Глава 4. Разработка с помощью Redis
Содержание
- Глава 4. Разработка с помощью Redis
В данной главе мы рассмотрим такие рецепты:
-
Когда применять Redis в вашем приложении.
-
Использование верных типов данных.
-
Применение правильного API Redis.
-
Соединение Redis с Java.
-
Подключение Redis в Python.
-
Сочленение Redis с Spring Data Redis.
-
Написание задания MapReduce для Redis.
-
Создание задания Spark для Redis.
В Главе 2, Типы данных и Главе 3, Свойства данных мы изучили имеющиеся типы данных и многие полезные свойства Redis. В этой главе мы сосредоточимся на теме разработки приложения при помощи Redis.
Вначале мы начнём с введения в некоторые распространённые варианты использования Redis, чтобы дать вам краткие мысли по поводу того как Redis работает в реальном мире.
После этого будут предоставлены некоторые руководящие правила того как ыбирать правильные типы значений и API. При разработке приложений с помощью Redis крайне важно следовать этим руководящим правилам, так как в отличии от большинства RDBMS вы почти ничего не можете делать для оптимизации вычислительной мощности Redis выполняя только настройку конфигурации на стороне своего сервера. Применение надлежащих типов данных и API с самого начала проектирования приложения является необходимым ключевым фактором для полного применения высокой производительности Redis и в то же самое время для обхода её ловушек.
После приведения руководящих правил мы собираемся показать как разрабатывать какое- то приложение с помощью Redis применяя Java и Python. Для разработки веб приложений также мы рассматриваем Spring Data Redis.
Наконец, самые последние два рецепта в данной главе рассмотрят как применять Redis в мире больших данных.
Поскольку вы уже видели мощные свойства Redis в предыдущих главах, мы можем быть удивлены тем, что redis может делать в некотором приложении и когда его следует применять. В данном рецепте мы покажем несколько сценариев приложений реального мира в которых Redis является наилучшим выбором по сравнению с прочими решениями хранения. Надеемся, что вы получите и дополнительные идеи применения Redis в ваших приложениях.
При современной архитектуре веб площадок позади одного или нескольких балансировщиков нагрузки присутствует множество веб серверов. Обычно требуется сохранять сеансы во внешних системах хранения. Если какой- либо из имеющихся серверов отключается, другой сервер может получить данный сеанс из такого внешнего хранилища и продолжить обслуживание обмена. Redis является исключительным хранилищем сеансов, так как он имеет очень низкую латентность доступа в сравнении с RDBMS. Кроме того, поддержка срока давности в Redis может естественным образом адаптирована для управления таймаутом сеанса.
Redis также может применяться для целей аналитики и статистики. Например, если вы желаете подсчитывать сколько пользователей просмотрели некий ресторан в вашем
приложении, мы можем просто воспользоваться командой INCR для инкрементального приращения своего счётчика при просмотре
данного ресторана. Нам не следует беспокоиться об условиях скорости, так как команды Redis являются атомарными. Более изощрённые счётчики или статистические данные,
захватываемые в системе могут быть построены при помощи таких типов данных как хэш, Сортированный набор и HyperLoglog.
При помощи Сортированного набора в Redis мы легко можем реализовать некий рейтинг. Как мы уже видели в рецепте Применение типа данных сортированного множества из Главы 2, Типы данных, мы можем создать
некое Сортированное множество ресторанов; значение суммы баллов в этом Множестве является числом голосов пользователей. Таким образом,
наша команда ZREVRANGE возвращает рестораны в соответствии с их популярностью. Ту же самую функциональность мы
также можем реализовать при помощи некоей RDBMS, такой как MySQL, однако запрос SQL будет намного медленнее чем Redis.
Вспомните команды с блокировкой PUSH/POP, которые мы представили в рецепте Применение типа данных списков в Главе 2, Типы данных. Как мы показали в этом рецепте,
список данных Redis можно применить для реализации некой простой очереди заданий. Широко применяемый проект
Resque, который является некоторой библиотекой Ruby на основе Redis для очередей заданий,
базируется на этой идее. При помощи команды RPOPLPUSH мы также можем реализовывать надёжные очереди с применением
списков Redis.
Допустим, что нам бы хотелось получить десятку ресторанов, которые были добавлены в наше приложение самыми последними. Если бы мы применяли RDBMS, мы бы должны были запустить некий запрос SQL, подобный такому:
SELECT * FROM restaurants ORDER BY created_at DESC LIMIT 10
Для решения этой задачи мы можем воспользоваться преимуществами списка Redis:
-
Введём в строй некий список Redis,
latest_restaurants -
При всяком новом добавлении ресторана выполняйте
LPUSH latest_restaurantsиLTRIM recent_restaurants 0 10. Таким образом наш список Redis всегда будет содержать самые последние десять ресторанов.
Так как Redis является системой хранения данных в оперативной памяти, использование Redis в качестве некоторого кэша спереди какой- то RDBMS обычно ускоряет обработку запроса такой базы данных. Вот некий пример варианта использования: прежде чем запрашивать свою RDBMS, мы вначале просматриваем записи в Redis. Если такой записи нет в Redis, мы выполняем запрос в своей RDBMS и помещаем соответствующую запись в Redis. При записи в нашу RDBMS мы также записываем эту запись в Redis. Записи в таком кэше связываются с неким таймаутом или с какой- то политикой отселения, например LRU (Least Recently Used, наиболее долго неиспользованных) для ограничения предела использования данного кэша.
Как показывают некоторые приведённые выше варианты применения, определённые задачи, которые являются медленными или трудно выполнимыми в RDBMS могут быть проще и быстрее делаться в Redis. Однако, redis не является вариантом для всех потребностей хранения. Во- первых, поскольку по умолчанию распределённый Redis хранит все данные в оперативной памяти (некоторые основанные на облачных решениях службы Redis предоставляют вариант применения SSD в качестве основы для хранения таких данных), если же размер данных превосходит размер имеющейся памяти, Redis не может удерживать все данные. Во- вторых, транзакции Redis не являются полностью совместимыми с Атомарностью, Согласованностью, Изолированностью и Устойчивостью (Atomicity, Consistency, Isolation и Durability, ACID). Если необходимы транзакции ACID, Redis не может применяться. Для таких вариантов применения следует использовать RDBMS или иную систему базы данных.
Для понимания смысла ACID обратитесь к справочным материалам https://en.wikipedia.org/wiki/ACID.
Относительно проекта Resque обратитесь к https://github.com/resque/resque.
В Главе 2, Типы данных мы изучили что Redis предоставляет богатые типы данных для наполнения деловых потребностей. Поэтому, когда при помощи Redis мы разрабатываем некоторое приложение, для нас крайне важно для начала быть знакомыми с этими типами данных. Такое знакомство включает в себя не только осведомлённость об имеющихся семантических различиях между ними, но также и выявление их сильных и слабых сторон когда мы собираемся реализовывать с их помощью определённые бизнес сценарии. Хотя не составляет труда при проектировании выбрать один или более типов данных для соответствия нашим требованиям, всегда имеется место для оптимизации когда мы рассматриваем значение производительности и потребления памяти.
В данном рецепте мы собираемся выполнить пример проектирования хранения пользовательских данных чтобы показать как применять верные типы данных для меньшего потребления памяти.
Вам требуется завершить установку своего Cервера Redis, которое мы описывали в своём рецепте Загрузка и установка Redis в Главе 1, Приступая к Redis.
Вам понадобится выполнить команду FLUSHALL для сброса всех имеющихся данных в вашем экземпляре Redis
прежде чем вы перейдёте к следующему разделу.
Для установки инструментов dos2unix в Ubuntu выполните следующую команду:
sudo apt-get install dos2unix
В macOS вы можете установить инструментарий dos2unix при помощи следующей команды:
brew install dos2unix
Чтобы показать как выполнять правильный выбор типа данных, мы пожелаем сохранять имеющуюся информацию пользователя Relp в Redis. В качестве прототипа подтверждения решения мы собираемся наполнить Redis некими образцами данных для 10 000 пользователей чтобы проверить что мы применяем наилучшую стратегию для хранения данных пользователей в Redis. Это означает, что при соблюдении потребностей дела данного приложения, мы попытаемся применять настолько мало памяти, насколько это возможно. Для иллюстрации целей для одного пользователя будет сохраняться следующая информация:
-
id: идентификатор пользователя. -
name: имя пользователя. -
sex: пол. -
register_time: временной штамп подписи. -
nation: национальная принадлежность пользователя.
-
Мы проверяем потребление памяти неким пустым экземпляром Redis:
127.0.0.1:6379> INFO MEMORY # Memory used_memory:827512 used_memory_human:808.12K -
Первое что приходит в голову это сохранять каждыё элемент информации в виде строковой пары ключ- значение:
$ cat populatedata0.sh #!/bin/bash DATAFILE="string.data" rm $DATAFILE >/dev/null 2>∓1 NAMEOPTION[0]="Jack" NAMEOPTION[1]="MIKE" NAMEOPTION[2]="Mary" SEXOPTION[0]="m" SEXOPTION[1]="f" NATIONOPTION[0]="us" NATIONOPTION[1]="cn" NATIONOPTION[2]="uk" for i in `seq -f "%010g" 1 10000` do namerand=$[ $RANDOM % 3 ] sexrand=$[ $RANDOM % 2 ] timerand=$[ $RANDOM % 30 ] nationrand=$[ $RANDOM % 3 ] echo "set \"user:${i}:name\" \"${NAMEOPTION[$namerand]}\"" >> $DATAFILE echo "set \"user:${i}:sex\" \"${SEXOPTION[$sexrand]}\"" >> $DATAFILE echo "set \"user:${i}:resigter_time\" \"`date +%s%N`\"" >> $DATAFILE echo "set \"user:${i}:nation\" \"${NATIONOPTION[$nationrand]}\"" >> $DATAFILE sleep 0.00000${timerand} done unix2dos $DATAFILE $ bin/redis-cli FLUSHALL OK $ bash populatedata0.sh unix2dos: converting file string.data to DOS format ... $ cat string.data | redis-cli --pipe All data transferred. Waiting for the last reply... Last reply received from server. errors: 0, replies: 40000 -
Внутри
redis-cliпроверим потребление памяти, воспользовавшисьINFO MEMORY:127.0.0.1:6379> INFO MEMORY # Memory used_memory:4231960 used_memory_human:4.04M -
Самой первой оптимизацией, которую мы собираемся сделать состоит в сохранении информации в виде строки JSON:
$ cat populatedata1.sh #!/bin/bash DATAFILE="json.data" ... (omit all the variables declared above) for i in `seq -f "%010g" 1 10000` do namerand=$[ $RANDOM % 3 ] sexrand=$[ $RANDOM % 2 ] timerand=$[ $RANDOM % 30 ] nationrand=$[ $RANDOM % 3 ] echo "set \"user:${i}\" '{\"name\":\"${NAMEOPTION[$namerand]}\",sex:\"${SEXOPTION[$sexrand]}\",resigter_time:`date +%s%N`,nation:\"${NATIONOPTION[$nationrand]}\"}'" >> $DATAFILE sleep 0.00000${timerand} done unix2dos $DATAFILE $ bin/redis-cli FLUSHALL OK $ bash populatedata1.sh unix2dos: converting file string.data to DOS format ... $ cat json.data | redis-cli --pipe All data transferred. Waiting for the last reply... Last reply received from server. errors: 0, replies: 10000 -
Проверяя потребление нами памяти мы обнаруживаем, что было сохранено около 43% ((4.04-2.29)/4.04) пространства памяти:
127.0.0.1:6379> INFO MEMORY # Memory used_memory:2398896 used_memory_human:2.29M -
После этого мы применим некий сценарий
Lua, который был представлен нами в Главе 3, Свойства данных, для упорядочения наших сырых строк JSON при помощи библиотекиmsgpack:$ cat setjsonasmsgpack.lua --EVAL 'this script' 1 some-key '{"some": "json"}' local key = KEYS[1]; local value = ARGV[1]; local mvalue = cmsgpack.pack(cjson.decode(value)); return redis.call('SET', key, mvalue); $ cat populatedata2.sh #!/bin/bash DATAFILE="msgpack.data" rm $DATAFILE >/dev/null 2>&1 ... (omit all the variables declared above) for i in `seq -f "%010g" 1 10000` do namerand=$[ $RANDOM % 3 ] sexrand=$[ $RANDOM % 2 ] timerand=$[ $RANDOM % 30 ] nationrand=$[ $RANDOM % 3 ] echo "user:00000${i}{\"name\":\"${NAMEOPTION[$namerand]}\",\"sex\":\"${SEXOPTION[$sexrand]}\",\"resigter_time\":`date +%s`,\"nation\":\"${NATIONOPTION[$nationrand]}\"}" >> $DATAFILE sleep 0.00000${timerand} done unix2dos $DATAFILE $ bin/redis-cli FLUSHALL OK $ bash populatedata2.sh unix2dos: converting file msgpack.data to DOS format ... $ cat msgpack.data | while read CMD; do var1=$(cut -d' ' -f1 <<< $CMD); var2=$(cut -d' ' -f2 <<< $CMD) ; /bin/redis-cli --eval setjsonasmsgpack.lua $var1 , $var2; done -
С помощью упорядочения
msgpackмы сохранили около 49% ((4.04-2.06)/4.04) памяти:127.0.0.1:6379> INFO MEMORY # Memory used_memory:2159048 used_memory_human:2.06M -
Далее мы продолжим попытки оптимизации своего решения при помощи типа данных хэша:
$ cat populatedata3.sh #!/bin/bash DATAFILE="hash.data" ... (omit all the variables declared above) for i in `seq -f "%010g" 1 10000` do namerand=$[ $RANDOM % 3 ] sexrand=$[ $RANDOM % 2 ] timerand=$[ $RANDOM % 30 ] nationrand=$[ $RANDOM % 3 ] echo "hset \"user:${i}\" \"name\" \"${NAMEOPTION[$namerand]}\" \"sex\" \"${SEXOPTION[$sexrand]}\" \"resigter_time\" `date +%s%N` \"nation\" \"${NATIONOPTION[$nationrand]}\"" >> $DATAFILE sleep 0.00000${timerand} done unix2dos $DATAFILE $ bin/redis-cli FLUSHALL OK $ bash populatedata3.sh unix2dos: converting file hash.data to DOS format ... $ cat hash.data | redis-cli --pipe All data transferred. Waiting for the last reply... Last reply received from server. errors: 0, replies: 10000 -
Снова проверим потребление памяти. Опаньки! кажется, что в сравнении с нашим предыдущим механизмом оптимизации при посощи
msgpackна этот раз используется больше памяти и примерно то же количество памяти, которое требовалось для решения со строками JSON:127.0.0.1:6379> INFO MEMORY # Memory used_memory:2399352 used_memory_human:2.29M -
Мы обнаружили это, хотя для сохранения данных пользователей мы применяли тип данных хэша, причём в сравнении с методом строк JSON общее количество ключей не устранено. Поэтому мы попробуем снизить общее число ключей путём разделения имеющегося идентификатора пользователя. Для начала мы изменим свои настройки значения максимального числа элементов и значения хеширования для применения
ziplist:$ vim conf/redis.conf hash-max-ziplist-entries 1000 hash-max-ziplist-value 64 -
Перезапустим свой Сервер Redis чтобы заставить работать свои сетевые настройки. После этого начнём проверку нашего прототипа:
$ cat populatedata4.sh #!/bin/bash DATAFILE="hashpartition.data" PLENGTH=3 ... (omit all the variables declared above) for i in `seq -f "%010g" 1 10000` do namerand=$[ $RANDOM % 3 ] sexrand=$[ $RANDOM % 2 ] timerand=$[ $RANDOM % 30 ] nationrand=$[ $RANDOM % 3 ] LENGTH=`echo ${#i}` LENGTHCUT=`echo $((LENGTH-PLENGTH))` LENGTHEND=`echo $((LENGTHCUT+1))` VALUE1=`echo $i | cut -c1-${LENGTHCUT}` VALUE2=`echo $i | cut -c${LENGTHEND}-${LENGTH}` echo "hset \"user:${VALUE1}\" $VALUE2 '{\"name\":\"${NAMEOPTION[$namerand]}\",\"sex\":\"${SEXOPTION[$sexrand]}\",\"resigter_time\":`date +%s%N`,\"nation\":\"${NATIONOPTION[$nationrand]}\"}'" >> $DATAFILE sleep 0.00000${timerand} done unix2dos $DATAFILE $ bin/redis-cli FLUSHALL OK $ bash populatedata4.sh unix2dos: converting file hashpartition.data to DOS format ... $ cat hashpartition.data | redis-cli --pipe All data transferred. Waiting for the last reply... Last reply received from server. errors: 0, replies: 10000 -
Проверим объём памяти для раздела хэша. Совершенно ясно видно, что было сохранено около 52% ((4.04-1.94)/4.04) памяти за счёт такой оптимизации:
127.0.0.1:6379> INFO MEMORY # Memory used_memory:2032160 used_memory_human:1.94M -
Наконец, мы попытаемся объединить свой раздел хэша и упорядочение
msgpackчтобы посмотреть чего мы достигнем:$ cat populatedata5.sh #!/bin/bash DATAFILE="hashpartitionmsgpack.data" PLENGTH=3 rm $DATAFILE >/dev/null 2>&1 ... (omit all the variables declared above) for i in `seq -f "%010g" 1 10000` do namerand=$[ $RANDOM % 3 ] sexrand=$[ $RANDOM % 2 ] timerand=$[ $RANDOM % 30 ] nationrand=$[ $RANDOM % 3 ] LENGTH=`echo ${#i}` LENGTHCUT=`echo $((LENGTH-PLENGTH))` LENGTHEND=`echo $((LENGTHCUT+1))` VALUE1=`echo $i | awk '{print substr($1,1,"'$LENGTHCUT'")}'` VALUE2=`echo $i | awk '{print substr($1,"'$LENGTHEND'","'$PLENGTH'")}'` echo "user:${VALUE1} $VALUE2 {\"name\":\"${NAMEOPTION[$namerand]}\",\"sex\":\"${SEXOPTION[$sexrand]}\",\"resigter_time\":`date +%s%N`,\"nation\":\"${NATIONOPTION[$nationrand]}\"}" >> $DATAFILE sleep 0.00000${timerand} done unix2dos $DATAFILE $ bin/redis-cli FLUSHALL OK $ bash populatedata5.sh unix2dos: converting file hashpartitionmsgpack.data to DOS format ... $ cat hashpartitionmsgpack.data | while read CMD; do var1=$(cut -d' ' -f1 <<< $CMD); var2=$(cut -d' ' -f2 <<< $CMD) ; var3=$(cut -d' ' -f3 <<< $CMD); /redis/bin/redis-cli --eval setjsonashashmsgpack.lua $var1 $var2 , $var3; done -
Ошеломлюяще обнаружить, что после всех оптимизаций наши образцы данных занимают только
1.34M, что составляет всего 33% (1.34/4.04) от объёма памяти, потребляемого в первоначальном решении:127.0.0.1:6379> INFO MEMORY # Memory used_memory:1403272 used_memory_human:1.34M
Когда мы приступаем к проектированию некоторого приложения с применением Redis, один из моментов, который следует держать на уме, состоит в том, что не всегда есть только один тип данных, который соответствует вашему бизнес сценарию. Это означает, что различные требования для хранения и производительности запроса приводят к различным решениям. Вашим заданием при проектировании является в вытаскивании на поверхность понимания того, какой именно тип данных является наилучшим в вашем случае применяя проверки различных прототипов, как в предыдущем примере.
В данном примере вначале вы делаем некий базовый проект, который является простым соответствием некоторого ключа атрибуту пользователя. Мы делаем это на самом первом этапе в качестве базового уровня потребления памяти для ссылок на него в дальнейшем.
После этого мы пытаемся уменьшить своё потребление памяти двумя различными способами. Один состоит в попытке уменьшения общего числа ключей. Причина по которой мы делаем это состоит в том, что Redis применяет для сопровождения какого- то ключа некие внутренние структуры данных. Именно уменьшение общего числа ключей приводит к меньшей стоимости внутренних структур данных, поэтому мы можем сберечь много памяти. Для данной цели, в своём предыдущем примере мы пытаемся применять строку JSON в качестве значения для одного пользователя и использовать тип данных хэша.
Особое внимание следует уделить разбиению на разделы ключа хэша. Мы собираемся хранить по 1000 записей в
некотором ключе хэша. Поэтому, самая первая вещь которую мы выполняем состоит в изменении значения настройки
hash-max-ziplist-entries на 1000 чтобы убедиться, что внутренним кодированием
для значения нашего ключа хэша является ziplist. В своём рецепте
Применение типа данных хэшей из
Главы 2, Типы данных, мы знаем, что если длина некоторого хэша в Redis меньше значения
hash-max-ziplist-entries, а размер каждого элемента в этом списке меньше чем
hash-max-ziplist-value, тогда ziplist является наиболее действенной
структурой данных, когда он применяется для внутреннего кодирования объектов хэша. Необходим повторный запуск Redis. Мы делим на разделы свои ключи
по самым первым семи цифрам идентификатора пользователя, а вся прочая информация пользователя хранится как некая строка JSON. Таким образом, один раздел
организован следующим образом и все разделы (кроме "user:0000000" и
"user:0000010") содержат 1000 записей:
$ bin/redis-cli hgetall "user:0000007"
088
{"name":"Mary","sex":"f","resigter_time":1506942816344887079,"nation":"uk"}
...
331
{"name":"Mary","sex":"f","resigter_time":1506942817274215585,"nation":"us"}
$ bin/redis-cli hlen "user:0000007"
(integer) 1000
Окончательное число ключей для данного примера составляет 11, что намного меньше чем первоначальное
количество (4000):
$ bin/redis-cli dbsize
(integer) 11
Другой способ уменьшения объёма используемой памяти состоит в сжатии самих значений данного ключа. В достижении этой цели играет важную роль
имеющаяся библиотека cmsgpack в нашем сценарии lua.
Окончательное решение сочетает оба этих метода.
Другой простой способ снижения потребления памяти состоит в уменьшении длины самого ключа. Например, мы можем применять
regt вместо "resigter_time" для краткости. Вы можете
опробовать эту стратегию чтобы увидеть насколько больше памяти вы можете сохранять.
Можно перечислить более сложные примеры, такие как подсчёт числа уникальных посетителей на ваш вебсайт; вы можете применять для своей цели множество, побитовое изображение или HyperLogLog. Вам придётся выбирать правильные типы данных. Чем лучше вы знакомы с имеющимися в Redis типами данных, тем больше способов вы можете отыскать для реализации своего приложения.
Помимо рассмотрения потребления памяти вам также следует уделять внимание производительности манипуляции выбранным вами типом данных. Постоянно следует рассматривать компромисс пространство- время. Наш следующий рецепт даст вам полезные советы относительно вопросов производительности некоторого проекта приложения с применением Redis.
За дополнительными подробностями оптимизации памяти отсылаем вас к https://redis.io/topics/memory-optimization.
Данный блог инженера Instagram описывает вариант успешного сбережения памяти.
Блог разработки Deliveroo, которая является Британской компанией доставки еды в реальном масштабе времени, описывает другую успешную практику сохранения ключей сеансов в Redis.
В Главе 2, Типы данных и в Главе 3, Свойства данных мы показали, что Redis предоставляет множество мощных API для манипуляции различными имеющимися видами типов данных. Когда вы собираетесь разрабатывать своё приложение с Redis, аналогично выбору типов данных, рассмотренного в нашем предыдущем рецепте Применение правильных типов данных, всегда имеется более одного API Redis для вас чтобы реализовать определённые потребности бизнеса. Чтобы гарантировать необходимую производительность некоторого экземпляра Redis, должны быть предприняты чрезвычайные предосторожности когда вы принимаете решение какой именно API вы будете использовать.
В данном рецепте мы рассмотрим различные примеры изучения того как применять правильные API для достижения какой- то хорошей производительности в Redis.
Вам требуется завершить установку своего Cервера Redis, которое мы описывали в своём рецепте Загрузка и установка Redis в Главе 1, Приступая к Redis.
Вам понадобится выполнить команду FLUSHALL для сброса всех имеющихся данных в вашем экземпляре Redis
прежде чем вы перейдёте к следующему разделу.
Для установки инструментов dos2unix в Ubuntu выполните следующую команду:
sudo apt-get install dos2unix
В macOS вы можете установить инструментарий dos2unix при помощи следующей команды:
brew install dos2unix
Чтобы показать как применять верные API Redis, необходимые этапы таковы:
-
В самом начале данного примера мы импортируем имеющиеся данные 1 миллиона пользователей в некие ключи хэша в Redis с помощью двух API:
HSETиHMSET. Для наилучшей иллюстрации мы исполним приводимый ниже сценарий, который соединится имеющимся Сервером Redis и заполнит необходимые данные пользователей в другом хосте, который рассматривается в качестве некоего сервера приложения. Возможно вам придётся подождать достаточно долго с тем чтобы исполнить этот сценарий и затем воспользоваться прерыванием и вернуться обратно для перехвата полученных результатов:$ cat hmset-vs-hset.sh #!/bin/bash HSETFILE="hset.cmd" HMSETFILE="hmset.cmd" rm $HSETFILE $HMSETFILE ... (omit all the variables declared above) printf "hmset \"user\" " >> $HMSETFILE for i in `seq -f "%010g" 1 1000000` do namerand=$[ $RANDOM % 3 ] sexrand=$[ $RANDOM % 2 ] timerand=$[ $RANDOM % 30 ] nationrand=$[ $RANDOM % 3 ] echo "hset \"user\" ${i} '{\"name\":\"${NAMEOPTION[$namerand]}\",\"sex\":\"${SEXOPTION[$sexrand]}\",\"resigter_time\":`date +%s%N`,\"nation\":\"${NATIONOPTION[$nationrand]}\"}'" >> $HSETFILE printf " ${i} '{"name":"${NAMEOPTION[$namerand]}","sex":"${SEXOPTION[$sexrand]}","resigter_time":`date +%s%N`,"nation":"${NATIONOPTION[$nationrand]}"}' " >> $HMSETFILE sleep 0.00000${timerand} done unix2dos $HSETFILE unix2dos $HMSETFILE time cat $HSETFILE |/redis/bin/redis-cli -h $SERVER sleep 10 time cat $HMSETFILE |/redis/bin/redis-cli -h $SERVER $ bin/redis-cli FLUSHALL OK $ bash hmset-vs-hset.sh ... real 0m4.557s user 0m0.696s sys 0m1.284s OK (0.51s) real 0m0.750s user 0m0.224s sys 0m0.496s -
Как только мы завершим импорт своих данных, мы попробуем получить все имеющиеся данные данного ключа
"user"хэша при помощиHGETALLи измерим время данной операции. Перед вызовомHGETALLмы откроем другой Терминал чтобы запустить некую проверку задержки при помощи параметра--latencyвredis-cli:$ bin/redis-cli --latency min: 0, max: 1, avg: 0.11 (136 samples) -
Мы выполняем выборку всех данных данного пользователя вызывая
HGETALL:$ bin/redis-cli HGETALL user -
В течении обработки
HGETALLв Redis выявляется высокая латентность:$ bin/redis-cli --latency min: 0, max: 57, avg: 0.13 (2474 samples) -
Остановим проверку латентности нажав
Ctrl + Cи перезапустив её:$ bin/redis-cli --latency min: 0, max: 1, avg: 0.08 (186 samples) -
Вместо
HGETALLмы попробуем на этот раз итерировать все имеющиеся данные пользователя с помощьюHSCAN:$ cat hscan.sh #!/bin/bash cr=0 key=$1 rm ${1}.dumpfile while true; do cr=`/redis/bin/redis-cli HSCAN user $cr MATCH '*' | { read a echo $a while read x; read y; do echo $x:$y >> ${1}.dumpfile done }` echo $cr if [ $cr == "0" ]; then break fi done $ bash hscan.sh user -
На протяжении итерации не выявляется никаких сюрпризов с задержками:
$ bin/redis-cli --latency min: 0, max: 1, avg: 0.09 (13423 samples)
Когда вы собираетесь проверять некое приложение с Redis, во внимание необходимо принять два принципа. Первый принцип состоит в том, что вам следует
предпринять все усилия по сочетанию манипуляций с данными во избежание получения RTT
(round-trip time, промежутка времени на передачу и подтверждение приёма). Данное понятие
RTT было введено нами при обсуждении имеющейся функциональности конвейера в рецепте Применение
конвейеров из Главы 3, Свойства данных. Redis осведомлён о своих наивысших скоростях при обработке
запросов. Поэтому, если вы можете снизить значение RTT, будет достигнуто впечатляющее улучшение производительности. Применение преимуществ конвейера
это хорошая мысль, в то время как некие API данных Redis могут снижать значение RTT естественным образом. Наша первая часть в предыдущем примере
является хорошим примером этого. По сравнению с установкой имеющихся значений хэша одного за другим при помощи
HSET, использование HMSET для установки в один приём очевидно лучший
способ делать то же самое задание если все данные могут быть подготовлены до их установки. Было сохранено 83.5%
(1- 0.750/4.557) времени!
Другой принцип, который вам следует иметь в виду состоит в том, что Redis в основном служба хранения данных с единственным потоком, что означает что
вам следует выбирать команды Redis чрезвычайно тщательно и иметь в виду их временную сложность. Имеющаяся документация Redis показывает значение
временной сложности для каждого API. Например, вы можете отыскать в имеющейся документации такое значение времени сложности
HGETALL:
Time complexity: O(N)
где N является значением размера данного хэша.
Здесь временная сложность обозначается при помощи нотации Большого О. Мы не будем много обсуждать нотацию Большого О кроме того, что это распространённый термин для описания значения временной сложности некоторого алгоритма. Для снабжения вас быстрой справкой следующая схема показывает скорость роста нотации Большого О:
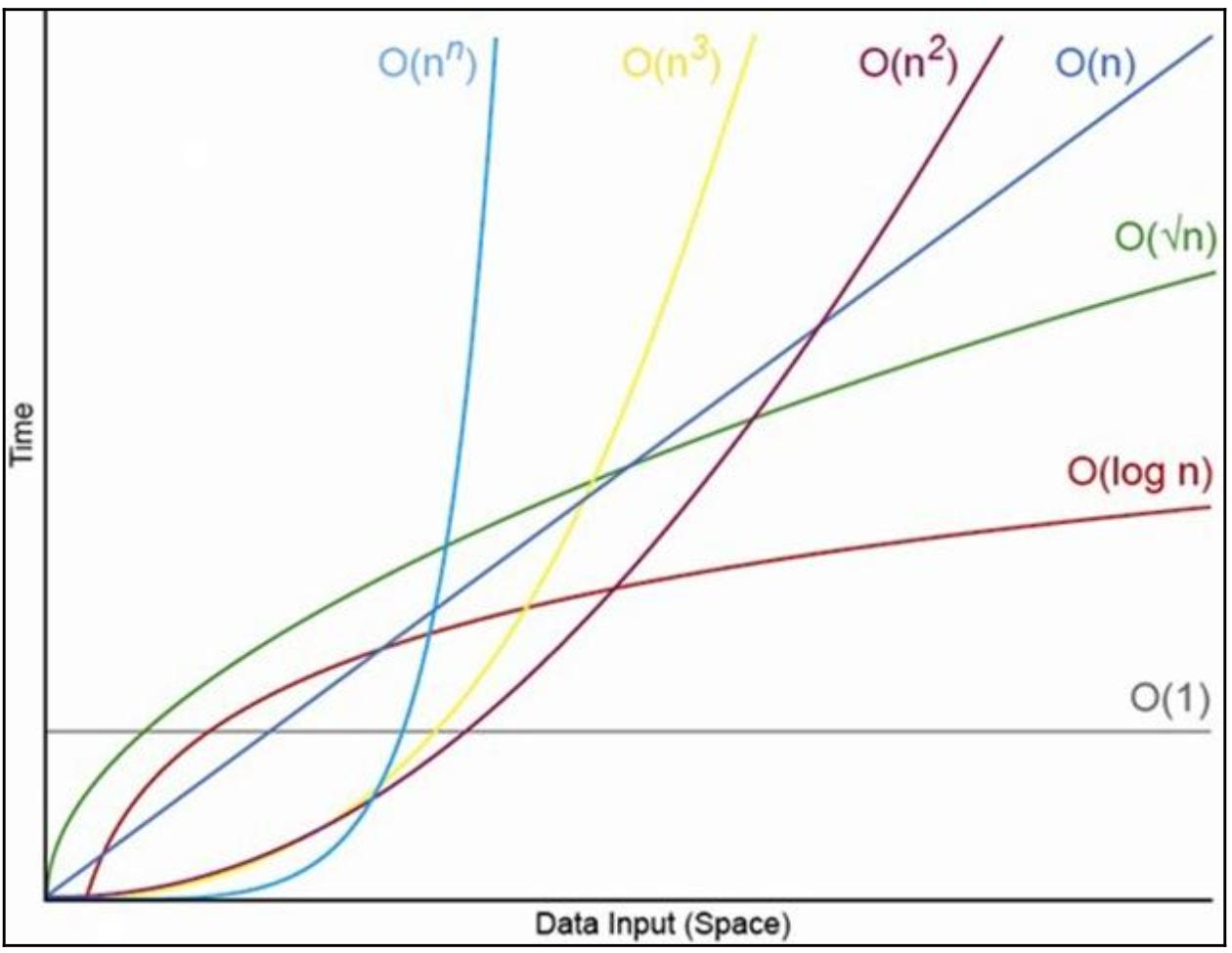
В нашем примере после установки всех данных в некий ключ хэша Redis, мы пытаемся выбрать все эти данные при помощи
HGETALL. Уловив ужасающую задержку, которая зачастую является неким ночным кошмаром для некоторой службы
данных Redis в реальном времени. Основная причина того, почему это происходит, состоит в том, что HGETALL
имеет временную сложность O(n), где n
является значением размера данного хэша. В нашем примере n равен
100000, что является достаточно большим числом для Redis в отношении его скорости обработки. При обработке
этой команды наш Сервер Redis не имеет возможности отвечать на любые иные запросы. Наилучшим способом достижения той же самой цели является
применение HSCAN для итеративной обработки данного ключа хэша. Данный API будет поступательно итерировать
данный ключ хэша, эффективно исключая нежелательный всплеск латентности.
Помимо прочих, наш Сервер Redis могут блокировать команды KEYS *, FLUSHDB,
DEL и HDEL. Говоря в целом, вам следует уделять особое внимание API Redis,
которое имеет временную сложность хуже чем, либо сопоставимую с O(n).
Если вы желаете отыскать какие именно операции замедляют ваш Сервер Redis, вы можете журнал замедления для записи команд
slow, обрабатываемых в вашем Сервере Redis. Для получения дополнительных подробностей по Выявлению медленных
операций/ запросов при помощи рецепта Выявление медленных запросов при помощи SLOWLOG из
Главы 10, Поиск неисправностей Redis.
Дополнительные механизмы поиска сложностей с задержками будут представлены в разделе Выявление неисправностей латентности Главы 10, Поиск неисправностей Redis.
Для получения дополнительных седений относительно нотации Большого О пользуйтесь https://en.wikipedia.org/wiki/Big_O_notation.
Чтобы применять Redis в приложениях Java, нам понадобится некий клиент Java Redis. Существует пара вариантов, которые вы можете отыскать в разделе Clients домашней страницы Redis. В данном рецепте вы представим Jedis, который является неким открытым исходным кодом и его достаточно просто применять в качестве клиента Java Redis.
Вам требуется завершить установку своего Cервера Redis, которое мы описывали в своём рецепте Загрузка и установка Redis в Главе 1, Приступая к Redis.
Вам потребуется установить JDK (Java Development Kit) версии 1.8.
Рекомендуется для применения, но не является обязательным Java IDE, такой как IntelliJ IDEA или NetBeans.
Чтобы показать как подключаться к Redis при помощи Java, самым первым требованием для применения Jedis в нашем приложении Java состоит во
включении его библиотеки в наш проект. Мы можем либо выгрузить необходимый файл JAR библиотеки Jedis и добавить его в путь к
CLASSPATH, либо применять инструменты, подобные Maven, Gradle или Bazel для управления имеющимися
зависимостями библиотек. В примерах данного рецепта мы применяем Gradle для включения Jedis в качестве зависимости своего проекта.
Добавьте приведённую ниже строку в раздел dependencies
build.gradle:
compile group: 'redis.clients', name: 'jedis', version: '2.9.0'
Подключение к серверу Redis
Создайте некий класс Java, dependencies, воспользовавшись следующим кодом:
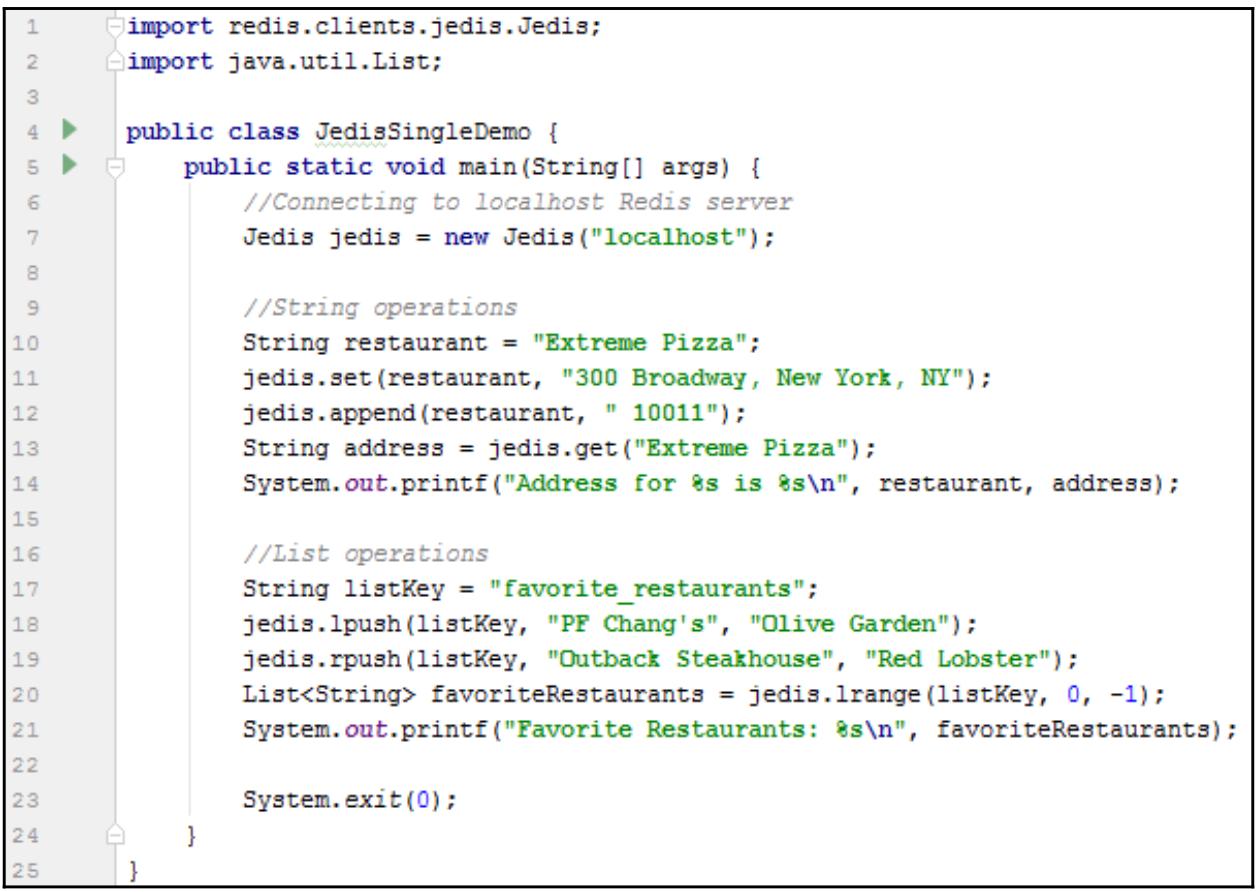
Наше демонстрационное приложение выведет следующие строки:
Address for Extreme Pizza is 300 Broadway, New York, NY 10011
Favorite Restaurants: [Olive Garden, PF Chang's, Olive Garden, PF Chang's, Indian Tandoor, Longhorn Steakhouse, Outback Steakhouse, Red Lobster, Outback Steakhouse, Red Lobster]
Применение конвейеров в Jedis
Давайте создадим другой класс Java, JedisPipelineDemo:
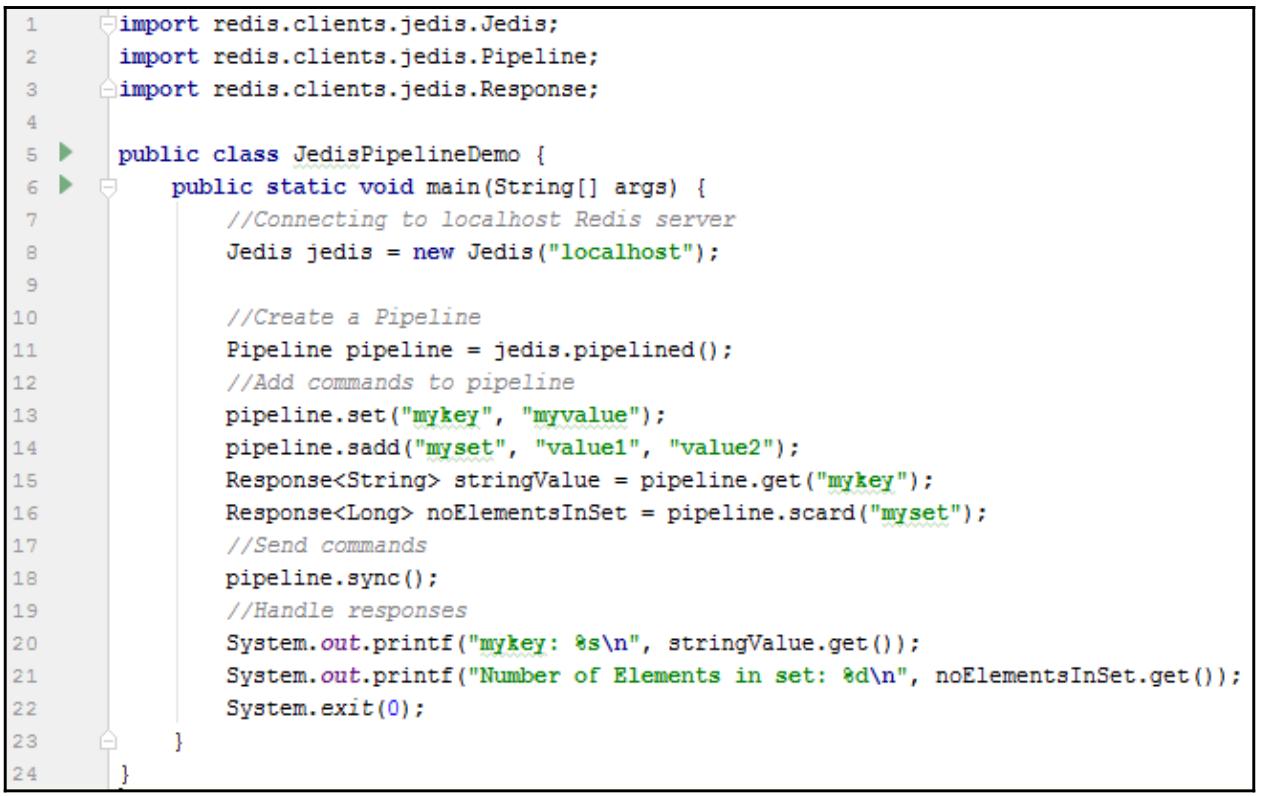
Вывод этой программы:
mykey: myvalue
Number of Elements in set: 2
Применение транзакций в Jedis
Давайте создадим некий класс Java, JedisTransactionDemo:
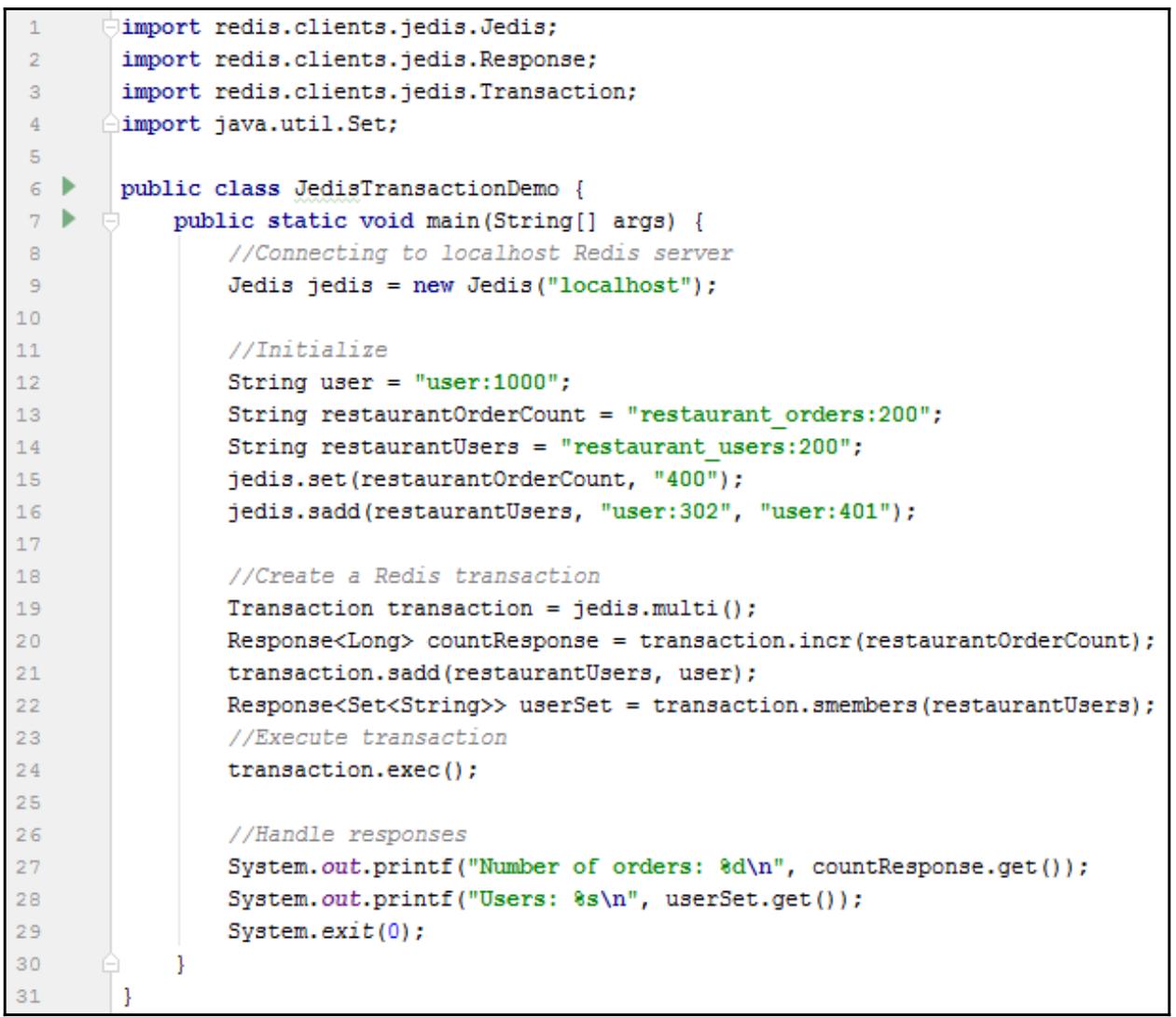
Вывод этой программы такой:
Number of orders: 401
Users: [user:1000, user:401, user:302]
Запуск сценариев Lua в Jedis
Напишите сценарий Lua, updateJson.lua, и поместите его в свою папку
Java resources. Содержимое этого сценария Lua можно отыскать в рецепте
Применение Lua из Главы 3, Свойства данных
Создайте некий класс Java, JedisLuaDemo:
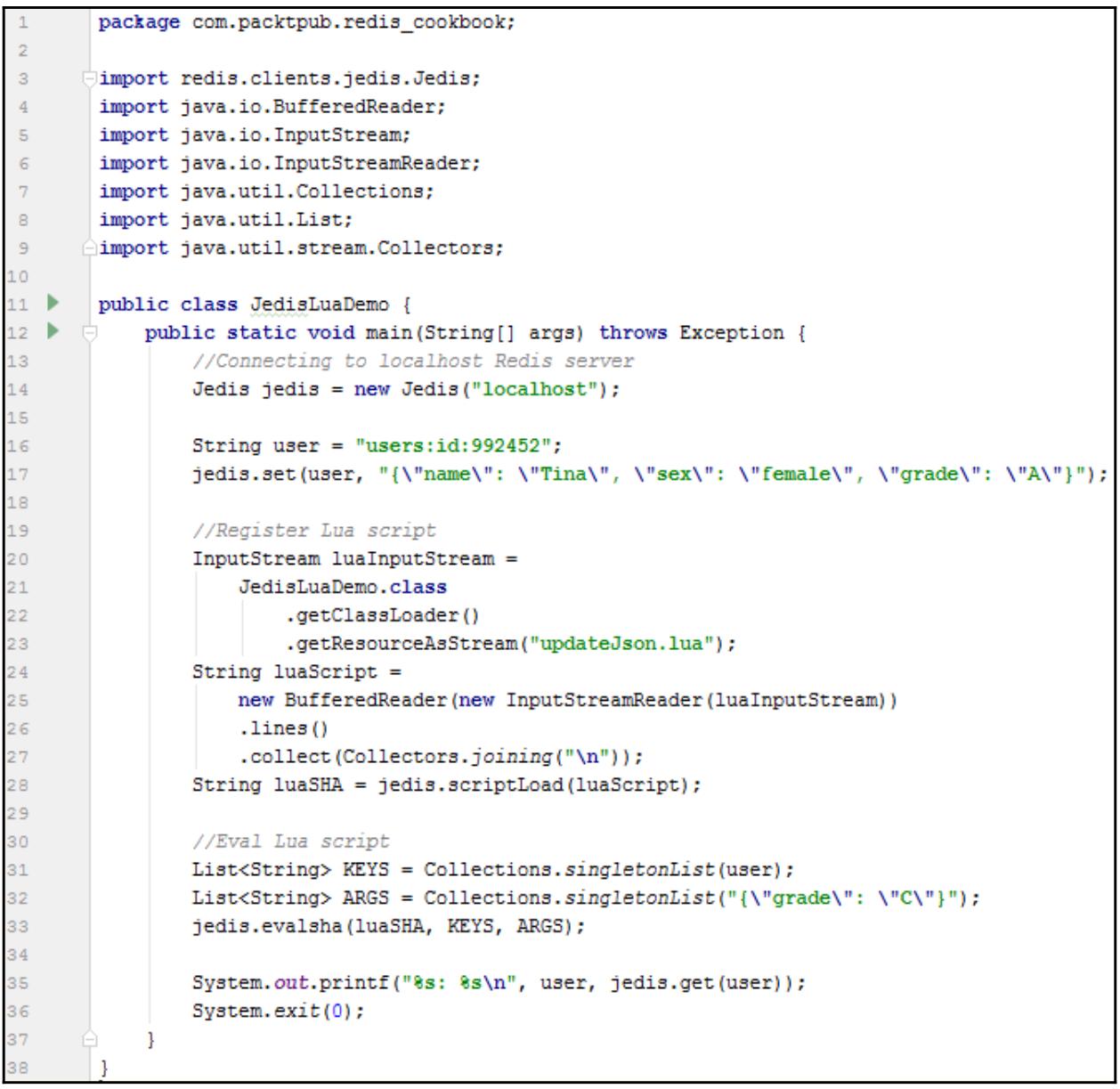
Вывод этой программы следующий:
users:id:992452: {"grade":"C","name":"Tina","sex":"female"}
Применение пула подключений в Jedis
Создайте некий класс Java, JedisPoolDemo:
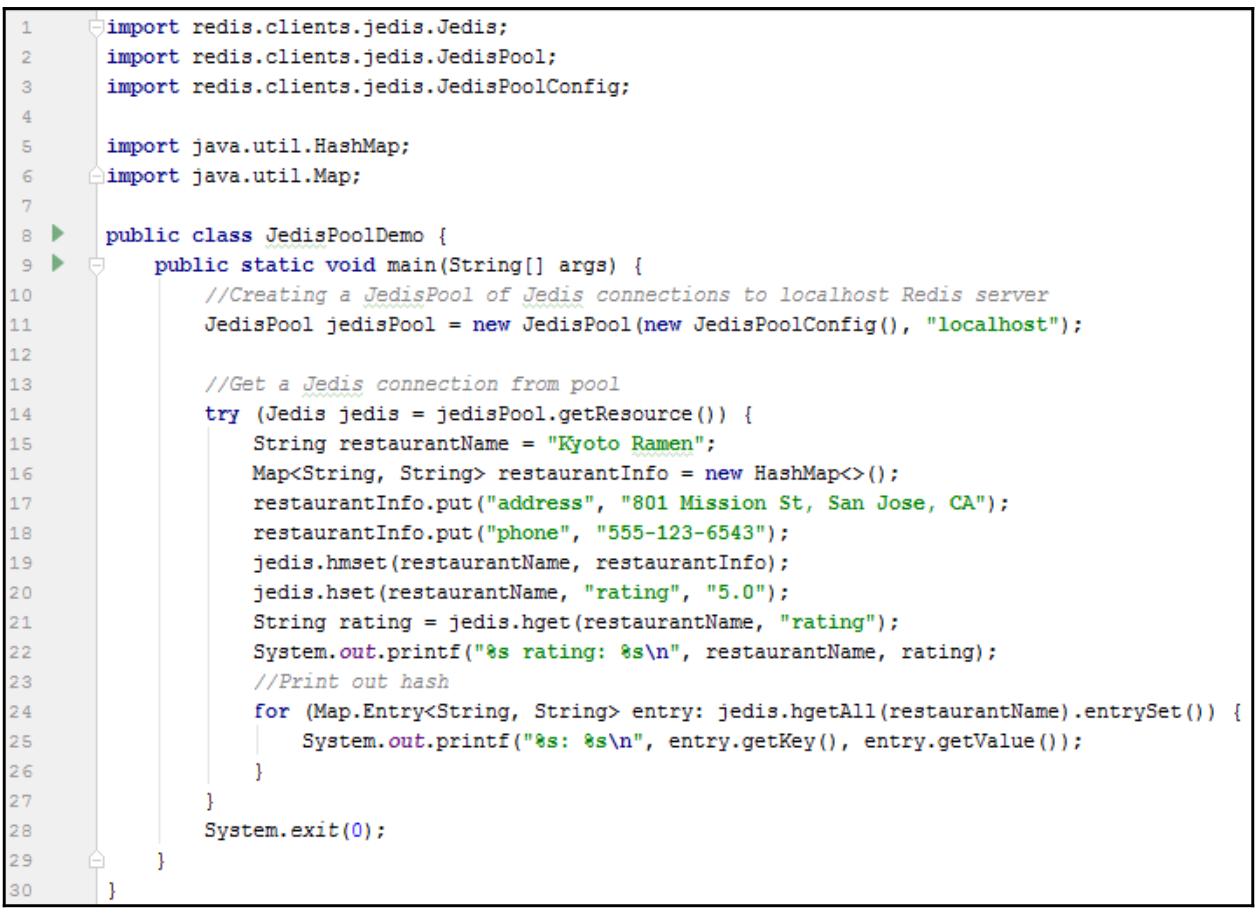
Вывод этой программы:
Kyoto Ramen rating: 5.0
rating: 5.0
phone: 555-123-6543
address: 801 Mission St, San Jose, CA
В нашем первом приложении, JedisSingleDemo, мы подключаемся к своему Серверу Redis создавая некий экземпляр
Jedis с именем хоста данного сервера. Если это не описано особенным образом, значением порта по молчанию
является 6379. Данный класс Jedis также имеет пару других конструкторов,
в которых мы можем определять значение порта сервера, тайимаут соединения и тому подобного.
Раз мы получили необходимый экземпляр Jedis, мы можем вызывать его функции для отправки команд в свой
Сервер Redis. Соответствующие названия функции в точности те же самые, что и имена команд Redis, которые мы определяли в предыдущих главах.
В своём рецепте Применение конвейеров из Главы 3, Свойства данных мы изучали как применять функциональность конвейеров Redis путём построения сырых строк RESP. Использование конвейера Redis при помощи Jedis намного проще, поскольку Jedis позаботится о необходимом построении для нас сырых строк RESP.
В JedisPipelineDemo мы применяем метод pipelined() для создания
экземпляра конвейера Jedis, затем мы можем добавлять команды в этот конвейер точно так же как мы исполняли команды напрямую. Основное отличие
здесь состоит в том, что отклики от команд являются объектами Response<T>, которые не доступны пока
данный конвейер выполняет отправку в свой сервер и исполняется. Наш sync() является собственно методом для
отправки этого конвейера в сервер, после чего могут быть возвращены отклики.
Аналогично созданию некоторого конвейера, в JedisTransactionDemo соответствующий метод
multi() применяется для создания некоторого экземпляра транзакции Redis, а
exec() исполняет эту транзакцию. Отклики задерживаются вплоть до завершения исполнения этой транзакции.
В JedisLuaDemo мы вначале считываем updateJson.lua из
ресурсов в виде некоторой строки, а затем регистрируем этот сценарий Lua при помощи scriptLoad() для
получения необходимого SHA. Мы используем evalsha() для исполнения данного сценария Lua;
KEYS и ARGS являются необходимыми типами списков строк Java и передаются
в evalsha() в качестве аргументов.
Тот экземпляр Jedis, который мы создали в предыдущих примерах не является сберегающим потоки, что означает, что
один и тот же экземпляр Jedis не может совместно использоваться в различных потоках. Вместо создания некоего
экземпляра Jedis для каждого потока, мы также можем воспользоваться
JedisPool, который является сберегающим потоки пулом соединений Jedis. Всякий раз когда нам требуется некое
подключение, мы запрашиваем одно из этого пула; после завершения необходимой работы мы возвращаем это подключение в данный пул. Таким образом мы можем
сберегать накладные расходы создания и закрытия подключений, поскольку соединения в данном пуле всегда установлены.
Соединения Jedis, запрашиваемые из данного JedisPool обязаны возвращаться в этот пул посредством вызова
close(). Так как класс Jedis реализует интерфейс
AutoClosable, мы также можем применять имеющийся блок try-resource
для закрытия и возврата его в свой пул.
Данный рецепт представляет собой всего лишь царапину на общей поверхности применения Jedis в приложениях Java. Поскольку Jedis является проектом с открытым исходным кодом, для изучения тех моментов, которые мы не охватили в данном рецепте (публикацию/ подписку, репликации и так далее), вы можете пользоваться справочными материалами на странице GitHub Jedis.
Существует пара клиентов Python для соединения с Redis. В данном рецепте мы кратко ознакомимся с тем как применять клиента Redis Python,
redis-py.
Вам требуется завершить установку сервера Redis как это было описано в рецепте Загрузка и установка Redis в Главе 1, Приступая к Redis.
Вам также потребуется иметь установленным Python 2.6+ или 3.4+.
Чтобы показать как подключить Redis к Python, прежде всего нам потребуется установить необходимую библиотеку
redis-py. При помощи PyPI можно запросто установить redis-py
исполнив:
pip install redis
Подключение к серверу Redis
Теперь давайте создадим RedisDemo.py со следующим кодом:

Данное демонстрационное приложение выведет следующие строки:
Address for Extreme Pizza is 300 Broadway, New York, NY 10011
Favorite Restaurants: [Olive Garden, PF Chang's, Olive Garden, PF Chang's, Indian Tandoor, Longhorn Steakhouse, Outback Steakhouse, Red Lobster, Outback Steakhouse, Red Lobster]
Применение конвейеров
Конвейеры Redis могут очень просто реализовываться при помощи redis-py.
Давайте создадим другой файл RedisPipelineDemo.py:

В данном примере мы получим некий список, который содержит соответствующие отклики команд SET,
SADD, GET и SCARD:
[True, 0, 'myvalue', 2]
Запуск сценариев Lua
redis-py предоставляет очень удобную функцию register_script()
дле регистрации сценариев Lua. register_script() возвратит некий экземпляр
Script, который может быть позднее применён как некая функция для вызова сценариев Lua. В рецепте
Применение Lua из главы
Главе 3, Свойства данных мы применяли SCRIPT LOAD и
EVALSHA для кэширования какого- то сценария Lua и его повторного применения. Давайте посмотрим как мы
можем делать это в redis-py:
Собственно содержимое updateJson.lua можно отыскать в рецепте
Применение Lua из главы
Главе 3, Свойства данных.
Создайте RedisLuaDemo.py со следующим кодом:
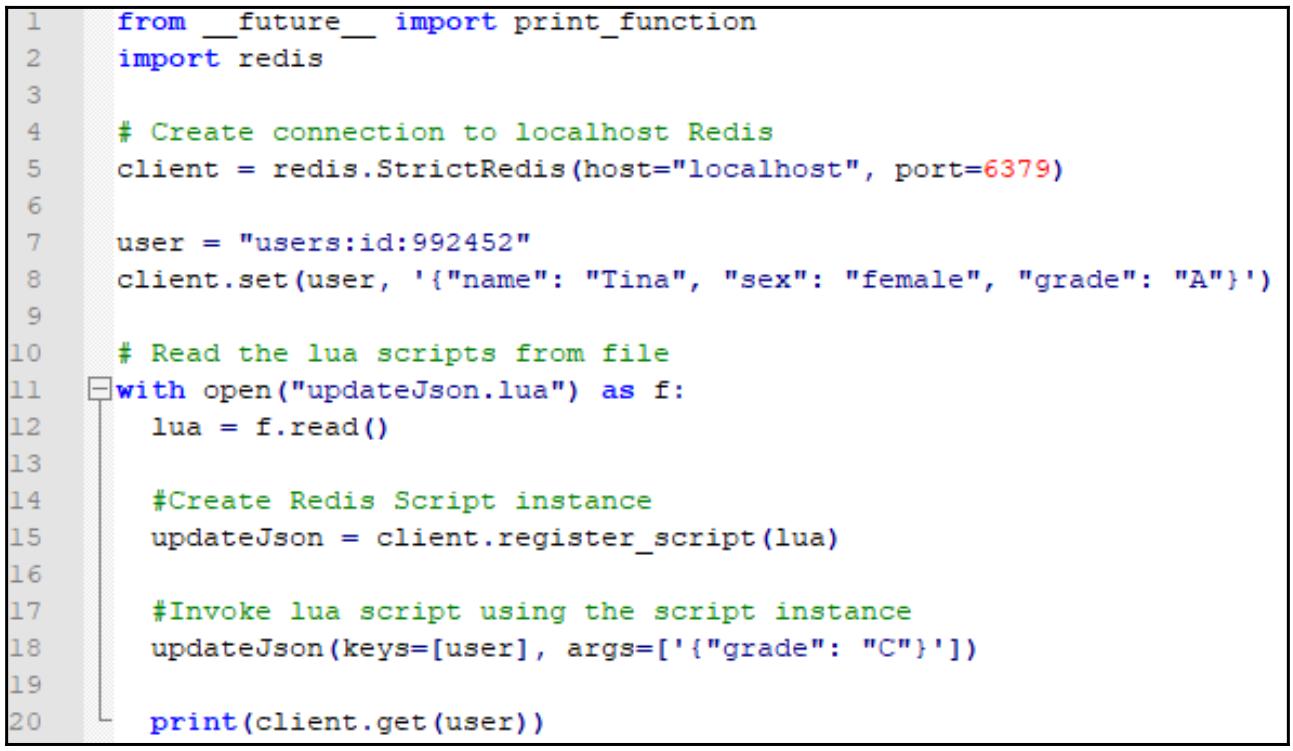
Выводом данной программы будет обновлённое значение JSON:
{"grade":"C","name":"Tina","sex":"female"}
Чтобы применять библиотеку redis-py, для начала нам необходимо импортировать соответствующий модуль при
помощи "import redis". "redis.StrictRedis()" в
строке 6 из RedisDemo.py создаст некий экземпляр StrictRedis, который
подключится к имеющемуся локальному хосту Сервера Redis. Методы в StrictRedis могут применяться для отправки
команд в ваш Сервер Redis. Большинство названий методов и их синтаксис являются теми же самыми, что и в самих командах Redis, которые мы ввели в
Главе 2, Типы данных и в Главе 3, Свойства данных.
Несколько имеющихся исключений мы поясним позднее в данном рецепте.
В RedisPipelineDemo.py соответствующий метод pipeline() создаст
некий экземпляр конвейера Redis, затем мы можем добавить команды в этот конвейер точно так же как когда мы непосредстенно исполняли команды.
Вызов execute() отправит эти команды в наш сервер и вернёт получаемые отклики команд в последовательности.
По умолчанию, redis-py обернёт все команды в некий конвейер с командами
MULTI и EXEC, делая эти команды какой- то транзакцией и исполняя их
атомарно. Это можно запретить установив соответствующий аргумент транзакции в значение False в методе
execute():
pipeline.execute(transaction=False)
В нашем примере RedisLuaDemo.py мы вначале считываем содержимое своего сценария Lua из некоторого внешнего
файла, а затем регистрируем этот сценарий вызывая register_script(). Возвращаемый в результате экземпляр может
применяться как некая функция; KEYS[] и ARGV[] в сценариях Lua могут
передаваться в необходимую функцию в виде ключей и аргументов для вызова данного сценария.
Методы из класса StrictRedis почти повторяют все официальные команды Redis в отношении названий команд и
синтаксиса за несколькими исключениями:
-
Команда
DELпереименовывает удаление, так какdelзарезервировано как ключевое слово в Python -
Команды
MULTI/EXECнаходятся не здесь, так как они реализованы в другом классеpipeline. -
Команда
SELECTне реализована по причине проблем сбережения числа потоков, что будет пояснено позднее. -
SUBSCRIBE/LISTENреализуются как определённый классPubSub.
В redis-py имеется также некий класс с тем же самым названием, Redis. Он является неким субкласом
StrictRedis для предоставления обратной совместимости с более ранними версиями
redis-py. Их очень небольшое отличие можно отыскать на странице
redis-py GitHub.
Наш экземпляр StrictRedis в redis-py является сберегающим потоки,
так как внутри имеется некий пул соединений, который управляет подключениями к нашему Серверу Redis. По умолчанию каждый экземпляр имеет свой собственный
пул соединений. Такое поведение можно переписать передавая некий экземпляр пула подключений в виде конкретного аргумента
connection_pool при создании нового экземпляра StrictRedis или
Redis. Такой экземпляр пула подключений может создавться вызовом
redis.ConnectionPool() и он должен создаваться до самого экземпляра StrictRedis
или Redis:
>>> connectionPool = redis.ConnectionPool(host="localhost", port=6379)
>>> client = redis.StrictRedis(connection_pool=connectionPool)
У нас нет возможности охватить в этом рецепте всё для redis-py. Так как он является проектом с открытым
исходным кодом, дополнительные подробности можно отыскать на его странице GitHub.
В двух своих предыдущих рецептах мы показывали как подключаться к Redis при помощи Java и Python. Настало время обсудить веб приложения. Когда доходит дело до веб разработки в мире Java, наиболее заметной инфраструктурой является Spring от Pivotal и она получает преимущества шаблонов MVC для простой и быстрой разработки надёжных веб приложений Java. Что касается Redis, при наличии соответствующей библиотеки Spring Data Redis мы можем обращаться с Redis в Spring сразу после установки.
В данном рецепте мы создадим некий демонстрационный проект, который реализует операции CRUD (create/ read/ update/ delete) некоторой модели пользователя для демонстрации того как подключать Redis при помощи библиотеки Spring Data Redis.
Вам требуется завершить установку сервера Redis как это было описано в рецепте Загрузка и установка Redis в Главе 1, Приступая к Redis.
Вам следует применить команду FLUSHALL для сброса всех данных в вашем экземпляре Redis перед тем как перейти
к нашему следующему разделу.
Для данного рецепта рекомендуется некий IDE. Здесь мы применяем Intellij IDEA (Community Edition, для красткости, Intellij). Вы можете скачать Intellij по ссылке.
Также понадобится JDK (8 или выше) для компиляции и запуска кода.
Из- за ограничений в пространстве данной книги мы не можем обсудить все подробности данного демонстрационного проекта. В последующих двух разделах будут обсуждены только сам код и установки, относящиеся к Redis. Для полного проекта вам следует обратиться к образцам данного кода, поставляемого с самой книгой.
Для показа того как соединять Redis с Spring Data Redis шаги таковы:
-
В IDEA создайте некий новый Проект и примените Spring Initializer:
-
Нажмите Next и и переместитесь к метаданным данного проекта и заполните их
-
Выберите зависимости для данной демонстрации и затем завершите создание этого проекта:
-
Вначале мы создадим некий класс
Userмодели пользователя как представление данных -
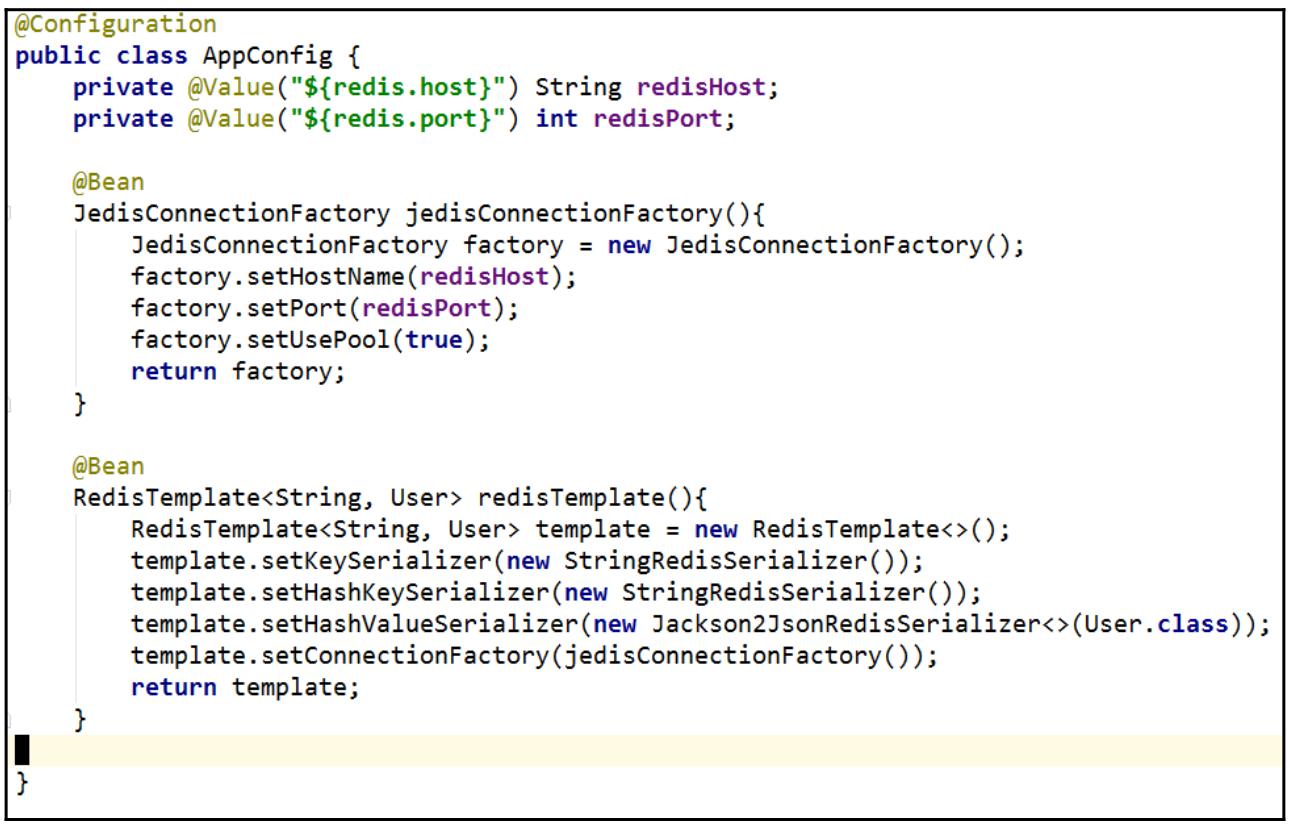
После этого конструируется некий класс настроек приложения в котором загружаются необходимые адрес и порт Сервера Redis, а далее создаётся экземпляр
RedisTemplate:
-
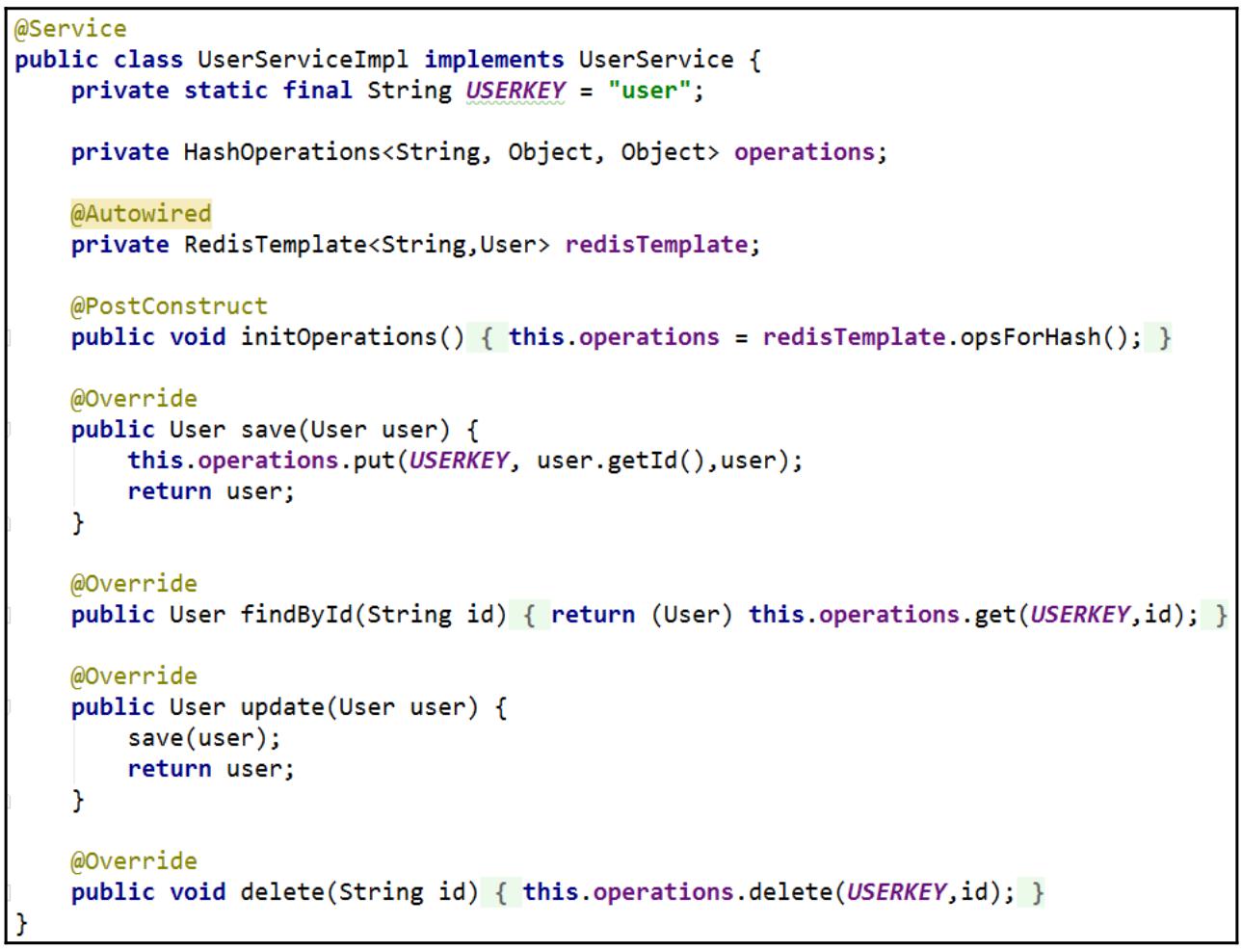
Для инкапсуляции операций с данными в Redis мы делаем некую службу взаимодействия с названием
UserService, а затем реализуем её для CRUD с данными пользователя:
-
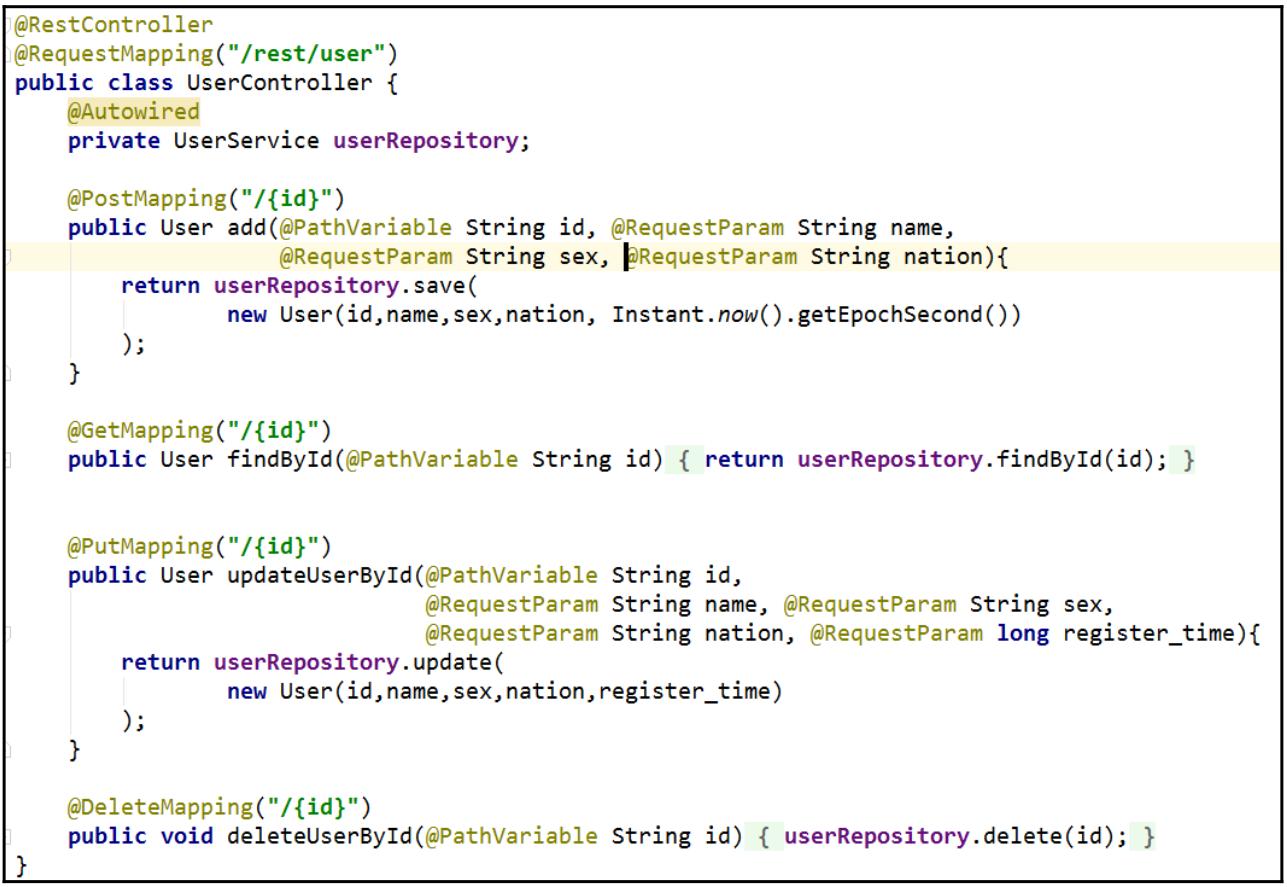
Для создания необходимого с операциями нашего пользователя мы применяем Spring
RestController:
-
По окончанию кодирования мы запускаем свою демонстрацию и проверяем полученный API при помощи Swagger-ui по адресу
http://127.0.0.1:8080/swagger-ui.html:
-
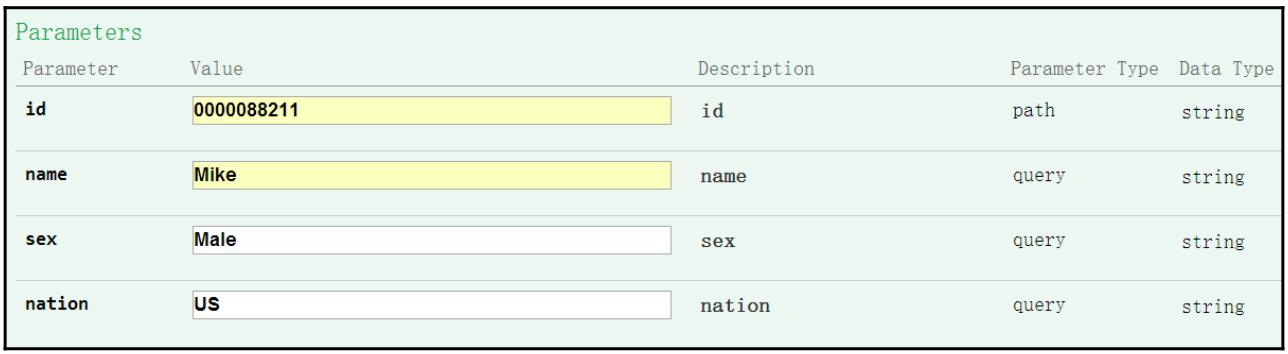
Для образца проверки мы создадим через вызов
/rest/user/{id}некоего пользователя при помощи методаPOST:
-
После создания пользователя с именем
Mikeмы просмотрим данные этого пользователя применивredis-cli:127.0.0.1:6379> hgetall user 1) "0000088211" 2) "{\"id\":\"0000088211\",\"name\":\"Mike\",\"sex\":\"Male\",\"nation\":\"US\",\"register_time\":1507448493}"


Самым первым экземпляром, который вам требуется создать для Spring Data Redis является RedisTemplate,
который будет применяться для манипуляции данными Redis. Прежде чем создан экземпляр RedisTemplate,
необходимо для Redis настроить адрес хоста и его порт через JedisConnectionFactory. Для более надёжного управления
соединением мы также включаем необходимый пул подключений своих клиентов Redis.
После получения необходимого экземпляра RedisTemplate мы устанавливаем соответственно преобразователь
последовательности его ключа, ключ хэша и значение хэша. Для значения основного ключа и ключа хэша данных в этой демонстрации мы просто применяем
обычный текст. Для значения хэша используется формат JSON с целью лучшей организации данных.
Так как мы подготовили сам экземпляр RedisTemplate и относящиеся к нему настройки, мы можем применять его
для реализации необходимого CRUD данных пользователя в Redis для нашей службы Spring.
На следующем этапе мы создаём качестве интерфейса RESTful API для манипуляции имеющимися данными пользователя.
На стадии проверки мы применяем Swagger для отправки данный некоего пользователя через настроенный REST API и подтверждения полученных
данных в Redis с помощью redis-cli.
Для ознакомления с дополнительными сведениями относительно Spring Redis Data обращайтесь к его главной странице.
В строке проверки мы применяем Swagger, популярный инструмент веб разработки. Если он интересует вас, вы можете отыскать дополнительные подробности на https://swagger.io/.
Redis может играть важную роль в проектировании и разработке вашего приложения, если вы являетесь инженером отрасли Больших данных. В некотором пакете сценария задания вы можете выбирать данные из Redis для выполнения неких сложных алгоритмов вычислений неким распределённым образом. Для какого- то запроса в реальном масштабе времени вы можете сохранять получаемый результат набора данных в Сервере Redis для достижения наилучшей производительности.
В оставшихся последних рецептах этой главы мы покажем вам как манипулировать данными в Redis при помощи MapReduce и Spark, которые оба чрезвычайно востребованы в инфраструктурах распределённых вычислений из мира Больших данных.
Вам требуется завершить установку сервера Redis как это было описано в рецепте Загрузка и установка Redis в Главе 1, Приступая к Redis.
Вам следует применить команду FLUSHALL для сброса всех данных в вашем экземпляре Redis перед тем как перейти
к нашему следующему разделу.
Основные требования к IDE и JDK в точности те же самые, что и для нашего предыдущего рецепта, Подключение к Redis при помощи Spring Data Redis.
Некий кластер Hadoop необходим, но не обязателен. Для целей демонстрации вы можете отлаживать и запускать вместо этого в локальном окружении
соответствующее задание MapReduce.
Для данного рецепта понадобятся базовые знания MapReduce.
Чтобы показать как создать некое задание MapReduce для Redis, допустим что каждый пользователь в Relp
имеет некий кредит, который может применяться для оплаты служб в данном приложении. В качестве некоего предложения мы собираемся добавить по 10$
в баланс кредита каждого пользователя Relp чтобы побудить такого пользователя использовать Relp. Мы бы хотели сделать это неким распределённым образом
при помощи инфраструктуры MapReduce.
-
Для начала мы подготовим данные образца при помощи своего сценария оболочки,
preparedata_mr.sh:$ bash preparedata_mr.sh OK unix2dos: converting file mr.data to DOS format ... All data transferred. Waiting for the last reply... Last reply received from server. errors: 0, replies: 10000 -
Затем мы изучим полученные данные посредством
redis-cli:127.0.0.1:6379> SCAN 0 1) "7" 2) 1) "user:0000006" 2) "user:0000000" 3) "user:0000008" 4) "user:0000004" 5) "user:0000003" 6) "user:0000002" 7) "user:0000007" 8) "user:0000001" 9) "user:0000009" 10) "user:0000005" 127.0.0.1:6379> SCAN 7 1) "0" -
Откроем IDEA и создадим некий новй проект воспользовавшись в качестве инфраструктуры поддержки Maven.
-
Чтобы продолжить и заполнить необходимые метаданные своего проекта нажмите Next.
-
В
pom.xmlдобавьтеMapReduceи другие относящиеся к нему зависимости:<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.5</version> </dependency> -
После этого, в качестве бина (bean) своих данных JSON мы создаём некий класс модели пользователя,
User. -
Для выборки необходимых данных из Redis мы персонализируем свой
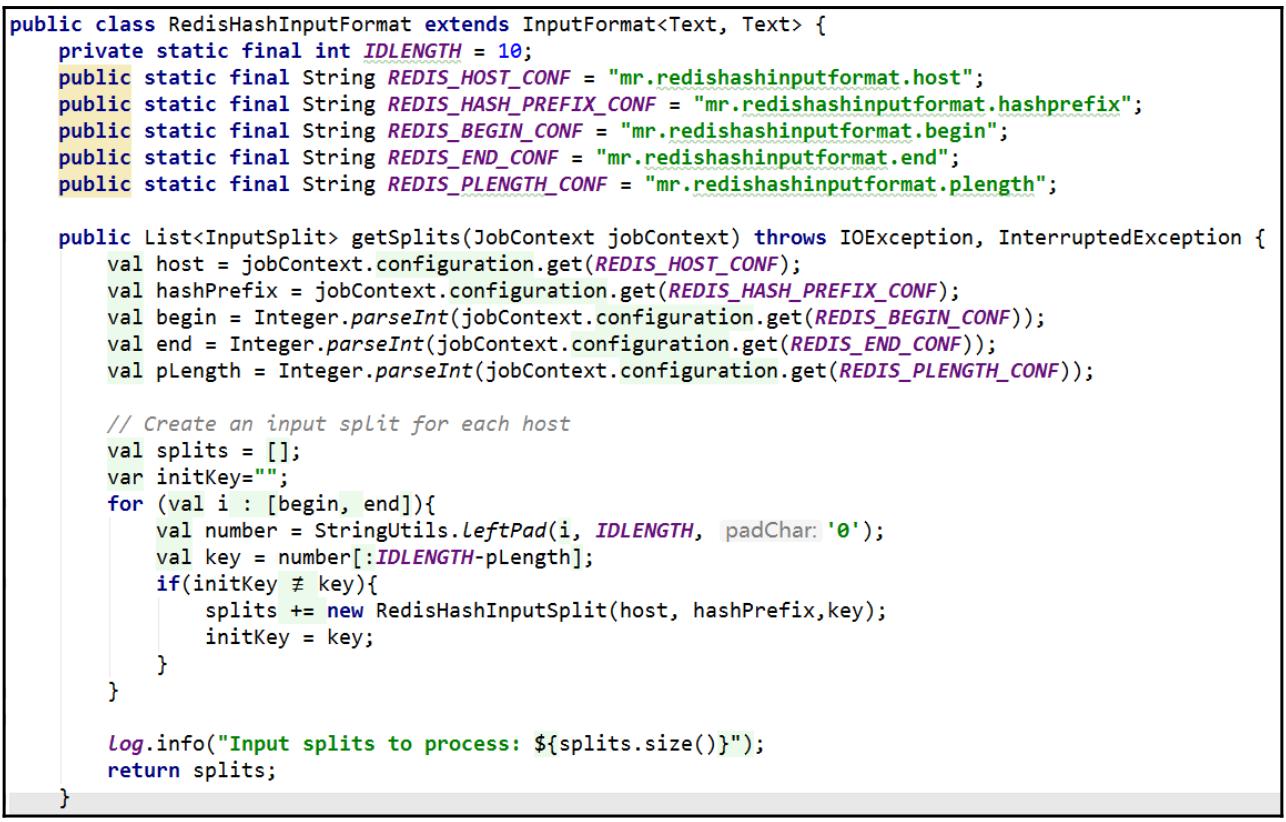
InputFormatдля заданияMapReduce:
-
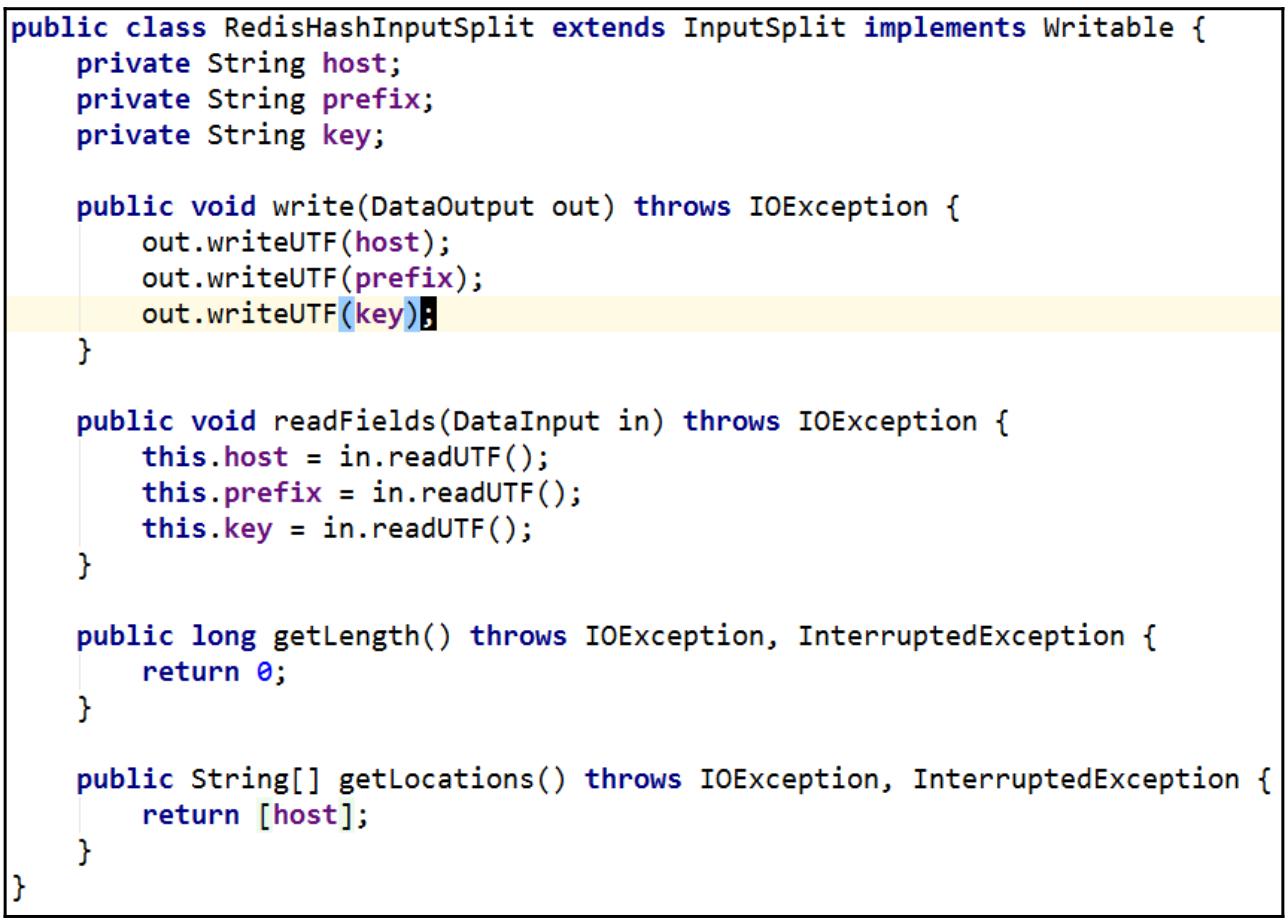
Для каждого раздела имеющихся ключей хэша мы применяем некий индивидуальный
InputSplitчтобы создать некое расщепление получения требуемых данных:
-
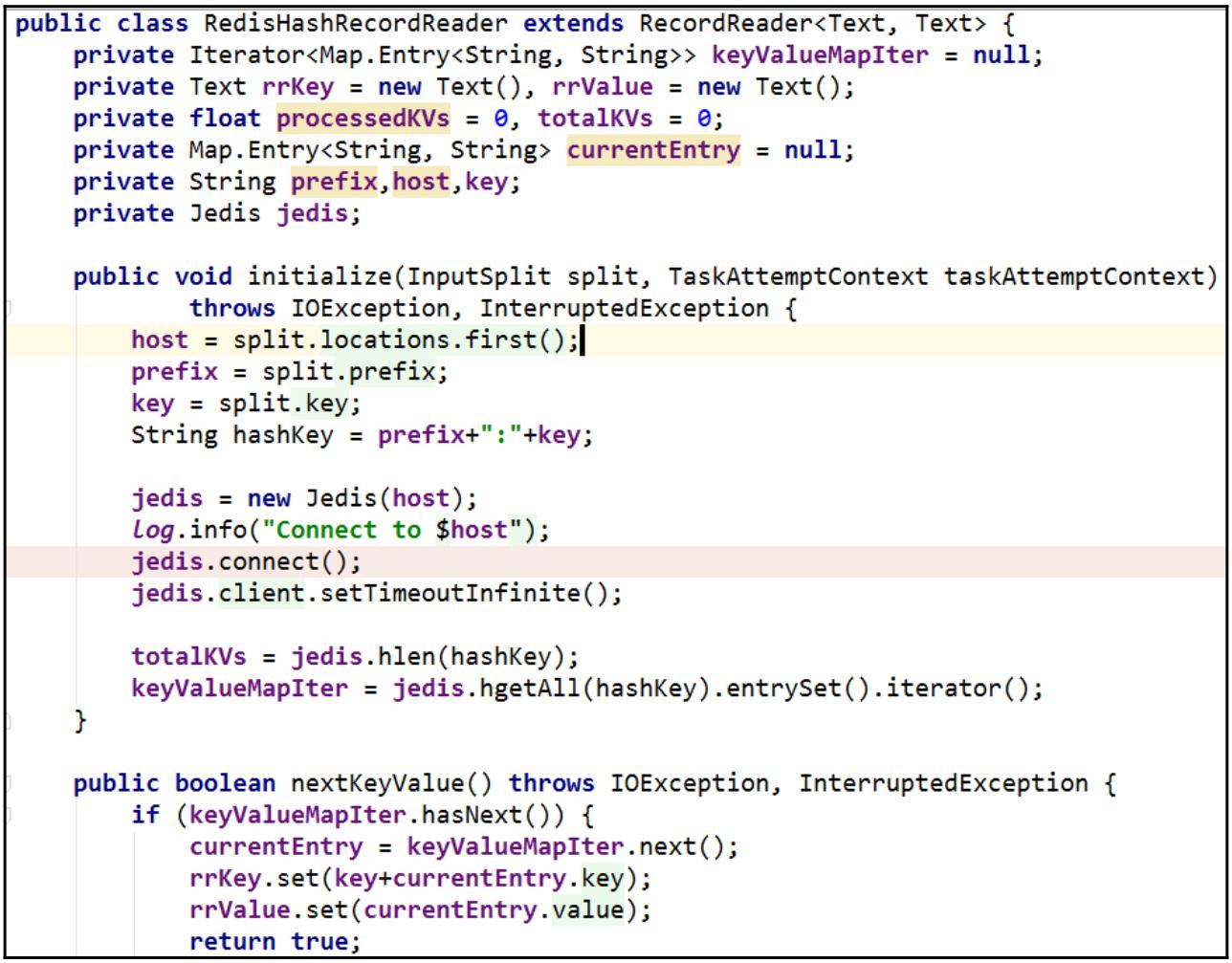
Для каждого ответвления мы выделяем некий
RecordReaderдля выполнения итераций по его данным в Redis при помощи библиотеки Jedis:
-
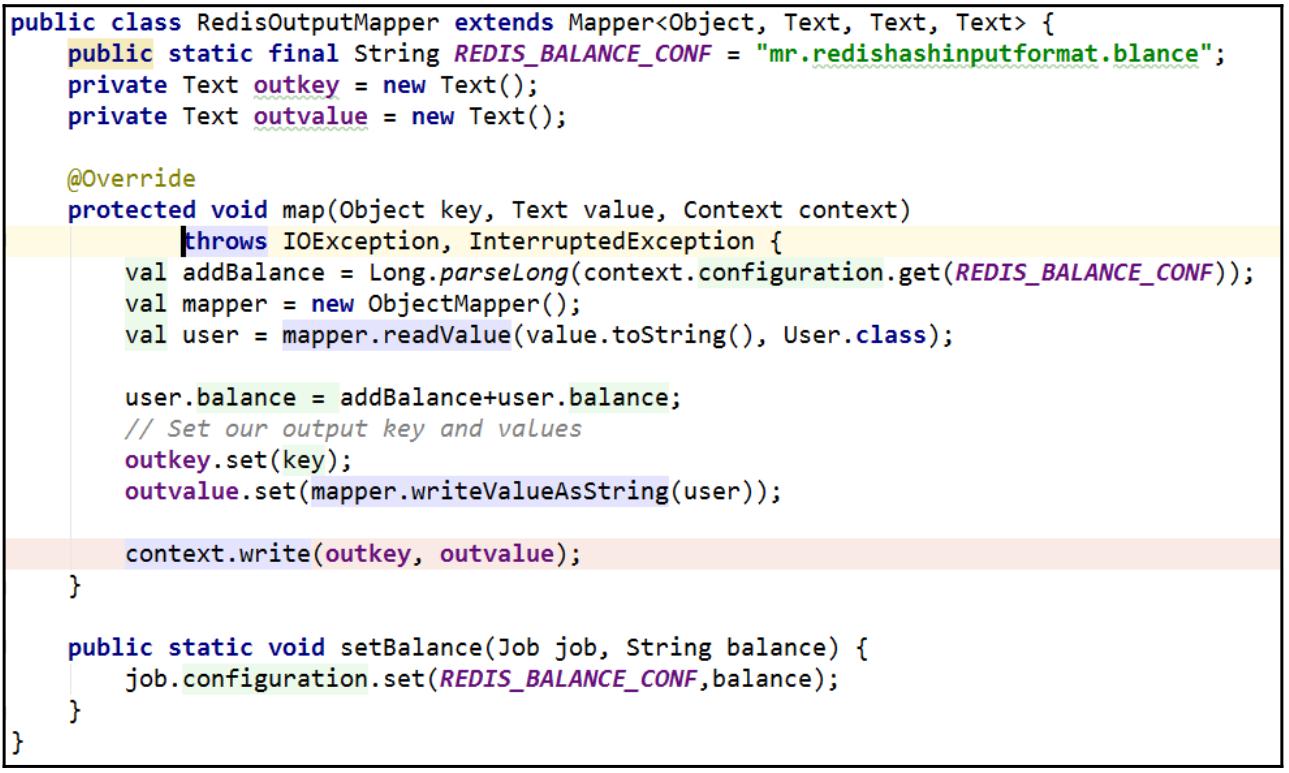
После выборки необходимых данных мы настраиваем соответствие для добавления 10$ кредита в соответствующий баланс каждого пользователя:
-
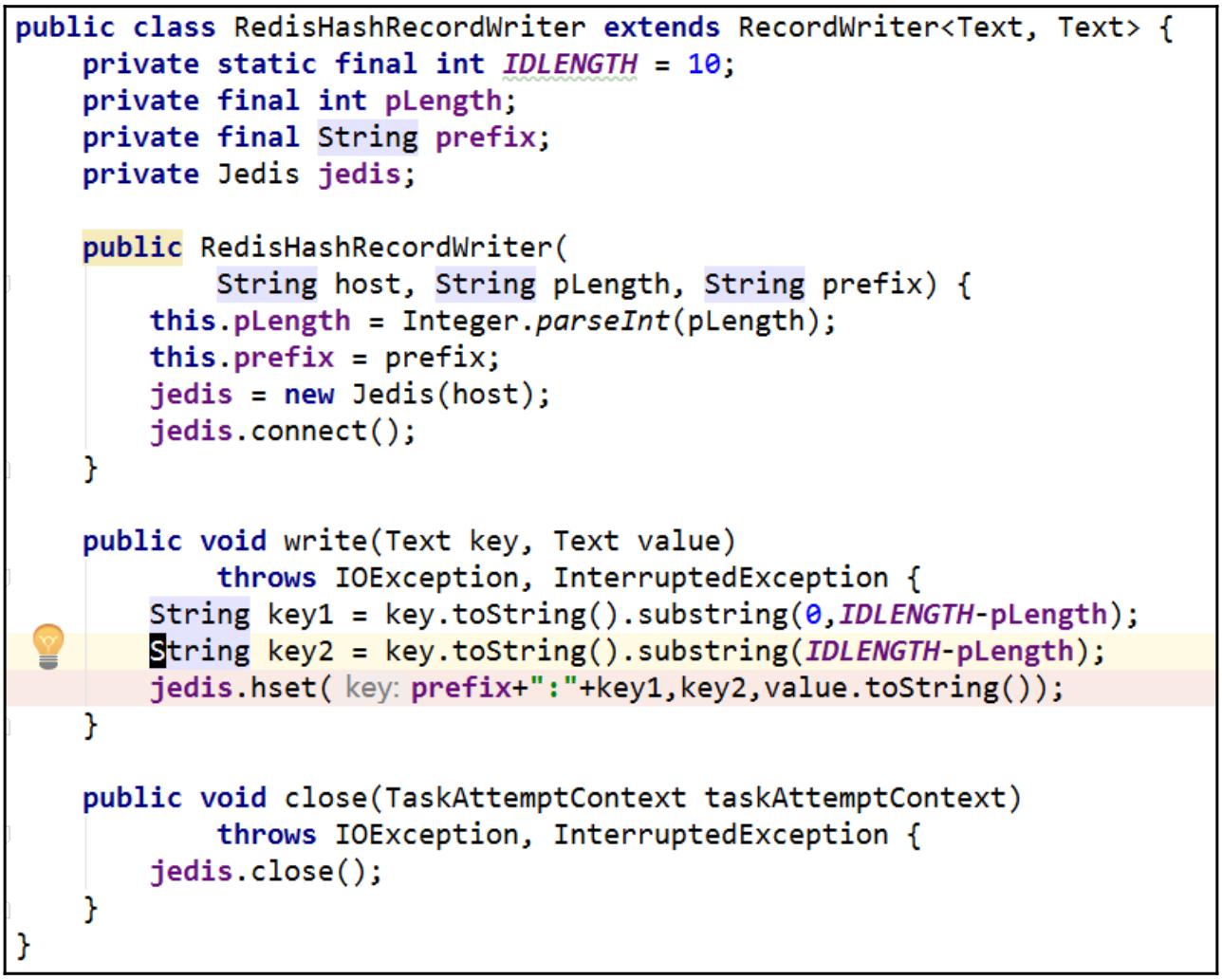
Для записи необходимых данных обратно в Redis мы расширяем
OutputFormatиRecordWriter:
-
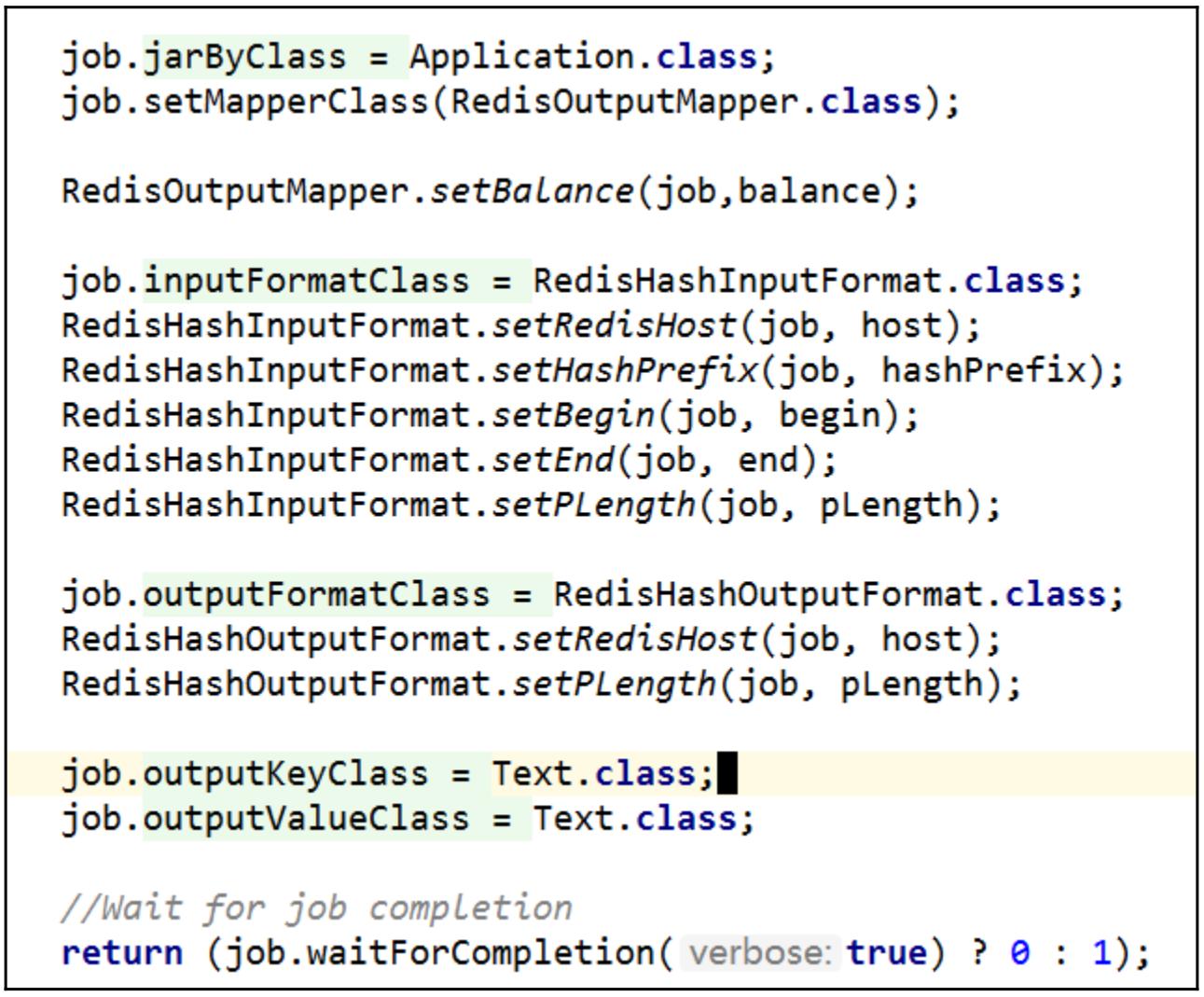
В самом конце мы создаём некий класс функций
main():
-
Подставляем полученное задание:
... 2017-10-10 11:54:42,154 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1374)) - map 100% reduce 0% 2017-10-10 11:54:42,154 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1385)) - Job job_local736372500_0001 completed successfully 2017-10-10 11:54:42,184 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1392)) - Counters: 18 ... -
Для того чтобы убедиться что наше задание выполнено, мы получим соответствующее значение хэша воспользовавшись
hgetизredis-cli:127.0.0.1:6379> hget "user:0000001" 123 "{\"name\":\"Jack\",\"sex\":\"m\",\"rtime\":1507607748117668688,\"nation\":\"uk\",\"balance\":103}"
Для выработки каких- то данных с целью демонстрации через свой сценарий мы помещаем в Redis образец данных пользователя. Мы делим на разделы этот образец данных применяя имеющиеся семь символов самого идентификатора пользователя и сохраняем его как некую структуру хэша.
Из- за имеющихся свойтсв своего образца данных в нашем приложении MapReduce, мы вначале персонализируем
имеющийся класс InputFormat расширяя этот класс InputFormat
чтобы создать определённый InputSplit для каждого раздела своих данных пользователя. Один
InputSplit предназначен для одного ключа хэша.
В каждом ответвлении, инициируется некий RedisHashRecordReader, который является неким подклассом
RecordReader, , для соответствующей выборки необходимых данных ключа хэша. В процессе инициации такого
RecordReader для создания соединения с Сервером Redis применяется имеющаяся библиотека Jedis, причём
получается значение длины соответствующего ключа хэша через вызов соответствующей команды HLEN и
осуществляется выборка всех данных этого ключа хэша при помощи команды HGETALL. После этого предоставляется
некий итератор.
Для добавления значения баланса каждому пользователю применяется некое средство соответствия. В сомом конце мы применяем персональные
OutputFormat и RecordWriter для записи получаемых в результате данных
пользователя в Redis в соответствии с первоначальным правилом деления на разделы.
По завершению кодирования мы подставляем полученное задание MapReduce и проверяем полученный результат.
Все полученные балансы наших данных пользователя были увеличены на десятку, как и ожидалось.
То, как получить запущенным некое локальное задание MapReduce выходит за рамки данной книги; вы можете
обратиться к следующему руководству.
В своём предыдущем рецепте мы обсудили как создать некое задание MapReduce для чтения и записи данных в Redis.
При разработке крупномасштабных вычислений с годами Apache Spark получил большую популярность нежели .span class="term">MapReduce.
Apache Spark является вычислительным механизмом с открытым исходным кодом распределённых Больших данных. При сопоставлении с
MapReduce он предоставляет лучшую производительность, а также более мощный и более дружественный к пользователю
API.
Когда дело доходит до примения Redis в задании Spark, Лабораторией Redis предоставляется некое подключение для манипуляции данными в Redis посредством Spark. В данном рецепте мы покажем вам как применять библиотеку подключения Spark-Redis для чтения и записи данных в Redis.
Вам требуется завершить установку сервера Redis как это было описано в рецепте Загрузка и установка Redis в Главе 1, Приступая к Redis.
Вам следует применить команду FLUSHALL для сброса всех данных в вашем экземпляре Redis перед тем как перейти
к нашему следующему разделу.
Основные требования к IDE и JDK в точности те же самые, что и для нашего предыдущего рецепта, Подключение к Redis при помощи Spring Data Redis.
Некий кластер Hadoop необходим, но не обязателен. На момент написания книги для Spark-Redis доступен только API Scala, поэтому в IDEA обязательны Scala v2.11 и соответствующий подключаемый модуль Scala. Кроме того для данного рецепта вам понадобятся базовые знания Spark и Scala.
Вы можете подставить своё задание в некий отдельно расположенный кластер Spark или какой- то кластер Yarn. Для целей демонстрации вместо этого мы можем отладить и запустить соответствующее задание Spark в локальном режиме.
В своём предыдущем рецепте мы предполагали, что у всякого пользователя имеется некий баланс. Чтобы показать как создавать некое задание Spark для Redis, в этом задании мы намерены вычислять сумму таких балансов всех пользователей в Relp:
-
Своим первым шагом мы собираемся подготовить данные образца при помощи своего сценария
preparedata_mr.sh:$ bash preparedata_mr.sh OK unix2dos: converting file mr.data to DOS format ... All data transferred. Waiting for the last reply... Last reply received from server. errors: 0, replies: 10000 -
При помощи
redis-cliмы можем изучить эти данные:127.0.0.1:6379> SCAN 0 1) "7" 2) 1) "user:0000006" 2) "user:0000000" 3) "user:0000008" 4) "user:0000004" 5) "user:0000003" 6) "user:0000002" 7) "user:0000007" 8) "user:0000001" 9) "user:0000009" 10) "user:0000005" 127.0.0.1:6379> SCAN 7 1) "0" 2) 1) "user:0000010" -
Открыв IDEA создаём некий новый проект Scala и заполняем метаданные этого проекта
-
В качсетве инфраструктуры поддержки этого проекта добавляем Maven
-
В
pom.xmlдобавляем относящиеся к Spark-Redis зависимости и соответствующий репозиторий:<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties> <dependencies> <!-- https://mvnrepository.com/artifact/RedisLabs/spark-redis --> <dependency> <groupId>RedisLabs</groupId> <artifactId>spark-redis</artifactId> <version>0.3.2</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.1.0</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> </dependencies> -
После этого мы создаём некий объект
SumBalance, который расширит имеющиеся свойства нашей прикладной программы. -
В самом теле
SumBalanceмы вначале создаём некую переменнуюSparkConfс соответствующим режимом исполнения и установками настроек своего хоста Redis:val conf = new SparkConf() .setMaster("local") .setAppName("Spark Redis Demo") .set("redis.host", "192.168.1.7") -
После обретения такой переменной
SparkConfмы инициализируем соответствующуюSparkSessionи затем получаем необходимый для применения Spark-RedisSparkContext://Initialize the sparksession val sparkSession = SparkSession.builder. master("local") .config(conf) .appName("spark session example") .getOrCreate() //Fetch the sparkcontext for spark-redis library val sc = sparkSession.sparkContext -
Для чтения данных из Redis мы применяем имеющийся API
fromRedisKeyPattern:// Read Hash data from Redis val userHashRDD= sc.fromRedisKeyPattern("user*").getHash() -
Прежде чем вычислить общую сумму всех балансов, мы вначале выполним синтаксический разбор соответствующих данных JSON:
import sparkSession.implicits._ val ds = sparkSession.createDataset(userHashRDD) //Preparing the schema of the JSON data val schema = StructType(Seq( StructField("name", StringType, true), StructField("sex", StringType, true), StructField("rtime", LongType, true), StructField("nation", StringType, true), StructField("balance", DoubleType,true) )) // Parse the json data and rename the columns val namedDS = ds .withColumnRenamed("_1","id") .withColumnRenamed("_2","jsondata") .withColumn("jsondata",from_json($"jsondata", schema)) -
Как только мы подготовим необходимые данные, наступит самое время для их вычисления. После определения значения суммы мы готовим эти данные для записи полученной суммы в виде некоей пары строковых ключ значение обратно в Redis в виде запроса в реальном времени:
//Generating the result [String, String] RDD val totalBalanceRDD = namedDS.agg(sum($"jsondata.balance")).rdd.map(total =>("totalBalance",total.get(0).toString())) -
Наконец, мы записываем полученный результат в Redis при помощи соответствующего API
toRedisKV, предоставляемого Spark-Redis:/Write the result back to Redis` sc.toRedisKV(totalBalanceRDD) -
Чтобы проверить то, что наше задание отработало как ожидалось, мы подставим это задание:
... 17/10/10 21:02:28 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 17/10/10 21:02:28 INFO DAGScheduler: ResultStage 1 (foreachPartition at redisFunctions.scala:226) finished in 0.130 s 17/10/10 21:02:28 INFO DAGScheduler: Job 0 finished: foreachPartition at redisFunctions.scala:226, took 2.675819 s 17/10/10 21:02:28 INFO SparkContext: Invoking stop() from shutdown hook 17/10/10 21:02:28 INFO SparkUI: Stopped Spark web UI at http://192.168.56.1:4040 17/10/10 21:02:28 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 17/10/10 21:02:28 INFO MemoryStore: MemoryStore cleared 17/10/10 21:02:28 INFO BlockManager: BlockManager stopped 17/10/10 21:02:28 INFO BlockManagerMaster: BlockManagerMaster stopped 17/10/10 21:02:28 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 17/10/10 21:02:28 INFO SparkContext: Successfully stopped SparkContext 17/10/10 21:02:28 INFO ShutdownHookManager: Shutdown hook called -
Из
redis-cliмы получим значение суммы имеющихся балансов всех пользователей:127.0.0.1:6379> GET totalBalance "492569.0"
Приводимый код достаточно хорошо сам себя объясняет. Единственный момент, на который стоит обратить ваше внимание, так это то, что по причине требований
самой библиотеки Spark-Redis, когда вы желаете записать полученные данные в Redis как некую простую пару ключ значение, требуется соответствующий
RDD[(String, String)]. Самой первой частью StringRDD является значение
того ключа, который вы бы хотели установить в Redis. Поэтому в данном примере прежде чем мы установим соответствующие данные в Redis, мы выполняем
преобразование получнного результата в StringRDD в виде некоего ключа с названием
totalBalance. Различные типы данных Redis требуют различных типов RDD в Spark-Redis.
Помимо манипуляций с неким отдельным Сервером Redis, Spark-Redis поддерживает в ваших приложениях подключения ко множеству Кластеров или экземпляров Redis.
За дополнительными сведениями относительно предоставляемых Spark-Redis API вы можете обратиться к https://github.com/RedisLabs/spark-redis.