Глава 7. Облачные вычисления
Содержание
Облачные вычисления это распределённые вычислительные службы, такие как серверы, ресурсы хранения, базы данных, сетевые среды, программное обеспечение, анализ и интеллект через всемирную паутину (облако). Основная цель данной главы состоит в предоставлении некого обзора основных вычислительных технологий в отношении языка программирования Python.
Прежде всего мы опишем платформу PythonAnywhere, в которой мы развернём облачное приложение Python. В контексте облачных вычислений будут обозначены две развивающиеся технологии: контейнеры и безсерверная технология.
Контейнеры представляют новый подход к виртуализации ресурсов, а безсерверная технология представляет некий шаг в направлении облачных служб, так как они способны ускорять выпуск приложений.
На самом деле вам не стоит беспокоиться относительно представления, сереверов или конфигураций необходимой инфраструктуры. Вам только придётся создавать функции (а именно, Лямбда функции), которые способны работать независимо от таких приложений.
В этой главе мы рассмотрим такие вопросы:
-
Что такое облачные вычисления?
-
Основные моменты архитектуры облачных вычислений
-
Разработка веб приложений при помощи PythonAnywhere
-
Докеризация приложения Python
-
Введение в безсерверные вычисления
Мы также рассмотрим как получать преимущества от инфраструктуры AWS Lambda при разработке приложений Python.
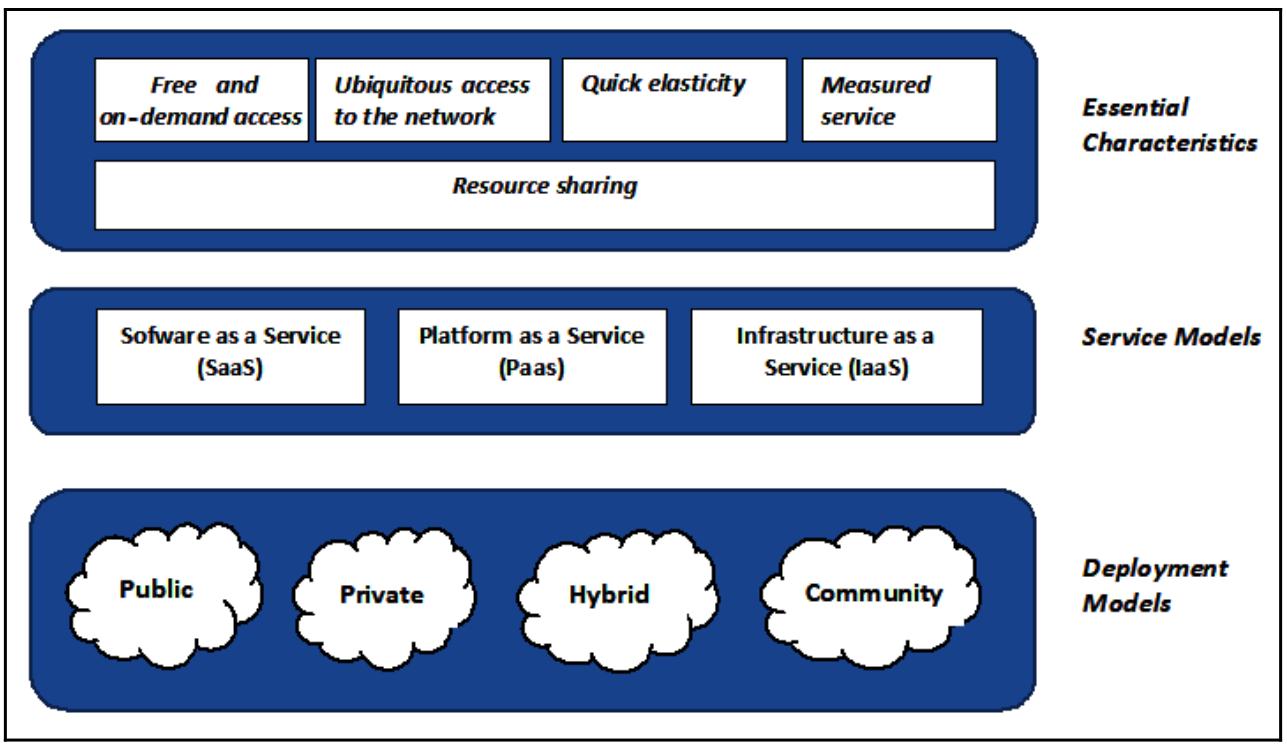
Облачные вычисления это вычислительная модель для распределённых служб на основе некого набора ресурсов, таких как виртуальная обработка, массовая память и сетевые среды, которые способны динамически агрегироваться и активироваться в качестве платформ для запуска приложений, удовлетворяя надлежащим уровням служб и оптимизации действенного применения ресурсов.
Они могут быстро выделяться и высвобождаться с минимальными усилиями по управлению или взаимодействию с поставщиком данной службы. Такая облачная модель составляется из пяти существенных характеристик, трёх моделей обслуживания и четырёх моделей развёртывания.
В частности, пять имеющихся существенных характеристик таковы:
-
Свободный и предоставляемый по запросу доступ: Это делает для пользователей возможным доступ - через дружественные пользователю интерфейсы - к тем службам, которые предлагаются поставщиком, причём без вмешательства персонала.
-
Повсеместный доступ к необходимой сетевой среде: Доступ к ресурсам осуществляется через имеющуюся сетевую среду и может осуществляться через стандартные устройства - такие как смартфоны, планшеты и персональные компьютеры.
-
Быстрая эластичность: Это способность рассматриваемого облачного решения увеличивать или уменьшать выделенные ресурсы быстрым и автоматическим образом, причём так, что пользователям будет казаться что они безграничны. Это предоставляет великолепную масштабируемость всей системе.
-
Служба измерения: Облачные системы постоянно выполняют мониторинг всех предлагаемых ресурсов и автоматически оптимизируют их на основании получаемых оценок использования. Тем самым все пользователи оплачивают только те ресурсы, которые реально применяются в таком определённом сеансе.
-
Совместное использование ресурсов: Сам поставщик предоставляет свои ресурсы через модель со множеством арендаторов с тем, чтобы они были способны выделяться и убираться динамически, на основании поступающих запросов пользователя и использоваться множеством потребителей:
Тем не менее, существует множество определений облачных вычислений, причём каждое из них обладает различными интерпретациями и значениями. NIST (National Institute of Standards and Technology) попытался предоставить подробное и официальное объяснение.
Другая функциональная возможность (не перечисленная в определении NIST, однако которая составляет основу облачных вычислений) это само понятие виртуализации. Это сама возможность выполнения множества ОС в одних и тех же ресурсах, гарантируя множество преимуществ, таких как масштабируемость, снижение стоимости и большие скорости в предоставлении новых ресурсов пользователям.
Наиболее общими подходами к виртуализации являются такие:
-
Контейнеры
-
Виртуальные машины
Оба решения обладают почти одинаковыми преимуществами в плане рассмотрения присутствия изоляции приложений, однако они работают на различных уровнях виртуализации, так как контейнеры выполняют виртуализацию ОС, а виртуальные машины виртуализируют оборудование. Это означает, что такие контейнеры более переносимы и эффективны.
Наиболее распространённым приложением виртуализации через контейнеры выступает Docker. Мы сделаем краткое введение в эту инфраструктуру и рассмотрим как упаковывать в контейнеры (или выполнять докеризацию) некого приложения Python.
Имеющаяся архитектура облачных вычислений ссылается на ряд компонентов и их составных частей, которые и составляют общую структуру самой системы. Обычно их можно сгруппировать на два основных раздела, Внешний и Внутренний (Frontend и Backend):
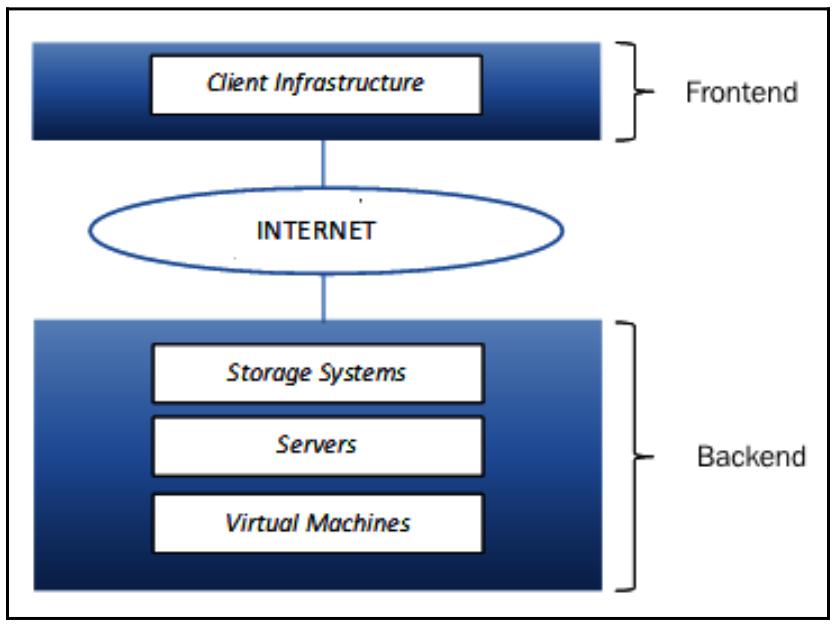
Каждый раздел обладает очень специфичными смыслами и сферами и соединяется с прочими через некую выиртуальную сеть или сетевую среду интернета.
Внешний интерфейс ссылается на ту часть облачных вычислений, которая видна его пользователю, которая реализуется через последовательность интерфейсов и приложений, позволяющих их потребителю выполнять доступ к рассматриваемой облачной системе. Различные облачные вычислительные системы обладают различными UI (User Interface, Интерфейсами пользователя).
Внутренний раздел это та часть, которая не видна его пользователю. Данный раздел содержит все те ресурсы, которые позволяют поставщику предоставлять облачные вычислительные службы, такие как серверы, системы хранения и виртуальные машины. Основная стоящая за внутренним разделом идея состоит в поручении необходимого управления всей такой системой отдельному центральному серверу, который таким образом имеет постоянно отслеживаемый обмен и запросы от пользователей, осуществляя управление доступом и реализацию протоколов взаимодействия.
Помимо различных составляющих такой архитектуры наиболее важным выступает Гипервизор, также имеющий название Диспетчера виртуальных машин. Это встроенное ПО, которое динамически выделяет ресурсы и также позволяет вам совместно использовать один экземпляр между множеством пользователей. Короче говоря, это именно та программа, которая и реализует виртуализацию, что и составляет одно из основных свойств облачного вычисления.
После предоставления определения облачного вычисления и пояснения существенных функциональных возможностей мы введём ту модель обслуживания, в которой могут предоставляться службы облачных вычислений.
Все предлагаемые службы облачных вычислений распадаются на три широкие категории:
-
SaaS - Software as a Service
-
PaaS - Platform as a Service
-
IaaS - Infrastructure as a Service
Эта классификация ведёт к определению некой схемы имеет название модели SPI (см. выделенные Жирным заглавные буквы из предыдущего перечня). Порой она именуется также стеком облачных вычислений, поскольку эти категории основываются одна на другой.
Сейчас мы приведём подробное описание каждого из этих уровней, следую походу рассмотрения сверху вниз.
SaaS
SaaS предоставляет пользователям программные приложения в виде служб, которые доступны через любое подключённое к интернету устройство, такое как браузер. Более того, сам поставщик размещает это прикладное программное обеспечение и лежащую в его основе инфраструктуру, освобождая своего потребителя от ноши управления и сопровождения таких действий как обновления программного обеспечения и самого приложения исправлениями безопасности.
Существует множество преимуществ использования такой модели как для пользователя, так и для самого поставщика. Для конкретного пользователя имеется значительное снижение в стоимости управления, а для поставщика решения имеется дополнительный контроль над всем обменом, позволяя тем самым ему избегать каких бы то ни было перекрытий. Неким примером SaaS выступают любые службы электронной почты на основе веб интерфейса, такие как Gmail, Outlook, Salesforce и Yahoo!.
PaaS
В отличии от SaaS, эти службы относятся ко всей среде разработки некого приложения, а не просто к его использованию. Таким образом, решение PaaS предоставляет некую облачную платформу, которая доступна через веб браузер для необходимых разработки, тестирования и управления программными приложениями. Более того, сам поставщик предоставляет интерфейсы на веб основе, архитектуру со множеством арендаторов и инструменты взаимодействия чтобы позволить разработчикам создавать приложения простым образом. Это поддерживает весь жизненный цикл такого программного обеспечения, а также поощряет к содружеству.
Примерами PaaS являются Microsoft Azure Services, Google App Engine и Amazon Web Services.
IaaS
IaaS это модель, которая предлагает необходимую вычислительную инфраструктуру как некую службу по запросу. Вы можете таким образом приобретать некие виртуальные машины, в которых вы можете запускать своё собственное программное обеспечение, ресурсы хранения (с возможностью быстрого увеличения или уменьшения объёма хранения на основе своих потребностей), сетевых сред и Операционных систем на основе оплаты реального использования. Некая динамичная инфраструктура такого вида добавляет отличное масштабирование, в то же время значительно снижая стоимости.
Такая модель используется как небольшими развивающимися компаниями, которые не обладают значительным капиталом для инвестиций, а также уже состоявшимися компаниями, ищущими обтекаемой формы своих аппаратных архитектур. Имеющийся диапазон продавцов IaaS чрезвычайно широк и включает Amazon Web Services, IBM и Oracle.
Архитектуры облачных вычислений не являются одинаковыми. По существу, имеется четыре модели распространения:
-
Public cloud - ощедоступные облака
-
Private cloud - частные облака
-
Cloud community - облачные сообщества
-
Hybrid cloud - Гибридные облака
Общедоступное облако
Эта модель распределения доступна всем, как индивидуальным пользователям, так и компаниям. Обычно такое общедоступное облако запущено в неком Центре обработки данных (ЦОД, DC), которым владеет поставщик услуг, обслуживающий оборудование, программные средства и прочие инфраструктуры поддержки. Таким образом, конечный пользователь освобождён от каких бы то ни было действий/ затрат на сопровождение.
Частное облако
Также именуемые внутренними облаками, частные облака предлагают те же самые преимущества, что и общедоступные облака, но предоставляют больший контроль над данными и процессами. Эта модель представляется как некая облачная инфраструктура, которая работает исключительно для какой- то компании и таким образом управляется и размещается в пределах границ такой компании. Очевидно, что использующие его организации могут расширять архитектуру для любой группы, которая соединена некими бизнес- связями.
Принимая на вооружение подобное решение, можно избежать проблем, связанных с нарушением конфиденциальности данных и промышленным шпионажем, не забывая о возможности использования упрощённой, настраиваемой и высокопроизводительной системы оеспечения работ. Именно по этой причине в последние годы существенно растёт число компаний, использующих частное облако.
Облачное сообщество
Концептуально данная модель описывает некую совместно используемую инфраструктуру, которая реализуется и управляется несколькими компаниями с общими интересами. Этот тип решения часто применяется по причине того что становится сложным разделение ответственностей и действий по управлению по различным участникам данного облачного сообщества.
Гибридное облако
NIST определил его как результат композиции всех трёх упомянутых выше моделей реализации (частной, общедоступной и облачного сообщества) в попытке получения преимуществ каждой из трёх чтобы компенсировать прочие слабые стороны. Применяемые облака остаются различными объектами, а это может приводить к отсутствию операционной согласованности. Поэтому перед компаниями, которые используют данную модель, лежит задача обеспечения за счёт частных технологий совместимости их серверов, оптимизации их под определённые роли, которые они должны выполнять.
Особенность, которая отличает гибридное облако от всех прочих, состоит в выплёскивании в облако, или в возможности перенесения избыточного обмена из частного облака в общедоступное облако при наличии большого пикового запроса.
Эта модель реализации применяется теми компаниями, которые намерены совместно использовать свои программные приложения, оставляя чувствительные сведения во внутренних облаках.
Платформы облачных вычислений являются наборами программного обеспечения и технологий, которые включают доставку ресурсов в само облако (по запросу, масштабируемо и в виде виртуальных ресурсов). Среди наиболее популярных платформ - платформы Google и, естественно, веха облачных вычислений: AWS (Amazon Web Services). Обе поддерживают Python в качестве языка программирования для разработки.
Тем не менее, в своём следующем рецепте мы сосредоточимся на PythonAnywhere, который является некой облачной платформой разработки специально для развёртывания веб приложений на языке программирования Python.
PythonAnywhere является средой интерактивной разработки и обслуживания на основе языка программирования Python. Зарегистрировавшись один раз на их сайте, вы будете направлены в свою инструментальную панель, которая содержит современную оболочку и текстовый редактор, целиком выполненные в коде HTML. При помощи этого вы имеете возможность создавать, изменять и выполнять свои собственные сценарии.
Более того, эта среда разработки также позволяет вам выбирать с какой версией Python работать. В ней простой мастер помогает нам с предварительной настройкой некого приложения.
Для началя давайте получим полномочия регистрации на этом сайте.
Приводимый ниже снимок экрана показывает различные типы подписок, а также возможность получения бесплатной учётной записи (пройдите, пожалуйста, по ссылке):
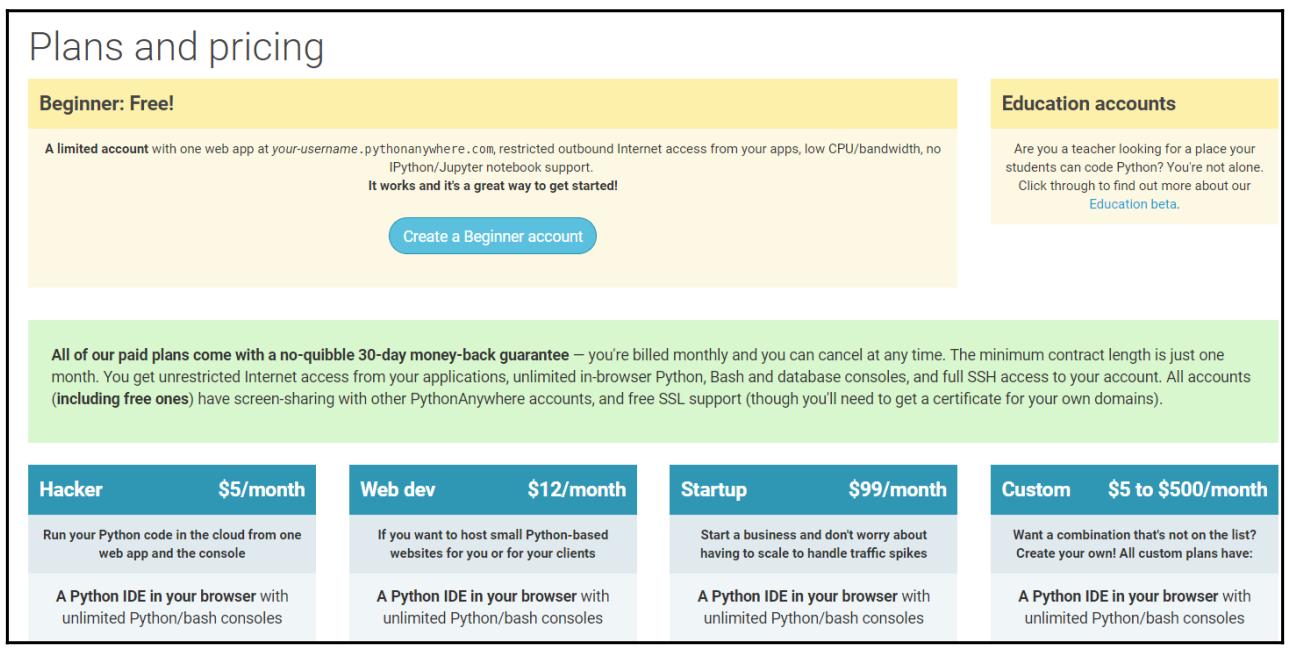
После получения доступа к данной площадке (мы рекомендуем вам создать некую учётную запись начинающего), мы регистрируемся. Принимая во внимание, что интегрированные в браузер оболочки Python очень полезны, в особенности для начинающих и для вводных курсов по программированию, они, несомненно, не новы с технологической точки зрения.
Вместо этого, дополнительная ценность PythonAnywhere начинает ощущаться сразу после того как вы входите в систему, получая доступ к персональной панели инструментов:
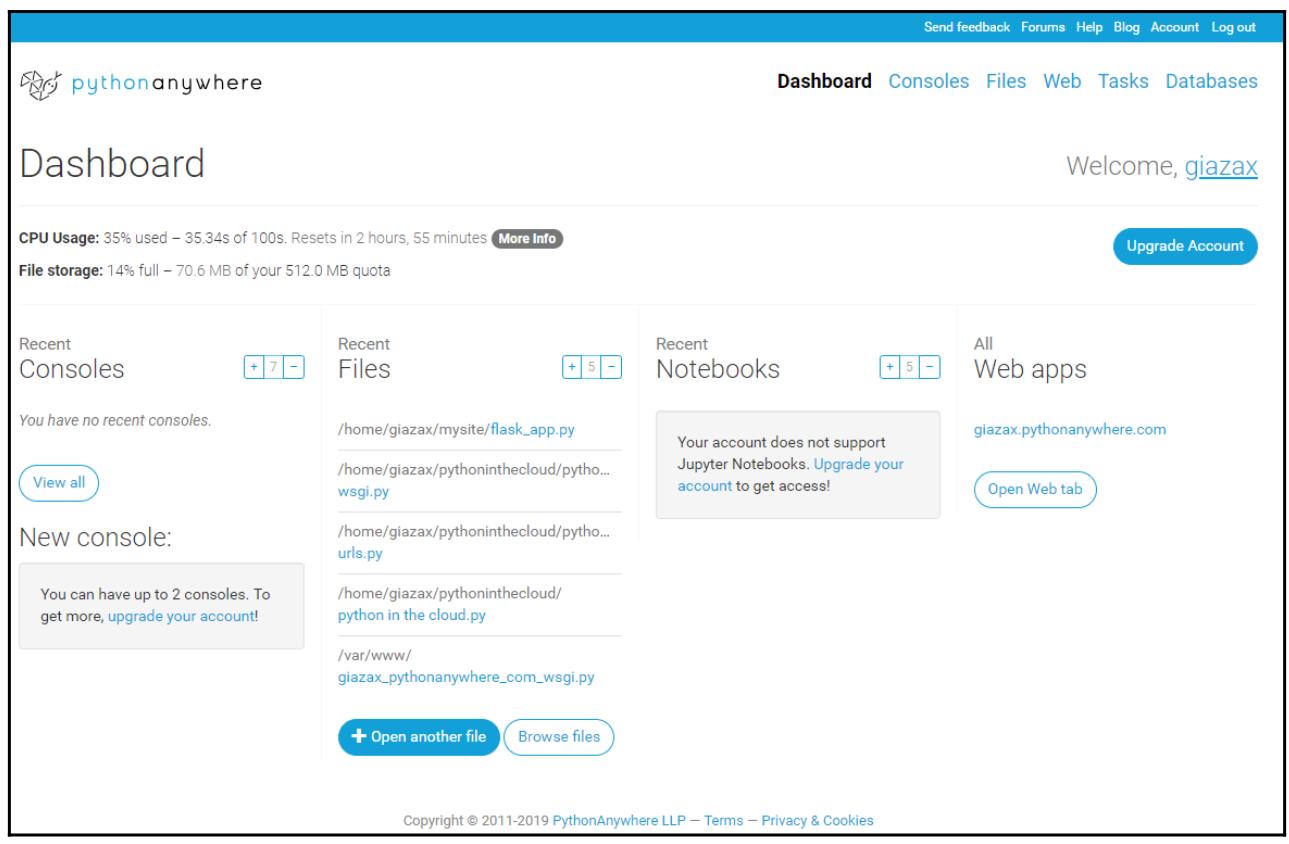
Посредством этой персональной панели инструментов мы можем выбрать какую именно версию Python запускать из 2.7 и 3.7, причё с интерфейсом IPython или без него:
Общее число доступных для использования консолей изменяется в зависимости от имеющегося у вас типа подписки. В нашем случае, обладая учётной записью начинающего, мы можем применять максимально две консоли Python. Выбрав оболочку Python, скажем, с версией 3.5, в вашем веб браузере должно открыться такое окно просмотра:
В своём следующем разделе мы хотим показать вам как применять PythonAnywhere для написания простого веб приложения.
Давайте рассмотрим следующие шаги:
-
находясь в Dashboard, откройте закладку Web:
-
Данный интерфейс сообщает нам что у нас нет ещё пока веб приложений. Выбрав Add a new web app, мы откроем следующее окно просмотра. Оно сообщит нам, что наши приложения будут иметь следующий веб адрес:
loginname.pythonanywhere.com(для данного примера веб адресом приложения выступаетgiazax.pythonanywhere.com):
-
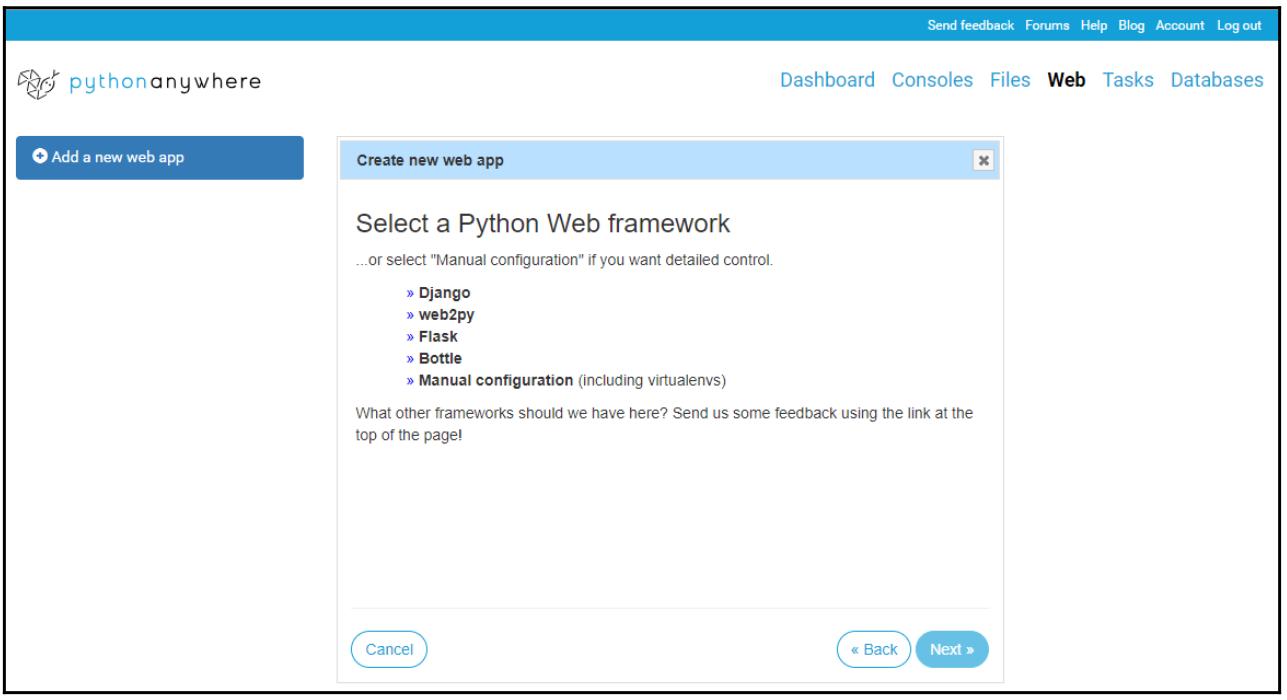
Когда мы кливкаем по Next, мы можем выбрать веб инфраструктуру Python, которую мы бы желали использовать:
-
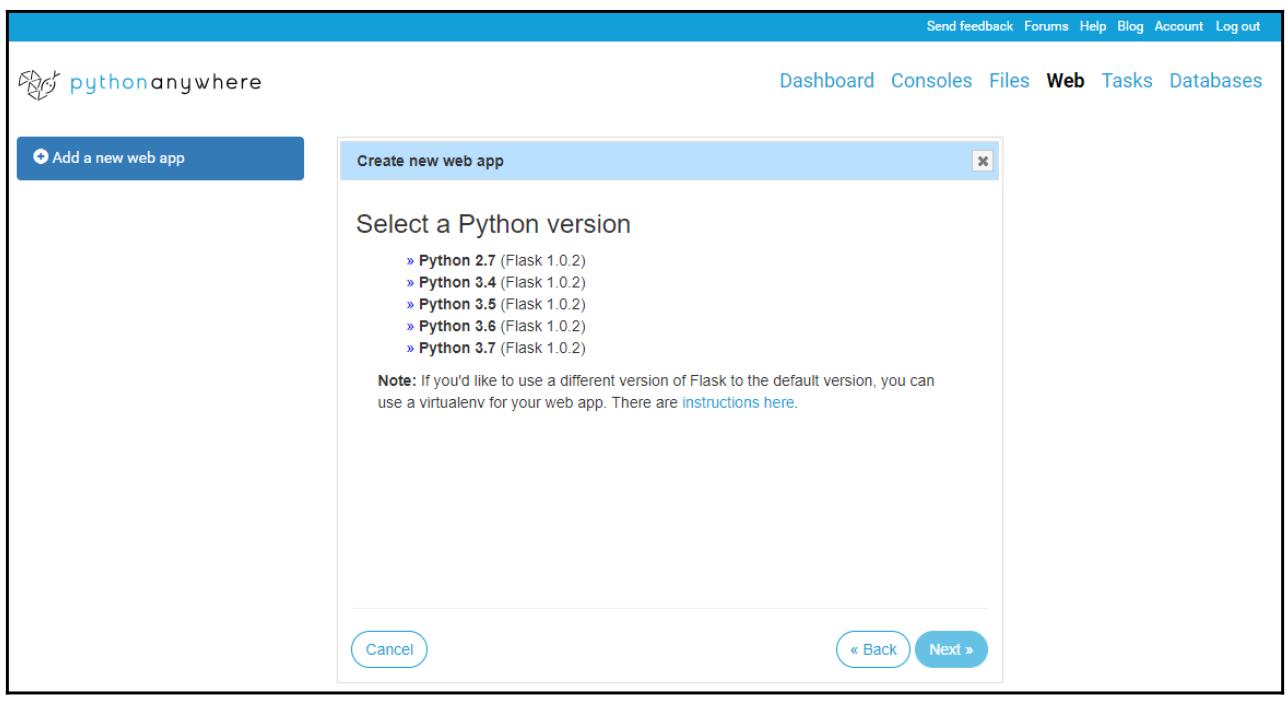
Мы выбираем в качестве веб инфраструктуры Flask, а затем жмём на Next чтобы выбрать ту версию Python, которой мы бы хотели воспользоваться здесь:
Flask является микро- инфраструктурой для Python, которая проста в установке и применении и используется такими компаниями как Pinterest и LinkedIn.
![[Замечание]](/common/images/admon/note.png)
Замечание Если вы желаете знать что представляет собой инфраструктура для создания веб- приложений, вы можете представить себе некий набор программ с целью облегчения разработки веб- служб, таких как веб серверы и интерфейсы API. Более подробные сведения относительно Flask можно найти по следующей ссылке.
-
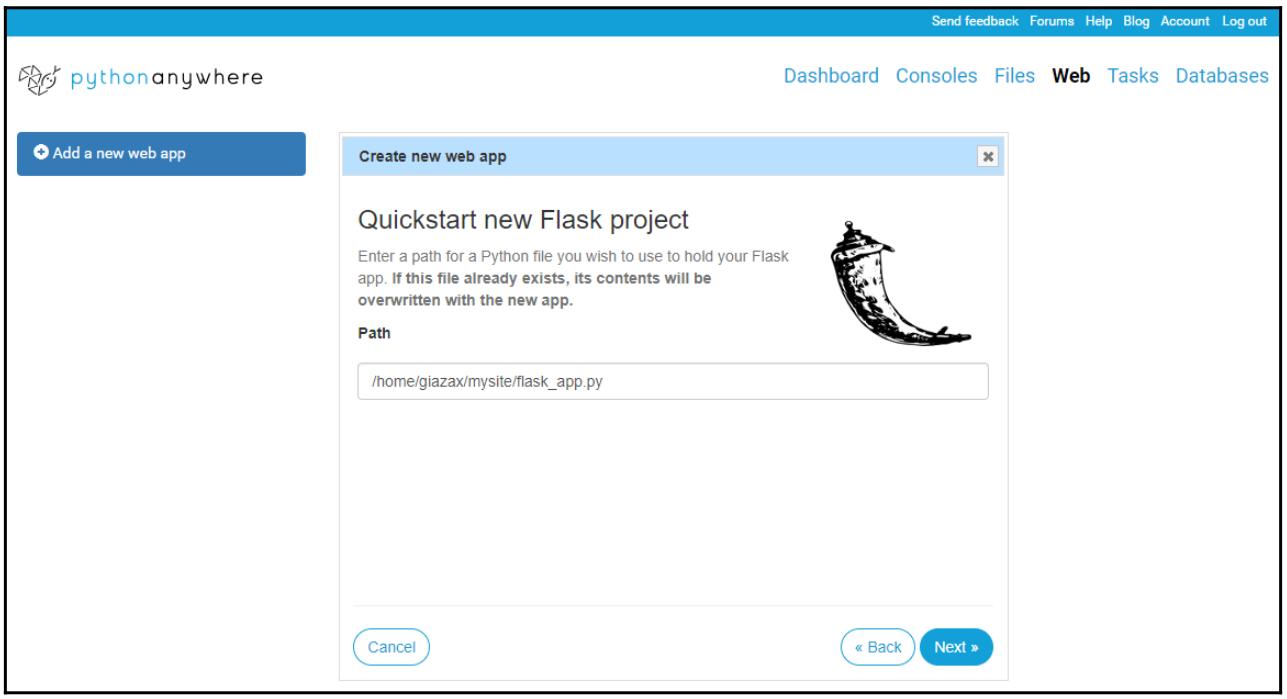
В своём предыдущем снимке экрана мы выбрали Python 3.5 для Flask 1.0.2, а затем кликнули по Next чтобы войти в необходимый путь файла Python чтобы применять его для размещения нашего приложения Flask. Здесь выбран устанавливаемый по умолчанию файл:
-
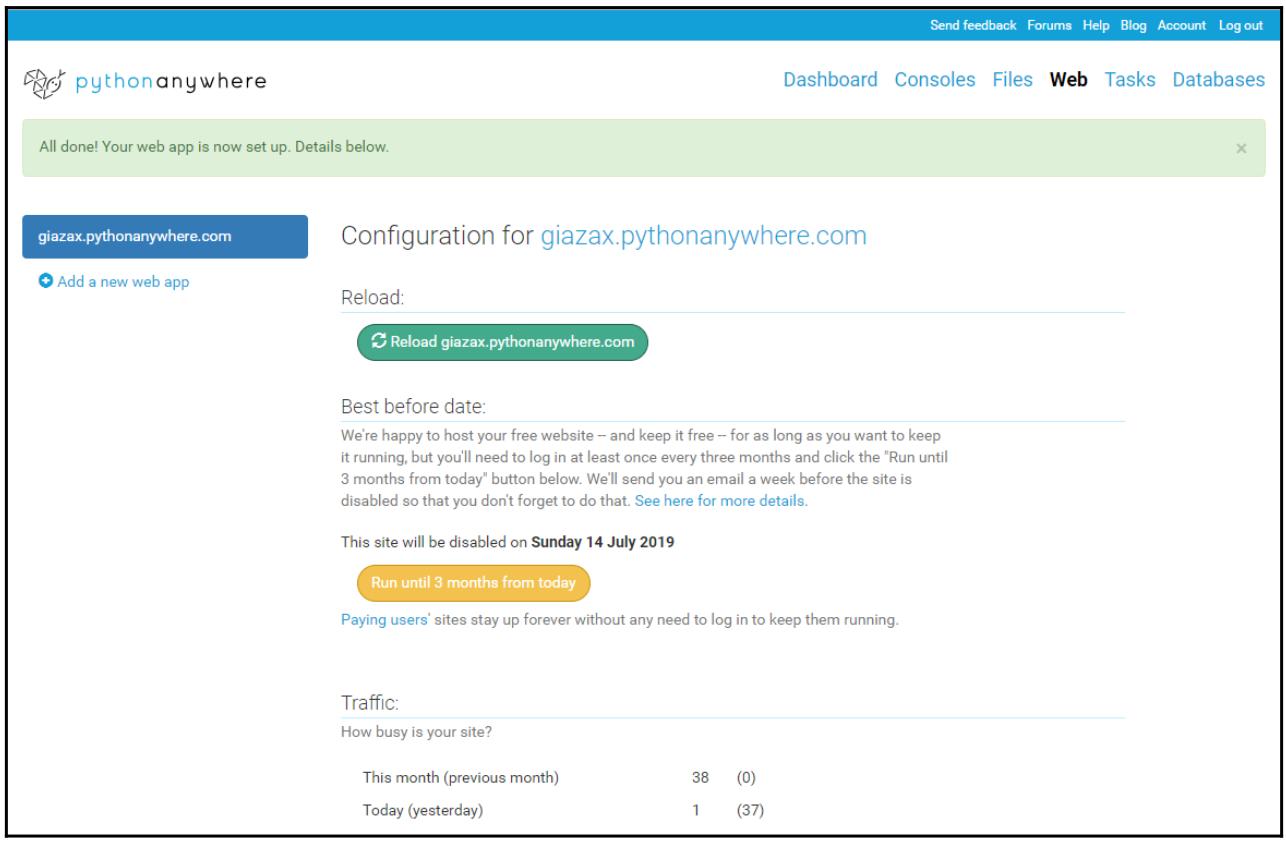
Когда мы кликаем по Next в последний раз, отображается следующий экран, который суммирует параметры настройки для нашего веб приложения:
Теперь мы рассмотрим что у нас получилось.
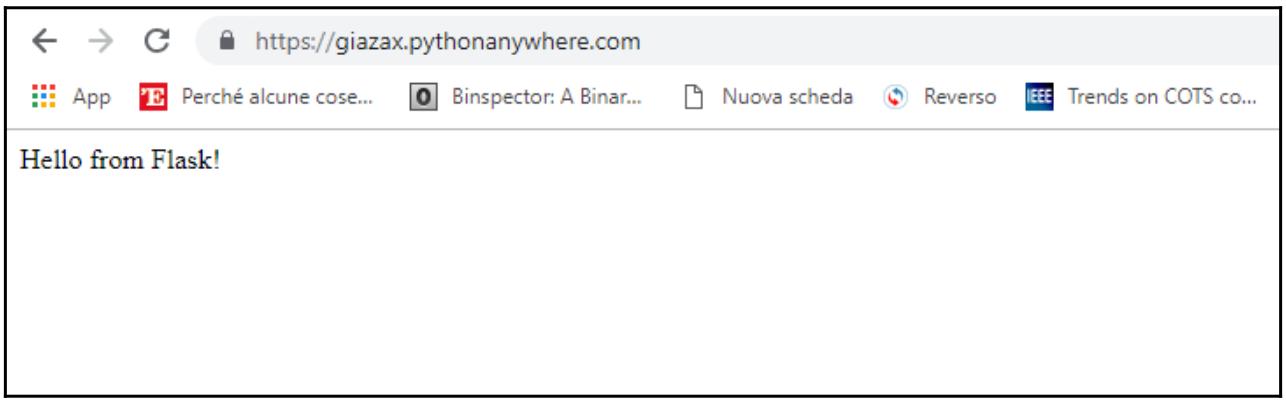
В адресной полосе своего веб браузера наберите URL нашего веб приложения, в нашем случае
https://giazax.pythonanywhere.com/. Этот сайт покажет простую
фразу приветствия:
Наш исходный код для данного приложения можно увидеть выбрав Go to directory в соответствии со значением метки Source code:
Здесь можно проанализировать те файлы, которые мы сделали для своего веб приложения:
Также имеется возможность загрузки новых файлов и возможность изменения содержимого. В данном случае мы
выбираем flask_app.py в качестве своего первого веб приложения. Его содержимое
выглядит как минимальное приложение Flask:
# A very simple Flask Hello World app for you to get started with...
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello from Flask!'
Декоратор route() применяется Flask для задания значения URL, которое
должно включать нашу функцию hello_world. Эта простейшая функция возвращает данное
отображаемое в нашем веб браузере сообщение.
Сам PythonAnywhere выполнен на HTML, что делает его переносимым по множеству платформ и браузеров, включая мобильные версии Apple. Имеется возможность удерживать открытыми определённые оболочки (с различным числом в соответствии с выбранным профилем учётной записи), разделять их с прочими пользователями или прекращать их в случае необходимости.
PythonAnywhere обладает достаточно современным текстовым редактором с расцветкой синтаксиса и автоматической расстановкой отступов, посредством которого вы обладаете возможностью создавать, изменять и выполнять свои собственные сценарии. Все файлы сохраняются в области хранения различного размера в зависимости от установленного для вашей учётной записи профиля, однако если вам недостаточно места, или вы желаете более плавной интеграции с файловой системой вашего ПК, тогда PythonAnywhere позволяет вам применять учётную запись Dropbox, создавая для вас разделяемую папку, доступную через эту популярную службу хранения.
Каждая оболочка может содержать сценарий WSGI, который соответствует конкретному URL. Также имеется возможность запуска оболочки bash, в которой вы можете вызывать Git и взаимодействовать с его файловой системой. Наконец, как мы можем видеть, имеется некий мастер, который позволяет нам предварительно настраивать приложение Django, web2py или Flask.
Более того, имеется возможность эксплуатации базы данных MySQL, что является последовательностью заданий cron, которые позволяют нам периодически исполнять определённые сценарии. Следовательно, мы получим истинную сущность PythonAnywhere: разработку веб приложения со скоростью света.
PythonAnywhere целиком полагается на инфраструктуру
Amazon EC2, поэтому нет никаких причин не доверять данной
службе. Поэтому она настоятельно рекомендуется для тех, кто задумывается о персональном использовании. Обсуждавшаяся
учётная запись начинающего предлагает больше ресурсов, чем соответствующие в Heroku, развёртывание проще чем для
OpenShift, а получаемая целиком система, как правило, гораздо более гибкая чем
Google App Engine.
Что касается Flask, вам рекомендуется посетить эти площадки для получения сведений как работать с этими библиотеками.
Контейнеры выступают средой виртуализации. Они содержат всё что требуется программному обеспечению, а именно: библиотеки, зависимости, файловые системы и сетевые интерфейсы. В отличии от классических виртуальных машин, все вышеупомянутые элементы совместно используют общее ядро в той машине, в которой они запущены. Таким образом, снижается воздействие на использование ресурсов самого хоста.
Это делает контейнеры крайне привлекательной технологией в плане масштабируемости, производительности и изоляции. Контейнеры не являются юной технологией; они были с успехом запущены Docker в 2013. {Прим. пер.: не стоит также забывать и наших соотечественников Virtuozzo, Parallels, aka SWSoft, одними из первых представившими контейнеры ещё в первой половине 2000-х.} Начиная с этого момента они полностью перевернули все стандарты, применяемые для разработки приложений и управления ими. {Прим. пер.: подробнее о докеризации на примере Rails.}
Докер является контейнерной платформой, основанной на реализации LXC (Linux Containers) и которая расширяет данную технологию возможностью управления контейнерами как самостоятельно наполняемыми образами, а также добавила инструменты для координации их жизненного цикла и сохранения их состояния. {Прим. пер.: так в тексте. На самом деле, начиная с версии 0.9 Docker содержит собственный компонент, libcontainer для непосредственного управления предлагаемых ядром Linux средств виртуализации (cgroup), дополнительно к применению интерфейсов абстракции виртуализации libvirt, LXC и systemd-nspawn.}
Основная идея контейнеризации состоит именно в том, чтобы разрешить выполнение данного приложения в любой системе, поскольку все её зависимости уже содержатся в самом контейнере.
Таким образом, подобное приложение становится обладающим высокой переносимостью и легко может проверяться и развёртываться в любом типе окружения, причём как на собственной площадке, так и помимо всего и в облачном решении.
Теперь давайте рассмотрим как осуществить докеризацию приложения Python с применением Docker.
Основное чутьё команды Docker состояло в том, чтобы взять свою концепцию контейнера и выстроить некую экосистему вокруг неё с тем, чтобы упростить его применение. Эта экосистема содержит некую последовательность инструментов:
Установка Docker for Windows
Вся установка достаточно проста: после того как вы выгрузите необходимый установщик, просто запустите его и это всё что вам требуется. Данный процесс установки в целом очень прямолинеен. Единственный момент, который требует внимания, так это завершающая стадия установки, которая может потребовать включения функциональности Hyper-V. Если это так, мы примем это и перезапустим свою машину. {Прим. пер.: Windows Server 2019 содержит лицензию на Docker Enterprise, который может быть вытащен и запущен без необходимости посещения Docker Hub, см. наш перевод 2 издания Полного руководства Windows Server 2019 Джордана Краузе. Кроме того, Windows Server 2019 имеет поддержку MobyVM и LCOW, которые позволяют контейнерам Linux работать на хосте контейнеров Windows Server, даже работая бок о бок с контейнерами Windows!}
После того как ваш компьютер перезапущен, в трее вашей системы должна появится иконка Docker в нижней правой части экрана.
Откройте приглашение командной строки или консоль PowerShell и убедитесь что всё хорошо, выполнив команду
docker version:
C:\> docker version
Client: Docker Engine - Community
Version: 18.09.2
API version: 1.39
Go version: go1.10.8
Git commit: 6247962
Built: Sun Feb 10 04:12:31 2019
OS/Arch: windows/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 18.09.2
API version: 1.39 (minimum version 1.12)
Go version: go1.10.6
Git commit: 6247962
Built: Sun Feb 10 04:13:06 2019
OS/Arch: linux/amd64
Experimental: false
Наиболее интересной частью в этом выводе является подраздел, который делается между самим клиентом и его сервером. Таким клиентом является наша локальная система Windows, в то время как сервером выступает та виртуальная машина Linux, которую Docker установил за сценой. Эти части взаимодействуют друг с другом благодаря уровню имеющемуся API, как это уже упоминалось во введении в данный рецепт.
Теперь давайте рассмотрим как контейнеризовать (докеризовать) простое приложение Python.
Давайте предположим, что мы хотим развернуть следующее приложение Python, которое мы назовём
dockerize.py:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
if __name__ == "__main__":
app.run(host="0.0.0.0", port=int("5000"), debug=True)
Данный пример приложения применяет уже знакомый нам модуль Flask. Он
реализует некое простейшее веб приложение с локальным адресом, {по порту} 5000.
Самый первый шаг состоит в создании следующего текстового файла с расширением .py,
который мы обзовём Dockerfile.py:
FROM python:alpine3.7
COPY . /app
WORKDIR /app
RUN pip install -r requirements.txt
EXPOSE 5000
CMD python ./dockerize.py
Перечисленный в предыдущем примере директивы выполняют следующие задачи:
-
FROM python: alpine3.7: указывает Docker на необходимость использования Python с версией 3.7. -
COPYкопирует наше приложение в имеющийся образ контейнера. -
WORKDIRустанавливает значение рабочего каталога (WORKDIR). -
Инструкция
RUNвызывает установщикpip, указывая для него файлrequirements.txt. Он содержит список зависимостей, которые обязано использовать данное приложение (в нашем случае этоflask). -
Директива
EXPOSEвыставляет значение того порта, который применяетflask.
Итак, в сумме мы написали три файла:
-
Подлежащее упаковке в контейнер приложение:
dockerize.py -
Dockerfile -
Файл списка зависимостей
В итоге нам требуется создать некий образ для своего приложения dockerize.py:
docker build --tag dockerize.py
Это пометит тегом мой образ my-python-app и построит его.
После того как построено приложение my-python-app, мы можем запустить его
в качестве контейнера:
docker run -p 5000:5000 dockerize.py
Далее наше приложение запускается в виде контейнера, после чего соответствующий параметр названия отсылает значение
названия этого контейнера, а параметр -p устанавливает соответствие значения
порта хоста 5000 порту этого контейнера 5000.
Затем нам следует открыть свой веб браузер, перейти в полосу адреса и набрать
localhost:5000. Если все отработало правильно, тогда вы должны обнаружить
следующую веб страницу:
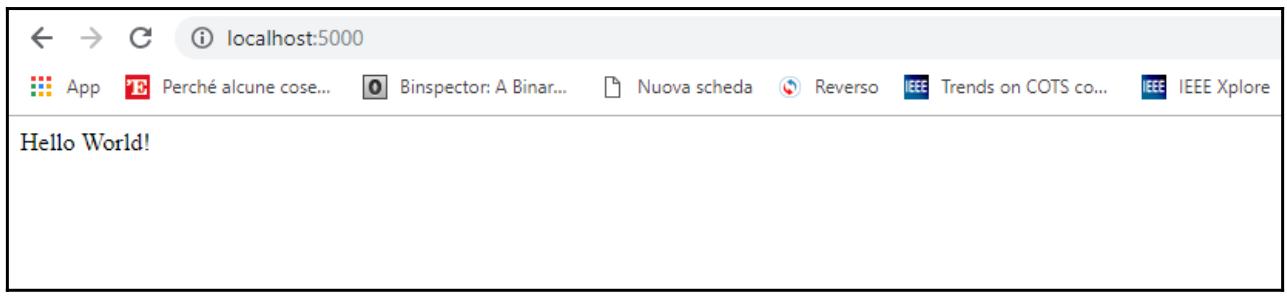
Docker запустил контейнер dockerize.py при помощи команды
run и результатом этого получено некое веб приложение. Наш образ содержит
все инструкции, которые требуются для работы с этим контейнером.
Взаимоотношения между контейнером и образом можно понять на примере парадигмы объектно- ориентированного программирования, связывающей получаемый образ с неким классом, а такой контейнер как результирующий экземпляр класса.
Будет полезным кратко повторить то что произошло при создании некого экземпляра контейнера:
-
Необходимый образ нашего контейнера (если он ещё не присутствует) загружается локально.
-
Создаётся некая среда, в которой запускается данный контейнер.
-
На ваш экран выводится сообщение.
-
Предварительно созданная среда затем остаётся брошенной.
Всё это происходит в несколько секунд, причём в некой простой, интуитивно ясной и доступной для чтения команде.
По всей видимости, контейнеры и виртуальные машины представляются очень похожими понятиями. Но хотя эти два решения и имеют общие характеристики, они представляют собой совершенно разные технологии, поэтому мы обязаны начинать представлять их себе как различные архитектуры наших приложений. Мы способны создать контейнер со своим монолитным приложением внутри него, но таким образом мы не будем в полной мере использовать всю силу контейнеров, а следовательно и Docker.
Возможная пригодная для контейнеров программная архитектура является классической архитектурой микрослужб. Основная идея состоит в разбиении своего приложения на множество небольших компонентов - каждое для соей собственной задачи - которые способны обмениваться сообщениями и сотрудничать друг с другом. Развёртывание таких компонентов затем будет происходить индивидуально, причём в виде множества контейнеров.
Некий сценарий, который может обрабатываться микрослужбами, совершенно не практичен для виртуальных машин, в силу того что каждому новому устанавливаемому экземпляру новой виртуальной машины потребуется достаточно значительные издержки в мощности для его машины хоста. Контейнеры, с другой стороны, обладают очень малым весом, так как они ответственны за совершенно иную виртуализацию от той, которую практикуют виртуальные машины:
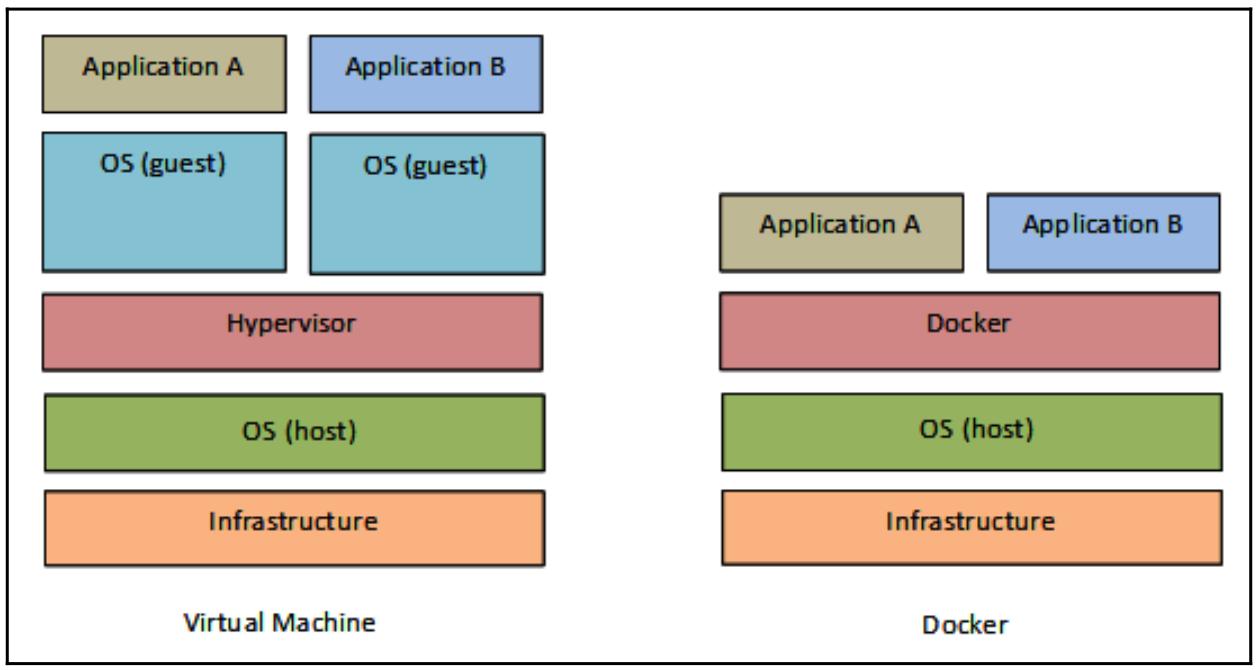
В виртуальных машинах некий инструмент с названием Гипаервизор заботится о резервировании (статическом или динамическом) определённого объёма ресурсов из ОС хоста для выделения одной или более ОС, имеющих название гостевых или размещаемых (hosts). Гостевая ОС будет целиком изолирована от ОС самого хоста. Такой механизм чрезвычайно затратен в плане ресурсов, а потому мысли сочетания микрослужб с какими- то виртуальными машинами совершенно невозможна.
С другой стороны контейнеры вносят в эту задачу совершенно иной вклад. Их изоляция намного более прозрачна, и все запущенные контейнеры совместно используют одно и то же ядро, что и сама базовая ОС. Затраты гипервизора целиком исчезают и один хост способен размещать сотни контейнеров.
Когда мы просим Docker запустить некий контейнер из его образа, он должен быть представлен на имеющемся локальном диске, в противном случае Docker выдаст нам сообщение о возникшей проблеме (с содержимым, которое читается как Unable to find image 'hello-world: latest' locally - не способен обнаружить локально 'hello-world: latest''hello-world: latest') и будет его выгружать в автономном режиме.
Чтобы отыскать какие образы были выгружены из Docker в наш компьютер, мы пользуемся командой
docker images:
C:\> docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
dockerize.py latest bc3d70b05ed4 23 hours ago 91.8MB
<none> <none> ca18efb44b3c 24 hours ago 91.8MB
python alpine3.7 00be2573e9f7 2 months ago 81.3MB
Данный репозиторий это контейнер относящихся к нему образов. Например, репозиторий
dockerize содержит различные версии докеризованных образов. В мире Docker термин
tag является более правильным для применения выражения
данного понятия сопровождения версий образов. В нашем предыдущем примере, данный образ был помечен тегом в качестве
самого последнего и при этом единственного тега, доступного для репозитория dockerize.
Самый последний (latest) тег является устанавливаемым по умолчанию тегом: всякий
раз когда мы ссылаемся на некий репозиторий без определения названия его тега, Docker будет подразумевать ссылку на на
этот тег latest, а когда он отсутствует, будет отображаться некая ошибка. Таким
образом, в качестве рекомендации, форма со значением тега репозитория будет более предпочтительной, так как она
позволяет лучше предсказывать соответствующее содержимое данного образа, избегая возможных конфликтов между контейнерами
и ошибок по причине отсутствия тега latest.
Технологии контейнеров очень обширное понятие, которое можно изучить, ознакомившись с многочисленными статьями и примерами приложений в Интернете. Однако, прежде чем начинать это долгое и трудное путешествие, желательно начать с основного веб- сайта, который является полным и абсолютно информативным.
{Прим. пер.: по нашему мнению великолепным образчиком для уяснения самой технологии разработки приложений на основе Docker может служить наш перевод Docker для разработчиков Rails Роб Айзенберг, в которой Rails запросто может быть заменён пытливым умом на любую иную инфраструктуру разработки - например, TensorFlow. Для тех, кто интересуется управлением очень больших количеств контейнеров, в том числе с автоматической балансировкой нагрузки, высокой доступностью и прочим, рекомендуем знакомство с перевод основных глав из Полного руководства Kubernetes Джиджи Сэйфана (2е издание).}
В своём следующем разделе мы изучим основные свойства безсерверных вычислений, основная цель которых состоит в том чтобы упростить для разработчиков программного обеспечения составление разрабатываемого кода для его запуска в некой облачной платформе.
В последние годы была разработана новая модель служб с названием FaaS (Function as a Service), которая также именуется как безсерверные вычисления (serverless computing).
Безсерверные вычисления это парадигма облачных вычислений, которая позволяет выполнять приложения не заботясь о проблемах, относящихся к лежащей ниже инфраструктуре. Сам термин безсерверное облако может быть несколько обманчивым; на самом деле его следует понимать так, что данная модель не предусматривает использование серверов обработки. На практике это указывает на то, что предоставление, масштабирование и управление теми серверами, в которых исполняются ваши приложения администрируются в автоматическом режиме и при этом совершенно прозрачным образом для самого разработчика. Всё это стало возможным благодаря новой архитектурной модели, носящей название безсерверной.
Самая первая модель относится к тем дням, когда Amazon реализовала свою службу AWS Lambda в 2014. Со временем дополнительно к решению Anazon появились прочие альтернативы, которые были разработаны основными производителями, такими как Microsoft с их Azure Functions, а также IBM и Google с их собственными Cloud Functions. Также существуют допустимые решения с открытым исходным кодом: из наиболее широко применяемых у нас имеются Apache OpenWhisk, которая используется IBM в их Bluemix для своего безсерверного предложения, а также OpenLambda и IronFunctions, причём последняя основывается на контейнерной технологии Docker.
В данном рецепте мы рассмотрим как реализовать безсерверную функцию Python через span class="term">AWS Lambda.
AWS это целый класс облачных служб, которые предлагаются и администрируются через некий общий интерфейс. Этот общий интерфейс, через который могут быть предложены такие службы в соответствующей веб консоли AWS можно достичь по ссылке.
Данный вид служб является платным. Однако на самый первый год доступен некий свободный слой. Это некий набор служб, использующих минимум ресурсов и его можно бесплатно применять для целей оценки таких служб, а также для разработки приложений.
|
| Замечание |
|---|---|
|
Для получения дополнительных сведений о том, как создать некую бесплатную учётную запись в AWS, будьте любезны ознакомиться с официальной документацией Amazon. |
В этом разделе мы обозначим основы запуска кода в AWS Labmda без необходимости предоставления каких бы то ни было
серверов или управления ими. Мы покажем создание в Лямбда функции Hello World
с применением консоли AWS Lambda. Мы также поясним как вручную вызывать функцию Лямбда применяя простые сведения о
событии и как интерпретировать получаемые на выходе параметры. Все показываемые нами в данном руководстве действия
могут быть выполнены как часть подобного свободного плана в
https://aws.amazon.com/free.
Мы рассмотрим следующие шаги:
-
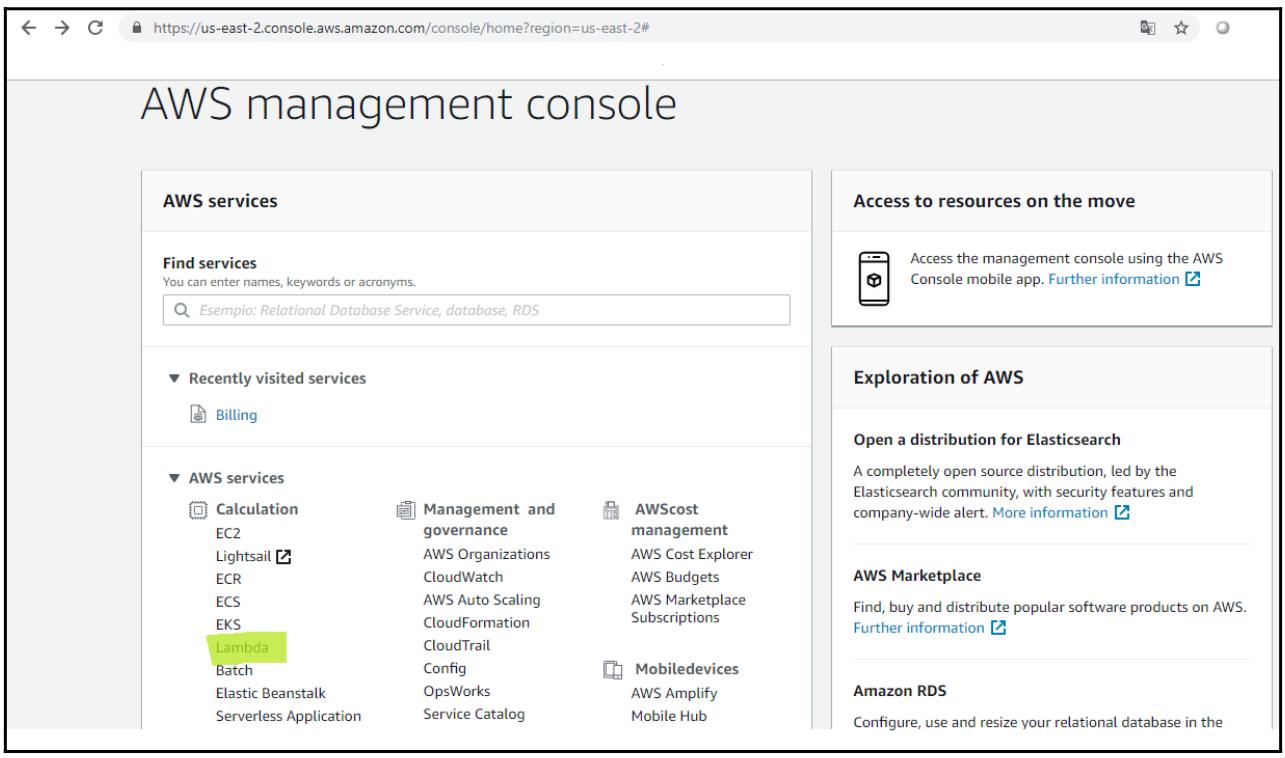
Прежде всего мы зарегистрируемся в консоли Лямбда. Затем вам потребуется определиться с местоположением и выбрать Lambda в вычислениях чтобы открыть необходимую консоль AWS Lambda (которая выделена зелёным на следующем снимке экрана):
-
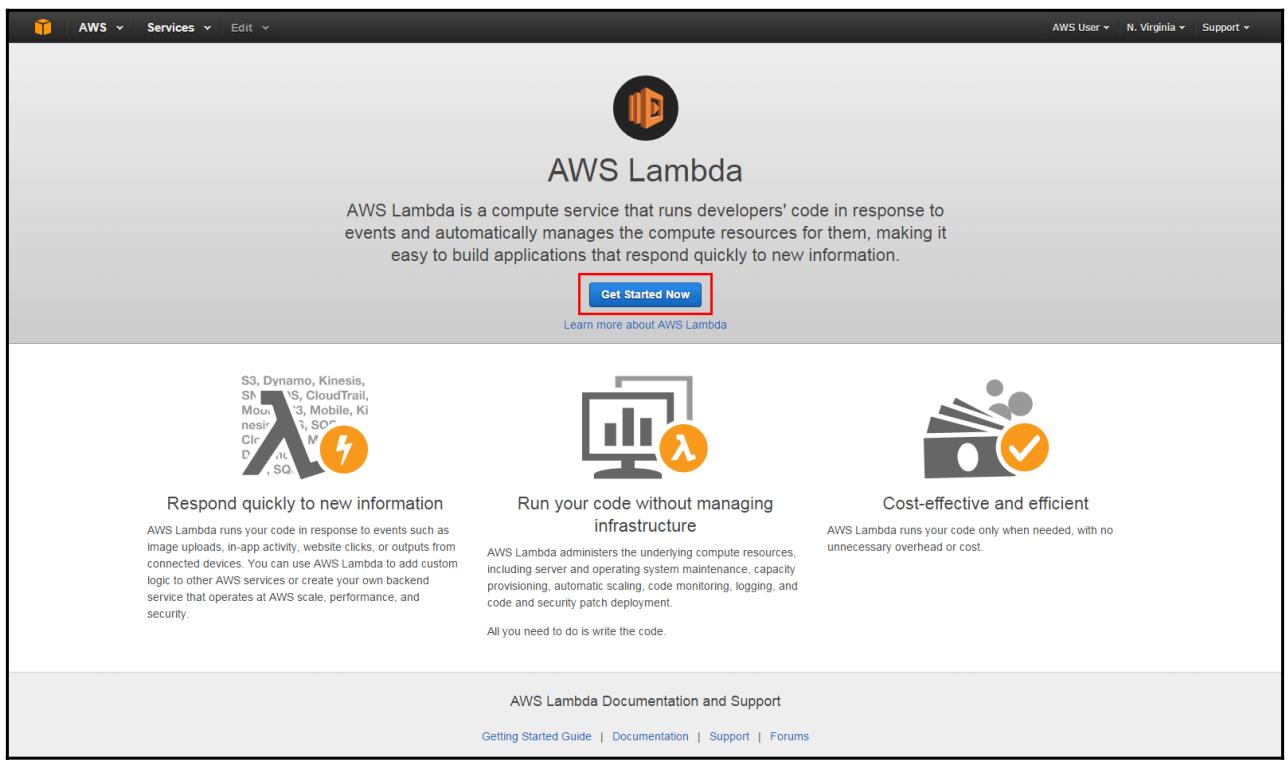
Затем в жтой консоли AWS Lambda выберите Get Started Now и вслед за этим создайте некую функцию Лямбда:
-
В своём блоке фильтрации наберите
hello-world-pythonи выберите копирку hello-world-python. -
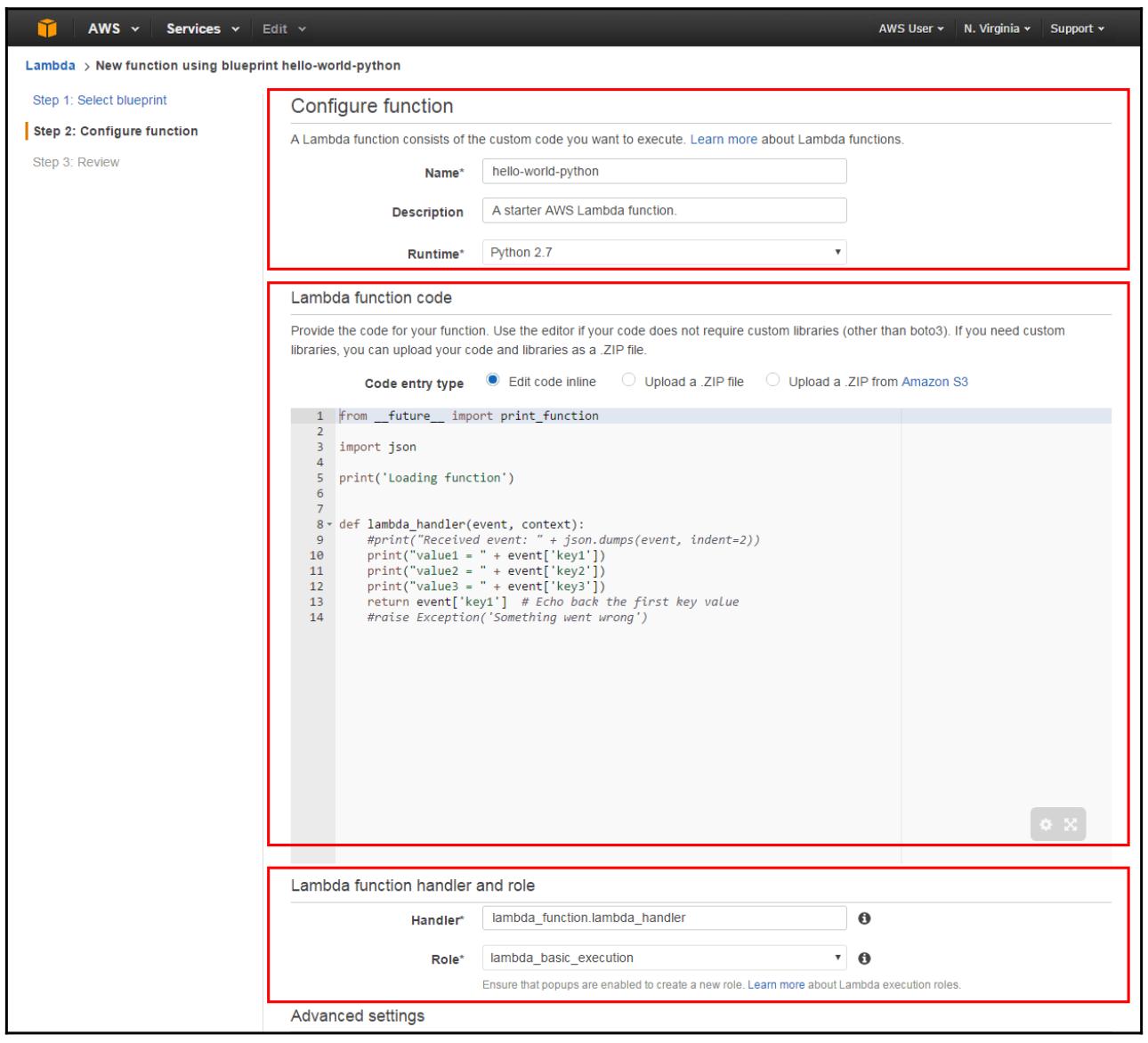
Теперь требуется настроить нашу функцию Лямбда. Наш следующий список показывает настройки и предоставляет образцы значений:
-
Функции настройки:
-
Name: Введите здесь название для своей функции. В данном руководстве мы применяем
hello-world-python. -
Description: Здесь вы можете вводить краткое описание данной функции. Этот блок имеет предварительную установку с фразой A starter AWS Lambda Function.
-
Runtime: На данный момент имеется возможность написанияя необходимого кода Лямбда функции в Java, Node.js, а также Python 2.7, 3.6 и 3.7. Для целей данного руководства мы настраиваем средой исполнения Python 2.7.
-
-
Код лямбда функции:
-
Как вы можете видеть на приводимом далее снимке экрана, имеется возможность просмотра примера нашего кода Python.
-
-
Обработчик и роль функции Лямбда:
-
Handler: Вы можете определить некий метод, в котором AWS Lambda может запускать на исполнение данный код. AWS Lambda предоставляет данные событий в качестве входа того обработчика, который будет обрабатывать эти события. В нашем примере Лямбда указывает на события из рассматриваемого примера кода, а потому данное поле будет компилироваться с lambda_function.lambda_handler.
-
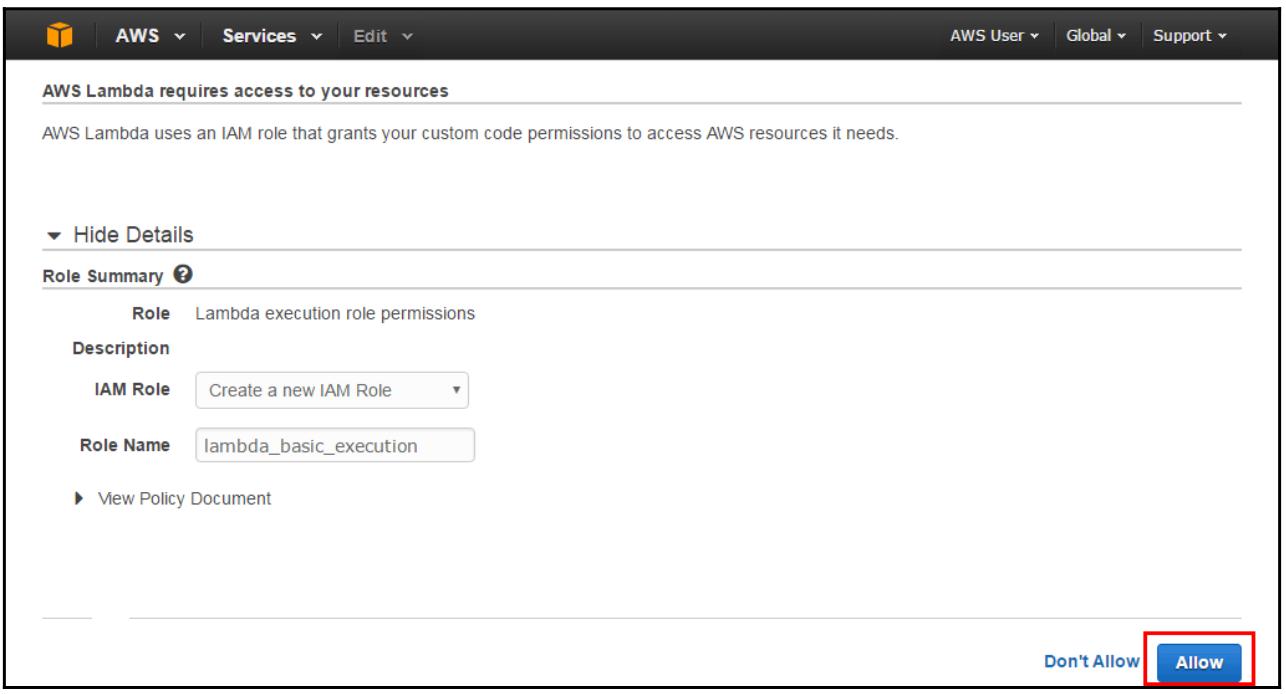
Role: Кликните по ниспадающему меню и выберите Basic Execution Role:
-
-
-
На данный момент необходимо создать некую роль для исполнения (имеющую название IAM Role) с необходимой авторизацией для интерпретации AWS Lambda в качестве исполнителя данной Лямбда функции. Кликнув по Allow, вы получите результатом страницу Configure function и будет выбрана функция lambda_basic_execution:
-
Данная консоль сохраняет весь код в сжатом файле, что представляется в его пакете распространения. Эта консоль далее загружает полученный пакет распространения в AWS Lambda для создания необходимой функции Лямбла:
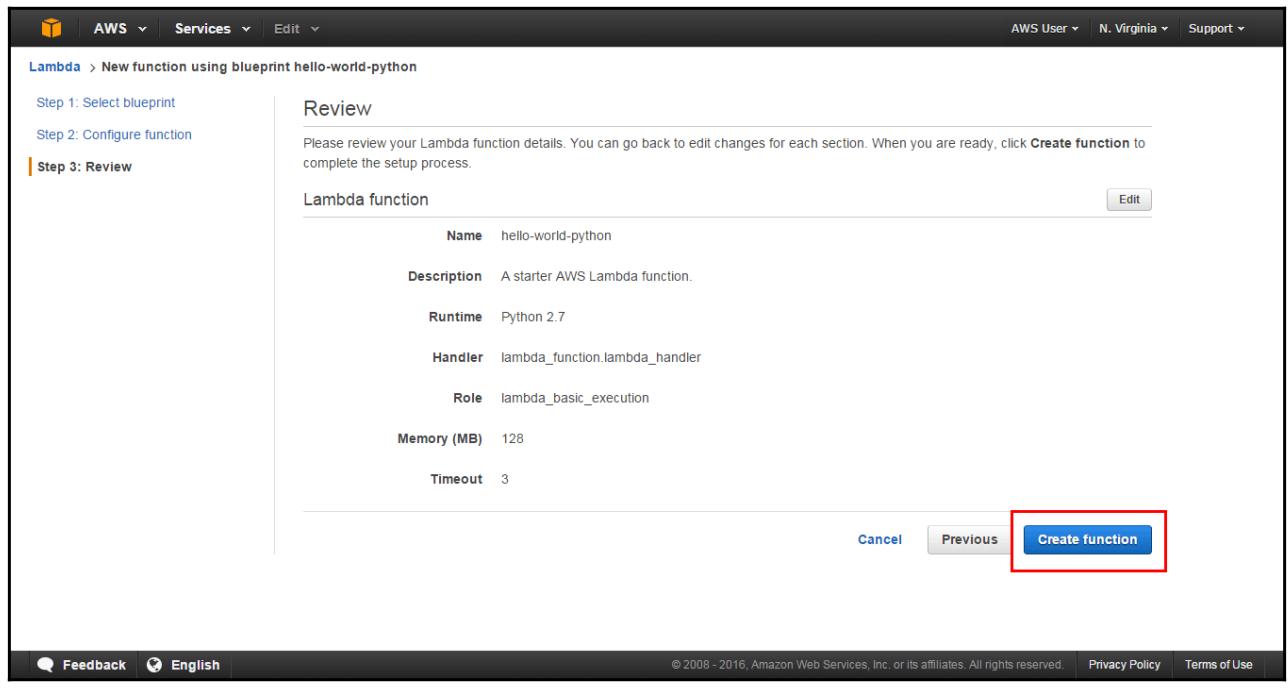
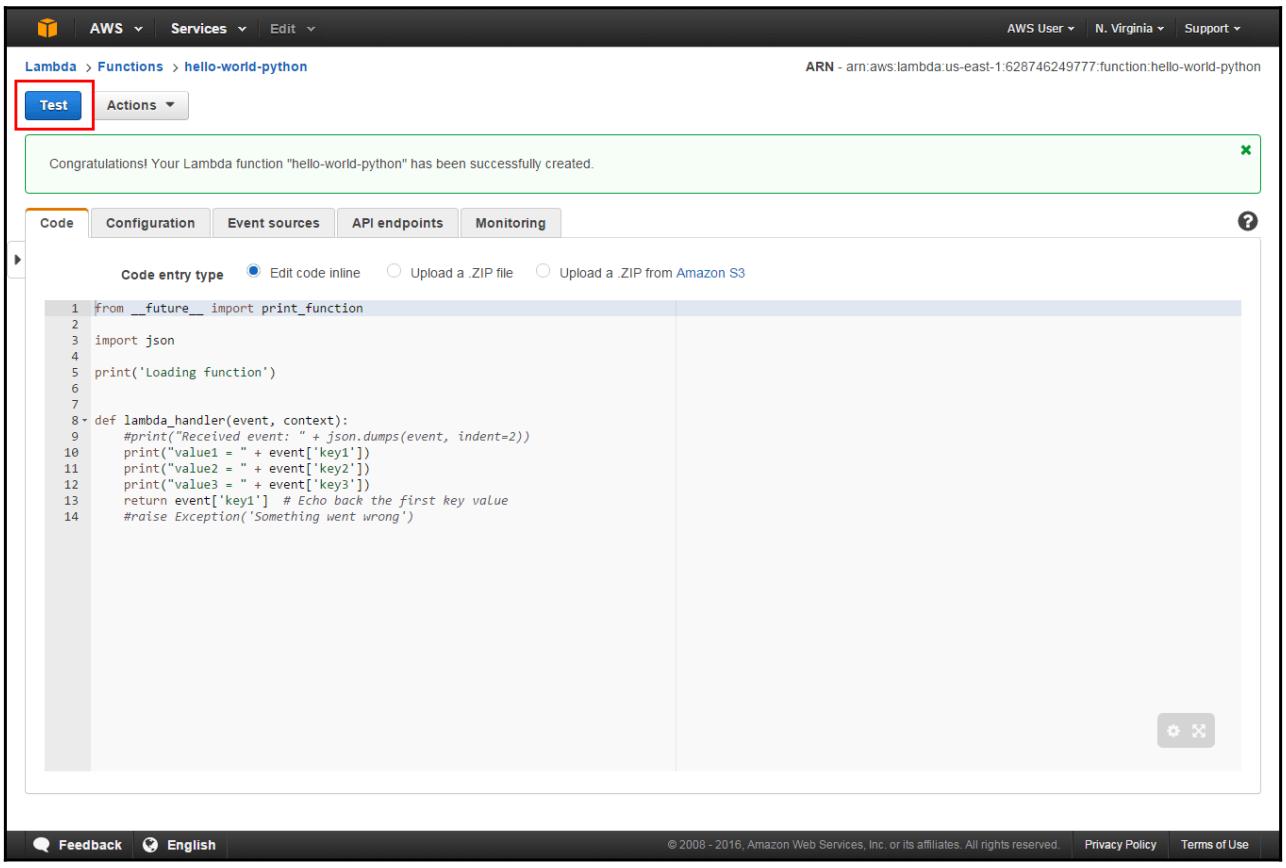
Теперь у нас имеется возможность проверки этой функции, сверки результатов и отображения регистрационных записей:
-
для запуска самой первой Лямбда функции, кликните по Test:
-
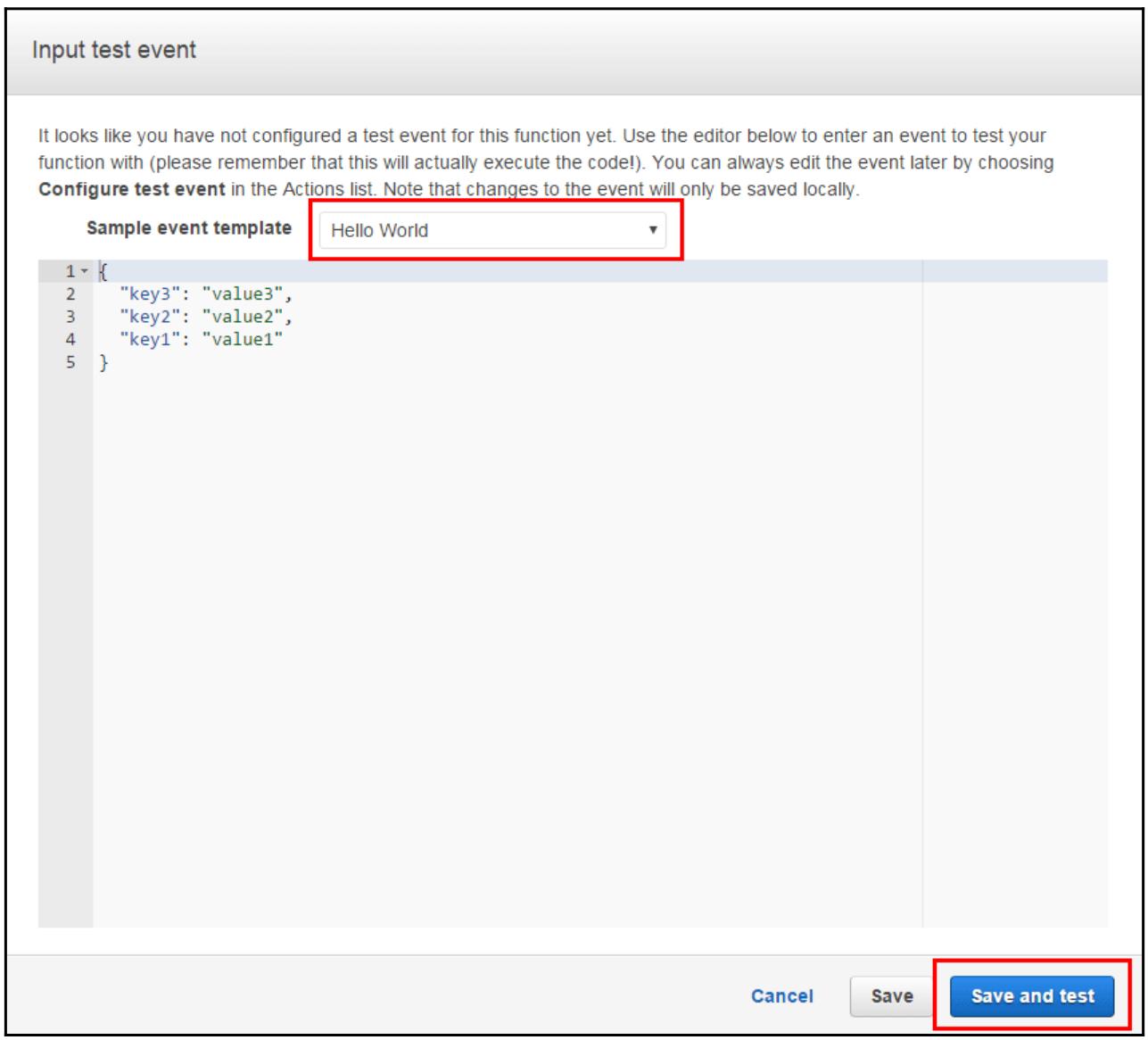
Во всплывающем редакторе введите некое событие для проверки своей функции.
-
Выберите из перечня Sample event template Hello World в соответствующей странице Input test event:
Кликните по Save and test. Затем AWS Lambda вцыполнит данную функцию от вашего имени.
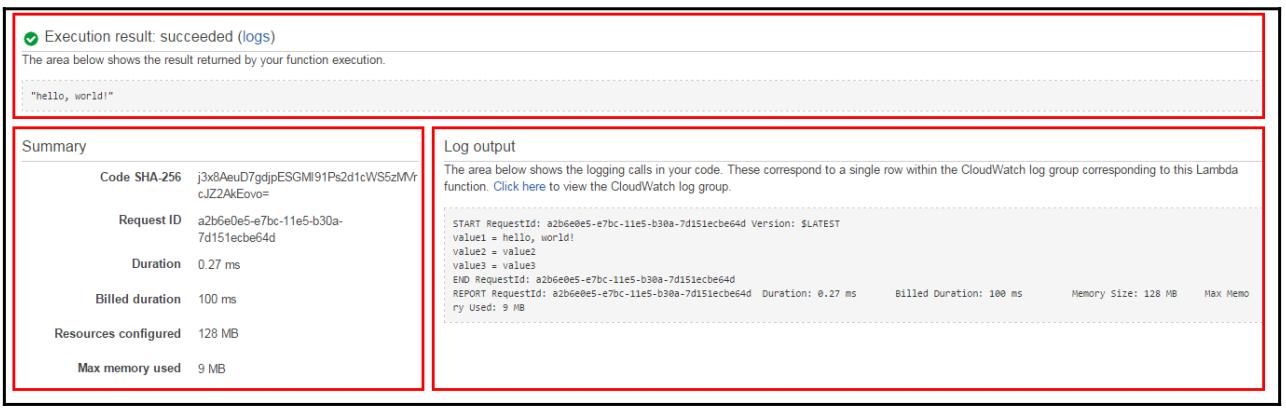
Когда выполнение завершится, имеется возможность просмотреть в своей консоли полученные результаты:
-
Раздел Execution result документирует правильность выполнения данной функции.
-
Раздел Summary показывает наиболее важные сведения из отчёта в разделе Log output.
-
Раздел Log output отображает все зарегистрированные записи исполнения вашей функции Лямбда:
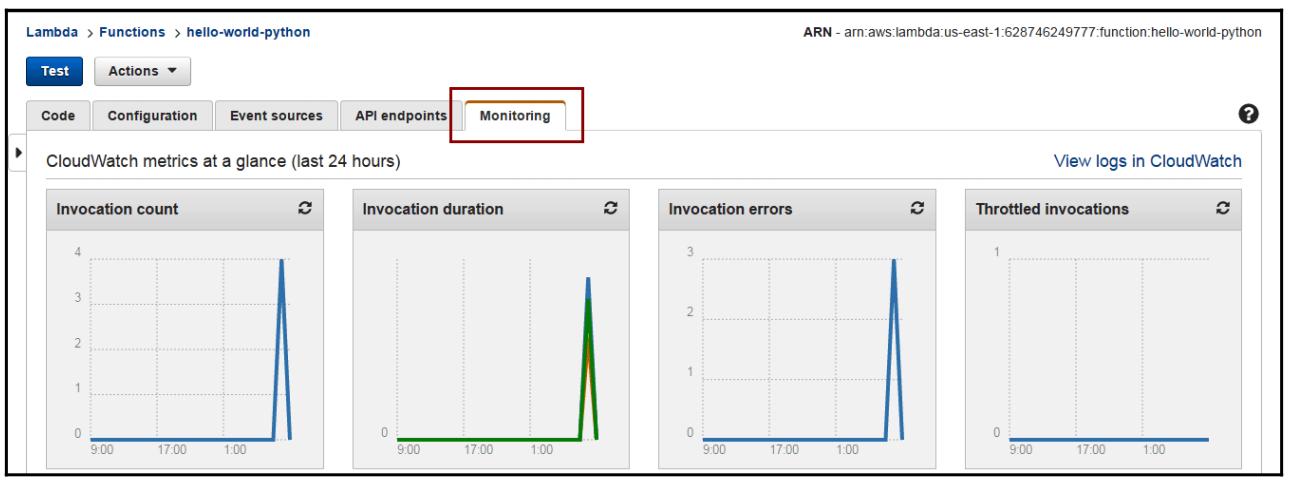
AWS Lambda отслеживает все функции и автоматически вырабатывает параметры отчётов через Amazon CloudWatch (смотрите на приводимом ниже снимке экрана). Для упрощения мониторинга вашего кода в процессе его исполнения, AWS Lambda автоматически отслеживает общее число запросов, значение задержки для каждого запроса, а также общее число запросов с ошибками, которые публикуются со связанными с ними параметрами:
Что такое функция Лямбда?
Функция Лямбда содержит код, который разработчик желает выполнить в ответ на некое событие. Сам разработчик заботится о настройках данного кода и определении необходимых требований в плане ресурсов внутри своей предоставляемой поставщиком консоли. Всё остальное, включая определение размера ресурсов, автоматически управляется поставщиком услуги на основе требований рабочей нагрузки.
Почему без сервера?
Преимущества безсерверного решения следующие:
-
Отсутствие управления инфраструктурой: Разработчики могут сосредоточиться на самом выстраиваемом продукте вместо того чтобы работать с серверами времени исполнения и управлять ими.
-
Автоматическое масштабирование: Все ресурсы автоматически калибруются чтобы справляться с любым типом рабочих нагрузок, причём без необходимости настроек масштабирования, а просто в качестве реакции на события в реальном масштабе времени.
-
Оптимизация использования ресурсов: Так как сама обработка и ресурсы хранения выделяются автоматически, больше нет необходимости в дальнейшем инвестиций в лишние мощности.
-
Снижение стоимости: При обычных облачных вычислениях плата за используемые ресурсы ожидается даже когда они в реальности не применяются. В случае безсерверного решения ваше приложение движимо событиями, что означает, что когда код не выполняется, никакая плата не взимается, поэтому вам не приходится платить за не используемые ресурсы.
-
Высокая доступность: Те службы, которые управляют данной инфраструктурой и вашим приложением, гарантируют высокую доступность и устойчивость к отказам.
-
Улучшение выхода на рынок: Исключение затрат на управление инфраструктурой позволяет разработчикам сосредоточиться на качестве продукта и быстрее привносит свой код в промышленное использование.
Возможные проблемы и ограничения
Существуют некие обманки, которые следует принимать во внимание при оценке приемлемости безсерверных вычислений:
-
Возможность утраты производительности: Когда ваш код не используется очень часто, тогда могут возникать некие проблемы с задержками в его исполнении. Они важны по сравнению с теми случаями, кода он постоянно исполняется в сервере, виртуальной машине или контейнере. Это происходит по той причине, что (в отличие от того что происходит при применении политик автоматического масштабирования) для модели без серверов поставщик облачного решения полностью высвобождает ресурсы в случае когда данный код не используется. Это подразумевает, что когда запуск требует какого- то времени, то на начальном этапе неизбежно появляется дополнительная задержка.
-
Режим без сохранения состояния: Безсерверные функции работают в режиме без сохранения состояния. Это означает, что когда вы желаете добавить логику сохранения неких элементов, таких как параметры для передачи аргументов в некую другую функцию, тогда вам требуется добавлять компонент какого- то постоянного хранилища в поток вашего приложения и соединять эти события друг с другом. Например, Amazon предоставляет некий дополнительный инструмент с названием AWS Step Functions, который координирует значения состояния и управляет ими для всех микрослужб и распределённых компонентов безсерверных приложений.
-
Ограничения на ресурсы: Безсерверные вычисления не годятся для некоторых видов рабочих нагрузок или вариантов использования, в частности, для высокопроизводительных вычислений и для ограничений в применении ресурсов, которые предоставляются поставщиком облачного решения (к примеру, AWS ограничивает общее число одновременно запущенных Лямбда функций). Это обусловлено как самой сложностью в предоставлении такого числа желательных серверов в неком размере, так и фиксацией периода времени.
-
Отладка и мониторинг: Когда вы полагаетесь на решения с открытым исходным кодом, тогда разработчики будут зависеть от производителей приложений отладки и мониторинга, а следовательно не смогут подробно диагностировать какие- либо проблемы с помощью дополнительных профилировщиков или отладчиков. Следовательно, им придётся полагаться на инструменты, предоставляемые соответствующим поставщиком услуг.
Как мы уже отмечали, отправной точкой для работы с безсерверными архитектурами является сама инфраструктура (AWS). По предыдущему URL вы сможете отыскать множество сведений и руководств, включая описанный в данном разделе пример. {Прим. пер.: также обращаем внимание на перевод кое- каких глав (2-5) из Kubernetes для приложений без сервера Русса МакКендрика.}