полезно выводить на печать значение
rankнекого процесса:print("my rank is : " , rank) -
Затем мы начнём рассматривать значение порядка (rank) данного процесса. В данном случае для данного процесса
rankравного0, мы устанавливаемdestination_processиdata(в данном случаеdata = 10000000) для отправки:if rank==0: data= 10000000 destination_process = 4 -
После этого, применив оператор
comm.send, установленные ранее данные отправляются в процесс получателя:comm.send(data,dest=destination_process) print ("sending data %s " %data + \ "to process %d" %destination_process) -
rank1destination_process8"hello"if rank==1: destination_process = 8 data= "hello" comm.send(data,dest=destination_process) print ("sending data %s :" %data + \ "to process %d" %destination_process) -
Процесс ос значением
rankравным4это процесс получателя. Действительно, значение параметра источника (то естьrankравный0) устанавливается как параметр в соответствующем оператореcomm.recv:if rank==4: data=comm.recv(source=0) -
Теперь, при помощи приводимого ниже кода полученные от процесса
0данные следует отобразить:print ("data received is = %s" %data) -
Самый последний подлежащий установке процесс, это процесс с номером
9. Здесь мы задаём значением процесс источника сrankравным1как некий параметр в оператореcomm.recv:if rank==8: data1=comm.recv(source=1) -
После этого на печать выводится
data1:print ("data1 received is = %s" %data1)
Мы выполнили данный пример с общим числом процессов, равным 9. Поэтому в
нашей группе средства связи comm у нас имелось девять задач, которые могли
взаимодействовать друг с другом:
comm=MPI.COMM_WORLD
Кроме того, для идентификации некой задачи или процесса мы используем значение его
rank:
rank = comm.rank
У нас имеются два отправляющих процесса и два получающих процесса. Наш процесс со значением
rank равным 0, отправляет данные
принимающему численные данные процессу с rank равным
4:
if rank==0:
data= 10000000
destination_process = 4
comm.send(data,dest=destination_process)
Аналогично, нам следует определить значением получающего процесс со значением
rank равным 4. Мы также обращаем
внимание на то, что наш оператор comm.recv должен содержать некий аргумент,
значение порядка своего процесса отправки:
if rank==4:
data=comm.recv(source=0)
Для других процессов отправки и получения (процесс со значением rank, равным
1, и процесс со значением rank, равным
8, соответственно) ситуация та же самая, с единственным отличием в типе самих
данных.
В данном случае для процесса отправителя у нас имеется на отправку некая строка:
if rank==1:
destination_process = 8
data= "hello"
comm.send(data,dest=destination_process)
if rank==8:
data1=comm.recv(source=1)
Наша следующая схема суммирует протокол взаимодействия точка- точка в mpi4py:
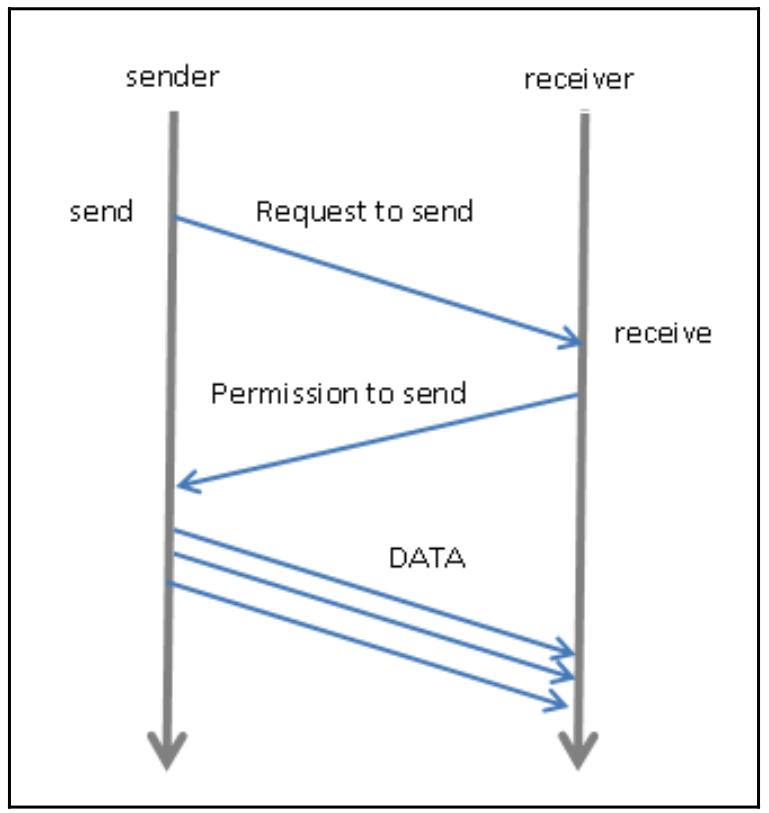
Как вы можете видеть, она описывает двухшаговый процесс, состоящий из отправки неких ДАННЫХ от одной задачи (отправителя, sender) другой задаче (получателю, receiver), получающей эти данные. Отправляющая задача обязана определить подлежащие отправке данные и своё пункт назначения (её процесс получатель), в то время как сама получающая задача обязана определить свой источник получаемого сообщения.
Для запуск этого сценария мы будем применять 9 процессов:
C:> mpiexec -n 9 python pointToPointCommunication.py
Вот тот вывод, который мы получили после запуска данного сценария:
my rank is : 7
my rank is : 5
my rank is : 2
my rank is : 6
my rank is : 3
my rank is : 1
sending data hello :to process 8
my rank is : 0
sending data 10000000 to process 4
my rank is : 4
data received is = 10000000
my rank is : 8
data1 received is = hello
Функции comm.send() и comm.recv()
являются блокирующими функциями, что означает, что они блокируют своего вызывающего до тех пор, пока буферизованные
данные, вовлекаемые в этот процесс, не будут безопасно использованы. Кроме того, в MPI имеются два метода управления
отправки и получения сообщений:
-
Режим с буферизацией: Имеющийся поток управления возвращается в данную программу сразу после того как отправляемые данные скопированы в некий буфер. Это не означает что данное сообщение отправлено или получено.
-
Синхронный режим: Сама функция завершится когда соответствующая функция
receiveприступит к получению сообщения.
Рекомендуем интересное руководство по данной теме.
Общей проблемой, с которой мы сталкиваемся, является взаимная блокировка (deadlock). Это ситуация, при которой два
(или более) процесса блокируют друг друга и ожидают от другой программы некого действия, которое обслуживает нечто
иное и наоборот. Модуль mpi4py не предоставляет никакое особенной
функциональности для разрешения проблемы взаимной блокировки, однако имеется ряд мер, которым стоит следовать
разработчикам во избежание данной проблемы взаимного блокирования.
Давайте проанализируем приводимый ниже код Python, который представляет типичную проблему взаимной блокировки. У нас
имеются два процесса - с rank равным 1 и
с rank равным 5 - которые взаимодействуют
друг с другом и оба имеют функции отправителя и получателя:
-
Импортируем библиотеку
mpi4py:from mpi4py import MPI -
Опредеяем
commкак средство связи и значение параметраrank:comm=MPI.COMM_WORLD rank = comm.rank print("my rank is %i" % (rank)) -
Процесс со значением
rankравным1отправляет и получает данные от процесса со значениемrankравным5:if rank==1: data_send= "a" destination_process = 5 source_process = 5 data_received=comm.recv(source=source_process) comm.send(data_send,dest=destination_process) print ("sending data %s " %data_send + \ "to process %d" %destination_process) print ("data received is = %s" %data_received) -
Аналогичным образом мы определяем сой процесс со значением
rankравным5:if rank==5: data_send= "b" -
Значения процессов отправителя и получателя равны
1:destination_process = 1 source_process = 1 comm.send(data_send,dest=destination_process) data_received=comm.recv(source=source_process) print ("sending data %s :" %data_send + \ "to process %d" %destination_process) print ("data received is = %s" %data_received)
Когда мы запускаем эту программу (имеет смысл запускать её только с двумя процессами), тогда мы замечаем, что ни один из наших двух процессов не может продолжить своё выполнение:
C:\> mpiexec -n 9 python deadLockProblems.py
my rank is : 8
my rank is : 6
my rank is : 7
my rank is : 2
my rank is : 4
my rank is : 3
my rank is : 0
my rank is : 1
sending data a to process 5
data received is = b
my rank is : 5
sending data b :to process 1
data received is = a
Оба процесса готовы принять сообщения от другой стороны и застряли в этом состоянии. Это происходит по причине того,
что MPI функция comm.recv() и MPI функция comm.send()
блокируют их. Это означает, что вызывавший её процесс ожидает завершения вызова. Что касается MPI
comm.send(), её завершение произойдёт когда все данные были отправлены и могут
быть перекрыты без изменения отправленного сообщения.
Соответствующее завершение MPI comm.recv() вместо этого происходит когда
необходимые данные были получены и могут использоваться. Для решения данной проблемы самая первая идея состоит в замене
MPI comm.recv() на comm.send()
следующим образом:
if rank==1:
data_send= "a"
destination_process = 5
source_process = 5
comm.send(data_send,dest=destination_process)
data_received=comm.recv(source=source_process)
print ("sending data %s " %data_send + \
"to process %d" %destination_process)
print ("data received is = %s" %data_received)
if rank==5:
data_send= "b"
destination_process = 1
source_process = 1
data_received=comm.recv(source=source_process)
comm.send(data_send,dest=destination_process)
print ("sending data %s :" %data_send + \
"to process %d" %destination_process)
print ("data received is = %s" %data_received)
Это решение, даже если оно и верно, не гарантирует что мы избежим взаимной блокировки. На самом деле,
взаимодействие осуществляется через буфер посредством инструкции comm.send().
MPI копирует подлежащие отправке данные. Этот режим работает без проблем, однако только когда имеющийся буфер
способен удерживать их все. Если этого не происходит, тогда имеется взаимная блокировка: отправитель не способен
завершить отправку своих данных по причине занятости общего буфера, а получатель не может получить данные, ибо он
блокирован своим вызовом MPI comm.send(), который всё ещё не завершён.
Для данного случая подходящим решением, которое позволит нам избежать взаимного блокирования является применение замены местами функций отправки и приёма с тем, чтобы сделать их асимметричными:
if rank==1:
data_send= "a"
destination_process = 5
source_process = 5
comm.send(data_send,dest=destination_process)
data_received=comm.recv(source=source_process)
if rank==5:
data_send= "b"
destination_process = 1
source_process = 1
comm.send(data_send,dest=destination_process)
data_received=comm.recv(source=source_process)
Окончательно мы получаем правильный вывод:
C:\> mpiexec -n 9 python deadLockProblems.py
my rank is : 4
my rank is : 0
my rank is : 3
my rank is : 8
my rank is : 6
my rank is : 7
my rank is : 2
my rank is : 1
sending data a to process 5
data received is = b
my rank is : 5
sending data b :to process 1
data received is = a
Предложенное для данной взаимной блокировки решение не является единственным.
Существует, например, некая функция, которая унифицирует единый вызов, который отправляет какое- то сообщение
заданному процессу и поучает другое сообщение, которое поступает от иного процесса. Такая функция имеет название
Sendrecv:
Sendrecv(self, sendbuf, int dest=0, int sendtag=0, recvbuf=None, int source=0, int recvtag=0, Status status=None)
Как вы можете видеть, необходимые ей параметры те же самые, что и у MPI comm.send()
с comm.recv() (в данном случае эта функция также блокирующая). Однако
Sendrecv предлагает существенное преимущество того, что оставляет подсистему
взаимодействия ответственной за проверку имеющихся зависимостей между отправителями и получателями, тем самым
избегая взаимной блокировок.
В таком случае наш код из предыдущего примера преобразуется в такой:
if rank==1:
data_send= "a"
destination_process = 5
source_process = 5
data_received=comm.sendrecv(data_send,dest=\
destination_process,\
source =source_process)
if rank==5:
data_send= "b"
destination_process = 1
source_process = 1
data_received=comm.sendrecv(data_send,dest=\
destination_process,\
source=source_process)
Некий забавный анализ относительно того насколько параллельное программирование сложно по причине управления взаимными блокировками можно найти по следующей ссылке.
{Прим. пер.: обращаем также ваше внимание на наши переводы Полного руководство параллельного программирования на Python Куан Нгуена и Asyncio в Python 3 Цалеба Хаттингха.}
В процессе разработки параллельного кода мы часто обнаруживаем себя в ситуации, при которой мы должны должны разделять, причём для множества процессов, конкретное значение определённой переменной во время исполнения или заданной операции для переменных, производимых всеми процессами (возможно с различными значениями).
Для разрешения подобных случаев применяются деревья взаимодействия (например, процесс 0 отправляет данные в процессы 1 и 2, которые, в свою очередь, заботятся об отправке их в процессы 3,4,5,6 и так далее).
Вместо этого MPI предоставляет функции, которые идеальны для такого обмена информацией или использования множества процессов, которые чётко оптимизированы под те машины, в которых они выполняются:

Метод взаимодействия, который вовлекает все те процессы, которые относятся к средству связи имеет название коллективного взаимодействия. В результате, в коллективное взаимодействие как правило вовлечено более двух процессов. Однако вместо этого мы можем вызывать такое коллективное взаимодействие широковещательно, при котором некий отдельный процесс отправляет одни и те же данные всем прочим процессам.
Функциональность широковещания mpi4py предоставляется таким методом:
buf = comm.bcast(data_to_share, rank_of_root_process)
Эта функция отправляет те сведения, которые содержатся в сообщении корневого процесса всем остальным процессам,
которые относятся к средству связи (коммуникатору) comm.
Давайте теперь рассмотрим пример, в котором мы воспользуемся функцией broadcast.
У нас имеется некий корневой процесс со значением rank равным
0, который разделяет свои собственные данные,
variable_to_share, со всеми прочими процессами, заданными в установленной
группе средства связи:
-
Давайте импортируем необходимую библиотеку
mpi4py:from mpi4py import MPI -
Теперь давайте определим общее средство связи и значение параметра
rank:comm = MPI.COMM_WORLD rank = comm.Get_rank() -
Когда дело касается процесса,
rankкоторого равен0, мы задаём значение переменной, подлежащей совместному использованию всеми прочими процессами:if rank == 0: variable_to_share = 100 else: variable_to_share = None -
Наконец, мы задаём широковещательную отправку, имея для его
rootпроцесс со значениемrankравным нулю:variable_to_share = comm.bcast(variable_to_share, root=0) print("process = %d" %rank + " variable shared = %d " \ %variable_to_share)
Наш корневой процесс со значением rank равным
0 создаёт экземпляр переменной
variable_to_share, который равен 100.
Эта переменная будет разделяться со всеми прочими процессами в установленной группе средства взаимодействия:
if rank == 0:
variable_to_share = 100
Для осуществления этого мы также вводим некий оператор широковещательного взаимодействия:
variable_to_share = comm.bcast(variable_to_share, root=0)
В данном случае значения параметров для нашей функции таковы:
-
Сами подлежащие совместному использованию данные (
variable_to_share). -
Значение корневого процесса, которым выступает процесс со значением порядка, равным нулю (
root=0).
Запустив этот код, мы получили группу средства связи из 10 процессов и разделяемую между всеми прочими
процессами в этой группе переменную variable_to_share. Наконец, наш оператор
print визуализирует значения порядка выполненных процессов и само значение
его переменной:
print("process = %d" %rank + " variable shared = %d " \
%variable_to_share)
После установки 10 процессов получаемый вывод таков:
C:\> mpiexec -n 10 python broadcast.py
process = 0
variable shared = 100
process = 8
variable shared = 100
process = 2 variable
shared = 100
process = 3
variable shared = 100
process = 4
variable shared = 100
process = 5
variable shared = 100
process = 9
variable shared = 100
process = 6
variable shared = 100
process = 1
variable shared = 100
process = 7
variable shared = 100
Коллективное взаимодействие делает возможным одновременную передачу данных между множеством процессов в некой
группе. Имеющаяся библиотека mpi4py предоставляет коллективное
взаимодействие, но только в версии с блокировкой (то есть она блокирует вызывающий метод до тех пор, пока вовлечённые
в процесс буферируемые данные не смогут применяться безопасно).
Наиболее распространёнными операциями коллективного взаимодействия являются такие:
-
Барьерная синхронизация для определённой группы процессов
-
Функции взаимодействия:
-
Широковещательная доставка данных от одного процесса всем процессам в установленной группе
-
Накопление (Gathering) данных от всех процессов одним процессом
-
Рассеивание (Scattering) данных от одного процесса всем процессам
-
-
Операции редукции
Для обращения к полному введению в Python и MPI отсылаем вас к следующей ссылке.
Функциональность разброса (scatter) очень схожа с широковещательным взаимодействием за одним важным исключением:
в то время как comm.bcast отсылает одни и те же данные всем ожидающим
процессам, comm.scatter способен отсылать фрагменты данных из массива различным
процессам.
Приводимая далее схема иллюстрирует данную функциональность разбрасывания:

Данная функция comm.scatter получает элементы заданного массива и
распределяет их по процессам в соответствии с их порядковыми номерами, для которых самый первым элемент отправляется
в процесс 0, второй элемент в процесс 1, и так далее. Реализующая это функция из
mpi4py такова:
recvbuf = comm.scatter(sendbuf, rank_of_root_process)
В своём следующем примере мы рассмотрим как распределять данные в различные процессы при помощи
функциональности scatter:
-
Импортируем нужную нам библиотеку
mpi4py:from mpi4py import MPI -
Далее задаём как обычно параметры
commиrank:comm = MPI.COMM_WORLD rank = comm.Get_rank() -
Для процесса со значением
rankравным0будет разбрасываться следующий массив:if rank == 0: array_to_share = [1, 2, 3, 4 ,5 ,6 ,7, 8 ,9 ,10] else: array_to_share = None -
После этого устанавливается
recvbuf. Нашим процессомrootявляется процесс со значениемrankравным0.recvbuf = comm.scatter(array_to_share, root=0) print("process = %d" %rank + " recvbuf = %d " %recvbuf)
Наш процесс со значением rank равным 0
распределяет значения структуры данных array_to_share во все прочие процессы:
array_to_share = [1, 2, 3, 4 ,5 ,6 ,7, 8 ,9 ,10]
Параметр recvbuf указывает на значение
iй переменной, которая будет отправляться в прочие процессы
через соответствующий оператор comm.scatter:
recvbuf = comm.scatter(array_to_share, root=0)
Получаемый вывод таков:
C:\> mpiexec -n 10 python scatter.py
process = 0 variable shared = 1
process = 4 variable shared = 5
process = 6 variable shared = 7
process = 2 variable shared = 3
process = 5 variable shared = 6
process = 3 variable shared = 4
process = 7 variable shared = 8
process = 1 variable shared = 2
process = 8 variable shared = 9
process = 9 variable shared = 10
Мы также обращаем ваше внимание на одно из ограничений comm.scatter,
которое состоит в том, что мы можем разбрасывать столько же элементов, сколько в выполняемом операторе имеется
процессов. На самом деле, если вы попытаетесь разбросать больше элементов, чем определено процессов
(в следующем примере три), тогда вы получите ошибку, подобную следующей:
C:\> mpiexec -n 3 python scatter.py
Traceback (most recent call last):
File "scatter.py", line 13, in
recvbuf = comm.scatter(array_to_share, root=0)
File "Comm.pyx", line 874, in mpi4py.MPI.Comm.scatter
(c:\users\utente\appdata\local\temp\pip-build-h14iaj\mpi4py\
src\mpi4py.MPI.c:73400)
File "pickled.pxi", line 658, in mpi4py.MPI.PyMPI_scatter
(c:\users\utente\appdata\local\temp\pip-build-h14iaj\mpi4py\src\
mpi4py.MPI.c:34035)
File "pickled.pxi", line 129, in mpi4py.MPI._p_Pickle.dumpv
(c:\users\utente\appdata\local\temp\pip-build-h14iaj\mpi4py
\src\mpi4py.MPI.c:28325)
ValueError: expecting 3 items, got 10
mpiexec aborting job...
job aborted:
rank: node: exit code[: error message]
0: Utente-PC: 123: mpiexec aborting job
1: Utente-PC: 123
Библиотека mpi4py также предоставляет две другие функции, применяемые
для разброса данных:
-
comm.scatter(sendbuf, recvbuf, root=0): Эта функция отправляет данные из одного процесса во все прочие из средства связи (коммуникатора). -
comm.scatterv(sendbuf, recvbuf, root=0): Данная функция разбрасывает данные из одного процесса во все прочие в некой заданной группе, которая предоставляет различные количества данных и смещения на стороне отправки.
Аргументы sendbuf и recvbuf
должны задаваться в терминах некого списка (как и в соответствующей функции точка- точка
comm.send):
buf = [data, data_size, data_type]
Здесь данные должны быть подобным буферу объектом data с установленным размером
data_size и значением типа данных data_type.
Занятное руководство по широковещательному MPI представлено по следующей ссылке.
Функция gather выполняет обратное функции
scatter действие. В этом случае все процессы отправляют данные процессу корня,
который собирает получаемые данные.
Реализуемая mpi4py функция gather
такова:
recvbuf = comm.gather(sendbuf, rank_of_root_process)
Здесь sendbuf являются подлежащими отправке данными, а
rank_of_root_process представляет обработку получения всех этих данных:

В нашем следующем примере мы представим то условие, которое представлено на предыдущей схеме, при котором
каждый из процессов строит свои собственные данные, подлежащие отправке в установленный корневой процесс, который
определяется значением rank равным нулю:
-
Наберите необходимый импорт:
from mpi4py import MPI -
Затем мы определяем три следующих параметра. Параметр
commэто наше средство связи,rankпредоставляет значение порядка для данного процесса, аsizeэто общее число имеющихся процессов:comm = MPI.COMM_WORLD size = comm.Get_size() rank = comm.Get_rank() -
Здесь мы определяем то значение, которое будет получено от процессора с соответствующим значением
rank:data = (rank+1)**2 -
Наконец, наш накопитель предоставляется через функцию
comm.gather. Кроме того обратите внимание, что нашим корневым процессом (тот процесс, который будет накапливать данные от прочих) является процессом нулевым значением порядка:data = comm.gather(data, root=0) -
Для процесса со значением
rankравным0, накапливаются все отправляемые данные, которые и выводятся на печать:if rank == 0: print ("rank = %s " %rank +\ "...receiving data to other process") for i in range(1,size): value = data[i] print(" process %s receiving %s from process %s"\ %(rank , value , i))
Наш корневой процесс с порядком 0 получает данные от всех прочих четырёх процессов,
как это и представлено на приводившейся ранее схеме.
Мы устанавливаем n (= 5)
процессов отправляющих свои данные:
data = (rank+1)**2
Когда значение rank равно 0, тогда
данные накапливаются в неком массиве:
if rank == 0:
for i in range(1,size):
value = data[i]
Вместо этого данные для накопления представлены такой функцией:
data = comm.gather(data, root=0)
Наконец, мы запускаем свой код, настроенный на группу с числом процессов, равным
5:
C:\> mpiexec -n 5 python gather.py
rank = 0 ...receiving data to other process
process 0 receiving 4 from process 1
process 0 receiving 9 from process 2
process 0 receiving 16 from process 3
process 0 receiving 25 from process 4
Для сбора данных mpi4py предоставляет такие функции:
-
Накопление в одной задаче:
comm.Gather,comm.Gathervиcomm.gather. -
Накопление во всех задачах:
comm.Allgather,comm.Allgathervиcomm.allgather.
Дополнительные сведения относительно mpi4py можно найти по
ссылке.
Коллективное взаимодействие Alltoall сочетает в себе функциональности
scatter и gather.
В своём следующем примере мы рассмотрим реализацию mpi4py
для comm.Alltoallю Мы рассмотрим некую группу взаимодействующих процессов, в
которой каждый процесс отправляет и получает некий массив численных данных от прочих определённых в его группе
процессов:
-
Для данного примера импортируются относящиеся к делу библиотеки
mpi4pyиnumpy:from mpi4py import MPI import numpy -
Как и в нашем предыдущем примере, нам требуется тот же самый набор параметров
comm,sizeиrank:comm = MPI.COMM_WORLD size = comm.Get_size() rank = comm.Get_rank() -
Таким образом, мы обязаны определить те данные, которые будут отправляться для каждого из процессов (
senddata) и в то же самое время данные, получаемые их прочих процессов (recvdata):senddata = (rank+1)*numpy.arange(size,dtype=int) recvdata = numpy.empty(size,dtype=int) -
Наконец, выполняется функция
Alltoall:comm.Alltoall(senddata,recvdata) -
Отображаются все отосланные и принятые данные для всех процессов:
print(" process %s sending %s receiving %s"\ %(rank , senddata , recvdata))
Метод comm.alltoall получает значения iх
объектов из соответствующего аргумента sendbuf задачи
j и копирует его в свой j
объект значения аргумента recvbuf задачи
i.
Когда мы запустим этот код с некой группой системы связи 5 процессов, тогда
наш вывод будет следующим:
C:\> mpiexec -n 5 python alltoall.py
process 0 sending [0 1 2 3 4] receiving [0 0 0 0 0]
process 1 sending [0 2 4 6 8] receiving [1 2 3 4 5]
process 2 sending [ 0 3 6 9 12] receiving [ 2 4 6 8 10]
process 3 sending [ 0 4 8 12 16] receiving [ 3 6 9 12 15]
process 4 sending [ 0 5 10 15 20] receiving [ 4 8 12 16 20]
Мы также можем выразить то что происходит при помощи такой схемы:
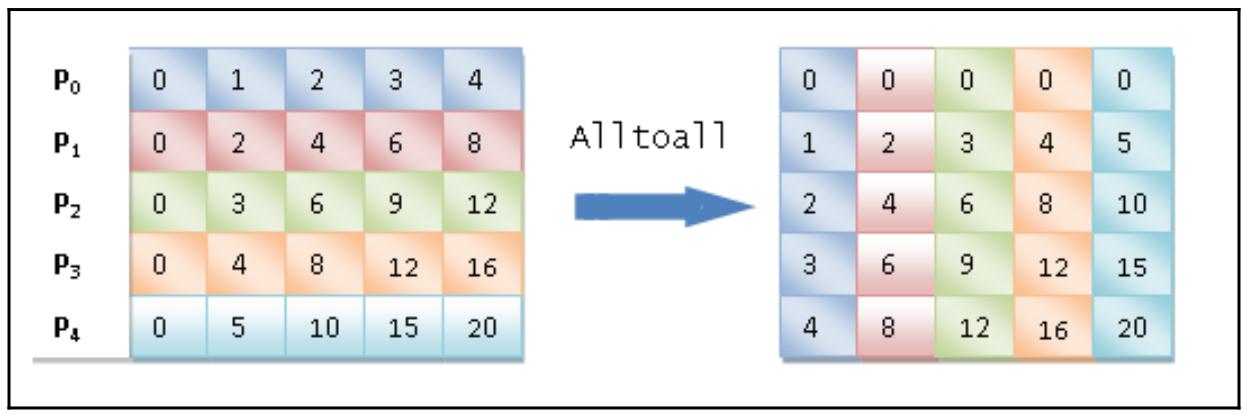
Наши относящиеся к этой схеме наблюдения таковы:
-
Наш процесс
P0содержит массив данных [0 1 2 3 4], в котором он присваивает 0 самому себе, 1 процессуP1, 2 процессуP2, 3 процессуP3и 4 процессуP4. -
Наш процесс
P1содержит массив данных [0 2 4 6 8], в котором он присваивает 0 процессуP0, 2 самому себе, 4 процессуP2, 6 процессуP3и 8 процессуP4. -
Наш процесс
P2содержит массив данных [0 3 6 9 12], в котором он присваивает 0 процессуP0, 3 процессуP1, 6 самому себе, 9 процессуP3и 4 процессуP4. -
Наш процесс
P3содержит массив данных [0 4 8 12 16], в котором он присваивает 0 процессуP0, 4 процессуP1, 8 процессуP2, 12 самому себе и 16 процессуP4. -
Наш процесс
P4содержит массив данных [0 5 10 15 20], в котором он присваивает 0 процессуP0, 5 процессуP1, 10 процессуP2, 15 процессуP3и 20 самому себе.
Alltoall воплощает взаимодействие, которое также называется
всеобщим обменом. Эта операция применяется в разнообразных параллельных алгоритмах, таких как быстрое преобразование
Фурье, транспонирование матриц, быстрая сортировка и некоторые операции соединения параллельных баз данных.
В mpi4py имеются три типа
коллективного взаимодействия Alltoall:
-
comm.Alltoall(sendbuf, recvbuf): Рассеяние/ набор данныхAlltoallдля всех- ко всем процессов в некой группе. -
comm.Alltoallv(sendbuf, recvbuf): Векторные рассеяние/ набор данныхAlltoallдля всех- ко всем процессов в некой группе, предоставляющее различные количества данных и смещений. -
comm.Alltoallw(sendbuf, recvbuf): Обобщённое взаимодействиеAlltoall, допускающее различные числа, смещения и типы данных для каждого из партнёров.
Некий забавный анализ модулей MPI Python можно выгрузить по следующей ссылке.
Аналогично comm.gather, comm.reduce
получает некий массив элементов на входе в каждом из процессов и возвращает некий массив элементов вывода в свой
корневой процесс. Получаемые элементы вывода сдержат результат свёртки.
В mpi4py мы определяем операции свёртки посредством такого оператора:
comm.Reduce(sendbuf, recvbuf, rank_of_root_process, op = type_of_reduction_operation)
Вам следует обратить внимание на то, что основное отличие от оператора comm.gather
заключается в наличии параметра op, который является тем оператором, который вы
бы желали применить к своим данным {для понижения порядка}, а модуль mpi4py
содержит некий набор операций свёртки, которые можно применять.
Теперь мы увидим как реализовывать суммирование некого массива элементов при помощи свёртки
MPI.SUM с использованием функциональности понижения порядка (reduction).
Все процессы будут манипулировать неким массивом с размеров 10.
Для манипуляций с массивом мы пользуемся теми функциями, которые предоставляются модулем Python
numpy:
-
Здесь импортируются относящиеся к делу библиотеки
mpi4pyиnumpy:import numpy from mpi4py import MPI -
Определяем параметры
comm,sizeиrank:comm = MPI.COMM_WORLD size = comm.size rank = comm.rank -
Далее устанавливается значение оазмера нашего массива (
array_size):array_size = 10 -
Задаются значения данных для отправки и получения:
recvdata = numpy.zeros(array_size,dtype=numpy.int) senddata = (rank+1)*numpy.arange(array_size,dtype=numpy.int) -
Выводятся на печать значения процесса отправителя и сами отправляемые данные:
print(" process %s sending %s " %(rank , senddata)) -
Наконец выполняется сама операция
Reduce. Обратите внимание, что значение процессаrootустанавливается в0, а параметрopустанавливается в значениеMPI.SUM:comm.Reduce(senddata,recvdata,root=0,op=MPI.SUM) -
Затем отображается получаемый вывод операции свёртки следующим образом:
print ('on task',rank,'after Reduce: data = ',recvdata)
Для выполнения свёртки суммой мы применяем оператор comm.Reduce.
Кроме того, мы указываем при помощи нулевого rank кто выступает процессом
root, который и будет содержать recvbuf,
представляющий окончательный результат нашего вычисления:
print ('on task',rank,'after Reduce: data = ',recvdata)
Существенно что мы запускаем свой код с некой группой системы звязи из 10
процессов, так как именно это размер нашего массива обработки.
Появляющийся вывод выглядит так:
C:\> mpiexec -n 10 python reduction.py
process 1 sending [ 0 2 4 6 8 10 12 14 16 18]
on task 1 after Reduce: data = [0 0 0 0 0 0 0 0 0 0]
process 5 sending [ 0 6 12 18 24 30 36 42 48 54]
on task 5 after Reduce: data = [0 0 0 0 0 0 0 0 0 0]
process 7 sending [ 0 8 16 24 32 40 48 56 64 72]
on task 7 after Reduce: data = [0 0 0 0 0 0 0 0 0 0]
process 3 sending [ 0 4 8 12 16 20 24 28 32 36]
on task 3 after Reduce: data = [0 0 0 0 0 0 0 0 0 0]
process 9 sending [ 0 10 20 30 40 50 60 70 80 90]
on task 9 after Reduce: data = [0 0 0 0 0 0 0 0 0 0]
process 6 sending [ 0 7 14 21 28 35 42 49 56 63]
on task 6 after Reduce: data = [0 0 0 0 0 0 0 0 0 0]
process 2 sending [ 0 3 6 9 12 15 18 21 24 27]
on task 2 after Reduce: data = [0 0 0 0 0 0 0 0 0 0]
process 8 sending [ 0 9 18 27 36 45 54 63 72 81]
on task 8 after Reduce: data = [0 0 0 0 0 0 0 0 0 0]
process 4 sending [ 0 5 10 15 20 25 30 35 40 45]
on task 4 after Reduce: data = [0 0 0 0 0 0 0 0 0 0]
process 0 sending [0 1 2 3 4 5 6 7 8 9]
on task 0 after Reduce: data = [ 0 55 110 165 220 275 330 385 440 495]
Обратите внимание, что с помощью параметра op=MPI.SUM мы применяем
значение операции суммы для всех элементов всоего массива колонок. Чтобы лучше разобраться с тем как работает
сама свёртка, посмотрите на следующую схему:
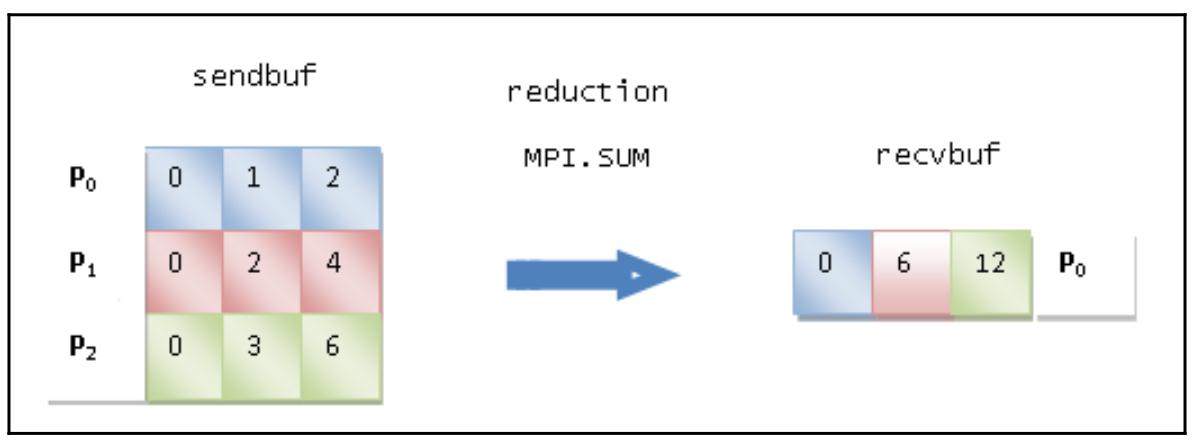
Наши операции отправки таковы:
-
Процесс P0 отправляет значения [0 1 2] массива данных.
-
Процесс P1 отправляет значения [0 2 4] массива данных.
-
Процесс P2 отправляет значения [0 3 6] массива данных.
наша операция свёртки суммирует iе элементы всех задач,
а затем помещает полученные результаты в iе элементы
в корневом процессе P0. Для самой операции получения,
наш процесс P0 получает массив данных
[0 6 12].
Вот некоторые операции свёртки, определяемые MPI:
-
op=MPI.MAX: Возвращает максимальное значение элемента. -
op=MPI.MIN: Возвращает минимальное значение элемента. -
op=MPI.SUM: Это сумма всех элементов. -
op=MPI.PROD: Это произведение всех элементов. -
op=MPI.LAND: Выполняет логическую операцию И по всем элементам. -
op=MPI.MAXLOC: Возвращает максимальное значение и значение порядка того процесса, который её содержит. -
op=MPI.MINLOC: Возвращает минимальное значение и значение порядка того процесса, который её содержит.
По ссылке вы можете найти хорошее руководство по данной теме и много чего ещё.
Неким интересным свойством предоставляемым MPI является относящаяся к виртуальным топологиям функциональность.
Как уже отмечалось, все функции взаимодействия (точка- точка или коллективные) относятся к некой группе процессов.
Мы уже применяли группу MPI_COMM_WORLD, которая содержит все процессы.
Она назначает некий порядок от 0 до
n-1 для каждого из процессов, которые относятся к системе связи с
размером n.
Однако MPI позволяет нам назначать некой системе связи (коммуникатору) какую- то виртуальную топологию. Она задаёт некое назначение меток различным процессам: путём построения виртуальной топологии, каждый узел способен взаимодействовать только со своим виртуальным соседом, причём улучшая производительность, так как это снижает время исполнения.
Например, при произвольном назначении порядка, некое сообщение может принуждаться к отправке во многие прочие узлы прежде чем оно достигнет своего пункта назначения. Помимо самого вопроса производительности, виртуальная топология гарантирует что ваш код будет понятнее и более читаемый.
MPI предоставляет две топологии построения. Первая конструкция создаёт Декартову топологии , в то время как последняя создаёт любой вид топологий. В частности, во втором случае мы должны предоставлять матрицу смежности своего графа для того что вы желаете построить. Мы будем иметь дело только с Декартовой топологией, посредством которой можно построить различные широко применяемые структуры, такие как сетка, кольцо и тороид.
Та функция mpi4py, которая применяется для создания Декартовой топологии выглядит
так:
comm.Create_cart((number_of_rows,number_of_columns))
Здесь number_of_rows и number_of_columns
определяют число строк и колонок получаемой в результате сетки.
В своём следующем примере мы покажем как реализовать Декартову топологию с размером
M×N. Кроме того мы определим некий набор координат для понимания
того как распологаются наши процессы:
-
Импортируем относящиеся к делу библиотеки:
from mpi4py import MPI import numpy as np -
Для продвижения по нашей топологии определяем следующие параметры:
UP = 0 DOWN = 1 LEFT = 2 RIGHT = 3 -
Для каждого из процессов наш следующий массив определяет его соседние процессы:
neighbour_processes = [0,0,0,0] -
В своей программе
mainмы далее определяем параметрыcomm.rankиsize:if __name__ == "__main__": comm = MPI.COMM_WORLD rank = comm.rank size = comm.size -
Теперь давайте построим необходимую топологию:
grid_rows = int(np.floor(np.sqrt(comm.size))) grid_column = comm.size // grid_rows -
Следующие приводимые условия гарантируют что наши процессы всегда находятся внутри этой топологии:
if grid_rows*grid_column > size: grid_column -= 1 if grid_rows*grid_column > size: grid_rows -= 1 -
Процес со значением
rankравным0запускает построение этой топологии:if (rank == 0) : print("Building a %d x %d grid topology:"\ % (grid_rows, grid_column) ) cartesian_communicator = \ comm.Create_cart( \ (grid_rows, grid_column), \ periods=(False, False), \ reorder=True) my_mpi_row, my_mpi_col = \ cartesian_communicator.Get_coords\ ( cartesian_communicator.rank ) neighbour_processes[UP], neighbour_processes[DOWN]\ = cartesian_communicator.Shift(0, 1) neighbour_processes[LEFT], \ neighbour_processes[RIGHT] = \ cartesian_communicator.Shift(1, 1) print ("Process = %s \row = %s\n \ column = %s ----> neighbour_processes[UP] = %s \ neighbour_processes[DOWN] = %s \ neighbour_processes[LEFT] =%s neighbour_processes[RIGHT]=%s" \ %(rank, my_mpi_row, \ my_mpi_col,neighbour_processes[UP], \ neighbour_processes[DOWN], \ neighbour_processes[LEFT] , \ neighbour_processes[RIGHT]))
Для каждого из процессов получаемый вывод должен читаться следующим образом: когда
neighbour_processes = -1, имеется топологическая близость, в противном
случае neighbour_processes отображает значение порядка близости данного
процесса.
Получаемой в результате топологией является сетка 2×2
(отсылаем вас к приводимой далее схеме для представления сетки), значение размера которой равно числу процессов на
входе; то есть, четырём:
grid_row = int(np.floor(np.sqrt(comm.size)))
grid_column = comm.size // grid_row
if grid_row*grid_column > size:
grid_column -= 1
if grid_row*grid_column > size:
grid_rows -= 1
Далее Декартова топология строится при помощи функции comm.Create_cart
(обратите также внимание на значение параметра periods = (False,False)):
cartesian_communicator = comm.Create_cart( \
(grid_row, grid_column), periods=(False, False), reorder=True)
Для того чтобы определять положение своего процесса мы применяем метод Get_coords()
в следующем виде:
my_mpi_row, my_mpi_col =\
cartesian_communicator.Get_coords(cartesian_communicator.rank )
Для самих процессов, дополнительно к поучению их координат мы должны вычислять и определять какой из процессов
является ближайшим топологически. Для этой цели мы применяем функцию
comm.Shift(rank_source,rank_dest):
neighbour_processes[UP], neighbour_processes[DOWN] =\
cartesian_communicator.Shift(0, 1)
neighbour_processes[LEFT], neighbour_processes[RIGHT] = \
cartesian_communicator.Shift(1, 1)
Получаемая топология выглядит следующим образом:

Как показывает данная схема, наш процесс P0 сцеплен с
процессами P1 (RIGHT)
и P2 DOWN). Процесс
P1 сцеплен с процессами
P3 (DOWN) и с
P0
(LEFT. Процесс P3
сцеплен с процессами P1
(UP и P2
(LEFT. А процесс P2
сцеплен с процессами P3
(RIGHT и P0
(UP.
Наконец, выполнив этот сценарий, мы получаем такой результат:
C:\>mpiexec -n 4 python virtualTopology.py
Building a 2 x 2 grid topology:
Process = 0 row = 0 column = 0
---->
neighbour_processes[UP] = -1
neighbour_processes[DOWN] = 2
neighbour_processes[LEFT] =-1
neighbour_processes[RIGHT]=1
Process = 2 row = 1 column = 0
---->
neighbour_processes[UP] = 0
neighbour_processes[DOWN] = -1
neighbour_processes[LEFT] =-1
neighbour_processes[RIGHT]=3
Process = 1 row = 0 column = 1
---->
neighbour_processes[UP] = -1
neighbour_processes[DOWN] = 3
neighbour_processes[LEFT] =0
neighbour_processes[RIGHT]=-1
Process = 3 row = 1 column = 1
---->
neighbour_processes[UP] = 1
neighbour_processes[DOWN] = -1
neighbour_processes[LEFT] =2
neighbour_processes[RIGHT]=-1
Для получения тороидальной топологии с размером M×N, давайте
снова воспользуемся comm.Create_cart, но на этот раз давайте установим значение
параметра periods в periods=(True,True):
cartesian_communicator = comm.Create_cart( (grid_row, grid_column),\
periods=(True, True), reorder=True)
Получается такой результат:
C:\> mpiexec -n 4 python virtualTopology.py
Process = 3 row = 1 column = 1
---->
neighbour_processes[UP] = 1
neighbour_processes[DOWN] = 1
neighbour_processes[LEFT] =2
neighbour_processes[RIGHT]=2
Process = 1 row = 0 column = 1
---->
neighbour_processes[UP] = 3
neighbour_processes[DOWN] = 3
neighbour_processes[LEFT] =0
neighbour_processes[RIGHT]=0
Building a 2 x 2 grid topology:
Process = 0 row = 0 column = 0
---->
neighbour_processes[UP] = 2
neighbour_processes[DOWN] = 2
neighbour_processes[LEFT] =1
neighbour_processes[RIGHT]=1
Process = 2 row = 1 column = 0
---->
neighbour_processes[UP] = 0
neighbour_processes[DOWN] = 0
neighbour_processes[LEFT] =3
neighbour_processes[RIGHT]=3
Полученный вывод описывает представленную здесь топологию:
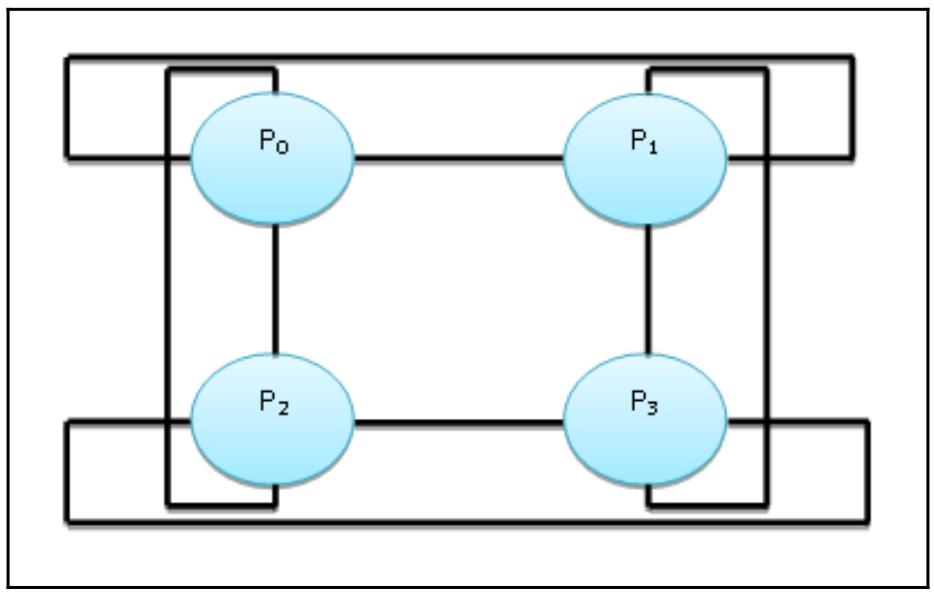
Эта представленная на предыдущей схеме топология указывает, что процесс P0
сцеплен с процессами P1(RIGHT
и LEFT) и P2(UP
и DOWN), процесс P1
сцеплен с процессами P3(UP
и DOWN) и P2(RIGHT
и LEFT), а процесс P2
сцеплен с процессами P3(RIGHT
и LEFT) и P0(UP
и DOWN).
Дополнительные сведения по MPI можно найти по следующей ссылке.