Глава 5. Репликации
Содержание
В этой главе мы обсудим следующие рецепты:
-
Настройку репликаций Redis.
-
Оптимизацию репликаций.
-
Поиск неисправностей в репликациях.
До сих пор мы изучали как устанавливать подключение к к некоторому отдельному Серверу Redis. В промышленной среде некий отдельный экземпляр базы данных зачатую является предметом отказов, таких как падения системы, разделение сетевой среды на части, либо выход из строя энергоснабжения. Как и все прочие системы баз данных, Redis также предоставляет некий механизм репликаций, который позволяет копирование данных с одного сервера Redis (хозяина, master) на один или более прочих Сереров Redis (подчинённые, slave).
Репликации не просто делают всю систему устойчивой к отказам, но также могут применяться для горизонтального масштабирования данной системы. При наличии интенсивных в отношении чтения приложений мы можем добавлять множество доступных только для чтения подчинённых для смягчения нагрузки на свой основной сервер.
Репликации Redis являются основопологающими для Кластера Redis и они предоставляют Высокую доступность. В данной главе мы вначале представим саму работу репликаций Redis и то как настраивать среду реплицирования хозяин- подчинённый. После этого мы покажем руководства по оптимизации и основные технологии поиска неисправностей, которые относятся к репликациям Redis.
В Главе 1, Приступая к Redis мы изучили как устанавливать Сервер Redis. По умолчанию Сервер Redis запускается в режиме хозяина. В данном рецепте мы продемонстрируем как настраивать некий подчинённый сервер Redis для реплицирования с основного сервера хозяина.
Вам требуется завершить установку Сервера Redis, как мы это описали в рецепте Загрузка и установка Redis из Главы 1, Приступая к Redis.
Подготовьте некий файл настроек для подчинённого сервера Redis. Вы можете сделать копию redis.conf и
переименовать её в redis-slave.conf, а затем внести в неё следующие изменения;
port 6380
pidfile /var/run/redis_6380.pid
dir ./slave
slaveof 127.0.0.1 6379
Не забудьте создать каталог /redis/slave, если его нет:
$mkdir -p /redis/slave
Необходимые этапы для настройки репликации Redis таковы:
-
Запустите экземпляр Сервера Redis на порт
6379локального хоста. Если этот сервер уже запущен, вы можете пропустить данный этап. Это наш сервер хозяина:$cd /redis $bin/redis-server conf/redis.conf -
Запустите другой экземпляр Сервера Redis с файлом настроек
redis-slave.conf. Это наш подчинённый сервер:$bin/redis-server conf/redis-slave.conf -
Откройте два Терминала и подключитесь при помощи
redis-cliк серверу хозяина по127.0.0.1:6379и по127.0.0.1:6380:$ bin/redis-cli -p 6379 127.0.0.1:6379> $ bin/redis-cli -p 6380 127.0.0.1:6380> -
Запустите в обоих терминалах
INFO REPLICATION:127.0.0.1:6379> INFO REPLICATION # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=557,lag=1 master_replid:1fee079fc47716706a59225779c56b0e7033f3b1 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:557 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:557 127.0.0.1:6380> INFO REPLICATION # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:7 master_sync_in_progress:0 slave_repl_offset:557 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:1fee079fc47716706a59225779c56b0e7033f3b1 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:557 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:557 -
В своём хозяине создайте новый ключ:
127.0.0.1:6379> SET "new_key" "value" OK -
В подчинённом попробуйте получить требуемое значение для необходимого нового ключа:
127.0.0.1:6380> GET "new_key" "value" -
В этом же подчинённом попробуйте создать некий новый ключ:
127.0.0.1:6380> SET "new_key_2" "value2" (error) READONLY You can't write against a read only slave. -
Остановите свой экземпляр подчинённого:
127.0.0.1:6380> shutdown save -
В основном хозяине создайте другой новый ключ:
127.0.0.1:6379> SET "another_new_key" "another_value" OK -
Перезапустите свой экземпляр подчинённого:
$bin/redis-server bin/redis-slave.conf -
Убедитесь что
another_new_keyимеется в подчинённом:127.0.0.1:6380> GET "another_new_key" "another_value"
В разделе Подготовка... мы обновили необходимый файл настроек чтобы указать своему подчинённому
серверу работать по порту 6380 и применяем некий рабочий каталог, отличный от рабочего каталога хозяина. Наша
новая добавленная строка подчинённого 127.0.0.1 6379, которую мы добавили в
redis-slave.conf указывает, что тот сервер, который выполняет ожидание по порту
6380 является подчинённым для 127.0.0.1:6379. Кроме того,
SLAVEOF является командой, которая может быть исполнена в redis-cli чтобы
сделать наш текущий Сервер Redis неким подчинённым другого экземпляра на лету.
Команда INFO выводит информацию о текущем сервере. На шаге 4 мы применяем
INFO REPLICATION чтобы проверить установлено ли соединение, необходимое для репликации. Большая часть элементов
информации репликации поясняет себя самостоятельно. Значение master_replid является некоторой случайной строкой,
которая вырабатывается в нашем сервере хозяина при его запуске. Наш сервер хозяина представляется master_replid
именно для целей репликации. Значение master_repl_offset является меткой самого потока репликации и увеличивается вместе
с событимя своих данных на нашем хозяине. Некая пара (master_replid; master_repl_offset)
может применяться для указания позиции в имеющемся потоке репликации из нашего экземпляра хозяина.
При надлежащем соединении экземпляров хозяина и подчинённого и установлении связи их реплицирования, имеющийся хозяин отправляет необходимые команды
write и они принимаются его подчинённым, а этот подчинённый применяет полученные команды чтобы выполнить синхронизацию
своих данных с данными хозяина.
Что епроисходит когда наш подчинённый подключается к своему хозяину в самый первый раз или когда это подчинённый восстанавливает подключение к своему
хозяину после прерывания данного подключения? В репликациях Redis имеются два механизма повторной синхронизации: частичная повторная синхронизация и
полная повторная синхронизация. После того как подчинённый экземпляр Redis запускается и подключается к своему экземпляру хозяина, он всегда будет
пробоввать запрашивать некую частичную повторную синхронизацию отправкой (master_replid;
master_repl_offset), что указывает на самый последний моментальный снимок в синхронизации с его хозяином. Если
наш хозяин принимает такую частичную повторную синхронизацию, он выльет необходимую часть инкрементального приращения тех команд, которые были запущены с
самого последнего смещения, на котором остановился данный подчинённый. В противном случае необходима полная синхронизация. Некая полная синхронизация
требуется при всяком самом первом подключении нашего подчинённого к его хозяину. Подробности того как имеющийся хозяин принимает решение принимать ли запрос
на некую частичную повторную синхронизацию будут рассмотрены в нашем следующем рецепте Оптимизация
репликации. Чтобы скопировать все необходимые данные в своего подчинённого, нашему хозяину необходимо сбросить дамп всех данных в некий файл RDB и затем
отправить этот файл своему подчинённому. После того как этот подчинённый получит такой файл RDB, он сбросит все свои данные в памяти и применит только что
полученные данные из этого файла RDB. Данный процесс реплицирования является для нашего хозяина является в чистом виде асинхронным, поэтому он совсем не
будет блокировать данный сервер в отношении обработки запросов клиентов.
Очевидно, что в сравнении с полной повторной синхронизацией частичная повторная синхронизация не требует передачи по сети всего дампа данных от своего хозяина. Кроме того, сброс дампа данных в соответствующий файл RDB ответвляет некий фоновый процесс и получает некие накладные раходы в оперативной памяти; мы изучим это в своей следующей главе.
Наши процессы частичной и полной повторных синхронизаций иллюстрируются на приводимой ниже схеме:
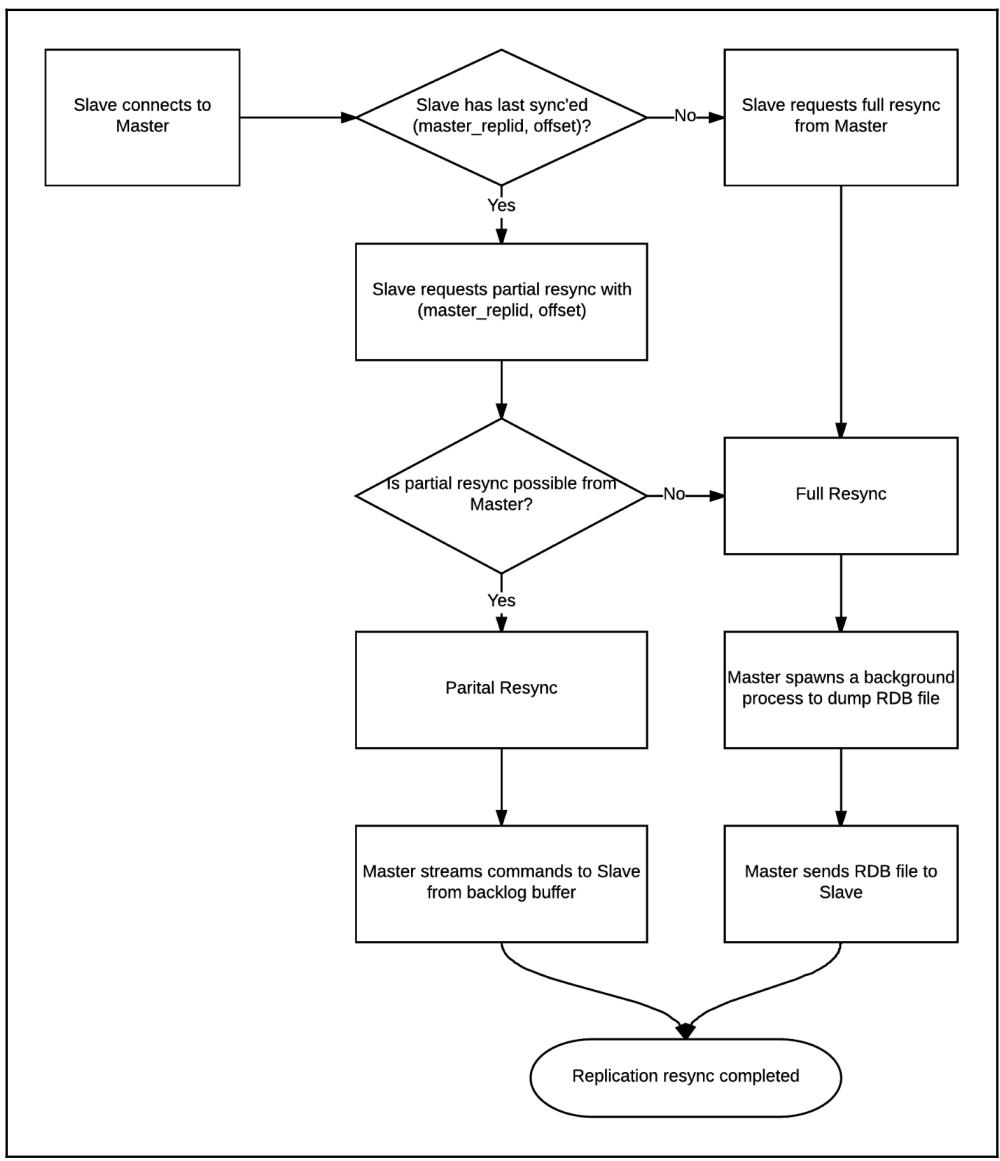
Давайте посмотрим на имеющиеся журналы в нашем подчинённом когда он подключается к своему хозяину в самый первый раз. Как мы можем видеть,
этот подчинённый запрашивает некую полную синхронизацию от своего хозяина, так как он никогда не подключался к этому хозяину ранее и, следовательно,
у него нет (master_replid; master_repl_offset):
15516:S 15 Oct 15:30:15.412 * Connecting to MASTER 127.0.0.1:6379
15516:S 15 Oct 15:30:15.412 * MASTER <-> SLAVE sync started
15516:S 15 Oct 15:30:15.412 * Non blocking connect for SYNC fired the event.
15516:S 15 Oct 15:30:15.412 * Master replied to PING, replication can continue...
15516:S 15 Oct 15:30:15.412 * Partial resynchronization not possible (no cached master)
15516:S 15 Oct 15:30:15.421 * Full resync from master: 1fee079fc47716706a59225779c56b0e7033f3b1:0
15516:S 15 Oct 15:30:15.511 * MASTER <-> SLAVE sync: receiving 175 bytes from master
15516:S 15 Oct 15:30:15.511 * MASTER <-> SLAVE sync: Flushing old data
15516:S 15 Oct 15:30:15.511 * MASTER <-> SLAVE sync: Loading DB in memory
15516:S 15 Oct 15:30:15.512 * MASTER <-> SLAVE sync: Finished with success
А вот соответствующий журнал регистрации в его хозяине:
15511:M 15 Oct 15:30:15.412 * Slave 127.0.0.1:6380 asks for synchronization
15511:M 15 Oct 15:30:15.412 * Full resync requested by slave 127.0.0.1:6380
15511:M 15 Oct 15:30:15.413 * Starting BGSAVE for SYNC with target: disk
15511:M 15 Oct 15:30:15.413 * Background saving started by pid 15520
15520:C 15 Oct 15:30:15.423 * DB saved on disk
15520:C 15 Oct 15:30:15.424 * RDB: 6 MB of memory used by copy-on-write
15511:M 15 Oct 15:30:15.511 * Background saving terminated with success
15511:M 15 Oct 15:30:15.511 * Synchronization with slave 127.0.0.1:6380 succeeded
Наш хозяин получает соответству3ющий запрос на полную повторную синхронизацию от своего подчинённого и запускает сброс дампа всех данных на диск путём ответвления некоторого фонового процесса. После этого он отправляет полученный дамп данных своему подчинённому.
Затем давайте взглянем на журнал нашего сервера относительно некоторого процесса частичной повторной синхронизации. В частности, мы остановили своего подчинённого на шаге 8 и повторно запустили его на шаге 10.
Вы можете обнаружить протоколирование соответствующей частичной повторной синхронизации в своём подчинённом:
15561:S 15 Oct 15:44:13.650 * Connecting to MASTER 127.0.0.1:6379
15561:S 15 Oct 15:44:13.650 * MASTER <-> SLAVE sync started
15561:S 15 Oct 15:44:13.650 * Non blocking connect for SYNC fired the event.
15561:S 15 Oct 15:44:13.650 * Master replied to PING, replication can continue...
15561:S 15 Oct 15:44:13.650 * Trying a partial resynchronization (request 1fee079fc47716706a59225779c56b0e7033f3b1:1126).
15561:S 15 Oct 15:44:13.650 * Successful partial resynchronization with master.
15561:S 15 Oct 15:44:13.650 * MASTER <-> SLAVE sync: Master accepted a Partial Resynchronization.
Вот что показывает журнал частичной повторной синхронизации сервера в самом хозяине:
15511:M 15 Oct 15:44:13.650 * Slave 127.0.0.1:6380 asks for synchronization
15511:M 15 Oct 15:44:13.650 * Partial resynchronization request from 127.0.0.1:6380 accepted. Sending 55 bytes of backlog starting from offset 1126.
Из предыдущих регистрационных записей мы можем видеть, что наш подчинённый отправил некий запрос на частичную повторную синхронизацию при помощи пары
(master_replid; offset) -
(1fee079fc47716706a59225779c56b0e7033f3b1; 1126). Его хозяин принял этот
запрос и начал отправку команд начиная со смещения 1126 из своего буфера невыполненных заданий. Отметьте, пожалуйста, что частичная повторная синхронизация
после перезапуска некоего подчинённого стала новой функциональностью в Redis 4.0. В реализации Redis 4.0 master_replid
и offset запоминаются в его файле RDB. Когда наш подчинённый аккуратно останавливается и повторно запускается,
master_replid и offset будут загружены в необходимом файле RDB, что сделает
возможной частичную повторную синхронизацию.
На шаге 7 мы пытаемся создать некий новый ключ в своём подчинённом, однако получаем некое сообщение об ошибке что данный сервер находится исключительно
в режиме доступа на чтение. Это происходит по причине установки в настройках slave-read-only yes. В большинстве
случаев эта установка рекомендуется во избежание любых несогласованностей данных между хозяином и подчинёнными.
Когда некий подчинённый экземпляр предлагается экземпляром хозяина, прочие подчинённые должны выполнить повторную синхронизацию с таким новым хозяином.
До Redis 4.0 этим процессом была полная повторная синхронизация, так как в таком хозяине изменялся master_replid.
Начиная с Redis 4.0 этот новый хозяин помнит значения master_replid и offset
со старого хозяина даже если значения master_replid в получаемых запросах различаются. В частности, когда происходит
отработка отказа хозяина, в полученном новом хозяине (master_replid;
master_repl_offset+1) будет скопирован в
(master_replid2; second_repl_offset).
За справочной информацией обращайтесь, пожалуйста, к теме Replication в официальной документации Redis.
Удержание Redis и сам формат RDB будут объясняться в Главе 6, Постоянство.
В своём предыдущем рецепте мы обсуждали базовый рабочий поток репликации Redis и изучали как настраивать в Redis репликацию хозяин- подчинённый. Хотя установка репликации достаточна проста, существует очень много критически важных параметров настройки для репликации Redis, которые заслуживают вашего пристального внимания. Более того, некоторые установленные по умолчанию значения этих параметров могут даже вызывать проблемы с производительностью при определённых обстоятельствах. В наших следующих двух рецептах этой главы мы собираемся обсуждать эти настройки для их оптимизации и поиска неисправностей в репликациях Redis.
В данном рецепте мы тщательно исследуем некий ключевой параметр с названием repl-backlog-size на предмет того,
как его регулировать для достижения наилучшей производительности репликаций Redis за счёт получения преимуществ от возможностей частичной повторной
синхронизации. Кроме того, также мы обсудим некоторые иные параметры, которые также могут оказывать воздействие на производительность наших репликаций.
Вам требуется завершить установку Сервера Redis, как мы это описали в рецепте Загрузка и установка Redis из Главы 1, Приступая к Redis.
В данном рецепте для целей иллюстрации мы будем применять в качестве межсетевого экрана iptables для имитации неких ситуаций сетевой изоляции; для манипуляций с iptables требуются полномочия root.
Основные этапы оптимизации репликаций заключаются в следующем:
-
Откройте консоль и переключите текущего пользователя на
root. Затем установит некоторые переменные в этой консоли для базовой информации о хозяине и подчинённом:$ M_IP=127.0.0.1 $ M_PORT=6379 $ M_RDB_NAME=master.rdb $ M_OUT=master.out $ S1_IP=127.0.0.2 $ S1_PORT=6380 $ S1_OUT=slave_1.out $ S1_RDB_NAME=slave_1.rdb -
Запустите два экземпляра Redis:
$ nohup /redis/bin/redis-server --port $M_PORT --bind $M_IP --dbfilename $M_RDB_NAME > $M_OUT & $ nohup /redis/bin/redis-server --port $S1_PORT --bind $S1_IP --dbfilename $S1_RDB_NAME > $S1_OUT& -
Подождите некоторое время пока эти экземпляры Redis на завершат свой запуск. После того как дождёмся завершения запуска, в одном из экземпляров Redis мы установим некие образцы данных:
$ sleep 10 $ echo set redis hello | nc $M_IP $M_PORT $ echo lpush num 1 2 3 | nc $M_IP $M_PORT -
Затем настройте репликацию этих двух Серверов Redis вызвав команду
SLAVEOF. Выполните ожидание в течении 10 секунд прежде чем завершится процесс репликации:$ echo slaveof 127.0.0.1 6379 | nc $S1_IP $S1_PORT $ sleep 10 -
После завершения синхронизации данных мы применим iptables для обрубания своего сетевого соединения между нашими хозяином и подчинённым:
$ echo "modify iptables" $ iptables -I INPUT -s 127.0.0.1 -d 127.0.0.2 -j DROP $ iptables -I OUTPUT -s 127.0.0.2 -d 127.0.0.1 -j DROP -
В процессе полученной сетевой изоляции мы наполним свой сервер хозяина некими данными:
$ bash preparerepldata.sh 1000 $ du -sh repl.data $ cat repl.data | /redis/bin/redis-cli --pipe -h $M_IP -p $M_PORT -
Затем мы восстановим своё сетевое соединения между нашими хозяином и подчинённым вызвав соответствующую команду
iptables. Перед восстановлением этого соединения мы выполним ожидание в течении 70 секунд:$ sleep 70 $ echo "restore iptables" $ iptables -D INPUT -s 127.0.0.1 -d 127.0.0.2 -j DROP $ iptables -D OUTPUT -s 127.0.0.2 -d 127.0.0.1 -j DROP -
После восстановления подключения мы выждем 10 секунд для повторной синхронизации всех данных от хозяина и затем остановим и сервер хозяина, и сервер подчинённого:
$ sleep 10 $ echo "SHUTDOWN" | nc $M_IP $M_PORT $ echo "SHUTDOWN" | nc $S1_IP $S1_PORT -
Проверим соответствующие журналы хозяина и его подчинённого. Вы можете обнаружить следующие относящиеся к репликации сообщения:
# cat master.out ... 29086:M 15 Oct 20:25:49.020 # Connection with slave 127.0.0.2:6380 lost. 29086:M 15 Oct 20:26:04.037 * Slave 127.0.0.2:6380 asks for synchronization 29086:M 15 Oct 20:26:04.037 * Partial resynchronization request from 127.0.0.2:6380 accepted. Sending 139107 bytes of backlog starting from offset 15. ... # cat slave_1.out ... 29087:S 15 Oct 20:25:49.020 # MASTER timeout: no data nor PING received... 29087:S 15 Oct 20:25:49.020 # Connection with master lost. 29087:S 15 Oct 20:25:49.020 * Caching the disconnected master state. 29087:S 15 Oct 20:25:49.020 * Connecting to MASTER 127.0.0.1:6379 29087:S 15 Oct 20:25:49.020 * MASTER <-> SLAVE sync started 29087:S 15 Oct 20:26:04.037 * Non blocking connect for SYNC fired the event. 29087:S 15 Oct 20:26:04.037 * Master replied to PING, replication can continue... 29087:S 15 Oct 20:26:04.037 * Trying a partial resynchronization (request e39b33ba4bb4bb0bf3623ad09d385a856f27463c:15). 29087:S 15 Oct 20:26:04.037 * Successful partial resynchronization with master. 29087:S 15 Oct 20:26:04.037 * MASTER <-> SLAVE sync: Master accepted a Partial Resynchronization. ... -
Очистим все файлы журналов и дампа. Повторим предыдущие шаги. На этот раз мы увеличим объём наполняемых данных в нашем хозяине в процессе разъединения сети на этапе 6:
$ bash preparerepldata.sh 11000 -
Мы выполним проверку своих журналов хозяина и подчинённого опять:
# cat master.out ... 31156:M 15 Oct 20:31:01.747 # Disconnecting timedout slave: 127.0.0.2:6380 31156:M 15 Oct 20:31:01.747 # Connection with slave 127.0.0.2:6380 lost. 31156:M 15 Oct 20:31:32.809 * Slave 127.0.0.2:6380 asks for synchronization 31156:M 15 Oct 20:31:32.809 * Unable to partial resync with slave 127.0.0.2:6380 for lack of backlog (Slave request was: 15). 31156:M 15 Oct 20:31:32.809 * Starting BGSAVE for SYNC with target: disk 31156:M 15 Oct 20:31:32.810 * Background saving started by pid 21293 21293:C 15 Oct 20:31:32.864 * DB saved on disk 21293:C 15 Oct 20:31:32.864 * RDB: 8 MB of memory used by copy-on-write 31156:M 15 Oct 20:31:32.898 * Background saving terminated with success 31156:M 15 Oct 20:31:32.898 * Synchronization with slave 127.0.0.2:6380 succeeded ... # cat slave_1.out ... 31157:S 15 Oct 20:31:01.746 # MASTER timeout: no data nor PING received... 31157:S 15 Oct 20:31:01.746 # Connection with master lost. 31157:S 15 Oct 20:31:01.746 * Caching the disconnected master state. 31157:S 15 Oct 20:31:01.746 * Connecting to MASTER 127.0.0.1:6379 31157:S 15 Oct 20:31:01.746 * MASTER <-> SLAVE sync started 31157:S 15 Oct 20:31:32.809 * Non blocking connect for SYNC fired the event. 31157:S 15 Oct 20:31:32.809 * Master replied to PING, replication can continue... 31157:S 15 Oct 20:31:32.809 * Trying a partial resynchronization (request a866cd909b0ceb7bbed690f73f633f97a471fd3d:15). 31157:S 15 Oct 20:31:32.810 * Full resync from master: a866cd909b0ceb7bbed690f73f633f97a471fd3d:1529121 31157:S 15 Oct 20:31:32.810 * Discarding previously cached master state. 31157:S 15 Oct 20:31:32.898 * MASTER <-> SLAVE sync: receiving 957221 bytes from master 31157:S 15 Oct 20:31:32.899 * MASTER <-> SLAVE sync: Flushing old data 31157:S 15 Oct 20:31:32.899 * MASTER <-> SLAVE sync: Loading DB in memory 31157:S 15 Oct 20:31:32.914 * MASTER <-> SLAVE sync: Finished with success ...
В своём предыдущем разделе мы запустили два Сервера Redis и настроили между ними репликацию. Проверяя журналы хозяина и подчинённого мы можем сказать что наша самая первая репликация была полной синхронизацией данных, что не является сюрпризом, так как это самая первая синхронизация данных наших хозяина и подчинённого:
# cat master.out
...
31156:M 15 Oct 20:29:40.618 * Ready to accept connections
31156:M 15 Oct 20:29:51.637 * Slave 127.0.0.2:6380 asks for synchronization
31156:M 15 Oct 20:29:51.637 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for '709e798b196d833e4b6ff34f1e1cf1a392aa81c4', my replication IDs are '9dd60b163d9aad07426704bd00c8fcdc5e509bd8' and '0000000000000000000000000000000000000000')
31156:M 15 Oct 20:29:51.638 * Starting BGSAVE for SYNC with target: disk
31156:M 15 Oct 20:29:51.638 * Background saving started by pid 31175
31175:C 15 Oct 20:29:51.661 * DB saved on disk
31175:C 15 Oct 20:29:51.661 * RDB: 6 MB of memory used by copy-on-write
31156:M 15 Oct 20:29:51.736 * Background saving terminated with success
31156:M 15 Oct 20:29:51.736 * Synchronization with slave 127.0.0.2:6380 succeeded
Затем мы отрубаем имеющееся сетевое соединение при помощи iptables. На протяжении данного отсоединения сети мы вырабатываем некие образцы данных и импортируем их в свой экземпляр хозяина Redis. После этого мы восстанавливаем подключение вновь и проверяем соответствующие журналы этих двух серверов Redis.
Самая интересная часть состоит в различных размерах наполняемых нами образцов данных, что приводит к различным видам синхронизации данных Redis.
Основная причина почему это происходит состоит в длительности того периода, на который хозяин теряет необходимое соединение со своим подчинённым,
и количества памяти, выделенное под некий кольцевой буфер в вашем хозяине Redis, который отслеживает все последние команды
write. Такой буфер в действительности является списком с фиксированной длиной.
В Redis мы именуем этот буфер как replication backlog (невыполненные репликации). Redis
применяет этот буфер отложенных операций для того чтобы принимать решение относительно того начинать ли полную или частичную повторную синхронизацию.
Точнее, после вызова соответствующей команды SLAVEOF, установленный подчинённый отправляет некий запрос на
частичную повторную синхронизацию своему хозяину с самого последнего смешения репликации и соответствующий идентификатор своего самого последнего
хозяина (master_replid). Когда необходимое соединение между нашими хозяином и подчинённым устанавливается, наш
хозяин вначале проверяет соответствует ли master_replid из запроса его собственному
master_replid. Затем, он проверит можно ли получить offset из этого запроса
из его буфера отложенных репликаций. Если значение offset находится в имеющемся диапазоне его
отложенных репликаций, все команды write на протяжении разъединения могут быть получены из него, что указывает на
то, что может быть выполнена некая частичная повторная синхронизация. В противном случае, если тот объём команд write ,
который ваш хозяин получил в процессе разъединения больше того что способен хранить буфер отложенных репликаций, полученный запрос на частичную повторную
синхронизацию будет отклонён. Вместо этого будет запущена полная повторная синхронизация данных. А именно, установленный по умолчанию для вашего
резервирования репликаций размер, который составляет 1 МБ, является достаточным для хранения команд write только
если в процессе разъединения соединения в вашего хозяина записывается небольшое количество данных.
Для своего тестирования в первый раз мы выработали около 96 кБ данных для импорта. Таким образом, когда наш подчинённый, подключаясь вновь к хозяину и
запрашивает частичную повторную синхронизацию, его хозяин направляется на выборку команд write на протяжении
разъединения из своего буфера отложенных репликаций и отправляет их своему подчинённому. В конце концов это подчинённый догоняет своего хозяина за счёт
частичной репликации. Основное преимущество частичной повторной синхронизации было объяснено в нашем предыдущем рецепте
Настройка репликации Redis.
Во втором случае нашей проверки мы вырабатываем 1.1 МБ данных для импорта в своего хозяина в процессе сетевого разъединения. Этот размер импортируемых данных превышает установленный по умолчанию размер буфера отложенных репликаций, поэтому нет никаких сомнений, что после восстановления подключения придётся выполнять полную повторную синхронизацию.
Из нашего предыдущего обсуждения мы можем заключить, что установленный по умолчанию размер нашего буфера отложенных репликаций не достаточен для гарантии
высокоскоростного обмена в ситуации когда происходит некое сетевое разъединение между хозяином и подчинённым. В большинстве случаев мы можем подкрутить
данный параметр на более высокое значение чтобы соответствовать нашим потребностям. Вычисляя значение дельты для параметра
master_repl_offset из данных команды INFO на протяжении часов пиковой нагрузки
мы можем выполнить оценку некоторого подходящего размера для вашего буфера отложенных репликаций:
t*(master_repl_offset2- master_repl_offset1)/(t2-t1)
t обозначает сколько может продолжаться разъединение в секундах.
Мы также можем применять эту формулу для оценки сетевого обмена между своими экземплярами хозяина и подчинённого Redis.
Говоря в общем, не имеет смысла устанавливать некое значение выше размера моментального снимка RDB. Сделав это вы не получите преимуществ от частичной повторной синхронизации и полная повторная синхронизация будет почти тем же самым.
Другим параметром для журнала отложенных репликаций является repl-backlog-ttl, который указывает, что в случае когда
все подчинённые отсоединены от своего хозяина, как долго этот экземпляр хозяина Redis будет дожидаться освобождения памяти своего журнала отложенных
репликаций. Устанавливаемое по умолчанию для данного параметра составляет 3600 с, что обычно не является проблемой, так как данный буфер отложенных
репликаций является достаточно малым в сравнении с общей памятью экземпляра Redis.
Помимо обсуждённого нами размера журнала отложенных репликаций имеется ещё ряд настроек, которые вы можете подстраивать для получения в некоторых
ситуациях лучшей производительности. С точки зрения сетевой передачи вы можете использовать меньшую полосу пропускания путём настройки параметра
repl-disable-tcp-nodelay в значение yes. Если установить
yes, Redis будет пробовать собирать несколько пакетов малой длины в один пакет. Это полезно когда местоположение
сервера хозяина удалено от его сервера подчинённого. Дополнительное внимание следует уделить тому факту, что это может приводить к задержкам репликаций до
40 мс.
С точки зрения ввода/ вывода и памяти хозяина вы можете отправлять содержимое RDB напрямую подчинённым без создания некоего файла RDB на своём диске
применяя репликацию без диска. Ваш хозяин Redis ответвляет некий новый процесс для выполнения необходимой передачи RDB. Такой механизм может сберегать много
дискового ввода/ вывода и какого- то объёма памяти в процессе создания моментального снимка RDB. если у вас медленный диск или высокая загруженность памяти
в вашем хосте Redis, в то время как сетевая полоса пропускания достаточна, вы можете изучить этот параметр и попробовать его. Вы можете переключить свой
механизм репликации с основанного на диске (установлено по умолчанию) на бездисковый установив
repl-diskless-sync в значение yes. Однако, эта функциональность в
настоящее время экспериментальная, поэтому будьте аккуратны при применении бездисковых репликаций в промышленной среде.
Относительно планирования частичной синхронизации в Redis пользуйтесь справочными материалами http://antirez.com/news/31.
Для проектирования бездисковой синхронизации в Redis воспользуйтесь справочными материалами http://antirez.com/news/81.
Подробности репликации Redis объясняются в рецепте Настройка репликации Redis в данной главе.
Вы также можете обнаружить многое за пределами настроек, обсуждаемых в данном рецепте на http://download.redis.io/redis-stable/redis.conf.
Если вы не знакомы с командой iptables, обратитесь к справочным материалам в её
странице man.
В реальной промышленной среде вы можете попадать во множество проблем и получать трудности при применении Redis. Многи факторы, такие как дисковый ввод/ вывод, связность сетевой среды, текущий размер наборов данных и длительные операции с блокировкой могут стать той основой, которая вызывает отказы репликаций.
В этом рецепте мы рассмотрим несколько случаев отказов репликаций и решения для просмотра того что можно предпринимать если репликации не работают как ожидалось.
Вам требуется завершить установку Сервера Redis, как мы это описали в рецепте Загрузка и установка Redis из Главы 1, Приступая к Redis. Вам также следует выполнить настройку репликации в соответствии с рекомендациями из рецепта данной главы Настройка репликации Redis.
Для генерации большого количества образцов данных мы применяем fake2db, упоминавшийся в рецепте
Ключи управления в Главе 2, Типы данных для
наполнения какими- то фабрикуемыми данными Redis. Из- за различий производительности аппаратных средств для завершения наполнения данными вам может
потребоваться до нескольких часов.
# fake2db --rows 3000000 --db redis
Кроме того, для целей тестирования мы предлагем другой генератор проверочных данных redis-random-data-generator
для записи образцов данных в Redis в реальном масштабе времени. Вы можете установить его следующим образом:
$ sudo apt-get install npm
$ npm i redis-random-data-generator
$ wget https://raw.githubusercontent.com/SaminOz/redis-random-data-generator/master/generator.js
Чтобы показать как пристрелить проблему репликации выполните следующие мероприятия:
-
Откройте консоль и получите информацию о репликации при помощи
redis-cliдля экземпляровmasterиslaveRedis:$ bin/redis-cli -p 6379 info Replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=1288,lag=1 master_replid:8f7b9821477006200651baef11d6af7451dede3d master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1288 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1288 $ bin/redis-cli -p 6380 info Replication # Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:1 master_sync_in_progress:0 slave_repl_offset:1302 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:8f7b9821477006200651baef11d6af7451dede3d master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1302 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1302 -
После проверки текущего состояния репликации мы попробуем заблокировать свой серевер хозяина на 80 секунд при помощи команды Redis
debug sleep:$ date;bin/redis-cli -p 6379 debug sleep 80; date Tue Oct 17 16:15:54 CST 2017 OK Tue Oct 17 16:17:14 CST 2017 -
Мы проверим соответствующие журналы для
SlaveиMasterв Redis:Slave log: 21894:S 17 Oct 16:16:52.823 # MASTER timeout: no data nor PING received... 21894:S 17 Oct 16:16:52.823 # Connection with master lost. 21894:S 17 Oct 16:16:52.823 * Caching the disconnected master state. 21894:S 17 Oct 16:16:52.823 * Connecting to MASTER 127.0.0.1:6379 21894:S 17 Oct 16:16:52.823 * MASTER <-> SLAVE sync started 21894:S 17 Oct 16:16:52.823 * Non blocking connect for SYNC fired the event. 21894:S 17 Oct 16:17:14.353 * Master replied to PING, replication can continue... 21894:S 17 Oct 16:17:14.353 * Trying a partial resynchronization (request 8f7b9821477006200651baef11d6af7451dede3d:565381621). 21894:S 17 Oct 16:17:14.353 * Successful partial resynchronization with master. 21894:S 17 Oct 16:17:14.353 * MASTER <-> SLAVE sync: Master accepted a Partial Resynchronization. Master log: 22024:M 17 Oct 16:17:14.353 # Connection with slave 127.0.0.1:6380 lost. 22024:M 17 Oct 16:17:14.353 * Slave 127.0.0.1:6380 asks for synchronization 22024:M 17 Oct 16:17:14.353 * Partial resynchronization request from 127.0.0.1:6380 accepted. Sending 0 bytes of backlog starting from offset 565381621. -
Мы подвесили своего подчинённого, раз уж наша повторная синхронизация завершена на данный момент:
$ date;bin/redis-cli -p 6380 debug sleep 80; date Tue Oct 17 20:46:43 CST 2017 OK Tue Oct 17 20:48:03 CST 2017 -
проверьте соответствующие журналы
MasterиSlave:Master: 22024:M 17 Oct 20:47:43.709 # Disconnecting timedout slave: 127.0.0.1:6380 22024:M 17 Oct 20:47:43.709 # Connection with slave 127.0.0.1:6380 lost. 22024:M 17 Oct 20:48:04.603 * Slave 127.0.0.1:6380 asks for synchronization 22024:M 17 Oct 20:48:04.603 * Partial resynchronization request from 127.0.0.1:6380 accepted. Sending 0 bytes of backlog starting from offset 565403937. Slave: 21894:S 17 Oct 20:48:03.697 # Connection with master lost. 21894:S 17 Oct 20:48:03.697 * Caching the disconnected master state. 21894:S 17 Oct 20:48:04.602 * Connecting to MASTER 127.0.0.1:6379 21894:S 17 Oct 20:48:04.602 * MASTER <-> SLAVE sync started 21894:S 17 Oct 20:48:04.603 * Non blocking connect for SYNC fired the event. 21894:S 17 Oct 20:48:04.603 * Master replied to PING, replication can continue... 21894:S 17 Oct 20:48:04.603 * Trying a partial resynchronization (request 8f7b9821477006200651baef11d6af7451dede3d:565403937). 21894:S 17 Oct 20:48:04.603 * Successful partial resynchronization with master. 21894:S 17 Oct 20:48:04.603 * MASTER <-> SLAVE sync: Master accepted a Partial Resynchronization. -
Для подготовки своего второго сценария мы передёрнем репликации своего подчинённого и сбросим все данные в этом экземпляре
slave. Затем мы установим репликацию вновь:127.0.0.1:6380> SLAVEOF NO ONE 127.0.0.1:6380> FLUSHALL 127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 -
В процессе установки репликации мы выполним пополнение большого объёма данных:
for i in `seq 5` do nohup node generator.js hash 1000000 session & done -
Мы немного подождём и проверим соответствующие журналы
MasterиSlaveснова:Master: 16027:M 18 Oct 14:20:40.767 * Slave 127.0.0.1:6380 asks for synchronization 16027:M 18 Oct 14:20:40.767 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for '40f921547ba9b599dff22d8d1fe2d7b03f284361', my replication IDs are '774fce0f0ffe5afad272937699d714949cdfd9e8' and '0000000000000000000000000000000000000000') 16027:M 18 Oct 14:20:40.767 * Starting BGSAVE for SYNC with target: disk 16027:M 18 Oct 14:20:40.826 * Background saving started by pid 22756 16027:M 18 Oct 14:21:04.240 # Client id=51 addr=127.0.0.1:41853 fd=7 name= age=24 idle=24 flags=S db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuffree=0 obl=16384 oll=16362 omem=268435458 events=r cmd=psync scheduled to be closed ASAP for overcoming of output buffer limits. 16027:M 18 Oct 14:21:04.256 # Connection with slave 127.0.0.1:6380 lost. 16027:M 18 Oct 14:22:04.896 * Slave 127.0.0.1:6380 asks for synchronization 16027:M 18 Oct 14:22:04.896 * Full resync requested by slave 127.0.0.1:6380 16027:M 18 Oct 14:22:04.896 * Can't attach the slave to the current BGSAVE. Waiting for next BGSAVE for SYNC 22756:C 18 Oct 14:22:13.932 * DB saved on disk 22756:C 18 Oct 14:22:13.949 * RDB: 5091 MB of memory used by copy-on-write 16027:M 18 Oct 14:22:14.049 * Background saving terminated with success 16027:M 18 Oct 14:22:14.049 * Starting BGSAVE for SYNC with target: disk 16027:M 18 Oct 14:22:14.111 * Background saving started by pid 22845 22845:C 18 Oct 14:23:46.883 * DB saved on disk 22845:C 18 Oct 14:23:46.912 * RDB: 22 MB of memory used by copy-on-write 16027:M 18 Oct 14:23:47.031 * Background saving terminated with success 16027:M 18 Oct 14:24:40.644 * Synchronization with slave 127.0.0.1:6380 succeeded Slave: 16022:S 18 Oct 14:20:40.765 * Connecting to MASTER 127.0.0.1:6379 16022:S 18 Oct 14:20:40.765 * MASTER <-> SLAVE sync started 16022:S 18 Oct 14:20:40.765 * Non blocking connect for SYNC fired the event. 16022:S 18 Oct 14:20:40.767 * Master replied to PING, replication can continue... 16022:S 18 Oct 14:20:40.767 * Trying a partial resynchronization (request 40f921547ba9b599dff22d8d1fe2d7b03f284361:607439042). 16022:S 18 Oct 14:20:40.826 * Full resync from master: 774fce0f0ffe5afad272937699d714949cdfd9e8:3644738860 16022:S 18 Oct 14:20:40.827 * Discarding previously cached master state. 16022:S 18 Oct 14:22:04.896 # Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value. 16022:S 18 Oct 14:22:04.896 * Connecting to MASTER 127.0.0.1:6379 16022:S 18 Oct 14:22:04.896 * MASTER <-> SLAVE sync started 16022:S 18 Oct 14:22:04.896 * Non blocking connect for SYNC fired the event. 16022:S 18 Oct 14:22:04.896 * Master replied to PING, replication can continue... 16022:S 18 Oct 14:22:04.896 * Partial resynchronization not possible (no cached master) 16022:S 18 Oct 14:22:14.111 * Full resync from master: 774fce0f0ffe5afad272937699d714949cdfd9e8:5669698739 16022:S 18 Oct 14:23:47.031 * MASTER <-> SLAVE sync: receiving 6503393438 bytes from master 16022:S 18 Oct 14:24:40.656 * MASTER <-> SLAVE sync: Flushing old data 16022:S 18 Oct 14:24:40.656 * MASTER <-> SLAVE sync: Loading DB in memory 16022:S 18 Oct 14:26:08.477 * MASTER <-> SLAVE sync: Finished with success
В своём рецепте Настройка репликации Redis мы изучили что после обработки команд
write, наш хозяин затем пошлёт их своим подчинённым чтобы осуществить их синхронизацию со своим хозяином.
С точки зрения хозяина, для определения того все ли его подчинённые ещё живы, он отправляет PING с
заданным интервалом времени. Вы можете регулировать этот промежуток настраивая repl-ping-slave-period в
файле конфигурации или из redis-cli. Устанавливаемым по умолчанию значением является период в 10 с.
С точки зрения подчинённого, он отправляет каждую секунду REPLCONF ACK {offset} для сообщения своего
смещения в репликациях. И для PING, и для REPLCONF ACK имеется некий
таймаут, определяемый repl-timeout. Его значение по умолчанию составляет 60 с. Если значение промежутка времени
между двумя PING или REPLCONF ACK превышает значение данного
таймаута, или же отсутствует обмен между хозяином и подчинёнными в пределах repl-timeout, данное соединение
репликации будет отсечено. Такой подчинённый предпримет инициативу другого запроса репликации.
В нашей первой проверке в 16:15:54 мы заблокировали своего хозяина на 80 с, что превышает значение
таймаута. Рассматриваемый подчинённый обнаруживает, что нет никаких данных или команды ping от его хозяина по достижению значения таймаута, поэтому в
16:16:52.823 он сбрасывает своё подключение к хозяину. После этого такой подчинённый пытается повторно установить
подключение к своему хозяину вплоть до 16:17:14.353, затем наш экземпляр хозяина возвращается в строй и даёт некий
отклик своему подчинённому. После этого наша репликация может продолжаться. После обрыва связи с хозяином мы вслед за этим отключам своего подчинённого на
80 с. Аналогичным образом могут быть получены записи журнала. Основной отличительной частью является то, что на этот раз наш хозяин прерывает данное
соединение репликации по достижению таймаута. После пробуждения подчинённого, он обнаруживает, что соединение с его хозяином было утрачено, поэтому он
предпринимает попытку другого подключения.
Второй вариант проверки является иной распространённой при промышленном применении проблемой. Как мы уже описывали в своём рецепте
Настройка репликации Redis, при установлении репликации некий экземпляр хозяина вначале сбрасывает
дамп своей памяти в виде какого- то файла RDB и отправляет его своим подчинённым. По завершению приёма данного файла RDB, подчинённые загружают этот файл
в свою память. на протяжении данных этапов все получаемые в экземпляре хозяина команды write будут
буферизовываться в некотором особом буфере с названием Slave client buffer. После загрузки RDB, этот хозяин отправит
содержимое данного буфера подчинённому.
Существует некое ограничение на размер такого буфера, которое, как только будет достигнуто, вызовет запуск репликации с самого начала. Значением предела по
умолчанию некоторого буфера является slave 256 MB 64 MB 60. Значение слова slave
указывает что этот размер буфера относится к подчинённым. Установленная величина 256 MB является жёстким пределом.
Как только будет достигнут этот предел размера буфера, данный хозяин немедленно закроет данное соединение. Значения 64 MB
и 60 являются мягкими пределами. Это означает, что данный хозяин закроет такое подключение, если размер данного
буфера превышает 64 МБ на протяжении непрерывного интервала времени в 60 секунд.
Вызывая CLIENT LIST в процессе синхронизации данных вы можете улавливать те данные репликации клиента, чьей
командой cmd является sysc или
psysc (cmd=sysc/psysc), а значением флага является
S (flag=S). Затем вы можете получить значение объёма памяти, применявшееся для
данного буфера клиента репликации из измерения omem:
127.0.0.1:6379> CLIENT LIST
id=115 addr=127.0.0.1:46731 fd=11 name= age=41 idle=38 flags=S db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=16382 oll=123 omem=2009753 events=r cmd=psync
В нашей предыдущей проверке, после запуска синхронизации, мы выполнили активную доставку большого объёма образцов данных, который определённо превосходит установленный предел для буфера клиента. Наш хозяин определяет данный факт и регистрирует все измерения клиента. Вскоре после этого данный хозяин отсекает данное соединение:
16027:M 18 Oct 14:21:04.240 # Client id=51 addr=127.0.0.1:41853 fd=7 name= age=24 idle=24 flags=S db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=16384 oll=16362 omem=268435458 events=r cmd=psync scheduled to be closed ASAP for overcoming of output buffer limits.
16027:M 18 Oct 14:21:04.256 # Connection with slave 127.0.0.1:6380 lost.
Через 60 секунд, что является установленным по умолчанию значением для таймаута репликации, его подчинённый обнаружит что нет никаких данных на получение от его сервера хозяина, поэтому от перезапустит данную репликацию автоматически:
16022:S 18 Oct 14:22:04.896 # Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value.
16022:S 18 Oct 14:22:04.896 * Connecting to MASTER 127.0.0.1:6379
В реальной промышленной среде значение repl-ping-slave-period должно быть меньше чем соответствующее значение
repl-timeout. В противном случае всякий раз когда между хозяином и подчинённым будет низкий уровень обмена, всякий
раз будет достигаться таймаут. Обычно некая операцияф с блокировкой может вызывать таймаут, так как обрабатывающий эту команду механизм Сервера Redis
состоит из единственного потока. Для предотвращения возникновения подобного таймаута вашей репликации вам следует попытаться применять наилучшую практику
избежания команд с длительным блокированием. Установленного по умолчанию значения repl-timeout вполне достаточно
для большинства вариантов применения.
особое внимание стоит уделить нашему второму сценарию. Значение времени, необходимого для выполнения дампа памяти мастера было продолжительнее 60 секунд, что не вызовет таймаута репликации. То же самое произойдёт если процесс передачи файла RDB будет длиться дольше значения, установленного для таймаута репликации. В этом случае репликация не будет прервана. В нашем следующем примере показывается, что обмен данными продолжался приблизительно 23 минуты и данная репликация была успешно завершена:
16022:S 18 Oct 21:13:56.517 * MASTER <-> SLAVE sync: receiving 3983178656 bytes from master
16022:S 18 Oct 21:36:35.325 * MASTER <-> SLAVE sync: Flushing old data
16022:S 18 Oct 21:36:35.325 * MASTER <-> SLAVE sync: Loading DB in memory
16022:S 18 Oct 21:37:09.933 * MASTER <-> SLAVE sync: Finished with success
В приводимых в данном рецепте примерах вы легко можете воспроизвести такой сценарий, применив команду Linux
tc для установки задержки в вашей кольцевой связи с некоторой учётной записью root:
# tc qdisc add dev eth0 root netem delay 200ms
Кроме того, медленная загрузка вашего файла RDB в соотвтествующем подчинённом не будет блокировать такого подчинённого и это не будет вызывать таймаута репликации, что показано в следующем примере:
13760:S 16 Oct 23:12:52.414 * MASTER <-> SLAVE sync: receiving 5289155794 bytes from master
13760:S 16 Oct 23:13:37.637 * MASTER <-> SLAVE sync: Flushing old data
13760:S 16 Oct 23:13:37.637 * MASTER <-> SLAVE sync: Loading DB in memory
13760:S 16 Oct 23:23:20.231 * MASTER <-> SLAVE sync: Finished with success
В целом, из имеющегося исходного кода Redis мы можем установить, что сам таймаут репликации будет инициирован только если нет никакого обмена между неким
хозяином и подчинённым при выполнении необходимой повторной синхронизации или когда конкретный экземпляр хозяина/ подчинённого не может получить
PING/REPLCONF ACK в пределах установленного таймаута.
В качестве совета для необходимого размера определённого буфера клиента репликации вы можете установить некий больший размер путём вызова команды
CONFIG SET или изменяя файл настроек и перезапуская этот экземпляр в своей промышленной среде с высокими значениями
обмена по записи. Особое внимание стоит уделять при установке данного значения с помощью CONFIG SET.
Не поддерживаются такие единицы как MB или GB. Вот некий пример установки значения жёсткого предела данного буфера в размере 512 МБ и 128 МБ/ 120с:
127.0.0.1:6379> config set client-output-buffer-limit 'slave 536870912 134217728 120'
Последним моментом, который мы бы хотели отметить, состоит в том, что Redis применяет для сроков истечения ключей политику, движимую хозяином. То есть,
скажем, когда у некого хозяина истекает действие какого- то ключа, он отправляет команду DEL всем своим
подчинённым. Данная команда DEL также буферизуется в имеющемся буфере клиента репликации в процессе синхронизации.
Кроме того, если вы настроите подчинённых доступными на запись, следует принимать предосторожности, поскольку вплоть до Redis 4.0 ключи с неким таймаутом в доступном на запись подчинённом Redis никогда не истекали. Данная проблема была исправлена начиная с Redis 4.0 RC3.
Вы также можете отыскать на http://download.redis.io/redis-stable/redis.conf все значения настроек, упоминавшихся в данном рецепте.