Приложение B. Эффективное применение RDMA для служб ключ- значение
Перевод статьи Anuj Kalia, Michael Kaminsky†, David G. Andersen Using RDMA Efficiently for Key-Value Services, Carnegie Mellon University, †Intel Labs, 2014
SIGCOMM’14, Aug 17-22 2014, Chicago, IL, USA
ACM 978-1-4503-2836-4/14/08.
http://dx.doi.org/10.1145/2619239.2626299
Содержание
Данная статья рассматривает проектирование и реализацию HERD, некоторой системы ключ- значение, которая разработана для применения наилучшим образом какой- то сетевой среды RDMA. В отличие от систем предшественниц ключ- значение на основе RDMA, HERD сосредоточен на проектировании уменьшения сетевого обмена в обе стороны при использовании действенных примитивов RDMA; получаемым результатом в конечном итоге являются низкая латентность и пропускная способность, которые насыщены современным, общедоступным оборудованием RDMA.
HERD обладает двумя нетрадиционными решениями: во- первых, он не применяет чтение RDMA, несмотря на общую привлекательность операций, которые полностью минуют удалённый ЦПУ. Во- вторых, он пользуется смесью глаголов (verb) RDMA и обмена сообщениями, несмотря на общепризнанное мнение что имеющиеся примитивы сообщений являются медленными. Некий клиент HERD записывает свои запросы в оперативную память сервера обработки; этот сервер вычисляет соответствующий отклик. Такой подход применяет некий единый путь в оба конца для всех запросов и поддерживает до 26 миллионов операций ключ- значение в секунду со средним временем задержки в 5 мкс. Следует отметить, что для небольших элементов ключ- значение наша полная пропускная способность системы аналогична присущей чтению RDMA пропускной способности и является почти в два раза выше чем предыдущие системы ключ- значение на основе RDMA. Мы полагаем, что HERD в дальнейшем послужит в качестве действенного шаблона для построения служб центра обработки данных на основе RDMA.
RDMA; InfiniBand; RoCE; Key-Value Stores
Данная статья изучает вопрос, который имеет важные последствия для проектирования современных кластерных систем: Какой метод является наилучшим для использования свойств RDMA при поддержке удалённого доступа к таблице хэшей? Для ответа на данный вопрос мы вначале оцениваем значение производительности, которое при достаточно аккуратном проектировании может быть достигнуто для каждого из имеющихся примитивов взаимодействия RDMA. Вооружившись этим знанием, мы показываем как применять некую неожиданную комбинацию методов и построений системы для достижения максимально возможного значения производительности в некоторой высокопроизводительной сетевой среде RDMA.
Основным мотивом для нашей работы послужил кажущийся контраст между имеющимися фундаментальными требованиями времени для обмена между узлами в сопоставлении с выборкой ЦПУ- оперативная память, а также теми недавно появившимися решениями, которые применяют множественные чтения RDMA (remote direct memory access - удалённого прямого доступа к памяти). С одной стороны, прохождение между узлами в грубом приближении требует 1- 3 мкс, в сравнении с 60- 120 нс для выборки из памяти, в предположении, что конструкция со множеством RTT {временем на передачу и подтверждение приёма, периодом кругового обращения}, как это было обнаружено в последних системах Pilaf [21] и FaRM [8] должна быть в целом медленнее чем построение с отдельным RTT. Однако, с другой стороны, некие чтение RDMA обходит множество потенциальных источников накладных расходов, таких как обслуживание прерывания и инициацию обменов управления, которые вовлекают в себя ЦПУ хоста. В данной статье мы показываем, что имеется лучший путь получения преимуществ RDMA для получения высокопроизводительного хранилища с низкой латентностью.
Некий вызов как для нашей, так и для предыдущих работ заключается в отсутствии богатства операций RDMA. Какая- то операция RDMA может всего лишь выполнять считывание или запись в удалённом местоположении. Последние работы построения хранилищ ключ- значение [21, 8] были сосредоточены исключительно на применении чтения RDMA для обхода удалённых структур данных, аналогично тому, как мы бы это выполняли если бы эти структуры располагались в локальной памяти. Такой подход неизменно требует множества двунаправленных обменов в имеющейся сетевой среде.
Рассмотрим некое идеальное хранилище ключ- значение на основе RDMA (или кэширования), в котором каждый запрос
GET требует только одного небольшого чтения. Проектирование такого хранилища настолько же сложно,
как и проектирование таблицы хэш- значений, в которой каждый запрос GET требует только одной
произвольной выборки из памяти. Вместо этого мы предлагаем некое решение более простой проблемы: мы проектируем некий кэш ключ-
значение, который предоставляет производительность, близкую к самому идеальному кэшированию. Однако, наше решение вовсе не применяет
операции чтения RDMA.
В данной статье мы представляем HERD, некий кэш ключ- значение, который использует свойства RDMA для предоставления низкой латентности
и высокой производительности. Позднее мы продемонстрируем, что операции чтения RDAM не могут быть приспособлены для получения полной
производительности имеющегося оборудования RDMA. В HERD клиенты передают свои запросы в память сервера при помощи операций записи.
Имеющийся ЦПУ сервера опрашивает свою память относительно получаемых запросов. При получении некоего нового запроса он исполняет операции
GET и PUT в своих локальных структурах и отправляет
соответствующий отклик обратно своему клиенту. Так как производительность операции записи RDMA не масштабируется вместе с имеющимся числом
исходящих соединений, получаемый отклик отправляется как некое сообщение SEND померх соединения дейтаграмм.
Наша работа достигает три основные цели:
-
Исчерпывающий анализ значений производительности глаголов (verbs) RDMA и формулирует все основные варианты организации систем ключ- значение.
-
Доказательство того, что "двусторонние" глаголы лучше операций чтения RDMA для систем ключ- значение, опровергая то предположение, которого придерживались ранее. [21, 8]
-
Описание проектирования и реализации HERD, некоторого кэширующего решения ключ- значение, которое предлагает максимально возможную производительность аппаратных средств RDMA.
Наши последующий раздел представляют краткое введение в хранилища ключ- значение и RDMA, а также описывают последние усилия в построении хранилищ ключ- значение с использованием RDMA. Раздел 3 обсуждает обоснование наших проектных решений и демонстрирует что глаголы обмена сообщениями являются лучшим выбором чем операции чтения RDMA для систем ключ- значение. Раздел 4 обсуждает общие проект и реализацию нашего кэша ключ- значение. В Разделе 5 мы выполняем оценку нашей системы в кластере из 187 узлов и сопоставляем её с FaRM [8] и Pilaf [21].
Данный раздел предоставляет базовую информацию по хранилищам ключ- значение и системам кэширования, которые составляют сердцевину HERD. Затем мы предоставляем некий обзор RDMA, покольку он существенен для остального текста нашей статьи.
Основанные на оперативной памяти хранилища ключ- значение и системы кэширования широко распространены в крупномасштабных службах
Интернет. Они используются как первичными хранилищами (такими как Redis [4] и
RAMCloud [23]), так и системами кэширования для интерфейса с лежащими в основе базами данных
(например, Memcached [5]). На своём базовом уровне эти системы экспортируют некий
традиционный интерфейс GET/PUT/DELETE. Внутри себя они используют разнообразные структуры данных
для предоставления быстрого, с уровнем эффективности оперативной памяти доступом к лежащим в его основе данным (например, таблице хэширования
или индексам на основе дерева).
В данной статье мы сосредоточимся на имеющейся архитектуре взаимодействия для поддержки обоих этих приложений; мы воспользуемся реализацией системы кэширования для повсеместной проверки своего получаемого в результате решения.
Хотя хранилища объектов в оперативной памяти последнего времени применяют как решения на основе деревьев, так и хэш- таблиц,
данная статья сосредоточится на хэш- таблицах в качестве основной структуре индексации данных. Решения с хэш- таблицами имеют длинную и
богатую историю и основное предпочтение, которое кто- то делает, в основном базируется на желательных целях оптимизации. В последние годы
некоторые системы применяли развитые архитектуры таблиц хэширования, такие как хэширование Cuckoo
[24, 17, 9]
и Hopscotch [12]. Таблицы хэширования Cuckoo являются привлекательным выбором для построения
быстрых систем ключ- значение [9, 31,
17], потому что при K функциях хэширования
(обычно K равен 2 или 3), они требуют только
K выборок из памяти для операций GET плюс некоторое
дополнительное развёртывание ссылки, если эти значения не хранятся в самой этой таблице. Во многих рабочих потоках
GET составляют более 95% всех операций
[6, 22]. Это свойство делает хэширование Cuckoo
привлекательной основой для хранилища ключ- значение на базе RDMA [21]. Архитектуры на основе
Cuckoo и Hopscotch часто сосредотачиваются на рабочих потоках с интенсивным чтением: операции
PUT требуют перемещения значений внутри имеющихся таблиц. В данной статье мы выполнили оценки и
для сбалансированных рабочих потоков (по 50% PUT/GET), и для нагрузок с интенсивным чтением
(95% GET).
Для обоих типов рабочих потоков без ограничений на свою производительность, HERD внутри себя применяет некую структуры данных
cache, которая может выселять элементы при своём заполнении. Однако, мы сосредоточимся
на самой архитектуре сетевого взаимодействия - наши результаты распространяются и на системы хэширования и на хранилища ключ- значение
до тех пор, пока выполняемая реализация достаточно быстрая, чтобы нуждаться в архитектуре высокоскоростного взаимодействия.
Архитектура кэширования HERD базируется на самой последней системе MICA [18], которая предоставляет
как семантику кэширования, так и семантику хранения. Режим кэширования MICA применяет ассоциативную индексацию с потерями для
установления соответствия от ключей к указателям и сохраняет все значения в некотором циклическом журнале, который является эффективным
в отношении оперативной памяти, избегая фрагментации и не требуя затратного сбора мусора. Данное решение требует всего лишь двух
произвольных доступов к памяти как для операций GET, так и для операций
PUT.
RDMA (Remote Direct Memory Access - удалённый прямой доступ к памяти) позволяет одному компьютеру получать прямой доступ к памяти без привлечения самой операционной системы в любом из хостов. Это делает возможным обмены с нулевым копированием, а также снижение латентности и накладных расходов ЦПУ. В данной работе мы сосредоточимся на двух видах предоставляющего RDMA интерконнекта: InfiniBand и RoCE (RDMA over Converged Ethernet). Однако мы полагаем, что наш решение применимо и для прочих поставщиков RDMA, таких как iWARP, Quadrics и Myrinet {Прим. пер.: а также Ангара}.
InfiniBand является сетевой средой многопортовой коммутации широко применяемой в высокопроизводительных вычислительных системах. RoCE является относительно новым сетевым протоколом , который делает возможным прямой доступ к памяти поверх Ethernet. NIC InfiniBand и RoCE достигают низкой латентности за счёт реализации определённых уровней сетевого стека (с транспортного по физический уровни) в аппаратных средствах, а также предоставляя RDMA и обход ядра. В данном разделе мы представим некий обзор функциональности RDMA и терминологии, которые применяются на протяжении остальной части данной статьи.
Сопоставление со стандартным Ethernet
Чтобы отличать RoCE, мы будем именовать сетевые среды Ethernet без предоставления RDMA как "классический Ethernet". В отличии от NIC классического Ethernet, NIC RDMA (RNIC) предоставляет надёжную доставку в приложения за счёт употребления основанного на оборудовании повторного отправления утраченных пакетов. Кроме того, RNIC предоставляет для всех взаимодействий обход ядра. Эти два момента снижают всеобщую латентность а также загрузку ЦПУ в вашим взаимодействующих хостах. Типичным значением латентности (1/2 RTT) в InfiniBand/ RoCE является 1 мкс {Прим. пер.: задержка на хоп Ангара 130 нс}, в то время как классические решения на основе Ethernet [2, 18] предоставляют 10 мкс. Основная часть этого зазора возникает за счёт различных акцентов в архитектуре самих NIC. По мере снижения стоимости соответствующего оборудования RDMA увеличивает своё присутствие в центрах обработки данных [21]. Стоимость RNIC 40 Gbps ConnectX-3 Mellanox составляет около $500, в то время как адаптеры 10 Gbps Ethernet стоят от $300 до $800. Предложение RoCE ещё форсировало присутствие RDMA, так как он позволяет сокетным приложениям работать в одной и той же сетевой среде совместно с приложениями RDMA.
Глаголы и пары очередей
Пространство пользователя программ осуществляет доступ RNIC напрямую при помощи функций, именуемых глаголами (verbs). Имеются различные типы глаголов. Наиболее существенными из них являются чтение RDMA (READ), запись RDMA (WRITE), SEND и RECEIVE. Глаголы отсылаются приложениями в очереди, которые поддерживаются внутри самой RNIC. Очереди всегда присутствуют в виде пар: некая очередь отправки (send queue) и очередь приёма (receive queue) формируют пару очередей (QP, queue pair). Каждая пара очередей имеет некую связанную с ней очередь завершения (CQ, completion queue), которую сам RNIC заполняет по мере завершения исполнения глагола.
Значение глагола формирует некое определение семантики самого интерфейса, предоставляемого RNIC. Существует два вида семантики глаголов: семантика памяти и семантика канала. {Прим. пер.: в современных реализациях RDMA также имеются атомарные глаголы Fetch и Add/ Cmp и Swap.}
Семантика памяти: Определённые глаголы RDMA (READ и WRITE) имеют семантику памяти: они определяют значения удалённых адресов памяти для переноса на них операций. Такие глаголы являются односторонними: ЦПУ отвечающей стороны не знает о происходящей операции. Такое отсутствие накладных расходов ЦПУ на отвечающей стороне делает привлекательными односторонние глаголы. Более того, они обладают среди всех глаголов самыми низкими значениями латентности и пропускной способности.
Семантика канала: SEND и RECEIVE (RECV) имеют семантику канала, т.е.
полезная нагрузка SEND записывается в адреса удалённой памяти, которые определяются соответствующей отвечающей стороной в предварительно
отправляемом RECV. Некоторой аналогией для этого может служить реализация небуферированных сокетов, которые требуют вызова
read() перед появлением отправляемого пакета. SEND и RECV являются
двусторонними, поскольку ЦПУ отвечающей стороны должен выставить некий RECV для обработки
какого- то входящего SEND. В отличии от случая глаголов памяти, в общий процесс вовлечён ЦПУ отвечающей стороны. Двусторонние глаголы
имеют слегка более высокую латентность и более низкую пропускную способность в сравнении с односторонними глаголами и отвергались как
неблагоприятные для систем ключ- значение [21, 8].
Хотя глаголы SEND и RECV технически являются глаголами RDMA, мы отличаем их от READ и WRITE. Мы называем READ и WRITE глаголами RDMA, в то время как SEND и RECV именуем глаголами обмена сообщениями.
Глаголы обычно выставляются в очередь отправки QP (за исключением RECV, который выставляется в очередь приёма). Для выставления какого- то глагола в соответствующем RNIC некое приложение выполняет вызов в соответствующем драйвере RDMA пространства пользователя. Затем этот драйвер подготавливает некий WQE (Work Queue Element - элемент очереди исполнителя) в оперативной памяти соответствующего хоста и звонит в дверной звонок ответного RNIC через PIO (Programmed IO). Для ConnectX и более новых RNICs, соответствующий дверной звонок содержит весь WQE [27]. Для глаголов WRITE и SEND, их WQE связывается с полезной нагрузкой, которая подлежит отправке в соответствующий удалённый хост. Некая полезная нагрузка вплоть до предельного размера PIO (в нашей установке 256 байт) может вкладываться в свой WQE, в противном случае она извлекается RNIC через чтение DMA. Вложенная отправка не вовлекает в себя операции DMA, снижая латентность и увеличивая пропускную способность для небольших полезных нагрузок.
Когда соответствующий RNIC выполняет необходимые шаги, относящиеся к данному глаголу, он помещает некое событие завершения в связанную со своей парой очередей очередь исполнения (CQ) через некую запись DMA. Применение завершающих событий добавляет дополнительные накладные расходы в шину PCIe своего RNIC. Эти накладные расходы могут быть уменьшены за счёт использования избирательных вызовов (selective signaling). При применении избирательных вызовов к очереди с размером S вплоть до S-1 последовательных глаголов могут не снабжаться сигналами, т.е. для этих глаголов могут не помещаться события исполнения. Очередь приёма не может применять избирательные вызовы. Так как S является большис (~ 128), взаимозаменяемо используем термины "избирательных вызовов" и "освобождения от сигналов" (selective signaling и unsignaled).
Виды доставки
Доставка RDMA может быть с выполнением соединения или без него (connected или unconnected). Доставка с соединением требует некоторого соединения между двумя парами очередей, которые взаимодействуют исключительно друг с другом. Современные реализации RDMA поддерживают два основных вида доставки с соединением: RC (Reliable Connection - достоверное соединение) и UC (Unreliable Connection - ненадёжное соединение). В UC нет никаких подтверждений приёма пакетов; пакеты могут теряться и находящиеся зависящие от них сообщения могут отбрасываться. Так как UC не вырабатывает пакетов ACK/ NAK, он вызывает меньший сетевой обмен чем RC.
При доставке без установления соединения одна пара очередей может взаимодействовать с любым числом прочих пар очередей. Имеющаяся в настоящее время реализация предоставляет только один вид транспорта без установления соединения: UD (Unreliable Datagram - ненадёжные дейтаграммы) {Прим. пер.: так в оригинале, на момент перевода реализации RDMA поддерживают достоверный обмен дейтаграммами - RD, Reliable Datagram, см., например, Обыкновенное чудо OmniPath, хотя отметим, что в этом релизе и описывается всего лишь эмуляция RDMA со стороны OmniPath. Сам OmniPath внутри себя применяет иной набор глаголов, но его микрокод эмулирует глаголы RDMA, хотя и при потере производительности.}. RNIC поддерживает состояние для каждой активной очереди в своём кэше контекста пар очередей, поэтому доставка дейтаграмм может лучше масштабироваться для приложений с топологией один- ко- многим.
InfiniBand и RoCE употребляют управление потоком на канальном уровне (link- level), а именно, управление потоком на основе доверительности и управление потоком с приоритетами (credit-based flow control и Priority Flow Control). Даже при ненадёжной доставке (UC/ UD) пакеты никогда не теряются из- за переполнения буферов. В качестве причин утраты пакетов могут выступать битовые ошибки в кабелях и аппаратные сбои, которые чрезвычайно маловероятны. По этой причине, наша разработка, аналогично выбору Facebook и прочих [22], приносит в жертву транспортный уровень повторной доставки в угоду более часто востребованному варианту производительности за счёт редких повторов на уровне приложений.
Некоторые виды доставки поддерживают только какое- то подмножество из всех доступных глаголов. Таблица 1 перечисляет те глаголы, которые поддерживаются каждым видом доставки {Прим. пер.: в данном переводе таблица расширена столбцом RD и строкой с атомарными глаголами (Fetch и Add/ Cmp и Swap)}. Рисунок 1 отображает шаги DMA и сетевой среды, вовлечённые в выставлении глаголов.
| Глагол | RС | UС | RD | UD |
|---|---|---|---|---|
|
V |
V |
V |
V |
|
V |
V |
V |
|
|
V |
|
V |
|
|
V |
|
V |
|
UC не поддерживает READ, а UD совсем не поддерживает RDMA. {К тому же, длина кадра UD ограничена значением MTU, в то время как размер прочих кадров определяется аппаратной реализацией, например, в OmniPath это 1ГБ.} |
||||
Рисунок 1
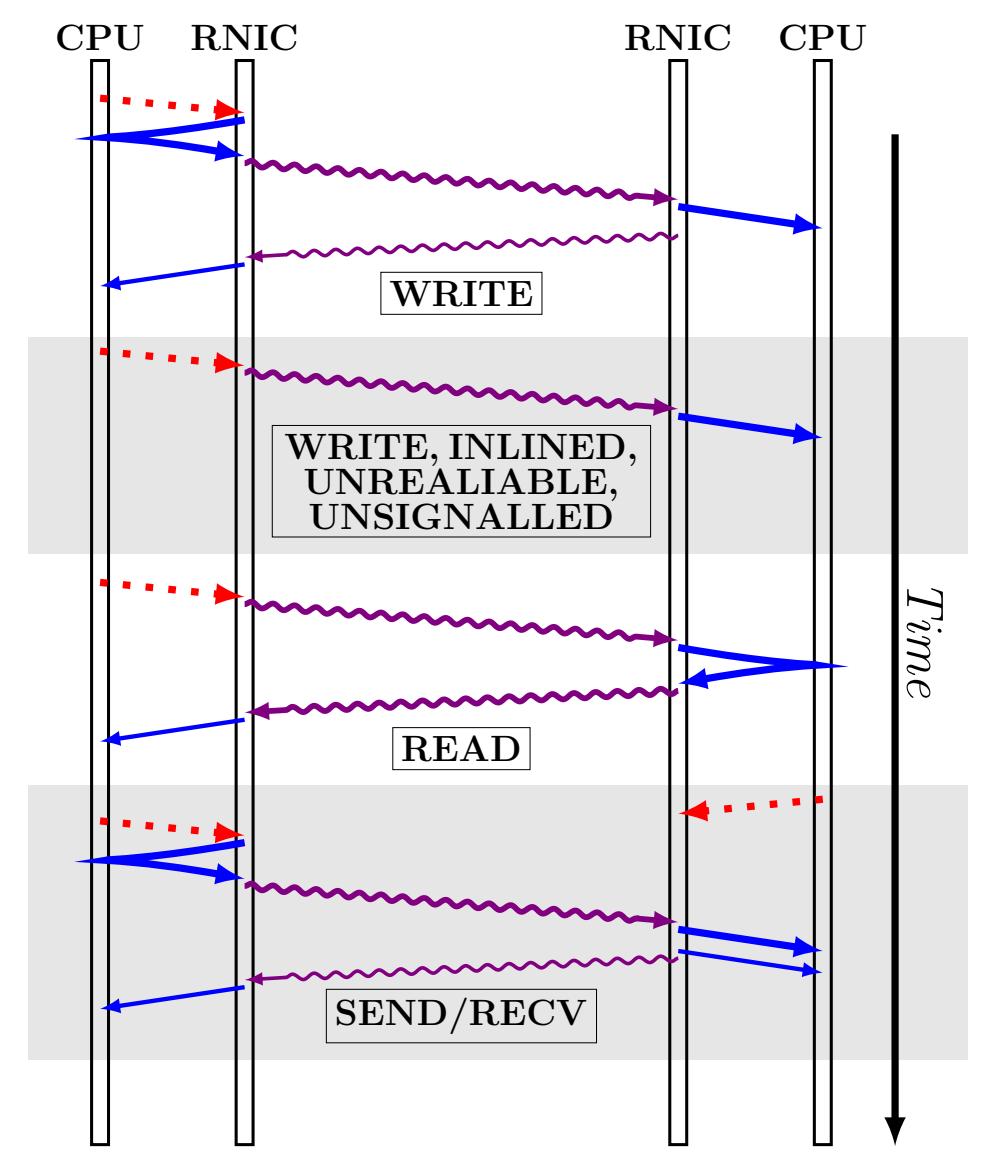
Вовлекаемые в выставление глагола этапы. Показанные точками стрелки являются операции PCIe и PIO. Сплошные, прямые стрелки являются операциями DMA: тонкие линии обозначают записи событий завершения. Толстые волнистые линии представляют пакеты данных RDMA, а тонкие волнистые линии являются ACK.
Pilaf [21] является хранилищем
ключ- значение, которое служит для целей высокой производительности и низкого использования ЦПУ. Для GET,
доступа клиента и таблицы хэширований Cuckoo в его сервере используется READ, что в среднем требует 2.6 отправок с возвратом для
отдельного запроса GET. Для PUT клиенты отправляют
свои запросы в имеющийся сервер при помощи сообщения SEND. Для гарантии согласованности GET при
наличии одновременных PUT, структуры данных Pilaf обладают
самопроверкой: все записи таблицы хэширования дополняются двумя 64- битными контрольными суммами.
Второе хранилище ключ- значение, с которым мы проводили сопоставление, основывается на хранилище, разработанным в FaRM [8]. Важно отметить, что FaRM предназначена для более распространённой целевой аудитории платформ распределённых вычислений, которая выставляет память некоторого кластера машин как некое совместно используемое адресное пространство; мы проводили сравнение только с хранилищем ключ- значение, реализуемым поверх FaRM, которое мы именуем FaRM-KV. В отличии от архитектуры клиент- сервер в Pilaf и HERD, FaRM является симметричным, более приличествующим решениям в качестве кластерной архитектуры; каждая машина выступает и как сервер, и как клиент.
Решение FaRM предоставляет для сопоставления два компонента. Первым является решение хранения ключ- значение, которое применяет некий
вариант хэширования Hopscotch [22] для создания осведомлённых о местоположении хэш- таблиц.
Для GET клиенты выполняют READ определённых последовательных слотов Hopscotch, один из которых
скорее всего содержит необходимый ключ. Ещё одно выполнение READ требуется для выборки самого значения, если оно не хранится в внутри
данной таблице хэширования. Для GET клиенты применяют операцию WRITE своих запросов в некий
циклический буфер в оперативной памяти данного сервера. Сам сервер опрашивает это буфер для определения новых запросов. Такое решение не
является особенным для FaRM - мы применили его только как некую сохранившуюся альтернативу архитектуре Pilaf на основе Cuckoo для выполнения
более глубокого сравнения с HERD.
Второй важной стороной FaRM является его симметричность: в этом он отличается от Pilaf и HERD. Для небольших пар ключ- значение с фиксированным размером FaRM может "встраивать" такое значение в сам ключ. При встраивании архитектура FaRM на основе чтения всё же достигает меньшего максимума пропускной способности в сопоставлении с HERD, но при этом меньше использует ЦПУ. Этот компромисс может быть справедлив в тех кластерах, в которых все машины слишком заняты чтобы выполнять вычисления; здесь мы не проводили оценок симметричного варианта применения, однако он заслуживает внимания для пользователей любых решений.
Для решения своей цели поддержки серверов ключ- значение, которые достигают наивысшей возможной пропускной способности при помощи RDMA, в данном разделе мы поясняем те основания, которые мы выбрали для использования - и не применяли - в особенности функциональности RDMA, а также прочие опции проектирования. Для начала мы представляем анализ общей производительности рассматриваемых глаголов RDMA; затем мы настраиваем вручную некую архитектуру взаимодействия, применяя самую быструю из тех, что могут поддерживать наши потребности приложений.
Как мы уже советовали в Разделе 1, одним из центральных решений, которое
предстоит выбрать, состоит в том, следует ли нам применять глаголы памяти (READ и WRITE RDMA), или глаголы обмена сообщениями (SEND и
RECV). Последние работы в сообществе подобных систем и сетевых сред, к примеру, были сосредоточены на операция READ RDMA в качестве
некоторого строительного блока, поскольку они целиком обходят имеющиеся удалённые сетевой стек и ЦПУ для
GET [21, 8].
В противовес этому, однако, сообщество HPC более широко применяло обмен сообщениями, причём как для кэширующих ключ- значение
[14], так и для взаимодействия с обычным назначением [16].
Эти последние системы масштабировались до тысяч машин, но предоставляли более низкую пропускную способность - менее одного миллиона
операций в секунду при memcached [14]. Основная причина для низкой пропускной способности в
[14] не очевидна, но мы подозреваем, что именно архитектура приложения делает данную систему
неспособной выжимать всю производительность из имеющихся RNIC.
Всё ещё остаётся значительным зазор между этими двумя направлениями проведения работ и, согласно тому что нам известно, HERD является самой первой системой, которая предоставляет всё наилучшее из этих обоих миров: пропускную способность даже лучшую чем ту, которой обладают системы на базе RDMA при масштабировании до нескольких сотен клиентов.
HERD применяет гибридный подход, применяя и RDMA и обмен сообщениями для достижения наилучшего эффекта. Тем не менее чтение RDMA не
являются привлекательными, поскольку они требуют множества доставок с возвратом. В HERD клиенты вместо этого применяют запись своих
запросов в соответствующий сервер при помощи RDMA поверх UC (Unreliable Connection). Такая запись помещает все запросы
PUT или GET в область памяти для каждого клиента в данном
сервере. Сам сервер выполняет опрос этих областей относительно новых запросов. После получения одного из них, процесс данного сервера
выполняется обычным образом применяя свои локальные структуры данных. Затем он отправляет некий ответ своему клиенту при помощи глаголов
сообщений: SEND поверх Unreliable Datagram.
Чтобы пояснить почему мы применяем такой гибрид RDMA и обмена сообщениями мы описываем соответствующие эксперименты и анализы производительности, которые их поддерживают. В особенности мы поясняем почему мы предпочитаем применять записи RDMA вместо чтений, не затрагивая преимуществ аппаратных повторов при вариантах с ненадёжной доставкой, а также применяем глаголы обмена сообщениями в пренебрежении общепринятой мудростью что они медленнее RDMA.
На протяжении остальной части статью мы применяем для чтений RDMA термин READ, а для записей RDMA WRITE. В данном разделе мы предоставляем микробенчмарки кластера Apt Emulab [29], большого современного тестового оборудования, снабжённого 56 Gbps InfiniBand. Так как Apt имеет только InfiniBand, в Разделе 5 мы также применяем кластер Susitna NSF PRObE [11] для оценок c RoCE. Аппаратные конфигурации этих кластеров приводятся в Таблице 2.
| Название | Узлы | Оборудование |
|---|---|---|
|
187 |
Intel Xeon E5-2450 CPUs. ConnectX-3 MX354A (56 Gbps IB) via PCIe 3.0 x8 |
|
36 |
AMD Opteron 6272 CPUs. CX-3 MX353A (40 Gbps IB) and CX-3 MX313A (40 Gbps RoCE) via PCIe 2.0 x8 |
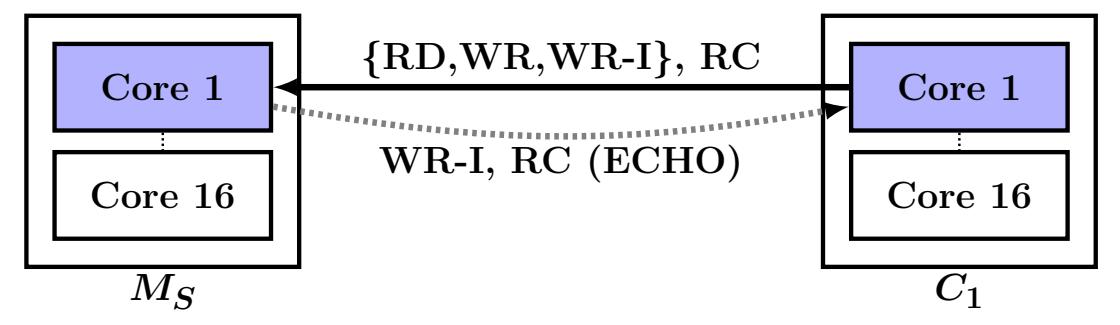
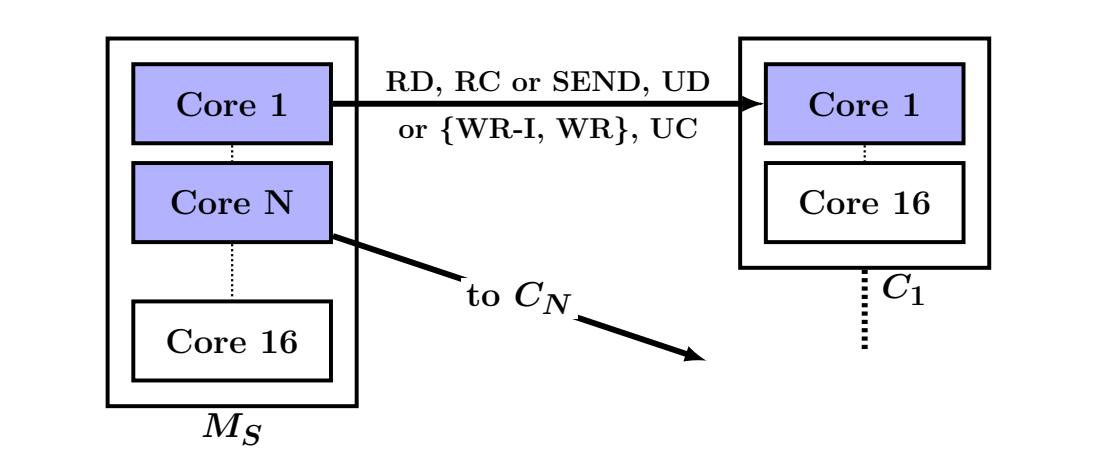
Данные эксперименты используют одну машину сервера и несколько машин клиентов. Мы отмечаем машину сервера как MS, а её RNIC как RNICS. Машина клиента i обозначается как Ci. Данные машины сервера и клиента могут соответственно исполнять множество процессов сервера и клиента. Мы называем некое сообщение от клиента к серверу запросом, а ответ сервера клиенту откликом. Вызывающий некий глагол хост является запрашивающей стороной, а его получатель стороной отклика. Для SEND и WRITE без сигнала поверх UC соответствующий хост получателя на самом деле не отправляет отклика, но мы всё ещё продолжаем именовать его стороной отклика.
Для экспериментов с пропускной способностью процессы сопровождают некое окно определённых невыполненных глаголов в их очередях отправки. Применение окон позволяет нам насыщать наши RNIC меньшим числом процессов. Во всех своих экспериментах пропускной способности мы вручную настраиваем размер такого окна для достижения максимальной агрегированной пропускной способности.
Для использования WRITE вместо READ имеется ряд преимуществ. WRITE может исполняться поверх доставки UC, которая сама по себе дарует определённые преимущества производительности. Поскольку стороне отклика не требуется отправлять пакеты обратно, его RNIC выполняет меньше обработки и тем самым может поддерживать более высокую производительность нежели вариант с READ. В конце концов, как можно ожидать, значение задержки WRITE без установки сигнала составляет примерно половину (1/2 RTT) от READ. Это позволяет заменить одну операцию READ на две WRITE, одну от- клиента- к- серверу и одну от- сервера- к- клиенту (формирующих пару запрос- отклик) без значительного увеличения латентности.
WRITE имеет меньшую латентность
Замер значения латентности WRITE без выставления сигнала не столь очевиден, поскольку соответствующая запрашивающая сторона не имеет индикации завершения. Тким образом, мы измеряем её косвенным образом через значение латентности ECHO. При некотором ECHO клиент передаёт какое- то сообщение в сервер, а этот сервер транслирует то же самое сообщение обратно своему клиенту. Если такое ECHO реализовать при помощи WRITE без выставления сигнала, оно составит почти половину значения задержки ECHO.
Мы также измерили значение латентности операций READ и WRITE с выставлением сигнала. Поскольку эти операции снабжены сигналом, для измерения латентности мы воспользовались их событием завершения. Для WRITE мы также замерили значение латентности с вложенной полезной нагрузкой.
Рисунок 2 отображает полученные средние значения латентности таких измерений. Для ECHO мы применяли WRITE с вложением и без выставления сигнала. В наших RNIC максимальный размер такой вложенной полезной нагрузки составляет 256 байт. Следовательно, значения графиков для WR-INLINE и ECHO показаны только до 256 байт.
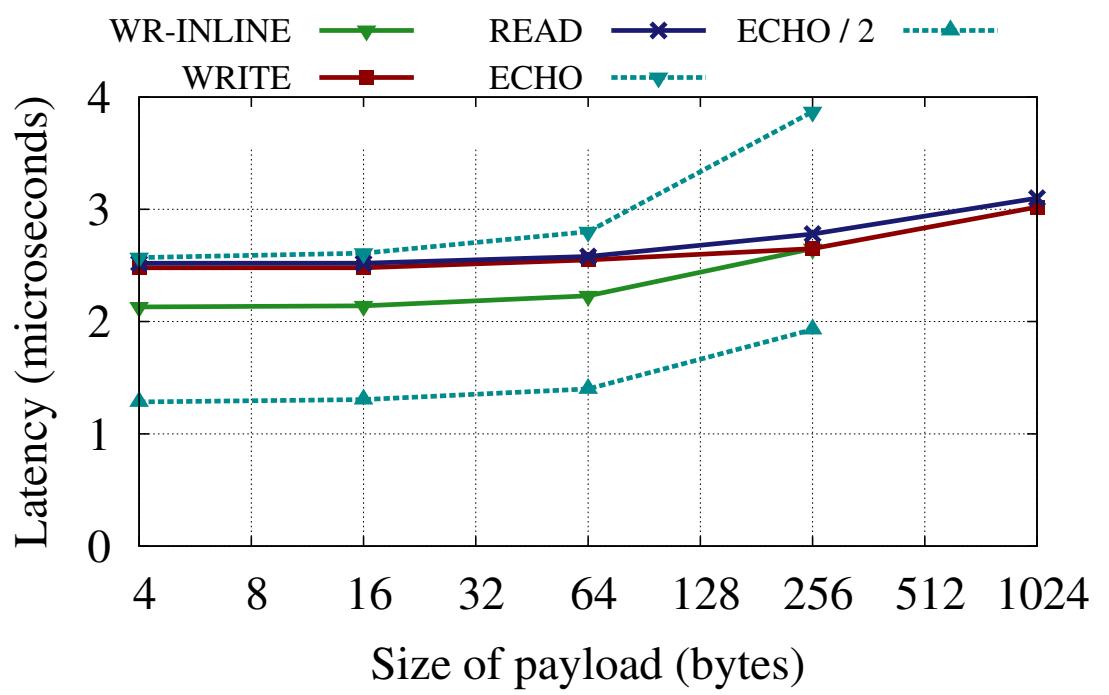
Глаголы без выставления сигнала: Для полезных нагрузок вплоть до 64 байт, значение латентности ECHO близко к задержкам READ, что подтверждает, что значение латентности односторонней операции WRITE составяет примерно половину от значения задержки READ. Для ECHO большего размера значение латентности растёт, так как определённое время тратится на запись в соответствующий RNIC через PIO.
Глаголы с сигналом: Сплошные линии на Рисунке 2 показывают значения латентности для трёх глаголов с сигналом - WRITE, READ и WRITE с вложением (WR-INLINE). Значения латентности для READ и WRITE близки, поскольку общая длина пути перемещения по сетевой среде/ PCIe идентична. За счёт обхода одной операции DMA вложение существенным образом уменьшает значение задержек небольших WRITE.
У WRITE выше пропускная способность
Для оценки пропускной способности, во- первых, необходимо обратить внимание, что взаимодействии с одним сервером большого числа машин клиентов, разные глаголы действуют совершенно различным образом при их использовании в этих клиентах (общающихся с одним сервером) и в самом сервере (общающемся со множеством клиентов).
Входящая пропускная способность: Для начала мы измеряем значения пропускной способности для глаголов входа (inbound), т.е. общее число глаголов, которое множество удалённых машин (клиентов) могут выпускать к одной машине (серверу). Применяя указанную выше нотацию, C1, ..., CN вызывают операции в отношении MS, как это показано на Рисунке 3a. Рисунок 3b показывает накапливаемую пропускную способность, наблюдаемую по всем активным машинам. Для полезных нагрузок вплоть до 128 байт, WRITE достигает 35 Mops, что примерно на 34% выше чем максимальное значение пропускной способности READ (26 Mops). Что интересно, надёжные WRITE доставляют значительно более высокие значения чем READ пренебрегая идентичностью их пути InfiniBand. Это объясняется следующим образом: записи требуют меньшего сопровождения состояния как на уровне RDMA, так и на уровне PCIe, так как инициатору не требуется ожидать какого бы то ни было отклика. Однако, для чтений такие запросы должны сопровождаться в памяти самого инициатора вплоть до появления отклика. На соответствующем уровне RDMA каждая пара очередей может обслуживать только несколько отложенных запросов READ (в наших RNIC 16). Аналогично, на уровне PCIe, чтения выполняются при помощи не откладываемых (non-posted) транзакций, в то время как записи применяют более экономичные транзакции с отсрочкой (posted).
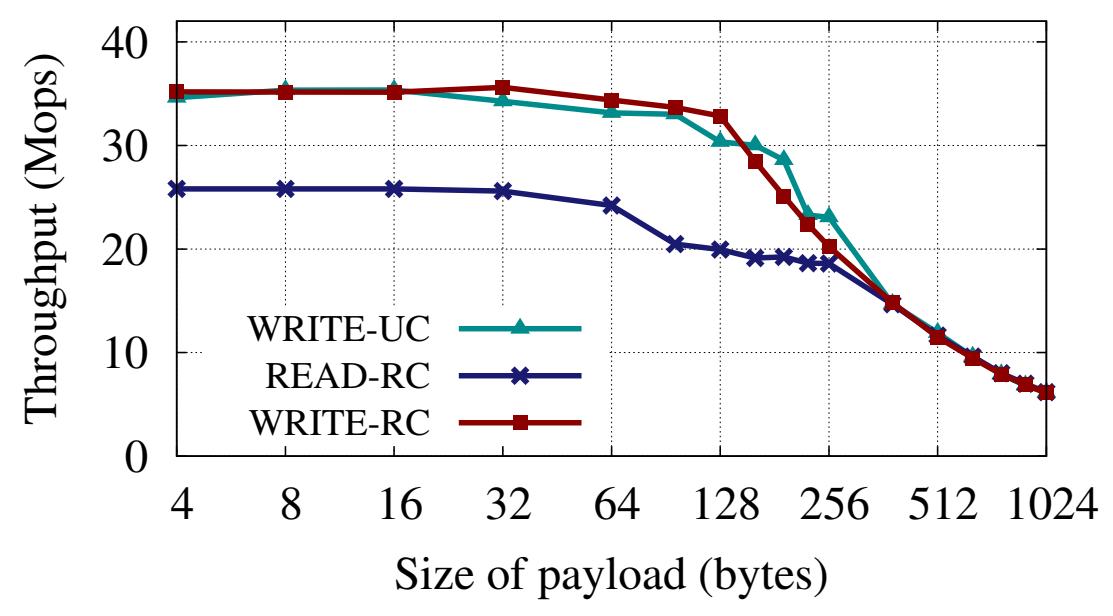
Хотя значения пропускной способности WRITE поверх UC и RC примерно равны, применение UC всё- таки предпочтительнее: оно требует меньше обработки в отношении RNICS и HERD использует её, сберегая мощность на отклики SEND.
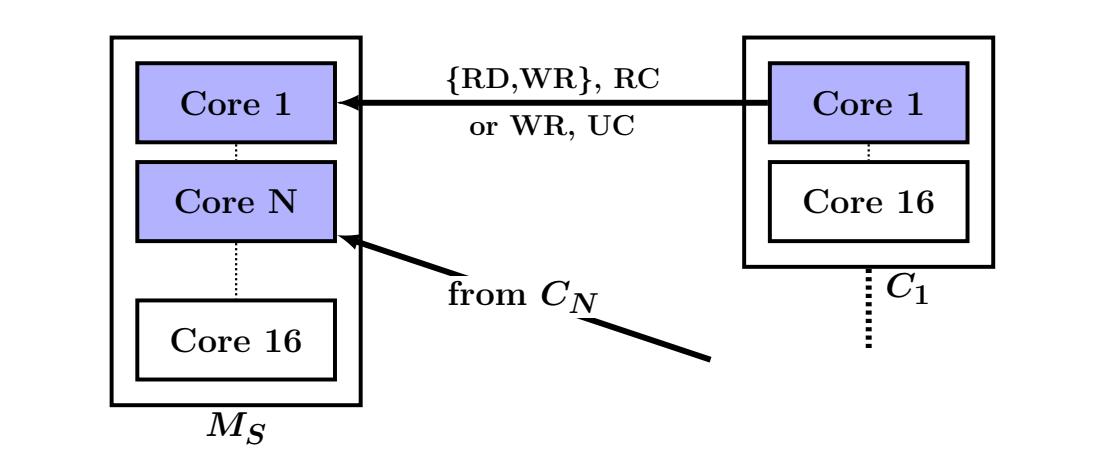
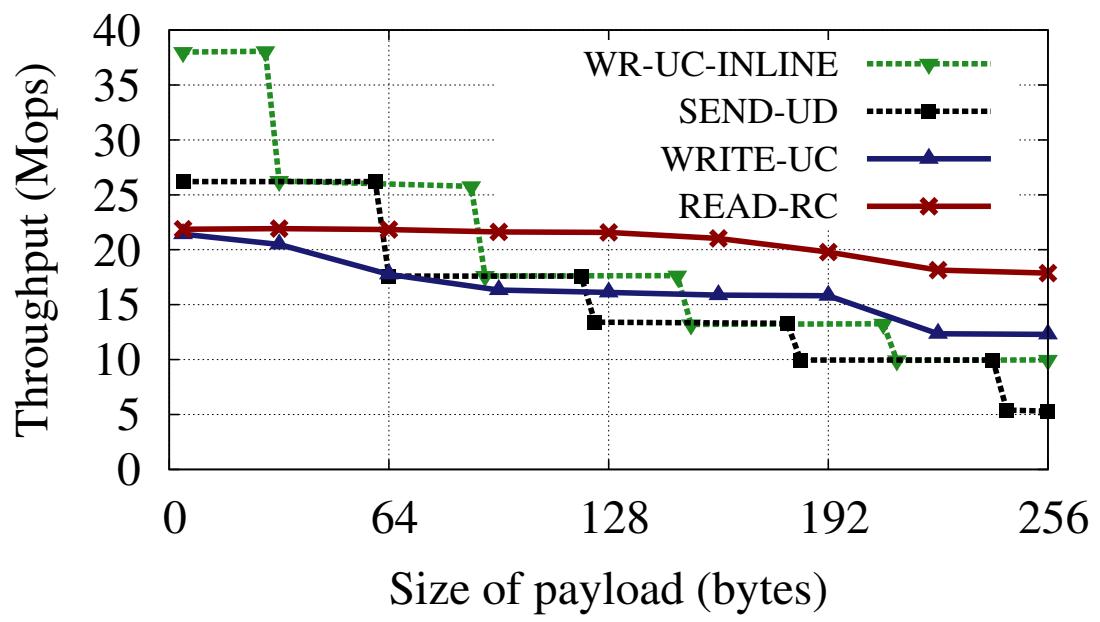
Исходящая пропускная способность: Далее мы змеряем пропускную способность для исходящих глаголов. В этом случае MS вызывает операции в отношении C1, ..., CN. Как показано на Рисунке 4a, в MS имеется N процессов. Процесс iй взаимодействует только с Ci (основная проблема в масштабировании состоит во взаимодействии всех- со- всеми, что мы объясним в Разделе 3.3). Рисунке 4b отображает значения пропускной способности, достигаемые MS для различных размеров полезной нагрузки. При малых размерах, WRITE и SEND с вложением имеют значительно более высокую пропускную способность нежели READ. При больших размерах значения всех вариантов WRITE и SEND ниже чем для READ, но они никогда не опускаются ниже 50% значения пропускной способности READ. Тем самым, даже для таких элементов с большим размером применение для откликов отдельного WRITE (или SEND) остаётся лучшим выбором по отношению к использованию множества READ для элементов ключ- значение.
Пропускная способность ECHO: представляет интерес по двум причинам. Во- первых, она предоставляет некое ограничение сверху для соответствующей величины кэширования ключ- значение на основе одного прохода в обе стороны при взаимодействии. Во- вторых, ECHO помогает охарактеризовать общую мощность обработки данного RNIC: хотя заявленная скорость обмена сообщениями 35 Mops, в обоих направлениях она может обрабатывать намного больше сообщений.
ECHO состоит из сообщения запроса и сообщения отклика. Изменение значений типов глаголов и доставки даёт совершенно различные реализации ECHO. Рисунок 5 отображает значения пропускной способности для некоторых возможных комбинаций и при полезных нагрузках в 32 байта. Данный рисунок также показывает, что использование вложений, избирательных вызовов и доставки UC значительно увеличивают общую производительность.
Рисунок 5
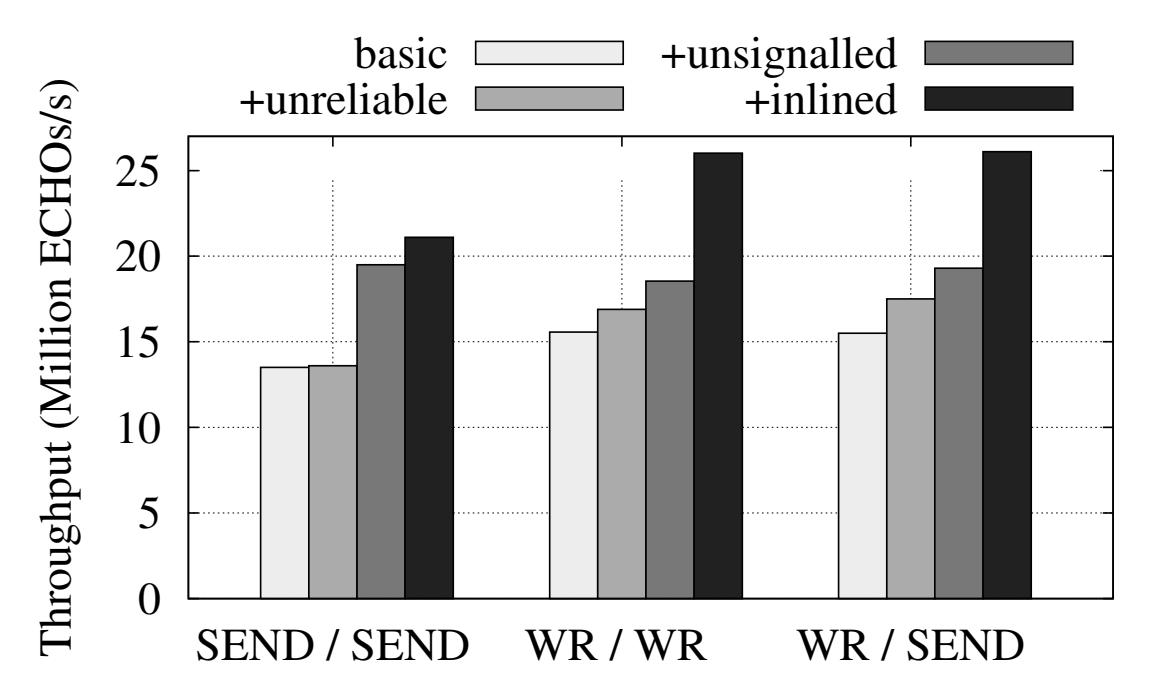
Пропускная способность ECHO при сообщениях длиной 32 байта. При WR-SEND соответствующий отклик отправляется поверх UD.
ECHO достигает максимальной пропускной способности (26Mops) когда и сам запрос, и отклик выполняются в виде записей RDMA. Тем не менее, как показывается в Разделе 3.3, такой подход не масштабируется при очень большом числе соединений. HERD применяет записи RDMA (поверх UC) для запросов и SEND (поверх UD) для откликов. Сервер ECHO с применением такого гибрида также достигает 26 Mops - это даёт значение производительности на уроне ECHO с WRITE, но с намного более лучшим масштабированием.
За счёт избегания значительных накладных расходов отправки RECV в свой сервер наш метод запросов на основе WRITE и откликов на базе SEND предоставляет лучшую производительность нежели ECHO с чистой основой на SEND. Тем не менее, интересно отметить, что после включения всех оптимизаций, общая производительность ECHO на основе SEND (без RDMA операций) составляет 21 Mops, что более трёх четвертей пикового значения входящей пропускной способности READ (26 Mops). И Pilaf, и FaRM отметили, что чтения RDMA в высшей степени превосходят ECHO на базе SEND, что находится в соответствии с нашими результатами если исключить наши оптимизации. При наличии данных оптимизаций, однако, SEND значительно превосходит READ в вариантах применения единого ECHO на основе SEND вместо множества READ для запроса.
Наши эксперименты показывают, что определённые решения ECHO, с различными степенями масштабируемости, могут выполняться лучше нежели решения со множественными READ. С точки зрения сосредоточения на сетевой среде это удача: это также означает, что решения, которые применяют только один RTT поперёк центра обработки данных, потенциально могут превосходить решения со множеством RTT как в отношении пропускной способности, так и касательно задержек.
Обсуждение пропускной способности глаголов: Карты ConneсtX-3 заявляют о поддержке 35 миллионов сообщений в секунду. Наши эксперименты показывают, что данная карта может достигать такой скорости для входящих WRITE (Рисунок 3b) и слегка превосходить его для очень маленьких исходящих WRITE (Рисунок 4b). Все прочие глаголы медленнее 30 Mops вне зависимости от размера операции. Хотя производитель и не декларирует двунаправленную пропускную способность обмена сообщениями, мы эмпирически знаем, что RNICS способен обслуживать 30 миллионов ECHO в секунду (ECHO на основе WRITE достигает 30 Mops при полезной нагрузке 16 байт; Рисунок 5 использует полезную нагрузку 32 байта), или, по крайней мере, 60 Mops в общем числе из входящих WRITE и исходящих SEND.
Снижения пропускной способности можно приписывать различным факторам:
-
Для исходящих WRITE больших 28 байт значение скорости обмена сообщениями RNIC ограничивается пределом пропускной способности PIO PCIe. Острый пик уменьшения в соответствующих графиках WR-UC-INLINE и SEND-UD на Рисунке 4b на интервалах 64 байт объясняются использованием для ускорения PIO буферов комбинирования записей. При такой оптимизации комбинирования записей самим элементом записей PIO является некая строка кэша, а не какое- то слово. Из- за большей длины заголовка дейтаграммы, значение пропускной способности для SEND-UD падает для меньших размеров полезных нагрузок в сравнении с WRITE.
-
Максимальное значение пропускной способности для входящих и исходящих READ составляют, соответственно, 26 Mops и 22 Mops,что значительно ниже чем предлагаемая скорость обмена сообщениями 35 Mops. В отличии от WRITE, READ обладают бутылочным горлышком в отношении производительной мощности RNIC. Это ожидаемо. Исходящие READ вовлекают операции PIO, доставку пакетов, приём пакетов, а также запись DMA, в то время как исходящие WRITE (с вложением и поверх UC) избегают последних двух этапов. Входящие READ требуют некоторого чтения DMA самой RNIC, вслед за которой идёт собственно передача пакета, в то время как входящие WRITE требуют только записи DMA.
Наши предыдущие эксперименты не показали что с ростом общего числа соединений скорость доставки в них начинает падать. Для снижения стоимости оборудования, энергопотребления и сложности проектирования, RNIC имеет на борту очень ограниченный объём оперативной памяти (SRAM) для кэширования таблиц трансляции адресов и содержимого контекста пар очередей [26]. Непопадание в таком кэше требует некоторой транзакции PCIe для выборке требующихся данных из памяти данного хоста. Производительность начинает страдать при исчерпании нагрузочной способности на входе или на выходе в данном кэше. Потенциально важно избегать этот эффект как при масштабировании кластера, так и по той причине что он оказывает влияние на решения самого кэша или архитектуры хранения. К примеру, для выстраиваемого нами решения кэширования в разделах HERD, собственно пространство ключей между различными процессами сервера с целью достижения эффективной загрузки ЦПУ и оперативной памяти. Эти разделы в последующем увеличивает нагрузочные возможности на входе и на выходе соединений для некоторой отдельной машины.
Для оценки данного эффекта мы изменили свои эксперименты с пропускной способностью, разрешив взаимодействия всех- со- всеми. Мы применяем N процессов клиентов (по одному процессу для каждого из клиентов C1, ..., CN) и N процессов сервера в MS. Для измерения производительности на входе некий процесс сервера выбирает случайным образом какого- то клиента и вызывает в нём WRITE. Результаты этих экспериментов сведены в Рисунке 6. Выделим некоторые результаты:
Рисунок 6
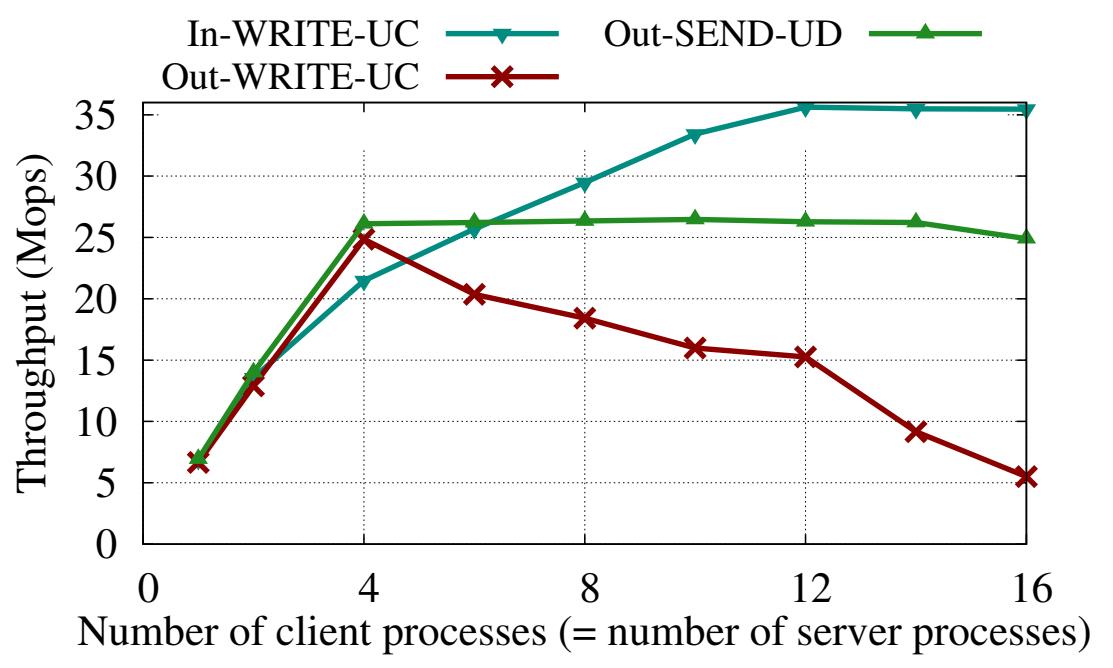
Сопоставление UD и UC для взаимодействия все- со- всеми при полезной нагрузке в 32 байта. Входящие WRITE поверх UC и исходящие SEND поверх UD хорошо масштабируются вплоть до 256 пар очередей. Исходящие WRITE поверх UC масштабируются недостаточно. Все операции с вложением и без выставления сигнала.
Бедное масштабирование исходящих WRITE: Для N = 16 имеется 256 активных пар очередей в RNICS и общая пропускная способность от сервера- к- клиенту деградирует на 21% от максимального значения пропускной способности исходящих WRITE (Рисунок 4b). При множестве активных пар каждый выставляемый глагол может взывать непопадание в кэш, определённым образом приводя к деградации кэширования.
Надлежащее масштабирование входящих WRITE: Пропускная способность от- клиента- к- серверу высокая даже для N = 16. Основной причиной для этого очереди операций исходящих глаголов обслуживаются на выполняющих запрос RNIC, а на осуществляющих отклик RNIC сопровождается очень небольшое состояние. Тем самым, RNIC отклика может поддерживать намного большее число активных пар очередей без залезания в промахи кэширования. Более высокие накладные расходы запрашивающей стороны компенсируются по причине того, что клиенты численно превосходят свой сервер.
В другом своём эксперименте мы воспользовались 1600 процессами клиентов, распределёнными по 16 машинам для вызова WRITE поверх UC к одному процессу сервера. HERD применяет такую конфигурацию многие- к- одному для снижения общего числа активных подключений на своём сервере (Раздел 4.2). Такая конфигурация также достигает 30 Mops.
Исходящие WRITE плохо масштабируются только потому, что RNICS должен управлять большим числом пар очередей соединений. Данную проблему невозможно решить если мы применяем доставку с соединением (RC/UC/XRC), поскольку для них требуется по крайней мере столько же пар очередей в MS, каково общее число машин клиентов. Масштабирование исходящих взаимодействий, таким образом, обязывает применять дейтаграммы. Доставка UD поддерживает взаимодействие один- ко- многим, т.е. одна очередь UD может применяться для вызова операций во множестве очередей удалённых UD. Основной проблемой при применении UD в высокопроизводительных приложениях является то, что они поддерживают только глаголы обмена сообщениями и никаких глаголов RDMA.
К счастью, глаголы обмена сообщениями обкладывают высокими накладными расходами только сторону отправки. Отправители могут напрямую отправлять свои запросы; только сам отправитель должен предварительно выставлять некий RECV перед тем как можно будет обработать SEND. Для такого отправителя та подлежащая исполнению работа по вызову SEND идентична той, которая требуется для выставления некоторого WRITE. Рисунок 6 показывает, что при исполнении поверх доставки Unreliable Datagram, пропускная способность стороны SEND является высокой и хорошо масштабируется со значительным числом соединений клиентов.
Незначительная деградация пропускной способности SEND свыше 10 клиентов происходит из- за того, что SEND не выставляют сигналы, т.е. процессы сервера не получают указания о завершении глагола. Это приводит к тому, что такие процессы сервера переполняют RNICS очень большим числом незавершённых операций, что приводит к промахам в кэше внутри данного RNIC. Так как HERD применяет SEND для откликов на запросы, он может применять новые запросы в качестве индикации своего завершения старых SEND, тем самым избегая данную проблему.
Для оценки того, будут ли такие движимые сетевой средой архитектурные решения работать в приложениях ключ- значение из реальной жизни, мы реализовали некий кэш KV {ключ- значение} на базе RDMA с названием HERD, основываясь на самых последних высокопроизводительных решениях ключ- значение. Наша установка HERD состоит из одной машины сервера и некоторого числа машин клиентов. Имеющаяся машина сервера запускает NS серверных процессов. NC клиентских процессов единообразно распределяются по имеющимся машинам клиентов.
Основной фундаментальной целью данной статьи является оценка наших сетевых и архитектурных решений в соответствующем контексте систем ключ- значение. Мы не сосредотачиваемся на наилучших серверных структурах данных ключ- значение, а вместо этого следуем имеющимся в MICA [18] решениям.
MICA является близким к реальному времени решением кэширования и хранения ключ- значение для классического Ethernet. Мы ограничили своё
решение для MICA его режимом кэширования. MICA использует индекс потерь для сопоставления ключей указателям и сохраняет фактические значения
в циклическом журнале. При вставке элементы могут выселяться из данного индекса (тем самым производя соответствующий индекс потерь)
или из соответствующего журнала неким FIFO образом. В HERD каждый процесс сервера выполняет индексацию для 64Mi ключей и
циклический журнал 4 ГБ. И для GET, и для PUT мы применяем
алгоритм MICA: каждый GET требует до двух случайных выборок из памяти, а каждый
PUT одну.
MICA разбивает своё пространство ключей на определённые разделы на основании какого- то хэширования ключей. В его режиме "EREW" каждое ядро сервера имеет исключительный доступ на чтение и запись к одному разделу. MICA использует функциональность Flow Director [3] современных NIC Ethernet для прямого запроса соответствующему ядру отклика для конкретного заданного ключа. HERD достигает того же самого эффекта посредством выделения в данном сервере памяти запросов для каждого ядра и позволяя клиентам выполнять WRITE своих запросов напрямую в соответствующее ядро.
Маскирование латентности динамической памяти при помощи предварительной выборки
Для обслуживания GET некий сервер HERD должен выполнить две случайных выборки из оперативной
памяти, подготовить соответствующий отклик SEND (с значением его ключа, встраиваемого в своём WQE), а затем выставить такой глагол SEND,
при помощи функции post_send(). Именно эти выборка из памяти и функция
post_send() являются двумя основными источниками задержек в данном сервере. Каждый случайный доступ
к памяти занимает 60-120 нс, а функция post_send() требует
около 150 нс. Хотя всё это и неизбежно, мы можем скрыть доступ к памяти одного запроса при
помощи вычисления другого запроса.
MICA и CuckooSwitch [18, 31]
маскируют латентность перекрытием извлечения и предварительной выборки или декодированием и предварительной выборкой запроса. HERD
выбирает иной подход: мы перекрываем предварительную выборку при помощи функции post_send(),
применяемой для доставки откликов. Для одновременной обработки множества запросов в отсутствии соответствующего драйвера, который
сам по себе обрабатывает группу пакетов ([2, 18,
31]), HERD создаёт некий конвейер запросов на соответствующем уровне приложений.
В HERD максимальное число выборок из памяти для каждого запроса равно двум. Таким образом, мы создаём некий конвейер запросов из
двух стадий. Когда некий запрос находится на стадии i, данного контейнера, он выполняет
свой i-й доступ к памяти для своего запроса и выдаёт некую предварительную выборку для своего
следующего адреса памяти. При таком подходе запросы осуществляют только доступ к памяти, к которой уже была выполнена предварительная
выборка. При обнаружении некоторого нового запроса, сервер вызывает предварительную выборку для необходимых групп индексов запроса,
продвигает в имеющемся конвейере свои старые запросы, размещает свои новые запросы и, в конечном итоге, вызывает
post_send() чтобы вызвать SEND для отклика для соответствующего выполненного запроса конвейера.
Сам процесс сервера ожидает, что соответствующая выдача предварительной выборки завершится ко времени возврата
post_send().
Рисунок 7 показывает действенность предварительной выборки. Мы используем сервер ECHO на основе WRITE/ SEND, однако в этот раз данный сервер выполняет N произвольных доступов к памяти перед отправкой своего запроса. Предварительная выборка делает возможной предоставление более высокой пропускной способности меньшим числом ядер: 5 ядер могут предоставить пиковую пропускную способность даже при N = 8. Мы пришли к выводу, что имеется значительный запас для реализации более сложных приложений ключ- значение, например, хранилищ ключ- значение, поверх механизма взаимодействия запрос- отклик HERD.
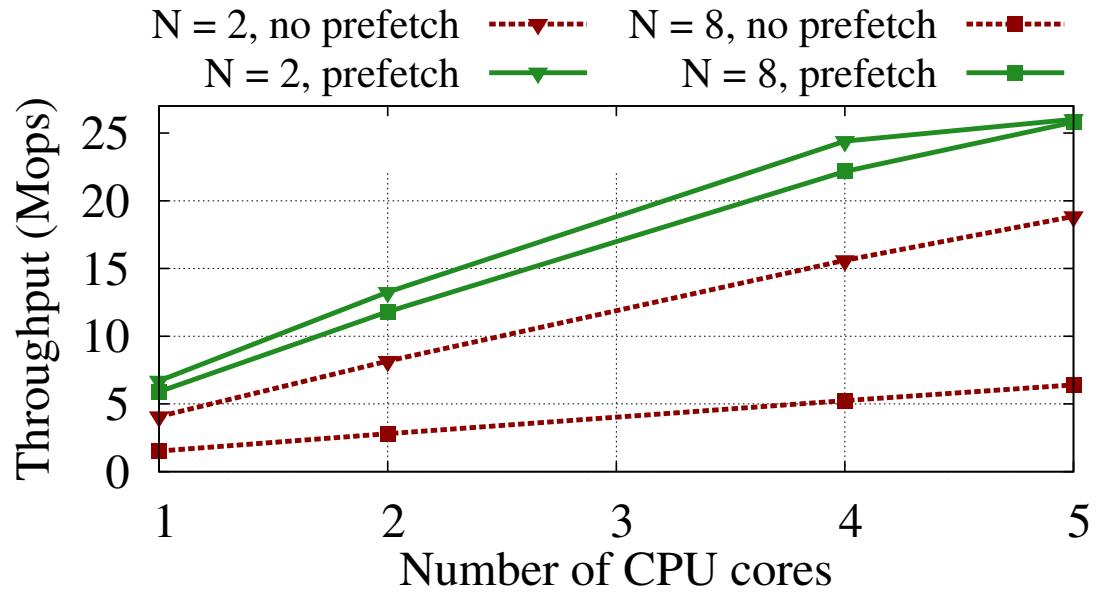
При большом числе серверных процессов такая конвейерная схема может приводить к некоторой тупиковой ситуации. Некий сервер не способен продолжить свою конвейерную обработку пока не получит некий новый запрос, а некий клиент не сможет продолжать свои запросы пока не получит отклика. Мы избегаем тупиковых ситуаций следующим образом. При выполнении опроса на наличие новых запросов, если некий сервер последовательно получает отказы для 100 итераций, он помещает в свой конвейер холостую команду (no-op).
Клиенты выполняют WRITE своих запросов GET и
PUT в непрерывную область памяти своей машины сервера, которая выделяется при инициализации.
Эта область памяти именуется областью запроса (request region) и совместно используется всеми
имеющимися серверными процессами с установкой соответствия их использования shmget(). Данная
область запроса подразделяется на слоты в 1 кБ (максимальный размер элемента ключ- значение в HERD установлен в 1 кБ).
Запросы форматируются следующим образом. Запрос GET составляется только из ключевых
хэшей в 16 байт. Запрос PUT содержит 16 байт ключа хэша, поле LEN в 2 байта (определяющее длину
значения) и до 1000 байт для самого значения. Для опроса входящих запросов мы применяем порядок слева- направо соответствующих записей
DMA RNIC [16, 8]. Мы применяем соответствующее новое
поле ключа хэша для опроса новых запросов; тем самым значение ключа записывается в самые правые 16 байт в имеющемся слоте 1 кБ.
Некий ненулевой ключ хэша указывает на какой- то новый запрос, поэтому мы не разрешаем своим клиентам применять нулевое значение
ключа хэширования. После отправки отклика наш сервер заполняет нулями соответствующее поле ключа хэша, высвобождая его обратно для
нового запроса.
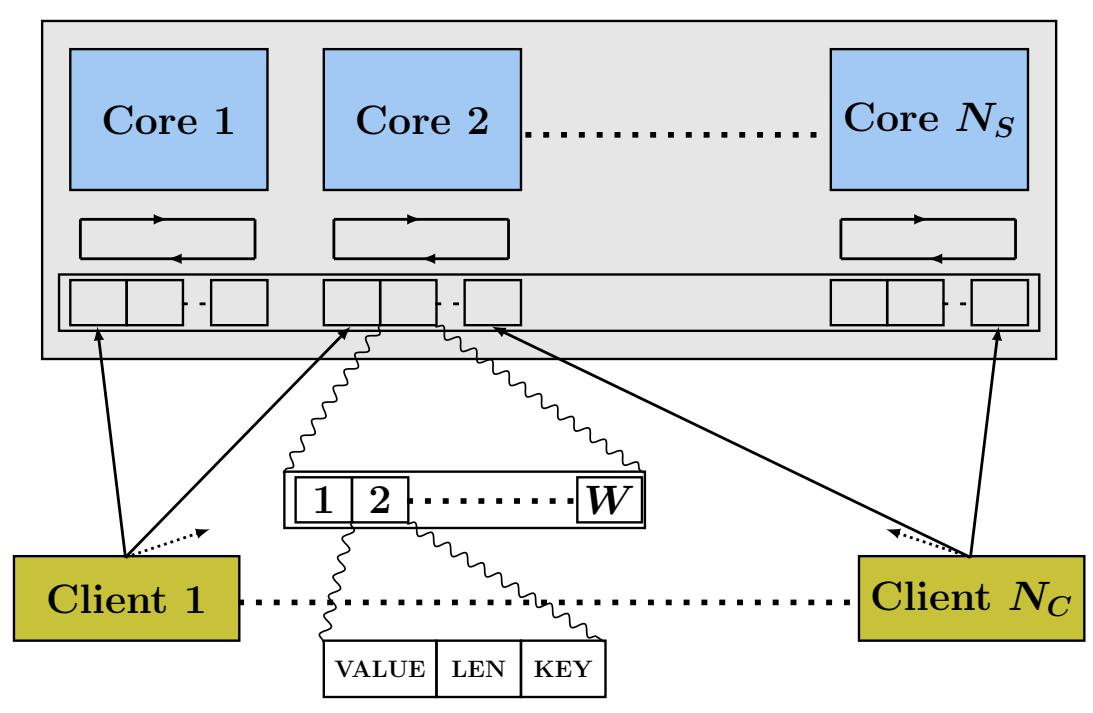
Рисунок 8 показывает схему такой области запроса в соответствующей
машине сервера. Она состоит из отдельных фрагментов для каждого серверного процесса , которые далее подразделяются на фрагменты
для каждого клиента. Каждый фрагмент клиента состоит из W слотов,
т.е. каждый клиент может выполнять задержку до W запросов для каждого серверного
процесса. Соответствующий размер такой области запроса равен NS · NC
· W кБ. При NC = 200,
NS = 16 и
W = 2, это приблизительно 6 МБ и помещается внутри кэша L3 сервера. Каждый серверный процесс
опрашивает свои фрагменты для клиентов на предмет новых запросов карусельным образом (round robin). Если процесс сервера
s обнаружил r запросов от клиента
с номером с, он опрашивает свою область запроса в соответствующем слоте запроса с номером
s·(W · NC)+ (c·W)+r mod W.
Некая сетевая конфигурация, применяющая двунаправленное взаимодействие все- ко- всем с доставкой при образовании соединения потребует
NC · NS пар очередей в своём сервере. HERD, однако, применяет
доставку с соединениями только для взаимодействия со со стороны своего запроса, и тем самым требует только
NC подключённых пар очередей. Данная конфигурация работает следующим
образом. Некий процесс инициализации создаёт необходимую область запроса, регистрирует её в
RNICS, устанавливает соединение UC с каждым клиентом и переходит в
спящее состояние. Соответствующий процесс сервера NS затем устанавливает
соответствие этой области запроса в своём адресном пространстве при помощи shmget() и
и не создаёт никаких соединений для приёмки запросов.
В HERD, отклики отправляются в виде SEND поверх UD. Каждый клиент создаёт
NS пар очередей (QP) UD, в то время как процесс сервера применяет только
одну UD QP. Прежде чем выполнить запись нового запроса в серверный процесс s,
клиент выставляет RECV в свой UD QP с номером s. Этот RECV определяет необходимую
область памяти в данном клиенте, в которую будет записан соответствующий отклик сервера. Каждый клиент выделяет некую
область отклика (response region), содержащую
W · NS слотов отклика: эта область в качестве целевой адресации для
соответствующих RECV. После записи W запросов, наш клиент начинает проверять
наличие откликов, опрашивая завершения RECV. При каждом успешном завершении он выставляет следующий запос.
Проектирование выполнено таким образом намеренно, чтобы переместить работу с RNIC сервера на клиентский RNIC, исходя из предположения, что машины клиентов обычно осуществляют прочую достойную работу, которая не имеет целью полностью насыщать полосу пропускания сетевой среды 40 или 56 гигабит. Серверы, однако, в таких приложениях как Memcached, зачастую целиком выделяются для этого и в них важно достигать наивысшей полосы пропускания.
Мы провели оценку HERD в двух кластерах: Apt и Susitna (Таблица 2). В силу пределов пространства мы ограничим своё обсуждение APT, а для Susitna представим только графики для RoCE. Подробное обсуждение наших результатов в Susitna можно найти в [15]. Хотя Susitna и применяет аналогичный Apt RNIC, более медленная шина PCIe 2.0 снижает общую пропускную способность всех сравниваемых систем. Несмотря на это наши результаты для Susitna остаются интересными: так же как карты ConnectX-3 перегружают PCIe 2.0 x8, мы ожидаем, что следующее поколение карт Connect-IB должно переполнять PCIe 3.0 x16. Наши вычисления показывают что:
-
HERD использует всю вычислительную мощность RNIC. Отдельный сервер HERD может обрабатывать вплоть до 26 миллионов запросов в секунду. Для значений с размером до 60 байт, пропускная способность запросов HERD выше чем естественная пропускная способность READ и значительно превосходит её для служб ключ- значение на основе READ: она в 2x раза превышает значения для FaRM-KV и Pilaf.
-
HERD предоставляет до 26 Mops со средним значением латентности приблизительно в 5 мкс. Его более чем в два раза ниже чем для Pilaf и FaRM-KV при соответствующих пиковых пропускных способностях.
-
HERD масштабируется до среднего размера кластера Apt, поддерживая пиковую пропускную способность для 250 подключённых процессов клиентов.
Мы завершаем свою оценку изучением кажущегося недостатка решения HERD относительно решения, основанного на READ - его более высокого использования ЦПУ сервера - и помещаем его в контекст с общим (клиент + сервер) потреблением ЦПУ, требуемым всей системой.
В Apt мы запускали все свои эксперименты пропускной способности и латентности на 18 машинах. Все 17 машин клиентов запускали до 3 клиентских процессов в каждой. При 4 исходящих запросах на клиента наша реализация требует по крайней мере 36 процессов клиента для насыщения общей пропускной способности сервера. Мы слегка перекрываем это значение, применяя 51 клиентский процесс. Наша машина сервера запускает 6 серверных процессов, причём каждый из них закрепляется за отдельным физическим ядром. Все конфигурации машин описаны в Таблице 2. Все машины работают под управлением Ubuntu 12.04 со стеком Mellanox OFED v2.2.
Сопоставление с упрощёнными версиями: При сохранении нашего основного акцента на понимание всех воздействий наших связанных с сетевой средой решений, мы сравниваем нашу (полную) реализацию HERD с упрощёнными реализациями Pilaf и FaRM-KV. Такие упрощённые реализации применяют те же самые сетевые методы, что и изначальные, но опускают реальное хранилище ключ- значение и вместо этого непосредственно возвращают некий результат. Мы принимаем это решение по двум причинам. Во- первых, при работе с кодом Pilaf мы усмотрели ряд возможностей оптимизации; мы не желаем чтобы наша оценка была зависимой от относительной настройки производительности систем. Во- вторых, у нас нет доступа к исходному коду FaRM и мы не имеем возможности запуска Windows Server в своём кластере. Вместо этого мы создаём и оцениваем версии двух данных систем, которые не содержат своих основ структур данных. Такой подход даёт данным системам все максимально возможные производительности, поэтому значения производительности, которые мы выдаём в отчётах и для Pilaf, и для FaRM-KV могут быть выше чем достигаемые в реальности в данных системах.
Pilaf основывается на 2-х уровневых выборках: таблица хэш- значений вводит соответствие ключей указателям. Данные указатели применяются для
поиск самого значения, связанного с данным ключом из линейных областей памяти, именуемых экстентами.
FaRM-KV в своём определённом по умолчанию режиме применяет выборку с единственным уровнем. Он достигает этого за счёт вложения самого значения в
хэш- таблице. Он также обладает неким режимом со вторым уровнем, когда его значение сохраняется "вне таблицы". Из- за сохранения вне
таблицы, для эффективности использования работы памяти с ключами переменной длины мы сопоставляем HERD с обоими режимами. В двух своих последующих
разделах мы обозначаем размер ключа, значения и указателя соответственно как SK,
SV и SP.
Эмуляция Pilaf
при хэшировании cuckoo K-B, каждый ключ может быть найден в K различных корзинах, определяемых
K ортогональными функциями. Для связности, каждая корзина (bucket) содержит B
слотов. Pilaf применяет хэширование cuckoo 3-1 с эффективностью памяти в 75% и в среднем 1.6 зондирований на GET
(более высокая эффективность памяти с меньшим числом более длинных в среднем пробников возможно при хэшировании cuckoo 2-4
[9]). Присчитывании значений индексов хэширования через RDMA самым меньшим подлежащим считыванию элементом
является некая корзина (bucket). В Pilaf корзина обладает всего лишь одним слотом, котоый содержит некий указатель из 4 байт, две 8- байтовые контрольные
суммы и несколько иных полей. Мы полагаем, что размер корзины в Pilaf должн составлять 32 байта для выравниваний.
GET: Некий GET в Pilaf состоит из
1.6 READ корзин (в среднем) для отыскания необходимого значения указателя, за которым следует READ SV
байт для выборки самого значения. Имеется возможность уменьшения задержек Pilaf за счёт одновременного вызова READ для обеих корзин cuckoo. Поскольку это
связано со снижением пропускной способности, мы ожидаем завершения самого первого READ и вызываем второй READ только в случае его необходимости.
PUT: Для PUT некий
клиент отправляет сообщение из SK + SV байт, содержащее необходимый новый
элемент ключ- значение в свой сервер. Такой запрос может потребовать перемещения элементов в хэш- таблице cuckoo, однако мы игнорируем это, так как
наша оценка сосредоточена исключительно на сетевом взаимодействии.
При эмуляции Pilaf мы вклюючаем все все свои оптимизации RDMA для обоих видов запроса; мы именуем получаемую в результате систему как Pilaf-em-OPT.
Эмуляция FaRM-KV
FaRM-KV применяет некий вариант хэширования Hopscotch для определения местоположения некоторого ключа приблизительно за одну операцию READ. Его алгоритм гарантирует что некая пара ключ- значение сохраняется в в некоторой малой окрестности соответствующей корзины, которую хэширует этот ключ. Такой размер данной близости является настраиваемым, но его авторы устанавливают его в 6 для баланса хорошего использования пространства и производительности для элементов менее 128 байт. FaRM-KV может встраивать свои значения в имеющиеся корзины, или же он может храниться отдельно и сохранять в этих корзинах только указатели. Мы именуем свою версию FaRM-KV со встроенными значениями как FaRM-em, а без встраиваний как FaRM-em-VAR (для значений с переменной длиной).
GET: В FaRM-em для GET требуется
READ 6 · SK + SV байт. В FaRM-em-VAR для GET
необходимо READ 6 · SK + SP байт с последующим READ
SV байт.
PUT: FaRM-KV обрабатывает PUT, отправляя
сообщения в свой сервер посредством WRITEs, аналогично HERD. Сам сервер уведомляет своего клиента о завершении PUT
применяя другой WRITE. Тем самым, некий PUT в FaRM-em (и FaRM-em-VAR)
состоит из одного WRITE SK + SV байт из некоторого клиента в его сервер.
Для более высокой пропускной способности мы выполняем эти WRITE поверх UC, в отличии от оригинальной статьи FaRM, которая применяет RC
(Рисунок 5).
Три главных параметра оказывают воздействие на значения пропускной способности и латентности некоторой системы ключ- значение: относительные частоты
PUT и GET,
размер элемента и перекос (skew).
Мы применяем два вида рабочих нагрузок: интенсивное чтение
(95% GET и 5%
PUT), интенсивная запись
(50% GET и 50%
PUT). Наша рабочая нагрузка может быть либо
единообразной, либо асимметричной (skewed). При некоторой единообразной
нагрузке ключи выбираются единообразно случайным образом из имеющегося 16 байтового пространства ключей хэширований. Наша асимметричная рабочая нагрузка
рисует ключи из распределения Zipf с параметром 0.99. Данный рабочий поток вырабатывается автономно при помощи
YCSB [7]. Мы сгененрировали 480 миллионов ключей за раз
{Прим. пер.: так в оригинале, не 408} и выделили по 8 миллионов ключей каждому из своих 51 процессов клиентов.
Теперь мы сравним всеобщую пропускную способность HERD с эмулируемыми версиями Pilaf и FaRM.
Рисунок 9 отображает значения пропускной способности этих систем для рабочих потоков с
интенсивным чтением и интенсивной записью для 48- байтных элементов (SK = 16,
SV = 32). Мы выбрали этот размер элемента, поскольку он представляет рабочие потоки
реального мира: анализ общего хранилища ключ- значение Facebook [6] показывает, что размер ключа около
30 имеет близкое к 50% значение, а их значения составляет длину 20 байт. Для сравнения GET Pilaf и FaRM
на основе READ c PUT SEND/ RECV Pilaf, мы также нанесли на график значение пропускной способности для
варианта, когда рабочая нагрузка составляет 100% PUT.
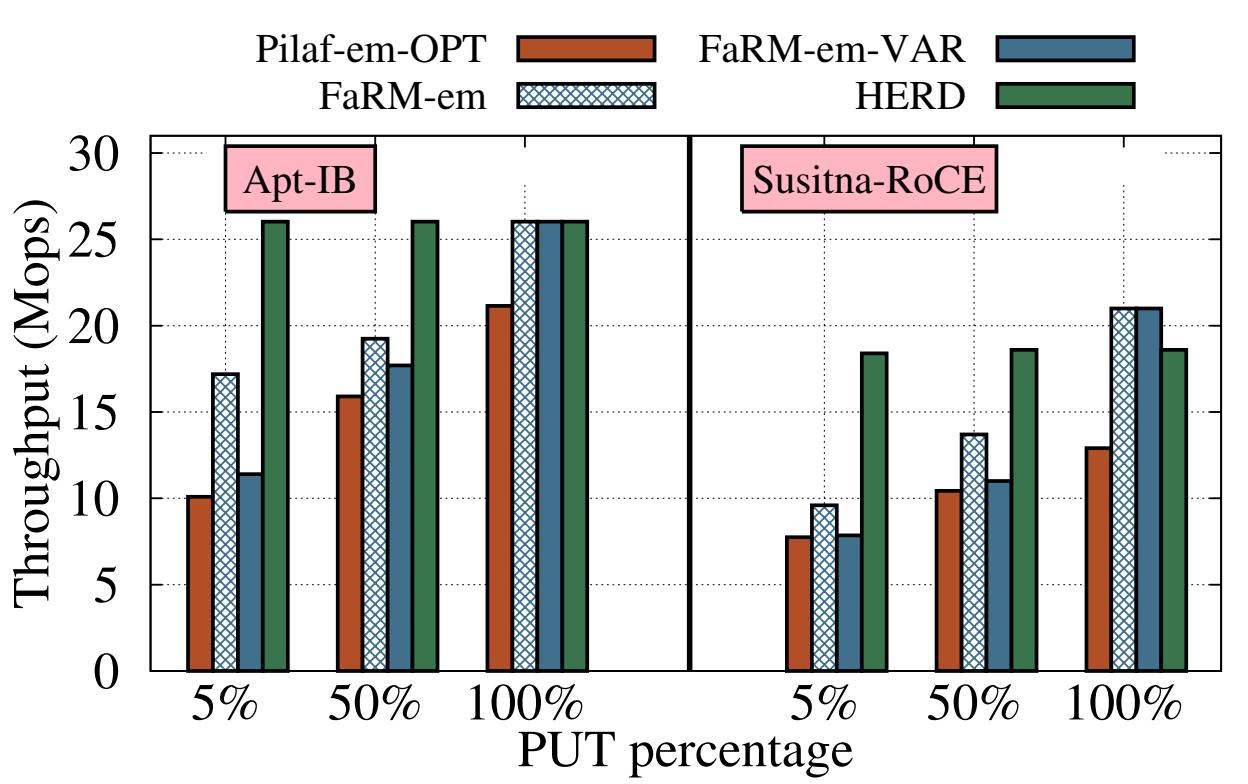
В HERD рабочие потоки и с интенсивным чтением, и с интенсивной записью, оба достигают 26 Mops, что слегка выше чем значение пропускной способности
естественных чтений RDMA аналогичного размера (Рисунок 3b). Для элементов с малым размером
ключа, имеется очень небольшая разница между запросами PUT и GET на
уровне RDMA, поскольку оба типа запросов умещаются внутри одной строки кэширования. Таким образом, значение пропускной способности не зависит от
составляющих рабочей нагрузки.
Пропускная способность GET для Pilaf-em-OPT и FaRM-em(-VAR) напрямую определяется пропускной способностью
READ RDMA. GET в Pilaf-em-OPT вовлекает (в среднем) 2.6 READ. Его пропускная способность
GET составляет 9.9 Mops, что приблизительно в 2.6X меньше максимальной пропускной способности READ. Для
GET FaRM-em требуется одиночный READ 288 байтов и он доставляет 17.2 Mops. FaRM-em-VAR требует второго
READ и имеет для GET пропускную способность 11.4 Mops.
Удивительно, но значение пропускной способности PUT для наших эмулируемых систем намного выше чем их
пропускная способность GET. В FaRM-em(-VAR) PUT применяет
WRITE поверх UC небольшого размера, который превосходит в производительности READ, требующийся для GET.
Pilaf-em-OPT применяет запросы и отклики на основе SEND/RECV для PUT. И Pilaf, и FaRM полагают, что ECHO
на основании обмена сообщений намного более затратно чем READ (Pilaf сообщает, что для 17- байтных сообщений значение пропускной способности чтений
READ составляет 2.449 Mops, в то время как значение пропускной способности ECHO на основе SEND/RECV составляет всего лишь 0.668 Mops). Если
SEND/RECV может составлять всего одну четверть от значения пропускной способности READ, для GET
имеет смысл применять множество READ.
Однако мы полагаем, что эти системы не достигли полной мощности SEND/RECV. После оптимизации SEND с применением ненадёжной доставки, встраивания полезной нагрузки и выборочного выставления сигналов, ECHO на основе SEND/RECV, как это показано на Рисунке 5, достигает 21 Mops, что значительно выше чем половина нашей пропускной способности READ (26 Mops). Таким образом, мы делаем заключение, что взаимодействие на основе SEND/RECV, при его действенном применении, более эффективно чем использование множества READ на запрос.
Рисунок 10 отображает значения пропускной способности для трёх систем с ключам в 16 байт и
различными размерами значений для рабочих потоков с интенсивной рабочей нагрузкой. Для элементов с длиной до 60- байт HERD достигает более 26 Mops,
что значительно выше чем пиковое значение пропускной способности для READ. Вплоть до значений с 32- байтами, FaRM-em также доставляет высокую
пропускную способность. Однако, его пропускная способность быстро падает при возрастании размера значения, так как сам размер READ для
FaRM-em быстро растёт (как 6 · (SV + 16)). Данная проблема является фундаментальной для
решений KV на основе Hopscotch, который расширяет размер READ для снижения числа доставок в обе стороны. FaRM-KV быстро насыщает полосу пропускания
соединения (PCIe или InfiniBand/RoCE) с меньшим числом элементов нежели HERD, который сберегает полосу пропускания сетевой среды передавая только
существенные данные. Рисунок 10 иллюстрирует данный эффект. FaRM-em насыщает полосу пропускания
PCIe 2.0 в Susitna посредством 4 байтовых значений, а полосу пропускания InfiniBand 56 Gbps в Apt при помощи значений с 32 байтами. HERD достигает
наивысшей производительности в Susitna на значения 32 байта, а в Apt на значениях с 60 байтами и получает бутылочное горлышко за счёт меньшей
полосы пропускания PIO PCIe.
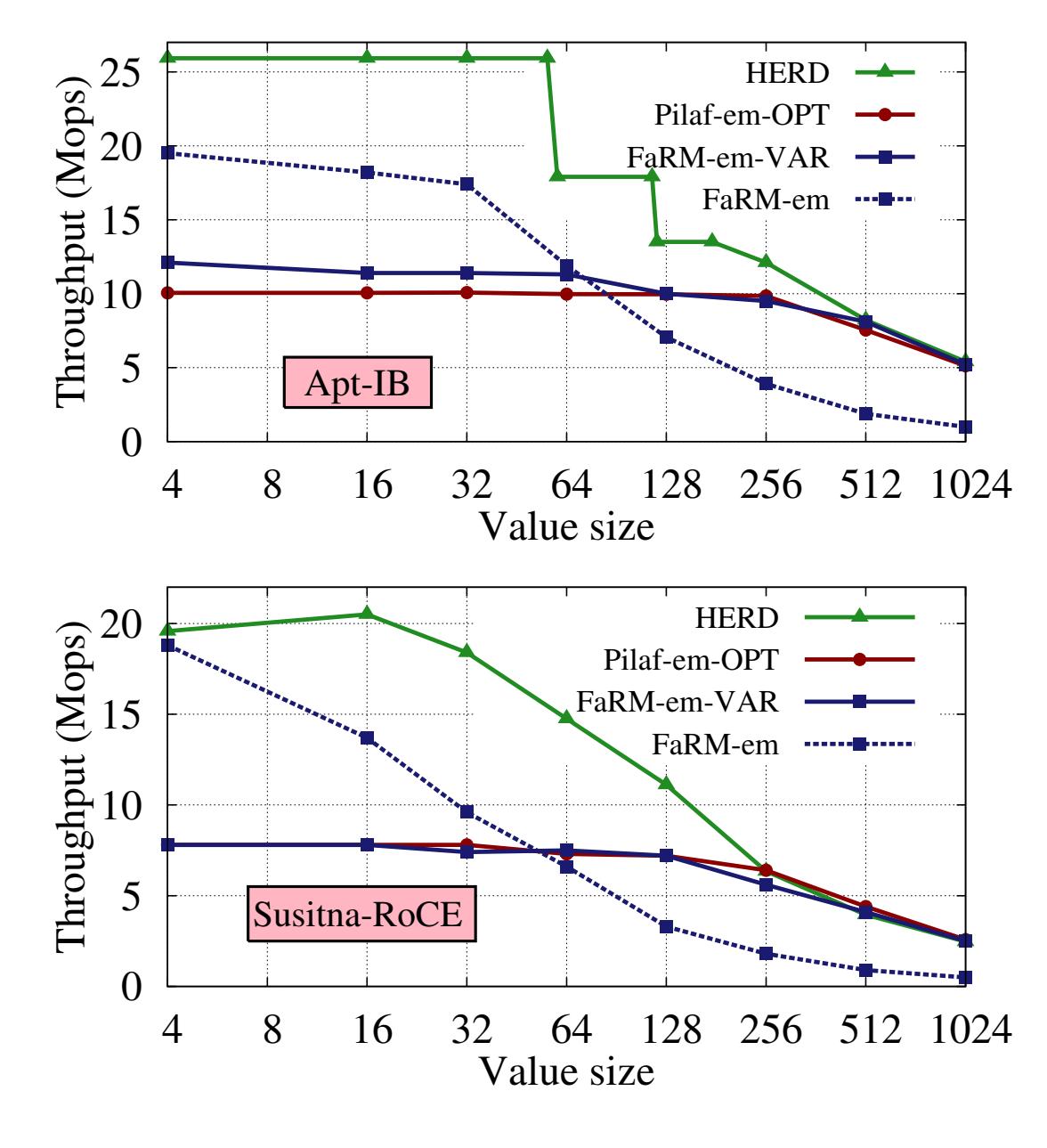
При больших значениях (144 байт в Apt, 192 для Susitna), HERD переключается на использование для откликов SEND без вложения. Значение исходящей пропускной способности для сообщений с большим вложением ниже чем для обмена сообщений без вложений, поскольку DMA превосходит в производительности PIO для больших полезных нагрузок (Рисунок 4b). Для больших значений величина пропускной способности HERD, FaRM-em, и Pilaf-em-OPT находится в пределах 10% друг от друга.
В отличии от FaRM-KV и Pilaf, HERD применяет только одну сетевую доставку в оба конца для любого запроса. FaRM-KV и Pilaf применяют одну двустороннюю
доставку для запросов PUT, но требует множества двусторонних доставок для
GET (за исключением случая, когда FaRM-KV встраивает значения в саму таблицу хэшей). Это приводит к тому, что их
задержки GET должны быть выше чем значения латентности некоторого отдельного READ RDMA.
Рисунок 11 сравнивает средние значения латентности рассматриваемых трёх систем для рабочих потоков с интенсивным чтением; значения столбцов ошибок показывают латентности 5 и 95 процентилей. Чтобы разобраться с такой зависимостью латентности от пропускной способности, мы увеличили нагрузку на свой сервер, добавляя дополнительных клиентов, пока сервер не достигнет насыщения. При использовании 6 ядер ЦПУ в нашем сервере, HERD способен доставлять 26 миллионов запросов в секунду приблизительно с 5 мкс задержкой в среднем. Для элементов ключ- значение с фиксированным FaRM-em предоставляет наинизшее значение латентности из всех трёх систем, так как ему требуется всего лишь одна двусторонняя доставка в сетевой среде (в отличие от Pilaf-em-OPT) и никаких вычислений в самом сервере (в отличие от HERD). Для переменных значений длины, однако, изменчивость длины FaRM может требовать двух RTT, давая худшую латентность, нежели HERD.
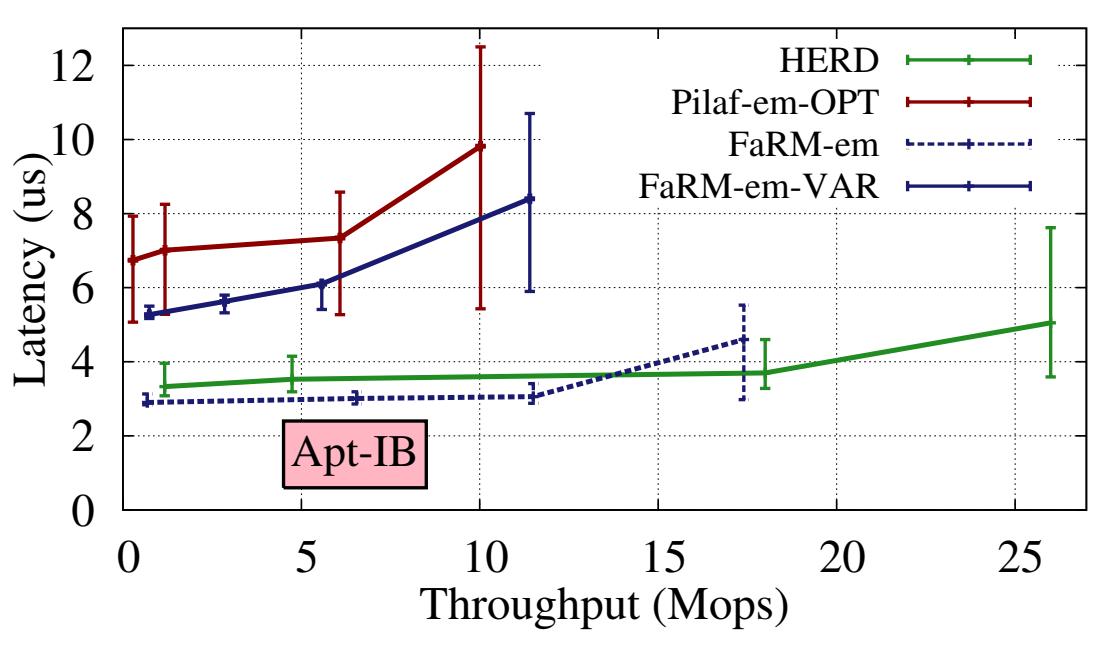
Значение латентности PUT для всех трёз систем (не отображены) являются аналогичными, так как сам сетевой
путь для перемещения данных один и тот же. Измеренное значение латентности для HERD было слегка более высоким чем в эмулируемых системах, так как
он выполнял реальное хэширование в таблицах и манипуляции с памятью для вставок, однако это некий артефакт того преимущества производительности,
которое мы получаем над Pilaf-em и FaRM-em.
Для того чтобы разобраться с масштабируемостью числа клиентов HERD, мы провели более крупный эксперимент. Мы применили одну машину для запуска 6 серверных процессов и все оставшиеся 186 машин для процессов клиентов. Данный эксперимент применял ключи из 16 байт и значения с 32 байтами.
Рисунок 12 отображает результаты данного эксперимента. HERD доставляет свою максимальную
пропускную способность вплоть до 260 процессов клиентов. При ещё большем числе клиентов пропускная способность HERD начинает снижаться почти линейным
образом.Данная скорость снижения может быть уменьшена за счёт увеличения общего числа исходящих запросов, поддерживаемых каждым клиентом, за счёт стоимости
более высокой задержки запроса. Рисунок 12 показывает полученные результаты для двух
размеров окна: 4 (значение по умолчанию HERD) и 16. Данный обзор подтверждает, что определённое ухудшение происходит по причине промахов кэша в
RNICS, поскольку большее число исходящих глаголов в некоторой очереди может снижать
сжатие кэша. Мы ожидаем, что данный предел масштабируемости будет разрешён с введением Dynamically Connected Transport в боле новых картах
Connect-IB [1, 8].
Рисунок 12
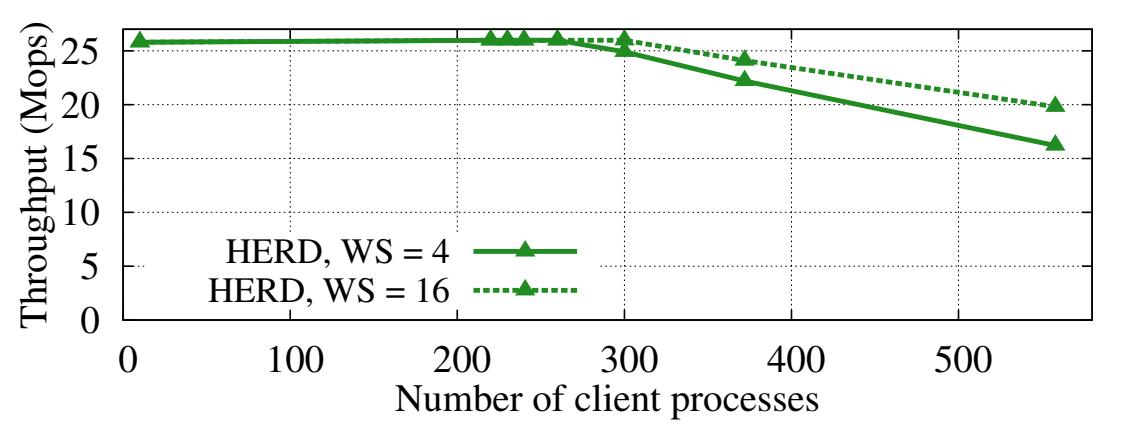
Пропускная способность с переменным числом процессов клиентов и различными размерами окна
Другим вероятным пределом масштабируемости в нашем текущем решении HERD является карусельный (round-robin) опрос на стороне сервера на предмет запросов. При тысячах клиентов применение WRITE для входящих запросов может приводить к слишком большим накладным расходам в ЦПУ; смягчение этого явления может неизбежно повлечь за собой переход к архитектуре SEND/SEND поверх доставки Unreliable Datagram. Рисунок 5 показывает, что при таком изменении имеется некое снижение на 4- 5 Mops, однако после этого наша система должна масштабироваться на многие тысячи клиентов и в то же время всё ещё превосходить в производительности архитектуру на основе READ RDMA. (Рисунок 5 применяет SEND поверх UC, однако мы убедились, что аналогичная пропускная способность возможна и с применением SEND поверх UD.) Мы ожидаем роста производительности архитектуры SEND/RECV, относящейся к WRITE- SEND с введением в картах Connect-IB RECV с вложением. Это снизит общую нагрузку на RNIC за счёт инкапсуляции необходимой полезной нагрузки RECV по завершению данного RECV.
Первейшим недостатком отсутствия использования READ в HERD является то, что операции GET требуют выполнения
запросом ЦПУ самого сервера, причём при обмене, для сохранения одного RTT через центр обработки данных.
Хтя на первый взгляд может и показаться, что использование HERD ЦПУ не должно быть выше чем у Pilaf и FaRM-KV, мы покажем, что на практике эти две
системы имеют существенные ресурсы для применения ЦПУ, которые снизят пределы этого различия.
Во- первых, дополнительные READ добавляют накладные расходы ЦПУ для соответствующих клиентов Pilaf и FaRM-KV. Для вызова своего второго READ такой клиент должен выполнить опрос на предмет завершения своего первого READ. HERD сдвигает эти накладные расходы на ЦПУ своего сервера, освобождая пространство для своих клиентов.
Во- вторых, обработка запросов PUT требует вовлечения ЦПУ на стороне сервера. Достижение низкой латентности
PUT требует выделения ядер ЦПУ сервера, которые опрашивают входящие запросы. Тем самым, точное использование ЦПУ
зависит от той части пропускной способности PUT, которую предоставляет
сервер, потому что именно это определяет те ресурсы ЦПУ, которые следует выделять. а не динамический реально применяемый объём. К примеру, наши эксперименты
показывают, что даже игнорируя стоимость обновления структур данных, предоставление для 100% пропускной спопосбности
PUT в Pilaf и FaRM-KV требует более 5 ядер ЦПУ.
Рисунок 13 показывает пропускную способность для
PUT с элементов ключ- значение в 48 байт FaRM-em и Pilaf-em-OPT и различные значения числа ядер ЦПУ в сервере.
Использование ЦПУ в Pilaf-em-OPTвыше, так как он должен выставлять RECV для новых запросов PUT, что может
быть более затратым, нежели опрос области запроса FaRM-em.
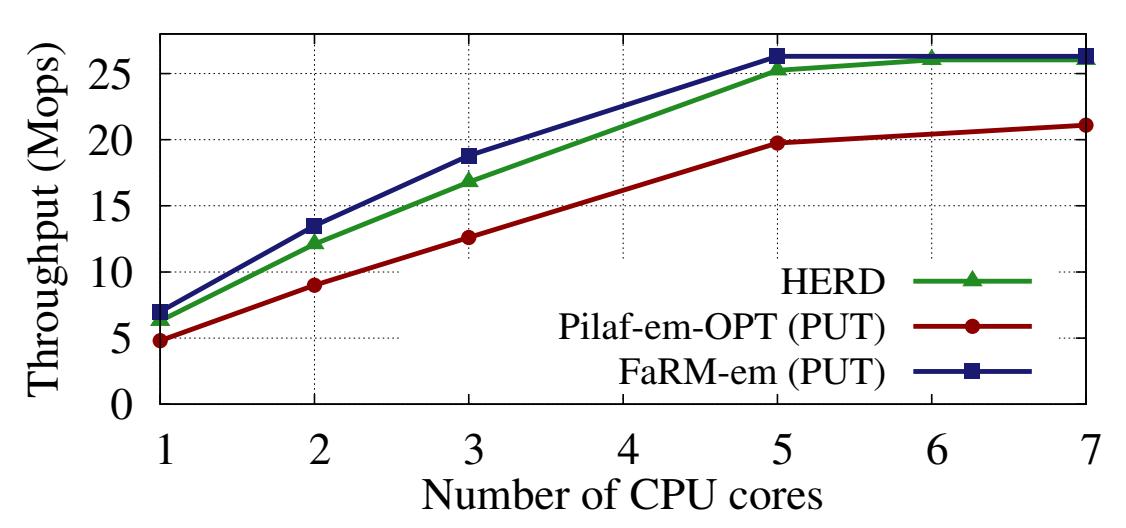
На Рисунке 13 мы также нанесли пропускную способность HERD для тех же самых рабочих нагрузок, изменяя общее число ядер ЦПУ сервера. HERD способен доставлять более 95% от своей максимальной пропускной способности с применением 5 ядер ЦПУ. Умеренный зазор с FaRM-em возникает по причине того, что наш сервер HERD в данном эксперименте обрабатывает выборки и обновления таблицы хэширования, в то время как эмулируемый FaRM-KV обрабатывает только свой сетевой обмен.
Мы верим, таким образом, что более высокие пропускная способность и латентность HERD, совместно со значительным потреблением ЦПУ в
Pilaf и FaRM-KV, оправдывает наше архитектурное решение иметь ЦПУ вовлечённым в общий путь GET для элементов с
небольшими элементами ключ- значение. Например, для рабочих потоков с 50% PUT умеренная дополнительная стоимость
добавления нескольких дополнительных ядер - или использования уже бесполезных циклов в имеющихся ядрах - скорее всего принесёт пользу многим
приложениям.
Чтобы понять как воздействуют отклонения (skew) на поведение HERD, мы провели его проверку с некоторым рабочим потоком, в котором его ключи берутся из распределения Zipf. HERD хорошо адаптируется к отклонениям даже когда значение параметра Zipf составляет 0.99. Устойчивость HERD к отклонениям исходя из двух моментов. Во- первых это сама архитектура MICA [18], которая применяется в HERD, хорошо работает при отклонениях; скошенная рабочая нагрузка распределяется по различным разделам, производящим небольшие вариации в нагрузках данных разделов в сравнении с сами отклонением в распределении рабочего потока. Применяя наши рабочие потоки с распределением Zipf, при 6 разделах, самое загруженное ядро ЦПУ наполнено только на 50% больше чем наименее нагруженное ядро, даже хотя самый популярный ключ более востребован в 105 раз чем среднее значение.
Во- вторых, так как все ядра ЦПУ совместно используют имеющийся RNIC, наиболее загруженные ядра способны получать преимущество от имеющегося времени простоя, предоставляемого менее используемыми ядрами. Рисунок 13 демонстрирует данный эффект: при единообразной рабочей нагрузке и применении только одного ядра, HERD может предоставлять 6.3 Mops. Когда наша система настроена с 6 ядрами - минимальное значение, требуемое HERD, для предоставления им пиковой пропускной способности - наша система предоставляет 4.32 Mops на ядро. Имеющееся снижение производительности на ядро происходит не по причине того что ЦПУ является узким местом, а потому что запущенные серверные процессы насыщают пропускную способность PIO PCIe. Таким образом, даже для скошенного рабочего потока в определённом ядре имеются достаточные габариты ЦПУ для обработки дополнительных запросов.
Рисунок 14 отображает пропускную способность HERD для каждого ядра при скошенной рабочей нагрузке. Нашей экспериментальной конфигурацией является: 48- байтные элементы, интенсивное чтение, скошенная нагрузка, в общей сложности 6 ядер ЦПУ. Для сопоставления включена также пропускная способность для ядер единообразного рабочего потока.
Рисунок 14
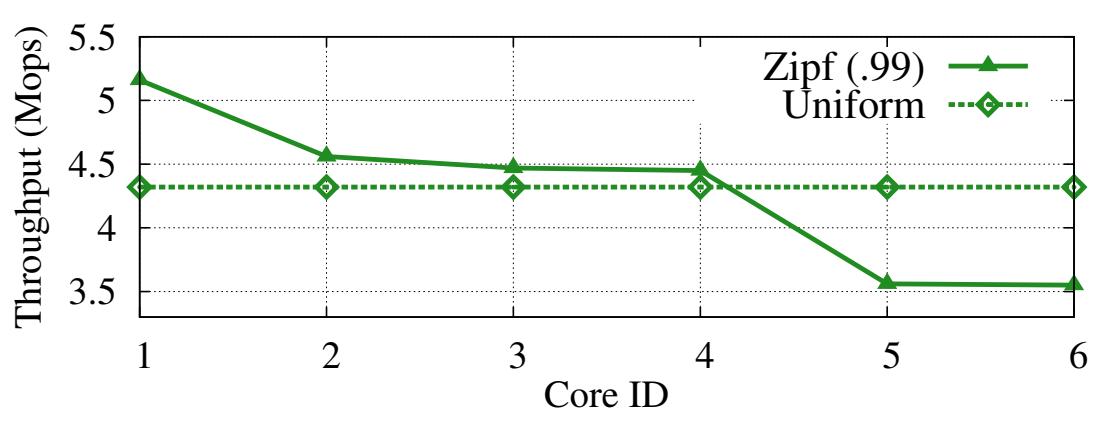
Поядерная пропускная способность для скошенных и единообразных рабочих потоков. Заметим, что ось y начинается не с нуля
Хранилища ключ- значение на базе RDMA: Были разработаны некоторые проекты подобных memcached систем поверх RDMA, отличные от Pilaf и FaRM. Panda и пр. [18] описывает некую реализацию memcached с применением гибридной доставки UD и RC. Оии используют обмен сообщениями SEND/RECV для всех запросов и избегают перегруженности доставки UD (вызываемой большим размером заголовка нежели у RC) активным переключением соединений между RC и UD. Хотя их кластер (ConnectX, 32 Gbps) и близок к Susitna (ConnectX-3, 40 Gbps), их скорость запросов меньше чем 1.5 Mops. Stuedi и пр. [25] описывают SoftiWARP [28], основывающийся на версии memcached с целью сбережения ЦПУ в wimpy узлах с 10 GbE.
Системы ускорения с применением RDMA: Определённые проекты применяли глаголы для
улучшения производительности таких систем, как HBase, Hadoop RPC, PVFS
[30, 13, 20].
Большинство из них используют только глаголы SEND/RECV в качестве некоторой быстрой альтернативы взаимодействию на основе сокетов. В реализации
PVFS поверх InfiniBand [30], операции read() и
write() в соответствующей файловой системе используют и RDMA, и SEND/RECV. Они предпочитают WRITE вместо
READ по тем же самым причинам, что и в прочих работах, предполагая что между различными поколениями оборудования InfiniBand имеется определённый
зазор в производительности. Были реализованы определённые версии MPI поверх InfiniBand
[16, 19].
MPICH2 применяет записи RDMA для обмена сообщениями в одну сторону: его сервер опрашивает получаемые заголовки в циклическом буфере. которые
записываются некими клиентами. HERD расширяет такие обмены сообщениями масштабируемым образом для взаимодействий запрос- отклик всех- ко- всем.
Хотя ранее [30, 13, 20,
16, 19] и проводилось эталонное тестирование производительности
глаголов, оно осуществлялось для больших сообщений в контексте приложений, подобных NFS и MPI. Наша работа эксплуатирует имеющиеся различия в
производительности, которые появляются только для сообщений малого размера и являются существенными для приложений с ограниченной скоростью обмена
сообщениями, подобных хранилищам ключ- значение.
Сетевые среды уровня пользователя: Собирая всё воедино, мы полагаем, что одно заключение, которое проистекает из общего объединения HERD, Pilaf, FaRM и MICA [18] состоит в том, что самое большое ускорение пропускной способности проистекает из обхода сетевого стека и избегания прерываний ЦПУ, причём не обязательно из полного обхода стороной имеющегося ЦПУ. Все эти четыре системы применяют механизмы, позволяющие программам уровня пользователя напрямую получать запросы или пакеты от соответствующего NIC: драйверы RDMA пользовательского уровня для HERD, Pilaf и FaRM, а также библиотека DPDK Intel для MICA. Как мы уже поясняли ранее, значения пропускной способности для этих систем схожи, однако требуемое для систем на основе DPDK группирование дарует некие преимущества латентности для систем с аппаратной поддержкой InfiniBand. Эти уроки советуют благоприятные свойства работы в плане выполнения систем классического Ethernet пользовательского уровня более переносимыми, более простыми в использовании и обладающие более низкими значениями латентности. Одним из происходящих в настоящее время проектов является NIQ [10], некая NIC с низкой латентностью на базе FPGA, которая применяет PIO с размером строки кэширования (без какого бы то ни было RDMA) для доставки и получения пакетов с малым размером. WRITE в RDMA с вложением применяют тот же самый механизм на запрашивающей стороне.
Хранилища ключ- значение общего назначения: MICA [18] является новейшей системой ключ- значение для классического Ethernet. Она назначает исключительные разделы ядрам сервера для минимизации соединений оперативной памяти и эксплуатирует имеющиеся возможности NIC для выруливания запросов в их соответствующее ядро [3]. Некий сервер MICA предоставляет 77 Mops 4 двухпортовыми, 10 Gbps PCIe 2.0 NIC, при среднем значении латентности 50 мкс (19.25 Gbps с одной картой PCIe 2.0). Это предлагает то, что сравнивание самых современных решений на основе классического Ethernet может предоставлять сопоставимые с пропускной способностью RDMA решения, хотя и с намного большими значениями латентности. RAMCloud [23] является неким основанном на оперативной памяти постоянном хранилище ключ- значение, которое применяет глаголы обмена сообшениями для взаимодействия с низким значением латентности.
Данная статья эксплуатирует имеющиеся варианты для реализации быстрой, системы ключ- значение с низкими показателями латентности поверх RDMA, прибывающие в некотором неожиданном и новаторском сочетании, которое превосходит по производительности имевшиеся ранее решения и применяет меньшее число двусторонних доставок. Наша работа показывает, что вопреки широко укоренившимся убеждениям в практике для RDMA, решения единственного RTT с вовлечённостью ЦПУ могут превосходить в производительности "оптимизированный" удалённый доступ к памяти с обходом ЦПУ когда подходы RDMA требуют множества RTT. Эти результаты привносятся не только как некий практический артефакт - высокопроизводительное кэширование ключ- значение с низкой латентностью HERD - но и улучшает понимание того, как применять RDMA для построения в будущем служб хранения на основе Оперативной памяти (DRAM).
Благодарности Мы благодарим своего пастыря Chuanxiong Guo и множество анонимных критиков за их обратную связь, которая помогла нам улучшить данную статью. Мы также благодарим Miguel Castro и Dushyanth Narayanan за обсуждение с нами FaRM. Kirk Webb и Robert Ricci за предоставление нам раннего доступа к их кластеру Apt, а также Hyeontaek Lim за его существенный инсайт. Данная работа была поддержена фондом National Science Foundation грантами CNS-1314721 и CCF-0964474, а также Intel через Intel Science and Technology Center for Cloud Computing (ISTC-CC). Кластер PRObE [11], применявшийся для многочисленных экспериментов частично поддерживается NSF грантами CNS-1042537 и CNS-1042543 (PRObE).
[1] Connect-IB: Architecture for Scalable High Performance Computing.
[2] Intel DPDK: Data Plane Development Kit.
[3] Intel 82599 10 Gigabit Ethernet Controller: Datasheet.
[4] Redis: An Advanced Key-Value Store.
[5] memcached: A Distributed Memory Object Caching System, 2011.
[6] B. Atikoglu, Y. Xu, E. Frachtenberg, S. Jiang, and M. Paleczny. Workload Analysis of a Large-Scale Key-Value Store. In SIGMETRICS, 2012.
[7] B. F. Cooper, A. Silberstein, E. Tam, R. Ramakrishnan, and R. Sears. Benchmarking Cloud Serving Systems with YCSB. In SoCC, 2010.
[8] A. Dragojevic, D. Narayanan, O. Hodson, and M. Castro. FaRM: Fast Remote Memory. In USENIX NSDI, 2014.
[9] B. Fan, D. G. Andersen, and M. Kaminsky. MemC3: Compact and Concurrent MemCache with Dumber Caching and Smarter Hashing. In USENIX NSDI, 2013.
[10] M. Flajslik and M. Rosenblum. Network Interface Design for Low Latency Request-Response Protocols. In USENIX ATC, 2013.
[11] G. Gibson, G. Grider, A. Jacobson, and W. Lloyd. PRObE: A Thousand-Node Experimental Cluster for Computer Systems Research.
[12] M. Herlihy, N. Shavit, and M. Tzafrir. Hopscotch Hashing. In DISC, 2008.
[13] J. Huang, X. Ouyang, J. Jose, M. W. ur Rahman, H. Wang, M. Luo, H. Subramoni, C. Murthy, and D. K. Panda. High-Performance Design of HBase with RDMA over InfiniBand. In IPDPS, 2012.
[14] J. Jose, H. Subramoni, K. C. Kandalla, M. W. ur Rahman, H. Wang, S. Narravula, and D. K. Panda. Scalable Memcached Design for InfiniBand Clusters Using Hybrid Transports. In CCGRID. IEEE, 2012.
[15] A. Kalia, D. G. Andersen, and M. Kaminsky. Using RDMA Efficiently for Key-Value Services. In Technical Report CMU-PDL-14-106, 2014.
[16] J. Li, J. Wu, and D. K. Panda. High Performance RDMA-Based MPI Implementation over InfiniBand. International Journal of Parallel Programming, 2004.
[17] H. Lim, B. Fan, D. G. Andersen, and M. Kaminsky. SILT: A Memory-efficient, High-performance Key-value Store. In SOSP, 2011.
[18] H. Lim, D. Han, D. G. Andersen, and M. Kaminsky. MICA: A Holistic Approach to Fast In-Memory Key-Value Storage. In USENIX NSDI, 2014.
[19] J. Liu, W. Jiang, P. Wyckoff, D. K. Panda, D. Ashton, D. Buntinas, W. Gropp, and B. Toonen. Design and Implementation of MPICH2 over InfiniBand with RDMA Support. In IPDPD, 2004.
[20] X. Lu, N. S. Islam, M. W. ur Rahman, J. Jose, H. Subramoni, H. Wang, and D. K. Panda. High-Performance Design of Hadoop RPC with RDMA over InfiniBand. In ICPP, 2013.
[21] C. Mitchell, Y. Geng, and J. Li. Using One-Sided RDMA Reads to Build a Fast, CPU-Efficient Key-Value Store. In USENIX ATC, 2013.
[22] R. Nishtala, H. Fugal, S. Grimm, M. Kwiatkowski, H. Lee, H. C. Li, R. McElroy, M. Paleczny, D. Peek, P. Saab, D. Stafford, T. Tung, and V. Venkataramani. Scaling Memcache at Facebook. In USENIX NSDI, 2013.
[23] D. Ongaro, S. M. Rumble, R. Stutsman, J. Ousterhout, and M. Rosenblum. Fast Crash Recovery in RAMCloud. In SOSP, 2011.
[24] R. Pagh and F. F. Rodler. Cuckoo Hashing. J. Algorithms, 2004.
[25] P. Stuedi, A. Trivedi, and B. Metzler. Wimpy Nodes with 10GbE: Leveraging One-Sided Operations in Soft-RDMA to Boost Memcached. In USENIX ATC, 2012.
[26] S. Sur, A. Vishnu, H.-W. Jin, W. Huang, and D. K. Panda. Can Memory-Less Network Adapters Benefit Next-Generation InfiniBand Systems? In HOTI, 2005.
[27] S. Sur, M. J. Koop, L. Chai, and D. K. Panda. Performance Analysis and Evaluation of Mellanox ConnectX Infiniband Architecture with Multi-Core Platforms. In HOTI, 2007.
[28] A. Trivedi, B. Metzler, and P. Stuedi. A Case for RDMA in Clouds: Turning Supercomputer Networking into Commodity. In APSys, 2011.
[29] B. White, J. Lepreau, L. Stoller, R. Ricci, S. Guruprasad, M. Newbold, M. Hibler, C. Barb, and A. Joglekar. An Integrated Experimental Environment for Distributed Systems and Networks. In OSDI, 2002.
[30] J. Wu, P. Wyckoff, and D. K. Panda. PVFS over InfiniBand: Design and Performance Evaluation. In Ohio State University Tech Report, 2003.
[31] D. Zhou, B. Fan, H. Lim, M. Kaminsky, and D. G. Andersen. Scalable, High Performance Ethernet Forwarding with CuckooSwitch. In CoNEXT, 2013.