Глава 5. Построение веб рассылки с микрослужбами
Содержание
- Глава 5. Построение веб рассылки с микрослужбами
- Цели TempMessenger
- Требования
- Что такое Nameko?
- Создание вашей первой службы Nameko
- Поблочное тестирование микрослужбы Nameko
- Выставление точек входа HTTP
- Интегрированная проверка микрослужб Nameko
- Запоминание сообщений
- Поставщики зависимостей Nameko
- Накопление сообщений
- Выборка всех сообщений
- Отображение сообщений в веб браузере
- Отправка сообщений через запросы POST
- Срок действия сообщений в Redis
- Сортировка сообщений
- Опрос браузера для сообщений
- Выводы
В современном мире разработки приложений Микрослужбы основным стандартом в планировании и проектировании распределённых систем. Такие компании как Netflix выступили первопроходцами в этом сдвиге и революционизировали тот способ, при помощи которого работают компании разработчики программного обеспечения, начиная с небольших автономных команд вплоть до разработки систем, которые просты для масштабирования.
В данной главе я буду руководить вами в процессе создания двух микрослужб,которые будут работать совместно для обмена сообщениями, которые применяют Redis в качестве некоего хранилища данных. Сообщения будут автоматически истекать по прошествию настроенного периода времени, поэтому в качестве цели данной главы давайте назовём его TempMessenger.
В этой главе мы обсудим следующие темы:
-
Что такое Nameko?
-
Создание вашей первой микрослужбы Nameko
-
Запоминание сообщений
-
Поставщики зависимостей Nameko
-
Сохранение сообщений
-
Выемка всех сообщений
-
Отображение сообщений в вашем веб браузере
-
Отправка сообщений через запросы
POST -
Опрос браузера относительно сообщений
Перед тем как мы приступим, давайте определим цели своего приложения:
-
Пользователь может заходить на вебсайт и отправлять сообщения
-
Пользователь может видеть отправленные прочими сообщения
-
У сообщений автоматически истекает срок после настроенного промежутка времени
Для достижения этого мы будем применять Nameko - некий каркас микрослужб для Python.
![[Замечание]](/common/images/admon/note.png) | Замечание |
|---|---|
|
Если в любой момент на протяжении данной главы вы пожелаете ознакомиться со всем кодом из этой главы целиком у вас есть возможность просмотреть его и попробовать по ссылке http://url.marcuspen.com/github-ppb. |
Для участия в действиях данной главы ваша локальная машина должна соответствовать следующему:
-
Иметь подключение к Интернет
-
Docker - если у вас ещё не установлен Docker, ознакомьтесь с официальной документацией: http://url.marcuspen.com/docker-install.
Все прочие требования будут устанавливаться по мере освоения нами данной главы.
Все инструкции в данной главе были отработаны в системах macOS или Debian/Ubuntu. Тем не менее, я предпринимал все усилия в заботе пользоваться только зависимостями переносимыми между платформами.
|
| Замечание |
|---|---|
|
На протяжении данной главы будут встречаться блоки кода. Различные типы кода будут иметь свои собственные префиксы, которые будут следующими:
|
Nameko это инфраструктура с открытым исходным кодом, применяемая для построения микрослужб а Python. Используя Nameko вы можете создавать микрослужбы, которые взаимодействуют друг с другом при помощи RPC (Remote Procedure Calls) через AMQP (Advanced Message Queueing Protocol).
RPC является сокращением Remote Procedure Call (удалённым вызовом процедур) и я кратко поясню это на коротком примере, основанном на системе заказов билетов в кино. Внутри такой системы заказов билетов в кино имеется множество микрослужб, однако мы сосредоточимся именно на службе бронирования, которая отвечает за заказ, а также службу обмена электронными почтовыми сообщениями, которая отвечает за отправку таких сообщений. Служба заказов билетов и служба обмена электронной почтой обе существуют на различных машинах и обе не осведомлены о том где расположена другая. При выполнении нового бронирования службе резервирования требуется отправить некое подтверждение электронным письмом своему пользователю, поэтому она делает Удалённый вызов процедуры (RPC) для своей службы электронной почты, который может выглядеть примерно так:
def new_booking(self, user_id, film, time):
...
self.email_service.send_confirmation(user_id, film, time)
...
Заметили ли в предыдущем коде что наша система бронирования делает свой вызов так, как если бы она исполняла код, который был для неё локальным? Он не заботится о наличии сетевой среды или её протокола и даже не входит в подробности на какой именно электронный почтовый адрес следует выполнять отправку. Для нашей службы бронирования адреса электронной почты и любые прочие понятия, относящиеся к электронной почте неуместны! Это позволяет данной службе бронирования твёрдо придерживаться Принципа единственной ответственности (Single Responsibility Principle), термина, введённого Робертом С. Мартином в его статье (Principles of Object Orientated Design), который постулирует:
"Класс должен иметь одну и только одну причину для изменения"
Сфера действия данной цитаты также может быть расширена и на микрослужбы и иногда мы должны иметь её в уме когда разрабатываем их. Это позволит нам сохранять свои микрослужбы автономными и составляющими единое целое. Если наш контеатр решит сменить своего поставщика электронной почты, тогда единственная служба которую следует изменить это сама служба электронной почты, что сводит нашу работу к минимуму и в свою очередь снижает риск ошибок и возможности времени простоя.
Однако RPC имеет и оборотные стороны при сопоставлении с такими технологиями как REST, самая главная из которых состоит в том, что может быть сложно видеть что некий вызов является удалённым. Можно выполнять не требующиеся удалённые вызовы, не осознавая того что это может быть дорогостоящим удовольствием, так как они проходят через сетевую среду и применяют внешние ресурсы. Поэтому при использовании RPC важно делать их заметно различными.
AMQP является сокращением для Advanced Message Queueing Protocol, который применяется Nameko в качестве транспорта для наших RPC. Когда наши службы Nameko выполняют RPC друг к другу, эти запросы помещаются в соответствующую очередь запросов, которая затем потребляется её лужбой получателем. Службы Nameko применяют исполнителей (workers) для потребления и осуществления запросов; когда делается некий RPC, наша целевая служба породит нового исполнителя для выполнения данной задачи. По завершению он уничтожается. Так может существовать множество исполнителей, которые выполняют задачи одновременно, Nameko может масштабироваться на то количество исполнителей, которое ему доступно. Если все исполнители исчерпаны, тогда сообщения останутся в своей очереди пока не появится свободный исполнитель.
Вы также можете выполнять горизонтальное масштабирование Nameko увеличивая общее количество экземпляров, которые исполняют вашу службу. Это называется кластеризацией и именно отсюда происходит название Nameko, так как грибы Nameko {Прим. пер.: по- нашему опята} растут в кластерах.
Nameko также отвечает за запросы от прочих протоколов, таких как HTTP и веб сокеты.
RabbitMQ применяется в качестве брокера сообщений для Nameko и позволяет применять AMQP. Прежде чем мы начнём, нам нужно установить его на своей машине; для этого мы воспользуемся Docker, который доступен во всех основных операционных системах.
Для тех, кому Docker в диковинку, он позволяет нам исполнять наш код в обособленной, автономной среде, именуемой контейнером. Внутри некоторого контейнера имеется всё что нужно для исполнения данного кода независимо от чего бы то ни было ещё. Вы также можете выгрузить и запустить предварительно построенные контейнеры, и именно так мы собираемся запустить RabbitMQ. Это убережёт нас от установки его в нашей локальной машине и минимизирует то количество проблем, которое может появится от запуска RabbitMQ в различных платформах таких как macOS или Windows.
Если вы ещё не имеете установленным Docker, посетите, пожалуйста, http://url.marcuspen.com/docker-install, где имеются подробные инструкции по установке на всех платформах. На протяжении оставшейся части главы мы предполагаем, что у вас имеется установленный Docker.
Запуск контейнера RabbitMQ
В своём терминале исполните следующее:
$ docker run -d -p 5672:5672 -p 15672:15672 --name rabbitmq rabbitmq
Это запустит контейнер RsbbitMQ со следующими настройками:
-
-d: определяет что вы желаете запустить этот контейнер в режиме демона (как фоновый процесс) -
-з: позволяет выставить порты5672и15672в данном контейнере в нашей локальной машине. Это требуется Nameko для взаимодействия с RabbitMQ. -
--name: Устанавливает название данного контейнера вrabbitmq.
Вы можете убедиться что ваш новый контейнер запущен, выполнив:
$ docker ps
Для данного проекта я применяю Python 3.6, который, на момент написания, является самой последней стабильной версией Python. Я рекомендую всегда применять самую последнюю стабильную версию Python не только из- за новых свойств, но также и для того чтобы гарантировать самые последние обновления безопасности, применяемые к вашей среде во все времена.
|
| Замечание |
|---|---|
|
Pyenv на самом деле простой вариант для установки и переключения между различными версиями Python: http://url.marcuspen.com/pyenv. |
Я также настоятельно рекомендую применять virtualenv для создания некоей изолированной среды установки наших требований Python. Установка Python без виртуальной среды может вызвать нежелательные сторонние эффекты на прочие приложения Python, или и того хуже, на вашу операционную систему!
|
| Замечание |
|---|---|
|
Для дополнительного изучения virtualenv и того как её устанавливать посетите: http://url.marcuspen.com/virtualenv {Прим. пер.: также, рекомендуем Создание виртуальной среды при помощи Python 3.6.x и PEP 405 в нашем переводе отдельных глав "Программирования MQTT на Python" Гастона К. Хайляра, май 2018, Packt Publishing}. |
Обычно, когда вы имеете дело с пакетами Python, вы создаёте некий файл requirements.txt, наполняете его своими
требованиями, а зает устанавливаете их. Я бы хотел показать вам другой способ, который позволит вам просто следовать за отслеживанием версий пакета
Python.
Для начала установите pip-tools внутри вашей virtualenv:
pip install pip-tools
Теперь создайте новую папку с названием requirements и создайте в ней два новых файла:
base.in
test.in
Ваш файл base.in будет содержать все требования, необходимые для самого ядра вашей запускаемой службы, в
то время как файл test.in будет содержать те требования, которые нужны при развёртывании кода в некотором
проекте микрослужбы. Важно сохранять эти требования раздельно, в особенности когда вы развёртываете код в какой- то архитектуре микрослужбы. Это
нормально для наших локальных машин иметь установленными проверяемые пакеты, однако развёртываемая версия нашего кода должна быть настолько минимальной
и легковесно, насколько это возможно.
В файле base.in разместите следующую строку:
nameko
В файле test.in поместите такую строку:
pytest
Если вы находитесь в том каталоге, который содержит вашу папку requirements, запустите следующее:
pip-compile requirements/base.in
pip-compile requirements/test.in
Это создаст два файла, base.txt и test.txtю
Вот небольшой пример base.txt:
...
nameko==2.8.3
path.py==10.5 # via nameko
pbr==3.1.1 # via mock
pyyaml==3.12 # via nameko
redis==2.10.6
requests==2.18.4 # via nameko
six==1.11.0 # via mock, nameko
urllib3==1.22 # via requests
...
Обратите внимание, что у нас теперь имеется файл, который содержит все самые последние зависимости и суб- зависимости Nameko. Он определяет
какие версии требуются, а также что заставляет устанавливать каждую из суб- зависимостей. Например, six
требуется nameko и mock.
на момент написания Nameko имел текущую версию 2.8.3, а Pytest 3.4.0. Не сдерживайте себя от применения самых последних версий этих пакетов при
их доступности, однако если испытаете проблемына протяжении книги, отыграйте обратно к указанным последним номерам версий в своих
base.in или test.in следующим образом:
nameko==2.8.3
Для установки имеющихся требований просто запустите:
$ pip-sync requirements/base.txt requirements/test.txt
Данная команда pip-sync установит все требования, определённые в указанных файлах и при этом также удалит
все пакеты в вашей среде, которые в них не определены. Это прекрасный способ поддержки вашей virtualenv в чистом состоянии. Вы качестве альтернативы
вы также можете применить:
$ pip-sync requirements/base.txt requirements/test.txt
Давайте начнём создавать новую папку с заголовком temp_messenger и поместим в неё новый файл с названием
service.py и следующим кодом:
from nameko.rpc import rpc
class KonnichiwaService:
name = 'konnichiwa_service'
@rpc
def konnichiwa(self):
return 'Konnichiwa!'
Мы начали с импорта rpc из nameko.rpc. Это позволит нам
снабдить свои методы декоратором rpc и выставить его в качестве точки входа в нашу службу. Некая точка входа
является любым методом в службе Nameko, которая действует как шлюз для нашей службы.
Для создания какой- либо службы Nameko мы просто создаём новый класс, KonnichiwaService и выполняем назначение
его атрибута name. Этот атрибут name снабжает нас пространством имён;
оно будет позднее применяться когда мы попытаемся делать удалённый вызов данной службы.
Мы создали в своей службе некий метод, который возвращает слово Konnichiwa! Отметим, что это метод декорирован
при помощи rpc. Данный метод konnichiwa мы теперь намереваемся
выставить через RPC.
Прежде чем мы проверим этот код, нам понадобится создать небольшой файл config, который сообщит Nameko
как выполнять доступ к RabbitMQ и какой обмен RPC применять. Создайте новый файл config.yaml:
AMQP_URI: 'pyamqp://guest:guest@localhost'
rpc_exchange: 'nameko-rpc'
|
| Замечание |
|---|---|
|
Указанные здесь настройки |
Теперь вы должны получить структуру каталога, которая похожа на следующее:
.
├── config.yaml
├── requirements
│ ├── base.in
│ ├── base.txt
│ ├── test.in
│ └── test.txt
├── temp_messenger
└── service.py
Теперь из своего терминала внутри корня вашего каталога проекта запустите следующее:
$ nameko run temp_messenger.service --config config.yaml
Вы должны получить следующий вывод:
starting services: konnichiwa_service
Connected to amqp://guest:**@127.0.0.1:5672//
Теперь наша микрослужба работает! Чтобы делать наши собственные вызовы, мы можем запустить некую оболочку Python, у которой имеется интегрированный Nameko, снабжающий нас для вызова точками входа. Для доступа к ней откройте новое терминальное окно и запустите следующее:
$ nameko shell
Она должна снабдить нас доступом к оболочке Python с возможностью выполнения Удалённых вызовов процедур (RPC). Давайте попробуем:
>>> n.rpc.konnichiwa_service.konnichiwa()
'Konnichiwa!'
Она работает! Мы успешно выполнили некий вызов своей службы Konnichiwa и приняли какой- то вывод обратно. Когда мы исполняем этот код в своей
оболочке Nameko, мы помещаем некое сообщение в имеющуюся очередь, которая затем получается нашей KonnichiwaService.
Затем она порождает нового исполнителя для обработки собственно задания RPC konnichiwa.
Согласно документации, Nameko это:
"Каркас микрослужб для Python, который позволяет разработчикам сконцентрироваться на логике приложения и поощряет возможности проверок."
Теперь мы сосредоточимся на части Nameko, отвечающей за проверки; она предоставляет некие очень полезные инструменты для изоляции и проверки своих служб.
Создадим новую папку tests и поместим внутри неё два файла __init__.py
(который можем оставить пустым) и test_service.py:
from nameko.testing.services import worker_factory
from temp_messenger.service import KonnichiwaService
def test_konnichiwa():
service = worker_factory(KonnichiwaService)
result = service.konnichiwa()
assert result == 'Konnichiwa!'
При запуске вне данного проверочного окружения Nameko порождает нового исполнителя для каждой вызываемой точки входа. Ранее, когда мы применяли
свой RPC konnichiwa, наша служба Konnichiwa выполняла ожидание для новых сообщений в имеющейся очереди Rabbit.
Когда она получает некое новое сообщение для данной конечной точки konnichiwa, она порождает какого- то нового
исполнителя, который позаботится об этом методе и затем будет уничтожен.
|
| Замечание |
|---|---|
|
Чтобы получить дополнительные сведения о Nameko, ознакомьтесь, пожалуйста, с http://url.marcuspen.com/nam-key. |
Для наших проверок Nameko предоставляет некий способ эмуляции через woker_factory. Как вы можете видеть,
наши тесты используют woker_factory, в который мы передаём свой класс службы,
KonnichiwaService. Это позволит нам выполнять вызов любой точки входа в этой службе и получать доступ к
возвращаемым результатам.
Для выполнения данного теста из корня вашего каталога кода просто исполните:
pytest
И это всё. Теперь должен быть выполнен весь комплект тестирования. Погуляйте пока рядом и попробуйте сделать перерыв.
Теперь мы создадим новую микрослужбу, которая отвечает за обработку запросов HTTP. Прежде всего давайте улучшим свои импорты в файле
service.py:
from nameko.rpc import rpc, RpcProxy
from nameko.web.handlers import http
Далее свой сделанный ранее KonnichiwaService, вставляем следующее:
class WebServer:
name = 'web_server'
konnichiwa_service = RpcProxy('konnichiwa_service')
@http('GET', '/')
def home(self, request):
return self.konnichiwa_service.konnichiwa()
Обратите внимание как следовать шаблону, аналогичному KonnichiwaService. Он имеет атрибут
name и декорированный метод для выставления его в качестве какой- то точки входа. В данном случае он
декорируется как определённая точка входа http. Мы определяем внутри своего декоратора
http, что он является неким запросом GET, а также само местоположение
данного запроса - в данном случае, это корень нашего вебсайта.
Также имеется ещё одно существенное отличие: эта служба сохраняет ссылку на нашу службу Konnichiwa через некий объект
RpcProxy. RpcProxy делает для нас возможным вызывать
другую службу Nameko через RPC. Мы инициализируем её через установленный атрибут name, который мы определили
ранее как KonnichiwaService.
Давайте попробуем всё это - просто перезапустим свой Nameko, применив ту же команду что и ранее (это необходимо, принимая во внимание изменения в нашем коде) и перейдя в http://localhost:8000/ в браузере по вашему выбору:
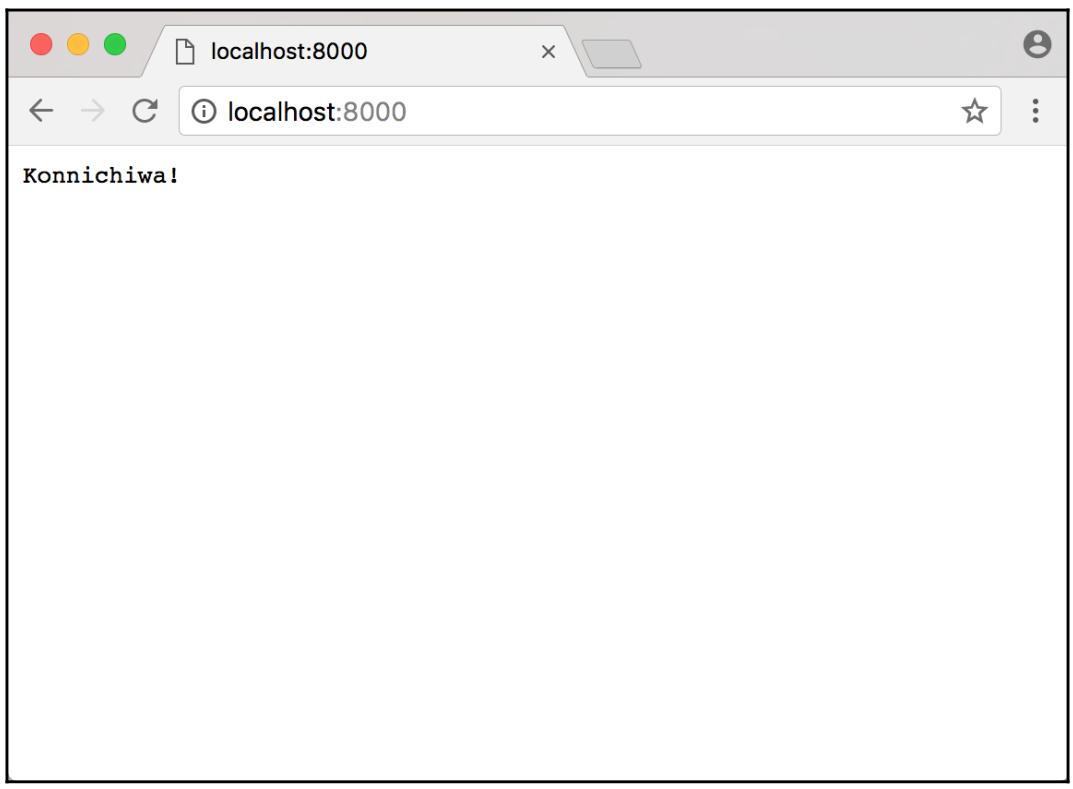
Она вертится! Теперь мы успешно сделали две микрослужбы - одна отвечает за отображение сообщения, а другая обслуживает веб запросы.
Ранее мы рассматривали проверку некоторой изолированной службы порождением отдельного исполнителя. Это великолепно для проверки элемента, но оказывается нежизнеспособным при интегрированной проверке.
Nameko предоставляет нам возможность проверки множества служб, работающих в тандеме в отдельной проверке. Рассмотрим следующее:
def test_root_http(web_session, web_config, container_factory):
web_config['AMQP_URI'] = 'pyamqp://guest:guest@localhost'
web_server = container_factory(WebServer, web_config)
konnichiwa = container_factory(KonnichiwaService, web_config)
web_server.start()
konnichiwa.start()
result = web_session.get('/')
assert result.text == 'Konnichiwa!'
Как вы можете видеть в приведённом выше коде, Nameko также предоставляет доступ к следующей арматуре проверок:
-
web_session: предоставляет нам сеанс чтобы делать запросы HTTP к нашей службе -
web_config: Делает возможным для нас доступ к настройкам нашей службы (извне проверки, что эквивалентно самому файлуconfig.yaml) -
container_factory: Это позволяет нам смоделировать службу в целом вместо всего лишь некоторого экземпляра исполнителя, что требуется при интегрированной проверке
Поскольку всё это работает как всамделишные службы, нам требуется определить местоположение своего брокера {сервера} AMQP, внедрив его в свой
web_config. Применяя container_factory мы создаём два контейнера:
web_server и konnichiwa. Затем мы запускаем оба эти контейнера.
Затем следует простой вариант применения web_session с тем чтобы выполнить запрос
GET к нашему корню площадки и убедиться в том, что полученный результат именно тот что мы ожидали.
По мере того как мы будем продвигаться по данной главе, я призываю вас писать свои собственные тесты для проверки кода, так как это не только предостережёт вас от ошибок, но также и поможет в основательности ваших знаний по данной теме. Это также хороший способ экспериментов с вашим собственными мыслями и изменениями кода , так как вы быстро получите сообщение если вдруг что- то сломаете.
|
| Замечание |
|---|---|
|
Для получения дополнительной информации о проверках Nameko, обратитесь к http://url.marcuspen.com/nam-test. |
Те сообщения, которые мы хотим отображать в своём приложении требуют временной действенности. Мы можем применять для этого реляционные базы данных, например RabbitMQ, но это означает наличие проекта и ведения какой- то базы данных для чего- то столь же простого как текст.
Redis является неким хранилищем данных в оперативной памяти (in- memory). Весь набор данных целиком может сохраняться в памяти, что делает намного более быстрыми чтения и записи, чем это происходит в случае реляционных баз данных, что полезно для данных, которые не требуют их удержания (persistence). Кроме того, мы можем сохранять данные не вырабатывая какой бы то ни было схемы, что просто замечательно если у нас нет потребности в сложных запросах. В нашем случае нам просто требуется некое хранилище данных, которое позволит нам сохранять сообщения, получать сообщения и прекращать срок действия сообщений. Redis превосходно отвечает таким целям использования!
Запуск контейнера Redis
В своём терминале выполните следующее:
$ docker run -d -p 6379:6379 --name redis redis
Это запустит контейнер Redis со следующими установками:
-
-d: определяет что мы хотим запустить свой контейнер в режиме демона (в качестве фонового процесса). -
-p: позволяет нам выставить порт данного контейнера6379в нашей локальной машине. Это требуется для взаимодействия Nameko с Redis. -
--name: устанавливает для данного контейнера имяredis.
Вы можете проверить, что ваш новый контейнер Redis запущен, выполнив:
$ docker ps
Установка Python клиента Redis
Вам также понадобится установить клиента Redis Python чтобы сделать для вас возможным взаимодействие с Redis через Python. Чтобы сделать это, я
рекомендую исправить ваш созданный ранее файл base.in чтобы включить в него
redis и перекомпилировать его для выработки нового файла base.txt.
В качестве альтернативы вы можете запустить pip install redis.
Применение Redis
Давайте вкратце рассмотрим те виды команд Redis, которые могут оказаться вам полезными для TempMessenger:
-
SET: Устанавливает определённый ключ для удержания заданной строки. Также позволяет вам установить срок истечения действия в миллисекундах. -
GET: Получает значение данных, сохранённых с заданным ключом. -
TTL: Получает время жизни для данного ключа в секундах. -
PTTL: Получает время жизни для данного ключа в миллисекундах. -
KEYS: Возвращает перечень всех ключей в определяемом хранилище данных.
На пробу мы можем воспользоваться redis-cli, которая является программой, сопровождающей наш контейнер Redis.
Чтобы получить к ней доступ, вначале зарегистрируйтесь в своём контейнере выполнив в своём терминале следующее:
docker exec -it redis /bin/bash
Затем получите в том же самом окне доступ к redis-cli, просто запустив:
redis-cli
Имеется ряд примеров, приводимых далее, с тем чтобы понять как применять redis-cli; если вы не знакомы с
Redis, я рекомендую вам самостоятельно поэкспериментировать с этими командами.
Для ключа msg1 установите некие данные, hello:
127.0.0.1:6379> SET msg1 hello
OK
Получите данные, сохранённые в ключе msg1:
127.0.0.1:6379> GET msg1
"hello"
Установите ещё данные, hi there, сохранённые в ключе msg2 и выполните
их выборку:
127.0.0.1:6379> SET msg2 "hi there"
OK
127.0.0.1:6379> GET msg2
"hi there"
Выполните выборку всех ключей, хранимых в Redis:
127.0.0.1:6379> > KEYS *
1) "msg2"
2) "msg1"
Сохраните данные в msg3 со сроком истечения их актуальности через 15 секунд:
127.0.0.1:6379> SET msg3 "это сообщение вскоре уничтожится" EX 15
OK
Получите время жизни для msg3 в секундах:
127.0.0.1:6379> TTL msg3
(integer) 10
Получите время жизни для msg3 в миллисекундах:
127.0.0.1:6379> PTTL msg3
(integer) 10
Получите msg3 пока оно присутствует:
127.0.0.1:6379> GET msg3
"это сообщение вскоре уничтожится"
Получите msg3 после истечения его срока действия:
127.0.0.1:6379> GET msg3
(nil)
При построении микрослужб Nameko поощряет к использованию поставщиков зависимостей для взаимодействия с внешними ресурсами, такими как базы данных, серверы или что- то ещё, от чего зависит наше приложение. Применяя некого поставщика зависимостей вы можете скрыть напрочь ту логику, которая специфична только для данной зависимости, оставляя код уровня вашей службы ясным и отрицающим все взаимодействия входа и выхода с таким внешним ресурсом.
Изменяя структуру своих микрослужб, подобных рассматриваемой, у нас имеется возможность легко переставлять или повторно применять постовщиков зависимостей в прочих службах.
|
| Замечание |
|---|---|
|
Nameko предоставляет список поставщиков зависимостей с открытым исходным кодом, которые готовы к применению . |
Так как Redis выступает для нашего приложения внешним ресурсом, мы создадим некоего поставщика зависимостей для него.
Разработка клиента
Для начала давайте создадим какую- то новую папку с названием dependencies внутри своей папки
temp_messenger. Вовнутрь положим новый файл redis.py. Теперь мы создадим
клиента Redis с простым методом, который получит сообщения для заданного ключа:
from redis import StrictRedis
class RedisClient:
def __init__(self, url):
self.redis = StrictRedis.from_url(
url, decode_responses=True
)
Мы начнём свой код с реализации необходимого метода __init__, который создаёт нашего клиента Redis и
назначает его self.redis. Для способного принимать множество необязательных аргументов
StrictRedis мы, тем не менее, определили только следующие:
-
url: Вместо того чтобы определять значения хоста, порта и номер базы данных по отдельности, мы можем воспользоватьсяfrom_urlизStrictRedis, что позволит нам определить все три в единой строке, например -redis://localhost:6379/0. Это намного удобнее когда позднее дело доходит до сохранения в нашемconfig.yaml. -
decode_responses: Автоматически преобразовывает все получаемые нами из Redis данные в некую строку Unicode. По умолчанию все данные выбираются байтами.
Теперь в том же самом классе давайте реализуем новый метод:
def get_message(self, message_id):
message = self.redis.get(message_id)
if message is None:
raise RedisError(
'Message not found: {}'.format(message_id)
)
return message
Вне нашего нового класса давайте также реализуем какой- то новый класс ошибки:
class RedisError(Exception):
pass
Теперь у нас имеется метод get_message, получающий message_id ,
который будет применяться в качестве нашего ключа Redis. Мы воспользуемся имеющимся методом get в своём
клиенте Redis для извлечения необходимого сообщения с нашим заданным ключом. При извлечении значений из Redis, если такой ключ отсутствует, то будет
просто возвращено None. Так как этот метод ожидает наличия сообщения, нам следует самостоятельно возбудить
некую ошибку. В данном случае мы создали некую простейшую исключительную ситуацию, RedisError.
Создание поставщика зависимостей
До сих пор мы создавали клиента Redis с единственным методом. Теперь нам необходимо создать Поставщика зависимостей Nameko для применения такого
клиента в наших службах. В том же самом файле redis.py измените импорты с тем чтобы они включали:
from nameko.extensions import DependencyProvider
Теперь давайте реализуем такой код:
class MessageStore(DependencyProvider):
def setup(self):
redis_url = self.container.config['REDIS_URL']
self.client = RedisClient(redis_url)
def stop(self):
del self.client
def get_dependency(self, worker_ctx):
return self.client
В нашем предыдущем коде вы можете видеть что наш новый класс MessageStore наследуется из имеющегося
класса DependencyProvider. Те методы, которые мы определили в своём новом классе
MessageStore будут вызываться в определённые моменты жизненного цикла нашей микрослужбы:
-
setup: будет вызываться перед запуском нашей службы Nameko. Здесь мы получаем значение URL Redis изconfig.yamlи создаём некоего новогоRedisClientпри помощи созданного нами ранее кода. -
stop: будет вызываться когда наша служба Nameko начнёт завершаться. -
get_dependency: этим методом следует реализовывать всех Поставщиков зависимостей. Когда поджигается некая точка входа, Nameko создаёт какого- то исполнителя и в этого исполнителя все результатыget_dependencyвсех определённых в данной службе зависимостей. В нашем случае это означает, что наши исполнители будут иметь доступ к какому- то экземпляруRedisClient.
|
| Замечание |
|---|---|
|
Nameko предлагает дополнительные методы для управления за тем как ваши Поставщики зависимостей функционируют в различные моменты жизненного цикла вашей службы:http://url.marcuspen.com/nam-writ. |
Создание нашей службы сообщений
В нашем service.py мы можем применять своего нового Поставщика зависимостей Redis. Давайте начнём с создания
некой новой службы, которая заменит нашу выполненную ранее службу Konnichiwa. Для начала нам требуется обновить свои импорты в вершине нашего файла:
from .dependencies.redis import MessageStore
Теперь мы можем создать свою новую службу:
class MessageService:
name = 'message_service'
message_store = MessageStore()
@rpc
def get_message(self, message_id):
return self.message_store.get_message(message_id)
Она аналогична нашим более ранним службам; однако, на этот раз мы определяем некий атрибут нового класса, message_store.
Наша точка входа RPC, get_message может теперь применить его и вызвать
get_message в нашем RedisClient, а потом просто вернуть полученный результат.
Нам придётся сделать это всё создав нового клиента Redis внутри своеё точки входа и реализовать некий GET
Redis. Однако, создав Поставщика зависимостей мы предоставили возможность повторного исполнения и напрочь скрыли нежелательное поведение Redis
возвращения им None когда не существует некий ключ. Это всего лишь небольшой пример почему Поставщики зависимостей
чрезвычайно хороши для разъединения наших служб с их внешними зависимостями.
Собираем воедино
Давайте попробуем тот код, который мы только что смастерили. Начнём с сохранения новой пары ключ- значение в Redis при помощи
redis-cli
127.0.0.1:6379> set msg1 "this is a test"
OK
Теперь запустим службы Nameko:
$ nameko run temp_messenger.service --config config.yaml
Сейчас мы можем применять nameko shell для выполнения удалённых вызовов в нашей новой
MessageService:
>>> n.rpc.message_service.get_message('msg1')
'this is a test'
Как и ожидалось, у нас была возможность достать отосланное ранее при помощи redis-cli сообщение через
свою точку входа MessageService.
Давайте теперь получим несуществующее сообщение:
>>> n.rpc.message_service.get_message('i_dont_exist')
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/Users/marcuspen/.virtualenvs/temp_messenger/lib/python3.6/sitepackages/nameko/rpc.py", line 393, in __call__
return reply.result()
File "/Users/marcuspen/.virtualenvs/temp_messenger/lib/python3.6/sitepackages/nameko/rpc.py", line 379, in result
raise deserialize(error)
nameko.exceptions.RemoteError: RedisError Message not found: i_dont_exist
Это не самая привлекательная из ошибок, и есть некоторые моменты, которые мы можем выполнить чтобы уменьшить приводимую здесь трассировку, однако самая последняя строка постулирует именно ту исключительную ситуацию, которую мы определили ранее, а это ясно даёт нам понять причину отказа данного запроса.
Теперь мы перейдём к сохранению сообщений.
Ранее я представил метод Redis SET. Он позволил нам сохранять произвольное сообщение в Redis, однако вначале
нам необходимо создать какой- то новый метод в нашем Поставщике зависимостей, который будет обрабатывать его.
Мы можем просто создать некий новый метод, который назовём redis.set(message_id, message), однако как
мы смогли бы обрабатывать новые идентификаторы сообщений? Это было бы немного проблематично, если бы мы ожидали, что наш пользователь подаёт на
вход какой- то новый идентификатор сообщения для всякого сообщения, которое он желает отправлять, не правда ли? Альтернативой было бы заставить
саму службу сообщений вырабатывать некий новый случайный идентификатор сообщения прежде чем она вызовет своего поставщика зависимостей, однако это
внесло бы беспорядок в нашу службу той логикой, которая может быть обрабатываться самой по себе данной зависимостью.
Мы решим эту проблему заставив свою зависимость создавать некую случайную строку, которая будет применяться в качестве идентификатора данного сообщения.
В redis.py давайте усовершенствуем импорты, добавив uuid4:
from uuid import uuid4
uuid4 вырабатывает для нас уникальную случайным образом определяемую строку, которую мы можем применять
в своём сообщении.
Теперь мы можем добавить свой новый метод save_message в нашего
RedisClient:
def save_message(self, message):
message_id = uuid4().hex
self.redis.set(message_id, message)
return message_id
Прежде всего мы генерируем новый идентификатор сообщения при помощи uuid4().hex. Наш атрибут
hex представляет нам полученный UUID как шестнадцатеричную строку из 32 символов. Затем мы можем применять её
в качестве некоего ключа для сохранения своего сообщения и его возврата.
Давайте теперь создадим конкретный метод RPC, который собирается вызвать метол нашего нового клиента. В наш
MessageService добавьте следующий метод:
@rpc
def save_message(self, message):
message_id = self.message_store.save_message(message)
return message_id
Здесь нет ничего поразительного, однако отметим, как просто стало добавлять новую функциональность в нашу службу. Мы отделили логику, которая относится данной зависимости от своей точки входа и в то же самое время сделав свой код повторно применяемым. Если другому методу RPC,который мы создадим в дальнейшем, понадобится сохранять некое сообщение в Redis, мы можем запросто сделать то же самое без необходимости повторно создавать тот же самый код снова.
Давайте проверим это целиком воспользовавшись только nameko shell - не забудьте перезапустить свою службу
Nameko, чтобы ваши изменения вступили в действие!
>>> n.rpc.message_service.save_message('Nameko is awesome!')
'd18e3d8226cd458db2731af8b3b000d9'
![[Совет]](/common/images/admon/tip.png) | Совет |
|---|---|
|
Тот идентификатор, что возвращён здесь является случайным и будет отличаться от получаемого вами в другом сеансе. |
>>> n.rpc.message_service.get_message
('d18e3d8226cd458db2731af8b3b000d9')
'Nameko is awesome!'
Как вы можете видеть, мы успешно сохранили своё сообщение и воспользовались UUID, который был возвращён для извлечения нашего сообщения.
Это всё так, и даже неплохо, однако для целей своей прикладной программы мы не ожидали, что нашему пользователю придётся сопровождать UUID сообщений чтобы считывать сообщения. Давайте сделаем это слегка более практичным и посмотрим как мы можем получать все свои сообжения из нашего хранилища Redis.
Аналогично предыдущим шагам нам потребуется добавить новый метод в нашу зависимость Redis чтобы дополнить ещё функциональности. На это раз мы создадим метод, который будет выполнять итерации по всем нашим ключам в Redis и возвращать в некий список все соответствующие сообщения.
Давайте добавим в свой RedisClient следующее:
def get_all_messages(self):
return [
{
'id': message_id,
'message': self.redis.get(message_id)
}
for message_id in self.redis.keys()
]
Мы начнём с применения self.redis.keys() для сбора всех ключей которые хранятся в Redis, которые, нашем
случае, являются идентификаторами сообщений. Затем мы получаем некий перечень, в котором мы будем выполнять итерации по всем идентификаторам сообщений
и создадим некий словарь для каждого из них, содержащий этот идентификатор сообщения и то сообщение, которое хранится в Redis, применяя
self.redis.get(message_id).
|
| Замечание |
|---|---|
|
Для приложений крупного масштаба в промышленности не рекомендуется применять метод |
Что касается меня лично, я предпочитаю применять здесь выразительность списка для построения данного перечня сообщений, однако если вы вступили в борьбу за понимание данного метода, я рекомендую создавать это как некий стандартный цикл.
Ради осмысления данного примера посмотрите следующий код для того же самого метода, выстраиваемый с помощью цикла:
def get_all_messages(self):
message_ids = self.redis.keys()
messages = []
for message_id in message_ids:
message = self.redis.get(message_id)
messages.append(
{'id': message_id, 'message': message}
)
return messages
Оба этих метода делают одно и то же. Какой вы предпочтёте? Я оставляю этот выбор вам...
Всякий раз, когда я создаю список или генератора словаря, я всегда начинаю с теста, который проверяет вывод моей функции или метода. Затем я пишу свой код с понятиями и проверяю его, чтобы гарантировать правильность вывода. Затем я изменю свой код на цикл for и убеждаюсь, что тест все ещё проходит. После этого я просматриваю обе версии своего кода и решаю, какой из них выглядит наиболее читаемым и чистым. Если код не должен быть сверхэффективным, я всегда выбираю код, который хорошо читается, даже если это означает ещё дополнительные строки. В конечном счёте такой подход окупается когда дело доходит до чтения и поддержки этого кода позже!
Теперь у нас есть способ получения всех сообщений из Redis. В своём предыдущем коде я мог получить просто возвращаемый перечень сообщений без генератора словаря, всего лишь все значения строк сообщения. Однако что если мы пожелаем позднее добавить ещё данных в каждое из сообщений? Например, некоторые метаданные чтобы информировать когда это сообщение было создано или как долго это сообщение будет действовать пока не истечёт его срок... позднее мы займёмся и этим! Применение словаря здесь для каждого сообщения позволит нам проще вовлекать свои структуры данных в дальнейшем.
Теперь мы рассмотрим добавление нового RPC в свой MessageService, который позволит нам получить все
сообщения.
Просто добавьте в наш класс MessageService:
@rpc
def get_all_messages(self):
messages = self.message_store.get_all_messages()
return messages
Я уверен, что сейчас мне, скорее всего, не нужно объяснять что здесь происходит! Мы просто вызываем метод, который мы сделали ранее в своей зависимости от Redis, и возвращаем результат.
Применяя внутри вашего virtualenv nameko shell мы можем теперь проверить этот вывод:
>>> n.rpc.message_service.save_message('Nameko is awesome!')
'bf87d4b3fefc49f39b7dd50e6d693ae8'
>>> n.rpc.message_service.save_message('Python is cool!')
'd996274c503b4b57ad5ee201fbcca1bd'
>>> n.rpc.message_service.save_message('To the foo bar!')
'69f99e5863604eedaf39cd45bfe8ef99'
>>> n.rpc.message_service.get_all_messages()
[{'id': 'd996274...', 'message': 'Python is cool!'},
{'id': 'bf87d4b...', 'message': 'Nameko is awesome!'},
{'id': '69f99e5...', 'message': 'To the foo bar!'}]
Мы получили это! Теперь мы можем извлекать все имеющиеся сообщения из своего хранилища данных. (В целях сохранения места и улучшения читабельности я усекаю здесь значения идентификаторов сообщений.)
Имеется одна проблема с возвращаемыми сюда сообщениями - можете ли вы определить, что они представляют? Тот порядок, в который мы помещаем свои сообщения в Redis - это не тот же самый порядок, который мы получаем, когда мы снова получаем вновь. Мы вернёмся к этому позже, но пока давайте перейдём к отображению этих сообщений в своём веб-браузере.
Ранее мы добавили свою микрослужбу WebServer для обработки запросов HTTP; теперь мы будем улучшать его с той целью,
чтобы когда наш пользователь загружает самый корень своей домашней страницей, ему бы показывались все сообщения нашего хранилища данных.
Одним из способов сделать это состоит в применении механизма шаблонов, такого как Jinja2. {Прим. пер.: подробнее в наших переводах Главы 3. Высвобождение всей мощи шаблонов Jinja2 Второго издания "Полного руководства Ansible" Джесса Китинга, Packt Publishing, Май 2017; раздела Шаблоны Jinja2 "Полное руководство работы с сетями на Python" Эрика Чоу, Packt Publishing, Июнь 2017.}
Jinja2 является механизмом шаблонов для Python, который очень схож с аналогичным механизмом шаблонов Django. Те, кто знаком с Django, будут чувствовать себя как дома применяя его.
Прежде чем мы начнём, вам следует улучшить свой файл base.in чтобы включить
jinja2, выполнить повторную компиляцию ваших требований и установить их. В качестве альтернативы просто запустите
pip install jinja2.
Создание шаблона отображения
При генерации простого шаблона HTML в Jinja2 требуются три следующие шага:
-
Создать какую- то среду шаблона
-
Определить сам шаблон
-
Представить этот шаблон
Проходя эти три этапа важно определять какие части никогда (или по крайней мере маловероятно) не являются предметом изменения при работе нашего приложения... а какие именно таковыми и являются. Держите это на уме пока я вам поясняю следующий код.
В свой каталог зависимостей добавьте новый файл, jinja2.py и начните с этого кода:
from jinja2 import Environment, PackageLoader, select_autoescape
class TemplateRenderer:
def __init__(self, package_name, template_dir):
self.template_env = Environment(
loader=PackageLoader(package_name, template_dir),
autoescape=select_autoescape(['html'])
)
def render_home(self, messages):
template = self.template_env.get_template('home.html')
return template.render(messages=messages)
В нашем методе __init__ понадобится название пакета и временный каталог. Вооружившись ими, далее мы можем
создать необходимую среду шаблона. Этой среде требуется некий загрузчик, который просто является неким способом загрузки наших файлов шаблона из
заданного пакета или каталога. Также мы должны определить что мы желаем разрешить в своих файлах для безопасности HTML автоматическое экранирование.
Затем нам следует сделать метод render_home, который позволит нам представлять наш шаблон
home.html когда мы его сделаем. Обратите внимание на то как мы представляем свой шаблон с
messages..., позже вы поймёте почему!
Вы поняли почему я создал структуру кода таким образом? Так как на метод __init__ исполняется всегда, я
поместил сюда создание нашей среды шаблонов, поскольку она вряд ли будет изменяться пока исполняется наше приложение.
Однако какие шаблоны мы желаем отобразить и какие переменные мы придаём ему, это всегда будет изменяться в зависимости от того к какой именно странице пользователь пытается осуществить доступ и какие именно данные доступны в этот определённый момент времени. В представленной выше структуре становится очень просто дабавлять новый метод для каждой веб страницы нашего приложения.
Давайте теперь рассмотрим как HTML запрашивает наш шаблон. Позвольте начать с создания нового словаря вблизи от наших зависимостей и назовём его
templates.
Внутри нашего нового каталога создадим следующий файл home.html:
<!DOCTYPE html>
<body>
{% if messages %}
{% for message in messages %}
<p>{{ message['message'] }}</p>
{% endfor %}
{% else %}
<p>No messages!</p>
{% endif %}
</body>
Этот HTML не представляет из себя ничего поражающего воображения и ничего более, чем конкретика логики шаблонов! Если вы не знакомы с шаблонами Jinja2 или Django, вы, скорее всего, думаете, что этот HTML выглядит странно со своими фигурными фигурными скобками. Jinja2 использует их, чтобы позволить нам вводить подобный Python синтаксис в наш шаблон.
В нашем предыдущем примере мы стартовали с оператора if чтобы проверить имеются ли у нас какие- либо сообщения
(сам формат и структура messages будет теми же самыми, что и для тех сообщений, которые мы возвращали с помощью
RPC get_all_messages, который мы делали ранее). Если это так, у нас имеется некоторая дополнительная логика, содержащая
цикл for, который будет выполнять итерации отображать текущее значение 'message' для каждого словаря из нашего
перечня messages.
Если же сообщений не, тогла будет показан всего лишь текст No messages!
|
| Замечание |
|---|---|
|
Для получения дополнительных сведений о Jinja2 посетите http://url.marcuspen.com/jinja2 {Прим. пер.: также рекомендуем свои переводы Главы 3. Высвобождение всей мощи шаблонов Jinja2 Второго издания "Полного руководства Ansible" Джесса Китинга, Packt Publishing, Май 2017 и раздела Шаблоны Jinja2 "Полное руководство работы с сетями на Python" Эрика Чоу, Packt Publishing, Июнь 2017.} |
Теперь нам требуется выставить свой TemplateRenderer в качестве Поставщика зависимостей Nameko.
В нашем сделанном ранее файле inja2.py обновите наши импорты чтобы вон включал следующее:
from nameko.extensions import DependencyProvider
Затем добавьте такой код:
class Jinja2(DependencyProvider):
def setup(self):
self.template_renderer = TemplateRenderer(
'temp_messenger', 'templates'
)
def get_dependency(self, worker_ctx):
return self.template_renderer
Он чрезвычайно похож на наши предыдущие зависимости Redis. Мы определяем некий метод setup, который
создаёт какой- то экземпляр нашего TemplateRenderer и метод
get_dependency, который будет внедрён в нашего исполнителя.
Теперь мы готовы воспользоваться своим WebServer.
Теперь мы можем применить свои новые зависимости Jinja2 в нашем WebServer . Вначале нам требуется
включить его в свои импорты в service.py:
from .dependencies.jinja2 import Jinja2
Теперь давайте улучшим свой класс WebServer чтобы он был следующим:
class WebServer:
name = 'web_server'
message_service = RpcProxy('message_service')
templates = Jinja2()
@http('GET', '/')
def home(self, request):
messages = self.message_service.get_all_messages()
rendered_template = self.templates.render_home(messages)
return rendered_template
Отметим, как мы осуществили назначение некоего нового атрибута, templates, так, как мы это делали ранее в
нашем MessageService с message_store. Наша точка входа HTTP теперь
просит наш MessageService выбрать все сообщения из Redis и применяет их для создания отображаемого шаблона
применяя нашу новую зависимость Jinja2. После этого мы возвращаем полученный результат.
Перезапустите свои службе Nameko и давайте испробуем их в своём браузере:
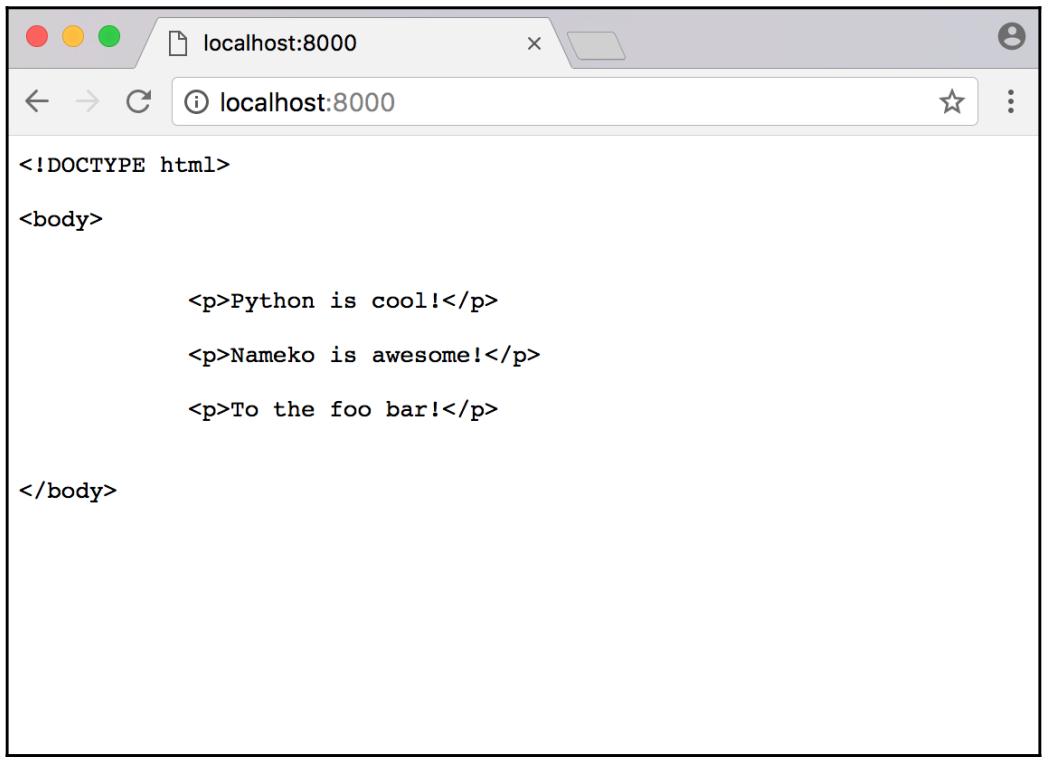
Это работает... в некотором виде! Все сообщения, которые мы сохранили в Redis ранее присутствуют, что означает, что установленная логика нашего шаблона работает
как ожидалось, но помимо этого у нас имеются теги HTML и отступы из home.html.
Основная причина для этого состоит в том, что мы пока ещё не определили никаких заголовков для своего отклика чтобы указать что это на самом деле
HTML. Для этого давайте создадим небольшую функцию помощника вне своего класса WebServer, который будет
преобразовывать наш отображаемый шаблон в некий отклик с соответствующими заголовками и неким кодом состояния.
В своём service.py улучшим свои импорты, чтобы они содержали:
from werkzeug.wrappers import Response
Затем вне своих классов добавим такую функцию:
def create_html_response(content):
headers = {'Content-Type': 'text/html'}
return Response(content, status=200, headers=headers)
Эта функция создаёт некий словарь заголовков, который содержит правильный тип содержимого, HTML. Затем мы создаём и возвращаем некий объект
Response с кодом состояния HTTP 200, наши заголовки и само
содержимое, которое в нашем случае будет тем самым отображаемым шаблоном.
Теперь мы можем улучшит свою точку входа HTTP чтобы она применяла нашу функцию помощника:
@http('GET', '/')
def home(self, request):
messages = self.message_service.get_all_messages()
rendered_template = self.templates.render_home(messages)
html_response = create_html_response(rendered_template)
return html_response
Наша точка входа HTTP home теперь использует create_html_reponse,
снабжая его отображаемым шаблоном, а затем возвращает свой выполненный отклик. Давайте испробуем его вновь в своём браузере:
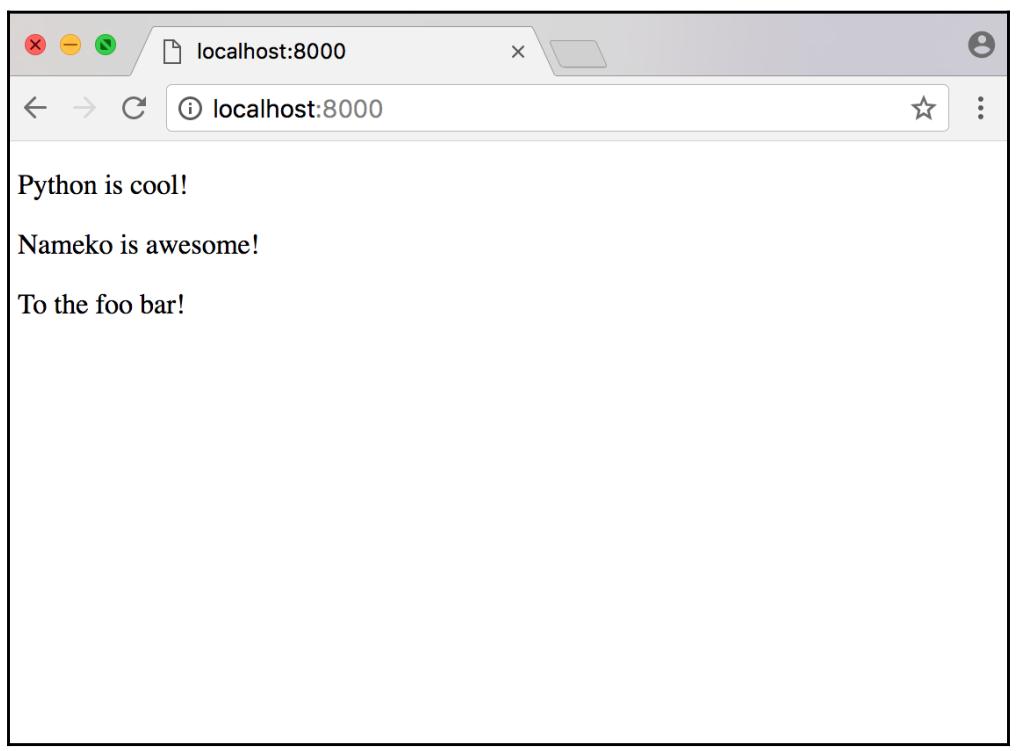
Как вы теперь можете видеть, наши сообщения теперь отображаются так как мы и ожидали их увидеть без тегов HTML, которые мы бы могли обнаружить!
Попробуйте удалить все данные в Redis с помощью соответствующей команды flushall воспользовавшись
redis-cli и перезагрузив эту веб страницу. Что произошло?
Теперь мы перейдём к отправке сообщений.
На данный момент у нас существенный прогресс; у нас имеется некий сайт, который имеет возможность отображать все имеющиеся сообщения из нашего
хранилища данных с двумя микрослужбами. Одна микрослужба обрабатывает всё хранимое и осуществляет выборку наших сообщений, а другая действует как
некий веб сервер для наших пользователей. Наша MessageService уже имеет возможность сохранять сообщения;
давайте выставим её в своём WebServer через некий запрос POST.
В своём service.py добавляем импорт:
import json
Теперь в наш класс WebServer добавляем следующее:
@http('POST', '/messages')
def post_message(self, request):
data_as_text = request.get_data(as_text=True)
try:
data = json.loads(data_as_text)
except json.JSONDecodeError:
return 400, 'JSON payload expected'
try:
message = data['message']
except KeyError:
return 400, 'No message given'
self.message_service.save_message(message)
return 204, ''
При помощи новой точки входа POST мы запускаем выделение своих данных из имеющегося запроса. Мы определяем
его параметр as_text=True так как в противном случае мы бы получили все данные обратно в виде байтов.
После того как мы получили необходимые данные, мы можем попробовать загрузить их из JSON в словарь Python. Если эти данные не являются допустимым
JSON, в нашей службе будет инициирована JSONDecodeError, поэтому будет лучше обрабатывать её и возвращать код
состояния плохого запроса 400. Не имея такой обработки исключительной ситуации наща служба возвратила бы
некую ошибку внутреннего сервера, которая имела бы код состояния 500.
Теперь,когда наши данные представлены в некотором формате словаря, мы можем получать в них необходимое сообщение. И снова нам придётся сделать некий
защитный код, который будет обрабатывать любые появления отсутствия ключа POST и возвращать другой
400.
Затем мы продолжим сохранением данного сообщения с применением RPC 'message', который мы создали ранее в нашем
MessageService.
Получив всё это TempMessenger теперь имеет возможность сохранять новые сообщения через HTTP запрос POST!
Если вы пожелаете, вы можете проверить это применив curl или иного клиента API следующим образом:
$ curl -d '{"message": "foo"}' -H "Content-Type: application/json" -X POST
http://localhost:8000/messages
Теперь мы обновили свой шаблон home.html с тем, чтобы он содержал возможность применения данного нового
запроса POST.
Теперь, перед тем как продолжить, разрешите мне рассказать, что на момент написания книги я не являюсь экспертом в JAvaScript. Мой опыт пролегает в основном в программировании серверной стороны, а не стороны интерфейса. При этом, если вы занимались веб разработкой более 10 минут, тогда вы знаете, что попытка избежать JavaScript практически невозможна. В какой- то момент времени нам скорее всего придётся немного потрудиться над ним просто чтобы выполнить рабочий фрагмент.
имея это в виду, будьте добры не предаваться панике!
Тот код, который Код, с которым вы собираетесь знакомиться, - это то, что я узнал, просто прочитав документацию jQuery, так что всё очень просто. Если вы разбираетесь с коде интерфейса, то я уверен, что, скорее всего, имеется миллион различных и, вероятно, при этом лучших способов сделать это в JavaScript, поэтому, пожалуйста, изменяйте его так как, вы сочтёте нужным.
Вначале вам требуется добавить после <!DOCTYPE html> следующее:
<head>
<script src="https://code.jQuery.com/jQuery-latest.js"></script>
</head>
Это выгрузит и запустит в нашем браузере самую последнюю версию jQuery.
В нашем home.html, прежде чем закрыть тег </body>
добавьте следующее:
<form action="/messages" id="postMessage">
<input type="text" name="message" placeholder="Post message">
<input type="submit" value="Post">
</form>
Мы начинаем здесь с некоторого простого HTML чтобы добавить какую- то базовую форму. Она имеет только поле ввода текста и кнопку подтверждения. Сама по себе она будет отражать некий блок текста и кнопку отправки, но он не будет делать ничего.
Давайте добавим следующий код с неким jQuery JavaScript:
<script>
$( "#postMessage" ).submit(function(event) { # ①
event.preventDefault(); # ②
var $form = $(this),
message = $form.find( "input[name='message']" ).val(),
url = $form.attr("action"); # ③
$.ajax({ # ④
type: 'POST',
url: url,
data: JSON.stringify({message: message}), # ⑤
contentType: "application/json", # ⑥
dataType: 'json', # ⑦
success: function() {location.reload();} # ⑧
});
});
</script>
Теперь он добавил какую- то функциональность к нашей кнопке отправки. Давайте вкратце обсудим что же здесь происходит:
-
Здесь для нашей страницы создаётся некое ожидание событие, которое ожидает события
postMessage. -
Применяя
event.preventDefault(); мы также предотвращаем установленное по умолчанию поведение кнопки submit в нашей форме. В данном случае в случае код отправит нашу форму и попытается выполнитьGETс/messages?message=I%27m+a+new+message. -
Если это сработает, мы затем обнаружим в своей форме необходимое сообщение и URL.
-
Получив это мы строим свой запрос AJAX, котоый является неким запросом POST/
-
Для преобразования своей полезной нашрузки в некий допустимый JSON мы применяем
JSON.stringify. -
Помните как ранее, когда мы строили некий отклик и предоставляли информацию заголовка, мы обозначили свой тип содержимого как
text/html? Да мы делаем такие же вещи здесь в своём запросе AJAX, но на этот раз нашим типом содержимого являетсяapplication/json -
Мы устанавливаем значение
datatypeвjson. Это сообщит нашему браузеру тот тип данных, который мы ожидаем обратно от своего сервера. -
Также мы регистрируем некий обратный вызов (callback), который перезагружает данную вебстраницу в случае успеха данного запроса. Это позволит нам увидеть новое своё новое сообщение в этой странице (и все прочие новые), так как он получит все эти сообщения снова. Это заставит данную страницу перезагрузиться не самым элегантным образом подобной обработки, но именно это мы делаем прямо сейчас.
Давайте перезапустим Nameko и попробуем его вновь в своём браузере:
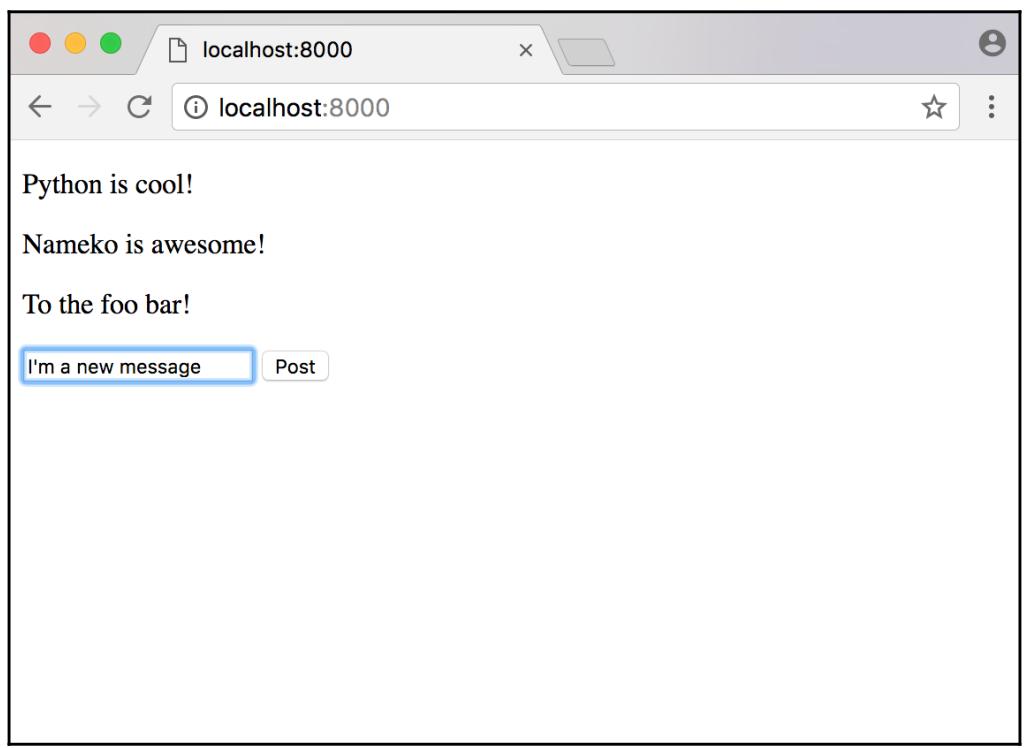
Если вы не вычистили свои данные из Redis (а это можно сделать, удалив их вручную или просто перезагрузив компьютер), вы всё ещё увидите старые сообщения, которые мы публиковали ранее.
Когда вы наберёте своё сообщение, кликните по кнопке Post для отправки вашего нового сообщения:
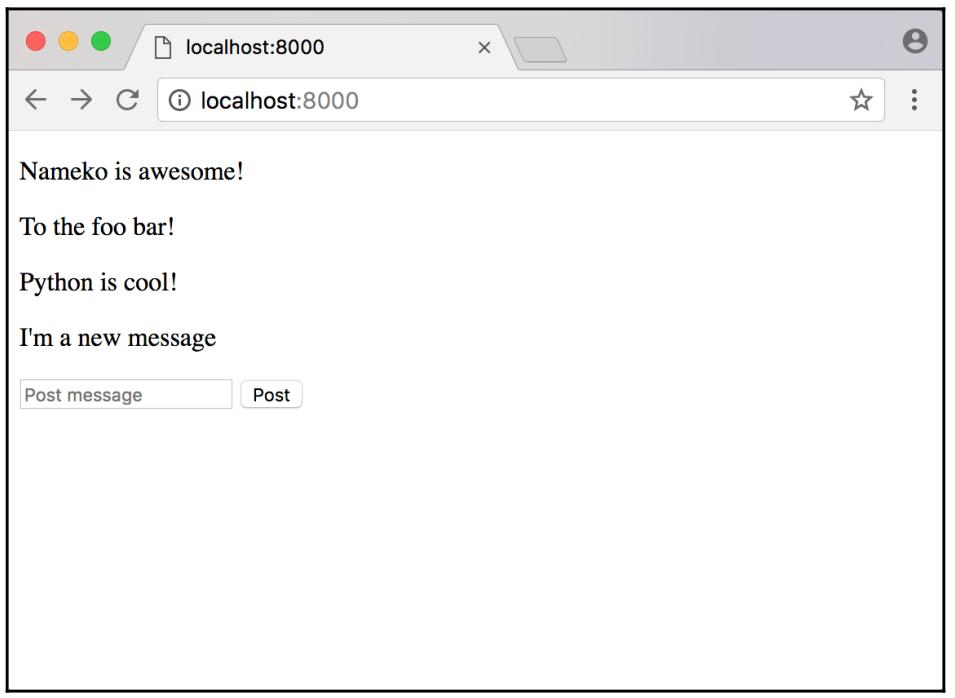
Выглядит как работающее! Наше приложение теперь обладает возможностью отправлять новые сообщения. Мы же теперь перейдём к самому последнем требованию для своего сообщения, которое установит срок истечения сообщений через заданный период времени.
Сейчас мы рассматриваем самое последнее требования для нашей прикладной программы, срок действия сообщениий. Так как мы применяем для хранения своих сообщений Redis, это становиться тривиальной задачей.
Давайте вернёмся назад к своему методу save_message в нашей зависимости Redis.
SET Redis имеет ряд необязательных параметров; самыми интересными двумя для нас являются здесь
ex и px. Оба делают для нас возможным устанавливать срок действия
данных, которые мы собираемся сохранять с одной единственной разницей: ex измеряется в секундах, а
px в миллисекундах:
def save_message(self, message):
message_id = uuid4().hex
self.redis.set(message_id, message, ex=10)
return message_id
В своём предыдущем коде мы можем отметить, что единственная сделанная мной поправка в этом коде состоит в добавлении
ex=10 к методу redis.set; это приведёт к тому, что срок действия сообщений
истечёт по прошествии 10 секунд. Перезапустите свою службу Nameko в этот раз и попробуйте её снова. После того как мы отправим новое сообщение и обновим
свою страницу по истечению 10 секунд, они должны пропасть.
|
| Отметьте, пожалуйста, |
|---|---|
|
если у вас имелись в Redis некие сообщения, которые вы сделали прежде чем выполнили данное изменение, они всё же должны присутствовать, поскольку
были сохранены без применения срока истечения. Для их удаления уничтожьте все данные в Redis с помощью команды |
Не стесняйтесь поиграть с установкой времени истечения, причём устанавливайте его как с параметрами ex,
так и с px. Одним из способов, которым вы можете улучшить положение вещей, состоит в перемещении значения
срока действия в константу файла настроек, который загружается при каждом запуске Nameko, однако на текущий момент достаточно и текущих действия.
Один из моментов, который вы вскоре заметите в текущем состоянии нашей прикладной программы состоит в том, что все сообщения не упорядочены ни коим образом. Когда вы отправляете какое- то новое сообщение, оно может быть вставлено в любом месте нашего потока сообщений, что делает нашу прикладную программу достаточно неуклюжей, если не сказать большего!
Чтобы излечиться от этого, мы будем сортировать свои сообщения по объёму времени, остающемуся до их срока истечения. Во- первых нам придётся улучшить
свой метод get_all_messages в нашей зависимости Redis, чтобы снабдить каждое из сообщений значением времени
жизни:
def get_all_messages(self):
return [
{
'id': message_id,
'message': self.redis.get(message_id),
'expires_in': self.redis.pttl(message_id),
}
for message_id in self.redis.keys()
]
Как вы могли отметить в всой предыдущий код мы добавили новое значение expires_in в каждое сообщение. Оно
применяет команду PTTL Redis, которая возвращает время жизни в миллисекундах для заданного ключа. В качестве альтернативы мы также можем применять
команду Redis TTL, которая возвращает значение времени жизни в секундах, но мы желаем чтобы это значение было максимально точным по возможности, чтобы
выполнить свою сортировку наиболее тщательно.
Теперь, когда наш MessageService вызывает get_all_messages, он также
будт знать сколько времени остаётся жить каждому из сообщений. Получая это мы можем создать новую функцию помощника для сортировки своих сообщений.
Для начала добавим в свои импорты следующее:
from operator import itemgetter
Вне своего класса MessageService создайте следующую функцию:
def sort_messages_by_expiry(messages, reverse=False):
return sorted(
messages,
key=itemgetter('expires_in'),
reverse=reverse
)
Она применяет встроенную функцию Python sorted, которая имеет возможность возвращать отсортированны
список из заданной последовательности; в нашем случае такой последовательностью является messages. Мы применяем
key для определения того как мы желаем сортировать messages. Поскольку
мы хотим сортировать messages по expires_in, мы применяем
itemgetter для выделения его с целью последующего применения для сравнения. Мы задали в качестве необязательного
параметра значение reverse функции sort_messages_by_expiry, которое,
если оно установлено в True, заставит sorted возвращать отсортированный
список в обратном порядке.
Получив такую новую функция помощника, мы можем теперь улучшить свой RPC get_all_messages в нашем
MessageService:
@rpc
def get_all_messages(self):
messages = self.message_store.get_all_messages()
sorted_messages = sort_messages_by_expiry(messages)
return sorted_messages
Наша прикладная программа теперь будет возвращать наши сообщения отсортированными с самыми новыми сообщениями в конце. Если же вы желаете иметь самые
новые сообщения вверху, тогда просто заменить sorted_messages на:
sorted_messages = sort_messages_by_expiry(messages, reverse=True)
Наша прикладная программа соответствует всем критериям приёмки, которые мы определили ранее. У нас имеется возможность отправлять сообщения и получать имеющиеся сообщения, а также у них у всех имеется срок действия после настройки продолжительности времени. Один из моментов, который пока не идеален, состоит в том что мы полагаемся на обновление браузера для забора самого последнего состояния наших сообщений. Мы можем исправить это целым рядом способов, но я продемонстрирую только один из простейших вариантов для этого; через опрос.
Применяя опрос (polling) наш браузер может постоянно выполнять запрос к своему серверу для получения самых последних сообщений не заставляя страницу обновляться. Для достижения этого нам придётся слегка углубиться в JavaScript, однако имеются и иные способы.
Когда наш браузер выполняет опрос для получения самых последних сообщений, наш сервер должен вернуть все сообщения в неком формате JSON. Для достижения этого нам понадобится создать новую оконечную точку HTTP, которая будет возвращать все сообщения в виде JSON, не применяя свои шаблоны Jinja2. Вначале мы сконструируем новую функцию помощника для выработки откликов JSON, устанавливающую правильное значение заголовков.
Вне своего WebServer создайте следующую функцию:
def create_json_response(content):
headers = {'Content-Type': 'application/json'}
json_data = json.dumps(content)
return Response(json_data, status=200, headers=headers)
Она похожа на нашу сделанную ранее create_html_response, однако тут мы устанавливаем
Content-Type в значение 'application/json' и преобразовываем свои данные в допустимый объект JSON.
Теперь внутри имеющегося WebServer создаём следующую оконечную точку HTTP:
@http('GET', '/messages')
def get_messages(self, request):
messages = self.message_service.get_all_messages()
return create_json_response(messages)
Она вызывает наш RPC get_all_messages и возвращает полученные результаты в виде отклика JSON в наш
браузер. Отметим, что теперь здесь для отправки нового сообщения мы применяем тот же самый URL,
/messages, так как мы это делали со своей конечной точкой. Это хороший пример следования RESTful. Мы применяем запрос
POST /messages для создания какого- то нового сообщения и мы применяем запрос GET
/messages для получения всех сообщений.
Чтобы позволить нашим сообщениям обновляться автоматически без обновления браузером, мы создадим две функции JavaScript -
messagePoll, которая будет получать самые последние сообщения и
updateMessages, которая будет обновлять значение HTML этими новыми сообщениями.
Начнём с замены своего блока if Jinja2 на свой home.html, который
выполняет итерации по нашему перечнб сообщений в такой строке:
<div id="messageContainer"></div>
Она будет применена позднее для помещения нашиз новых сообщений, вырабатываемых нашей функцией jQuery.
Внутри всех тегов <script> в нашем home.html запишем такой
приводимый ниже код:
function messagePoll() {
$.ajax({
type: "GET", # ①
url: "/messages",
dataType: "json",
success: function(data) { # ②
updateMessages(data);
},
timeout: 500, # ③
complete: setTimeout(messagePoll, 1000), # ④
})
}
Это другой запрос AJAX, аналогичный тому, который мы применяли ранее для отправки нового сообщения со следующими отличиями:
-
Здесь мы выполняем запрос
GETк своей новой оконечной точке, которую мы сделали ранее в своёмWebServerвместо запросаPOST. -
В случае успеха мы применяем имеющийся обратный вызов
successдля вызова своей функцииupdateMessages, которую мы создадим впоследствии. -
Устанавливаем
timeoutв значение 500 миллисекунд - это та продолжительность времени, которое мы должны ожидать отклик от своего сервера прежде чем отказаться от ожидания. -
Применяем
complete, который позволяет нам определить что происходит после выполнения обратного вызова -successилиerror- в данном случае мы устанавливаем на вызовpollснова по истечению 1000 миллисекунд при помощи имеющейся функцииsetTimeout. -
Вначале мы получаем
messageContainerвнутри данного HTML с тем чтобы обновлять его. -
Мы вырабатываем некий пустой массив
messageList. -
Мы генерируем свой текст
emptyMessages. -
Мы выполняем проверку не равно ли общее число сообщений
0:-
Если так, мы применяем
.html()чтобы заменить HTMLmessageContainerна"No messages!". -
В противном случае для всех сообщений в
messagesмы вначале расчленяем все HTML теги, которые могут быть представлены при помощи встроенной в jQuery функции.text(). Затем мы обёртываем своё сообщение в теги<p>и добавляем их в конец своегоmessageList, применяя.push().
-
-
Наконец, мы применяем
.html()чтобы заменить имеющийся HTMLmessageContainerнаmessagesList.
Теперь мы создадим необходимую функцию updateMessages:
function updateMessages(messages) {
var $messageContainer = $('#messageContainer'); # ①
var messageList = []; # ②
var emptyMessages = 'No messages!
'; # ③
if (messages.length === 0) { # ④
$messageContainer.html(emptyMessages); #
} else {
$.each(messages, function(index, value) {
var message = $(value.message).text() || value.message;
messageList.push('' + message + '
'); #
});
$messageContainer.html(messageList); # ⑤
}
}
Применяя эту функцию мы можем заменить всесь имеющийся код в своём шаблоне HTML, который вырабатывает полный перечень сообщений в имеющемся шаблоне Jinja2. Давайте пройдём по ней шаг за шагом:
|
| Совет |
|---|---|
|
В пункте |
Это отнюдь не самый лучший способ решения проблемы принудительного обновления нашего браузера для изменения новыми сообщениями, однако это один из самых простых для меня вариантов продемонстрировать это в данной книге. Вероятно, существуют более элегантные пути достижения опроса, и если вы на самом деле желаете делать такую функциональность, тогда здесь вам помощником в наилучшем решении будут Websocket.
Теперь мы вплотную приблизились к руководству по созданию нашего приложения TempMessenger. Если ранее вы никогда не применяли Nameko и не создавали микрослужбы, я надеюсь, что снабдил вас хорошей точкой опоры чтобы удерживать службы небольшими и целенаправленными.
Мы начали с создания некоторой службы с единственным методом RPC и затем применили её внутри другой службы через HTTP. Затем мы рассмотрели способы, при помощи которых мы можем проверять службы Nameko внутри арматуры, которая позволяет нам порождать исполнителей и даже сами по себе службы.
Мы ввели поставщиков зависимостей и создали клиента Redis с возможностью получения отдельного сообщения. Сделав это мы расширили зависимости Redis методами, которые позволяют нам сохранять новые сообщения, устанавливать срок действия сообщения и возвращать их все списком.
Мы рассмотрели как мы можем возвращать HTML в свой браузер при помощи Jinja2 и через создание поставщика зависимостей. Затем мы рассмотрели некий код JavaScript и jQuery, который позволяет нам делать запросы из своего браузера.
Одна из основных тем, которую вы вероятно отметили, состоит в необходимости сохранения логики зависимости отдельно от вашего кода службы. Соблюдая это
правило, мы оставляем свои службы невосприимчивыми к тем работам, которые являются особыми только для таких зависимостей. Что произойдёт если мы решим
переключиться с Redis на базу данных MySQL? Для нашего кода это было бы всего лишь неким вариантом создания какого- то нового поставщика зависимостей для
MySQL и новых методов клиентов, которые соответствовали бы ожидаемым со стороны нашей MessageService. Затем мы внесли
бы минимальные изменения в своей MessageService для переключения с Redis на MySQL. Если бы мы не писали свой код таким
образом, тогда это потребовало от нас затратить больше времени и усилий чтобы внести изменения в свою службу. Мы бы также расширили область для возникновения
возможных ошибок.
Если вы знакомы с прочими общими схемами Python, вы теперь должны понимать, что Nameko позволяет нам запросто создавать масштабируемые микрослужбы и при этом снабжая дополнительными возможностями не входящих в комплект батареек в сравнении с чем- то подобным Django. Когда наступает время создавать небольшие службы, которые обрабатывают отдельную цель, которая сосредоточена в задачах серверной стороны, Nameko также может стать исключительным выбором.
В своей следующей главе мы рассмотрим расширение TempMessenger микрослужбой Аутентификации пользователя с применением базы данных PostgreSQL.